1、atpp_case_remote case远程通信插件测试,容灾场景:
a、消息发送端在网络异常场景下,第一次发送消息失败之后的处理。
手段:拔网线模拟;
结果:开发设计之初没有考虑这种场景,后增加一个google的queue依赖
解决这个问题。实现方式是,当第一次发送失败后会将发送数据保存一份到本地文件中,然后不断进行重试发送,直到发送成功;
2、法网狙击项目暴露了很多异常测试和容灾测试方面的考虑欠缺:
a、 PMC流程某个节点服务调用异常的情况下,系统的处理。
按照开发的设计,需要在此时进行调用重试,每2分钟一次,共重试5次,最后失败才生成小二任务。
手段:日常下,利用TCC工具对azeroth里面的代码进行异常注入,使代码运行到该方法时抛出异常,从而模拟异常场景。
结果:发现从开始使用PMC开始,就没有对这些异常情况进行考虑,所有的异常都是马上生成了小二任务进行处理,甚至有一些流程就这样一直卡住,没有任何补救措施。
解决:修改PMC的配置,添加异常重试的处理,按照之前的设计进行。
b、 调用消保的冻结、解冻、转移保证金接口,发生不同的异常场景,返回不同的ERROE CODE,最后本系统进行处理的细节考虑不全。
系统间交互容易出现的问题(针对hsf调用):
(异常场景)
1、超时时抛出超时异常;
2、序列化/反序列化失败时抛出HSF异常;
3、没有可用的目标服务地址时抛出HSF异常;
4、服务端抛出业务异常,返回同样的业务异常;
5、依赖应用封装了下一级应用的异常,返回相应的ERROE_CODE;
6、调用的目标服务地址有通信问题,自动尝试有限次数重新选址;
(并发场景)
1、识别可能存在并发的场景,模拟依赖应用返回并发的ERROR_CODE
(幂等调用)
1、如何模拟幂等调用??看对方是怎样判断幂等性的,如果无法真实模拟对方返回幂等调用结果的场景,则mock掉真实的调用情况,直接返回幂等调用时候的ERROR_CODE。
解决方案:
测试场景应该细化考虑异常场景,包括,超时异常,hsf异常以及各种业务异常返回的处理,而不仅仅是类似系统异常(RuntimeException然后看系统是否重试这么简单而已)
采用的方式,mockHsf服务调用的返回。之前的方式(bugfix的时候)通过开发在日常debug,修改服务调用返回值来处理。
第一步,先梳理所有调用到消保接口的类和方法;
第二步,每个调用到的地方都尝试进行mock超时、hsf异常返回的处理,并且明确其他业务异常的返回和处理。
第三部,补充接口脚本覆盖这些场景。
3、 盖亚项目中测试品质保障流程中,自动赔付功能,采用mock异常的方式,成功找到了一个严重的系统bug:
Bug描述如下:
【接口测试】支付宝余额不足冻结支付宝余额失败的情况下,没有去转移保证金,自动赔付失败。
按照之前的设计,在支付宝不足的情况下,也是要继续进行保证金转移的,转移失败了才自动赔付失败转人工。在此,mock调用消保的冻结接口返回余额不足的errorcode来驱动下面的逻辑,结果发现不符合期望,促进开发修改掉了这个bug。
二. 我们线容灾测试的展望
总结我们先所遇到的异常场景,既不是天灾造成的一些异常,也不是由于大访问量造成的压力过大而带来的灾难,我们线的客观情况也注定了我们的访问量也不会达到很夸张的程度,所以也没有像交易线那样的各种开关,流控容灾措施。相应的,我们是依赖其各种线的应用比较多的,所以应用间的强弱依赖关系,对强依赖挂掉和弱依赖挂掉之后或者返回异常的容灾处理应该是我们线容灾测试的重点。
所以我们的目标应该是:在其他依赖挂掉的情况下,不会影响到我们应用的正常运行,所以需要加强这些方面的容灾测试。
第一步是要梳理整个服务线的应用强弱依赖关系图。并针对不同的依赖容灾点进行相应的测试,保证最后达到容灾的目标。
针对这个,已经有同事提供了解决方案,具体实践这种方案,暂时没有看到实例,还需要进一步实践观察。
最近一直在学习
Selenium,打算先从 Selenium IDE入手。IDE 很简单,最重要的就是如何定位目标元素,本人推荐使用CSS来定位你的目标元素。css如何定位在这就不在赘述,google上一堆,对于在
学习遇到的问题,强烈建议使用google,
百度对于技术方面的搜索太渣渣。
下面我说说我今天遇到的一个问题,今天在写脚本的时候,定位不到combo box中的值。通过google最终找到解决的方法
一次使用 click, mouserover, click, command命令来选中combo box中的值。
</head> <body> <table cellpadding="1" cellspacing="1" border="1"> <thead> <tr><td rowspan="1" colspan="3">New