队列的基本概念
队列(简称队)也是一种特殊的线性表,队列的数据元素以及数据元素间的逻辑关系和线性表完全相同。差别是线性表允许在任意位置插入和删除,而队列只允许在一端进行插入操作而在另一端进行删除操作。
队列中允许插入操作的一端称为队尾,允许进行删除操作的一端称为队头。队列的插入操作通常称为入队列,队列的删除操作通常称为出队列。
根据队列的定义,每次入队列的数据元素都放在原来的队尾之后成为新的队尾元素,每次出队列的数据元素都是队头元素。这样,最先入队列的数据元素总是最先出队列。最后入队列的数据元素总是最后出队列,所以队列也称为先进先出表。
队列的抽象数据类型
1、数据集合:队列的数据集合可以表示为a1,a2,a3,a4,每个数据元素的数据类型可以是任意类类型
2、操作集合:1、入队列操作(append())
2、出队列操作(delete())
3、取队列的头元素(getFront())
4、判断队列是否为空(isEmpty())
源代码------顺序存储结构
队列接口代码
package com.queue; //队列接口 public interface Queue { //入队列操作 public void append(Object object); //出队列操作 public Object delete(); //取队列头元素 public Object getFront(); //判断队列是否为空 public boolean isEmpty(); } |
队列接口实例化类
package com.queue; public class SeqQueue implements Queue { //相关属性和构造方法 //默认大小 static final int defauleSize=10; //队头 int front; //队尾 int rear; //队列元素个数统计 int count; //队列初始化大小 int maxSize; //队列数据信息 Object[] data; public void initiate(int sz){ maxSize=sz; front=rear=0; count=0; data=new Object[sz]; } public SeqQueue(){ initiate(defauleSize); } public SeqQueue(int length){ initiate(length); } @Override public void append(Object object) { // TODO Auto-generated method stub if(count>0&&front==rear){ return; } data[rear]=object; //求模运算 rear=(rear+1)%maxSize; count++; } @Override public Object delete() { // TODO Auto-generated method stub Object object=null; if(count==0){ object="404"; return object; }else{ object=data[front]; //求模运算 front=(front+1)%maxSize; count--; return object; } } @Override public Object getFront() { // TODO Auto-generated method stub Object object=null; if(count==0){ object="404"; return object; }else{ return data[front]; } } @Override public boolean isEmpty() { // TODO Auto-generated method stub return count!=0; } }
|
实验结果:
package com.queue; public class QueueTest { /** * @param args */ public static void main(String[] args) { // TODO Auto-generated method stub SeqQueue queue=new SeqQueue(); //判断队列是否为空 boolean target=queue.isEmpty(); System.out.println("队列是否为空:"+target); //入队列 queue.append("c"); queue.append("c++"); queue.append("c#"); queue.append("object-c"); queue.append("php"); queue.append("java"); queue.append("ruby"); queue.append("javascript"); queue.append("ext"); queue.append("jquery"); //再次判断队列是否为空 boolean targets=queue.isEmpty(); System.out.println("再次判断队列是否为空:"+targets); //出队列 Object object=queue.delete(); System.out.println("出队列的元素是:"+object); //取队列头元素 Object front=queue.getFront(); System.out.println("队列头元素是:"+front); } } |
图片展示:
源代码--------链式存储结构
项目做好了,更高的要求被提出来,比如,要多
数据库支持,怎么办?移植!有没有人做过这事,我好参考一下?哦,这有一个…
一、前言
公司原来的项目是基于Oracle数据库的,Oracle功能强大,但是部署和管理较复杂,更重要的是,购买Oracle的费用不是每个客户都愿意承担的。因此,迫切需要把公司项目所用数据库移植到一个简单好用的数据库上。当然,如您所料,我们选择了广受欢迎的MySQL。
作为一个开源数据库,MySQL用无数案例证明了她的可用性,因此让我们把重点放在如何将Oracle移植到MySQL上。已经有很多的
文章和专题介绍了Oracle移植到MySQL的方法和步骤,也有相当多的工具可以辅助这种移植过程。但是,由于数据库实现的差异,完美的移植工具是不存在的,移植过程中不断碰到的问题证明了这一点,特别是您使用了Oracle的一些高级特性时。
从Oracle移植到MySQL主要有六个方面的内容需要移植,一是表Table,包括表结构和数据,二是触发器Trigger,三是存储过程Procedure,函数function和包Package,四是任务Job,五是用户等其他方面的移植,六是具体应用程序通过
SQL语句访问时的细节差异克服。
笔者用来移植
测试的数据库是:Oracle 9i ,MySQL 6.0,
Windows 2000环境。
二、表的移植
这个部分的移植是最容易用工具实现的部分,因为很多MySQL的图形管理工具都自带这样的移植工具,比如SQLYog,MySQL Administrator等。但是,这些工具的移植能力各有不同,对字段类型转换﹑字符集等问题都有自己的处理方式,使用时请注意。
笔者使用“SQLYog Migration Toolkit”工具按提示步骤移植后,表的主要结构和数据将成功移植,主要包括表的字段类型(经过映射转换,比如number会转换为double,date转换为timestamp等,请小心处理日期字段的默认值等),表的主键,表的索引(Oracle的位图索引会被转成BTree索引,另外表和字段的注释会丢失)等信息。需要特别注意的是,Oracle的自增字段的处理。
大家知道,Oracle通常使用序列sequence配合触发器实现自增字段,但是MySQL和SQL Server等一样,不提供序列,而直接提供字段自增属性。所以,请把Oracle里面的自增字段实现直接改为MySQL的字段属性,而且,这个字段必须是主键(key)并且不能有默认值。
还有一个问题,如果您的应用要直接使用Oracle的某个序列,那么您只能在MySQL里面模拟实现一个,具体方法就是利用MySQL的自增字段实现的。
三、触发器的移植
首先,MySQL在6.0以后才支持触发器!
