
一、实现一个最简单的线程
public class LiftOff implements Runnable{ protected int countDown = 10; private static int taskCount = 0; private final int id = taskCount++; public LiftOff() {} public LiftOff(int countDown) { this.countDown = countDown; } public String status() { return "#" + id + "(" + (countDown > 0 ? countDown : "LiftOff!") + ")"; } /* (non-Javadoc) * @see java.lang.Runnable#run() */ @Override public void run() { while (countDown-- > 0) { System.out.println(status()); Thread.yield(); // 告诉CPU可以进行线程切换。 } } } |
然后,你以后再调用以下代码就可以开启一个新线程。下面代码调用t.start()函数之后就会执行 LiftOff类的run函数。
Thread t = new Thread(new LiftOff()); t.start(); |
实例是由
操作系统中的一组内存区和一系列的操作系统进程组成,数据库则是指
Oracle保存数据的一系列物理结构和逻辑结构,用户在访问Oracle数据库时主要是在与实例打交道,由实例访问数据库,并返回相应的操作结果。
最简单的Oracle数据库结构是由一个实例和一个数据库组成,不过对于RAC(或OPS)架构的Oracle数据库,一个数据库会对应多个实例。
在Oracle数据库,实例和数据库可以理解成两个相互间有关联的独立个体,每个数据库都至少有一个与之对应的实例(对于OPS/RAC架构的Oracle数据库,一个数据库会对应多个实例),每个实例在其生命周期内同时只能对应一个数据库。所谓的启动Oracle数据库时,实际上是连接到实例,说的更直白点儿,就是连接到操作系统的某些进程,并由这些进程访问处理内存中的对象,至于这些对象时如何从磁盘被读取到内存,那正是实例所做的
工作。
数据库则是:数据库文件--数据文件+REDO日志+控制文件、密码文件、初始化参数文件等
数据库服务器等于:实例+数据库 ==》对客户机来说,通过服务连接数据库,只需要知道服务。
Oracle中的实例有内存结构和进程结构两大部分组成。
服务器进程和实例后台进程区别:
实例的一部分是内存结构,实例的另外一部分就是进程。与内存不同,进程都是实实在在的存在,你可以看得见(不过摸不着)。通过相关进程,Oracle实现数据库与实例的连通;通过相关进程,Oracle实现数据库与实例的互动;通过相关进程,Oracle实现对Oracle数据库的应用。
Oracle进程分为两类:服务器进程(Server Process)和后台进程(Background Process),下面分别进行区分。
服务器进程
Oracle的服务器进程有Oracle实例自动创建,用来处理连接到实例的客户端进程发出的请求,用户必须通过连接到Oracle的服务器进程来获取数据库中的信息。对于专用服务器模式,客户端进程和Oracle服务器进程是一一对应的,而在共享服务器模式下,一个Oracle服务器进程可能同时服务多个客户端进程。
专有连接模式 :用户进程对应一个SERVER PROCESS
此时新增一个服务器进程,大约需要的内存是: AIX 5-10M ;LINUX 3-5M内存
建库时默认是专有连接模式
服务器进程主要用来执行下列的任务:
从磁盘数据文件中读取必须的数据块到SGA得数据缓存区。
以适当形式返回SQL语句执行结果。
user process用户进程
通过tnsnames.ora中的服务名,连接到数据库服务器的服务器进程。要经过监听到服务器进程--PGA
后台进程:
服务器进程主要是与客户端进程打交道,后台进程则是让内存区与物理文件打交道。像Oracle数据库这么庞大的结构,要保持高效、稳定并且具有良好的性能,只有几个经纪人显然不行的,因此各项标准服务都由特定进程专门处理,比如写数据文件要有DBWR进程,写归档文件要有ARCH进程等。由Oracle在后台自动启动、管理和维护,因此这些进程才被称为后台进程。
进程(Process)是具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位。程序只是一组指令的有序集合,它本身没有任何运行的含义,只是一个静态实体。而进程则不同,它是程序在某个数据集上的执行,是一个动态实体。它因创建而产生,因调度而运行,因等待资源或事件而被处于等待状态,因完成任务而被撤消,反映了一个程序在一定的数据集上运行的全部动态过程。
线程(Thread)是进程的一个实体,是CPU调度和分派的基本单位。线程不能够独立执行,必须依存在进程中,由进程提供多个线程执行控制。从内核角度讲线程是活动体对象,而进程只是一组静态的对象集,进程必须至少拥有一个活动线程才能维持运转。
当某个应用程序调用一个创建进程的函数比如CreateProcess或者用户执行某一个程序(其实
windows下用户执行一般普通程序是由explorer.exe调用CreateProcess来完成),
操作系统把这个过程分成以下步骤来完成:
1.打开将要在该进程中执行的映像文件。
2.创建Windows执行体进程对象。
3.创建初始线程(栈、堆执行环境初始化及执行线程体对象)。
4.通知Windows子系统新进程创建了(子系统是操作系统的一部分它是一个协助操作系统内核管理用户态/客户方的一个子系统具体的进程为Csrss.exe)。
5.开始执行初始线程(如果创建时候指定了线程的CREATE_SUSPENDED状态则线程暂时挂起不执行)。
6.在新进程和线程环境中完成地址空间的初始化(比如加载必须的DLL和库),然后开始到进程入口执行。
到这里操作系统完成一个新进程的创建过程。下面来看下具体每一步操作系统所做的
工作:
1.打开将要在该进程中执行的映像文件。
首先操作系统找到执行的Windows映像然后创建一个内存区对象,以便后面将它映射到新的进程地址空间中。
2.创建Windows执行体进程对象。
接下来操作系统调用内部的系统函数NtCreateProcess来创建一个Windwos执行体进程对象。具体步骤是:
(1)建立EPROCESS
*分配并初始化EPROCESS结构块
*从父进程处继承得到进程的亲和性掩码
*分配进程的最大最小工作集尺(由两个参数决定PsMinimumWorkingSet PsMaximumWorkingSet)
*降新进程的配额块设置为父进程配额块地址,并递增父进程配额块的引用计数
*继承Windows的设备名字空间
*将父进程进程ID保存在新进程对象的InheritedFormUniqueProcessId中
*创建该进程的主访问令牌
*初始化进程句柄表
*将新进程的退出状态设置为STATUS_PENDING
(2)创建初始的进程地址空间
*在适当的页表中创建页表项,以映射初始页面
*从MmresidentAvailablePage算出进程工作集大小
*系统空间的非换页部分和系统缓存的页表被映射到进程
