
想要拷贝一份项目代码到家里,但是由于是从公司svn服务器上checkout下来的,其中有很多.svn文件。所以就写了个小工具删除.svn文件夹。就可以缩小整个工程大小。
package delete.file; import java.io.File; public class DeleteFile { //要删除的文件夹
static String delFileStr = ".svn";
public static void main(String args[]){
File file = new File("E:\\mnvdaoPlan");
File [] files = file.listFiles();
findFile(files);
}
private static void findFile(File [] files){
for(File file : files){
if(file.exists() && file.isDirectory()){
String name = file.getName();
if(delFileStr.contains(name)){
//对.svn文件夹所有内容 进行递归删除
deleteFile(file.listFiles());
//删除.svn文件夹里面内容之后 删除该文件夹
file.delete();
}else{
findFile(file.listFiles());
}
}
}
}
private static void deleteFile(File [] files){
for(File file: files){
if(file.isFile()){
file.delete();
}else if(file.isDirectory()){
deleteFile(file.listFiles());
file.delete();
}
}
}
} |
操作系统性能监控优化不外乎对CPU、Memory、IO、Network这四个方面,下面分别介绍使用工具和指标
一、CPU
1、良好状态指标
CPU利用率:User Time <= 70%,System Time <= 35%,User Time + System Time <= 70%。
上下文切换:与CPU利用率相关联,如果CPU利用率状态良好,大量的上下文切换也是可以接受的。
可运行队列:每个处理器的可运行队列<=3个线程。
2、监控工具
vmstat
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
14 0 140 2904316 341912 3952308 0 0 0 460 1106 9593 36 64 1 0 0
17 0 140 2903492 341912 3951780 0 0 0 0 1037 9614 35 65 1 0 0
20 0 140 2902016 341912 3952000 0 0 0 0 1046 9739 35 64 1 0 0
17 0 140 2903904 341912 3951888 0 0 0 76 1044 9879 37 63 0 0 0
16 0 140 2904580 341912 3952108 0 0 0 0 1055 9808 34 65 1 0 0 |
重要参数:
r,run queue,可运行队列的线程数,这些线程都是可运行状态,只不过CPU暂时不可用;
b,被blocked的进程数,正在等待IO请求;
in,interrupts,被处理过的中断数
cs,context switch,系统上正在做上下文切换的数目
us,用户占用CPU的百分比
sys,内核和中断占用CPU的百分比
id,CPU完全空闲的百分比
上例可得:
sy高us低,以及高频度的上下文切换(cs),说明应用程序进行了大量的系统调用;
这台4核机器的r应该在12个以内,现在r在14个线程以上,此时CPU负荷很重。
查看某个进程占用的CPU资源
$ while :; do ps -eo pid,ni,pri,pcpu,psr,comm | grep 'test_command'; sleep 1; done
PID NI PRI %CPU PSR COMMAND
28577 0 23 0.0 0 test_command
28578 0 23 0.0 3 test_command
28579 0 23 0.0 2 test_command
28581 0 23 0.0 2 test_command
28582 0 23 0.0 3 test_command
28659 0 23 0.0 0 test_command
…… |
二、Memory
1、良好状态指标
swap in (si) == 0,swap out (so) == 0
应用程序可用内存/系统物理内存 <= 70%
2、监控工具
vmstat
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 3 252696 2432 268 7148 3604 2368 3608 2372 288 288 0 0 21 78 1
0 2 253484 2216 228 7104 5368 2976 5372 3036 930 519 0 0 0 100 0
0 1 259252 2616 128 6148 19784 18712 19784 18712 3821 1853 0 1 3 95 1
1 2 260008 2188 144 6824 11824 2584 12664 2584 1347 1174 14 0 0 86 0
2 1 262140 2964 128 5852 24912 17304 24952 17304 4737 2341 86 10 0 0 4 |
重要参数:
swpd,已使用的 SWAP 空间大小,KB 为单位;
free,可用的物理内存大小,KB 为单位;
buff,物理内存用来缓存读写操作的buffer大小,KB 为单位;
cache,物理内存用来缓存进程地址空间的 cache 大小,KB 为单位;
si,数据从 SWAP 读取到 RAM(swap in)的大小,KB 为单位;
so,数据从 RAM 写到 SWAP(swap out)的大小,KB 为单位。
上例可得:物理可用内存 free 基本没什么显著变化,swapd逐步增加,说明最小可用的内存始终保持在 256MB(物理内存大小) * 10% = 2.56MB 左右,当脏页达到10%的时候就开始大量使用swap。
free
$ free -m
total used free shared buffers cached
Mem: 8111 7185 926 0 243 6299
-/+ buffers/cache: 643 7468
Swap: 8189 0 8189 |
三、磁盘IO
1、良好状态指标
iowait % < 20%
提高命中率的一个简单方式就是增大文件缓存区面积,缓存区越大预存的页面就越多,命中率也越高。
Linux 内核希望能尽可能产生次缺页中断(从文件缓存区读),并且能尽可能避免主缺页中断(从硬盘读),这样随着次缺页中断的增多,文件缓存区也逐步增大,直到系统只有少量可用物理内存的时候 Linux 才开始释放一些不用的页。
2、监控工具
查看物理内存和文件缓存情况
$ cat /proc/meminfo
MemTotal: 8182776 kB
MemFree: 3053808 kB
Buffers: 342704 kB
Cached: 3972748 kB |
这台服务器总共有 8GB 物理内存(MemTotal),3GB 左右可用内存(MemFree),343MB左右用来做磁盘缓存(Buffers),4GB左右用来做文件缓存区(Cached)。
sar
$ sar -d 2 3
Linux 2.6.9-42.ELsmp (webserver) 11/30/2008 _i686_ (8 CPU)
11:09:33 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11:09:35 PM dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:09:35 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11:09:37 PM dev8-0 1.00 0.00 12.00 12.00 0.00 0.00 0.00 0.00
11:09:37 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11:09:39 PM dev8-0 1.99 0.00 47.76 24.00 0.00 0.50 0.25 0.05
Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
Average: dev8-0 1.00 0.00 19.97 20.00 0.00 0.33 0.17 0.02 |
重要参数:
await表示平均每次设备I/O操作的等待时间(以毫秒为单位)。
svctm表示平均每次设备I/O操作的服务时间(以毫秒为单位)。
%util表示一秒中有百分之几的时间用于I/O操作。
如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢。
如果%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷的在工作,该磁盘可能存在瓶颈。
四、Network IO
对于UDP
1、良好状态指标
接收、发送缓冲区不长时间有等待处理的网络包
2、监控工具
netstat
对于UDP服务,查看所有监听的UDP端口的网络情况
$ watch netstat -lunp
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
udp 0 0 0.0.0.0:64000 0.0.0.0:* -
udp 0 0 0.0.0.0:38400 0.0.0.0:* -
udp 0 0 0.0.0.0:38272 0.0.0.0:* -
udp 0 0 0.0.0.0:36992 0.0.0.0:* -
udp 0 0 0.0.0.0:17921 0.0.0.0:* -
udp 0 0 0.0.0.0:11777 0.0.0.0:* -
udp 0 0 0.0.0.0:14721 0.0.0.0:* -
udp 0 0 0.0.0.0:36225 0.0.0.0:* - |
RecvQ、SendQ为0,或者不长时间有数值是比较正常的。
对于UDP服务,查看丢包情况(网卡收到了,但是应用层没有处理过来造成的丢包)
$ watch netstat -su
Udp:
278073881 packets received
4083356897 packets to unknown port received.
