
对于
安卓手机,我们听到最多的抱怨就是不流畅,在选购前,问的最多的问题也是这款手机流畅不流畅。
有的人看配置,但是同样配置的手机,流畅性天差地别,而有些低配手机反而很流畅;有的人看跑分,但是有些手机跑分很高,流畅性却很差;更糟的是,因为人和人的流畅标准不同,同样的手机,张三觉得不流畅,李四觉得还不错,选购前问别人也无法有个正确的参考。
那么到底应该看什么呢?我们来做个解读。
一、什么是手机的流畅性
所谓手机的流畅性,其实是iPhone出现后,手机有了拖动滑屏概念以后出现得。以前电阻屏,WM系统的手机是谈不上拖动流畅的。
而屏幕要滑动,就有个帧数的概念。我们看到的动态画面,是一帧帧静态画面联动起来后达到的。这利用了人眼的视觉暂留。一秒内静态画面越多,我们眼睛的感觉就越流畅。静态画面的数量,我们叫帧数。
我们看到的电影是24帧到29帧,就是一秒钟24幅静态画面,因为电影的每一帧都是模糊帧,包含一定的时间信息,所以24帧我们看着就很流畅了。
我们看的动画、玩3D游戏,因为每一帧都是清晰的画面,所以需要1秒钟60帧才会感觉流畅,有些眼睛特别敏感的甚至需要85帧。不过大多数人60帧就足够了,所以我们的液晶屏幕都是每秒60帧来刷新的。而手机要流畅,也需要在滑动的时候达到每秒60帧,这就是手机的流畅性。
手机的流畅性,其实是分不同场景的。在滑动桌面的时候流畅,但是玩游戏就不一定流畅;看视频的时候流畅,但是缩放图片的时候就不一定流畅。所以手机流畅性的测试也需要多种软件和方法。
(一)系统界面的流畅性
系统界面的流畅性,我们通常用一个软件MobileXPRT 2013,这个软件带有两个测试项目,一个是
性能测试,还有一个是用户体验测试。性能测试和诸如安兔兔之类的性能测试差不多,跑的是处理器的理论性能,而用户体验测试就可以测试出来系统界面的流畅性。
UX Tests就是测试用户体验的
用户体验测试
上图是用户体验测试的具体项目,包括菜单滑动、界面滑动、图库滑动、网页浏览滑动和放大缩小。就这台手机的测试项目来看,图库滑动的帧数不足,会有不流畅的感觉,其他滑动都是60帧,系统体验还是非常流畅的。
(二)常用软件的流畅性
MobileXPRT 2013的用户体验测试虽然不错,但是只能代表系统自带用户界面的流畅性,不能代表用户所使用软件的流畅性,而用户使用软件是个性化的。如何判断自己常用的软件在准备购买的手机上是否流畅呢?
这种情况我们用 FPS meter来测试,FPS meter是一个实时帧数显示软件(需要root),后台运行,可以实时显示当前程序滑动或者运行的帧数。
FPS meter
开启这个软件,然后打开你常用的程序,快速滑动(测游戏不需要滑动,只要看帧数)看这个软件显示的实时帧数是否在60以上,就可以判断你常用的程序能否在手机上运行流畅。
实时帧数
三、帧数之外的流畅性
除了帧数以外,还有两个因素决定着人们使用安卓手机的流畅性。
(一)程序开启速度
在点击程序后,程序多长时间开启,直接决定用户体验。这个就是硬件性能比拼,但是简单看安兔兔总分是看不出来的,因为安兔兔总分包含东西太多,你看安兔兔得分里面的安卓虚拟机得分一项比较准确,
(二)响应时间
安卓系统有个毛病,就是触摸和屏幕响应的间隔时间比较长。Windows和IOS都要好很多。这也是各个厂商优化的重点所在,这个测试没有软件可以解决,高速摄像机用户不具备,有个建议的方法是拖动图标快速转圈,看图标和手指的距离远近,同样转圈速度,图标距离手指的距离越近越好。
安卓通常的安兔兔跑分并不能代表用户体验,高配置因为高分辨屏幕和系统优化的原因,也未必能带来流畅体验,而上述的几个方法可以比较准确的测试安卓手机是否流畅,拿起你的手机试一下吧。
JT项目总结
一、概述
JT项目到目前为止来看是失败的,其中不乏
测试的原因。在整个测试过程中,还是存在一些问题,在
测试计划、执行、进度把控以及测试质量方面都存在缺陷。
二、测试计划
1、测试计划的安排是基于整个项目的进度,虽然当时有大线表,但是开发基本上都没有按照或者接近时间点完成,导致测试
工作无法提前安排,出现了要么没事做,要么加班通宵的情况。
2、当有测试任务的时候,没有正确估算出测试时间,或者急于出结果,导致测试不详细、不全面,连续通宵的加班和提测时无止境的等待,人员情绪低落,不能提交高质量的测试版本。
3、测试前期有相关文档,后期由于时间问题,没有充分了解需求,对于提测的功能也是在摸索中测试,不能准备充分测试。
4、当测试人员较多的时候,测试任务的分配不是很清楚,出现了“三不管”地方。
三、测试执行及进度
1、前期写好的
测试用例没有高效的执行,前期的测试准备不能指导后期的测试。原因很多,包括需求的变动等。
2、需求的变动,使得测试出现无效工作,之前已经花费时间做过了,后期由于需求变动,又要重新测试。
3、在测试执行过程中,人员之间缺乏沟通,测试的结果或者测试方向错误。
四、测试质量
1、测试功能全面性:在测试过程中,发现测试会出现漏测的现象。由于前期的测试计划工作没有做好,比如没有测试用例,没有进行测试需求的挖掘,在模块提测后进行随机的测试,没有条理,容易导致漏测的现象。
2、测试深度:在测试过程中,只关注前台界面显示或者功能实现是远远不够的,很多隐藏的bug都是通过
数据库体现出来的。比如数据库的主键设置不合理,或者是数据库信息不全面,那么在前台显示的信息也是不全面的,特别是商品详情页的相关测试。
3、测试广度:测试的时候容易只关注自己模块的东西,不能把整个流程都串联起来,如果是对整个流程的测试,也会发现不少问题。
五、测试规划
目前在后期的项目中会规范项目流程,测试作为项目整体中很重要的一部分,也要规范测试流程。
1、文档完整。
在现有需求文档和开发设计文档的情况下,编写测试用例并评审。测试用例作为测试执行的指导,是很有必要的,可以帮助测试人员更好更深入的理解需求及我们程序到底是要做什么,而不是在开发提交测试后测试人员边测边摸索。