(3)初始化内核进程块KPROCESS
(4)结束进程地址空间的创建过程
(5)建立PEB
(6)完成执行体进程对象的创建过程
3.创建初始线程(栈、堆执行环境初始化及执行线程体对象)。 这时候Windows执行体进程对象已经完全建立完成,但它还没有线程所以无法执行,接下来系统调用NtCreateThread来创建一个挂起的新线程它就是进程的主线程体。
4.通知Windows子系统新进程创建了(子系统是操作系统的一部分它是一个协助操作系统内核管理用户态/客户方的一个子系统具体的进程为Csrss.exe)。接下来操作系统通过客户态(Kernel32.dll)给Windows子系统(Csrss)发送一个新进程线程创建的数据消息,让子系统建立自己的进程线程管理块。当Csrss接收到该消息时候执行下面的处理:
*复制一份该进程和线程句柄
*设置进程优先级
*分配Csrss进程块
*把新进程的异常处理端口绑定到Csrss中,这样当该进程发生异常时,Csrss将会接收到异常消息
*分配和初始化Csrss线程块
*把线程插入到进程的线程列表中
*把进程插入到Csrss的线程列表中
*显示进程启动光标
5.开始执行初始线程(如果创建时候指定了线程的CREATE_SUSPENDED状态则线程暂时挂起不执行)。到这里进程环境已经建立完毕进程中开始创建的主线程到这里获得执行权开始执行线程。
6.在新进程和线程环境中完成地址空间的初始化(比如加载必须的DLL和库),然后开始到进程入口执行。
到这步实质是调用ldrInitializeThunk来初始化加载器,堆管理器NLS表TLS数组以及临界区结构,并且加载任何必须要的DLL并且用
DLL_PROCESS_ATTACH功能代码来调用各DLL入口点,最后当加载器初始化例程返回到用户模式APC分发器时进程映像开始在用户模式下执行,然后它调用线程启动函数开始执行。
到这里操作系统完成了所有的创建工作,我们写的程序就这样被操作系统调用运行起来了。
有时候为了方便,想写一
Python脚本,让其既能在windows下运行又可以在linux中运行,只需要改一下后缀。
由于python是解释性的语言,所以在不同平台下执行其对应的代码,而不必担心针对某个平台的代码块不符合当前平台,使整个文件不能运行。我们只需要通过if语句来判断当前平台,执行相应代码块即可:
通过以下方法:
在windows中运行结果为 : win32
或者:
import platform platform.system() |
在windows中的运行结果为: windows
刚接触
ORACLE的人肯定会对实例和
数据库感到困惑,实例到底代表些什么?为什么会有这个概念的出现?
ORACLE实例 = 进程 + 进程所使用的内存(SGA)实例是一个临时性的东西,你也可以认为它代表了数据库某一时刻的状态!
数据库 = 重做文件 + 控制文件 + 数据文件 + 临时文件
数据库是永久的,是一个文件的集合。
ORACLE实例和数据库之间的关系
1.临时性和永久性
2.实例可以在没有数据文件的情况下单独启动 startup nomount , 通常没什么意义
3.一个实例在其生存期内只能装载(alter database mount)和打开(alter database open)一个数据库
4.一个数据库可被许多实例同时装载和打开(即RAC),RAC环境中实例的作用能够得到充分的体现!
下面对实例和数据库做详细的诠释:
在Oracle领域中有两个词很容易混淆,这就是“实例”(instance)和“数据库”(database)。作为Oracle术语,这两个词的定义如下:
数据库(database):物理
操作系统文件或磁盘(disk)的集合。使用Oracle 10g的自动存储管理(Automatic Storage Management,ASM)或RAW分区时,数据库可能不作为操作系统中单独的文件,但定义仍然不变。
实例(instance):一组Oracle后台进程/线程以及一个共享内存区,这些内存由同一个计算机上运行的线程/进程所共享。这里可以维护易失的、非持久性内容(有些可以刷新输出到磁盘)。就算没有磁盘存储,数据库实例也能存在。也许实例不能算是世界上最有用的事物,不过你完全可以把它想成是最有用的事物,这有助于对实例和数据库划清界线。
这两个词有时可互换使用,不过二者的概念完全不同。实例和数据库之间的关系是:数据库可以由多个实例装载和打开,而实例可以在任何时间点装载和打开一个数据库。实际上,准确地讲,实例在其整个生存期中最多能装载和打开一个数据库!稍后就会介绍这样的一个例子。
是不是更糊涂了?我们还会做进一步的解释,应该能帮助你搞清楚这些概念。实例就是一组操作系统进程(或者是一个多线程的进程)以及一些内存。这些进程可以操作数据库;而数据库只是一个文件集合(包括数据文件、临时文件、重做
日志文件和控制文件)。在任何时刻,一个实例只能有一组相关的文件(与一个数据库关联)。大多数情况下,反过来也成立:一个数据库上只有一个实例对其进行操作。不过,Oracle的真正应用集群(Real Application Clusters,RAC)是一个例外,这是Oracle提供的一个选项,允许在集群环境中的多台计算机上操作,这样就可以有多台实例同时装载并打开一个数据库(位于一组共享物理磁盘上)。由此,我们可以同时从多台不同的计算机访问这个数据库。Oracle RAC能支持高度可用的系统,可用于构建可扩缩性极好的解决方案。
一个实例在其生存期中最多只能装载和打开一个数据库。要想再打开这个(或其他)数据库,必须先丢弃这个实例,并创建一个新的实例。
重申一遍:
实例是一组后台进程和共享内存。
数据库是磁盘上存储的数据集合。
实例“一生”只能装载并打开一个数据库。
数据库可以由一个或多个实例(使用RAC)装载和打开。
前面提到过,大多数情况下,实例和数据库之间存在一种一对一的关系。可能正因如此,才导致人们很容易将二者混淆。从大多数人的经验看来,数据库就是实例,实例就是数据库。
运行一个Oracle实例,但是它访问的数据库每天都可能不同(甚至每小时都不同),这取决于我的需求。只需有不同的配置文件,我就能装载并打开其中任意一个数据库。在这种情况下,任何时刻我都只有一个“实例”,但有多个数据库,在任意时间点上只能访问其中的一个数据库。
所以,你现在应该知道,如果有人谈到实例,他指的就是Oracle的进程和内存。提到数据库时,则是说保存数据的物理文件。可以从多个实例访问一个数据库,但是一个实例一次只能访问一个数据库。
1.oracle数据库系统中,DBMS可以管理多个数据库实例吗?还是需要一个oracle服务管理一个实例?
oracle里面一个数据库系统可以又多个实例。你可以运行dbca,在界面里面你可以看到可以创建新的实例,但是大多数情况下,oracle都只是建立一个实例。
2需要建立教务数据库,财务数据库两个db,
是可以的,不过通常的做法是建再2个用户放在不同的tablespaces上面。一个用户存储教务数据库表数据,一个存放财务数据库表数据。
3.oracle中的schema属于哪个层次?
schema简单来讲,你可以理解成一个用户以及用户所拥有的所有对象。其实就相当于sqlserver的库。
4.oracle中这样做。
create user Test;
grant [connect,……]to Test;
create table……
创建属于此用户的表及其他对象,那么这个用户数否可以代表为一个应用db?