2474435364 packet receive errors
1079038030 packets sent |
packet receive errors 这一项数值增长了,则表明在丢包。
这里有对“packet receive errors”的稍微详细些的解释,它包含了7种错误,and通常表明是checksum错误。不过我们通常通过这个数值的变化来判断UDP服务是否丢包(第2项错误),不知道是否有其他什么方法来判断UDP的丢包?:
"packet receive errors" usually means:
1) data is truncated, error in checksum while copying
2) udp queue is full, so it needs to be dropped
3) unable to receive udp package from encapsulated socket
4) sock_queue_rcv_skb() failed with -ENOMEM
5) it is a short packet
6) no space for header in udp packet when validating packet
7) xfrm6_policy_check() fails
many times it means the checksum is not right. |
对于TCP(来自david的经验,thx~~)
1、良好状态指标
对于TCP而言,不会出现因为缓存不足而存在丢包的事,因为网络等其他原因,导致丢了包,协议层也会通过重传机制来保证丢的包到达对方。
所以,tcp而言更多的专注重传率。
2、监控工具
# cat /proc/net/snmp | grep Tcp:
Tcp: RtoAlgorithm RtoMin RtoMax MaxConn ActiveOpens PassiveOpens AttemptFails EstabResets CurrEstab InSegs OutSegs RetransSegs InErrs OutRsts
Tcp: 1 200 120000 -1 78447 413 50234 221 3 5984652 5653408 156800 0 849
重传率 = RetransSegs / OutSegs
至于这个值在多少范围内,算ok的,得看具体的业务了。
业务侧更关注的是响应时间。
今天一时兴起想起了在SQL Server中使用DateTime.MinValue插入时间时报错的问题,原因就在于数据库的最小时间和.Net里的最小时间不一致导致的,网上查阅了些资料,找到如下结果
Net Framewrok 中,
DateTime.MinValue => 0001/01/01 00:00:00
SqlDateTime.MinValue.Value => 1753/01/01 00:00:00
SQL Server 2005 中,
DateTime 最小值 => 1753/01/01 00:00:00
SmallDateTime 最小值 => 1900/01/01 00:00:00
Net Framewrok 中,
DateTime.MaxValue => 9999/12/31 23:59:59.999
SqlDateTime.MaxValue.Value => 9999/12/31 23:59:59.997
SQL Server 2005 中,
DateTime 最大值 => 9999/12/31 23:59:59.997
SmallDateTime 最大值 =>2079.6.6 |
所以需要在数据库插入最小时间时不能使用DateTime.MinValue,需要使用
SqlDateTime.MinValue.Value。
好了到现在SQL Server数据库时间问题解决了,突然又想起了系统中有个啥1970年1月1日的时间。那这个时间又是啥来来历呢,怀着好奇宝宝的心理我有在网上查阅了一番得到如下解释:
1.可以简单的这样认为:UNIX系统认为1970年1月1日0点是时间纪元,所以我们常说的UNIX时间戳是以1970年1月1日0点为计时起点时间的。这个解释是懒人最爱^_^
2.这个比较科学
最初计算机操作系统是32位,而时间也是用32位表示。32位能表示的最大值是2147483647。另外1年365天的总秒数是31536000,2147483647/31536000 = 68.1,也就是说32位能表示的最长时间是68年,而实际上到2038年01月19日03时14分07秒,便会到达最大时间,过了这个时间点,所有32位操作系统时间便会变为10000000 00000000 00000000 00000000,也就是1901年12月13日20时45分52秒,这样便会出现时间回归的现象,很多软件便会运行异常了。
到这里,我想问题的答案已经出来了:因为用32位来表示时间的最大间隔是68年,而最早出现的UNIX操作系统考虑到计算机产生的年代和应用的时限综合取了1970年1月1日作为UNIX TIME的纪元时间(开始时间),至于时间回归的现象相信随着64为操作系统的产生逐渐得到解决,因为用64位操作系统可以表示到292,277,026,596年12月4日15时30分08秒,相信我们的N代子孙,哪怕地球毁灭那天都不用愁不够用了,因为这个时间已经是千亿年以后了。
此文是前文的后续,内容是在前轮性能测试的调优后,进行的调优结果验证。演示了如何对比两轮测试的结果,如何分析突然出现波动的原因,如何根据大量的数据验证调优的效果、验证能否达到预期性能目标,以及更重要的思考过程。这是一个比较不错性能测试调优后验证的实例。可以清楚看到专业人事,对性能调优后的数据,进行客观的比较,分析,再进一步判断调优的效果。故分享之。
由于本人能力不够,很多术语,不太明确其中文翻译,如大家看到有错误,请不吝赐教。例如,在文章图片中% Difference in XXXX 和5.Per.Mov.Avg不知道是如何计算,又该如何翻译的好。
Spike - 数据增加明显,形成一个尖,暂译:波动
Peak - 数据到达最大值,暂译:高峰或者峰值
Degradation / Degrade - 性能变差,暂译:退化
Job - 定期执行的后台程序或服务,暂译:作业
原文连接: http://apmblog.compuware.com/2013/07/11/an-integrated-approach-to-load-test-analysis-part-2-the-follow-up-test/
以下为正文
本文由Andreas Grabner共同撰写,他是Compuware的APM卓越中心的团队负责人(Team Lead for the Compuware APM Center of Excellence)。
在之前的一篇文章中,我演示了如何做更深入的分析 - 合并了由Compuware APM网络负载测试工具(Compuware APM Web Load Test,以下简称WLT)得到的外部网络负载测试结果和由Compuware PureStack技术收集硬件设备的状态数据。但是,现在我们已经测试过系统一次,在“解决”我们发现的问题之后,如果我们再次进行测试,那又会出现什么呢?使用前一轮测试时相同的参数,再运行一轮测试,就知道性能得到显著改善?我们系统能够达到期望的负载目标吗 - 支持200个虚拟用户,很少或者没有性能退化?