Test</td></tr> </thead><tbody> <tr> <td>open</td> <td>/login.htm</td> <td></td> </tr> <tr> <td>selectAndWait</td> <td>id=ddlWebsite</td> <td>乐学</td> </tr> <tr> <td>clickAndWait</td> <td>css=a:contains("班级管理")</td> <td></td> </tr> <tr> <td>click</td> <td>id=btn1</td> <td></td> </tr> <tr> <td>pause</td> <td>5000</td> <td></td> </tr> <tr> <td>sendKeys</td> <td>txtTitle</td> <td>Selenium</td> </tr> <tr> <td>click</td> <td>id=comboxText_cbClassCategory</td> <td></td> </tr> <tr> <td>waitForVisible</td> <td>id=comboxlist_cbClassCategory</td> <td></td> </tr> <tr> <td>waitForElementPresent</td> <td>css=div.listitem[onclick=OnChangeEvent('cbClassCategory','d9806437-84a1-4b5d-9670-baa5aff64086','脱产班','');;;]</td> <td></td> </tr> <tr> <td>mouseOver</td> <td>css=div.listitem[onclick=OnChangeEvent('cbClassCategory','d9806437-84a1-4b5d-9670-baa5aff64086','脱产班','');;;]</td> <td></td> </tr> <tr> <td>click</td> <td>css=div.listitem[onclick=OnChangeEvent('cbClassCategory','d9806437-84a1-4b5d-9670-baa5aff64086','脱产班','');;;]</td> <td></td> </tr> </tbody></table> </body> </html> |
如果你要定位的元素 id class name 全相同可以使用这个语法定位你想要定位的值
css=tag.class[attribute=value]
ex:css=div.listitem[onclick=OnChangeEvent('cbClassCategory','d9806437-84a1-4b5d-9670-baa5aff64086','脱产班','');;;]
版权声明:本文出自 pigsea 的51Testing软件测试博客:http://www.51testing.com/?301228
最近看了一下关于
java的基础知识,对此作了一下搜集整理:
java中的继承,方法覆盖(重写)override与方法的重载overload的区别
方法的重写(Overriding)和重载(Overloading)是Java多态性的不同表现。
重写(Overriding)是父类与子类之间多态性的一种表现,而重载(Overloading)是一个类中多态性的一种表现。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写 (Overriding) 。子类的对象使用这个方法时,将调用子类中的定义,对它而言,父类中的定义如同被"屏蔽"了。如果在一个类中定义了多个同名的方法,它们或有不同的参数个数或有不同的参数类型或有不同的参数次序,则称为方法的重载(Overloading)。不能通过访问权限、返回类型、抛出的异常进行重载。
1. Override 特点
1、覆盖的方法的标志必须要和被覆盖的方法的标志完全匹配,才能达到覆盖的效果;
2、覆盖的方法的返回值必须和被覆盖的方法的返回一致;
3、覆盖的方法所抛出的异常必须和被覆盖方法的所抛出的异常一致,或者是其子类;
4、方法被定义为final不能被重写。
5、对于继承来说,如果某一方法在父类中是访问权限是private,那么就不能在子类对其进行重写覆盖,如果定义的话,也只是定义了一个新方法,而不会达到重写覆盖的效果。(通常存在于父类和子类之间。)
2.Overload 特点
1、在使用重载时只能通过不同的参数样式。例如,不同的参数类型,不同的参数个数,不同的参数顺序(当然,同一方法内的几个参数类型必须不一样,例如可以是fun(int, float), 但是不能为fun(int, int));
2、不能通过访问权限、返回类型、抛出的异常进行重载;
3、方法的异常类型和数目不会对重载造成影响;
4、重载事件通常发生在同一个类中,不同方法之间的现象。
5、存在于同一类中,但是只有虚方法和抽象方法才能被覆写。
其具体实现机制:
overload是重载,重载是一种参数多态机制,即代码通过参数的类型或个数不同而实现的多态机制。 是一种静态的绑定机制(在编译时已经知道具体执行的是哪个代码段)。
override是覆盖。覆盖是一种动态绑定的多态机制。即在父类和子类中同名元素(如成员函数)有不同 的实现代码。执行的是哪个代码是根据运行时实际情况而定的。
Overrride实例 :
class A{ public int getVal(){ return(5); } } class B extends A{ public int getVal(){ return(10); } } public class override { public static void main(String[] args) { B b = new B(); A a= (A)b;//把 b 强 制转换成A的类型 int x=a.getVal(); System.out.println(x); } } |
结果:10
Overload实例:
//Demostrate method voerloading. class OverloadDemo { void test(){ System.out.println("NO parameters"); } void test(int a){ System.out.println("a:"+a); }//end of Overload test for one integer parameter. void test(int a, int b){ System.out.println("a and b:"+a+" "+b); } double test(double a){ System.out.println("double a:"+a); return a*a; } } public class Overload{ public static void main(String[] args) { OverloadDemo ob = new OverloadDemo(); double result; ob.test(); ob.test(10); ob.test(10, 20); result = ob.test(123.25); System.out.println("Result of ob.test(123.25):"+result); } } |
结果:
NO parameters
a:10
a and b:10 20
double a:123.25
Result of ob.test(123.25):15190.5625
在s2sh写sql语句的时候,需要对时间经行特殊的处理。时间在
数据库中都为Date类型
1.转换成string类型:
2.在页面使用My97DatePicker/WdatePicker等时间插件工具
进行查询时,需要进行格式化:
1.CPU在上电后,进入操作系统的main()之前必须做什么?
加电后,会触发CPU的reset信号,导致CPU复位,然后CPU会跳到(arm下0x00000000,x86下0xfffffff0)执行指令.主 要是做CPU初始化,确定CPU的
工作模式,mmu初始化。建立页表段表,初始化中孤单控制器和中断向量表,初始化输入和输出,初始化 nandflash,把OS的TEXT区加载到sdram,然后跳转到sdram的main()
2.什么是中断?中断时CPU做什么工作?
中断是指在计算机执行期间,系统内发生任何非寻常的或非预期的急需处理事件,使得CPU暂时中断当前正在执行的程序而转去执行相应的事件处理程序。待处理完毕后又返回原来被中断处继续执行或调度新的进程执行的过程。
3.简术ISO OSI的物理层Layer1,链路层Layer2,网络层Layer3的任务。
网络层:资料传送的目的地寻址,再选择出传送资料的最佳路线;
链路层:负责网络上资料封包如何传送的方式;
物理层:在设备与传输媒介之间建立及终止连接。参与通讯过程使得资源可以在共享的多用户中有效分配,对信号进行调制或转换使得用户设备中的数字信号定义能与信道上实际传送的数字信号相匹配
4.makefile文件的作用是什么?
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后 编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为 makefile就像一个Shell脚本一样,其中也可以执行操作系统的命令。makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个 make命令,整个工程完全自动编译,极大的提高了
软件开发的效率。make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大 多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,
Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
5.UNIX显示文件夹中文件名的命令是什么?能使文件内容显示在屏幕的命令是什么?
ls cat
type tail
6.Linux文件属性有哪些?(共十位)
-rw-r--r—1
第一个属性代表这个文件是【目录、文件或连结文件】,当为[ d ]则是目录,为[ - ]则是文件,若是[ l ]则表示为连结档(link file);
若是[ b ]则表示为装置文件里面的可供储存的接口设备;
若是[ c ]则表示为装置文件里面的串行端口设备,例如键盘、鼠标。
接下来的属性中,三个为一组,且均为【rwx】三个参数的组合,其中[r]代可读、
[w]代表可写、[x]代表可执行:
第一组为【拥有人的权限】,
第二组为【同群组的权限】;
第三组为【其它非本群组的权限】。
7.Linux中常用到的命令
显示文件目录命令ls
改变当前目录命令cd 如cd / /home
建立子目录mkdir mkdir xiong
删除子目录命令rmdir 如 rmdir /mnt/cdrom
删除文件命令RM 如 rm /ucdos.bat
文件复制命令cp 如 cp /ucdos/* /fox
获取帮助信息命令man 如 man ls
显示文件的内容less 如 less mwm.lx
重定向与管道type 如type readme>>direct,将文件readme的内容追加到文direct中
8.进程通信有哪些方式?
