
数据库失败的类型分为几大类。对于每种失败来说,Oracle都会提供适当的解决方法。
所有失败类型最好被记录在一个服务级别协议内,同时在程序手册中还要记录解决失败的相关步骤。
第四种失败类型:用户错误
就Oracle而言,所关心的是事务。对于DML错误来说,用户在提交之前发现错误时仍然有机会回滚错误的语句。但是对于DDl语句来说,用户是无法回滚错误的语句。
因为,commit被内置到DDL语句中。
解决用户错误的理想方式是首先防止这些错误的出现。培训用户只是其中的一部分工作,不过最重要的是设计软件。从而使任何用户进程都不允许用户执行不存在where子句的update语句。然而设计最完美的软件也没法防止用户发出与指定业务不相符的sql语句。Oracle为修正用户错误的dba提供了许多可用的方法,不过使用这些方法通常极为困难,尤其是用户错误在一段时间内未被报告时更是如此。可能的技术包括闪回查询,闪回删除,闪回数据库和不完全恢复。
闪回查询时针对过去某时存在的数据库所运行的查询。通过使用撤销数据,可以只为当前会话构造读一致性的数据库。
如下:有一位用户不小心删除了emp表中的所有行,并提交了删除操作,那么随后通过针对5分钟之前的表执行子查询检索这些行。
SQL> delete from emp;
15 rows deleted.
SQL> commit;
Commit complete.
SQL> select count(*) from emp;
COUNT(*)
----------
0
SQL> insert into emp (select * from emp as of timestamp(sysdate-5/1440));
15 rows created.
SQL> select count(*) from emp;
COUNT(*)
----------
15
(2)利用闪回删除来恢复被删掉的表
如下:
SQL> drop table emp;
Table dropped.
SQL> select count(*) from emp;
select count(*) from emp
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> flashback table emp to before drop;
Flashback complete.
SQL> select count(*) from emp;
COUNT(*)
----------
15 |
对于撤销用户错误来说,不完全恢复与闪回数据库是作用更为显著的方法。使用上述任一种方法,整个数据库会返回发生错误前的时刻。前面介绍的其他方法在保持数据库其他部分不发生变化的情况只撤销错误的事务。但是,一旦执行了数据库的不完全恢复或闪回操作,就会失去从返回到的时刻开始的所有工作,而不仅仅失去错误的事务。
一、oracle安装
需要注意一下几个问题:
1、设置监听需启动后台OracleOraDb11g_home1TNSlistener服务。
2、需设置环境变量ORACLE_HOME为数据库的安装路径,如:E:\app\Administrator\product\11.2.0\dbhome_1
二、通过plsql导入dmp文件
1、用system登录数据库,链接为SYSDBA,创建表空间jmis和用户jmis。
创建表空间jmis语句:
CREATETABLESPACE jmis
DATAFILE 'E:\app\Administrator\product\11.2.0\dbhome_1\oradata\sample\jmis.dbf'SIZE 600M REUSE
AUTOEXTEND ON NEXT 1M MAXSIZE UNLIMITED EXTENTMANAGEMENT LOCAL; |
注意路径:
E:\app\Administrator\product\11.2.0\dbhome_1\oradata\sample\jmis.dbf是新建的,是以前不存在的。
创建用户jmis语句:
CREATE USER jmis IDENTIFIED BY jmis
PROFILE DEFAULT
DEFAULT TABLESPACE jmis
TEMPORARY TABLESPACE TEMP
ACCOUNT UNLOCK; |
用户名为jmis,密码为jmis,使用系统默认的用户配置文件,默认表空间为jmis,临时表空间为TEMP。
2、编辑用户jmis,在其角色栏中添加dba.
