
因为loadrunner原生未提供针对mysql测试的功能
国内网络上流传的都是ODBC连接mysql进行性能测试,过程较为繁琐
而LR本身推荐的是使用提供的dll库或者自行编写dll库进行测试。
只要能在网上找到支持自编写dll库的license即可
本文方法参考的主要是Bish.co.uk论坛,有mysql,php和loadrunner板块,
使用它们编写的mysql链接库
---–待测试库环境准备--------
GRANT ALL PRIVILEGES ON *.* TO'root'@'windowsIP'
IDENTIFIED BY'root'WITHGRANTOPTION;
配置好测试数据库和表
-----–LoadRunner运行库准备-------
a.解压MySQL LoadRunner libraries.zip版本1 版本2 中的文件至LR安装目录
b.在LR的vuser脚本的init中加入实例信息
#include "Ptt_Mysql.h"
#define MYSQLSERVER "192.168.2.5"
#define MYSQLUSERNAME "root"
#define MYSQLPASSWORD "root"
#define MYSQLDB "tpch_1"
#define MYSQLPORT "5029" |
c.在action脚本中 每个sql语句前加入
lr_load_dll("libmysql.dll");
-------–vu脚本编写方法,c语言--------–
//action中加入
char chQuery[128];
MYSQL *Mconn;
//将sql语句保存在 char中
lr_load_dll("libmysql.dll");
//每个sql前加入读取dll库
Mconn = lr_mysql_connect(MYSQLSERVER, MYSQLUSERNAME,
MYSQLPASSWORD, MYSQLDB,
atoi(MYSQLPORT));
//从init的define中读取连接参数
sprintf(chQuery, "select N_NATIONKEY,N_NAME,N_REGIONKEY from
nation limit 3;");
lr_mysql_query(Mconn, chQuery);
//在输出中打印语句,调用dll中的lr_mysql_query方法执行语句
lr_save_string(row[0][0].cell, "sN_NATIONKEY");
lr_save_string(row[1][0].cell, "sN_NAME");
lr_save_string(row[2][0].cell, "sN_REGIONKEY");
//结果集要保存到多维数组中也可以直接忽略输出
lr_output_message(lr_eval_string("N_NATIONKEY: {sN_NATIONKEY};
N_NAME: {sN_NAME}; N_REGIONKEY Description:{sN_REGIONKEY}"));
lr_save_string(row[0][1].cell, "sN_NATIONKEY");
lr_save_string(row[1][1].cell, "sN_NAME");
lr_save_string(row[2][1].cell, "sJobDesc");
lr_output_message(lr_eval_string("N_NATIONKEY: {sN_NATIONKEY};
N_NAME: {sN_NAME}; N_REGIONKEY Description:{
//vu_end中加入
lr_mysql_disconnect(Mconn);
//断开连接
自己录制脚本例子
#include "Ptt_Mysql.h"
#define MYSQLSERVER "192.168.20.67"
#define MYSQLUSERNAME "root"
#define MYSQLPASSWORD "111111"
#define MYSQLDB "mysql"
#define MYSQLPORT "3306"
MYSQL *Mconn;
vuser_init(){
lr_load_dll("libmysql.dll");
Mconn=lr_mysql_connect(MYSQLSERVER,MYSQLUSERNAME,MYSQLPASSWORD,MYSQLDB,atoi(MYSQLPORT));
return 0;
}
Action()
{
char chQuery[128];
//sprintf(chQuery,"SELECT `HOST`, `USER`, `PASSWORD` FROM user1;");
lr_mysql_query(Mconn,chQuery);
lr_save_string(row[0][0].cell,"HOST");
lr_save_string(row[1][0].cell,"USER");
lr_save_string(row[2][0].cell,"PASSWORD");
lr_output_message(lr_eval_string("HOST: {HOST}; USER: {USER};PASSWORD:{PASSWORD}"));
}
vuser_end()
{
lr_mysql_disconnect(Mconn);
return 0;
} |
版权声明:本文出自 juiwo 的51Testing软件测试博客: http://www.51testing.com/?37338 原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。 |
前言
前段时间做了一次数据迁移,针对数据迁移类型的测试方法进行了一些了解和总结,以下工具愚公移山和精卫为淘宝开发的工具,已使用于多个产品、项目中,质量有保障。
一、工具介绍
1、愚公移山
概述:
数据的动态迁移,可完成数据全量、增量迁移,进行数据比对,保证数据的正确;目前较多运用在数据迁移中,已经被很多团队使用,是很成熟可靠的数据迁移工具
适用范围:
可支持:支持oracle和mysql,分库分表,实时同步,数据比对
不支持:涉及到外部依赖,迁移规则非常复杂的数据
性能情况:
没有对愚公进行压测,性能情况参考以下的例子
例子:迁移一个1000万的表。 16个线程,开启批量写入,半个小时以内完成。
影响点:机器的负载,并行的任务数,配置的线程数
愚公百科:(不知道可以可以贴!有需要可联系作者)
2、精卫工具
概述:
精卫是一个基于MySQL数据库的数据复制组件,较多运用在数据双写的场景中,是比较成熟的一个数据复制组件
解析数据库的binlog文件,A库的所有的数据变更传到B库。binlog:描述数据变更的文件
适用范围:
同库不同表数据复制、多库多表数据冗余、标准化去O支持、数据变化通知
性能情况:
性能压测,性能结果满足交易主库同步备库需求
例子:主库1000tps,延迟在50sms以内
【精卫+metaq性能测试结论.msg】
精卫百科:(不知道可以可以贴!)
