
今儿接到一需求如下:
比如一个给定的数字2975,让你去猜。6次机会。如果第一次输入2509,系统会提示 1A2B:其中数字“2”位置猜对&&数字也猜对。称为1A,而“9”和“5”数字猜对了但是位置没有猜对。称为2B。。如果输入2975那么就是4个数字都猜对了并且位置也是对的系统提示4A0B。民间俗称猜数字游戏:
百度百科传送门:http://baike.baidu.com/view/358630.htm。
做个简单分析。客户端输入一个数字,经过游戏内部的猜测,返回一个结果给客户端。嗯,还好,不算难。由于准备做TDD实践。所以我们
Test First.Why? 如果您对TDD不是很了解。就跟我一起做下去,显然我也是新手。我们的目标是“没有蛀牙!”。
准备
工作:VS任意一个版本(C#)、任意一款
测试工具、纸、笔(真彩0.5的)。
第一步:笔和纸拿出来。思考思考如何把这个小游戏拆分了。然后我们一步一步去完成它。写一个To-Do-List。
To-Do-List:
猜测数字
输入验证
生成答案
输入次数
输出猜测结果
...............
暂时想起这么多。比如还有选择游戏难度、输入日志、重新开始游戏、中途退出等等。
今天我要完成这个游戏的核心功能(猜测数字),我称它为Guesser。传入一个数字,返回一个结果。分析一下它可能输出的几种情况:4a0b(全对)、 0a4b(数字全对,位置全错)、2a2b(一半一半)、0a0b(全错)。这4个CASE应该Cover了所有情况了。如果有补充,请Follow。
今天的TO-DO-LIST:
假设我们这局游戏的答案是2975。
输入“2975” 输出4a0b。
输入“2957” 输出2a2b。
输入“9257” 输出0a4b。
输入“1348” 输出0a0b。
完成Guesser类.
新建一个TEST 写测试。
开始第一个CASE:输入2975 与答案正匹配,输出4a0b 。
[TestMethod] public void Test1() { var inputNumber = "2975"; var actual = new Guesser().Guess(inputNumber); Assert.AreEqual("4a0b", actual); } |
这个测试方法的命名一眼好像看不出它要测什么。单独看测试的名字很是迷茫。我们修改一下让它看起来很整洁。一眼看上去就知道是啥意思。要测试什么。
[TestMethod] public void should_return_4a0b_when_input_numbers_all_figures_and_positions_are_right() { var inputNumber = "2975"; var actual = new Guesser().Guess(inputNumber); Assert.AreEqual("4a0b", actual); } |
修改完之后在看这个方法的命名。 是不是清晰了很多。看到方法的命名应该就能够猜测到此方法是在什么情况下测试什么功能。
OK。我们的第一个CASE搞定了。Run一下。
redis相比很多人都知道,是一个内存式的key-value数据库,存取速度极快,使用非常简单,支持多种语言。本文对其使用进行一个简要说明,并进行简单
测试。
1.下载与编译
可以从redis官网下载最新的源码包:http://www.redis.io/
编译十分简单make既可。
2.redis安装与配置
实际上并不需要安装。redis编译后会在src目录下生成redis-server,它是一个可执行文件,即启动redis服务。不过它需要一个配置文件。配置文件写法网上很多了,这里直接给出一个示例:
daemonize yes pidfile /tmp/redis/var/redis.pid port 6379 timeout 300 loglevel debug logfile /tmp/redis/var/redis.log databases 16 save 900 1 save 300 10 save 60 10000 rdbcompression yes dbfilename dump.rdb dir /tmp/redis/var/ appendonly no appendfsync always #glueoutputbuf yes #shareobjects no #shareobjectspoolsize 1024 |
将其保存为redis.conf
然后直接运行./redis-server redis.conf就可以启动redis服务了,是不是很方便呢?
3.C/C++访问redis
在redis源码目录下有一个deps目录,下面有一个hiredis目录。redis编译时会自动编译该目录生成libhiredis.a,通过引用hiredis.h 和 libhiredis.a就可以访问redis了。具体步骤如下:
1)创建一个redisContext
2)通过redisContext执行命令
3)从返回redisReply中获取所需数据
代码如下:
<pre code_snippet_id="151033" snippet_file_name="blog_20140110_2_9509153" name="code" class="cpp">redisContext * c = redisConnect((char *)"192.168.150.135",6379); const char * pData = "this is a test"; <pre code_snippet_id="151033" snippet_file_name="blog_20140110_2_9509153" name="code" class="cpp">redisReply *reply1 = (redisReply *)redisCommand(c,"SET 100 %s",pData); <pre code_snippet_id="151033" snippet_file_name="blog_20140110_2_9509153" name="code" class="cpp"><pre code_snippet_id="151033" snippet_file_name="blog_20140110_2_9509153" name="code" class="cpp"><pre code_snippet_id="151033" snippet_file_name="blog_20140110_2_9509153" name="code" class="cpp">freeReplyObject(reply1);</pre> <pre></pre> <pre></pre> <pre></pre> <pre></pre> <pre></pre> <p></p> <pre></pre> <pre></pre> <br> <pre code_snippet_id="151033" snippet_file_name="blog_20140110_3_730653" name="code" class="cpp"><pre code_snippet_id="151033" snippet_file_name="blog_20140110_3_730653" name="code" class="cpp"><pre code_snippet_id="151033" snippet_file_name="blog_20140110_3_730653" name="code" class="cpp">redisReply *reply2 = (redisReply *)redisCommand(c,"GET 100");</pre> <pre></pre> <pre></pre> printf("%s\n",reply2->str);<br> freeReplyObject(reply2);<br> <pre></pre> <pre></pre> <pre></pre> |
是不是非常简单呢?
