
(51Testing软件测试网获人民邮电出版社和作者授权连载本书部分章节。任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。)
操作完毕后,可看到如图5-17所示的新建项目。

图5-17 新建的Java项目
2.添加引用
(1)在Package Explorer中用鼠标右键单击Project1,选择Properties,如图5-18所示。
(2)选择Java Build Path,在右边选择Libraries,单击Add External JARs,如图5-19所示。
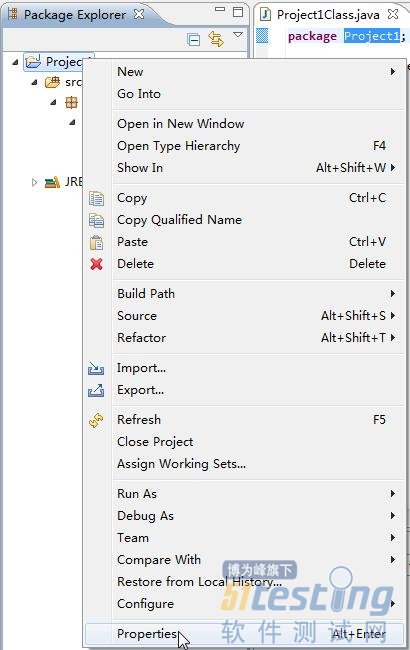
图5-18 选择Properties菜单命令
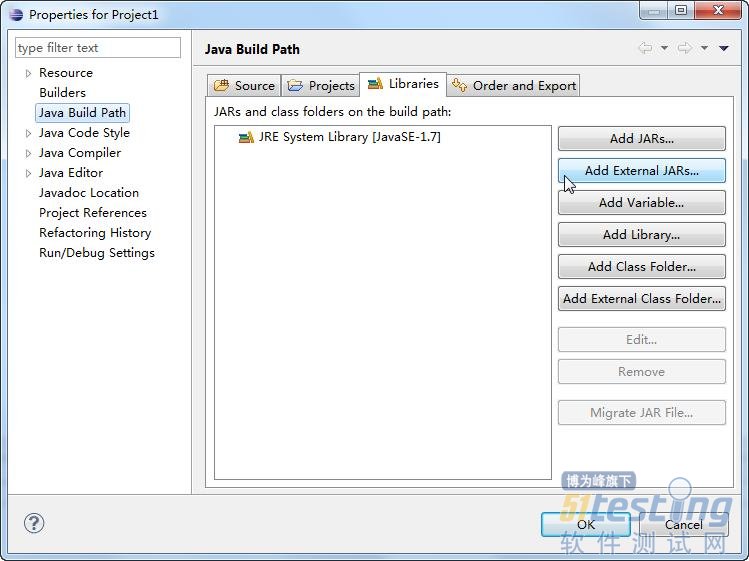
图5-19 Add External JARs按钮
(3)选择要添加的jar文件,如图5-20所示。
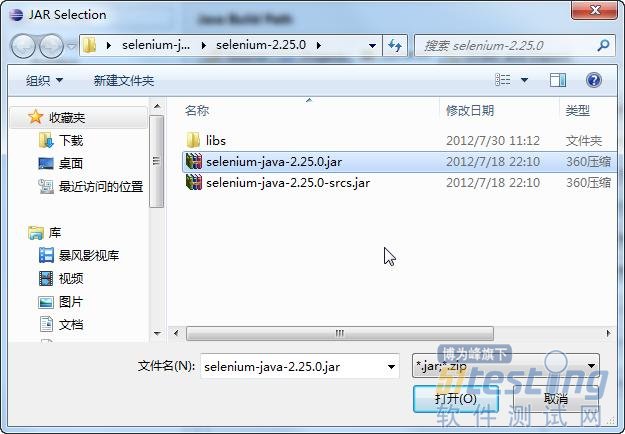
图5-20 选择要添加的Jar文件
(4)单击“打开”按钮后,再单击Add External JARs按钮,如图5- 所示。
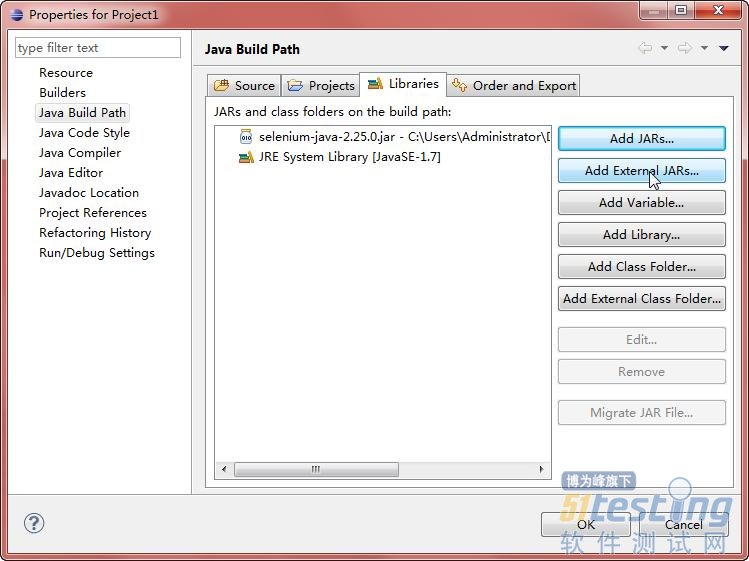
(5)选择Selenium的Libs文件夹中所有与Java相关的基础框架,如图5- 所示。
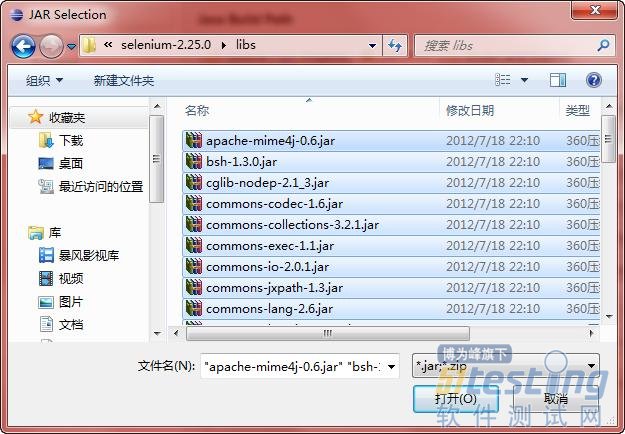
图5- 选择与Java相关的基础框架
(6)单击“打开”按钮,然后单击OK按钮在Package Explorer中,可以看到刚才添加的包,如图5-21所示。
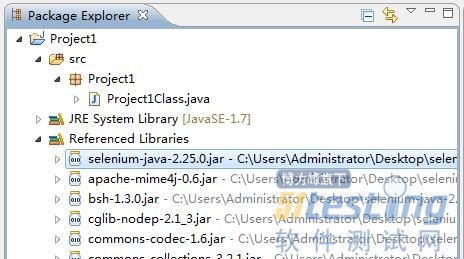
图5-21 查看添加的包
(7)在main函数中输入如图5-22所示的代码,然后按F11执行。