二、迁移类测试策略
1、概述
随着业务需求或数据量增长到一定程度,往往需要进行数据库切换,这里就伴随这数据迁移。
关键字: 全量数据迁移,增量数据迁移,分库分表,数据双写,oracle、mysql、hbase…,新老数据兼容,数据订正
2、发布方案(迁移方案)
两大类:正常发布、停机发布
正常发布:可以实现线上业务无缝切换,不影响用户使用,需要保证新老数据兼容,发布过程中的数据写入等。
停机发布 : 优点在于可以避免发布过程中的新数据写入,缺点是发布过程中,不能正常提供服务。
发布方案的制定是根据具体业务情况制定发布方案,对业务无影响的情况下较常采用停机发布,方便简单。
介绍一种无缝对接的正常发布方案
A库历史库 mysql分库分表 到 B库新库hbase
步骤1、全量dump1:A库数据全量迁移至B库
步骤2、打开双写:同时写入到A库历史库和B库新库
步骤3、全量dump2:开启双写前的所有差集,将差集灌回B数据库,这里是补充全量dump1期间和开启双写前只写入到A的数据。保证了A、B数据库数据的完全一致,同时已经开启了双写。
步骤3’、测试介入,可对A、B库取某一时间段前所有数据进行数据验证。
步骤4、停止对A库的写入,发布前端应用,切换至B库新库

注意点:
1、双写时,B库不存在被写源数据或B库数据状态异常等情况,需要从业务上考虑,是否直接从A库中获取数据并覆盖至B库
2、以上步骤中的多次dump和双写有多个写入B库的场景,需要以保证B库和A库一致为原则,如B库的重复写入等情况的处理。
3、测试策略
在进行数据迁移测试前,需确认的CheckList
CheckList
1、 哪些表需要迁、哪些表不需要迁;需要迁移的表老库和新库的对应关系是怎样的
2、 明确表的关联关系,关联表是否需要迁移,不迁移怎么处理
3、 迁移的表中,哪些字段要迁移,哪些不迁移,对应关系是怎样的
4、 新表中的字段,老表是不是一定有,如果不一定,怎么处理可能为空的情况,尤其是必填字段的处理
5、 迁移前,新表是否为空,不为空是否可能存在数据重复的情况,怎么处理
6、 新老表中的字段类型、长度的定义是否一致,可否正确转换
7、 需迁移的表数据量为多少
8、 开发做了哪些数据迁移正确性的保障
针对不同的业务场景需要测试人员设计不同的测试方案,主要都是两个层面的验证,数据层面的数据验证和功能层面的功能验证
1、数据验证:使用工具或设计对账程序全量验证
a、全量数据验证
b、增量数据验证
c、抽样数据验证
根据业务情况判断需要进行哪一项或几项数据验证
工具使用:可以选用目前较成熟的迁移工具:愚公移山, 兼全量数据验证和增量数据验证功能
验证方式:若迁移场景不在愚公的适用范围内,全量验证和增量数据验证需要另外设计适用于该场景下的数据验证方案
可采用的一些验证方式:考虑根据不同数据的存储方式,数据量的大小
a、关系数据库,直接新老数据库中jdbc方式获取数据,一条条进行对比,新老数据存在规则转换的情况需要在对账程序中同时进行规则判断。
b、全量或抽样dump历史库和新库两份文件进行对比,数据库非常大的时候推荐使用hadoop
2、功能验证:主要是抽样数据的功能测试
a、功能测试:对历史数据常见的操作方式为,在历史库准备一批历史数据,准备什么样的历史数据依赖于具体业务的数据情况,通过迁移程序将历史数据迁移至新库后,验证这批数据的存储和功能展现。新数据的验证则以新增功能的方式进行测试。
b、自动化测试:API自动化+页面自动化:只有数据迁移没有上层业务变更的情况下,如果已经存在自动化脚本,采用自动化脚本可以快速回归,重点在DAO层的方法。
以下情况需要特别设计用例进行功能验证
1、 老表字段进行类型或长度等转换迁移至新表
2、 老表中可能为空的字段,新表中直接为空或默认一个初始值
3、 老表数据通过特殊处理转换为新表中的值
4、 需要进行数据订正的字段
数据双写
数据双写往往伴随着数据迁移进行,精卫工具能很好的支持数据复制,并进行数据比对。
在精卫工具的试用范围外的数据双写,一般是应用中加入双写代码,这里也需要涉及数据比对程序,类似于数据迁移的比对程序;
可采用的验证方式:
1、根据数据双写的实时性的特性, 在不影响应用功能、性能的情况下,可以考虑在双写代码中加入验证程序,即每完成一次双写,即对插入的新老数据进行数据比对。
2、枚举所有涉及双写的场景,逐个场景进行功能验证
3、以全量的方式进行数据比对,数据双写进行到一定程度,能确保所有需要双写的场景都已经进行过,那么,对双写的两张表的数据截取gmt_modify时间为某一时间段以前的所有数据进行比对,约等于迁移的全量数据验证。
其他关注点:
1、 考虑id预留空间:+**,需要足够大,保证没有主键冲突
2、 关注sql性能:分库分表,尤其是跨库查询时需要关注性能情况,数据量比较大的情况下,可以考虑走搜索
本节重点
处理下拉框
switch_to_alert()
accept()
下拉框是我们最常见的一种页面元素,对于一般的元素,我们只需要一次就定位,但下拉框里的内容需要进行两次定位,先定位到下拉框,再定位到下拉框内里的选项。
drop_down.html
<html> <body> <select id="ShippingMethod" onchange="updateShipping(options[selectedIndex]);" name="ShippingMethod"> <option value="12.51">UPS Next Day Air ==> $12.51</option> <option value="11.61">UPS Next Day Air Saver ==> $11.61</option> <option value="10.69">UPS 3 Day Select ==> $10.69</option> <option value="9.03">UPS 2nd Day Air ==> $9.03</option> <option value="8.34">UPS Ground ==> $8.34</option> <option value="9.25">USPS Priority Mail Insured ==> $9.25</option> <option value="7.45">USPS Priority Mail ==> $7.45</option> <option value="3.20" selected="">USPS First Class ==> $3.20</option> </select> </body> </html> |
将上面的代码保存成html通过浏览器打开会看到一个最简单常见的下拉框,下拉列表有几个选项。
现在我们来选择下拉列表里的$10.69
#-*-coding=utf-8 from selenium import webdriver import os,time driver= webdriver.Firefox() file_path = 'file:///' + os.path.abspath('drop_down.html') driver.get(file_path) time.sleep(2) m=driver.find_element_by_id("ShippingMethod") m.find_element_by_xpath("//option[@value='10.69']").click() time.sleep(3) driver.quit() |
