
1、容器类
JDK API中专门设计用来存储其他对象的类,一般称为对象容器类,简称容器类,这组类和接口的设计结构也被统称为集合框架(Collection Framework)。集合框架中容器类的关系如下图示
主要从两方面来选择容器:
(1)存放要求
无序:Set,不能重复
有序:List,允许重复
“key-value”对:Map
(2)读写数据效率
Hash:两者都最高。
Array:读快改慢。
Linked:读慢改快。
Tree:加入元素可排序使用。
2、泛型
应用背景:存入容器的对象在取出时需要强制转换类型,因为对象加入容器时都被转化为Object类型,而取出时又要转成实际类型。
在Java中向下类型转换时容易出现ClassCastException的异常,这时应当尽量避免。有什么办法可以让装入容器中的数据保存自己的类型而不被转化为Object对象呢,这就需要用到JDK5.0支持的新功能——Java的泛型。
定义:泛型只是编译时的概念,是供编译器进行语法检查用的。所谓泛型,就是在定义(类型的定义,方法的定义,形式参数的定义,成员变量的定义等等)的时候,指定它为通用类型,也就是数据类型可以是任意的类型,如List<?> list = null,具体调用时,要将通用类型转换成指定的类型。泛型提高了大型程序的类型安全和可维护性。
目的:
努力将运行时异常转换成编译时的问题,减少运行时异常数量(提高了编译器的能力)。
解决模版编程的问题。
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
上图展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在O(log2n)的复杂度内获取到相应数据。
创建索引可以大大提高系统的性能。
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?因为,增加索引也有许多不利的方面。
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。一般来说,应该在这些列上创建索引:在经常需要搜索的列上,可以加快搜索的速度;在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。
唯一索引
唯一索引是不允许其中任何两行具有相同索引值的索引。
当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。例如,如果在employee表中职员的姓(lname)上创建了唯一索引,则任何两个员工都不能同姓。
主键索引
数据库表经常有一列或列组合,其值唯一标识表中的每一行。该列称为表的主键。
在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
聚集索引
在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。
如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。
局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
B-/+Tree索引的性能分析
到这里终于可以分析B-/+Tree索引的性能了。
上文说过一般使用磁盘I/O次数评价索引结构的优劣。先从B-Tree分析,根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
综上所述,用B-Tree作为索引结构效率是非常高的。
应该花时间学习B-树和B+树数据结构
=============================================================================================================
1)B树
B树中每个节点包含了键值和键值对于的数据对象存放地址指针,所以成功搜索一个对象可以不用到达树的叶节点。
成功搜索包括节点内搜索和沿某一路径的搜索,成功搜索时间取决于关键码所在的层次以及节点内关键码的数量。
在B树中查找给定关键字的方法是:首先把根结点取来,在根结点所包含的关键字K1,…,kj查找给定的关键字(可用顺序查找或二分查找法),若找到等于给定值的关键字,则查找成功;否则,一定可以确定要查的关键字在某个Ki或Ki+1之间,于是取Pi所指的下一层索引节点块继续查找,直到找到,或指针Pi为空时查找失败。
2)B+树
B+树非叶节点中存放的关键码并不指示数据对象的地址指针,非也节点只是索引部分。所有的叶节点在同一层上,包含了全部关键码和相应数据对象的存放地址指针,且叶节点按关键码从小到大顺序链接。如果实际数据对象按加入的顺序存储而不是按关键码次数存储的话,叶节点的索引必须是稠密索引,若实际数据存储按关键码次序存放的话,叶节点索引时稀疏索引。
B+树有2个头指针,一个是树的根节点,一个是最小关键码的叶节点。
所以 B+树有两种搜索方法:
一种是按叶节点自己拉起的链表顺序搜索。
一种是从根节点开始搜索,和B树类似,不过如果非叶节点的关键码等于给定值,搜索并不停止,而是继续沿右指针,一直查到叶节点上的关键码。所以无论搜索是否成功,都将走完树的所有层。
B+ 树中,数据对象的插入和删除仅在叶节点上进行。
这两种处理索引的数据结构的不同之处:
a,B树中同一键值不会出现多次,并且它有可能出现在叶结点,也有可能出现在非叶结点中。而B+树的键一定会出现在叶结点中,并且有可能在非叶结点中也有可能重复出现,以维持B+树的平衡。
b,因为B树键位置不定,且在整个树结构中只出现一次,虽然可以节省存储空间,但使得在插入、删除操作复杂度明显增加。B+树相比来说是一种较好的折中。
c,B树的查询效率与键在树中的位置有关,最大时间复杂度与B+树相同(在叶结点的时候),最小时间复杂度为1(在根结点的时候)。而B+树的时候复杂度对某建成的树是固定的。
通过简单的ping命令,查看返回的TTL值来判断对方的
操作系统 生存时间(TTL)是IP分组中的一个值,网络中的路由器通过察看这个值就可以判断这个IP分组是不是已经在网络中停留了很久,进而决定是否要将其丢弃。出于多种原因,一个IP分组可能在很长一段时间内不能抵达目的地。例如:错误的路由有可能导致一个IP分组在网络中无限地循环。一种解决方法就是在一定时间后丢弃这个分组,然后发送一个信息通知这个分组的发送者,由它决定是否重发这个分组。TTL的初始值一般是系统缺省值,它位于IP分组的头部,占用8个二进制位。最初设定TTL值的目的是,让它来指定一段特定的时间(以秒为单位),当这段时间耗尽的时候就将这个分组丢弃。由于每个路由器至少会让这个TTL值减一,所以这个TTL只经常用来指定在一个分组被丢弃之前允许经过的路由器数。每个路由器收到一个分组后就将它的TTL 值减一,一旦这个值被减为0,路由器就会丢弃这个分组,并发送一个ICMP信息给这个分组的最初的发送者。
UNIX 及类 UNIX 操作系统 ICMP 回显应答的 TTL 字段值为 255
Compaq Tru64 5.0 ICMP 回显应答的 TTL 字段值为 64
Windows NT/2K操作系统 ICMP 回显应答的 TTL 字段值为 128
Windows 95 操作系统 ICMP 回显应答的 TTL 字段值为 32
注:ICMP报文的类型包括如下:
ECHO (Request (Type 8), Reply (Type 0))--回显应答,
Time Stamp (Request (Type 13), Reply (Type 14))--时间戳请求和应答,
Information (Request (Type 15), Reply (Type16))--信息请求和应答,
Address Mask (Request (Type 17), Reply (Type 18))--地址掩码请求和应答等
不同的操作系统,它的TTL值是不相同的。默认情况下:
Windows NT/2000/XP系统的TTL值为128,
Windows 98系统的TTL值为32,
UNIX主机的TTL值为255。
公司使用的是多数为Windows 2000服务器,TTL值默认为128,如果将该值修改为255,攻击者可能会以为这个服务器是Linux系统或UNIX系统,那么他们就会针对Linux系统或UNIX系统来查找Windows 2000服务器的安全漏洞,不过他们是不会找到什么安全漏洞的,这样一来,服务器相来说增加了安全性。
具体实现方法:
修改TTL值其实非常简单,通过注册表编辑器就可以实现,点击“开始→运行”,在“运行”对话框中输入“regedit”命令并回车,弹出
“注册表编辑器”对话框,展开“HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\ Parameters”,找到“DefaultTTL”,将该值修改为十进制的“255”,重新启动服务器系统后即可。
基本流程
新建一个测试工程( Android
