
测试驱动开发(
TDD)已经是耳熟能详的名词,既然是测试驱动,那么
测试用例代码就要写在开发代码的前面。但是如何写测试用例?写多少测试用例才够?我想大家在实际的操作过程都会产生这样的疑问。
3月15日,我参加了thoughtworks组织的“结对编程和TDD Openworkshop”活动,聆听了tw的资深咨询专家仝(tong2)键的精彩讲解,并在讲师的带领下实际参与了一次TDD和结对编程的过程。活动中,仝键老师对到底写多少测试用例才够的问题,给出了下面一个解释:
我们写
单元测试,有一个重要的原因是用来防止自己犯低级错误的。我们不能把写实现代码的人当作我们的敌人,一定要把全部情况都测到,以防止他们在里面故意留下各种隐蔽的陷阱。测试写的再多可能也没有办法覆盖全部情况,所以只要能让自己感到安全即可。怎样才能让自己感到安全呢?这是没有标准答案的,只能是写多了测试以后慢慢体会。
另外,写测试也要花时间的,比如compare这个方法的实现部分,我们只花了一两分钟就写完了,而这些测试代码,我们花了足足半个多小时,这样做值得吗?对于简单的业务逻辑来说,当然是不值得的,毕竟我们还很多
工作等着做,老板花钱是为了我们的产品代码,而不是测试代码。
再考虑一种情况,我要创业,想了一个点子,做了一个网站,我当然是想以最快的速度把它做成型让别人用。如果我在完全不知道人们会不会喜欢的时候,先花大量时间写测试,最后发现没人用只能丢掉,这些测试岂不是白写了。
所以还是上面那句话:单元测试是让你提升自己对代码的信心的,只要你感觉安全可以继续开发时就够了,不是越多越好。
我相信上面一段解释对于本文中提出的问题大家都没有什么异议。但是这里我们不考虑特殊情况,在实际操作中,是否有办法对单元测试这一工作进行衡量?来判断是否足够?
使用代码覆盖率来衡量单元测试是否足够
常见的代码覆盖率有下面几种:
语句覆盖(Statement Coverage):这是最常用也是最常见的一种覆盖方式,就是度量被测代码中每个可执行语句是否被执行到了。
判定覆盖(Desicion Coverage):它度量程序中每一个判定的分支是否都被测试到了。
条件覆盖(Condition Coverage):它度量判定中的每个子表达式结果true和false是否被测试到了。
路径覆盖(Path Coverage):它度量了是否函数的每一个分支都被执行了。
前三种覆盖率大家可以查看下面的引用的第3篇
文章,这里就不再多说。我们通过一个例子,来看看路径覆盖。比如下面的测试代码中有两个判定分支
int foo(int a, int b) { int nReturn = 0; if (a < 10) {// 分支一 nReturn+= 1; } if (b < 10) {// 分支二 nReturn+= 10; } return nReturn; } |
我们仔细看看逻辑,nReturn的结果一共有4种可能,我们通过路径覆盖的方法设计出来的测试用例:
Perfect。但是实际中的代码往往比上面的例子复杂,如果代码中有5个if-else,那么按照路径覆盖的方法,至少需要25=32个测试用例。这样简直要疯掉了。
没必要追求代码覆盖率,真正要覆盖的是逻辑
简单追求代码结构上的覆盖率,容易导致产生大量无意义的测试用例或者无法覆盖关键业务逻辑。我们再看看上面解释的第一段话。
我们写单元测试,有一个重要的原因是用来防止自己犯低级错误的。我们不能把写实现代码的人当作我们的敌人,一定要把全部情况都测到,以防止他们在里面故意留下各种隐蔽的陷阱。测试写的再多可能也没有办法覆盖全部情况,所以只要能让自己感到安全即可。怎样才能让自己感到安全呢?这是没有标准答案的,只能是写多了测试以后慢慢体会。
怎么才算让自己感到安全?覆盖逻辑,而不是代码。站在使用者的角度考虑,需要关心的是软件实现逻辑,而不是覆盖率。如下面的例子:
public class UserBusiness { public string CreateUser(User user) { string result = "success"; if (string.IsNullOrEmpty(user.Username)) { result = "usename is null or empty"; } else if (string.IsNullOrEmpty(user.Password)) { result = "password is null or empty"; } else if (user.Password != user.ConfirmPassword) { result = "password is not equal to confirmPassword"; } else if (string.IsNullOrEmpty(user.Creator)) { result = "creator is null or empty"; } else if (user.CreateDate == new DateTime()) { result = "createdate must be assigned value"; } else if (string.IsNullOrEmpty(user.CreatorIP)) { result = "creatorIP is null or empty"; } if (result != "success") { return result; } user.Username = user.Username.Trim(); user.Password = BitConverter.ToString(MD5.Create().ComputeHash(Encoding.UTF8.GetBytes(user.Password))); UserDataAccess dataAccess = new UserDataAccess(); dataAccess.CreateUser(user); return result; } } 在写UserBusiness.CreateUser的测试用例的时候,我们定义了下面几个单元测试用例: [TestClass()] public class UserBusinessTest { private TestContext testContextInstance; /// <summary> ///Gets or sets the test context which provides ///information about and functionality for the current test run. ///</summary> public TestContext TestContext { get { return testContextInstance; } set { testContextInstance = value; } } [TestMethod()] public void Should_Username_Not_Null_Or_Empty() { UserBusiness target = new UserBusiness(); User user = new User(); string expected = "usename is null or empty"; string actual = target.CreateUser(user); Assert.AreEqual(expected, actual); } [TestMethod()] public void Should_Password_Not_Null_Or_Empty() { UserBusiness target = new UserBusiness(); User user = new User() { Username = "ethan.cai" }; string expected = "password is null or empty"; string actual = target.CreateUser(user); Assert.AreEqual(expected, actual); } |
[TestMethod()] public void Should_Password_Equal_To_ConfirmPassword() { UserBusiness target = new UserBusiness(); User user = new User() { Username = "ethan.cai", Password = "a121ww123", ConfirmPassword = "a121ww1231" }; string expected = "password is not equal to confirmPassword"; string actual = target.CreateUser(user); Assert.AreEqual(expected, actual); } [TestMethod()] public void Should_Creator_Not_Null_Or_Empty() { UserBusiness target = new UserBusiness(); User user = new User() { Username = "ethan.cai", Password = "a121ww123", ConfirmPassword = "a121ww1231" }; string expected = "password is not equal to confirmPassword"; string actual = target.CreateUser(user); Assert.AreEqual(expected, actual); } [TestMethod()] public void Should_CreateDate_Assigned_Value() { UserBusiness target = new UserBusiness(); User user = new User() { Username = "ethan.cai", Password = "a121ww123", ConfirmPassword = "a121ww123", Creator = "ethan.cai" }; string expected = "createdate must be assigned value"; string actual = target.CreateUser(user); Assert.AreEqual(expected, actual); } [TestMethod()] public void Should_CreatorIP_Not_Null_Or_Empty() { UserBusiness target = new UserBusiness(); User user = new User() { Username = "ethan.cai", Password = "a121ww123", ConfirmPassword = "a121ww123", Creator = "ethan.cai", CreateDate = DateTime.Now }; string expected = "creatorIP is null or empty"; string actual = target.CreateUser(user); Assert.AreEqual(expected, actual); } [TestMethod()] public void Should_Trim_Username() { UserBusiness target = new UserBusiness(); User user = new User() { Username = "ethan.cai ", Password = "a121ww123", ConfirmPassword = "a121ww123", Creator = "ethan.cai", CreateDate = DateTime.Now, CreatorIP = "127.0.0.1" }; string expected = "ethan.cai"; target.CreateUser(user); Assert.AreEqual(expected, user.Username); } [TestMethod()] public void Should_Save_MD5_Hash_Password() { UserBusiness target = new UserBusiness(); User user = new User() { Username = "ethan.cai ", Password = "a121ww123", ConfirmPassword = "a121ww123", Creator = "ethan.cai", CreateDate = DateTime.Now, CreatorIP = "127.0.0.1" }; string actual = target.CreateUser(user); Assert.IsTrue("success" == actual && user.Password == BitConverter.ToString(MD5.Create().ComputeHash(Encoding.UTF8.GetBytes("a121ww123")))); } [TestMethod()] public void Should_Create_User_Successfully_When_User_Is_OK() { UserBusiness target = new UserBusiness(); User user = new User() { Username = "ethan.cai ", Password = "a121ww123", ConfirmPassword = "a121ww123", Creator = "ethan.cai", CreateDate = DateTime.Now, CreatorIP = "127.0.0.1" }; string expected = "success"; string actual = target.CreateUser(user); Assert.IsTrue(expected == actual); } } |
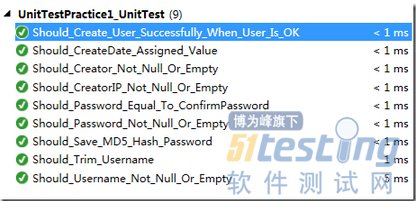
如果仅从代码覆盖率的角度来看,单元测试Should_Trim_Username、Should_Save_MD5_Hash_Password不会增加覆盖率,似乎没有必要,但是从逻辑上看,创建的账户的Username头尾不能包含空白字符,密码也不能明文存储,显然这两个用例是非常有必要的。
单元测试写多少才够?这个问题没有确定的答案,但原则是让你自己觉得安全。代码覆盖率高不能保证安全,真正的安全需要用测试用例覆盖逻辑。
今天
学习了
性能测试的关联。以前都是从ppt上简单知道关联操作,不懂得那些操作需要关联,关联意义,为什么需要关联,那些字段需要关联。今天在kelly帮助讲解下,了解了关联的意义。
举例从创建预收货订单保存订单-》保存商品明细-》审核-》确认收货 最终状态是完全收货。
其中涉及需要关联有商品明细的保存、审核、收货确认 均需要关联
操作关联步骤:
1.录制脚本,进行回放发现,回放一次只会在在原来的订单下新增一条商品明细,不会每次回放均新增一条记录,同时状态均是新增,故存在问题。
2.寻找问题出在商品保存的时候,一直获取是原因的订单的ID和OrderNO ,所以每次保存即在原来的订单下进行保存。
3.把脚本切换到TREE目录下,查找商品明细保存的这段的request的内容,在<Operation>的节点中,看到代码写的方法,可以看到变量,分析哪些变量是不变,哪些变量是更新。从中得知ID和OrderNO,是一直保存于订单头部的一致。
4.ID和OrderNO是可以从订单头部的保存自动生成,即在TREE的Response的XML下可以找到服务器反馈回来的值。
5.此时需要在订单头部查找到Response函数,然后点击函数右键,保存在一个参数里。即Response全部信息均保存在参数里。
6.由于商品保存只需要获得ID和OrderNO,所以需要把这两个另存为其他参数,在商品保存可以直接调用。
7.在商品保存查看Request和tree模式下,找到ID和OrderNO,点击save value in parameter 。即name可以是默认,XML Source是来源头部保存的参数。
8.此时在Script脚本下,在商品保存中,去把ID和OrderNO参数化,调用在request中保存的参数即可。
9.审核和收货确认也一样进行分析。
10.从新跑脚本即可以新增一条订单,同时状态是完全收货。
根据官方文档的介绍:
SQLite does not have a separate Boolean storage class. Instead, Boolean values are stored as integers 0 (false) and 1 (true).
sqlite数据库中没有单独的Boolean存储类,Booean值以0(false)和1(true)来存储.
经我短时间
测试的实践, 显示boolean 有三种状态, 0(false) 1(true) 和 null,如下图所示,
经过下列插入语句,测试,均可插入成功.而且, 可以通过
select * from stu where flag ="
数据库"
查询到name 为a9 的行.
insert into stu (name,flag) values ('a1','true'); -- 0 insert into stu (name,flag) values ('a2','ture'); -- 0 insert into stu (name,flag) values ('a3',1); -- 1 insert into stu (name,flag) values ('a4','null'); --0 insert into stu (name,flag) values ('a5','1'); --1 insert into stu (name,flag) values ('a6',null); -- null insert into stu (name,flag) values ('a7','2'); --1 insert into stu (name,flag) values ('a8',15); --1 insert into stu (name,flag) values ('a9',"数据库"); --0 |
insert into [stu] values('a1', 0); insert into [stu] values('a2', 0); insert into [stu] values('a3', 1); insert into [stu] values('a4', 0); insert into [stu] values('a5', 1); insert into [stu] values('a6', null); insert into [stu] values('a7', 1); insert into [stu] values('a8', 1); insert into [stu] values('string', 0); insert into [stu] values('string2', 0); insert into stu (name,flag) values ('a9',0); --0 |
如此, 猜想, sqlite 是采用了 字符型存储插入的boolean类型数据, 但是,取出的时候, 会将插入的字符型数据转换成int类型来使用.
因此,可以得到下面的结论:
-- 字符可转换为int类型的为且不为0的为 true, 转换失败或转换后为0的为 false(0)
-- int ,long double 等数字,0为false, 其他>=1的为 true(1)
-- 布尔类型报错, null为 null,默认值
ps:尚未对其进行深入了解,目前是实践测试的结论,纯属猜测,如果有知情者,可告知.
