
在命令行输入:
date
显示当前时间 Fri Aug 3 14:15:16 CST 2007
date '+%x %X'
显示当前时间 2009年08月03日 14时15分00秒
date -s
按字符串方式修改时间
可以只修改日期,不修改时间,输入: date -s 2007-08-03
只修改时间,输入:date -s 14:15:00
同时修改日期时间,注意要加双引号,日期与时间之间有一空格,输入:date -s "2007-08-03 14:15:00"
修改完后,记得输入:clock -w
把系统时间写入CMOS
查看机器的bios时间(clock==hwclock):
hwclock [-rw]
-r:检视目前的 BIOS 时间
-w:将目前
Linux 的时间写入 BIOS 当中!
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
从安卓平台上给了我个SQLite数据库,要求程序能够读取不同的文件。由于字段实在太多,不愿意直接使用原来直接读取datatable的方式来做,手动写映射太痛苦...于是想起来EF来。
那么问题来了,学习EF的时候,一般都是直接在app.config或者
web.config中写入connectionstring,操作一个数据库的时候挺好,但是如果要操作的数据库需要临时指定的话,就比较麻烦,写进去不太合适。
我的第一个想法,就是使用DbContext构造函数的重载
public MyDbContext () :base("ConnectionStringorName") { } |
这里面可以接受一个连接字符串或者config文件的name。
P.S. 使用连接字符串的时候,直接填入就可以,使用name的时候,填入的样子类似"name=myconn"
使用name不合适了,直接使用连接字符串呢,provider怎么指定?不指定会不会直接用
SQL EXPRESS呢?自己想了想,没有再去试了,应该也是可以的,写完再补。
第二个办法,就是使用Database.Connection设置连接字符串,具体方法如下:
public MyDbContext(string connection) { Database.Connection.ConnectionString = GetSqliteString(connection); } |
这里不调用base里面的方法,对于mysqlite,getsqlitestring如下:
private string GetSqliteString(string connect) { return "Data Source=" + connect; } |
这样就能操作connectionstring了,只需要连接的时候传递一个路径就可以了。
同理,使用其他类型的数据库也可以这么操作,虽然实际上估计这么用的人不多。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
初学
JAVA很容易被其中的很多概念弄的傻傻分不清楚,首先从概念上理解一下吧,JDK(Java Development Kit)简单理解就是Java开发工具包,JRE(Java Runtime Enviroment)是Java的运行环境,JVM( java virtual machine)也就是常常听到Java虚拟机。JDK是面向开发者的,JRE是面向使用JAVA程序的用户,上面只是简单的区别,一般网上好多都讲概念,我就不讲了,直接截图应该会更清晰一点,我安装的JDK1.8,效果如图:
JDK和JRE
通过上图发现发现有两个JRE文件夹,如果细看里面的内容基本上是一样的,如果是只是Java程序使用者,那么只会有最外层的那个JRE目录,JDK中是JRE自带的,你如果安装了JDK必然里面会有一个JRE.那么问题来了,为什么会有两套JRE呢?
最开始使用JAVA的时候设置JAVA环境变量的时候除了设置JAVA_Home中JDK的路径之外,还会需要设ClassPath,%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;dt.jar和tools.jar是两个java最基本的包,里面包含了从java最重要的lang包到各种高级功能如可视化的swing包,是java必不可少的。而path下面的bin里面都是java的可执行的编译器及其工具,如java,javadoc等,你在任意的文件夹下面运行cmd键入javac,系统就能自动召见java的编译器就是归功于这个环境变量的设置 ;如果修改其中tools.jar的名字,cmd运行的时候会报错:
报错的原因就是输入的javac的命令不是去JDK中bin目录去找的javac.exe,而是去JDK中lib目录中的tools.jar中com.sun.tools.javac.Main中执行,因此javac.exe只是一个包装器(Wrapper),存在的目的是为了让开发者免于输入过长的指命。这个时候发现JDK里的工具几乎是用Java所编写,同属于Java应用程序,因此要使用JDK所附的工具来开发Java程序,所以自身需要附一套JRE才能运行。上图中与jdk同级目录下的JRE就是用来运行一般Java程序用的。
两套JRE运行的时候究竟运行哪一个呢,这个时候JDK中java.exe先从自身目录中找,然后父级目录中找,如果都没有就去注册表中找:
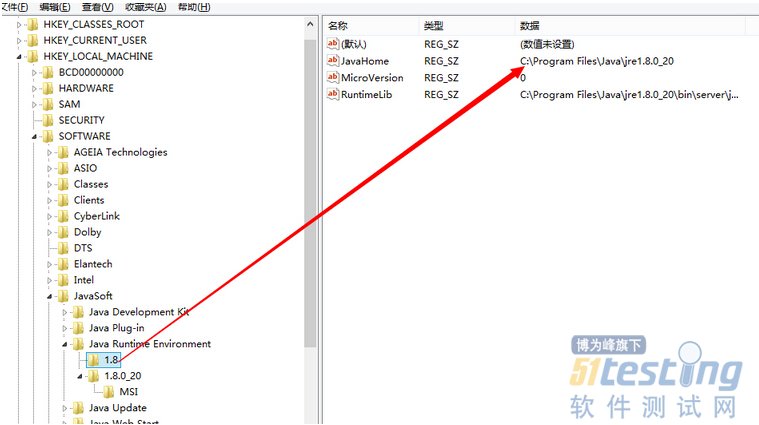
所以java.exe的运行结果与你的电脑里面哪个JRE被执行有很大的关系,JDK和JRE应该算是说完了,下面说说JRE和JVM.