管道通信、消息通信、内存共享
9.说说分段和分页。
页是信息的物理单位,分页是为实现离散分配方式,以消减内存的外零头,提高内存的利用率;或者说,分页仅仅是由于系统管理的需要,而不是用户的需要。
段是信息的逻辑单位,它含有一组其意义相对完整的信息。分段的目的是为了能更好的满足用户的需要。页的大小固定且由系统确定,把逻辑地址划分为页号和页内 地址两部分,是由机器硬件实现的,因而一个系统只能有一种大小的页面。 段的长度却不固定,决定于用户所编写的程序,通常由编辑程序在对源程序进行编辑时,根据信息的性质来划分。
分页的作业地址空间是维一的,即单一的线性空间,程序员只须利用一个记忆符,即可表示一地址。分段的作业地址空间是二维的,程序员在标识一个地址时,既需给出段名,又需给出段内地址
10.什么是进程和线程?有何区别?
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.
线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.一个线程可以创建和撤销另一个线程;同一个进程中的多个线程之间可以并发执行.
11.Windows下的内存是如何管理的?
Window操纵内存可以分两个层面:物理内存和虚拟内存。
其中物理内存由系统管理,不允许应用程序直接访问,应用程序可见的只有一 个2G地址空间,而内存分配是通过堆进行的,对于每个进程都有自己的默认堆,当一个堆创建后,就通过虚拟内存操作保留了相应大小的地址块(不占有实际的内 存,系统消耗很小),当在堆上分配一块内存时,系统在堆的地址表里找到一个空闲块(如果找不到,且堆创建属性是可扩充的,则扩充堆大小)为这个空闲块所包 含的所有内存页提交物理对象(物理内存上或硬盘上的交换文件上)。这时可以就访问这部分地址了。提交时,系统将对所有进程的内存统一调配,如果物理内存不 够,系统试图把一部分进程暂时不访问的页放入交换文件,以腾出部分物理内存。释放内存时,只在堆中将所在的页解除提交(相应的物理对象被解除),继续保留 地址空间。
如果要知道某个地址是否被占用/可不可以访问,只要查询此地址的虚拟内存状VirtualQuery),如果是提交,则可以访问。如果仅仅保留,或没保留,则产生一 个 软件异常。此外有些内存页可以设置各种属性。如果是只读,向内写也会产生软件异常
12.操作系统的内容分为几块?什么叫做虚拟内存?优点管理属于操作系统的内容吗?
13.进程是一个比较重要的概念,那么进程有哪几种状态?
基本状态有3种,即ready(就绪),running(运行),wait(等待).
14.说出你所知道的保持进程同步的方法?
进程间同步的主要方法有内存屏障,互斥锁,信号量和锁,管程,消息,管道
15.OS中如何实现物理地址到逻辑志址的转换?
16.解释一下分页式管理。
用户程序的地址空间被划分成若干固定大小的区域,称为“页”,相应地,内存空间分成若干个物理块,页和块的大小相等。可将用户程序的任一页放在内存的任一块中,实现了离散分配.
17.什么是死锁,其条件是什么?怎么避免死锁?
死锁是指,在两个或多个并发进程中,如果每个进程持有某种资源而又都等待别的进程释放它们现在保持着的资源,否则就不能向前推进.此时,每个进程都占用了 一定的资源但是又不能向前推进,称这一组进程产生了死锁. 通俗的讲,就是两个或多个进程无止境的等候着永远不会成立的条件的一种系统状态. 其条件是为
1.互斥:存在这样一种资源,它在某个时刻只能被分配给一个执行绪使用;
2.持有:当请求的资源已被占用从而导致执行绪阻塞时,资源占用者不但无需释放该资源,而且还可以继续请求更多资源;
3.不可剥夺:执行绪获得到的互斥资源不可被强行剥夺,换句话说,只有资源占用者自己才能释放资源;
4.环形等待:若干执行绪以不同的次序获取互斥资源,从而在由多个执行绪组成的环形链中,每个执行绪都在等待下一个执行绪释放它持有的资源。
避免死锁:按顺序访问,事务最小化
18.什么是缓冲区溢出?有什么危害?其原因是什么?