解析:
这里可能和之前的操作有所不同,首先要定位到下拉框的元素,然后选择下拉列表中的选项进行点击操作。
m=driver.find_element_by_id("ShippingMethod")
m.find_element_by_xpath("//option[@value='10.69']").click()
百度搜索设置下拉框操作
#-*-coding=utf-8 from selenium import webdriver import os,time driver= webdriver.Firefox() driver.get(http://www.baidu.com)
#进入搜索设置页
driver.find_element_by_link_text("搜索设置").click()
#设置每页搜索结果为100条
m=driver.find_element_by_name("NR") m.find_element_by_xpath("//option[@value='100']").click() time.sleep(2)
#保存设置的信息
driver.find_element_by_xpath("//input[@value='保存设置']").click() time.sleep(2) driver.switch_to_alert().accept() #跳转到百度首页后,进行搜索表(一页应该显示100条结果) driver.find_element_by_id("kw").send_keys("selenium") driver.find_element_by_id("su").click() time.sleep(3) driver.quit() |
解析:
当我们在保存百度的设置时会会弹出一个确定按钮;我们并没按照常规的方法去定位弹窗上的“确定”按钮,而是使用:
driver.switch_to_alert().accept()
完成了操作,这是因为弹窗比较是一个具有唯一性的警告信息,所以可以用这种简便的方法处理。
– switch_to_alert()
焦点集中到页面上的一个警告(提示)
– accept()
接受警告提示
相关文章:
轻松自动化---selenium-webdriver(python) (九)
轻松自动化---selenium-webdriver(python) (十一)
在cmd运行窗口中输入:sqlldr customermanager/123@orcl control="E:\CustomerData\excelInputOracle\insert.ctl" log=E:\CustomerData\excelInputOracle\log.txt skip=1
说明:
{
sqlldr是sqlloader的命令语句
customermanager/123@orcl是连接数据库,用户名/密码@服务名
control控制命令 后接控制文本的地址
log 定义日志文件的存放
skip跳过前几行,因为文件第一行是表头,因此跳过第一行
先在数据库里建立相同的字段名称 详细见 insert.ctl文件
还得把excel数据保存成csv格式文件
}
insert.ctl文件就是一个txt文本文件,拷贝以下内容到这个文件(注意修改)
load data
CHARACTERSET ZHS16GBK
infile 'E:\CustomerData\excelInputOracle\20130726.csv'
append into table ORIGINAL_DATA
fields terminated by ','
optionally enclosed by '"'
trailing nullcols
(ZCRQ,
XQSLH,
LWDW,
FZ,
FJ,
FHR,
DZ,
DJ,
HZPM,
HZPL,
YSTZHZ,
QQCS,
QQLX,
PZCS,
PZCZ,
ZCCS,
ZCCZ,
YDJH,
YWC,
SHE,
JY,
HYSR,
HPSR,
JSJJ,
FQ,
DQ) |
实际开发过程中,写单元测试是非常难的一件事情,其主要原因是代码结构不够好,导致单元测试不好写。特别是Dao层,因为Dao层代码都是与数据库相关的,所以我们在对Dao层代码进行单元测试的时候,不仅仅要考虑我在上篇文章中提到的代码隔离,还要注意单元测试不能带来脏数据。另外,dao层实例依赖spring上下文,我们怎么样来解决这个问题?
看看下面的一个的测试实例:
/**
* @author lisanlai <br />
* Mail: sanlai_lee@qq.com<br />
* Blog:http://blog.lisanlai.cn <br />
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration({ "/META-INF/spring/sellmanager-context.xml",
"/META-INF/spring/dao-context.xml",
"/META-INF/spring/mvc-context.xml" })
//@Transactional
public class SysEmployeeDaoTest {
/**
* 测试deleteEmployee方法 .
* Method Name:deleteEmployee .
* the return type:void
*/
@Test
public void deleteEmployee() {
Employee employee = new Employee();
employee.setEmployeeCode(""+new Date().getTime());
employee.setEmployeeName("lisanlai");
employee.setDelFlag("0");
String empId = sysEmployeeDao.save(employee);
Assert.assertNotNull("新增的员工ID为null",empId);
//把该id对应的员工删除
sysEmployeeDao.deleteEmployee(empId);
//再用该ID去查数据库,如果为空,说明删除方法逻辑正确
Employee emp = sysEmployeeDao.get(empId);
Assert.assertNotNull(emp);
Assert.assertArrayEquals("deleteEmployee方法逻辑不正确,员工没有被删除",
new String[]{"1"}, new String[]{emp.getDelFlag()});
//删除员工对象
sysEmployeeDao.delete(emp);
}
/**
* 测试saveEmployee方法 .
* Method Name:saveEmployee .