图5-22 Java代码
运行结果如图5-23所示。
在本章中的所有Java程序都可按照这种方式进行创建。
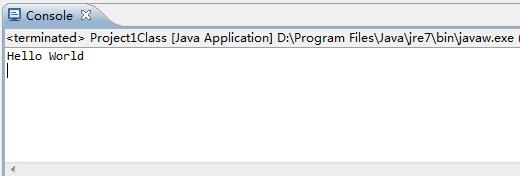
图5-23 程序运行结果
5.3 选择浏览器开始测试
要开始测试,首先得清楚要测试什么浏览器,在Selenium 2中,一共支持以下几种浏览器的测试。
Firefox (FirefoxDriver)。
IE (InternetExplorerDriver)。
Chrome (ChromeDriver)。
Opera (OperaDriver)。
Android (AndroidDriver)。
iPhone (IPhoneDriver)。
需要注意的是,其中前3个浏览器是很容易就能测试的,只需在电脑中安装相应的浏览器就可以开始测试了。
而对于Opera浏览器,C#和Java的处理方式各不相同。而对于Android和iPhone,它们在测试前需要安装支持软件,这些都将在“8.1 对Opera/IPhone/Android进行测试”中进行介绍。
所以,在最开始阶段,假定只会用到前面3种浏览器,并且已经在自己机器上进行过安装,然后就可以开始测试了。
要开始测试,首先得创建Selenium的实例,也就是对应的Driver。
如果需要对Firefox进行测试,则需要用到FirefoxDriver,代码如程序清单5-3或程序清单5-4所示。
程序清单5-3 C#代码
usingSystem;
usingOpenQA.Selenium;//注意这里引用了Selenium的命名空间
usingOpenQA.Selenium.Firefox;//注意这里引用了Selenium的命名空间
namespaceConsoleApplication1
{
classProgram
{
staticvoidMain(string[]args)
{
IWebDriverdriver=newFirefoxDriver();
}
}
} |
程序清单5-4 Java代码
packageProject1;
importorg.openqa.selenium.*;//注意这里导入了selenium包中内容
importorg.openqa.selenium.WebDriver.*;//注意这里导入了selenium包中内容
importorg.openqa.selenium.firefox.*;//注意这里导入了selenium包中内容
publicclassProject1Class{
publicstaticvoidmain(String[]args){
//如果启动出现问题,可以使用System.setProperty指出firefox.exe的路径
//System.setProperty("webdriver.firefox.bin","D:\\ProgramFiles(x86)\\MozillaFirefox\\firefox.exe");
WebDriverdriver=newFirefoxDriver();
}
} |
注意程序清单5-3和程序清单5-4中引用了一个名为OpenQA.Selenium.Firefox的命名空间,FirefoxDriver位于该命名空间内。
如果要使用IE,则命要对名空间和实例化对象部分更改,如程序清单5-5或程序清单5-6所示。
程序清单5-5 C#代码
using System;
using OpenQA.Selenium;
using OpenQA.Selenium.IE;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
IWebDriver driver =new InternetExplorerDriver();
}
}
} |
程序清单5-6 Java代码
package Project1;
import org.openqa.selenium.*;
import org.openqa.selenium.WebDriver.*;
import org.openqa.selenium.ie.*;
public class Project1Class {
public static void main(String[] args) {
//如果启动出现问题,可以使用System.setProperty指明webdriver.ie.driver的路径,webdriver.ie.driver可以在http://code.google.com/p/selenium/downloads/list下载
//System.setProperty("webdriver.ie.driver","E:\\IEDriverServer.exe");
WebDriver driver=new InternetExplorerDriver();
}
} |
对Chrome也是一样的,只需将命名空间改为OpenQA.Selenium.Chrome,实例化对象改为new ChromeDriver()即可。
编译并执行程序清单的代码,对应的浏览器将会打开,如图5-24所示。
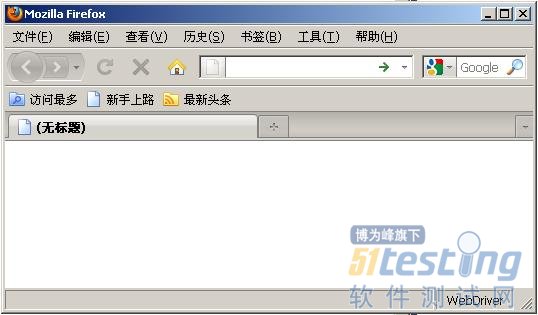
图5-24 打开的浏览器
5.4 浏览器导航对象Navigation
打开了浏览器器之后,就可以打开指定的页面来进行测试了。在Selenium 1中,可以直接通过Selenium的open()方法来打开页面,但在Selenium 2中则不同,要导航页面,需要用到Navigation对象。
可以通过WebDriver的Navigate()方法获得Navigation对象实例,代码如程序清单5-7和程序清单5-8所示。
程序清单5-7 C#代码
IWebDriver driver = new FirefoxDriver();
INavigation navigation = driver.Navigate(); |
程序清单5-8:Java代码
WebDriver driver = new FirefoxDriver();
Navigation navigation = driver.navigate(); |
在获取该对象后,就可以执行跳转到指定URL、前进、后退、刷新页面等操作了。
5.4.1 GoToUrl()/to()
对C#来说,可以用GoToUrl()方法来实现页面的跳转;而对Java来说,可以使用to()来进行跳转。在这两个方法中,只需将URL作为参数即可,如程序清单5-9或程序清单5-10所示。
程序清单5-9 C#代码
IWebDriver driver = new FirefoxDriver();
INavigation navigation = driver.Navigate();
navigation.GoToUrl(http://www.baidu.com); |
程序清单5-10 Java代码
WebDriver driver = new FirefoxDriver();
Navigation navigation = driver.navigate();
navigation.to(http://www.baidu.com);
执行代码,将打开百度主页,如图5-25所示。
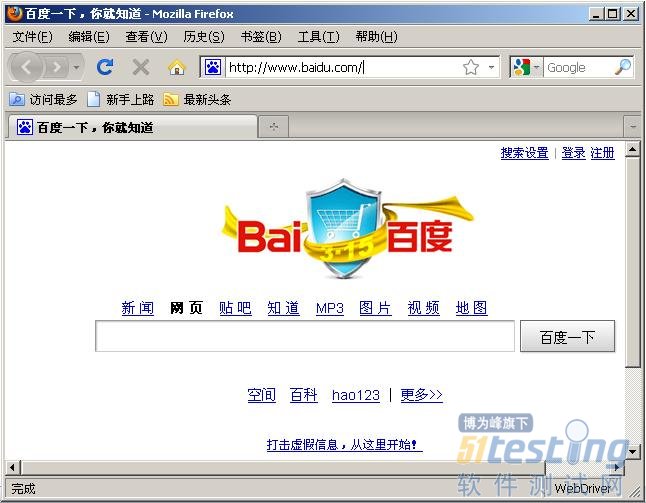
图5-25:跳转到百度主页
注意:执行GoToUrl()/to()方法时,代码会自动等待页面加载完毕再执行下一句,也就是浏览器状态栏为“完成”时再执行下一句。
5.4.2 Back()/Forward()
在浏览器上,可以按“前进”和“后退”按钮来进行导航,通过Back()/Forward()方法,也可以实现这种导航功能。
下面将举例说明先打开百度主页,再打开Google主页,之后进行后退和前进操作,代码如程序清单为防止执行过快,每个操作后面加了3秒等待时间Thread.Sleep(3000)。
程序清单5-11 C#代码
using System;
using OpenQA.Selenium;
using OpenQA.Selenium.Firefox;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
IWebDriver driver = new FirefoxDriver();
INavigation navigation = driver.Navigate();
navigation.GoToUrl(http://www.baidu.com);
navigation.GoToUrl("http://www.google.com.hk");
System.Threading.Thread.Sleep(3000);
navigation.Back();
System.Threading.Thread.Sleep(3000);
navigation.Forward();
}
}
} |
本文选自《Selenium自动化测试指南》第五章节,本站经人民邮电出版社和作者的授权,近期将进行部分章节的连载,敬请期待!
版权声明:51Testing软件测试网获人民邮电出版社和作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。
相关文章:
安装并引用Selenium 2—Selenium自动化测试指南(1)
查找条件对象By—Selenium自动化测试指南(3)
(51Testing软件测试网获人民邮电出版社和作者授权连载本书部分章节。任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。)
第5章 Selenium 2(WebDriver)
Selenium 2(即WebDriver)是一种用于Web应用程序的自动测试工具,它提供了一套友好的API,与Selenium 1(Selenium-RC)相比,Selenium 2的API更容易理解和使用,其可读性和可维护性也大大提高。Selenium 2完全就是一套类库,不依赖于任何测试框架,不需要启动其它进程或安装其它程序,也不必像Selenium 1那样需要先启动服务。
另外,二者所采用的技术方案也不同。Selenium 1是在浏览器中运行JavaScript来进行测试,而Selenium 2则是通过原生浏览器支持或者浏览器扩展直接控制浏览器。
Selenium 2针对各个浏览器而开发的,它取代了嵌入到被测Web应用中的JavaScript。与浏览器的紧密集成,支持创建更高级的测试,避免了JavaScript安全模型的限制。除了来自浏览器厂商的支持,Selenium 2还利用操作系统级的调用模拟用户输入。WebDriver支持Firefox(FirefoxDriver)、IE(InternetExplorerDriver)、Opera(OperaDriver)和Chrome (ChromeDriver)浏览器。对Safari的支持由于技术限制在本版本中未包含,但是可以使用SeleneseCommandExecutor模拟。它还支持Android(AndroidDriver)和iPhone(IPhoneDriver)的移动应用测试。此外,Selenium 2还包括一个基于HtmlUnit的无界面实现,称为HtmlUnitDriver。Selenium 2 API可以通过Python、Ruby、Java和C#等编程语言访问,支持开发人员使用他们常用的编程语言来创建测试。
但是,我们不能简单的从版本号就判定Selenium 2比Selenium 1更加先进。严格地说,它们完全属于两个不同的产品而不是简单的升级关系,更像是互补关系。它们之间各有优劣:Selenium 2可以弥补Selenium 1存在的缺点(例如能够绕过JS限制、API更易使用),而Selenium 1也可以解决Selenium 2存在的问题(例如支持更多的浏览器)。
5.1 Selenium 2——基于对象的测试
为什么说Selenium 2是基于对象的测试呢?可以对Selenium 1和Selenium 2的代码进行一下对比,同样是实现系统登录这种简单的操作,它们的代码却各有不同,如程序清单5-1和程序清单5-2所示。
程序清单5-1 Selenium 1的代码
static void Main(string[] args)
{
//实例化Selenium1对象
ISelenium selenium = new DefaultSelenium("localhost", 4444, "*firefox", http://www.360buy.com);
selenium.Start();
//打开京东登录页面
selenium.Open("https://passport.360buy.com/new/login.aspx");
//填写符合xpath的用户名文本框、密码文本框,单击登录
selenium.TypeKeys(@"//input[@id='loginname']", "UserName1");
selenium.TypeKeys(@"//input[@id='loginpwd']", "Password");
selenium.Click(@"//input[@id='loginsubmit']");
} |
程序清单5-2 Selenium 2的代码
static void Main(string[] args)
{
//实例化Selenium2对象
IWebDriver driver = new FirefoxDriver();
//打开京东登录页面
INavigation navigation = driver.Navigate();
navigation.GoToUrl(https://passport.360buy.com/new/login.aspx);
//分别获取用户名文本框,密码文本框,登录按钮
IWebElement loginName = driver.FindElement(By.Id("loginname"));
IWebElement loginPwd = driver.FindElement(By.Id("loginpwd"));
IWebElement loginButton = driver.FindElement(By.Id("loginsubmit"));
//输入用户名,密码,单击登录
loginName.SendKeys("UserName1");
loginPwd.SendKeys("Password");
loginButton.Click();
} |
可以看到Selenium 2与Selenium 1存在很明显的差异。尽管它们都属于浏览器自动化的API,但对于用户来说,Selenium 1提供的更多的是基于方法的API,所有方法都在一个类中开放,而Selenium 2的API则面向对象,不同的对象拥有不同的操作方法。
5.2 安装并引用Selenium 2
Selenium 2的下载地址为:http://seleniumhq.org/download/,位于“Selenium Client Drivers”栏,选择使用的编程语言版本下载即可,这些包中同时包含了Selenium 1和Selenium 2的文件,如图5-1所示。
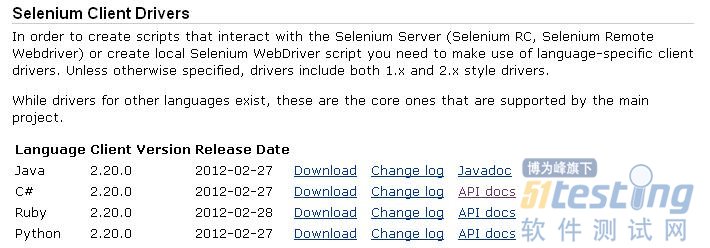
图5-1 下载Selenium 1
由于在本书中的Selenium示例都将采用C#或Java编写,因此需要至少掌握C#或Java中的一种语言。如果您是C#或Java的初学者,可以先在网上参阅相关的资料。
接下来分别介绍如何在C#和Java的 IDE环境中进行使用并创建程序。
5.2.1 在C#IDE中使用Selenium C#
下载之后进行解压,可以看到两个不同的文件夹,一个是.Net 3.5版本,另一个是.Net 4.0,可以根据自己的版本进行选择,然后进入对应版本的文件夹,如图5-2所示。
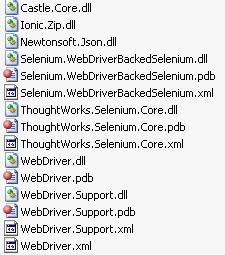
图5-2 Selenium .Net类库
接下来分别介绍部分文件的作用。
Castle.Core.dll:Castle的核心,它是个轻量级容器,实现了IoC(Inversion of Control)模式的容器,基于此核心容器所建立的应用程序,可以达到程序组件的松散耦合,让程序组件可以进行验证,这些特性使得可以简化整个应用程序的架构,并且使得易于维护此文件与测试的关系不大。
Ionic.Zip.dll:用于压缩和解压的库文件,可以把文件压缩成WinZip格式,也可以从该格式中解压。此文件与测试的关系不大。
Selenium.WebDriverBackedSelenium.dll:通过这个类库,可以实现用Selenium 1的语法来执行Selenium 2。这是一种过渡性方案,基本是针对老的Selenium 1代码,让它们以最小的代价迁移到Selenium 2去。
ThoughtWorks.Selenium.Core.dll:Selenium 1的主要API文件,在使用Selenium 1自动化测试时就靠这个类库来实现。
WebDriver.dll:Selenium 2的主要API文件,在使用Selenium 2进行自动化测试时主要就靠这个类库来实现。它是本章关注的重点。
WebDriver.Support.dll:WebDriver支持类,起辅助作用。其中包含一些HTML元素选择、条件等待、页面对象创建等的辅助类。本章将对其进行详细介绍。
至于.pdb类型的程序数据库文件,一般用于dll文件的调试,与Selenium 测试本身没多大关系。而.xml文件则是各个dll文件的API参考文档,应该仔细研究。
C#编程使用的是Visual Studio,Visual Studio 2010的下载地址是:
http://www.microsoft.com/visualstudio/zh-cn/download
关于Visual Studio的安装,可参见:
http://www.cnblogs.com/eastson/archive/2012/05/30/2525831.html
安装结束后,打开Visual Studio,然后选择“新建”→“项目”菜单命令,如图5-3所示。

