摘要:
在WEB应用程序的软件测试中,安全测试是非常重要的一部分,但常常容易被忽视掉。在安全测试中,防止SQL注入攻击尤其重要。本文介绍了SQL注入攻击产生的后果以及如何进行测试。
关键字:安全测试 SQL 注入攻击 防火墙
正文:
WEB应用程序的安全测试,防止SQL注入攻击,下面举一些简单的例子加以解释。——Inder P Singh。
许多应用程序运用了某一类型的数据库。测试下的应用程序有一个接受用户输入的用户界面,这些输入值用来执行下列任务。
给用户显示相关的存储数据。例如,程序通过用户输入的登录信息检查用户凭证(权限),从而只显示相关的功能和数据。
将用户输入的数据存储到数据库中。例如,用户填写了一张表格并提交,程序立即将之存储到数据库中;从而,用户可以在本次会话和下次会话中获取这些数据。
一些用户输入值可能会被接下来程序将执行的SQL语句运用到,而程序有可能不会正确执行用户输入的值。如果是这样的话,蓄意用户可以向程序提供非法数据,这些数据接下来被运用到框架中并且用来在数据库中执行SQL语句。这就是SQL注入。该行为的结果令人鸣起警钟。
SQL注入可能导致以下结果:
用户可以以另一用户的身份登录到程序,甚至是管理员的身份。
用户可以看到其他用户的隐私信息,如其他用户的简介细节,交易细节。
用户可以修改应用程序配置信息以及其他用户的数据。
用户可以修改数据库的结构,甚至是删除应用数据库中的表格。
用户可以控制数据库服务器并且按照自己意愿随意执行命令。
因为允许SQL注入的结果是相当严重的,所以在应用程序的安全测试阶段应对SQL注入进行测试。通过对SQL注入技术有一个总体的概括,让我们来理解一些SQL注入的实际例子!
重点:SQL注入问题只能在测试环境中测试
若应用程序页面有登录功能,程序有可能使用如下所示的动态SQL语句。这条语句本应从用户表中返回至少一条用户详细信息作为结果,当SQL语句中含有输入的用户名和密码时。
| SELECT * FROM Users WHERE User_Name = ‘” & strUserName & “‘ AND Password = ‘” & strPassword & “’;” |
如果测试人员输入John作为用户名(用户名文本框),输入Smith作为密码(密码文本框),上述SQL语句就变成:
| SELECT * FROM Users WHERE User_Name = ‘John’ AND Password = ‘Smith’ |
如果测试人员输入John’-作为用户名,不输入密码,那么SQL语句变成:
| SELECT * FROM Users WHERE User_Name = ‘John’– AND Password = ‘’; |
我们可以注意到,SQL语句中John后面的部分成为了注释。如果用户表中有一些用户用户名为“John”,那么程序能够允许测试人员以用户John的身份登录,这样,测试人员可以看到用户John的隐私信息。
如果测试人员不知道任何程序中已存在的用户该怎么办呢?在这种情况下,测试人员可以尝试相似的用户名像“admin”,“administrator”,“sysadmin”。如果这些用户名在数据库中都不存在,测试人员可以输入John’ or ‘x’=’x作为用户名,Smith’ or ‘x’=’x作为密码。那么SQL语句如以下所示:
| SELECT * FROM Users WHERE User_Name = ‘John’ or ‘x’='x’ AND Password = ‘Smith’ or ‘x’=’x’; |
因为‘x’=’x’这一条件总是成立的,结果集包含用户表中所有行。程序允许测试人员以用户表中第一个用户的身份登录进去。
重点:测试人员在尝试下列SQL注入之前应该请求拥有数据库管理员或者开发人员权限以备份有问题的表格。
如果测试人员输入John’; DROP table users_details;’—作为用户名,任意值作为密码,那么SQL语句如下所示:
| SELECT * FROM Users WHERE User_Name = ‘John’; DROP table users_details;’ –‘ AND Password = ‘Smith’; |
这条语句将造成表格“users_details”从数据库中永久删除。
虽然上述例子说明的是页面中登录功能上运用SQL注入技术,但是测试人员应在应用程序中所有接受用户输入的页面运用该技术测试,如搜索页面,反馈页面等等。
SQL注入可能出现在运用了SSL的程序中,即使是防火墙也不能防御SQL注入攻击。
本文中,我尽量以简单的形式解释SQL注入技术。再次强调,SQL注入只能在测试环境中测试,不能再开发环境,生产环境或者其他任何环境下测试。除了手工测试程序是否易受SQL注入攻击,我们还应该使用web vulnerability scanner(一款扫描工具)来检查SQL注入。
图形用户界面测试
界面是软件和用户交互的最直接的层面,界面决定了用户对软件的印象,GUI,设计良好GUI—轻松愉悦的感觉。Web应用+网页制作--->GUI设计的兴起.
流行的界面风格:多窗体风格,单窗体风格,资源管理器风格
特性:易用性,规范性,帮助,合理性,美观与协调,菜单位置,独特性,快捷方式的结合,安全性考虑,多窗口的应用与系统资源。
GUI测试重点是正确性,易用性和视觉效果,文字检查和拼写检查是GUI测试的重要环节。
用户通过GUI拖动鼠标,单击按钮等来驱动软件完成需要的功能,这个涉及到:
GUI输入主要是由一系列的事件或行动完成,拥有大量需要测试的状态,输入和状态转移不仅仅与当前的输入事件有关,而且还与以前的输入事件相关
GUI软件的输入和事件的排列组合的数据非常巨大,执行路径比较多(想想100阶乘和101阶乘的区别)
GUI中包含了大量复杂的组件和控件,允许多个窗口被激活,彼此之间存在一些同步机制,窗口中每个对象可以影响和控制其他对象
GUI界面之间相互影响,相互依赖。--耦合度高
GUI软件是基于事件和消息的。
GUI测试中的很多方法是重复而枯燥的。
除了考虑图形对象测试的本身特性,系统工作流程的测试也是一个重点,数据库设计,程序结构设计最终要界面设计的
GUI测试的基本过程:1.执行用户操作,2.获取检测状态,3.对比验证内容
基本原理:测试者在运行应用程序的同时,把他的所有的动作(键盘操作,鼠标操作)捕获或者录制下来,生成一个脚本文件,这个脚本文件以后可以被”回放“(playback),也就是按照上一次的所有执行动作重复执行一遍,实现自动运行和测试。在实际的测试过程中,同一动作的重复执行意义不大,而是根据测试需求为其进行一些必要的修改。
GUI自动化测试工具的捕获/录制模式--->原型级的实现--->插入检查点,维护脚本--->编程修改,GUI自动化测试:软件规范过程,在录制前设计好测试用例.
GUI自动测试工具:开源的Java的GUI测试工具—Selenium。SWTBot用于SWT,基于Eclipse应用的GUI测试工具,提供了能简化访问SWT和Eclipse组件的API,基于Apache2许可协议。其测试运行配置和JUnit非常的相似,测试方法的结构也很相似
1.JavaGUI基础类库应用测试
JavaGUI: SWT/JFace,Swing,AWT(Abstract WindowingToolkit)--->java.awt,JFC的一部分--->提供了JavaApplet,JavaApplicaton中可用的GUI中的基本组件,Swing自己绘制控件,调用本地图形子系统中的底层例程,而不是依赖于OS的高层模块。模仿原生系统,纯Java,轻量级,大量运用MVC模式的GUI工具包。SWT/JFace—Eclipse--高效的GUI程序
1.1JFCUnit单元测试工具的介绍
Xp测试驱动开发观念,单元测试技术,Java-->JUnit+Ant,JUnit的局限性,HttpUnit--Web测试,GUI--JFCUnit。
JFCUnit是JUnit的扩展框架,扩展了针对SwingGUI的单元测试工具,提供的一些基本功能:
①捕获取窗体/对话框的句柄
②在一个进程的组件容器内,确定所需要的组件
③模拟触发组件的事件
④用于GUI测试的多线程方法
JFCUnit从2.0开始,提供XML录制和回放功能,允许使用者快速,自动地生成/编辑用于驱动测试的脚本。XMLAPI是公开的,可以定义自己的XML标签句柄。
1.2JFCUnit基本测试方法
思路:提供了很多方法,可以用来模拟许多本地应该有传统测试人员手工进行的触发事件:单击按钮,在文本矿中输入字符,数字,鼠标双击事件,从而实现测试的自动化。
两种方式模拟交互:①Junit.Extensions.Jfcunit.JFCTestHelper的EevenQueue来激活事件队列②使用Junit.Extensions.Jfcunit.RobotTestHelper来封装java.awt.Robot
JFCUnit的测试用例类似于任何其他的JUnit测试用例。其主要不同在于它的
测试用例类应继承自基类Junit.Extensions.Jfcunit.JFCTestCase,而不是基
类:Junit.Framework.TestCase。
1.3 JFCunit环境的建立
JFCUnit—SourceForge.net—Eclipse插件安装—配置路径(jfcunit.jar,jakarta-regexp-1.2.jar{正则表达式java包,如果没有这个包,jfc就会发生错误})
1.4测试资源应用
JFCunit是扩展了Junit,具有很多属于自己的测试资源。
1.4.1 JFCUnit核心函数的应用方式
⑴setUp()和tearDown()
在junit框架中用于测试的初始化和结束测试,释放资源
setUp()在测试方法调用前,负责初始化测试方法所需要的测试环境
tearDown()在每个测试方法被调用之后调用,负责撤销测试环境
流程:测试开始-->setUp()-->testXXX-->tearDown()-->测试结束
⑵Find-Component
JFCUnit中对对象测试的基础是捕获测试对象的实例,关键是find...Component系列API的应用.具体查找主要基于两个方面,对象组件的”Name”数据和容器中的Index。
PublicComponent find(final Container cont,final int index){
returnfind(new Container[] {cont},index);
} |
⑶assert函数
assertNull(Stringmessage,Object object);
assertNotNull(Stringmessage,Object object);
assertEquals(Stringmessage,Object expected,Object actual);
assertTrue(Stringmessage,boolean condition);
assertFalse(Stringmessage,boolean condition);
assertSame(Stringmessage,Object expected,Object actual);
assertNotSame(Stringmessage,Object expected,Object actual); |
⑷JFCTesthelper和TestHelper
JFCTesthelper继承TestHelper中很多用于自动画界面操作的方法。
1.5 JFCUnit的使用--GUI类和实验
突然间发现自己做了很多的重复的工作,处在互联网3.0的时代,我们应该充分的利用网络,以下是我google的一些JFCUnit的文章,写得还是相当的不错的。
JFCUnit实战:http://www.ltesting.net/ceshi/open/kydycsgj/2007/0525/5733.html
使用JFCUnit进行GUI单元测试 :http://www.blogjava.net/wukaichun600/archive/2006/10/19/76026.html
以上仅仅是google后第1,2页显示的结果,google让知识的获取变得更加的简单了。知识的来源不再是仅仅局限于书本,通过搜索引擎(google,baidu)从Internet上获取知识渐渐成为一个更为便捷有效的方式。这件事情既是机遇也是挑战。
机遇:人类从未如此便捷的获取知识过,搜索引擎加速了信息的流通,使得我们可以更为方便的整合知识。
挑战:随着可获取的信息量的膨胀,在如此庞大的信息中识别出有效的信息成为了一个问题。此外,搜索引擎提供的普遍的知识原始的材料,如何处理和整合这些信息从而创造出更有价值的知识无疑将成为当代知识分子的所面临的挑战。
1.6JFCUnitXML测试框架
JFCUnitXML是一个建立的XML框架之上的测试框架。XML框架支持Swing和非Swing的测试,框架图示如下:
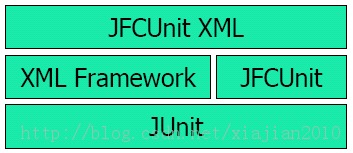
JFCUnitXML允许开发者编写XML代码来开发用于各种测试目的的测试集。录制生成XML的方式使大多数的测试生成过程自动化,可复用性高
1.3 JFCunit环境的建立
JFCUnit—SourceForge.net—Eclipse插件安装—配置路径(jfcunit.jar,jakarta-regexp-1.2.jar{正则表达式java包,如果没有这个包,jfc就会发生错误})
1.4测试资源应用
JFCunit是扩展了Junit,具有很多属于自己的测试资源。
1.4.1 JFCUnit核心函数的应用方式
⑴setUp()和tearDown()
在junit框架中用于测试的初始化和结束测试,释放资源
setUp()在测试方法调用前,负责初始化测试方法所需要的测试环境
tearDown()在每个测试方法被调用之后调用,负责撤销测试环境
流程:测试开始-->setUp()-->testXXX-->tearDown()-->测试结束
⑵Find-Component
JFCUnit中对对象测试的基础是捕获测试对象的实例,关键是find...Component系列API的应用.具体查找主要基于两个方面,对象组件的”Name”数据和容器中的Index。
PublicComponent find(final Container cont,final int index){
returnfind(new Container[] {cont},index);
} |
⑶assert函数
assertNull(Stringmessage,Object object);
assertNotNull(Stringmessage,Object object);
assertEquals(Stringmessage,Object expected,Object actual);
assertTrue(Stringmessage,boolean condition);
assertFalse(Stringmessage,boolean condition);
assertSame(Stringmessage,Object expected,Object actual);
assertNotSame(Stringmessage,Object expected,Object actual); |
⑷JFCTesthelper和TestHelper
JFCTesthelper继承TestHelper中很多用于自动画界面操作的方法。
1.5 JFCUnit的使用--GUI类和实验
突然间发现自己做了很多的重复的工作,处在互联网3.0的时代,我们应该充分的利用网络,以下是我google的一些JFCUnit的文章,写得还是相当的不错的。
JFCUnit实战:http://www.ltesting.net/ceshi/open/kydycsgj/2007/0525/5733.html
使用JFCUnit进行GUI单元测试 :http://www.blogjava.net/wukaichun600/archive/2006/10/19/76026.html
以上仅仅是google后第1,2页显示的结果,google让知识的获取变得更加的简单了。知识的来源不再是仅仅局限于书本,通过搜索引擎(google,baidu)从Internet上获取知识渐渐成为一个更为便捷有效的方式。这件事情既是机遇也是挑战。
机遇:人类从未如此便捷的获取知识过,搜索引擎加速了信息的流通,使得我们可以更为方便的整合知识。
挑战:随着可获取的信息量的膨胀,在如此庞大的信息中识别出有效的信息成为了一个问题。此外,搜索引擎提供的普遍的知识原始的材料,如何处理和整合这些信息从而创造出更有价值的知识无疑将成为当代知识分子的所面临的挑战。
1.6JFCUnitXML测试框架
JFCUnitXML是一个建立的XML框架之上的测试框架。XML框架支持Swing和非Swing的测试,框架图示如下:
JFCUnitXML允许开发者编写XML代码来开发用于各种测试目的的测试集。录制生成XML的方式使大多数的测试生成过程自动化,可复用性高
JFCUnitXML基础
XML是一种基于SGML的标记语言,成为网络数据交互的强大工具。XML提供了定义和处理GUI测试的一个有效的方法,在JFCUnit类中开发出了XML接口,XML执行接口。
XMLJunit框架:定义特性—可以在作用域范围内允许它在测试用例之间使用,定义在XML中的各个测试用例可以访问定义在父类或者祖父类的特性,父级可以通过执行特性名来隐式访问,或者”../”父访问路径来显式访问。特性可以通过${name}访问。程序可以在测试集和测试用例上定义,父类能够在更高级层次上定义---可以生成程序库。
两个保留程序:setUp,tearDown—对应TestCase.setUp|tearDown
扩展XML接口,taghandler结合Java后端开发并写入XML中,taghandler通过XML脚本定义进行注册/不注册,taghandler的概念:
Suitetags: 1.引入定义在其他XML文件中有关文件中的有关集的文件标签,2.程序标签定义3.在测试用例间共享特性标签
Suiteof Suites:
<suitename=”Abc”>
<filename=”a.xml”/>
<filename=”b.xml”/>
<filename=”subdir/c.xml”>
</suite> 程序标签
<suite name=”Procedure Example”>
<procedure name=”Login”>
…..
</procedure>
<procedure name=”Logout”>
…..
</procedure>
<test name=”Login”>
<procedurecall=”Login”>
</test>
</suite> |
特性标签
标签名对应于相应值
作用域
访问文法:${name}syntax
定义:<propertyname=”debug” value=”true”/>
其他定义
向程序员传递数据
判定标签进行分支跳转
对各种标签进行循环处理
Chose/When/Otherwise,Echo, Noop, Assert/Fail, Evaluate, Foreach, Indexof,Dump,
AssertHasFocus,AssertEnabled,AssertTableCellContains,AssertTextFieldContains
1.7 小节
JFCUnit XML:说到底就是JFCUnit的一种高一个层次封装,通过XML来描述测试用例,然后使用某中类型的代码生成器将XML描述转换为JFCUnit代码,从而避免了手工Code。高层次的抽象带来的好处就是可以屏蔽一些繁琐的细节,从而让程序员专注更加重要的应用上,而不是浪费时间在底层细节上。这中思想在很多的方面被广泛的应用,操作系统,编程语言,编译系统等等。
2 Web页面测试
Internet技术发展,Web系统变得越來越复杂,Web工程:测试,确认,验收。Web环境:浏览器平台不兼容,网络多样化,应用复杂等诸多特性。
Web测试分类:页内测试(IntraPageTest)和跨页测试(InterPageTest)
页内测试的方法:人工走查,使用web页面测试工具.
页面测试准则:直观,一致,灵活,舒适
2.1web页面测试工具
web页面测试的两种思路:1.浏览器测试2.协议测试(在Http上的JavaScript级测试,JavaScript伪协议, POST, WebService).在一些功能测试中,协议测试用的比较的多。
Web测试工具:
1.HttpUnit:HttpUnit是在JUnit之上构建的测试框架,支持Web应用的黑盒测试和in-container容器内测试。作为功能测试工具,也可以用它验证软件是否符合业务需求,以及是否在可视的级别符合预期的行为。HttpUnit的目的加强HTTP对Web应用的访问,支持的特性:状态管理(cookies),提交请求,应答解析(HTML解析),以及网络爬虫(webspider)。HttpUnit还有一个支持容器内测试的类ServletUnit.JUnit提供的断言功能和结果报告的基础上,HttpUnit提供了一个非常有用的web应用测试工具。www.httpunit.org.
2.JWebUnit:HttpUnit上创建的一个辅助工具包,减少测试web程序所要编写的代码,简单当作HttpUnit的宏程序库,提供到HttpUnit代码段的快速方式,简化web程序测试中的大多数行为,HttpUnit的底层接口可以让测试人员定制很多事情,JWebUnit对代码有更好的控制。jwebunit.sourceforge.net
3.StrutsTestCase:是为了测试Struts应用而在Junit基础上创建的测试框架,Structs(MVC模式)使web程序容器间的功能测试和单元测试变得更复杂了。Struts使web程序容器之间(in-container)的功能测试和单元测试变得复杂了,Struts处于servlet容器和程序之间,HttpUnit独立于程序和容器之间.StrutsTestCase转为Struts程序的容器间测试而设计的.strutstestcase.sourceforge.net
4.Selenium:用于web应用程序测试的工具,将核心组件插入到浏览器中,整个测试直接在浏览器中运行,如同真正的用户在操作一样,所有的测试都是可见的。支持的浏览器:IE,Mozilla,Firefox等.测试兼容性,测试系统功能。seleniumhq.org/download
5.HtmlUnit:具有浏览器基本功能的Java组件,HtmlUnit是Junit的扩展测试框架之一。支持HTML,提供API
2.2HttpUnit
工作原理:模拟浏览器行为,处理页面帧(frames),cookies,页面重定向(redirects)等,通过HttpUnit提供的功能,可以和服务器进行信息交互,将返回的网页内容作为普通文本,XMLDOM对象或者链接,页面框架,图像,表单,表格等集合。
核心组件:
发送请求并接受响应的web客户机
分析并验证响应内容的方法集
HttpUnit—功能测试--极限编程(XP)中起到重要的作用
商业的web工具都是通过录制回放实现的,HttpUnit关注的重点是控件的内容,而不是控件的外在表现形式.HttpUnit无GUI,开源,API简单性—灵活性和强大
2.2 HttpUnit的使用
google一下可以找到很多关于这个的,个人决定不再增加冗余信息。列举一二个人觉得比较好的。
使用HttpUnit进行集成测试 :http://www.blogjava.net/relax/archive/2005/01/27/743.html
HttpUnit基础教程:http://wenku.baidu.com/view/ed3be4f77c1cfad6195fa7d0.html
除此以外,不要忘记HttpUnit官方网站以及研究HttpUnit源代码这样的方法
2.3JWebUnit
JwebUnit是基于Java的用于测试网络程序的框架,架构在HttpUnit之上----即JWebUnit以HttpUnit和JUnit单元测试框架为基础,适合做Web应用的验收测试。JWeb是HttpUnit的高层封装,提供访问Web应用程序的高级API,组合一组断言。JWebUnit是以jar文件形式提供的,方便使用,JWebUnit轻量级集成HtmlUnit和Selenium。
2.3.1 环境建立:sourceforge.net/projects/jwebunit --说穿了,就是一些jar包,在使用JWebUnit的时候将其添加到构建路径中
2.3.2 JWebUnit应用方法
依然google,不增加无用信息:
JWebUnit官方地址:http://sourceforge.net/projects/jwebunit/?source=directory
JWebUnit For Web Regression Tests: http://www.intertech.com/Blog/jwebunit-for-web-regression-tests/
备注:国外的人写的技术博客含金量还相当的高,一方面人家没有语言障碍,二不像国内这么浮躁(社会环境所致)。虽然有点语言的障碍,但是如果想从事IT这一行的话,英语就是一项必不可缺的的技能:因为最新的技术总是用英文写的或者最早转换的语言就是英文。而且国内的技术水平落后国际有5到10年的差距,当然这个数据不是一陈不变的,但是学习并阅读英文资料总是有好处的,当然刚一开始时可能会不太适应,但是过一段时间就好了。至少个人是这么认为的。
参考文献:
[1]软件测试实验指导教程/蔡建平, 清华大学出版社, 2009.11
相关文章:
软件测试实验学习笔记系列5-单元覆盖测试
本节重点:
简单对象的定位
-----自动化测试的核心
对象的定位应该是自动化测试的核心,要想操作一个对象,首先应该识别这个对象。一个对象就是一个人一样,他会有各种的特征(属性),如比我们可以通过一个人的身份证号,姓名,或者他住在哪个街道、楼层、门牌找到这个人。
那么一个对象也有类似的属性,我们可以通过这个属性找到这对象。
定位对象的目的一般有下面几种
· 操作对象
· 获得对象的属性,如获得测试对象的class属性,name属性等等
· 获得对象的text
· 获得对象的数量
webdriver提供了一系列的对象定位方法,常用的有以下几种
· id
· name
· class name
· link text
· partial link text
· tag name
· xpath
· css selector
我们可以看到,一个百度的输入框,可以用这么用种方式去定位。
#coding=utf-8 from selenium import webdriver
import time browser = webdriver.Firefox() browser.get("http://www.baidu.com")
time.sleep(2) #########百度输入框的定位方式########## #通过id方式定位
browser.find_element_by_id("kw").send_keys("selenium") #通过name方式定位
browser.find_element_by_name("wd").send_keys("selenium") #通过tag name方式定位
browser.find_element_by_tag_name("input").send_keys("selenium") #通过class name 方式定位
browser.find_element_by_class_name("s_ipt").send_keys("selenium") #通过CSS方式定位
browser.find_element_by_css_selector("#kw").send_keys("selenium") #通过xphan方式定位
browser.find_element_by_xpath("//input[@id='kw']").send_keys("selenium") ############################################ browser.find_element_by_id("su").click()
time.sleep(3)
browser.quit() |
OK~!通过上面一个例子,就帮我们展示了几种定位方式,下面来介绍每种定位方式:
id 和 name
--------------------------------------------------------------------------------
id 和 name 是我们最最常用的定位方式,因为大多数控件都有这两个属性,而且在对控件的id 和name命名时一般使其有意义也会取不同的名字。通过这两个属性使我们找一个页面上的属性变得相当容易
我们通过前端工具,找到了百度输入框的属性信息,如下:
<input id="kw" class="s_ipt" type="text" maxlength="100" name="wd" autocomplete="off">
id=”kw”
通过find_element_by_id("kw") 函数就是捕获到百度输入框
name=”wd”
通过find_element_by_name("wd")函数同样也可以捕获百度输入框
tag name 和class name
--------------------------------------------------------------------------------
从上面的百度输入框的属性信息中,我们看到,不单单只有id 和 name两个属性,比如class 和 tag name(标签名)
<input>
input 就是一个标签的名字,可以通过find_element_by_tag_name("input") 函数来定位。
class="s_ipt"
通过find_element_by_class_name("s_ipt")函数捕获百度输入框。
但是,碰下面的一组控件属性,我们就哭了。
<th width="95"></th>
<th width="">文件名</th>
<th class="c1">创建时间</th>
<th class="c1">状态</th>
<th class="c1">文件大小</th>
<th class="c1">时长</th> |
下面的css 和 XPath就没有上面的那么直观,如果不懂前端的话可能不太好理解
CSS定位
--------------------------------------------------------------------------------
CSS(Cascading Style Sheets)是一种语言,它被用来描述HTML和XML文档的表现。CSS使用选择器来为页面元素绑定属性。这些选择器可以被selenium用作另外的定位策略。
CSS的比较灵活可以选择控件的任意属性,上面的例子中:
find_element_by_css_selector("#kw")
通过find_element_by_css_selector( )函数,选择取百度输入框的id属性来定义
也可以取name属性
<a href=http://news.baidu.com name="tj_news">新 闻</a>
driver.find_element_by_css_selector("a[name=\"tj_news\"]").click() |
可以取title属性
| <a onclick="queryTab(this);" mon="col=502&pn=0" title="web" href=http://www.baidu.com/>网页</a>driver.find_element_by_css_selector("a[title=\"web\"]").click() |
也可以是取..:
<a class="RecycleBin xz" href="javascript:void(0);">
driver.find_element_by_css_selector("a.RecycleBin").click() |
虽然我也没全部理解CSS的定位,但是看上去应该是一种非常灵活和牛X 的定位方式
扩展阅读:
http://www.w3.org/TR/css3-selectors/
http://www.w3school.com.cn/css/css_positioning.asp
XPath
--------------------------------------------------------------------------------
什么是XPath:http://www.w3.org/TR/xpath/
XPath基础教程:http://www.w3schools.com/xpath/default.asp
selenium中被误解的XPath : http://magustest.com/blog/category/webdriver/
XPath是一种在XML文档中定位元素的语言。因为HTML可以看做XML的一种实现,所以selenium用户可是使用这种强大语言在web应用中定位元素。
XPath扩展了上面id和name定位方式,提供了很多种可能性,比如定位页面上的第三个多选框。
xpath:attributer (属性)
driver.find_element_by_xpath("//input[@id='kw']").send_keys("selenium")
#input标签下id =kw的元素 xpath:idRelative (id相关性)
driver.find_element_by_xpath("//div[@id='fm']/form/span/input").send_keys("selenium")
#在/form/span/input 层级标签下有个div标签的id=fm的元素
driver.find_element_by_xpath("//tr[@id='check']/td[2]").click()
# id为'check' 的tr ,定闪他里面的第2个td xpath:position (位置)
driver.find_element_by_xpath("//input").send_keys("selenium")
driver.find_element_by_xpath("//tr[7]/td[2]").click()
#第7个tr 里面的第2个td xpath: href (水平参考)
driver.find_element_by_xpath("//a[contains(text(),'网页')]").click()
#在a标签下有个文本(text)包含(contains)'网页' 的元素
xpath:link
driver.find_element_by_xpath("//a[@href='http://www.baidu.com/']").click()
#有个叫a的标签,他有个链接href='http://www.baidu.com/ 的元素 |
link 定位
--------------------------------------------------------------------------------
有时候不是一个输入框也不是一个按钮,而是一个文字链接,我们可以通过link
#coding=utf-8 from selenium import webdriver
import time browser = webdriver.Firefox() browser.get(http://www.baidu.com)
time.sleep(2)
browser.find_element_by_link_text("贴 吧").click()
time.sleep(2)
browser.quit() |
一般一个那页面上不会出现相同的文件链接,通过文字链接来定位也是一种简单有效的定位方式。
Partial Link Text 定位
--------------------------------------------------------------------------------
通过部分链接定位,这个有时候也会用到,我还没有想到很好的用处。拿上面的例子,我可以只用链接的一部分文字进行匹配:
browser.find_element_by_partial_link_text("贴").click()
#通过find_element_by_partial_link_text() 函数,我只用了“贴”字,脚本一样找到了"贴 吧" 的链接 |
相关文章:
轻松自动化---selenium-webdriver(python) (二)
轻松自动化---selenium-webdriver(python) (四)