* the return type:void
*/
@Test
@Transactional
@Rollback(true)
public void saveEmployee() {
Employee employee = new Employee();
employee.setEmployeeName("lisanlai");
String empCode = ""+new Date().getTime();
employee.setEmployeeCode(empCode);
sysEmployeeDao.saveEmployee(employee);
//通过code查找员工
List<Employee> emps = sysEmployeeDao.findByNamedParam(
new String[]{"employeeCode"},
new String[]{empCode});
Assert.assertTrue("saveEmployee方法逻辑错误,员工保存失败!", !emps.isEmpty());
}
} |
注意类上的三个注解:
//指定测试用例的运行器 这里是指定了Junit4
@RunWith(SpringJUnit4ClassRunner.class)
//指定Spring的配置文件 路径相对classpath而言
@ContextConfiguration({ "/META-INF/spring/sellmanager-context.xml",
"/META-INF/spring/dao-context.xml",
"/META-INF/spring/mvc-context.xml" })
//如果在类上面使用该注解,这样所有的测试方案都会自动的 rollback
//@Transactional
再注意saveEmployee方法上的两个注解:
//这个注解表示使用事务
@Transactional
//这个表示方法执行完以后回滚事务,如果设置为false,则不回滚
@Rollback(true) |
进程:正在进行中的程序。 每一个进程执行都有一个执行顺序,该顺序是一个执行路径,或者叫一个控制单元。
线程:就是进程中一个执行单元或执行情景或执行路径负责进程中程序执行的控制单元 。一个进程中至少要有一个线程。当一个进程中线程有多个时,就是多线程。
为什么要用多线程
1,让计算机"同时"做多件事情,节约时间。
2,后台运行程序,提高程序的运行效率.。
3,多线程可以让程序"同时"处理多个事情。
4,计算机CPU大部分时间处于空闲状态,浪费了CPU资源。
1.创建线程的两种方式:
方式一步骤:继承Thread类
子类覆盖父类中的run方法,将线程运行的代码存放在run中。
建立子类对象的同时线程也被创建。
通过调用start方法开启线程。
public class ThreadTest extends Thread{
private int i;
public void run() {
for (i = 0; i < 100; i++)
System.out.println(Thread.currentThread().getName() + "-------"+ i);
}
public static void main(String[] args) {
Demo d1 = new Demo();
Demo d2 = new Demo();
d1.start();
d2.start();
for (int i = 0; i < 60; i++)
System.out.println(Thread.currentThread().getName()+"----------" + i);
}
} |
方式二步骤:实现Runnable接口
子类覆盖接口中的run方法。
通过Thread类创建线程,并将实现了Runnable接口的子类对象作为参数传递给Thread类的构造函数。
Thread类对象调用start方法开启线程。
public class RunnableTest implements Runnable { private int num = 100; @Override
public void run() {
while (true) {
if (num > 0) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "----->"
+ num--);
} else {
break;
}
}
} public static void main(String args[]) {
RunnableTest rt = new RunnableTest();
Thread t1 = new Thread(rt, "新线程1");
Thread t2 = new Thread(rt, "新线程2");
Thread t3 = new Thread(rt, "新线程3");
t1.start();
t2.start();
t3.start();
} |
2.两种创建方式的对比
Runnable接口相对于继承Thread类的好处:
1.适合多个相同程序代码的线程去处理同意资源的情况,把虚拟CPU(线程)同程序的代码,数据有效分离,较好的体现了面向对象的设计思想。
2.可以避免由于java的单继承特点带来的局限。当我们要将已经继承了某一个类的子类放入多线程中,由于一个类不能同时有两个父类,所以只能使用Runnable接口方法。
3.有力与程序的健壮性,代码能给被多个线程共享,代码与数据是独立的。
线程的四种状态及其转换
同步代码块
1)同步的前提:
A.必须有两个或两个以上的线程
B.必须保证同步的线程使用同一个锁。必须保证同步中只能有一个线程在运行。
好处与弊端:解决了多线程的安全问题。多个线程需要判断锁,较为消耗资源。
public class RunnableTest implements Runnable { private int num = 100;
Object obj = new Object(); @Override
public void run() {
while (true) {
synchronized (obj) {
if (num > 0) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()
+ "----->" + num--);
} else {
break;
}
}
}
} public static void main(String args[]) {
RunnableTest rt = new RunnableTest();
Thread t1 = new Thread(rt, "新线程1");
Thread t2 = new Thread(rt, "新线程2");
Thread t3 = new Thread(rt, "新线程3");
t1.start();
t2.start();
t3.start();
} } |
1.新建用户。
//登录MYSQL
@>mysql -u root -p
@>密码
//创建用户
mysql> insert into mysql.user(Host,User,Password) values("localhost","phplamp",password("1234"));
//刷新系统权限表
mysql>flush privileges;
这样就创建了一个名为:phplamp 密码为:1234 的用户。
然后登录一下。
mysql>exit;
@>mysql -u phplamp -p
@>输入密码
mysql>登录成功 |
2.为用户授权。
//登录MYSQL(有ROOT权限)。我里我以ROOT身份登录.