图5-3 选择“新建C#项目1”菜单命令
在弹出的“新建项目”对话框中选择“控制台应用程序”,如图5-4所示。

图5-4 “新建项目”对话框
创建完毕后,将打开新建立的项目,可以看到默认创建了一个名为Program.CS的类文件,如图5-5所示。

图5-5 默认创建的Program.CS类文件
在解决方案资源管理器中,用鼠标右键单击“引用”,选择“添加引用”,如图5-6所示。
打开“添加引用”窗口,选择与WebDriver相关的dll文件,单击“确定”按钮,如图5-7所示。


图5-6 “添加引用”命令 图5-7 选择相关的.dll文件
在解决方案资源管理器中可看到该引用,如图5-8所示。
然后在main函数中输入如图5-9中所示的代码,然后按F5执行。
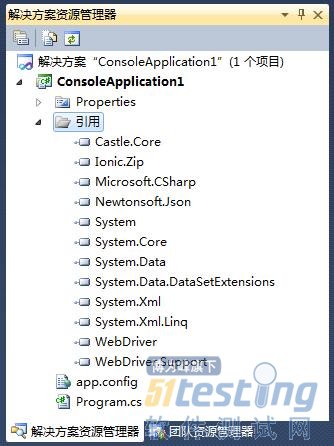

图5-8 添加引用3 图5-9 C#代码
运行结果如图5-10所示。
在本章中的C#程序都可按照这种方式进行创建。

图5-10 C#运行结果
5.2.2 在Java IDE中使用Selenium
下载之后进行解压,可以看到如图5-12所示的内容。
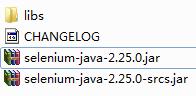
这些文件和文件夹的作用如下。
Libs文件夹:其中包含各种Java相关的基础框架。
CHANGELOG:记录了Selenium的变更情况,可以用记事本将其打开阅读。
Selenium-java-2.25.0.jar:Selenium 1和Selenium 2的主要API文件,在进行自动化测试时主要就靠这个类库来实现。
Selenium-java-2.25.0-srcs.jar:Selenium的部分源码,感兴趣的读者可以仔细研究。
运行Java程序和Selenium 服务器都需要先安装JDK,JDK的下载地址为:
http://www.oracle.com/technetwork/java/javase/downloads/index.html
注意下载时要选择对应的操作系统版本,下载后直接单击“下一步”按钮安装即可。
然后安装Eclipse,下载地址是:
http://www.eclipse.org/downloads/
下载Eclipse Classic,然后解压即可使用。
1.创建Java项目
(1)打开Eclipse,然后选择New→Java Project,如图5-13所示。