1 简介
目前没有对SQL注入技术的标准定义,
微软中国技术中心从2个方面进行了描述[1]:
(1) 脚本注入式的攻击
(2) 恶意用户输入用来影响被执行的SQL脚本
根据Chris Anley的定义[2], 当一个攻击者通过在查询语句中插入一系列的SQL语句来将数据写入到应用程序中,这种方法就可以定义成SQL注入。Stephen Kost[3]给出了这种攻击形式的另一个特征,“从一个
数据库获得未经授权的访问和直接检索”,SQL注入攻击就其本质而言,它利用的工具是SQL的语法,针对的是应用程序开发者编程过程中的漏洞,“当攻击者能够操作数据,往应用程序中插入一些SQL语句时,SQL注入攻击就发生了”。实际上,SQL注入是存在于常见的多连接的应用程序中一种漏洞,攻击者通过在应用程序中预先定义好的查询语句结尾加上额外的SQL语句元素,欺骗数据库服务器执行非授权的任意查询。这类应用程序一般是网络应用程序(Web Application),它允许用户输入查询条件,并将查询条件嵌入SQL请求语句中,发送到与该应用程序相关联的数据库服务器中去执行。通过构造一些畸形的输入,攻击者能够操作这种请求语句去获取预先未知的结果。
在风险方面,SQL注入攻击是位居前列的,与缓冲区溢出等漏洞基本相当。而且如果要实施缓冲区溢出攻击,攻击者必须首先能绕过站点的防火墙;而对于SQL注入攻击,由于防火墙为了使用户能访问网络应用程序,必须允许从Internet到Web服务器的正向连接,因此一旦网络应用程序有注入漏洞,攻击者就可以直接访问数据库进而甚至能够获得数据库所在的服务器的访问权,因此在某些情况下,SQL注入攻击的风险要高于所有其他漏洞。
SQL注入攻击利用的是SQL语法,这使得这种攻击具有广泛性。理论上说,对于所有基于SQL语言标准的数据库软件包括SQL Server,
Oracle,
MySQL, DB2,Informix等以及与之连接的网络应用程序包括Active/Java Server Pages, Cold Fusion Management, PHP或Perl等都是有效的。当然各种软件有自身的特点,实际的攻击代码可能不尽相同。SQL注入攻击的原理相对简单,且各类基于数据库系统的应用程序被广泛使用,介绍注入漏洞和利用方法的公开出版物也大量问世,造成近年SQL注入攻击的数量一直增长,注入攻击的形式也有被滥用的趋势。
关于针对MS SQL Server的普通SQL注入技术的详细介绍,可以参考Chris Anley所撰的“SQL Server应用程序中的高级SQL注入”[2]一文和其后续“更多的高级SQL注入”[4],Cesar Cerrundo所撰的“利用SQL注入操纵Microsoft SQL Server” [5]一文,以及SPI实验室的Kevin Spett撰写的白皮书“SQL注入 你的网络应用程序是否会受攻击?” [6];而针对Oracle的普通SQL注入技术介绍,可以参考Stephen Kost的“针对Oracle开发人员的SQL注入攻击简介”[3]一文。
1.2 SQL注入攻击的防御手段
由于越来越多的攻击利用了SQL注入技术,也随之产生了很多试图解决注入漏洞的方案。目前被提出的方案有:
(1) 在服务端正式处理之前对提交数据的合法性进行检查;
(2) 封装客户端提交信息;
(3) 替换或删除敏感字符/字符串;
(4) 屏蔽出错信息。
方案(1)被公认是最根本的解决方案,在确认客户端的输入合法之前,服务端拒绝进行关键性的处理操作,不过这需要开发者能够以一种安全的方式来构建网络应用程序,虽然已有大量针对在网络应用程序开发中如何安全地访问数据库的文档出版,但仍然有很多开发者缺乏足够的安全意识,造成开发出的产品中依旧存在注入漏洞;方案(2)的做法需要RDBMS的支持,目前只有Oracle采用该技术;方案(3)则是一种不完全的解决措施,例如,当客户端的输入为“…ccmdmcmdd…”时,在对敏感字符串“cmd”替换删除以后,剩下的字符正好是“…cmd…”;方案(4)是目前最常被采用的方法,很多安全文档都认为SQL注入攻击需要通过错误信息收集信息,有些甚至声称某些特殊的任务若缺乏详细的错误信息则不能完成,这使很多安全专家形成一种观念,即注入攻击在缺乏详细错误的情况下不能实施。
而实际上,屏蔽错误信息是在服务端处理完毕之后进行补救,攻击其实已经发生,只是企图阻止攻击者知道攻击的结果而已。本文所介绍SQL盲注技术就是一些攻击者使用的新技术,其在错误信息被屏蔽的情况下使攻击者仍能获得所需的信息,并继续实施注入攻击。
1.3 本文的结构组织
为了理解盲注攻击,我们首先将介绍确定SQL注入漏洞所需的服务器的最小响应;其次,我们将构造一个合乎语法的SQL请求,并可以将之替换成任何有效的SQL请求;最后,我们将讨论在没有详细错误信息的情况下如何利用UNION SELECT语句。本文所讨论的盲注攻击的条件是我们在攻击前对网络应用程序、数据库类型、表结构等等信息都一无所知,这些信息都需要在注入的过程中通过探测获得。
2 确定注入漏洞
要进行SQL注入攻击,首先当然是确认要攻击的网络应用程序存在注入漏洞,因此攻击者首先必须能确立一些与服务器产生的错误相关的提示类型。尽管错误信息本身已被屏蔽,网络应用程序仍然具有能区分正确请求和错误请求的能力,攻击者只需要学习去识别这些提示,寻找相关错误,并确认其是否和SQL相关。
2.1 识别错误
一个网络应用程序主要会产生两种类型的错误,第一种是由Web服务器产生的代码异常(exception),类似于“500:Internal Server Error”,通常如果SQL注入语句出现语法错误,比如出现未闭合的引号,就会使服务器抛出这类异常。如果要屏蔽该类错误,一般会采用将默认的错误信息替换成一个事先定制的HTML页面,但只要观察到有这种响应出现,就可以确认其实是发生了服务器错误。在其他情况下,为了进一步屏蔽该类错误,有些服务器一出现异常,会简单地跳转到主页面或前一个访问过的页面, 或者显示一条简单的错误消息但不提供任何细节。
第二类错误是由应用程序代码产生的,这代表其开发者有较好的编程习惯。这类应用程序考虑到可能会出现一些无效的情况,并分别为之产生了一个特定的错误信息。尽管出现这类错误一般会返回一个请求有效的响应(200 OK),但页面仍然会跳转到主页面,或者采用某种隐藏信息的办法,类似于“Internal Server Error”。
为了区分这两种错误,我们看一个例子:有两个电子商务的应用程序,A和B,两个应用程序都使用同一个叫proddetails.asp的页面,该页面期待获得一个参数,叫ProdID。它获取该参数后,从数据库中提取相应的产品详细信息数据,然后对返回的结果进行一些处理。两个应用程序都是通过一个产品列表页面上的链接调用proddetails.asp,因此能保证ProdID一直都是存在且有效的。应用程序A认为这样就不会出现问题,因此对参数不做额外的检查,而如果攻击者篡改了ProdID,插入了一个在数据表中不存在的id,数据库就会返回一个空记录。由于应用程序A没有料到可能会出现空记录,当它试图去处理该记录中的数据时,就可能会出现异常,产生一个“500:Internal Server Error”。而应用程序B,会在对记录进行处理前确认记录的大小超过0,如果是空记录,则会出现一个错误提示“该产品不存在”,或者开发者为了隐藏该错误,会将页面重新定位到产品的列表页面。
因此攻击者为了进行SQL盲注,会首先尝试提交一些无效的请求,并观察应用程序如何处理这些错误,以及如果出现SQL错误会发生什么情况。
2.2 定位错误
对要攻击的应用程序有了初步的认识后,攻击者会试图定位由人为构造的输入而产生的错误信息。这时,攻击者就会使用标准的SQL注入测试技术,比如添加一些SQL关键字(如OR,AND等)和一些META字符(如;或’等)。每一个参数都被独立地进行测试,而获得的响应将被检验用来判断是否产生了错误。通过一个拦截代理服务器(intercepting proxy)或者类似的工具可以方便地识别页面跳转和其他一些可预测的隐藏错误,而任何一个返回错误的参数都有可能存在SQL注入漏洞。而在单独测试每个参数过程中,必须保证其他参数都是有效的,因为需要避免除注入以外任何其他可能的原因所导致的错误影响了判断结果。测试的结果一般是一个可疑参数的列表,列表中的一些参数可能的确可以进行注入利用,另外一些参数则可能是由一些SQL无关的错误所造成,因此需要被剔除。攻击者接下来就需要从这些参数中挑选真正存在注入漏洞的参数,我们称之为确定注入点。
2.3 确定注入点