@>mysql -u root -p
@>密码
//首先为用户创建一个数据库(phplampDB)
mysql>create database phplampDB;
//授权phplamp用户拥有phplamp数据库的所有权限。
>grant all privileges on phplampDB.* to phplamp@localhost identified by '1234';
//刷新系统权限表
mysql>flush privileges;
mysql>其它操作
/*
如果想指定部分权限给一用户,可以这样来写:
mysql>grant select,update on phplampDB.* to phplamp@localhost identified by '1234';
//刷新系统权限表。
mysql>flush privileges;
*/ |
3.删除用户。
@>mysql -u root -p
@>密码
mysql>DELETE FROM user WHERE User="phplamp" and Host="localhost";
mysql>flush privileges;
//删除用户的数据库
mysql>drop database phplampDB;
4.修改指定用户密码。
@>mysql -u root -p
@>密码
mysql>update mysql.user set password=password('新密码') where User="phplamp" and Host="localhost";
mysql>flush privileges;
mysql> desc mysql.user; |
我在IOS编程使用的FMDatabase这个sqlite框架,需要客户端与服务器做一些数据同步工作,有时得执行比较多的命令(增删改表当然是手写,但如果要手写插入几百上千条记录是很不现实的,也只需要用php从mysql中读取记录便可),而且因为客户端的缘故,mysql数据库里的一些字段并不需要写入到客户端的sqlite中,所以我们可以用PHP写一个接口页面,以JSON传递我们希望传达的数据,然后再在客户端进行处理。
传递的数据有两种格式,一种是直接执行的命令,我把它存放在“query”数组当中,另一种是要插入的记录,把它存放在“record”当中。“query”中的的命令直接执行,而“record”里的记录以“key”=>“value”的方式,在客户端循环出SQL语句执行。
$update_array['database']['query'] = array(); $update_array['table']['wares_category']['query'] = array();
$update_array['table']['wares_category']['record'] = $all_wares_category; |
//客户端的同步函数 -(void)databaseUpdate
{
FMDatabase *db = [self getDatabase];
NSURL *updateUrl = [[NSURL alloc]initWithString:[Api stringByAppendingPathComponent:@"databaseUpdate/databaseupdate"]];
NSData *updateData = [[NSData alloc]initWithContentsOfURL:updateUrl];
NSError *error = nil;
NSDictionary *updateDictionary = [NSJSONSerialization JSONObjectWithData:updateData options:NSJSONReadingMutableContainers error:&error];
int i;
//database数组
if([[[updateDictionary objectForKey:@"database"]objectForKey:@"query"] count] > 0){
for (i = 0; i < [[[updateDictionary objectForKey:@"database"]objectForKey:@"query"] count]; i++){
NSString *query = [[[updateDictionary objectForKey:@"database"]objectForKey:@"query"]objectAtIndex:i];
[db executeUpdate:query];
}
}
//table数组
if([[updateDictionary objectForKey:@"table"] count] > 0){
for(id tableName in [updateDictionary objectForKey:@"table"]){
if([[[[updateDictionary objectForKey:@"table"] objectForKey:tableName] objectForKey:@"query"] count] > 0){
for (i = 0; i < [[[[updateDictionary objectForKey:@"table"] objectForKey:tableName] objectForKey:@"query"] count]; i++){
NSString *query = [[[[updateDictionary objectForKey:@"table"] objectForKey:tableName] objectForKey:@"query"]objectAtIndex:i];
[db executeUpdate:query];
}
}
if([[[[updateDictionary objectForKey:@"table"] objectForKey:tableName] objectForKey:@"record"] count] > 0){
for (i = 0; i < [[[[updateDictionary objectForKey:@"table"] objectForKey:tableName] objectForKey:@"record"] count]; i++){
NSMutableArray *keys = [[NSMutableArray alloc] init];
NSMutableArray *values = [[NSMutableArray alloc] init];
for (id fieldsName in [[[[updateDictionary objectForKey:@"table"] objectForKey:tableName] objectForKey:@"record"]objectAtIndex:i]){
NSString *fieldsValue = [[[[[updateDictionary objectForKey:@"table"] objectForKey:tableName] objectForKey:@"record"]objectAtIndex:i]objectForKey:fieldsName];
[keys addObject:[NSString stringWithFormat:@"'%@'",fieldsName]];
if(fieldsValue == (NSString*)[NSNull null]){
fieldsValue = @"";
}
[values addObject:[NSString stringWithFormat:@"'%@'",fieldsValue]];
}
NSString *keyString = [keys componentsJoinedByString:@", "];
NSString *valueString = [values componentsJoinedByString:@", "];
NSString *sql = [NSString stringWithFormat:@"INSERT INTO %@ (%@) VALUES (%@)",tableName, keyString, valueString];
[self alertByString:sql];
[db executeUpdate:sql];
}
}
}
}
} |
摘要:Perf是Linux kernel自带的系统性能优化工具。Perf的优势在于与Linux Kernel的紧密结合,它可以最先应用到加入Kernel的new feature。pef可以用于查看热点函数,查看cashe miss的比率,从而帮助开发者来优化程序性能。
1.perf的安装
由于我们经常是在自己编译的内核上进行开发工作,这里需要有包含调式信息的内核启动镜像文件vmlinux,在自定义内核的基础之上,进入linux内核源码,linux/tools/perf
make
make install
提示:
1)可能在编译的时候,有报错大概是由于平台问题,数据类型不匹配,导致所有的warning都被当作error对待:出现这问题的原因是-Werror这个gcc编译选项。只要在makefile中找到包含这个-Werror选项的句子,将-Werror删除,或是注释掉就行了
2)安装完毕,perf可执行程序往往位于当前目录,可能不在系统的PATH路径中,此时需要改变环境变量PATH
2.perf的运行原理
性能调优工具如 perf,Oprofile 等的基本原理都是对被监测对象进行采样,最简单的情形是根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文。假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,但我想只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 tick 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。
稍微扩展一下思路,就可以发现改变采样的触发条件使得我们可以获得不同的统计数据:
以时间点 ( 如 tick) 作为事件触发采样便可以获知程序运行时间的分布。
以 cache miss 事件触发采样便可以知道 cache miss 的分布,即 cache 失效经常发生在哪些程序代码中。如此等等。
因此让我们先来了解一下 perf 中能够触发采样的事件有哪些。
使用perf list(在root权限下运行),可以列出所有的采样事件

事件分为以下三种:
1)Hardware Event 是由 PMU 硬件产生的事件,比如 cache 命中,当您需要了解程序对硬件特性的使用情况时,便需要对这些事件进行采样;
2)Software Event 是内核软件产生的事件,比如进程切换,tick 数等 ;
3)Tracepoint event 是内核中的静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等。
上述每一个事件都可以用于采样,并生成一项统计数据,时至今日,尚没有文档对每一个 event 的含义进行详细解释。
3.perfstat——概览程序的运行情况
面对一个问题程序,最好采用自顶向下的策略。先整体看看该程序运行时各种统计事件的大概,再针对某些方向深入细节。而不要一下子扎进琐碎细节,会一叶障目的。
有些程序慢是因为计算量太大,其多数时间都应该在使用CPU进行计算,这叫做CPUbound型;有些程序慢是因为过多的IO,这种时候其CPU利用率应该不高,这叫做IObound型;对于CPUbound程序的调优和IObound的调优是不同的。
如果您认同这些说法的话,Perfstat应该是您最先使用的一个工具。它通过概括精简的方式提供被调试程序运行的整体情况和汇总数据。
本篇中,我们将在以后使用这个例子test1.c:
测试用例:test1
<SPAN style="FONT-SIZE: 14px"> //test.c
void longa()
{
int i,j;
for(i = 0; i < 1000000; i++)
j=i; //am I silly or crazy? I feel boring and desperate.