3、用jmis登录数据库,链接为Normal。
4、导入dmp文件,在运行中输入cmd 弹出命令行窗口 ,找到你的oracle 的安装目录 找到bin目录 之后 在bin目录下 输入:
imp userid=用户名/密码@orcl file=d:\nc60.dmp full=y ignore=y
如:impuserid=jmis/jmis@orcl file=f:\jmis.dmp full=y ignore=y
(full=y 是否全部导入 只有当前用户是dba的时候 才能用此选项 。
希望能帮助你。ignore=y解决了弹出警告时,终止导入的问题)
5、导入.pdc的数据表:
工具——导入表——Sql插入
在SQLplus可执行文件栏中填入如下路径:
E:\app\Administrator\product\11.2.0\dbhome_1\BIN\imp.exe
导入文件栏填入:pdc文件路径。
我接触了当前市场上大多数的android端的自动化测试架构,也研究了一些偏门左道的一些测试工具,而当我见到calabash这套框架时,内心还是小小的开心了一下。
优势
先说一下calabash的优点,这样大家可能更有兴趣看下去:
1.calabash是BDD驱动开发,编写自动化测试脚本比Robotium提高100%
2.calabash是脚本与TC分离设计,在业务变化的情况下,只要功能存在基本只需要修改TC,在业务不变,功能变化的情况下,基本只需要修改脚本
3.calabash既支持android也支持ios,真正实现了套脚本跨平台设备运行,小试了一把很酷
4.calabash是支持扩展的,而且非常容易扩,当前也支持webview的脚本编写
运行原理
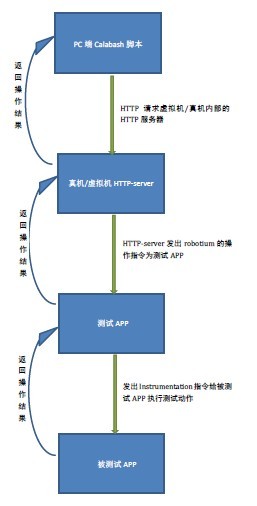
calabash-android架构其实与IOS是相同的,不过本篇只讲android,编写calabash架构的脚本,其实内部使用的是cucumber(cucumber是一种BDD测试框架,有兴趣的可以看看)这种核心为cucumber的calabash的脚本在运行测试的时候会在虚拟机/真机上预装一个web服务器,这个web服务器就是解释calabash的脚本,将其解释为robotium的脚本,然后这个web服务器会想测试app发送robotium的脚本,测试app拿到robotium脚本后,将其解释为instumentation命令向被测试的app发送这些命令,被测试的app执行这些命令,然后将结果返回给测试app,然后一级一级返得到最后的测试结果。
结构框架
calabash完全采用了cucumber的结构模式,给大家展示一下在命令行中展示出来的结构模式

feature为主件夹,step_definitions内是你封装的脚本,my_first.feature文件就是你的TC逻辑。再看一下其中的内容:
my_first.feature
Feature: 登陆
Scenario: 输入正确的用户名密码能够正常登陆
When 打开登陆页面
And 输入用户名XXX输入密码XXX
And 点击登陆
Then 验证登陆成功
看起来很简单吧,想要验证其他功能也是类似的语言描述即可。如果你没有用过cucumber或者calabash那么你肯定现在有一个疑问,计算机怎么能识别汉字来进行测试的呢,那么看一下step_definition:
以输入用户名XXX输入密码XXX为例:
When /^ 输入用户名\"([^\\\"]*)\" 输入密码\"([^\\\"]*)\" $/ do |username,password|
performAction('enter_text_into_numbered_field',username,1)
performAction('enter_text_into_numbered_field',password,2)
end |
现在应该能明白为什么你需要写汉字的脚本就可以了吧。在这里解释一下为什么如果业务存在功能修改这种情况,自动化脚本的修改量会小,还是以这个登录脚本为例,加入现在输入用户名和密码的输入框顺序变了,在你的页面显示上,可能是从左下角移到中间了,这种变化,那么feature文件你不用改,只需要改step_definition脚本就好了。
运行报告
calabash-android支持很多报告生成模式,支持html,json,junit等等报告模式,只需要你在run的时候添加-f参数-o参数就可以了。
例如 calabash-android run xxxx.apk -f html -o report.html,上图展示一下强大html报告

对web请求(HTTP/HTML)进行性能测试,确认请求响应时间。分别使用Loadrunner和JMeter进行测试,比较测试结果。
1、LoadRunner测试web请求响应时间
1.1 编制(录制)脚本
创建单协议(HTTP/HTML)脚本,调用如下web_url,作为一个简单事务:
lr_start_transaction("test");
web_url("www.baidu.com",
"URL=http://www.baidu.com/",
"TargetFrame=",
"Resource=0",
"RecContentType=text/html",
"Snapshot=t1.inf",
"Mode=HTML",
LAST );
lr_end_transaction("test"); |
1.2 运行时设置
在Virtual User Generator,打开Vuser/Runtime Setting,设置browser emulation。设置每个迭代使用新的vuser,同时不使用cache,模拟用户第一次发送请求效果,如下:
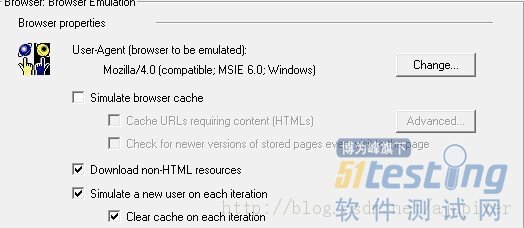
图1 设置browser emulation
1.3 单个用户运行
设置脚本以单用户在vu generator中运行,迭代10次。
通过调用lr_start_timer和lr_end_timer函数获取web_url消耗时间,调用lr_get_transaction_wasted_time获取事务浪费时间,并调用lr_output_message打印到replay log中。
执行结果:
Action.c(129): web_url("www.baidu.com") was successful, 24357 body bytes, 2474 header bytes, 38 chunking overhead bytes [MsgId: MMSG-26385]
Action.c(144): web_url elapsed = 1.085238
Action.c(167): lr_get_transaction_wasted_time = 0.868584
Action.c(172): Duration = 1.118885 , Waste = 0.868584
Action.c(182): Notify: Transaction "DL_PC" ended with "Fail" status (Duration: 1.1315 Wasted Time: 0.8686).