2、测试执行及进度。
1)在执行测试的过程中,必须按照测试用例执行,在保证测试用例100%执行的情况下,可以自由测试。执行测试用例是保证测试质量的有效方法之一,所以必须保证用例的100%执行。在测试过程中,不管bug大小及优先级,只要是发现的bug,全部提交到bugfree中,开发可以根据优先级和严重程度来修改bug,而不是说测试的时候只提严重bug。
2)测试的过程中,测试人员之间要及时沟通,避免出现无人测试的地方。每个测试人员都要非常清楚的知道所有的流程,有助于测试过程理解及加强测试广度及深度。
3)在测试过程中,必须对数据表和和数据流转很清楚。数据的交互,一定要及时关注数据表,保证自己当前测试的模块数据存储都是正确的,关注与其他模块交互的数据字段或数据表,保证和其他模块的数据交互也是绝对ok的。
4)根据线表来计划测试时间,保证测试有充分的时间来执行用例和自由测试。
5)执行测试的过程中,及时提交bug到bugfree上,既然有bugfree就要执行。任何以文档记录的bug在最后是非常难统计的,作为以后的参考或者是项目bug统计,所有的bug都必须直接提交在bugfree上。开发人员已更改状态的bug,在修改bug的版本上测试要及时验证。
6)对于与开发有争议的bug,有些要确认需求是否是这样,保证提交的bug是有效的。对于开发不改的情况,可以举例示范,拿出相关文档来说服。如若还是有争议,那么可以找需求或者项目负责人来商定是否需要修改。对于某些问题的修改,可能会考虑到修改效率和成本,只要能达成一致即可。尽可能确保在发布版本前,所有的bug都被关注到并且处理。
除了功能测试外,还应该要关注
web测试的其他方面,比如
性能测试,数据库测试,
安全测试等。鉴于目前大家掌握的技能有别,可以抽出时间分享自己掌握的测试技能,共同提高和进步,提升整个团队的素质。
PS:首次作为项目负责人难免会有很多失误,在以后的项目过程中一定会更加努力,避免再犯类似的错误,正确把好质量关。
MySQL作为一种低成本、高性能、可靠性良好而且开源的
数据库产品,在
互联网企业中应用非常广泛。例如,淘宝网就有数千台MySQL服务器。虽然近两年来NoSQL的发展很快,新产品层出不穷,但在业务中应用NoSQL对开发者来说要求比较高,而MySQL拥有成熟的中间件、运维工具, 已经形成一个良性的生态圈。因此,在现阶段的应用中仍然以MySQL为主,NoSQL为辅。
在过去一年里,我们在MySQL托管平台方向做了大量
工作,设计和实现了一套UMP(Unifield MySQL Platform)系统,提供低成本和高性能的MySQL云数据库服务。开发者从平台上申请MySQL实例资源,通过平台提供的单一入口来访问数据。UMP系统内部维护和管理资源池,以透明的形式提供主从热备、数据备份、迁移、容灾、读写分离和分库分表等一系列服务。平台通过在一台物理机上运行多个 MySQL实例的方式来降低成本,并且实现了资源隔离,按需分配和限制CPU、内存和I/O资源,同时在不影响提供数据服务的前提下,支持根据用户业务的 发展来动态扩容和缩容。
架构的演变
UMP系统第一版基于 MySQL Proxy 0.8版修复了若干
Bug,并对Proxy插件中管理用户连接和数据库连接的状态机流程进行了修改;编写了Lua脚本实现到中心数据库获取用户认证信息和 后台数据库地址,来对用户进行验证;建立了到后台数据库的连接和转发数据包等逻辑(如图1所示)。
图1 UML系统的第一版(当时称作RDS系统)采用MySQL Proxy
在开发和部署第一版的过程中,我们逐渐认识到几个问题。
首先,MySQL Proxy 0.8版对多线程的支持比较简单粗暴,多个工作线程共享同一个消息队列,同时监听着同一个socketpair通道。当有新事件进入消息队列 后,socketpair会被写入一个字节,所有休眠中的线程都会被唤醒,去竞争一个互斥锁从消息队列中取任务。这种实现有几个问题:一是造成“惊群”现 象,多个线程被唤醒但只有一个线程需要去完成任务;二是任务的CPU亲缘性比较差,在同一个状态机上触发的事件会在多个处理器上来回切换执行。此 外,MySQL Proxy中还使用了全局Lua锁,同时仅允许一个工作线程执行Lua脚本(计划在0.9版本中改进)。因此,在多线程模式下,MySQL Proxy的性能远不能同CPU核数保持线性增长,甚至在16核上的性能还不如4核。而使用单进程模式时,一台物理机上需要部署多个进程才能有效利用机器 的处理能力,但给部署、监控和服务的升级带来麻烦。
其次,由于MySQL Proxy的框架在功能上不容易扩展,所以实现用户的连接数限制、QPS限制及主从切换、读写分离、分库分表等功能比较困难。
最后,MySQL Proxy的社区近些年并不活跃,且C语言对开发者功底的要求比较高,很难要求团队所有成员协同开发出兼顾优雅和正确性的代码。
因此,我们决定用Erlang语言重新编写Proxy服务器,替换了原有的MySQL Proxy模块。目前,整个项目拥有5万行Erlang源码,3万行C/C++源码,2万行其他语言源码。
为什么选择Erlang语言
Erlang 是一个结构化的、动态的、函数式的编程语言。常见的一种说法是Erlang是面向并发的(Concurrent-Oriented),这主要指 Erlang在语言中定义了Erlang进程的概念和行为(本文中提到的“Erlang进程”都是指Erlang语言中定义的进程,以区分于大家熟悉的
操作系统进程)。与操作系统的进程/线程相比,Erlang进程同样是并发执行的单位,但特别轻量级,它是在Erlang虚拟机内管理和调度的“绿进程”, 即用户态进程(如图2所示)。举个例子,在关闭了HiPE和SMP支持的Erlang虚拟机中,一个新创建的进程占用的内存仅为309个字 (Word,64位服务器上为8个字节)。其中233个字为堆空间(包含栈),创建和结束一个进程约耗时1~3微秒,而一个Erlang虚拟机中可以同时 支持几十万甚至更多个进程。