同3一样,你可以这样理解成一个用户以及用户下面所有的对象其实就是sqlserver中的db了,实际生产环境中,为了减少成本和充分利用oracle数据库的资源,我们都是一个项目一个用户,一个应用一个用户,然后在不同的用户下面建立相应的表、视图、存储过程、存储函数、序列等等。
下面来看一个简单的例子。假设我们刚安装了Oracle 10g10.1.0.3。我们执行一个纯软件安装,不包括初始的“启动”数据库,除了软件以外什么都没有。
通过pwd命令可以知道当前的工作目录(这个例子使用一个Linux平台的计算机)。我们的当前目录是dbs(如果在Windows平台上,则是database目录)。执行ls–l命令显示出这个目录为“空”。其中没有init.ora 文件,也没有任何存储参数文件(stored parameter file,SPFILE);存储参数文件将在第3章详细讨论。
使用ps(进程状态)命令,可以看到用户ora10g运行的所有进程,这里假设ora10g是Oracle软件的所有者。此时还没有任何Oracle数据库进程。
然后使用ipcs命令,这个UNIX命令可用于显示进程间的通信设备,如共享内存、信号量等。目前系统中没有使用任何通信设备。
然后启动SQL*Plus(Oracle的命令行界面),并作为SYSDBA连接(SYSDBA账户可以在数据库中做任何事情)。连接成功后,SQL*Plus报告称我们连上了一个空闲的实例:
我们的“实例”现在只包括一个Oracle服务器进程,见以下输出中粗体显示的部分。此时还没有分配共享内存,也没有其他进程。
现在来启动实例:
这里提示的文件就是启动实例时必须要有的一个文件,我们需要有一个参数文件(一种简单的平面文件,后面还会详细说明),或者要有一个存储参数文件。现在就来创建参数文件,并放入启动数据库实例所需的最少信息(通常还会指定更多的参数,如数据库块大小、控制文件位置,等等)。
然后再回到SQL*Plus:
这里对startup命令加了nomount选项,因为我们现在还不想真正“装载”数据库(要了解启动和关闭的所有选项,请参见SQL*Plus文档)。
注意
在Windows上运行startup命令之前,还需要使用oradim.exe实用程序执行一条服务创建语句。
现在就有了所谓的“实例”。运行数据库所需的后台进程都有了,如进程监视器(process monitor,PMON)、日志写入器(log writer,LGWR)等,这些进程将在第5章详细介绍。
再使用ipcs命令,它会首次报告指出使用了共享内存和信号量,这是UNIX上的两个重要的进程间通信设备:
注意,我们还没有“数据库”呢!此时,只有数据库之名(在所创建的参数文件中),而没有数据库之实。如果试图“装载”这个数据库,就会失败,因为数据库根本就不存在。下面就来创建数据库。有人说创建一个Oracle数据库步骤很繁琐,真是这样吗?我们来看看:
这里创建数据库就是这么简单。但在实际中,也许要使用一个稍有些复杂的CREATE DATABASE命令,因为可能需要告诉Oracle把日志文件、数据文件、控制文件等放在哪里。不过,我们现在已经有了一个完全可操作的数据库了。可能还需要运行$ORACLE_HOME/rdbms/admin/ catalog.sql脚本和其他编录脚本(catalog script)来建立我们每天使用的数据字典(这个数据库中还没有我们使用的某些视图,如ALL_OBJECTS),但不管怎么说,数据库已经有了。可以简单地查询一些Oracle V$视图(具体就是V$DATAFILE、V$LOGFILE和V$CONTROLFILE),列出构成这个数据库的文件:
Oracle使用默认设置,把所有内容都放在一起,并把数据库创建为一组持久的文件。如果关闭这个数据库,再试图打开,就会发现数据库无法打开:
一个实例在其生存期中最多只能装载和打开一个数据库。要想再打开这个(或其他)数据库,必须先丢弃这个实例,并创建一个新的实例。
重申一遍:
1.实例是一组后台进程和共享内存。
2.数据库是磁盘上存储的数据集合。
3.实例“一生”只能装载并打开一个数据库。
4.数据库可以由一个或多个实例(使用RAC)装载和打开。
前面提到过,大多数情况下,实例和数据库之间存在一种一对一的关系。可能正因如此,才导致人们很容易将二者混淆。从大多数人的经验看来,数据库就是实例,实例就是数据库。
不过,在许多测试环境中,情况并非如此。在我的磁盘上,可以有5个不同的数据库。测试主机上任意时间点只会运行一个Oracle实例,但是它访问的数据库每天都可能不同(甚至每小时都不同),这取决于我的需求。只需有不同的配置文件,我就能装载并打开其中任意一个数据库。在这种情况下,任何时刻我都只有一个“实例”,但有多个数据库,在任意时间点上只能访问其中的一个数据库。
所以,你现在应该知道,如果有人谈到实例,他指的就是Oracle的进程和内存。提到数据库时,则是说保存数据的物理文件。可以从多个实例访问一个数据库,但是一个实例一次只能访问一个数据库。
下载地址:http://jmeter.apache.org/download_jmeter.cgi
目前最新版为2.9,其余文件如源代码等也可从如下官网下载:
http://jmeter.apache.org/download_jmeter.cgi
2、安装Jmeter之前
安装Jmeter之前需要先配置
Java环境,我们下载的是jmeter2.9,所以java版本最好是选用java6以后的版本。
安装JDk1.6的步骤如下:
点击下载的JDK文件-dk-6u18-windows-i586.exe,点击下一步直至安装完成,然后开始配置环境:
点击我的电脑----属性----高级----环境变量----在系统变量中----点击新建,
在变量名中输入:JAVA_HOME
变量值中输入:C:\Program Files (x86)\Java\jdk1.6.0_18
再次点击新建:
在变量名中输入:CLASSPATH,
变量值中输入:.;%JAVA_HOME%/lib/dt.jar;%JAVA_HOME%/lib/tools.jar;
然后再系统变量中找到Path,点击编辑,在变量值中加上:
%JAVA_HOME%/bin;%JAVA_HOME%/jre/bin;(如果前面没有“;”需要加上)
