
一、运行
1,solr运行容器,tomcat
2,拷贝apache-solr-3.6.0.war到tomcat的webapps目录下,并改名为solr.war
3,tomcat的conf目录下建立结构为conf/Catalina/localhost的两个文件夹。建立结构为solr-tomcat/solr的两个文件夹(solr的HOME目录),如建在D盘根目录,d:/solr-tomcat/solr,solr-tomcat文件夹名字可任意命名,将apache-solr-3.6.0\example\solr下的所有文件及文件夹拷贝到这下面
4,在localhost文件夹下建立solr.xml,并保存如下内容:
<Context docBase="D:\tomcat-6.0\webapps\solr.war" debug="0" crossContext="true" > <Environment name="solr/home" type=" java.lang.String" value="D:/solr-tomcat/solr" override="true" /> </Context> |
5,此时可以运行tomcat,地址栏输入:http://localhost:8080/solr/admin进行验证
6,开始为导入
数据库数据添加配置。将jdbc驱动jar和apache-solr-3.6.0\dist\apache-solr-dataimporthandler-3.6.0.jar 两个jar拷贝到tomcat的webapps/solr/WEB-INF/lib下。将apache-solr-3.6.0\example\example-DIH\solr下的所有文件及文件夹拷贝(并覆盖)到solr的HOME目录,如:d:/solr-tomcat/solr
7,更改solr Home目录下的conf/solrconfig.xml,添加如下内容:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">D:\solr-tomcat\solr\db\conf\db-data-config.xml</str> <!-- 根据自己电脑里的db-data-config.xml的实际路径来写 -- > </lst> </requestHandler> |
8, 将solr Home目录下面的solrconfig.xml和schema.xml拷贝到db文件夹下面的conf中,注意:导入的字段要先在schema.xml中定义
定义如:<field name="firstname" type="string" stored="true" indexed="true"/>
9,修改db\conf\db-data-config.xml,可参考如下:
<dataConfig> <dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/langsin1" user="root" password="root"/> <document name="userss"> <entity name="users" pk="id" query="select * from users"> <field column="id" name="id" /> <field column="firstname" name="firstname" /> <field column="lastname" name="lastname" /> <field column="age" name="age" /> </entity> </document> </dataConfig> |
10,启动TOMCAT,输入地址进行导入,导入分为很多模式:我选用的全部倒入模式
http://localhost:8080/solr/db/dataimport?command=full-import
11,如果有中文,修改tomcat的
server.xml文件
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8"
12,添加中文分词,如:mmseg4j, 在$SOLR_HOME下建立lib和dic两个目录,讲mmseg4j-all-1.8.4.jar拷贝到lib目录,将data里的.dic文件拷贝到dic目录
13,修改Schema.xml
添加fieldType
Xml代码
<types> <fieldType name="textComplex" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="/opt/solr/example/solr/dic"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType> <fieldType name="textMaxWord" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" dicPath="/opt/solr/example/solr/dic"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType> <fieldType name="textSimple" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="/opt/solr/example/solr/dic"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType> .. </types> |
Xml代码
<fieldname="simple"type="textSimple"indexed="true"stored="true"multiValued="true"/> <fieldname="complex"type="textComplex"indexed="true"stored="true"multiValued="true"/> <fieldname="maxword"type="textMaxWord"indexed="true"stored="true"multiValued="true"/> |
Xml代码
<copyField source="simple" dest="text"/> <copyField source="complex" dest="text"/> |
14,重启tomcat,
进入 http://yourhost:8080/solr-example/admin/analysis.jsp,测试中文分词
谈及开源Web
自动化测试工具,相信很多人立刻会想到
Selenium。本文给大家介绍的是另一款开源Web
自动化测试工具Sahi。Sahi的网站上有关于与Selenium的对比,不过这不是我们今天探讨的主题。这篇
文章的主要目的是向读者简单的介绍一下Sahi并分享一下个人使用Sahi测试Dojo应用的经验,希望对大家能有所帮助。
1. Web2.0应用测试的困境
在开始介绍Sahi之前,我们一起来看看在开发Web 自动化测试(特指Web 2.0应用)时常面临的两大技术问题。
页面元素的识别
根据个人经验,以下几点会给页面元素的识别带来障碍:
页面DOM树随着产品版本升级频繁发生变化。
页面元素没有id属性或者id属性值是动态的。
页面中具有相同属性的元素不止一个。
通常的解决方案:
针对第一点,恐怕没有太好的解决方案,所以只能随着产品的改变更新自动化测试的代码。关于这一点,如果能够存在某种元素识别方法能够以最小的代码改动应对产品变化,那就是最理想的了。
针对第二点,解决方案是要求开发团队对所有测试中用到的元素增加用以识别元素的静态属性值。这听起来容易,但做起来未必简单。一来,开发团队通常以开发新产品功能为最高优先级,所以不太愿意花时间在这上面;二来,如果产品本身使用了某种封装后的技术框架,恐怕也会存在技术上的局限。
第三点事实上是识别的精确性的问题,这个问题可以使用XPath和CSS选择器来解决。但两者对于相对关系的限制都过于严格从而导致代码不能灵活适应DOM树的变化,最终会使维护成本直线上升。但是它很“脆弱”,当DOM树结构的变化很容易导致XPath的失效。并且,CSS选择器的使用还必须考虑浏览器的兼容性问题,如果需要支持的浏览器种类比较多,代码编写的成本也会比较高。
那我们来看看Sahi关于元素识别的策略:
Sahi倡导使用“可见”属性识别元素,也就是元素的value, title等属性。这样做的好处很明显,就是可以减少对Firebug, Chrome Developer Tools的使用,从而提高开发效率。也就是“所见即所得”。当然,我们知道,只靠这些“可见”属性值是不够的。Sahi使用的元素识别方式是传入一个属性值,Sahi按照预先的设置进行查找。例如,_div(“name”)用来获取一个div, “name”或许是id也或许是name。Sahi允许用户针对每种元素类型定义新的属性并设置新的查找顺序,这也包括自定义属性名。
Sahi提供了基于上下文的元素识别API。目前它支持三种方式:
_in,在某个DOM节点下查找某个元素 (这显然好过用XPath或者CSS选择器)
_near,在某个元素附近查找符合条件的最近的一个元素。这也是个很有用的定位方式。
_under,在某个元素下方查找符合条件的最近的一个元素(前提是,两个元素需要有相同的偏移量(offset)), 比如table中同一个column中的cell就可以用这种方式相对定位。
Sahi API中所有的identifier参数都支持正则表达式,例如,_div(/name.*/) 用来识别所有以某种预属性值是name开头的div。
因此,Sahi基本上能够较好地解决前面提到的三大关于元素识别的障碍。
页面等待
通常Web 2.0应用中有很多AJAX的应用。由于请求响应的返回是异步的,自动化测试程序如何决定是否可以继续下一个操作或者是开始验证呢?如果下一步操作在AJAX请求响应还没有返回时就执行了,毫无疑问会导致
测试用例的失败,并且是误判。
通常的做法是:
等待固定的时间,比如5秒。多长的等待算是合理呢?如果时间设置过短,被测应用在远程,由于网络因素使响应变慢,测试用例很可能失败;如果时间设置过长,即便在正常响应时间情况下,仍然要等待同样的时间,无疑是浪费。
