我比较倾向于直接在
web应用中配置
数据库连接,例如使用struts或者是Hibernate的连接池,这样的好处是无需了解不同的应用服务器在配置数据源的差别,应用实施的时候比较简单。
所以我最近的一些项目都是采用这种架构,但是这种方式有一些不足的就是当应用服务器配置了多个应用,而这些应用使用同一个数据库,这就会导致不必要的资源浪费,也就是同一个应用服务器中存在针对同一个数据库的多个连接池。
也就是说我们希望每个应用服务器只有一个连接池的实例,在这个应用服务器上运行的所有项目都可以使用这个连接池,下面介绍这种方式在Tomcat和Resin下的配置。
Tomcat使用JNDI Resource来配置各种资源,包括数据库连接池。这些Resource有两种运行范围,第一个就是Context级别,也就是说Context特有的Resource,该Resource只能被其所属的Context访问,显然这不是我们所要的。
另外一种就是定义全局命名资源,然后在Context中进行引用,下面是一个配置的例子(
server.xml):
<Server port="8005" shutdown="SHUTDOWN"> <GlobalNamingResources> <!-- 全局有效的JDBC资源 --> <Resource name="jdbc/dlog" auth="Container" type="javax.sql.DataSource" maxActive="100" maxIdle="30" maxWait="10000" defaultTransactionIsolation="1" defaultAutoCommit="false" poolPreparedStatements="true" maxOpenPreparedStatements="1000" initialSize="1" username="root" password="root" driverClassName="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/dlogcn?autoReconnect=true"/> </GlobalNamingResources> <!-- Define the Tomcat Stand-Alone Service --> <Service name="Catalina"> <!-- Define a non-SSL HTTP/1.1 Connector on port 8080 --> <Connector port="8080" maxHttpHeaderSize="8192" maxThreads="150" minSpareThreads="25" maxSpareThreads="75" enableLookups="false" redirectPort="8443" acceptCount="100" connectionTimeout="20000" disableUploadTimeout="true" /> <!-- Define the top level container in our container hierarchy --> <Engine name="Catalina" defaultHost="localhost"> <Host name="localhost" appBase="webapps"> <Context path="" docBase="C:/PROJECTS/JAVA/DLOG4J_V3/webapp" reloadable="true"> <!-- 在Context引用全局JDBC资源 --> <ResourceLink name="jdbc/dlog" global="jdbc/dlog"/> </Context> </Host> </Engine> </Service> </Server> |
相比较Tomcat来说,Resin更为简单,在Resin2中连接池的配置如下
<caucho.com> <http-server> <http port='80'/> <servlet-mapping url-pattern='*.xtp' servlet-name='xtp'/> <servlet-mapping url-pattern='*.jsp' servlet-name='jsp'/> <resource-ref res-ref-name="java:/comp/env/jdbc/dlog" res-type="javax.sql.DataSource"> <init-param driver-name="com.mysql.jdbc.Driver"/> <init-param url="jdbc:mysql://localhost:3306/dlogcn?autoReconnect=true"/> <init-param user="root"/> <init-param password="moabc"/> <init-param maxConnections="100"/> </resource-ref> <!-- default host if no other host matches --> <host id=''> <web-app id='' app-dir='C:/PROJECTS/JAVA/DLOG4J_V3/webapp' /> </host> </http-server> </caucho.com> |
你可以把这段配置放在web-app中,则该连接池只有对应的webapp才能访问,放在<host>则,host中的所有web-app都可以访问,放在<http-server>中,则整个resin的所有webapp都可以访问。
(实验过程中发现resin2的文档有误,如果res-ref-name写为jdbc/dlog,则webapp怎么都找不到这个资源,改成java:/comp/env/jdbc/dlog即可。)
接下来我们就可以在应用中使用如下代码来获取连接池的DataSource实例
Context initContext = new InitialContext();
Context envContext = (Context)initContext.lookup("java:/comp/env");
DataSource ds = (DataSource)envContext.lookup("jdbc/dlog");
其他的应用服务器的配置可以按照这个思路参考它的手册进行配置。应该说不管是采用何种方式,性能上不会有太大的区别,如何选择就在于你整个服务器的项目结构。
另外从上面Tomcat和Resin的配置来看,尽管Resin的配置要简单于Tomcat,但是灵活性和扩展性就相对要差一些
我一直从事B/S测试
工作,因为对网游(主要是C/S结构的)比较感兴趣,所以现在开始
学习游戏开发方面的知识(刚开始看),比如opengl、、VC++游戏设计入门、
windows游戏编程大师技巧、数据结构算法等,为以后转游戏
测试做准备,既然做C/S测试,安装/卸载是测试的很重要的部分之一,所以利用空闲时间写一下自己的安装/卸载
用例设计思路,练习一下,如果你觉得写的不好或者觉得有需要补充的地方,请大家提出来,大家共同学习,共同进步,谢谢!
