
这个问题虽然说很小,但是却还是经常会出现的问题,特别是刚入门php的同学更是如此。而这个问题呢,我也经常被问到,所以就在这里总结一下。
首先php.ini文件并不是隐藏文件,寻找php.ini文件的方法有很多种,这里介绍两种最快的方法吧。
1. 使用如下脚本:
当你在浏览器中运行此脚本时,函数phpinfo()可得到下图中所显示的信息,从中你可以获得更多更具体的信息。
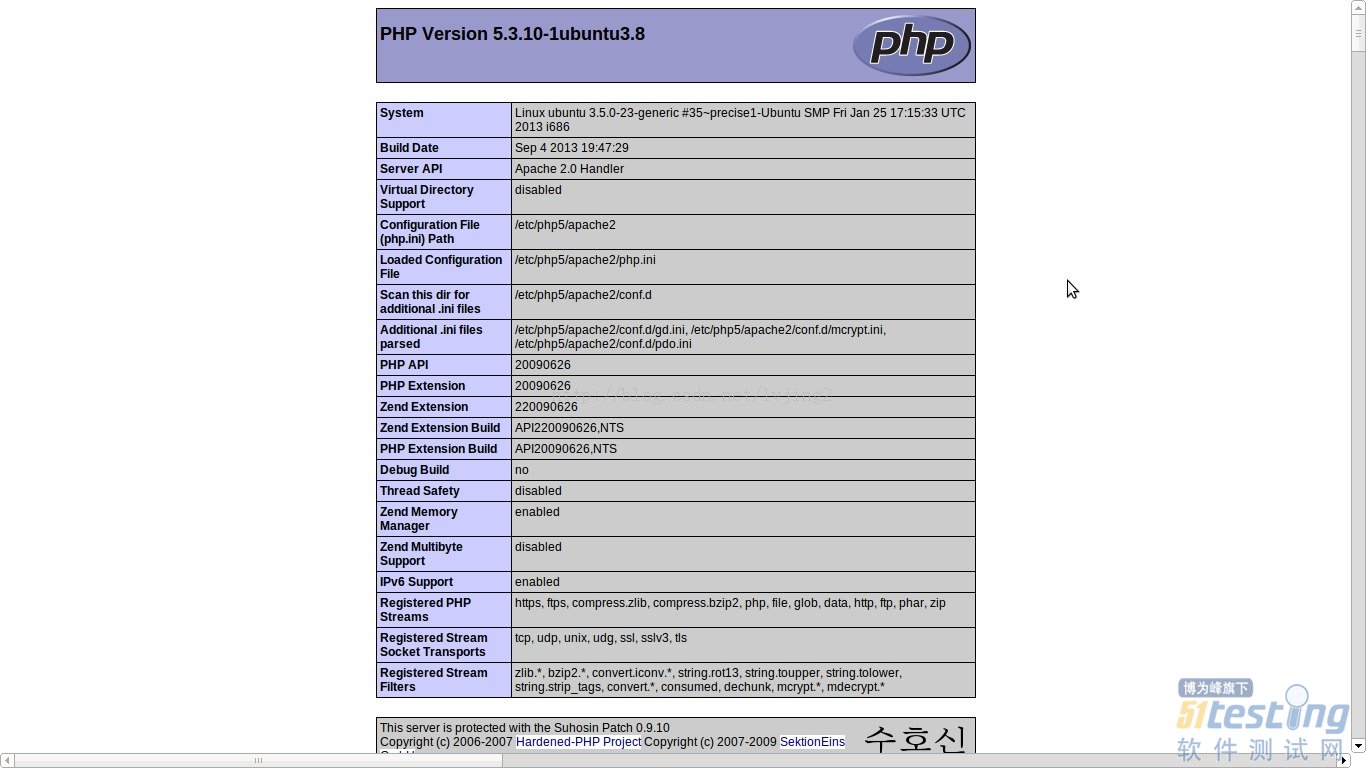
在图中的Loaded Configuration File一栏可以看到php.ini的位置信息。例:我在ubuntu12.04LTS的位置是:/etc/php5/apache2/php.ini
2.在linux下可以使用bash命令脚本:
| sudo find / -name 'php.ini' |
这个语句则会在你整个系统盘中查找php.ini的位置,如果系统很大的话这个可能速度就比较慢,所有如果你确定php.ini是在/etc的话,则可以把bash脚本中的'/'换成“/etc”.
3. 各操作系统中php.ini的位置
| OS | PATH |
|---|
| Linux | /etc/php.ini
/usr/bin/php5/bin/php.ini
/etc/php/php.ini
/etc/php5/apache2/php.ini |
| Mac OSX | /private/etc/php.ini |
| Windows (with XAMPP installed) | C:/xampp/php/php.ini |
希望这篇文章对你们能有帮助。
需要下commons-dbcp commons-pool 这两个jar包
import org.apache.commons.dbcp.BasicDataSource;
import org.apache.commons.dbcp.BasicDataSourceFactory;
import java.sql.SQLException;
import java.sql.Connection;
import java.util.Properties;
public class ConnectionSource {
private static BasicDataSource dataSource = null;
public ConnectionSource() {
}
public static void init() {
if (dataSource != null) {
try {
dataSource.close();
} catch (Exception e) {
//
}
dataSource = null;
}
try {
Properties p = new Properties();
p.setProperty("driverClassName", "oracle.jdbc.driver.OracleDriver");
p.setProperty("url", "jdbc:oracle:thin:@192.168.0.1:1521:testDB");
p.setProperty("password", "scott");
p.setProperty("username", "tiger");
p.setProperty("maxActive", "30");
p.setProperty("maxIdle", "10");
p.setProperty("maxWait", "1000");
p.setProperty("removeAbandoned", "false");
p.setProperty("removeAbandonedTimeout", "120");
p.setProperty("testOnBorrow", "true");
p.setProperty("logAbandoned", "true");
dataSource = (BasicDataSource) BasicDataSourceFactory.createDataSource(p);
} catch (Exception e) {
//
}
}
public static synchronized Connection getConnection() throws SQLException {
if (dataSource == null) {
init();
}
Connection conn = null;
if (dataSource != null) {
conn = dataSource.getConnection();
}
return conn;
}
} |
接下来,在我们的应用中,只要简单地使用ConnectionSource.getConnection()就可以取得连接池中的数据库连接,享受数据库连接带给我们的好处了。当我们使用完取得的数据库连接后,只要简单地使用connection.close()就可把此连接返回到连接池中,至于为什么不是直接关闭此连接,而是返回给连接池,这是因为dbcp使用委派模型来实现Connection接口了。
在使用Properties来创建BasicDataSource时,有很多参数可以设置,比较重要的还有:
testOnBorrow、testOnReturn、testWhileIdle,他们的意思是当是取得连接、返回连接或连接空闲时是否进行有效性验证(即是否还和数据库连通的),默认都为false。所以当数据库连接因为某种原因断掉后,再从连接池中取得的连接,实际上可能是无效的连接了,所以,为了确保取得的连接是有效的, 可以把把这些属性设为true。当进行校验时,需要另一个参数:validationQuery,对oracle来说,可以是:SELECT COUNT(*) FROM DUAL,实际上就是个简单的SQL语句,验证时,就是把这个SQL语句在数据库上跑一下而已,如果连接正常的,当然就有结果返回了。
还有2个参数:timeBetweenEvictionRunsMillis 和 minEvictableIdleTimeMillis, 他们两个配合,可以持续更新连接池中的连接对象,当timeBetweenEvictionRunsMillis 大于0时,每过timeBetweenEvictionRunsMillis 时间,就会启动一个线程,校验连接池中闲置时间超过minEvictableIdleTimeMillis的连接对象。