<p></p> <p>不过需要注意的是,redis接受的数据是字符串,对于二进制数据,可以通过base64编码来解决。具体可参看我的另一篇文章。</p> <p></p> <h1><a name="t3"></a>4.Java访问redis</h1> <p>redis可以支持多种语言,当然也可以支持Java。</p> <p>首先需要下载redis的java包。jedis.jar。这里提供一个下载地址:<a target="_blank" href="http://download.csdn.net/detail/jmppok/6834151">redis的Java客户端jedis</a></p> <p>使用如下:</p> <p></p> <pre code_snippet_id="151033" snippet_file_name="blog_20140110_4_2824204" name="code" class="java">Jedis jedis = new Jedis("192.168.150.135"); jedis.set("100","this is a test"); String data = jedis.get("100"); </pre><br> <br> <p></p> <h1><a name="t4"></a>5.性能测试</h1> <p>测试方法:向redis写一个1M的数据,分别写10次,读10次,计算其耗时。分C++和Java两个版本进行测试。<br> </p> <h2><a name="t5"></a>C++测试代码</h2> <p></p> <pre code_snippet_id="151033" snippet_file_name="blog_20140110_5_8505805" name="code" class="cpp">#include <stdio.h> #include "hiredis.h" #include <string.h> #include <time.h> int main(int argc, char **argv) { printf("CLOCKS_PER_SEC:%d\n",CLOCKS_PER_SEC); redisContext *c; redisReply *reply; c = redisConnect((char *)"one-60",6379); char * pData; reply = (redisReply *)redisCommand(c,"GET 0"); int size = strlen(reply->str); pData = new char[size+1]; strcpy(pData,reply->str); freeReplyObject(reply); clock_t start, finish; start = clock(); for(int i=0;i<10; i++) { reply = (redisReply *)redisCommand(c,"GET %d",i); freeReplyObject(reply); } finish = clock(); double duration = (double)(finish - start) / CLOCKS_PER_SEC*1000; printf("GET Time used:%f ms.\n",duration); start = clock(); for(int i=0;i<10; i++) { reply = (redisReply *)redisCommand(c,"SET %d %s",i,pData); freeReplyObject(reply); } finish = clock(); duration = (double)(finish - start) / CLOCKS_PER_SEC*1000; printf("SET Time used:%f ms.\n",duration); delete []pData; redisFree(c); } </pre>测试结果 <p></p> <p></p> <pre code_snippet_id="151033" snippet_file_name="blog_20140110_6_1363508" name="code" class="plain">CLOCKS_PER_SEC:1000000 GET Time used:190.000000 ms. SET Time used:70.000000 ms. </pre><br> <br> <p></p> <h2><a name="t6"></a>Java测试代码<br> </h2> <p></p> <pre code_snippet_id="151033" snippet_file_name="blog_20140110_7_633160" name="code" class="java">import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.util.Date; import redis.clients.jedis.Jedis; public class JedisTest { public static void main(String[] args) { Jedis jedis = new Jedis("10.100.211.232"); String f = "/tmp/e2.txt.backup"; try { File file = new File(f); BufferedReader reader = new BufferedReader(new FileReader(file)); String data = reader.readLine(); reader.close(); Date