SQL字段可以被划分为三个主要类型:数字、字符串和日期。虽然每个类型都有其特点,但却与注入的过程无关。每一个从网络应用程序提交给SQL查询的参数都属于以上三个类型中的一类,其中数字参数被直接提交给服务器,而字符串和日期则需要加上引号才被提交,例如:
SELECT * FROM Products WHERE ProdID = 4
与
SELECT * FROM Products WHERE ProdName = 'Book'
而SQL服务器,并不关心它接受到的是什么类型的参数表达式,只要该表达式是相关的类型即可。而这个特点则使攻击者能够很容易地确认一个错误是否和SQL相关。如果是数字类型,最简单的处理办法是使用基本的算术操作,例如以下请求:
/mysite/proddetails.asp?ProdID=4
测试该参数的一种办法是插入4’作为参数,另一种是使用3+1作为参数,假设这两个参数已直接被提交给SQL请求语句,则将形成以下两个SQL请求语句:
(1) SELECT * FROM Products WHERE ProdID = 4'
(2) SELECT * FROM Products WHERE ProdID = 3 + 1
第一个SQL语法有问题,将一定会产生一个错误,而第二个如果被顺利地执行,返回和最初的请求(即ProdID等于4)一样的产品信息,这就提示该参数是存在注入漏洞的。
类似的技术可以被应用于用一个符合SQL语法的字符串表达式替换该参数,这里有两个区别:第一,字符串表示式是放在引号中的,因此需要阻断引号;第二,不同的SQL服务器连结字符串的语法不同,比如MS SQL Server使用符号+来连结字符串,而Oracle使用符号||来连结。例如以下请求:
/mysite/proddetails.asp?ProdName=Book
要测试该ProdName参数是否有注入漏洞,可以先其替换成一个无效的字符串比如Book’,然后再替换成一个可能生成正确字符串的表达式,比如B’+’ook(对于Oracle,是B’||’ook)。这就会形成以下两个SQL请求语句:
(1) SELECT * FROM Products WHERE ProdName = 'Book''
(2) SELECT * FROM Products WHERE ProdID = 'B' + 'ook'
则第一个仍然可能产生一个SQL错误,而第二个则可能返回和最初的请求一样的值为Book的产品。
我们注意到,即使应用程序已经过滤了’和+等META字符,我们仍然可以在输入时过把字符转换成URL编码(即字符ASCII码的16进制)来绕过检查,例如:
/mysite/proddetails.asp?ProdID=3+1就等于/mysite/proddetails.asp?ProdID=3%2B1
/mysite/proddetails.asp?ProdID=B’+’ook就等于/mysite/proddetails.asp?ProdID=B%27%2B%27ook
类似的,任何表达式都可以用来替换最初的参数。而特殊的系统函数也可以被用来提交以返回一个数字,一个字符串或一个日期,比如Oracle中sysdate返回一个日期表达式,而在SQL Server中,getdate()会返回日期表达式。其他的技术同样可以被用来判断是否存在SQL注入漏洞。
通过以上介绍可以发现,即使没有详细的错误信息,对于攻击者来说,判断是否存在SQL注入漏洞仍然是一个非常简单的任务。
3 实施注入攻击
攻击者在确定注入点后,就要尝试进行注入利用,这需要其能确定符合SQL语法的注入请求表达式,判断出后台数据库的类型,然后构造出所需的利用代码。
3.1 确定正确的注入句法
这是SQL盲注攻击中最难也最有技巧的步骤,如果最初的SQL请求语句很简单,那么确定正确的注入语法也相对容易,而如果最初的SQL请求语句较复杂,那么要想突破其限制就需要多次的尝试,但进行这些尝试所需要的基本技术却是非常简单。
确定基本的句法的过程即通过标准的SELECT … WHERE语句,被注入的参数(即注入点)就是WHERE语句的一部分。为了确定正确的注入句法,攻击者必须能够在最初的WHERE语句后添加其他数据,使其能返回非预期的结果。对一些简单的应用程序,仅仅加上OR 1=1就可以完成,但在大多数情况下如果想构造出成功的利用代码,这样做当然是不够的。经常需要解决的问题是如何配对插入语符号(parenthesis,比如成对的括号),使之能与前面的已使用的符号,比如左括号匹配。另外常见的问题是一个被篡改的请求语句可能会导致应用程序产生其他错误,这个错误往往难于和一个SQL错误相区分,比如应用程序一次如果只能处理一个记录,在请求语句后添加OR 1=1可能使数据库返回1000条记录,这时就会产生错误。由于WHERE语句本质上是一串通过OR、AND或插入语符号连接起来的值为TRUE或FALSE的表达式,因此要想确定正确的注入句法,关键就在于能否成功地突破插入语符号限制并能顺利地结束请求语句,这就需要进行多次组合测试。例如,添加AND 1=2能将整个表达式的值变为FALSE,而添加OR 1=2则不会对整个表达式的值产生影响(除非操作符有优先级)。
对于一些注入利用,仅仅改变WHERE语句就足够了,但对于其他情况,比如UNION SELECT注入或存储过程(stored procedures)注入,还需要能先顺利地结束整个SQL请求语句,然后才能添加其他攻击者所需要的SQL语句。在这种情况下,攻击者可以选择使用SQL注释符号来结束语句,该符号是两个连续的破折号(--),它要求SQL Server忽略其后同一行的所有输入。例如,一个登录页面需要访问者输入用户名和密码,并将其提交给SQL请求语句:
SELECT Username, UserID, Password FROM Users WHERE Username = ‘user’ AND Password = ‘pass’
通过输入john’--作为用户名,将会构造出以下WHERE语句:
WHERE Username = ‘john’ --'AND Password = ‘pass’
这时,该语句不但符合SQL语法,而且还使用户跳过了密码认证。但是如果是另外一种WHERE语句:
WHERE (Username = ‘user’ AND Password = ‘pass’)
注意到这里出现了插入语符号,这时再使用john’--作为用户名,请求语句就会错误:
WHERE (Username = ‘john' --' AND Password = ‘pass’)
这是因为有未配对的插入语符号,请求语句就不会被执行。
这个例子显示出使用注释符号能够用来判断请求语句是否被顺利地结束了,如果添加了注释符号且没有产生错误,这就意味着注释符号前的语句已经顺利地被结束。如果出现了错误,这就需要攻击者进行更多的请求尝试。
3.2 判断数据库类型
攻击者一旦确定了正确的注入句法后,就会开始利用注入去判断后台数据库的类型,这个步骤比确定注入句法要简单得多。攻击者一般会使用以下几种技巧,这些技巧是基于不同类型数据库引擎在具体实现上的差异。下面只介绍如何区分Oracle和MS SQL Server:
最简单的办法,就是前面提到的利用字符串的连结符号,在注入句法已经确定的情况下,攻击者可以对WHERE语句自由地添加额外的表达式,那么就可以利用字符串的比较来区分数据库,例如:
AND 'xxx' = 'x' + 'xx' (或者 AND %27xxx%27+%3D+%27x%27+%2B+%27xx%27)
通过将+替换成||,就可以判断出是数据库是Oracle还是MS SQL Server,或者是其他类型。
其他的办法是利用分号字符(即;),在SQL中,分号是用来将几个SQL语句连接在同一行中。在注入时,也可以在注入代码中使用分号,但Oracle驱动程序却不允许这样使用分号。假设在前面使用注释符号时没有出现错误,那么在注释符号前加上分号对MS SQL Server是没有影响的,但如果是Oracle就会产生错误。另外,还可以使用COMMIT语句来确认是否允许在分号后再执行其他语句(例如,注入语句xxx' ; COMMIT --),如果没有出现错误就可以认为允许多句执行。
最后,表达式还可以被替换成能返回正确值的系统函数,由于不同类型的数据库使用的系统函数也是不同的,因此也可以通过使用系统函数来确定数据库类型,比如2.3节提到的MS SQL Server的日期函数getdate()与Oracle的sysdate.