图2 Erlang的轻量级进程
说到Erlang语言,就必须提及OTP(Open Telecom Platform,开放电信平台)。OTP是用于开发分布式的、高容错性的Erlang应用程序的框架与平台。例如,一个Erlang节点连接并注册到 Erlang集群上,发现集群中的其他节点,并与它们进行RPC通信,这些都在OTP里的Kernel服务中实现。OTP和Erlang语言关系如此紧 密,以至于两者通常合称为Erlang/OTP,因此从严格的意义上来讲,应该说我们选择了Erlang/OTP来构造UMP系统。Erlang/OTP 很好地抽象了开发一个分布式的、高容错性的应用程序所需的要素,包括网络编程框架、序列化和反序列化、容错、热部署。
为了支持并发,服务器 端多采用多进程/多线程模型,即每个进程/线程处理一个客户端连接。但受限于操作系统资源,每台服务器可以处理的并发连接数并不高,且由于进程/线程上下文切换开销,系统性能会受到影响。而开发高并发、高性能服务器一般采用事件驱动的状态机模型,底层采用非阻塞I/O(Linux中的epoll,BSD系 统中的kqueue,Java中的nio)或者异步I/O,或者采用异步的事件通知的I/O框架,例如C/C++下的ACE、boost::asio、 libevent,Java下的MINA等。在业务层则使用状态机来表示每个客户端连接,通过I/O事件、超时事件驱动状态机进行跳转,每个进程/线程可 处理成千上万个客户端连接。与多进程/多线程模型相比,虽然事件驱动的状态机模型并发量更大、性能更好,但把业务逻辑表达成状态机是一件困难的事情。相比 之下,多进程/多线程模型中的业务逻辑可以实现为顺序执行的代码,开发起来要简单得多。
Erlang/OTP中的网络编程模型则结合了两者 的优点,每个Erlang进程处理一个客户端连接,业务逻辑是顺序执行的。Erlang进程是极轻量级的,可以认为每个Erlang进程是一个状态机,堆 和栈上的数据是这个状态机的状态。Erlang进程收到数据包或者其他进程发来的消息后执行处理例程,相当于状态机的跳转,因此也具有高并发和高性能的优 势。
Erlang/OTP定义了“External Term Format”协议将Erlang数据结构与二进制字符串相互转化,并用C实现在Erlang虚拟机中,在进行跨节点通信时遵从这个协议。因此,开发者无须额外考虑序列化和反序列化问题。
在容错方面,Erlang进程的数据空间是相互隔离的,没有共享内存,因此一个Erlang进程崩溃不会影响其他Erlang进程运行,更不会造成 Erlang虚拟机崩溃。OTP提供了监督树机制和heart模块,前者在监控到Erlang进程崩溃时进行故障恢复,后者在发现Erlang虚拟机失去 响应时重启程序。
Erlang/OTP提供热部署方式,可以避免服务升级时造成不可用时间。此外,OTP还提供了一些在系统运行时观察系统状态的工具。例如lcnt工具,可以统计虚拟机内部的锁使用次数和冲突次数,指导系统的优化。
当前系统架构
在设计UMP系统时,我们遵循了以下几条原则。
系统对外保持单一入口,对内维护单一资源池。
保证服务的高可用性,消除单点故障。
保证系统是弹性可伸缩的,可以动态地增加、删减计算与存储节点。
保证分配给用户的资源也是弹性可伸缩的,资源之间相互隔离。
UMP系统中的角色包括:Controller服务器、Proxy服务器、Agent服务器、API/Web服务器、日志分析服务器和信息统计服务器。图3是当前UMP系统的架构图。UMP系统依赖Mnesia、LVS、RabbitMQ、ZooKeeper等开源组件。
图3 当前UMP系统架构图
Mnesia是OTP提供的分布式数据库,与MySQL NDB出自同门,都是20世纪90年代中期Ericsson为电信业务研发的数据产品。Mnesia支持事务、支持透明的数据分片,利用两阶段锁实现分布式事务,可以线性扩展到至少50个节点。
从CAP理论的角度来说,Mnesia更倾向于牺牲可用性来换取强一致性,属于CP阵营。但它也提供了脏读、脏写操作,可以绕过事务管理去操作数据,这时不 保证一致性,有点类似于AP的系统。在工程实践中,我们用事务去修改关键数据(例如路由表),而用脏写接口去写非关键数据(例如用户的状态信息),读取数 据用脏读接口。
Controller服务器向UMP集群提供各种管理服务,实现元数据存储、集群成员管理、MySQL实例管理、故障恢复、 备份、迁移和扩容等功能。Controller服务器上运行了一组Mnesia分布式数据库服务,系统的元数据如集群成员、用户的配置和状态信息,以及用 户名到后端MySQL实例地址的映射关系(路由表)等都存储在Mnesia里,其他服务器组件通过发送请求到Controller服务器获取用户数据。
为了达到高可用性,系统中会部署多台Controller服务器,它们通过ZooKeeper提供的分布式锁算法选举出一个leader,这个leader 负责调度和监控各种系统任务,例如创建和删除数据库实例、备份和迁移等。这些系统任务可以分成多个步骤,而且会涉及系统中的多个组件,例如主库、从库和 Proxy服务器等,还需要提供失败时回滚的方法。因此,我们采用类似工作流的方式来实现。每个系统任务都分成多个阶段的Erlang进程,每执行完一个 步骤跳进下个步骤之前会把中间状态持久化到Mnesia中。如果任务因为节点故障停止的话,leader能检测到并重新发起该任务,任务重启后会从上一次 失败的“断点”继续向下执行。
