
Linux系统出现问题时,我们不仅需要查看系统日志信息,而且还要使用大量的性能监测工具来判断究竟是哪一部分(内存、CPU、硬盘……)出了问题。在Linux系统中,所有的运行参数保存在虚拟目录/proc中,换句话说,我们使用的性能监控工具取到的数据值实际上就是源自于这个目录,当涉及到系统高估时,我们就可以修改/proc目录中的相关参数了,当然有些是不能乱改的。下面就让我们了解一下这些常用的性能监控工具。
工具
功能描述
uptime ---- 系统平均负载率 dmesg ---- 硬件/系统信息 top ----- 进程进行状态
iostat -------- CPU和磁盘平均使用率 vmstat --------- 系统运行状态 sar --------- 实时收集系统使用状态 KDE System Guard --- 图形监控工具 free ---------------内存使用率
traffic-vis ------------网络监控(只有SUSE有) pmap ------------- 进程内存占用率 strace --------- 追踪程序运行状态 ulimit ---------系统资源使用限制 mpstat -------------多处理器使用率
1、uptime
uptime命令用于查看服务器运行了多长时间以及有多少个用户登录,快速获知服务器的负荷情况。
uptime的输出包含一项内容是load average,显示了最近1,5,15分钟的负荷情况。它的值代表等待CPU处理的进程数,如果CPU没有时间处理这些进程,load average值会升高;反之则会降低。 load average的最佳值是1,说明每个进程都可以马上处理并且没有CPU cycles被丢失。对于单CPU的机器,1或者2是可以接受的值;对于多路CPU的机器,load average值可能在8到10之间。
也可以使用uptime命令来判断网络性能。例如,某个网络应用性能很低,通过运行uptime查看服务器的负荷是否很高,如果不是,那么问题应该是网络方面造成的。 以下是uptime的运行实例:
9:24am up 19:06, 1 user, load average: 0.00, 0.00, 0.00
也可以查看/proc/loadavg和/proc/uptime两个文件,注意不能编辑/proc中的文件,要用cat等命令来查看,如:
liyawei:~ # cat /proc/loadavg 0.00 0.00 0.00 1/55 5505
2、dmesg
dmesg命令主要用来显示内核信息。使用dmesg可以有效诊断机器硬件故障或者添加硬件出现的问题。
另外,使用dmesg可以确定您的服务器安装了那些硬件。每次系统重启,系统都会检查所有
硬件并将信息记录下来。执行/bin/dmesg命令可以查看该记录。 dmesg输入实例:
ReiserFS: hda6: checking transaction log (hda6) ReiserFS: hda6: Using r5 hash to sort names
Adding 1044184k swap on /dev/hda5. Priority:-1 extents:1 across:1044184k parport_pc: VIA 686A/8231 detected
parport_pc: probing current configuration parport_pc: Current parallel port base: 0x378
parport0: PC-style at 0x378 (0x778), irq 7, using FIFO [PCSPP,TRISTATE,COMPAT,ECP] parport_pc: VIA parallel port: io=0x378, irq=7 lp0: using parport0 (interrupt-driven).
e100: Intel(R) PRO/100 Network Driver, 3.5.10-k2-NAPI e100: Copyright(c) 1999-2005 Intel Corporation
ACPI: PCI Interrupt 0000:00:0d.0[A] -> GSI 17 (level, low) -> IRQ 169
e100: eth0: e100_probe: addr 0xd8042000, irq 169, MAC addr 00:02:55:1E:35:91 usbcore: registered new driver usbfs usbcore: registered new driver hub
hdc: ATAPI 48X CD-ROM drive, 128kB Cache, UDMA(33) Uniform CD-ROM driver Revision: 3.20
USB Universal Host Controller Interface driver v2.3 3、top |
top命令显示处理器的活动状况。缺省情况下,显示占用CPU最多的任务,并且每隔5秒钟做一次刷新。
Process priority的数值决定了CPU处理进程的顺序。LIUNX内核会根据需要调整该数值的大小。nice value局限于priority。priority的值不能低于nice value(nice value值越低,优先级越高)。您不可以直接修改Process priority的值,但是可以通过调整nice level值来间接地改变Process priority值,然而这一方法并不是所有时候都可用。如果某个进程运行异常的慢,可以通过降低nice level为该进程分配更多的CPU。
Linux 支持的 nice levels 由19 (优先级低)到-20 (优先级高),缺省值为0。 执行/bin/ps命令可以查看到当前进程的情况。
4、iostat
iostat由Red Hat Enterprise Linux AS发布。同时iostat也是Sysstat的一部分,可以下载到,网址是http://perso.wanadoo.fr/sebastien.godard/
执行iostat命令可以从系统启动之后的CPU平均时间,类似于uptime。除此之外,iostat还对创建一个服务器磁盘子系统的活动报告。该报告包含两部分:CPU使用情况和磁盘使用情况。
iostat显示实例:
avg-cpu: %user %nice %system %iowait %steal %idle 0.16 0.01 0.03 0.10 0.00 99.71
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn hda 0.31 4.65 4.12 327796 290832 avg-cpu: %user %nice %system %iowait %steal %idle 1.00 0.00 0.00 0.00 0.00 100.00
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn hda 0.00 0.00 0.00 0 0 avg-cpu: %user %nice %system %iowait %steal %idle 0.00 0.00 0.00 0.00 0.00 99.01
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn hda 0.00 0.00 0.00 0 0 |
CPU占用情况包括四块内容
%user:显示user level (applications)时,CPU的占用情况。 %nice:显示user level在nice priority时,CPU的占用情况。 %sys:显示system level (kernel)时,CPU的占用情况。 %idle: 显示CPU空闲时间所占比例。 磁盘使用报告分成以下几个部分: Device: 块设备的名字
tps: 该设备每秒I/O传输的次数。多个I/O请求可以组合为一个,每个I/O请求传输的字节数不同,因此可以将多个I/O请求合并为一个。 Blk_read/s, Blk_wrtn/s: 表示从该设备每秒读写的数据块数量。块的大小可以不同,如1024, 2048 或 4048字节,这取决于partition的大小。
例如,执行下列命令获得设备/dev/sda1 的数据块大小: dumpe2fs -h /dev/sda1 |grep -F "Block size" 输出结果如下
dumpe2fs 1.34 (25-Jul-2003) Block size: 1024
Blk_read, Blk_wrtn: 指示自从系统启动之后数据块读/写的合计数。
也可以查看这几个文件/proc/stat,/proc/partitions,/proc/diskstats的内容。
5、vmstat
vmstat提供了processes, memory, paging, block I/O, traps和CPU的活动状况
procs -----------memory---------- ---swap-- -----io---- -system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 513072 52324 162404 0 0 2 2 261 32 0 0 100 0 0 0 0 0 513072 52324 162404 0 0 0 0 271 43 0 0 100 0 0 0 0 0 513072 52324 162404 0 0 0 0 255 27 0 0 100 0 0 0 0 0 513072 52324 162404 0 0 0 28 275 51 0 0 97 3 0 0 0 0 513072 52324 162404 0 0 0 0 255 21 0 0 100 0 0 各输出列的含义: Process
– r: The number of processes waiting for runtime.