start = new Date(); for(int i=0; i<10; i++) { jedis.set(i+"", data); } Date end = new Date(); System.out.println("Set used(ms):"+(end.getTime()-start.getTime())); start = new Date(); for(int i=0; i<10; i++) { String v = jedis.get(i+""); } end = new Date(); System.out.println("Get used(ms):"+(end.getTime()-start.getTime())); }catch (Exception e) { e.printStackTrace(); } jedis.disconnect(); } }</pre><br> |
测试结果
<p></p> <p></p> <pre code_snippet_id="151033" snippet_file_name="blog_20140110_8_8615272" name="code" class="plain">Set used(ms):1212 Get used(ms):1437</pre><br> |
6.总结
<p></p> <p>redis效率还是非常高的,读写1M数据的数据,耗时都在10ms左右。<br> </p> <p><br> </p> <pre></pre> <pre></pre> </pre></pre></pre></pre></pre></pre> |
自己在2014年写的自动化的感想和规划
1、
互联网在深耕细作的发展阶段需要测试发挥更多的影响。
4、持续关注个人的成长,测试人员更注重价值体现。
PPT解读: 1、互联网是快速发展的行业,时刻需要idea迅速的转化为生产力。频繁迭代的开发,追求建立快速的响应机制,要求测试的时效性。较短的测试排期需要加入技术成分从而替代手工回归测试所带来的工作量。
2、测试是技术岗,测试环节的上游是代码产品,对上游环节的摸索和尝试是不可拒绝的。测试人员越来越了解和参与开发职位的工作既可以起到测试前置的作用也可以扩大测试的范围。测试和开发必将在未来融合。
3、测试团队需要持续发展的节奏,技术成长是其中的重要一环。学习型的团队最具竞争力、战斗力和向心力。
4、
功能测试是互联网时代产物,也会随着时代的发展而消亡。测试人员普遍存在危机感,对于测试技术的学习和成长要求是迫切的。测试人员越来越不满足于手工测试所带来的成就感。
自动化技术的应用场所
1、功能回归测试、冒烟测试。
2、数据精度要求高的测试,数据计算、比较、统计测试。
3、简单重复的大批量测试,测试组合众多,需要测试覆盖。
4、疲劳测试。
5、接口、底层、代码测试。
6、其他不便于进行手工的测试。
PPT解读:
自动化测试是个较大的范畴,所有不用手工进行操作通过程序驱动的测试都可以理解为自动化测试。从技术层面来讲,但凡被技术实现的东西都可以被技术模拟和测试。在人们实践的过程中,自动化技术应用的领域会越来越广,测试也是一样,自动化本身不会去约束方式和行为,自动化能够做什么会超出我们的想象。
POP的自动化领域
1、平台SOA化
3、数据挖掘
PPT解读: O2O做为2014年京东的战略在POP端会持续发酵。平台的发展需要模块化,越来越来可适配。公共模块直接会被底层服务化,而前端模块大量的被暴露数据接口,更多的测试要求在不可视化的情况下进行。POP的发展积累了庞大的历史数据和商家数据而且还在增长,对于海量数据进行迁移、计算、合并、修改和数据挖掘,需要精准的完成数据测试,需要倚赖自动化测试。虽然移动端未在POP中应用,但是商家说不定哪天就有在
手机上管理商品的需要,移动端在POP的布局现在没影,但是需要的时候也会很迅猛,这些都需要我们未雨绸缪。
为什么需要测试框架
1、降低实现门槛。
2、统一技术风格。
3、量化测试成果。
4、底层前端分离。
PPT解读: 没有测试框架也可以实现自动化。每个测试人员技术背景不尽相同,擅长的语言、脚本、实施的技术水平参差不齐,没有框架约束技术实现和风格,他人的维护难度会很大,不利于大家朝同一个技术方向进行分享和交流。 框架本身已经封装了很多实际需要的接口和工具,测试人员不需要花费大量的精力再度开发,集中精力快速实现测试需求本身。统一的结构不仅多人可以同时维护一个项目,也便于测试结果的分析和汇总,众多项目的批量运行。框架和项目的分离,使双方各自影响的范围得到有效控制,便于项目单点维护和迁移。开发需要框架,同样测试开发作为一种开发活动也需要框架。
功能测试人员做自动化
1、实践为主培训为辅
2、差别化培养
3、测试意识的转化
4、触发危机意识
5、考核标准
PPT解读: 1、开展定期的技术培训,包括灌输测试理念,扩展测试思路,培训新的测试技术。培训更多的是了解和灌输理念。重点是实际的动手。培训只占个人成长的10%,需要制定挑战性的任务,让每个人主动亦或是被动的去动手完成,在动手的过程中发现问题解决问题。技术是练出来的,而不是培训出来的。
2、功能测试人员中个人水平和意愿不尽相同,对有一定技术能力或者有强烈自动化愿望的人重点培训,开小灶,单独辅导,让他们成长的更快一些,对没有自信或者对自动化产生疑虑的人,起到示范带头的效果。
3、功能测试人员需要在日常测试中转化意识,一个需求过来先考虑如何用自动化实现,当不能实现的时候再考虑手工测试,人们往往按照自己熟悉的方式进行,但是不一定是最好的方式,自动化做的多了,意识转化的也就越快。 4、测试行业本身的竞争很激烈,需要让测试人员意识到这一点。 5、放在KPI中进行考核,效果是不容小觑的。
自动化效果体现
1、测试前置效果体现
2、测试范围效果体现
3、Daily Test 和批量执行效果体现
4、其他指标