} void foo2()
{
int i;
for(i=0 ; i < 10; i++)
longa();
} void foo1()
{
int i;
for(i = 0; i< 100; i++)
longa();
} int main(void)
{
foo1();
foo2();
} </SPAN> |
将它编译为可执行文件 test1
gcc – o test1 – g test.c
注意:此处一定要加-g选项,加入调试和符号表信息。
下面演示了 perf stat 针对程序 test1 的输出:
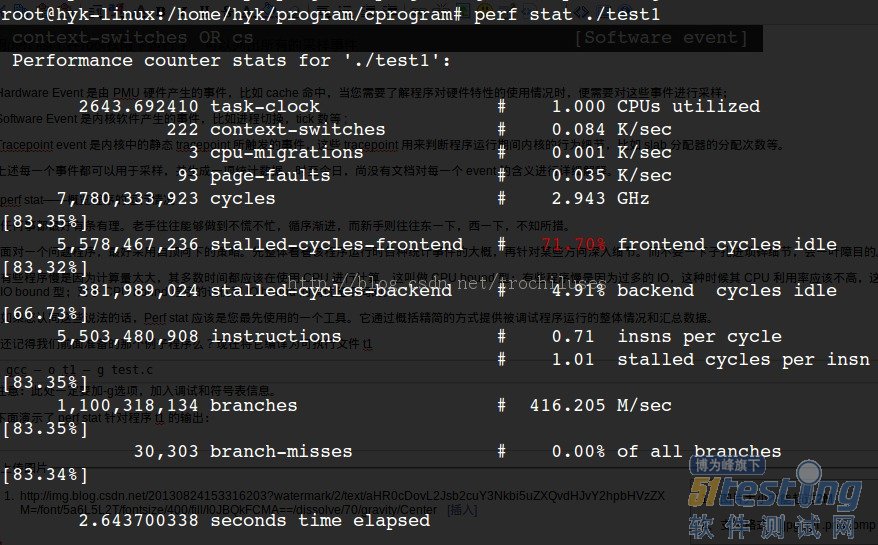
结果分析:
对 test1进行调优应该要找到热点 ( 即最耗时的代码片段 ),再看看是否能够提高热点代码的效率。
缺省情况下,除了 task-clock-msecs 之外,perf stat 还给出了其他几个最常用的统计信息:
Task-clock-msecs:CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。
Context-switches:进程切换次数,记录了程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的。
Cache-misses:程序运行过程中总体的 cache 利用情况,如果该值过高,说明程序的 cache 利用不好
CPU-migrations:表示进程 t1 运行过程中发生了多少次 CPU 迁移,即被调度器从一个 CPU 转移到另外一个 CPU 上运行。
Cycles:处理器时钟,一条机器指令可能需要多个 cycles,
Instructions: 机器指令数目。
IPC:是 Instructions/Cycles 的比值,该值越大越好,说明程序充分利用了处理器的特性。
Cache-references: cache 命中的次数
Cache-misses: cache 失效的次数。
4.精确制导——定位程序瓶颈perf record && perf report
4.1查找时间上的热点函数
perf record – e cpu-clock ./test1
perf report
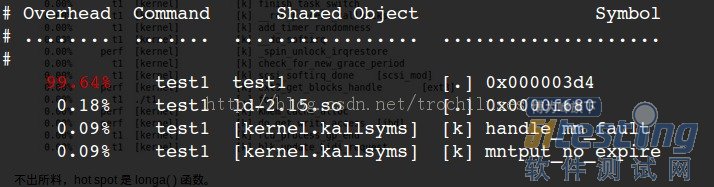
3个问题:
1)perf未能定位本地符号表对应的symbol和地址的对应关系:0x000003d4对应的什么函数?
2)采样频率不够高,失去了一些函数的信息:显然一些内核函数没有显示在上面的结果中,因为采样频率如果不够高,那么势必会有一些函数中的采样点没有/
3)如何克服采样的随机性带来的问题:为了在测量更加逼近正确值,我们采用多次重复取平均值的方法来逼近真实值。(这里可以用-r来指定重复次数)
对于问题2),我们可以用perf record -F count 来指定采样频率加以解决:
<SPAN style="FONT-SIZE: 14px">root@hyk-linux:/home/hyk/program/cprogram# perf record -F 50000 -e cpu-clock ./test1
[ perf record: Woken up 3 times to write data ]
[ perf record: Captured and wrote 0.532 MB perf.data (~23245 samples) ]