– b: The number of processes in uninterruptable sleep. Memory
– swpd: The amount of virtual memory used (KB). – free: The amount of idle memory (KB).
– buff: The amount of memory used as buffers (KB). Swap
– si: Amount of memory swapped from the disk (KBps).
– so: Amount of memory swapped to the disk (KBps). IO
– bi: Blocks sent to a block device (blocks/s).
– bo: Blocks received from a block device (blocks/s). System
– in: The number of interrupts per second, including the clock. – cs: The number of context switches per second. CPU (these are percentages of total CPU time)
- us: Time spent running non-kernel code (user time, including nice time). – sy: Time spent running kernel code (system time).
– id: Time spent idle. Prior to Linux 2.5.41, this included IO-wait time.
– wa: Time spent waiting for IO. Prior to Linux 2.5.41, this appeared as zero. |
6、sar
sar是Red Hat Enterprise Linux AS发行的一个工具,同时也是Sysstat工具集的命令之一,可以从以下网址下载:http://perso.wanadoo.fr/sebastien.godard/
sar用于收集、报告或者保存系统活动信息。sar由三个应用组成:sar显示数据、sar1和sar2用于收集和保存数据。
使用sar1和sar2,系统能够配置成自动抓取信息和日志,以备分析使用。配置举例:在/etc/crontab中添加如下几行内容
同样的,你也可以在命令行方式下使用sar运行实时报告。
从收集的信息中,可以得到详细的CPU使用情况(%user, %nice, %system, %idle)、内存页面调度、网络I/O、进程活动、块设备活动、以及interrupts/second liyawei:~
# sar -u 3 10
Linux 2.6.16.21-0.8-default (liyawei) 05/31/07
10:17:16 CPU %user %nice %system %iowait %idle 10:17:19 all 0.00 0.00 0.00 0.00 100.00 10:17:22 all 0.00 0.00 0.00 0.33 99.67 10:17:25 all 0.00 0.00 0.00 0.00 100.00 10:17:28 all 0.00 0.00 0.00 0.00 100.00 10:17:31 all 0.00 0.00 0.00 0.00 100.00 10:17:34 all 0.00 0.00 0.00 0.00 100.00 7、KDE System Guard |
KDE System Guard (KSysguard) 是KDE图形方式的任务管理和性能监视工具。监视本地及远程客户端/服务器架构体系的中的主机。
8、free
/bin/free命令显示所有空闲的和使用的内存数量,包括swap。同时也包含内核使用的缓存。
total used free shared buffers cached
Mem: 776492 263480 513012 0 52332 162504 -/+ buffers/cache: 48644 727848 Swap: 1044184 0 1044184 |
9、Traffic-vis
Traffic-vis是一套测定哪些主机在IP网进行通信、通信的目标主机以及传输的数据量。并输出纯文本、HTML或者GIF格式的报告。
注:Traffic-vis仅仅适用于SUSE LINUX ENTERPRISE SERVER。 如下命令用来收集网口eth0的信息:
traffic-collector -i eth0 -s /root/output_traffic-collector
可以使用killall命令来控制该进程。如果要将报告写入磁盘,可使用如下命令: killall -9 traffic-collector
要停止对信息的收集,执行如下命令:killall -9 traffic-collector 注意,不要忘记执行最后一条命令,否则会因为内存占用而影响性能。 可以根据packets, bytes, TCP连接数对输出进行排序,根据每项的总数或者收/发的数量进行。
例如根据主机上packets的收/发数量排序,执行命令:
traffic-sort -i output_traffic-collector -o output_traffic-sort -Hp
如要生成HTML格式的报告,显示传输的字节数,packets的记录、全部TCP连接请求和网络中每台服务器的信息,请运行命令:
traffic-tohtml -i output_traffic-sort -o output_traffic-tohtml.html 如要生成GIF格式(600X600)的报告,请运行命令:
traffic-togif -i output_traffic-sort -o output_traffic-togif.gif -x 600 -y 600 GIF格式的报告可以方便地发现网络广播,查看哪台主机在TCP网络中使用IPX/SPX协议并隔离网络,需要记住的是,IPX是基于广播包的协议。如果我们需要查明例如网卡故障或重复IP的问题,需要使用特殊的工具。例如SUSE LINUX Enterprise Server自带的Ethereal。 技巧和提示:使用管道,可以只需执行一条命令来产生报告。如生成HTML的报告,执行命令: cat output_traffic-collector | traffic-sort -Hp | traffic-tohtml -o output_traffic-tohtml.html 如要生成GIF文件,执行命令:
cat output_traffic-collector | traffic-sort -Hp | traffic-togif -o output_traffic-togif.gif -x 600 -y 600
10、pmap
pmap可以报告某个或多个进程的内存使用情况。使用pmap判断主机中哪个进程因占用过多内存导致内存瓶颈。 pmap <pid>
liyawei:~ # pmap 1 1: init
START SIZE RSS DIRTY PERM MAPPING 08048000 484K 244K 0K r-xp /sbin/init 080c1000 4K 4K 4K rw-p /sbin/init 080c2000 144K 24K 24K rw-p [heap] bfb5b000 84K 12K 12K rw-p [stack] ffffe000 4K 0K 0K ---p [vdso] Total: 720K 284K 40K
232K writable-private, 488K readonly-private, and 0K shared |
11、strace
strace截取和记录系统进程调用,以及进程收到的信号。是一个非常有效的检测、指导和调试工具。系统管理员可以通过该命令容易地解决程序问题。 使用该命令需要指明进程的ID(PID),例如:
strace -p <pid> # strace –p 2582rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
read(7, "\"\\\"\\\\\\\"\\\\\\\\\\\\\\\"\\\\\\\\\\\\\\\\\\\\\\\\"..., 16384) = 321 write(3, "}H\331q\37\275$\271\t\311M\304$\317~)R9\330Oj\304\257\327"..., 360) = 360
select(8, [3 4 7], [3], NULL, NULL) = 2 (in [7], out [3]) rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0 rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
read(7, "\"\\\"\\\\\\\"\\\\\\\\\\\\\\\"\\\\\\\\\\\\\\\\\\\\\\\\"..., 16384) = 323 write(3, "\204\303\27$\35\206\\\306VL\370\5R\200\226\2\320^\253\253"..., 360) = 360
select(8, [3 4 7], [3], NULL, NULL) = 2 (in [7], out [3]) rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0 rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
read(7, "\"\\\"\\\\\\\"\\\\\\\\\\\\\\\"\\\\\\\\\\\\\\\\\\\\\\\\"..., 16384) = 323 write(3, "\243\207\204\277Cw\0162\2ju=\205\'L\352?0J\256I\376\32"..., 360) = 360 select(8, [3 4 7], [3], NULL, NULL) = 2 (in [7], out [3]) rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0 rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