API/Web服务器向用户提供了系统管理界面。它们是基于开源项目Mochiweb和Chicago Boss开发的,Mochiweb提供HTTP/HTTPS服务,而Chicago Boss是由Nginx的作者之一Evan Miller开发的,提供类似Rails的MVC框架。与Rails比,Erlang开发的框架天生就对并发有很好的支持,每个请求占用一个轻量级的 Erlang进程,而Rails虽然在最近引入了多线程安全,但处理每条请求时仍然是独占整个进程的,因此需要使用多进程模型处理并发请求,通过 Phusion Passenger等应用服务器进行派发。
Proxy服务器向用户提供访问MySQL数据库的服务,它完全实现了 MySQL协议,用户可以使用已有的MySQL客户端连接到Proxy服务器,Proxy服务器通过用户名获取到用户的认证信息、资源配额的限制(例如最 大连接数、QPS和IOPS等),以及后台MySQL实例的地址(列表),再将用户的SQL查询请求转发到正确的MySQL实例上。
除了数据路由的基本功能外,Proxy服务器中还实现了资源限制、屏蔽MySQL实例故障、读写分离、分库分表、记录用户访问日志等功能。Proxy服务器是无 状态的,服务器宕机不会对系统中其他服务器造成影响,只会造成连接到该Proxy的用户连接断开。多台Proxy服务器采用LVS HA方案实现负载均衡,用户应用重连后会被LVS定向到其他的Proxy上。
Agent服务器部署在运行MySQL进程的机器上,用来管理每台物理机上的MySQL实例,执行创建、删除、备份、迁移和主从切换等操作,收集和分析MySQL进程的统计信息、bin log和slow query log。
日志分析服务器会存储和分析Proxy服务器传入的用户访问日志,并实现了实时索引供用户查询一段时间内的慢日志和统计报表。信息统计服务器定期将采集到的 用户连接数、QPS数值,以及MySQL实例的进程状态用RRDtool进行统计,可画图展示到Web界面上,也可为今后实现弹性的资源分配和自动化的 MySQL实例迁移提供依据。
UMP系统中各节点间的通信(不包括SQL查询、日志等大数据流的传输,这些还是直接走TCP的)都通过RabbitMQ,作为消息通信的中间件来使用,以保证消息发送的可靠性。ZooKeeper则主要发挥配置服务器、分布式锁,以及监控所有MySQL实例的作用。
在多个组件的协同作业下,整个系统实现了对用户透明的容灾、读写分离、分库分表功能。系统内部还通过多个小规模用户共享同一个MySQL实例,中等规模用户独占一个MySQL实例,多个MySQL实例共享同一个物理机的方式实现资源的虚拟化,降低整体成本。在资源隔离方面,通过Cgroup限制MySQL进 程资源,以及在Proxy服务器端限制QPS相结合的方法,UMP系统能在实现资源虚拟化的同时保障用户的服务质量。此外,UMP系统综合运用SSL数据 库连接、数据访问IP白名单、记录用户操作日志、SQL拦截等技术保护用户的数据安全。
结束语
UMP系统的一些组件,例如Proxy服务器和日志分析服务器,目前已经运用在天猫的聚石塔平台中,为电商和ISV提供安全的数据云服务。此外,UMP系统还运 用在淘宝的店铺装修平台中,为开发者提供数据服务。下一阶段,我们希望UMP系统能进一步为企业降低数据存储的成本。
在现在常用的发行版本里都集中了MySQL安装包
CentOS系统中的YUM中包含了MySQL安装包,版本是MySQL5,rpm软件包的名称是mysql-server
yum list | grep mysql:这条命令是将YUM仓库里包含MySQL的软件包都列出来。
在执行上面命令后所列出的软件包中mysql.i686是一个MySQL的客户端,而mysql-server是MySQL的服务端;一般情况下,会把MySQL服务端,客户端都装上,也可以把开发相关的部件都装上,其命令为:
yum install -y mysql-server mysql mysql-devel
查询软件版本的信息:rpm -qi mysql-server
service mysqld start:对mysql进行初始化,这是将mysql启动起来,自动对mysql进行初始化。mysql服务叫mysqld
给mysql的root用户进行初始化并设置密码:
mysqladmin -u root password '密码'
登陆mysql用root用户登陆,并验证密码:mysql -u root -p
设置mysql随着计算机的启动而自动启动:chkconfig mysql on
查看mysql的配置文件(my.cnf),这个文件保存在etc目录下:cd /etc ls my.cnf
查看mysql配置文件中的内容:cat my.cnf
mysql的数据文件保存在/var/lib/mysql,如果我们新建一个
数据库,那么在这个文件夹中就会多一个以新建数据库名的文件夹,这个文件夹中中保存着新建数据库的数据文件(另外查看mysql配置文件中的内容时其中datadir为设置mysql数据文件的保存位置,可以修改)
mysql的日志文件保存在/var/log文件夹下,在这个文件夹中有一个mysqld.log,这个文件保存着mysql报错信息和其他信息。
netstat -tupln 查看哪些服务监听哪些端口
2.安装自己下载最新的MySQL安装包
1)第一步:rpm -ivh MySQL-client-5.6.11-2.el6.i686.rpm MySQL-server-5.6.11-2.el6.i686.rpm
上面这句话,虽然把client放到
server的前面, 但是安装的时候还是先安装server,毕竟,没有server,客户端client连什么去
安装完毕 ,会出现下面的信息