3.3 构造注入利用代码
当所有相关的信息都已获得后,攻击者就可以开始进行注入利用,而且在构造注入利用代码过程中也不再需要详细的错误信息,构造利用代码本身可以参考其他描述标准SQL注入攻击的文档。
由于对于普通的SQL注入利用,已经有很多其他论文进行了详细的讨论,故本文只会在下一节介绍一种UNION SELECT注入。
4 UNION SELECT注入
尽管通过篡改SELECT…WHERE语句来注入对于很多应用程序非常有效,但在盲注情况下,攻击者仍然愿意使用UNION SELECT语句,这是因为与WHERE语句所进行的操作不同,使用UNION SELECT可以让攻击者在没有错误信息的情况下依然能访问数据库中所有表。
进行UNION SELECT注入需要预先获知数据库的表中的字段个数和类型,而这些信息一般被认为在没有详细错误信息的提示下是不可能获得的,但本文下面就将给出解决该问题的方法。
另外需要注意的是,进行UNION SELECT的前提是攻击者已经确定了正确的注入句法,本文的前面一节已经阐明了这在盲注条件下是可以实现的,而且在使用UNION SELECT语句之前,SQL语句中所有的插入语符号都应该已经完成配对,从而可以自由地使用UNION或者其它指令进行注入。UNION SELECT还要求当前语句和最初的语句查询的信息必须具有相同的数和相同的数据类型,不然就会出错。
4.1 统计列数
当错误信息没有被屏蔽时,要获取列数只需要在进行UNION SELECT注入时每次尝试使用不同的字段数即可,当错误信息由“列数不匹配”变成“列的类型不匹配”时,当前尝试的列数就是正确的。但在盲注条件下,由于我们对无法获悉错误信息究竟是哪个,所以该方法也就失去了作用。
新的办法是利用ORDER BY语句,在SELECT语句最后加上ORDER BY能够改变返回的记录集的次序,一般是按一个指定的列名的值进行排序。例如,当通过产品号查询产品时,一个有效的注入语句如下:
SELECT ProdNum FROM Products WHERE (ProdID=1234) ORDER BY ProdNum --
AND ProdName=’Computer’) AND UserName=’john’
人们往往会忽略的是ORDER BY语句后还可以使用数字指代列名,在上例中如果ProdNum是查询请求返回的记录中的第一列,则注入1234) ORDER BY 1--返回的结果是一样的。由于上例查询请求只返回一个字段,注入1234) ORDER BY 2 --就会出错,即返回的记录无法按指定的第二个字段排序。这样,ORDER BY就可以被利用来对列数进行统计了。由于每个SELECT语句都至少返回一个字段,故攻击者可以先在注入句法中添加ORDER BY 1来确定语句是否能被正确执行,有时对字段的排序也可能会产生错误,这时添加关键字ASC或DESC可以解决该问题。一旦确定ORDER BY句法是有效的,攻击者就会对排序列号从列1到列100进行遍历(或者到列1000,直到列号被确定为无效),理论上当出现第一个错误时,前一个列号就是要统计的列数,但在实际情况中,有些字段可能不允许排序,那么在出现第一次错误时可以再多尝试一到两个数字,以确认列号已遍历完。
4.2 判断列的数据类型
在统计完列数后,攻击者需要再判断列的数据类型,在盲注情况下判断类型也是有技巧的,由于UNION SELECT要求前后查询语句查询的字段类型相同,故如果字段数有限,可以简单地利用UNION SELECT语句对字段类型进行暴力穷举(brute force),但如果字段数较多,判断就会出现问题。根据前文,字段的类型只有数字、字符串和日期三种可能的类型,一旦字段数有10个,那么就意味着有310(约60,000)种可能的组合,假设每一秒可以自动进行20次尝试,穷举一遍也需要近一个小时,如果字段数更多,那么测试所需时间就会令人难以忍受。
一种简单的办法是利用SQL的关键字NULL,与静态字段的注入需要区分是数字类型还是字符类型不同,NULL可以匹配任何一种数据类型。因此可以注入一个所有查询字段都为NULL的UNION SELECT语句,那么就不会出现任何类型不匹配的错误。让我们再举一个与前面类似的例子:
SELECT ProdNum,ProdType,ProdPrice,ProdProvider FROM Products
WHERE (ProdID=1234 AND ProdName=’ Computer’) AND UserName=’john’
假设攻击者已经获得了列数(在该例中为4),那么就可以很简单地构造一个UNION SELECT语句,其中所有查询字段都为NULL,还需要构造一个不会产生权限问题的FROM语句。对于MS SQL Server,即使忽略FROM语句也不会出错,但对于Oracle,则可以使用一个名叫dual的表。最后,还需要一个值一定为FALSE的WHERE语句(比如WHERE 1=2),这是为了确保查询不会返回只包含null值的记录集,以杜绝产生其他可能的错误。那么针对MS SQL Server的注入语句如下:
SELECT ProdNum,ProdType,ProdPrice,ProdProvider FROM Products
WHERE (ProdID=1234) UNION SELECT NULL,NULL,NULL,NULL
WHERE 1=2 -- AND ProdName=’ Computer’) AND UserName=’john’
这个NULL注入语句有两个目的,主要目的是构造一个不会产生任何错误的UNION SELECT语句以测试UNION语句是否可以被执行,另一个目的是为了对数据库类型的判断进行100%确认(可以通过在FROM语句里添加一个数据库开发商预置的表名进行测试)。
如果NULL注入语句被顺利执行,那么就可以快速地对每个列的类型进行判断。在每一轮尝试中,只对一个字段类型进行测试,由于类型只有三类,所以每个字段最多被测试三次就会有结果,这样尝试的次数最多是列数的三倍,而不是以3为底数以列数为指数的次数。假设ProdNum属于数字类型,其它三个字段都属于字符串类型,那么以下顺序的注入语句就可以判断出正确的类型:
1234) UNION SELECT NULL,NULL,NULL,NULL WHERE 1=2 --
无错 句法正确,使用的是MS SQL Server数据库
1234) UNION SELECT 1,NULL,NULL,NULL WHERE 1=2 --
无错 第一个字段是数字类型
1234) UNION SELECT 1,2,NULL,NULL WHERE 1=2 --
出错 第二个字段不是数字类型
1234) UNION SELECT 1,’2’,NULL,NULL WHERE 1=2 --
无错 第二个字段是字符串类型
1234) UNION SELECT 1,’2’,3,NULL WHERE 1=2 --
出错 第三个字段不是数字类型
1234) UNION SELECT 1,’2’,’3’,NULL WHERE 1=2 --
无错 第三个字段是字符串类型
1234) UNION SELECT 1,’2’,’3’,4 WHERE 1=2 --
出错 第四个字段不是数字类型
1234) UNION SELECT 1,’2’,’3’,’4’ WHERE 1=2 --
无错 第四个字段是字符串类型
攻击者现在就已经获得了每一列的数据类型,盲注还可以被应用于从数据库的表中获取数据,比如获得数据表的列表以及它们各自的列名,还可以从应用程序中获得数据,而这些技术在其他一些关于SQL注入的论文中已经有讨论,故本文不再继续介绍。
在看普泽关于pezybase的
测试报告的时候,发现里面有用到jmeter(http协议)并发测试下载文件,考虑到后面可能需要在公司pezybase的并发下载,把之前使用过的loadrunner下载文件脚本重新运行和整理一下。
一、http协议
loadrunner使用http协议是无法录制到下载过程的,只会往服务器发送一个下载请求,其实服务器已经把数据返回给客户端了,但是loadrunner是录制不到保存文件到本地这个过程,所以就是需要我们手动把收到的内容保存打本地即可。(http协议上传文件的完整过程是可以直接录制的,在UC中已经使用过)。
注意:下面脚本中用到的LR函数如下,还使用了一些C语言基本的文件操作方法。在脚本中还可以加入一些判断来进行事务是否成功以及文件大小是否正确等的判断;
web_reg_save_param:关联函数,放在http请求前面,保存请求返回的内容;
web_url:http请求函数,向指定的url发送请求,下载文件也就是直接往下载链接发送请求;