read(7, "\"\\\"\\\\\\\"\\\\\\\\\\\\\\\"\\\\\\\\\\\\\\\\\\\\\\\\"..., 16384) = 320 write(3, "6\270S\3i\310\334\301\253!ys\324\'\234%\356\305\26\233"..., 360) = 360 select(8, [3 4 7], [3], NULL, NULL) = 2 (in [7], out [3]) rt_sigprocmask(SIG_BLOCK, [CHLD], [], 8) = 0 rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0 |
12、ulimit
ulimit内置在bash shell中,用来提供对shell和进程可用资源的控制
liyawei:~ # ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited file size (blocks, -f) unlimited pending signals (-i) 6143 max locked memory (kbytes, -l) 32
max memory size (kbytes, -m) unlimited open files (-n) 1024 pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200 stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited max user processes (-u) 6143
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited |
-H和-S选项指明所给资源的软硬限制。如果超过了软限制,系统管理员会收到警告信息。硬限制指在用户收到超过文件句炳限制的错误信息之前,可以达到的最大值。 例如可以设置对文件句炳的硬限制:ulimit -Hn 4096 例如可以设置对文件句炳的软限制:ulimit -Sn 1024 查看软硬值,执行如下命令: ulimit -Hn ulimit -Sn
例如限制Oracle用户. 在/etc/security/limits.conf输入以下行: soft nofile 4096 hard nofile 10240
对于Red Hat Enterprise Linux AS,确定文件/etc/pam.d/system-auth包含如下行 session required /lib/security/$ISA/pam_limits.so
对于SUSE LINUX Enterprise Server,确定文件/etc/pam.d/login 和/etc/pam.d/sshd包含如下行:
session required pam_limits.so 这一行使这些限制生效。
13、mpstat mpstat是Sysstat工具集的一部分,下载地址是http://perso.wanadoo.fr/sebastien.godard/
mpstat用于报告多路CPU主机的每颗CPU活动情况,以及整个主机的CPU情况。 例如,下边的命令可以隔2秒报告一次处理器的活动情况,执行3次 mpstat 2 3
liyawei:~ # mpstat 2 3
Linux 2.6.16.21-0.8-default (liyawei) 05/31/07
10:23:03 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:23:05 all 0.50 0.00 0.00 1.99 0.00 0.00 0.00 97.51 271.64
10:23:07 all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 261.00
10:23:09 all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 261.50
Average: all 0.17 0.00 0.00 0.67 0.00 0.00 0.00 99.17 264.73 |
如下命令每隔1秒显示一次多路CPU主机的处理器活动情况,执行3次
mpstat -P ALL 1 3
liyawei:~ # mpstat -P ALL 1 10
Linux 2.6.16.21-0.8-default (liyawei) 05/31/07
10:23:31 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
10:23:32 all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 273.00 |
在web ui自动化测试中,frame一直是令人头痛的问题,就像上班必须挤公车坐地铁一般,frame的问题总是令人气闷纠结为之黯然神伤。
以前在使用watir 1.6x的时候,frame也是颇为棘手的一个问题。不但要照本宣科的进行一系列的设置,而且在进行实际代码编写的过程中会遇到各种奇奇怪怪的问题。frame就像中国男足的后防线,问题多多难以解决。
selenium webdriver处理frame比较简单,这点比某些测试工具要先进一些,令人身心愉悦。
以下面的html代码为例,我们看一下如何定位frame上的元素。
frame.html
<html>
<head>
<title>Frame</title>
<style>
#f_1 {width: 10em; height: 10em; border: 1px solid #ccc; }
#f_2 {display: none}
</style>
</head>
<body>
<p id = "p">Outside frame</p>
<iframe id = "f_1" f1" src = "part1.htm"></iframe>
<iframe id = "f_2" src = "part2.htm"></iframe>
</body>
</html>
part1.htm
<html>
<head><title>Part1</title></head>
<body>
<p id = "f_p">This is part 1</p>
<input id = "btn" type = "button" value = "click me" onclick = "alert('hello')" />
</body>
</html> |
switch_to方法会new1个TargetLocator对象,使用该对象的frame方法可以将当前识别的"主体"移动到需要定位的frame上去。
require 'rubygems'
require 'selenium-webdriver'
dr = Selenium::WebDriver.for :firefox
frame_file = 'file:///'+File.expand_path(File.join(File.dirname(__FILE__), 'frame.html'))
dr.navigate.to frame_file
# 定位default content上的p元素
p dr.find_element(:id => 'p')
# 将当前识别主体移动到id为f_1的frame上去
dr.switch_to.frame('f_1')
# 点击frame上的button
dr.find_element(:id =>'btn').click # --> a alert will popup
# 此时再去定位frame外的p元素将出现错误
p dr.find_element(:id => 'p') # --> error
# 将识别的主体切换出frame
dr.switch_to.default_content
p dr.find_element(:id => 'p') # --> ok |
webdriver的frame处理方式让人感觉那个不痛越来越轻松,这点进步值得肯定。
下一节我们将介绍如何定位弹出的新窗口
相关文章:
Selenium webdriver系列教程(4)—如何定位测试元素
Selenium webdriver系列教程(6)—如何捕获弹出窗口
1 在使用./dynamo -i windows 主机IP -m linux主机IP 命令时候,要在root身份下,不然会有错误。
2 如果发现使用了以上命令,貌似显示的是连接成功,如下面情况:
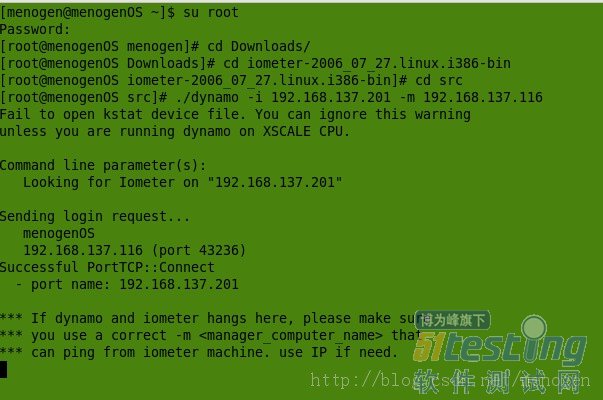
,但window下面iometer总是出现不响应,实际上,这是需要关闭window跟linux下的防火墙就可以了。linux中关闭防火墙也是得在root身份下。如下:利用service iptables stop

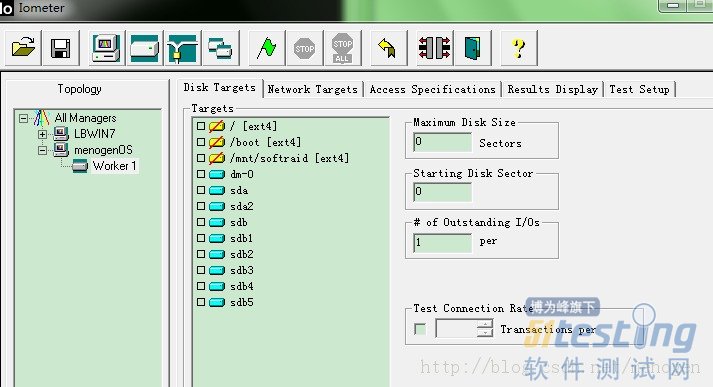
这样后,你现在linux中输入1中的命令,再打开windows下面的iometer,linux下界面是这样的:

而window下能见到linux下的磁盘情况了:
构造方法定义:
【修饰符】 构造方法名(形参列表)
{
}
【修饰符】:构造方法的上一级单元是类,所以修饰符可以public、protected(父子类访问权限)、private(本类访问权限)、默认(包访问权限)
【没有返回类型】
【构造方法名】:必须与类名一致
a.一般概念
构造方法不能够被继承,也就构造方法不能够被重写
构造方法是特殊的方法,不能够被程序员直接调用,必须使用new关键字来调用,或者在构造方法中this(实参)调用本类构造方法,
或者在构造方法中super(实参)调 用父类构造方法。
b.创建对象执行过程
首先分配内存空间,并且执行默认初始化操作(根、父、子类的顺序分配空间),此时对象已经创建成功。
然后执行初始化代码块,在执行构造方法(根初始化代码块、根构造方法、父初始化代码块、父构造方法、子初始化代码块、子构造方法的顺序执行)。
c.构造方法调用的规则
首先判断子类中是否有super(必须在构造方法中第一条语句使用)调用父类构造方法,如果有,则调用super匹配的父类构造方法。
如果没有,如果父类显式定义构造方法,则判断是否有无参构造方法,如果有,则调用父类无参构造方法。
如果没有,则编译出错。
如果父类没有定义构造方法,则系统自动默认一个无参构造方法,并且执行体为空。
最后判断是否有this(必须在构造方法中第一条语句使用)调用本类构造方法,如果有,则调用this匹配的本来构造方法
d.构造方法中使用成员变量
如果要调用父类的成员变量,可以使用super.变量
如果要调用本类的成员变量,可以使用this.变量
如果要调用局部变量,可以直接使用变量
e.构造方法中使用成员方法