A RANDOM PASSWORD HAS BEEN SET FOR THE MySQL root USER ! You will find that password in '/root/.mysql_secret'. You must change that password on your first connect, no other statement but 'SET PASSWORD' will be accepted. See the manual for the semantics of the 'password expired' flag. Also, the account for the anonymous user has been removed. In addition, you can run: /usr/bin/mysql_secure_installation which will also give you the option of removing the test database. This is strongly recommended for production servers. See the manual for more instructions. Please report any problems with the /usr/bin/mysqlbug script! The latest information about MySQL is available on the web at http://www.mysql.com Support MySQL by buying support/licenses at http://shop.mysql.com New default config file was created as /usr/my.cnf and will be used by default by the server when you start it. You may edit this file to change server settings |
意思就是告诉我们,MySQL安装成功!但不接受任何命令,除非先设置密码(SET PASSWORD),默认密码放到 '/root/.mysql_secret'里了
2)第二步:设置密码
于是,我们去目录'/root'去找,当输入ll或者ls的时候,发现找不到文件,因为在linux内,已点'.'开头的文件都属于隐藏文件,所以我们'll -a'就可以看到'.mysql_secret'文件,vi一下就能看到里面的密码,或者cat 输入文件内容
当我们获得密码后,
首先:要启动mysql,/etc/init.d/mysql start,或者service mysql start,都可以
然后:输入mysql -u root -p,回车后会提示我们输入密码,也就是刚才的密码,输入后,linux的命令前缀变为'mysql>'这就证明登录成功!
下步修改密码,输入 set password = password('abc');如下:(也可以SET PASSWORD = PASSWORD('ABC');,不要忘记分号。 )
mysql> set password = password('abc');
当出现:Query OK, 0 rows affected (0.10 sec)的时候,证明密码成功修改为abc!
然后输入exit/quit退出MySQL
3)第三步:初始化MySQL
紧接上一步,当退出MySQL后,输入/usr/bin/mysql_secure_installation, 然后会问你要数据库密码,输入即可,不然不让你继续设置,然后又问你是否需要修改root的密码,我们刚才设置了,所以没有必要,输入n就可以,剩下的一路回车,要知道在这个设置里,回车=Y,但是到其他地方可
不一定是这样,谨记!
卸载MySQL
1)rpm -e MySQL-server-5.6.11-2.el6.i686 MySQL-client-5.6.11-2.el6.i686
很多人操作完第一步,就以为成功删除了MySQL,如果再次重装的话,会发现MySQL安装完后没有任何的提示,也没有要求你去修改密码
这就说明MySQL没有删除干净
2)找出残留的MySQL文件
利用Find命令:find / -name mysql
也就是说我们还有三个部分没有删掉,第二文件夹是属于第一个文件夹的,所以我们只需要删除第一个/var/lib/mysql,第三个/usr/lib/mysql和/usr/my.cnf就行了,于是:
rm -Rrf /var/lib/mysql rm -Rrf /usr/lib/mysql rm -rf /usr/my.cnf(残留配置文件,一般不会注意到它,可删可不删,对下一步安装没影响) |
再按装试试,是不是就出现要求修改密码的提示了,其实仔细分析一下,因为在第一次安装的时候,数据库已经建立,密码什么的肯定存上了,但是卸载MySQL时,为了安全起见,数据库会保留,当然上次设置的密码也就保留下来了,其实只需要删除/var/lib/mysql就可以了,重装一下试试,肯定会出现要求修改密码的提示。
2)第二步:设置密码
于是,我们去目录'/root'去找,当输入ll或者ls的时候,发现找不到文件,因为在linux内,已点'.'开头的文件都属于隐藏文件,所以我们'll -a'就可以看到'.mysql_secret'文件,vi一下就能看到里面的密码,或者cat 输入文件内容
当我们获得密码后,
首先:要启动mysql,/etc/init.d/mysql start,或者service mysql start,都可以
然后:输入mysql -u root -p,回车后会提示我们输入密码,也就是刚才的密码,输入后,linux的命令前缀变为'mysql>'这就证明登录成功!
下步修改密码,输入 set password = password('abc');如下:(也可以SET PASSWORD = PASSWORD('ABC');,不要忘记分号。 )
mysql> set password = password('abc');
当出现:Query OK, 0 rows affected (0.10 sec)的时候,证明密码成功修改为abc!
然后输入exit/quit退出MySQL
3)第三步:初始化MySQL
紧接上一步,当退出MySQL后,输入/usr/bin/mysql_secure_installation, 然后会问你要数据库密码,输入即可,不然不让你继续设置,然后又问你是否需要修改root的密码,我们刚才设置了,所以没有必要,输入n就可以,剩下的一路回车,要知道在这个设置里,回车=Y,但是到其他地方可
不一定是这样,谨记!
卸载MySQL
1)rpm -e MySQL-server-5.6.11-2.el6.i686 MySQL-client-5.6.11-2.el6.i686
很多人操作完第一步,就以为成功删除了MySQL,如果再次重装的话,会发现MySQL安装完后没有任何的提示,也没有要求你去修改密码
这就说明MySQL没有删除干净
2)找出残留的MySQL文件
利用Find命令:find / -name mysql
也就是说我们还有三个部分没有删掉,第二文件夹是属于第一个文件夹的,所以我们只需要删除第一个/var/lib/mysql,第三个/usr/lib/mysql和/usr/my.cnf就行了,于是:
rm -Rrf /var/lib/mysql rm -Rrf /usr/lib/mysql rm -rf /usr/my.cnf(残留配置文件,一般不会注意到它,可删可不删,对下一步安装没影响) |
再按装试试,是不是就出现要求修改密码的提示了,其实仔细分析一下,因为在第一次安装的时候,数据库已经建立,密码什么的肯定存上了,但是卸载MySQL时,为了安全起见,数据库会保留,当然上次设置的密码也就保留下来了,其实只需要删除/var/lib/mysql就可以了,重装一下试试,肯定会出现要求修改密码的提示。
在
TestNG基本注释一中,我们给出来一个用eclipse IDE生成的TestNG测试类:
package test.java.com.testng.test; import org.testng.annotations.Test; import org.testng.annotations.BeforeMethod; import org.testng.annotations.AfterMethod; import org.testng.annotations.DataProvider; import org.testng.annotations.BeforeClass; import org.testng.annotations.AfterClass; import org.testng.annotations.BeforeTest; import org.testng.annotations.AfterTest; import org.testng.annotations.BeforeSuite; import org.testng.annotations.AfterSuite; public class LoginTest { @Test(dataProvider = "dp") public void f(Integer n, String s) { } @BeforeMethod public void beforeMethod() { } @AfterMethod public void afterMethod() { } @DataProvider public Object[][] dp() { return new Object[][] { new Object[] { 1, "a" }, new Object[] { 2, "b" }, }; } @BeforeClass public void beforeClass() { } @AfterClass public void afterClass() { } @BeforeTest public void beforeTest() { } @AfterTest public void afterTest() { } @BeforeSuite public void beforeSuite() { } @AfterSuite public void afterSuite() { } } |
上面代码中的具体解释如下:
@BeforeSuite - 针对测试套件,在当前的测试套件运行前执行的方法 @AfterSuite - 针对测试套件,在当前的测试套件运行后执行的方法 @BeforeTest - 针对测试套件, 在任何属于这个类的并且用<test>标签标记的测试方法运行前运行 @AfterTest - 针对测试套件, 在任何属于这个类的并且用<test>标签标记的测试方法运行后运行 @BeforeGroups: 在属于这个组的第一个测试方法运行前运行 @AfterGroups: 在属于这个组的最后一个测试方法被调用后运行 @BeforeClass - 在当前已经被调用的类的第一个测试方法运行前运行 @AfterClass - 在当前类的所有测试方法运行完成后运行 @BeforeMethod - 在每个测试方法前运行 @AfterMethod - 在每个测试方法后运行 |
相关文章:
这里先来推荐一个在
QTP中实现weblist自动化选择的一种方法,推荐的理由是网上的方法很多不可行,或是太过于复杂。其实事情往往很简单,只是思考他的人总是会认为它很复杂,所以才有了那么多复杂的事。
废话不多说,来讲原理:
由于本台本本上没有具体的代码,所以只有用记忆外加口头来描述如何进行weblist自动化的选择
一般我们录制一个weblist的选择,大体会是下面这样:
browser(一个页面).page(一个页面).frame(一个框架).weblist(一个下拉选择表).select 具体值
对于weblist,一般来说用Objectspy来查看,一般情况下会在属性名为"all items"之类的属性下,对应有"值1;值2;值3...."。这里,我们可以使用这个完整的值段来进行自动选择的参考取值。我们首先可以使用getROproperty("all items")的方式来取出该值段,随后我们需要解决的就是如何把这个完整的值段分成若干份然后存入一个数组变量来供我们使用。
相信大部分的读者已经想到了使用split函数来对这个完整的值段来进行分割了吧!没错,我们使用的正是这个帅气的函数,我们可以像这样写split(browser(一个页面).page(一个页面).frame(一个框架).weblist(一个下拉选择表).getROproperty("all items"),";",-1,1)的方式来获得这个值段中每一小块我们需要的是值(关于split函数不明白的我就不做阐述了,请不懂的童鞋参考网上的资料哦~~)分割了以后,我们可以把它存入一个数组变量中,然后剩下所需做的就是如何对该数组进行随机选择其值了。
在QTP中,我们可以使用Randomnumber(下界,上界)来进行随机取值,不过剩下最关键的是我们如何获得该数组的上界呢?说到这里就很简单了~那就是ubound函数!没错,一个小小的函数就成为了我们做自动取值的关键~(说到这里是不是有点觉得复杂的事情其实是很简单的呢?)
下面我们这样做:
Dim rand_select
rand_select=split browser(一个页面).page(一个页面).frame(一个框架).weblist(一个下拉选择表).getROproperty("all items"),";",-1,1
browser(一个页面).page(一个页面).frame(一个框架).weblist(一个下拉选择表).select randomnumber(0,ubound(rand_select))
这样,我们就很简单的实现了weblist的自动化选择了!
版权声明:本文出自 ftdtest 的51Testing软件测试博客:http://www.51testing.com/?15001542
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
这里简单总结一下ios应用开发过程中的真机
测试,不详细赘述。必须条件:99美刀的开发者帐号、测试设备。
真机测试要经历如下几个步骤:
一、创建测试/发布许可证书
1、如果当前pc是首次连接设备进行测试,需要下载AppleWWDRCA.cer文件到当前pc,这个文件是测试以及发布ios应用必须的一个文件,这个文件只要下载一次就够了,这是调试以及发布iOS应用必须的一个文件,这个文件只要下载一次就够了,即使你有多个iDP,无论是调试程序,还是发布程序,也只需要一个。
2、打开钥匙串 > 从证书颁发机构请求证书 > 生成证书请求文件
3、用这个证书请求文件到开发者网站上申请测试许可证书,将测试许可证书双击安装到当前pc。
二、创建应用唯一标示
创建一个App ID,一个唯一性的字符串。App ID 分为两种: Explicit(明确的)App ID 和 WildCard(通配的)App ID。
三、绑定测试设备
将你的设备绑定到开发者帐号上。
四、创建应用配置文件
创建provisioning file(配置文件),绑定相应的测试证书、测试设备、App ID。
更详细的操作步骤可以参照:http://eric-gao.iteye.com/blog/1337007
外部依赖对象
对于LogAnalyzer对象来说, Service和Email就是两个外部依赖对象. 我们需要自己写Stub和Mock来模拟这两个外部依赖对象。这样我们才能控制他们。
我们在测试的代码中新建StubWebService和MockEmailService.这两个class分别实现了IWebService和IEmailService.
public class StubWebService : IWebService { public void LogError(string message) { throw new Exception("StubWebService throw exception"); } } public class MockEmailService : IEmailService { public string To; public string From; public string Subject; public string Message; public void SendEmail(string to, string from, string subject, string message) { To = to; From = from; Subject = subject; Message = message; } } |
工作流程图如下
最后我们来看看我们的测试代码,
我们把StubWebService和MockEmailService两个类的实例注入到产品代码中。(因为多态特性嘛)。
通过控制StubWebService中的LogError方法,抛出一个异常。
然后判断MockEmailService中的SendEmail方法有没有被调用. 被调用了说明发送了Email(我们不需要真的收到一封邮件,因为SendEmail功能是IEmailService实现的,)
[TestMethod] public void TestMethod1() { StubWebService stubWebService = new StubWebService(); MockEmailService mockEmailSender = new MockEmailService(); LogAnalyzer log = new LogAnalyzer(); log.Emailservice = mockEmailSender; log.WebService = stubWebService; // Act string tooShortFileName = "1.txt"; log.Analyze(tooShortFileName); // Assert Assert.AreEqual("to@test.com", mockEmailSender.To); Assert.AreEqual("from@test.com", mockEmailSender.From); Assert.AreEqual("WebSerive log error", mockEmailSender.Subject); } |
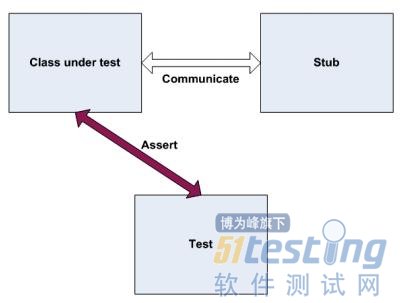
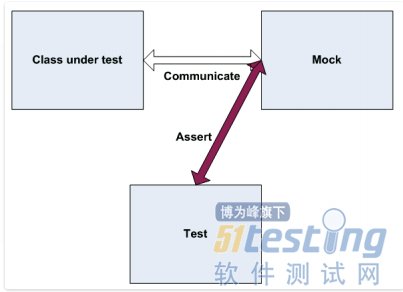
Stub和Mock的相同处
从上面的例子我们可以看出, Stub和Mock都是模拟外部依赖,以便我们能控制。
Stub 和Mock 的区别
Stub是完全模拟一个外部依赖, 而Mock用来判断测试通过还是失败
良好的产品代码才能单元测试
外部依赖对象
对于LogAnalyzer对象来说, Service和Email就是两个外部依赖对象. 我们需要自己写Stub和Mock来模拟这两个外部依赖对象。这样我们才能控制他们。
我们在测试的代码中新建StubWebService和MockEmailService.这两个class分别实现了IWebService和IEmailService.