linux有很多开源工具用来测试服务器负载,而windows上非常少,几乎没有除了几个复杂的JMeter WET等
将两个好用的工具是Linux版本通过Cygwin移植过来,方便广大windows人员使用,经过初步测试效果一致,是命令行简单易用的测试软件
1 http_load
程序非常小,http_load以并行复用的方式运行,用以测试web服务器的吞吐量与负载。但是它不同于大多数压力测试工
具,它可以以一个单一的进程运行,一般不会把客户机搞死。还可以测试HTTPS类的网站请求。
源码官方下载地址:http://www.acme.com/software/http_load/http_load-12mar2006.tar.gz 或者http://soft.vpser.net/test/http_load/http_load-12mar2006.tar.gz
Windows版本下载:http://download.csdn.net/detail/masonwu21/6254461
命令格式:http_load -p 并发访问进程数 -s 访问时间 需要访问的URL文件
参数其实可以自由组合,参数之间的选择并没有什么限制。比如你写成http_load -parallel 5 -seconds 300 urls.txt也是可以的。
我们把参数给大家简单说明一下。
-parallel 简写-p :含义是并发的用户进程数。
-fetches 简写-f :含义是总计的访问次数
-rate 简写-p :含义是每秒的访问频率
-seconds简写-s :含义是总计的访问时间
准备URL文件:urllist.txt,文件格式是每行一个URL,URL最好超过50-100个测试效果比较好.文件格式
如下:
http://www.vpser.net/uncategorized/choose-vps.html
http://www.vpser.net/vps-cp/hypervm-tutorial.html
http://www.vpser.net/coupons/diavps-april-coupons.html
http://www.vpser.net/security/vps-backup-web-mysql.html
例如:
http_load -p 30 -s 60 urllist.txt
参数了解了,我们来看运行一条命令来看看它的返回结果
命令:% ./http_load -rate 5 -seconds 10 urls说明执行了一个持续时间10秒的测试,每秒的频率为5。
49 fetches, 2 max parallel, 289884 bytes, in 10.0148 seconds5916 mean bytes/connection4.89274
fetches/sec, 28945.5 bytes/secmsecs/connect: 28.8932 mean, 44.243 max, 24.488 minmsecs/first
-response: 63.5362 mean, 81.624 max, 57.803 minHTTP response codes: code 200 — 49 |
结果分析:
1.49 fetches, 2 max parallel, 289884 bytes, in 10.0148 seconds
说明在上面的测试中运行了49个请求,最大的并发进程数是2,总计传输的数据是289884bytes,运行的时间是10.0148秒
2.5916 mean bytes/connection说明每一连接平均传输的数据量289884/49=5916
3.4.89274 fetches/sec, 28945.5 bytes/sec
说明每秒的响应请求为4.89274,每秒传递的数据为28945.5 bytes/sec
4.msecs/connect: 28.8932 mean, 44.243 max, 24.488 min说明每连接的平均响应时间是28.8932 msecs
,最大的响应时间44.243 msecs,最小的响应时间24.488 msecs
5.msecs/first-response: 63.5362 mean, 81.624 max, 57.803 min
6、HTTP response codes: code 200 — 49 说明打开响应页面的类型,如果403的类型过多,那可能
要注意是否系统遇到了瓶颈。
特殊说明:
测试结果中主要的指标是 fetches/sec、msecs/connect 这个选项,即服务器每秒能够响应的查询次数,
用这个指标来衡量性能。似乎比 apache的ab准确率要高一些,也更有说服力一些。
Qpt-每秒响应用户数和response time,每连接响应用户时间。
测试的结果主要也是看这两个值。当然仅有这两个指标并不能完成对性能的分析,我们还需要对服务器的
cpu、men进行分析,才能得出结论
2 siege
一款开源的压力测试工具,可以根据配置对一个WEB站点进行多用户的并发访问,记录每个用户所有请求过程的相应时间,并在一定数量的并发访问下重复进行。
Siege官方下载:http://www.joedog.org/
Windows版本下载:http://download.csdn.net/detail/masonwu21/6254773
使用
siege -c 200 -r 10 -f example.url
-c是并发量,-r是重复次数。 url文件就是一个文本,每行都是一个url,它会从里面随机访问的。
example.url内容:
http://www.licess.cn
http://www.vpser.net
http://soft.vpser.net
或者直接使用Siege格式模拟一个负载测试,5个并发用户在10秒内访问网站www.example. com。需要说明一下,使用Siege时的并发被称为事务。因此我们要模拟的测试是使用Siege命令让Web服务器在10秒的时间内一次满足5个同时发生的事务:
siege -c 5 -t10S http://www.example.com/
结果说明
Lifting the server siege… done.