如果要调用父类的成员方法,可以使用super.方法名(实参);
如果要调用本类的成员方法,可以使用this.方法名(实参)或者方法名(实参);
注意点:如果父类构造方法中调用普通方法,并且此普通方法在子类中被重写,则父类构造方法中调用的普通方法为子类的普通方法,
(也就是执行子类的普通方法),但此时子类的引用变量为null时没有进行显式初始化,所以有可能导致null指针异常(如果在
子类普通方法中使用子类的引用变量计算)。
JDBC连接各个数据库的className与url
JDBC连接DB2
private String className="com.ibm.db2.jdbc.net.DB2Driver";
private String url="jdbc:db2://localhost:8080/lwc";
JDBC连接Microsoft SQLServer(microsoft)
private String className="com.microsoft.jdbc.sqlserver.SQLServerDriver";
private String url="jdbc:microsoft:sqlserver://
localhost:1433;SelectMethod=Cursor;dataBaseName=lwc";
JDBC连接Sybase(jconn2.jar)
private String className="com.sybase.jdbc2.jdbc.SybDriver";
private String url="jdbc:sybase:Tds:localhost:2638";
JDBC连接MySQL(mm.mysql-3.0.2-bin.jar)
private String className="org.gjt.mm.mysql.Driver";
private String url="jdbc:mysql://localhost:3306/lwc";
JDBC连接PostgreSQL(pgjdbc2.jar)
private String className="org.postgresql.Driver";
private String url="jdbc:postgresql://localhost/lwc";
JDBC连接Oracle(classes12.jar)
private String className="oracle.jdbc.driver.OracleDriver";
private String url="jdbc:oracle:thin:@localhost:1521:lwc"; |
JDBC连接数据库案例
package com.itlwc; import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement; public class DBConnection {
private static Connection conn = null;
private String user = "";
private String password = "";
private String className = "com.microsoft.jdbc.sqlserver.SQLServerDriver";
private String url = "jdbc:microsoft:sqlserver://"
+ "localhost:1433;SelectMethod=Cursor;dataBaseName=lwc"; private DBConnection() {
try {
Class.forName(this.className);
conn = DriverManager.getConnection(url, user, password);
System.out.println("连接数据库成功");
} catch (ClassNotFoundException e) {
System.out.println("连接数据库失败");
} catch (SQLException e) {
System.out.println("连接数据库失败");
}
} public static Connection getConn() {
if (conn == null) {
conn = (Connection) new DBConnection();
}
return conn;
} // 关闭数据库
public static void close(ResultSet rs, Statement state, Connection conn) {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
rs = null;
}
if (state != null) {
try {
state.close();
} catch (SQLException e) {
e.printStackTrace();
}
state = null;
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
conn = null;
}
} // 测试数据库连接是否成功
public static void main(String[] args) {
getConn();
}
} |
基本CURD
获取数据库连接请查考JDBC连接常用数据库
private Connection conn = DBConnection.getConn(); |
增加方法
使用拼sql增加
public void add1(Student student) {
String sql = "insert into student values(" + student.getId() + ",'"
+ student.getCode() + "','" + student.getName() + "',"
+ student.getSex() + "," + student.getAge() + ")";
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
DBConnection.close(null, ps, conn);
}
使用替换变量增加
public void add2(Student student) {
String sql = "insert into student values(?,?,?,?,?)";
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
ps.setString(1, student.getCode());
ps.setString(2, student.getName());
ps.setString(3, student.getSex());
ps.setString(4, student.getAge());
ps.setString(5, student.getId());
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
DBConnection.close(null, ps, conn);
} |
删除方法
使用拼sql删除
public void delete1(String id) {
String sql = "delete from student where id='" + id+"'";
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
DBConnection.close(null, ps, conn);
}
使用替换变量删除
public void delete2(String id) {
String sql = "delete from student where id=?";
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
ps.setString(1, id);
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
DBConnection.close(null, ps, conn);
} |
修改方法
使用拼sql修改
public void update1(Student student) {
String sql = "update student set code='" + student.getCode()
+ "',name='" + student.getName() + "',sex=" + student.getSex()
+ ",age=" + student.getAge() + " where id=" + student.getId();
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
DBConnection.close(null, ps, conn);
}
使用替换变量修改
public void update2(Student student) {
String sql = "update student set code=?,name=?,sex=?,age=? where id=?";
PreparedStatement ps = null;
try {
ps = conn.prepareStatement(sql);
ps.setString(1, student.getCode());
ps.setString(2, student.getName());
ps.setString(3, student.getSex());
ps.setString(4, student.getAge());
ps.setString(5, student.getId());
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
DBConnection.close(null, ps, conn);
} |
查询方法
查询得到一个对象
public Student findById(int id) {
String sql = "select * from student where id=" + id;
Student student = new Student();
PreparedStatement ps = null;
ResultSet rs = null;
try {
ps = conn.prepareStatement(sql);
rs = ps.executeQuery();
if (rs.next()) {