root@hyk-linux:/home/hyk/program/cprogram# perf report
# ========
# captured on: Mon Aug 26 09:54:45 2013
# hostname : hyk-linux
# os release : 3.10.9
# perf version : 3.10.9
# arch : i686
# nrcpus online : 4
# nrcpus avail : 4
# cpudesc : Intel(R) Core(TM) i5-2430M CPU @ 2.40GHz
# cpuid : GenuineIntel,6,42,7
# total memory : 4084184 kB
# cmdline : /media/usr/src/linux-3.10.9/tools/perf/perf record -F 50000 -e cpu-c
# event : name = cpu-clock, type = 1, config = 0x0, config1 = 0x0, config2 = 0x0
# HEADER_CPU_TOPOLOGY info available, use -I to display
# pmu mappings: cpu = 4, software = 1, tracepoint = 2, uncore_cbox_0 = 6, uncore
# ========
#
# Samples: 13K of event 'cpu-clock'
# Event count (approx.): 273580000
#
# Overhead Command Shared Object Symbol
# ........ ....... ................. ...............................
#
99.77% test1 test1 [.] 0x000003c3
0.07% test1 ld-2.15.so [.] 0x00004c99
0.02% test1 [kernel.kallsyms] [k] __wake_up_bit
0.01% test1 [kernel.kallsyms] [k] __kunmap_atomic
0.01% test1 [kernel.kallsyms] [k] load_elf_binary
0.01% test1 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.01% test1 libc-2.15.so [.] 0x00097d8e
0.01% test1 [kernel.kallsyms] [k] exit_itimers
0.01% test1 [kernel.kallsyms] [k] profile_munmap
0.01% test1 [kernel.kallsyms] [k] get_page_from_freelist
0.01% test1 [kernel.kallsyms] [k] vma_interval_tree_remove
0.01% test1 [kernel.kallsyms] [k] change_protection
0.01% test1 [kernel.kallsyms] [k] link_path_walk
0.01% test1 [kernel.kallsyms] [k] prepend_path
0.01% test1 [kernel.kallsyms] [k] __inode_wait_for_writeback
0.01% test1 [kernel.kallsyms] [k] aa_free_task_context
0.01% test1 [kernel.kallsyms] [k] radix_tree_lookup_element
0.01% test1 [kernel.kallsyms] [k] _raw_spin_lock </SPAN> |
结果解释:
The column 'Overhead' indicates the percentage of the overall samples collected in the corresponding function. The second column reports the process from which the samples were collected. In per-thread/per-process mode, this is always the name of the monitored command. But in cpu-wide mode, the command can vary. The third column shows the name of the ELF image where the samples came from. If a program is dynamically linked, then this may show the name of a shared library. When the samples come from the kernel, then the pseudo ELF image name [kernel.kallsyms] is used. The fourth column indicates the privilege level at which the sample was taken, i.e. when the program was running when it was interrupted:
[.] : user level
[k]: kernel level
[g]: guest kernel level (virtualization)
[u]: guest os user space
[H]: hypervisor
The final column shows the symbol name.
代码是非常复杂难说的,t1 程序中的 foo1() 也是一个潜在的调优对象,为什么要调用 100 次那个无聊的 longa() 函数呢?但我们在上图中无法发现 foo1 和 foo2,更无法了解他们的区别了。
我曾发现自己写的一个程序居然有近一半的时间花费在 string 类的几个方法上,string 是 C++ 标准,我绝不可能写出比 STL 更好的代码了。因此我只有找到自己程序中过多使用 string 的地方。因此我很需要按照调用关系进行显示的统计信息。
使用 perf 的 -g 选项便可以得到需要的信息:
perf record -g -e cpu-clock ./test1
perf report

当然,这里符号表没有定位的问题有依然没有解决!
perf record的其他参数:
-f:强制覆盖产生的.data数据
-c:事件每发生count次采样一次
-p:指定进程
-t:指定线程
4.2 perf report的相关参数:
-k:指定未经压缩的内核镜像文件,从而获得内核相关信息
--report:cpu按照cpu列出负载
5.使用tracepoint
当 perf 根据 tick 时间点进行采样后,人们便能够得到内核代码中的 hot spot。那什么时候需要使用 tracepoint 来采样呢?
我想人们使用 tracepoint 的基本需求是对内核的运行时行为的关心,如前所述,有些内核开发人员需要专注于特定的子系统,比如内存管理模块。这便需要统计相关内核函数的运行情况。另外,内核行为对应用程序性能的影响也是不容忽视的:
以之前的遗憾为例,假如时光倒流,我想我要做的是统计该应用程序运行期间究竟发生了多少次系统调用。在哪里发生的?
下面我用 ls 命令来演示 sys_enter 这个 tracepoint 的使用:
[root@ovispoly /]# perf stat -e raw_syscalls:sys_enter ls
bin dbg etc lib media opt root
selinux sys usr
boot dev home lost+found mnt proc sbin srv
tmp var
Performance counter stats for 'ls':
101 raw_syscalls:sys_enter
0.003434730 seconds time elapsed
[root@ovispoly /]# perf record -e raw_syscalls:sys_enter ls
[root@ovispoly /]# perf report
Failed to open .lib/ld-2.12.so, continuing without symbols
# Samples: 70
#
# Overhead Command Shared Object Symbol
# ........ ............... ............... ......
#
97.14% ls ld-2.12.so [.] 0x0000000001629d
2.86% ls [vdso] [.] 0x00000000421424
#
# (For a higher level overview, try: perf report --sort comm,dso)
# |
这个报告详细说明了在 ls 运行期间发生了多少次系统调用 ( 上例中有 101 次 ),多数系统调用都发生在哪些地方 (97% 都发生在 ld-2.12.so 中 )。
有了这个报告,或许我能够发现更多可以调优的地方。比如函数 foo() 中发生了过多的系统调用,那么我就可以思考是否有办法减少其中有些不必要的系统调用。
您可能会说 strace 也可以做同样事情啊,的确,统计系统调用这件事完全可以用 strace 完成,但 perf 还可以干些别的,您所需要的就是修改 -e 选项后的字符串。
罗列 tracepoint 实在是不太地道,本文当然不会这么做。但学习每一个 tracepoint 是有意义的,类似背单词之于学习英语一样,是一项缓慢痛苦却不得不做的事情。'
5.2同样,我们跟踪一下wirteback子系统的相关情况:
<SPAN style="FONT-SIZE: 14px">root@hyk-linux:/home/hyk/program/cprogram# perf record -e writeback:* lsa.out cscope.po.out perf.data.old t2.c test1 testperf
cscope.in.out malloc.c t1 tags test1s testperf.c
cscope.out perf.data t2 test test.img
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.013 MB perf.data (~548 samples) ]
root@hyk-linux:/home/hyk/program/cprogram# perf report
