
走进单元测试一:初认Unit Test
前言:在公司写单元测试已经有两个多月了(思想上有过纠结),说实话有点像赶鸭子上架,在项目收尾的时候才做,很明显它的作用已经是名副其实了,而且还找像我这样的新手来写(一开始我都不怎么熟悉业务流程),所以现在一直努力学好单元测试,写好它,把自己的事做好!
我也是在读程序员修炼之道 - 单元测试这本书之后,再阅读了园子中的各个文章后的感悟把,写出来跟大家一起分享!
电子书下载地址:http://www.kuaipan.cn/file/id_29568238492847284.htm
测试是贯穿整个整个软件工程的始末,做好测试对软件的质量会有一个质的保证,减少查找BUG的工作量,所以作为一个开发者需要了解各种测试流程以及核心思想,然而这次的单元测试是我们开发者必须要具备的技能,这次就让我们走进单元测试(Unit Test)!
1.个人对单元测试的初识
①坚持的开发中编写单元测试,并把它培养成一种习惯!
②写出高效的单元测试,这种能力需要在实践中慢慢积累!
③提高对单元测试的认识高度,把它和编码工作同等对待!
2.什么是单元测试?
通俗讲单元测试就是检查一个函数执行后它的返回结果或者它对系统数据造成的影响(或者其它方面的影响)是否跟你的期望一致,也就是为了证明代码的行为和我期望的一致!
3.我们为什么要使用单元测试?
①最直接的原因是保证我们函数的正确性,如果这个函数在没有保证正确的情况下就被上层代码调用,那么随着项目的深入,调用层次会越来越深,就很容易产生严重的BUG问题,从而增加开发难度,降低开发效率!
②根本原因是减轻我们开发人员的工作量,使我们的工作变的轻松(这只是一个相对说法)!
4.单元测试的内涵
如果把单元测试上升到一定程度后,它可以把我们的代码变的更加完美和简洁!
5.单元测试的本质
请记住一点,不是为工作而编写单元测试,单元测试是方便我们开发人员的,可以使我们的工作变的轻松!
单元测试可以减少我们花在解决不必要的BUG之上(并不是说没有BUG,而是说减少不必要的BUG),而把大量时间专注于业务需求上!
6.函数的行为和预期的一致吗?
如果测试只考虑在正确的环境下造成正确的影响,那么这样的单元测试是不及格的!
做测试就要考虑全面,各个方面都要涉及的到,如:环境因素(也可以是系统所处在的环境),各种异常,边界值等等,所以尽可能的考虑特殊情况,做到做到百密而无一疏(尽自己的最大努力达到)!
7.需要依赖单元测试吗?
答案是肯定的!
当你很自信的认为你写的函数是绝对正确的且没有测试代码做为依据的时候往往会出现意想不到的错误,因为你会疏忽了其它的一些情况,所以编写单元测试来保证我们函数的准确性是非常有必要的!
注:后面会说明测试应该测哪些情况!
8.单元测试干了什么,作用是什么?
①最直接的是保证了函数的正确性(这个大家都知道)!
②还有我们可以根据单元测试来判断此函数是用来干什么的,也就说单元测试类似于一个可执行文档,其它开发人员可以通过看单元测试就会明白你测试的函数是用来干嘛的!
9.如何进行单元测试?
这边我们使用的VS2008,2010自带的单元测试框架!
① 使用VS自带的Unit Test,简单易学!
② 测试要全面!
③ 保证所有测试都能通过,不管旧的还是新的测试代码,都要通过!
④ 保证所有测试没有对系统中任何模块产生影响(这个很重要)!
⑤ 及时运行测试代码,查看运行结果,保证系统的运行正常!
10.不要为没写测试代码找借口
一般情况的看来当你写的一个函数已经不太需要修改了,你就应该编写这个函数的单元测试代码!
大多数情况下开发人员的大量时间都是修改BUG,如果能尽早的做单元测试将会减轻你的工作量(虽然不可能没有BUG,但写Unit Test却对你是有益无害的),即使在以后的时间里出现BUG,我想你能很快的定位产生BUG的位置!
最后写Unit Test千万不要放在项目末期,如果此时写单元测试的人还是一个刚进项目新手的话,写单元测试就是扯淡,这样的方式是不能体现单元测试的核心观念的,而我就刚好处于这个状态,真的很后怕,所以还需要多多加油,努力了解系统流程!
11.如果真的没有时间写单元测试,请思考下面几个问题?
①对于你所编写的代码,你花在调试上面的时间有多少?
②你目前认为你的代码正确无比,但很有可能在系统中却存在严重隐患,你是否花了很多时间来查找这些隐患?
③对于一个新的BUG,你花了多长时间来定位这个BUG在源码中的位置?
总结:随着项目的深入,你的函数会被调用的越来越深,那么特殊情况就会经常发生,万一出现什么情况你将会耗费很多的精力来解决它,另一方面,适当的单元测试代码会很大程度上减少你的工作量,这是经过实践检验的!
总结:好了基本的单元测试思想就这么多了,希望园友们能指点一二,单元测试系列将持续更新中!
相关文章:
走进单元测试二:测试需要从哪些方面着手
IETester
这一款是专门用来测试网页在IE家族浏览器下表现的工具,对任何用户都免费。我平时用的就是这个比较多,强烈推荐!。Chrome 、Firefox等浏览器对web标准的遵循度一向很高,唯一需要单独测试的也就是IE浏览器的,并且IE浏览器还有个最大的特点:每个版本的用户群体都比较多,IE6 IE7 IE8 IE9 IE10.而这个IETester可以模拟包括IE10, IE9, IE8, IE7 IE 6 and IE5.5在内的多种版本,实乃测试网页在IE下兼容性的好工具。
Spoon Browser Sandbox
进去之后点击你要测试的浏览器环境,之后会有一个注册界面,然后会下载一个针对性的插件,安装完插件就可以测试了。

Browsershots
这个测试工具...咳咳,有时候挺有用的,不过测试的浏览器环境太全面了,各种浏览器的各种版本都有。每次用这个测试的时候,就要手动在那里取消一大堆不需要的浏览器。
Microsoft Expression Web 4
微软自己发布的浏览器测试开发工具,继承了MS一向体积庞大的优点,有将近100MB大小。没用过,据说很强大,这里我给排在最后了。
1.背景
应用的性能测试与优化目前主要停留在服务器端的反馈,而对于前端性能标准的研究与测试相对比较空白,缺乏统一的标准与工具。众所周知,浏览器html组件的下载及渲染性能直接影响最终的用户体验,目前应用的前端性能有许多优化空间,因此对前端性能进行测试与监控,有利于提升客户体验,做到全方位的性能监控,实现“客户第一”的价值。
2.前端性能标准
目前较为流行且免费的前端性能评测标准及工具,是以yahoo的yslow及google的pagespeed为主。yslow和page speed是两款firefox浏览器下功能类似的插件,其主要功能是在用户访问网页时,可用此插件对当前访问的网页按若干条固定的评分标准进行前端性能评分。另有dynatrace也提供与yslow和page speed类似的评价标准。
2.1 yslow
评分标准:主要有35条评分标准,具体标准参见官方文档http://developer.yahoo.com/performance/rules.html。
插件下载:http://developer.yahoo.com/yslow/
插件运行:插件运行后,在firefox中访问网页,插件将会显示对该网页的评分,15个标准(使用到的评分标准数在不同版本的yslow插件中有所不同)从A-F进行打分。下图是对阿里巴巴中文网站首页的一个打分情况:

2.2 page speed
评分标准:pagespeed主要的评标准有29条http://code.google.com/speed/page-speed/docs/rules_intro.html
插件下载:http://code.google.com/speed/page-speed/download.html
插件运行:pagespeed除了支持firefox外,还支持google chrome浏览器,下图是在firefox中用page speed评估http://www.1688.com的结果

2.3 dynatrace ajax edition
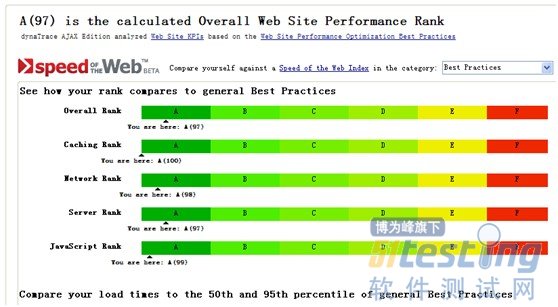
评分标准:评分标准分为四个大类,包括Cache、网络、Server端、JavaScript代码,每个大类都有A~F六个等级,各个大类下面的最佳实践细则与yslow及page speed类似http://community.dynatrace.com/ext/ajax/PUB/Best+Practices+on+Web+Site+Performance+Optimization。
下载安装:https://www.dynatrace.com
运行情况:dynatrace可以支持firefox和ie,且其可支持到函数级的度量分析,在windows下运行dynatrace如下图所示
3.方案选择
3.1dynaTrace Ajax Edition
dynaTrace Ajax Edition是一款免费的前端性能评测工具,与非常优秀的yslow及page speed相比,其仍有几个不容忽视的优点:
1)支持IE浏览器,这个优点直接秒杀另外两个工具
2)支持JS函数级的性能分析
3)对每条细则的建议更加详细具体
3.2showslow
showslow是yslow的数据收集与展示平台http://www.showslow.com/,它是一个开源的php项目,可以用来与firefox的yslow插件、page speed插件或者dynatrace通信,收集插件或程序所发送过来的信息并集中展示。只需要在dynatrace安装目录下进行一些设置,即可自动实现上传结果到showslow平台作为存档、分析及监控。
4.环境搭建与工具使用
4.1dynatraceAjax Edition
4.1.1 安装运行
从dynatrace官网http://ajax.dynatrace.com下载安装最新版本的dynatraceAjax Edition即可。dynatrace的启动可直接从菜单栏中进行运行,也可在IE插件栏中点击按钮运行。
4.1.2上传结果至showslow
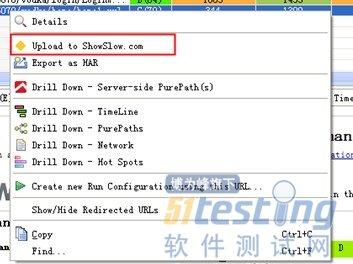
对相应的链接右击,就可将相应结果上传到showslow
4.1.3 showslow中查看结果
showslow中看到的结果页面如下图所示:

4.2showslow环境搭建
1. 如是Linux平台,需要预先安装如下软件:libmcrypt-2.5.8,ncurses-5.7.tar.gz,zlib-1.2.3(要用64位方式编译http://blog.sina.com.cn/s/blog_5f66526e0100gkzu.html)。
2.安装mysql,要求mysql5以上版本。
3.安装Apache,最好安装2.0以上版本。
4.安装php,要求php5.2以上版本。
在Linux平台上搭建apache+php+mysql的文档网上有很多,大家可参阅,我在安装过程中遇到的问题,在文档最后有一个环境问题总结,可能会对大家有帮助。搭建完成基本的mysql+apache+php之后,再用如下的步骤可搭建showslow环境http://www.showslow.org/Installation_and_configuration:
第一步,下载showslow
下载showslow:https://github.com/sergeychernyshev/showslow/downloads
第二步,解压
解压showslow至某一文件夹,如:/www/showslow
第三步,设置apache
将showslow文件设置为apache的DocumentRoot,修改或添加httpd.conf文件内容如下:
<VirtualHost *:80>
DocumentRoot/www/showslow #目录主路径,必须有这个目录才写
DirectoryIndexindex.htm index.html index.jsp index.php default.html defautl.htm default.jsp
ErrorLoglogs/market-error_log
CustomLoglogs/market-access_log common
</VirtualHost> |
第四步,新建数据库
在mysql中新建一个数据库showslow,授所有权限给showslowuser用户:
mysql> createdatabase showslow;
mysql> grant all onshowslow.* to showslowuser identified by 'showslow';
并在showslow文件夹下的config.sample.php文件中进行如下所示的数据库参数的修改,修改完成后另存为config.php:
$db = 'showslow';
$user = 'showslowuser';
$pass = 'showslow';
$host = '10.20.155.4'; |
第五步,更新数据库
绑定showslow到我们台式机的hosts文件里,方便访问(也可以直接ip访问):
10.20.155.4 www.myshowslow.com
启动Apache,可在http://www.myshowslow.com看到showslow平台,报错是因数据库未更新,访问http://www.myshowslow.com/dbupgrade.php和http://www.myshowslow.com/users/dbupgrade.php将数据库中的表更新至与当前版本showslow一致。
第六步,设置dynatrace
dynatrace安装文件下的dtajax.ini文件增加如下三行,其中第三行可设置dynatrace自动上传结果至showslow:
-Dcom.dynatrace.diagnostics.ajax.beacon.uploadurl=http:// 10.20.155.4:8070/beacon/dynatrace
-Dcom.dynatrace.diagnostics.ajax.beacon.portalurl=http:// 10.20.155.4:8070/
-Dcom.dynatrace.diagnostics.ajax.beacon.autoupload=true |
第七步,大功造成,上传并显示结果
按4.1节中的上传结果至showslow.com即可将前端性能分析结果上传至shlowslow。

4.3 dynatrace+showslow与UI自动化结合
只需要在ruby语言所写的自动化脚本中加入如下两行,即可在运行UI自动化脚本时,把UI自动化所访问到的页面的前端性能数据,通过所安装的dynatrace自动上传至showslow平台。
ENV['DT_IE_AGENT_ACTIVE'] = 'true'
ENV['DT_IE_SESSION_NAME'] = 'Watir Sample Test'
一个完整的示例代码也只需要8行:
require 'pwatir'
ENV['DT_IE_AGENT_ACTIVE'] = 'true'
ENV['DT_IE_SESSION_NAME'] = 'Watir Sample Test'
b = Watir::IE.new
b.goto('http://www.baidu.com')
b.text_field(:id, 'kw').set 'watir'
b.button(:id, "su").click
b.close() |
4.4 Linux中安装mysql+apache+php问题小结
4.4.1Can't connect to local MySQL server through socket‘xxx’
安装mysql后,运行mysql命令会出现ERROR 2002(HY000): Can't connect to local MySQL server through socket ‘xxx’错误,通常是由于安装完成mysql之后未启动造成的,执行/etc/init.d/mysqlstart即可。
mysql安装好之后,默认的root密码是空,mysql –uroot –p后在密码输入行直接回国即可命令模式以root进入mysql。
4.4.2 安装php时configure及make时报错的问题
从源码安装php时,要运行如下的编译项:
./configure --prefix=/usr/local/php5--with-charset=utf8 --with-extra-charsets=gbk,gb2312,utf8 --with-apxs2=/usr/local/httpd/bin/apxs--with-config-file-path=/usr/local/lib/php --with-mysql=/data/mysql--enable-mbstring --with-mysqli=/data/mysql/bin/mysql_config--with-mcrypt=/usr/local/libmcrypt
因此需要安装apache,mysql,mcrypt等软件之后,才能安装php。
4.4.3 php安装过程中httpd.conf相关的配置修改
在从源码安装php过程中,运行make命令后将php源代码目录modules下的libphp5.so拷贝至httpd/modules下,并在httpd.conf中加载这个module并添加两种文件类型:
LoadModule php5_module modules/libphp5.so
AddType application/x-httpd-php .php
AddType application/x-httpd-php .html
安装完成php后,需要将php源代码目录下的php.ini-dist拷贝至--with-config-file-path指定的/usr/local/lib/php目录下并改名为php.ini,同时在httpd.conf文件中指定php.ini文件位置:
PHPIniDir "/usr/local/lib/php"
dynaTrace Ajax内测版发布已有两周了。它给你的第一印象是什么。那段时间内我们收到的所有反馈意见(例如来自Steve Souders的意见,以及来自所有其他联系形式和在线论坛的意见)使这款工具从它的早期版本过渡到它的第一个“官方”发布版成为可能。
在这篇博客里,我将就dynaTrace Labs为什么要构建Ajax版工具展开讨论,它解决了什么问题,以及如何在一个关于Google Maps的例子中使用它。
为什么要开发dynaTrace Ajax版——为什么免费?
在dynaTrace网站,我们看到我们的客户跟业界一样,将以浏览器和运行时(Javascript、DOM)为基础的Web应用作为其应用平台。那些新兴的框架,像jQuery、GWT、YUI、Dojo等,让构建web 2.0应用越显轻松——但是,也越来越难以确认应用中的问题到底是功能性的,还是与性能相关的。
即便是在企业环境中,排名第一的仍然是IE浏览器。IE的诊断工具在涉及问题分析时,常会给开发和测试人员带来痛苦。在Web2.0/Ajax应用中所面对的挑战不仅是要了解网络交互(有多少资源以及什么时候载入),而且要了解这些交互是如何影响性能的。该问题所涉及的领域已经延伸到JavaScript、XmlHttpRequests、DOM操作、框架、布局和渲染。dynaTrace Ajax版的来临即可解决这类问题,以帮助用户了解是什么原因导致现代Ajax应用中出现性能和功能问题。
那么,为什么免费呢?免费是因为我们想帮助开发和测试人员通过使用这款工具来解决web 2.0带来的各种挑战。我们也希望推广dynaTrace APM解决方案理念,即结合Ajax版所带来的端到端的浏览器到服务器的以事务为中心的应用性能管理解决方案。在这里可以继续阅读完整的关于软件免费的原因说明。
动手分析Google Maps——从安装到分析的学习指南
我已经导出了学习这篇博文所需要的dynaTrace Ajax的session文件,点击这里免费下载,然后用它跟着我对我收集的这些数据进行逐步分析。如果你已经安装了dynaTrace Ajax版软件,就解压缩这个zip文件,点击工具栏中的导入按钮导入session文件(.dtas),然后跳过前三步。
第一步:下载并安装dynaTrace Ajax版
最一开始就是——对了,下载并安装。
打开浏览器,进入dynaTrace Ajax版网站,点击Download按钮下载最新版本。你必须先注册一个账户,这个账户不仅可以让你下载该工具,还能给你在社区网站开通权限,在那里你可以获得资讯、咨询问题,甚至为软件期望的功能提供建议。
第二步:启动并查看dynaTrace Ajax版
点击开始->所有程序->dynaTrace->dynaTrace AJAX Edition启动dynaTrace。客户端将出现Cockpit面板(译者注:左侧)及欢迎界面(译者注:右侧)。在我们开始追踪Google Maps之前,让我们先来浏览一下一些数据收集选项:
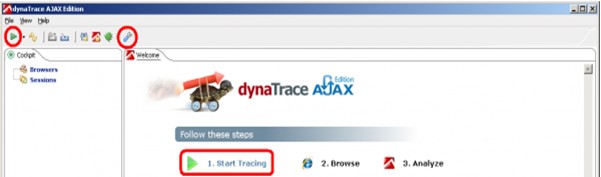
开始分析之前运行配置和预置功能
dynaTrace使用被称为运行配置的方式,使你可以直接浏览你要分析的网站而不用每次都要在你的浏览器里键入url。你可以通过左上角工具栏中的下拉菜单来管理你的运行配置(添加新的、修改或者删除现有的配置)。选择Manage Run Configuration来预置http://www.google.com网站,参看下面的截图:

管理网址
如截图所示,也可以让dynaTrace在开始追踪网站之前情空浏览器缓存。这一功能在你要测试你的网站在没有缓存的情况下运行的怎么样时非常有用。另外一件重要的事是通过点击工具栏最右侧的按钮可以启动Preference(预置)对话框。
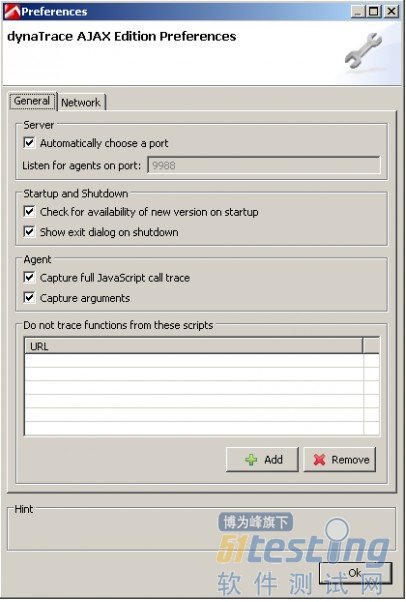
在Preference对话框中启用捕捉参数
你可以在这里指定多个不同的配置。值得注意的是那个开启/关闭捕捉JavaScript和DOM方法调用的选项,以及开启/关闭Javascript一般追踪的选项。在下面的练习里,请勾选“Capture arguments”以及“Capture full JavaScript call trace”选项。
第三步:开始分析Google Maps
让我们开始吧。你既可以通过选择工具栏中的Google运行配置,或者点击欢迎界面的“Start Tracing”,再或者直接按F4快捷键来启动软件。接下来,dynaTrace将启动一个IE的新窗口。如果你选择了清除浏览器缓存,dynaTrace将在打开http://www.google.com之前开始执行这个操作(这可能会占用几秒钟的时间)。你可以通过浏览器程序图标是否改变来判断dynaTrace此时是否正在追踪页面执行过程——你会在浏览器窗口的左上角看到一个小dynaTrace图标,以及一个dynaTrace工具栏显示“已连接”:
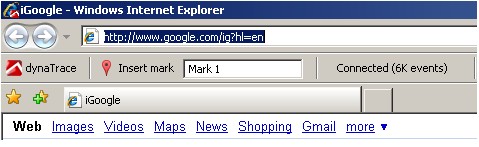
通过dynaTrace启动浏览器
如果你没有看到这种情况出现,请到论坛的General Usage Question(译者注:常见使用问题)版块查询故障排除技巧,或者通过在线反馈或论坛联系我们。接下来,请跟我完成这些步骤:
在搜索框里一字一顿的键入“dynaTrace”——每次输入,你都会看到弹出Google的搜索建议框
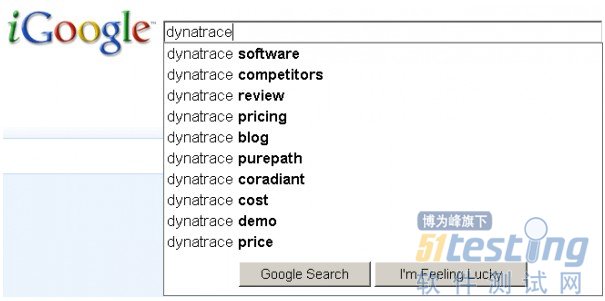
搜索“dynaTrace”
完成输入后,按回车键或者点击Google Search按钮;
当出现搜索结果后,点击页面顶部的“Maps”链接,切换到Google Maps;
你将看到很多关于dynaTrace地点的搜索结果。点击在“95 Hayden Avenue,Lexington,MA”的“dynaTrace Software”,让地图显示这个地址。
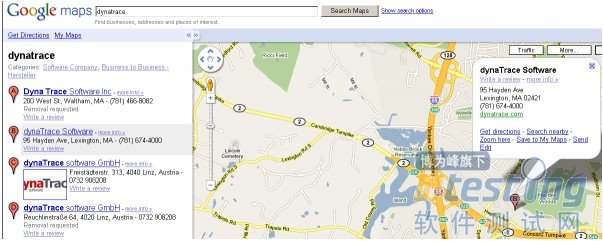
用Google Maps搜索dynaTrace
这是我的测试结果。在我们关闭浏览器之前,你可以快速看一下dynaTrace软件界面,你会看到在“Bowsers”下面有一个节点,那就是当前正在从IE中收集的信息。我们可以在运行浏览器的同时分析这些数据,也可以关闭浏览器,然后再分析我们捕获的。让我们动手分析吧——关闭浏览器,切换回dynaTrace AJAX软件界面。
第四步:Summary视图(摘要视图)——高级分析
浏览器中记录的事件被自动存储在一个session(译者注:会话)中,我们可以在浏览器关闭的情况下分析这些被捕获的浏览器活动记录。在左侧cockpit面板中,你可以双击session,或者展开这个session节点,双击Summary节点。这两种操作都会启动Summary视图,它为我们呈现session记录中所有活动的高级分析结果:
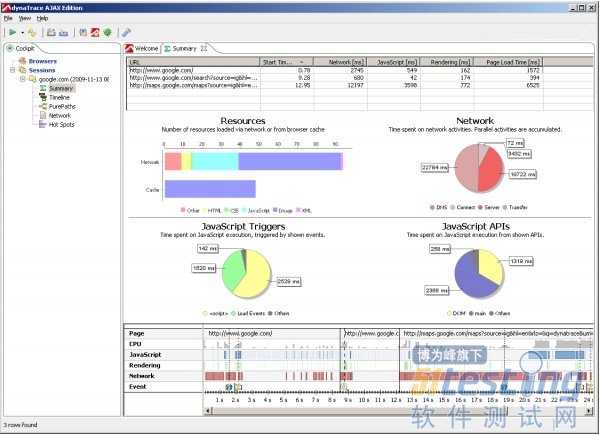
Summary视图显示每个访问过的URL的高级分析结果
Summary视图显示了session记录中所有访问过的URL链接的信息。点击顶部表格中某个具体的url下方就会更新图表和时间线来显示所选链接的数据。在这个视图中我们可以得到以下信息:
载入页面所耗时间:Page Load Time[ms](页面载入时间[毫秒])栏显示从页面开始载入到浏览器派发onload事件所经历的时间;
网络请求花了多长时间:下方NetWork饼图从DNS解析、网络连接、服务器响应以及网络传输方面详细分解网络请求过程,由于网络内容在这段时间里是并行下载的,所以NetWork[ms]栏则显示的是所有网络请求时间的总和;
下载了多少以及什么类型的资源文件,对比有多少资源是从浏览器缓存读取的(Resource条形图);
通过JavaScript触发器(脚本载入、载入完毕、鼠标、键盘等事件)和JavaScript API或库执行的所有JavaScript函数一共耗时多长时间;
渲染页面所占时间。浏览器必须计算布局并渲染页面显示。浏览器重新计算布局和重绘的时间取决于你的HTML、样式表以及动态DOM操作。Rendering[ms]栏显示了页面在渲染工作上实际消耗的时间。
屏幕下方的时间轴图显示精确的页面生命周期:该图反映了页面进程中网络资源下载、JavaScript执行、页面发生渲染的时间,CPU占用情况,以及发生了哪些事件。例如:onLoad事件、鼠标或键盘交互、XmlHttpRequests等。
在我们的例子中,以下内容引起了我的注意:
maps.google.com页面的页面载入时间为6.5秒:这是页面在派发onload事件之前浏览器初始化html和所有引用的对象所消耗的时间;
这页面的网络时间耗时12秒。当我观察该页面的Network饼图时,我发现50%多的时间消耗在传输内容(这也可能意味着我的网速慢)上,42%的时间花在服务器响应上(指过了多长时间服务器开始响应),以及8%的时间消耗在与服务器建立物理连接上。
总耗时3.6秒的JavaScript也是重要角色。JavaScript trigger饼图显示时间的具体消耗情况:载入script耗时2.1秒,onload事件派发耗时1.3秒,剩下的由鼠标点击事件处理占用。
时间轴还显示页面发出了2个XmlHttpRequest请求。它由一个小图标标注在event行中请求发生的时间点上。下一节将进行更详细的讨论。
通过dynaTrace启动浏览器
如果你没有看到这种情况出现,请到论坛的General Usage Question(译者注:常见使用问题)版块查询故障排除技巧,或者通过在线反馈或论坛联系我们。接下来,请跟我完成这些步骤:
在搜索框里一字一顿的键入“dynaTrace”——每次输入,你都会看到弹出Google的搜索建议框
搜索“dynaTrace”
完成输入后,按回车键或者点击Google Search按钮;
当出现搜索结果后,点击页面顶部的“Maps”链接,切换到Google Maps;
你将看到很多关于dynaTrace地点的搜索结果。点击在“95 Hayden Avenue,Lexington,MA”的“dynaTrace Software”,让地图显示这个地址。
用Google Maps搜索dynaTrace
这是我的测试结果。在我们关闭浏览器之前,你可以快速看一下dynaTrace软件界面,你会看到在“Bowsers”下面有一个节点,那就是当前正在从IE中收集的信息。我们可以在运行浏览器的同时分析这些数据,也可以关闭浏览器,然后再分析我们捕获的。让我们动手分析吧——关闭浏览器,切换回dynaTrace AJAX软件界面。
第四步:Summary视图(摘要视图)——高级分析
浏览器中记录的事件被自动存储在一个session(译者注:会话)中,我们可以在浏览器关闭的情况下分析这些被捕获的浏览器活动记录。在左侧cockpit面板中,你可以双击session,或者展开这个session节点,双击Summary节点。这两种操作都会启动Summary视图,它为我们呈现session记录中所有活动的高级分析结果:
Summary视图显示每个访问过的URL的高级分析结果
Summary视图显示了session记录中所有访问过的URL链接的信息。点击顶部表格中某个具体的url下方就会更新图表和时间线来显示所选链接的数据。在这个视图中我们可以得到以下信息:
载入页面所耗时间:Page Load Time[ms](页面载入时间[毫秒])栏显示从页面开始载入到浏览器派发onload事件所经历的时间;
网络请求花了多长时间:下方NetWork饼图从DNS解析、网络连接、服务器响应以及网络传输方面详细分解网络请求过程,由于网络内容在这段时间里是并行下载的,所以NetWork[ms]栏则显示的是所有网络请求时间的总和;
下载了多少以及什么类型的资源文件,对比有多少资源是从浏览器缓存读取的(Resource条形图);
通过JavaScript触发器(脚本载入、载入完毕、鼠标、键盘等事件)和JavaScript API或库执行的所有JavaScript函数一共耗时多长时间;
渲染页面所占时间。浏览器必须计算布局并渲染页面显示。浏览器重新计算布局和重绘的时间取决于你的HTML、样式表以及动态DOM操作。Rendering[ms]栏显示了页面在渲染工作上实际消耗的时间。
屏幕下方的时间轴图显示精确的页面生命周期:该图反映了页面进程中网络资源下载、JavaScript执行、页面发生渲染的时间,CPU占用情况,以及发生了哪些事件。例如:onLoad事件、鼠标或键盘交互、XmlHttpRequests等。
在我们的例子中,以下内容引起了我的注意:
maps.google.com页面的页面载入时间为6.5秒:这是页面在派发onload事件之前浏览器初始化html和所有引用的对象所消耗的时间;
这页面的网络时间耗时12秒。当我观察该页面的Network饼图时,我发现50%多的时间消耗在传输内容(这也可能意味着我的网速慢)上,42%的时间花在服务器响应上(指过了多长时间服务器开始响应),以及8%的时间消耗在与服务器建立物理连接上。
总耗时3.6秒的JavaScript也是重要角色。JavaScript trigger饼图显示时间的具体消耗情况:载入script耗时2.1秒,onload事件派发耗时1.3秒,剩下的由鼠标点击事件处理占用。
时间轴还显示页面发出了2个XmlHttpRequest请求。它由一个小图标标注在event行中请求发生的时间点上。下一节将进行更详细的讨论。
第五步:Timeline视图(时间轴视图)——近距离观察页面生命周期事件
时间轴视图可以通过双击Cockpit面板中的Timeline节点打开,或者在Summary视图中通过在某个URL上点击右键,选择“Drill Down-TimeLine”打开。我们用这种方式打开maps.google.com页面:
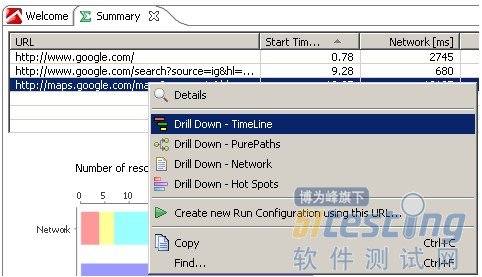
查看某个url的Timeline
点击“drill down(译者注:详细)”菜单将打开所选页面的Timeline视图,通过工具栏和右键菜单,你可以打开更多选项,比如内容类型和JavaScript触发器的颜色值,或者显示更多事件,比如鼠标移动,点击和键盘事件。下面的截图显示时间轴开启更多选项的效果:
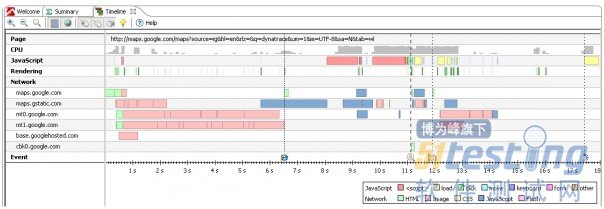
针对选定页面的Timeline显示网络、JavaScript、渲染、CPU和事件
我们可以在此视图下做如下观测:
网络请求并行下载来自6个不同域的内容;
到浏览器派发onload事件大约需要6.5秒(图中由IE图标标识);
从maps.gstatic.com下载main.js耗时2.41秒(鼠标悬停在这段上可以看到详细信息);
main.js下载完成后,可以看到脚本实际执行耗时1.1秒,并触发两个JavaScript文件的下载(1秒)和另外2个JavaScript的执行(2秒);
CPU占用率显示JavaScript执行占用的浏览器CPU时间;
Event轴显示了鼠标点击事件,XmlHttpRequest事件和onUnload事件。
我们缩大鼠标第一次点击到产生XmlHttpRequest请求的时段。在我的例子中,这个时间片是从11秒到12秒。通过在开始处点击鼠标左键拖拽到结束位置来执行放大操作。当你松开鼠标拖拽的,视图将放大到下面截图中显示的时间片上:

放大时间轴以显示事件详细信息
时间轴上显示了点击事件,一个XmlHttpRequest事件,其后紧随一个onError事件,再后一点还有一个XmlHttpRequest(XHR)事件。鼠标悬停在事件上将显示实际派发事件的DOM元素。鼠标悬停在JavaScript上将显示脚本执行事件处理的时间,悬停在network请求上将显示下载了哪些资源。我们也能看到浏览器执行了哪些类型的渲染。我们发现第一次鼠标点击事件处理函数触发新内容的加载——包括一个来自maps.gstatic.com的JavaScript文件。执行这个JavaScript文件——一旦它被加载以后——触发了一个XHR请求。我们还能看到一个onError时间处理函数被触发并且运行了240毫秒。
第六步:PurePath视图(路径视图)——JavaScript、DOM和Ajax问题的详细说明
从Timeline视图(和从其他视图一样)我们可以更进一步进入每个动作去观察事件触发执行了哪些JavaScript函数和哪些JavaScript函数发出了XHR请求。在时间轴上点右键选择“Drill Down to Timeframe”(进入详细时间片)将来到PurePath视图,并显示当前所放大的时间片上所有的活动——如下图:
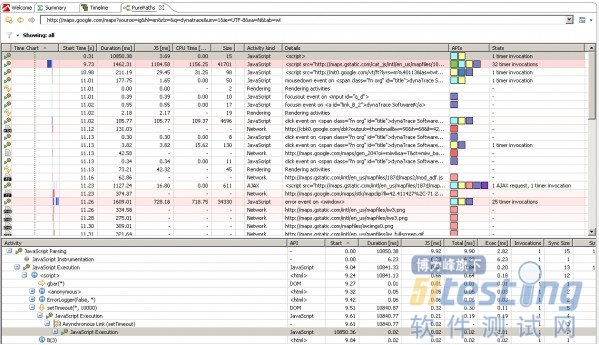
进入指定时间片的PurePath视图
在界面上方,我们可以看到所选时间片中浏览器的所有活动,包括由script标签或事件响应触发的JavaScript的执行情况。也包括网络请求和渲染次数。Stats(译者注:统计)栏显示该行执行的JavaScript触发的是计时器还是Ajax请求。那些占总体响应时间较多的活动会被彩色高亮显示。
在PurePath列表中选择一个活动,PurePath或JavaScript追踪树将更新显示当前所选活动的信息。PurePath树显示了JavaScript代码执行过程,包括每个方法执行的时间和调用的参数以及返回值(我们在第二步中开启了参数捕获选项)。代码跟踪也追踪计时器调用,并把这些调用当做树的一部分。我们不仅能看到JavaScript方法,也能看到DOM访问和AJAX请求。
我们后退一步,回到前一个Timeline视图。我对Ajax请求比较感兴趣。双击Event行中的图标打开一个新的PurePath视图,软件会在JavaScript跟踪中找出实际执行这个XmlHttpRequest的位置:
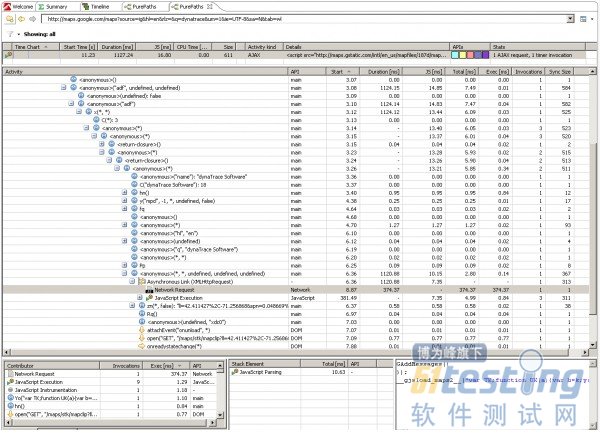
进入PurePath视图分析XmlHttpRequest细节
在界面上方我们能看到的执行这段代码的JavaScript文件——请看Details栏。在树中我们能看到发出这个XHR请求的整个JavaScript执行过程,包括方法调用次数和调用参数。duration栏显示JavaScript执行共耗时1127毫秒。这个时间包含了XHR返回的时间和等待JavaScript计时器的时间。打开这个网络请求的详细信息(译者注:在PurePath树中定位的Network Request上点右键,选择“Details”),将显示Http请求和响应头、请求的精确时间,包括连接、等待、服务器响应和网络传输时间,还有从服务器返回的实际内容(译者注:在Details面板底部有个切换标签Details/Response Content可以查看)。

XmlHttpRequest请求详细信息
这个请求有趣的地方是服务器花了372毫秒返回了一个空的json对象。从这我们可以继续分析,看一下是什么实际完成这个Ajax响应的。回到PurePath树,我们“drill down”到onreadystatechange事件处理函数(译者注:在NetWork Request下有三个“JavaScript Execution”,是onreadystatechange触发的三次函数调用,展开第三个可以看到这里的readyState为4,开始调用响应函数,一个匿名函数anonymous即是onreadystatechange的事件处理函数)。下面的截图显示了这个处理函数,右下方显示这个函数的代码:
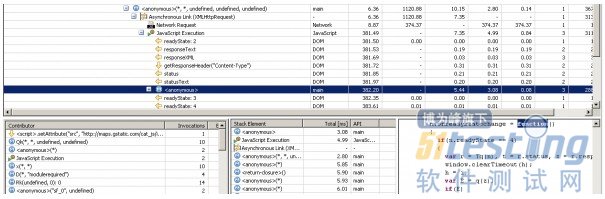
分析XHR请求的JavaScript处理函数
这里最有意思的是左下方Contributor栏显示了当前所选子树的所有JavaScript活动。最上面一行显示使用了一个动态script标签,标签的内容被写入一段脚本来让浏览器动态加载了一个JavaScript文件。双击Contributor栏中的这条数据定位到PurePath树中的位置(译者注:可能要拖动横向滚动条、拉宽PurePath树的显示宽度才能看到,这个位置折叠的层级很深):

动态创建一个Script标签并插入到DOM中
在这里我观察到:
一个计时器用了大概740毫秒来触发计时器处理函数——注意截图中第三行的setTimeout方法调用;
创建了一个动态Script标签,并把它添加到head中,指示浏览器下载这个Script文件。(译者注:通过观察我觉得“<标签名>”即指代一个[标签名]类型的DOM对象,.setAttrbute、.appendChild即为调用该DOM对象的DOM方法。)
PurePath视图提供了多种分析方法。你可以通过直接键入(译者注:几乎在任何地方都可以执行键入查找操作,只要点击一下要查找信息的控件,使其获得焦点,然后按键即可)你要查找的内容来筛选或查找你需要的数据项。通过右键菜单或工具栏按钮添加过滤规则可以让软件只显示特定信息。
第七步:Network视图(网络视图)——分析“对话”
Network视图显示了发生在浏览器或各自页面中的所有网络请求。通过双击左侧Cockpit面板中的Network节点,或从Summary视图中某个URL上右击选择“Drill Down – Network”进入到Network视图。在我的例子中,我回到Summary视图,然后“Drill Down”进入maps.google.com的Network视图:
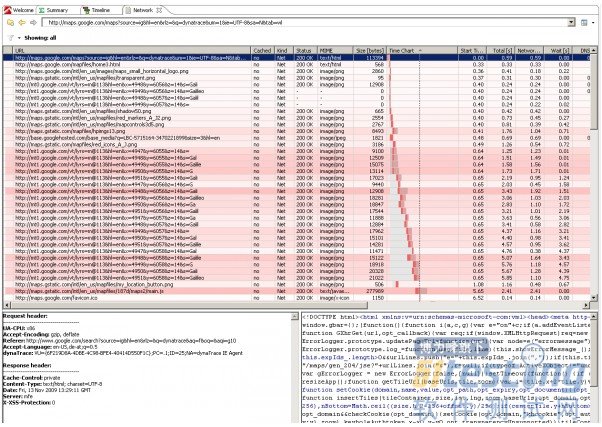
Network视图高亮标记出超慢的请求以及连接等待时间
这个视图下会用颜色标记每个请求,并且用红色高亮标记出耗时最长的下载请求。默认情况下,这个视图是按“Time Chart”栏排序的,Time Chart栏显示浏览器发送的请求队列。
从每个请求上我们可以到的资源是否来自浏览器缓存(Cached栏),请求类型(Network或Ajax),HTTP状态,Mime类型,大小,在DNS、网络连接、服务器响应、网络传输和等待上消耗的时间。界面底部显示了HTTP请求和响应头以及返回的实际内容。这个页面中有趣的地方是从mt0.google.com和mt1.google.com取回数据时的等待时间。每个浏览器针对每个域名都有一个连接数上限。
在我的例子中(WinXP系统,IE7浏览器)是每个域名最多保持两个连接数。20个PNG图片从两个域中加载过来。由于连接数限制,使得每个域名只能并行下载两个图片。其他图片便是不得不等待一个可用的连接数。这就解释了为什么这些图片和不断增加的等待时间呈“瀑布”型。我们可能不希望在不同浏览器和不同连接数情况下出现像这里这样的效果。解决这个问题是使用域名碎片(Domain Sharding)或者CSS拼图(CSS Sprite)。
和其他视图一样,从这里可以进入PurePath。我们定位到页面上第二个Ajax请求。对Kind列进行排序,然后选择一个响应类型为text/xml的请求。点击鼠标右键,选择Drill Down->PurePath,进入PurePath视图,软件将自动定位到JavaScript追踪中发出这个XHR请求的JavaScript函数上。

进入PurePath视图
如果你的服务端运行有dynaTrace APM,则可以进入Server-side PurePath视图,将显示Java或.NET程序在服务端响应Ajax请求执行的细节。这里有视频可以了解更多。
第八步:Hotspot视图(热点视图)——哪些地方降低了性能
最后一个有趣的视图就是Hotspot视图。通过Cockpit面板打开,或者Summary视图打开来分析一个具体URL。本例中我们从Cockpit中打开HotSpot视图来分析我访问过的页面中所有的JavaScript、DOM和渲染动作。
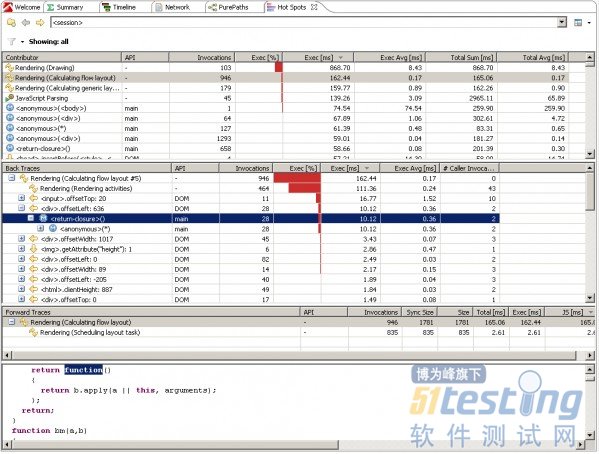
Hotspot视图显示了有问题的活动,包括活动前后的追踪
上方的表格以聚合的方式显示所有JavaScript、DOM和渲染动作。我们可以看到130次的Drawing动作,946次Reflow动作以及在一个div上调用了一个匿名函数1293次。这个列表是按总的执行时间排序的,性能越高排序越靠上。
双击这些中的一个,将显示它执行前后的追踪结果。Back Traces表显示了谁来调用这些动作,Forward Traces表显示的是这个动作又触发了哪些动作。界面底部显示了在Back Traces树或Forward Traces树中选中的JavaScript的源码。我双击了那个调用946次的reflow动作。reflow动作在浏览器下载图片或者其他对象或者应用样式时触发。不过,它也在访问某些DOM属性或调用某些DOM方法时触发。在Back Traces中显示读取offset或height属性会引起浏览器渲染引擎的一个reflow动作。回溯可以看到哪个JavaScript方法访问了DOM。从界面上方的Contributor表可以进入PurePath视图。打开PurePath将展开包含当前选中的方法的PurePath树——类似前面我们展开XHR请求的PurePath树。
第九步:自动化数据集
除了用dynaTrace手动收集数据,也可以用脚本工具代替人工方式驱动浏览器自动收集数据。当你用像Selenium、Watir、WebAii这样的工具运行测试脚本是,dynaTrace可以自动从每个浏览器session中收集性能信息。这里有篇博文《5步实现性能自动分析》,教你如何用Watir配合dynaTrace自动分析。
第十步:与你的同事分享数据
收集信息并制成离线版分析数据是dynaTrace的功能之一,上面你已经领略到了。如果你在别人的代码中发现了问题,或者你想跟你的同事分享你的发现,你需要一种简单的方式共享你收集到的数据。这可以通过把你的session导出为session文件实现。在Cockpit面板中的右键菜单或者工具条里的导出按钮能完成这一工作。导入文件的操作与此类似。
导入导出dynaTrace session文件
总结和反馈
dynaTrace AJAX版是一款非常棒的针对IE6、7、8的分析和测试工具。社区已大力推广第一个官方版软件,它兼容前一个测试版。我们鼓励大家积极参与这款软件的推进工作,通过社区网站或软件工具栏的报告功能报告使用问题。

工具栏中的反馈、分享和报告问题按钮
工具栏里有三个按钮可以让你与好友分享这款软件、给我们反馈信息或者报告使用问题。目前我们的许多客户使用AJAX版来确定和解决他们的浏览器前端组件问题,至今我们已经从他们那里得到了一些很好的意见。这些用户也使用了集成dynaTrace无缝APM解决方案,为他们提供从浏览器到后台的端到端全方位分析。感谢你跟着我一起完成了这个有点长的学习指南。欢迎给这篇博客留言,说说你在dynaTrace或者其他工具使用上的经验。
原文地址http://www.wangyuxiong.com/archives/51421
打印URL
上一节讲到,可以将浏览器的title打印出来,这里再讲个简单的,把当前URL打印出来。其实也没啥大用,可以做个凑数的用例。
#coding=utf-8 from selenium import webdriver
import time browser = webdriver.Firefox() url= 'http://www.baidu.com' #通过get方法获取当前URL打印
print "now access %s" %(url)
browser.get(url) time.sleep(2)
browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
time.sleep(3)
browser.quit() |
其实,我们可以把这用户登录成功后的URL打印,用于验证用户登录成功。
又或者,我们打印其它信息,比如,一般的登录成功页会出现“欢迎+用户名”,可以将这个信息打印表明用户登录成功。(如何实现,你自己琢磨一下吧~!)
将浏览器最大化
我们知道调用启动的浏览器不是全屏的,这样不会影响脚本的执行,但是有时候会影响我们“观看”脚本的执行。
#coding=utf-8 from selenium import webdriver
import time browser = webdriver.Firefox() browser.get(http://www.baidu.com)
time.sleep(2) print "浏览器最大化"
browser.maximize_window() #将浏览器最大化显示
time.sleep(2) browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
time.sleep(3)
browser.quit() |
设置浏览器固定宽、高
最大化还是不够灵活,能不能随意的设置浏览的宽、高显示?当然是可以的。
#coding=utf-8
from selenium import webdriver
import time browser = webdriver.Firefox() browser.get(http://m.mail.10086.cn)
time.sleep(2) print "设置浏览器宽480、高800显示"
browser.set_window_size(480, 800) #参数数字为像素点
time.sleep(3)
browser.quit() |
这个需求也还是有的,比如我们通过PC浏览器在访问一下手机网站时,调整浏览器为手机屏幕的宽、高,容易发现一些显示问题。(上面的手机邮箱网站就是笔者测试过的一个产品)
操控浏览器前进、后退
浏览器上有一个后退、前进按钮,对于浏览网页的人是比较方便的;对于做web自动化测试的同学来说应该算是一个比较难模拟的问题;其实很简单,下面看看python的实现方式
#coding=utf-8 from selenium import webdriver
import time browser = webdriver.Firefox() #访问百度首页
first_url= 'http://www.baidu.com'
print "now access %s" %(first_url)
browser.get(first_url)
time.sleep(2) #访问新闻页面
second_url='http://news.baidu.com'
print "now access %s" %(second_url)
browser.get(second_url)
time.sleep(2) #返回(后退)到百度首页
print "back to %s "%(first_url)
browser.back()
time.sleep(1) #前进到新闻页
print "forward to %s"%(second_url)
browser.forward()
time.sleep(2) browser.quit() |
为了使过程让你看得更清晰,在每一步操作上都加了print 和sleep 。
说实话,这两个功能平时不太常用,所能想到的场景就是几个页面来回跳转,但又不想用get url的情况下。
相关文章:
轻松自动化---selenium-webdriver(python) (一)
轻松自动化---selenium-webdriver(python) (三)
通常java应用程序在访问数据库时,直接创建一个数据库连接,使用完毕后释放连接。
如图:

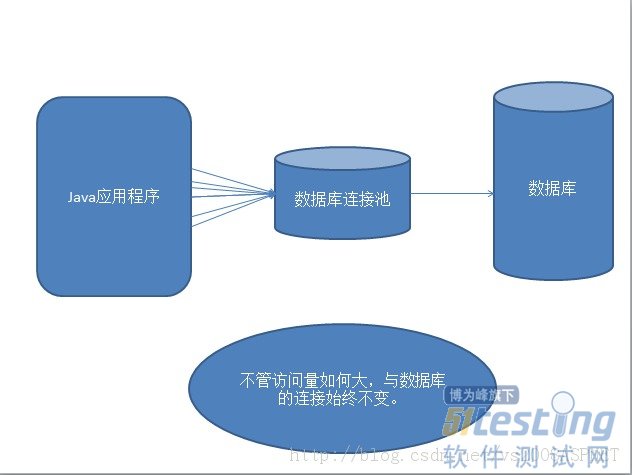
当数据库连接量小的时候这样做并无不妥,但若在访问量大的时候就显得低效了,如某网站一天访问量在1000万次,那么在这一天web应用程序与数据库就要进行等量的连接和断开操作。
为了解决这个问题,引入了数据库连接池技术(个人认为数据库连接池技术是为解决这个问题的),它是批量创建一批数据库连接,放到一个数据库连接池,在需要数据库连接时,就像这个池子拿,用完后则将数据库连接还回池子,数据库连接的维护由池负责维护,这样不管访问量如何大,程序与数据库的连接是不变的,不过当数据库连接池的连接已用完,这时又有新的连接请求,此时池中已无连接,那么就只能等待或返回异常,所以数据库连接池一次批量创建的连接数量应根据实际情况来设置。
采用数据库连接池技术如图:
根据数据库连接池工作原理来手动写一个数据库连接池,实现基本功能。
1.从池中拿出数据库连接
2.用完后还回池里
3.数据库连接的存放与维护
Code
package xgn.jdbc; import java.io.InputStream;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
import java.sql.Connection;
import java.sql.DriverManager;
import java.util.LinkedList;
import java.util.Properties; /***
* 数据库连接池实现类
* @author dream
*
*/
public class JDBCPool {
//存放连接的集合
private static LinkedList<Connection> dblist=new LinkedList<Connection>();
//连接池容量
private static final int number=100;
static{
try{
Properties config=new Properties();
InputStream in= JDBCPool.class.getClassLoader().getResourceAsStream("config.properties");
config.load(in);
for(int i=0;i<number;i++){
Connection cn= DriverManager.getConnection(config.getProperty("Connstr"),config.getProperty("user"),config.getProperty("pwd"));
ConnectionProxy conn=new ConnectionProxy(cn);
Connection proxycn=conn.getConnectionProxy(cn,new Class[]{Connection.class},conn);
dblist.addFirst(proxycn);
}
}catch(Exception ex){
throw new RuntimeException(ex);
}
}
public static void recoverConnection(Connection cn){
dblist.addFirst(cn);
}
public static Connection getConnection(){
if(dblist.size()<=0){
throw new RuntimeException("数据库连接池无数据库连接!");
}
return dblist.removeFirst();
}
public static int getConnectionNumber(){
return dblist.size();
}
/***
* 数据库连接代理类
* @author dream
*
*/
public static class ConnectionProxy implements InvocationHandler {
private Object obj=null;
private Object proxyobj=null;
@Override
public Object invoke(Object arg0, Method arg1, Object[] arg2)throws Throwable {
Object ret=null;//方法返回值
if(arg1.getName()=="close"){
System.out.println("close");
JDBCPool.recoverConnection((Connection)this.proxyobj);
return ret;
}
ret=arg1.invoke(this.obj, arg2);
return ret;
}
public ConnectionProxy(Connection cn){
this.obj=cn;
}
public Connection getConnectionProxy(Connection cn,Class[] cls,InvocationHandler h){
this.proxyobj= Proxy.newProxyInstance(cn.getClass().getClassLoader(),cls,h);
return (Connection)this.proxyobj;
}
}
} |
常用的数据库连接池有:DBCP、tomcat 的数据库连接池(内部也是DBCP)、C3P0等。
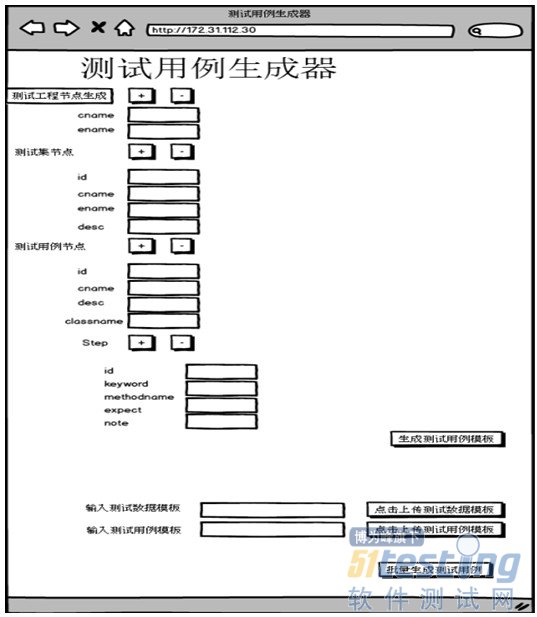
Fitnesse是通过wiki形式来展示、管理和执行测试用例,若要在Fitnesse上设计测试用例,前提是必须熟悉一定的wiki语法,虽然wiki语法简单,但是若要设计成百上千的测试用例还是有很大的工作量。特别是针对接口测试,测试用例的复杂度和接口本身参数的复杂度会是测试用例脚本编写的工作量增大。因此如何能够自动化生成测试用例脚本是本阶段的一个重点需求。
针对单一接口测试(单个接口)用例脚本的生成功能我们已经在第一阶段解决,如何对于复杂流程如包含多个接口调用的测试用例进行用例脚本生成是本阶段重点。
关于具体设计思路如下所示:ccuwtuny
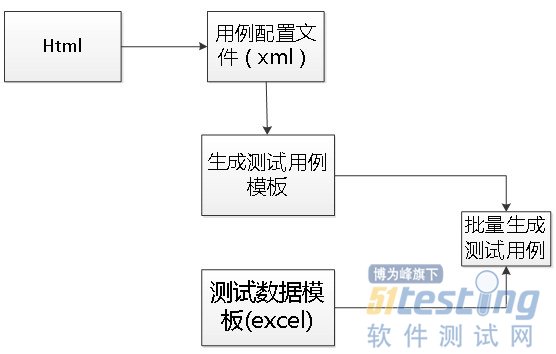
主要是通过Html这种可以点击操作的方式去生成一个用例配置文件,这个用例配置文件如下图所示:

Html上可以通过增加或删除节点来产生用例配置文件,如下图所示:
1,首先创建数据库工具类 DButil.java
代码如下:
package com.dd.dd.util; import android.content.Context;
import android.database.sqlite.SQLiteDatabase;
import android.database.sqlite.SQLiteOpenHelper;
import android.util.Log; public class DButil extends SQLiteOpenHelper {
private static final int VERSION = 1; // 此处控制版本信息
private static final String DBNAME = "school.db";// 此处是要创建的数据库名
private static final String TAG = "DButil"; // 这个是要输出的标签名 public DButil(Context context) { // 创建构造方法,把Content对象传进去
super(context, DBNAME, null, VERSION); // 调用父类
} @Override
public void onCreate(SQLiteDatabase db) { // 当没找到表时,就返回来执行这个方法,去创建表
Log.i(TAG, "执行onCreate()方法");
db.execSQL("create table student (id integer primary key,name varchar(20))"); // 创建表
Log.i(TAG, "执行完onCreate()方法");
} @Override
public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) { // 这个方法是控制版本的
} } |
2,第二步是要创建dao层,dao层在学习javaee时大家都已经深刻接触了吧!这里就不多说了StudentDao
代码如下:
package com.dd.dd.dao; import java.util.List; import android.content.Context;
import android.database.Cursor;
import android.database.sqlite.SQLiteDatabase;
import android.util.Log; import com.dd.dd.model.Student;
import com.dd.dd.util.DButil; public class StudentDao {
private DButil helper;
private SQLiteDatabase db;
private static final String TAG = "StudentDao"; // 这里也是一个标签,大家看自己要输出什么,就。。。 public StudentDao(Context context) {
helper = new DButil(context); // 这里是在构造方法里调用刚才那个数据库工具类DButil.java
} // 添加
public void add(Student student) {
db = helper.getWritableDatabase(); //调用getWritableDatabase()
Log.i(TAG, student.getName() + student.getId()); //在日志输出那里输出获得的数据
db.execSQL("insert into student (id,name) values(?,?)", new Object[] {
student.getId(), student.getName() }); //这里是执行添加语句,和mysql都是一致的
} } |
3,接下来就是创建测试类方法StudentDaoTest.java
代码如下
package com.dd.dd.dao; import android.test.AndroidTestCase;
import android.util.Log; import com.dd.dd.model.Student; public class StudentDaoTest extends AndroidTestCase {
private static final String TAG = "StudentDaoTest"; // 标签名 public void testadd() {
Log.i(TAG, "数据库连接成功!"); // 输出日志
StudentDao studentDao = new StudentDao(this.getContext()); // 创建StudentDao实例,并传入this.getContext()
Student student = new Student(); // 创建Student实例,Student就是bean类
student.setId(1); // 传递数据
student.setName("旺旺");
studentDao.add(student);// 调用add方法
Log.i(TAG, "数据添加成功!");
}
} |
然后就这些了,忘了给大家写那个Student类的代码了,
其实里面就是一个id 还有一个name 俩个属性,然后封装就完成了!

然后就是运行并且看日志输出就可以了
lint简史
1979年,贝尔实验室SteveJohnson于1979在PCC(PortableCCompiler)基础上开发的出了代码分析工具Lint,可以检查出很多的不符合规范的的错误(如将“==”写成了“=”)以及函数接口参数不一致性的问题等,完成代码健壮性的检查。Lint后来形成了一系列的工具,包括PC-Lint/FlexeLint(Gimpel),LintPlus(Cleanscape)以及Splint.
功能
通常C/C++编译器假设程序是正确的,Lint恰好相反,因此它有优于编译器执行的一般性的代码检查。Lint还可以在多个文件之间执行错误检查和代码分析。下面是一些Lint可以检查出来的部分的错误列表:
可能的空指针
在释放内存后使用了指向该内存的指针
赋值次序问题
拼写错误
被0除
失败的case语句(遗漏了break语句)
不可移植的代码(依赖了特定的机器实现)
宏参数没有使用圆括号
符号的丢失
异常的表达式
变量没有初始化
可疑的判断语句(例如,if(x=0))
printf/scanf的格式检查
现有的Lint程序主要有两个版本:①PC-Lint,由GimpelSoftware提供的支持C/C++的商用程序。官方地址:http://www.gimpel.com/html/pcl.htm②Splint(原来的LCLint)是一个有GNU免费授权的Lint程序,只支持c,而不支持c++.官方地址:http://www.splint.org/
由于PC-lint是商业软件,虽说功能强大,但是容易获取。这里主要介绍GNU的splint工具。
开源的代码静态分析工具SP-lint
Splint是一个动态检查C语言程序安全弱点和编写错误的一个程序,会进行多种错误检查:未使用变量,类型不一致,使用未定义的变量,无法执行的代码,忽略返回值,执行路径没有返回,无限循环等错误。
Splint的安装
1.在Linux下的安装
1.1rpm安装:
rpm-ivh splint.xxx.rpm
rpm安装包是著名的Linux发行商Redhat推出的基于源代码的软家包方式。这种安装方式的缺点是如软件依赖项有很多并且你没有安装那些依赖项时,哈哈,恭喜你,你有事忙了,需要满互联网的找到那些依赖项并安装好;如果依赖项还有依赖项并且你又没有安装,我只能说,哥们你中彩了。
1.2Ubuntu或者Debian下安装
sudoapt-get install splint
这种安装最省事,唯一的缺点是,安装的软件的版本可能不是最新的,以及总是按照默认的配置来安装的软件的---不够灵活
1.3源代码安装(通用)
tar -zxvf splint-3.1.2.src.gz
cd xxx/splint-3.1.2
./configure
make
makeinstall |
2.在window下安装
可以使用源代码安装的方式.最新的官网提供了window下的软件安装包(msi格式),地址是:https://github.com/maoserr/splint_win32/downloads
由于本人使用的是Ubuntu12.04LTS,splint安装使用的是apt-get的安装方式,splint的版本是3.1.2,以下的介绍都是以次为基础的。
3.splint的应用
空引用错误:/*@null@*/--splint支持的注释类型,表明其后跟随的值可能为null
实例程序,null.c:
/*Program:null.c -- a example code for null reference error*/
//'/*@null@*/'is a special annotation the splint tool supported
char firstChar1(/*@null@*/char*s){
return *s;
}
char firstChar2(/*@null@*/char*s){
if(s ==NULL) return '\0';
return *s;
} |
splint命令: splint null.c
结果输出:
Splint 3.1.2--- 03 May 2009
Spec filenot found: null.lcl
null.c:2:65:Comment starts inside comment
A commentopen sequence (/*) appears within a comment. This usually means an
earliercomment was not closed. (Use -nestcomment to inhibit warning)
null.c: (infunction firstChar1)
null.c:4:10:Dereference of possibly null pointer s: *s
A possiblynull pointer is dereferenced. Value is either the result of a
functionwhich may return null (in which case, code should check it is not
null), ora global, parameter or structure field declared with the null
qualifier.(Use -nullderef to inhibit warning)
null.c:3:33:Storage s may become null
Finishedchecking --- 2 code warnings |
函数firstChar1和firstChar2都使用了null的说明,表示指针s可能是一个空指针,所以splint会对s的值使用情况进行检查,由于firstChar2中对s的值进行了判断,所以没有对firstChar2函数中s输出警告信息。
未定义变量错误:C中使用没有定义变量会出错,/*@in@*/说明的变量表示必须先进行定义./*@out*@/表明在执行过函数后,这个变量就进行了定义。--个人感觉/*@out*@/类似与C#中的out关键字。
实例1:usedef.c
/*Program:usedef.c -- use splint check the varible undefined error or warnings */
//out represent varible *x will be defined after execution of function
extern void setVal(/*@out@*/int *x);
//in represent varible *x has been defined before the execution.
extern int getVal(/*@in@*/ int *x);
extern int mysteryVal(int *x);
int dumbfunc(/*@out@*/int *x,int i){
if(i>3) return *x;
else if(i>1)
return getVal(x);
else if(i==0)
return mysteryVal(x);
else{
setVal(x);
return *x;
}
} |
splint命令:splint usedef.c
splint执行的结果:
Splint 3.1.2--- 03 May 2009
usedef.c:(in function dumbfunc)
usedef.c:8:17:Value *x used before definition
#在一些执行路径中一个右值的被使用的时候可能没被初始化,
An rvalueis used that may not be initialized to a value on some executionpath. (Use-usedef to inhibit warning)
usedef.c:10:17:Passed storage x not completely defined (*x is undefined):
getVal(x)
Storagederivable from a parameter, return value or global is not defined.
Use/*@out@*/ to denote passed or returned storage which need not bedefined.