安装卸载用例设计思路(界面、易用方面的没写)
一、安装路径:
1、缺省路径安装
2、自定义安装路径:
a) 通过浏览,选择自定义路径
b) 手动输入路径(存在的路径、不存在的路径)
c)非C盘安装
d)指定路径下已有同名文件
e) 中文路径(中文路径、中英文混合路径)
f) 包含空格的路径(空格、下划线等合法路径)
g) 非法路径(路径中输入特殊字符,看处理是否正确)
二、安装环境:
1、没安装过
2、已安装过老版本(系统正在使用、系统未使用)
3、已安装了最新版本
4、卸载系统重新安装
5、安装一半,异常退出(比如在线安装断网、本地安装点取消、断电等),可重新安装
6、磁盘空间不足
7、删除了部分文件(可正常安装、修复、卸载系统)
8、操作系统Windows(WindowsXP、Windows2000、Windows2003、Vista等,区分专业版、服务器版以及不同补丁环境)、Unix 、 Macintosh 、
Linux等
9、杀毒软件:金山、江民、瑞星、诺顿、卡巴斯基、安全卫士等(根据需求,测试相应的环境)
10、标准配置安装、推荐配置安装、最低配置安装、未达到最低配置安装(硬件环境)
三、安装类型:
1、标准安装
2、推荐安装
3、自定义安装
四、安装完成
1、安装成功,检查版本信息是否正确
2、安装完成,文件属性为非只读
3、安装完成,快捷方式检查,创建快捷方式正确
4、双击快捷方式,可以正常打开系统
5、打开系统所在目录,双击打开(右键打开),可正常使用系统
6、安装过程中,任意步点击取消,成功取消安装
7、卸载过程中,任意步点击取消,成功取消卸载
9、不同分辨率下,系统可正常运行
五、卸载方式:
(1、正常卸载后检查文件是否全部卸载,注册表是否有残余信息,控制面板中检查系统是否被删除。2、异常卸载是否正确处理 )
1、添加/删除程序中卸载
2、开始→程序,快捷方式中卸载
3、使用安装程序卸载
4、使用系统提供的卸载文件卸载
5、直接删除文件夹(删除后,验证再次安装是否报错)
6、系统正在使用,卸载系统
六、网络环境:(针对以来网络的系统;比如网游等)
1、不同上网方式是否能正常使用系统(比如:专线上网、代理(需要密码,不需要密码)上网等)
2、不同网络提供商提供的网络环境下是否能正常使用系统:电信、网通、百灵、铁通等(根据需求测对应的网络提供商)
七、用户类型:(针对需要序列号的安装)
1、体验用户(体验期/超过体验期,卸载后安装)
2、付费用户(付费期/超过付费期,卸载后安装)
最近做项目的时候,监控一个带有额外存储
数据库服务器系统是
Windows Server 2008,发现DISK TIME 很多大于100的,大家知道DISK TIME是一个百分比,理论上最大也就100%.
异常的数据如下:
% Disk Time 328.1876 49.0227 1433.891 141.8331 661.2175 1001.768 651.9919 117.3368 797.8396 921.1879 64.84509 1112.133 1254.004 151.9364 |
经过查资料发现,DISK TIME计数器在有多个磁盘的情况下会重复统计,所以此时的disk time 就没啥参考意义了...
那怎么办呢?
当前服务器的D盘(外挂存储)是放置数据库文件的,所以在计数器中增加一个 _d Idle time,用100-_d Idle time 得到的就是 D盘的IO情况
最近在做性能测试,在性能调优过程中查阅了些虚拟机相关的知识,下面对虚拟机所用的性能监控的工具做个简单的介绍和汇总。
一、JDK命令行工具
1.jps:虚拟机进程状况工具
列出正在运行的虚拟机进程,显示虚拟机执行祝列的名称,已经这些进程的本地虚拟机的唯一ID。此命令虽然功能单一,但它是使用频率最高的JDK命令工具。
Jps 命令格式:
jps [options] [hostid]
2. jstat:虚拟机统计信息监视工具
jstat(JVM Statistics Monitoring Tool)是用于监视虚拟机各种运行状态信息的命令行工具。它可以显示本地或远程虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。在没有GUI图形界面,只提供了纯文本控制台环境服务器上,它将是运行期定位虚拟机性能问题的首选工具。
jstat命令格式:
jstat [option vmid [ interval [s|ms] [count] ] ]
参数interval和count代表查询的间隔和次数,如果省略这两个参数,说明只查询一次。
例如:jstat –gc 3232 500 20
命令含义为:每500ms查询一次进行3232垃圾收集器的状况,一共查询20次。
选项option代表用户希望查询虚拟机信息,主要分为3类;类装载、垃圾收集和运行期编译状况。
3. jinfo:Java配置信息工具
jinfo(Configuration Info for Java)实时查看和调整虚拟机的各项参数。想知道未被显示指定的参数的系统默认值,可以使用jinfo的-flag选项进行查询,jinfo还可以使用-sysprops选项把虚拟机进行的System.getProperties()的内容打印出来。
jinfo命令格式:
jinfo [option] pid
4.jmap:Java内存映像工具
jmap(Memory Map for Java)于生成堆转储快照,查询finalize执行队列,Java堆和永久代的详细信息等。
jmap命令格式:
jmap [option] vmid
5.jstack:Java堆栈跟踪工具
jstack(Stack Trace for Java)用于生成虚拟机当前时刻的线程快照,定位线程出现长时间停顿的原因。
jstack命令格式:
jstack [option] vmid
二、 JDK可视化工具
1. Jconsole:java监视与管理控制台
JConsole可以说是前面介绍的所有功能性JDK工具的一个可视化版本,几乎实现了JVM Manage API中提供的所有的功能。
通过JDK/bin目录下的“jconsole.exe”启动JConsole。如图1,双击其中一个进程即可开始监控,也可以使用“远程进程”功能来连接远程服务器,对远程虚拟机进行监控。
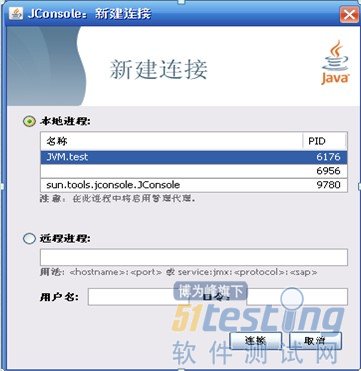
图1

图2
1)图2“概述”页显示整个虚拟机主要运行数据的概览。
2)内存监控
“内存”页签相当于可视化的jstat命令,用于监视收集器管理的虚拟机内存(java堆和永久代)的变化趋势。
3)线程监控
“线程”页签的功能相当于可视化的jstack命令,遇到线程停顿的时候可以时候线程监控进行分析
2.VisualVM:多合一故障处理工具
VisualVM它除了运行监视、故障处理外,还提供了很多其他方面的功能。如性能分析(profiling),VisualVM的性能分析功能甚至比起JProfiler专业且收费工具都不会逊色多少,而且VisualVM还有一个很大的优点:不需要被监视的程序基于特殊的Agent运行,因此它对应用程序的实际性能影响很小,使得他可以直接应用在生产环境中。
1)启动VisualVM
通过JDK/bin目录下的“jvisualvm”启动VisualVM,可以根据需要给VisualVM装扩展插件,点击“工具”-->“插件”菜单。
2)生成和浏览堆转储快照
可以通过以下2种方式生成:
在“应用程序”窗口中右键单机应用程序节点,然后选择“堆dump”;
在“应用程序”窗口双击应用晨曦节点打开应用程序标签,然后再“监视”标签中单击“堆dump”。
生成了dump文件之后,应用程序页签将在堆的应用程序下增加以[heapdump]开头的子节点,并在主页签中打开该转储快照,如图3。

“摘要”面板可以看到应用程序dump时运行的参数、线程堆栈等信息。
“类”面板以类为统计口径统计的类的实例数量和容量信息。
“实例”面板需要通过“类”面板进去,在“类”中选择关系的类后点击,即可在实例中查看此类的实例信息。
3)分析程序性能
在Profiler页签中,提供了程序运行期间方法级的CPU执行时间分析及内存烦心,进行profiling肯定会对程序运行性能有比较大的影响,所以一般不在生产环境中使用这项功能。
选择“cpu”或“内存”,VisualVM会记录这段时间中应用程序执行过的方法。Cpu分析会统计每个方法执行的次数、执行耗时。分词分析则会统计每个方法关联对象数及这些对象所占用的空间,如图4。
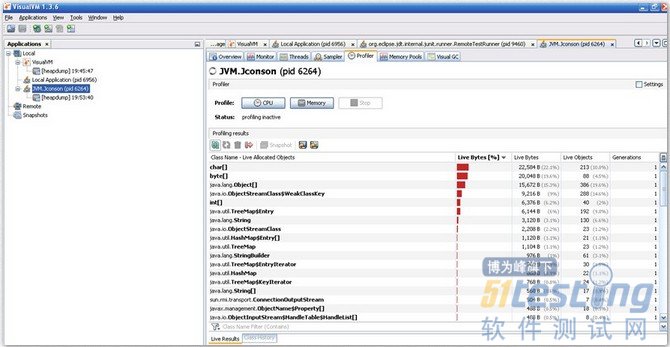
图4
即是web用户在访问一个页面时所要花费的时间总和。即一个完全意义上的用户响应时间,相对于服务器的响应时间而言还会包括更多的内容和影响因素。那么一个web页面的完整请求包括了哪些部分的时间总和就是web前段性能分析和优化所需要了解的基础知识,先了解一下用户从浏览器访问一个url后到页面完全展示所有内容的整个过程吧。
页面的请求过程:
1、浏览器的url请求
2、递归寻找DNS服务器
3、连接目标IP并建立TCP连接
4、向目标服务器发送http请求
5、web服务器接收请求后处理
6、web服务器返回相应的结果【无效、重定向、正确页面等】
7、浏览器接收返回的http内容
================================前端解析分割线===========================================
8、开始解析html文件,当然是自上而下,先是头部,后是body
9、当解析到头部css外部链接时,同步去下载,如果遇到外部js链接也是下载【不过js链接不建议放在头部,因为耽误页面第一展现时间】
10、接着解析body部分,边解析边开始生成对应的DOM树,同时等待css文件下载
11、一旦css文件下载完毕,那么就同步去用已经生成的DOM节点+CSS去生成渲染树
12、渲染树一旦有结构模型了,接着就会同步去计算渲染树节点的布局位置
13、一旦计算出来渲染的坐标后,又同步去开始渲染
14、10-13步进行过程中如果遇到图片则跳过去渲染下面内容,等待图片下载成功后会返回来在渲染原来图片的位置
15、同14步,如果渲染过程中出现js代码调整DOM树机构的情况,也会再次重新来过,从修改DOM那步开始
16、最终所有节点和资源都会渲染完成
=========================================分析结束分割线==============================================
17、渲染完成后开始page的onload事件
18、整个页面load完成
整个过程中会有很多的分别请求,所以TCP连接会很多,并且每一个用完都会自己关了,除非是keep-live类型的可以请求多次才关闭。
综上所述:
一个页面的请求等于一个或多个url的请求,因此一个页面里包含的外部请求数会影响页面的整体性能
【每请求一次就要多占用一次cpu使用、多一次tcp连接】
每个url的请求又包括寻址、连接、请求传输、返回传输、断连的过程;因此每个阶段的外部环境也会影响整体性能
【DNS服务器的寻址时间,请求和返回内容时的网络环境】
除了URL请求数量外,每个请求的内容大小也是影响性能的主要因素
【文件越大消耗在传输过程中的时间就越长】
请求同样多的资源,并行请求和串行请求速率是不一样的,所以请求的资源要尽量支持同步请求
【同步请求不同资源,即请求被发送到不同的资源服务器即可】
依据浏览器的加载、渲染机制,选择合适的HTML内容排版方式
【减少反复创建对象实例的次数、充分利用缓存机制】
优先加载用户关注的内容
【css加载优于js内容,首屏内容优于非首屏内容】
关注完http请求的过程后,再来关注整个请求过程中关注的几个时间点,通过确定时间点就可以确定影响性能的时间段,就是确定影响性能的因素。根据上面的介绍主要的几个时间点又可以分页面的整体时间点、以及单个url请求过程中的时间点。【基于httpanalyzer工具的指标】
单个url请求的主要时间点:
1、Cache Read:缓存读取时间,或304错误的处理时间
2、Block:请求等待时间,取决于缓存检查,网络连接等待
3、DNS Lookup:DNS服务器查找时间,取决于dns服务的数量,dns注册的域
4、Connect:tcp连接的总时间,取决于连接类型,ssh,keepalive都会比http长
5、Send first to last:发送请求内容的时间,取决于请求内容大小,及上行的传输速度
6、Wait:等待响应的时间,取决于网络环境的响应,web服务器的处理时间
7、Receive first to last:接收响应内容的时间,取决于响应内容,下行的传输速度,也要考虑服务器的带宽
8、Time to first byte:从请求一直到接收到第一个字符的总时间,等于1+2+3+4+5+6
9、Network:网络消耗时间,等于3+4
10、Begin to end:整个请求的总时间,等于1+2+3+4+5+6+7
单个页面的主要时间点:
1、DOM Ready Time: DOM完成的时间,从接收html到完全转换成dom树所需的时间
2、DOM Ready to Page Load: 页面元素的加载和渲染完成时间,包括html,css,img及其它内容
3、Page Load Time: page页onload事件的时间,其实际时间等于总时间 - (DOM ready + 元素渲染时间)
4、URL Requests Begin to End:url请求所消耗的所有时间,从发送请求发起到接收最后一个字节断开
5、Network Time:消耗在网络上的时间,即tcp的连接时间
6、Begin to End:所有消耗的时间,包括请求结束后的渲染时间
这里只是介绍Web测试相对于其他类型软件的测试额外需要了解的内容,关于测试方法不是本文的重点,里面谈到的每一项在以后的文章中再说明。大家看到这些内容可能都不陌生,我晒出的内容也许不对或有误导,请大家指正。
1. HTTP/HTTPS协议
· 你应该去了解什么是http协议
· 什么是GET, POST, session, cookie等
· Get与Post的区别是什么?
· session与cookie的区别是什么?
· 什么是无状态?
2. 浏览器机制
· 理解浏览器在处理javascript及渲染CSS的机制
· 了解IE与其他浏览器的差异
· 为什么兼容性测试时需要特别关注IE
· 浏览器在加载javascript,CSS有时在前面有时在后面,为什么?
· 加载顺序会对视觉和使用上有什么影响呢?
· 各种浏览器使用的内核分别是什么?
3. web架构
也许你会说这是架构师的事儿,没错,基本是他们的活儿,但是理解了web架构能让我们测试的更深入。你要知道:
· 软件出错时怎么个报警法?是否有详尽的log记录?
· 服务器缓存机制如何?
· 数据库如何主从同步,如何备份的?
· 集群如何处理session的?
4. 安全
因为web应用的特殊性,你需要掌握的安全技能:
· 如何进行SQL注入测试?如何防止SQL注入?
· 什么是跨站脚本攻击(XSS)?如何开展此类测试,应该如何防范XSS?
· 什么是DOS,DDOS?开发人员如何coding来避免?
· 传输哪些重要数据时需要加密
· 哪些页面需要使用SSL/https来加密传输
· 什么是跨站伪造请求攻击 cross site request forgeries (XSRF),如何避免?
· 安全证书的意义,浏览器在证书失效时提示是怎样的?
5. web性能
你应该知道的web性能知识:
· web前端的性能极大影响了用户,如何观察这些数据?CSS和图片的合并压缩的意义
· 了解浏览器cache及服务端cache
· 对于图片请求过多的网站,为何要把图片放置在不同的域名下,最好使用CDN?
· 确认你的网站有一个 favicon.ico 文件放在网站的根下,如 /favicon.ico.每当有用户收藏网站/网页时,浏览器会自动请求这个文件,就算这个图标文件没有在你的网页中明显说明,浏览器也会请求。如果你没有这个文件,就会出大量的404错误,这会消耗你的服务器带宽,服务器返回404页面会比这个ico文件可能还大
· 知道单个页面的http请求数越少越好
· 顺序加载和异步加载的优劣,何时需要使用AJAX?懒加载的意义,用于何处?
· 如何使用性能测试工具Jmeter/LR等开展性能测试?
6. SEO
只要是WEB应用,都会有SEO,因为它是种免费的搜索引擎推广方式,否则在百度搜索你们网站,是没有结果的。所以,你需要知道:
· XML sitemap的意义,可以让搜索引擎了解你的网站地图
· 了解 robots.txt 和搜索引擎爬虫是如何工作的
· 搜索引擎喜欢什么样的URL?
· 重定向301和302对于搜索引擎的意义?
· 网页Meta信息中title,description等的重要性
7. 用户体验
网站的功能只是说实现了什么,而用户体验则诠释了做的有多好,用户使用起来是否有难度,是否会爱上这个网站(当然12306除外,咯咯)
· 访问网站的用户操作行为是怎么样的?页面的访问频率占比如何?因为测试的精力和侧重点也要根据这个数据而定
· 网站部署时是否会影响到用户使用,如何避免?
· 不要直接显示不友好的错误提示,是否有友好的提示信息?
· web应用不能泄漏用户的隐私信息
· 页面是在当前页打开还是另开一个tab?
· 页面元素的布局如何影响到用户体验的?
8. 使用工具
· HttpWatch,基于IE的网络数据分析工具,包括网页摘要,Cookies管理,缓存管理,消息头发送/接受,字符查询,POST 数据和目录管理功能等
· FireBug,用途同上,基于firefox的
· Yslow,前端网站性能工具,显示测试结果的分析,分为等级、组件、统计信息
· Fiddler,强大的web前端调试工具,它能记录/拦截所有客户端和服务器的http和https请求,允许你监视,设置断点,甚至修改输入输出数据,也可用于安全测试
· Chrome扩展程序:浏览器兼容性检测工具,分析网站的兼容性情况
· ShowIP:显示访问网站的IP,web测试中你是否经常因为访问的网站IP不对,而被开发人员BS呢?它能帮助到你。
谈到的内容很多,囊括了诸多内容,也有些没有罗列出来,因为都太细节了,不是此文的范围。本来只是做了个Overview,抛砖引玉罢了,因为里面每一子项都可以成为一个专题。
最近看到坛子里有人在问WebTable控件获取数据后,存储和使用的便捷方式。
这里我就献丑写一下我在这块上的处理方式,我自己做了个简单的页面,来演示一些使用:
比如上面这个页面,取数据不难,主要是直观,所以我用的方法是用数组与字典结合的方式:
Dim oTable Set oTable = Browser("无标题文档").Page("无标题文档").WebTable("表格") Dim oRow, oCol oRow = oTable.RowCount oCol = oTable.ColumnCount(1) Dim arrData() ReDim arrData(oRow) Dim i , j For i = 1 to oRow-1 Set arrData(i)=CreateObject("Scripting.Dictionary") For j = 1 to oCol arrData(i).Add Trim(oTable.GetCellData(1,j)) , oTable.GetCellData(i+1,j) Next Next print arrData(3)("姓名") print arrData(9)("数据3") |
下面的是使用和打印的效果。
OK,算是抛砖引玉吧。
本例通过一个使用HTTP/HTML协议发送、获取服务器数据的vuser脚本,分析LoadRunner如何进行HTTP关联。
下面这个例子包括两个事务:上传数据到服务器、下载服务器数据,通过关联将服务器返回的数据保存下来,方便就行分析。
1、定义变量
在Action最前面定义变量,否则会报错。
代码:
merc_timer_handle_t timer;
double wasteTime=0;
char *ActualBuffer;
int NumberOfBytes;
char *tmp;
char tmpcode[24]={0};
//iterator
int i=0;
int j = 0;
int m = 0; //mobile
char codearray[100][24]={0}; //存储mobile下载的代码,每个代码暂设为24字节长
char* code;
short codelen; //存储mobile下载的代码的长度
short codenum; //总代码个数
int retUL = -1; //上传返回值
//int lenUL = 0; //上传返回长度
int retDL = -1; //下载返回值
int lenDL = 0; //下载返回长度
int flag = 0; //符合的code总数 //pc
//char retcodeUL[10]={0};
//char retcodeDL[2048]={0};
char* pcretUL;
char pccode[24]={0};
char pccodearray[1024][24]={0};
short pccodelen=0; |
2、保存服务返回数据
在定义变量或常量后,开始定义事务、进行关联。
代码:
web_set_max_html_param_len("2000000");//设置页面接收最大的字节数,该设置应大于下载文件的大小 //使用关联函数获取下载文件的内容,在这里不定义左右边界,获得服务器响应的所有内容
web_reg_save_param("filecontent",
"LB=",
"RB=",
"Search=BODY",
LAST);
lr_rendezvous("Re_UL_PC"); lr_start_transaction("UL_PC");
//pc上传
web_url("create",
"URL=http://10.15.107.112:9089/sys/userdata/create?userid={userid}&content={'group0':[{'data':'{code1}.stk','time':1376904823299640},{'data':'{code2}.stk','time':1376904823299647},{'data':'{code3}.stk','time':1376904823299651},{'data':'{code4}.stk','time':1376904836969909}]}&fileName=mystock.json&rawtype=true&Accept=json",
"Resource=0",
"RecContentType=text/html",
"Referer=",
"Snapshot=t1.inf",
"Mode=HTTP",
LAST); pcretUL = lr_eval_string("{filecontent}");
if(NULL != strcmp(pcretUL,"{\"state\":1"))
lr_end_transaction("UL_PC",LR_PASS);
else
lr_end_transaction("UL_PC",LR_FAIL); |
在上述代码中,web_reg_save_param函数起到了关联作用,必须在调用web_url之前使用,它的作用类似一个注册机制。调用了语句web_reg_save_param("filecontent", "LB=", "RB=", "Search=BODY", LAST);之后,LoadRunner自动将服务器返回的HTTP数据的BODY中左右边界(LB左边界,RB右边界)之内的内容保存到变量filecontent中。具体参数说明请参考帮助文档。
filecontent由系统自动分配,我们只需要给它传个名字,以后可以直接使用该变量。pcretUL = lr_eval_string("{filecontent}");将变量filecontent的内容提取赋值给我们自定义变量pcretUL。注意调用形式。
获取到服务器数据后,通过添加自己的判断逻辑,来断定事务成功或失败。