public class StubWebService : IWebService { public void LogError(string message) { throw new Exception("StubWebService throw exception"); } } public class MockEmailService : IEmailService { public string To; public string From; public string Subject; public string Message; public void SendEmail(string to, string from, string subject, string message) { To = to; From = from; Subject = subject; Message = message; } } |
工作流程图如下
最后我们来看看我们的测试代码,
我们把StubWebService和MockEmailService两个类的实例注入到产品代码中。(因为多态特性嘛)。
通过控制StubWebService中的LogError方法,抛出一个异常。
然后判断MockEmailService中的SendEmail方法有没有被调用. 被调用了说明发送了Email(我们不需要真的收到一封邮件,因为SendEmail功能是IEmailService实现的,)
[TestMethod] public void TestMethod1() { StubWebService stubWebService = new StubWebService(); MockEmailService mockEmailSender = new MockEmailService(); LogAnalyzer log = new LogAnalyzer(); log.Emailservice = mockEmailSender; log.WebService = stubWebService; // Act string tooShortFileName = "1.txt"; log.Analyze(tooShortFileName); // Assert Assert.AreEqual("to@test.com", mockEmailSender.To); Assert.AreEqual("from@test.com", mockEmailSender.From); Assert.AreEqual("WebSerive log error", mockEmailSender.Subject); } |
Stub和Mock的相同处
从上面的例子我们可以看出, Stub和Mock都是模拟外部依赖,以便我们能控制。
Stub 和Mock 的区别
Stub是完全模拟一个外部依赖, 而Mock用来判断测试通过还是失败
良好的产品代码才能单元测试
如果产品代码是下面那样,你就没办法测试了。 因为WebService和EmailService两个类没有继承接口。我们无法把StubWebService和MockEmailService两个类注入到产品代码。
public class LogAnalyzer { private WebService webService; private EmailService emailService; public WebService WebService { get { return webService; } set { webService = value; } } public EmailService Emailservice { get { return emailService; } set { emailService = value; } } public void Analyze(string fileName) { if (fileName.Length < 8) { try { WebService.LogError("Filename too short:" + fileName); } catch (Exception e) { Emailservice.SendEmail("to@test.com", "from@test.com", "WebSerive log error", e.Message); } } } } |
Mock框架
其实我们没有必要自己写MockEmailService方法。 已经有现成的Mock框架可以用了, .NET中有Rhino Mock 和 Moq, 这两个框架比较好用

如图 我们看到 配置这里最顶端的几个项 1 项目名称 顾名思义 构建的JOB名 我们尽量命名为比较符合我们构建要求的 比如我们给DEV环境进行构建 那么我们就将名称命名为XXX_DEV 如果我们进行的是deploy操作 那么可以这样命名 XXX_DEPLOY
描述 就是注释 给我们这个job一个更便于其他查看的详解
下来我们看到丢弃旧的构建功能
策略 log
Rotation 日志循环
保持构建的天数 意思就是根据你所填写的天数来保存构建记录
保持构建的最大个数 意思就是有几条构建记录就保存几条
|
发布包保留天数 例如我们发布的war包 等 保存的天数
|
发布包最大保留#个构建 例如我们发布了几个war包 就保存几个
|

下来我们看看 参数化构建构成 这样方便我们管理项目配置


CVS符号名称参数


这个参数相当于一个数组
在CHOICES 里面可以填写多个值

文件参数
flie location 填写 文件的路径







1.首先解压缩文件:
# tar xvf dnw_for_linux.tar.gz
另:在Ubuntu下右键解压也很方便
目录如下:
dnw_linux/ dnw_linux/secbulk/ dnw_linux/secbulk/Makefile dnw_linux/secbulk/secbulk.c dnw_linux/dnw/ dnw_linux/dnw/dnw.c |
其中secbulk.c是PC端USB驱动, dnw.c是写入工具
2 编译并加载secbulk.c内核模块
$cd secbulk
$make -C /lib/modules/`uname -r`/build M=`pwd` modules
编译成功后在当前目录下可以看到secbulk.ko
3.编译完成后,会生成secbulk.ko文件:
# ls
Makefile Module.symvers secbulk.ko secbulk.mod.o
modules.order secbulk.c secbulk.mod.c secbulk.o
# sudo insmod ./secbulk.ko (注意要在root权限下)
# dmesg (查看是否加载成功)
secbulk:secbulk loaded
usbcore: registered new interface driver secbulk (看到这样两行就说明成功了)
开机的时候不会自动加载.ko文件,这样每次都要先加载才可以使用,此时将其加入开机脚本,
使其得到自动加载,编辑/etc/init.d/rc.local 在最后加上 insmod /所在路径/secbulk.ko。
5.下面开始编译dnw工具
# cd ../dnw
# gcc -o dnw dnw.c
(编译完成,会看到dnw可执行文件)
6.将文件copy到/usr/local/bin目录
# sudo cp dnw /usr/local/bin
(这样就可以在
shell下面直接使用dnw命令了)