此文将带领你一步一步,比较两次负载测试的结果再判断调优之后性能的改善(或退化)。
第1步:根据第一次测试的结果,确定问题和进行调优
在4月14日的负载测试期间,我和Andreas Grabner发现我们网站在高负载下,有显着的性能问题,这时的负载已远超目前水平,即使是在APM社区网站人气最高时的负载水平。这些问题是造成负载水平达不到开发团队想要达到的目标 - 200个虚拟用户。

汇总的数据视图展现4月14日的负载测试中的外部和内部性能指标
在4月14日负载测试执行时,我们发现了一些环境问题。系统团队记录下关键问题包括:
部署关键的APM社区程序到其他的机器,以防止某一层的性能负面地影响到其他层(Deployment of critical APM Community applications to different machines to prevent the application performance of one layer negatively affecting another laye)
优化应用程序层 - APM社区网站的页面生成方式,以降低CPU使用率
优化Confluence的缓存设置,当加载常用的对象时,可以减少来回查询数据库次数
增加虚拟机的CPU分配,以便他们能够处理更多的负载。
第2步:再次运行测试(使用相同的参数!)
一旦这些调整完成后,根据第二轮测试的结果,在调优后的环境上,验证是否能够达到预期的目标 - 200 虚拟用户并发,且没有响应时间退化的现象。第二轮负载测试被安排在整整1周后,即4月21日,并使用第一轮测试时相同的参数(负载增压(load ramping)的细节设置参考前一篇文章)。使用相同的测试参数(负载增压,测试脚本,测试位置,测试数据等)是至关重要的,只有如此,测试结果的对比才有意义(Using the same test parameters (load ramp, test scripts, testing locations, databanks, etc.) is critical in order to allow a like-for-like comparison to occur.)。任何测试参数的偏差,会影响到最终结果,影响对应用程序环境的判断,可能导致对调优的不真实的信任(或怀疑)。
当4月21日这轮负载测试完成后,我们开始分析测试结果,初步的数据(更高的吞吐量,更快的响应时间,更低的CPU占用率和更低的数据库负载),表明这轮负载测试比前一轮的测试更为成功。这个初步结论是基于性能图表(包含了我们分析4月14日测试时曾使用的相同的数据),这个图表直接对比其关键数据,突出在两轮测试执行之间,性能表现是否存在了巨大的变化。
第3步:对比测试结果
好了,开始对比分析,我们从4月14日和4月21日两轮测试的结果中采取了三个关键指标,并把两轮数据放在一起比较对比:外部负载测试(External WLT)的平均响应时间;负载测试(WLT)的每分钟事务数;网络服务器的CPU利用率。只需对比这三组数据,很显然,这两轮负载测试有非常不同的性能表现。
从WLT测试的平均响应时间(负载测试中脚本里事务汇总后,完全下载的所有内容所需的时间 - the time required to completely download all of the content in the scripted synthetic transactions used in the load test),很明显,在08:50 - 测试开始后的40分钟,响应时间的线开始出现分支,随后也分得越来越远,表现两轮测试的不同结果。从这个数据上看,21日的平均响应时间比14日的短50%左右(注:移动平均线,5分钟平均响应时间的变化差值的百分比,是一条更清晰的走向 - the Moving Average of percentage change averages 5 minutes of response time change to produce an clearer trend line)。21日的测试中,又花了近20分钟,平均事务响应时间才达到20秒,即使当时负载水平跟14日时是一样的。

响应时间的对比表明在4月21日的APM社区网站负载测试的提升 - 更短的平均响应时间
WLT每分钟事务数(负载测试中,WLT的一分钟内事务执行的数量)显示出一个共同点,其中21日测试和14日测试的数据也是在08:50出现差异。由于从08:50开始,直到测试结束,一直保持更短的WLT平均响应时间,4月21日测试中系统每分钟处理的事务数量比4月14日测试中的要多出40%~50%。

每分钟事务数对比表明在4月21日的APM社区网站负载测试的提升 - 更多的每分钟事务数
第三个指标也显示出明显提升:网络服务器的CPU利用率(机器上系统和应用程序的执行所有必要的任务所使用的CPU百分比)。纵观4月21日的测试中,网络服务器,经由更多的硬件和优化网页渲染方式的帮助,CPU在整个测试过程的压力有所减小,达到100%的使用率时远远晚于4月14日测试时的表现。

CPU使用率对比表明在4月21日的APM社区网站负载测试的提升 - 09:40之前的更低的CPU使用率
这三个指标直接关系到每分钟网络请求数量(记录于4月21日测试的Confluence 应用程序层)。这个数据在4月21日的测试中高峰时达到每分钟125~140个,而相比4月14日的测试,其中高峰时每分钟约100 个请求。
尽管看似成功的4月21日的第二轮负载测试,仍然存在有一些问题。4月21日负载测试的综合数据图表,显示当CPU使用率达到100%的边界后(下图中的红色竖线),出现了多个性能数据波动。这表明,尽管上面所讨论的环境有所改善,但在较高负载时还存在着CPU瓶颈。
在数据库结果中记录了两轮测试之间一个极端反差。4月14日的测试中数据库的统计数据清晰显然(请参考在第1步中的性能指标图),包含在程序达到CPU的瓶颈前,查询的数量和执行时间都出现大波动。但想要在4月21日测试中,找到同一指标,你得用上你的显微镜和非常贴近地看向图表的底部(you have to break out your microscope and look very closely at the bottom of the chart)。

4月21日负载测试的外部与内部性能表现数据
数据库负载的减少,是4月14日负载测试后,启用优化的缓存设置的直接结果。随着更多的数据被存储在应用程序缓存中,需要直接在数据库中查询的数量下降,此数据层在此目前负载量下不能再算为一个潜在的瓶颈。