JRE和JVM
JVM -- java virtual machineJVM就是我们常说的java虚拟机,它是整个java实现跨平台的最核心的部分,所有的java程序会首先被编译为.class的类文件,这种类文件可以在虚拟机上执行,class文件并不直接与机器的操作系统相对应,而是经过虚拟机间接与操作系统交互,由虚拟机将程序解释给本地系统执行,类似于C#中的CLR。
JVM不能单独搞定class的执行,解释class的时候JVM需要调用解释所需要的类库lib。在JDK下面的的jre目录里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib和起来就称为jre。JVM+Lib=JRE,如果讲的具体点就是bin目录下的jvm.dll文件, jvm.dll无法单独工作,当jvm.dll启动后,会使用explicit的方法(就是使用Win32 API之中的LoadLibrary()与GetProcAddress()来载入辅助用的动态链接库),而这些辅助用的动态链接库(.dll)都必须位 于jvm.dll所在目录的父目录之中。因此想使用哪个JVM,只需要设置PATH,指向JRE所在目录下的jvm.dll。
JDK在目前为止还是模糊的概念,这个时候可以通过JDK的目录文件来看下:
在目录下面有五个文件夹、一个src类库源码压缩包和几个声明文件,其他五个文件夹分别是:bin、db、include、lib、 jre,db这个文件看业务需求~
bin:最主要的是编译器(javac.exe);
db:jdk从1.6之后内置了Derby数据库,它是是一个纯用Java实现的内存数据库,属于Apache的一个开源项目。用Java实现的,所以可以在任何平台上运行;另外一个特点是体积小,免安装,只需要几个小jar包就可以运行了。
include:java和JVM交互用的头文件;
lib:常用类库
jre:java运行环境
JDK包含JRE,而JRE包含JVM,总的来说JDK是用于java程序的开发,而jre则是只能运行class而没有编译的功能,Eclipse、IntelliJ IDEA等其他IDE有自己的编译器而不是用JDK bin目录中自带的,所以在安装时只需选中jre路径就ok了,最后用张网络图片总结下吧:
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一个门外汉要
学习做一件事情,应该都会有犯错的过程,都会走弯路,干傻事。有时候,经验是通过流血撞墙得到的。
在做
配置管理的过程中,我应该有过好几次这样碰得鼻青脸肿的经验。
第一次,移库。当时刚接触配置库,对于svn移库不方便这事很不能理解。(需要先在服务器上checkout到本地,再上传到新库另一个repo)。系统管理员一个人干需要几天。于是想发动大家的力量去移库。最后发现,与几十个人沟通的成本远远超过移库本身需要的
工作量。最后灰头土脸的只好自己干。
第二次,担任某项目的cm。完全不懂研发流程,对cm流程也不了解。去跟项目开例会,完全听不懂。无法和研发人员沟通。最后灰头土脸的退出(我完全不知道要做什么)。项目cm的推行也就此作罢。成果是大概了解了一下项目的态度。后来开始自己吭哧吭哧搭流程,朝着可操作的方向走。直到比较成熟之后,开始挨个培训项目cm,手把手教他们做一二三四。
第三次,配置项版本发布。招了个实习生,吭哧吭哧指使人家把很多文档都走OA流程发布到svn上。结果没什么用,那些文档后来被我删了。那个实习生最后也没来我们公司上班。唯一的成果是: 得出配置项这么发布不行的结论。
第四次,又来一个实习生。让他一起写一个指引文档。当时写了几十页。后来基本没怎么看过。也没发布出来用。但是,后面一些模板倒是用的很普遍。
第五次,想跟领导申请专职的岗位,招聘专职项目cm搭建团队,无果。岗位职责定义的时候,除了配置管理工程师,还配备一个系统管理员专门做配置工具,结果被领导开会时当着很多人骂了(其实我到现在也不知道为什么骂我,用专业的人干专业的事有啥不对吗?)。现在,兼职的项目cm有希望用专职的替换(答应给人了),系统管理员还是没戏。
第六次,培训。最初尝试给大家培训,往往很多人不来,就是总监发话也没用。来了要么带个笔记本,要么玩