缓冲区溢出是指当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量溢出的数据覆盖在合法数据上,
危害:在当前网络与分布式系统安全中,被广泛利用的50%以上都是缓冲区溢出,其中最著名的例子是1988年利用fingerd漏洞的蠕虫。而缓冲区溢出 中,最为危险的是堆栈溢出,因为入侵者可以利用堆栈溢出,在函数返回时改变返回程序的地址,让其跳转到任意地址,带来的危害一种是程序崩溃导致拒绝服务, 另外一种就是跳转并且执行一段恶意代码,比如得到shell,然后为所欲为。
通过往程序的缓冲区写超出其长度的内容,造成缓冲区的溢出,从而破坏程序的堆栈,使程序转而执行其它指令,以达到攻击的目的。造成缓冲区溢出的原因是程序中没有仔细检查用户输入的参数
19.什么是临界区?如何解决冲突?
每个进程中访问临界资源的那段程序称为临界区,每次只准许一个进程进入临界区,进入后不允许其他进程进入。
① 如果有若干进程要求进入空闲的临界区,一次仅允许一个进程进入。
② 任何时候,处于临界区内的进程不可多于一个。如已有进程进入自己的临界区,则其它所有试图进入临界区的进程必须等待。
③ 进入临界区的进程要在有限时间内退出,以便其它进程能及时进入自己的临界区。
④ 如果进程不能进入自己的临界区,则应让出CPU,避免进程出现“忙等”现象。
20.解释一下P操作与V操作。
P就是请求资源,V就是释放资源
21.中断和轮询的特点。
做Web开发,难免要对自己开发的页面进行性能检测,自己写工具检测,工作量太大。网上有几款比较成熟的检测工具,以下就介绍一下,与大家分享。
互联网现有工具
基于网页分析工具:
1.阿里测
2.百度应用性能检测中心
2.Web PageTest
3.PingDom Tools
4.GTmetrix
基于浏览器分析工具:
1.Chrome自带工具F12
2.Firefox插件:YSlow(Yahoo工具)
3.Page Speed(google)
(以下以分析博客园网站为例)
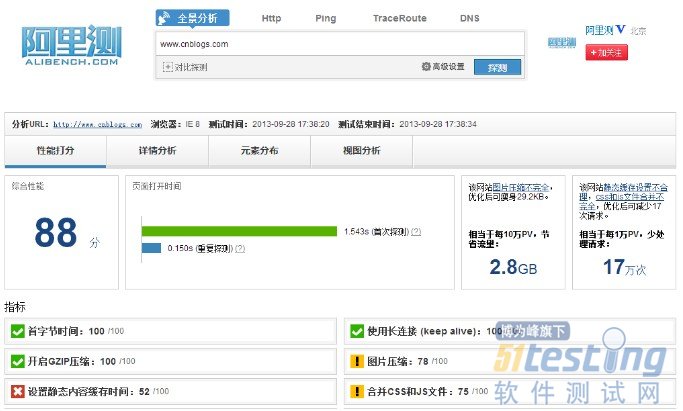
首页:
一、性能打分
a)首字节时间
指标解释:浏览器开始收到服务器响应数据的时间(后台处理时间+重定向时间)
评估方法:达标时间=DNS解析时间+创建连接时间+SSL认证时间+100ms. 比达标时间每慢10ms减1分.