第4步:结果分析和下一步
在4月21日测试Confluence / Atlassian的处理过程没有突然的波动(连同数据库的波动)的,是由于在运行的负载测试期间,移除了应用程序层定期执行的作业(job)。这个作业会影响到系统和用户体验,当Andreas审查他的数据,很快就确认出这个作业问题。一旦这个作业被确认是造成这个问题的元凶,4月21日测试时它就被移除掉了,完全消除了这个早在4月14日测试时遇到的性能瓶颈。
教训:不要在流量高峰期安排会影响系统的作业;找到流量最低的一个时间段,并在此时间段执行这些作业,以便尽可能最少的游客受到影响。
正如我们在这篇文章的开始说的,表面上看,4月21日的负载测试比4月14日的测试,更加成功。然而目前,尽管21日的负载测试性能表现有所提升,结果仍然显示出还有其他性能问题有待解决。问题表现在负载测试运行后90分钟,在09:40和09:50之??间,响应时间出现非常奇怪的波动。
当系统开始性能退化,它会体现在这3个关键指标:WLT平均响应时间;WLT每分钟的交易;CPU利用率。当正在运行的事务开始需要更长的时间来执行,同时网络到应用层请求数下降和测试工具中每分钟执行事务数下降,在下面的图表可以看到它的根本原因,此图去掉了一些数据(decreasing both the number of incoming web requests to the application layer and the number of transactions per minute executed by the load generation system, the root cause can be seen in the chart below, which removes some of the data series)。
当167个虚拟用户时,是系统的临界值,之后突然10分钟内性能下降,然后恢复后,测试稳定在200个虚拟用户(点击图片见大图)
在负载测试进行到09:40时,这个性能下降期间被检测出来,同时:
WLT工具达到167个虚拟用户
网络服务器的CPU使用率达到100%
WLT工具的每分钟事务数为平均130
Confluence的网络请求达到每分钟135次(这是APM社区网站的应用程序)
有趣的是,10分钟后,这个问题彻底消失了,除了事务响应时间。响应时间没有回到波动前的水平,而是现在的平均响应时间比波动前的平均值要高出近20秒。随着系统到了200个虚拟用户顶峰时,并没有额外的负载增加,看着其他指标立即回到波动前的水平 - 尤其是每分钟事务数和每分钟请求数,非常有趣。因此,波动后随着这33个虚拟用户增加,系统表现出又直接受到CPU瓶颈的影响,更高的负载并不能增加在应用程序层处理的请求数量。
抛开这些数据(Out of this sea of metrics),我们看到的是对比4月14日的测试,4月21日的负载测试时程序性能变现的确有所提升,但第二轮测试仍无法达到预期目标 - 200个虚拟用户,存在一个瓶颈,导致性能急剧下降。
分析退化
要找到阻碍4月21日测试达到目标(200个虚拟用户并且没有或很少性能退化)的CPU瓶颈的根源,我们必须更深入一些,检查服务器端的指标,特别是那些和应用程序服务器的健康状态相关的指标。事务数下降是伴随系统出现的问题,当系统达到167个虚拟用户(The dip in transactions throughout the system is aligned with the issue captured when the system hit 167 VUs.)。现在的问题是:事务处理数下降和事务响应时间增加是这种负载下的结果?还是性能下降真正根源的一个症状?
服务器端的数据显示,高垃圾回收(Garbage Collection)可能是一个问题,因为当系统性能下降,这个自动的过程凑巧地也同时发生了。很显然,当网络服务器的CPU已经被耗尽时,再执行一个非常有影响的任务,会导致性能大幅下降。
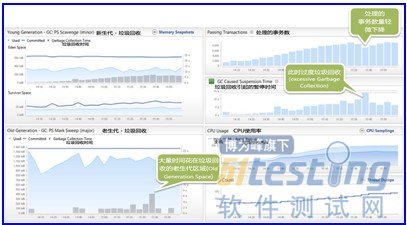
当负载增加,GC的增加是正常的 - 但有一个不寻常的波动正是当我们看到的这个事务数量下降
检查在应用程序服务器具体的事务响应时间,很容易发现潜在问题。下面的图表显示,“又一个”后台作业依然在每隔一小时周期性地压榨已经被耗尽系统的CPU。

当虚拟用户经历性能下降时,后台作业每隔一小时执行一次,占用CPU的300S
检查这些事务,该作业是每小时执行的更新作业,同步缓存的用户对象以及用户目录数据库(user directory database)。这需要相当长的也值得重视的时间,因为我们APM社区系统中有65000多个用户。该更新的作业导致了很多对象的创建和销毁 - 因此增加的内存和GC活动。

同步作业是性能下降的根本原因,导致高GC活动,消耗了大量的CPU以及增加内存分配
通过4月14日,4月21日的两轮负载测试,找出系统无达到200虚拟用户目标的不少的问题。但是现在,我们知道阻碍达成这个目标的罪魁祸首,因此努力在高负载下,集中精力减少或消除此更新作业对系统的影响。
结论
在这两轮测试中,无论你是如何衡量“成功的”负载测试,通过汇总测试中内部和外部硬件的指标,我们现在知道,4月14日的负载测试之后进行的调优,使得系统在预定作业会导致了严重性能下降的情况下,能够每分钟处理额外40%~50%的事务,支持多达167个虚拟用户。
只有有了这个数据才能转为可操作项,因为我们有一个程序能将防火墙内部采集到的数据,很轻松地整合外部负载测试工具的结果数据。这样,尽管是在非常受控的情况,也成为分析系统性能的一个因素。(This data was only able to be turned into actionable information because we had a process in place that allowed results captured from inside the firewall to be easily aligned with the external results from the load test system. By doing this, the customer, albeit in a very controlled form, becomes a factor in the analysis of system performance.)
