
本节知识点:
多层框架或窗口的定位:
switch_to_frame()
switch_to_window()
智能等待:
implicitly_wait()
对于一个现代的web应用,经常会出现框架(frame) 或窗口(window)的应用,这也就给我们的定位带来了一个难题。
有时候我们定位一个元素,定位器没有问题,但一直定位不了,这时候就要检查这个元素是否在一个frame中,seelnium webdriver 提供了一个switch_to_frame方法,可以很轻松的来解决这个问题。
frame.html
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<title>frame</title>
<script type="text/javascript" async=""
src="http://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js
"></script>
<link href=http://netdna.bootstrapcdn.com/twitter-bootstrap/2.3.2/css/bootstrap-combined.min.css rel="stylesheet" />
<script type="text/javascript">
$(document).ready(function(){
});
</script>
</head>
<body>
<div class="row-fluid">
<div class="span10 well">
<h3>frame</h3>
<iframe id="f1" src="inner.html" width="800",
height="600"></iframe>
</div>
</div>
</body>
<script src="http://netdna.bootstrapcdn.com/twitter-bootstrap/2.3.2/js/bootstrap.min.js"></script>
</html> |
inner.html
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<title>inner</title>
</head>
<body>
<div class="row-fluid">
<div class="span6 well">
<h3>inner</h3>
<iframe id="f2" src="http://www.baidu.com" width="700"
height="500"></iframe>
<a href="javascript:alert('watir-webdriver better than
selenium webdriver;')">click</a>
</div>
</div>
</body>
</html>
|
frame.html 中嵌套inner.html ,两个文件和我们的脚本文件放同一个目录下:
switch_to_frame()
操作上面页面,代码如下:
#coding=utf-8
from selenium import webdriver
import time
import os browser = webdriver.Firefox()
file_path = 'file:///' + os.path.abspath('frame.html')
browser.get(file_path) browser.implicitly_wait(30)
#先找到到ifrome1(id = f1)
browser.switch_to_frame("f1")
#再找到其下面的ifrome2(id =f2)
browser.switch_to_frame("f2")
#下面就可以正常的操作元素了
browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
time.sleep(3)
browser.quit() |
driver.switch_to_window()
有可能嵌套的不是框架,而是窗口,还有真对窗口的方法:switch_to_window
用法与switch_to_frame 相同:
driver.switch_to_window("windowName")
implicitly_wait()
细心的话会发现上面的例子中有browser.implicitly_wait(30),它的用法应该比time.sleep() 更智能,后者只能选择一个固定的时间的等待,前者可以在一个时间范围内智能的等待。
文档解释:
selenium.webdriver.remote.webdriver.implicitly_wait(time_to_wait)
隐式地等待一个无素被发现或一个命令完成;这个方法每次会话只需要调用一次
time_to_wait: 等待时间
用法:
driver.implicitly_wait(30)
相关文章:
轻松自动化---selenium-webdriver(python) (六)
轻松自动化---selenium-webdriver(python) (八)
作符
主要操作符:+、-、*、/、=、++、--、+=、-=、==、!=、&&、||、!、&、^、~、>=、<=、>、< …..
几乎所有的操作符只能够操作”基本数据类型”,=、==、!=可以操作所有的数据类型及对象
String类型支持+、+=连接操作
优先级问题:
此处注意:任何数据类型与String类型进行+连接都将会先将其他的数据类型转变为String在连接成String类型
而此时的+不再会做任何的计算
demo:
int i = 1;
int j = 2;
System.out.println("result:" + i + j);//result:12
System.out.println("i == j : " + i == j);// ×
System.out.println("i == j : " + (i == j));// √ |
关于赋值操作符:取右边的值(即右值),把它复制给左边(即左值)。右值可以是任何常数、变量、或者表达式(只要它能够生成一个值就行)。但左值必须是一个明确的、已命名的变量,也就是必须有一个物理空间可以存储等号右边的值
基本数据类型赋值:直接将一个地方的值复制到另外一个地方
a = b;//b的内容复制给a,若修改a或b其中的一个值,另外一个值不会受到任何影响
对象赋值:真正操作的是对象的引用,
所以将对象赋值给另外一个对象实际上是将一个对象的引用复制到另外一个地方
它们其实指向的是内存中的同一块内容
demo:ObjectRefrenceTest.java
packagejavabase.flowcontrol;
publicclassObjectRefrenceTest{
/**
*对象赋值测试
*/
publicstaticvoidmain(String[]args){
Rowidrowid=newRowid();
rowid.rowid="LIYIHUIZHANYUANYING";
TiptopERPtopprod=newTiptopERP();
TiptopERPtoptest=newTiptopERP();
topprod.seesionId=0;
topprod.DBType="Oracle";
topprod.rowid=rowid;
toptest=topprod;//对象赋值
System.out.println("Before:");
System.out.println("topprod:"+topprod.seesionId+topprod.DBType+topprod.rowid.rowid);
System.out.println("toptest:"+toptest.seesionId+toptest.DBType+toptest.rowid.rowid);
System.out.println("Afterchangetopprodobject:");
//toptest.DBType="Informix";
topprod.DBType="Informix";
topprod.rowid.rowid="5201314131413141314";//此处改变了topprod.rowid对象的成员变量
System.out.println("topprod:"+topprod.seesionId+topprod.DBType+topprod.rowid.rowid);