Action.c(185): actualElapsedTime = 1.146042 |
上述消息显示,web_url请求成功返回,消耗时间1.085238秒,其中浪费时间0.868584秒。注意,Duration值稍大于web_url elapsed时间。
那么,该事务的实际消耗时间,应该是Duration - Wasted Time,为0.2629秒。10次迭代平均值约为0.255秒,见下表。
表1 LR测试的web_url请求平均duration时间和浪费时间
迭代次数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 2~10次平均 |
web_url time | 1.408252 | 0.231590 | 0.371534 | 0.416005 | 0.235011 | 0.215672 | 0.255214 | 0.215151 | 0.211167 | 0.255022 | 0.267374 |
wasted_time | 0.910228 | 0.018863 | 0.010128 | 0.013624 | 0.010553 | 0.010947 | 0.010819 | 0.010799 | 0.011404 | 0.010636 | 0.011975 |
接下来,在JMeter上执行相同的操作,记录单个请求的平均响应时间。
2、 JMeter测试web请求响应时间
2.1 测试计划
在JMeter测试计划的线程组下,添加HTTP Cache Manager,勾选clear cache each iteration?,以使得每次迭代模拟用户第一次操作效果。
然后添加测试HTTP采样器,集合报告,查看结果树等等。
HTTP采样器的路径填写:http://www.baidu.com/。
2.2 单线程组运行
线程组的线程数属性设为1,迭代次数设为10,ramp-up设为0。
执行结果
在ORACLE中移动数据库文件在ORACLE中移动数据库文件
--ORACLE数据库由数据文件,控制文件和联机日志文件三种文件组成。
--由于磁盘空间的变化,或者基于数据库磁盘I/O性能的调整等,
--我們可能会考虑移动数据库文件。
--下面以LUNIX平台为例,分别讨论三种数据库文件的移动方法。
一.移动数据文件:
-- 可以用ALTER DATABASE,ALTER TABLESPACE两种方法移动数据文件。
1. ALTER DATABASE方法;
-- 用此方法,可以移动任何表空间的数据文件。
STEP 1. 下数据库:
$ sqlplus /nolog
SQL> CONNECT INTERNAL;
SQL> SHUTDOWN;
SQL> EXIT;
STEP 2.用操作系统命令移动数据文件:
-- 将数据文件 'test.ora' 从/ora/oracle/data1目录移动到/ora/oracle/data2目录下:
$ mv /ora/oracle/data1/test.ora /ora/oracle/data2
STEP 3. Mount数据库,用ALTER DATABASE命令将数据文件改名:
$ sqlplus /nolog
SQL> CONNECT INTERNAL;
SQL> STARTUP MOUNT;
SQL> ALTER DATABASE RENAME FILE '/ora/oracle/data1/test.ora' TO '/ora/oracle/data2/test.ora';
STEP 4. 打开数据库:.