Test Project),选择你要测试的工程,或者说你要测试的类所在的工程,创建
测试用例,如果有需要还可以建立TestSuite来配置要测试的用例,最后右键选择测试用例类,run as – >“Android Junit Test” 即可。然后你也可以直接在被测试工程中测试,这样不需要建立测试工程。
1、建立测试工程
图 1
2、选择要测试的工程
图 2
3、选择目标平台
图 3
4、选择finish后,在AndroidManifest.xml中填写如下代码:
<! – 添加InstrumentationTestRunner ,targetPackage修改成你的测试工程的包名即可--> <instrumentation android:name="android.test.InstrumentationTestRunner" android:targetPackage="com.example.umengsocialtest" /> <! – application 添加test runner --> <application android:icon="@drawable/ic_launcher" android:label="@string/app_name" > <! – 添加test runner --> <uses-library android:name="android.test.runner" /> </application> |
5、右键点击测试工程的“src”目录,选择”new”-->“Junit Test Case”,然后输入测试用例名称和要继承的测试类,正常情况下,继承自AndroidTestCase即可,如果你要测试的类依赖于Activity,你可以继承自ActivityInstrumentationTestCase2<T>,其中T为你mock的Activity,你可以在测试工程下新建一个Activity用于测试,这里我们选择继承自ActivityInstrumentationTestCase2。最后选择你要测试的类,这里我选择的是UMAppAdapter。选择”next”,然后选择你要测试的方法,勾选即可。如图4
图 4
6、选择要测试的方法
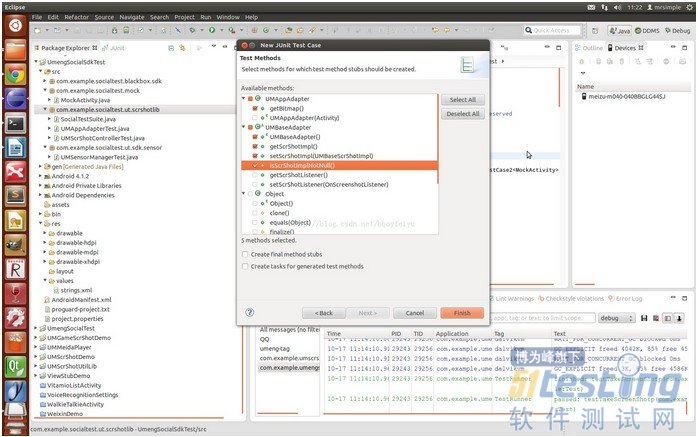
图 5
7、如果你要测试的类需要Activity参数,你可以创建一个Activity来用于测试,使用AndroidTestCasse则不需要这么做。代码如下:
public class MockActivity extends Activity { @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); } } |
8、在测试用例中,填写代码
public class UMAppAdapterTest extends ActivityInstrumentationTestCase2<MockActivity> { /** * */ private Activity mActivity = null; /** * */ private UMBaseAdapter mAdapter = null; /** * @Title: UMAppAdapterTest * @Description: * UMAppAdapterTest Constructor * * @param activityClass */ public UMAppAdapterTest(Class<MockActivity> activityClass) { super(activityClass); } public UMAppAdapterTest() { super(MockActivity.class); setName("MockActivity"); } @Before protected void setUp() throws Exception { super.setUp(); mActivity = getActivity(); assertNotNull(mActivity); } @After protected void tearDown() throws Exception { super.tearDown(); mActivity = null; clearState(); } @Test public void testGetBitmap() { mAdapter = new UMAppAdapter(mActivity); // 实际会触发截屏操作,返回当前截屏 assertNotNull(mAdapter.getBitmap()); // 使用控制器来截图, 实际上调用的是mAdapter.getBitmap() UMScrShotController controller = UMScrShotController.getInstance(); controller.setAdapter(mAdapter); assertNotNull(controller.takeScreenShot()); } } |
为了篇幅简短,这里只列出了部分测试用例代码。
字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿
二、TestSuite的使用
1、新建一个JunitTest Case,父类选择TestSuite,如图6。
图 6
2、样例代码如下,覆写suite(),然后添加你要测试的测试用例即可。com.example.socialtest.ut.scrshotlib.UMAppAdapterTest是UMAppAdapterTest这个测试用例的完整路径,添加进去即可。多个测试用例使用逗号隔开。如下:
public class YourTestSuite extends TestSuite { public static Test suite() { return new TestSuiteBuilder(SocialTestSuite.class).includePackages( "com.example.socialtest.ut.scrshotlib.UMAppAdapterTest", "com.example.socialtest.ut.scrshotlib.UMScrShotControllerTest" ).build(); } } |
3、最后右键选择你的TestSuite类,选择”runas “, 然后选择android Junit Test即可运行TestSuite.。
如图7。
页面元素的定位可以说是WebDriver中最核心的内容了,我们定位元素的目的主要有:操作元素,获取该元素的属性,获取元素的text以及获取元素的数量,WebDriver 为我们提供了以下几种方法来帮我们定位
web元素:
通过元素的id获取
通过元素的name获取
通过元素的tag name 获取
通过css xpath 获取
通过xpath 获取
通过class name 获取
通过一部分的link text 获取元素
通过全部的link text 获取元素
唯一元素的定位:
package org.coderinfo.demo; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.chrome.ChromeDriver; public class FindSingleElements { private static final String URL = "file:///C:/Desktop/Selenium/login.html"; // 需要更改这个URL到你自己的login.html 的文件路径 public static void main(String[] args) throws InterruptedException { WebDriver driver = new ChromeDriver(); driver.manage().window().maximize(); //最大化浏览器界面 driver.get(URL); //访问谷哥的首页 ,此处放弃度娘。 