web_get_int_property:获取下载请求返回的文件长度;
web_set_max_html_param_len:设置web_set_max_html_param_len方法中参数的最大长度,要求大于需要下载文件的大小;
Action() { int flen;//定义一个整型变量保存获得文件的大小 long fileContent;//保存文件句柄,也就是文件的内容 char fileName[]="";//保存文件路径及文件名 char * strNumber; strNumber=lr_eval_string("test{NewParam}");//获取一个随机数并转化成字符串 ,NewParam设置参数为随机类型,这里根据自己需要进行参数化设置 strcat(fileName,"C:/test/");//将路径保存到file变量中 strcat(fileName,strNumber); //拼接文件名 strcat(fileName,".pdf");//拼接后缀名,根据需要设置,最后就完成了完整的路径和文件名 web_set_max_html_param_len("20000");//设置参数的最大长度,注意该值必须大于文件的大小 //使用关联函数获取下载文件的内容,在这里不定义左右边界,获得服务器响应的所有内容 web_reg_save_param("fcontent", //返回的内容全部存储在fcontent这个参数中 "LB=", "RB=", "SEARCH=BODY", LAST); lr_start_transaction("下载文件"); #设置的事务开始点 #web_url方法你可以直接编写,也可以在启动录制的时候,输入下载链接URL进行简单录制,主要注意URL和Resource这两个参数即可; web_url("file.php", #函数名,没有实际作用 "URL=http://forum.ubuntu.org.cn/download/file.php?id=129973&sid=78fc8d76767ef49b606595824ceb963d", #下载链接,也就是该链接输入到浏览器会提示下载,获取方法很多; "Resource=1", #1表示是下载资源,0表示是页面资源 "RecContentType=application/octetstream", "Referer=", "Snapshot=t1.inf", LAST); flen = web_get_int_property(HTTP_INFO_DOWNLOAD_SIZE);//获取响应中的文件长度 if(flen > 0) { //以写方式打开文件 fileContent = fopen(fileName, "wb"); if(fileContent == NULL) #看是否正确打开了需要保存下载内容的文件,fileName是上面准备组织的文件路径; { lr_output_message("打开文件失败!"); return -1; } fwrite(lr_eval_string("{fcontent}"), flen, 1, fileContent);//写入文件内容 fclose(fileContent);//关闭文件 } lr_end_transaction("下载文件",LR_AUTO);#事务结束点 return 0; } |
二、java user协议
使用java user协议更简单,就是直接使用java编写一段从指定链接下载文件的脚本即可;
import java.io.BufferedInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.net.MalformedURLException; import java.net.URL; import java.net.URLConnection; import lrapi.lr; public class Actions { public int init() throws Throwable { return 0; }//end of init public int action() throws Throwable { int DownLoadSize = 0; String path = "c:\\temp\\"; //设置下载文件保存路径 String vuid = String.valueOf(lr.get_vuser_id()); //获取当前虚拟用户ID并转换成字符串 DownLoadSize = UrlTools.getHttpFileByUrl("http://forum.ubuntu.org.cn/download/file.php?id=129973&sid=78fc8d76767ef49b606595824ceb963d",vuid,path); //调用UrlTools.getHttpFileByUrl() return 0; }//end of action public int end() throws Throwable { return 0; }//end of end } class UrlTools { public static int getHttpFileByUrl(String address,String userid,String path) { //定义下面需要用到的变量 URL url; URLConnection conn = null; int BUFF_SIZE = 1024; byte[] buf = new byte[BUFF_SIZE]; int DownLoadSize = 0; BufferedInputStream bis; FileOutputStream fos = null; int size = 0; try { url = new URL(address); //address为传递进来需要下载的链接 conn = url.openConnection();//使用url实例化需要下载的链接 bis = new BufferedInputStream(conn.getInputStream()); //把需要下载的文件内容保存在bis这个输入流中 fos = new FileOutputStream(path+"\"+userid+"test000001"+“.pdf”));//组成完整路径,并实例化到输出流,这里可以进行参数化,如参数化文件名, // 路径需要事先手动创建好,当然你也可以在脚本中创建实现不同的路径 System.out.println("需要下载的文件大小为:" + conn.getContentLength()/1024 + "k"); while((size = bis.read(buf)) != -1) #按照设置的buf大小写文件并记录下载的大小 { fos.write(buf,0,size); DownLoadSize = DownLoadSize+size; } bis.close(); fos.close(); System.out.println("用户" + userid + "下载" + url +"完成!"); }catch(MalformedURLException e) { System.out.println("下载发生异常:"); e.printStackTrace(); }catch(IOException e) { System.out.println("下载发生异常:"); e.printStackTrace(); } return DownLoadSize/1024; } } |
这里从我们team的代码中来总结下常见的几种找页面元素的方法:
(1)通过WebElement的ID
如果某个WebElement提供了ID,
<input type="text" name="passwd"id="passwd-id" />
(2)通过WebElement的name查找:
WebElement element = driver.findElement(By.name("passwd"));
(3)通过WebElement的xpath查找:
WebElement element =driver.findElement(By.xpath("//input[@id='passwd-id']"));
(4)通过WebElement的样式查找:
<div class="cheese"><span>Cheddar</span></div><divclass="cheese"><span>Gouda</span></div>
可以通过这样查找页面元素:
List<WebElement>cheeses = driver.findElements(By.className("cheese"));
(5)通过超链接文本查找:
<ahref="http://www.google.com/search?q=cheese">cheese</a>>
那么可以通过这样查找:
WebElement cheese =driver.findElement(By.linkText("cheese"));
这是两个很绕口的词。而且乍一看起来好像就是同一份
工作。今儿聊聊我个人对于这两者的认识。
举例:
有一天,一家
手机公司要做一个UI自动化
测试,于是他们聘请了一名工程师。
这个工程师需要做的事情,首先就是setup一个
自动化测试环境。单单从这方面来说,测试工程师和自动化工程师需要做的是完全一样的。比如搭建起来一套完整的UiAutomator环境。
之后就会有区别了。当环境搭建好以后,测试工程师的主要精力就会铺到编写脚本,执行测试上。而自动化工程师则会把精力放在如何优化UiAutomator环境上
比如,大家都知道UiAutomator的case编写完成后,首先需要通过ant编译,然后再通过adb命令进行push,最后才能执行。这一点上,一般来说测试工程师就不会做什么改变了,但是自动化工程师一定会做一个程序或者批处理或者其他的什么,让这几个步骤变成点一下就全干完的事情。
什么是测试自动化:
这是一种让测试过程脱离人工的一次变革。对于控制成本,控制质量,回溯质量和减少测试周期都有积极影响的一种研发过程。
什么是自动化测试:
通过将测试执行部分部分或者全部交由机器执行的一种测试,叫做自动化测试。这种测试不需要人的实时参与。同时这种测试在小规模应用时会比手动测试昂贵许多。
自动化测试可以看作测试自动化的一部分。
不同的工程师,工作不同:
一个自动化工程师,会比较专注于测试工具的研发。最主要的是这个工程师会从成本的角度去考虑问题。这一点比较像PM。他所做的一切是为了减少自己或者团队的工作量,尽可能的将重复的,有规律可循的工作代码化,自动化。
一个自动化测试工程师,会比较专注于测试代码的开发,以及测试结果的分析。对于被测设备本身非常感兴趣。他们比较倾向于一种完美主义者,追求的是高质量而经常忽略成本。这一点更像开发人员。
现在绝大多数公司都会执着于自动化测试,而忽略测试自动化。这一点会让整个AT(automation
test,下同)成本变得非常高。
我曾经
面试过一家公司的AT工程师,对方对于AT的做法就是每天都在release新的测试代码,每天都在run不同的测试。每天都在修改之前的case。我说你这个并不是自动化测试,而是一种用代码测试产品的手动测试。这样的测试,经常被冠以自动化测试之名混水摸鱼。
这家公司很明显的只是将代码
单元测试贴上了自动化的幌子。
自动化测试的几个准则:
并不是将测试用例代码化了,就可以称之为自动化测试了。这是现在很多公司宣称自己做AT的一个噱头。
AT的代码有很多的要求。
首先就是你的覆盖面要够广。个位数case的自动化完全没有意义。
第二就是你的case必须要能够复用:软件每天都在变,如果你的case要天天跟着软件变,那你的case是完全不合格的。
第三就是测试的规模要够大:要么时间长(case多或者是压力测试),要么测试产品多。这样才能体现出来自动化测试的优势。、
测试自动化的几个准则:
第一个就是要减少除工具研发部门外,其他所有测试部门的人力成本。这个是测试自动化追求的终极目标之一。、
第二个就是提高测试质量,不仅仅包括测试执行的质量,还包括测试的统计质量,数据回溯质量,等等等等。这些质量的提高可以帮助测试团队修正他们的测试方法,而不是每天将精力铺在无止境的数据收集和分析中。
第三个就是要抢出时间。某一项工作自动化后的时间,要么比人手做时间短,要么可以在非工作的16个小时中进行。通过让电脑OT的方法来解放工程师或者项目经理。
自动化的三大入手点:
自动化的三大入手点其实和三大准则是一样的。看哪个需求更加迫切:
1. 成本:自动化并不一定围绕测试执行,还可以包括测试的准备,log的提取,数据分析等等。将所有的与测试有关的工作逐一列出,然后找到重复的,可以被代码化的部分,评估现有工作成本和自动化成本,寻找到收益最大的工作块并顺序将之代码化。
2. 质量:和成本差不多,只是在评估的时候需要评估的是该工作块现有的质量状况和需求质量间的差异,寻找到差异最多的那个模块,并将所有质量差的模块逐一进行自动化。
3. 时间:和以上两点一样,都需要寻找到与测试有关的所有步骤和工作块,将其中关键路径上,动作最慢,耗时最大的部分进行自动化。
版权声明:本文出自 zeustest 的51Testing软件测试博客:http://www.51testing.com/?15030005
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
一 、界面检查
进入一个页面
测试,首先是检查title,页面排版,字段等,而不是马上进入文本框校验
1、页面名称title是否正确
2、当前位置是否可见 您的位置:xxx>xxxx
3、文字格式统一性
4、排版是否整齐
5、列表项显示字段是否齐全,列表项字段名称是否跟表单统一
6、同一页面,是否出现 字段名称相同、值取不同的问题。
7、数据加载情况:除了文本框的值,还要注意:
复选框,是否保存打√,或者保存不打√
下拉框,是否保存选择的值
多文本框,值是否都被保存,空格,换行是否保存
二、单文本框(type=text)
边界:字段长度
判空:是否可以为空
唯一性:是否唯一 (小归结:边界、判空、唯一性、特殊字符、正确性)
考虑语言,操作环境
特殊符号测试输入:
' or 1<>'1 ' or '1'='1 ' or '1'<>'2 "|?><
where a='xxx' 下划线是否允许 输入全部空格 输入 单引号
><script>alert(“123”);</script>>
特殊字段输入限定:
框内容是否合法(tel,ip,url,email)序号等,直接限制输入数字,其他过滤掉
输入金额文本框,整数首位为0,过滤掉,小数点后面,一般保留两个有效数字。
正确性测试:(必不可少的步骤)
1)、(字段长度输入最大允许长度时)数据允许长度的测试:
a、页面是否被挤出的测试(都输入长英文字符串,是否断行);
b、
数据库是否允许最大字符(都输入汉字、都输入英文、混合……);
c、最短长度的正确流程,最大长度的正确流程覆盖。
2)、对于允许为空的字段,不填入,再次数据传递后,看是否报500错误。
3)、未规定字段长度(或者数值大小),不按死板输入,输入非常多字符(或者非常大的数值)时,做允许动作的正确性校验,看是否报错。(要达到的结果:不管有没有长度限制(没有给最长、最大限制让你去测?),最终页面不能抛数据库异常。)monkey
test 说明:通过不断输入长字符串,看是否有长度校验;
最终都会出现以下两种情况的一种:
A、页面(前台)有校验长度、大小; 或者
B、无校验,数据库报错。
所以: 所有字段都要做长度、大小限制(不管需求有没有给出明确要求,不管测试颗粒度,都要限制长度,不允许报数据库错误,都要测!!!)。最大长度限制可限定方法:1、不允许再输入;2、自动截断处理,并且给用户提示
关于长度概念:
1、 数据库规定的字节长度A
2、 页面上可以输入的字符数B
控制方法:
1)、页面上,不管输入什么字符(全角如汉字、半角如字母),统一规定不能超过B个字符,此种限制,
测试点:全部输入全角B个,测试(B*3字节)会不会超过数据库字节长度
全部输入半角B个,测试(B*1字节)会不会超过数据库字节长度
混合输入全角X半角Y,测试(X*3+Y字节)会不会超过数据库长度
2)、页面上,不以字符统计,以总的输入字节数统计,比如,全部输入全角字符,允许可以输入A/3个字符,全部输入半角字符,允许输入A个字符( 民生网的设计)
测试点:全部输入全角,看是否允许输入A/3个字符
全部输入半角,看是否允许输入A个字符
混合输入全角X,半角Y,看是否允许X*3+Y=A
(5个:判空、唯一、边界值、特殊字符、正确流程(多种数据、多种分支))
+测试校验位置:ajax鼠标事件校验、前台提交按钮js校验,服务器拿到数据后再次验证
三、多文本框(type=textarea)
1)、空格和换行的问题,看需求,是否需要做支持HTML Encoding
输入全部空格时,是否判空处理?””空格, 。
输入折行,是否也显示折行?
比如:列点说明原因,就需要支持。
2)、字母截断的问题
对于一串字母,开发人员往往会忘掉做截断,这样如果展示在我们的平台上的话,这一串字母就会把我们的UI撑开
3)、长度控制格式, 您还可以输入***个字符
四、添加按钮
添加动作检查范围:
失败:是否提示
提示内容是否正确
失败时:保存用户已输入的内容,避免重新再输入
成功:对话框消失
记录是否可直接查看(还需要刷新?)
列表记录顺序
重复提交情况,点击一次后,是否变成disable
上传附件的添加:
A. 文件名称:文件名称很长;文件名称字符多样化(汉字,英文,符号);文件名称重复。
B. 判空?
C. 附件格式类型支持?
D. 附件个数?
E. 附件空间大小。
五、移除按钮
1.一般都要在前台先给出一个提示操作“确定移除该……”
2.相关联的东西,是否需要限制移除“该类型下存在应用,无法移除”有到后台比较
3.确定后,真正执行移除操作。
结果:
移除后,列表数据是否立即消失。
必须有确认删除的提示信息
六、列表
1)、列表记录顺序
2)、是否需要翻页、有没有翻页功能
3)、字段名称是否与表单一致
七、搜索-文本框
1、功能点、需求点考虑:
是否提供模糊查询、输入数值有种类有限定时,是否考虑换成下拉框搜索;
2、检查点:
文本框值是否消失(是否回填条件值),再次点击“查询”可查看所有记录;
考虑搜索结果:是否存在分页,分页是否正常;是否有序;
注意:分页是否仍保存查询条件,检查后面的记录是否符合条件
3、查询数据多样性:
输入不存在的字段值测试、包括特殊字符查询测试例如:' or '1'='1;
输入类似程序语句的条件时是否执行查询,如:XXXX”、XXX and ;
4、操作类型:
1) 不输入的查询
2) 输入全部空格的查询
3) 模糊查询(输入部分字段,或者说,输入英文字母,查询到相关中文数据)
4) 输入不存在的查询
5) 输入存在的查询
6) 单个查询和多个条件复合查询。
八、搜索-下拉框
检查点:
a) 搜索结果是否有序;
b) 下拉框值是否齐全;(下拉框值本身也是一个动态查询的结果)
c) 下拉框值是否自动消失,再次点击“查询”可查看所有记录(是否要回填条件值);
d) 分页时,是否保存搜索条件。
(从UI、开发、业务逻辑、用户使用等角度测试)
PS:
以上总结的, 是比较纯粹的从页面控件角度测试点出发, 对于完整测试一个整体页面,需要各类测试有机结合起来:
1)UI测试:
页面布局; 页面样式检查;控件长度是否够长;显示时,是否会被截断;支持的快捷键,Tab键切换焦点顺序正确性等。
2)功能测试:页面上各类控件的测试范围,测试点,可参考上方
结合控件的实际作用来补充检查点: 比如, 密码框是否*显示, 输入是否做trim处理等
3)安全测试:输入特殊字符,sql注入,脚本注入测试
后台验证测试,对于较重要的表单 ,绕过js检验后台是否验证
数据传输是否加密处理,比如, 直接请求转发,地址栏直接显示发送字符串?
数据库存储,特别密码等,是否加密形式存储
4)兼容性测试
5)性能测试
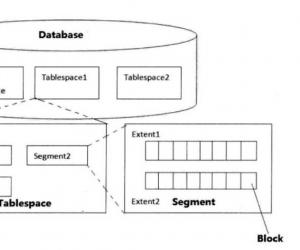
oracle的体系逻辑结构
(1)表空间(TABLESPACE) ,包括:系统表空间、回滚段表空间、临时表空间、用户表空间(除用户表空间外其他三张表空间有各自特定的用途,不可随意更改和破坏)
在建表时,可以指定表空间,例如: create table t(id int) tablespace tbs_test;
建各类表空间的方法:
① 普通数据表空间
create tablespace TBS_LJB(表空间名) datafile 'E:\ORADATA\ORA11\DATAFILE\TBS_LJB_01.DBF'(数据文件全路径) size 100M(大小) extent management local --(这两句,在oracle 10g及以上版本,可以取消) segment space management auto; |
②临时表空间
CREATE TEMPORARY TABLESPACE temp_ljb
TEMPFILE 'E:\ORADATA\ORA11\DATAFILE\TMP_LJB.DBF' SIZE 100M;
③回滚段表空间
create undo tablespace undotbs2
datafile 'E:\ORADATA\ORA11\DATAFILE\UNDOTBS2.DBF' size 100M;
补充:
1、建用户,并将先前建的表空间 tbs_ljb 和临时表空间 temp_ljb 作为 ljb 用户的默认使用空间。
create user ljb identified by ljb default tablespace tbs_ljb temporary tablespace temp_ljb; -- 赋给ljb dba权限 grant dba to ljb; |
2、如果表空间不足,可以有两种方法:
第一种,增加数据文件:
ALTER TABLESPACE TBS_LJB(表空间名) ADD DATAFILE '......'(数据文件全路径名) SIZE 100M;
第二种,把表空间设置为自动扩展:
ALTER DATABASE DATAFILE '.......'(数据文件全路径名) autoextend on; (在创建表空间时,就可以加上这个关键字,表示该表空间自动扩展)
3、删除表空间
drop tablespace TBS_LJB
including contents and datafile;
如果表空间有数据,不增加 including contents 将无法删除成功,增加 and datafiles 关键字在linux 及
unix 下可自动删除数据文件,而在windows 环境下需要手动删除
4、UNDO 表空间和 TEMP 表空间在数据库建好是必然已经创建好了,不过,它们都可以新建,并且用户都可以指定新建的空间。
5、oracle 可以为不同的用户指定不同的临时表空间,而且可以为同一用户的不同session 设置不同的临时表空间(临时表空间组),从而减缓IO 竞争。
(2)段(SEGMENT)
每建立一张表,往往对应一个段,如果是分区表,那么各个分区又独立成段。在表上建一个索引,则又会有一个对应的索引段。
(3)区(EXTENT)
oracle 分配空间的最小单位
(4)块(BLOCK)
oracle 的最小逻辑数据单位
 11
11
Java代码
// BufferedReader in = null; // BufferedWriter out = null; Reader in = null; Writer out = null; try { // in = new BufferedReader(new FileReader(src)); // in = new BufferedReader(new InputStreamReader(new FileInputStream(src))); // out = new BufferedWriter(new FileWriter(new File(dir, src.getName()))); // out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File(dir, src.getName())))); in = new FileReader(src); out = new FileWriter(new File(dir, src.getName())); System.out.println("正在拷贝文件(" + src + ")到目录("+dir+")下"); char[] buffer = new char[1024]; int len = 0; while((len = in.read(buffer)) != -1) { out.write(buffer, 0, len); out.flush(); } return true; } catch (Exception e) { return false; } finally { closeIO(in, out); } |
乱码情况
| <img src="http://img.blog.csdn.net/20140414090344562?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvaWNlcl93ZWk=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast" alt=""> |
怎样解决?
我想知道这种情况是怎么造成的?又该怎样解决?