SQL> ALTER DATABASE OPEN;
SQL>SELECT NAME,STATUS FROM V$DATAFILE; |
2. ALTER TABLESPACE方法:
-- 用此方法,要求此数据文件既不属于SYSTEM表空间,也不属于含有ACTIVE回滚段或临时段的表空间。
STEP1. 将此数据文件所在的表空间OFFLINE:
$ sqlplus /nolog
SQL> CONNECT INTERNAL;
SQL> ALTER TABLESPACE test OFFLINE;
SQL> EXIT;
STEP2. 用操作系统命令移动数据文件:
将数据文件 'test.ora' 从/ora/oracle/
data1目录移动到/ora/oracle/data2目录下:
$ mv /ora/oracle/data1/test.ora /ora/oracle/data2
STEP3. 用ALTER TABLESPACE命令改数据文件名:
$ sqlplus /nolog
SQL> CONNECT INTERNAL;
SQL> ALTER TABLESPACE test RENAME DATAFILE '/ora/oracle/data1/test.ora' TO '/ora/oracle/data2/test.ora';
STEP4. 将此数据文件所在的表空间ONLINE:
SQL> ALTER TABLESPACE test ONLINE;
SQL> SELECT NAME,STATUS FROM V$DATAFILE; |
二. 移动控制文件:
-- 控制文件 在 INIT.ORA文件中指定。移动控制文件相对比较简单,下数据库,
-- 编辑INIT.ORA,移动控制文件,重启动数据库。
STEP 1. 下数据库:
$ sqlplus /nolog
SQL> CONNECT INTERNAL;
SQL> SHUTDOWN;
SQL> EXIT; STEP 2.用操作系统命令 移动控制文件:
--将控制文件'ctl3orcl.ora' 从/ora/oracle/data1目录移动到/ora/oracle/data2目录下:
$ mv /ora/oracle/data1/ctrlorcl3.ora /ora/oracle/data2 STEP 3. 编辑INIT.ORA文件:
INIT.ORA文件的在$ORACLE_HOME/dbs目录下,
修改参数 "control_files",其中指定移动后的控制文件:
control_files = (/ora/oracle/data1/ctrlorcl1.ora,/ora/oracle/data1/ctrlorcl2.ora,/ora/oracle/data2/ctrlorcl3.ora) STEP 4. 重启动数据库:
$ sqlplus /nolog
SQL> CONNECT INTERNAL;
SQL> STARTUP;
SQL>SELECT name FROM V$CONTROLFILE;
SQL> EXIT; |
按Oracle原理,启动过程分为三个步骤nomount/mount/open.
PHASE0:nomount前,即数据库完全关闭了.
此时可以将数据库control files/data files/redo log files在OS下用mv命令任意移动(实际上,只要未被open的文件都是可以mv的),然后根据各种file location在Oracle中的存放位置,采用不同的方式来告诉Oracle:"偶已将原文件移动到另一个地方了".
其中初始参数文件中的control_files参数指定了具体的control file的location.所以移动了control file可在参数文件被open前直接改参数值Oracle就明白了.(PFILE/SPFILE的具体使用此处不多累赘).
PHASE1:nomount阶段. 打开了初始参数文件和backupground_dump_dest下的 alert_sid.log和background processes 的trace files.
PHASE2:mount阶段是打开了control file.
control file中存放的东东如下:
Database name and identifier
Time stamp of database creation
Tablespace names
Names and locations of data files and redo log files
Current redo log file sequence number
Checkpoint information
Begin and end of undo segments
Redo log archive information
Backup information |
所以偶们在PHASE0中所做操作就得在PHASE3真正open这些文件之前,告诉Oracle(因为信息记录在control file中,所以又得在PHASE2中,control file被open后做),偶们已改了file location.
于是可用alter database的data file clause或log file clause的rename 命令来更新control file,于是Oracle会在PHASE3时,到新file location去找相应的文件.
PHASE3:open阶段打开所有非offline的data files和redo log files.
因为文件已打开了.所以此时,只能对已经offline或还可以offline的文件作rename操作.原理也是通过更新control file中的内容来告诉Oracle:File location has been changed.
在梳理用户故事时,一个常见问题是:我们应不应该有独立的性能测试相关的用户故事?