PPT解读: 1、接口和单测可以通过BUG数量进行衡量。这个阶段所发现的BUG含金量更高,修复的成本更低,更有价值。此外代码行数、用例数量、代码覆盖率也可以很好的统计测试实际的效果。
2、自动化可以解决以往手工不能进行的测试,比如大数据量、中间件、随机数据等测试,可以列举由于引进自动化而增加的各种测试类型。
3、100个用例执行一次体现不了什么,但是100个用例在后续的两个月里执行了100次,所替代的人工就是很可观的。自动化项目坚持每日BUILD,一方面可以及时发现问题,维护更新用例。另一个方面每日测试的汇总数据也是自动化测试效果的展示。可以通过邮件、报告进行测试项目和用例的数据汇总,如果达到一定的量级还是很震撼的。
4、自动化还有代码行数,编译次数等指标。放在部署有平均部署时间,放在数据有平均一次生成数据量等。前端自动化不宜用BUG数量来衡量,因为主要选取的相对比较稳定的业务线和模块。
自动化开展的步骤
1、特殊测试需求响应
2、重点业务线全局自动化
3、其他业务线局部自动化
4、流程性约束
5、技术分享和外部推广
PPT解读: 自动化的开展需要的有重点、分步骤的进行。既要保证效果,又要体现团队的技术提升,分成两条线,各不冲突。
1、对于特殊的测试需求,比如大数据量、中间件、复杂的底层服务和技术接口、高性能组件等对技术能力要求较高的测试需求由专门的自动化组来承担。一方面集中优势力量可以快速完成任务,另一方面挑战性的任务可以实践和摸索新的测试方法,积累新的技术经验。
2、重点业务线可以选择一个,偏中间件和接口,或者功能测试人员尚未覆盖的业务线,由自动化组承担。目前的人力来看,可以独立承担一个业务模块全部测试,避免混用投放功能测试人员和自动化测试人员。作为试验田从代码编写到最后的上线,由自动化全覆盖,进行整体流程的尝试和布局,方便快速产生短期效果。自动化人员也可以避免不会长期脱离业务线。
3、其他业务线在统一培训之后,使用框架根据自己的业务特点在局部开展自动化,各自形成独立的项目。后续会尝试接入Matrix或者开发自己的平台和容器,进行整体项目群的维护和管理。随着自动化覆盖度的慢慢提升,长期效果将会展现。
4、长期效果的展现的同时需要在测试流程上进行一些制约,比如测试报告上面增加自动化的选项和测试覆盖,比如开发提测前需要先进行自动化的冒烟测试等,保证自动化长期有效的实施。
5、整个技术团队有了自动化显著提升,可以推广到其他团队,可以进行跨部门的技术交流。
自动化目前还需要什么样的条件
1、稳定的测试环境
2、独立的业务线
3、多样的技术测试人才
4、团队共识 PPT解读: 1、测试环境的稳定是自动化成败的关键。不稳定环境会使效果大打折扣,掩盖本应该发现的很多功能问题,会使自动化的实施有很强挫败感。同时本地调试和远程批量运行,同样对环境的稳定性有较高的要求。如果有足够的条件,可以为自动化量身一套环境,测试数据相对独立,也避免和手工测试互相干扰。
2、专门的自动化测试人员需要拥有独立的业务线,一方面防止长期脱离业务,闭门造车。另一方面可以在业务线上不受干扰的实施自己的思路。
3、需要更多的测试人才。内部挖潜,从目前来看,难度很大,很多人在技术方面是一张白纸,也无法为技术测试提供更多的支持。如果有社招的机会,选才第一标准还是技术,标准定得高一些,好的技术人才还是非常难得的,相较业务也需要很长的时间才能培养出来。随着自然的新陈代谢,整个团队的技术水准也会有所提升。
4、从领导到员工对自动化开展要尽量达成共识,大家有共同的努力方向。一个人的成功不算成功,团队提升才是最重要的。虽然每个人的水平有高有低,但是本着不抛弃不放弃的原则,希望带动每个人都有所成长。让周围人变的足够优秀,让测试快乐起来,才是我们做自动化的真正意义。
本文出自 hanlingzhi 的51Testing软件测试博客:http://www.51testing.com/?547282
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
一:AndroidPN环境配置
AndroidPN框架实现了从服务器到
android移动平台的文本信息推送。下面是AndroidPN的环境配置
2.下载androidpn-client-0.5.0.zip和androidpn-server-0.5.0-bin.zip
网址:http://sourceforge.net/projects/androidpn/
解压两个包,Eclipse导入client,配置好目标平台,打开raw/androidpn.properties文件,
apiKey=1234567890
xmppHost=10.0.2.2
xmppPort=5222
如果是模拟器来运行客户端程序,把xmppHost配置成10.0.2.2 (模拟器把10.0.2.2认为是所在主机的地址,127.0.0.1是模拟器本身的回环地址).
如果是真机,配置成本机的IP地址 比如我在局域网内的IP是192.168.1.101
xmppPort=5222 是服务器的xmpp服务监听端口(注意5222端口貌似是固定的,我改成其他端口就行了)
从命令行运行androidpn-server-0.5.0\bin\run.bat启动服务器(有些朋友说会一闪而过启动不了,注意要从命令行进入该目录了在运行),从浏览器访问http://127.0.0.1:7070/index.do (androidPN
Server有个轻量级的
web服务器,在7070端口监听请求,接受用户输入的文本消息)
运行客户端,客户端会向服务器发起连接请求,注册成功后,服务器能识别客户端,并维护和客户端的IP长连接
进入Notifications界面,输入消息发送
真机客户端接受到server推送来的消息
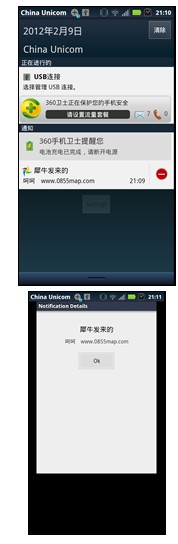
最后,我把AndroidPN服务器配置的VPS进行测试,同样的测试成功!