student.setId(rs.getString(1));
student.setCode(rs.getString(2));
student.setName(rs.getString(3));
student.setSex(rs.getString(4));
student.setAge(rs.getString(5));
}
} catch (SQLException e) {
e.printStackTrace();
}
DBConnection.close(rs, ps, conn);
return student;
}
查询得到一组数据
@SuppressWarnings("unchecked")
public List find() {
String sql = "select * from student";
List list = new ArrayList();
PreparedStatement ps = null;
ResultSet rs = null;
try {
ps = conn.prepareStatement(sql);
rs = ps.executeQuery();
while (rs.next()) {
Student student = new Student();
student.setId(rs.getString(1));
student.setCode(rs.getString(2));
student.setName(rs.getString(3));
student.setSex(rs.getString(4));
student.setAge(rs.getString(5));
list.add(student);
}
} catch (SQLException e) {
e.printStackTrace();
}
DBConnection.close(rs, ps, conn);
return list;
} |
统计数据库总条数
public int getRows() {
int totalRows = 0;
String sql = "select count(*) as totalRows from student";
PreparedStatement ps = null;
ResultSet rs = null;
try {
ps = conn.prepareStatement(sql);
rs = ps.executeQuery();
if (rs.next()) {
totalRows = Integer.valueOf(rs.getString("totalRows"));
}
} catch (SQLException e) {
e.printStackTrace();
}
DBConnection.close(rs, ps, conn);
return totalRows;
} |
执行存储过程
第一种
public String retrieveId(String tableName,String interval) throws SQLException {
Connection conn = DBConnection.getConn();
String sql = "exec p_xt_idbuilder '" + tableName + "','" + interval+ "'";
PreparedStatement ps = conn.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
String maxId = "";
if(rs.next()){
maxId = rs.getString("bh");
}
DBConnection.close(rs, ps, conn);
return maxId;
}
第二种
public String retrieveId(String tableName,String interval) throws SQLException {
Connection conn = DBConnection.getConn();
CallableStatement cs = conn.prepareCall("{call p_xt_idbuilder(?,?,?)}");
cs.setString(1, tableName);
cs.setString(2, interval);
cs.registerOutParameter(3,java.sql.Types.VARCHAR);
cs.executeUpdate();
String maxId = "";
maxId=cs.getString(3);
DBConnection.close(null, cs, conn);
return maxId;
} |
WAS 的负载使用说明(一)
一、准备工作
为了测试数据的准备性,首先需要删除缓存和Cookies等临时文件。启动IE后打开“工具”菜单下的“Internet”选项命令,在打开的“Internet选项”窗口的“常规”选项卡中,单击“Internet临时文件”区域的“删除Cookies”和“删除文件”按钮将临时文件删除。
WAS说明:WAS可以通过记录浏览器活动、导入服务器日志文件或评估WEB文件夹的内容来帮助创建测试脚本:
几种方式的比较:1、记录浏览器活动的方式以精确的方式捕捉所有用户的交互活动,任何从浏览器发往服务器的URL指向,应用程序参数HTTP头部信息都会被自动地记录在新的测试脚本里。
2、导入服务器日志文件的方法在站点已经进入投入使用阶段,有了真实的用户流量的情况下使用最好,但是,一个新的站点未必有这么多真实用户使用数据,进一步说,可能还需要合并大量的日志文件来达到较好的体现用户活动的目的,这将需要创建大量的测试脚本,蒋需要客户端更多的系统资源。
3、选取WEB内容文件夹的方法最好用在测试多数是静态HTML文件的站点,这种方法允许在已有服务器的WEB页面的基础上快速创建测试脚本,然而这种方法并不捕捉任何由大多数应用程序文件产生的参数)
二、录制测试脚本
安装并启动WAS,程序运行时会打开“Cteate new script”对话框,即建立一个新的脚本窗口(如图1),如果运行WAS没有打开该窗口可以单击WAS主程序窗口工具栏上第一个按钮“New Script”即可。
因为是初次使用,所以在新建脚本窗口上单击“Record”按钮打开创建向导对话框“Browser Recorder-Step 1 of 2”,其中三个选项的作用是选择要记录的内容,分别为Request(请求)、Cookies(网上信息块)以及Host headers(主机标题),可根据需要选择(图2),然后单击“Next”即会打开“Browser Recorder-Step 2 of 2”窗口,单击“Finish”按钮。这样WAS会自动启用,并且会打开一个浏览器窗口,此时我们就可以在浏览器的地址栏中输入要测试的网站网址。随着要测试的网站内容的不断显示,在WAS主界面的“Recording”选项卡中的信息会实时更新(如图3)。
当浏览器的状态栏显示为“完成”时,我们就可以返回WAS窗口,单击“Stop Recording”按钮返回脚本窗口。
三、测试设置
为了使测试更加准确,更加接按真实效果,需要对录制的测试脚本进行一些设置。
去除静态干扰
由于网页是由图片、文字以及其它动态源码组成的,而一般的静态内容消耗的带宽并不是很大,因此我们可以将其排除在外。在脚本中选中指向图像、文字以及其它静态文件项目前的灰色按钮,然后单击工具栏上的“Delete”按钮将其删除(图4)。
设置并发数
然后在单击“New Recorded Script”下的“Settings”标签,其中“Concurrent Connections”是设置并发连接数的,其下面的“Stress level (threads)”和 “Stress multiplier(sockets perthread)” 分别设置对目标服务器的压力及负载程度的,其中Level是客户端所产生的线程数目,一个线程可以产生多个Socket并发请求,因此将两者的数值相乘,所获得的数字就是客户端同时连接的并发数(图5)。
时间设置
时间设置包括“Test Run Time”(测试运行时间)和“Request Delay”(停止响应)以及“Suspend”(挂起时间)三项。其中测试运行时间是以日、小时、分钟和秒来设定的,建议该项时间不宜太短,如果设置的并发数较多,那么时间应该按比较增长,以便产生足够多的请求;而停止时间是指连接时超出这个时间即作超时处理;在挂起时间处部分为Warmup和Cooldown两项,一般可以设置为两三分钟为宜,这样做的目的是避免测试开始和结束时数据的变形,影响测试的准确性。
指定带宽瓶颈
“Bandwith”是指定带宽瓶颈的,即选择访问该网站大多数用户所使用的带宽。例如访问该网站的绝大部分用户是拨号,那么可以选择56K。
四、开始测试
做好基本的设置工作后,就可以在左侧选中新建的脚本“New Recorded Script”项,然后单击工具栏上的“Run Script”按钮,或者打开“Scripts”菜单下的“Run”命令,这样就开始测试了。测试过程中会以进度条的方式实时显示,待进度条结束我们即可进行测试结果分析了。
五、数据分析
现在我们就可以打开测试报告来查看测试结果了。单击“View”菜单,选择“Reports”,在打开的窗口左侧会按时间显示所有测试报告。根据时间选择本次测试报告,在窗口右侧即可查看具体内容。
在测试报告中最重要的部分就是“Socket Errors”部分和“Result Codes”部分。其中Socket Errors部分共分为Connect、Send 、Recv和Timeouts。其中Connect表示客户端不能与服务器取得连接的次数;Send表示客户端不能正确发送数据到服务器的次数;Recv表示客户端不能正确从服务器接次的次数;Timeouts表示超时的线程数目。由此我们可以如果这四个数值都比较小,甚至为0则说明我们的服务器是经得起考验的;如果数值居高不下,甚至接近设置的并发数,那么则要好好的检查你的服务器了(图6)。
另外在“Result Codes”部分,如果Code列表下的数值都为200,那么表示所有请求都经服务器成功返回,如果数值出现400或大于400,例如404,那么则需要在左侧找到“Page Data”节点,查看具体的错误项目,然后作出改正了。
其实要完整的反映出一个网站在服务器上的运行情况,需要不断增减其并发数,并且进行多次测试,才能了解服务器所能承受的限度,然后才可以在IIS中设置允许连接的最大数目,从而保证网站正常运行。
WAS 的负载使用说明(二)
测试脚本的准备
1、在测试客户端机器上启动Web Application Stress Tool,在弹出的“建立新脚本”对话框中选择“Record”按钮;