Thread.sleep(2000); //Wait for page load driver.findElement(By.id("inputEmail")).sendKeys("coderinfo@163.com"); // use id to find a web element Thread.sleep(2000); driver.findElement(By.name("password")).sendKeys("#####"); // use name to find a web element Thread.sleep(2000); driver.findElement(By.cssSelector("#inputEmail")).clear(); // use css selector to find a web element Thread.sleep(2000); driver.findElement(By.linkText("UseLink")).click(); // use link text to find a web element Thread.sleep(2000); driver.findElement(By.partialLinkText("Use")).click(); // use partial link text to find a web element Thread.sleep(2000); String formClassName = driver.findElement(By.tagName("form")).getAttribute("class"); //use tag name to find a web element System.out.println(formClassName); Thread.sleep(2000); String text = driver.findElement(By.xpath("/html/body/form/div[1]/div")).getText(); // use xpath to find a web element System.out.println(text); String inputText = driver.findElement(By.className("inputClass")).getAttribute("placeholder"); // use class name to find a web element System.out.println(inputText); Thread.sleep(5000); driver.quit(); //彻底退出WebDriver } } |
字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿
这里是要测试的页面login.html的源码:
<!DOCTYPE html> <html> <head> <title>For Selenium Test</title> <style type="text/css"> div { margin-top:10px } #inputEmail { color:red } </style> </head> <body> <center> <h3>Find Single Element</h3> </center> <form class="form-h"> <div class="items"> <div class="item"> Use ID:<input type="text" id="inputEmail" name="email" placeholder="Email"/> </div> </div> <div class="items"> <div class="item"> Use Name:<input type="password" id="inputPassword" name="password" placeholder="Password" class="inputClass"/> </div> </div> <div class="items"> <div class="item"> Use Link:<a href="#">UseLink</a> </div> </div> </form> </body> </html> |
一组元素的定位 :
package org.coderinfo.demo; import java.util.List; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; public class FindElements { private static final String URL = "file:///C:/user/Desktop/Selenium/checkbox.html"; //改为你自己的url public static void main(String[] args) { WebDriver driver = new ChromeDriver(); //create a chrome driver driver.manage().window().maximize(); // max size the chrome window driver.get(URL); //open URL with the chrome browser try { Thread.sleep(2000); // wait for web loading } catch (InterruptedException e) { e.printStackTrace(); } List<WebElement> webElements = driver.findElements(By.cssSelector("input[type='checkbox']")); // Use css selector to get all the checkbox for (WebElement webElement : webElements) { // loop through all elements webElement.click(); // click current element == select the current checkbox } System.out.println("Count: " + webElements.size()); //print the count of all the elements try { Thread.sleep(3000); // wait 3s } catch (InterruptedException e) { e.printStackTrace(); } webElements = driver.findElements(By.tagName("input")); // use tag name to get all the checkbox webElements.get(webElements.size()-1).click(); // Cancel the last selected checkbox try { Thread.sleep(5000); // wait 5s } catch (InterruptedException e) { e.printStackTrace(); } driver.quit(); // close webdriver } } |
测试页面checkbox.html的代码:
<!DOCTYPE html> <html> <head> <title>Get ALl CheckBox</title> <style type="text/css"> h2 { text-align:center } </style> </head> <body> <h2>CheckBox<h2/> <form class="form-h"> <div class="input-c"> <input type="checkbox" class="in" id="in1"/> <div> <div class="input-c"> <input type="checkbox" class="in" id="in2"/> <div> <div class="input-c"> <input type="checkbox" class="in" id="in3"/> <div> <div class="input-c"> <input type="checkbox" class="in" id="in4"/> <div> <div class="input-c"> <input type="checkbox" class="in" id="in5"/> <div> </form> </body> </html> |
相关文章:
摘要:对基于TTCN-3的测试系统进行逆向分析,可以帮助测试人员从更高层次上把握测试系统的设计,同时可以检验测试设计和测试实现之间的一致性,这些工作对于测试系统的评估、维护以及扩展都有重大的意义和重要的价值。本文首先简要介绍了逆向工程和基于TTCN-3测试系统的逆向工程的特点,设计了逆向模型发现的系统框架,并详细介绍了静态分析器的设计和实现。
关键词:TTCN-3;逆向工程;测试系统;静态分析;元模型
TTCN-3是由ETSI制定和推动的测试规范和测试实现标准。它是一种描述能力丰富的基于黑盒的测试描述规范,能够应用于多种形式的分布式系统的测试规约描述。随着TTCN-3测试技术的不断发展,它已经被越来越多地应用到各种测试领域,基于TTCN-3的测试系统开发已经具备了和软件开发相似的特征。但随着测试系统规模的增长以及测试人员的变更,对于庞大的测试系统的管理和维护,已经变得越来越困难。因此对基于TTCN-3的测试系统进行逆向工程,可以帮助测试人员从更高层次把握测试系统的设计,同时可以检验测试设计和测试实现之间的一致性,对于测试系统的维护、扩展以及评估都有重大的意义和重要的价值。