图5-13 Java Project菜单命令
(2)在打开New Java输入Project name,JRE选择当前安装的JRE,然后单击Finish,如图5-14所示。

图5-14 New Java Project对话框
(3)进入项目页面,在Package Explorer中右键单击该项目名称,选择New→Class命令,如图5-15所示。

图5-15 选择Class菜单命令
(4)输入包名称和类名称,并勾选Public static void main以生成main函数,如图5-16所示。

本文选自《Selenium自动化测试指南》第五章节,本站经人民邮电出版社和作者的授权,近期将进行部分章节的连载,敬请期待!
版权声明:51Testing软件测试网获人民邮电出版社和作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。
相关文章:
新书介绍:Selenium自动化测试指南—51Testing鼎力推荐
选择浏览器开始测试—Selenium自动化测试指南(2)
51Testing软件测试网获人民邮电出版社和作者授权连载本书部分章节。任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。)
程序清单5-12 Java代码
package Project1;
import org.openqa.selenium.*;
import org.openqa.selenium.WebDriver.*;
import org.openqa.selenium.firefox.*;
public class Project1Class {
public static void main(String[] args) {
//如果启动出现问题,可以使用System.setProperty指出firefox.exe的路径
//System.setProperty("webdriver.firefox.bin","D:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe");
WebDriver driver = new FirefoxDriver();
Navigation navigation = driver.navigate();
navigation.to("http://www.baidu.com");
navigation.to("http://www.google.com.hk");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
navigation.back();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
navigation.forward();
}
} |
程序清单代码执行后可以发现,程序共打开了两个页面:百度和谷歌。然后,页面先后退到了第一个页面(百度),再前进到了第二个页面(谷歌)。
5.4.3 Refresh()
使用该方法将刷新整个页面(类似于按F5的效果),多用于执行某些操作后需要刷新的情况(例如登录后页面未自动刷新),代码如程序清单5-13或程序清单5-14所示。
程序清单5-13 C#代码
using System;
using OpenQA.Selenium;
using OpenQA.Selenium.Firefox;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
IWebDriver driver = new FirefoxDriver();
INavigation navigation = driver.Navigate();
navigation.GoToUrl("http://www.baidu.com");
navigation.Refresh();
}
}
} |
程序清单5-14 Java代码
package Project1;
import org.openqa.selenium.*;
import org.openqa.selenium.WebDriver.*;
import org.openqa.selenium.firefox.*;
public class Project1Class {
public static void main(String[] args) {
//如果启动出现问题,可以使用System.setProperty指出firefox.exe的路径
//System.setProperty("webdriver.firefox.bin","D:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe");
WebDriver driver = new FirefoxDriver();
Navigation navigation = driver.navigate();
navigation.to("http://www.baidu.com");
navigation.refresh();
}
} |
5.5 查找条件对象By
在导航到对应页面后,就可以对页面上的元素进行操作了。然而,在进行操作之前,必须要找到相应的元素。如何才能找到这些元素呢?需要使用查找条件对象“By”进行查找。
根据HTML的不同,查找条件也各有不同。例如,可以按HTML元素的ID进行查找,也可以按Name属性查找,或者直接按HTML标签查找,接下来将列举常用的查找条件。
5.5.1 Id(idToFind)
可以按照HTML元素的ID属性进行查找。例如,百度首页有一个搜索文本框,如图5-26所示。

图5-26 百度搜索文本框
其HTML代码如下:
<input id="kw" class="s_ipt" type="text" maxlength="100" name="wd" autocomplete="off">
如要操作该文本框,则可以通过ID(id="kw")作为查找条件获取该对象,代码如程序清单5-15或程序清单5-16所示。
程序清单5-15 C#代码
IWebDriverdriver=newFirefoxDriver();
INavigationnavigation=driver.Navigate();
navigation.GoToUrl(http://www.baidu.com);
IWebElementbaiduTextBox=driver.FindElement(By.Id("kw"));
baiduTextBox.SendKeys("找到文本框"); |
程序清单5-16 Java代码
WebDriver driver = new FirefoxDriver();
Navigation navigation = driver.navigate();
navigation.to(http://www.baidu.com);
WebElement baiduTextBox = driver.findElement(By.id("kw"));
baiduTextBox.sendKeys("找到文本框"); |
代码driver.FindElement(By.Id("kw"));表示寻找ID为“kw”的元素。
找到文本框之后,执行“baiduTextBox.SendKeys("找到文本框");”,在搜索文本框中输入“找到文本框”。
代码清单5-15和5-16的执行结果如图5-27所示。

5.5.2 Name(nameToFind)
Name方法按Name进行查找与按ID进行查找类似,例如百度首页上面有“登录”超级链接,如图5-28所示。

图5-28 “登录”超级链接
其HTML代码如下:
<a name="tj_login" href=http://passport.baidu.com/?login&tpl=mn>登录</a>
注意,它的name属性为“tj_login”,可以用其作为查找条件来获取登录链接对象,使用方法如程序清单5-17或程序清单5-28所示。
程序清单5-17 C#代码
IWebElement loginButton= driver.FindElement(By.Name("tj_login")); |
程序清单5-18 Java代码
WebElement loginButton= driver.findElement(By.name("tj_login")); |
5.5.3 LinkText(linkTextToFind)
LinkText方法按链接的文本进行查找。例如,百度首页上有“登录”超级链接,如图5-29所示。

图5-29 “登录”超级链接
它的链接文本为属性为“登录”,可以用它作为查找条件来获取登录链接对象。先打开百度页面,然后单击“登录”,代码如程序清单5-19或程序清单5-20所示。
程序清单5-19 C#代码
IWebDriver driver = new FirefoxDriver();
INavigation navigation = driver.Navigate();
navigation.GoToUrl(http://www.baidu.com);
IWebElement baiduLogin = driver.FindElement(By.LinkText("登录"));
baiduLogin.Click(); |
程序清单5-20 Java代码
WebDriver driver = new FirefoxDriver();
Navigation navigation = driver.navigate();
navigation.to(http://www.baidu.com);
WebElement baiduLogin = driver.findElement(By.LinkText("登录"));
baiduLogin.click(); |
5.5.4 PartialLinkText(partialLinkTextToFind)
PartialLinkText方法按链接的文本进行模糊查找。例如,百度首页上有“登录”超级链接,如图5-30所示。

图5-30 “登录”超级链接
它的链接文本属性为“登录”。PartialLinkText可用于模糊查询,它可以用“录”字作为查找条件来获取“登录”链接对象。先打开百度页面,然后单击“登录”超级链接,代码如程序清单5-21或程序清单5-22所示。
程序清单5-21 C#代码
IWebDriver driver = new FirefoxDriver();
INavigation navigation = driver.Navigate();
navigation.GoToUrl(http://www.baidu.com);
IWebElement baiduLogin = driver.FindElement(By.PartialLinkText("录"));
baiduLogin.Click(); |
程序清单5-22 Java代码
WebDriver driver = new FirefoxDriver();
Navigation navigation = driver.navigate();
navigation.to(http://www.baidu.com);
WebElement baiduLogin = driver.findElement(By.partialLinkText("录"));
baiduLogin.click(); |
5.5.5 ClassName(classNameToFind)
ClassName方法按链接的文本进行模糊查找。例如,百度贴吧上有“贴吧搜索”超级链接,如图5-31所示。
图5-31 “贴吧搜索”超级链接
使用FireBug查看其HTML代码,如图5-32所示。

图5-32 HTML代码
其Class属性为“j_global_search”,可以用其作为查找条件来获取“贴吧搜索”链接。先打开贴吧页面,然后单击“贴吧搜索”链接,代码如程序清单5-23或程序清单5-24所示。
程序清单5-23 C#代码
IWebDriver driver = new FirefoxDriver();
INavigation navigation = driver.Navigate();
navigation.GoToUrl(http://tieba.baidu.com/index.html);
IWebElement tiebaSearch = driver.FindElement(By.ClassName("j_global_search"));
tiebaSearch.Click(); |
程序清单5-24 Java代码
WebDriver driver = new FirefoxDriver();
Navigation navigation = driver.navigate();
navigation.to(http://www.baidu.com);
WebElement tiebaSearch = driver.findElement(By.className("j_global_search"));
tiebaSearch .click(); |
5.5.6 TagName(TagNameToFind)
TagName方法按标记名称进行查找,并返回第一个匹配项。例如,百度首页有“搜索设置”超级链接,如图5-33所示。