轮询界面上某个指定元素,直至它出现从而继续下一步操作或者是超时,测试用例判定为失败。这种做法的坏处在于:一、必须找到这个“指定元素”,这往往不是那么容易的;二、如果AJAX在你所测应用中很普遍,这种代码可能会充斥你这个测试程序,从而导致开发速度下降。
Sahi能够判断AJAX请求是否已经处理完毕,然后继续下一步操作,这一点对用户是“隐式”的,也就是说用户不需要写任何代码。事实是,绝大多数情况下用户确实不需要自己写代码处理页面等待的问题,但是,有时应用的某个功能是执行多个AJAX请求完成的(例如,长时间操作的进度条显示),此时Sahi便无法胜任。这种情况下,用户只能利用Sahi提供的等待固定时间以及基于条件等待的API自己编写代码实现页面等待。
问题:
LoadRunner的HP Web Tours应用程序服务启动不了,提示1080端口被占用的问题
解决方法:
1. 查看占用1080端口的进程
Cmd窗口输入netstat–ano找到占用该端口的PID
2. 在任务管理器中找到该PID的进程名,我这里显示的是oracle.exe占用(怕影响其他服
务,所以不做终止这个服务的操作,重新考虑修改LoadRunner的HP Web Tours应用服务端口)
3. 找到LoadRunner安装目录下,C:\Program Files\HP\LoadRunner\WebTours,打开xitami.cfg
配置文件,找到portbase=1000(默认值)这项,修改它。[注:端口1080=portbase+80] 4. 我们修改portbase=2000,保存,端口就变成了2080,然后服务启动成功。 5. 浏览器地址栏输入:http://localhost:2080/WebTours/.但显示下列错误。 Internal error:your request was unsuccessful Cannot create GUI process-program not found
6. 找到C:\Program Files\HP\LoadRunner\WebTours目录配置文件run.bat 原来的路径如下:
SET PATH=C:\PROGRA~1\HP\LOADRU~1\bin
cd C:\PROGRA~1\HP\LOADRU~1\WebTours start xigui32.exe 修改成下面路径:
SET PATH=C:\PROGRA~1\HP\LOADRU~1\bin;c:\strawberry\c\bin;c:\strawberry\perl\bin cd C:\PROGRA~1\HP\LOADRU~1\WebTours start xigui32.exe
7. 重启服务。
8. 刷新浏览器地址,可以出现登录页面
9. 输入用户名jojo密码bean 可以正常进入系统
附:[查看C盘下是否有strawberry文件夹下,
如果没有就需要下载strawberry-perl-5.10.1.0.msi并安装,然后刷新浏览器就可以看到程序成功打开] 网上有人这样说,但我的没有找到strawberry文件夹也能正常浏览。
发现直接在resource中加载含有calss的vbs文件,
QTP无法识别类,导致脚本中无法new类对象。
解决办法有四种:
1、直接在action脚本中定义类,然后action中任何地方都可以实例化类
2、用executefile引入类定义文件,然后action中任何地方都可以实例化类
3、在function lib中定义类,并实例化类,然后再action中直接使用类实例
4、在function lib中定义类,并定义一个实例化类的函数,然后再action中调用该函数对类进行实例化
补充:第四种实现方法如下:
把vbs文件加载到Resources中后,我用以下方法绕过QTP不识别导入的vbs文件中的类的问题。
在放置class(类)的vbs文件中,放置以下函数:
------------------------------------------------------------------------------------------------------------------ ' '* 功能:由于QTP不识别导入的VBS文件中的类,因此定义此函数来返回相应的对象 '* 输入参数:className :要建立对象的类名 '* 返回值:返回类对象 '* 编写人: chenyb '* 编写日期:2008-10-16 '* 其他说明:以下只是方法,根据需要再扩展 ' Public Function newClass(className) Dim strSentence,obj strSentence = strSentence & "set obj = New " & className '创建对象 Execute strSentence '执行字符串语句 Set newClass = obj '返回对象 End Function |
参考QTP下vbs伪类构造器的设计:
有一段时间没上博客了,不过博客还是不能拖呢,每每在我快要放弃的时候总会有许多网友在告诉我该更新了,我们等着你的讲座,虽然讲座写到后来已经有些疲倦,但有了你们的支持,我还会一直继续,讲座还会一直继续。
进入正题,今天要讲的内容与VBS类关联比较密切,在看本次讲座之前建议大家首先熟悉一下类的组成, 这样对于
学习本次讲座内容会比较轻松。如果平时在
自动化测试过程中经常使用类的朋友应该会清楚,在Resources中引用带有类的vbs函数库之后,是不可以直接在QTP脚本编辑器中直接进行类的初始化的。具体我们来看下例子。
1.首先我们编写一个vbs函数库,脚本如下:
Class ExcelClass Sub t1() MsgBox "t1" End Sub Sub t2() MsgBox "t2" End Sub End Class |
2.在QTP的File --> Settings --> Resources中引用此函数库
今天的
TDD练习又开始了。回头看看上一次留下的任务。
To-Do-List:
猜测数字
输入验证
生成答案
输入次数
输出猜测结果
今天我们把输入验证和随机生成答案搞定。
新建ValidationTest文件。
分析需求:(1)不重复。(2)4位(3)数字。(4)不为空。
按照我们分析出来的4个明确点我们开始写CASE。
注意命名!
[TestClass] public class ValidatorTest { private Validator validator; [TestInitialize] public void Init() { validator = new Validator(); } [TestMethod] public void should_return_input_must_be_four_digits_when_input_figures_digit_is_not_four_digits() { var input = "29546"; validator.Validate(input); var actual = validator.ErrorMsg; Assert.AreEqual("the input must be four digits.", actual); } [TestMethod] public void should_return_input_must_be_fully_digital_when_input_is_not_all_digital() { var input = "a4s5"; validator.Validate(input); var actual = validator.ErrorMsg; Assert.AreEqual("the input must be fully digital.", actual); } [TestMethod] public void should_return_input_can_not_be_empty_when_input_is_empty() { var input = ""; validator.Validate(input); var actual = validator.ErrorMsg; Assert.AreEqual("the input can't be empty.", actual); } [TestMethod] public void should_return_input_can_not_contain_duplicate_when_input_figures_contain_duplicate() { var input = "2259"; validator.Validate(input); var actual = validator.ErrorMsg; Assert.AreEqual("the input figures can't contain duplicate.", actual); } } |
按照第一篇的步骤。实现validator。争取让所有的CASE都过。
public class Validator { public string ErrorMsg { get; private set; } public bool Validate(string input) { if (string.IsNullOrEmpty(input)) { ErrorMsg = "the input can't be empty."; return false; } if (input.Length != 4) { ErrorMsg = "the input must be four digits."; return false; } var regex = new Regex(@"^[0-9]*$"); if (!regex.IsMatch(input)) { ErrorMsg = "the input must be fully digital."; return false; } if (input.Distinct().Count() != 4) { ErrorMsg = "the input figures can't contain duplicate."; return false; } return true; } } |
Run...