本文设计了逆向模型发现的系统框架,基于Eclipse平台使用插件机制很好的实现了框架的扩展和复用。然后,通过扩展TRex工程中的TTCN-3静态分析器,设计相应的接口实现静态基本信息、静态测试配置、测试数据、调用关系等的提取。同时使用Testing Technologies公司的TTworkbench工具运行测试用例,获得测试轨迹,实现动态测试配置的提取。本工具正是从静态和动态两个方面向测试人员和维护人员展示了测试系统的基本信息和抽象设计,用于辅助测试系统的维护和更新。
1、逆向工程介绍
逆向工程是软件工程领域的一个重要分支,随着软件复杂性的提高和遗留系统的增多,逆向工程越来越受到人们的重视,从而有了广阔的发展空间。Chikofsky和Cross将逆向工程定义为一个分析目标系统的过程,它一般包括如下两个部分:
(1)识别系统的构件并分析构件之间的依赖关系;
(2)建立系统另外的或在更高抽象级别上的表达形式。按照上述定义的逆向工程本质上也是一个知识恢复、知识发现工程,对于软件这种无形的人工产物来说,逆向工程的主要目的首先是重现考察对象所体现的原有设计知识,其次是能发现一些在设计中没有明显表示出的、存在于设计人员头脑中的设计知识。
由逆向工程的定义可见,软件逆向工程的任务包括分析系统、抽象系统和展现系统,从而实现协助用户理解系统的目的。分析系统是指分析系统的结构及运行过程,但不管目标系统面向何种应用领域,分析系统不外乎是分析系统的静态信息和动态信息;目标系统面对不同的应用领域,要实现抽象目标系统的任务,需要领域知识和专家的经验;展现系统最好的方式是使系统可视化。由于系统的抽象过程离不开领域知识和专家经验,所以很难有统一的方法,因此一般只讨论分析系统的过程,即静态信息和动态信息的获取。
本文将传统的逆向方法应用到TTCN-3测试系统之上,分别从静态和动态两个方面获取信息,然后制定领域相关的算法,提取描述测试系统的抽象模型并进行展示。通过逆向工程,有利于测试人员和维护人员理解和维护测试系统。
2、基于TTCN-3测试系统的逆向工程
随着软件测试作用的日益突出,测试作为软件过程中的重要一环越来越受到人们的重视。传统的软件测试主要集中在手工测试阶段,更多的只是重复劳动。随着自动化测试技术的日益成熟,使得软件测试进入了飞速发展的阶段,但测试描述还没有一个统一的规范,目前广泛使用的有XML、TCL等。如何使测试变得更高效、规范和可重用,成为人们热烈讨论的话题。随着2001年ETSI组织的TTCN-3测试规范的提出,这个问题逐渐找到了解决的方法。TTCN-3测试规范中的核心语言类似于传统的程序设计语言,可以在更广泛的应用领域描述测试,为测试集的编写提供更大的方便性和灵活性。由于TTCN-3是在测试驱动之下产生的,所以其语法和传统的编程语言相类似,并带有专用的测试扩展特性。因此,TTCN-3比传统的程序设计语言更关注于对测试判断的处理、对SUT(System Under Test,被测系统)的激励和期望接收到的反馈信息的模板匹配机制、对计时器的处理、测试执行控制机制、动态测试配置、同步/异步通信功能、测试进程的分布方式和信息编码的能力等。
由于TTCN-3语言所特有的动态配置、同步异步通信机制等强大功能,使得测试人员在从测试设计到测试实现阶段很难保证彼此之间的一致性;其次,面对庞大的测试系统的管理和维护,也需要有工具辅助。这些问题必将随着TTCN-3测试语言的日益成熟而受到人们更多的关注。对基于TTCN-3的测试系统进行逆向分析,可以帮助测试人员和维护人员从更高层次上把握测试系统的设计,同时可以检验测试设计和测试实现之间的一致性,这些工作对于测试系统的维护、扩展以及评估都有重大的意义。
基于TTCN-3测试系统的逆向工程,本质上是一个测试设计和测试模型的发现过程。逆向工程的一个核心问题就是为目标系统进行建模,因此必须解决如何为TTCN-3测试系统建立元模型,进而在元模型基础上生成测试系统模型。然后在测试系统模型上施加领域相关的算法,实现测试设计和测试模型的抽象和提取。
3、模型发现系统框架设计
一般来说,逆向工程包括如下两个部分:一是识别构件并分析构件之间的依赖关系;二是建立系统的另外的或在更高抽象级别上的表达形式。逆向工程本质上是一个知识恢复、知识发现的过程。因此本文将逆向工程分为三个步骤:
(1)数据的提取:此时的数据是未经处理,通过静态或动态分析获得源文件的元数据,这是逆向分析和模型发现的基础;
(2)知识的组织:将提取到的元数据进行分类和存储,此时主要使用已经定义的通用模型或规格等将元数据进行重组,实现知识的构建;
(3)信息的展现:在已获得知识的基础上,施加某种领域相关的算法实现系统更高层次信息的组织和提取。
基于对逆向工程和模型发现技术的总结,本文为基于TTCN-3测试语言的逆向工程设计了模型发现的系统框架,如图1所示。该框架建立在Eclipse平台之上,使用了Eclipse平台所提供的插件扩展机制,使得该框架易于维护和扩展。同时该框架还重用了Eclipse平台所提供的大量基础设施,利于系统的集成和开发。框架主要分为三个部分:静态分析部分输入为TTCN-3测试集,输出为抽象语法树和符号表,同时还包括动态轨迹的提取,即获取了测试集的元数据;建模部分输入为U2TP和TTCN-3规范,在这个过程中设计了TTCN-3测试系统元模型,实现了U2TP到TTCN-3映射规则,输出为TTCN-3测试系统模型,即实现了数据的重组和信息的形成;展现部分输入为TTCN-3测试系统模型,通过施加领域相关的算法实现测试设计和测试模型的发现,输出为TTCN-3测试系统的各种视图,即进行了模型的展现。

图1 逆向模型发现框架
4、TTCN-3测试系统元模型设计
TTCN-3虽然提供了诸如TFT和GFT这种表格和图形化的描述形式,但只是描述测试用例的一种格式而已,无法展现一个测试系统的整体结构和逻辑。为了解决维护、改进和复用大量遗留测试系统代码的问题,需要为TTCN-3测试系统提供一个抽象层次更高的描述方法。因此,本文针对模型发现目标,借用U2TP中的具体概念,实现了U2TP和TTCN-3之间的映射关系,设计了TTCN-3测试系统元模型。
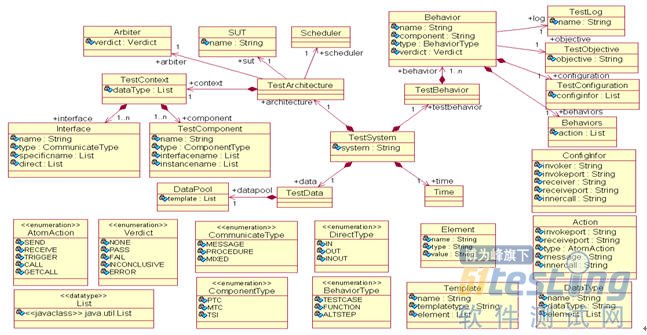
图2 TTCN-3测试系统元模型
参照U2TP对测试系统的描述和上面所制定的映射规则,本文将TTCN-3测试集抽象为四个部分:TestArchitecture、TestBehavior、TestData、Time,并定义了如图2所示的测试系统元模型。在设计过程中,本文考虑了逆向工程的特殊需求,对TTCN-3的元模型进行了相应的裁剪,方便测试系统模型的表示和展现。同时为了便于TTCN-3测试系统中基本信息的组织和存储,测试系统元模型中还定义了用于测试信息记录的相关数据结构。从图中可以看到,整个测试系统的根节点是TestSystem,每个测试系统会有自己的名字system,一般都是抽象测试集的名字。一个TestSystem中会包括四个逻辑部分,TestArchitecture、TestBehavior、TestData和Time。
此外,测试系统元模型还包括了TTCN-3测试语言中所特有的的测试特性,主要是一些枚举值的定义。主要包括通信的原子操作AtomAction、测试判定结果Verdict、测试通信类型CommunicateType、测试构件类型ComponentType、测试通信方向类型DirectType、测试函数类型BehaviorType等。
5、TTCN-3静态分析器的设计与实现
5.1 三种静态分析器的比较
为了便于定制需要的逆向分析工具,本文主要调研了开源的TTCN-3静态分析器。目前,主要有三种开源的面向TTCN-3的静态分析器可用,下面是对这三种静态分析器的对比分析:
ttthreeparser:由德国Testing Technologies公司早期开发的分析器,目前只支持TTCN-3v1.1.2版本,这是TTCN-3最早的一个版本,目前的测试脚本都是基于TTCN-3v3.1.1,在语法上进行了较大的调整,所以对本文的研究价值不大;
ttcn3parser:由Debian开源组织提供的基于Python的静态分析器,支持TTCN-3v3.1.1,但由于没有提供合适的接口和文档,因此需要重新改写里面的大部分文法,工作量太大;
TRex:由Motorola和德国的Gottingen大学合作开发,用于TTCN-3测试集的评估和重构,其中包括对TTCN-3v3.1.1的静态分析,并且定义了明确的接口和数据结构。
通过对上面工具的调研,本课题选用了TRex作为静态分析的工具,并在开源工具TRex静态分析器的基础上实现相应的接口、定义相应的数据结构,通过静态的逆向分析获取TTCN-3测试系统的基本信息和模型定义。TRex对TTCN-3的现有标准支持较好,同时还是一个开放源代码的研究性工程。另外,TRex以Eclipse插件的形式出现,这对于系统的扩展和集成非常有利。
5.2 TRex介绍