触发器的移植没有现成工具,因为两者之间的语法差异较大,您只能通过手工对照着原来的逻辑一个一个添加。
这里要说明一下,MySQL的SQL过程语法和Oracle PL/SQL大致相同,但还是有些细微差别:
1. 变量声明Declare部分,在Oracle中Declare语句位于Begin之前,在MySQl中,Declare位于Begin之后;
2. 注释不同,在Oracle中,可用 “—“ 注释一行或“/* */”注释一段,在MySQL中,需用 “/* */”或“#”来注释
3. 对触发前后变量值的引用方法不同;在Oracle中,用 :new.eid, :old.eid表示新旧值,
在MySQL中,用 New.eid,old.eid表示新旧值
4. 移植中发现的问题
1)Oracle的自治事务autonomous_transaction ,MySQL不支持,您必须用其他方式实现,MySQL不允许在触发器过程中执行对触发器所在表的操作(包括读写)
2)MySQL函数和trigger中不能执行动态SQL语句,也就是说,您不能在触发器里面组合出来一个SQL字符串,然后用exec来执行
3)Oracle的表级触发器,MySQL还不支持,所以必须改成使用行级触发器,注意这会导致有时SQL语句的执行效率很低
四、存储过程,函数和程序包的移植
程序包是Oracle用来组织逻辑功能的一个Object,MySQL不支持,因此需要将包里的存储过程﹑函数等全部放到该数据库公有过程和函数里面。
MySQL的过程和函数语法与Oracle类似,但还是有细微差别,除了数据类型需要转换,还有:
1.格式不同,例如:
Oracle为:
CREATE OR REPLACE procedure procedure1(TableName in varchar2) is
MySQL应该为:
CREATE procedure procedure1( in TableName varchar(200))
2.赋值语句不同:
Oracle赋值语句为:
strSQL := ‘update table set field1=1’;
MySQL应该为:
Set StrSQL = ‘update table set field1=1’;(用:=也行)
3. 一些要用到游标的过程请注意
MySQL过程不支持嵌套游标,不支持带参游标,不支持记录类型%ROWTYPE,不支持数组等,原Oracle用到这些的必须改写
五、Job的移植
Job是Oracle的定时任务实现的方法,MySQL6中用Event实现,具体语法请参考MySQL手册。
在MySQL中使用event请注意,默认它是不运行的,您可以
1) 保证MySQL定时任务event scheduler运行,需要MySql 5.1.6以上,并且在启动后执行SET GLOBAL event_scheduler = ON;(也可以在初始配置文件比如my.ini中加入event_scheduler = ON的参数)
2) 启用event功能后,每次执行会往MySQL的错误日志文件写一些信息(data目录下的“主机名.err”文件),导致这个文件越来越大(除非经常做flush log操作)。所以,如果您的event执行很频繁,可在my.ini中加参数console=TRUE,这样执行event的信息就不会写进来了
六、用户的移植
Oracle的用户管理和MySQL下有较大区别,请分别建立用户,并赋予合适的权限。
七、应用程序的移植
由于语法细节上的差异,导致很多SQL语句需要改写。笔者记下了所有移植过程中碰到的SQL语句细节差异,这些也是一般项目可能会用到的地方,虽然肯定不全,但也列出来以供参考:
1)Oracle的to_char函数不能再使用,换用如CONCAT(14.3)的形式,为了提高应用程序兼容性,建议手工写一个
2)Oracle的to_date函数不能再使用,建议手工写一个添加到MySQL数据库
3)Oracle的decode函数不能再使用,换用SELECT CASE 1 WHEN 1 THEN 'one' WHEN 2 THEN 'two' ELSE 'more' END 的形式
4)nvl这样的一些专用函数,MySQL是没有的,可以把
select nvl(to_char(num),'nothing') from t_equipment转换成
select case num when num then num else 'nothing' end from t_equipment
5)instr之类的函数,函数名相同,但参数个数不同
6)Oracle的sysdate要写成sysdate()的形式
7)包的形式已经取消,所以原来以包的方式调用的过程如xx_pack.xxx要写成xxx()
8)带进制字符转数字
Oracle风格:TO_NUMBER(strTmp,'XX') TO_NUMBER(’9’)
MySQL风格:CONV(strTmp,16,10) CONV(’9’,10,10) 如果字符串前后有加减操作,会隐含转换成数字
9) 不能再有直接调用序列的形式,如果一定需要,可以模拟实现一个
10)日期直接加减的含义不同了,比如Oracle中sysdate + 1 变成了sysdate() + interval 1 day(注意如果写成sysdate() + 1 语法还是正确的,但含义是错误的)
查询select sysdate() + 1 from dual 在MySQL得到比如 20080223153234(= 20080223153233 + 1)的数
而在Oracle中会得到第二天当前时刻。
11) MySQL单纯的date类型只是日期不带时间,DATETIME或TIMESTAMP带有时间,用DATE_FORMAT函数可以控制显示形式
12)select 'abc' || 'd' from dual 两个数据执行的结果不同(语法都能通过),MySQL要写成selectconcat('abc' , 'd')的形式
13) Oracle高级功能,如带有暗示索引的select语句,MySQL是不支持的(语法可以通过)
14)有些MySQL的保留字不能直接用在SQL语句里,要加表名或别名限制,如select RIGHT FROM XX要改成select a.RIGHT FROM XX a
15) Oracle的子查询可以不起别名,但MySQL是必须的,比如下面的别名aa:
select field1 from (select sysdate() as field1 from dual) as aa
16)很多系统表名都是不同的,比如,列出某个表的信息:
select * from tab where TName='T_TEST'改成
select table_name,table_type from information_schema.tables where table_schema = 'user' and table_name=' T_TEST '
17)MySQL下update时不能有本身的子查询
update T_TEST set Flag = 0 where field1 in
(select distinct b.field1 from T_TEST b where b.flag=1)
18)Oracle下’’和null等价,而MySQL则不然
select 1 from dual where '' is null在Oracle下可以取到记录,在MySQL下不能
dual表的使用,substr、trim等函数的主要使用方式和Oracle类似
八、小结和建议
看起来,Oracle移植到MySQL似乎挺麻烦,有没有一键完成的简单办法?呵呵,我没有找到,除非您只使用基本表,只使用基本SQL语句访问它。当然,建议大家初始设计的时侯,就考虑到多数据库的支持,权衡一下使用一些高级功能带来的好处和对可移植性方面带来的损害,这会大大减少后期移植时面对的问题;另外,在应用架构设计时,也建议使用较好的框架去屏蔽这些差异,比如J2EE的Hibernate框架等。
感谢伟大的Oracle,给我们提供了很多的高级功能,有很多是MySQL没有的,因此,在移植时你不得不放弃一些非必须的功能,比如,全表cache﹑物化视图﹑函数索引等;如果该功能是必须的,您可能要使用别的方式来实现,或者转到应用程序层面来考虑。当然,这些功能MySQL今天没有,不代表明天也没有,我们可以拭目以待。
由于开源软件的原因,MySQL的bug或者缺陷有时还会干扰你,请仔细测试和优化您的应用程序,调整MySQL的配置参数,确保它可以运行得和Oracle下一样好。
我们可以用 http://uptime.netcraft.com/up/graph?site=www.baidu.com 进行查看
一时好奇,想看看这些大网站的 Web 服务器信息(操作系统/Web 服务器/应用服务器软件). 在网上找到些数据(这些数据是在Netcraft得到的.)
除了有两个节点操作系统看出来是
Linux 外,其他的都是未知的. Web 服务器用的都是 GWS ? 估计是 Google Web Server 的缩写.(个人
测试结果是google应该用的是
unix系统作为服务器)
Yahoo!
操作系统都是 FreeBSD. 其他的都不可知.Yahoo! 的网络安全据说是一级棒!