一个CASE对应这一个IF。也可合并2个CASE。可以用"^\d{4}$"去Cover"4位数字"。可以根据自己的情况去定。
小步前进不一定要用很小粒度去一步一步走。这样开发起来的速度可能很慢。依靠你自身的情况去决定这一小步到底应该有多大。正所谓"步子大了容易扯到蛋,步子小了前进太慢"。只要找到最合适自己的步子。才会走的更好。
这么多IF看起来很蛋疼。有测试。可以放心大胆的重构。把每个IF抽出一个方法。看起来要清晰一些。
public class Validator { public string ErrorMsg { get; private set; } public bool Validate(string input) { return IsEmpty(input) && IsFourdigits(input) && IsDigital(input) && IsRepeat(input); } private bool IsEmpty(string input) { if (!string.IsNullOrEmpty(input)) { return true; } ErrorMsg = "the input can't be empty."; return false; } private bool IsFourdigits(string input) { if (input.Length == 4) { return true; } ErrorMsg = "the input must be four digits."; return false; } private bool IsDigital(string input) { var regex = new Regex(@"^[0-9]*$"); if (regex.IsMatch(input)) { return true; } ErrorMsg = "the input must be fully digital."; return false; } private bool IsRepeat(string input) { if (input.Distinct().Count() == 4) { return true; } ErrorMsg = "the input figures can't contain duplicate."; return false; } } |
为了确保重构正确。重构之后一定要把所有的CASE在跑一遍,确定所有的都PASS。
To-Do-List:
猜测数字
输入验证
生成答案
输入次数
输出猜测结果
验证搞定了。我们来整整随机数。
分析需求:产品代码需要一个随机生成的答案。(1)不重复。(2)4位(3)数字。
这里有个问题:大家都知道随机数是个概率的问题。因为每次生成的数字都不一样。看看之前Guesser类的代码。
public class Guesser { private const string AnswerNumber = "2975"; public string Guess(string inputNumber) { var aCount = 0; var bCount = 0; for (var index = 0; index < AnswerNumber.Length; index++) { if (AnswerNumber[index]==inputNumber[index]) { aCount++; continue; } if (AnswerNumber.Contains(inputNumber[index].ToString())) { bCount++; } } return string.Format("{0}a{1}b", aCount, bCount); } } |
这里我们如果把private const string AnswerNumber = "2975";改为随机的话,那Guesser类测试的结果是不能确定的。也就是说测试依赖了一些可变的东西。比如:随机数、时间等等。
遇到这种情况应该怎么办呢?一种随机数是给产品代码用,我们可以MOCK另外一种"固定随机数"(但是要满足生成随机数的条件)来给测试用。
还是一样先写测试。
[TestClass] public class AnswerGeneratorTest { [TestMethod] public void should_pass_when_answer_generator_number_is_four_digits_and_fully_digital() { Regex regex = new Regex(@"^\d{4}$"); var answerGenerator = new AnswerGenerator(); var actual = regex.IsMatch(answerGenerator.Generate()); Assert.AreEqual(true, actual); } [TestMethod] public void should_pass_when_answer_generator_number_do_not_repeat() { var answerGenerator = new AnswerGenerator(); var actual = answerGenerator.Generate().Distinct().Count() == 4; Assert.AreEqual(true, actual); } } |
实现AnswerGenerator类让测试通过。
引用cao大一段代码稍加修改
public class AnswerGenerator { public string Generate() { var answerNumber = new StringBuilder(); Enumerable.Range(0, 9) .Select(x => new { v = x, k = Guid.NewGuid().ToString() }) .OrderBy(x => x.k) .Select(x => x.v) .Take(4).ToList() .ForEach(num => answerNumber.Append(num.ToString())); return answerNumber.ToString(); } } |
运行测试。
为了解决测试依赖可变的问题。定义IAnswerGenerator。让两种随机数类继承。
public interface IAnswerGenerator { string Generate(); } [csharp] view plaincopy public class AnswerGenerator : IAnswerGenerator { public string Generate() { var answerNumber = new StringBuilder(); Enumerable.Range(0, 9) .Select(x => new { v = x, k = Guid.NewGuid().ToString() }) .OrderBy(x => x.k) .Select(x => x.v) .Take(4).ToList() .ForEach(num => answerNumber.Append(num.ToString())); return answerNumber.ToString(); } } public class AnswerGeneratorForTest : IAnswerGenerator { public string Generate() { return "2975"; } } |
AnswerGenerator给产品代码用。AnswerGeneratorForTest给测试代码用。这样就可以避免测试依赖可变的问题。
相应的给Guesser类以及测试代码做个修改。
public class Guesser { public string AnswerNumber { get; private set; } public Guesser(IAnswerGenerator generator) { AnswerNumber = generator.Generate(); } public string Guess(string inputNumber) { ... } } [TestClass] public class GuesserTest { private Guesser guesser; [TestInitialize] public void Init() { guesser = new Guesser(new AnswerGeneratorForTest()); } ... } |
这样我在测试代码当中就会给一个不可变的随机数。AnswerGeneratorForTest。所以之前的Guesser测试代码也不会因为每次的随机数不一样导致挂掉。
产品代码呢?直接丢AnswerGenerator进去就妥妥地。
To-Do-List:
猜测数字
输入验证
生成答案
输入次数
输出猜测结果
OK。今天的收获。
(1)小步前进:依靠自身情况决定“小步”应该有多大。
(2)重构:之前的测试是我们重构的保障。
(3)测试依赖:测试不应该依赖于一些可变的东西。
都到这了,有没有点TDD的感觉。知道TDD的步骤了吗?