# ========
# captured on: Mon Aug 26 08:59:58 2013
# hostname : hyk-linux
# os release : 3.10.9
# perf version : 3.10.9
# arch : i686
# nrcpus online : 4
# nrcpus avail : 4
# cpudesc : Intel(R) Core(TM) i5-2430M CPU @ 2.40GHz
# cpuid : GenuineIntel,6,42,7
# total memory : 4084184 kB
# cmdline : /media/usr/src/linux-3.10.9/tools/perf/perf record -e writeback:* ls
# event : name = writeback:writeback_dirty_page, type = 2, config = 0x291, confi
# event : name = writeback:writeback_dirty_inode_start, type = 2, config = 0x290
# event : name = writeback:writeback_dirty_inode, type = 2, config = 0x28f, conf
# event : name = writeback:writeback_write_inode_start, type = 2, config = 0x28e
# event : name = writeback:writeback_write_inode, type = 2, config = 0x28d, conf
# event : name = writeback:writeback_queue, type = 2, config = 0x28c, config1 =
# event : name = writeback:writeback_exec, type = 2, config = 0x28b, config1 = 0
# event : name = writeback:writeback_start, type = 2, config = 0x28a, config1 =
# event : name = writeback:writeback_written, type = 2, config = 0x289, config1
# event : name = writeback:writeback_wait, type = 2, config = 0x288, config1 = 0
# event : name = writeback:writeback_pages_written, type = 2, config = 0x287, co
# event : name = writeback:writeback_nowork, type = 2, config = 0x286, config1 =
# event : name = writeback:writeback_wake_background, type = 2, config = 0x285,
# event : name = writeback:writeback_bdi_register, type = 2, config = 0x284, con
# event : name = writeback:writeback_bdi_unregister, type = 2, config = 0x283, c
# event : name = writeback:wbc_writepage, type = 2, config = 0x282, config1 = 0x
# event : name = writeback:writeback_queue_io, type = 2, config = 0x281, config1
# event : name = writeback:global_dirty_state, type = 2, config = 0x280, config1
# event : name = writeback:bdi_dirty_ratelimit, type = 2, config = 0x27f, config
# event : name = writeback:balance_dirty_pages, type = 2, config = 0x27e, config
# event : name = writeback:writeback_sb_inodes_requeue, type = 2, config = 0x27d
# event : name = writeback:writeback_congestion_wait, type = 2, config = 0x27c,
# event : name = writeback:writeback_wait_iff_congested, type = 2, config = 0x27
# event : name = writeback:writeback_single_inode_start, type = 2, config = 0x27
# event : name = writeback:writeback_single_inode, type = 2, config = 0x279, con
# HEADER_CPU_TOPOLOGY info available, use -I to display
# pmu mappings: cpu = 4, software = 1, tracepoint = 2, uncore_cbox_0 = 6, uncore
# ========
#
# Samples: 0 of event 'writeback:writeback_dirty_page'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 1 of event 'writeback:writeback_dirty_inode_start'
# Event count (approx.): 1
#
# Overhead Command Shared Object Symbol
# ........ ....... ................. ......................
#
100.00% ls [kernel.kallsyms] [k] __mark_inode_dirty
# Samples: 1 of event 'writeback:writeback_dirty_inode'
# Event count (approx.): 1
#
# Overhead Command Shared Object Symbol
# ........ ....... ................. ......................
#
100.00% ls [kernel.kallsyms] [k] __mark_inode_dirty
# Samples: 0 of event 'writeback:writeback_write_inode_start'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_write_inode'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_queue'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_exec'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_start'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_written'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_wait'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_pages_written'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_nowork'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_wake_background'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_bdi_register'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_bdi_unregister'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:wbc_writepage'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_queue_io'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:global_dirty_state'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:bdi_dirty_ratelimit'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:balance_dirty_pages'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_sb_inodes_requeue'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
#
# Samples: 0 of event 'writeback:writeback_congestion_wait'
# Event count (approx.): 0
#
# Overhead Command Shared Object Symbol
# ........ ....... ............. ......
</SPAN> |
都说Maven2是Ant的替代品,今天稍微使用了下Maven,记录备忘。
通过Maven单独运行一个Junit测试用例(无需配置surefire):
mvn -Dtest=TestXXX test
为Maven运行添加JVM参数,比如想给运行Maven的JVM分配更多内存,或者进行profiling等。有两种方法,一种是全局方法,即设置一个全局的环境变量MAVEN_OPTS。
linux下可修改.profile或者.bash_profile文件:export MAVEN_OPTS=-Xmx1024m
windows下可以添加环境变量MAVEN_OPTS
这样对于所有的maven进程都会启用这个JVM参数,所以是一个全局变量,具体可在bin\mvn.bat或者mvn.sh文件中找到如下内容:(%MAVEN_OPTS%即为全局JVM参数)
@REM Start MAVEN2
:runm2
%MAVEN_JAVA_EXE% %MAVEN_OPTS% -classpath %CLASSWORLDS_JAR% "-Dclassworlds.conf=%M2_HOME%\bin\m2.conf" "-Dmaven.home=%M2_HOME%" org.codehaus.classworlds.Launcher %MAVEN_CMD_LINE_ARGS%
如果有更加specific的需求,比如要单独运行一个JUnit Testcase,并且要fork出一个新的JVM来运行,还要为这个JVM加上特定的参数,那就需要更改项目的pom.xml文件了。具体方法是,修改项目的pom.xml在<build>-><plugins>,添加一个plugin,目的是配置surefire,使得每运行一个testcase,都单独fork出一个新的JVM来运行,若还要添加JVM参数,则可通过maven.test.jvmargs来进行传递:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<forkMode>pertest</forkMode>
<argLine>${maven.test.jvmargs}</argLine>
</configuration>
</plugin> |
然后在<properties>标签下加入,这样maven能够知道maven.test.jvmargs这个参数存在,默认值为空,通过运行时命令行传入:
<deploy.target/>
<maven.test.jvmargs></maven.test.jvmargs> |
最后通过如下命令来运行,其中-Dtest是需要运行的testcase的名称,-Dmaven.test.jvmargs指需要传入的JVM参数,maven将这个参数传给新的fork出来的JVM运行。
mvn -Dtest=TestXXX -Dmaven.test.jvmargs='-agentlib:xxxagent -Xmx128m' test