这样AndroidPN的环境就搭好了。真机环境也测试通过
问题:
1.asmack的包太大,3百多K。
2.只是完成Android的Push功能使用XMPP协议感觉很笨重。
3.androidpn服务器端的负载很难控制,除非自己改写。
第一个问题关系不大,毕竟一个软件多了300多K不算什么,如果自己来控制socket连接,我估计没有100K也很难控制好。
第二个问题确实如此,使用XMPP的后果是带来了60%的信息冗余量
第三个问题,负载的控制应该来说,用到socket都必须要考虑的,负载方面,androidpn用到了MINA这个socket框架,而在socket的处理方面,很多人都是用的socket来处理的。
总的来说,源代码的开放是最大的优点,就算用到androidpn,无论如何也是要在原有的基础上进行修改的,照搬照抄肯定是不行的。但是比自己用socket来控制,在服务器和客户端之间建立一个网关,要来的容易。
注意:需将lib 冲命名 改为libs,然后在build path里面导入libs这个包,否则会报类找不到的错误
首先,基础中的基础,就是按照第一篇日志中所说,使用模拟器完成web推送。这一块非常简单,按照第一篇去做完全可行,可能出错的地方就是你忘记更改配置文件了。
后来我下载了第二篇日志中博主提供的tomcat版本服务端,放在自己本机tomcat下,并且启动。用模拟器去测试发现无法推送,配置文件也没有错。检查后发现,原来自己tomcat的端口是8080,而server中配置的是7070。只要打开config.properties,修改admin.console.port=端口号,即可。
再接着,用同一个局域网内其他机子的客户端模拟器进行测试,只要将androidpn.properties中的xmppHost=服务端所在内网IP就可以啦。比如192.168.1.150。
用真机测试,其实和模拟器没啥区别,只要配置文件不写错,原则是不会出问题的。但是我测试的时候,还是出现无法推送成功的问题。仔细检查后,原因有二。
1.客户端android版本太低,换个android4.0版本就可以。貌似是不兼容低版本。
2.真机上其他的应用中,也有应用到这个androidpn的。其中,在androidpn.properties中,apikey默认是123456789。因为那个应用和我自己本机都选择了默认的,所以我将自己这里的apikey改掉了。切记!这里有一点需要注意的,客户端androidpn.properties中更改了apikey,服务端config.properties也要随之修改。!!
OK,基本上单独的web推送就完成了。
接下来就是整合到自己项目中,也就是从自己项目后台将数据推送到客户端,至于androidpn的server端,则作为中间的桥梁。
这里需要注意一点,androidpn会在你本地数据库中新增一个表apn_user。如果你本地数据库有权限,拒绝的话,你最好自己先手动增加这么一张表。
首先,我单独启动一个新的tomcat,将server端部署到这下面,修改配置文件config。properties,jdbc.properties。jdbc.properties这个文件是配置你本地数据库的参数的,不能有错。启动后,简单测试成功,在自己项目中使用http协议将数据POST到server端这个org.androidpn.server.console.controller.NotificationController类的send方法中。具体参数名称及获取参数的代码,可以修改server端。
在这里插一句,不论时间多么紧张,至少你得追一边代码,尤其这个类。
代码写好后可以执行,断点跟踪下,只要你代码正确,配置文件没错,是可以正常推送的。
基本上,写到这里的话,应该可以满足项目需求了。如果你还需要将哪些用户在线的功能整合到你自己项目中。那你就得自己跟踪下代码了。
我项目做到这里,基本上都是在windows环境下。将项目部署到linux环境下,又出问题了。
路径问题比较容易坚决,按照后台日志中提示的地方,将路径修改下。
关键是在linux下重启server端,会发现报错,5222端口被占用。因为时间限制,能力有限,没办法修改代码,只能每次重启时,都先用命令将5222端口杀掉。
基于优秀的图像对比库opencv的
测试工具,测试脚本使用
Python编写,非常强大。如果你的app没有源码,可以选择它;或者你想做
系统测试(跨app的测试),也可以选择它。其它的还是用下面说的那些个吧。
我通过其核心包sikuli-script.jar实现了
android的sikuli化,暂时不打算开源。其实原理挺简单的,认真看过sikuli源码的应该都能写出来。
看lz的意思应该只是想问应用层的,我来说点应用层的
先说说开源的吧:
Robotium
Monkeyrunner
Robolectric
CTS
还有个新兴的测试工具,以前在GitHub看到,现在找不到了,好像是BDD类型的语法;现在还不成熟。
有两种:
基于Remote Server的:官方提供了