TRex是基于Eclipse插件机制实现的TTCN-3度量和重构工具,由Motorola公司和德国的哥廷根大学合作开发了这套系统。正向的TTCN-3工具一般都专注于核心编译器与测试执行器的开发,TRex属于逆向工程支持工具,其目标是分析和优化测试系统代码。Motorola公司发现,TTCN-3的编辑和执行固然需要工具支持,同样TTCN-3测试系统的维护和评估也需要有工具辅助。TRex的出现,使得TTCN-3测试代码的自动化度量和重构变为现实,同时也为评估测试系统设计的好坏提供了有力的依据。然而TRex无法帮助测试人员从更高层次上把握测试系统的设计,无法检验测试设计和测试实现之间的一致性。随着TTCN-3的发展,必将有更多的遗产测试系统需要被维护和升级,测试人员如何在最短时间内理解和掌握已有的测试系统,以及如何检验测试设计和测试实现之间的一致性,必将作为一个重大的问题受到人们的关注。本文的研究工作很好的满足了TTCN-3发展中的这种要求,同时结合TRex工具,必将为TTCN-3测试系统的管理和维护提供强有力的支持。
TRex主要用于TTCN-3测试系统的度量和重构,它主要分为三个模块,如图3:
● 将TTCN-3测试集作为输入,通过静态分析获得抽象语法树和符号表,即测试集的元数据;
● 将测试集的元数据作为输入,通过计算获取测试集的度量值,为测试集的好坏提供数据上的依据;
● 将测试集的元数据和度量值作为输入,通过变换语法树完成测试代码的重构。
通过静态分析、度量和重构,为测试集的维护提供了依据,同时输出质量更高的TTCN-3测试集。
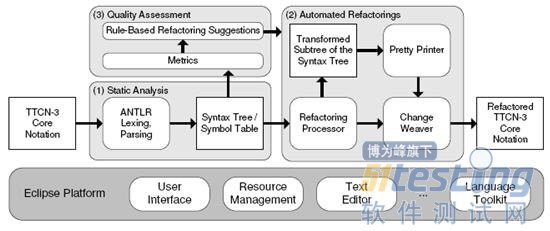
图3 TRex体系结构
5.3 对TRex的扩展
编译器首先把程序员写的源程序转换成一种方便处理的数据结构,那么这个转换过程就是词法分析和语法分析。通过TRex分析TTCN-3源代码,可以获得抽象语法树和符号表。抽象语法树使用Tree作为数据结构,因为Tree有很强的递归性,将Tree中的任何结点Node提取出来后,Node依旧是一棵完整的Tree。这一点符合现在编译原理分析的形式语言,比如在函数里面使用函数、循环中使用循环、条件中使用条件等等,那么就可以很直观地表示在Tree这种数据结构上。
针对本论文研究所要解决的问题,主要考察了de.ugoe.cs.swe.trex.core中的de.ugoe.cs.swe.trex.core.analyzer.rfparser包,它里面包含了TTCN-3的静态分析器,
TRex按照ANTLR的文法定义了TTCN-3语言的BNF范式,然后使用ANTLR提供的工具包生成了TTCN-3的静态分析器。通过静态分析器对TTCN-3源文件的分析,可以获取TTCN-3的抽象语法树,然后使用符号表对基本信息进行再组织。
TRex中重要的数据结构包括Symbol、LocationAST、Scope和SymbolTable,如图4所示:

图4 TRex的符号表
TTCN-3中定义了丰富的元素类型,可以方便用户定义测试配置、测试行为和测试数据等。TRex为每个TTCN-3元素都定义了一种Symbol,如图5所示。

图5 TRex中的符号
在逆向分析过程中,本文主要分析了ModuleSymbol、TypeSymbol、SignatureSymbol、EnumSymbol、PortInstanceSymbol、SubtypeSymbol、TemplateSymbol、TestcaseSymbol、FunctionSymbol、AltstepSymbol等关键数据结构。
TRex主要用于TTCN-3测试集的度量和重构,TTCN-3脚本的编辑功能和静态分析功能是整个工具的核心。在此,本文还分析了TRex的编辑器、编辑器之上的事件响应策略模式、静态分析器的工厂模式以及TTCN-3静态分析器的入口程序。本文通过对静态分析器核心代码的研读,在TTCN3Analyzer中加入了自己定义的数据结构和接口,用于访问静态分析获得的各种信息,实现模型的逆向发现。
6、总结
本文设计实现了逆向模型发现的系统框架,并详细介绍了静态分析器的设计实现。测试模型的抽象和提取在技术报告《基于TTCN-3测试系统的静态测试配置模型和数据模型的发现》和《基于TTCN-3测试系统的调用模型和动态测试配置模型的发现》中详细介绍,而实验在技术报告《基于TTCN-3测试系统的逆向工程的实验及数据分析》中详细介绍。对基于TTCN-3的测试系统进行逆向工程,可以帮助测试人员从更高层次把握测试系统的设计,同时可以检验测试设计和测试实现之间的一致性,对于测试系统的维护、扩展以及评估都有重大的意义和重要的价值。
1、AbstractSpringContextTests类[1],该类全部方法是protected的,通常不使用这个类,而使用它的子类们。
2、AbstractDependencyInjectionSpringContextTests类[2]:继承于类[1]:名字N长的。如果仅仅使用Spring依赖注入功能,可以让
测试用例继承该类。
3、AbstractTransactionalSpringContextTests类[3]:继承于类[2],继承该类的测试用例在spring管理的事务中进行,测试完后对
数据库的记录不会造成任何影响。你对数据库进行一些操作后,它会自动把数据库回滚,这样就保证了你的测试对于环境没有任何影响
4、AbstractTransactionalDataSourceSpringContextTests:继承于类[3],功能更强大,用于测试持久层组件,看其源代码,有一行"protected JdbcTemplate jdbcTemplate;",提供了一个JdbcTemplate的变量,通过该对象可以直接操作数据库。
[url]http://lighter.iteye.com/blog/41733[/url] 还提供了两个用spring来进行集成测试(对数据库操作进行测试),业务测试(对业务层进行测试)的例子供下载。
***如何在你的TestCase Class里取得spring context (注意路径问题)?***
你的TestCase Class必须继承的是上述四个AbstractXXXSpringContextTests中的其中一个,那么就必须实现下面这个方法来取得spring context:
protected abstract String[] getConfigLocations();
例如:
public String[] getConfigLocations() { String[] configLocations = { "applicationContext.xml","hibernate-context.xml" }; return configLocations; } |
请 注意要加载的context xml file的路径问题:上述的代码是基于classpath,因此applicationContext.xml和hibernate- context.xml必须放在classpath里(方法一是把xml files放到WEB-INF/classes目录下,另一种方法就是在project properties里把xml files的路径加到classpath里)
那么如果你一定要把context xml files放到WEB-INF目录下,也是可以的,那么应该基于file(基于file的相对路径是相对于project root folder),代码如下:
public String[] getConfigLocations() { String[] configLocations = { "file:WebContent/WEB-INF/applicationContext.xml"}; return configLocations; } |
AbstractXXXSpringContextTests就会根据根据getConfigLocations方法返回的context xml位置的数组来加载并且对加载的Context提供缓存。 这是非常重要的,因为如果你在从事一个大项目时,启动时间可能成为一个问题--这不是Spring自身的开销,而是被Spring容器实例化的对象在实例 化自身时所需要的时间。例如,一个包括50-100个Hibernate映射文件的项目可能需要10-20秒的时间来加载上述的映射文件,如果在运行每个 测试fixture里的每个测试案例前都有这样的开销,将导致整个测试
工作的延时,最终有可能(实际上很可能)降低效率。
在某种极偶然的情况下,某个测试可能“弄脏”了配置场所,并要求重新加载--例如改变一个bean的定义或者一个应用对象的状态--你可以调用 AbstractDependencyInjectionSpringContextTests 上的 setDirty() 方法来重新加载配置并在执行下一个测试案例前重建application context
当类 AbstractDependencyInjectionSpringContextTests(及其子类)装载你的Application Context时,你可以通过Setter方法来注入你想要的来自context的bean,而不需要显式的调用applicationContext.getBean(XXX)。因为AbstractDependencyInjectionSpringContextTests会从getConfigLocations()方法指定的配置文件中帮你自动注入