手机,效果不算好。态度上不重视是普遍的。真正有效的培训是从项目cm的一对一培训开始。因为我们不止步于每人2小时的一对一培训,接下来还要实操,写配置文档,做计划,打基线,查svn使用规范,组织项目成员培训。一轮下来再不用心的人也知道怎么该做什么了。这个过程中,发现虽然很多项目经理还是不太重视配管(有时兼职与研发任务冲突),但是由于责任明确到人,有计划,有规范,执行的效果还是不错的。如果再遇到个有责任心的项目cm,效果更明显。
后来一切似乎好起来了,大家好像突然重视一些了。副总要求重视版本发布。产线领导主动提自动构建的需求,打工程基线的需求。有些项目经理会主动提审计要求,还有领导提度量的要求,提权限控制的要求,有项目cm提增加基线的要求。我打算年后完善配置的重点-变更控制。还在跟QA商量上一套合适的系统,把配置状态报告自动化实现(虽然现在看起来有难度,公司向来不肯投钱买系统。)如果这一切做好了,
CMMI二级算不算达到了呢?差不多了吧。
从没有任何资源支持,没有人认可,没有人看好,从菜鸟到门内汉。现在这个状态,用QA的话来说是“好太多了”。虽然我一度想逃跑,但因为种种的原因默默坚持下来了。没有人管的好处是可以自由发挥。虽然干了很多蠢事,走了很多弯路,结果现在看起来还凑合。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
提供了生产负载的虚拟用户运行状态的相关信息,可以帮助我们了解负载生成的结果。
Rendezvous(负载过程中集合点下的虚拟用户):
当设置集合点后会生成相关数据,反映了随着时间的推移各个时间点上并发用户的数目,方便我们了解并发用户的变化情况。
Errors(错误统计):
通过错误信息可以了解错误产生的时间和错误类型,方便定位产生错误的原因。
Errors per Second(每秒错误):
了解在每个时间点上错误产生的数目,数值越小越好。通过统计数据可以了解错误随负载的变化情况,定为何时系统在负载下开始不稳定甚至出错。
Average Transaction Response Time(平均事务响应时间):
反映随着时间的变化事务响应时间的变化情况,时间越小说明处理的速度越快。如果和用户负载生成图合并,就可以发现用户负载增加对系统事务响应时间的影响规律。
Transactions per Second(每秒事务):
TPS吞吐量,反映了系统在同一时间内能处理事务的最大能力,这个数据越高,说明系统处理能力越强。
Transactions Summary(事务概要说明)
统计事物的Pass数和Fail数,了解负载的事务完成情况。通过的事务数越多,说明系统的处理能力越强;失败的事务数越小说明系统越可靠。
Transaction performance Summary(事务性能概要):
事务的平均时间、最大时间、最小时间柱状图,方便分析事务响应时间的情况。柱状图的落差越小说明响应时间的波动小,如果落差很大,说明系统不够稳定。
Transaction Response Time Under Load(用户负载下事务响应时间):
负载用户增长的过程中响应时间的变化情况,该图的线条越平稳,说明系统越稳定。
Transactions Response time(事务响应时间百分比):
不同百分比下的事务响应时间范围,可以了解有多少比例的事物发生在某个时间内,也可以发现响应时间的分布规律,数据越平稳说明响应时间变化越小。
Transaction Response Time(各时间段上的事务数):
每个时间段上的事务个数,响应时间较小的分类下的是无数越多越好。
Hits per Second(每秒点击):
当前负载重对系统所产生的点击量记录,每一次点击相当于对服务器发出了一次请求,数据越大越好。
Throughput(吞吐量):
系统负载下所使用的带宽,该数据越小说明系统的带宽依赖就越小,通过这个数据可以确定是不是网络出现了瓶颈。
HTTP Responses per Second(每秒HTTP响应):
每秒服务器返回各种状态的数目,一般和每秒点击量相同。点击量是客户端发出的请求数,而HTTP响应数是服务器返回的响应数。如果服务器的响应数小于点击量,那么说明服务器无法应答超出负载的连接请求。
Connections per Second(每秒连接):