配置完成之后,点击确定保存,然后cmd打开命令窗口输入:java或者javac,出现大串字符串表示配置成功。
也可以输入:java -version 查看java版本来查看是否配置成功。
OK,JDK安装成功之后,就可以下一步安装Jmeter了。
3、安装Jmeter
解压apache-jmeter-2.9.zip文件至目录,我的是D:\Program Files目录。
点击我的电脑----属性----高级----环境变量----在系统变量中----点击新建,
变量名输入:JMETER_HOME
变量值输入:D:\Program Files\apache-jmeter-2.9
然后编辑CLASSPATH变量,加上%JMETER_HOME%\lib\ext\ApacheJMeter_core.jar;%JMETER_HOME%\lib\jorphan.jar;%JMETER_HOME%\lib\logkit-2.0.jar;然后确定即可
操作完上面的步骤,我们就可以点击Jmeter中bin目录下面的jmeter.bat文件即可打开Jmeter了。
注意:打开的时候会有两个窗口,Jmeter的命令窗口和Jmeter的图形操作界面,不可以关闭命令窗口。
二、录制Jmeter脚本
录制Jmeter脚本有两种方法,一种是设置代理;一种则是利用badboy软件,badboy软件支持导出jmx脚本。
这里我们介绍第二种方法,利用badboy录制脚本,然后导出Jmeter需要的jmx文件。
首先,在地址栏中输入要录制脚本的地址,然后点击绿色按钮即可开始录制(工具栏中的红色按钮也可以点击进行录制),点击红色圆形按钮旁边的正方形黑色按钮结束脚本录制(如果使用过loadrunner,那么步骤是一样的),在内嵌的浏览器上面操作你需要
测试的动作即可,它会自己记录你的相关行为动作。
然后点击黑色按钮录制完成之后,我们可以导出jmx文件:
保存为“登录开发者.jmx”。
三、使用Jmeter开始测试
1、打开脚本
用Jmeter打开我们上面保存的文件。
打开之后如图所示:
2、修改脚本
a、线程组
在测试计划里面选择添加既可以看到线程组。
如上图:
名称:可以随意取,我们保持创建是自动分配的名称
注释:随意
在取样器错误后要执行的动作:我们选择继续,错误之后依然继续执行
线程数:一般我们用来表示多少个用户,即我们测试时的用户数量
Ramp-up Period(in Seconds):表示每个用户启动的延迟时间,上述我设为1秒,表示系统将在1秒结束前启动我设置的1000个用户,如果设置为1000秒,那么系统将会在1000秒结束前启动这1000个用户,开始用户的延迟为1秒, 如果我设置为0秒,则表示立即启动所有用户。
循环次数:如果你要限定循环次数为10次的话,可以取消永远的那个勾,然后在后面的文本框里面填写10;在这里我们勾上永远,表示如果不停止或者限定时间将会一直执行下去, 是为了方便调度器的调用。
调度器的配置:我们勾选调度器时,将会出现这个面板
启动时间:表示我们脚本开始启动的时间,当你不想立即启动脚本测试,但是启动脚本的时间不会再电脑旁的时候,你可以设定一个启动的时间,然后再运行那里点击启动,系统将不会立即运行,而是会等到你填写的时间才开始运行。
结束时间:与启动时间对应,表示脚本结束运行的时间。
持续时间:表示脚本持续运行的时间,以秒为单位,比如如果你要让用户持续不断登录1个小时,你可以在文本框中填写3600。如果在1小时以内,结束时间已经到达,它将会覆盖结束时间,继续执行。
启动延迟:表示脚本延迟启动的时间,在点击启动后,如果启动时间已经到达,但是还没有到启动延迟的时间,那么,启动延迟将会覆盖启动时间,等到启动延迟的时间到达后,再运行系统。
注意:如果我们需要用到调度器来设定持续时间,如果线程数不够多到持续时间结束,我们就必须将循环次数勾选为永远,特别地,如果线程组里面有其他的循环,我们也需将该循环次数勾选为永远(如我上面录制的脚本中的Step1也是一个循环,需要将永远勾选),否则,按我如上配置,将永远去掉勾选,文本里填1,那么无论你将持续时间启动时间结束时间等设置多少,系统运行1000次后,将会停止不再运行。
b、关于HTTP请求
关于HTTP请求,我们录制的脚本里面就有,这里就介绍一些常用的属性。
如图所示:
点击HTTP请求,将会出现如下界面:
其中:
名称:可以随意取,我们可以根据录制脚本的路径来命名
注释:可以对该界面做一个简单介绍
服务器名称或IP:即我们的服务器或者IP的地址,我因为是在本机上的项目,故填写localhost,可以填写127.0.0.1。
端口号:我用的是tomcat,自己设置的端口号为8086(tomcat默认为8080)
后面的超时定义可以不用填写。
Implementation:这里我们录制时默认填写为JAVA
协议填写为:http
方法为:GET
Content encoding:编码可以不用填写
路径:即页面的路径;下面的重定向等选择可以根据需要勾选,这里我们保持录制不修改。
Parameters参数:即跟着路径一起发送的参数及文件
下面的代理服务器等可以忽略,按需要填写。
c、参数化
如下,我们为请求发送的参数来参数化。
上述的例子为登录的用例,登录有两个参数:EMAIL和DEVELOPER_PASSWORD,在实际测试中,当我们需要用到不同的用户来登录的时候,我们就可以用到参数化。
1)、我们新建一个文件,这里我新建的是一个txt文件,命名为c.txt,里面的内容为
web@qq.com,111111
col@qq.com,111111
mon@qq.com,111111
2)、在jmeter中的【选项】中选择【函数助手对话框】,将会弹出如下对话框:
其中:
CSV file to get values from | *alias:要读取的文件路径,为绝对路径
CSV文件列号| next| *alias:从第几列开始读取,注意第一列是0
如上图所示,我们读取的是c.txt里面的第一列用户名(如果要读取第二列的密码,只需将0改成1即可,往后类推),点击【生成】按钮即可生成函数,我们使用时即拷贝生成的函数字符串:${__CSVRead(E:\c.txt,0)}。
其他函数后面介绍。
d、断言验证