下面的例子就是通过setter方法来获得context里的ProductManager bean:
public class MyTest extends AbstractDependencyInjectionSpringContextTests { ProductManager productManager; public String[] getConfigLocations() { String[] configLocations = { "file:WebContent/WEB-INF/applicationContext.xml" }; return configLocations; } public void testGetProduct() { assertEquals("tomson",productManager.getProductByName("tomson").getName()); } //通过setter方法自动从context里注入productManager bean,而不用显示调用applicationContext.getBean(XXX) public void setProductManager(ProductManager productManager) { this.productManager = productManager; } } |
但是如 果context里有多个bean都定义为一个类型(例如有多个bean都是ProductManager class类型的),那么对这些bean就无法通过setter方法来自动依赖注入(因为有多个bean同一个类型,不知要自动注入哪个)。在这种情况下 你需要显示的调用applicationContext.getBean(XXX)来注入。如:
public class MyTest extends AbstractDependencyInjectionSpringContextTests { ProductManager productManager; public String[] getConfigLocations() { String[] configLocations = { "file:WebContent/WEB-INF/applicationContext.xml" }; return configLocations; } public void onSetUp() { productManager = (ProductManager) applicationContext.getBean("productManager"); } public void testGetProduct() { assertEquals("tomson",productManager.getProductByName("tomson").getName()); } } |
如果你的TestCase不使用依赖注入,只要不定义任何setters方法即可。或者你可以继承 AbstractSpringContextTests --这个 org.springframework.test 包中的根类,而不是继承AbstractDependencyInjectionSpringContextTests(及其子类)。这是因为AbstractSpringContextTests 只包括用来加载Spring Context的便利方法但没有自动依赖注入的功能。
我从
项目管理的角度来谈一下这个问题吧,因为我觉得这个问题更是一个项目管理的问题。
难控制的意思就是经常超出自己的意料,实际进展不能吻合
测试计划。
从计划角度来说,测试执行的阶段最难控制的原因主要体现在两个方面:
测试环境的不稳定性和缺陷的数量及修复难度
这两方面都将较大程度的影响测试主管制定测试计划和执行测试计划,正所谓计划赶不上变化
从项目的渐进明细角度来说,测试前期对整个测试周期的估算都是理想的,前期乐观后期悲观是咱们的常态。
无论计划、文档完整度、需求变更、程序质量、版本控制、测试人员自身能力甚至沟通顺畅度都是乐观的。
随着
工作的开展,项目工作越来越明晰的时候,问题和风险就来了。
计划赶不上变化,文档也不够完善,需求竟然还变更了,程序缺陷无数、版本无法控制甚至与开发沟通的各种问题统统集中出现了。
而作为测试经理的领导在这个时候也无能为力,作为测试小兵的咱们已经痛苦不堪,早已习惯一旦进入执行阶段即意味着加班的无底洞。
这些问题大多在风险管理环境没有做好,前期阶段没有做好风险应对方案以及预留解决这些问题的时间,导致时间只能从执行阶段的加班时间中挤出。
风险管理没做好的结果是进入执行阶段将为前期没做好的事情买单。
本身环境不稳定和缺陷数据和修复难度就已经让测试阶段的进度难以控制了,再加上前期种种问题的积累,压在测试人员的身上喘不过气来。
PS:沟通管理在项目管理中是最重要的部分,包括前期测试人员对需求理解时与业务人员、开发人员所进行的沟通以及测试执行过程中缺陷汇报以及进度报告的沟通。
人在沟通上,感情和矛盾都是可以积累的,若积累的是矛盾将导致和包括开发在内的其他人员沟通越来越困难
无论在缺陷处理过程中开发不及时修复,还是验证阶段摆不平客户,这些都属于沟通管理的部分。
1、关联是获取服务器返回给客户端的动态数据(字符串),把该字符串保存在参数中,在后面的函数中调用
2、注意关联函数的位置
例子
Action() { web_reg_save_param("UserSession", "LB=name=userSession value=", "RB=>", "Ord=1", "Search=NoResource", LAST); web_url("WebTours", "URL=http://127.0.0.1:1080/WebTours/", "TargetFrame=", "Resource=0", "RecContentType=text/html", "Referer=", "Snapshot=t1.inf", "Mode=HTML", LAST); web_submit_data("login.pl", "Action=http://127.0.0.1:1080/WebTours/login.pl", "Method=POST", "TargetFrame=body", "RecContentType=text/html", "Referer=http://127.0.0.1:1080/WebTours/nav.pl?in=home", "Snapshot=t2.inf", "Mode=HTML", ITEMDATA, "Name=userSession", "Value={UserSession}", ENDITEM, "Name=username", "Value=xxx", ENDITEM, "Name=password", "Value=xxx", ENDITEM, "Name=JSFormSubmit", "Value=off", ENDITEM, "Name=login.x", "Value=53", ENDITEM, "Name=login.y", "Value=8", ENDITEM, LAST); return 0; } |
服务器响应的信息
<input type=hidden name=userSession value=110598.691130012fziiQcApVHfDtVDDpfcVAf>
运行的结果
Action.c(11): Notify: Saving Parameter "UserSession = 110598.555285541fziiQVDpViHfDtVDDptHQVcf". Action.c(11): Found resource "http://127.0.0.1:1080/WebTours/images/mer_login.gif" in HTML "http://127.0.0.1:1080/WebTours/nav.pl?in=home" [MsgId: MMSG-26659] Action.c(11): web_url("WebTours") was successful, 6445 body bytes, 1608 header bytes [MsgId: MMSG-26386] Action.c(21): Notify: Parameter Substitution: parameter "UserSession" = "110598.555285541fziiQVDpViHfDtVDDptHQVcf" |
一、Java Class文件是什么
《The JavaTM Virtual Machine Specification》(Second Edtion)中有表述:Java Class文件由8位字节流组成,所有的16位、32位和64位数据分别通过读入2个、4个和8个字节来构造,多字节数据总是按照Big-endian顺序来存放,即高位字节在前(放在低地址)。每个Class文件都包含且仅包含一个Java类型(类或者接口)。