2、在“Record”参数设置第一步中,所有的checkbox都不用选择,NEXT
到第二步时直接点击“finish”,点击后弹出一个IE窗口以便记录浏览器活动,同时WAS会被置于记录模式,在新出现的IE窗口的地址栏输入你的目的站点的地址,在WAS的窗口你将看到HTTP信息在跟随你的浏览活动而实时改变着,当完成了你的站点浏览后,返回Web Application Stress Tool,停止Record(点击Stop Recording按钮),终止记录并产生一个新的测试脚本(在右边的窗口将看到一个列出所有脚本的列表)。
3、将一些没用的记录删去(比如:/Apply/test/index.htm),只留下如下图所示的五条记录:
指定目标WEB服务器:Server默认地目标服务器为Localhost,修改为IP地址或目标服务器的域名
端口号不用输入。左边的窗口中改一下脚本名字,比如改为Joinwork Test;
4、5个测试用例在实际使用环境中被访问的概率是不一样的。我们可以在Page Groups中定义几个Page Group来模拟这种访问分布:
在上图中我们定义了5个Group,分别对应:查询可启动流程列表、启动流程、查询个人待办工作任务、显示任务执行表单和执行任务,它们被点击的次数比率为:1 : 1 : 5 : 5 : 4。
回到脚本主页面,分别将5条记录的Group改为刚才建立的Page Group。这样在运行脚本的时候就会按Group定义的比率来产生点击了;
5、设置测试并发用户数和测试运行时间
到 如下图的Settings页面,通过Stress Level (threads)和Stress mulitiplters来设置并发用户数,Test RUn Time来设置测试时长。因为我们要做性能压力测试,不要设置延时时间(Request Delay)。可以在实际测试时间之前,设置一段warm up运行时间,这段时间的数据是不会记录到最后的报告里的;其他设置可以保持缺省值不变;
测试运行
一切准备完成后,回到脚本主页面,然后点击工具条上的“Run Script”按钮就开始测试了;
测试报告查看
测试运行结束后,我们就可以通过点击工具条上的"Reports"按钮查看测试报告了;
测试报告里比较重要的数据是:每秒处理的请求数(Requests per Second)和每个页面的平均响应时间。
上面两张图的数据是笔者直接使用Joinwork开发版的缺省配置(JBoss 3.2.2和JBoss自带的数据库Hsql),一台主频1.5M HZ(奔腾移动)、内存725M的笔记本作服务器,一台主频2.0M HZ的台式机作客户端,测试的数据。
数据显示在100并发用户数下,每秒可处理89.26个请求,其中响应时间最长的页面是任务执行,平均响应时间是1.66秒。
Web Application Stress Tool也可以采集服务器的CPU利用率等服务器端数据,有兴趣的话可以查看帮助文件。
Web Application Stress 是Microsoft免费提供的一款软件专门对WEB服务进行压力测试用的工具软件。我经常会需要测试一些服务器的运行状态和响应时间什么的,比如在网络中新加了一台防火墙做好设置以后,它的改动对于网络中应用层的服务影响怎么样,客户会不会明显感觉到IE 打开站点的速度明显减慢等等,尤其是在防火墙工作在透明代理模式下加上了一些对于应用服务的内容限制以后,设置前后速度上的改变都是非常重要参考数据的,我需要知道到底速度的影响有多大是否可以忽略不计。
部分数据解析
下面我们用其进行一次简单的压力测试。
打开主程序,点击"Record"按钮,选择"Record Delay between request",然后"next",再"finish"。接下来会弹出一个浏览器,输入所要测试的WEB服务器地址,随便浏览一些页面,然后将其关闭,返回到Web Application Stress中,点击"stop recording"按钮。点击"Settings",就可以进入设置界面,填入一些参数。在此例中,threads我填入了50,run time我填入了2分钟,其它默认。然后选择"Scripts"菜单项中的"Run",对服务器进行压力测试,等待2分钟。
结束后,选择"Window"下的"Reports",可以看到类似于下面的压力测试结果(我已经将其简化了)。
============================================================
Number of test clients: 1
Number of hits: 6121
Requests per Second: 51.01
Socket Statistics
------------------------------------------------------------
Socket Connects: 6163
Total Bytes Sent (in KB): 1750.10
Bytes Sent Rate (in KB/s): 14.58
Total Bytes Recv (in KB): 29227.62
Bytes Recv Rate (in KB/s): 243.55
Socket Errors
------------------------------------------------------------
Connect: 0
Send: 0
Recv: 0
Timeouts: 0
RDS Results
------------------------------------------------------------
Successful Queries: 0 |
下面对其进行简单解释。测试时间内,虚拟的用户点击页面6121次,平均每秒51个请求,Socket连接数6163,其中没有连接、发送、接收、超时错误。从这个压力测试报告来看,服务器对于50个用户同时操作,应该没有任何问题。需要特别说明的是,这个只是简化的部分结果。
这只是一个简单的示例,Web Application Stress的功能远不止于此,还需要在实践中总结才是。
对Struts2进行单元测试,以struts 2.2.1.1为例 ,可以使用struts2发行包中的struts2-junit-plugin-2.2.1.1.jar,它里面提供了两个类StrutsTestCase、StrutsSpringTestCase,分别提供对纯struts应用和struts+spring整合时的单元测试支持。下面分别说明。
1.StrutsTestCase
首先准备一个纯struts2工程,建立工程过程略,但有如下的类:
Account.java,是bean
package model; public class Account {
private String userName;
private String password; public Account() {
} public Account(String userName, String password) {
this.userName = userName;
this.password = password;
} public String getUserName() {
return userName;
} public void setUserName(String userName) {
this.userName = userName;
} public String getPassword() {
return password;
} public void setPassword(String password) {
this.password = password;
}
} |
AccountAction.java
package action; import com.opensymphony.xwork2.ActionSupport;
import model.Account; import java.util.logging.Logger; public class AccountAction extends ActionSupport{ private Account accountBean;
public String execute() throws Exception {
return SUCCESS;
} public void validate(){
if (accountBean.getUserName().length()==0){
addFieldError("accountBean.userName","User name is required.");
} if (accountBean.getUserName().length()<5){
addFieldError("accountBean.userName","User name must be at least 5 characters long.");
} if (accountBean.getUserName().length()>10){
addFieldError("accountBean.userName","User name cannot be at more thant 10 characters long.");
}
} public Account getAccountBean() {
return accountBean;
} public void setAccountBean(Account accountBean) {
this.accountBean = accountBean;
}
} |
字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿
测试类:
TestAccountAction.java
package ut; import action.AccountAction;
import com.opensymphony.xwork2.ActionProxy;
import com.opensymphony.xwork2.config.ConfigurationProvider;
import org.apache.struts2.StrutsTestCase; import static org.testng.AssertJUnit.*;
public class TestAccountAction extends StrutsTestCase {
private AccountAction action;
private ActionProxy proxy;
private void init() {
proxy = getActionProxy("/createaccount"); //action url,可以写扩展名".action"也可以干脆不写