Transactions: 3419263 hits //完成419263次处理
Availability: 100.00 % //100.00 % 成功率
Elapsed time: 5999.69 secs //总共用时
Data transferred: 84273.91 MB //共数据传输84273.91 MB
Response time: 0.37 secs //相应用时1.65秒:显示网络连接的速度
Transaction rate: 569.91 trans/sec //均每秒完成 569.91 次处理:表示服务器后
Throughput: 14.05 MB/sec //平均每秒传送数据
Concurrency: 213.42 //实际最高并发数
Successful transactions: 2564081 //成功处理次数
Failed transactions: 11 //失败处理次数
Longest transaction: 29.04 //每次传输所花最长时间
Shortest transaction: 0.00 //每次传输所花最短时间 |
单元测试有两种方法:根据具体情况而选择
1.在项目本身创建单元测试类,需要对项目清单文件:AndroidManifest.xml进行配置.
在<application></application>之间加<uses-library android:name="android.test.runner" />
之后加
<instrumentation
android:name="android.test.InstrumentationTestRunner"
android:label="Test For My App."
android:targetPackage="测试类的的包名" />
在Outline视图右键写好的测试方法依次 Run As > Android Junit Test

之后可查看测试结果 如:
2.针对具体项目创建单元测试项目
此方法不需要自己配置清单文件,创建项目时便自动配置好了,更加专业化应选此方法
1 概述
脚本录制编写是性能测试的一个重要环节。在性能测试过程中,虚拟用户模拟真实用户使用被测系统,这个“模拟”的过程正是通过性能测试脚本来实现的。因此,编写一个准确无误的脚本对性能测试有至关重要的意义。完成性能测试脚本包括两个步骤:脚本录制和脚本编写,本文重点关注脚本编写。
2 脚本录制
2.1.录制方式
HTTP协议脚本录制可选两种方式:基于HTML和基于URL。选择哪种录制方式的原则如下:基于浏览器的HTTP应用系统选择HTML,基于其他方式的HTTP应用系统选择URL。
2.2.录制注意点
取消录制期间自动关联功能;
如果部分测试脚本出现问题,需要重新录制,可以只录制存在问题的片断脚本,方法是不选中录制启动对话框中的Record the application startup。
3 脚本编写
3.1.常用技术
LoadRunner性能测试脚本编写常用的技术包括参数化,关联,逻辑控制和脚本模块化。
3.1.1.参数化
参数化就是将脚本中的常量转化为变量的过程。通过录制生成的脚本所有的数据都是常量,为了达到向服务器发送的数据多样化的目的,需要将一些数据常量转化为变量。
3.1.2.关联
关联就是查找动态数据,并把查询到的数据以参数的形式保存起来。在B/S或者C/S系统中,服务器返回给客户端的数据有些是动态改变的,例如客服系统的人工来话流水号和工作流系统的工单流水号。当打开工单生成页面后,工单流水号已经从服务器端获取到了,而在提交工单步骤,需要将该流水号返回给服务器。因此,在提交工单之前,在脚本中必须获得流水号。获得流水号的方法就是关联。
使用关联功能动态保存的参数跟直接通过参数化生成的参数是一致的。唯一不同的是,通过参数化生成的参数在脚本中可以高亮显示。
3.1.3.逻辑控制
业务系统在实际应用中,业务操作步骤间往往存在逻辑。比如,客服3.0工作流系统,业务代表处理工单,如果待办区没有工单等待处理,则先从工单池中提取工单到待办区,然后进行处理,并且需要优先处理超时或即将超时的工单。在工单处理的性能测试脚本中,也必须遵从这种业务逻辑。
LoadRunner性能测试脚本采用C语言,因此脚本逻辑控制同C语言一致,使用if,switch,while/for/do控制结构。
3.1.4.脚本模块化
脚本模块化的目的是:提高脚本可读性、可重用性和脚本生产效率。脚本模块化的本质是抽取函数,一些很通用的函数甚至可以封装为DLL。模块化性能测试脚本的思想跟自动化测试的ActionWord有相似之处。
例如:客服3.0系统的登录功能,无论是工作流、知识库、公告便签还是培训考试,它们都使用相同的登录页面。我们可以把登录脚本抽取为一个函数csp_login(char *staffno,char * password),需要登录操作时,不需要录制和拷贝脚本,只要调用这个函数就可以了。
注意:并不是所有的脚本代码块都需要做模块化处理,只有那些稳定不变、并且经常用到的代码块才需要做模块化处理。不做得不偿失的事。
3.2.典型函数
LoadRunner中,常用的函数有很多,这里只介绍编写性能测试脚本过程中那些必然用到的函数。本文重点关注这些典型函数的应用场合及注意点,至于函数详细使用说明请参见LoadRunner帮助文档。
3.2.1.事务相关
3.2.1.1. lr_start_transaction/lr_end_transaction
功能:事务开始/结束标记。
应用场合:需要统计某一段代码块执行所需要的时间,这两个函数需要成对使用。
举例:工作流系统性能测试中有一个需求,300人在线,提交工单操作平均响应时间在3秒以内,则需要在提交工单请求步骤之前插入lr_start_transaction,提交工单请求步骤之后插入lr_end_transaction。
注意点:这两个函数只是标记函数,用于标记事务开始/结束,因此可以嵌套使用,即事务中还可以包含子事务。
3.2.1.2. lr_think_time
功能:模拟思考时间,即等待时间。
应用场合:在线用户测试,为了让每一个虚拟用户模拟一个真实用户的行为,即让一个虚拟用户对系统产生的压力跟真实用户相当,就必须使用这个函数。这是因为,用户在使用系统的过程中,从一个操作转换到另一个操作,是需要时间的,这个时间就是思考时间。
举例:客服3.0工作流系统在线用户测试。对于工单查询操作,输入查询条件后提交查询,从输入查询条件至提交查询的时间间隔就是思考时间。因为LoadRunner无法模拟键盘输入的过程,它只能模拟键盘输入的等待时间,此时需要在提交查询的那个动作前插入lr_think_time函数。
注意点:在录制脚本中,原子事务内不要包含lr_think_time函数,否则该思考时间将被统计到事务响应时间中,造成结果不准确。另外lr_think_time是否启作用,可通过runtime-seting进行设置。
注:原子事务指那些不能再分割为更小事务的事务,它经常指一个单一的业务操作,通常表现为一个URL请求。
3.2.1.3. lr_rendezvous
功能:在Vuser脚本中设置集合点。
应用场合:并发测试。
举例:客服3.0培训考试系统,100人同时打开同一份试卷。则需要在打开试卷的语句前插入lr_rendezvous函数,并在场景中设置集合点策略。
注意点:非并发测试,例如在测试系统的处理能力时,最好不要设置集合点,因为一旦设置了集合点,将导致一些VUser处于等待状态,在这等待过程中服务器将是空闲的,这将导致不能准确的测试出服务器的真实性能水平。集合点更多用于发现系统的并发问题。
3.2.2.参数化/关联
3.2.2.1.lr_save_string/lr_save_int
功能:将某一字符串/整型保存为参数。
应用场合:有些变量的值通过C语言生成,之后在测试脚本中要使用这些变量。