b)使用长连接(keep alive)
指标解释: 服务器开启长连接后针对同一域名的多个页面元素将会复用同一下载连接(socket)
评估方法:服务器是否返回了"Connection: keep-alive"HTTP响应头,或者浏览器通过同一连接下载了多个对象
c)开启GZIP压缩
指标解释:仅检查文本类型("text/*","*javascript*")
评估方法:服务器是否返回了"Transfer-encoding: gzip"响应头。假如全部压缩就是满分,否则:得分=满分x(100%-全部gzip后节省的比例%)
d)图片压缩
评估方法:
对于GIF - 略过
对于PNG - 必须是8位或更低
对于JPEG - 对比使用photoshop质量选择50后的图片,尺寸超出10%以内及格,10%-50%警告,50%以上不达标
得分=满分x(100%-图片重新压缩后可以节省的比例%)
e)设置静态内容缓存时间
指标解释:css,js,图片资源都应该明确的指定一个缓存时间
评估标准:如果有静态文件的过期时间设置小于30天,将会得到警告
f)合并css和js文件
指标解释:合并js和css文件可以减少连接数
评估方法:每多一个css文件减5分,每多一个js文件减10分
g)压缩JS
指标解释:除了开启gzip,使用js压缩工具可以进行代码级的压缩
评估方法:js文件会通过jsmin压缩.如果原始文件gzip过,jsmin处理过的文件也会gzip后再进行对比.如果能节省>5KB或者%10的尺寸,评估失败.如果能节省>1KB同样会收到警告.
h)合理使用cookie
指标解释:cookie越小越好,而且对于静态文件需要避免设置cookie
评估方法:只要对静态文件域设置了cookie,评估失败. 对于其他请求,cookie尺寸过大会得到警告.
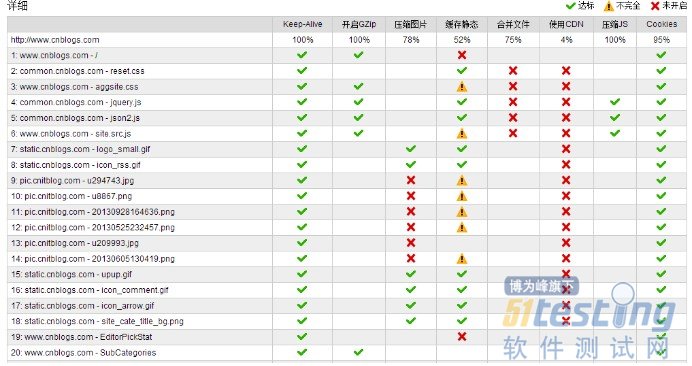
二、详情分析

i)首次探测(首次探测会清空DNS缓存和浏览器缓存),重复探测(保留首次探测的缓存,进行再次探测)。
j)页面加载时间:从页面开始加载到页面onload事件触发的时间。
k)首字节时间:从开始加载到收到服务器返回数据的第一字节的时间。
l)开始渲染时间:从开始加载到浏览器开始渲染第一个html元素的时间。
m)Speed index:
n)元素个数:页面中包含的所有DOM节点个数
o)页面加载(包括加载时间,请求数,下载总计):从页面开始加载到onload事件触发这个时间段内的统计数据,一般来说onload触发代表着直接通过HTML引用的CSS,JS,图片资源已经完全加载完毕。
p)完全加载:随着ajax应用的流行,很多资源都会通过JS脚步异步加载,所以onload事件并不意味着完全加载,onload之后js可能依然在异步加载资源。完全加载的定义是:页面onload后2秒内不再有网络请求时刻。
q)元素瀑布图:通过元素瀑布图可以很直观得到以下信息。
i.资源的加载顺序。
ii.每个资源的排队延迟,加载过程。
iii.加载过程中CPU和贷款的变化曲线。
iv.统计出出错请求、大图片请求、onload之后的请求、开始渲染之前的请求、首字节较慢的请求及DNS解析较慢的请求个数。
r)连接视图展现了页面加载过程中创建的(keep-alive)连接,以及通过每个连接所加载的资源。
三、元素分布

s)资源类型统计:css,html,image,js,other(请求数,大小)
t)资源域名统计:请求域名个数及次数
四、视图分析
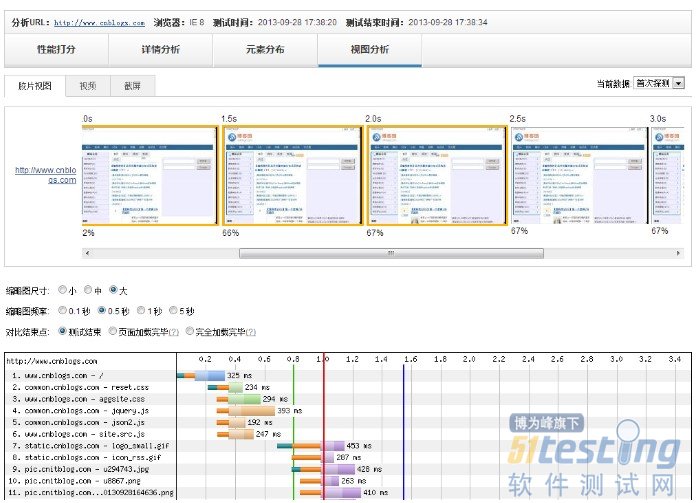
将整个网页生成的过程以胶片视图、视频、截屏的形式展现出来,并提供详细的状态栏加载日志。
YSlow:
火狐插件(自行安装)
评分等级指标:
1.确保少量的HTTP请求(合并JS,CSS图片等)
2.使用内容分发CDN
3.设置过期的HTTP Header.设置Expires Header可以将脚本, 样式表, 图片, Flash等缓存在浏览器的Cache中。