通过创建一个完整的性能角度,PureStack比只提供负载下系统技术指标的,提供得更多。当进行结果分析时,PureStack视用户体验的重要性如CPU,数据库和应用程序处理请求数一般。根据用户体验的重要性,然后决定如何划分问题的优先级和如何解决他们。这些对最终用户有影响的问题提供了真实世界的反馈 - 您的应用程序在峰值期间所出现性能问题的真实成本(The importance of the user experience then dictates how infrastructure issues are prioritized and resolved, as the effect these issues have on end users provides real-world feedback into the true cost of performance issues that occur to your application during peak periods)。
根据负载测试中的数据,可以确定系统需要的额外修改,特别是页面呈现方面,需要进一步降低CPU负荷,使系统能够达到和保持负载峰值为200的虚拟用户。随着Confluence应用软件的升级 - 2013年7月初部署的程序 - 达到预期的目标。但假设这是不够的,一旦系统已经稳定运行,2013年7月将会有对新Confluence系统的额外负载测试。并且通过使用4月14日和21日的负载测试中同样事务的路径,将对新系统进行验证,以确认升级能带来所期望的性能表现。
版权声明:本文出自 在劫录 的51Testing软件测试博客:http://www.51testing.com/?166582
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
一 Jmeter概述
Jmeter是Apache组织开发的基于Java的压力测试工具。最初被应用于WEB应用测试,后来扩展到其它测试领域,它可用于测试静态和动态文件、Java小服务程序、CGI脚本、Java对象、数据库、FTP服务器等。
二 配置
1 下载
从官网上可以下载最新版的Jmeter,目前测试用的是
apache-jmeter-2.9.zip。已经放在了当前目录下。
2 启动前准备
启动Jmeter需要配置jdk,版本在1.6或1.6以上就可以了
三 使用方法
1 Jmeter安装
文件直接解压即可用
2 运行的方法
运行windows下的Jmeter方法有两种:
1) 双击在bin目录下的ApacheJMeter.jar
2) 在cmd下输入进入bin的路径。
运行jmeter.bat文件
例如:
E:\synchcontrol\apache-jmeter-2.9\bin>jmeter.bat
3 Jmeter用法
1)最基本的操作有打开计划、启动页面、关闭页面等。
2)建立新工程
主要包括必不可少的几个页面
A:新建线程组
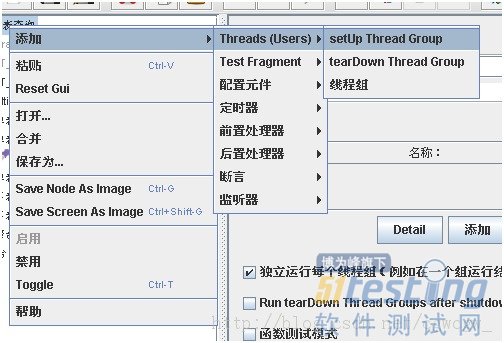
B 添加jdbc配置页面
C:jdbc配置
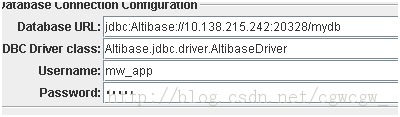
以Altibase为例
D:添加Jdbc Request
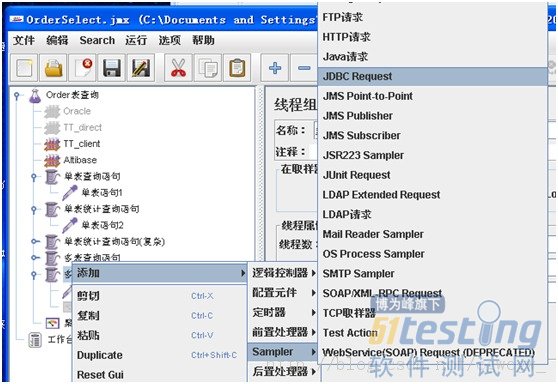
E: 显示结果主要有聚合报告和查看结果树两种会比较常用

4 实际测试中用到的配置和方法
A:配置用户自定义变量,更改线程数和循环数,实现多线程测试;定义随机数最大值,因为有的测试用到了循环的一些变量
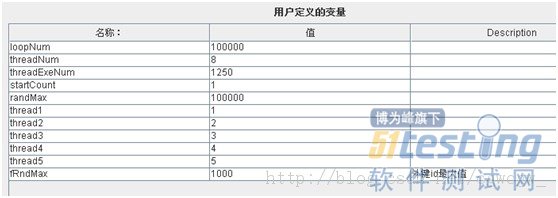
B:循环控制器、随机变量控制器、计数器.这些比较容易理解。
C: 把Oracle和Timesent、Atlibase配置在了同一个工程下,测那个数据库把别的关掉,启用数据库的配置就可以

D:工具提供了文档,有问题的可以这里查看
上一讲我们介绍了如何部署selenium 2.0的开发环境,这一讲我们将介绍如何使用selenium提供给我们的接口进行浏览器的简单操作。
本文将先介绍适合初级用户的一些常用方法,然后将对一些高级用法和实现源码进行稍微深入一些的分析。
如何打开一个测试浏览器
做自动化测试一般情况下我们都需要首先打开测试浏览器,浏览器开启后我们方可"命令"浏览器去打开新页面,点击特定的链接,判断具体的逻辑等等。因此该操作为"万里长征的第一步",必须给以重视。具体代码如下。需要注意的是如果使用chrome进行测试,那么必须下载安装chrome driver。
require 'rubygems'
require 'selenium-webdriver'
# 打开firefox
dr = Selenium::WebDriver.for :firefox
dr = Selenium::WebDriver.for :ff
# 打开ie
dr = Selenium::WebDriver.for :ie
dr = Selenium::WebDriver.for :internet_explorer
# 打开chrome
dr = Selenium::WebDriver.for :chrome |
如何打开1个具体的url
打开浏览器后我们需要转到我们的测试url。下面的代码可以达成这个目的。
require 'rubygems'
require 'selenium-webdriver'
dr = Selenium::WebDriver.for :firefox
# 使用get方法
dr.get url
# 使用navigate方法,然后再调用to方法
dr.navigate.to url |
如何关闭浏览器
测试结束后往往需要关闭浏览器,下面的代码可以完成这个任务。
require 'rubygems'
require 'selenium-webdriver'
dr = Selenium::WebDriver.for :firefox
dr.get url
# 使用quit方法
dr.quit
# 使用close方法
dr.close |
如何返回当前页面的url
有时候我们需要返回当前测试页面的url。比如在使用soso进行搜索时,当我们提交了搜索请求后,soso返回的url应该是包含我们所需要搜索的关键字的。
例如如果我们搜索webdriver,那么提交搜索请求后,页面应当转到url为http://www.soso.com/q?pid=s.idx&cid=s.idx&w=webdriver的页面,这时候我们取到这个页面的url,然后通过正则表达式去匹配一下就能够得到我们所搜索的关键字了。具体代码如下。
require 'rubygems'
require 'selenium-webdriver'
dr = Selenium::WebDriver.for :firefox
url = 'http://www.soso.com'
dr.navigate.to url
search_input = dr.find_element :id => 's_input'
search_input.send_keys 'webdriver'
search_input.submit
match = dr.current_url.match(/\b\w+$/)
keyword = match[0] if match |
如何返回当前页面的title
require 'rubygems'
require 'selenium-webdriver'
dr = Selenium::WebDriver.for :firefox
url = 'http://www.soso.com'
dr.navigate.to url
puts dr.title |
其他方法
window_handles : 返回当前所有打开浏览器的窗口句柄
window_handle : 返回当前的浏览器的窗口句柄
page_source : 返回当前页面的源码
visible: 当前浏览器是否可见,并不保证支持所有浏览器
深入讨论
操作浏览器的方法主要封装在lib\selenium\webdriver\common\driver.rb文件中。
该文件定义了Selenium::WebDriver::Driver类。我们启动浏览器就是调用这个类的for方法。
接下来
这一节讨论了浏览器的简单操作,下一节我们将讨论如何在页面上执行js代码。
本节重点:
ActionChains 类
context_click() 右击
double_click() 双击
drag_and_drop() 拖动
测试的产品中有一个操作是右键点击文件列表会弹出一个快捷菜单,可以方便的选择快捷菜单中的选择对文件进行操作(删除、移动、重命名),之前学习元素的点击非常简单:
driver.find_element_by_id(“xxx”).click()
那么鼠标的双击、右击、拖动等是否也是这样的写法呢?例如右击:
driver.find_element_by_id(“xxx”).context_click()
经过运行脚本得到了下面的错误提示:
AttributeError: 'WebElement' object has no attribute 'context_click'
提示右点方法不属于webelement 对象,通过查找文档,发现属于ActionChains 类,但文档中没有具体写法。这里要感谢 北京-QC-rabbit 的指点,其实整个python+selenium 学习过程都要感谢 北京-QC-rabbit 的指点。
下面介绍鼠标右键的用法,以快播私有云为例:
#coding=utf-8 from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time driver = webdriver.Firefox()
driver.get(http://passport.kuaibo.com/login/?referrer=http%3A%2F%2Fwebcloud.kuaibo.com%2F) #登陆快播私有云
driver.find_element_by_id("user_name").send_keys("username")
driver.find_element_by_id("user_pwd").send_keys("123456")
driver.find_element_by_id("dl_an_submit").click()
time.sleep(3) #定位到要右击的元素
qqq =driver.find_element_by_xpath("/html/body/div/div[2]/div[2]/div/div[3]/table/tbody/tr/td[2]")