举例:客服3.0业务配置台系统增加业务代表操作,业务代表的工号和姓名使用C语言函数生成。工号和姓名分别保存在staff_no和staff_name变量中,则在脚本中可以使用lr_save_int(staff_no,"staffno"),lr_save_string(staff_name, "stafffname")将工号和姓名参数化。
注意点:无。
3.2.2.2.web_reg_save_param
功能:在服务器返回的文本中查找一个或者多个字符串,并将搜索到的字符串值保存在参数中。
应用场合:在B/S或者C/S系统中,服务器返回给客户端的数据有些是动态改变的,在脚本的下一个步骤中,需要使用该动态数据。这时,就需要使用关联获得该动态数据。
举例:客服3.0工作流系统,工单办理每次都从待办区中打开第一条工单,为打开第一条工单,需要获取第一条工单的完整URL(包括URL中的parameter及其值),而每一次进入待办区,第一条工单有可能是不一样的。为获取第一条工单的URL,将打开工单的URL做关联。已知打开待办区操作获得的HTML有如下片断:
<a href="#"onclick="javascript:openseviceforprocess('/iwflow/FindJspID.jsp?serialNo=2008092200000033&serviceID=0099&nodeID=140004&dealID=2008092200000056&hisFlag=0&skillID=020401&dealSkillID=020101&dealStaff=1200','false');">
可在打开待办区的操作前插入如下语句:
web_reg_save_param("tt_url", "LB=javascript:openseviceforprocess('","RB=','false')", "Ord=1","IgnoreRedirections=Yes", "Search=Body","RelFrameId=1", LAST );
运行脚本后,tt_url的值为:
/iwflow/FindJspID.jsp?serialNo=2008092200000033&serviceID=0099&nodeID=140004&dealID=2008092200000056&hisFlag=0&skillID=020401&dealSkillID=020101&dealStaff=1200
这个URL就是打开第一条工单的URL,有了URL,便可打开工单。
注意点:
(1)LoadRunner工具只能识别文本,在HTTP协议中只能识别HTML文档,因此关联的依据是HTML源码,而不是经过浏览器解析后的可视化文本。这一点很重要。
(2)关联还能将多个匹配的参数保存在数组中,方法是指定ORD的属性值为ALL,之后通过“{参数名_1}”, “{参数名_2}”, “{参数名_3}”格式可获得数组元素的值。
(3)该函数有一个属性NOTFOUND,默认值为ERROR,也就是说,如果找不到要查找的数据,将报出错误,在必要的时候,例如脚本逻辑控制需要,可以将NOTFOUND的属性值设为WARNING,这样LoadRunner将不产生错误。
3.2.2.3.lr_save_searched_string
功能:在某一个字符缓冲区中搜索指定的字符串,并将搜到的字符串保存在参数中。
应用场合:可配合LoadRunner的关联功能,灵活获取服务器端返回的数据。
举例:客服3.0工作流系统,工单处理每次都从待办区中打开第一条工单,打开工单的URL已经通过关联保存在tt_url参数中,在工单处理提交时,需要使用serviceNo,serviceID,nodeID,dealID,tt_url的值如下:
/iwflow/FindJspID.jsp?serialNo=2008092200000033&serviceID=0099&nodeID=140004&dealID=2008092200000056&hisFlag=0&skillID=020401&dealSkillID=020101&dealStaff=1200
可使用以下函数保存serviceNo,serviceID,nodeID,dealID的值。
//保存serialNo,serviceID,nodeID,dealID参数
int getTTData(){
int i = 0;int j=0;
char *tt_url = lr_eval_string("{tt_url}");
int len= strlen(tt_url);
while(tt_url[i]!='='){i++;} while(tt_url[j]!='&'){j++;}
lr_save_searched_string(tt_url,len,0,"serialNo",1,j-i-1,"serialNo");
i++;j++;while(tt_url[i]!='='){i++;} while(tt_url[j]!='&'){j++;}
lr_save_searched_string(tt_url,len,0,"serviceID",1,j-i-1,"serviceID");
i++;j++;while(tt_url[i]!='='){i++;} while(tt_url[j]!='&'){j++;}
lr_save_searched_string(tt_url,len,0,"nodeID",1,j-i-1,"nodeID");
i++;j++; while(tt_url[i]!='='){i++;} while(tt_url[j]!='&'){j++;}
lr_save_searched_string(tt_url,len,0,"dealID",1,j-i-1,"dealID");
return 0;
} |
注意点:无
3.2.2.4.lr_save_datetime
功能:将时间保存为参数。
应用场合:应用系统需要把时间数据提交给服务器端。
举例:客服3.0工作流系统活动工单查询,默认查询从当天开始的最近三天工单。 则查询的开始时间和结束时间可用lr_save_datetime获取。
lr_save_datetime("%y-%m-%d00:00", DATE_NOW-2*ONE_DAY, "queryBeginTime");
lr_save_datetime("%y-%m-%d23:59", DATE_NOW, "queryEndTime");
注意点:无
3.2.2.5. web_save_timestamp_param
功能:将当前时间戳保存为参数。
应用场合:应用系统需要把时间戳提交给服务器端。
举例:多媒体坐席客户端,在向MClient提交信息时,需要附带客户端的时间戳,则可以使用该函数获取当前时间戳。
注意点:与lr_save_datetime不同的是,本函数保存的是时间戳,而lr_save_datetime保存的是日期和时间。
3.2.2.6.lr_eval_string
功能:将某一字符串中包含的所有参数替换为真实值,并返回替换后的字符串。
应用场合:欲查看某一参数的值,可使用该函数。
举例:客服3.0工作流系统,生成工单时打开工单页面准备工单提交,提交之前想查看已通过关联保存的serialNo参数的值。方法如下:
lr_output_message(lr_eval_string("TheserialNo is {serialNo}"));
注意点:如果不存在该参数,将把“{参数名}”当作普通字符串输出。如本例,如果不存在serialNo参数,则输出:The serialNo is {serialNo}。
3.2.3.验证点
3.2.3.1.web_reg_find
功能:在HTML文档中查找指定的字符串。