这个问题并不能简单地回答是或否,在系统的复杂度不同以及团队职责分布不同的情况下,情形会有所不同。
对一般小的产品,测试比较简单,可以将性能指标作为一个用户故事验收条款的一部分,这时就不需要独立的用户故事条目。
对于复杂大系统,性能测试的环境搭建就可能不是易事,这时可以将性能测试及其优化相关的用户故事独立出来,此时有可能分成两类用户故事:
一类是得到各项性能指标和分析结果,用户为内部干系人或者系统购买方,目标是帮助分析系统瓶颈和为下一步的系统性能优化提供依据,而系统购买方的目标可能是便于规划系统容量、选择布署方案以及管理最终用户期望等。此时用户故事的描述可能是这样的:
作为一个系统架构师,我想得到X系统当前的各项性能指标,以便于分析系统瓶颈和制定恰当的优化行动
作为系统规划师,我想得到X系统当前的各项性能指标,以便于制定系统布署方案
另一类则是故事本身不仅包含得到系统的各项性能数据,而且必须满足设定的性能指标(质量属性,系统好到什么程度,可以按程度分成若干用户故事),此时描述用户故事时,最需要注意的是此时的用户故事并不是性能测试本身,而是系统性能应该满足的性能指标。比如对于高可用性(high availability)的用户故事,要描述的是系统局部出现故障后对用户的影响,在具体的验收条款里,可以使用given, when, then格式描述在某些具体场景下系统应该如何反应,对哪些用户产生影响及其程度,如果要求工作正常,需要回归测试最主要的功能(smoke testing)或者全面回归测试全部功能,视风险程度和测试自动化水平而定。例如:
作为X系统的用户,我想要在系统运行的多个数据中心的一个完全损毁的情况下继续使用该系统,以便于不影响我的工作。
通常的性能优化可分为三步:
第一步:
明晰不同的系统配置(包括硬件和软件运行环境)和不同测试场景的质量属性的需求 (质量属性可能包括延迟,容量,响应时间,流量,稳定性,峰值等等)
明晰测量质量属性时要监控的系统状况指标 (CPU利用率,内存占用率,disk IO吞吐率,网络接口流量,内部各种buffer的使用情况等等)
各种场景下的测试方法和测试工具 (是否需要自己编写测试程序或脚本等)
第二步:
各种场景要考虑和定义用户或系统的典型行为,以及极端行为 (特别是容量和性能测试时),模拟或触发这些行为做测试。
展开测试,得到各项数据,编写当前系统的性能测试报告,分析与需求之间的GAP,识别瓶颈
在端到端测试即便得到数据,也无法判断瓶颈所在的情况下,分析可能的瓶颈所在,在风险最大的地方分段分component测试
第三步:
根据瓶颈分步优化,注重系统整体性能,切忌过度局部优化
第一步是基本的环境,为后面作准备,通常并不作为独立的用户故事。不过当需要开发相关的测试工具时,也可以作为独立的用户故事。第二步和第三步可以分成多个用户故事来做。
最后,特别需要注意,对于每一次交付的软件,我们要清晰地知道并告知客户和用户具体的性能指标和其它质量属性。一些公共的质量属性可以放入DoD,要求所有的用户故事必须满足,否则不能算Done。同时应该尽量避免出现质量属性下降的情况,即便不能达到新的更高要求,原有的质量属性至少需要保持。这就需要有强大的持续集成、自动化测试、自动化布署和系统级自动化性能测试系统,以及以特性团队方式工作,这样才能使得有可能在同一迭代之内完成对系统的质量属性的多次测试以及必要的优化。如果做不到在同一迭代期内获得所有质量属性数据,也要尽量缩短间隔时间,并根据实际的数据和优先级排定优化次序。
题目一:进程和线程区别?
1.进程是资源分配的基本单位,也是调度运行的基本单位;线程是调度的基本单位。
2.进程有独立的虚拟地址空间。父子进程共享文件表,但不共享用户地址空间。
*优点:一个进程崩溃后不会对其他进程产生影响。
*缺点:进程间共享数据变得困难,必须使用显式的IPC机制。
*进程虚拟地址空间包括:代码段、堆栈段(临时数据:如函数参数、返回地址和局部变量)、数据段(包括全局变量)、堆(动态分配的内存)等等。
3.线程运行在进程的上下文中,所有运行在一个进程内的线程共享该进程的整个虚拟地址空间:代码、数据、堆、共享库和打开文件。
*每个线程有自己的线程上下文:一个线程ID、栈、栈指针、程序计数器、通用目的的寄存器和条件吗。
4.创建、切换和终止开销小:线程的上下文比进程的上下文小很多,所以线程的创建、上下文切换和终止要比进程快很多。
*线程间共享数据容易,因为多个线程共享进程地址空间,但需要同步。
5.补充程序和进程区别(选自操作系统概念第7版):
*程序本身不是进程,程序只是被动实体,如存储在磁盘上的一系列指令的文件内容(常被成为可执行文件)
*进程是活动实体,它有一个程序计数器来表示下一个要执行的命令和相关资源集合。
*当一个可执行文件被装入内存时,一个程序才成为进程。
*虽然多个进程可以与统一程序相关,但是它们被当做两个独立的执行序列,都是独立的进程,虽然文本段相同,但是数据段、堆、堆栈段都不同。
题目二:进程间通信方式?