在web测试中,有的时候,即使我们测试返回的response code为200,也不能保证该测试是正确的,这时候,我们可以用到响应断言,通过对比响应的内容来判断返回的页面是否是我们确定要返回的页面。
选择我们要判断的页面,点击添加断言----响应断言,将会出现如下图:
名称:随意,这里我们不做改动
注释:随意
Apply to:这里我们选择默认值
要测试的响应字段:这里我们选择响应的文本,即返回的页面信息
模式匹配规则:这里我们选择包括,即响应的文本是否包括我们验证的信息
要测试的模式:开发者名称,即我们需要验证,开发者名称是否在响应文本中存在,也可以添加更多的字段来验证。
其他还有文件大小和响应时间等的断言,后面介绍。
e、添加监听器
我们做性能测试的时候,经常需要各种数据来验证我们的测试结果,Jmeter里面也提供了相关的功能,这里主要说一下Aggregate Report聚合报告。
点击添加---监听器,选择:查看结果树,和聚合报告,如果需要看到断言信息也可以选择断言结果,将设置的一切保存之后,然后点击启动,系统将会运行,将结果在监听器中表现出来。
四、分析结果
1、查看结果树
如图所示:成功的为绿色,失败则显示为红色。如果测试的结果太多,你只需要看到错误的页面,则勾选【仅日志错误】
2、聚合报告(Aggregate Report)
其中:
Label:标签,即我们上面的请求名称
#Samples:本次场景中一共发出了多少个请求
Average:平均响应时间
Median:中位数,也就是50%的用户的响应时间
90%Line:表示90%的用户的响应时间,如果最小值和最大值相差很大的话,我们一般选择这个作为最终测试结果
Min:最小响应时间
Max:最大响应时间
Error%:出错率,本次测试中出现错误的请求的数量/请求的总数
Throughput:吞吐量
KB/sec:每秒从服务器端接受到的数据量
五、监控内存及CPU等
很多时候,我们测试性能都需要查看内存和CPU等信息来判断系统瓶颈,关于CPU和内存的监控,Jmeter并没有很好的支持,很多时候,我们都只能通过系统的资源监控器来观察,一闪而过不会记录下来,很不方便。幸好google开发了一款专门监控的Jmeter插件,弥补了Jmeter这方面的不足,下面就来介绍一些这款插件——JMeterPlugins,目前我用的是0.5.6版本。
1、JMeterPlugins的下载地址
地址:http://code.google.com/p/jmeter-plugins/downloads/list,选择需要的版本,下载
2、JMeterPlugins的配置使用
将下载的文件解压,得到如下目录:
将JMeterPlugins.jar包复制到Jmeter的lib目录下面的ext目录下面,重新启动Jmeter,我们点击添加就可以看到出现了很多的jp@gc-开头的文件.
这里监控内存我们使用的是:jp@gc - PerfMon Metrics Collectot
在使用之前,我们需要运行/serverAgent/startAgent.bat这个文件,我们需要将serverAgent目录及下面的文件复制到我们测试的服务器上,然后点击打开(我这里是本机,直接在本机上面打开这个应用系统即可),它的默认端口为4444。
一切准备好后,点击启动,即可得到如下图:
你就可以得到系统运行时,你所需要的常用的性能值了。
六、监控内存及CPU等(jconsole)
最近逛论坛的时候,发现了一个比较好的监控内存CPU等的小工具,本着开源小工具多多益善的原则,记录一下。
打开这个小工具的步骤很简单,如果你已经配置好了Jmeter运行的环境,那么你也就不用去做其他的配置,直接 点击:开始——》运行——》输入cmd——》然后在出现的命令行界面输入“jconsole”即可弹出一个【java监视和管理控制台】,
将会弹出如下界面:
这里我们选择本地进程,并点击一下sun.tools.jconsole.JConsole这一行,然后点击连接,就可以查看我们的内存和CPU的使用情况了。
当然,我们要得到服务器的内存使用等信息,也可以选择 本地进程下面的远程进程,在文本框中输入我们需要测试的服务器的IP地址:端口,然后在下面输入用户名和密码,点击连接,看看会出现什么情况。
一般在客户端通过
LoadRunner对服务器进行
压力测试,都需要实时监控服务器端的系统资源,本篇主要简单介绍一下如何设置在LoadRunner的Controller中配置监控
Windows Resources,其实也可以直接在远程连接服务器端在上面开启任务管理器或者在控制面板中找到性能计数器来监控也可以,但是为了在LR进行施压过程中更便捷,我们还是要学会这个基本的配置。关于此处的配置,需要针对不同的服务器
操作系统进行不同的设置,但基本思路相同。本篇以Windows系统为例,具体配置如下:
1、通过客户端与服务器进行网络测试,保证通信畅通
2、开启服务器端Windows中的如下两个服务,如下图:
3、需要对服务器的系统本地策略进行更改,这个很重要,也是决定客户端能不能访问服务器端的关键步骤,具体需要进入控制面板下的管理工具中,找到本地安全策略,如下:
注意:这里一定要改成经典模式,默认为仅来宾模式。
4、在客户端进行测试,在“运行”栏中输入服务器的ip地址,后面跟上C$,表示服务器C盘下的系统资源目录,如:“\\192.168.96.135\C$”,看看是否可以访问服务器C盘目录,通常情况下可能需要输入用户名和密码,填充服务器端的账户和密码就ok,如下所示:
注:如果显示可以访问该页面表示,可以正常访问服务器端的系统资源,也就可以监控。
5、切换到LoadRunner的Controller中在Windows Resources下配置监控目标,具体如下:
通过上图发现,这种配置方式跟系统的性能计数器配置基本类似。
6、看看配置完成后的实时监控记录,如下图所示:
以上是在压力测试过程中,所实时监控的目标服务器的系统资源。
LR是一个功能比较全面的性能测试工具,所以很多细节的功能可能不好设置,但是作用却很大。下次有机会将总结LoadRunner如何监控Linux系统资源。
1.使用索引可以快速的访问
数据库表中的特定信息,索引是对数据库表中一列或多列的值进行排序的一种结构,例如 employee 表的姓名(name)列。如果要按姓查找特定职员,与必须搜索表中的所有行相比,索引会帮助您更快地获得该信息。但是有些索引会因为