操作系统全是
Windows 2003(如果使用 Linux 会被笑死) , 看来 Windows 2000 已经退出微软自己的舞台.Web 服务器用的是Microsoft-IIS/6.0.(现在用的是windows sever 2008了)
eBay
操作系统用:Windows Server 2003 /2000, Web服务器用 Microsoft-IIS/6.0 (5.0). 对这个检测有些怀疑.eBay 大规模使用 Windows ?(经个人测试,好像的确是windows 的系统)
GNU.org
操作系统全是 Debian Linux(没错,Debian 是 GNU 正宗传人). Web 服务器: Apache/1.3.31 (Debian GNU/Linux) mod_python/2.7.10 Python/2.3.4 , 也有的配置是:Apache/1.3.26 (Unix) Debian GNU/Linux mod_python/2.7.8 Python/2.1.3.GNU.org 对
Python 用的比较多的.
看看国内的一些公司.
操作系统是 Linux . Web 服务器: Apache/1.3.29 (Unix) mod_alibaba/1.0 Resin/2.1.13 .
(+mod_gzip/1.3.26.1a). mod_alibaba 模块估计是专门定制的.
Sina
操作系统是 FreeBSD. Web 服务器都是 Apache/2.0.54 .
操作系统是 Linux , Web 服务器: Apache/1.3.27. 整齐划一.
搜狐
操作系统居然是 SCO UNIX ,Web 服务器信息: Apache/1.3.33 (Unix) mod_gzip/1.3.19.1a
网易
操作系统:Linux. Web 服务器信息: Apache/2.0.5x
这些数据是在Netcraft得到的.
分析一下上述数据,可以得到的基本信息如下:
1. Linux vs FreeBSD 半斤八两.很多公司用 Linux , FreeBSD 也不乏拥趸.但开源操作系统做 Web 应用是首选已经是一个既定事实.
2. 关于 Apache ,虽然 Apache 目前还是推荐使用 1.3 版本. 但是很多公司还是使用了 2.0 版.而 Apache.org 自己也全在使用 Apache 2.0 .甚至是 2.2 .
3. Mod_gzip 被一些公司有选择的使用.
4. 技术实力强的公司定制自己专用的模块.
附上(一些其他的评论):
MSN/Microsoft/Live
操作系统:Windows Server 2003
WEB服务器: Microsoft-IIS/6.0
微软的标准应用,呵呵
flickr
操作系统:Linux
WEB服务器:Apache/2.0.52
WIKI
操作系统:Linux
WEB服务器:Apache
百度
操作系统:Linux
WEB服务器:Apache/1.3.27
(看来技术方面跟Google还有差距)
网易
操作系统:Linux
WEB服务器:Apache/2.0.55
TOM
操作系统:NetApp NetCache
WEB服务器:Apache/1.3.34 PHP/5.1.2-1
淘宝
操作系统:Linux
WEB服务器:Apache
搜狐
操作系统:SCO UNIX
WEB服务器:Apache/1.3.33
新浪
操作系统:FreeBSD
WEB服务器:Apache/2.0.54
腾讯
操作系统:Linux
WEB服务器:Apache
中国政府网站
操作系统:Linux
WEB服务器:Apache
新华网
操作系统:Linux
WEB服务器:Apache
CCTV
操作系统:Linux
WEB服务器:Netscape-Enterprise/4.1
51JOB
操作系统:Linux
WEB服务器:Apache/1.3.29
猫扑
操作系统:Linux
WEB服务器:Apache/2.0.55
招商银行
Windows 2000
WEB服务器:Microsoft-IIS/5.0
中国工商银行
Windows 2000
WEB服务器:Microsoft-IIS/5.0
中国银行
NetApp NetCache IBM_HTTP_SERVER/1.3.26 Apache/1.3.26 (Unix) 和Windows 2000 Microsoft-IIS/5.0 两种
建设银行
Linux
WEB服务器:Apache/2.0.54 (Unix)
农业银行
AIX IBM_HTTP_Server/2.0.47.1
WEB服务器:Apache/2.0.47 (Unix)
汇丰
Windows Server 2003
交通银行
AIX WebSphere Application Server/5.0
中国人民银行
Windows Server 2003 WHSys-AdvSvr/2.31
发现大部分网站使用的都是开源软件~~但是银行网站大多选用Windows(瘟倒死),可能Windows2003安全性能的确不错,不过它是收费的。
不过我也特地去测试了一下,曾经是被骂得一塌糊涂的CNN的:
结果是使用的是linux+apache。
还有瑞士银行的:F5 Big-IP+apache。这个和中国的银行相比,究竟是为什么呢?不好评论!(个人感觉不是很好)
引言
众所周知,MapReduce编程框架(以下简称MR)一直是大并发运算以及海量数据读写应用设计的利器。在MR编程体系下,一个job通常会把输入的数据集切分为若干块,由map task以完全并行的方式处理消化这些数据块。框架会对map的输出先进行排序,然后把结果作为输入提交给reduce任务。通常作业的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和监控,以及重新执行已经失败的任务。典型的MR程序有如下重要模块结构构成:
类似hive这样的应用,拿到用户一句简单sql查询(假设无需二次执行的简单sql)后,将hdfs上的海量数据进行切分,然后每个map task分别对自己负责的那部分数据执行相同的sql查询,最后将各自获得的结果汇总输出给用户,这便可以保证在海量数据中以较快的速度获得查询结果。
简单介绍完MR编程框架后,我们再来谈谈常规
压力测试的特点和需求。
以
LoadRunner和JMeter为例,这两种工具都可以对
web应用进行大并发访问,模拟线上的高并发压力测试,并且也都相应的提供了多机联合产生负载这样的方式进一步模拟现实情况增大被测对象的压力。这是为了解决“如果一台测试机器模拟的虚拟用户数过多,他本身性能的下降也会直接影响到测试效果”这个问题。分析LR和JMeter的多机联合产生负载这种测试方式,我们不难发现类似MR框架的一些特点,即测试分作如下几步(以LR为例):
1. 设置测试机,即在多台用于测试的机器上安装Load Generator
2. 设置测试任务,即各种configure
3. 同时调度测试任务,通过agent执行对web应用的访问
4. Controller负责统一调度运行场景并收集测试信息和执行结果
无论是LR还是JMeter都是优秀的压测工具,但是总有一些非常规的压力测试场景无法通过LR或JMeter方便的实现,例如对分布式系统做数据读写压力测试,被测目标并非一个单独的节点,而是由很多节点组成的,这样的压力测试场景意味着多机联合对单一节点产生的负载被分担到了很多个节点上。LR和JMeter针对这样的场景往往在设置上就很复杂。
此外,对很多特定的压测目标,测试人员在设计了专属
测试工具之后,往往也需要有一个类似上述LR测试步骤的过程,即工具分发、调度执行、收集结果和过程信息这样一个测试执行框架,如果自己去实现这一套框架,耗费的人月数都是相当可观的,且复用程度有限。于是在云梯项目中我通过自己的实践,想到了将MR编程框架体系与压力测试需求相结合。
从事例说起
先从简单实现类似LR多机联合负载这样一个压测场景展开。被测目标是这样的:一个web应用服务,用于收集分布式系统的跨机房流量信息,后端采用hbase作为存储
数据库,接口为单一节点的http listen端口,需要模拟真实跨机房场景,利用较少的机器数量(约真实系统的50分之一)模拟线上系统的并发度。
测试工具代码是发送http request部分,出于安全考虑,重要部分略过:
while(System.currentTimeMillis() - start <= runtime){ StringBuffer sb = new StringBuffer(); List<String> data = new ArrayList<String>(); HttpURLConnection httpurlconnection = null; try{ URL url = new URL(this.reportAd); httpurlconnection = (HttpURLConnection) url.openConnection(); httpurlconnection.setConnectTimeout(5000); httpurlconnection.setReadTimeout(5000); httpurlconnection.setDoOutput(true); httpurlconnection.setRequestMethod("POST"); httpurlconnection.setRequestProperty("Content-type", "text/plain"); for(long i=0; i<this.recordnum; i++){ 。。。。。。 s = Math.abs(R.nextLong())%102400000+1024; staticWriteSize += s; reporter.incrCounter("TestTool", "Write Size", s); staticWriteTime += (endTime - startTime); reporter.incrCounter("TestTool", "Write Time", endTime - startTime); 。。。。。。 }else{ 。。。。。。 reporter.incrCounter("TestTool", "Read Size", s); staticReadTime += (endTime - startTime); reporter.incrCounter("TestTool", "Read Time", endTime - startTime); 。。。。。。 } Pair p = value.get(R.nextInt(value.size())); 。。。。。。 