1.管道
2.消息队列
3.共享内存
4.套接字
5.信号量
6.信号:异步通信方式,软件层次上对中断机制的一种模拟。
题目三:进程的组成部分和状态?
(一)进程的组成部分:进程控制块、程序段和数据段。
(二)进程的状态(注意状态之间切换条件):
1.三种基本状态:运行态、就绪态、阻塞态。
2.挂起状态(从内存换出到磁盘):当内存中的所有进程都处于阻塞态,OS把被阻塞的进程换出到磁盘中的“挂起队列”(将进程置于挂起态,并将它转移到磁盘),内存中释放的空间可被调入的另一个进程使用。取哪个进程到内存执行的选择:新创建的进程或调入一个以前被挂起的进程(倾向于这个,不会增加系统的负载)。
3.新建态和终止态。
题目四:死锁的条件和预防?
一 死锁的充分必要条件:
*互斥:一次只有一个进程可以使用一个资源。
*占有且等待:当一个进程等待其他进程时,继续占有已经分配的资源。
*不可抢占:不能强行抢占进程已占有的资源。
*环路等待:存在一个封闭的进程链,使每个进程至少占有此链中下一个进程所需要的一个资源。
前三个是死锁的必要条件,第四个是前三个条件的潜在结果。
二 处理死锁的基本方法:
*死锁预防:通过设置某些限制条件,去破坏死锁的四个条件中的一个或几个条件,来预防发生死锁。但由于所施加的限制条件往往太严格,因而导致系统资源利用率和系统吞吐量降低。
*死锁避免:允许前三个必要条件,但通过明智的选择,确保永远不会到达死锁点,因此死锁避免比死锁预防允许更多的并发。(例如银行家算法)。
*死锁检测:不须实现采取任何限制性措施,而是允许系统在运行过程发生死锁,但可通过系统设置的检测机构及时检测出死锁的发生,并精确地确定于死锁相关的进程和资源,然后采取适当的措施,从系统中将已发生的死锁清除掉。
*死锁解除:与死锁检测相配套的一种措施。当检测到系统中已发生死锁,需将进程从死锁状态中解脱出来。常用方法:撤销或挂起一些进程,以便回收一些资源,再将这些资源分配给已处于阻塞状态的进程。
题目五:内存管理技术有哪些?
1.固定分区(连续分区):将内存用户空间划分为多个固定大小的静态分区,进程被装入大于或等于自身大小的分区。
*分区的大小可以是长度都相等;或者不等,分为多个较小分区、适量中等分区,少量较大分区。
*优点:实现简单,开销小。
*缺点:有内部碎片,内存使用不充分;活动进程的最大数目是固定的。
2.动态分区(连续分区):分区是动态创建的,每个进程可以被装入与自身大小相等的分区中。
*优点:没有内部碎片;可以充分使用内存。
*缺点:有外部碎片,由于需要压缩外部碎片,处理器利用率低。
3.简单分页:内存被划分为许多大小相等的页框;每个进程被划分成许多大小与页框大小相等的页;要装入进程,需要把进程的所有页都装入内存中不一定连续的某些页框中。
*优点:没有外部碎片。
*缺点:有少量内部碎片。
4.简单分段(段的大小不固定):每个进程被划分成许多段;要装入进程需要把进程包含的所有段都装入内存中不一定连续的某些动态分区中。
*优点:没有内部碎片,相对于动态分区,提高了内存利用率,减少了开销。
*缺点:存在外部碎片。
5.虚拟内存分页:除了不需要把进程的所有页都装入内存之外,与简单分页一样;非驻留页在以后需要时调入内存。
*优点:没有外部碎片;巨大的虚拟地址空间。
*缺点:复杂的内存管理开销。
6.虚拟内存分段:除了不需要把进程的所有段都装入内存之外,与简单分段一样;非驻留段在以后需要时调入内存。
*优点:没有外部碎片;巨大的虚拟地址空间;支持共享和保护。
*缺点:复杂的内存管理开销。
题目六:分页与分段相同点和区别?
一 相同点:两者都采用离散分配方式,且都需要地址映射机构来实现地址变换。
二 不同点:
(1)页时信息的物理单位,分页是为实现离散分配方式,以消减内存的外部碎片,提高内存利用率,也就是说分页仅仅是由于系统管理的需要而不是用户的需要;段则是信息的逻辑单位,它含有一组其意义相对完整的信息,分段的目的是更好的满足用户的需要。
(2)页的大小固定且由系统决定,在系统中只有一种大小的页面;而段的长度不固定,决定于用户编写的程序,通常由编译程序在对源程序进行编译时,根据信息的性质来划分。
(3)段的优点:
*信息共享和信息保护:信息共享和信息保护都是以信息的逻辑单位为基础。
*等等。
题目七:页面置换算法有哪几种?