(1)新增一个测试。
(2)运行所有的测试程序并失败。
(3)做一些小小的改动。
(4)运行所有的测试,并且全部通过。
(5)重构代码以消除重复设计,优化设计。
(6)重复上面的工作。实现1~5小范围迭代。直到满足今天的Story。
上一篇还有个遗留的问题。我把它记在小本上。
相关文章:
这是一个星期四的晚上,快乐时光即将开始。你会尽快走出办公室。你整天都忙于准备一份报告,第二天早上还需继续,因此你将电脑锁屏。这足够安全,是吗?因为你使用了高强度密码,并全盘加密,Ophcrack或者可引导的linux发行版例如kali不起作用。你自认为安全了,其实你错了。为了得到重要材料,攻击者越来越无所不用其极,这包括使用取证领域的最新技术。
计算机中存在一个单独的区块:活动内存,任何一个攻击者都愿意把手伸到这个存储有敏感信息完全未加密的区块。系统为了方便调用,在内存中存储了多种有价值信息;全盘加密机制也必须在内存的某个地方存储密钥。同样,Wi-fi密钥也是如此存储的。
Windows在内存中存有注册表键值,系统和SAM hive。许多剪贴板内容和应用程序密码也在存储于内存中。即问题在于,内存存储了系统在某时刻需要的大量有价值信息。攻击者要获得它,需要使用一些同样的取证技术。本文有助于向
渗透测试工具包中增加这些技术。
设置环境
信息转储可以很容易的构建系统全貌。近年来,内存捕获价值已经得到取证专家的高度重视,但却并未获得渗透测试人员的足够重视。这有众多原因。取证调查人员使用专业软件捕获内存,同时记录进设备中。他们使用这些捕获信息,寻找恶意软件或隐藏进程。渗透测试人员将会对哈希值、文件、运行进程更感兴趣。如果已经拥有系统的访问权限,他们很大可能不再需要内存捕获来得到这些信息。
但是,在一些情境下,内存捕获对渗透测试人员作用极大。设想如下场景:在一个内部行动中,测试人员获得了接触机器的权限。客户满信心认为测试人员不可能利用这些机器获得对系统的访问。这些机器使用了全盘加密,拥有阻止从Ophcrack和下载hash的功能。运行中的机器全部处于锁定状态。客户不知道的是,测试人员拥有丰富的技术经验,能够抓取运行系统内存中的内容。需要强调的是有两种技术可以用于这样的情景:冷启动攻击和火线接口攻击。
冷启动攻击
2008年年初,普林斯顿大学电子前沿基金会和温瑞尔系统公司的研究人员联合发表了一篇题为《鲜为人知的秘密:对密钥的冷启动攻击》的
文章,该文详解了从运行系统获取内存信息的一种新型攻击方式。该类攻击基于数据遗留。人们的普遍看法是机器一旦断电,内存中的数据就会立刻丢失;即按开电源开关,所有数据在刹那间消失。
然而,研究人员指出真相并非如此。事实上,数据从内存中丢失需要一定的时间。断开一台机器的电源一到两秒,大部分数据会完好无损。该效果可通过冷却内存延长。研究人员借助一种老式社交游戏,倒置一灌压缩空气,做了测试。冷却内存确实可以使数据保持很多秒,甚至好几分钟。这促使研究人员开发一系列工具,用来从即将关闭电源的机器内存中提取信息,然后再次启动系统。
使用这种方法捕获内存,存在小错误的几率会相对较高,这就是它被取证组织大量摒弃的原因。但是,渗透测试人员并不需要内存的法律上的取证镜像。如果密钥或SAM数据库完好无损,即使内存有2%的破坏也是可以接受的。即使有点难,这种方法对内部渗透测试人员来说,也是一个合适的攻击向量。
The Lest We Remember团队创造了大量用于攻击的工具,可以在普林斯顿网站https://citp.princeton.edu/research/memory/code/下载到。主要工具是一个USB/PXE镜像工具,可以下载到源码。研究团队制作了许多makefiles文件使编译更容易,他们也在源码中打包了优秀的文档。32位的提取器应该在32位虚拟机或32位物理机器上编译,64位的提取器同样需要在64位虚拟机或物理机器上编译。需要为目标机器使用合适的提取器,如果32位提取器在64位机器上使用,它将不能抓取全部的内存空间,因为32位提取器不能完全访问到64位的内存地址空间。
Makefile编译的结果是一个命名为scraper.bin的文件,其实是一个可以拷贝到USB设备的可引导启动的镜像工具。该USB同时需要用于存储内存镜像,建议使用大存储量的USB设备;因为当前主流系统使用4G到8G的内存,所以建议使用至少16GB容量的USB设备。以root用户权限,使用dd工具把scraper文件拷贝到USB设备,命令中sdb是硬盘驱动器的挂载点:
sudo dd if=scraper.bin of=/dev/sdb
这个时候,为目标系统准备好USB设备。理想情况下,渗透测试人员准备好一个32位的8G和一个64位的16G可以在内部环境使用的USB设备,同时备好一罐压缩空气。目标机器必须是一个运行中,且锁定的系统,有无用户登录无关紧要。同时,目标必须被全盘加密,否则启动Kali或Ophcrack,只需少量
工作,就可以获得出色效果。
一旦合适的目标被定位后,渗透测试人员(从客户处获得了适当的授权)应该打开机箱,露出内存。同时,他们需要插入USB设备。一切准备就绪后,渗透测试人员可以倒置灌装压缩空气并喷射覆盖,以冷却内存。由于这会导致在芯片上成霜,小心使用软管浇内存,不要碰到主板其他部分。图1显示了已经被冷冻用于攻击的笔记本内存。
图1 为冷启动攻击冷却内存
内存冷却足够后,渗透测试人员需要尽可能快地切断并恢复供电。在桌面计算机上,这相对简单,按reset电源键就可实现。但是大部分的笔记本并没有reset按键,进行这样快速的重置电源操作本质上很困难。最好的办法是快速替换电池,并按电源键。上述两种机器环境,越是快速恢复供电,内存镜像就越完好。
当渗透测试人员从USB启动机器,scraper工具会自动复制内存镜像至USB设备。图2的屏幕截图显示了scraper工具在工作。
图2 Scraper工具
根据内存大小和USB端口速率,捕获过程需要一会儿,对大容量内存则需要数小时。Scraper程序完全复制内存后,它将立即重新启动系统。渗透测试人员只需移除USB设备并插回编译scraper的机器。在源码中有一个叫做USBdump的工具,它只是简单地使用如下命令:
sudo ./usbdump /dev/sdb > memdump.img
把USB设备上的每个字节拷贝至渗透测试人员的机器。再次,根据内存捕获镜像的大小,这可能需要数小时。最终结果是内存镜像的完全拷贝文件,包含目标机器的一个字节一个字节的捕获镜像,同时有望使错误最少。
火线接口攻击
电气和电子工程师协会的1394接口,是初始设计用于取代SCSI的一个高速通信接口,更因为苹果公司以火线命名实现而知名。火线的主要部分是它的高速数据传输速率,这也是它大量应用于音视频传输的原因。火线接口高速率的一个主要特征是,它可以完全绕过CPU,通过直接内存访问DMA的方式访问内存。这对从相机下载数小时连续镜头的视频编辑者来说是一个好消息,对于渗透测试人员同样如此。
火线接口的直接内存访问使具有目标机器物理接触能力的渗透测试人员,可以通过重写包含访问控制功能的内存部分,绕过操作系统的密码保护机制。DMA同样可以让渗透测试人员下载小于4GB内存镜像。即使火线接口仅能访问少于4GB的内存且能使用反病毒软件保护DMA,这类型的访问还是揭示了IEEE1394标准中重大的安全缺陷。由于火线接口的热插拔功能,即使目标机器在锁定情况下,攻击同样能够进行。此外,虽然大部分操作系统试图对知名火线接口设备如iPods进行DMA授权限制,但是欺骗设备很容易。