4.使用gzip压缩
5.将CSS放置html头部
6.将JavaScript放置底部
7.Avoid CSS expressions
8.使用外部引用JavaScript与CSS
9.减少DNS解析
10.压缩JavaScript和CSS
11.避免URL重定向。URL redirects are made using HTTP status codes 301 and 302. They tell the browser to go to another location.
12.删除重复JavaScript和CSS
13.设置ETags
一.概述
1.1目的
为了确保XXX“XXX”活动的正常和有续进行,检验系统的承压性能和稳定性能,对平台进行
性能测试,同时发现系统中存在的性能瓶颈,起到优化系统的目的;测试的依据是产品的需求规格说明书和性能标准说明。
1.2名词解释
性能测试:性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试。负载测试和压力测试都属于性能测试,两者可以结合进行。
二.测试需求分析
2.1测试对象
产品名称:XXX平台
版本:V1.0
版本日期:2013.10.10
2.2系统结构
请参考设计说明书
2.3测试范围
XXX平台的各项性能:服务器CPU使用情况,内存使用情况,网络吞吐量情况,并发登陆承载模拟.
性能指标:
1.Memory:AvailableMBytes
2.Memory:Page/sec
3.Processor:ProcessorQueueLength
4.Processor:ProcessorTime
5.Processor:ContextSwitches/sec
6.Ethernet:Throughput
2.4测试环境
系统环境:
Sever:Windows2008severIIS7.0
Client:Windows7
硬件环境:
IPCPUOSMemoryStorage
XXX.XXX.XXX.XXXXeonCPUE526200@2GHzWindows2008sever16G300G
测试工具:
Laodrunner11.0
三.测试场景设计
3.1场景
1.模拟多人登陆系统后,选择商品,进行购买,购买成功后进行付款。
3.1.1测试目的
测试在多人登陆,产生大数据量的情况下,系统和服务器的承载和处理能力。
3.1.2测试步骤
使用loadrunner形成脚本
1.登陆系统
2.输入用户名,密码
3.输入查询条件选择出商品
4.选择该商品,放入购物车
5.提交购物车中的商品,形成订单
6.进行付款
场景
1.加载多个用户运行生成的脚本
2.观察运行期间内的服务器各项性能指标
3.1.3测试结论
根据压力测试的各项数据结果,系统在多用户登陆的情况下,运行稳定,正常,压力承载在可承受范围内
一. 目的与区别
我曾在2010年在国内知名搜索引擎服务商公司
工作,主要负责网页前端
自动化测试工具的开发,我们当时的做法已经其实和现在网页自动化测试方法基本一致,即在watir和watir-webdriver上开发一套自己的封装层,但当时没有引入cucumber做BDD, 而是让其他测试人员直接编写RUBY脚本,require我们制做的封装层,其实理论上讲,只是没有打包成gem,也没有进行测试。 在此过程中遇到的最大的困难就是将我们的封装层部署到每个测试人员的计算机中,并可以指导每个测试人员编写ruby脚本。因此,以上所提及的point都是针对大型网站服务商的测试工具开发的基本薄弱点,也是为中型公司和大型公司开发测试工具的不同点。
为大型公司开发测试工具必须要引入AGILE的方法,才能使整个测试工具从开发到使用是可控的。但本文不着重讲AGILE的方法,主要讲的内容是如何BUILD你最初的整体MAVEN架构,如何利用MAVEN去开发和发布自己的gem或是ruby home.