(1)最佳置换算法(OPT):选择置换下次访问距离当前时间最长的那些页。
*该算法导致最少的缺页中断,但由于无法预知一个进程在内存的若干个页面哪个是未来最长时间不再被访问的,因而该算法无法实现,但是可以作为一种标准来衡量其他置换算法。
(2)最近最久未使用算法(LRU:Least Recently Used):置换内存中上次使用距离当前最远的页。
*LRU策略性能接近于OPT,但比较难实现(需要系统较多硬件支持,需要大量开销)。
(3)FIFO策略:淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面予以淘汰。
*该算法实现简单,但性能相对较差。
(4)时钟策略(Clock置换算法):
1.简单的Clock置换算法(使用位):给每一个页框关联一个附加位,称为使用位。当某一页首次装入内存中,将该页框的使用位设为1;当该页随后被访问到时,它的使用位也为1。页面置换算法中,用于置换的候选页框集合被看做一个循环缓冲区,并且有一个指针与之关联。
*过程:
~当需要置换一页时,系统扫描缓冲区,以查找使用位被置为0的一页框。当遇到使用位为1的页框时,操作系统就将该位重新设置为0。
~如果所有页框使用位都为1时,则指针在缓冲区中循环一周,把所有使用位都置0,并且停留在最初位置,置换该页框中的页。
2.改进的Clock置换算法(使用位+修改位):将一个页面换出时,如果该页已被修改过,便须将该页重新写回到磁盘上;如果该页未被修改,则不必将它拷回磁盘。在改进的的Clock置换算法中,除要考虑页面的使用情况,还需考虑置换代价。选择页面换出时,既要是未使用过的页面,又要是未被修改过的页面,把同时满足这两个条件的页面作为首选淘汰页面。
Junit最后需要做覆盖测试,查了一下资料,发现Eclemma这个插件还比较好用,所以在这里给大家分享一下Eclemma的简单使用
(1) 安装Eclemma,具体步骤可见截图
(2) 完成上篇文章《[Junit]初次体验Junit》的例子
(3) 利用Eclemma完成覆盖测试

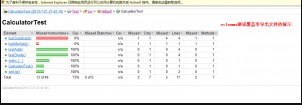
结果显示如图:
A.标记源码
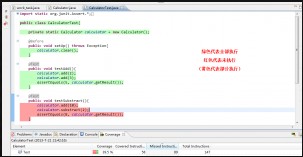
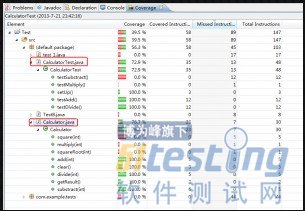
B.Coverage视图,显示测试的覆盖率
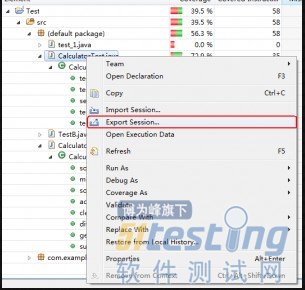
(4) 导出测试报告
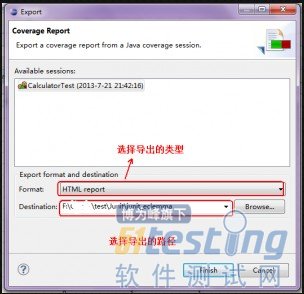
导出文件可见截图:
相关文章:
初次体验Junit
MBT框架的实现需要用到2种技术:参数组合技术与代码生成技术。
参数组合技术:抽象出测试场景的参数,并对参数做等价类及边界值分析后,利用迪卡尔乘积对多类参数进行组合,并过滤掉不需要组合,这里多半是用例建模时需要考虑。框架需要提供的是组合算法与过滤算法,用户在使用这些算法的比较易懂、实用。
代码生成技术:框架应能执行模型代码,执行模型后能生成可执行的测试代码,这有点类似病毒,代码执行后,能产生出与自己等价的代码。举例如下:
原始模型代码:
from MTest import TestCaseBase, Model, Scenario, Action, Assert, Logger @Action(DespFormat="Called with {0}, {1}")
def JustReturnArg1(arg1, arg2):
if arg1 == 1:
return arg2
return arg1 @Model()
class SimpleModel(TestCaseBase): @Scenario(Param={
'p1':[1, 2],
'p2':['a', 'b']
}, Where={'combine':['p1','p2'],'strategy':'add'}) def TestJustReturnSelf(self):
Logger.Step('Call JustReturnSelf and Validate')
p1 = self.Param['p1']
p2 = self.Param['p2']
rsp = JustReturnArg1(p1, p2)
Assert.AreEqual(p1, rsp, 'p1 check')
if __name__ == '__main__':
import sys
from MTestLauncher import MTestLoader
MTestLoader.Run(None, False, "MTestRunConfig.xml", [sys.argv[0]],
"mtest") |
在执行后,生成3个测试用例
@Model(TestModule="")
def SimpleModel(TestCaseBase): @Scenario(Param={'p1': 1, 'p2': 'a'})