java接口的,但是Python版的官方里面却没有。我非常喜欢Python,所以自己实现了并且开源到了GitHub:https://github.com/truebit... 有问题大家可以提到上面
基于Instrumentation的:已经在Android SDK r14里面可以安装了
不开源的就多了,不过我见过的一般是以下几种思路:
1. 基于Android Java Instrumentation框架:
基于Robotium,比如bitbar的产品:http://bitbar.com/products
基于Instrumentation,那就海了去了,很多公司自家写的工具都基于这个;另外Robotium就是基于这个的
2. 基于Android lib层的各种命令,比如sendevent,getevent, monkey, service这些,然后用各种语言封装
MonkeyRunner还是很有前景的,
Google自己弄的。现在最新的dev版本已经有支持UI的id操作的EasyMonkey了。可以git clone git://android.kernel.org/platform...看看
在SoapUI中可以定义一个个的测试用例TestCase,但是有些用例是依赖于之前的用例的,如果纯拷贝的话可能会导致用例比较臃肿而且不好维护,比如说存在如下两个TestCase:
1)CreateUserTestCase:测试创建用户,通过发送Soap报文方式创建用户同时需要校验
数据库中值是否正确
2)ChangUserInfoTestCase:测试修改用户信息,通过发送Soap报文方式修改用户信息,需要校验修改前和修改后的用户信息
ChangUserInfo之前必须得创建一个用户,纯拷贝肯定是不可取的,因为后续如果创建用户的接口稍有变动,则需要同时在ChangUserInfoTestCase和CreateUserTestCase修改请求报文。
SoapUI在TestCase中提供Run TestCase的Step,可以直接调用指定的TestCase,但是需要前一个TestCase中将属性传递出来,步骤如下:
1)在被调用TestCase中设置返回属性
testRunner.testCase.setPropertyValue("属性名称",“属性值”)
2)在调用TestCase中增加Run TestCase指向被调用TestCase
3)在调用TestCase中的其它
Test Step中获取属性
例如:在CreateUserTestCase中将创建好的用户ID传给ChangUserInfoTestCase,则步骤如下:
1)在CreateUserTestCase中通过Groovy Script. 设置返回属性:
testRunner.testCase.setPropertyValue("UserID",context.getProperty("UserID"))
2) 在ChangUserInfoTestCase中增加Run TestCase:RunNewUserTestCase指向CreateUserTestCase并指定UserID属性为输入值
3)在ChangUserInfoTestCase中获取执行CreateUserTestCase得到的用户ID
def NewUserProperties = testRunner.testCase.getTestStepByName( "RunNewUserTestCase" ); log.info(NewUserProperties .getPropertyValue( "UserID" )) |
本文出自 wendy-qian 的51Testing软件测试博客:http://www.51testing.com/?15017055
为了成功地领导和运作一个组织,需要采用一种系统和透明的方式进行管理。针对所有相关方的需求,实施并保持持续改进其业绩的管理体系,使组织获得成功。组织为实现质量目标,应遵循以下八项质量管理原则。
原则1: 以顾客为中心
组织依存于其顾客。因此,组织应理解顾客当前的和未来的需求,满足顾客要求并争取超越顾客期望。
1、 组织实施本原则的主要利益
2、 组织实施本原则时一般要采取的主要措施
3、 本原则在标准中的体现
原则2: 领导作用
领导将本组织的宗旨、方向和内部环境统一起来,并创造使员工能够充分参与实现组织目标的环境。
1、 组织实施本原则的主要利益
2、 组织实施本原则时一般要采取的主要措施
3、 本原则在标准中的体现
原则3: 全员参与
各级人员是组织之本。只有他们的充分参与,才能使他们的才干为组织带来最大的收益。
1、 织实施本原则的主要利益
2、 组织实施本原则时一般要采取的主要措施
3、 本原则在标准中的体现
原则4: 过程方法
将相关的资源和活动作为过程进行管理,可以更高效地得到期望的结果。
过程方法的原则不仅适用于某些较简单的过程,也适用于由许多过程构成的过程网络。在应用于质量管理体系时,2000版ISO9000族标准建立了一个过程模式。此模式把管理职责、资源管理、产品实现、测量、分析与改进作为体系的四大主要过程,描述其相互关系,并以顾客要求为输入,提供给顾客的产品为输出,通过信息反馈来测定的顾客满意度,评价质量管理体系的业绩。