应用场合:该函数是检查点函数,在脚本中需要插入检查点的地方使用。
举例:客服3.0工作流系统,提交工单生成后,需要验证工单是否提交成功。则可根据页面提示“工单生成成功”进行验证。在提交生成工单步骤前插入:
web_reg_find("Text=工单生成成功",LAST);
注意点:该函数是注册型参数,需要在请求服务器数据步骤之前插入该函数。与该函数功能类似的函数是web_find,但是web_find只对HTML方式的脚本起作用,对URL方式脚本则不起作用,而且web_find函数效率低下,已被废弃。
3.2.3.2. web_image_check
功能:判断某一个图片是否存在HTML页面中。
应用场合:同web_reg_find函数一样,该函数也是检查点函数,在脚本中需要插入检查点的地方使用。
举例:客服3.0培训考试系统并发测试,50个人同时打开试卷,为了验证打开试卷成功,根据试卷中的图片public/images/onexam.gif进行验证:
web_image_check("web_image_check","Src=public/images/onexam.gif",LAST);
注意点:要使该函数生效,需要在runtime-seting中将打开。与web_reg_find不一样的是,该函数不是注册型函数,因此需要在请求返回步骤之后插入该函数。上文提过,LoadRunner只能识别文本,因此web_image_check函数其本质仍然是文本验证,完全可以用web_reg_find替代,而且强烈推荐使用web_reg_find作为检查点函数。
3.2.4.日志输出
3.2.4.1. lr_output_message
功能:将VUser的消息打印到日志文件和输出窗口中,打印的消息带有脚本行信息。
应用场合:方便查看运行信息,辅助问题定位。
举例:客服3.0系统,登录工号已经参数化,调试脚本时将当前的登录工号输出到Replay Log窗口中。代码如下:
lr_output_message("Thestaffno is %s",lr_eval_string("{staffno}"));
注意点:与该函数具有类似功能的还有:lr_debug_message,lr_log_message lr_message,lr_error_message它们之间的不同之处这里不作详细介绍,请参见LoadRunner帮助文档。
3.2.4.2. lr_vuser_status_message
功能:将VUser的消息输出到场景运行的VUser状态窗口。
应用场合:将一些关键信息输出到VUser运行状态窗口,方便场景执行时查看。
举例:在场景运行过程中,出现了错误。根据错误窗口提示,该错误属于VUser ID为2的虚拟用户,为了方便将系统登录用户名与VUser ID对应起来,以方便问题定位。可以使用以下代码:
lr_vuser_status_message("Thelogin username is %s", lr_eval_string("{username}"));
场景执行时,可方便查看到VUserID与登录用户名的对应关系,如下图:
注意点:无
3.2.5.其它实用函数
3.2.5.1. lr_get_vuser_ip
功能:获得VUser的IP地址。
应用场合:在使用IP欺骗时,为了验证IP欺骗是否成功,可以使用该函数。
举例:在场景运行过程中,将每一个VUser的IP在VUser运行状态窗口中显示出来。
char *ip;
ip = lr_get_vuser_ip();
if (ip)
{
lr_vuser_status_message("The IP addressis %s", ip);
} |
注意点:为了使IP欺骗成功,使用IP欺骗向导设置好IP后,还要将打开才可。
3.2.5.2. lr_load_dll
功能:加载外部DLL。
应用场合:脚本需要使用外部DLL时,使用该函数加载DLL。
举例:函数getDateTime(char * time,int seconds,char * resultTime)已封装在timeutil.dll中,getDateTime的功能是根据传入的日期字符串time(如2008-09-24 16:56:24),秒偏移量seconds,计算返回结果日期字符串resultTime,代码如下:
int hours =atoi(lr_eval_string("hours"));
char acceptEndTime[20];
lr_load_dll("../timeutil.dll");
getDateTime(lr_eval_string("{acceptBeginTime}"),3600*hours,acceptEndTime); |
注意点:该函数为LoadRunner提供了调用外部接口的能力。
3.3.封装,构建可重用脚本
3.3.1.简单函数封装
LoadRunner使用C语言作为脚本,因此只要是合法的C代码都可以在LoadRunner中运行。为了提高脚本可读性和脚本生产效率,有必要将性能测试脚本模块化。
客服3.0工作流系统,查询工单池是一个很常见的操作。我们可以把查询工单池操作封装为一个queryTTPool函数,函数体如下,在脚本中,将所有的查询工单池操作替换为queryTTPool函数调用,提高了脚本的可读性:
//查询工单池
int queryTTPool(char* nodeType){
lr_save_string(nodeType,"nodeType");
lr_save_datetime("%Y-%m-%d 00:00",DATE_NOW-2*ONE_DAY, "acceptBeginTime");
lr_save_datetime("%Y-%m-%d 23:59", DATE_NOW,"acceptEndTime");
lr_start_transaction("WF_查询工单池工单");
web_submit_data("IWFController",
"Action=http://{wf_sysurl}/IWFController",
"Method=POST",
"RecContentType=text/html",
"Referer=http://{wf_sysurl}/iwflow/common/UnitQueryDealForm.jsp?pageNo=1", "Snapshot=t32.inf",
"Mode=HTML",
ITEMDATA,
"Name=ACTIONID","Value=UniteQueryDealAction", ENDITEM,
"Name=pageNo", "Value=1", ENDITEM,
"Name=sortType", "Value=", ENDITEM,
"Name=sortField", "Value=", ENDITEM,
"Name=reSortFlag", "Value=", ENDITEM,
"Name=acceptPhone", "Value=", ENDITEM,
"Name=serialNo", "Value=", ENDITEM,
"Name=serialFlag", "Value=0", ENDITEM,
"Name=serviceName", "Value=", ENDITEM,
"Name=serviceID", "Value=", ENDITEM,
"Name=acceptBeginTime","Value={acceptBeginTime}", ENDITEM,
"Name= acceptEndTime ", "Value={acceptEndTime}",ENDITEM,
"Name=urgentID", "Value=", ENDITEM,
EXTRARES,
"Url=/iwflow/image/kms-1_23.gif", ENDITEM,