SQL代码使用不当导致索引不被使用,所以在
软件测试中我们应该纠正那些不当的SQL代码。以下就是sql代码需要优化的情况:
(1)在主键上建了索引,查询条件主键使用or。
select *from tb_user where fd_userid=19 or fd_userid=21;这时建在fd_userid的索引将不被使用。
建议改成 where fd_userid in(19,21)
(2)尽量避免使用union。
(3)尽量避免使用not,可以用运算符代替。
(4)隔离条件上的列,如:select * from tb_a where fd_value+=100。这时建在fd_value的索引将不被使用。
(5)尽量不单独使用and,可以用between…and…如:where fd_time>100 and fd_time<120。可以改成fd_time between 100 and 120。
(6)尽量避免使用like的特殊形式:“%”或“_”开头,如:“%bn” “_bn”。
(7)减少冗余条件
(8)避免使用having,也会影响字段的索引
(9)少用distinct
(10)避免使用any all,如select fd_id from tb_a where fd_id<=all(select fd_id from tb_b);可以改成<=(select min(fd_id) from tb_b+++)
(11)避免使用原生态的SQL语句,容易有sql注入。
1、与市场人员沟通项目的基本情况,客户主要领导、部门的情况,主要参与人员的关系,前期的一些目标、期望、工期。
了解项目采用的技术路线、客户信息部门的情况。
2、根据项目基本情况,了解相关的背景知识,以免说外行话,尽量采用与客户习惯相同的术语
3、根据经验和
工作量估算,组建项目团队,确定需要的人员能力、数量等(一般不要选择多于2人的女士,女士不要太漂亮,要沉稳些)
4、安排项目总体计划(最好分解为阶段计划,采用迭代方式进行,每个小计划明确目标,周期控制在1-1.5月,先完成主要的、难度大的部分)、培训计划与程序经理确定项目采用的ide、基础环境、工具、os等,并统一版本
5、培训内容包括业务培训、技术培训、编码标准培训。
6、组织需求调研工作,项目经理必须参与,了解第一手的资料,组织用户收集系统初始化数据
8、制定业务标准,如系统提示的内容。统一一份术语表,统一系统中使用的术语、采用拼音还是英文单词进行命名
9、系统分析设计师进行系统的分析和设计,形成动态和静态视图
10、对分析设计成果进行需求对应,明确是否所有的需求都进行了设计,并达到需求的目标。(可以采用同行评审的方式,但必须保证所有的内容评委都进行了认识和了解)
11、对设计结果进行编码计划编制(程序经理编制),计划必须包括时间期限、工作内容、达到的目标、测试用例(方法),必须具体,对于较大的工作也需要进行分解,最好不要超过2周,一般都控制在1周以内
12、跟踪每周计划和完成情况,对
单元测试、集成测试进行每周的检查,明确编码完成的质量,经常测算完成量与计划量的差别,必要时调整计划或减少功能,尽量保证阶段计划的按时间完成,功能变更可以放在下一个版本内完成
13、和组员沟通,及时发现困难、问题、风险,采取相应的措施(说起来容易,做起来很难,哈哈)
14、与用户沟通,了解他们的想法和对系统的反馈
14.1、完成相关用户手册等文档
15、集成测试,验证需求是否都得到实现
15.1、用户现场展示工作成果,并根据用户进行调整
16、安排用户培训计划,用户现场环境的安装与调试(
数据库规划、安装、参数调整、
web服务安装、调试等,并完成安装
日志,提交客户系统维护人员),系统试点单位或部门人员安排
17、初始化系统数据
18、搭建测试环境、正式环境,供用户使用。搭建调试环境供维护人员使用
19、用户培训,收集用户意见反馈(提供统一样式)
19.1 根据用户反馈,讨论修改方案(需要双方签字)
20、召开项目运行大会
21、系统验收
22、系统日常维护,优化操作,完善系统维护工具
摘要:对基于TTCN-3的测试系统进行逆向分析,可以帮助测试人员从更高层次上把握测试系统的设计,同时可以检验测试设计和测试实现之间的一致性,这些工作对于测试系统的评估、维护以及扩展都有重大的意义和重要的价值。本文首先简要介绍了逆向工程和基于TTCN-3测试系统的逆向工程的特点,设计了逆向模型发现的系统框架,并详细介绍了静态分析器的设计和实现。
关键词:TTCN-3;逆向工程;测试系统;静态分析;元模型
TTCN-3是由ETSI制定和推动的测试规范和测试实现标准。它是一种描述能力丰富的基于黑盒的测试描述规范,能够应用于多种形式的分布式系统的测试规约描述。随着TTCN-3测试技术的不断发展,它已经被越来越多地应用到各种测试领域,基于TTCN-3的测试系统开发已经具备了和软件开发相似的特征。但随着测试系统规模的增长以及测试人员的变更,对于庞大的测试系统的管理和维护,已经变得越来越困难。因此对基于TTCN-3的测试系统进行逆向工程,可以帮助测试人员从更高层次把握测试系统的设计,同时可以检验测试设计和测试实现之间的一致性,对于测试系统的维护、扩展以及评估都有重大的意义和重要的价值。
本文设计了逆向模型发现的系统框架,基于Eclipse平台使用插件机制很好的实现了框架的扩展和复用。然后,通过扩展TRex工程中的TTCN-3静态分析器,设计相应的接口实现静态基本信息、静态测试配置、测试数据、调用关系等的提取。同时使用Testing Technologies公司的TTworkbench工具运行测试用例,获得测试轨迹,实现动态测试配置的提取。本工具正是从静态和动态两个方面向测试人员和维护人员展示了测试系统的基本信息和抽象设计,用于辅助测试系统的维护和更新。
1、逆向工程介绍
逆向工程是软件工程领域的一个重要分支,随着软件复杂性的提高和遗留系统的增多,逆向工程越来越受到人们的重视,从而有了广阔的发展空间。Chikofsky和Cross将逆向工程定义为一个分析目标系统的过程,它一般包括如下两个部分:
(1)识别系统的构件并分析构件之间的依赖关系;