#对定位到的元素执行鼠标右键操作
ActionChains(driver).context_click(qqq).perform()
'''
#你也可以使用三行的写法,但我觉得上面两行写法更容易理解
chain = ActionChains(driver)
implement = driver.find_element_by_xpath("/html/body/div/div[2]/div[2]/div/div[3]/table/tbody/tr/td[2]")
chain.context_click(implement).perform()
'''
time.sleep(3) #休眠3秒
driver.close() |
这里需要注意的是,在使用ActionChains 类之前,要先将包引入。
右击的操作会了,下面的其它方法比葫芦画瓢也能写出来。
鼠标双击的写法:
#定位到要双击的元素
qqq =driver.find_element_by_xpath("xxx")
#对定位到的元素执行鼠标双击操作
ActionChains(driver).double_click(qqq).perform()
鼠标拖放操作的写法:
#定位元素的原位置
element = driver.find_element_by_name("source")
#定位元素要移动到的目标位置
target = driver.find_element_by_name("target") #执行元素的移动操作
ActionChains(driver).drag_and_drop(element, target).perform() |
ActionChains 类不仅仅是只包含了上面的三个方法,下面将方法列出:
class ActionChains(driver) driver:The WebDriver instance which performs user actions.
Generate user actions. All actions are stored in the ActionChains object. Call perform() to fire stored actions.
– perform()
Performs all stored actions.
– click(on_element=None)
Clicks an element.
on_element:The element to click. If None, clicks on current mouse position.
– click_and_hold(on_element)
Holds down the left mouse button on an element.
on_element:The element to mouse down. If None, clicks on current mouse position.
– context_click(on_element)
Performs a context-click (right click) on an element.
on_element:The element to context-click. If None, clicks on current mouse position.
– double_click(on_element)
Double-clicks an element.
on_element:The element to double-click. If None, clicks on current mouse position.
– drag_and_drop(source, target)
Holds down the left mouse button on the source element, then moves to the target element and releases the mouse button.
source:The element to mouse down.
target: The element to mouse up.
– key_down(key, element=None)
Sends a key press only, without releasing it. Should only be used with modifier keys (Control, Alt andShift).
key:The modifier key to send. Values are defined in Keys class.
element:The element to send keys. If None, sends a key to current focused element.
– key_up(key, element=None)
Releases a modifier key.
key:The modifier key to send. Values are defined in Keys class.
element:The element to send keys. If None, sends a key to current focused element.
– move_by_offset(xoffset, yoffset)
Moving the mouse to an offset from current mouse position.
xoffset:X offset to move to.yoffset:Y offset to move to.
– move_to_element(to_element)
Moving the mouse to the middle of an element.
to_element: The element to move to.
– move_to_element_with_offset(to_element, xoffset, yoffset)
Move the mouse by an offset of the specificed element. Offsets are relative to the top-left corner of the
element.
to_element: The element to move to.xoffset:X offset to move to.yoffset:Y offset to move to.
– release(on_element)
Releasing a held mouse button.
on_element:The element to mouse up.
– send_keys(*keys_to_send)
Sends keys to current focused element.
keys_to_send:The keys to send.
– send_keys_to_element(self, element,*keys_to_send):
Sends keys to an element.
element:The element to send keys.keys_to_send:The keys to send. |
相关文章:
selenium-webdriver(python) (十四) -- webdriver原理
Selenium 1.x时代已经远去,它理应躺在历史的角落里,靠着壁炉烤着火,抽着旱烟,在袅袅的升起的青烟中回忆那曾经属于自己的美好时代。
不过事实却并非如此,现今原本早应退役的selenium 1.x却还是多数人坚定的选择,究其原因不过是1.x时代遗留下了大量的文档,代码,教程让人们误以为1.x还是这个年代的主流,还应该光鲜亮丽在前台演出属于它的美好。长江后浪推前浪,最为前浪的selenium 1.x的宿命应该是死在沙滩上。
好了,直入主题,由于开源社区不再维护selenium 1.x再加之更为先进的selenium 2.0确实有不少优势之初可以完全取代1.x,在这里笔者会花一些笔墨,若干篇幅,争取深入浅出的讲解selenium 2.0的一些基本知识,常用方法和高级扩展,但由于笔者水平和时间精力等确实有限,文中应该避免不了谬误和臆断之处,还望众位读者多多海涵。
本文中所以代码和示例均由Ruby编写,本文介绍的webdriver api也主要是ruby binding。所以首先请确保ruby语言在开发环境上正确安装。
教程的第一节从selenium 2.0和webdriver关系说起。
Selenium 2.0 和webdriver之间有什么关系,有什么不可告人的秘密?说来话长,但也简单。Selenium 2.0其实就是webdriver。就像张飞就是张翼德,关羽就是关云长一样,叫法不同但内容却是一样的。
安装selenium webdriver
(1)安装ruby1.8.7或1.9.2。注意selenium-webdriver只支持1.8.7以上的ruby版本;
(2)使用gem安装selenium-webdriver;打开命令行,输入下列代码完成安装。注意,如果你的开发环境需要http proxy的话,请注意在gem命令中加入--http_proxy参数;
gem install selenium-webdriver [--http_proxy]
(3)在命令行中输入gem list,如果selenium-webdriver正确安装,则其应该出现在结果列表里。在文本写作时,selenium webdriver的最新版本应该是2.2.0;
gem list selenium-webdriver
(4)安装firefox。本文使用firefox作为测试浏览器进行讲解,所以请确保开发环境上正确安装了firefox。由于firefox版本更新较快,我们只需要选择1个稳定版本安装既可,本文中笔者使用的版本是FF 5.0;
简单的google test
下面我们写几行代码在初次感受一下webdriver的魅力,好吧,说老实话原生的selenium webdriver并没有什么独特的魅力,相反到是watir-webdriver更加的平易近人老少咸宜。这个不是文本讨论的范畴,暂且打住。
require 'rubygems'
require 'selenium-webdriver'
driver = Selenium::WebDriver.for :firefox
driver.navigate.to http://google.com
sleep 3
element = driver.find_element(:name, 'q')
element.send_keys "Hello WebDriver!"