"Url=/iwflow/buttons/obtainProcess-2.gif", ENDITEM,
LAST);
lr_end_transaction("WF_查询工单池工单",LR_AUTO);
} |
3.3.2.DLL封装
使用DLL有很多好处。高度重用的函数制作成DLL,方便脚本调用。将与IVR交互的消息函数封装成DLL后,便可利用LoadRunner测试IVR性能。制作DLL可以选择VC或者MinGW Developer Studio等工具,至于DLL的制作细节,本文不作介绍,请参见相关指导书。
4 脚本调试
LoadRunner的VUser Generator本身的调试功能比较弱,只能设置断点,无法单步跟踪。当脚本出现问题时,可以使用lr_debug_message,lr_output_message,lr_eval_string等函数协助定位。
脚本错误大部分原因都是向服务器发送的数据不对,因此还可以利用HttpAnalyzer工具进行HTTP协议跟踪,通过比较LoadRunner发送的数据和浏览器发送的数据,便能很快定位出问题根源。
在web自动化测试中点击一个链接然后弹出新窗口是比较司空见惯的事情。
webdriver中处理弹出窗口跟处理frame差不多,以下面的html代码为例
window.html
<html>
<head><title>Popup Window</title></head>
<body>
<a id = "soso" href = http://www.soso.com/ target = "_blank">click me</a>
</body>
</html> |
下面的代码演示了如何去捕获弹出窗口
require 'rubygems'
require 'pp'
require 'selenium-webdriver'
dr = Selenium::WebDriver.for :firefox
frame_file = 'file:///'.concat File.expand_path(File.join(File.dirname(__FILE__), 'window.html'))
dr.navigate.to frame_file
dr.find_element(:id =>'soso').click
# 所有的window handles
hs = dr.window_handles
# 当前的window handle
ch = dr.window_handle
pp hs
pp ch
hs.each do |h|
unless h == ch
dr.switch_to.window(h)
p dr.find_element(:id => 's_input')
end
end |
捕获或者说定位弹出窗口的关键在于获得弹出窗口的handle。
在上面的代码里,使用了windowhandles方法获取所有弹出的浏览器窗口的句柄,然后使用windowhandle方法来获取当前浏览器窗口的句柄,将这两个值的差值就是新弹出窗口的句柄。
在获取新弹出窗口的句柄后,使用switchto.window(newwindow_handle)方法,将新窗口的句柄作为参数传入既可捕获到新窗口了。
如果想回到以前的窗口定位元素,那么再调用1次switch_to.window方法,传入之前窗口的句柄既可达到目的。
相关文章:
Selenium webdriver系列教程(5)—如何定位frame中的元素
Selenium webdriver系列教程(7)—如何处理alert和confirm
--测试工具:
QuickTest Professional(
QTP)
QualityCenter、TestDirector
全部是HP公司产品,最早由Mercury Interactive(MI)开发
Junit、Jtest(parasoft)
--如何访问
1、打开DOS,查看虚拟机的IP
ipconfig
2、打开IE浏览器
输入:
http://172.166.0.252:8080/qcbin
http协议
172.166.0.252 要访问的QC服务器的IP
8080 端口号
应用层协议http(超文本传输协议)默认使用的是80端口,而我们在安装QC的时候,没有使用默认端口,而是设置为8080,所以访问时必须指出
qcbin 虚拟路径(必须小写)
在一个服务器中,可以同时发布多个网站,这样每个网站程序必须放在不同的目录中,用户访问才不会混淆,让用户访问的路径一般称为虚拟路径
使用物理机中的浏览器,访问虚拟机中的QC服务
虚拟机的概念
利用虚拟技术在物理机中模拟出计算机的硬件和软件
虚拟机软件名称:Vmware workstation
所承担的任务——QC服务器
QC的安装
1、只能安装在服务器版的
操作系统中(windows server2003/2008)
2、操作系统中要有IIS(internet information service
互联网信息服务),windows自带的
web服务器
3、安装JDK(提供Java运行环境)
4、安装MS-SQLServer2005数据库
5、安装QC
QC的三大框架(模块)
1、站点管理(site administrator)
首页:点击“site administrator”,
登录:
User name/password是在安装QC时设定的
Login:登录
2、项目的自定义管理
首页:Quality Center
登录:
Login name/password
点击“authenticate”按钮(验证、鉴权)
然后选择要登录的项目(目前只能登录default域中的qualitycenter_demo,安装QC时创建的一个练习项目)
菜单:Tools(工具)-customize(定制、自定义)
3、测试管理(核心)
首页:QualityCenter
登录
管理“版本信息”、“需求信息”、“
测试用例管理”、“缺陷跟踪管理”
版权声明:本文出自 wsophie 的51Testing软件测试博客:http://www.51testing.com/?14995102
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
好像今天没有什么源码读,那么就来看看java的这两种HashMap有啥不一样的地方吧,在这之前先普及一下HashMap的一些基本知识:
(1)放入HashMap的元素是key-value对。
(2)底层说白了就是以前数据结构课程讲过的散列结构。
(3)要将元素放入到hashmap中,那么key的类型必须要实现实现hashcode方法,默认这个方法是根据对象的地址来计算的,具体我也记不太清楚了,接着还必须覆盖对象的equal方法。
用一张图来表示一下散列结构吧:
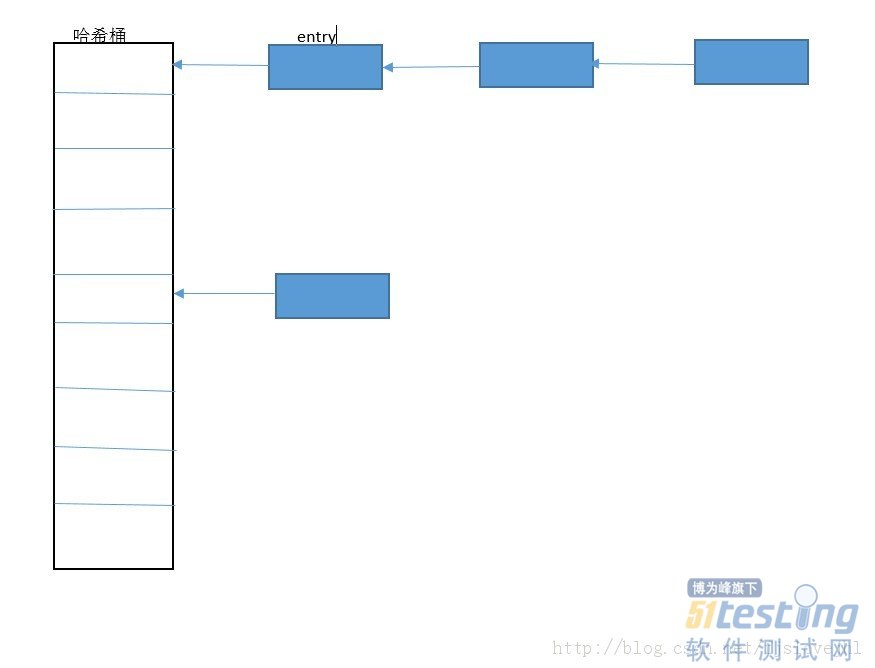
在这里hashCode函数就是用于确定当前key应该放在hash桶里面的位置,这里hash桶可以看成是一个数组,最简单的通过一些取余的方法就能用来确认key应该摆放的位置,而equal函数则是为了与后面的元素之间判断重复。
好了,这里我们接下来来看看java的这两种类库的用法吧:
由于他们都实现了Map接口,将元素放进去的方法就是put(a,b),这里我们先来分析比较简单的HashMap吧:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key); //获取当前key的hash值
int i = indexFor(hash, table.length); //返回在hash桶里面的位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) { //遍历当前hansh桶后面的元素