action = (AccountAction) proxy.getAction();
} public void testUserNameErrorMessage() throws Exception {
request.setParameter("accountBean.userName", "Bruc");
request.setParameter("accountBean.password", "test"); init();
proxy.execute(); assertTrue("Problem There were no errors present in fieldErrors but there should have been one error present",
action.getFieldErrors().size() == 1);
assertTrue("Problem field account.userName not present in fieldErrors but it should have been",
action.getFieldErrors().containsKey("accountBean.userName"));
} public void testUserNameCorrect() throws Exception{
request.setParameter("accountBean.userName", "Bruce");
request.setParameter("accountBean.password", "test"); init();
String result=proxy.execute(); assertTrue("Problem There were errors present in fieldErrors but there should not have been any errors present",
action.getFieldErrors().size()==0); assertEquals("Result returned form executing the action was not success but it should have been.",
"success", result); }
} |
测试逻辑比较简单,action中的validate方法会保证用户名长度在5--9之间。
定义struts.xml,放在类路径的根目录下,而非web-inf/classes下,否则会找不到,不会加载你定义的内容。
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
http://struts.apache.org/dtds/struts-2.0.dtd>
<struts>
<package name="testit" namespace="/" extends="struts-default">
<action name="createaccount" class="action.AccountAction">
<result name="success">/index.jsp</result>
<result name="input">/createaccount.jsp</result>
</action>
</package>
</struts> |
至于action/result的定义中用到的jsp页面,不必真实存在,保持不为空就行,否则,action测试的时候,会说result未定义之类的错误,因为此测试会模拟action真实状态下的运行。运行,一切OK。
正因为会模拟真实状态下的运行,所以拦截器也会正常被触发,下面再定义一个拦截器测试一下:
MyInterceptor.java
package interceptor; import com.opensymphony.xwork2.ActionInvocation;
import com.opensymphony.xwork2.interceptor.AbstractInterceptor; public class MyInterceptor extends AbstractInterceptor{ public String intercept(ActionInvocation actionInvocation) throws Exception {
System.out.println("before processing");
String rst= actionInvocation.invoke();
System.out.println("bye bye "+actionInvocation.getProxy().getMethod());
return rst;
}
} |
修改一下struts.xml,加入拦截器的定义:
<package name="testit" namespace="/" extends="struts-default">
<interceptors>
<interceptor name="testInterceptor" class="interceptor.MyInterceptor"/>
</interceptors>
<action name="createaccount" class="action.AccountAction">
<result name="success">/index.jsp</result>
<result name="input">/createaccount.jsp</result>
<interceptor-ref name="defaultStack"/>
<interceptor-ref name="testInterceptor"/>
</action>
</package> |
运行,控制台会输出:
before processing
bye bye execute
都是struts发行包提供的,其它不相关的jar不要加,尤其是以plugin.jar结尾的文件,更不要加struts2-spring-plugin-2.2.1.1.jar,加了会加载相关的东西,但这里却提供不了,导致测试无法运行。实际spring-beans-2.5.6.jar和spring-context-2.5.6.jar也不是必须的,但加了也无所谓,在StrutsSpringTestCase是需要的。另外,web.xml不需要配置,根本不会去这里找配置信息。
2.StrutsSpringTestCase
这个和前面的过程类似,需要的类分别如下。
MathAction.java
package action; import com.opensymphony.xwork2.ActionContext;
import com.opensymphony.xwork2.ActionSupport;
import org.apache.struts2.ServletActionContext;
import service.MathService; public class MathAction extends ActionSupport{
private MathService service; public String execute() throws Exception {
ServletActionContext.getRequest().setAttribute("add.result",service.add(1,2));
return SUCCESS;
} public MathService getService() {
return service;
} public void setService(MathService service) {
this.service = service;
}
} |
MathService.java
package service; public class MathService {
public int add(int a,int b){
return a+b;
}
} |
测试类TestMathAction,测试一下MathService.add是否能正确地返回两个数相加的值。
import action.MathAction;
import com.opensymphony.xwork2.ActionProxy;
import org.apache.struts2.StrutsSpringTestCase; public class TestMathAction extends StrutsSpringTestCase{
private MathAction action;
private ActionProxy proxy; protected String getContextLocations() {
return "spring/applicationContext.xml";
} private void init(){
proxy=getActionProxy("/add");
action=(MathAction)proxy.getAction();
}
public void testAdd() throws Exception{
init();
proxy.execute();
assertEquals(request.getAttribute("add.result"),3);
}
} |
这里有一个小trick,默认情况下,applicationContext.xml也要放在classpath的根目录下,但如果项目需要不放在那里,就要覆盖getContextLocations方法返回其class path,开头可以有也可以没有“/”,这里我放在包spring下,所以就返回spring/applicationContext.xml,至于struts和spring整合的配置就不用写了,想必大家都会。需要的jar在上面的基础上,加入struts2-spring-plugin-2.2.1.1.jar就行了,对了,两种测试都需要jsp-api.jar和servlet-api.jar,去tomcat里copy一份即可,junit.jar也是需要的(废话?!)
昨天因为要装watir-webdriver的原因将用了快一年的ruby1.8.6升级到了1.9。由于1.9是原生支持unicode编码,所以我们可以使用中文进行自动化脚本的编写工作。
做了简单的封装后,我们可以实现如下的自动化测试代码。请注意,这些代码是可以正确运行并作为正式的自动化测试用例的。这样一来,自动化测试脚本跟手工测试用例就非常相似了,大言不惭的说相似程度可以达到60%。
这样做有什么好处呢?