staticCount++; } reporter.incrCounter("TestTool", "Record num", this.recordnum); reporter.setStatus("Record: "+staticCount+"("+staticWrite+"w, "+staticRead+"r), Write Size: " +staticWriteSize+", Write Time: "+staticWriteTime +", Read Size: "+staticReadSize+", Read Time: "+staticReadTime); httpurlconnection.getOutputStream().write(sb.toString().getBytes()); httpurlconnection.getOutputStream().flush(); httpurlconnection.getOutputStream().close(); int code = httpurlconnection.getResponseCode(); if(code != 200) { LOG.warn("send data to master server failed, code=" + code); } reporter.incrCounter("TestTool", "Http Post num", 1); map.staticPost.addAndGet(1); Thread.sleep(interval); } catch (Exception e) { map.staticPost.addAndGet(1); reporter.incrCounter("TestTool", e.getClass().toString(), 1); LOG.warn(e.getMessage(), e); } finally { if (httpurlconnection != null) { httpurlconnection.disconnect(); } } |
有了工具代码之后,我们通过实现Mapper来封装该工具,因此上述代码中我使用了“org.apache.hadoop.mapred.Reporter”的方法“incrCounter(Stringarg0, String arg1, long arg2)”来对测试中的重要过程数据进行计数,该方法会将所有map/reduce task中汇报的arg0|arg1定义的值arg2进行相加,输出到MR的jobtracker页面上,通过观察作业执行页面可以实时获取这些测试执行过程信息。此外,我还调度了“setStatus(String arg0)”方法,该方法可以实时更新当前所处task的页面信息,提供更详细的单个task执行情况信息。jobdetails.jsp页面观察结果如下所示:

更多的执行过程信息,我们则通过“org.apache.commons.logging.Log”来收集,通过tasklog页面可以查阅到这些详细的日志信息。
作为map task的输入,我通过在hdfs上生成的一堆随机数据来实现,InputSplit类读取了hdfs上作为模拟真实数据的输入后,将其根据map数切分成n份(n=自定义的map数量),并将其分发给对应的map task,map task拿到自己那份数据后,立即启动多个线程执行上述测试工具代码:
public void map(LongWritable key, List<Pair> value, OutputCollector<Text, LongWritable> context, Reporter reporter) throws IOException { 。。。。。。 for(int i=0; i < this.threadnum; i++){ SCNThread t = new SCNThread(value, reporter, start, this); t.start(); this.alivethread.addAndGet(1); } |
。。。。。。
各task自行同步线程启动数量,当所有线程都启动之后,输出收集器开始运作:
long now = System.currentTimeMillis(); if (now > this.start + this.interval) { this.start += this.interval; context.collect(new LongWritable(this.start), new LongWritable( this.writeBlocks)); } |
。。。。。。
可以看到key是时间戳,value是我们想收集的数值,收集器收集到的数据将进一步提供给Reducer来分析,这里有一个压力测试的关键点,即最大并发开始时间点和结束时间点的判断。观察Reducer类的reduce方法:
public void reduce(Text key, Iterator<LongWritable> value,
OutputCollector<Text, Text> context, Reporter reporter)
由于所有map都以相同的时间戳作为key,因此同一时刻迭代器value的size代表了有多少个map已经达到了最大并发度,我们判断这个size,当其与我们预期的map总数一致时,则可以将该时间戳作为最大并发压力的开始时间点,当size开始小于预期map总数时,则代表最大并发压力的结束时间点,测试结果分析时可以掐取这一段数据作为测试结果,免去开始准备阶段和快结束阶段压力变小对测试结果的干扰。
更进一步我们可以在hdfs上设计一个标志位,当一个maptask执行完毕之后,通过该标志位通知到其他所有map task,以便快速结束当前的测试。
测试结果被reducer分析汇总后输出到hdfs上,最终我们只需要查看一下这个输出文件的内容就可以得到我们需要的测试结果了。
其实我们不难发现,这种测试框架与DDoS攻击很类似,当手握数千台机器之后,基本上就具备了指哪毁哪的能力,MR框架体系蕴藏的能量的确是非常巨大的。
流程图
没有流程图,上述文字描述终归不够直观,因此详细流程请看下图所示:
多语言测试工具的支持
对于java类测试工具,我们可以应用该流程图所示方案进行大并发度的压力测试,对于非java语言类的测试工具,我们一方面可以自行撰写其他编程语言的进程调度和收集器,另一方面也可以使用hadoop streaming这个编程工具来实现。Hadoop Streaming是 Hadoop提供的一个编程工具,它允许用户使用任何可执行文件或脚本文件作为 Mapper和 Reducer。这样一来我们用python或shell编写的测试工具也可以通过streaming简单的调度起来执行。有关streaming编程工具的技术细节请自行搜索脑补,这里不再赘述。
第二个例子
第二个例子是关于如何使用MR编程框架压测HDFS文件系统的,该例子涉及到Hadoop更底层的技术细节,以及对性能指标的分析等内容,因此留作《工欲善其事必先利其器》系列的下一弹专门介绍一下,敬请期待。
总结
为什么把本篇作为系列文章的首弹,是因为Hadoop相关的测试工具大多不离该篇所使用到的技术。Hadoop是一个生态圈,因此测试工具作为生态圈的一部分也没必要且不应该脱离这个生态圈去独立生存。MR编程框架大大缩减了分布式应用程序的开发周期,其编程思想更值得每个码农去深挖学习。本弹是笔者一个非常粗浅的思考开端,期望能够抛砖引玉与更多码农进行分享和探讨。系列文章之二《HDFS性能压测工具浅析》将进一步分享一下有关HDFS相关的技术细节。
在玩转
Google开源C++单元
测试框架Google
Test系列(gtest)之四 - 参数化中已经介绍过了如何使用gtest进行参数化测试。在twitter上应 @xlinker 的要求,我在这里提供一个参数化的完整例子。这个例子也是我当初了解gtest时写的,同时这个例子也在《玩转》系列中出现过。最后,我再附上整个demo工程,里面有一些其他的示例,刚开始上手的同学可以直接拿我的demo工程去试,有任何疑问都欢迎提出。以下是使用TEST_P宏进行参数化测试的示例:
#include "stdafx.h" #include "foo.h" #include <gtest/gtest.h> class IsPrimeParamTest : public::testing::TestWithParam<int> { }; // 不使用参数化测试,就需要像这样写五次 TEST(IsPrimeTest, HandleTrueReturn) { EXPECT_TRUE(IsPrime(3)); EXPECT_TRUE(IsPrime(5)); EXPECT_TRUE(IsPrime(11)); EXPECT_TRUE(IsPrime(23)); EXPECT_TRUE(IsPrime(17)); } // 使用参数化测试,只需要: TEST_P(IsPrimeParamTest, HandleTrueReturn) { int n = GetParam(); EXPECT_TRUE(IsPrime(n)); } // 定义参数 INSTANTIATE_TEST_CASE_P(TrueReturn, IsPrimeParamTest, testing::Values(3, 5, 11, 23, 17)); // ----------------------- // 更复杂一点的参数结构 struct NumberPair { NumberPair(int _a, int _b) { a = _a; b = _b; } int a; int b; }; class FooParamTest : public ::testing::TestWithParam<NumberPair> { }; TEST_P(FooParamTest, HandleThreeReturn) { FooCalc foo; NumberPair pair = GetParam(); EXPECT_EQ(3, foo.Calc(pair.a, pair.b)); } INSTANTIATE_TEST_CASE_P(ThreeReturn, FooParamTest, testing::Values(NumberPair(12, 15), NumberPair(18, 21))); |
setupTest做些初始化的
工作,每个线程只执行一次
teardownTest做些清理工作,每个线程只执行一次
runTest具体的
测试执行工作,每个并发每次循环都将执行一次
SampleResult记录测试结果,result.sampleStart()一个事务开始,result.sampleEnd()一个事务结束
main方法用于调试