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { //如果有相同的key,那么需要替换value
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue; //返回以前的value
}
} modCount++;
addEntry(hash, key, value, i); //放入entry
return null;
} |
这个函数其实本身还是很简单的,首先通过hash函数获取当前key的hash值,不过这里需要注意的是,对hashCode方法返回的值HashMap本身还会进行一些处理,具体什么样子的就不细说了,然后再调用indexFor方法用于确定当前key应该属于当前Hash桶的位置,接着就是遍历当前桶后面的链表了,这里equal方法就派上用场了,这里看到如果equal是相等的话,那么就直接用新的value来替换原来的value就好了。。。
当然最多的情况还是,桶后面的链表没有与当前的key相同的,那么这个时候就需要调用addEntry方法,将要加入的key-value放入到当前的结构中了,那么接下来来看看这个方法的定义吧:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); //相当于重新设置hash桶
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
} createEntry(hash, key, value, bucketIndex); //创建新的entry,并将它加入到当前的桶后面的链表中
} |
其实这个方法很简单,首先来判断当前的桶的大小,如果觉得太小的话,那么需要扩充当前桶的大小,这样可以让添加元素存放的更离散化一些,优化擦入和寻找的效率。
然后就是创建一个新的entry,用于保存要擦入的key和value,然后再将其链到应该放的桶的链表上就好了。。
好了,到这里位置,整个HashMap的擦入元素的过程就已经看的很清楚了,在整个这个过程中没有看到有加锁的过程,因此可以说明HashMap是不支持并发的,不是线程安全的,在并发的环境下使用会产生一些不一致的问题。。。
因此java新的concurrent类库中就有了ConcurrentHashMap用于在并发环境中使用。。
那么我们再来看看ConcurrentHashMap的put操作是怎么搞的吧:
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key); //获取hash值
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment //用于获取相应的片段
s = ensureSegment(j); //这里表示没有这个片段,那么需要创建这个片段
return s.put(key, hash, value, false); //这里就有分段加锁的策略
} |
这里刚开始跟HashMap都差不太多吧,无非是先获取当前key的hash值,但是接下来进行的工作就不太一样了,这里就有了一个分段的概念:
ConcurrentHashMap将整个Hash桶进行了分段,也就是将这个大的数组分成了几个小的片段,而且每个小的片段上面都有锁存在,那么在擦入元素的时候就需要先找到应该插入到哪一个片段,然后再在这个片段上面进行擦入,而且这里还需要获取锁。。。。
那我们来看看这个segment的put方法吧:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//这里的锁是计数锁,同一个锁可以被同一个线程获取多次,但是不能被不同的线程获取
HashEntry<K,V> node = tryLock() ? null : //如果获取了当前的segment的锁,那么node为null,待会自己分配就好了
scanAndLockForPut(key, hash, value); //如果没有加上锁,那么等吧,有可能的话还要分配entry,反正有时间干嘛不多做一些事情
V oldValue;
try {
//这里表示已经获取了锁,那么将在相应的位置放入entry
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index); //找到存放entry的桶,然后获取第一个entry
for (HashEntry<K,V> e = first;;) { //从当前的第一个元素开始
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) { //如果key相等,那么直接替换元素
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
//如果元素太多了,那么需要重新调整当前的hash结构,让桶变多一些,这样元素放的更离散一些
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock(); //这里必须要在finally里面释放已经获取的锁,这样才能保证锁一定会被释放
}
return oldValue;
}
|
其实在这里ConcurrentHashMap和HashMap的区别就已经很明显了:
(1)ConcurrentHashMap对整个桶数组进行了分段,而HashMap则没有
(2)ConcurrentHashMap在每一个分段上都用锁进行保护,从而让锁的粒度更精细一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。。。
最后用一张图来表来说明一下ConcurrentHashMap吧:
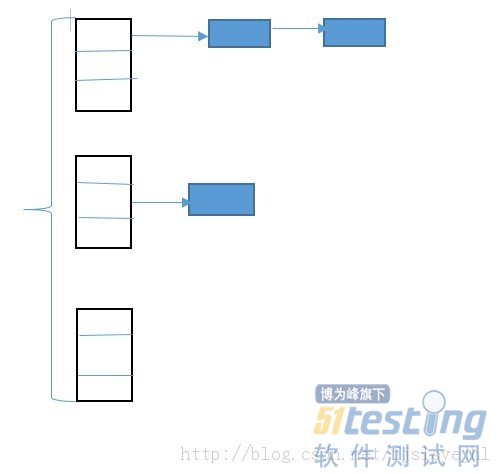
最后,在并发的情况下,要么使用concurrent类库中提供的容器,要么就需要自己来管理数据的同步问题了。。。
通过实现MySQL数据库镜像(复制),可以远程实时备份MySQL数据库。这样如果主机出现故障,或者主机帐号被封,都能迅速切换zencart网店到新的服务器上。
数据库镜像,需要两台服务器(或者用两台VPS主机)。一台为主服务器,另一台为从服务器,所有主服务器上数据库的变化,都实时镜像到从服务器上。
1. 在主服务器上,创建用于数据库镜像的数据库用户,从服务器用这个帐号连接主服务器。
该数据库用户可以是任何数据库用户,只要有REPLICATION SLAVE权限,由于该用户名、密码将明文保存在master.info文件中,因此建议创建、使用单独的镜像用户。
创建一个镜像用户 repl 的命令:
mysql> GRANT REPLICATION SLAVE ON *.*
-> TO 'repl'@'localhost' IDENTIFIED BY 'slavepass'; |
2. 设置主服务器
首先,主服务器必须打开二进制日志的功能。每台参与镜像的服务器都必须有一个唯一的标识符。该标识符为 1-231 之间的一个任意整数,只要各服务器的标识符不重复。
要设置二进制日志和服务器标识符,必须停止MySQL服务器,然后在 my.cnf 或者 my.ini 配置文件中加入下面的定义:
3. 设置从服务器
从服务器只需要设置服务器标识符。停止MySQL服务器,然后在 my.cnf 或者 my.ini 配置文件中加入下面的定义:
[mysqld]
log-bin=mysql-bin
server-id=1 |
如果设置多台从服务器,每台服务器都需要有唯一的标识符。从服务器不需要打开二进制功能,除非你想把从服务器作为另一台镜像服务器的主服务器。
4. 获取主服务器的信息