或许,《The JavaTM Virtual Machine Specification》中的表述不够明确,那么我们可以参考一下《Inside the Java Virtual Machine》(Second Edtion)中的表述:Java Class文件特指以.class为后缀名的Java虚拟机可装载的文件。
分析一下两者的表述,我觉得都不够全面、不够明确。我是这么定义的:Java Class文件就是指符合特定格式的字节流组成的二进制文件。这个特定的格式就是指第二节要讨论的Class文件格式,亦即在《The JavaTM Virtual Machine Specification》中定义的Class文件格式。从另一个角度来说,这个特定格式就是指JVM能够识别、能够装载的格式。为什么这么说呢?因为JVM在装载class文件时,要进行class文件验证,以保证装载的class文件内容符合正确的内部结构。这个内部结构指的就是这个特定格式,只要是符合这个特定格式的Class文件都是合法的、规范的Class文件,都是JVM能够装载的Class文件。如果觉得这样的表述还是不够明确,我只能建议你读完这篇
文章之后再回头来理解看看了J
为了讨论方便,在下文中将对这两个参考资料做个简记:
1)《The Java Virtual Machine Specification》(Second Edtion)简记为《JVM Spec》(2nded)。
2)《Inside the Java Virtual Machine》(Second Edtion) 简记为《Inside JVM》(2nded)。
二、Java Class文件的格式
在讲Class文件的格式之前,要介绍三个概念:
1)数据类型:《JVM Spec》(2nded)中指出,Java Class文件的数据用自己定义的一个数据类型集来表示,即u1,u2,u4,分别用于表示一个无符号类型的、占1,2,4个字节的数据。在《Inside JVM》(2nded)一书中,作者把这个数据类型集称之为Class文件的基本类型,本人觉得比较形象,便于理解。所以,在本文中,我们也用基本类型来表示Java Class文件的数据。
2)表:根据《JVM Spec》(2nded)中的定义,表(table)由项(定义见3)组成,用于几种Class文件结构中。《JVM Spec》(2nded)中指出,Java Class文件格式用一个类似于C结构的记号编写的伪结构来表示。这个伪结构指的就是这里的表,例如下面的ClassFile表就是这种伪结构的一个典型例子,下文中所有的表都是指这种伪结构的表。表的大小是可变的,这是因为它的组成部分项是可变的。注意;这里的可变是针对Class层次而言的,即在不同的Class文件中该项的大小可能不一样的,但是对于每一个具体的Class文件来说,这个项的大小又是一定的,因而这个表的大小也是一定的。那么,项为什么是可变的呢?请看下面的分析。
3)项:描述Java Class文件格式的结构的内容称为项(items)。每个项都有自己的类型和名称。项的类型可能是基本类型,也可能是一个表的名字,这种项都是一些数组项。数组项的每一个元素都是一个表,这个表同顶层的ClassFile表一样,也都是一种伪结构,也都是由一些项构成的,而且这些表不一定是同一种格式的,因此数组项也可以看作一个可变大小的结构流J。这些表对于该数组项来说就是子项,当然子项可能还有子项(目前子项的深度最多就两层)。项的名称,没有什么好说的,就是《JVM Spec》(2nded)中指定的一些名称。另外,项也是有大小的,对于没有子项的项来说,其大小是固定的;对于有子项的项来说,其大小是可变的。在一个具体的Class文件中,一个可变项(数组)的大小都会在其前一项中指定,为什么会是这样的呢?因为《JVM Spec》(2nded)中就是这么定义的!在Class文件中,每个项按规范中定义好的顺序存储在Class文件中,相邻的项之间没有任何间隔,连续的项(数组)也是按顺序存储,不进行填充或者对齐,这样可以使Class文件紧凑。
好了,我想这三个概念我已经解释地比较清楚了,下面开始正式解析Class文件的格式。
首先要来解析一下ClassFile表结构,这是《JVM Spec》(2nded)中定义的Class文件最外层的结构,换言之,就是Class文件的格式。
ClassFile表结构
ClassFile { u4 magic; u2 minor_version; u2 major_version; u2 constant_pool_count; cp_info constant_pool[constant_pool_count-1]; u2 access_flags; u2 this_Class; u2 super_Class; u2 interfaces_count; u2 interfaces[interfaces_count]; u2 fields_count; field_info fields[fields_count]; u2 methods_count; method_info methods[methods_count]; u2 attributes_count; attribute_info attributes[attributes_count]; } |
ClassFile表结构由16个不同的项组成,其中的各项可以简要地分析如下:
(1) magic
每个Class文件的前4个字节被称为它的魔数(magic number): 0xCAFEBABE。魔数的作用在于:可以轻松地分辨出Java Class文件和非Java Class文件。(如果一个文件不是以0xCAFEBABE开头,它就肯定不是Java Class文件,因为它不符合规范J)。当Java还称为“Oak”的时候,这个魔数就已经定下来了,它预示了Java这个名字的出现。魔数的来历请大家自己查阅J
(2) minor_version和major_version
Class文件的下面4个字节包含了次、主版本号。通常只有给定主版本号和一系列次版本号后,Java虚拟机才能够读取Class文件。如果Class文件的版本号超出了Java虚拟机所能够处理的有效范围,Java虚拟机将不会处理该Class文件。例如J2SE5.0版本的虚拟机就不能执行由J2SE6.0版本的编译器编译出来的Class文件。
(3) constant_pool_count
版本号后面的项是constant_pool_count即常量池计数项,该项的值必须大于零,它给出该Class文件中常量池列表项的元素个数,这个计数项包括了索引为0的constant_pool表项,但是该表项不出现在Class文件的constant_pool列表中,因为它被保留为Java虚拟机内部实现使用了,因此常量池列表的元素个数constant_pool_count-1,各个常量池表项的索引值分别为1到constant_pool_count-1。
注:在这里,有几个术语需要解释一下,常量池即为constant_pool,常量池列表就是指constant_pool[ ],常量池表项即指常量池列表中的某一个具体的表项(元素)。这些常量池表项的可能类型如下述的cp_type表所示:
cp_type
入口类型 标志值
CONSTANT_Class 7
CONSTANT_Fieldref 9
CONSTANT_Methodref 10
CONSTANT_InterfaceMethodref 11
CONSTANT_String 8
CONSTANT_Integer 3
CONSTANT_Float 4
CONSTANT_Long 5
CONSTANT_Double 6
CONSTANT_NameAndType 12
CONSTANT_Utf8 1
(4) constant_pool[ ]
constant_pool_count项下面是constant_pool[ ]项,即常量池列表,其中存储了该ClassFile结构及其子结构中引用的各种常量,诸如文字字符串、final变量值、类名和方法名等等。在Java Class文件中,常量池表项是用一个cp_info结构来描述的,常量池列表就是由constant_pool_count-1个连续的、可变长度的cp_info表结构构成的constant_pool[ ]数组。为什么是constant_pool_count-1个constant_pool的原因,在上面已经解释了。每一个常量池表项都是一个变长结构,其通常格式如下所示:
cp_info
cp_info表的tag项是一个无符号的byte类型值,它表明了cp_info表的类型和格式,具体的tag类型见上表。