element.submit
puts driver.title
driver.quit |
日常开放中 平台中通常不会只有单一的环境,因此跨平台的通讯 通常会使用标准的AES,DES等加密规则
公司的项目开发中 遇到了JAVA和PHP的加密解密跨平台的问题 经过多方查找资料以及研究找出一个通用的基础加解密方案如下
1:JAVA代码 (3DES版)
import javax.crypto.Cipher;
import javax.crypto.SecretKey;
import javax.crypto.spec.SecretKeySpec;
import org.apache.log4j.Logger;
import sun.misc.BASE64Decoder;
import sun.misc.BASE64Encoder;
/**
* Java版3DES加密解密,适用于PHP版3DES加密解密(PHP语言开发的MCRYPT_3DES算法、MCRYPT_MODE_ECB模式、PKCS7填充方式)
* @author G007N
*/
public class DesBase64Tool {
private static SecretKey secretKey = null;//key对象
private static Cipher cipher = null; //私鈅加密对象Cipher
private static String keyString = "AKlMU89D3FchIkhKyMma6FiE";//密钥
private static Logger log = Logger.getRootLogger();
static{
try {
secretKey = new SecretKeySpec(keyString.getBytes(), "DESede");//获得密钥
/*获得一个私鈅加密类Cipher,DESede是算法,ECB是加密模式,PKCS5Padding是填充方式*/
cipher = Cipher.getInstance("DESede/ECB/PKCS5Padding");
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
/**
* 加密
* @param message
* @return
*/
public static String desEncrypt(String message) {
String result = ""; //DES加密字符串
String newResult = "";//去掉换行符后的加密字符串
try {
cipher.init(Cipher.ENCRYPT_MODE, secretKey); //设置工作模式为加密模式,给出密钥
byte[] resultBytes = cipher.doFinal(message.getBytes("UTF-8")); //正式执行加密操作
BASE64Encoder enc = new BASE64Encoder();
result = enc.encode(resultBytes);//进行BASE64编码
newResult = filter(result); //去掉加密串中的换行符
} catch (Exception e) {
log.error(e.getMessage(), e);
}
return newResult;
}
/**
* 解密
* @param message
* @return
* @throws Exception
*/
public static String desDecrypt(String message) throws Exception {
String result = "";
try {
BASE64Decoder dec = new BASE64Decoder();
byte[] messageBytes = dec.decodeBuffer(message); //进行BASE64编码
cipher.init(Cipher.DECRYPT_MODE, secretKey); //设置工作模式为解密模式,给出密钥
byte[] resultBytes = cipher.doFinal(messageBytes);//正式执行解密操作
result = new String(resultBytes,"UTF-8");
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* 去掉加密字符串换行符
* @param str
* @return
*/
public static String filter(String str) {
String output = "";
StringBuffer sb = new StringBuffer();
for (int i = 0; i < str.length(); i++) {
int asc = str.charAt(i);
if (asc != 10 && asc != 13) {
sb.append(str.subSequence(i, i+1));
}
}
output = new String(sb);
return output;
}
/**
* 加密解密测试
* @param args
*/
public static void main(String[] args) {
try {
String strText = "Hello world!";
String deseResult = desEncrypt(strText);//加密
System.out.println("加密结果:"+deseResult);
String desdResult = desDecrypt(deseResult);//解密
System.out.println("解密结果:"+desdResult);
} catch (Exception e) {
e.printStackTrace();
}
}
} |
2:PHP版本(3DES)
3des的已经不再使用了,因此没有专门整理成类
凑活看吧哈哈
function pkcs5_pad($text, $blocksize)
{
$pad = $blocksize - (strlen($text) % $blocksize);
return $text . str_repeat(chr($pad), $pad);
}
function pkcs5_unpad($text)
{
$pad = ord($text{strlen($text)-1});
if ($pad > strlen($text))
{
return false;
}
if( strspn($text, chr($pad), strlen($text) - $pad) != $pad)
{
return false;
}
return substr($text, 0, -1 * $pad);
}
$key = "AKlMU89D3FchIkhKyMma6FiE";
//$key = pack("H48", $key);
$iv = "0102030405060708";
$iv = pack("H16", $iv);
$td = mcrypt_module_open(MCRYPT_3DES, '', MCRYPT_MODE_ECB, '');
mcrypt_generic_init($td, $key, $iv);
$str = base64_encode(mcrypt_generic($td,pkcs5_pad("1qaz2ws",8)));
echo $str ."";
mcrypt_generic_deinit($td);
mcrypt_module_close($td);
$td = mcrypt_module_open(MCRYPT_3DES, '', MCRYPT_MODE_ECB, '');
mcrypt_generic_init($td, $key, $iv);
$ttt = pkcs5_unpad(mdecrypt_generic($td, base64_decode($str)));
mcrypt_generic_deinit($td);
mcrypt_module_close($td);
echo $ttt;
exit; |
3:JAVA版本(AES)
将代码1中的如下行修改
/*密钥为16的倍数*/
private static String keyString = "AKlMU89D3FchIkhK";//密钥
/*AES算法*/
secretKey = new SecretKeySpec(keyString.getBytes(), "AES");//获得密钥
/*获得一个私鈅加密类Cipher,DESede-》AES算法,ECB是加密模式,PKCS5Padding是填充方式*/
cipher = Cipher.getInstance("AES/ECB/PKCS5Padding"); |
4:PHP版本(AES)
开发中选择了AESclass CryptAES
{
protected $cipher = MCRYPT_RIJNDAEL_128;
protected $mode = MCRYPT_MODE_ECB;
protected $pad_method = NULL;
protected $secret_key = '';
protected $iv = '';
public function set_cipher($cipher)
{
$this->cipher = $cipher;
}
public function set_mode($mode)
{
$this->mode = $mode;
}
public function set_iv($iv)
{
$this->iv = $iv;
}
public function set_key($key)
{
$this->secret_key = $key;
}
public function require_pkcs5()
{
$this->pad_method = 'pkcs5';
}
protected function pad_or_unpad($str, $ext)
{
if ( is_null($this->pad_method) )
{
return $str;
}
else
{
$func_name = __CLASS__ . '::' . $this->pad_method . '_' . $ext . 'pad';