要设置镜像,必须查找主服务器的二进制日志的当前记录点。在从服务器启动镜像功能时需要该数据。
操作步骤分A、B两步:
A. 锁定主数据库
mysql> FLUSH TABLES WITH READ LOCK;
|
锁定数据库后,不要退出客户端(命令行),否者数据库解锁。
B. 查找二进制日志的当前记录点
| mysql > SHOW MASTER STATUS; |
+---------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+---------------+----------+--------------+------------------+
| mysql-bin.003 | 73 | test | manual,mysql |
+---------------+----------+--------------+------------------+
上面File栏下显示日志文件名,Position栏下显示当前记录点,记下这两个数据。
5. 使用mysqldump导出zencart网店的数据库初始数据
首先要将主服务器上的现有数据传到从服务器上。在第4步的客户端仍然锁定数据库的情况下,新开一个session连接到主服务器,然后执行:
| shell> mysqldump database_name1 --lock-all-tables > dbdump_database_name1.db |
其中,database_name1是需要镜像的zencart网店的数据库名。如果有多个zencart网店的数据库需要镜像,重复mysqldump导出。
然后将导出的 dbdump_database_name1.db 传送到从服务器上。
现在,可以在第4步的客户端,解锁数据库:
6. 启动从服务器的实时数据库镜像
在从服务器上恢复第5步导出的主服务器的zencart网店的初始数据
A. 起动从服务器数据库,带参数 --skip-slave-start:
shell> /etc /init.d/mysqld stop
shell> /etc /init.d/mysqld start --skip-slave-start |
B. 导入初始数据:
| shell> mysql < dbdump_database_name1.db |
C. 设置从服务器的参数:
mysql> CHANGE MASTER TO
-> MASTER_HOST='master_host_name',
-> MASTER_USER='replication_user_name',
-> MASTER_PASSWORD='replication_password',
-> MASTER_LOG_FILE='recorded_log_file_name',
-> MASTER_LOG_POS=recorded_log_position; |
D. 开启镜像功能:
注意:如果主服务器有防火墙,需要开通MySQL的端口3306,该端口只要对从服务器的IP开放就可以了。
今天在做《Junit In Action》关于cactus和jetty结合进行集成测试的例子,看看源代码很简单,但总是运行不起来,一波三折了好几个小时才搞定。我用的cactus是1.8.1,闲言少叙,上源代码,就2个类:
待测试的servlet:
package junitbook.container; import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession; public class SampleServlet extends HttpServlet
{
public boolean isAuthenticated(HttpServletRequest request)
{
HttpSession session = request.getSession(false); if (session == null)
{
return false;
}
String authenticationAttribute =
(String) session.getAttribute("authenticated");
return Boolean.valueOf(
authenticationAttribute).booleanValue();
}
}
|
测试类:
package junitbook.container; import org.apache.cactus.ServletTestCase;
import org.apache.cactus.WebRequest; public class TestSampleServletIntegration extends ServletTestCase
{
private SampleServlet servlet; public static Test suite()
{
System.setProperty("cactus.contextURL", "http://localhost:8080/test");// 这步很重要,一定要有 TestSuite suite = new TestSuite("All tests with Jetty");
suite.addTestSuite(TestSampleServletIntegration.class);
return new Jetty5XTestSetup(suite);
} protected void setUp()
{
servlet = new SampleServlet();
}
public void testIsAuthenticatedAuthenticated()
{
session.setAttribute("authenticated", "true");
assertTrue(servlet.isAuthenticated(request));
} public void testIsAuthenticatedNotAuthenticated()
{
assertFalse(servlet.isAuthenticated(request));
} public void beginIsAuthenticatedNoSession(WebRequest request)
{
request.setAutomaticSession(false);
}
public void testIsAuthenticatedNoSession()
{
assertFalse(servlet.isAuthenticated(request));
}
} |
有几点要说明:
1.测试类要继承ServletTestCase,内置了session,request,response,可直接用
2.jetty不要用单独下载的版本,每个cactus发行版都内置了一个jetty,在lib目录下可以找到,显然是改写过的,如果你用单独下载的,一定会抛出java.lang.NoSuchMethodException: org.mortbay.jetty.nio.SelectChannelConnector.setPort(java.lang.String),因为在单独的jetty发行版中,setPort用的参数是int,所以会抛异常,不知cactus为什么要这样搞。
3.还要依赖commons codec这个jar
4.如果jetty是5.x,用Jetty5XTestSetup,如果是6.x,用Jetty6XTestSetup,不过当前这个cactus用的还是jetty5.1.9(org.mortbay.jetty-5.1.9.jar),所以就用Jetty5XTestSetup。
就这些,jetty启动很快,过段时间还要研究一下怎么来测试struts2。