1、 实施本原则的主要利益
2、 组织实施本原则时一般要采取的主要措施
3、 本原则在标准中的体现
原则5: 管理的系统方法
针对设定的目标,识别、理解并管理一个由相互关连的过程所组成的体系,有助于提高组织的有效性和效率。
ISO/DIS9000的3.3列出了建立和实施质量管理体系的十三个步骤:
1、 实施本原则的主要利益
2、 组织实施本原则时一般要采取的主要措施
3、 本原则在标准中的体现
原则6: 持续改进
持续改进是组织的一个永恒的目标。
1、 实施本原则的主要利益
2、 组织实施本原则时一般要采取的主要措施
3、 本原则在标准中的体现
原则7: 基于事实的决策方法
对数据和信息的逻辑分析或直觉判断是有效决策的基础。
以事实为依据做决策,可防止决策失误。在对信息和资料做科学分析时,统计技术是最重要的工具之一。统计技术可以用来测量、分析和说明产品和过程的变异性。统计技术可以为持续改进的决策提供依据。
1、 实施本原则的主要利益
2、 组织实施本原则时一般要采取的主要措施
3、 本原则在标准中的体现
原则8: 互利的供方关系
通过互利的关系,增强组织及其供方创造价值的能力。
供方提供的产品将对组织向顾客提供满意的产品可能产生重要的影响,一次处理好与供方的关系,影响到组织能否持续稳定地提供顾客满意地产品。对供方不能只讲控制,不讲合作互利。特别对关键供方,更要建立互利关系。这对组织和供方双方都是有利的。
1、 实施本原则的主要利益
2、 组织实施本原则时一般要采取的主要措施
3、 本原则在标准中的体现
十三个步骤
企业管理器
--右键"数据库"
--所有任务
--还原数据库
--"还原为数据库库"中输入还原后的数据库名
--还原选择"从设备"--选择设备--添加--添加你的备份文件--确定,回到数据库还原的界面
--备份号--选择内容--选择你要恢复那次备份的内容
--选项--将"移至物理文件名"中的物理文件名修改为你的数据文件要存放的文件名
--如果要还原的数据库已经存在,选择"在现有数据库上qz还原"-
-确定
restore database 数据库 from disk='c:\你的备份文件名'
还原数据库
企业管理器中的操作:
1.进行完整恢复
企业管理器--右键"数据库"--所有任务--还原数据库
--"还原为数据库库"中输入还原后的数据库名,设为:test
--还原选择"从设备"--选择设备--添加--添加你的备份文件
--确定,回到数据库还原的界面
--"还原备份集",选择"数据库--完全"
--选项--将"移至物理文件名"中的物理文件名修改为你的数据文件要存放的文件名
--如果要还原的数据库已经存在,选择"在现有数据库上qz还原"
--"恢复完成状态",选择"使数据库不再运行,但能还原其它事务日志"
--确定
--或用SQL语句:
restore database 数据库 from disk='c:\你的完全备份文件名' with norecovery
2.进行差异恢复
企业管理器--右键"数据库"--所有任务--还原数据库
--"还原为数据库库"中选择数据库名:test
--还原选择"从设备"--选择设备--添加--添加你的备份文件
--确定,回到数据库还原的界面
--"还原备份集",选择"数据库--差异"
--"恢复完成状态",选择"使数据库不再运行,但能还原其它事务日志"
--确定
--或用SQL语句:
restore database 数据库 from disk='c:\你的差异备份文件名' with norecovery
3.进行日志恢复
企业管理器--右键"数据库"--所有任务--还原数据库
--"还原为数据库库"中选择数据库名:test
--还原选择"从设备"--选择设备--添加--添加你的备份文件
--确定,回到数据库还原的界面
--"还原备份集",选择"事务日志"
--"恢复完成状态",选择"使数据库可以继续运行,但无法还原其它事务日志"
--确定
--或用SQL语句:
restore log 数据库 from disk='c:\你的日志备份文件名' with recovery
--解决还原数据库目录不对的详细步骤:
1.企业管理器中的方法:
--右键"数据库"
--所有任务
--还原数据库
--"还原为数据库库"中输入还原后的数据库名
--还原选择"从设备"--选择设备--添加--添加你的备份文件--确定,回到数据库还原的界面
--备份号--选择内容--选择你要恢复那次备份的内容
--选项--将"移至物理文件名"中的物理文件名修改为你的数据文件要存放的文件名
--如果要还原的数据库已经存在,选择"在现有数据库上qz还原"-
-确定2.用SQL语句的方法(假设你的备份文件名为: c:\xx.bak
--列出备份文件中的逻辑文件名
restore filelistonly from disk='c:\xx.bak'
--用语句恢复,根据上面列出的逻辑文件名使用move选项
restore database 恢复后的数据库名
from disk='c:\xx.bak'
with move '逻辑数据文件名1' to 'c:\物理数据文件名1'
,move '逻辑数据文件名2' to 'c:\物理数据文件名2'
...