System.out.println("toptest:"+toptest.seesionId+toptest.DBType+toptest.rowid.rowid);
System.out.println("-----------------------------");
TiptopERPerp=newTiptopERP();
TiptopERPmrpII=newTiptopERP();
erp.seesionId=2;
erp.DBType="DB2";
erp.rowid=rowid;//此处直接将先前的rowid对象直接赋值给erp.rowid
mrpII.seesionId=erp.seesionId;//对象成员变量int单独赋值
mrpII.DBType=erp.DBType;//对象成员变量String单独赋值
mrpII.rowid=erp.rowid;
System.out.println("Before:");
System.out.println("erp:"+erp.seesionId+erp.DBType+erp.rowid.rowid);
System.out.println("mrpII:"+mrpII.seesionId+mrpII.DBType+mrpII.rowid.rowid);
System.out.println("Afterchangrowid:");
erp.rowid.rowid="LIYIHUIZHANYUANYING";//此处改变了erp.rowid对象的成员变量
System.out.println("erp:"+erp.seesionId+erp.DBType+erp.rowid.rowid);
System.out.println("mrpII:"+mrpII.seesionId+mrpII.DBType+mrpII.rowid.rowid);
System.out.println("Afterchangeerpobject:");
erp.seesionId=1;
erp.DBType="Mysql";
erp.rowid.rowid="5201314131413141314";//此处改变了erp.rowid对象的成员变量
System.out.println("erp:"+erp.seesionId+erp.DBType+erp.rowid.rowid);
System.out.println("mrpII:"+mrpII.seesionId+mrpII.DBType+mrpII.rowid.rowid);
}
}
classTiptopERP{
intseesionId;//基本数据类型
StringDBType;//String对象
Rowidrowid;//一般对象
}
classRowid{
Stringrowid;
}
/*输出结果:
Before:
topprod:0OracleLIYIHUIZHANYUANYING
toptest:0OracleLIYIHUIZHANYUANYING
Afterchangetopprodobject:
topprod:0Informix5201314131413141314//rowid值改变了
toptest:0Informix5201314131413141314//rowid值改变了
-----------------------------
Before:
erp:2DB25201314131413141314//rowid值改变了
mrpII:2DB25201314131413141314//rowid值改变了
Afterchangrowid:
erp:2DB2LIYIHUIZHANYUANYING//rowid值改变了
mrpII:2DB2LIYIHUIZHANYUANYING//rowid值改变了
Afterchangeerpobject:
erp:1Mysql5201314131413141314//rowid值改变了
mrpII:2DB25201314131413141314//rowid值改变了
*/
|
demo:PassObject.java
package javabase.flowcontrol; class Letter{
char c;
}
public class PassObject {
/**
*对象引用
*/
static void f(Letter y){
y.c = 'z';
}
public static void main(String[] args) {
Letter x = new Letter();
x.c = 'a';
System.out.println("before:x.c = " + x.c);
f(x);
System.out.println("after:x.c = " + x.c);
}
}
/*输出结果:
before:x.c = a
after:x.c = z
*/ |
此类对于传递对象引用而引起的问题在Think In Java被称做”别名问题”
使用中应注意此类陷阱
++或--:前缀++/--先运算再生成值,后缀++/--先生成值再运算
==与equals:
比较2个实际值是否相等:对象用equals,基本数据类型用==
比较对象的地址是否相等:对象/基本数据类型都用==
demo:EqualsTest.java
package javabase.flowcontrol; class ValueInt{
int id;
}
class ValueString{
String id;
@Override
public boolean equals(Object obj) {
boolean instanceFlag;
instanceFlag = obj instanceof ValueString;
if(!instanceFlag)
return super.equals(obj);
else{
ValueString vTemp = (ValueString)obj;
if(vTemp.id.equals(this.id)){
return true;
}
return false;
}
}
}
public class EqualsTest {
/**
* ==操作符、equals的区别
*/
public static void main(String[] args) {
//基本数据类型
int i1 = 100;
int i2 = 100;
System.out.println("i1 == i2 : " + (i1 == i2));
//对象
Integer n1 = new Integer(250);
Integer n2 = new Integer(250);
System.out.println("n1 == n2 : " + (n1 == n2));
System.out.println("n1 equals n2 : " + n1.equals(n2));
//自定义对象
ValueInt vInt1 = new ValueInt();
ValueInt vInt2 = new ValueInt();
vInt1.id = vInt2.id = 32;
System.out.println("vInt1 == vInt2 : " + (vInt1 == vInt2));
System.out.println("vInt1 equals vInt2 : " + vInt1.equals(vInt2));
ValueString vString1 = new ValueString();
ValueString vString2 = new ValueString();
vString1.id = vString2.id = "李艺辉";
System.out.println("vString1 == vString2 : " + (vString1 == vString2));
System.out.println("vString1 equals vString2 : " + vString1.equals(vString2));
//String 对象比较复杂,后面会有String对象的详细解析
}
}
/*输出结果:
i1 == i2 : true
n1 == n2 : false
n1 equals n2 : true
vInt1 == vInt2 : false
vInt1 equals vInt2 : false //这是因为equals默认行为是比较2个对象的引用
vString1 == vString2 : false
vString1 equals vString2 : true //复写该对象的equals方法后的比较
*/ |
逻辑操作符:&&、||、!