(2)建立系统另外的或在更高抽象级别上的表达形式。按照上述定义的逆向工程本质上也是一个知识恢复、知识发现工程,对于软件这种无形的人工产物来说,逆向工程的主要目的首先是重现考察对象所体现的原有设计知识,其次是能发现一些在设计中没有明显表示出的、存在于设计人员头脑中的设计知识。
由逆向工程的定义可见,软件逆向工程的任务包括分析系统、抽象系统和展现系统,从而实现协助用户理解系统的目的。分析系统是指分析系统的结构及运行过程,但不管目标系统面向何种应用领域,分析系统不外乎是分析系统的静态信息和动态信息;目标系统面对不同的应用领域,要实现抽象目标系统的任务,需要领域知识和专家的经验;展现系统最好的方式是使系统可视化。由于系统的抽象过程离不开领域知识和专家经验,所以很难有统一的方法,因此一般只讨论分析系统的过程,即静态信息和动态信息的获取。
本文将传统的逆向方法应用到TTCN-3测试系统之上,分别从静态和动态两个方面获取信息,然后制定领域相关的算法,提取描述测试系统的抽象模型并进行展示。通过逆向工程,有利于测试人员和维护人员理解和维护测试系统。
2、基于TTCN-3测试系统的逆向工程
随着软件测试作用的日益突出,测试作为软件过程中的重要一环越来越受到人们的重视。传统的软件测试主要集中在手工测试阶段,更多的只是重复劳动。随着自动化测试技术的日益成熟,使得软件测试进入了飞速发展的阶段,但测试描述还没有一个统一的规范,目前广泛使用的有XML、TCL等。如何使测试变得更高效、规范和可重用,成为人们热烈讨论的话题。随着2001年ETSI组织的TTCN-3测试规范的提出,这个问题逐渐找到了解决的方法。TTCN-3测试规范中的核心语言类似于传统的程序设计语言,可以在更广泛的应用领域描述测试,为测试集的编写提供更大的方便性和灵活性。由于TTCN-3是在测试驱动之下产生的,所以其语法和传统的编程语言相类似,并带有专用的测试扩展特性。因此,TTCN-3比传统的程序设计语言更关注于对测试判断的处理、对SUT(System Under Test,被测系统)的激励和期望接收到的反馈信息的模板匹配机制、对计时器的处理、测试执行控制机制、动态测试配置、同步/异步通信功能、测试进程的分布方式和信息编码的能力等。
由于TTCN-3语言所特有的动态配置、同步异步通信机制等强大功能,使得测试人员在从测试设计到测试实现阶段很难保证彼此之间的一致性;其次,面对庞大的测试系统的管理和维护,也需要有工具辅助。这些问题必将随着TTCN-3测试语言的日益成熟而受到人们更多的关注。对基于TTCN-3的测试系统进行逆向分析,可以帮助测试人员和维护人员从更高层次上把握测试系统的设计,同时可以检验测试设计和测试实现之间的一致性,这些工作对于测试系统的维护、扩展以及评估都有重大的意义。
基于TTCN-3测试系统的逆向工程,本质上是一个测试设计和测试模型的发现过程。逆向工程的一个核心问题就是为目标系统进行建模,因此必须解决如何为TTCN-3测试系统建立元模型,进而在元模型基础上生成测试系统模型。然后在测试系统模型上施加领域相关的算法,实现测试设计和测试模型的抽象和提取。
3、模型发现系统框架设计
一般来说,逆向工程包括如下两个部分:一是识别构件并分析构件之间的依赖关系;二是建立系统的另外的或在更高抽象级别上的表达形式。逆向工程本质上是一个知识恢复、知识发现的过程。因此本文将逆向工程分为三个步骤:
(1)数据的提取:此时的数据是未经处理,通过静态或动态分析获得源文件的元数据,这是逆向分析和模型发现的基础;
(2)知识的组织:将提取到的元数据进行分类和存储,此时主要使用已经定义的通用模型或规格等将元数据进行重组,实现知识的构建;
(3)信息的展现:在已获得知识的基础上,施加某种领域相关的算法实现系统更高层次信息的组织和提取。
基于对逆向工程和模型发现技术的总结,本文为基于TTCN-3测试语言的逆向工程设计了模型发现的系统框架,如图1所示。该框架建立在Eclipse平台之上,使用了Eclipse平台所提供的插件扩展机制,使得该框架易于维护和扩展。同时该框架还重用了Eclipse平台所提供的大量基础设施,利于系统的集成和开发。框架主要分为三个部分:静态分析部分输入为TTCN-3测试集,输出为抽象语法树和符号表,同时还包括动态轨迹的提取,即获取了测试集的元数据;建模部分输入为U2TP和TTCN-3规范,在这个过程中设计了TTCN-3测试系统元模型,实现了U2TP到TTCN-3映射规则,输出为TTCN-3测试系统模型,即实现了数据的重组和信息的形成;展现部分输入为TTCN-3测试系统模型,通过施加领域相关的算法实现测试设计和测试模型的发现,输出为TTCN-3测试系统的各种视图,即进行了模型的展现。

图1 逆向模型发现框架
4、TTCN-3测试系统元模型设计
TTCN-3虽然提供了诸如TFT和GFT这种表格和图形化的描述形式,但只是描述测试用例的一种格式而已,无法展现一个测试系统的整体结构和逻辑。为了解决维护、改进和复用大量遗留测试系统代码的问题,需要为TTCN-3测试系统提供一个抽象层次更高的描述方法。因此,本文针对模型发现目标,借用U2TP中的具体概念,实现了U2TP和TTCN-3之间的映射关系,设计了TTCN-3测试系统元模型。
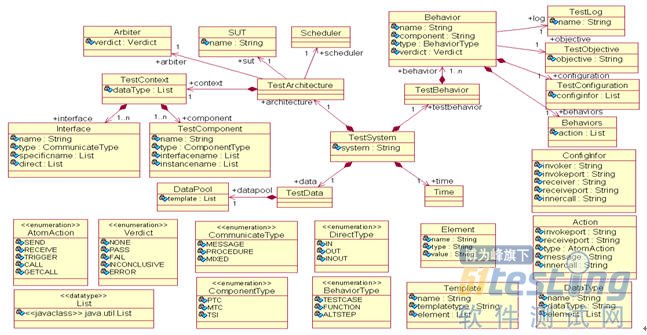
图2 TTCN-3测试系统元模型
参照U2TP对测试系统的描述和上面所制定的映射规则,本文将TTCN-3测试集抽象为四个部分:TestArchitecture、TestBehavior、TestData、Time,并定义了如图2所示的测试系统元模型。在设计过程中,本文考虑了逆向工程的特殊需求,对TTCN-3的元模型进行了相应的裁剪,方便测试系统模型的表示和展现。同时为了便于TTCN-3测试系统中基本信息的组织和存储,测试系统元模型中还定义了用于测试信息记录的相关数据结构。从图中可以看到,整个测试系统的根节点是TestSystem,每个测试系统会有自己的名字system,一般都是抽象测试集的名字。一个TestSystem中会包括四个逻辑部分,TestArchitecture、TestBehavior、TestData和Time。
此外,测试系统元模型还包括了TTCN-3测试语言中所特有的的测试特性,主要是一些枚举值的定义。主要包括通信的原子操作AtomAction、测试判定结果Verdict、测试通信类型CommunicateType、测试构件类型ComponentType、测试通信方向类型DirectType、测试函数类型BehaviorType等。