统计终端的连接和新建的连接数,方便了解每秒对服务器产生连接的数量。同时连接数越多,说明服务器的连接池越大,当连接数随着负载上升而停止时,说明系统的连接池已满,通常这时候服务器会返回504错误。需要修改服务器的最大连接来解决该问题。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
介绍
曾经有一段时间,人们习惯于在MS Excel里面编写
单元测试用例,然后开发人员就按照单元
测试用例一步一步的来实现用例。这通常是很耗时的漫长的过程,尤其是如果应用很大或者UI很复杂的话。
这一套单元测试的执行过程常常成为瓶颈,因为任何代码修改都会带来手工执行大量单元测试,以确保新的修改没有破坏原有功能。
如今是个快节奏时代,人们希望
工作能够无需人工介入、自动化的快速完成。每个人都喜欢执行一个命令就能把工作搞定,而且在执行期间不需要人工介入。需要做的仅仅是检查一下最终的输出结果。
当这个世界正在迈向自动化时,
自动化测试也不甘落后,不论是在
功能测试方面还是UI测试方面。每天我们都能听说自动化测试方面涌现出的新软件。
本文提供了一些信息给那些想用
Coded UI自动测试框架来进行应用界面自动化的.Net开发者。
什么是Coded UI?
最近我一直在寻找一个自动化的用户
接口测试的解决方案。用户接口测试需要用户多次进行手工输入操作,这是一个既枯燥又费时的过程。因此,我想寻找一种更智能的自动化UI测试的方案,这种UI测试在不需要人工干预下,能够被保存,记录并提供支持 ,快速测试代码的改变。
Coded UI 采用用户接口来驱动应用的进行自动化测试。这些测试包括UI控制的功能性测试。他们使你可以验证整个应用的功能是否正确,其中包括了用户接口。Coded UI尤其适合用于用户接口中存在校验或者其它的登录方式的测试,比如网页。Coded UI也可以用于人工测试用例的自动化。
Coded UI 测试帮助用户测试应用程序的用户接口。这些测试允许用户验证应用程序的功能。Coded UI 多数时间用于帮助验证在UI层本身的有效逻辑。它能够验证值对用户接口的控制的正确性。
其它方案
市场有许多自动化用户接口的方案,比如HP的QuickTest Professional,
IBM Rational Functional Tester. 其它著名的,易于使用的开源工具解决用户接口自动化问题的有
Selenium,也能够记录测试,需要的时候回放。市场上还有来自Microsoft的也能不需要太多努力做同样的事。用Visual Studio Microsoft还有Coded UI的方案用于单元测试。
Coded UI适合在哪儿用?
大多数安装了Visual Studio的开发者都喜欢在Visual Studio的环境里进行单元测试,而不是使用第三方工具。由
微软提供的Coded UI,在Visual Studio环境里可谓上手即用。在开发者的机器上无需另外安装任何东西。一旦你安装了Visual Studio的Premium版或者Ultimate版,你就同时也安装好了Coded UI。
Coded UI可用性
为了使用Coded UI,需要安装Visual Studio 2010/2012/2013的Premium版或者Ultimate版。
Coded UI 测试的组成
Coded UI 测试的组成容易理解。它可分成下列文件:
UIMap.uitest
这个文件是UIMap类的XML表示。UIMap类包括视窗,控件,属性,方法,断言和动作。
UIMap.cs
对UIMap的自定义部分都存在这文件里。如果修改直接存在UIMap.designer.vb文件的话,那些修改都会在记录结束后丢失,因为这个文件重新创建了。
给每个在测应用程序中的每个模块创建一个独立的UIMap文件。
UIMap.Designer.cs
这是部分类表达各种类。这各种类是给多样的控件和他们的范围,属性,方法的类。
提示:不要直接修改 UIMap.Designer.cs。加入你这样做,这个修改会被覆盖掉。
CodedUITest.cs
这类表示的实际的CodeUI测试类,方法调用,和断言调用,所有的方法和断言默认都是从UIMap.Designer.cs文件调用的。这类有具有【codedUITest】属性TestClass和包含具有【TestMethod】属性的多种方法。
Coded UI的特性/好处
进行用户界面测试的同时进行校验.