二. 整体思路
主要有两种方法,
其一是比较传统的打包成gem,发送给所有的测试人员,让其安装本地gem,前提条件是每个测试人员都必须安装同样版本的ruby 或者jruby,这一点来说并不好控制,因此,该方法优点就是方便快捷,但缺点就是没有办法管理基础层的版本。
其二是将整个ruby home打包成zip发布,因为ruby的目录程序是不需要安装的,拷贝到任何一台计算机都可以直接使用,只需要设置一下ruby home即可,而且还可以使用ide去进行开发,这样的方法是我主要推荐的,所有的版本都在测试工具开发人员的掌握之中,不会因为ruby的版本变化,或者ruby中安装的其他的gem的影响,而导致整个测试框架的不稳定或者完全崩溃
三. maven项目的目录结构
-RobinJ (Project name)
-- org.robinj.robinj-gem
-- org.robinj.jrubyhome
-- org.robinj.test
-- org.robinj.test.chrome
-- org.robinj.test.firefox
-- org.robinj.test.ie
四. 模块介绍
<span style="font-size:18px;"><execution> <id>import jruby complete and own gems</id> <phase>process-resources</phase> <goals> <goal>copy</goal> </goals> <configuration> <artifactItems> <artifactItem> <groupId>org.jruby</groupId> <artifactId>jruby-complete</artifactId> <version>${jruby.version}</version> <type>jar</type> <overWrite>true</overWrite> <outputDirectory>${basedir}/tmp</outputDirectory> </artifactItem> <artifactItem> <groupId>org.robinj</groupId> <artifactId>robinj-gem</artifactId> <version>${project.parent.version}</version> <type>gem</type> <outputDirectory>${basedir}</outputDirectory> </artifactItem> </artifactItems> </configuration> </execution></span> |
package MyMath; //生成随机数 调用的是系统的方法 public class random { public static void main(String args[]) { Random random=new Random(5); for(int i=0;i<10;i++) { System.out.println(random.nextInt()); } } } |
引用java 类库的实现方法
下面自己写随机,,了解一下种子数,,其实对同一个种子生成的随机数是相同的,,但是种子数是不对更新的
package MyMath; public class random1 { public static void main(String args[]) { double []r=new double[2]; r[0]=5.0; for(int i=0;i<10;i++) { System.out.println(rand1(r)); } } public static double rand1(double []r) { double temp1,temp2,temp3,p,base; base=256.0; int a=17,b=139; temp1=r[0]*17+139; temp2=(int)(temp1/256); temp3=temp1-temp2*base; r[0]=temp3; p=temp3/256; return p; //基本思想 就是 递推法 r[i]=mod(a*r[i-1],base); 随机数 p=r[i/base; //这个随机数 确实是随机的 但是缺陷就是它并不符合 正态分布 种子的选取会影响后来的分布的 } } |
引用一些公式就实现了符合正态分布的
public class random2 { public static void main(String args[]) { double []r=new double[2]; r[0]=5.0; for(int i=0;i<10;i++) { System.out.println(randZT(2.0,3.5,r)); } } //符合正态分布的随机算法 /* * * */ public static double rand1(double []r) { double temp1,temp2,temp3,p,base; base=256.0; int a=17,b=139; temp1=r[0]*17+139; temp2=(int)(temp1/256); temp3=temp1-temp2*base; r[0]=temp3; p=temp3/256; return p; //基本思想 就是 递推法 r[i]=mod(a*r[i-1],base); 随机数 p=r[i/base; //这个随机数 确实是随机的 但是缺陷就是它并不符合 正态分布 种子的选取会影响后来的分布的 } public static double randZT(double u,double t,double []r) { int i; double total=0.0; double result; for(i=0;i<12;i++) { total+=rand1(r); } result=u+t*(total-6.0); return result; } } |