5、TTCN-3静态分析器的设计与实现
5.1 三种静态分析器的比较
为了便于定制需要的逆向分析工具,本文主要调研了开源的TTCN-3静态分析器。目前,主要有三种开源的面向TTCN-3的静态分析器可用,下面是对这三种静态分析器的对比分析:
ttthreeparser:由德国Testing Technologies公司早期开发的分析器,目前只支持TTCN-3v1.1.2版本,这是TTCN-3最早的一个版本,目前的测试脚本都是基于TTCN-3v3.1.1,在语法上进行了较大的调整,所以对本文的研究价值不大;
ttcn3parser:由Debian开源组织提供的基于Python的静态分析器,支持TTCN-3v3.1.1,但由于没有提供合适的接口和文档,因此需要重新改写里面的大部分文法,工作量太大;
TRex:由Motorola和德国的Gottingen大学合作开发,用于TTCN-3测试集的评估和重构,其中包括对TTCN-3v3.1.1的静态分析,并且定义了明确的接口和数据结构。
通过对上面工具的调研,本课题选用了TRex作为静态分析的工具,并在开源工具TRex静态分析器的基础上实现相应的接口、定义相应的数据结构,通过静态的逆向分析获取TTCN-3测试系统的基本信息和模型定义。TRex对TTCN-3的现有标准支持较好,同时还是一个开放源代码的研究性工程。另外,TRex以Eclipse插件的形式出现,这对于系统的扩展和集成非常有利。
5.2 TRex介绍
TRex是基于Eclipse插件机制实现的TTCN-3度量和重构工具,由Motorola公司和德国的哥廷根大学合作开发了这套系统。正向的TTCN-3工具一般都专注于核心编译器与测试执行器的开发,TRex属于逆向工程支持工具,其目标是分析和优化测试系统代码。Motorola公司发现,TTCN-3的编辑和执行固然需要工具支持,同样TTCN-3测试系统的维护和评估也需要有工具辅助。TRex的出现,使得TTCN-3测试代码的自动化度量和重构变为现实,同时也为评估测试系统设计的好坏提供了有力的依据。然而TRex无法帮助测试人员从更高层次上把握测试系统的设计,无法检验测试设计和测试实现之间的一致性。随着TTCN-3的发展,必将有更多的遗产测试系统需要被维护和升级,测试人员如何在最短时间内理解和掌握已有的测试系统,以及如何检验测试设计和测试实现之间的一致性,必将作为一个重大的问题受到人们的关注。本文的研究工作很好的满足了TTCN-3发展中的这种要求,同时结合TRex工具,必将为TTCN-3测试系统的管理和维护提供强有力的支持。
TRex主要用于TTCN-3测试系统的度量和重构,它主要分为三个模块,如图3:
● 将TTCN-3测试集作为输入,通过静态分析获得抽象语法树和符号表,即测试集的元数据;
● 将测试集的元数据作为输入,通过计算获取测试集的度量值,为测试集的好坏提供数据上的依据;
● 将测试集的元数据和度量值作为输入,通过变换语法树完成测试代码的重构。
通过静态分析、度量和重构,为测试集的维护提供了依据,同时输出质量更高的TTCN-3测试集。
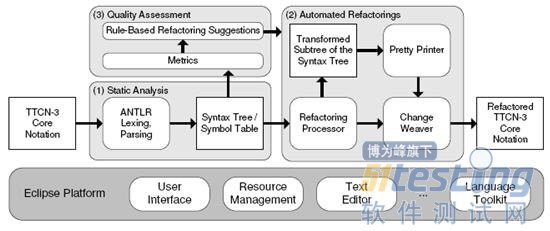
图3 TRex体系结构
5.3 对TRex的扩展
编译器首先把程序员写的源程序转换成一种方便处理的数据结构,那么这个转换过程就是词法分析和语法分析。通过TRex分析TTCN-3源代码,可以获得抽象语法树和符号表。抽象语法树使用Tree作为数据结构,因为Tree有很强的递归性,将Tree中的任何结点Node提取出来后,Node依旧是一棵完整的Tree。这一点符合现在编译原理分析的形式语言,比如在函数里面使用函数、循环中使用循环、条件中使用条件等等,那么就可以很直观地表示在Tree这种数据结构上。
针对本论文研究所要解决的问题,主要考察了de.ugoe.cs.swe.trex.core中的de.ugoe.cs.swe.trex.core.analyzer.rfparser包,它里面包含了TTCN-3的静态分析器,
TRex按照ANTLR的文法定义了TTCN-3语言的BNF范式,然后使用ANTLR提供的工具包生成了TTCN-3的静态分析器。通过静态分析器对TTCN-3源文件的分析,可以获取TTCN-3的抽象语法树,然后使用符号表对基本信息进行再组织。
TRex中重要的数据结构包括Symbol、LocationAST、Scope和SymbolTable,如图4所示:

图4 TRex的符号表
TTCN-3中定义了丰富的元素类型,可以方便用户定义测试配置、测试行为和测试数据等。TRex为每个TTCN-3元素都定义了一种Symbol,如图5所示。

图5 TRex中的符号
在逆向分析过程中,本文主要分析了ModuleSymbol、TypeSymbol、SignatureSymbol、EnumSymbol、PortInstanceSymbol、SubtypeSymbol、TemplateSymbol、TestcaseSymbol、FunctionSymbol、AltstepSymbol等关键数据结构。
TRex主要用于TTCN-3测试集的度量和重构,TTCN-3脚本的编辑功能和静态分析功能是整个工具的核心。在此,本文还分析了TRex的编辑器、编辑器之上的事件响应策略模式、静态分析器的工厂模式以及TTCN-3静态分析器的入口程序。本文通过对静态分析器核心代码的研读,在TTCN3Analyzer中加入了自己定义的数据结构和接口,用于访问静态分析获得的各种信息,实现模型的逆向发现。
6、总结
本文设计实现了逆向模型发现的系统框架,并详细介绍了静态分析器的设计实现。测试模型的抽象和提取在技术报告《基于TTCN-3测试系统的静态测试配置模型和数据模型的发现》和《基于TTCN-3测试系统的调用模型和动态测试配置模型的发现》中详细介绍,而实验在技术报告《基于TTCN-3测试系统的逆向工程的实验及数据分析》中详细介绍。对基于TTCN-3的测试系统进行逆向工程,可以帮助测试人员从更高层次把握测试系统的设计,同时可以检验测试设计和测试实现之间的一致性,对于测试系统的维护、扩展以及评估都有重大的意义和重要的价值。