def TestJustReturnSelf_p1(self): Logger.Step("Call JustReturnSelf and Validate")
rsp1 = JustReturnArg1(self.Param["p1"],
self.Param["p2"])
Assert.AreEqual(self.Param["p1"], rsp1, "p1 check") @Scenario(Param={'p1': 1, 'p2': 'b'})
def TestJustReturnSelf1_p2(self): Logger.Step("Call JustReturnSelf and Validate")
rsp1 = JustReturnArg1(self.Param["p1"],
self.Param["p2"])
Assert.AreEqual(self.Param["p1"], rsp1, "p1 check") @Scenario(Param={'p1': 2, 'p2': 'a'})
def TestJustReturnSelf2_p1(self): Logger.Step("Call JustReturnSelf and Validate")
rsp1 = JustReturnArg1(self.Param["p1"],
self.Param["p2"])
Assert.AreEqual(self.Param["p1"], rsp1, "p1 check") |
以SpecExplore为例:
<!--[if !supportLists]-->1. <!--[endif]-->开发出建模脚本,通过解析脚本结合接口定义生成出测试用例。但这样的伪代码的开发成本和使用难道都比较大,没有语法检查,几乎靠经验摸索着使用。
<!--[if !supportLists]-->2. <!--[endif]-->利用对象的属性值变化作为模型转换的状态。对于初学者,来定位一个模型逻辑问题,难度和要求都是很高的。
<!--[if !supportLists]-->3. <!--[endif]-->在执行模型时,根据在脚本中对模型接口定义好的枚举参数进行组合并且根据模型实现确定每一个参数。
在MTest中,建模与一般的写测试用例的方式是一致,先进行参数组合,再执行模型,模型通过一个全局属性获取参数或者直接传给测试用例。为使能生成代码,在执行模型过程需要记住模型的执行路径,拦截住执行每个接口函数调用的入参和期待的输出。其中,期待的输出是从对接口的校验中获取。因此,拦截接口函数调用的入参与输出是关键的技术。
从语言层面看,要拦截函数的入参和输出:
<!--[if !supportLists]-->1. <!--[endif]-->Java里有spring可以做些拦截,但创建对象的必须从spring的容器中获取。即使通过这种拦截能达到上面的效果,将其引入测试,配置和使用会异常复杂。
<!--[if !supportLists]-->2. <!--[endif]-->C#跟Java类似,C++就更不可能了。
只能求助脚本语言了,Python语言的一个特性刚好可以做到这一点:获取Python对象的属性或函数都是通过__getattribute__来做到的,在定义类时覆盖这个函数,返回包装好这个函数执行的代理函数,就可以拦截函数的入参、执行和给出一个模拟的输出。以一个例子说明如下:
class A:
def __getattribute__(self, name):
print("Here, can return a delegate for function: %s, not just itself" % name)
return object.__getattribute__(self, name)
def bFun(self):
print('b Called')
A().bFun() |
输出:
Here, can return a delegate for function: bFun, not just itself
b Called
实际上,在mtest模式执行模型时,MTest中对bFun的代理函数并不会真实的去执行bFun,而是直接返会了一个动态结果DynamicResult,交给Assert.AreEqual去校验,而Assert.AreEqual也不会被真正的执行,而是仅仅是记住这个动态结果的期望值。这就知道了函数执行时的入参和输出。因此,只要是引用到动态结果的函数都应该是能被代理掉的。否则,这个函数得到将是一个未知的动态结果对象。从另外一个角度看,这实际上是对函数调用的一次Mock!
另注:MTest里标记为@Action的函数和所有以Logger和Assert开始的函数都是能被代理掉的;能生成Python的代码,引入不同的代码生成技术,同样可以生成Java,C#,Ruby,JS、JMeter性能测试脚本的代码