生成VB.Net/C#代码.
测试用例可以被记录和重放.
集成了ALM Story
能够作为每日构建的一部分来运行.
根据需要进行高级扩展.
和Visual Studio集成在一起,所以无需单独购买许可.
Coded UI对Web和Windows应用同样适用.
著名的Microsoft支持.
创建Coded UI测试
Coded UI测试可以用下列方式创建
使用MTM进行快速自动构建
从现有的记录(从手动测试中记录下来的操作)中创建Coded UI
在Coded UI Test Builder创建的底稿的基础上创建一个新的Coded UI测试.
自己写Coded UI.
这个白皮书的范围仅限于“在Coded UI Test Builder创建的底稿之上创建一个新的Coded UI测试”。
小贴士: 尽量使用Coded UI Test Builder。
Coded UI Test Builder
每一个Coded UI测试的生成都需要遵从下列步骤.
记录/停止/暂停
编辑记录下来的步骤
添加断言
生成代码
创建Coded UI 测试
创建新的Coded UI 项目
要开始使用Coded UI,首先我们需要创建一个测试项目,用来保存所有Coded UI测试。创建一个新的Coded UI项目包含下列步骤
打开Visual Studio 2012
选择 File > New > Project
选择需要的语言模板 (C# or VB.Net). 我们选择了C#.
选择Coded UI Project
输入一个名字
点击 OK 按钮
添加 Coded UI 测试
Visual Studio默认配置为创建Coded UI 测试使用 "Generate a new Coded UI Test from scratch using Coded UI Test Builder"
提示:在测试的应用程序中,当你创建UI控件时尽量使用有意义的名称,从而对于自动生成的控件显得更加有意义和可用。
一旦 Coded UI 测试工程创建完成,将会自动打开生成Coded UI 测试代码的对话框,请给出以下选项的设置。
记录操作,编辑UI地图或添加断言
使用一个已经存在的操作记录
默认情况下 选择记录操作,编辑UI地图或添加断言,无需做任何操作,然后点击 "ok"
Coded UI Test Builder
选择了上述选项后,Coded UI Test Builder就会被打开,同时Visual Studio窗口被最小化。这意味着我们已经为记录操作做好了准备。
正如之前描述的,Coded UI Test Builder基于下列4个操作来做记录
Record Steps
Update or Delete Steps
Verify Results (Add Assertions)
Generate Code
小贴士: 如果用户界面(UI)变化了,就重新记录测试方法或断言方法,或者重新记录一个既有测试方法中受影响的部分。
记录一个序列的操作.
记录一个操作主要需要下列几步.
Start Recording, 通过选择Record按钮即可.
Pause Recording, 用来处理记录过程中的其它操作,即Generate Code.
Edit/Delete 操作, 以防错误的操作被记录。
Generate code为记录下来的操作创建编号。会给每一个记录下来的操作都生成编号。
Add Assertions 用来校验结果。
小贴士: 创建断言最好使用Coded UI Test Builder,因为它会在UIMap.Designer.cs文件中自动添加一个断言方法。
为记录动作做计划
任何事情的成功都取决于它计划得有多好。较好地计划最大限度保证了任务成功完成。这样总是比较好,在开始记录动作之前,我们计划好所有的所有要计划的步骤。
这里我们将要使用应用程序Windows计算器来记录步骤。我们要自动地加和减两个数字。在记录加和减两个数字的时候,下面的步骤将会用到。
。点击“开始记录”控件
。到开始,点击执行
。在执行窗口,输入”calc"
。停止记录,看记录的步骤
。删除错误的步骤(存在的话)
。产生代码;提供和动作相匹配的名字。比如,打开计算器。
提示:当你产生一个方法时候,使用一个有意义的方法的名字,代替默认名字。
有意义的名字帮助识别方法的木的。
。重新记录,提供第一个数字,暂停记录产生代码
。重新记录,提供操作(加或者减),暂停记录,产生代码
。重新记录,提供第二个数字,暂停记录,产生代码。
。加断言
提示: 产生你的测试作为一系列记录的方法
提示: 可以的时候,限制每个方法小于10个动作。这模块化的方法让UI改变时候容易替换方法。
结论
我们已经看到了Coded UI可以使开发者的生活变得多么轻松,尤其是遇到每次都需要进行很多输入的复杂页面的时候。这时,测试用例只需要被记录一次,就可以按照需要执行任意多次。使用Coded UI比使用其它工具的好处是,它能自动适配Web页面和Windows窗口应用。Coded UI测试可以用Visual Studio 2010来运行,也可以用任何版本的VS来运行,它们的功能正变得越来越强大。无需多说,Coded UI是一个由技术领导者提供的强大工具,想要体验Coded UI测试的强大,我们应该开始在项目中使用它看看它能带来多少ROI,我确信Coded UI不会让你失望。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1. 自动故障转移