图5-33 登录按钮
使用FireBug查看其HTML代码,可以发现它是整个页面的第一个“a”标记,如图5-34所示。
图5-34 HTML代码
因此,可以用它的标记名称“a”作为查找条件来获取“搜索设置”链接。先打开百度主页,然后单击“搜索设置”超级链接,代码如程序清单5-25和程序清单5-26所示。
程序清单5-25 C#代码
IWebDriver driver = new FirefoxDriver();
INavigation navigation = driver.Navigate();
navigation.GoToUrl(http://tieba.baidu.com/index.html);
IWebElement searchSetting = driver.FindElement(By.TagName("a"));
searchSetting .Click(); |
程序清单5-26 Java代码
WebDriver driver = new FirefoxDriver();
Navigation navigation = driver.navigate();
navigation.to(http://www.baidu.com);
WebElement searchSetting = driver.findElement(By.tagName("a"));
searchSetting .click(); |
本文选自《Selenium自动化测试指南》第五章节,本站经人民邮电出版社和作者的授权,近期将进行部分章节的连载,敬请期待!
版权声明:51Testing软件测试网获人民邮电出版社和作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。
相关文章:
选择浏览器开始测试—Selenium自动化测试指南(2)
操作页面元素WebElement—Selenium自动化测试指南(4)
一、线程共享数据
a)继承Thread,那么我们可以创建很多个这样的类,但是每个这样的类都是相互不关联的,也就是说我们Thread类中的内容每个创建出来的类都有一份,因此它不适合作为数据共享的线程来操作。同时由于Java继承的唯一性,我们只能继承一个对象。
b)使用runnable就可以解决唯一性和不能共享的问题(不是说使用runnable就解决了共享问题,只是相对于创建Thread来说,它可以算的上是共享了,为了获得更精确的共享问题,它必须的使用线程同步操作)。实现了runnable接口的类比较适合用作共享数据。
一个测试例子à证明runnable能实现数据共享,thread不能
Thread_thread一个继承了Thread的线程
Thread_runnable是一个时间了runnable的接口,他们在run里面有共同的方法
for(int i=0;i<20;i++){
if(ticket>0){
System.out.println(ticket);
ticket--;
}
}
thread_thread th1=new thread_thread();
thread_thread th2=new thread_thread();
thread_thread th3=new thread_thread();
th1.start();
th2.start();
th3.start(); |
输入了三组321321321
因为创建的是三个对象,每一个对象都拥有自己的一个备份
将一个runnable作为参数,实例化三个thread对象
thread_runnable ru=new thread_runnable();
Thread th1=new Thread(ru);
Thread th2=new Thread(ru);
Thread th3=new Thread(ru);
th1.start();
th2.start();
th3.start(); |
输入了32133
虽然说着不是完整意义上的数据共享,但是相当于上述打印三组完整的数据来说,它已经实现了数据共享,我们从中也可以看到,我们只创建了一个runnable对象(数据只产生了一份),它由三个Thread调用。
新建三个runnable对象,分别给每一个thread传递
Thread th1=new Thread(new thread_runnable());
Thread th2=new Thread(new thread_runnable());
Thread th3=new Thread(new thread_runnable());
th1.start();
th2.start();
th3.start(); |
打印结果是321321321
我们可以看到我们产生了三个runnable对象,每一个都有自己的一份使用
综上所述:只有将一个runnable对象作为参数,传递给thread对象才能实现数据共享。
注意:当我们创建一个Thread对象,并多次调用start方法的时候,系统是不会给你创建多个Thread线程的,它只会运行那个唯一的Thread一次而已,也就是说你运行了一次start方法之后再调用一个它的start方法是没有意义的(那个Thread没有结束的情况下),系统不会给你多次运行的。
二、线程同步
a)线程代码块(在代码中添加Synchronized(对象){})
i.Synchronized(对象),每个对象都有个标志位,当我们进入synchronized代码块中,系统就让这个对象的标志位变为0,就相当于给这个对象添加上了一把锁,当别的代码运行到这个代码块的时候因为加了锁,所以不能进去,当第一个程序它运行出去之后,系统就会让标志位变为1,相当于解锁。这样别的代码又可以访问了。从而实现同步(安全)操作。
ii.当我们将我们的标志位对象放在run方法里面定义的时候,我们是不能实现同步的,因为我们每次运行一个线程,都将调用它的run方法,从而每次都会创建一个新的标志位对象,也就是说我们所有的run方法都含有自己的一个标志位对象,因此不能实现加锁的过程。一般都是放在runnable接口中进行定义的。
b)线程方法(在代码的方法申明中public和void之间添加synchronized)
i.每次只能有一个线程调用这个同步方法,而且每次这个方法都得运行完,这就是同步代码方法。
ii.同步方法默认使用的是this来作为标志对象位的,这个this就是我们的当前类。
c)注意:
i.当一个同步代码块和一个同步代码方法使用的不是同一个对象作为标志位的时候,它们就不会实现同步,这也就是数,当两个同步代码块不使用同一个对象作为标志位,那他们就不能实现同步。
ii.调用线程的Start方法的时候,并没有真正的运行这个代码,而只是说这个代码已经准备就绪,有运行的可能。
三、线程通信
a)当我们的代码中使用了synchronized(对象)同步代码块的时候,如果我们想实现线程通信,也就是如果我们想使用wait、notify或者notifyall时,我们必须在静态代码块中使用对象.wait()、对象.notify()、对象.notifyAll()来通信,不然的话讲会报Illegal的错误。
b)Notify是唤醒同一监视器下(相当于同一个标志位对象)的第一个wait线程,而notifyall是唤醒所有的处于同一监视器下的(同一标志位对象)的线程。
最近对云主机进行性能测试,第一次涉及到了网络方面的性能测试,其实不能算是一次很全面的网络性能方面的性能测试,只是针对不同的测试目标进行了测试,在这期间,了解了网络性能测试需要掌握的性能指标、测试工具、功能选型和对比等。下面一一介绍下:
网络性能指标
常见的网络性能测试指标包含:网络吞吐量(Throughput)、网络延迟(latency)、抖动(jitter)、丢包率等
网络吞吐量:单位时间内通过某个网络(或信道、接口)的数据量,吞吐量受网络的带宽或者网络的额定速率限制的,例如家庭带宽为10M网络,表明网络吞吐量不可能超过10Mbits/s,吞吐量的单位通常表示为位元每秒(bit/s或bps)。
网络延迟:通俗的讲,就是数据从电脑这边传到那边所用的时间。这儿有个问题需要确认,数据是指一个数据包的传输还是任意大小,和你传输的数据量相关。可以明显的看到,从A到B传送1个字节的时间和传送100MB的时间肯定是不一样的。标准意义上的延迟,应该仅仅指1个字节的传输时间,类似网络课上讲到的传播时延。(不同意见欢迎讨论)。同样存在一个名词叫做传播延时,这个应该可以标识整个数据包的传输时间,不论包大小为多少。
抖动:用于描述包在网络中的传输延时的变化,抖动越小,说明网络质量越稳定越好。抖动是评价一个网络性能的最重要的因素。
丢包率:测试中所丢失的数据包数量占所发送的数据包的比率,因为我们知道TCP协议是可靠的,所以,一般在使用UDP传输时,才会统计丢包率。
网络性能测试工具
大家熟知的,常用的开源网络性能测试工具有两个:iperf 和 netperf,这两种工具都是可以测试TCP协议和UDP协议的,从可测试的网络性能指标,我们对两种工具进行下对比:
可测试的网络性能指标:
| 工具 | 吞吐量 | 网络延时 | 抖动 | 丢包 | 其他 |
| iperf | 是 | 是 | 否 | 是 | |
| netperf | 是 | 是 | 是 | 是 | 重传、CPU利用率、延时分布等
|
可见,iperf也可以完成基本的网络性能测试,但是工具比netperf要略差些,我们测试过程中,选用的工具为netperf,下面对netperf进行下详细介绍:
安装:netperf的安装可以找SA部署,但是SA安装的版本时2.4版本,很多功能没有实现,可以自己make安装netperf 2.6版本,是目前为止最新的版本。
基本命令:netperf -H hostname -l testtime: 例如 netperf -H 172.0.0.2 -l 60,表示发送到172.0.0.2(这台机器上需要启动netserver进程),发送时间为60s,默认的发送方式为TCP Stream方式。
发送方式:netperf 可以支持多种不同的发送方式,通过 -t 参数指定:
TCP_STREAM、UDP_STREAM模式:即不停往发送方发送数据,可以通过-m 参数指定发送数据的大小,默认大小为socket size。
TCP_RR模式:即Request、Response模式,类似模拟http请求、数据库请求等,默认大小Request size 和 Response size 均为1byte,可以通过 -r 64,32K 设置 Request、Response size。
统计数据:默认得到的数据只有传输时间和吞吐量等,可以通过-k 参数设置要显示的结果数据:
MIN_LATENCY,MAX_LATENCY,MEAN_LATENCY,P50_LATENCY,P90_LATENCY:可以得到延迟相关的统计数据,延迟最大最小值、平均延迟,延迟50、70、90、99值等。
STDDEV_LATENCY:延迟标准差,可以通过该值反应网络的抖动情况
THROUGHPUT:两台机器之间当前的吞吐量
LOCAL_CPU_UTIL,REMOTE_CPU_UTIL:发送方和接收方的CPU使用率
REQUEST_SIZE,RESPONSE_SIZE:RR模式时,Request、Response size
LOCAL_TRANSPORT_RETRANS:重传次数
通过上面对netperf命令的描述,可以看到该工具基本可以测试得到所有网络性能方面的指标,但是netperf、iperf这种工具可能更适合作为一种基准工具,进行压力测试,作为负载测试工具还不是很合适,测试过程中,可以通过-b -w的参数制定发送数据包个数和发送间隔,但是不能从根本上限制网络吞吐量仅占网络带宽的50%等情况。
googletest是一个用来写C++单元测试的框架,它是跨平台的,可应用在windows、linux、Mac等OS平台上。下面,我来说明如何使用最新的1.6版本gtest写自己的单元测试。
本文包括以下几部分:1、获取并编译googletest(以下简称为gtest);2、如何编写单元测试用例;3、如何执行单元测试。4、google test内部是如何执行我们的单元测试用例的。
1. 获取并编译gtest
gtest试图跨平台,理论上,它就应该提供多个版本的binary包。但事实上,gtest只提供源码和相应平台的编译方式,这是为什么呢?google的解释是,我们在编译出gtest时,有些独特的工程很可能希望在编译时加许多flag,把编译的过程下放给用户,可以让用户更灵活的处理。这个仁者见仁吧,反正也是免费的BSD权限。
源码的获取地址:http://code.google.com/p/googletest/
svn checkout
怎么编译呢?
先进入gtest目录(解压gtest.zip包过程就不说了),执行以下两行命令:
Changes for 1.6.0: * New feature: ADD_FAILURE_AT() for reporting a test failure at the
given source location -- useful for writing testing utilities.
。。。 。。。
* Bug fixes and implementation clean-ups.
* Potentially incompatible changes: disables the harmful 'make install'
command in autotools. |
就是最下面一行,make install禁用了,郁闷了吧?UNIX的习惯编译方法:./configure;make;make install失灵了,只能说google比较有种,又开始挑战用户习惯了。
那么怎么编译呢?
先进入gtest目录(解压gtest.zip包过程就不说了),执行以下两行命令:
g++ -I./include -I./ -c ./src/gtest-all.cc
ar -rv libgtest.a gtest-all.o |
之后,生成了libgtest.a,这个就是我们要的东东了。以后写自己的单元测试,就需要libgtest.a和gtest目录下的include目录,所以,这1文件1目录我们需要拷贝到自己的工程中。
编译完成后怎么验证是否成功了呢?(相当不友好!)
cd ${GTEST_DIR}/make
make |
如果看到:
Running main() from gtest_main.cc
[==========] Running 6 tests from 2 test cases.
[----------] Global test environment set-up.
[----------] 3 tests from FactorialTest
[ RUN ] FactorialTest.Negative
[ OK ] FactorialTest.Negative (0 ms)
[ RUN ] FactorialTest.Zero
[ OK ] FactorialTest.Zero (0 ms)
[ RUN ] FactorialTest.Positive
[ OK ] FactorialTest.Positive (0 ms)
[----------] 3 tests from FactorialTest (0 ms total) [----------] 3 tests from IsPrimeTest
[ RUN ] IsPrimeTest.Negative
[ OK ] IsPrimeTest.Negative (0 ms)
[ RUN ] IsPrimeTest.Trivial
[ OK ] IsPrimeTest.Trivial (0 ms)
[ RUN ] IsPrimeTest.Positive
[ OK ] IsPrimeTest.Positive (0 ms)
[----------] 3 tests from IsPrimeTest (0 ms total) [----------] Global test environment tear-down
[==========] 6 tests from 2 test cases ran. (0 ms total)
[ PASSED ] 6 tests. |
那么证明编译成功了。
2、如何编写单元测试用例
以一个例子来说。我写了一个开地址的哈希表,它有del/get/add三个主要方法需要测试。在测试的时候,很自然,我只希望构造一个哈希表对象,对之做许多种不同组合的操作,以验证三个方法是否正常。所以,gtest提供的TEST方式我不会用,因为多个TEST不能共享同一份数据,而且还有初始化哈希表对象的过程呢。所以我用TEST_F方式。TEST_F是一个宏,TEST_F(classname, casename){}在函数体内去做具体的验证。
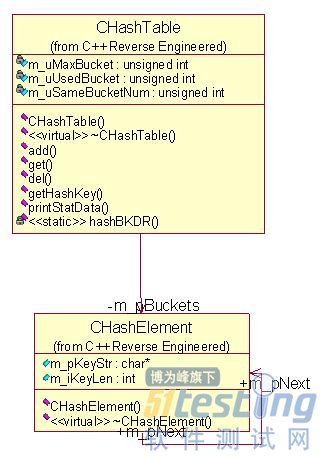
上面是我要执行单元测试的类图。那么,我需要写一系列单元测试用例来测试这个类。用gtest,首先要声明一个类,继承自gtest里的Test类:

代码很简单:
class CHashTableTest : public ::testing::Test {
protected:
CHashTableTest():ht(100){ }
virtual void SetUp() {
key1 = "testkey1";
key2 = "testkey2";
} // virtual void TearDown() {}
CHashTable ht; string key1;
string key2;
}; |
然后开始写测试用例,用例里可以直接使用上面类中的成员。
TEST_F(CHashTableTest, hashfunc)
{
CHashElement he; ASSERT_NE(\
ht.getHashKey((char*)key1.c_str(), key1.size(), 0),\
ht.getHashKey((char*)key2.c_str(), key2.size(), 0)); ASSERT_NE(\
ht.getHashKey((char*)key1.c_str(), key1.size(), 0),\
ht.getHashKey((char*)key1.c_str(), key1.size(), 1)); ASSERT_EQ(\
ht.getHashKey((char*)key1.c_str(), key1.size(), 0),\
ht.getHashKey((char*)key1.c_str(), key1.size(), 0));
} |
注意,TEST_F宏会直接生成一个类,这个类继承自上面我们写的CHashTableTest类。
gtest提供ASSERT_和EXPECT_系列的宏,用于判断二进制、字符串等对象是否相等、真假等等。这两种宏的区别是,ASSERT_失败了不会往下执行,而EXPECT_会继续。
3、如何执行单元测试
首先,我们自己要有一个main函数,函数内容非常简单:
#include "gtest/gtest.h" int main(int argc, char** argv) {
testing::InitGoogleTest(&argc, argv); // Runs all tests using Google Test.
return RUN_ALL_TESTS();
} |
InitGoogleTest会解析参数。RUN_ALL_TESTS会把整个工程里的TEST和TEST_F这些函数全部作为测试用例执行一遍。
执行时,假设我们编译出的可执行文件叫unittest,那么直接执行./unittest就会输出结果到屏幕,例如:
[==========] Running 4 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 4 tests from CHashTableTest
[ RUN ] CHashTableTest.hashfunc
[ OK ] CHashTableTest.hashfunc (0 ms)
[ RUN ] CHashTableTest.addget
[ OK ] CHashTableTest.addget (0 ms)
[ RUN ] CHashTableTest.add2get
testCHashTable.cpp:79: Failure
Value of: getHe->m_pNext==NULL
Actual: true
Expected: false
[ FAILED ] CHashTableTest.add2get (1 ms)
[ RUN ] CHashTableTest.delget
[ OK ] CHashTableTest.delget (0 ms)
[----------] 4 tests from CHashTableTest (1 ms total) [----------] Global test environment tear-down
[==========] 4 tests from 1 test case ran. (1 ms total)
[ PASSED ] 3 tests.
[ FAILED ] 1 test, listed below:
[ FAILED ] CHashTableTest.add2get |
可以看到,对于错误的CASE,会标出所在文件及其行数。
如果我们需要输出到XML文件,则执行./unittest --gtest_output=xml,那么会在当前目录下生成test_detail.xml 文件,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<testsuites tests="3" failures="0" disabled="0" errors="0" time="0.001" name="AllTests">
<testsuite name="CHashTableTest" tests="3" failures="0" disabled="0" errors="0" time="0.001">
<testcase name="hashfunc" status="run" time="0.001" classname="CHashTableTest" />
<testcase name="addget" status="run" time="0" classname="CHashTableTest" />
<testcase name="delget" status="run" time="0" classname="CHashTableTest" />
</testsuite>
</testsuites> |
如此,一个简单的单元测试写完。因为太简单,所以不需要使用google mock模拟一些依赖。后续我再写结合google mock来写一些复杂的gtest单元测试。
下面来简单说下gtest的工作流程。
4、google test内部是如何执行我们的单元测试用例的
首先从main函数看起。
我们的main函数执行了RUN_ALL_TESTS宏,这个宏干了些什么事呢?
#define RUN_ALL_TESTS()\
(::testing::UnitTest::GetInstance()->Run()) } // namespace testing |
原来是调用了UnitTest静态工厂实例的Run方法!在gtest里,一切测试用例都是Test类的实例!所以,Run方法将会执行所有的Test实例来运行所有的单元测试,看看类图:

为什么说一切单元测试用例都是Test类的实例呢?
我们有两种写测试用例的方法,一种就是上面我说的TEST_F宏,这要求我们要显示的定义一个子类继承自Test类。在TEST_F宏里,会再次定义一个新类,继承自我们上面定义的子类(两重继承哈)。
第二种就是TEST宏,这个宏里不要求用户代码定义类,但在google test里,TEST宏还是定义了一个子类继承自Test类。
所以,UnitTest的Run方法只需要执行所有Test实例即可。
个单元测试用例就是一个Test类子类的实例。它同时与TestResult,TestCase,TestInfo关联起来,用于提供结果。
当然,还有EventListen类来监控结果的输出,控制测试的进度等。

以上并没有深入细节,只是大致帮助大家理解,我们写的几个简单的gtest宏,和单元测试用例,到底是如何被执行的。接下来,我会通过gmock来深入的看看google单元测试的玩法。
处理文本值是程序员的日常工作,通常用标准的Java String类来完成与文本有关的需求。它对于很多小任务确实很适用,但是如果处理的是大型任务,它会大量消耗系统资源。由于这个原因,JDK引入了StringBuffer类以提供一条处理字符串的有效路径。让我们来看看怎样用这个类来提升性能。
为什么不用标准的String?
Java String对象是常量字符串。一旦被初始化和付值,它的值和所分配的内存就被固定了。如果硬要改变它的值,将会产生一个包含新值的新String对象。这就是String对象会消耗掉很多资源的原因。下面的代码创建了一个String对象并使用串联(+)符号来为它添加更多字符:
String sample1=new String(“Builder.com”);
sample1+=”is”;
sample1+=”the place”;
sample1+=”to be.”; |
系统最终会创建四个String对象来完成上面的替换。其中第一个的文本是Builder.com。然后每次添加文本时都会创建一个新的对象。
这种方法的问题在于为了这么一个简单的过程而消耗了太多的资源。在这个例子中其影响也许很小(指给出了很少的代码),但是在一个拥有多得多操作的大型应用程序中这样做就会使性能下降。StringBuffer类所要解决的正是这个问题。
用StringBuffer处理字符串
StringBuffer类被设计用与创建和操作动态字符串信息。为该对象分配的内存会自动扩展以容纳新增的文本。有三种方法来创建一个新的StringBuffer对象:使用初始化字符串、设定大小以及使用默认构造函数:
StringBuffer sb=new StringBuffer();
StringBuffer sb=new StringBuffer(30);
StringBuffer sb=new StringBuffer(“Builder.com”); |
第一行创建了不包含任何文本的对象,默认的容量是16个字符。类的第二个实例也不包含文本,容量是30个字符,最后一行创建了一个拥有初始化值的对象。StringBuffer类位于java.lang基础包中,因此要使用它的话不需要特殊的引入语句。
一旦创建了StringBuffer类的对象,就可以使用StringBuffer类的大量方法和属性。最显著的方法是append,它将文本添加到当前StringBuffer对象内容的结尾。下面的代码示例了append方法的语法:
StringBuffer sb=new StringBuffer();
sb.append(“B”);
sb.append(“u”);
sb.append(“i”);
sb.append(“l”);
sb.append(“d”);
sb.append(“e”);
sb.append(“r”);
sb.append(“.com”);
System.out.println(sb.toString()); |
这些代码创建了Builder.com字符串并将它送往标准输出,但是只创建了一个对象。如果使用String对象就需要八个以上的对象。注意代码利用了StringBuffer类的toString方法。这个方法将其内容转换成一个可以被用于输出的字符串对象。它允许操作对应的文本用于输出或数据存储。
append方法有十种重载形式,允许将各种类型的数据添加到对象的末尾。StringBuffer类还提供了处理对象内部数据的方法。
StringBuffer的容量
可以使用capacity和length方法来设定对象内的字符数。capacity方法返回为对象分配的字符数(内存)。如果超过了容量,它会自动扩展以符合需求。length方法返回对象目前存储的字符数。可以通过setLength方法来增加其长度。另外,对象的容量可以通过ensureCapacity方法来扩展。它建立了对象的最小容量,因此如果超出则不会有任何问题。下面的代码用到了这些方法:
StringBuffer sb=new StringBuffer();
sb.ensureCapacity(40);
sb.append(“Builder.com is awesome!”);
Systrm.out.println(sb.toString());
sb.setLength(11);
Systrm.out.println(sb.toString()); |
代码设置了字符串的容量并为其付值。length属性被重新设置了,因此文本被截断了。输入结果如下:
Builder.com is awesome!
Builder.com
操作字符串
还有更多的方法来处理存储在StringBuffer对象内的字符串。以下列举了几个例子:
CharAt返回字符串中的单个字符。
SetCharAt为字符串中的单个字符付值或进行替换。
GetChars返回字符串的一个子字符串。
Insert在字符串指定位置插入值。它有多个重载版本以容纳各种数据类型。
Substring返回字符串的一个子集。
Reverse倒置StringBuffer的内容。
所有的方法对于操作值来说都是很有用的,但是reverse方法最酷了——它使你只用一个调用就轻松地倒置了一个字符串。下面的代码和数出结果作了示范:
StringBuffer sb=new StringBuffer();
sb.ensureCapacity(100);
sb.append(“Builder.com!”);
System.out.println(sb.toString());
sb.reverse();
Systrm.out.println(sb.toString()); |
输出:
Builder.com!
!moc.redliuB
StringBuffer的优势
字符串的使用贯穿于决大多数应用程序,不管是作为用户界面的标识或在后台处理从数据库取回的值。通常,这些值并不符合要求,需要处理。你可以使用String类,但是它并不是设计成处理动态值的。而StringBuffer类正好填补了这个需求并使得系统资源的利用更加有效。
只需要传入一个想要查找的值,即可查询出这个值所在的表和字段名。
前提是要将这个存储过程放在所查询的数据库。
CREATE PROCEDURE [dbo].[SP_FindValueInDB]
(
@value VARCHAR(1024)
)
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
DECLARE @sql VARCHAR(1024)
DECLARE @table VARCHAR(64)
DECLARE @column VARCHAR(64)
CREATE TABLE #t (
tablename VARCHAR(64),
columnname VARCHAR(64)
)
DECLARE TABLES CURSOR
FOR
SELECT o.name, c.name
FROM syscolumns c
INNER JOIN sysobjects o ON c.id = o.id
WHERE o.type = 'U' AND c.xtype IN (167, 175, 231, 239)
ORDER BY o.name, c.name
OPEN TABLES
FETCH NEXT FROM TABLES
INTO @table, @column
WHILE @@FETCH_STATUS = 0
BEGIN
SET @sql = 'IF EXISTS(SELECT NULL FROM [' + @table + '] '
SET @sql = @sql + 'WHERE RTRIM(LTRIM([' + @column + '])) LIKE ''%' + @value + '%'') '
SET @sql = @sql + 'INSERT INTO #t VALUES (''' + @table + ''', '''
SET @sql = @sql + @column + ''')'
EXEC(@sql)
FETCH NEXT FROM TABLES
INTO @table, @column
END
CLOSE TABLES
DEALLOCATE TABLES
SELECT *
FROM #t
DROP TABLE #t
End |
例如,要查询值'BBQ CHIC SW',结果如下:

返回三条记录,说明这个值存在于三个表中,分别为_dts_menudef, g_dts_menudef和g_recipe中,字段名分别为name1, name1, name。
1、保护密码
即便是相信您的朋友,一起打牌的时候还是要切一下牌。同样道理,即便是您对自己的记忆里充满信心,最好也保存一张含有密码的启动磁盘,这样万一您忘记了密码,还可以有方便的解决办法。具体操作步骤是,第一,找一张已经格式化好的空白软盘,然后在任意的资源管理器窗口或者IE 窗口的地址栏上键入“控制面板/ 用户账户”并回车,在“用户账户”窗口中选择您的账户,在相关的任务列表中,点击“阻止一个已忘记的密码”,然后根据后面的“忘记密码向导”的提示完成操作。
2、绕过忘记的密码
如果您没有准备带有密码的启动盘,然后用其他的管理原级别的账户登录,按照第16条中的方法打开“用户账户”设置界面,选择忘记了密码的那个账户,点击“更改密码”,然后按照提示重新设置新的密码。
如果您无法使用另外一个管理员级别的用户名进行登录,请您重新启动计算机,然后在深度纯净雨林木风安装版Windows 启动标志出现时按“F8”键,进入Windows 的启动选项界面。使用上下键移动到“安全模式”然后按回车键。当您看到欢迎界面时,选择Administrator(这是一个隐藏的账户,而且默认不需要任何密码),接下来的操作和第17条所描述的一样,重新设置账户密码,最后重新启动计算机。
3、成为一个Power User
在Windows 2000 中文版中称其为权限高的用户。当您以管理员用户登录系统的时候,您的系统容易受到特洛伊木马等恶意程序的攻击。当您以一个“Power User”登录系统时,就可以避免很多危险,而且您通常需要使用的功能基本上和管理原级别的用户一样,当然,如果有必要的话,切换回管理员级别的用户也比较方便。
设置Power User的操作步骤如下:选择“开始”/“运行”,键入windows7旗舰版“lusrmgr.msc”命令行后回车,进入“本地用户和组”窗口,在左边点击“组”,然后双击右侧的“Administrators”。在这里您需要确认一下“成员”列表里有另外一个账户,即当您需要完全的管理原级别的权限时还可以用这个账户登录系统。选择您想降级的账户,点击“删除”*“确认”。接下来在左侧点击“Power Users”*“添加”,键入您指定的账户名称,最后点击“确认”2 次。
4、当一次临时管理员
Power user 可以运行管理员级别的程序,例如前面第3 条中提到的Lusrmgr.msc 程序,而无须注销再以管理员级别的账户重新登录。具体的操作是,在资源管理器中,按住键盘上的“Shift”键,然后用鼠标右键点击您想运行的程序或快捷方式,从弹出菜单中选择“运行方式”,然后选择“以下面的用户身份运行程序”(在Windows 2000 下)或者“下列用户”(在Windows XP下),然后键入您希望使用的管理员级别的用户身份名称和密码(如果有必要的话还需要键入域名),最后点击“确认”即可。
5、使用Windows 的网络安装向导
如果您是第一次连接计算机网络,Windows XP 的“网络安装向导”是个不错的选择,它可以一步一步地帮助您设置好各种细节。如果您想手动运行该向导,可以选择“开始”*“运行”,然后在命令行的位置键入“netsetup”,回车即可。
6 、安装无线网络
当您在计算机中插入一块无线网络适配器时,XP会自动弹出一个“连接到无线网络”的对话框。用鼠标右键点击系统栏中的无线网络图标,然后在弹出菜单中选择“查看可以使用的无线网络”,并从中选择您指定的无线连接,最后点击“连接”按钮。如果您没有看到这个图标,请在“资源管理器”或者文件夹窗口的地址栏键入“控制面板/网络连接”,然后用鼠标右键点击无线网络连接的图标。
前言:android应用的自动化测试必然会涉及到注册登录功能,而许多的注册登录或修改密码功能常常需要输入短信验证码,因此有必要能够自动获得下发的短信验证码。
主要就是实时获取短信信息。
android上获取短信信息主要有BroadcastReceiver方式与数据库方式,要实时的话就BroadcastReceiver比较方便
public class SMSReceiver extends BroadcastReceiver{
private String verifyCode="";
public static final String TAG = "SMSReceiver";
public static final String SMS_RECEIVED_ACTION = "android.provider.Telephony.SMS_RECEIVED";
@Override
public void onReceive(Context context, Intent intent){
if (intent.getAction().equals(SMS_RECEIVED_ACTION)){
SmsMessage[] messages = getMessagesFromIntent(intent);
for (SmsMessage message : messages){
Log.i(TAG, message.getOriginatingAddress() + " : " +
message.getDisplayOriginatingAddress() + " : " +
message.getDisplayMessageBody() + " : " +
message.getTimestampMillis());
String smsContent=message.getDisplayMessageBody();
Log.i(TAG, smsContent);
writeFile(smsContent);//将短信内容写入SD卡
}
}
} public final SmsMessage[] getMessagesFromIntent(Intent intent){
Object[] messages = (Object[]) intent.getSerializableExtra("pdus");
byte[][] pduObjs = new byte[messages.length][];
for (int i = 0; i < messages.length; i++)
{
pduObjs[i] = (byte[]) messages[i];
}
byte[][] pdus = new byte[pduObjs.length][];
int pduCount = pdus.length;
SmsMessage[] msgs = new SmsMessage[pduCount];
for (int i = 0; i < pduCount; i++) {
pdus[i] = pduObjs[i];
msgs[i] = SmsMessage.createFromPdu(pdus[i]);
}
return msgs;
}
//将短信内容写到SD卡上的文件里,便于将文件pull到PC,这样可方便其它如WWW/WAP平台的自动化
@SuppressLint("SdCardPath")
public void writeFile(String str){
String filePath="/mnt/sdcard/verifyCode.txt";
byte [] bytes = str.getBytes();
try{
File file=new File(filePath);
file.createNewFile();
FileOutputStream fos=new FileOutputStream(file);
fos.write(bytes);
fos.close();
}catch(IOException e){
e.printStackTrace();
}
} |
如此当有短信收到时就可以将短信内容写到SD卡中的文件里
在另一个java类中写个读取文件内容的方法,并在写测试用例过程中,将得到的String按验证码的具体位置截取即可。
public String read(String str) throws IOException{
File file=new File(str);
FileInputStream fis=new FileInputStream(file);
StringBuffer sb=new StringBuffer();
BufferedInputStream bis=new BufferedInputStream(fis);
BufferedReader read = new BufferedReader (new InputStreamReader(bis));
int c=0;
while ((c=read.read())!=-1) {
sb.append((char) c);
}
read.close();
bis.close();
fis.close();
Log.i(TAG, sb.toString());
String verify=sb.toString();
return verify;
} |
最后需要在manifest中增加申明,且注册权限
<receiver android:name="com.cplatform.surfdesktop.test.util.SMSReceiver">
<intent-filter>
<action android:name="android.provider.Telephony.SMS_RECEIVED" />
</intent-filter>
</receiver>
<uses-permission android:name="android.permission.RECEIVE_SMS"></uses-permission>
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"></uses-permission>
<uses-permission android:name="android.permission.READ_SMS"/> |
测试过程中需要用到短信验证码时就可以实时获取了