由于攻击主要针对火线接口,对同一总线下的任何设备同样有效;这些包括ExpressCard,PC Card和所有苹果新产品都可以使用的雷电端口。
Carsten Maartmann-Moe已经开发了一个叫做Inception的工具,可以轻松利用火线接口。该工具可在http://www.breaknenter.org/projects/inception/找到。Inception必须从一个Linux桌面运行。这种情况下,Linux系统不能是一个虚拟机,因为虚拟机不能实现火线接口传输(出于安全原因)。另外,渗透测试人员需要Python3和Freddie Witherden的1394包。最后,攻击和目标机器都需要具备一个火线接口,EC,雷电或者PC card接口。
Inception安装准备就绪后,渗透测试人员仅需通过一个火线接口电缆,简单的连接攻击和目标机器,并在root权限模式下运行命令
incept
Incept将会访问内存中负责访问控制的部分并“修补”它们,使我们可以无密码访问机器。当然,目标机器内存含有丰富的信息,渗透测试人员可以使用
incept –d
命令转储小于4GB的内存镜像。
内存转储分析
转储内存镜像是一会事,分析数据则是一个更难的阻碍。幸运地是,一系列专注于此目的的工具可以获得。在思路上,很少工具是设计用于渗透测试的。许多是取证分析工具用于寻找运行的进程,恶意软件和隐藏的数据。内存取证仍然是一个相对崭新的领域,尤其是64位环境下的分析。许多出色的工具仍然局限于法律取证使用。这就是说,大量可执行的任务可以向客户揭示风险。
Lest We Remember团队也创建了一个分析工具,用于捕获内存镜像。他们论文的主题是密钥可以从内存中恢复;他们的工具命名为AESKeyFind,用于在捕获的内存镜像中搜索AES密钥次序表并恢复密钥。该工具可从下载Scraper程序的同一站点下载。最后,该工具携带一个易于编译的makefile文件。该工具编译后,可以用命令
./aeskeyfind –v memoryimage.raw
运行,在内存镜像文件中执行搜索AES密钥并在显示屏上打印它们。AESKeyFind将搜索128位和256位的密钥,即使镜像不完全或存在错误,该工具也可能恢复密钥。例如,图3显示了从一个包含大量错误的镜像文件中恢复AES密钥。
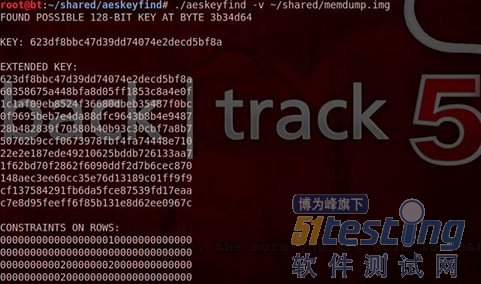
图3 在破损内存镜像中找打AES密钥
这些AES密钥序列可以被大量不同的应用使用。它们可能是用于全盘加密,VPN,无线网络的主要密钥。如果它们被恢复,接下来的步骤就是破译。
另一个有用的工具是Volatility,一个开源的内存取证分析框架。Volatility拥有众多模块可以让渗透测试人员抽取运行进程中有用信息和目标机器设置。如果内存镜像完好,渗透测试人员甚至能够抽取出Windows的hashes。
首先是识别出内存镜像的架构,这样Volatility才知道到哪个位置找,该项工作由imageinfo模块完成。图4显示了imageinfo模块被调用,且内存配置文件结果被Volatility识别。
图4 Imageinfo模块识别出镜像架构
使用这些信息,渗透测试人员可以用额外的模块识别出SAM和来自注册表的系统hives文件。由于在机器使用时,windows在活动内存中存储注册表信息;Volatility的hivelist模块可以用于识别内存中的每个注册表位置。图5显示了hivelist模块正在被imageinfo模块识别出的配置文件调用。
图5 hivelist模块显示SAM和System Hives地址
在32位系统中,Volatility有一个hashdump模块,当给出SAM和System hives地址时,能够自动抽取密码hash。遗憾的是,这个模块当前在64位系统中不能工作,所以限制了它的用途。就是说,Volatility是开源的,没有理由不能实现64位模块。另外,一旦SAM和System hives地址确定,一个技术性可能是从镜像文件中抽取它们并使用其他工具抽取密码hashes。
小结
微软公司的安全响应中心有10个不变的安全法则。第3号法则是,如果一个坏家伙不受限制地访问你的机器,这已经不是你的机器了。许多客户认为,全盘加密和强密码弥补了攻击者对机器的任何物理直接访问。他们没有考虑到活动内存的危险。活动内存中存储了足够多的信息,渗透测试人员可以从其中获得重要信息或对内部网络的访问权。这从来没有被认为是问题,因为对外部攻击者来说不存在事实方式获得内存镜像。但是,特定环境下冷却启动和火线接口攻击,不但使获得内存访问,而且使获得密钥的突破访问成为可能。
zlib作为最常用的压缩工具,本文对其使用进行简单说明,并进行一个简单的
性能测试。
1.下载编译
可以从zlib官网下载:http://www.zlib.net/
下载后直接make既可。make后再目录下生成libz.a.
2.使用
引用zlib.h和libz.a既可。关键在于zlib.h,它提供了一些函数。
以下是引自“http://www.cppblog.com/woaidongmao/archive/2009/09/07/95495.html”的关于zlib.h的说明:
都在zlib.h中,看到一堆宏不要晕,其实都是为了兼容各种编译器和一些类型定义.死死抓住那些主要的函数的原型声明就不会受到这些东西的影响了.
关键的函数有那么几个:
(1)int compress (Bytef *dest, uLongf *destLen, const Bytef *source, uLong sourceLen);
把源缓冲压缩成目的缓冲, 就那么简单, 一个函数搞定
(2) int compress2 (Bytef *dest, uLongf *destLen,const Bytef *source, uLong sourceLen,int level);
功能和上一个函数一样,都一个参数可以指定压缩质量和压缩数度之间的关系(0-9)不敢肯定这个参数的话不用太在意它,明白一个道理就好了: 要想得到高的压缩比就要多花时间
(3) uLong compressBound (uLong sourceLen);
计算需要的缓冲区长度. 假设你在压缩之前就想知道你的产度为 sourcelen 的数据压缩后有多大, 可调用这个函数计算一下,这个函数并不能得到精确的结果,但是它可以保证实际输出长度肯定小于它计算出来的长度
(4) int uncompress (Bytef *dest, uLongf *destLen,const Bytef *source, uLong sourceLen);
解压缩(看名字就知道了:)
(5) deflateInit() + deflate() + deflateEnd()
3个函数结合使用完成压缩功能,具体用法看 example.c 的 test_deflate()函数. 其实 compress() 函数内部就是用这3个函数实现的(工程 zlib 的 compress.c 文件)
(6) inflateInit() + inflate() + inflateEnd()
和(5)类似,完成解压缩功能.
(7) gz开头的函数.用来操作*.gz的文件,和文件stdio调用方式类似. 想知道怎么用的话看example.c 的 test_gzio() 函数,很easy.
(8) 其他诸如获得版本等函数就不说了.
总结:其实只要有了compress() 和uncompress() 两个函数,在大多数应用中就足够了. 3.性能测试
针对1M数据分别调用compress压缩和uncompress解压缩,循环10次。
代码如下:
#include <stdio.h> #include <time.h> #include "zlib.h" const int MAX_BUFFER_SIZE = 1024*1024*4; unsigned char DATA_BUFFER[MAX_BUFFER_SIZE]; void testCompress() { const char * file = "/tmp/e2.txt.backup"; FILE *f1 = fopen(file,"r"); if(f1) { fseek(f1,0,2); int len = ftell(f1); fseek(f1,0,0); char * data = new char[len]; fread(data,1,len,f1); fclose(f1); //uLong dst_len = MAX_BUFFER_SIZE; //Bytef * dst = (Bytef*)DATA_BUFFER; clock_t start = clock(); for(int i=0; i<10; i++) { uLong dst_len = MAX_BUFFER_SIZE; Bytef * dst = (Bytef*)DATA_BUFFER; compress(dst,&dst_len,(Bytef *)data,(uLong)len); } clock_t end = clock(); printf("time used(ms):%.2f\n",1000.0*(end-start)/CLOCKS_PER_SEC); delete [] data; } } void testunCompress() { const char * file = "/tmp/2.gz"; FILE *f1 = fopen(file,"r"); if(f1) { fseek(f1,0,2); int len = ftell(f1); fseek(f1,0,0); char * data = new char[len]; fread(data,1,len,f1); fclose(f1); //uLong dst_len = MAX_BUFFER_SIZE; //Bytef * dst = (Bytef*)DATA_BUFFER; clock_t start = clock(); for(int i=0; i<10; i++) { uLong dst_len = MAX_BUFFER_SIZE; Bytef * dst = (Bytef*)DATA_BUFFER; uncompress(dst,&dst_len,(Bytef *)data,(uLong)len); } clock_t end = clock(); printf("time used(ms):%.2f\n",1000.0*(end-start)/CLOCKS_PER_SEC); delete [] data; } } int main(int argc, char **argv) { testCompress(); testunCompress(); return 0; } |
测试结果:
time used(ms):470.00 time used(ms):40.00 |
4.总结
zlib压缩1M数据耗时47ms左右,解压缩4ms左右。解压非常快。
Mongodb亿级数据量的性能测试,分别测试如下几个项目: (所有插入都是单线程进行,所有读取都是多线程进行)
1) 普通插入性能 (插入的数据每条大约在1KB左右)
2) 批量插入性能 (使用的是官方C#客户端的InsertBatch),这个测的是批量插入性能能有多少提高
3) 安全插入功能 (确保插入成功,使用的是SafeMode.True开关),这个测的是安全插入性能会差多少
4) 查询一个索引后的数字列,返回10条记录(也就是10KB)的性能,这个测的是索引查询的性能
5) 查询两个索引后的数字列,返回10条记录(每条记录只返回20字节左右的2个小字段)的性能,这个测的是返回小数据量以及多一个查询条件对性能的影响
6) 查询一个索引后的数字列,按照另一个索引的日期字段排序(索引建立的时候是倒序,排序也是倒序),并且Skip100条记录后返回10条记录的性能,这个测的是Skip和Order对性能的影响
7) 查询100条记录(也就是100KB)的性能(没有排序,没有条件),这个测的是大数据量的查询结果对性能的影响
8) 统计随着测试的进行,总磁盘占用,索引磁盘占用以及数据磁盘占用的数量
并且每一种测试都使用单进程的Mongodb和同一台服务器开三个Mongodb进程作为Sharding(每一个进程大概只能用7GB左右的内存)两种方案
其实对于Sharding,虽然是一台机器放3个进程,但是在查询的时候每一个并行进程查询部分数据,再有运行于另外一个机器的mongos来汇总数据,理论上来说在某些情况下性能会有点提高
基于以上的种种假设,猜测某些情况性能会下降,某些情况性能会提高,那么来看一下最后的测试结果怎么样?
备注:测试的存储服务器是 E5620 @ 2.40GHz,24GB内存,CentOs操作系统,打压机器是E5504 @ 2.0GHz,4GB内存,
Windows Server 2003操作系统,两者千兆网卡直连。
一、卸载掉原有mysql
我们通过工具SecureCRT 5.1连接到linux服务器,要用root管理员用户,如果是普通用户登录的话,可以通过su - root切换为root管理员用户。
我下载的Linux系统集成了mysql数据库在里面,我们可以通过命令来查看我们的操作系统上是否已经安装了mysql数据库:
rpm -qa | grep mysql
有的话,我们就通过命令卸载掉:
rpm -e --nodeps mysql
删除完以后我们再用 rpm -qa | grep mysql 命令来查看mysql是否已经卸载成功!
二、通过yum来进行mysql的安装
我们输入命令来查看yum上提供的mysql数据库可下载的版本:
yum list | grep mysql
然后安装服务端和客户端:
yum install -y mysql-server mysql mysql-deve
安装完后我们查看数据库是否安装成功:
rpm -qi mysql-server
这里安装的mysql-server并不是最新版本,如果要安装最新版本,那就去mysql官网下载rpm包安装。
三、mysql数据库的初始化及相关配置
启动mysql数据库:
service mysqld start
第一次启动mysql服务器以后会提示非常多的信息,目的就是对mysql数据库进行初始化操作,当我们再次重新启动mysql服务时,就不会提示这么多信息,重启一下:
service mysqld restart
我们在使用mysql数据库时,都得首先启动mysqld服务,我们可以通过命令来查看mysql服务是不是开机自动启动:
chkconfig --list | grep mysqld
如果是 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭 这种情况,则说明没有开机启动,我们设置为开机启动:
chkconfig mysqld on
mysql数据库安装完以后只会有一个root管理员账号,但是此时的root账号还并没有为其设置密码,我们可以通过命令来给我们的root账号设置密码:
mysqladmin -u root password 'root'
我们将mysql管理员root的密码设置为root,然后我们就可以登录数据库了,用命令:
mysql -u root -p
然后输入密码

我们可以通过mysql> show databases;来查看默认的几个数据库,通过按键盘ctrl+c退出mysql命令界面。
四、修改mysql的默认编码集
我们可以通过show variables like '%character%';来查看默认的编码集:
我们会发现基本都设置成了latin1的编码方式,此时我们需要将其修改成utf8的编码格式。
我们通过工具SSH Secure File Transfer Client连接到linux服务器上,将/usr/share/doc/mysql-server-5.0.95目录下的文件my-large.cnf拉到我们系统下来
编辑该文件两处地方:
1、在[client]下增加 default-character-set=utf8 字段
2、在[mysqld]下增加 default-character-set=utf8 字段,同时加上init_connect='SET NAMES utf8' (设定连接mysql数据库时使用utf8编码,以让mysql数据库为utf8运行)
保存该文件,并命令为my.cnf,然后通过工具拉倒linux的/etc目录下。然后重新启动mysqld服务,要先退回用户操作界面ctrl+c,然后输入
service mysqld restart
这时我们再次登陆到mysql里面,然后输入 show variables like '%character%'; 命令来查看一下当前数据库的编码方式时,发现已经由原来的 latin1 变成了 utf8 编码方式了:
如果做了以上修改如果直接数据库再创建表,然后存入中文,取出来的还是问号的话。
此时我们可以通过如下的解决办法:创建数据库的时候指明默认字符集为utf8
例如:create database huangzbDB charset=utf8;
五、MySQL创建用户以及权限管理
我们现在创建一个数据库huangzbDB,然后将该数据库的所有权限赋给新创建的mysql用户:huangzb,然后我们可以通过SQLyogEnt工具登录管理该数据库。
1、登录
[root@bogon ~]# mysql -u root -p,然后输入密码
2、创建数据库
mysql> create database huangzbDB;
3、创建用户
mysql> use mysql; Database changed mysql> insert into user (Host,User,Password) values ('%','huangzb',PASSWORD('huangzb')); Query OK, 1 row affected, 3 warnings (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) |
上面是创建了一个名为huangzb,密码为huangzb的用户。(之所以host要复制为'%',是为了通过SQLyogEnt工具可以登录)
4、通过SQLyogEnt工具登录Linux的mysql服务器
我们看到,现在该用户还没有属于他权限的数据库,他也无法直接创建数据库,接下来,我们给该用户赋予一些权限。
5、给huangzb用户管理huangzbDB数据库的权限
mysql> use huangzbDB; Database changed mysql> grant all privileges on huangzbDB to huangzb@'%'; Query OK, 0 rows affected (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) |
然后我们刷新sqlyog对象数据库,可以看到
SQL攻击(SQL injection,台湾称作SQL资料隐码攻击),简称注入攻击,是发生于应用程序之
数据库层的安全漏洞。简而言之,是在输入的字符串之中注入SQL指令,在设计不良的程序当中忽略了检查,那么这些注入进去的指令就会被数据库服务器误认为是正常的SQL指令而运行,因此遭到破坏。
有部份人认为
SQL注入攻击是只针对Microsoft SQL Server而来,但只要是支持批处理SQL指令的数据库服务器,都有可能受到此种手法的攻击。
原因
在应用程序中若有下列状况,则可能应用程序正暴露在SQL Injection的高风险情况下:
在应用程序中使用字符串联结方式组合SQL指令。
在应用程序链接数据库时使用权限过大的账户(例如很多开发人员都喜欢用sa(内置的最高权限的系统管理员账户)连接Microsoft SQL Server数据库)。
在数据库中开放了不必要但权力过大的功能(例如在Microsoft SQL Server数据库中的xp_cmdshell延伸预存程序或是OLE Automation预存程序等)
太过于信任用户所输入的数据,未限制输入的字符数,以及未对用户输入的数据做潜在指令的检查。
作用原理
SQL命令可查询、插入、更新、删除等,命令的串接。而以分号字符为不同命令的区别。(原本的作用是用于SubQuery或作为查询、插入、更新、删除……等的条件式)
SQL命令对于传入的字符串参数是用单引号字符所包起来。《但连续2个单引号字符,在SQL数据库中,则视为字符串中的一个单引号字符》
SQL命令中,可以注入注解《连续2个减号字符 -- 后的文字为注解,或“/*”与“*/”所包起来的文字为注解》
因此,如果在组合SQL的命令字符串时,未针对单引号字符作取代处理的话,将导致该字符变量在填入命令字符串时,被恶意窜改原本的SQL语法的作用。
以上内容摘自维基百科@
最近翻到一本有关SQL注入攻击与防御的一本书,当然这本书内容很长,我还只读了前两章部分,后续我会慢慢把书里的知识梳理到我的博客中来!
SQL 注入攻击的主要原因,是因为以下两点原因:
1. php 配置文件 php.ini 中的 magic_quotes_gpc选项没有打开,被置为 off;
2. 开发者没有对数据类型进行检查和转义。
不过事实上,第二点最为重要。我认为, 对用户输入的数据类型进行检查,向 MYSQL 提交正确的数据类型,这应该是一个
web 程序员最最基本的素质。但现实中,常常有许多小白式的 Web 开发者忘了这点,从而导致后门大开。
为什么说第二点最为重要?因为如果没有第二点的保证,magic_quotes_gpc 选项,不论为 on,还是为 off,都有可能引发 SQL 注入攻击。下面来看一下技术实现:
一、 magic_quotes_gpc= Off 时的注入攻击
magic_quotes_gpc = Off 是 php 中一种非常不安全的选项。新版本的 php 已经将默认的值改为了 On。但仍有相当多的服务器的选项为 off。毕竟,再古董的服务器也是有人用的。
当magic_quotes_gpc = On 时,它会将提交的变量中所有的 '(单引号)、"(双号号)、(反斜线)、空白字符,都会在前面自动加上 。下面是 PHP的官方说明:
magic_quotes_gpc boolean
Sets the magic_quotes state for GPC (Get/Post/Cookie) operations. When magic_quotes are on, all ' (single-quote), " (double quote), (backslash) and NUL's are escaped with a backslash automatically
如果没有转义,即 off 情况下,就会让攻击者有机可乘。以下列
测试脚本为例:
<? if (isset($_POST["f_login"])) { // 连接数据库... // ...代码略... // 检查用户是否存在 $t_strUname = $_POST["f_uname"]; $t_strPwd = $_POST["f_pwd"]; $t_strSQL = "SELECT * FROM tbl_users WHERE username='$t_strUname' AND password = '$t_strPwd' LIMIT 0,1"; if ($t_hRes = mysql_query($t_strSQL)) { // 成功查询之后的处理. 略... } } ?> <html><head><title>test</title></head> <body> <form method="post" action=""> Username: <input type="text" name="f_uname" size=30><br> Password: <input type=text name="f_pwd" size=30><br> <input type="submit" name="f_login" value="登录"> </form> </body> |
在这个脚本中,当用户输入正常的用户名和密码,假设值分别为 zhang3、abc123,则提交的 SQL 语句如下:
SELECT * FROM tbl_users WHERE username='zhang3' AND password = 'abc123' LIMIT 0,1
如果攻击者在 username 字段中输入:zhang3' OR 1=1 #,在 password 输入 abc123,则提交的 SQL 语句变成如下:
SELECT * FROM tbl_users WHERE username='zhang3' OR 1=1 #' AND password = 'abc123' LIMIT 0,1
由于 # 是 mysql中的注释符, #之后的语句不被执行,实现上这行语句就成了:
SELECT * FROM tbl_users WHERE username='zhang3' OR 1=1
这样攻击者就可以绕过认证了。如果攻击者知道数据库结构,那么它构建一个 UNION SELECT,那就更危险了:
假设在 username 中输入:zhang3 ' OR 1 =1 UNION select cola, colb,cold FROM tbl_b #
在password 输入: abc123,
则提交的 SQL 语句变成:
SELECT * FROM tbl_users WHERE username='zhang3 ' OR 1 =1 UNION select cola, colb,cold FROM tbl_b #' AND password = 'abc123' LIMIT 0,1
这样就相当危险了。
二、magic_quotes_gpc = On 时的注入攻击
当 magic_quotes_gpc = On 时,攻击者无法对字符型的字段进行 SQL 注入。这并不代表这就安全了。这时,可以通过数值型的字段进行SQL注入。
在最新版的 MYSQL 5.x 中,已经严格了数据类型的输入,已默认关闭自动类型转换。数值型的字段,不能是引号标记的字符型。也就是说,假设 uid 是数值型的,在以前的 mysql 版本中,这样的语句是合法的:
INSERT INTO tbl_user SET uid="1";
SELECT * FROM tbl_user WHERE uid="1";
在最新的 MYSQL 5.x 中,上面的语句不是合法的,必须写成这样:
INSERT INTO tbl_user SET uid=1;
SELECT * FROM tbl_user WHERE uid=1;
这样我认为是正确的。因为作为开发者,向数据库提交正确的符合规则的数据类型,这是最基本的要求。
那么攻击者在 magic_quotes_gpc = On 时,他们怎么攻击呢?很简单,就是对数值型的字段进行 SQL 注入。以下列的 php 脚本为例:
<? if (isset($_POST["f_login"])) { // 连接数据库... // ...代码略... // 检查用户是否存在 $t_strUid = $_POST["f_uid"]; $t_strPwd = $_POST["f_pwd"]; $t_strSQL = "SELECT * FROM tbl_users WHERE uid=$t_strUid AND password = '$t_strPwd' LIMIT 0,1"; if ($t_hRes = mysql_query($t_strSQL)) { // 成功查询之后的处理. 略... } } ?> <html><head><title>test</title></head> <body> <form method="post" action=""> User ID: <input type="text" name="f_uid" size=30><br> Password: <input type=text name="f_pwd" size=30><br> <input type="submit" name="f_login" value="登录"> </form> </body> </html> |
上面这段脚本要求用户输入 userid 和 password 登入。一个正常的语句,用户输入 1001和abc123,提交的 sql 语句如下:
SELECT * FROM tbl_users WHERE userid=1001 AND password = 'abc123' LIMIT 0,1
如果攻击者在 userid 处,输入:1001 OR 1 =1 #,则注入的sql语句如下:
SELECT * FROM tbl_users WHERE userid=1001 OR 1 =1 # AND password = 'abc123' LIMIT 0,1
攻击者达到了目的。
三、如何防止 PHP的SQL 注入攻击
如何防止 php sql 注入攻击?我认为最重要的一点,就是要对数据类型进行检查和转义。总结的几点规则如下:
1. php.ini 中的 display_errors 选项,应该设为 display_errors = off。这样 php 脚本出错之后,不会在 web 页面输出错误,以免让攻击者分析出有作的信息。
2. 调用 mysql_query 等 mysql 函数时,前面应该加上 @,即 @mysql_query(...),这样 mysql 错误不会被输出。同理以免让攻击者分析出有用的信息。另外,有些程序员在做开发时,当 mysql_query出错时,习惯输出错误以及 sql 语句,例如:
<php $t_strSQL = "SELECT a from b...."; if (mysql_query($t_strSQL)) { // 正确的处理 } else { echo "错误! SQL 语句:$t_strSQL 错误信息" . mysql_query(); exit; } ?> |
这种做法是相当危险和愚蠢的。如果一定要这么做,最好在网站的配置文件中,设一个全局变量或定义一个宏,设一下 debug 标志:
<?php //全局配置文件中: define("DEBUG_MODE", 0); // 1: DEBUG MODE; 0: RELEASE MODE //调用脚本中: $t_strSQL = "SELECT a from b...."; if (mysql_query($t_strSQL)) { // 正确的处理 } else { if (DEBUG_MODE) { echo "错误! SQL 语句:$t_strSQL错误信息" . mysql_query(); } exit; } ?> |
3. 对提交的 sql 语句,进行转义和类型检查。
四、我写的一个安全参数获取函数
为了防止用户的错误数据和 php + mysql 注入 ,我写了一个函数 PAPI_GetSafeParam(),用来获取安全的参数值:
<?php define("XH_PARAM_INT", 0); define("XH_PARAM_TXT", 1); function PAPI_GetSafeParam($pi_strName, $pi_Def = "", $pi_iType = XH_PARAM_TXT) { if (isset($_GET[$pi_strName])) { $t_Val = trim($_GET[$pi_strName]); } else if (isset($_POST[$pi_strName])) { $t_Val = trim($_POST[$pi_strName]); } else { return $pi_Def; } // INT if (XH_PARAM_INT == $pi_iType) { if (is_numeric($t_Val)) { return $t_Val; } else { return $pi_Def; } } // String $t_Val = str_replace("&", "&", $t_Val); $t_Val = str_replace("<", "<", $t_Val); $t_Val = str_replace(">", ">", $t_Val); if (get_magic_quotes_gpc()) { $t_Val = str_replace("\"", """, $t_Val); $t_Val = str_replace("\''", "'", $t_Val); } else { $t_Val = str_replace(""", """, $t_Val); $t_Val = str_replace("'", "'", $t_Val); } return $t_Val; } ?> |
在这个函数中,有三个参数:
$pi_strName:变量名
$pi_Def:默认值
$pi_iType: 数据类型。取值为 XH_PARAM_INT,XH_PARAM_TXT,分别表示数值型和文本型。
如果请求是数值型,那么调用 is_numeric() 判断是否为数值。如果不是,则返回程序指定的默认值。
简单起见,对于文本串,我将用户输入的所有危险字符(包括HTML代码),全部转义。由于 php 函数 addslashes()存在漏洞,我用 str_replace()直接替换。get_magic_quotes_gpc( ) 函数是 php 的函数,用来判断 magic_quotes_gpc 选项是否打开。
刚才第二节的示例,代码可以这样调用:
<?php if (isset($_POST["f_login"])) { // 连接数据库... // ...代码略... // 检查用户是否存在 $t_strUid = PAPI_GetSafeParam("f_uid", 0, XH_PARAM_INT); $t_strPwd = PAPI_GetSafeParam("f_pwd", "", XH_PARAM_TXT); $t_strSQL = "SELECT * FROM tbl_users WHERE uid=$t_strUid AND password = '$t_strPwd' LIMIT 0,1"; if ($t_hRes = mysql_query($t_strSQL)) { // 成功查询之后的处理. 略... } } ?> |
这样的话,就已经相当安全了。PAPI_GetSafeParam的代码有点长,但牺牲这点效率,对保证安全,是值得的。希望大家多批评指正。