if ( is_callable($func_name) )
{
$size = mcrypt_get_block_size($this->cipher, $this->mode);
return call_user_func($func_name, $str, $size);
}
}
return $str;
}
protected function pad($str)
{
return $this->pad_or_unpad($str, '');
}
protected function unpad($str)
{
return $this->pad_or_unpad($str, 'un');
}
public function encrypt($str)
{
$str = $this->pad($str);
$td = mcrypt_module_open($this->cipher, '', $this->mode, '');
if ( empty($this->iv) )
{
$iv = @mcrypt_create_iv(mcrypt_enc_get_iv_size($td), MCRYPT_RAND);
}
else
{
$iv = $this->iv;
}
mcrypt_generic_init($td, $this->secret_key, $iv);
$cyper_text = mcrypt_generic($td, $str);
$rt=base64_encode($cyper_text);
//$rt = bin2hex($cyper_text);
mcrypt_generic_deinit($td);
mcrypt_module_close($td);
return $rt;
}
public function decrypt($str){
$td = mcrypt_module_open($this->cipher, '', $this->mode, '');
if ( empty($this->iv) )
{
$iv = @mcrypt_create_iv(mcrypt_enc_get_iv_size($td), MCRYPT_RAND);
}
else
{
$iv = $this->iv;
}
mcrypt_generic_init($td, $this->secret_key, $iv);
//$decrypted_text = mdecrypt_generic($td, self::hex2bin($str));
$decrypted_text = mdecrypt_generic($td, base64_decode($str));
$rt = $decrypted_text;
mcrypt_generic_deinit($td);
mcrypt_module_close($td);
return $this->unpad($rt);
}
public static function hex2bin($hexdata) {
$bindata = '';
$length = strlen($hexdata);
for ($i=0; $i < $length; $i += 2)
{
$bindata .= chr(hexdec(substr($hexdata, $i, 2)));
}
return $bindata;
}
public static function pkcs5_pad($text, $blocksize)
{
$pad = $blocksize - (strlen($text) % $blocksize);
return $text . str_repeat(chr($pad), $pad);
}
public static function pkcs5_unpad($text)
{
$pad = ord($text{strlen($text) - 1});
if ($pad > strlen($text)) return false;
if (strspn($text, chr($pad), strlen($text) - $pad) != $pad) return false;
return substr($text, 0, -1 * $pad);
}
}
$aes = new CryptAES();
//密钥修改成了16位 和JAVA的一致
$aes->set_key('AKlMU89D3FchIkhK');
//$aes->set_key('AKlMU89D3FchIkhKyMma6FiE');
$aes->require_pkcs5();
$rt = $aes->encrypt('1qaz2ws');
echo $rt . '<br/>';
echo $aes->decrypt($rt) . '<br/>';
exit; |
1、启动和关闭数据库实例
sqlplus /nolog
!echo $ORACLE_SID
connect / as sysdba
startup
shutdown immediate |
2、静态参数文件
在Oracle 9i 之前,通过静态文本存放初始化参数,可通过文本编辑器编辑。
在参数文件中,可以为相同的参数设置多个条目,对于这样的重复参数,Oracle会选最后一个。
在Oracle 9i之前,如果在启动实例时没有指定参数文件,那么Oracle会首先在默认的目录下查找initSID.ora文件,Linux的默认目录是$ORACLE_HOME/dbs,Windows的默认目录是$ORACLE\database;如果没找到,会查找init.ora是否存在;如果没找到,就会报错:在处理系统参数时失败,不能打开参数文件。
在启动时,也可以直接指定pfile,命令为:
startup pfile = ’你的路径/你的pfile文件名.ora‘
3、动态参数文件
从Oracle 9i开始,提供了动态参数,也就是修改了内存中的参数值后,不用重启,就能使参数生效的机制,同时提供了动态参数文件spfile,这是一个二进制文件,不能用notepa或者vi编辑器编辑,如果希望对参数的修改持久化,那么也必须修改spfile中的参数值。
另外,rman支持对spfile的自动备份,但不支持pfile的自动备份。
在参数文件中,每个参数都有一个前缀,* 表示对所有实例有效,“实例名称”表示只对这个实例有效。
由于加了动态参数文件,系统在启动时,查找参数文件的顺序也有所变化:默认路径下的spfileSID.ora --> spfile.ora - -> initSID.ora --> init.ora,startup pfile ='...'这样的命令还是有用的,注意不支持这样的语法:startup spfile = ’...' 。
通过pfile来创建spfile,如果下面的命令不指定路径,那么用的都是默认路径:
create spfile =’/u01/app/oracle‘ from pfile = '/u01/app/oracle/initora10g.ora'
--禁用自动内存管理
alter system set sga_target = 0
--显示参数的值
show parameter spfile
show parameter shared_pool_size
--另一种方法显示参数的值
select value from v$parameter where name = 'spfile'
select value from v$spparameter where name = 'shared_pool_size'
--只在内存中修改参数的值,重启后,还是spfile的值,而不是这里的100M
alter system set shared_pool_size = 100M scope = memory
--只在spfile文件中修改参数的值,重启后才会生效
alter system set shared_pool_size = 100M scope = spfile
--同时修改spfile和内存中的值
alter system set shared_pool_size = 100M scope = both
下面显示了,如果把spfile中的一个参数设置为一个无效的值后,如何解决系统再次启动时,无法启动的问题:
alter system set sga_target = 1000000M scope = spfile
shutdown immediate
startup |
报错:out of memory
alter system set sga_target = 1000M
报错:oracle 不可用
create pfile = '/u01/init.ora' from spfile
可以打开pfile文件,手动编辑,也可以直接在文件最后加一行:
!echo '*.sga_target = 1000M' >> /u01/init.ora
create spfile from pfile = '/u01/init.ora'
startup |
4、实例的启动和关闭的具体步骤
nomount阶段:找到参数文件,并根据其中的值启动实例,打开告警日志 alterSID.log,路径为backgroud_dump_dest参数所指定的目录。
mount阶段:根据参数文件中的control_files参数的值,打开所有的控制文件,只要有一个打开失败,就不能成功进入mount阶段。打开文件后,取得所有的数据文件、联机日志文件的路径,但不会验证这些文件是否存在。
open阶段:打开所有的数据文件、联机日志文件。
具体的启动步骤可以是下面的一种:
startup nomount
alter database mount
alter database open
startup mount
alter database open
startup open |
实例关闭时,有多个选项:
abort:相当于模拟服务器突然断电的情况。
immediate:强制回滚当前正在运行的所有事务,把内存中的脏数据写入数据文件,清空实例的所有内存。一般采用这个选项。
transactional:等待当前正在运行的事务主动提交或回滚,之后中断所有连接,写回数据文件,清空实例内存。
normal:等待当前正在运行的事务主动提交或回滚,同时还会等待所有用户主动中断连接。
需要注意的是startup force相当于 shutdown abort ,然后再 startup