
java.sql.PreparedStatement接口。PrepareStatement接口继承Statement接口。
PrepatredStatement实例包含已编译的
SQL语句,由于PreparedStatement对象已预编译过哦哦,所以执行速度快于Statement对象。
包含于PreparedStatement对象中的SQL语句具有一个或多个IN参数。IN参数的值在SQL语句创建时未被指定。该语句为每一个IN参数保留一个问号(“?”)作为占位符。每个问号的值必须在语句执行之前,通过适当的Setxxx方法提供。
代码如下:
public void add(BookInfAdd bookinfadd){ String sqlStr ="insert into booktypeadd values(?,?,?,?,?,?,?,?)"; try (PreparedStatement s =DBconnection.getConnection().prepareStatement(sqlStr)){ s.setString(1,bookinfadd.getType()); s.setString(2,bookinfadd.getBookname()); s.setString(3,bookinfadd.getActor()); s.setString(4,bookinfadd.getChubanshe()); s.setString(5,bookinfadd.getYizhe()); s.setString(6,bookinfadd.getChubanriqi()); s.setString(7,bookinfadd.getDanjia()); s.setInt(8,Integer.parseInt(bookinfadd.getISBN())); s.executeUpdate(); int result =s.executeUpdate(); if(result>0){ System.out.println("添加成功"); } } catch (SQLException ex) { ex.printStackTrace(); } } |
如果运行JMeter客户端的机器性能不能满足测试需要,那么测试人员可以通过单个JMeter GUI客户端来控制多个远程JMeter服务器,以便对服务器进行压力测试,模拟足够多的并发用户。通过远程运行JMeter,测试人员可以跨越多台低端计算机复制测试,这样就可以模拟一个比较大的服务器压力。一个JMeter GUI客户端实例,理论上可以控制任意多的远程JMeter实例,并通过它们收集测试数据,如图11-3所示。这样一来,就有了如下特性:
保存测试采样数据到本地机器。
通过单台机器管理多个JMeter执行引擎。
没有必要将测试计划复制到每一台机器,JMeter GUI客户端会将它发往每一台JMeter服务器。
每一台JMeter远程服务器都执行相同的测试计划。JMeter不会在执行机间做负载均衡,每一台服务器都会完整地运行测试计划。
在1.4GHz~3GHz的CPU、1GB内存的JMeter客户端上,可以处理线程100~300。但是Web Service例外。XML处理是CPU运算密集的,会迅速消耗掉所有的CPU。一般来说,以XML技术为核心的应用系统,其性能将是普通Web应用的10%~25%。另外,如果所有负载由一台机器产生,网卡和交换机端口都可能产生瓶颈,所以一个JMeter客户端线程数不应超过100。
采用JMeter远程模式并不会比独立运行相同数目的非GUI测试更耗费资源。但是,如果使用大量的JMeter远程服务器,可能会导致客户端过载,或者网络连接发生拥塞。
请注意,假如测试人员将JMeter执行引擎安装在应用服务器(测试目标)上,那么这显然会加重应用服务器的负担,测试结果也将变得不可信。作者推荐的方式是将JMeter远程服务器放在应用服务器(测试目标)所在的同一个网段内。这样做既可以减少JMeter收集测试结果对网络产生的冲击,又可以避免对应用服务器(测试目标)性能产生影响。
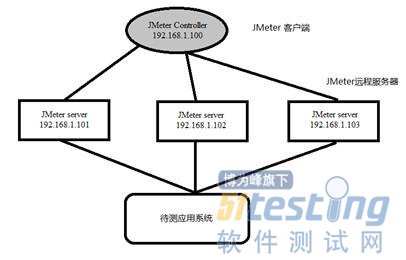
图11-3 JMeter远程测试原理图
下面是启动JMeter远程测试的基本步骤:
步骤1:配置节点
确保所有节点(JMeter客户端和JMeter远程服务器)运行相同版本的JMeter。尽可能在所有操作系统上使用相同的Java版本。
如果测试用到了外部数据文件,那么请注意这些文件不会被JMeter客户端分发,因此测试人员需要确保每台执行机上都保存了这些数据文件(其所在目录也必须正确)。如果有必要,用户可以为每台执行机设置不同的属性变量,即在JMeter远程服务器上编辑user.properties或者system.properties文件。这些属性将会在JMeter远程服务器启动时被识别,并有可能被应用到测试计划之中,从而影响测试执行(例如,与其他远程服务器发生交互)。另外,不同的JMeter远程服务器可能会使用不同内容的数据文件(例如,每台服务器必须使用不同的ID,就以此来划分数据文件)。
步骤2:启动远程服务器
要启动JMeter远程节点,请在执行机上运行JMETER_HOME/bin/jmeter-server (UNIX)或者JMETER_HOME/bin/jmeter-server.bat(Windows)脚本。
请注意,每个远程节点上只能运行一个JMeter远程服务器脚本,除非采用不同的RMI端口。从JMeter 2.3.1开始,JMeter远程服务器会自己启动RMI注册;用户没有必要单独启动RMI注册。假设测试人员一定要单独启动RMI注册,可以在远程节点上定义JMeter属性server.rmi.create=false。
默认情况下,JMeter远程服务器的RMI使用动态端口号。这样就会为防火墙配置带来麻烦,因此JMeter 2.3.2及其以后的版本,会检查JMeter属性server.rmi.localport。如果该值非零,JMeter远程服务器就会用它来作为本地端口号。
步骤3:将JMeter远程服务器的IP地址添加到客户端属性文件中
编辑JMeter控制机的属性文件。在/bin/jmeter.properties文件中找到属性"remote_hosts",使用JMeter远程服务器的IP地址作为其属性值。可以添加多个服务器的IP地址,以逗号作为分隔。
请注意测试人员还可以使用-R命令行选项来指明将会使用的远程服务器。这与使用-r 和-Jremote_hosts={服务器列表}的效果相同。例如jmeter -Rhost1,127.0.0.1,host2。
如果测试人员定义JMeter属性server.exitaftertest=true,那么远程服务器在运行完单个测试后就会退出。-Z标志也有同样的效果,参见后面的内容。
利用Javascript注入,来读取不同Ajax调用框架的Ajax request status,一直等到Ajax调用全部返回才开始分析操作Dom元素
演示代码如下:
protected void syncAjaxByJQuery(String timeout) { boolean isSucceed = false; try { "selenium.browserbot.getCurrentWindow().jQuery.active == 0", timeout); isSucceed = true; } catch (SeleniumException se) { LOG.error(se); } catch (Exception re) { throw new RuntimeException(re.getMessage()); } operationCheck(isSucceed); } protected void syncAjaxByPrototype(String timeout) { boolean isSucceed = false; try { selenium.waitForCondition( "selenium.browserbot.getCurrentWindow().Ajax.activeRequestCount == 0", timeout); isSucceed = true; } catch (SeleniumException se) { LOG.error(se); } catch (Exception re) { throw new RuntimeException(re.getMessage()); } operationCheck(isSucceed); } protected void syncAjaxByDojo(String timeout) { boolean isSucceed = false; try { selenium.waitForCondition( "selenium.browserbot.getCurrentWindow().dojo.io.XMLHTTPTransport.inFlight.length == 0", timeout); isSucceed = true; } catch (SeleniumException se) { LOG.error(se); } catch (Exception re) { throw new RuntimeException(re.getMessage()); } operationCheck(isSucceed); } Other Tips |
加载IEDriver的时候,通常会因为兼容模式的设置问题,而无法启动,尝试在创建IEDriver对象的时候,加入合适的参数设置:
DesiredCapabilities ieCapabilities = DesiredCapabilities.internetExplorer(); ieCapabilities.setCapability(InternetExplorerDriver.INTRODUCE_FLAKINESS_BY_IGNORING_SECURITY_DOMAINS, true); return new InternetExplorerDriver(ieCapabilities); |
一、OCUnit概述
添加OCUnit到工程中有两种方法,一种是在创建工程时添加,勾选“include Unit Tests”;另一种是在现有工程中添加“Cocoa Touch Unit Testing Bundle”Target来实现。详细添加过程略。
一个完整的测试类组成像下图:
框架会自动查找所有工程中SenTestCase的子类,运行其中全部命名类似testXXX的无返回值方法。
setUp方法是初始化方法,tearDown方法是释放资源的方法,setUp和tearDown方法在每次调用测试方法之前和之后调用,因此在测试类运行的生命周期中这两个方法可能多次运行。如下所示:
二、代码示例
ZYViewController.h: @property (weak, nonatomic) IBOutlet UITextField *textField; ZYViewController.m: - (int)doubleValue:(int)value{ return value * 2; } |
- (void)testDoubleValue{ ZYViewController* viewController = [[ZYViewController alloc] init]; int value = 1; int expect = value*2; int doubleValue = [self.viewController doubleValue:value]; XCTAssertTrue(expect == doubleValue, @"期望值:%d,实际值:%d",expect,doubleValue); |
- (int)getValue{ static int value = 1; value +=1; NSLog(@"test 2 value:%d",value); return value; } - (void)doTest:(int)value expect:(int)expect{ int doubleValue = [self.viewController doubleValue:value]; XCTAssertTrue(expect == doubleValue, @"期望值:%d,实际值:%d",expect,doubleValue); } - (void)testDoubleValue{ for (int count = 0; count < 10; count++) { int value = [self getValue]; [self doTest:value expect:value*2]; } } |
3、测试异步调用(UI操作、网络等操作);
- (void)testInput{ ZYAppDelegate* delegate = [[UIApplication sharedApplication] delegate]; UIWindow *window = delegate.window; viewController = (ZYViewController*)window.rootViewController; viewController.textField.placeholder = @"请输入..."; [[NSRunLoop currentRunLoop] runUntilDate:[NSDate dateWithTimeIntervalSinceNow:10]]; XCTAssertTrue([viewController.textField.text length]>0, @"textField had not input"); } |
3月8号,我去参加了一个叫孙弘美女关于中小型项目
性能测试的讲座,简要录一下
一、关于高大上的项目性能测试,需要具备什么?
1、历史数据收集分析
2、未来市场的预测
3、充足的测试时间
4、构建数学模型
二、中小型项目性能测试,作为客户真正关心的是什么?因为客户一般要求做性能测试,也不会向你提出性能指标,通常会让测试人员提出一份关于性能的测试报告。
1、网站能否正常运行,能否被用户使用
2、用户是否能够容忍网站的响应速度
3、网站能否支持一定的用户,会不会运行一段时间就崩溃了
4、一台服务器能否维持当前网站的需要,是否需要增加服务器
三、如何区分项目的大小?
一般日pv量达到亿级只有少数几个之名的网站,如
百度,
腾讯。百万级的访问量如搜房网,51job。根据站长统计分析所得,一般大部分存活的网站日pv量只有1000左右,对于这种访问量的中小型网站该如何做性能测试?
四、我们关注中小型性能测试方向有以下几点
1、低成本,不需要做数据统计分析,直接利用共有的性能指标来做性能测试
2、快速反馈
五、如何做中小型性能测试?
1、基准测试,关注一个用户访问网站的情况
2、日常压力测试
3、峰值测试
4、绝对并发测试
5、稳定性能测试
六、一般中小型项目不区分服务器端性能测试还是前端性能测试,通常是一起考虑,那么影响性能关键问题在哪?
1、数据库-索引;锁(死锁等)
2、Js脚本-加载顺序以及自身脚本缺陷等
3、接口/集成-与其他服务商提供的接口有关
4、网络原因-取决于服务器使用的是电信、网通以及用户使用的是何种网络服务商
5、服务器的硬盘空间-通常服务器的硬盘空间不足,服务器打的日志写不进去将导致服务器运行缓慢等问题
七、性能测试脚本考虑重点:
1、关键路径以及场景
2、使用频率
3、容易出错的地方
1.如何查找iframe里面的元素
一般情况下,selenium 多是结合 Xpath 获取元素属性,但当页面包括iframe 元素 ,并且 iframe 的src 是另一个page.html,这时如果要通过xpath 直接获取iframe里的元素,算是跨域访问,是获得不到的,这时候capybara 的 within 方法,便可解决。 within_frame(frame_id) ,默认是iframe 的id,也可支持name,xpath 方式获得。
ruby 代码:
| within_frame("frame_id") do 2 click_button "上传表单" 3 end |
2.如何测试confirm 对话框
capybara 测试confirm 对话框 ,有两种情形:第一种判断confirm 对话框的返回结果,如修改密码成功等,另一种,删除操作,弹出类似确定删除的对话框。
针对第一种情形解决方法:等待返回结果文本,进行和预期对比,ruby 代码:
| alert=page.driver.browser.switch_to.alert2 # sleep Capybara.default_wait_time 若是ajax异步请求,则需要休眠等待 3 assert alert.text.should == "success!" 4 alert.accept |
针对第二种情形:是对页面弹出操作进行返回结果为真,进行
测试,ruby 代码:
| page.evaluate_script('window.confirm = function() { return true; }')2 page.click_link "Destroy" |
这是我在从事网站
自动化测试的
工作当中构建出的一个“生态系统”。“生态系统”这个概念是我从公司的前辈身上学到的,他一直以来都认为自动化测试人员不应仅仅局限于编写测试代码,还应该让整个自动化测试的过程(测试代码的持续集成、分发、执行等)都自动化,形成一个“系统”,这个系统的自动化程度越高,自动化测试人员就越省力。
一、概念
这里我画了一张示意图:
之所以称之为“生态系统”,是因为建成之后需要的人为干涉很少,其余的时间都是系统内部循环运作。作为自动化测试人员的你只需要提交代码,之后便可以在AutomationDashboard上看到运行的结果了,其余的事情都由系统内部消化。当然,结果的分析还是需要人来完成,机器还没有聪明到可以灵活分析出各种各样让case fail掉的原因。
我们可以把整个系统看作一个黑盒子,那么上面的图可以变成:
实际上这里画的人不仅限于自动化测试人员,也可以是:
(1)产品的管理者,比如产品经理需要从自动化回归测试知道这次release有无推迟风险;
(2)团队的管理者,比如开发经理、QA经理需要从自动化的daily/weekly regression知道最近的代码质量如何;
(3)开发人员,他们也许会想通过quick regression(提交的产品代码被部署到测试环境之后运行的测试)知道自己刚提交的代码有没有破坏系统的基本功能;
(4)其他帮忙做自动化测试的开发人员、刚刚开始
学习编写自动化测试代码的手动测试人员,他们不必关心生态系统的内部实现。
二、实现
说完概念,接下来该说说具体实现了。我这里讲的是我认为最适合我所测试的产品的实现,工具不止一种,方式不止一种。Jenkins可以用TeamCity或其它CI替换,git也可以是svn或tfs,AutomationDahsboard可以用.NET、SpringMVC、ROR等等实现,运行测试的slave可以是Windows/Linux/Mac(土豪!),总之选择一种最适合你所测试的产品的实现。还有一点就是自动化测试代码是用关键字驱动思想实现的,这是另外一个话题了,有时间另外写篇文。
好,进入正题。依次说说系统的每个重要组成部分吧:
1、SCM(Source Code Management)。我选的是git,可以是git服务器(公司自己搭建了一个git
server),也可以是一个bare repo(http://www.saintsjd.com/2011/01/what-is-a-bare-git-repository/) 。
2、CI(continuous integration)。我选的是部署方便、插件丰富的Jenkins。
它的职责是:
(1)从git上取出代码,build(.NET对应msbuild,如果是ruby则不用build了,直接部署即可);
(2)把build好的*.dll部署(这里即是拷贝)到所有的slave上;
(3)启动或停止所有slave上的AutomationService(后面还会讲到AutomationService),从而控制测试的执行。我在Jenkins的这些个job配置起来还是比较繁琐的,要细讲又可以另外写一篇文了。这里就特别提到两个很实用的插件吧:
(1)Parameterized Trigger Plugin(https://wiki.jenkins-ci.org/display/JENKINS/Parameterized+Trigger+Plugin):可以在一个build step中触发其它project的build。
它最有用的就是这个“Block until the triggered projects finish their builds”选项,勾上的话Jenkins就能在所有trigger的project完成build之后(而非仅仅trigger其它project的build,不等它们完成就继续下一个build step)再继续下一个build step,做到真正的依次执行每个build step。
(2)NodeLabel Parameter Plugin(https://wiki.jenkins-ci.org/display/JENKINS/NodeLabel+Parameter+Plugin):在所有“Possible nodes”标有指定标签(“Label”)的Jenkins节点(就是Jenkins master或Jenkins slave)上触发指定project(被触发的project是参数化的)。
比如我有一个project叫“StartClassicROLATServiceOnAllNodes”,它有一个build step是这样设定的:
再来看看“StartClassicROLATServiceOnASingleNode”这个project的设定:
这个project有一个Node类型的参数,参数名“NodeX”与之前Label Factory中的“NodeX”对应,“Possible nodes”选的是“ALL”,那么列出的所有node(master、10.107.122.152、10.107.122.153、10.107.122.154)都在判断范围之内(判断其是否有“Node”标签,有则执行project)。
另外,列出的所有node我都为其加了一个“Node”标签。
这样,当我trigger “StartClassicROLATServiceOnAllNodes”之后,就会在master、10.107.122.152、10.107.122.153、10.107.122.154这4个node上同时执行“StartClassicROLATServiceOnASingleNode”。
3、AutomationDashboard,这里姑且译作“自动化测试控制面板”吧。实际上它应该和Jenkins一起并称控制面板,不过因为Jenkins有API可以调用,所以想做的画两者也是可以统一成一个web界面的。这个dashboard完全是用.NET+IIS+SQLServer一点点从数据库设计构建、数据访问层、业务层、表现层做起来的,要细讲……额……又会是另外一篇文了(Oh man, not again!)。反正我觉得,虽然我是做自动化测试工作的,但不应该把自己局限于测试。为了更好地进行自动化测试,开发网站、安装配置虚拟机以及其它要用到的工具,都应该抽时间去学习、掌握。
好,来说说这个dashboard。这里只讲两个主要组成部分,一个网站(以下简称dashboard)、一个Windows Service(以下简称ATService)和一个console application(以下称ConsoleRunner):
(1)dashboard,它的主要功能:
a、展示测试的运行状况:有多少正在运行/执行完毕,分别在哪台slave上执行等等。
b、通过call Jenkins的API来trigger Jenkins的job,间接控制测试的执行。
c、展示测试的结果:发生错误的是哪个case、出错时间、错误信息、代码回溯(stack trace)、甚至可以包含一张出错时的截图。
主要界面如下:
a、Summary,顾名思义是汇总信息,case有多少pass多少fail、case按分类每一类有多少等等。(其实这里我少做了一张很重要的图,就是coverage饼状图)
b、Queue,测试队列,包含当前正在运行的、运行完的、等待运行的test fixture或test case(依据测试工具的不同,NUnit、JUnit、RSpec等,fixture的叫法可能不同,总之就是包含多个test case的集合)。可以启动、停止、终止(终止之后可以清空)测试执行或清空当前队列。
c、TestCase,生态系统中的所有测试用例会展示在这里,可以看到它们最后一次执行的时间和状态(pass/fail),点击某条case可以跳转到该条case的所有test result。可以按状态(pass/fail/other)筛选用例,可以勾选部分用例重新执行、或重新执行所有fail的case。“Reload Test Cases”主要是考虑到*.dll文件中的test case可能会在某次部署之后发生变化,需要重新加载。不过后来我修改了Jenkins里的job在每次部署之后都自动重新加载,所以这个按钮其实没什么用了。
d、TestSuite,包含多个fixture的集合是一个suite。勾选多个suite点击“Run Suite”即可把这些suite中包含的fixture添加到Queue。
这里的suite是对NUnit中的Category的一个补充,点击“New Suite”你可以任意选择fixture来组成自己想要的suite:
e、TestResult,展示所有test case的运行结果,可以按test case id进行筛选,点击TC#这一列的id就只显示这条case的结果。
点右边的蓝色“i”图标可以跳到这条结果的详细页面,截图功能暂未启用,根据RunnerMessage和RunnerStackTrace可以知道报错的代码位置,进而尝试重现问题。
对一个开发人员来说,除了保质保量按时完成功能需求外,非功能也不可忽视。
决定一个软件的成败往往是非功能性需求比如性能,若是用户体验不好那么必定是个失败的作品。
那么一个开发人员如何去做关于自己模块又或者整体的基准
性能测试呢?以下将从测试的切入点和具体测试的指标来说明。
切入点:
通常,基准性能测试有两个切入点,一方面可以通过从整体系统的角度做一个全栈式(即打通上下各层)的性能测试用于发现整体系统的性能瓶颈点,另一方面又可以具体到某个层或者模块进一步分析性能问题。
测试目标:
从定量工具的角度来说性能测试一般关注以下3点:
1. 单位时间内系统处理请求、事务的次数:比如测试模块的接口性能,可以针对一个接口调用N次并求平均值。
2. 响应时间(延迟):目的是求出最大响应时间和最小响应时间,并对响应性能做一个预估用百分法来表示。比如对一个接口或协议发起请求10次,若有一次响应时间大于10ms,其他都小于10ms,那么可以说针对该接口有90%的概率系统响应时间小于10ms,当然要求准确的话需要更多地测试。
3. 吞吐量:这里的指标常有如IOPS,常见于测试存储系统的性能测试用于发现系统最大流量。
从测试价值的角度来说性能测试还需要以下2点:
1. 可伸缩性
可伸缩性需要和单纯的性能测试区别开,当系统只有一个访问者无其他负载的情况下为单纯的性能测试,若有性能问题可从代码、设计上分析研究。而伸缩性指得是在整个系统负载变化的情况下(比如增加访问者并发量),要求系统保持一定的性能(响应时间、吞吐量)。测试过程中可以尝试对测试环境的硬件进行扩展(垂直、横向扩展都行),看性能是否能够在持续增压的条件下满足性能需求。在持续对系统增加并发访问量的情况下通过查看系统的持续响应时间基准测试结果发现系统的设计缺陷。从一定层度上来讲,系统的伸缩性在设计上就已决定。
2. 并发性
对于并发通常有各种理解,但是对于系统性能测试领域来说,更准确地评判服务器的并发性指得是高峰时期单位时间内的请求数。对我们来说更多应该关注的是
工作的并发量,比如同时处理请求的线程数或连接数。并发测试更多地是以一种辅助的手段配合性能测试,比如通过并发的手段持续加压达到测试系统伸缩性的目的。
BUG标题:
开发同学更换图片缓存资源后,老的资源在客户端中仍然加载,chrome下查看并未加载此链接。
BUG影响:
1、老资源由于占用空间比较大,达到700kb,严重影响用户进入游戏页面的时间,影响用户体验。
2、导致用户流失率大大增加。
3、浪费用户流量,给用户造成金钱损失。
BUG发现阶段:
BUG发现过程:
1、在摩天轮上执行hybird测试时,前端同学更换了页面上的一个图片资源后,hybird测试结果页面仍然展示在下载新图片资源的同时,老的图片资源仍然会下载。但是通过PC端的chrome浏览器去访问该H5页面,查看页面源代码后,确实console中没有老图片资源的下载链接了。
2、开始开发同学给出的答案是怀疑可能是
手机有缓存之类的,而且自己也看到确实代码中没有老图片资源的下载链接。
3、为了确定原因,通过联系平台维护hybird适配测试的人确认已经将手机缓存全部清除掉,但是清除掉手机缓存之后仍然展示下载了老图片资源。
4、通过网上查看chrome下与真机下页面加载时是不是有什么不同的地方,后来就怀疑是不是前端同学的缓存有问题,查看后果然是缓存出了问题,老资源链接在配置中未删除掉。
BUG解决方法:
H5页面的缓存是通过<html manifest="http://h5.m.taobao.com/manifest/jhswap-hn-v2.manifest">这个标签中的manifest进行指定的,格式如下:
##VERSION: Sat Jan 04 23:52:49 CST 20141388850767000
CACHE:XX资源
原来是前端同学在增加新图片资源的时候,忘记把老的图片资源的链接删除掉。只要在配置文件中将老资源删掉即可。
GBA传承
1、注意区分H5页面在PC端加载和在手机加载机制的相同点与不同点。
个人感受:
1、对“可能”说不,对问题的原因追根究底,不放过任何一个存在疑问的地方。
2、对细节点进行关注。
1. MAVEN + SVN + HUDSON + SONAR集成测试环境搭建、
1.1 软件准备
Hudson、Jenkins、Sonar
1.2 软件安装
说明:本例均使用将应用程序部署至
web容器下,Hudson和Sonar有其他部署启动方式,如有需要请自行使用,本文不做赘述。
1.2.1 安装hudson
1)将下载到的hudson.war文件部署至web容器中,启动web容器。
2)访问地址http://localhost:8080/hudson,显示如下:
(8080是容器默认端口,hudson是项目名称)
1.2.2 安装sonar
说明:以下内容是快速安装的示例。
1)解压sonar.zip,进入war文件夹下,运行build-war文件,会生成sonar.war文件
2)将sonar.war文件部署至web容器下,启动容器
3)访问地址http://localhost:8080/sonar/,显示如下:
4)(8080是容器默认端口,sonar是项目名称)
1.3 软件配置
1.3.1 配置sonar
a)Sonar需要数据库的支持,其本身自带Derby同时支持MySQL5.x,
Oracle 10g XE,Postgresql和MS SqlServer 2005,推荐使用
MySQL。
b)创建数据库:MySQL中创建用户sonar,同时创建数据库sonar,未用户sonar赋予权限。
说明:表和索引活在sonar激活后自动创建。
2)配置数据库,编辑conf/sonar.properties
sonar.jdbc.username: sonar sonar.jdbc.password: sonar sonar.jdbc.url: jdbc:mysql://localhost:3306/sonar?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true sonar.jdbc.driverClassName:com.mysql.jdbc.Driver |
说明:更改数据库配置,请注意extensions/jdbc-driver/mysql/目录下是否有对应的驱动
1.3.2 配置hudson
请保证Hudson已经安装以下插件:
进入Manage Hudson ->Config System进行配置,显示如下:
1)系统信息配置:
Home directory:hudson目录
System Message:hudson系统说明信息
# of executors:同时可执行最大数
Quiet period:构建工程之前的等候时间,单位是s,此项较重要可以保证构建工程时项目的完整性
SCM checkout retry count:检出失败重试次数2)安全信息配置:
3)JDK配置:
如果系统配置已为JDK配置了环境变量,则此处可以不做设置
4)Maven配置:
Name:为你的maven指定名称
MAVEN_HOME:指定maven安装路径
5)SVN配置:
Exclusion revprop name:指定项目SVN路径
1.4 环境集成
1.4.1 Maven与Sonar集成
编辑$MAVEN_HOME/conf或者~/.m2下的setting.xml文件,添加如下内容:
<!--sonar --> <profile> <id>sonar</id> <activation> <activeByDefault>true</activeByDefault> </activation> <properties> <!-- mysql--> <sonar.jdbc.url> jdbc:mysql://localhost:3306/sonar?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true </sonar.jdbc.url> <sonar.jdbc.driver> com.mysql.jdbc.Driver</sonar.jdbc.driver> <sonar.jdbc.username>sonar</sonar.jdbc.username> <sonar.jdbc.password>sonar</sonar.jdbc.password> <!--remote host--> <sonar.host.url>http://localhost:8080/sonar</sonar.host.url> </properties> </profile> |
说明: 因为sonar是通过Maven2插件来分析源代码并把结果注入到数据库的,所以必须在Maven的配置里设置数据库的属性。
1.4.2 hudson与sonar集成
1)安装sonar插件
2)配置Sonar参数(服务地址和数据库地址)
1.5 创建和配置job
1.5.1 创建JOB,点击New Job,显示如下:
1.5.2 点击OK,显示如下:
1)工程概要配置:
2)工程高级配置:
3)源码管理:
高级配置:
4)构建
2.Eclipse中IDE环境下集成测试
说明:在IDE环境下集成测试非常方便,可以使用的组件有dashboard、cobertura、findbugs
2.1 Findbugs:根据既定规则检查代码bug
1)修改工程的pom.xml文件,添加findbugs-maven-plugin插件
<plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>findbugs-maven-plugin</artifactId> <version>2.5.1</version> <configuration> <threshold>High</threshold> <effort>Default</effort> <findbugsXmlOutput>true</findbugsXmlOutput> <!-- findbugs xml输出路径--> <findbugsXmlOutputDirectory>target/site</findbugsXmlOutputDirectory> </configuration> </plugin> |
2)输入命令:
mvn findbugs:findbugs
3)结果会生成在target/目录下findbugsXml.xml文件中
2.2 Cobertura:测试覆盖率插件
1)修改工程的pom.xml文件,添加cobertura-maven-plugin插件
<plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>cobertura-maven-plugin</artifactId> <version>2.5.1</version> </plugin> |
2)输入命令:
mvn cobertura:cobertura
3)结果生成在target/site/cobertura目录下
2.3 Dashboard:图表显示测试结果
1)修改工程的pom.xml文件,添加dashboard-maven-plugin插件
<plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>dashboard-maven-plugin</artifactId> <version>1.0.0-beta-1</version> </plugin> |
2)输入命令:
mvn site mvn dashboard:dashboard |
3)在项目targe/site目录下打开dashboard页面查看结果
如果安装了dashboard插件,可以在dashaboard文件中查看所有测试结果信息。