逻辑操作只可以应用于布尔值,注意逻辑操作的”短路”情况
test(1) && test(2) && test(3) //顺序判断,只要前面有一个test为假后面的判断就不需要执行了
test(1) || test(2) || test(3) //顺序判断,只要前面有一个test为真后面的判断就不需要执行了
按位操作符:位与(&)、位或(|)、位非(~)、
有符号位左移(<<):低位补0
有符号位右移(>>):若符号为正则高位补0,若符号为负则高位补1
无符号位左移(<<<):无论正负低位全部补0
无符号位右移(>>>):无论正负高位全部补0
如果对char、byte、short类型数值进行移位处理,那么在移位之前它们都将先被转换为int类型,
并且得到的结果也是int类型,且移位后的数值结果只有低5位才有用(int类型为2的5次方)
三元操作符:
boolean-exp ? value0 : value1
如果布尔表达式boolean-exp为true则计算value0,否则计算value1
控制执行流程
关键字:Java控制执行流程主要涉及的关键字if-else、while、do-while、for、return、break、continue
Java并不支持goto語句,但是在java中仍然保留了goto
条件判断:所有条件判断都利用条件表达式的真或假来决定执行流程
注意:java不允许将一个数字等非boolean值作为布尔值使用,如果要在布尔测试中使用一个非布尔值则首先必须用一个条件表达式将其转换成布尔值。
Ex:a是非boolean类型值 if(a)×à if(a!=0) √
while:先判断条件表达在执行循环体,条件为false则一次都不执行
do-while:先执行循环体,再判断条件表达式,因此至少会执行一次
for语句:for(int i = 1, j = 5;i < 5;i++,j = i+2)
for语句初始化部分实际上可以定义任意数量的变量,注意:但是这些变量都必须是同一种数据类型
for语句中可以使用一系列有逗号表达式分隔的语句
增强行的for循环:for(char c : “hello world”.toCharArray())
如果for循环有索引或是步进,则上述增强行的for循环不能够直接满足需求
Think in java 建议自写一个range()方法配合增强型的for循环
import static net.mindview.util.range.* //此包需从www.mindview.com上下载
Ex:for(int i : range(10)) //range(10)返回数组,元素为0..9
for(int i : range(5,10)) //range(5,10)返回数组,元素为5..9
for(int i : range(5,10,3)) //range(5,10,3)返回数组,元素为5..10 step 3
while(true) = for(;;)
switch .. case...break语句:
switch(integral-selector) //integral-selector:选择因子必需是int或是char那样的整数值
case integral-value1:statement:break;
//
Default:statement; |
单一case satatement后面需有break,避免case穿透到下一case statement
return:指定一个方法的返回值,并退出该方法。
如果一个方法声明有非void的返回值,那么必须确保每一条代码路径都将返回一个值
break:终止当前循环体
continue:停止循环体的当前迭代,然后退回循环起始处,开始下一次迭代
goto:虽然java不再使用goto语句,但是依然保留了goto作为关键字
在java中如果想实现goto一样跳转语句的功能可以使用标签编程
请看如下demo:GotoLabel.java
package javabase.flowcontrol; public class GotoLabel {
/**
*java标签编程应用
*/
public static void main(String[] args) {
int i = 0;
outer: //此处不可以写其它的任何代码
//System.out.println("outer man!");
for(;true;){
inner: //此处不可以写其它的任何代码
//System.out.println("innter man!");
for(;i<10;i++){
System.out.println("i = " + i);
if(i == 2){
System.out.println("continue");
continue;
}
if(i == 3){
System.out.println("break");
i++;
break;
}
if(i == 7){
System.out.println("continue outer");
i++;
continue outer;
}
if(i == 8){
System.out.println("break outer");
break outer;
}
for(int k = 0; k < 5; k++){
if(k == 3){
System.out.println("continue inner");
continue inner;
}
}
}
System.out.println("hello world");
}
System.out.println("fuck in java");
}
}
/*输出结果:
i = 0
continue inner
i = 1
continue inner
i = 2
continue
i = 3
break
hello world
i = 4
continue inner
i = 5
continue inner
i = 6
continue inner
i = 7
continue outer
i = 8
break outer
fuck in java
*/ |
一般的continue会退回最内层循环的开头,并继续执行
带标签的continue会到达标签的位置,并重新进入紧接在那个标签后面的循环
一般的break会中断并跳出当前的循环体
带标签的break会中断并跳出标签所指的循环
1 、确定数据库的sid 和db_name
sid='hsj'
db_name='hsj'
2、设置环境变量env
ORACLE_BASE=/u01/app
ORACLE_HOME=$ORACLE_BASE/oracle
ORACLE_SID=hsj
PATH=$ORACLE_HOEM/bin:$PATH;
LD_LIBRARY_PATH=$ORACLE_HOME/lib:$LD_LIBRARY_PATH
export ORACLE_BASE ORACLE_HOME ORACLE_SID PATH LD_LIBRARY_PATH |
3、设置登录方法,使用操作系统登录还是远程登录
使用本地操作系统用户,具有dba权限的oracle用户
sqlplus /nolog
conn as sysdba;
4、创建一个使用的pfile文件
vi inithsj.ora
hsj.__db_cache_size=385875968
hsj.__java_pool_size=4194304
hsj.__large_pool_size=4194304
hsj.__shared_pool_size=163577856
hsj.__streams_pool_size=0
audit_file_dest='/u01/app/admin/hsj/adump'
background_dump_dest='/u01/app/admin/hsj/bdump'
compatible='10.2.0.1.0'
control_files='/u01/app/oradata/hsj/control01.ctl','/u01/app/oradata/hsj/control02.ctl','/u01/app/oradata/hsj/control03.ctl'