01 package com . xxx . yyy . perf; 02 03 import org.apache.jmeter.config.Argument; 04 import org.apache.jmeter.config.Arguments; 05 import org.apache.jmeter.protocol.java.sampler.AbstractJavaSamplerClient; 06 import org.apache.jmeter.protocol.java.sampler.JavaSamplerContext; 07 import org.apache.jmeter.samplers.SampleResult; 08 import org.springframework.context.ApplicationContext; 09 import org.springframework.context.support.ClassPathXmlApplicationContext; 10 11 import com.xxx.udb.client.PersonService; 12 import com.xxx.udb.client.result.PersonResult; 13 14 /** 15 * 16 * @author flynewton 17 */ 18 public class GetPersonByLongId extends AbstractJavaSamplerClient { 19 private static final ApplicationContext ctx = new ClassPathXmlApplicationContext( 20 "spring-udb.xml"); 21 private static PersonService personService = null; 22 private static final String loginId = "00000sb"; 23 private static final String siteId = "CN"; 24 25 26 @Override 27 public void setupTest( JavaSamplerContext context) { 28 super . setupTest( context); 29 personService = ( PersonService) ctx . getBean( "personServiceClient"); 30 } 31 32 @Override 33 public void teardownTest( JavaSamplerContext context) { 34 super . teardownTest( context); 35 } 36 37 public SampleResult runTest( JavaSamplerContext arg0) { 38 SampleResult result = new SampleResult(); 39 PersonResult personResult = null; 40 41 result . setSampleLabel( "result"); 42 43 try { 44 result . sampleStart(); 45 personResult = personService . getPersonByLongId( siteId , loginId); 46 result . sampleEnd(); 47 } catch ( Throwable t) { 48 this . getLogger (). error( "Exception:" + t); 49 return null; 50 } 51 52 if ( personResult != null && personResult . getCode() == 0) { 53 result . setSamplerData( personResult . toString()); 54 result . setSuccessful( true); 55 } else { 56 result . setSuccessful( false); 57 } 58 59 return result; 60 } 61 62 static void printResult( SampleResult res) { 63 System . out . println( " test is success:" + res . isSuccessful() + " used:" 64 + ( res . getEndTime() - res . getStartTime()) + "ms " + " result:" 65 + res . getSampleLabel() + ":" + res . getSamplerData()); 66 } 67 68 public static void main( String [] args) { 69 GetPersonByLongId service = new GetPersonByLongId(); 70 JavaSamplerContext context = new JavaSamplerContext( null); 71 service . setupTest( context); 72 SampleResult res1 = service . runTest( context); 73 printResult( res1); 74 service . teardownTest( context); 75 System . exit( 0); 76 } 77 78 } |
2.多接口性能测试
按照上面的方法进行测试,每个需要测试的接口和场景都需要写一个这样的测试类,对于有些具有相似初始化,清理等
工作,只有具体的那行事务代码不一样的情况,会有很多重复的工作。如下:
可以考虑采用反射的方式来解决这个问题,尤其是业务非常类似的接口和场景。当然,反射会带来压力机的性能消耗,
但是这个可以通过调整JMeter的JVM参数和增加JMeter实例来解决。
1)利用反射后的结构如下:
2)AbstractServiceClient是一个抽象基类
package com . xxx . yyy . perf . base; import java.lang.reflect.Method; import org.apache.jmeter.protocol.java.sampler.AbstractJavaSamplerClient; import org.apache.jmeter.protocol.java.sampler.JavaSamplerContext; import org.apache.jmeter.samplers.SampleResult; /** * Comment of AbstractServiceClient * @author flynewton */ public abstract class AbstractServiceClient extends AbstractJavaSamplerClient { public Object invokeTest( String testName , JavaSamplerContext context ,SampleResult sample) { Method [] methods = this . getClass (). getMethods(); for ( Method m : methods) { if ( m . getName (). equalsIgnoreCase( testName)) { try { return m . invoke( this , context , sample); } catch ( Throwable t) { this . getLogger (). error( "execute method:" + testName + " falied" , t); } } } return null; } } |
3)GetPersonTest为某一类具有相似业务场景的测试类
其中 getDefaultParameters方法设置默认参数:test传入具体要执行的测试方法;info传入日志级别,利用main方法进行调试时设置为true,真正进行性能测试的时候设置为false
package com . xxx . yyy . perf; import org.apache.jmeter.config.Argument; import org.apache.jmeter.config.Arguments; import org.apache.jmeter.protocol.java.sampler.JavaSamplerContext; import org.apache.jmeter.samplers.SampleResult; import org.springframework.context.ApplicationContext; import org.springframework.context.support.ClassPathXmlApplicationContext; import com.xxx.udb.client.PersonService; import com.xxx.udb.client.result.MultiPersonResult; import com.xxx.udb.client.result.PersonResult; import com.xxx.udb.perf.base.AbstractServiceClient; /** * Test get person * @author flynewton */ public class GetPersonTest extends AbstractServiceClient { private static final ApplicationContext ctx = new ClassPathXmlApplicationContext( "spring-udb.xml"); private static PersonService personService = null; private static String loginIdCache = "00000sb"; private static String loginIdWithoutCache = "01haytham"; private static String siteIdCache = "CN"; private static String siteIdWithoutCache = "IN"; private static String alimailCn = "gchg2008@zzgcchen.cn"; private static String alimailUdb = "000001@lvcuinm.com.cn"; private static String uidCache = "300113578"; private static String uidWithoutCache = "in5002997"; private static String emailCache = "00000sb@alibaba-test.com"; private static String emailWithoutCache = "5002997@alibaba-inc.com"; @Override public void setupTest( JavaSamplerContext context) { super . setupTest( context); personService = ( PersonService) ctx . getBean( "personServiceClient"); } public Arguments getDefaultParameters() { Arguments params = new Arguments(); params . addArgument( "test" , "testMethod"); params . addArgument( "info" , "false"); return params; } @Override public void teardownTest( JavaSamplerContext context) { super . teardownTest( context); } public Object testGetPersonByLongIdViaCache( JavaSamplerContext arg0 , SampleResult sample) { PersonResult personResult = null; try { sample . sampleStart(); personResult = personService . getPersonByLongId( siteIdCache , loginIdCache); sample . sampleEnd(); } catch ( Throwable t) { this . getLogger (). error( "Exception:" + t); return null; } return personResult; } public Object testGetPersonByLongIdWithoutCache( JavaSamplerContext arg0 , SampleResult sample) { PersonResult personResult = null; try { sample . sampleStart(); personResult = personService . getPersonByLongId( siteIdWithoutCache , loginIdWithoutCache); sample . sampleEnd(); } catch ( Throwable t) { this . getLogger (). error( "Exception:" + t); return null; } return personResult; } public Object testGetPersonByAlimailCN( JavaSamplerContext arg0 , SampleResult sample) { PersonResult personResult = null; try { sample . sampleStart(); |
mvn package -DskipTests
临时性跳过测试代码的编译:
mvn package -Dmaven.test.skip=true
maven.test.skip同时控制maven-compiler-plugin和maven-surefire-plugin两个插件的行为,即跳过编译,又跳过测试。
指定测试类
mvn
test -Dtest=RandomGeneratorTest
以Random开头,Test结尾的测试类
mvn test -Dtest=Random*Test
mvn test -Dtest=ATest,BTest
指定即使没有任何测试用例也不要报错
test参数必须匹配至少一个测试类,否则会报错并导致构建失败。此时可使用以下配置来指定即使没有任何测试用例也不要报错。
mvn test -Dtest -DfailIfNoTests = false
POM文件配置包含与排除测试用例
使用** / * Test.java 来匹配所有以Tests结尾的
Java类。两个星号**用来匹配任意路径,一个星号*用来获取除路径风格符外的0个或多个字符。还可使用excludes来排除一些测试类。
<plugin> <groupId>org.apahce.maven.plugins<groupId> <artifactId>maven-surefire-plugin</artifactId> <version>2.5</version> <configuration> <includes> <include>**/*Tests.java</include> </includes> </configuration> </plugin> |
在实际
性能测试过程中,为了更真实的模拟不同用户提交不同的数据,需要对提交的数据进行参数化处理,但是,所录制的脚本中,要提交的数据可能已经经过编码(如UTP-8),如下图所示脚本中的节点均经过UTF-8编码:
编码、解码对比:
在测试过程中,需要将需要参数化的数据,利用编码工具转化为UTF-8格式,再作为参数化数据,进行参数化处理。
推荐使用该小工具—Encode/Decode tools,小巧又好用!
Appache JMeter 以及 SOAP 协议简述
JMeter 是 Apache 基金会 Jakarta 上的一个纯 Java 开源项目,起初用于基于 Web 的
压力测试(pressure
test),后来其应用范围逐渐扩展到对文件传输 FTP, 大型
数据库(JDBC 方式),脚本程序(CGI, Perl 等),Web Services,Java 应用系统等方面的测试。JMeter 本身主要用于
性能测试,如系统压力等。除此之外,JMeter 能够对应用系统做
功能测试和回归测试,并且能够通过使用带有断言的脚本程序来验证系统然后返回用户期望的结果。为了提高工具的应用灵活性,JMeter 允许使用正则表达式创建断言。正是由于它的灵活性和可扩展性,JMeter 逐渐成为流行的开源测试工具。
消息传递协议:SOAP
SOAP(Simple Object Access Protocol)称为简单对象访问协议, 是 W3C 定义的一种标准消息传递协议,而它通常被认为是 Web Services 的事实标准。SOAP 协议使用 XML 语言来描述,SOAP 消息格式是由 XML Schema 模式定义,因而通过使用 XML 命名空间使得 SOAP 具有很强的可扩展性。
SOAP 是在去中心化(Decentralized)分布式(Distributed)环境中用来信息交换的一个轻量级协议。SOAP 本身并不定义像程序模型或实施声明等形式的语法,而只定义了一种简单机制:通过提供模块化的包装模型编码机制来传输应用信息。
SOAP 基本结构:
1) 信封 Envelope Envelope 元素是 SOAP 中的根元素,并且定义为在 SOAP 消息中必须出现。Envelope 元素中可以包含多可选的 Header 元素,但同时必须要包含一个 Body 元素。
2) 消息头 Header Header 可能出现在 SOAP 消息中,是一个可选元素。如果出现在消息中,那么 Header 一定要是 SOAP 中的第一个元素。SOAP Header 在 Web Services 中的应用越来越广泛,例如在应用程序的安全性事物中使用标准的消息头文件,因而成为扩展 SOAP 协议的一个非常有效的方法。
3)消息体 Body Body 元素是 SOAP 中必须出现的一个元素,它要包含应用程序中的传输数据或者反馈消息。 应用程序中的传输数据可以是任意形式的 XML 数据。SOAP 消息接收者最终来处理 SOAP Body 体。
JMeter 调用 SOAP 框架机制
SOAP 使用 RPC(远程过程调用)和消息传递来建立通信服务,SOAP RPC 定义了用于表示远程过程调用和应答的协议。SOAP 协议本身仅仅定义了消息的交换结构,它可以和许多现存因特网协议结合在一起使用,其中包括超文本传输协议( HTTP),多用途网际邮件扩充协议(MIME),Java 消息服务(JMS)以及简单邮件传输协议(SMTP)等。目前与 SOAP 应用最为广泛的是 HTTP 协议和 JMS 协议,而与之相对应的两种应用就是 SOAP Over HTTP 和 SOAP Over JMS。
根据 JMS 的规范,消息交换有 2 种方式:消息发布 / 订阅方式和点对点方式。由这两种交换方式所建立的消息收发系统都是异步的,即 JMS 客户机可以发送消息而不必等待回应。如果应用程序测试者或测试脚本开发者希望每一条消息都能够被处理并且消息总是能够被传送到指定的位置,那么应该使用点对点消息模型而不是消息发布 / 订阅模型。
HTTP(超文本传送协议)是属于应用层的面向对象的协议,是万维网 (WWW) 的基础,由于其简单快速、灵活、无连接、无状态的方式,适用于分布式网络信息系统。SOAP Over HTTP 应用就是指的是遵守 SOAP 编码规则的 HTTP 请求 / 响应,我们可以用简单的公式来对此作一个描述:HTTP + XML = SOAP。
JMeter 也同样提供了两种 Sampler 分别建立对这两种服务的调用:Web Services (SOAP) Request 和 JMS Point-to-Point。前者使用
互联网中最为广泛的超文本传输协议( HTTP)而后者使用 JMS 协议,JMS 是 Java 平台面向消息中间件的技术规范,用它来提供创建、发送、接收、读取消息的服务。许多厂商目前都支持 JMS,包括 BEA 的 WebLogic JMS service,
IBM 的 MQSeries 和 Progress 的 SonicMQ。
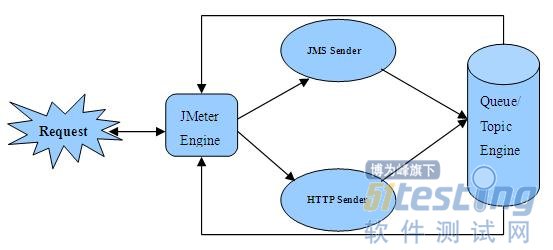
图 1.JMeter 框架基于上述两种不同的协议对 SOAP 消息的一次简单调用机制流程
准备测试环境
当精心编写好测试脚本满怀信心的去运行测试计划时,发现所有的测试脚本都 failed 掉了,原因可能是你的测试环境中并没有完全准备好。下面给出了准备测试环境的详细步骤:
1.环境变量设置:JMeter 运行在 JRE/JDK 之上,在所有开始之前要设置 JMeter 自动检测的环境变量 JAVA_HOME=#JAVA INSTALL DIRECTORY#.