■ 手工测试用例更加容易“翻译”正自动化测试用例:
测试浏览器 = Watir::Browser.new :firefox
测试浏览器.转到 'www.google.com'
在(测试浏览器.的.text_field(:name, "q")).中.输入 "qq"
点击 测试浏览器.的.button(:name, "btnG")
等待(测试浏览器.的.div(:id, "resultStats"))
断言 '测试通过' if 测试浏览器.的.text.包含('腾讯QQ')
关闭 测试浏览器 |
由于加入了符合自然语义的”的”及“在”函数,整个测试用例的自然度得到大大提升,基本可以做到不熟悉自动化代码的人员可以大致猜测到用例的真实用例。让用例自己说话,这比反复释疑和解惑要好上一些;
■ 手工测试人员编写用例的门槛相对降低:
由于代码的灵活度及兼容性相对较大(ruby语言的特性)及测试api相对简单(watir的特性),手工测试人员应该可以更加方便的理解和编写代码,这样用例编写的门槛降低;
■ 用例维护成本降低:
中文化的用例代码可以很容易的进行review。大家应该有这样的经验,在有些代码中会出现一些随意的ab, zb之类难以理解的变量或方法名。纠其原因无非是不好的编程习惯或词穷的英文积淀。用上中文之后这些情况会有很大好转。代码本地化这项工作日本这些年一直在做,而且成果丰硕。我们完全可以通过ruby借鉴这一点;
■ webdriver的强大特性
上面的测试代码是基于watir-webdriver编写的。由于webdriver支持多种浏览器,如ff,chrome,safiri,ie等,代码的扩展性非常强。在配置合理及框架支撑的前提下,基本可以做到一套脚本多浏览器运行,这对回归测试来说应该是一个利好消息;
当然,测试脚本中文化,自然化口语化也会带来一些列的问题,这点我们也必须清楚认识到。
1.用例编写会相对费时一些;中英文结合编码在输入速度上确实不如纯英文;
2.对程序员来说上面的代码会有些怪异或者是令人难以忍受的;对于完美主义者来说,上面的代码是“不纯粹”且有些难看的;
总结一下,个人的观点如下:
对于产品代码来说,中英文混编的风格目前来说应该是不合时宜的。但对于测试脚本来说,中文越多,用例可读性越高,自动化测试代码越接近手动用例,这反而应该是一件不错的事情。这在里先抛砖引玉,希望有志同道合者可以一起研究,让自动化脚本更加的人性、自然、可读、可维护。也许在不远的将来,手动用例可以直接拿来当自动化用例执行也未尝不可能。
下面是用例的完整代码,由于只是演示兴致,因此只是随意在Module层进行了简单的可视化封装,过于简陋和demo,还望砖家手下留情。
# encoding: utf-8
require 'rubygems'
require 'watir-webdriver'
module CWrap
def 点击(obj)
obj.click rescue obj.class.to_s + '对象无法进行点击'
end
def 加载完毕()
self
end
alias :中 :加载完毕
alias :的 :中
alias :应该 :的
def 在(obj)
obj
end
def 等待(obj)
obj.wait_until_present rescue puts('该' + obj.class.to_s + '对象无法进行等待操作')
end
def 关闭(obj)
obj.close rescue puts('无法关闭这个' + obj.class.to_s + '对象')
end
def 输入(text)
self.set text rescue puts('这个' + self.class.to_s + '对象无法进行输入')
end
def 转到(url)
self.goto url rescue puts(self.class.to_s + '对象不是一个浏览器对象')
end
def 包含(text)
self.include? text rescue puts self.class.to_s + '对象无法进行包含操作'
end
def 断言(text)
puts text
end
end
include CWrap 测试浏览器 = Watir::Browser.new :firefox
测试浏览器.转到 'www.google.com'
在(测试浏览器.的.text_field(:name, "q")).中.输入 "qq"
点击 测试浏览器.的.button(:name, "btnG")
等待(测试浏览器.的.div(:id, "resultStats"))
断言 '测试通过' if 测试浏览器.的.text.包含('腾讯QQ')
关闭 测试浏览器 |
想要拷贝一份项目代码到家里,但是由于是从公司svn服务器上checkout下来的,其中有很多.svn文件。所以就写了个小工具删除.svn文件夹。就可以缩小整个工程大小。
package delete.file; import java.io.File; public class DeleteFile { //要删除的文件夹
static String delFileStr = ".svn";
public static void main(String args[]){
File file = new File("E:\\mnvdaoPlan");
File [] files = file.listFiles();
findFile(files);
}
private static void findFile(File [] files){
for(File file : files){
if(file.exists() && file.isDirectory()){
String name = file.getName();
if(delFileStr.contains(name)){
//对.svn文件夹所有内容 进行递归删除
deleteFile(file.listFiles());
//删除.svn文件夹里面内容之后 删除该文件夹
file.delete();
}else{
findFile(file.listFiles());
}
}
}
}
private static void deleteFile(File [] files){
for(File file: files){
if(file.isFile()){
file.delete();
}else if(file.isDirectory()){
deleteFile(file.listFiles());
file.delete();
}
}
}
} |
一、写一个算法对1,8,5,2,4,9,7进行顺序排列并给出所使用方法。
我所用的方法:
int[] a={1,8,5,2,4,9,7};
for(int i=0;i<a.length;i++){
for(int j=i+1;j<a.length;j++){
if(a[i]>a[j]){
//通过交换位置进行排序
int k=a[i];
a[i]=a[j];
a[j]=k;
}
}
System.out.print(a[i]+",");
} |
编程思想:看到题目上的数字,首先应该想到循环输出,自然想到for循环了,接下来就要思考输出的顺序了。对于新手来说顺序输出应该有点难度,通过比较数字大小来排序输出,利用数组顺序输出并在控制台打印出。
在网上搜集到的方法:
//用连性表的 形式 这样可以做到释放内存 同时高速排序数量小的情况 用楼上的 数量多 用这种 高速高效
TreeMap demo = new TreeMap();
demo.put("1",null);
demo.put("8",null);
demo.put("5",null);
demo.put("2",null);
demo.put("4",null);
demo.put("9",null);
demo.put("7",null);
Iterator it= demo.keySet().iterator();
while(it.hasNext()){
System.out.print(it.next()+",");
}
it.remove();
demo.clear(); |
二、一个简单的银行账务系统,其数据大致涉及:
客户(客户名、身份证号,年龄,性别,住址,电话);
存款账户(账号,类别,余额);
存款帐分录(交易日期,借贷标志,金额)。
1.采用任一主流数据库(oracle,DB2,MS SQL Server,Mysql)等DDL写出表的定义。
2.列出某客户(张三)之所有账户号;
3.李四是一位新开户的客户,添加所涉及的数据库表;
4.列出客户(李四)在2012/3/1到2012/3/7期间发生的交易金额记录。
如果是去涉及到银行开发的公司第二题这种类型的数据库题目是必考的,迄今为止,本人还没能全部写出,希望IT大神不吝赐教,写出您的思考方法,好让以后面试此类题的人能得心应手。