core_dump_dest='/u01/app/admin/hsj/cdump'
db_block_size=8192
db_domain=''
db_file_multiblock_read_count=16
db_name='hsj'
db_recovery_file_dest='/u01/app/flash_recovery_area'
db_recovery_file_dest_size=2147483648
dispatchers='(PROTOCOL=TCP) (SERVICE=hsjXDB)'
job_queue_processes=10
log_archive_format='%t_%s_%r.dbf'
open_cursors=300
pga_aggregate_target=187695104
processes=150
remote_login_passwordfile='EXCLUSIVE'
sga_target=563085312
undo_management='AUTO'
undo_tablespace='UNDOTBS1'
user_dump_dest='/u01/app/admin/hsj/udump' |
5、根据pfile文件创建想对应的目录
需要在$ORACLE_BASE/admin 下创建一个目录 hsj及其相关的子目录
$ORACLE_BASE/oradate 下面增加一个目录 hsj 及其子目录 archivelog
6、根据pfile文件创建spfile
startup nomount;
create spfile from pfile;
shutdown immediate;
7、在$ORACLE_HOME/dbs/ 下创建 orapwhsj
orapwd file=orapwhsj password=root entries=5
8、使用spfile启动数据库到nomount状态
startup up nomount
9、使用脚本创建数据库
spool db.log;
CREATE DATABASE "hsj"
USER SYS IDENTIFIED BY root
USER SYSTEM IDENTIFIED BY root
MAXDATAFILES 500
MAXINSTANCES 8
MAXLOGFILES 32
CHARACTER SET "UTF8"
NATIONAL CHARACTER SET AL16UTF16
ARCHIVELOG
DATAFILE '/u01/app/oradata/hsj/system01.dbf' size 300M
EXTENT MANAGEMENT LOCAL
SYSAUX DATAFILE '/u01/app/oradata/hsj/sysaux01.dbf' SIZE 325M REUSE
DEFAULT TEMPORARY TABLESPACE temp TEMPFILE '/u01/app/oradata/hsj/tempts01.dbf' SIZE 100M
EXTENT MANAGEMENT LOCAL
UNDO TABLESPACE "UNDOTBS1"
DATAFILE '/u01/app/oradata/hsj/undotbs01.dbf' SIZE 200M
LOGFILE
GROUP 1 (
'/u01/app/oradata/hsj/redo01a.rdo',
'/u01/app/oradata/hsj/redo01b.rdo'
) SIZE 100M,
GROUP 2 (
'/u01/app/oradata/hsj/redo02a.rdo',
'/u01/app/oradata/hsj/redo02b.rdo'
) SIZE 100M,
GROUP 3 (
'/u01/app/oradata/hsj/redo03a.rdo',
'/u01/app/oradata/hsj/redo03b.rdo'
) SIZE 100M
;
spool off; |
10 运行脚本创建数据字典
@ORACLE_HOME/admin/catalog.sql(@/u01/app/oracle/admin/catalog.sql)
@ORACLE_HOME/admin/catproc.sql(@/u01/app/oracle/admin/catproc.sql)
11 启动数据库
startup
12 备份数据库
backup database
如果不指定测试用例的执行顺序,默认是按字典的顺序执行。如果要指定执行的顺序,可以通过testng.xml文件来指定。
<?xml version="1.0" encoding="UTF-8"?>
<suite name="Suite" parallel="false">
<test name="Demo" >
<classes>
<class name="com.test.Demo">
<methods preserve-order="true">
<include name="login" />
<include name="addItem" />
<include name="updateItem" />
<include name="deleteItem" />
<include name="logout" />
</methods>
</class>
</classes>
</test>
</suite> |
设置好xml文件后,对testng.xml右键,选择RunAs->TestNG Suite
执行结果
[TestNG] Running:
C:\Users\zhangyj\workspace\Demo\src\testng.xml
BeforeClass初始化。。。
login开始执行
addItem开始执行
updateItem开始执行
deleteItem开始执行
logout开始执行
AfterClass销毁中。。。
===============================================
Suite
Total tests run: 5, Failures: 0, Skips: 0
===============================================
1. Test::Unit框架
Test::Unit框架基本上是将3个功能包装到一个整洁的包中:
1) 它提供了一种表示单个测试的方式。
2) 它提供了一个框架来组织测试。
3) 它提供了灵活的方式来调用测试。
Test::Unit提供一系列断言来达到与if语句相同的目标,虽然存在许多不同风格的断言,但是它们基本上都遵循相同的模式,例如:
require 'test/unit'
Class TestBug < Test::Unit::TestCase
def test_simple
assert_equal('ok', MyClass.new(1).to_s)
assert_equal('error', MyClass.new(2).to_s)
end
end |
还可以测试是否引发异常,例如:
require 'test/unit'
Class TestBug < Test::Unit::TestCase
def test_raise
assert_raise(RuntimeError) {MyClass.new('null')}
assert_nothing_raised() {MyClass.new('normal')}
end
end |
2. 组织测试
单元测试,可以被组织成更高层的形式,叫做测试用例,或分解成较底层的形式,也就是测试方法。测试用例通常包括和某个特定功能或特性相关的所有测试。
表示测试的类必须是Test::Unit::TestCase的子类。含有断言的方法名必须以test开头。Test::Unit使用反射来查找要运行的测试,而只有以test开头的方法才符合条件。
可以把通用的一些代码提取到setup和teardown方法中。在一个TestCase类中,一个叫做setup的方法将在每个测试方法之前运行,而叫做teardown的方法在每个测试方法结束之后运行,例如:
require 'test/unit'