需要说明的是,cp_info只是一个抽象的概念,在Class文件中,它表现为一系列具体的、形如CONSTANT_Xxxx_info的constant_pool结构,其具体的格式由cp_info表的tag项(即第一个字节)来确定。不同的cp_info表,其info[]项也是不一样的,例如,CONSTANT_Class_info表的info[]项为“u2 name_index”,而CONSTANT_Utf8_info表的info[]项为“u2 length; u1 bytes[length];”,显然,这两个cp_info表是不一样的,大小更是不一样的,因而常量池表项的大小是可变的。由于常量池列表中的每个常量池表项的结构是不一样,因此常量池列表的大小也是可变的。在Class文件中,常量池列表项是一个可变长度的结构流。
由cp_info表以及cp_type表我们可以知道,若cp_info表中tag(标志)项的值为1时,当前的cp_info就是一个CONSTANT_Utf8_info表结构,若cp_info表中tag项的值为3,当前的cp_info就是一个CONSTANT_Integer_info表结构,其它情况类推。这些表的结构可以查阅《JVM Spec》(2nded)的第四章或者《Inside JVM》(2nded)的第六章。
(5) access_flags
紧接常量池后的两个字节称为access_flags,access_flags项描述了该Java类型的一些访问标志信息。例如,访问标志指明文件中定义的是类还是接口;访问标志还定义了在类或接口的声明中,使用了哪些修饰符;类和接口是抽象的还是公共的等等。实际上,access_flags项的值是Java类型声明中使用的访问标志符的掩码(mask,这里掩码指的是access_flags的值是所有访问标志值的总和,当然,未被使用的标志位在Class文件中都被设置为0。例如,若access_flags的值就是0x0001,就表示该Java类型的访问标志符是ACC_PUBLIC;若access_flags的值是0x0011,就表示该Java类型的访问标志符是ACC_PUBLIC和ACC_FINAL,因为只有这两个标志位的和才可能是0x0011;其它情况类推)。
一个Java类型的所有access_flags标志符如下表所示:
access_flags
标志名称 值 含义
ACC_PUBLIC 0x0001 声明为public,可以从它的包外访问
ACC_FINAL 0x0010 声明为final,不允许有子类
ACC_SUPER 0x0020 用invokespecial指令处理超类的调用
ACC_INTERFACE 0x0200 表明是一个接口,而不是一个类
ACC_ABSTRACT 0x0400 声明为abstract,不能被实例化
需要说明的是,这是针对一个Java类型的访问标志符列表,有的标志符只有类可以使用,有的标志符只有接口才可以使用,详情请查阅《JVM Spec》(2nded)。
ClassFile表结构由16个不同的项组成,其中的各项可以简要地分析如下:
(1) magic
每个Class文件的前4个字节被称为它的魔数(magic number): 0xCAFEBABE。魔数的作用在于:可以轻松地分辨出Java Class文件和非Java Class文件。(如果一个文件不是以0xCAFEBABE开头,它就肯定不是Java Class文件,因为它不符合规范J)。当Java还称为“Oak”的时候,这个魔数就已经定下来了,它预示了Java这个名字的出现。魔数的来历请大家自己查阅J
(2) minor_version和major_version
Class文件的下面4个字节包含了次、主版本号。通常只有给定主版本号和一系列次版本号后,Java虚拟机才能够读取Class文件。如果Class文件的版本号超出了Java虚拟机所能够处理的有效范围,Java虚拟机将不会处理该Class文件。例如J2SE5.0版本的虚拟机就不能执行由J2SE6.0版本的编译器编译出来的Class文件。
(3) constant_pool_count
版本号后面的项是constant_pool_count即常量池计数项,该项的值必须大于零,它给出该Class文件中常量池列表项的元素个数,这个计数项包括了索引为0的constant_pool表项,但是该表项不出现在Class文件的constant_pool列表中,因为它被保留为Java虚拟机内部实现使用了,因此常量池列表的元素个数constant_pool_count-1,各个常量池表项的索引值分别为1到constant_pool_count-1。
注:在这里,有几个术语需要解释一下,常量池即为constant_pool,常量池列表就是指constant_pool[ ],常量池表项即指常量池列表中的某一个具体的表项(元素)。这些常量池表项的可能类型如下述的cp_type表所示:
cp_type
入口类型 标志值
CONSTANT_Class 7
CONSTANT_Fieldref 9
CONSTANT_Methodref 10
CONSTANT_InterfaceMethodref 11
CONSTANT_String 8
CONSTANT_Integer 3
CONSTANT_Float 4
CONSTANT_Long 5
CONSTANT_Double 6
CONSTANT_NameAndType 12
CONSTANT_Utf8 1
(4) constant_pool[ ]
constant_pool_count项下面是constant_pool[ ]项,即常量池列表,其中存储了该ClassFile结构及其子结构中引用的各种常量,诸如文字字符串、final变量值、类名和方法名等等。在Java Class文件中,常量池表项是用一个cp_info结构来描述的,常量池列表就是由constant_pool_count-1个连续的、可变长度的cp_info表结构构成的constant_pool[ ]数组。为什么是constant_pool_count-1个constant_pool的原因,在上面已经解释了。每一个常量池表项都是一个变长结构,其通常格式如下所示:
cp_info
cp_info表的tag项是一个无符号的byte类型值,它表明了cp_info表的类型和格式,具体的tag类型见上表。
需要说明的是,cp_info只是一个抽象的概念,在Class文件中,它表现为一系列具体的、形如CONSTANT_Xxxx_info的constant_pool结构,其具体的格式由cp_info表的tag项(即第一个字节)来确定。不同的cp_info表,其info[]项也是不一样的,例如,CONSTANT_Class_info表的info[]项为“u2 name_index”,而CONSTANT_Utf8_info表的info[]项为“u2 length; u1 bytes[length];”,显然,这两个cp_info表是不一样的,大小更是不一样的,因而常量池表项的大小是可变的。由于常量池列表中的每个常量池表项的结构是不一样,因此常量池列表的大小也是可变的。在Class文件中,常量池列表项是一个可变长度的结构流。
由cp_info表以及cp_type表我们可以知道,若cp_info表中tag(标志)项的值为1时,当前的cp_info就是一个CONSTANT_Utf8_info表结构,若cp_info表中tag项的值为3,当前的cp_info就是一个CONSTANT_Integer_info表结构,其它情况类推。这些表的结构可以查阅《JVM Spec》(2nded)的第四章或者《Inside JVM》(2nded)的第六章。
(5) access_flags
紧接常量池后的两个字节称为access_flags,access_flags项描述了该Java类型的一些访问标志信息。例如,访问标志指明文件中定义的是类还是接口;访问标志还定义了在类或接口的声明中,使用了哪些修饰符;类和接口是抽象的还是公共的等等。实际上,access_flags项的值是Java类型声明中使用的访问标志符的掩码(mask,这里掩码指的是access_flags的值是所有访问标志值的总和,当然,未被使用的标志位在Class文件中都被设置为0。例如,若access_flags的值就是0x0001,就表示该Java类型的访问标志符是ACC_PUBLIC;若access_flags的值是0x0011,就表示该Java类型的访问标志符是ACC_PUBLIC和ACC_FINAL,因为只有这两个标志位的和才可能是0x0011;其它情况类推)。
一个Java类型的所有access_flags标志符如下表所示:
access_flags
标志名称 值 含义
ACC_PUBLIC 0x0001 声明为public,可以从它的包外访问
ACC_FINAL 0x0010 声明为final,不允许有子类
ACC_SUPER 0x0020 用invokespecial指令处理超类的调用
ACC_INTERFACE 0x0200 表明是一个接口,而不是一个类
ACC_ABSTRACT 0x0400 声明为abstract,不能被实例化
需要说明的是,这是针对一个Java类型的访问标志符列表,有的标志符只有类可以使用,有的标志符只有接口才可以使用,详情请查阅《JVM Spec》(2nded)。