2.JMeter 安装:本文下面下载栏提供了 Apache JMeter 下载地址,首先要取得最新版本的 JMeter 测试工具,JMeter 最新版本包含了构建和运行绝大部分测试类型的文件,包括 Web (HTTP/HTTPS), FTP, JDBC, LDAP, Java, 和 JUnit 等。
3.准备 jar 包:JMeter 虽然提供了对 SOAP Over HTTP 以及 SOAP Over JMS 测试的 Sampler,但是出于对 licence 的考虑它本身并没有提供 JMS 需要使用的 jar 包。因此,在运行测试之前需要将这些包复制到 JMeter 的 lib 目录下,下面列表对测试所需 jar 包作了详细说明。
4.BeanShell 脚本处理:如果在测试用例中用到了 BeanShell 脚本,则需要将 BeanShell 包拷贝到 JMeter bin 目录下。BeanShell 是一种兼容 Java 语言的轻量级脚本语言,JMeter 脚本中可能会经常用它来做日志处理,正则表达式后处理(Post- Process)等。如果在测试用例中用到了 Mail Visualiser, Mail Reader 以及 Web Services (SOAP) sampler,则需要将 MAIL 包拷贝到 JMeter bin 目录下。如果在测试用例中用到了 JMS 相关的 sampler,则需要将 JMS 包拷贝到 JMeter bin 目录下。
下面的列表列出了不同的测试用例所需要的 jar 包,以及其下载地址:
bsh-2.0b4.jarhttp://www.beanshell.org/
mail.jar http://java.sun.com/products/javamail/index.jsp
jms.jarhttp://java.sun.com/products/jms/docs.html
调试脚本中非常有用的信息日志:jmeter.log 在脚本的调试和运行过程中,所以的日志信息都会记录在 jmeter.log 中,因此你会在这个文件中找到比较有用的信息。
注意事项
如果 JMeter 在执行测试脚本过程中应该修改 jmeter.bat 文件中的一些参数,参数大小可以根据测试计划合理确定:
HEAP=-Xms256m – Xmx1024m
NEW=-XX:NewSize=128m -XX:MaxNewSize=128m
TENURING=-XX:MaxTenuringThreshold=2
EVACUATION=-XX:MaxLiveObjectEvacuationRatio=20%
PERM=-XX:PermSize=64m -XX:MaxPermSize=64m
DEBUG=-verbose:gc -XX:+PrintTenuringDistribution
此外,在搭建测试环境时还需要更多注意的地方:
JMeter 使用兼容 JKD1.4 或者更高版本
JMeter 无法识别 zip 格式的包文件,所以需要的包文件均要求以 .jar 结尾
JMeter 会自动在 JMETER_HOME/lib 和 ext 目录下寻找需要的类
对于使用 CSVDataSet, 那么不要勾选 "Memory Cache"否则数据无法迭代
使用 JMeter 连接 SOAP Over HTTP 服务
JMeter 提供了 Web Service (SOAP) sampler,用以调用基于 HTTP 的 Web 服务。下面详细说明 SOAP Over HTTP 服务调用的各个属性。
图 2.SOAP Over HTTP 服务调用的各个属性
SOAP Over HTTP 服务调用的各个属性说明:
WSDL URL:指定 WSDL 文件的目标地址
Web Methods:选择本次请求调用的方法
Protocol:指定使用的协议,默认为 HTTP
Server Name Or IP:服务的地址(服务器名或 IP 地址)
Path:调用方法所在的位置
Timeout:设置请求超时限制
SOAPAction:存在于 WSDL 文件中的调用方法,默认不必填写
Soap/XML-RPC Data:请求数据
下面是一次完整的 HTTP 请求与 HTTP 响应 SOAP 数据:
HTTP Request <soapenv:Envelope> <soapenv:Body> <q0:getEndDate> <ip_id>12</ip_id> </q0:getEndDate> </soapenv:Body> </soapenv:Envelope> HTTP Response <soapenv:Envelope> <soapenv:Header/> <soapenv:Body> <p928:getEndDateResponse> dstSavings=3600000,useDaylight=true,startYear=0,startMode=3,startMonth=2, startDay=8,startDayOfWeek=1,startTime=7200000,startTimeMode=0,endMode=3, endMonth=10,endDay=1,endDayOfWeek=1,endTime=7200000,endTimeMode=0]], firstDayOfWeek=1,minimalDaysInFirstWeek=1,ERA=1,YEAR=2005,MONTH=8, WEEK_OF_YEAR=37,WEEK_OF_MONTH=2,DAY_OF_MONTH=7,DAY_OF_YEAR=250,DAY_OF_WEEK=4, DAY_OF_WEEK_IN_MONTH=1,AM_PM=0,HOUR=0,HOUR_OF_DAY=0,MINUTE=0,SECOND=0, MILLISECOND=0,ZONE_OFFSET=-18000000,DST_OFFSET=3600000] </p928:getEndDateResponse> </soapenv:Body> </soapenv:Envelope> |
使用 JMeter 连接 SOAP Over HTTP 服务
JMeter 提供了 Web Services (SOAP) sampler,用以调用基于 HTTP 的 Web 服务。下面详细说明 SOAP Over HTTP 服务调用的各个属性。

图 3.SOAP Over HTTP 服务调用的各个属性
SOAP Over JMS 服务调用的各个属性说明:
QueueConnectionFactory:连接工厂的默认 JNDI 实体
JNDI name Request queue:JNDI 请求队列名字
JNDI name Receive queue:JNDI 接收队列名字
Timeout:请求超时设置
Communication style:通讯形式(包括仅仅请求和请求应答)
Content:请求信封
JMS Properties:JMS 的一些属性设置(对于 IBM WAS 必须要有 targetService 属性)
Initial Context Factory:JNDI 的初始会话工厂
Provider URL:服务提供地址
下面是一次完整的 JMS 请求与 JMS 响应 SOAP 数据:
JMS Request <soapenv:Envelope> <soapenv:Body> <tns0:getAuEmpPositionId> <ev_id>6098</ev_id> </tns0:getAuEmpPositionId> </soapenv:Body> </soapenv:Envelope> JMS Response <soapenv:Envelope> <soapenv:Header/> <soapenv:Body> <p150:getAuEmpPositionIdResponse> <getAuEmpPositionIdReturn xsi:nil="true"/> </p150:getAuEmpPositionIdResponse> </soapenv:Body> </soapenv:Envelope> |
设计高效的测试用例集
压力测试或者系统测试不同于功能测试,测试的重点不在系统产品是不是满足设计需求。它所看重的是系统在大的用户量和负载情况下的可靠性以及系统响应 , 它目标是测试系统的执行效率,特别是在较短时间内系统负载快速增长时系统的相应速度。在实际的测试过程中,大量用户同时访问的系统节点也可能成为产品潜在的效率瓶颈。因此 , 压力测试和系统测试也往往是在功能测试之后进行。
对于普通的软件系统 , 产品的瓶颈可能会在数据库服务器上,Web 服务器上,而对于 SOAP 服务系统测试,Web Services 服务器和 JMS 服务器是客户端请求的主要节点 , 同时,主要业务逻辑的处理也都分布在这些节点上,它们很有可能成为系统访问的瓶颈,如果这些节点出现问题,那么对整个系统的效率会有致命的影响,也是压力测试和系统测试要优先考虑的。
改进测试策略、测试方法、测试过程,使用高效的测试用例集,从而保证产品质量。这个是主要目的,也是最直接的目的。一个高效的测试用例集应包含以及适应如下要素:
在什么时候确定要执行系统测试
如何去检测并解决系统性能和负载问题
收集监视服务器性能数据(I/O,CPU,MEM)
尽量减少因为个人配置和某些测试用例而造成系统出现错误和瓶颈
所有测试工作都得到有效协调并目标一致
当已经确定了所需的 JMeter Samplers,并且在此基础上设计出一个通用的测试计划,那么就可以构建我们的测试脚本了。本文的测试用例以及最终的测试计划也是建立在这些要素之上。
测试计划(Test Plan)描述了测试运行过程中 JMeter 的执行顺序、过程以及步骤,一个完整的测试计划包括一个或者多个线程组 (Thread Groups)、循环控制器(Loop Controllers)、监听器 (Listener)、逻辑控制器(Logic Controller)、定时器(Timer)、断言(Assertions)、配置信息(Config Elements)等。
在测试计划中添加一个用户定义变量配置元素(User Defined Variables), 可以在里面定义服务器地址,日志路径,超时限制等变量,提供脚本重用。同时添加两个用户组,一个是 SOAP Over HTTP Group,一个是 SOAP Over JMS Group。在每个用户组下面分别添加一个总的循环控制器(Loop Controller),用以控制脚本循环次数。在总循环控制器下面添加随机选择器(Random Selector)用以随机选择运行测试脚本。下图是我们整个的 Test Plan。

图 4. 设计完成之后的 SOAP 测试计划
启动 SOAP 服务测试
当准备好我们的测试计划之后就可以启动执行压力测试了,为了记录测试结果和信息,要增加 Listener 来完成这个任务。JMeter 提供了可视化的界面以及统计报表来供我们选择。这里我们使用表格(Summary Report)的形式来查看和分析测试结果。
你可以通过下面的步骤来给每个 Group 增加 Summary Report 监视器 :
1. 选中 Test Plan 中要添加 Listener 的 Group 节点,这里我们选择 SOAP Over JMS Group。
2. 右击选择 Add-->Listener-->Summary Report, 界面右边会相应的出现我们选择的 Listener 的设置信息。
在经过一系列工作之后,已经完成了整个 Test Plan,现在可以选择 JMeter 菜单 run-->start 来启动我们的压力测试了。下图是运行过程中测试统计数据的实时跟新信息。为了增加请求负载和获得更有价值的数据,我们可以更改线程数、等待时间和循环次数。
图 5. 基于吞吐量的测试结果报表(Summary Report)
获得的经验
总结:
使用 JMeter 来作为测试工具对 SOAP 协议的服务进行压力和系统测试是一个很好选择,选择 JMeter 来进行 SOAP 测试具有以下显著的优点:首先 JMeter 提供了强大全面的 SOAP 请求 / 接收以及监视功能,允许你执行、捕获在客户端和服务器端的 SOAP 流量分析。其次,可以使用 JMeter 可以设计出高效、易维护的测试用例甚至测试计划。最后,我们可以选择 JMeter 提供的符合我们情况的结果 Listener,并且可以从这些 Listener 中很容易的分析出系统或者是服务存在的问题和瓶颈。总体上讲,我们在 JMeter 测试框架中构建的 SOAP 测试计划很好的完成了对 SOAP 协议的系统测试。下面详细列出了我们在本次测试过程中获得的技巧以及经验。
测试工具的选择
测试工具在软件和产品测试中是必不可少的,包括系统测试,压力测试,性能测试以及功能测试。它也会与要测试的产品,测试的领域以及测试的重点有很大的关系。因此,选择一款合适的测试工具对高效的完成测试是至关重要的。
设计高效的测试计划
一个高效的测试用例集可以快速的诊断出系统的性能瓶颈。 为此应该全面的分析了解要测试系统的架构与应用,尽量避免盲目或者重复的测试用例,最终来构建效率尽可能高的测试用例集。
尽量全面的系统监控
软件缺陷和系统性能瓶颈的诊断可能会需要各个方面的检测数据,它们对问题的解决会提供很大的帮助,因此测试过程中应该有全面的系统监控,包括服务器的各项数据(CPU,I/O,MEM), 后台数据库的各项数据,相应时间以及网络流量等。
关注 SOAP 请求的超时(Timeout)
基于 SOAP 协议的请求,无论是 SOAP Over HTTP 还是 SOAP Over JMS 都会有请求超时(Timeout),引起请求超时的原因可能是多方面的(服务器的响应速度,效率,网络带宽等),合理的分析以及设置请求超时能更准确的掌握产品的性能情况。