,move '逻辑数据文件名n' to 'c:\物理数据文件名n'
没有什么要特别注意的,和企业版之间的备份/还原要注意的东西一样:
1.要注意备份时的设置问题,不要指定多个备份文件,否则还原时也要指定多个备份文件
2.要注意备份的媒体处理方式问题,用重写,而不是追加,否则还原的时候要指定备份号
3.要注意备份的方式,用完全备份,而不是其他备份方式,否则还原时还要其他备份文件支持
oracle客户端的安装是非常简单的,关键在tns配置,我这里使用的rpm安装包,oracle本身就不是开源,那使用rpm安装时最简单的。
1.要远程使用oracle,先下载下面三个文件,注意版本最好一致。
oracle-instantclient-basic-10.2.0.4-1.i386.rpm oracle-instantclient-sqlplus-10.2.0.4-1.i386.rpm oracle-instantclient-devel-10.2.0.4-1.i386.rpm |
2.PM安装
oracle-instantclient-basic-10.2.0.4-1.i386.rpm是基本的动态库、jar包,默认安装路径是:/usr/lib/oracle/10.2.0.4/client oracle-instantclient-sqlplus-10.2.0.4-1.i386.rpm是客户端sqlplus安装包, 默认安装路径是:/usr/lib/oracle/10.2.0.4/client oracle-instantclient-devel-10.2.0.4-1.i386.rpm是api接口文件,默认安装路径是:/usr/include/oracle/10.2.0.4/client |
这里不需要修改默认路径,直接安装即可:
sudo rpm-avi oracle-instantclient-basic-10.2.0.4-1.i386.rpm sudo rpm-avi oracle-instantclient-sqlplus-10.2.0.4-1.i386.rpm sudo rpm-avi oracle-instantclient-devel-10.2.0.4-1.i386.rpm |
3.配置环境变量
vi /etc/profile export ORACLE_HOME=/usr/lib/oracle/10.2.0.4 export TNS_ADMIN=$ORACLE_HOME/network/admin export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK exportLD_LIBRARY_PATH=$ORACLE_HOME/client/lib:$LD_LIBRARY_PATH exportOCI_HEADERS_HOME=/usr/include/oracle/10.2.0.4/client export OCI_LIBS_HOME=$ORACLE_HOME/client/lib |
后面两项是为了我们的程序程序编译时使用方便,编译时直接加入选项:
-I$( OCI_HEADERS_HOME) –L$( OCI_LIBS_HOME) –l occi
4.配置监听器和网络环境
[huangxw@ubuntu admin]$ cat/usr/lib/oracle/10.2.0.4/network/admin/tnsnames.ora test_base= (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = *.*.*.*)(PORT = ****)) ) (CONNECT_DATA = (SERVICE_NAME = tt4adol) ) ) |
5.测试连接
[huangxw@ubuntu bin]$./sqlplus USERNAME/PASSWD@test_base SQL*Plus: Release 10.2.0.4.0 - Production onMon Jan 13 10:09:31 2014 Copyright (c) 1982, 2007, Oracle. All Rights Reserved. Connected to: Oracle Database 11g Enterprise Edition Release11.2.0.2.0 - 64bit Production With the Partitioning, OLAP, Data Mining andReal Application Testing options SQL> select * from USERNAME.TABLENAME where accountid = 8401428; ACCOUNTID INVTA SNDA RAINA INSB SPEN REMN ---------- ---------- ---------- -------------------- ---------- ---------- INVTC SPDC REIN ---------- ---------- ---------- 8401428 0 0 100000 0 0 0 0 0 0 |
1.监控准备:
监控方:
1)安装tcp/ip协议下的netbios
2)用administrator登录
被监控方:
Remote ProcedureCall(RPC)和Remote Registry Service
开启位置:右键“我的电脑”->管理->服务和应用程序->服务
2)被监控的Windows中要有C$共享文件夹
查看位置:右键“我的电脑”->管理->共享文件夹->共享,在这里面要有C$这个共享文件夹,要是没有自己手动加
3)被监控的Windows有管理员的权限,包括用户名和密码
4)修改网络安全设置:
(组策略gpedit.msc windows设置-安全设置-本地策略-安全选项-右侧网络访问-本地帐户的共享和安全模式->修改为“经典”,默认是“仅来宾”,这个对应注册表键值:”forceguest”=dword:00000000;
注:这一步可以先不操作,如果在LR添加Windows监控,会报错时再操作,你可以自己形成一个.reg文件如
test.reg,然后双击修改对应注册表的值。test.reg.reg具体输入内容为:
Windows Registry Editor Version 5.00 [HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlLsa] “forceguest”=dword:00000000 |
或者采用手动修改的方式实现
5)验证是否可以连接:
在安装LR的机器上使用运行.输入被监视机器IPC$,如192.168.133.99C$然后输入管理员帐号和密码,如果能看到被监视机器的C盘了,就说明你得到了那台机器的管理员权限,可以使用LR去连接了,不过这步有可能提示“找不到网络路径”,可以先不管,在LR上面尝试添加监控,看看效果,可以的话就OK了
2.用LR监视windows资源
这个比较简单,直接添加度量即可,如果有弹出windows资源选择对象的窗口即成功了:
鼠标选择windows资源监视窗口,点击右键弹出菜单中选择“ADDMeasurements..”
点“添加”把监视的服务器ip地址输入,点确定
如果可以正常联机到服务器,则在资源度量中会显示全部计数器,此时如果点“确定”则系统默认全部选中,在监视窗口中会显示所有性能曲线,无法单独过滤显示某条曲线,如果选中某个计数器后点“添加”则弹出该项目下的其它性能指标,选择需要的计数器后点“添加”
此时要注意,你登陆客户端(也就是你装有loadrunner机器)的用户应该是管理员身份,同时还要保证该用户在被监视的服务器上也是管理员身份。这样选择虽然监视窗口中仍会显示所有性能曲线,但是可以通过鼠标右键弹出菜单,选中你指定的某条曲线单独显示。方法是双击监视窗口放大显示,然后右键选择“仅显示指定图”监视窗口还可以互相叠加等操作,功能强大,通过右键菜单选择可以进行复杂显示操作。常用的还有
web程序服务器图、
数据库服务器资源图等,添加方法雷同。
3. Windows资源监控参数分析