require 'dbi'
Class TestDB < Test::Unit::TestCase
def setup
@db = DBI.connetct('DBI:mysql:playlists')
end
def test_count
assert_equal('10', MyClass.new(1).get_count)
end
def teardown
@db.disconnect
end
end |
1、测试人员必顺熟悉软件开发流程
软件测试需熟悉软件开发流程,重点掌握软件测试本身部分过程以及测试与各个阶段的接口,有哪些文档需要编写,编写的内容是什么。其它方面不需要很多细节都了解,那是QA和EPG的事。
2、测试人员必顺熟悉产品所涉及的业务
测试人员主要的测试还是功能测试,那怎么做好功能测试,在仔细、耐心的基础上还需要精通产品的业务。实际是往往项目组中的培训往不够的,我个人的经验是如果有条件能够参加需求调研的话是最好的。如果是产品化的产品有机会的最好去工程实施的一两次。
3、测试人员技术的要求
测试技术的要求我就不多说了,大家关心的可能是开发工具,我个人认为测试人员必须精通一门比较大众化语言,如C、或JAVA,否则在测试驱动化测试时,就需要开发人员协助。以前我碰到这么一个需求“在个用户同时操作,一个用户插入十万条数据、一个用户UPDATE十万条数据,一个用户删除十万条数据”如果我们自己不能写点小程序,是很受制于人。还有必须对自己项目所使用的开发工具有所了解,要做到能安装、搭建、编译、调试问题(能找到错误点)。
4、测试人员对于工具
现在网上测试工具很多,我看了很多人天天在说,学哪种好。我是根据测试不同需求去选一种比较大众化,适何目前情况的工具,比如果我就划分三种:测试管理、功能测试、性能测试。根据这三种去找适何的工具,学习并应用到项目里。
1.计算机专业技能计算机领域的专业技能是测试工程师应该必备的一项素质,是做好测试工作的前提条件。尽管没有任何IT背景的人也可以从事测试工作,但是一名要想获得更大发展空间或者持久竞争力的测试工程师,则计算机专业技能是必不可少的。
计算机专业技能主要包含三个方面:
1)测试专业技能现在软件测试已经成为一个很有潜力的专业。要想成为一名优秀的测试工程师,首先应该具有扎实的专业基础,这也是本书的编写目的之一。因此,测试工程师应该努力学习测试专业知识,告别简单的“点击”之类的测试工作,让测试工作以自己的专业知识为依托。测试专业知识很多,本书内容主要以测试人员应该掌握的基础专业技能为主。测试专业技能涉及的范围很广:既包括黑盒测试、白盒测试、测试用例设计等基础测试技术,也包括单元测试、功能测试、集成测试、系统测试、性能测试等测试方法,还包括基础的测试流程管理、缺陷管理、自动化测试技术等知识。
2)软件编程技能“测试人员是否需要编程?”可以说是测试人员最常提出的问题之一。实际上,由于在我国开发人员待遇普遍高于测试人员,因此能写代码的几乎都去做开发了,而很多人则是因为做不了开发或者不能从事其它工作才“被迫”从事测试工作。最终的结果则是很多测试人员只能从事相对简单的功能测试,能力强一点的则可以借助测试工具进行简单的自动化测试(主要录制、修改、回放测试脚本)。软件编程技能实际应该是测试人员的必备技能之一,在微软,很多测试人员都拥有多年的开发经验。因此,测试人员要想得到较好的职业发展,必须能够编写程序。只有能给编写程序,才可以胜任诸如单元测试、集成测试、性能测试等难度较大的测试工作。此外,对软件测试人员的编程技能要求也有别于开发人员:测试人员编写的程序应着眼于运行正确,同时兼顾高效率,尤其体现在与性能测试相关的测试代码编写上。因此测试人员要具备一定的算法设计能力。依据作者的经验,测试工程师至少应该掌握Java、C#、C++之类的一门语言以及相应的开发工具。
3)网络、操作系统、数据库、中间件等知识:与开发人员相比,测试人员掌握的知识具有“博而不精”的特点,“艺多不压身”是个非常形象的比喻。由于测试中经常需要配置、调试各种测试环境,而且在性能测试中还要对各种系统平台进行分析与调优,因此测试人员需要掌握更多网络、操作系统、数据库等知识。在网络方面,测试人员应该掌握基本的网络协议以及网络工作原理,尤其要掌握一些网络环境的配置,这些都是测试工作中经常遇到的知识。操作系统和中间件方面,应该掌握基本的使用以及安装、配置等。例如很多应用系统都是基于Unix、linux来运行的,这就要求测试人员掌握基本的操作命令以及相关的工具软件。而WebLogic、Websphere等中间件的安装、配置很多时候也需要掌握一些。数据库知识则是更应该掌握技能,现在的应用系统几乎离不开数据库。因此不但要掌握基本的安装、配置,还要掌握SQL。测试人员至少应该掌握Mysql、MS Sqlserver、Oracle等常见数据库的使用。作为一名测试人员,尽管不能精通所有的知识,但要想做好测试工作,应该尽可能地去学习更多的与测试工作相关的知识。
2.行业知识行业主要指测试人员所在企业涉及的行业领域,例如很多IT企业从事石油、电信、银行、电子政务、电子商务等行业领域的产品开发。行业知识即业务知识,是测试人员做好测试工作的又一个前提条件,只有深入地了解了产品的业务流程,才可以判断出开发人员实现的产品功能是否正确。很多时候,软件运行起来没有异常,但是功能不一定正确。只有掌握了相关的行业知识,才可以判断出用户的业务需求是否得到了实现。行业知识与工作经验有一定关系,通过时间即可以完成积累。
3.个人素养作为一名优秀的测试工程师,首先要对测试工作有兴趣:测试工作很多时候都是显得有些枯燥的,因此热爱测试工作,才更容易做好测试工作。因此,除了具有前面的专业技能和行业知识外,测试人员应该具有一些基本的个人素养,即下面的“五心”。
专心:主要指测试人员在执行测试任务的时候要专心,不可一心二用。经验表明,高度集中精神不但能够提高效率,还能发现更多的软件缺陷,业绩最棒的往往是团队中做事精力最集中的那些成员。
细心:主要指执行测试工作时候要细心,认真执行测试,不可以忽略一些细节。某些缺陷如果不细心很难发现,例如一些界面的样式、文字等。
耐心:很多测试工作有时候显得非常枯燥,需要很大的耐心才可以做好。如果比较浮躁,就不会做到“专心”和“细心”,这将让很多软件缺陷从你眼前逃过。
责任心:责任心是做好工作必备的素质之一,测试工程师更应该将其发扬光大。如果测试中没有尽到责任,甚至敷衍了事,这将会把测试工作交给用户来完成,很可能引起非常严重的后果。
自信心:自信心是现在多数测试工程师都缺少的一项素质,尤其在面对需要编写测试代码等工作的时候,往往认为自己做不到。要想获得更好的职业发展,测试工程师们应该努力学习,建立能“解决一切测试问题”的信心。
“五心”只是做好测试工作的基本要求,测试人员应该具有的素质还很多。例如测试人员不但要具有团队合作精神,而且应该学会宽容待人,学会去理解“开发人员”,同时要尊重开发人员的劳动成果——开发出来的产品。案例:测试人员首先要学会尊重自己软件测试人员首先应该尊重自己的劳动成果——软件缺陷报告。
我见过很多测试人员都不能清晰地描述一个软件缺陷,尤其分不清缺陷跟踪系统中Summary和Description的区别,例如图2-2中的软件缺陷描述——Summary和Description中就输入了完全一样的内容。严格的讲,Summary通常用于概要性地描述软件缺陷内容或者发生问题时的现象,主要用于项目经理进行缺陷分配,因此要用最简短、精悍的语言来描述是什么缺陷,使项目经理很快明白是什么问题、应该分配给哪个开发人员;而Description则用来描述缺陷的详细信息,通常描述缺陷的重现步骤,主要供开发人员修改缺陷时候查看。图2-3就是一个非常规范的软件缺陷描述。软件缺陷报告是测试人员最直接的劳动成果,因此应该认真地描述自己所提交的每一个软件缺陷,这也是尊重自己劳动成果的一种表现。缺陷描述不清晰,不但将会增加沟通成本,更重要的是不会得到开发人员的认可与尊重。测试人员在为开发人员的成果——产品找问题的同时,也要保证自己的成果没有问题。因此,作为测试人员首先要学会清晰、准确地报告一个缺陷,这将是与开发人员互相赢得对方尊重的开端,也是尊重自己的表现。试想,如果自己都不爱惜自己的劳动成果,那别人如何会尊重你的成果呢?
ab的全称是ApacheBench,是 Apache 附带的一个小工具,专门用于 HTTP Server 的benchmark testing,可以同时模拟多个并发请求。这个小工具在apache的bin目录下面,但是每次使用都要先跳到该目录下,为了能够直接在cmd下使用,可以讲ab.exe这个文件移到C:\WINDOWS\system32路径下,这样每次使用就很方便了。
loadrunner用的好好的为什么要研究这个ab呢?我给我自己的理由是:
1.ab是开源的,很多大公司都喜欢开源的因为loadrunner太贵了,所以想成为一个性能测试高手必须要懂几个开源的性能测试工具,个人意见;
2.ab这个工具小巧使用并且很简单,上手快学习起来比较简单,而loadrunner相比起来就太复杂了,脚本开发抛开不说,就loadrunner这个工具就够学上个一个月的。
3.ab虽然很小,但是功能还是 很强大的,提供的数据足够我们使用了,其实loadrunner中虽然提供了很多功能,但是我们用能使用多少呢,性能监控这块,我 基本不用全部都是第三方监控或者linux命令,loadrunner中给出的很多指标对我们很有用的也就是1、事物的响应时间 2、事物的成功率 3、系统的吞吐量 3、在单位时间内完成的事物数这些ab基本上都可以实现。
4.如果遇到临时任务或者很简单的一个测试,可以这么说吧,开发写了一个接口让你帮他看一下性能如何,只需大概,正好你有没有loadrunner安装包,那怎么办呢,其他不说就下个loadrunner安装包估计就让开发等的不耐烦了,使用ab就不一样了很快就可以给他结果;
总而言之2者各有特点,如果做大项目,逻辑关系比较复杂的项目ab就无能为力了,所以做为一名性能测试人员就必须掌握2~3种性能测试工具,不同情况下可以使用不同的测试工具。
说了这么对废话,咱们下面就看一看这块小巧的性能测试工具吧:
我们在使用一个新工具之前当然首先看的帮助文档了,那下面我们就看看ab这个工具的帮助文档:
-n requests Number of requests to perform
//在测试会话中所执行的请求个数。默认时,仅执行一个请求
-c concurrency Number of multiple requests to make
//一次产生的请求个数。默认是一次一个。
-t timelimit Seconds to max. wait for responses
//测试所进行的最大秒数。其内部隐含值是-n 50000。它可以使对服务器的测试限制在一个固定的总时间以内。默认时,没有时间限制。
-p postfile File containing data to POST
//包含了需要POST的数据的文件.
-T content-type Content-type header for POSTing
//POST数据所使用的Content-type头信息。
-v verbosity How much troubleshooting info to print
//设置显示信息的详细程度 - 4或更大值会显示头信息, 3或更大值可以显示响应代码(404, 200等), 2或更大值可以显示警告和其他信息。 -V 显示版本号并退出。
-w Print out results in HTML tables
//以HTML表的格式输出结果。默认时,它是白色背景的两列宽度的一张表。
-i Use HEAD instead of GET
// 执行HEAD请求,而不是GET。
-x attributes String to insert as table attributes
//
-y attributes String to insert as tr attributes
//
-z attributes String to insert as td or th attributes
//
-C attribute Add cookie, eg. 'Apache=1234. (repeatable)
//-C cookie-name=value 对请求附加一个Cookie:行。 其典型形式是name=value的一个参数对。此参数可以重复。
-H attribute Add Arbitrary header line, eg. 'Accept-Encoding: gzip'
Inserted after all normal header lines. (repeatable)
-A attribute Add Basic WWW Authentication, the attributes
are a colon separated username and password.
-P attribute Add Basic Proxy Authentication, the attributes
are a colon separated username and password.
//-P proxy-auth-username:password 对一个中转代理提供BASIC认证信任。用户名和密码由一个:隔开,并以base64编码形式发送。无论服务器是否需要(即, 是否发送了401认证需求代码),此字符串都会被发送。
-X proxy:port Proxyserver and port number to use
-V Print version number and exit
-k Use HTTP KeepAlive feature
-d Do not show percentiles served table.
-S Do not show confidence estimators and warnings.
-g filename Output collected data to gnuplot format file.
-e filename Output CSV file with percentages served
-h Display usage information (this message)
|
下面是一个很简单的例子:
ab -n 100 -c 10 http://www.baidu.com/
向百度发送100个请求,以10个并发用户同时进行,这就模拟了loadrunner中的并发用户了
his is ApacheBench, Version 2.0.41-dev <$Revision: 1.121.2.12 $> apache-2.0
Copyright (c) 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Copyright (c) 2006 The Apache Software Foundation, http://www.apache.org/
Benchmarking www.baidu.com (be patient).....done
Server Software: BWS/1.0 //被测试平台使用的web服务器
Server Hostname: www.baidu.com
//服务器主机名
Server Port: 80
//服务器端口号
Document Path: /
//测试的页面的路径,这是在根目录下
Document Length: 7677 bytes
//测试的页面的大小
Concurrency Level: 10 //并发数
Time taken for tests: 9.187500 seconds //整个测试持续的时间
Complete requests: 100 //总共完成的请求数
Failed requests: 0 //失败的请求数量
Write errors: 0
Total transferred: 805879 bytes //整个场景中的网络传输量
HTML transferred: 767700 bytes//整个场景中的HTML内容传输量
Requests per second: 10.88 [#/sec] (mean)//大家最关心的指标之一,相当于 LR 中的 每秒事务数 ,后面括号中的 mean 表示这是一个平均值
Time per request: 918.750 [ms] (mean)//大家最关心的指标之二,相当于 LR 中的 平均事务响应时间 ,后面括号中的 mean 表示这是一个平均值
Time per request: 91.875 [ms] (mean, across all concurrent requests)//每个请求实际运行时间的平均值
Transfer rate: 85.55 [Kbytes/sec] received//平均每秒网络上的流量,可以帮助排除是否存在网络流量过大导致响应时间延长的问题
Connection Times (ms)
min mean[+/-sd] median max
Connect: 15 90 76.4 62 343
Processing: 47 792 277.9 844 1265
Waiting: 15 434 285.2 406 1203
Total: 93 883 296.5 937 1390 //网络上消耗的时间的分解,相当于loadrunner中的网页细分图
Percentage of the requests served within a certain time (ms)
50% 937
66% 1000
75% 1078
80% 1140
90% 1218
95% 1250
98% 1312
99% 1390
100% 1390 (longest request) |
//整个场景中所有请求的响应情况。在场景中每个请求都有一个响应时间,其中50%的用户响应时间小于937 毫秒,60% 的用户响应时间小于1000 毫秒,最大的响应时间小于1390 毫秒
由于对于并发请求,cpu实际上并不是同时处理的,而是按照每个请求获得的时间片逐个轮转处理的,所以基本上第一个Time per request时间约等于第二个Time per request时间乘以并发请求数
本节知识点:
操作对象:
· click 点击对象
· send_keys 在对象上模拟按键输入
· clear 清除对象的内容,如果可以的话
WebElement 另一些常用方法:
· text 获取该元素的文本
· submit 提交表单
· get_attribute 获得属性值
======================================
操作测试对象
前面讲到了不少知识都是定位元素,定位只是第一步,定位之后需要对这个原素进行操作。
鼠标点击呢还是键盘输入,这要取决于我们定位的是按钮还输入框。
一般来说,webdriver中比较常用的操作对象的方法有下面几个
· click 点击对象
· send_keys 在对象上模拟按键输入
· clear 清除对象的内容,如果可以的话
在我们本系列开篇的第一个例子里就用到了到click 和send_skys ,别翻回去找了,我再贴一下代码:
# coding = utf-8
from selenium import webdriver browser = webdriver.Firefox() browser.get(http://www.baidu.com)
browser.find_element_by_id("kw").clear()
browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
browser.quit()
|
send_keys("XX") 用于在一个输入框里输入内容。
click() 用于点击一个按钮。
clear() 用于清除输入框的内容,比如百度输入框里默认有个“请输入关键字”的信息,再比如我们的登陆框一般默认会有“账号”“密码”这样的默认信息。clear可以帮助我们清除这些信息。
WebElement 另一些常用方法:
· text 获取该元素的文本
· submit 提交表单
· get_attribute 获得属性值
text
用于获取元素的文本信息
下面把百度首页底部的声明打印输出
#coding=utf-8
from selenium import webdriver import time driver = webdriver.Firefox()
driver.get(http://www.baidu.com)
time.sleep(2) #id = cp 元素的文本信息
data=driver.find_element_by_id("cp").text
print data #打印信息 time.sleep(3)
driver.quit() |
输出:
>>>
2013 Baidu 使用百度前必读 京ICP证030173号
submit
提交表单
我们把“百度一下”的操作从click 换成submit :
#coding=utf-8
from selenium import webdriver import time driver = webdriver.Firefox()
driver.get(http://www.baidu.com) driver.find_element_by_id("kw").send_keys("selenium")
time.sleep(2)
#通过submit() 来操作
driver.find_element_by_id("su").submit() time.sleep(3)
driver.quit() |
这里用submit 与click的效果一样,我暂时还没想到只能用submit 不能用click的场景。他们之间到底有啥区别,知道的同学请留言告诉我。
get_attribute
获得属性值。
这个函数的用法前面已经有出现过,在定位一组元素的时候有使用到它,只是我们没有做过多的解释。
一般用法:
select = driver.find_element_by_tag_name("select") allOptions = select.find_elements_by_tag_name("option") for option in allOptions: print "Value is: " + option.get_attribute("value") option.click() |
具体应用参考:
定位一组元素:http://www.cnblogs.com/fnng/p/3190966.html
小结:
学到这里我们是不是已经撑握了不少知识,简单的操作浏览器,定位元素,操作元素以及打印一些信息。其实,我们前面的学习中大多使用的是WebElement 里的方法。
WebElement的方法:
一般来说,所有有趣的操作与页面进行交互的有趣的操作,都通过 WebElement 完成
classselenium.webdriver.remote.webelement.WebElement(parent, id_)
这个类代表HTML页面元素
id_ #当前元素的ID tag_name #获取元素标签名的属性 text #获取该元素的文本。 click() #单击(点击)元素 submit() #提交表单 clear() #清除一个文本输入元素的文本 get_attribute(name) #获得属性值 s_selected(self) #元素是否被选择 Whether the element is selected. is_enabled() #元素是否被启用 find_element_by_id(id_) find_elements_by_id(id_) #查找元素的id find_element_by_name(name) find_elements_by_name(name) #查找元素的name find_element_by_link_text(link_text) find_elements_by_link_text(link_text) #查找元素的链接文本 find_element_by_partial_link_text(link_text) find_elements_by_partial_link_text(link_text) #查找元素的链接的部分文本 find_element_by_tag_name(name) find_elements_by_tag_name(name) #查找元素的标签名 find_element_by_xpath(xpath) #查找元素的xpath find_elements_by_xpath(xpath) #查找元素内的子元素的xpath find_element_by_class_name(name) #查找一个元素的类名 find_elements_by_class_name(name) #查找元素的类名 find_element_by_css_selector(css_selector) #查找并返回一个元素的CSS 选择器 find_elements_by_css_selector(css_selector) #查找并返回多个元素的CSS 选择器列表 send_keys(*value) #模拟输入元素 |
相关文章:
轻松自动化---selenium-webdriver(python) (五)
轻松自动化---selenium-webdriver(python) (七)
如果测试用例间有依赖性,也就是如果想执行B,就必须要先执行A。那么用例的执行顺序就很关键,如何来指定用例的顺序呢,有这样几种方法:
1. 给用例加编号:
public void test01Login(){
XXX
}
public void test02Add(){
XXX
}
public void test03Delete(){
XXX
} |
2. 加上关键字
硬依赖的例子:
@Test
public void serverStartedOk() {}
@Test(dependsOnMethods = { "serverStartedOk" })
public void method1() {} |
此例中,method1() 依赖于方法 serverStartedOk(),从而保证
serverStartedOk() 总是先运行。
public class Demo1 {
WebDriver driver;
@BeforeClass
public void beforeClass() {
System.setProperty("webdriver.ie.driver","E:\\WebDriver\\IEDriverServer.exe");
driver = new InternetExplorerDriver();
}
//登录博客
@Test
public void login() throws InterruptedException {
System.out.println("login开始执行了");
driver.get(http://blog.ifeng.com);
driver.findElement(By.id("username")).sendKeys("itest20");
driver.findElement(By.id("password")).sendKeys("123456");
driver.findElement(By.xpath("//input[@value='登录']")).click();
driver.navigate().refresh();
}
//验证标题是否为空
@Test(dependsOnMethods = { "login" })
public void noSubject() throws InterruptedException{
System.out.println("noSubject开始执行了");
driver.get(http://blog.ifeng.com);
String originalHandle = driver.getWindowHandle();
driver.findElement(By.linkText("发表博文")).click();
for(String winHandle: driver.getWindowHandles()){
if(winHandle!=originalHandle)
driver.switchTo().window(winHandle);
driver.manage().window().maximize();
}
Thread.sleep(2000);
Assert.assertTrue(FindElement.isElementExist(driver, By.id("saveArticle")));
driver.findElement(By.id("saveArticle")).click();
//判断当标题为空时提示是否正确
boolean expected = true;
boolean actual = (driver.findElement(By.id("blog_tishi")).getText()).endsWith("请填写文章标题");
Assert.assertEquals(actual, expected, "标题为空");
Thread.sleep(3000);
}
//验证内容是否为空
@Test(dependsOnMethods = { "noSubject" })
public void noContent() throws InterruptedException{
System.out.println("noContent开始执行了"); |
本节要解决的问题:
层级定位
场景:
假如两个控件,他们长的一模样,还都叫“张三”,唯一的不同是一个在北京,一个在上海,那我们就可以通过,他们的城市,区,街道,来找到他们。
在实际的测试中也经常会遇到这种问题:页面上有很多个属性基本相同的元素,现在需要具体定位到其中的一个。由于属性基本相当,所以在定位的时候会有些麻烦,这时候就需要用到层级定位。先定位父元素,然后再通过父元素定位子孙元素。
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<title>Level Locate</title>
<script type="text/javascript" async="" src="http://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js"></script>
<link href=http://netdna.bootstrapcdn.com/twitter-bootstrap/2.3.2/css/bootstrap-combined.min.css rel="stylesheet" />
</head>
<body>
<h3>Level locate</h3>
<div class="span3">
<div class="well">
<div class="dropdown">
<a class="dropdown-toggle" data-toggle="dropdown" href="#">Link1</a>
<ul class="dropdown-menu" role="menu" aria-labelledby="dLabel" id="dropdown1" >
<li><a tabindex="-1" href="#">Action</a></li>
<li><a tabindex="-1" href="#">Another action</a></li>
<li><a tabindex="-1" href="#">Something else here</a></li>
<li class="divider"></li>
<li><a tabindex="-1" href="#">Separated link</a></li>
</ul>
</div>
</div>
</div>
<div class="span3">
<div class="well">
<div class="dropdown">
<a class="dropdown-toggle" data-toggle="dropdown" href="#">Link2</a>
<ul class="dropdown-menu" role="menu" aria-labelledby="dLabel" >
<li><a tabindex="-1" href="#">Action</a></li>
<li><a tabindex="-1" href="#">Another action</a></li>
<li><a tabindex="-1" href="#">Something else here</a></li>
<li class="divider"></li>
<li><a tabindex="-1" href="#">Separated link</a></li>
</ul>
</div>
</div>
</div>
</body>
<script src="http://netdna.bootstrapcdn.com/twitter-bootstrap/2.3.2/js/bootstrap.min.js"></script>
</html> |
将这段代码保存复制到记事本中,将保存成level_locate.html文件,(注意,这个页面需要和我们的自动化脚本放在同一个目录下)浏览器打开:

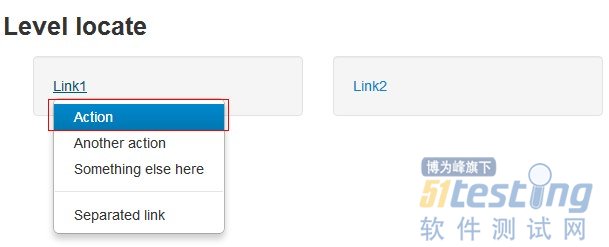
这里自制了一个页面,上面有两个文字链接,点击两个链接会弹出一模一样的的两个下拉菜单,这两个菜单的属性基本一样。那么我如何区分找到相应的菜单项呢?
方法如下:
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
import time
import os dr = webdriver.Firefox()
file_path = 'file:///' + os.path.abspath('level_locate.html')
dr.get(file_path) #点击Link1链接(弹出下拉列表)
dr.find_element_by_link_text('Link1').click() #找到id 为dropdown1的父元素
WebDriverWait(dr, 10).until(lambda the_driver: the_driver.find_element_by_id('dropdown1').is_displayed())
#在父亲元件下找到link为Action的子元素
menu = dr.find_element_by_id('dropdown1').find_element_by_link_text('Action') #鼠标定位到子元素上
webdriver.ActionChains(dr).move_to_element(menu).perform() time.sleep(2) dr.quit() |
定位思路:
具体思路是:先点击显示出1个下拉菜单,然后再定位到该下拉菜单所在的ul,再定位这个ul下的某个具体的link。在这里,我们定位第1个下拉菜单中的Action这个选项。
---------------------------------------------------------------------
虽然我每行代码前叫了注释,但可能还是不太容易理解,因为里面多了不少以前没见过的新东东。
WebDriverWait(dr, 10)
10秒内每隔500毫秒扫描1次页面变化,当出现指定的元素后结束。dr就不解释了,前面操作webdriver.firefox()的句柄
is_displayed()
该元素是否用户可以见
class ActionChains(driver)
driver: 执行用户操作实例webdriver
生成用户的行为。所有的行动都存储在actionchains对象。通过perform()存储的行为。
move_to_element(menu)
移动鼠标到一个元素中,menu上面已经定义了他所指向的哪一个元素
to_element:元件移动到
perform()
执行所有存储的行为
------------------------------需要我们日常工作中细细品味、慢慢消化这些函数的用法
其实,啰嗦了这么多,我们只是想达到一种效果,“下拉列表中Action选项处于被选中状态”,通过鼠标移动到选项上就达到到了这种效果,但通过程序模拟确实比较麻烦:
--------------------------
相关文章:
轻松自动化---selenium-webdriver(python) (四)
轻松自动化---selenium-webdriver(python) (六)