(Use-compdef to inhibit warning)
usedef.c:12:21:Passed storage x not completely defined (*x is undefined):
mysteryVal(x)
Finishedchecking --- 3 code warnings |
错误原因:由于程序中没有对X定义,所以报出未定义的错误.但是由于setVal()使用了/*@out*@/说明,所以在语句“setVal(x)”和“returnx”中,没有报未定义错误。
类型错误:C语言中的变量类型比较多,彼此之间有些细微的差别,splint可以对变量的类型进行检查:
实例1.typeerr.c
/*Program: typeerr.c -- use splint to check type varible error */
int foo(int i,char *s,bool b1,bool b2){
if(i=3) return b1;
if(!i || s) return i;
if(s) return 7;
if(b1 == b2)
return 3;
return 2;
} |
splint命令:splint typeerr.c
splint执行的结果:
Splint 3.1.2--- 03 May 2009
typeerr.c:(in function foo)
typeerr.c:3:5:Test expression for if is assignment expression: i = 3
Thecondition test is an assignment expression. Probably, you mean to use==
instead of=. If an assignment is intended, add an extra parentheses nesting
(e.g., if((a = b)) ...) to suppress this message. (Use -predassign to
inhibitwarning)
#错误类型:if语句中的条件表达式是一个赋值语句。
typeerr.c:3:5:Test expression for if not boolean, type int: i = 3
Testexpression type is not boolean or int. (Use -predboolint to inhibit
warning)
#错误类型:if语句中的条件表达式返回值不是bool类型而是int类型
typeerr.c:3:17:Return value type bool does not match declared type int: b1
Types areincompatible. (Use -type to inhibit warning)
#错误类型:!的操作数不是bool类型而是int类型的i
typeerr.c:4:6:Operand of ! is non-boolean (int): !i
Theoperand of a boolean operator is not a boolean. Use +ptrnegate toallow !
to be usedon pointers. (Use -boolops to inhibit warning)
#错误类型:||操作符的右操作数不是bool类型而是整型
typeerr.c:4:11:Right operand of || is non-boolean (char *): !i || s
##错误类型:不应该使用==对两个bool类型进行比较,而应该使用&&
typeerr.c:6:5:Use of == with boolean variables (risks inconsistency because of
multipletrue values): b1 == b2
Two boolvalues are compared directly using a C primitive. This may produce
unexpectedresults since all non-zero values are considered true, so
differenttrue values may not be equal. The file bool.h (included in
splint/lib)provides bool_equal for safe bool comparisons. (Use -boolcompare
to inhibitwarning)
Finishedchecking --- 6 code warnings
实例2.malloc1.c
/*Program: malloc1.c -- check varible type */
#include<stdlib.h>
#include<stdio.h>
int main(){
char * some_mem;
int size1 = 1048567;
//size_t size1 = 1048567;
some_mem = (char*) malloc(size1);
printf("Malloced 1M Memory!\n");
free(some_mem);
exit(EXIT_SUCCESS);
} |
splint命令:splint malloc1.c
使用是splint检查malloc1.c
Splint 3.1.2--- 03 May 2009
malloc1.c:(in function main)
malloc1.c:8:28:Function malloc expects arg 1 to be size_t gets int: size1
To allowarbitrary integral types to match any integral type, use
+matchanyintegral.
将size1的定义修改为:
size_t size1= 1048567;
再次使用splint将行检查:splintmalloc1.c
Splint 3.1.2--- 03 May 2009
Finishedchecking --- no warnings
内存检查:缓冲区溢出是一种非常危险的c语言错误,大部分安全漏洞都与它有关,splint可以对缓冲区的使用进行检查,报告溢出或越界错误。
实例:overflow.c
/*Program: overflow -- splint check overflow error */
int main(){
int buf[10];
buf[10] = 3;
return 0;
} |
splint命令:splint overflow.c +bounds +showconstraintlocation
splint执行的结果:-
Splint 3.1.2--- 03 May 2009
CommandLine: Setting +showconstraintlocation redundant with current value
overflow.c:(in function main)
overflow.c:4:2:Likely out-of-bounds store: buf[10]
Unableto resolve constraint:
requires9 >= 10
neededto satisfy precondition:
requiresmaxSet(buf @ overflow.c:4:2) >= 10
A memorywrite may write to an address beyond the allocated buffer. (Use
-likelyboundswriteto inhibit warning)
Finishedchecking --- 1 code warning
错误类型:数组buf的大小是10字节,最大也可使用的buf[9],但是程序中使用了buf[10],数组越界了,所以报错了。
实例程序2.bound.c
/*Program: bound.c -- use splint checking bound overflow error */
void updateEnv(char * str){
char *tmp;
tmp = getenv("MYENV");
if(tmp != NULL) strcpy(str,tmp);
} void updateEnvSafe(char * str, size_t strSize){
char *tmp;
tmp = getenv("MYENV");
if(tmp != NULL){
strncpy(str,tmp,strSize -1);
str[strSize-1]='\0';
}
} |
splint命令:splint bound.c +bounds +showconstraintlocation
splint执行的结果:
Splint3.1.2 --- 03 May 2009
CommandLine: Unrecognized option: +
A flag isnot recognized or used in an incorrect way (Use -badflag to inhibit
warning)
Spec filenot found: showconstraintlocation.lcl
Cannot openfile: showconstraintlocation.c
bound.c: (infunction updateEnv)
bound.c:5:18:Possible out-of-bounds store: strcpy(str, tmp)
Unableto resolve constraint:
requiresmaxSet(str @ bound.c:5:25) >= maxRead(getenv("MYENV") @
bound.c:4:8)
neededto satisfy precondition:
requiresmaxSet(str @ bound.c:5:25) >= maxRead(tmp @ bound.c:5:29)
derivedfrom strcpy precondition: requires maxSet(<parameter 1>) >=
maxRead(<parameter2>)
A memorywrite may write to an address beyond the allocated buffer. (Use
-boundswriteto inhibit warning)
bound.c: (infunction updateEnvSafe)
bound.c:13:3:Possible out-of-bounds store: str[strSize - 1]
Unableto resolve constraint:
requiresmaxSet(str @ bound.c:13:3) >= strSize @ bound.c:13:7 + -1
neededto satisfy precondition:
requiresmaxSet(str @ bound.c:13:3) >= strSize @ bound.c:13:7 - 1
Finishedchecking --- 2 code warnings
错误类型:由于使用strcpy函数,没有指定复制字符串的长度,所以,可能导致缓冲区溢出。UpdateEnvSafe中使用strncpy进行字符串复制,从而避免了缓冲区溢出的错误。
4.小结
在命令行下使用的splint非常的强大,splint同样可以可以集成到IDE 中.具体的要IDE的其他工具的设置。splint同样也可以写到在makefile文件中,然后使用make命令来预先检查代码中常见的静态错误。
有了上面的这些简单的实例的演示,我们可以感受到splint的强大之处,当然,这里的介绍仅仅是一个简单抛砖引玉。更多的有关splint的内容可以参考参考文献[4],更多关于splint的使用可以参考splint 的官方手册[4].
除了C有静态的代码工具以外,java中也有一款开源的功能强大的静态代码检查工具FindBugs。
相关文章:
软件测试实验学习笔记系列1
软件测试实验学习笔记系列3--单元测试
现阶段移动终端应用软件五花八门,各公司也将原有的web项目移至终端。经过三个终端项目的测试,个人认为做终端测试需要注意的地方,如下:
1.明确需求
整个项目的完成,测试越早介入越好,产品需求评审是一定要参加的,在大家讨论的同 时,自己也可以发表遇到的问题,如果可以给产品提一些好的建议是最好不过了。需求评审前尽可能多的发现问题,有设计不合理或者流程不通的地方大胆的向产品提,尽量的减少后期需求的变更。后期产品的变更不仅会影响到开发,对已经设计好的用例等都会有影响,如果变更大的话甚至会影响整个项目的进度。
2.编写测试用例,通过评审
在完他了解需求的基础上,根据产品需求编写测试用例,除了覆盖所有的功能外,最主要的要有质疑精神,各种异常的操作、非法操作、用户体验(界面是否友好、物理键操作)等也需要详细设计到用例中。我之前的一个项目就存在一个这样的问题,我们的产品下有一个更多功能,是我们公司的其它产品,更多列表下可以下载,而当时设计用例的时候下载这个用例考虑的不全,后期开发将所有产品都调用这个更多,代码重用。就这个问题我大概总结了下:
注:默认下载需借助浏览器(与开发沟通结果),无浏览器直接下载,任务项提示进度
1)联网正常+空间充足+浏览器正常情况
2)断网情况下+空间+浏览器正常充足
3)软件装在手机上+浏览器正常+空间充足
4)软件装在手机上+浏览器正常+空间不足
5)软件装在T卡+浏览器正常+空间充足
6)软件装在T卡+浏览器正常+空间不足
7)卸载浏览器,默认可以下载,任务栏显示下载进度(此处会存在异常中断,属bug)
8)浏览器正常,弹出选择存储位置,选择空间充足
9)浏览器正常,不弹出选择存储位置,默认空间不充足
10)浏览器正常,弹出选择存储位置,选择空间不充足
以上用例在空间不足应给出提示,而经常会出现异常中断,需开发作处理,我之前多次出现这种情况,有的手机也会由于兼容性导致异常中断,做为测试可以提更好的建议给开发:
像360,91等手机助手,在自己的平台上下载、安装、暂停,我们可以任意控制,此问题解决了所有兼容性,又简代了下载考虑的测试情况,不需要借助浏览器等,从根本上解决了下载的问题。
另在评审前,先将用例发给相关产品、开发,他们看过后会提前了解,评审的时候会提出,产品和开发只观注需求和流程的问题,建议在评审时,可以邀请同为测试的同事一起参加,站在测试的角度可以更多的提出测试要考虑的问题,使我们的测试用例更完善。评审时,有的用例需要更改或者删除,为了节省时间先标出来,待评审完成后,完善后发给大家,有意见再完善。
3.测试执行用例
产品提测后,开始测试,根据之前的测试用例将所有功能过一遍,保证所有功能正常。当然用例也只是起到一起指导作用,除了执行用例外,还需要反复测试,站在用户的角度多次操作,要有足够的耐心去完成它。所提的bug要描述清楚,必要时附上截图(可使用360,91手机助手截图)等,及时跟开发沟通,开发要求复现bug及时配合,复现给开发看。待开发有新版本出来后,及时跟踪bug,修复 完成后,再验下与之相关的功能,保证修复后的bug未影响到其它功能。在开发拒改bug时,一定要让开发备注不改的原因,因为有的bug开发是比较专业,他们的意见有足够的说明性。
4.兼容性测试
1)不同的手机操作系统
2)不同的网络GPRS(联通,移动),WIFI等
3)不同的分辨率
4)应用目标人群, 主流操作系统,如小米
5.测试报告
测试报告,主要突出用例执行率,bug总数,修复数,未修复数,测试的建议,发送给相关人员。
以上是我测试移动终端所遇到的问题以及解决办法,希望在后期的测试过程中还能够不断完善。经验是自己总结的,鼓励自己越做越好。