1.1 将故障转移模式改成自动,如果实例为
SQL Server故障转移实例则配置无效。
1.2 在SERVER03自动转移,CLUSTEST03\CLUSTEST03手动转移的情况下,kill SERVER03的SQL Server服务。如下界面
1.3 无法发送自动故障转移,整个可用性主失败,如下所示
2. 计划手动故障转移
2.1 计划手动故障转移,需要将可用性模式改成同步提交,待所有副本都同步后,开始手动转移
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
大家知道
测试用例里测试步骤和预期结果,用Excel无法实现,下面介绍一下
Test Case Migrator Plus这个工具。
1、excel格式如下,把测试用例
工作项中的必填字段都填上,另外加上操作步骤和预期结果,字段名字不一定与流程中的一致
2、打开Test Case Migrator Plus,进入欢迎页面,如图:
3、数据源类型选择Excel Workbook
4、选择项目和工作项类型,如图:
5、创建一个新的配置文件
6、为字段建立映射关系,在Destination Field中,带*的表示必须建立映射关系,带+号的表示这些字段的值,系统自动填充
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
第1种方法:
[root@lx_web_s1 ~]# export PATH=/usr/local/webserver/mysql/bin:$PATH
再次查看:
[root@lx_web_s1 ~]# echo $PATH /usr/local/webserver/mysql/bin:/usr/local/webserver/mysql/bin/:/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin |
说明添加PATH成功。
上述方法的PATH 在终端关闭 后就会消失。所以还是建议通过编辑/etc/profile来改PATH,也可以修改家目录下的.bashrc(即:~/.bashrc)。
第2种方法:
# vim /etc/profile
在最后,添加:
export PATH=$PATH:/usr/local/webserver/mysql/bin
保存,退出,然后运行:
#source /etc/profile
不报错则成功。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
第一中方法:比较详细
以下的
文章主要介绍的是
MySQL 数据库开启远程连接的时机操作流程,其实开启MySQL 数据库远程连接的实际操作步骤并不难,知识方法对错而已,今天我们要向大家描述的是MySQL 数据库开启远程连接的时机操作流程。
1、d:\MySQL\bin\>MySQL -h localhost -u root
这样应该可以进入MySQL服务器
复制代码代码如下:
MySQL>update user set host = '%' where user = 'root';
MySQL>select host, user from user;
2、MySQL>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'mypassword' WITH GRANT OPTION
予任何主机访问数据的权限
3、MySQL>FLUSH PRIVILEGES
修改生效
4、MySQL>EXIT
退出MySQL服务器
这样就可以在其它任何的主机上以root身份登录啦!
以上的相关内容就是对MySQL 数据库开启远程连接的介绍,望你能有所收获。
第二种方法:
1、在控制台执行 mysql -u root -p mysql,系统提示输入数据库root用户的密码,输入完成后即进入mysql控制台,这个命令的第一个mysql是执行命令,第二个mysql是系统数据名称,不一样的。
2、在mysql控制台执行 GRANT ALL PRIVILEGES ON *.* TO ‘root'@'%' IDENTIFIED BY ‘MyPassword' WITH GRANT OPTION;
3、在mysql控制台执行命令中的 ‘root'@'%' 可以这样理解: root是用户名,%是主机名或IP地址,这里的%代表任意主机或IP地址,你也可替换成任意其它用户名或指定唯一的IP地址;'MyPassword'是给授权用户指定的登录数据库的密码;另外需要说明一点的是我这里的都是授权所有权限,可以指定部分权限,GRANT具体操作详情见:http://dev.mysql.com/doc/refman/5.1/en/grant.html
4、不放心的话可以在mysql控制台执行 select host, user from user; 检查一下用户表里的内容。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters