
1引言
互联网和电子商务技术的发展,人们可以足不出户完成在线购物、实时通讯、信息检索等操作,这些系统大部分是B/S架构。对于系统本身而言,其性能直接决定了可容纳的在线用户数和用户体验满意度,而用户数的攀升意味着广告等收入增长,所以性能测试在B/S系统中起到了一个非常关键的作用,尤其是面向公众的互联网系统。
2什么是性能测试
性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试,包括负载测试,强度测试,批量测试等类型。在性能测试过程中,会发现很多系统潜在的问题,这些问题往往与一定规模的访问量有关,所以无法通过简单手工测试发现。借助于测试工具或者自己编写的脚本,模拟实际场景对目标系统进行全方位性能测试,能够将问题暴露在上线之前,减少后期维护成本。
3性能测试阶段划分
性能测试整个过程大体可以划分为测试规划、测试执行和结果分析。本文引入一个测试模型用于实例讲解,相关信息见下表1:
表1 测试模型
模型系统名称 网上购物系统
模型系统架构 基于MVC三层架构的B/S系统
模型系统功能 商品浏览:用户随意进入网站进行商品浏览。
订单提交:注册用户登录后,下订单购买商品,系统返回成功与否。
后台处理:数据库每天晚上11点自动执行数据库脚本,清算当日的交易数据。
4性能测试规划
测试规划是整个性能测试最复杂,也最有价值的一部分。测试规划包括:确认测试目标、整理业务流程、制定量化指标、制定测试用例与场景、准备测试资源、安排测试计划。
4.1确认测试目标
针对不同被测系统,需首先明确本次测试的目标。比如设定为“检验当前系统各业务功能的并发处理能力”,由于系统参与人员的职责不同,对性能测试的目标定位也不相同,需综合实际情况来确定。在本文测试模型中,假定有产品经理和技术经理两个角色,他们对于性能测试目标简要归纳为表2所述,综合两者就能确认本次测试目标。
表2 测试目标
职责 测试目标
产品经理 检验系统能够支撑的最大用户访问量、最佳用户访问量、每秒钟最大事务处理数、是否能够满足预期业务量7 * 24小时运行需要。
技术经理 检验系统性能瓶颈所在、有没有内存泄漏、中间件和数据库的资源利用率是否合理。
一般而言,性能测试是作为一个上线之前的验收环节。处于这个阶段的系统功能基本都已开发完成,测试目标主要是对系统整体的一个性能测验。此时发现核心组件需要修改,调整的代价是很昂贵的。我们可以在项目建设初期就可以引入性能检测,在开发过程中就对各业务模块进行测试,进一步细化各阶段的测试目标,如下图所示:
图 1. 性能测试切入点
从图1可以看出,系统本身有很多测试切入点。当用户界面层还不稳定的话,可以从业务逻辑层着手,对系统进行性能检测。如果把系统看作是一幢大楼,则至下而上的每一层就是一个组件,组件本身牢固了,房子整体才结实。
4.2整理业务流程
测试目标确认之后,就需要针对这个目标,对业务流程进行整理,对于功能复杂的系统,还需要业务和开发人员的参与,以下方面可以关注:
1:区分用户操作流程与系统的处理流程。两者都是业务流程,但是系统处理流程是后台发起,用户不可见。例如,本文测试模型中,商品浏览属于用户操作流程;数据库自动执行批处理是系统处理流程。
2:站在用户的角度模拟业务操作,要覆盖到所有的操作分支,包括容易产生的操作中断。
业务流程整理直接关系到后续的测试用例和场景设计,两者决定了性能测试数据是否能够真实反映系统状况,当遇到性能测试实施团队不熟悉业务的情况,性能测试项目经理需安排支援。
4.3制定量化指标
在性能测试报告中,系统性能状况会体现为一堆测试指标及对应的数值。被测目标不同,指标集合也不同,针对本文测试模型,可以制定以下简单的指标(更加细化的指标可参阅相关文档)。
功能层:事务平均响应时间、每秒完成的事务数、成功的事务数、失败的事务数。
中间件:JVM内存使用情况、中间件队列、线程池利用率。
数据库:队列长度、最占资源的SQL、等待时间、共享池内存使用率。
操作系统:CPU平均利用率、CPU队列、内存利用率、磁盘IO。
有了指标,我们还需要根据测试目标,设定其对应的数值范围。例如根据产品经理要求,在并发一千人访问的情况下,系统平均一次事务响应时间不超过5秒,则可以设定响应时间的数值范围是小于5秒成功,大于5秒失败。还可以指定CPU利用率、JVM内存利用率等性能指标的数值范围(表3),需要说明的是,不同测试工具支持的指标集是不同的,可利用多个测试工具进行协同收集。
表3 性能指标数值范围
指标项目 测试场景 合理指标值
平均CPU利用率 并发一千用户 < 85%
平均JVM利用率 并发一千用户 < 80%
量化的性能指标能够给系统带来优化的目标,当我们说性能符合预期,指的是所有指标的值都在理想范围以内,那么如何制定正确的数值范围呢,这个就必须靠经验和系统历史数据来进行分析。前者是类比同类型系统的性能指标,后者需要挖掘运维数据,包括用户访问峰值,每秒最高事务处理数等。
4.4制定测试用例与场景
性能测试用例是对整理过的业务流程进行再分解,描述其成为可测试的功能点,结合性能指标转换为测试执行代码。本文测试模型中,用户登录的用例简要描写如下(省略掉用例前置条件,例如系统配置和部署信息):
表4 测试用例1
登录测试用例
1:用户打开网站首页,页面应该正常展现,超过60秒则算失败。
2:用户输入账号和密码,点击登录按钮,等待系统提示成功或失败,如果等待超过60秒,则算登录失败。
测试用例1中,用户与系统有两次交互(打开网址和点击登录按钮),需分别统计每一次交互的等待时间。考虑到用户实际操作的话,会有一定的停顿,我们可在脚本中添加思考时间来模拟(固定或随机等待时间)。不要小看这个设置,在用户量大的情况下,对系统施加的压力是完全不同的,然后在在统计的时候,去掉这部分思考时间。
性能测试用例执行需对应的场景,用于模拟系统实际运行状况。全面的系统测试在理论上是不可行的,所以设计测试场景的时候,主要定位是用户典型的应用场景。可粗略划分为两类:功能点测试场景和复杂业务测试场景。前者的目标主要是检验系统某个功能点的并发能力,后者更加贴近系统实际运行情况。对于测试模型的用户登录功能,设计功能点测试场景1如下:
表5 测试场景1
并发用户数:总共300,起始数量100,每1秒钟增加10个用户。
运行方式:每一个并发用户循环执行登录测试用例,持续15分钟。
考虑到业务流程可以交叉进行,例如测试模型中数据库批处理与用户操作混搭,我们设计一个复杂的测试场景如表6所示:
表6 测试场景2
并发用户数:总共300,起始数量100,每1秒钟增加10个用户。
运行方式:数据库启动批处理清算,同时并发200个用户进行循环登录,另外100个用户随机浏览商品。
4.5准备测试资源
测试资源包括4个方面:
1:硬件资源。性能测试环境应该采用与生产环境一致的硬件条件,严格来说,如果硬件环境不一致,性能测试报告是不具备说服力的。
2:软件资源。性能测试目标系统需要部署与生产一致的软件,在系统上生产之后,往往会增加一个监控软件,但监控软件也是有资源损耗的,尤其是B/S系统,频繁的抓取JVM数据,会造成较大的压力。
3:数据资源。数据量对性能的影响非常大,分两种情况考虑测试数据,第一种是已经运行的系统做改造,则可以把生产环境的数据备份到测试环境。另外一种是首次上线的系统,这个时候业务数据是空的,需要造一些测试数据。至于数据量的级别,可以预测两年后,业务数据量会有多少,性能测试需要有一定的前瞻性。
4:人力资源。性能测试会发现很多问题,而问题的定位和解决,需要更加专业的人来完成,包括商业软件提供商。测试过程中,保持与开发团队的紧密沟通,是顺利开展项目的关键。
4.6安排测试计划
当测试资源、可执行代码准备好之后,就需制定一个测试计划并分阶段实施,简单示例如表7所示。
表7 测试计划
测试项 描述 测试类型/测试目标(简要)
基准测试 收集系统基准测试性能指标 强度测试,获取基准测试数据数据。
开发调试 开发修复性能测试发现的Bug
功能点测试 对各业务功能点进行性能测试 强度测试,获取系统最大并发值等数据。
复杂业务测试 复杂业务场景性能测试 容量测试,获取最佳用户访问值等数据。
开发调试 开发修复性能测试发现的Bug
长时间负载测试 系统在一定负载的情况下,长时间运行。 疲劳测试,发现内存泄漏等情况。
表7测试计划说明如下:
1:表7中省略掉了测试项目的起止时间,包括了开发调试的工作。这是因为在实施过程中,如果遇到性能问题,开发是需要时间去修复的,性能测试有可能需要暂停。
2:首先进行功能点测试,通过之后再进行复杂业务测试,这是因为单个功能点相对简单,业务逻辑复杂度不高,资源竞争与数据锁等问题不太容易暴露。
3:基准测试是系统日后升级的性能比较对象,例如在硬件升级后,同样的测试场景,是否会得到更优的结果,系统新技术的引进或版本升级,对性能的影响是正面还是负面,都可以通过与基准测试比较得出。
4:每一个测试阶段都有相应的测试目标,采用的测试类型也不同,具体需根据之前的测试规划来制定。
5性能测试执行
执行过程需要注意以下事项:
1:注意保存测试运行过程的数据,作为测试结果的佐证。
2:有问题尽快反馈,系统的修改可能导致测试返工。
3:基准功能点测试过程中,需清理测试现场后再进行后续的测试,因为系统可能存在缓存。
4:按优先级测试各业务场景。
6测试结果分析
每次执行完测试后,会得到一个测试结果。先别着急完成后续的测试任务,可以先简要的分析一下本次测试结果,看看数据是否符合逻辑。例如,对于同一个测试场景,增加并发用户数(强度测试中常见),却发现响应时间反而变短,这就不符合逻辑。当所有的测试任务完成后,分析数据并提交测试报告,注意以下方面:
1:针对不同角色的人员出具不同的测试报告,对于技术人员,可以有较多的性能数据和分析。
2:进行一些前瞻性的预测,综合本次测试的资源情况和指标数据,分析系统性能扩展的瓶颈。
7总结
性能测试不是一锤子买卖,随着系统不断升级,性能测试需要作为一个常态被关注。性能测试领导者也需保持对业务的关注,及时调整测试策略。
3.13.3 Web Services脚本
完成Web Services服务端和客户端两个小程序的编写、编译、执行后,您需要确保服务端程序是开启的,关闭已运行的客户端小程序。
接下来,您启动LoadRunner 11.0,选择“Web Services”协议,如图13-122所示。


图13-121 “样例演示-客户端”对话框 图13-122 “New Virtual User”对话框
单击【Create】按钮,创建“Web Services”协议,在LoadRunner 脚本编辑环境单击录制红色按钮,在弹出的“Recording Wizard”对话框中单击【Import】按钮,在弹出的“Import Service”对话框中选择“URL”选项,在文本框中输入“http://localhost:5678/wsdl/IMyHello”,单击【Import】按钮,如图13-123所示。

图13-123 “Recording Wizard-Add Services页”对话框
稍等片刻,将出现图13-124所示界面信息,单击【下一步(N)>】按钮。
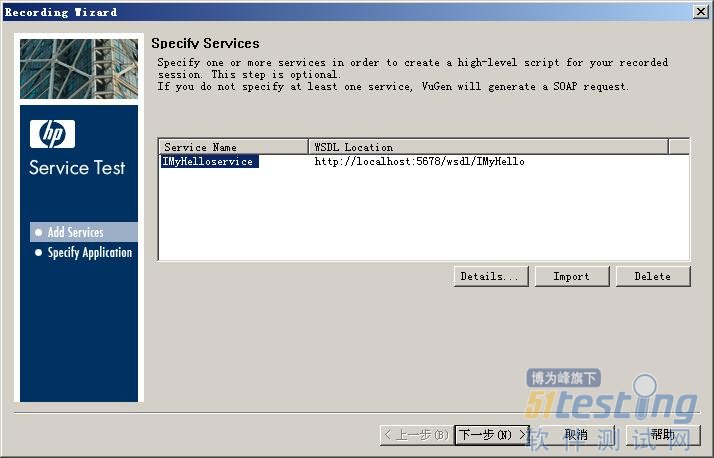
图13-124 “Recording Wizard”对话框
在图13-125所示对话框中输入客户端路径相关信息“C:\mytest\client\Client.exe”,工作目录为“C:\mytest\client”,(如果您的应用是基于B/S的,则选择“Record default web browser”选项并输入相应URL)单击【完成】按钮。
此时将会在输入框下方出现“欢迎于涌同学!”字符串,如图13-126所示。


图13-125 “Recording Wizard-Specify Application页”对话框 图13-126 “样例演示-客户端”对话框
此时将会产生如下代码:
Action() { web_add_header("Content-Type", "text/xml"); web_add_header("SOAPAction", "\"urn:MyHelloIntf-IMyHello#Welcome\""); web_add_header("User-Agent", "Borland SOAP 1.2"); soap_request("StepName=Welcome", "URL=http://localhost:5678/soap/IMyHello", "SOAPEnvelope=<?xml version=\"1.0\" encoding=\"GBK\" standalone=\"no\"?" "><SOAP-ENV:Envelope xmlns:SOAP-ENC=\"http://schemas.xmlsoap.org/soap/" "encoding/\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\" " "xmlns:xsd=\"http://www.w3.org/2001/XMLSchema\" xmlns:SOAP-ENV=\"http:/" "/schemas.xmlsoap.org/soap/envelope/\"><SOAP-ENV:Body SOAP-ENV" ":encodingStyle=\"http://schemas.xmlsoap.org/soap/encoding/\"><NS1" ":Welcome xmlns:NS1=\"urn:MyHelloIntf-IMyHello\"><name xsi:type=\"xsd" ":string\">于涌</name></NS1:Welcome></SOAP-ENV:Body></SOAP-ENV:Envelope>", "Snapshot=t1.inf", "ResponseParam=response", LAST); return 0; } |
我们最关心的内容应该是Web Services服务接口返回的内容,所以需要对脚本进行完善,脚本信息如下,黑色字体为新添加内容。
Action() { web_add_header("Content-Type", "text/xml"); web_add_header("SOAPAction", "\"urn:MyHelloIntf-IMyHello#Welcome\""); web_add_header("User-Agent", "Borland SOAP 1.2"); soap_request("StepName=Welcome", "URL=http://localhost:5678/soap/IMyHello", "SOAPEnvelope=<?xml version=\"1.0\" encoding=\"GBK\" standalone=\"no\"?" "><SOAP-ENV:Envelope xmlns:SOAP-ENC=\"http://schemas.xmlsoap.org/soap/" "encoding/\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\" " "xmlns:xsd=\"http://www.w3.org/2001/XMLSchema\" xmlns:SOAP-ENV=\"http:/" "/schemas.xmlsoap.org/soap/envelope/\"><SOAP-ENV:Body SOAP-ENV" ":encodingStyle=\"http://schemas.xmlsoap.org/soap/encoding/\"><NS1" ":Welcome xmlns:NS1=\"urn:MyHelloIntf-IMyHello\"><name xsi:type=\"xsd" ":string\">于涌</name></NS1:Welcome></SOAP-ENV:Body></SOAP-ENV:Envelope>", "Snapshot=t1.inf", "ResponseParam=response", LAST); lr_save_string(lr_eval_string("{response}"), "XML_Input_Param"); lr_xml_get_values("XML={XML_Input_Param}", "ValueParam=OutputParam", "Query=/*/*/*/return", LAST ); lr_output_message(lr_eval_string("返回结果 = {OutputParam}")); return 0; }
|
脚本的执行信息如下:
Virtual User Script started at : 2012-11-11 14:56:30 Starting action vuser_init. Ending action vuser_init. Running Vuser... Starting iteration 1. Starting action Action. Action.c(4): Warning -26593: The header being added may cause unpredictable results when applied to all ensuing URLs. It is added anyway [MsgId: MWAR-26593] Action.c(4): web_add_header("Content-Type") highest severity level was "warning" [MsgId: MMSG-26391] Action.c(6): web_add_header("SOAPAction") was successful [MsgId: MMSG-26392] Action.c(8): web_add_header("User-Agent") was successful [MsgId: MMSG-26392] Action.c(10): SOAP request "Welcome" started Action.c(10): SOAP request "Welcome" was successful Action.c(26): "lr_xml_get_values" succeeded, 1 match processed Action.c(31): 返回结果 = 欢迎于涌同学! Ending action Action. Ending iteration 1. Ending Vuser... Starting action vuser_end. Ending action vuser_end. Vuser Terminated. |
也许有的读者会说:“我想先看看服务端返回的信息,这可不可以呢?”。“当然没问题”,您只需要在脚本中加入“lr_output_message("%s",lr_eval_string("{response}")); ”(lr_xml_get_values()函数在前面已经介绍过,其在进行该协议类型脚本关联时非常重要,请读者朋友务必掌握),执行脚本时就会打印出响应的相关数据信息,如图13-127所示。

图13-127 WebServices相关脚本及执行结果
为了让大家对返回的内容看得更加清楚,这里我将其拷贝出来,放置到my.xml文件中,其内容如图13-128所示。

图13-128 服务返回的XML相关信息
从图13-128您会看到有一串乱码,凭直觉这应该是“欢迎于涌同学!”,那么直觉对不对呢?您可以在脚本中加入以下两行代码,如图13-129所示。

图13-129 转码及输出函数
其输出结果果真为“欢迎于涌同学!”。图13-129 中使用“lr_convert_string_encoding()”的函数就是将UTF8编码转码为系统语言编码的函数,经过转码后信息显示正确了。也许有的读者会问:“系统返回的xml响应信息有些显得十分混乱,有没有什么方法直接能看出其层次关系呢?”您可以借助树视图,单击“Tree”按钮,将出现图13-130所示界面信息,是不是一目了然了呢!这也方便了您应用lr_xml_get_values()函数时填写“Query”部分内容。

图13-130 WebServices响应结果树视图
【重要提示】
(1)从上面Web Services程序编写和脚本应用中,相信大家对该协议的应用已经有了非常清晰的认识,我们给大家演示的是基于C/S的小程序,在实际工作中您测试的应用可能是基于B/S的,它们在实际应用上并没有大的区别,所以请读者朋友们举一反三。
(2)也许您也会像我一样,在机器上安装有杀毒软件,如果您应用本书此客户端和服务器端小程序时,有可能您的杀毒软件会对其产生干扰,如:将小程序自动删除、运行小程序没反应等情况,此时应暂时关闭杀毒软件,确保小应用可以正常运行。
(未完待续)
版权声明:51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像。51testing软件测试网欢迎与业内同行进行有益的合作和交流,如果有任何有关内容方面的合作事宜,请联系我们。
相关链接:
精通软件性能测试与LoadRunner最佳实战 连载十三
翻看之前的文章才发现,最近一次记录持续集成竟然是3年前,并且只记录了两篇,实在是惭愧。不过,持续集成的这团火焰却始终在心中燃烧,希望这次的开始可以有些突破。
测试是持续集成的基石,没有测试的集成基本上是毫无意义的。如何写好测试就是横亘在我面前的第一个问题。那就从数据访问层开始吧。说起来可笑,从3年前第一次准备做持续集成式,就开始考虑测试数据访问层的一些问题:
难道我要在测试服务器上装一个MySQL?
数据库结构发生了变化怎么办?
怎么样才能消除测试间的依赖?
测试数据怎么管理?何况测试数据间还有那么多的逻辑?
结果如何验证?
……
这些问题在我脑海萦绕很久,《一代宗师》里说“宁在一思进,莫在一思停”,及时想破脑袋,不如直接实践。那就一个个问题来。
在继续之前,先交代一下当前程序的架构,很经典的Spring + Spring Data + Hibernate + MySQL,所以下面的解决方案都是基于这个架构。另外,程序是通过Maven构建。
一、用内存数据库替代MySQL
我选择了HSQLDB,官网上有很多示例可以参考。HSQLDB提供几种不同的使用模式,这里只选用内存模式。Spring通过<jdbc:embedded-database>标签提供对了嵌入式数据库的支持,在applicationContext-test.xml中对数据源的配置十分简单:
| <jdbc:embedded-database id="dataSource" type="HSQL"/> |
HSQL不需要安装,在pom.xml将jar包作为依赖引入即可:
<dependency>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
<version>2.2.8</version>
<scope>test</scope>
</dependency> |
二、数据库结构的维护
在项目的开发过程中,一直使用flyway维护数据库结构变化。虽然Spring也通过<jdbc:initialize-database>提供了执行SQL的机会,但是经过测试发现并且不能完成flyway完成的任务。这个就开始思考:是否一定要选用flyway,并且通过SQL来控制结构改变?flyway主要是参考了ruby的db migration机制,每次修改都是上一次版本的基础进行的,从而不会影响正在运行的逻辑。可是在开发阶段并没有必要使用flyway来控制,并且对SQL的维护也是要花费精力。于是就把目光转向了Hibernate对DDL的支持,便有了下面的配置:
<!-- Jpa Entity Manager 配置 -->
<bean id="entityManagerFactory"
class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="jpaVendorAdapter" ref="hibernateJpaVendorAdapter"></property>
<property name="packagesToScan" value="com.noyaxe.myapp" />
<property name="jpaProperties">
<props>
<!-- 命名规则 My_NAME->MyName -->
<prop key="hibernate.ejb.naming_strategy">org.hibernate.cfg.ImprovedNamingStrategy</prop>
<prop key="hibernate.show.sql">true</prop>
<prop key="hibernate.hbm2ddl.auto">update</prop>
</props>
</property>
</bean> |
可是对于Hibernate的DDL支持,我还是心存疑虑:1. 如果数据库中已经存在数据,那么字段类型改变会如何处理?2. 如何才能更好维护DDL的变化?
(待续)
在上一篇中,完成了对测试用数据源的配置。下面继续构建可运行的测试。
三、使用DBUnit管理数据
测试的维护一直是我比较头疼的问题,期望可以有一个比较易于维护和可复用的方法来管理这些数据。在没有更好的方法之前,暂时选用DBUnit。(反思:其实我一直在为没有发生的事情担心,使得事情根本没有进展。从已存在的、最简单的地方入手,才是正确的处理方式。)
在pom.xml中引入dbunit和springtestdbunit包,后者提供通过注解方式使用DBUnit:
<dependency>
<groupId>org.dbunit</groupId>
<artifactId>dbunit</artifactId>
<version>2.4.9</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.github.springtestdbunit</groupId>
<artifactId>spring-test-dbunit</artifactId>
<version>1.0.1</version>
<scope>test</scope>
</dependency> |
DBUnit使用xml文件管理数据集,通过使用第三方的库也可以很方便的支持JSON格式。这里使用xml:
<xml version="1.0" encoding="utf-8"?>
<dataset>
<building id="1" name="SOHO"/>
<building id="2" name="New Gate Plaza"/>
<floor id="1" floor_num="2" building="1"/>
<floor id="2" floor_num="3" building="1"/>
<floor id="3" floor_num="5" building="2"/>
</dataset> |
这个数据文件放在了 /src/test/resources/中,与测试用例在同一个级别的目录中。为了便于区分,我采用了:Dao类名-被测试的方法名-dataset.xml 的命名方式,例如:UserDao-findByname-dataxml.set。以后如果测试用例需要修改,就可以根据名字很方便地找到对应的数据集,并且不会影响其他测试用例。
注意:
1. 这里的Element及其Attribute名称要和数据库的结构一一对应,而不是实体类。
2. 如果同一个数据对象初始化时,需要初始化的字段数目不一样,比如:一条数据需要初始化的字段是8个,而另外一个是4个。那么一定要字段数多的放在前面。
四、编写测试用例
在编写用例前,还是看下被测试的代码。用到的两个实体类:
package com.noyaxe.myapp.entity; import javax.persistence.Entity;
import javax.persistence.Table; @Entity
@Table(name = "building")
public class Building extends IdEntity {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
} |
package com.noyaxe.myapp.entity; import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.JoinColumn;
import javax.persistence.ManyToOne;
import javax.persistence.Table; @Entity
@Table(name = "floor")
public class Floor extends IdEntity {
private Integer floorNum;
private Building building; @Column(name = "floor_num")
public Integer getFloorNum() {
return floorNum;
} public void setFloorNum(Integer floorNum) {
this.floorNum = floorNum;
} @ManyToOne(optional = false)
@JoinColumn(name = "building")
public Building getBuilding() {
return building;
} public void setBuilding(Building building) {
this.building = building;
}
} |
被测试的FloorDao:
package com.noyaxe.myapp.repository; import com.noyaxe.myapp.entity.Floor;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.data.repository.PagingAndSortingRepository; import java.util.List; public interface FloorDao extends JpaSpecificationExecutor<Floor>, PagingAndSortingRepository<Floor, Long> {
public Floor findByBuildingNameAndFloorNum(String building, Integer floorNum); public List<Floor> findByBuildingName(String building);
} |
测试用例也十分简单:
package com.noyaxe.myapp.repository; import com.github.springtestdbunit.annotation.DatabaseSetup;
import com.noyaxe.myapp.entity.Floor;
import org.junit.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import org.springframework.test.context.support.DependencyInjectionTestExecutionListener;
import org.springframework.test.context.support.DirtiesContextTestExecutionListener; import java.util.List; import static junit.framework.Assert.assertNull;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertNotNull; @RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:applicationContext-test.xml")
@TestExecutionListeners({
DependencyInjectionTestExecutionListener.class,
DirtiesContextTestExecutionListener.class,
TransactionDbUnitTestExecutionListener.class})
public class FloorDaoTest {
@Autowired
private FloorDao floorDao; @Test
<PRE class=java name="code"> @DatabaseSetup("FloorDao-findbByBuidlingName-dataset.xml")</PRE> public void testFindByBuildingName(){ List<Floor> singleFloorList = floorDao.findByBuildingName("SOHO"); assertEquals(1, singleFloorList.size()); List<Floor> twoFloorList = floorDao.findByBuildingName("New Gate Plaza"); assertEquals(2, twoFloorList.size()); List<Floor> emptyFloorList = floorDao.findByBuildingName("Test"); assertEquals(0, emptyFloorList.size()); } @Test<BR><PRE class=java name="code"> @DatabaseSetup("FloorDao-findbByBuidlingNameAndFloorNum-dataset.xml")</PRE> public void testFindByBuildingNameAndFloorNum(){ Floor floor = floorDao.findByBuildingNameAndFloorNum("SOHO", 2); assertNotNull(floor); Floor empty = floorDao.findByBuildingNameAndFloorNum("New Gate Plaza", 7); assertNull(empty); empty = floorDao.findByBuildingNameAndFloorNum("No Building", 7); assertNull(empty); }} |
通过代码,可以很清楚的看到通过DatabaseSetup完成了对测试数据的引入。这里在每个测试方法前引入不同的文件,如果所有的方法可以通过一个文件包括,那么也可以在类前面使用DatabaseSetup引入数据文件。
至此,一个完整的数据层测试用例已经呈现,并且可以运行。可是实际的过程却并没有这么顺利,接下来的文章就要总结一下遇到的问题。
相关文章:
持续集成之路——数据访问层的单元测试
我们曾经和大家探讨过全面剖析Java ME单元测试理念,其实在Android上实现JUnit单元测试也不是很困难,主要是在配置文件和测试环境上将花费很长时间,下面从四步简单讲一下在Android上实现Junit单元测试。
第一步:新建一个TestCase,记得要继承androidTestCase,才能有getContext()来获取当前的上下文变量,这在Android测试中很重要的,因为很多的Android api都需要context。
Java代码
public class TestMath extends AndroidTestCase {
private int i1;
private int i2;
static final String LOG_TAG = "MathTest";
@Override
protected void setUp() throws Exception {
i1 = 2;
i2 = 3;
}
public void testAdd() {
assertTrue("testAdd failed", ((i1 + i2) == 5));
}
public void testDec() {
assertTrue("testDec failed", ((i2 - i1) == 1));
}
@Override
protected void tearDown() throws Exception {
super.tearDown();
}
@Override
public void testAndroidTestCaseSetupProperly() {
super.testAndroidTestCaseSetupProperly();
//Log.d( LOG_TAG, "testAndroidTestCaseSetupProperly" );
}
} |
第二步:新建一个TestSuit,这个就继承Junit的TestSuite就可以了,注意这里是用的addTestSuite方法,一开始使用addTest方法就是不能成功。
Java代码
public class ExampleSuite extends TestSuite {
public ExampleSuite() {
addTestSuite(TestMath.class);
}
} |
第三步:新建一个Activity,用来启动单元测试,并显示测试结果。系统的AndroidTestRunner竟然什么连个UI界面也没有实现,这里只是最简单的实现了一个
Java代码
public class TestActivity extends Activity {
private TextView resultView;
private TextView barView;
private TextView messageView;
private Thread testRunnerThread;
private static final int SHOW_RESULT = 0;
private static final int ERROR_FIND = 1;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
resultView = (TextView)findViewById(R.id.ResultView);
barView = (TextView)findViewById(R.id.BarView);
messageView = (TextView)findViewById(R.id.MessageView);
Button lunch = (Button)findViewById(R.id.LunchButton);
lunch.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
startTest();
}
});
}
private void showMessage(String message) {
hander.sendMessage(hander.obtainMessage(ERROR_FIND, message));
}
private void showResult(String text) {
hander.sendMessage(hander.obtainMessage(SHOW_RESULT, text));
}
private synchronized void startTest() {
if (testRunnerThread != null
&& testRunnerThread.isAlive()) {
testRunnerThread = null;
}
if (testRunnerThread == null) {
testRunnerThread = new Thread(new TestRunner(this));
testRunnerThread.start();
} else {
Toast.makeText(this,
"Test is still running",
Toast.LENGTH_SHORT).show();
}
}
public Handler hander = new Handler() {
public void handleMessage(Message msg) {
switch (msg.what) {
case SHOW_RESULT:
resultView.setText(msg.obj.toString());
break;
case ERROR_FIND:
messageView.append(msg.obj.toString());
barView.setBackgroundColor(Color.RED);
break;
default:
break;
}
}
};
class TestRunner implements Runnable, TestListener {
private Activity parentActivity;
private int testCount;
private int errorCount;
private int failureCount;
public TestRunner(Activity parentActivity) {
this.parentActivity = parentActivity;
}
@Override
public void run() {
testCount = 0;
errorCount = 0;
failureCount = 0;
ExampleSuite suite = new ExampleSuite();
AndroidTestRunner testRunner = new AndroidTestRunner();
testRunner.setTest(suite);
testRunner.addTestListener(this);
testRunner.setContext(parentActivity);
testRunner.runTest();
}
@Override
public void addError(Test test, Throwable t) {
errorCount++;
showMessage(t.getMessage() + "\n");
}
@Override
public void addFailure(Test test, AssertionFailedError t) {
failureCount++;
showMessage(t.getMessage() + "\n");
}
@Override
public void endTest(Test test) {
showResult(getResult()); }
@Override
public void startTest(Test test) {
testCount++;
}
private String getResult() {
int successCount = testCount - failureCount - errorCount;
return "Test:" + testCount + " Success:" + successCount + " Failed:" + failureCount + " Error:" + errorCount;
}
}
} |
第四步:修改AndroidManifest.xml,加入,不然会提示找不到AndroidTestRunner,这里需要注意是这句话是放在applications下面的,我一开始也不知道,放错了地方,浪费了不少时间
Xml代码
xml version="1.0" encoding="utf-8"?>
<manifest xmlns:Android=http://schemas.Android.com/apk/res/Android
package="com.test.sample"
Android:versionCode="1"
Android:versionName="1.0">
<application Android:icon="@drawable/icon" Android:label="@string/app_name" Android:debuggable="true"> <activity Android:name=".TestActivity"
Android:label="@string/app_name">
<intent-filter>
<action Android:name="Android.intent.action.MAIN" />
<category Android:name="Android.intent.category.LAUNCHER" />
intent-filter>
activity>
<uses-library Android:name="Android.test.runner" />
application>
<uses-sdk Android:minSdkVersion="4" />
manifest |
在最近的r应用的单元测试中,经常需要用到mock,可以说mock在ut (unit test)中是无处不在的。而在r的ut实践中也找到了一种很简洁的mock方式,不仅解决了ut中所有需要mock的地方,而且可以很少量的代码来完成mock。详见下文。
一.Mock的使用场景:
比如以下场景:
1. mock掉外部依赖的应用的HSF service的调用,比如uic,tp 的hsf服务依赖。
2. 对DAO层(访问mysql、oracle、tair、tfs等底层存储)的调用mock等。
3. 对系统间异步交互notify消息的mock。
4. 对method_A里面调用到的method_B 的mock 。
5. 对一些应用里面自己的 class(abstract, final, static),interface,annotation ,enum,native等的mock。
二. Mock工具的原理:
mock工具工作的原理大都如下:

1. record阶段:录制期望。也可以理解为数据准备阶段。创建依赖的class 或interface或method ,模拟返回的数据,及调用的次数等。
2. replay阶段:通过调用被测代码,执行测试。期间会invoke 到 第一阶段record的mock对象或方法。
3. verify阶段:验证。可以验证调用返回是否正确。及mock的方法调用次数,顺序等。
三. 当前的一些Mock工具的比较:
历史曾经或当前比较流行的Mock工具有EasyMock、jMock、Mockito、Unitils Mock、PowerMock、jmockit等工具。
他们的功能对比如下:
从这里可以看到,当前为什么jmockit为什么这么火爆了!所以我们的UT中的mock工具也选择了目前无所不能的jmockit。
而在使用的过程中,感觉到jmockit的 Auto-injection of mocks 及 Special fields for "any" argument matching 及各种有用的 Annotation 给测试代码精简和测试效率提升带来了实实在在的好处。

四. Jmockit的简介:
JMockit 是用以帮助开发人员编写测试程序的一组工具和API,它(https://code.google.com/p/jmockit/)完全基于 Java 5 SE 的 java.lang.instrument 包开发,内部使用 ASM 库来修改Java的Bytecode。正是由于基于instrument,可以修改字节码。所以这也是它强大的原因。
Jmockit可以mock的种类包含了:1.class(abstract, final, static) ;2.interface ;3.enum ;4.annotation ;5.native 。
Jmockit 有两种mock的方式:
1. Behavior-oriented(Expectations & Verifications) ;
2. State-oriented(MockUp<GenericType>) 。
通俗点讲,Behavior-oriented是基于行为的mock,对mock目标代码的行为进行模仿,更像黑盒测试。State-oriented 是基于状态的mock,是站在目标测试代码内部的。可以对传入的参数进行检查、匹配,才返回某些结果,类似白盒。而State-oriented的 new MockUp基本上可以mock任何代码或逻辑。非常强大。
以下是jmockit的APIs和tools:

可以看到jmockit常用的Expectation、NonStrictExpectations 期望录制 及Annotation @Tested、@Mocked,@NonStrict、@Injectable 等简洁的mock代码风格。而且jmockit 还自带了code coverage的工具供本地UT时候看逻辑覆盖或代码覆盖率使用。
五.Jmockit的实践:
第一步:添加jmockit的jar包依赖
在refund的单元测试过程中,第一步:应用pom中引入jmockit的jar包,可以顺带引入jmockit自带的code coverage的jar。

第二步:一个完整的Jmockit的示例:

这个是对refundmanager里面查询可退款金额范围 queryRefundFeeRange的单元测试。通过看被测代码可以看到这个方法的实现里面调用了
feeResultDO = confirmGoodsService.queryConfirmToSellerRefundFee(detailId);
这个外部的hsf依赖 获取了feeResultDO 。
这个hsf调用是需要mock的。
传统的mock或ut ,对 confirmGoodsService 这个bean是需要初始化,通过spring的配置,初始化加载等 一大堆代码。
jmockit通过了注解的方式:
@Injectable
private ConfirmGoodsService confirmGoodsService ; |
一个Annotation就搞定了所有的配置,加载等问题。直接复用开发代码里面的bean,节省了大量的代码。
另外 @Tested RefundManagerImpl refundManagerImpl = new RefundManagerImpl();
这里也用到了注解 @Tested 表示被测试的class 。
另外还有常用的注解:@Mocked,@NonStrict等。
而这段代码就是mock的核心:录制被mock的method的行为及期望返回:
new Expectations(){
{
confirmGoodsService.queryConfirmToSellerRefundFee(anyLong);
result = feeResultDOmock;
times = 1;
}
} ; |
其中
result 可以返回任意需要的测试类型;
times 表示期望被调用的次数。
是不是看起来非常简洁明了。
而上面该段代码如果 换成基于状态的mockup 代码如下:

采用MockUp的方式,可以mock任意的mock对象或方法,因为它直接改写了原method的实现逻辑,直接返回需要的数据。
这也是jmockit彪悍的地方之一。
最后数据回收,防止各个testcase的mock相互影响的方式:
Mockit.tearDownMocks();
这一步也可以省略。
还要重点介绍的就是mock期望里面的入参 any。
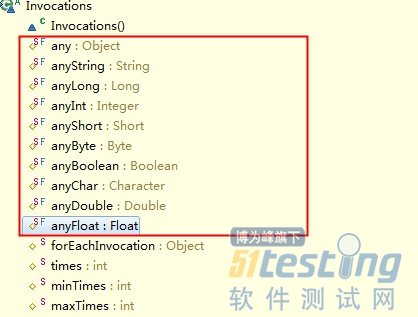
这个any系列的万能入参类型,也可以节省很多mock代码,可以高效的准备任何入参类型。
以上,一个最简单的,也最实用的jmockit的示例。
jmockit的更多,对interface及method的单元测试的示例,将在后续总结汇总。
六、 Jmockit自带的code coverage :
工程的 pom文件中引入 jmockit-coverage 后,本地eclipse启动单元测试后, 会自动统计单元测试的代码覆盖率。关于行覆盖,方法覆盖,类覆盖,分支逻辑覆盖等各种数据都可以看到。

IDE启动UT时候,加载 code coverage 组件,
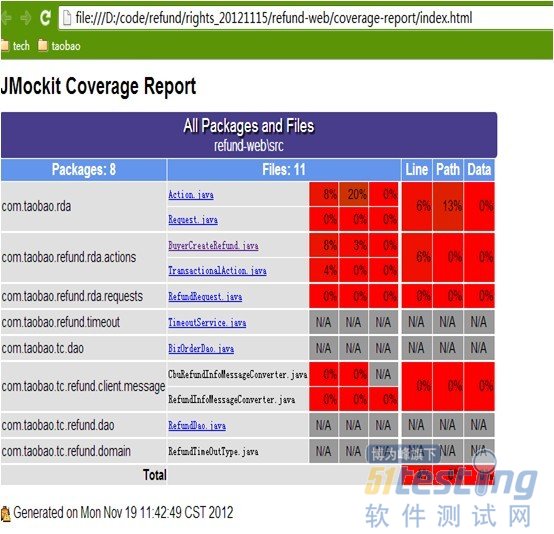
点击进去,可以看到具体的覆盖逻辑:
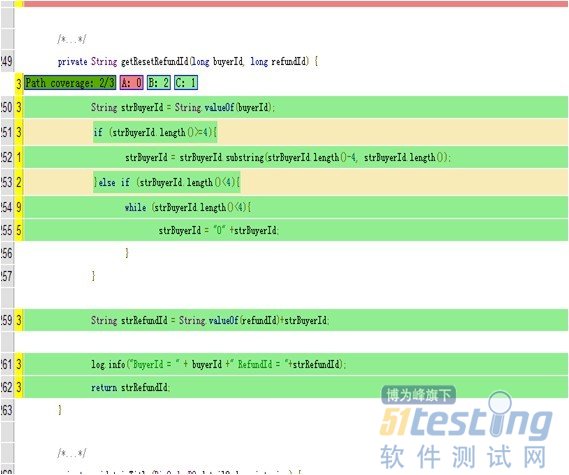
其中绿色部分表示源代码被run过。
代码覆盖对指导单元测试的测试逻辑,覆盖等提供了直观的指示。
以上,就是在单元测试中mock技术的应用:Jmockit的使用介绍及实际应用示例。它在单元测试中确实可以很少的代码mock掉外部依赖,提高ut的效率,并且 自带的code coverage可很方便的看到ut对被测代码的覆盖效果,指导测试设计。
在编写数据访问层的单元测试时,遇到不少问题,有些问题可以很容易Google到解决方法,而有些只能自己研究解决。这里分享几个典型的问题以及解决方法。
先交代一下用到的测试框架 Spring Test + SpringTestDbUnit + DbUnit。
一、先说一个低级的问题。
Spring通过<jdbc:embedded-database>标签提供对内存数据的支持,形如:
| <jdbc:embeded-database id="dataSource" type="HSQL"> |
可是在启动时,却总是提示错误:
Caused by: org.xml.sax.SAXParseException; lineNumber: 31; columnNumber: 57; cvc-complex-type.2.4.c: 通配符的匹配很全面, 但无法找到元素 'jdbc:embedded-database' 的声明。
at com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.createSAXParseException(ErrorHandlerWrapper.java:198)
at com.sun.org.apache.xerces.internal.util.ErrorHandlerWrapper.error(ErrorHandlerWrapper.java:134)
at com.sun.org.apache.xerces.internal.impl.XMLErrorReporter.reportError(XMLErrorReporter.java:437)
……
翻来覆去对标签修改了很多次,文档和dtd也看了很多遍,始终没有发现问题。最后无意间看到context文件头部对标签的声明上好像有问题:
<beans xmlns=http://www.springframework.org/schema/beans
xmlns:p=http://www.springframework.org/schema/p
xmlns:xsi=http://www.w3.org/2001/XMLSchema-instance
xmlns:context=http://www.springframework.org/schema/context
xmlns:tx=http://www.springframework.org/schema/tx xmlns:jpa=http://www.springframework.org/schema/data/jpa
xmlns:task=http://www.springframework.org/schema/task xmlns:aop=http://www.springframework.org/schema/aop
xmlns:jdbc=http://www.springframework.org/schema/jdbc
xsi:schemaLocation="http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.2.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.2.xsd
http://www.springframework.org/schema/txhttp://www.springframework.org/schema/tx/spring-tx-3.2.xsdBR> http://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa.xsd
http://www.springframework.org/schema/taskhttp://www.springframework.org/schema/task/spring-task-3.2.xsd
http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/<SPAN style="COLOR: #ff0000">tx</SPAN>/spring-jdbc-3.2.xsd"> |
仔细看了下,原来当时从tx处复制声明时,只是将最后的tx改成了jdbc,却忘记了将路径中tx改为jdbc。更改后,启动正常。所有,如果有同学遇到类似的问题,应该先检查头部。
二、外键关联导致的删除失败。
在刚开始写测试时,每个用例单独运行都没有问题,可是一旦一起运行,就出现下面的异常:
Tests run: 5, Failures: 0, Errors: 3, Skipped: 0, Time elapsed: 0.879 sec <<< FAILURE! - in com.noyaxe.nso.service.DeviceServiceTest
testInitializedForBindedSpaceForceBind(com.noyaxe.nso.service.DeviceServiceTest) Time elapsed: 0.309 sec <<< ERROR!
java.sql.SQLIntegrityConstraintViolationException: integrity constraint violation: foreign key no action; FK_L6IDVK78B2TLU8NO6EDJ0G6U8 table: CUSTOM_TABLE_COLUMN_SPACE_TYPE
at org.hsqldb.jdbc.Util.sqlException(Unknown Source)
at org.hsqldb.jdbc.Util.sqlException(Unknown Source)
at org.hsqldb.jdbc.JDBCStatement.fetchResult(Unknown Source)
……
……
Caused by: org.hsqldb.HsqlException: integrity constraint violation: foreign key no action; FK_L6IDVK78B2TLU8NO6EDJ0G6U8 table: CUSTOM_TABLE_COLUMN_SPACE_TYPE
at org.hsqldb.error.Error.error(Unknown Source)
at org.hsqldb.StatementDML.performReferentialActions(Unknown Source)
at org.hsqldb.StatementDML.delete(Unknown Source)
at org.hsqldb.StatementDML.executeDeleteStatement(Unknown Source)
at org.hsqldb.StatementDML.getResult(Unknown Source)
at org.hsqldb.StatementDMQL.execute(Unknown Source)
at org.hsqldb.Session.executeCompiledStatement(Unknown Source)
at org.hsqldb.Session.executeDirectStatement(Unknown Source)
at org.hsqldb.Session.execute(Unknown Source)
at org.hsqldb.jdbc.JDBCStatement.fetchResult(Unknown Source)
……
看异常信息,应该是删除记录时,外键级联导致的问题。在实体类里改变级联设置并不起作用。最后在StackOverflow上找了一个解决方法:编写一个类,继承AbstractTestExecutionListener,在beforeTestClass中取消级联依赖。具体如下:
import org.dbunit.database.DatabaseDataSourceConnection;
import org.dbunit.database.IDatabaseConnection;
import org.springframework.test.context.TestContext;
import org.springframework.test.context.support.AbstractTestExecutionListener; import javax.sql.DataSource; public class ForeignKeyDisabling extends AbstractTestExecutionListener {
@Override
public void beforeTestClass(TestContext testContext) throws Exception {
IDatabaseConnection dbConn = new DatabaseDataSourceConnection(
testContext.getApplicationContext().getBean(DataSource.class)
);
dbConn.getConnection().prepareStatement("SET DATABASE REFERENTIAL INTEGRITY FALSE").execute(); }
} |
把这个新的Listener添加测试类的注解中:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:applicationContext-test.xml")
@TestExecutionListeners({
DependencyInjectionTestExecutionListener.class,
DirtiesContextTestExecutionListener.class,
TransactionDbUnitTestExecutionListener.class,
ForeignKeyDisabling.class}) |
参考:http://stackoverflow.com/questions/2685274/tdd-with-hsqldb-removing-foreign-keys
三、PROPERTY_DATATYPE_FACTORY引起的警告
在jenkins中构建时,总是可以看到如下的警告信息:
WARN getDataTypeFactory, Potential problem found: The configured data type factory 'class org.dbunit.dataset.datatype.DefaultDataTypeFactory' might cause problems with the current database 'HSQL Database Engine' (e.g. some datatypes may not be supported properly). In rare cases you might see this message because the list of supported database products is incomplete (list=[derby]). If so please request a java-class update via the forums.If you are using your own IDataTypeFactory extending DefaultDataTypeFactory, ensure that you override getValidDbProducts() to specify the supported database products.
意思很好理解,就说默认的DataTypeFactory可能会引起问题,建议设置该属性值。解决方法也很明显:就是设置数据库连接的PROPERTY_DATATYPE_FACTORY属性的值。尝试了用Before、BeforeClass或者自定义ExecutionListener中都无法实现对该属性的设置。
那就只能先找到抛出这个异常的位置,然后向前推,逐步找到获取连接的地方。最后发现,连接是在DbUnitTestExecutionListener.prepareDatabaseConnection中获取连接,并且没有做什么进一步的处理,所以前面的设置都不起作用。看来又只能通过重写源代码来达成目的了。
直接上源码吧:
CustomTransactionDbUnitTestExecutionListener类: 完全复制DbUnitTestExecutionListener,只是增加一句代码。注意该类的包路径和DbUnitTestExecutionListener一致。
private void prepareDatabaseConnection(TestContext testContext, String databaseConnectionBeanName) throws Exception {
Object databaseConnection = testContext.getApplicationContext().getBean(databaseConnectionBeanName);
if (databaseConnection instanceof DataSource) {
databaseConnection = DatabaseDataSourceConnectionFactoryBean.newConnection((DataSource) databaseConnection);
}
Assert.isInstanceOf(IDatabaseConnection.class, databaseConnection);
<SPAN style="COLOR: #33cc00">((IDatabaseConnection)databaseConnection).getConfig().setProperty(DatabaseConfig.PROPERTY_DATATYPE_FACTORY, new HsqldbDataTypeFactory());
</SPAN> testContext.setAttribute(CONNECTION_ATTRIBUTE, databaseConnection);
} |
绿色就是真正发挥作用的代码。
可是这个类并不能直接饮用,而是通过TransactionDbUnitTestExecutionListener的CHAIN被调用的,而TransactionDbUnitTestExecutionListener同样无法更改,同样只能建一个自定义的TransactionDbUnitTestExecutionListener类,CustomTransactionDbUnitTestExecutionListener:
public class CustomTransactionDbUnitTestExecutionListener extends TestExecutionListenerChain { private static final Class<?>[] CHAIN = { TransactionalTestExecutionListener.class,
CustomDbUnitTestExecutionListener.class }; @Override
protected Class<?>[] getChain() {
return CHAIN;
}
} |
那么测试类的注解也要修改:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:applicationContext-test.xml")
@TestExecutionListeners({
DependencyInjectionTestExecutionListener.class,
DirtiesContextTestExecutionListener.class,
CustomTransactionDbUnitTestExecutionListener.class,
ForeignKeyDisabling.class}) |
四、@Transactional标签引起的问题
按照spring-dbunit-test的文档中说法,可以使用@Transactional确保数据的清洁。使用简单,只需要将上面的注解增加一个@Transactional,
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:applicationContext-test.xml")
@Transactional
@TestExecutionListeners({
DependencyInjectionTestExecutionListener.class,
DirtiesContextTestExecutionListener.class,
CustomTransactionDbUnitTestExecutionListener.class,
ForeignKeyDisabling.class}) |
可是运行时,却出现了异常:
org.springframework.transaction.TransactionSystemException: Could not roll back JPA transaction; nested exception is javax.persistence.PersistenceException: unexpected error when rollbacking at org.springframework.orm.jpa.JpaTransactionManager.doRollback(JpaTransactionManager.java:544) at org.springframework.transaction.support.AbstractPlatformTransactionManager.processRollback(AbstractPlatformTransactionManager.java:846) at org.springframework.transaction.support.AbstractPlatformTransactionManager.rollback(AbstractPlatformTransactionManager.java:823) at org.springframework.test.context.transaction.TransactionalTestExecutionListener$TransactionContext.endTransaction(TransactionalTestExecutionListener.java:588) at org.springframework.test.context.transaction.TransactionalTestExecutionListener.endTransaction(TransactionalTestExecutionListener.java:297) at org.springframework.test.context.transaction.TransactionalTestExecutionListener.afterTestMethod(TransactionalTestExecutionListener.java:192) …… Caused by: javax.persistence.PersistenceException: unexpected error when rollbacking at org.hibernate.ejb.TransactionImpl.rollback(TransactionImpl.java:109) at org.springframework.orm.jpa.JpaTransactionManager.doRollback(JpaTransactionManager.java:540) ... 32 more Caused by: org.hibernate.TransactionException: rollback failed at org.hibernate.engine.transaction.spi.AbstractTransactionImpl.rollback(AbstractTransactionImpl.java:215) at org.hibernate.ejb.TransactionImpl.rollback(TransactionImpl.java:106) ... 33 more Caused by: org.hibernate.TransactionException: unable to rollback against JDBC connection at org.hibernate.engine.transaction.internal.jdbc.JdbcTransaction.doRollback(JdbcTransaction.java:167) at org.hibernate.engine.transaction.spi.AbstractTransactionImpl.rollback(AbstractTransactionImpl.java:209) ... 34 more Caused by: java.sql.SQLNonTransientConnectionException: connection exception: connection does not exist at org.hsqldb.jdbc.Util.sqlException(Unknown Source) at org.hsqldb.jdbc.Util.sqlException(Unknown Source) …… ... 35 more Caused by: org.hsqldb.HsqlException: connection exception: connection does not exist at org.hsqldb.error.Error.error(Unknown Source) at org.hsqldb.error.Error.error(Unknown Source) ... 40 more |
最后通过查看源代码发现,CustomDbUnitTestExecutionListener会先于TransactionalTestExecutionListener执行,而前者在执行完毕就关闭了数据库连接,后者在回滚时,就发生了连接不存在的异常。
解决方法很简单,修改CustomTransactionalDbUnitTestExecutionListener:
| private static final Class<?>[] CHAIN = {CustomDbUnitTestExecutionListener.class, TransactionalTestExecutionListener.class}; |
也就是数组两个元素调换下位置。
unittest是python单元测试框架,又叫做PyUnit。
之所以称为框架是它代替开发人员完成了一些调用、IO等与单元测试无直接关系的支撑代码,让开发人员可以专注与测试用例的编写,简化单元测试工作。
单元测试是一种基本的,由开发人员(而不是测试人员)完成的测试,保证一个程序基本单元的正确性。“单元”的概念我个人理解就类似电子设备中的元器件,一个个元器件(单元)组成了整个电子设备(程序)。而元器件的功能是单一的、确定的,可以在电子设备未完全成型(程序未完全实现)之前对其正确性进行测试(即单元测试)。同时,这些元器件是独立的,可以方便的更换(高内聚,低耦合,可以任意重构——只要满足前面的单元测试)。所以单元测试是测试驱动开发、极限编程、敏捷中的重要概念。
一个简单的例子:
#FileName: ut_target.py
class EqualToZero(Exception): pass
class SplitZero(object):
def splitzero(self, num):
if num > 0:
return "num is bigger than zero"
elif num < 0:
return "num is smaller than zero"
else:
raise EqualToZero
#FileName: utest.py
from ut_target import SplitZero, EqualToZero
import unittest
class SzTestCase(unittest.TestCase):
def setUp(self):
print "test start"
def tearDown(self):
print "test stop"
def testSzBig(self):
num = 10
sz = SplitZero()
self.assertEqual(sz.splitzero(num),
"num is bigger than zero")
def testSzSmall(self):
num = -10
sz = SplitZero()
self.assertEqual(sz.splitzero(num),
"num is smaller than zero")
def testSzEqual(self):
num = 0
sz = SplitZero()
self.assertRaises(EqualToZero, sz.splitzero, num)
if __name__ == "__main__":
unittest.main()
执行python utest.py -v
testSzBig (__main__.SzTestCase) ... test start
test stop
ok
testSzEqual (__main__.SzTestCase) ... test start
test stop
ok
testSzSmall (__main__.SzTestCase) ... test start
test stop
ok
----------------------------------------------------------------------
Ran 3 tests in 0.000s
OK |
unittest基本使用方法
1.import unittest
2.定义一个继承自unittest.TestCase的测试用例类
3.定义setUp和tearDown,在每个测试用例前后做一些辅助工作。
4.定义测试用例,名字以test开头。
5.一个测试用例应该只测试一个方面,测试目的和测试内容应很明确。主要是调用assertEqual、assertRaises等断言方法判断程序执行结果和预期值是否相符。
6.调用unittest.main()启动测试
7.如果测试未通过,会输出相应的错误提示。如果测试全部通过则不显示任何东西,这时可以添加-v参数显示详细信息。
1.前言:
LoadRunner 最重要也是最难理解的地方--测试结果的分析.其余的录制和加压测试等设置对于我们来讲通过几次操作就可以轻松掌握了.针对 Results Analysis 我用图片加文字做了一个例子,希望通过例子能给大家更多的帮助.这个例子主要讲述的是多个用户同时接管任务,测试系统的响应能力,确定系统瓶颈所在.客户要求响应时间是1 个人接管的时间在5S 内.
2.系统资源:
2.1 硬件环境:
CPU:奔四2.8E
硬盘:100G
网络环境:100Mbps
2.2 软件环境:
操作系统:英文windowsXP
服务器:tomcat 服务
浏览器:IE6.0
系统结构:B/S 结构
3.添加监视资源
下面要讲述的例子添加了我们平常测试中最常用到的一些资源参数.另外有些特殊的资源暂时在这里不做讲解了.我会在以后相继补充进来。
Mercury Loadrunner Analysis 中最常用的5 种资源.
1. Vuser
2. Transactions
3. Web Resources
4. Web Page Breakdown
5. System Resources
在Analysis 中选择“Add graph”或“New graph”就可以看到这几个资源了.还有其他没有数据的资源,我们没有让它显示.

如果想查看更多的资源,可以将左下角的display only graphs containing data 置为不选.然后选中相应的点“open graph”即可.
打开Analysis 首先可以看的是Summary Report.这里显示了测试的分析摘要.应有尽有.但是我们并不需要每个都要仔细去看.下面介绍一下部分的含义:
Duration(持续时间):了解该测试过程持续时间.测试人员本身要对这个时期内系统一共做了多少的事有大致的熟悉了解.以确定下次增加更多的任务条件下测试的持续时间。
Statistics Summary(统计摘要):只是大概了解一下测试数据,对我们具体分析没有太大的作用.
Transaction Summary(事务摘要):了解平均响应时间Average单位为秒.
其余的看不看都可以.都不是很重要.
【注】 51Testing授权IT168独家转载,未经明确的书面许可,任何人或单位不得对本文内容复制、转载或进行镜像,否则将追究法律责任。
内容导航
4.分析集合点
在录制脚本中通常我们会使用到集合点,那么既然我们用到了集合点,我们就需要知道Vuser 是在什么时候集合在这个点上,又是怎样的一个被释放的过程.这个时候就需要观察Vuser-Rendezvous 图.
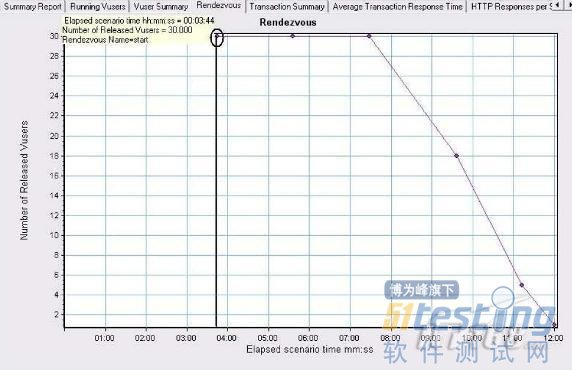
图1
可以看到大概在3 分50 的地方30 个用户才全部集中到start 集合点,持续了3 分多,在7 分30 的位置开始释放用户,9 分30 还有18 个用户,11 分10 还有5 个用户,整个过程持续了12 分.
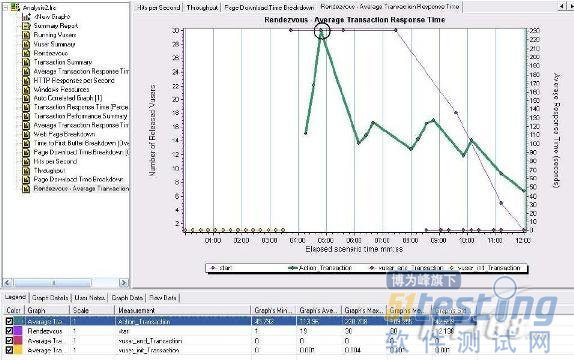
图2
上面图2 是集合点与平均事务响应时间的比较图.
注:在打开analysis 之后系统LR 默认这两个曲线是不在同一张图中的.这就需要自行设置了.具体步骤如下:
点击图上.右键选择merge graphs.然后在select graph to merge with 中选择即将用来进行比较的graph.如图3:
图3
图2 中较深颜色的是平均响应时间,浅色的为集合点,当Vuser 在集合点持续了1分后平均响应时间呈现最大值,可见用户的并发对系统的性能是一个很大的考验.接下来看一下与事务有关的参数分析.下看一张图.
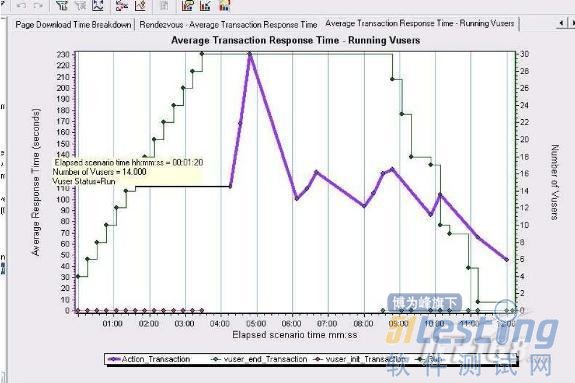
图4
这张图包括Average Transaction Response Time 和Running Vuser 两个数据图.从图中可以看到Vuser_init_Transaction(系统登录)对系统无任何的影响,Vuser 达到15 个的时候平均事务响应时间才有明显的升高,也就是说系统达到最优性能的时候允许14 个用户同时处理事务,Vuser 达到30 后1 分,系统响应时间最大,那么这个最大响应时间是要推迟1 分钟才出现的,在系统稳定之后事务响应时间开始下降说明这个时候有些用户已经执行完了操作.同时也可以看出要想将事务响应时间控制在10S 内.Vuser 数量最多不能超过2 个.看来是很难满足用户的需求了.
做一件事有时候上级会问你这件事办得怎么样了.你会说做完一半了.那么这个一半的事情你花了多少时间呢?所以我们要想知道在给定时间的范围内完成事务的百分比就要靠下面这个图(Transaction Response Time(Percentile)
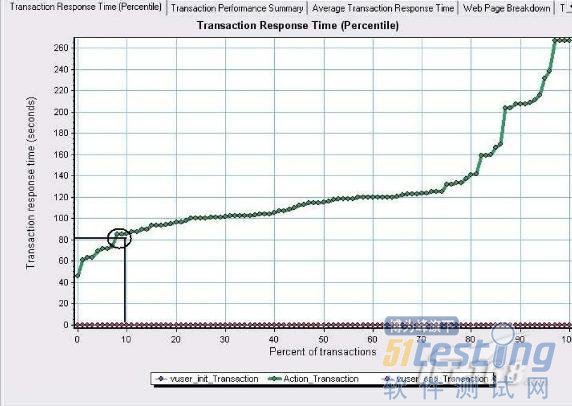
图中画圈的地方表示10%的事务的响应时间是在80S 左右.80S 对于用户来说不是一个很小的数字,而且只有10%的事务,汗.你觉得这个系统性能会好么!
实际工作中遇到的事情不是每一件事都能够在很短的时间内完成的,对于那些需要时间的事情我们就要分配适当的时间处理,时间分配的不均匀就会出现有些事情消耗的时间长一些,有些事情消耗的短一些,但我们自己清楚.LR 同样也为我们提供了这样的功能,使我们可以了解大部分的事务响应时间是多少?以确定这个系统我们还要付出多少的代价来提高它.
Transaction Response Time(Distribution)-事务响应时间(分布)
显示在方案中执行事务所用时间的分布.如果定义了可以接受的最小和最大事务性能时间,可以通过此图确定服务器性能是否在可接受范围内.

很明显大多数事务的响应时间在60-140S.在我测试过的项目中多数客户所能接受的最大响应时间也要在20S 左右.140S 的时间!很少有人会去花这么多的时间去等待页面的出现吧!
通过观察以上的数据表.我们不难看到此系统在这种环境下并不理想.世间事有果就有因,那么是什么原因导致得系统性能这样差呢?让我们一步一步的分析.
系统性能不好的原因多方面,我们先从应用程序看.有的时候我不得不承认LR 的功能真的很强大,这也是我喜欢它的原因.先看一张页面细分图.

一个应用程序是由很多个组件组成的,整个系统性能不好那我们就把它彻底的剖析一下.图片中显示了整个测试过程中涉及到的所有web 页.web page breakdown中显示的是每个页面的下载时间.点选左下角web page breakdown 展开,可以看到每个页中包括的css 样式表,js 脚本,jsp 页面等所有的属性
在select page to breakdown 中选择页面.
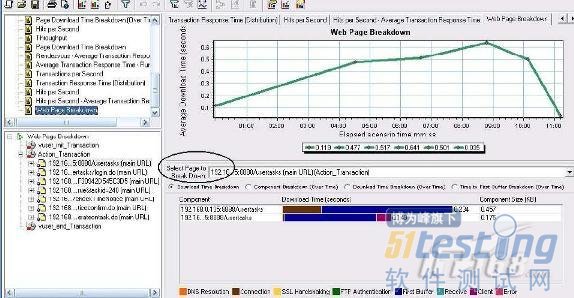
见图.
在 Select Page To Breakdown 中选择http://192.168.0.135:8888/usertasks 后,在下方看到属于它的两个组件,第一行中Connection 和First Buffer 占据了整个的时间,那么它的消耗时间点就在这里,我们解决问题就要从这里下手.


也有可能你的程序中client 的时间最长.或者其他的,这些就要根据你自己的测试结果来分析了.下面我们来看一下CPU,内存.硬盘的瓶颈分析方法:
首先我们要监视CPU,内存.硬盘的资源情况.得到以下的参数提供分析的依据.
%processor time(processor_total):器消耗的处理器时间数量.如果服务器专用于sql server 可接受的最大上限是80% -85 %.也就是常见的CPU 使用率.
%User time(processor_total)::表示耗费CPU的数据库操作,如排序,执行aggregate functions等。如果该值很高,可考虑增加索引,尽量使用简单的表联接,水平分割大表格等方法来降低该值。
%DPC time(processor_total)::越低越好。在多处理器系统中,如果这个值大于50%并且Processor:% Processor Time非常高,加入一个网卡可能会提高性能,提供的网络已经不饱和。
%Disk time(physicaldisk_total):指所选磁盘驱动器忙于为读或写入请求提供服务所用的时间的百分比。如果三个计数器都比较大,那么硬盘不是瓶颈。如果只有%Disk Time比较大,另外两个都比较适中,硬盘可能会是瓶颈。在记录该计数器之前,请在Windows 2000 的命令行窗口中运行diskperf -yD。若数值持续超过80%,则可能是内存泄漏。
Availiable bytes(memory):用物理内存数. 如果Available Mbytes的值很小(4 MB 或更小),则说明计算机上总的内存可能不足,或某程序没有释放内存。
Context switch/sec(system): (实例化inetinfo 和dllhost 进程) 如果你决定要增加线程字节池的大小,你应该监视这三个计数器(包括上面的一个)。增加线程数可能会增加上下文切换次数,这样性能不会上升反而会下降。如果十个实例的上下文切换值非常高,就应该减小线程字节池的大小。
%Disk reads/sec(physicaldisk_total):每秒读硬盘字节数.
%Disk write/sec(physicaldisk_total):每秒写硬盘字节数.
Page faults/sec:进程产生的页故障与系统产生的相比较,以判断这个进程对系统页故障产生的影响。
Pages per second:每秒钟检索的页数。该数字应少于每秒一页Working set:理线程最近使用的内存页,反映了每一个进程使用的内存页的数量。如果服务器有足够的空闲内存,页就会被留在工作集中,当自由内存少于一个特定的阈值时,页就会被清除出工作集。
Avg.disk queue length:读取和写入请求(为所选磁盘在实例间隔中列队的)的平均数。该值应不超过磁盘数的1.5~2 倍。要提高性能,可增加磁盘。注意:一个Raid Disk实际有多个磁盘。
Average disk read/write queue length: 指读取(写入)请求(列队)的平均数Disk reads/(writes)/s:理磁盘上每秒钟磁盘读、写的次数。两者相加,应小于磁盘设备最大容量。
Average disk sec/read:以秒计算的在此盘上读取数据的所需平均时间。Average disk sec/transfer:指以秒计算的在此盘上写入数据的所需平均时间。
Bytes total/sec:为发送和接收字节的速率,包括帧字符在内。判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较Page read/sec:每秒发出的物理数据库页读取数。这一统计信息显示的是在所有数据库间的物理页读取总数。由于物理 I/O 的开销大,可以通过使用更大的数据高速缓存、智能索引、更高效的查询或者改变数据库设计等方法,使开销减到最小。
Page write/sec:(写的页/秒)每秒执行的物理数据库写的页数。
内容导航
1. 判断应用程序的问题
如果系统由于应用程序代码效率低下或者系统结构设计有缺陷而导致大量的上下文切换(context switches/sec显示的上下文切换次数太高)那么就会占用大量的系统资源,如果系统的吞吐量降低并且CPU的使用率很高,并且此现象发生时切换水平在15000以上,那么意味着上下文切换次数过高.
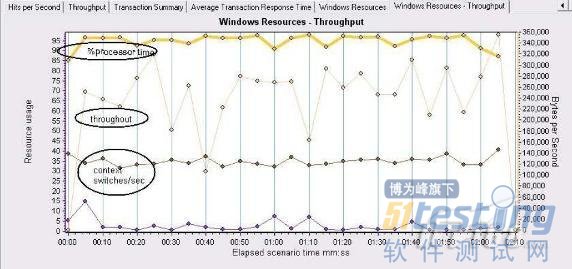
从图的整体看.context switches/sec变化不大,throughout曲线的斜率较高,并且此时的contextswitches/sec已经超过了15000.程序还是需要进一步优化.
2. 判断CPU瓶颈
如果processor queue length显示的队列长度保持不变(>=2)个并且处理器的利用率%Processortime超过90%,那么很可能存在处理器瓶颈.如果发现processor queue length显示的队列长度超过2,而处理器的利用率却一直很低,或许更应该去解决处理器阻塞问题,这里处理器一般不是瓶颈.
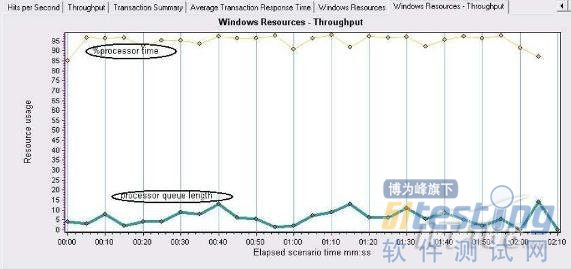
%processor time平均值大于95,processor queue length大于2.可以确定CPU瓶颈.此时的CPU已经不能满足程序需要.急需扩展.
3. 判断内存泄露问题
内存问题主要检查应用程序是否存在内存泄漏,如果发生了内存泄漏,process\private bytes计数器和process\working set 计数器的值往往会升高,同时avaiable bytes的值会降低.内存泄漏应该通过一个长时间的,用来研究分析所有内存都耗尽时,应用程序反应情况的测试来检验.
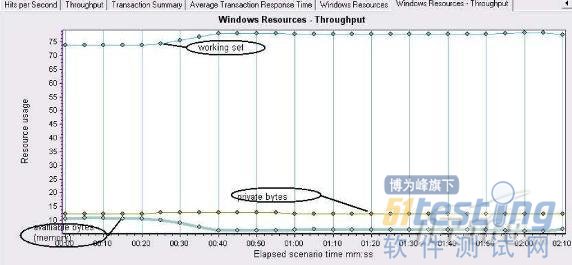
图中可以看到该程序并不存在内存泄露的问题.内存泄露问题经常出现在服务长时间运转的时候,由于部分程序对内存没有释放,而将内存慢慢耗尽.也是提醒大家对系统稳定性测试的关注.
附件:
CPU信息:
Processor\ % Processor Time 获得处理器使用情况。
也可以选择监视 Processor\ % User Time 和 % Privileged Time 以获得详细信息。
Server Work Queues\ Queue Length 计数器会显示出处理器瓶颈。队列长度持续大于 4 则表示可能出现处理器拥塞。
System\ Processor Queue Length 用于瓶颈检测通过使用 Process\ % Processor Time 和 Process\ Working Set
Process\ % Processor Time过程的所有线程在每个处理器上的处理器时间总和。
硬盘信息:
Physical Disk\ % Disk Time
Physical Disk\ Avg.Disk Queue Length
例如,包括 Page Reads/sec 和 % Disk Time 及 Avg.Disk Queue Length。如果页面读取操作速率很低,同时 % Disk Time 和 Avg.Disk Queue Length的值很高,则可能有磁盘瓶径。但是,如果队列长度增加的同时页面读取速率并未降低,则内存不足。
Physical Disk\ % Disk Time
Physical Disk\ Avg.Disk Queue Length
例如,包括 Page Reads/sec 和 % Disk Time 及 Avg.Disk Queue Length。如果页面读取操作速率很低,同时 % Disk Time 和 Avg.Disk Queue Length的值很高,则可能有磁盘瓶径。但是,如果队列长度增加的同时页面读取速率并未降低,则内存不足。
请观察 Processor\ Interrupts/sec 计数器的值,该计数器测量来自输入/输出 (I/O) 设备的服务请求的速度。如果此计数器的值明显增加,而系统活动没有相应增加,则表明存在硬件问题。
Physical Disk\ Disk Reads/sec and Disk Writes/sec
Physical Disk\ Current Disk Queue Length
Physical Disk\ % Disk Time
LogicalDisk\ % Free Space |
测试磁盘性能时,将性能数据记录到另一个磁盘或计算机,以便这些数据不会干扰您正在测试的磁盘。
可能需要观察的附加计数器包括 Physical Disk\ Avg.Disk sec/Transfer 、Avg.DiskBytes/Transfer,和Disk Bytes/sec。
Avg.Disk sec/Transfer 计数器反映磁盘完成请求所用的时间。较高的值表明磁盘控制器由于失败而不断重试该磁盘。这些故障会增加平均磁盘传送时间。对于大多数磁盘,较高的磁盘平均传送时间是大于 0.3 秒。
也可以查看 Avg.Disk Bytes/Transfer 的值。值大于 20 KB 表示该磁盘驱动器通常运行良好;如果应用程序正在访问磁盘,则会产生较低的值。例如,随机访问磁盘的应用程序会增加平均 Disk sec/Transfer 时间,因为随机传送需要增加搜索时间。
Disk Bytes/sec 提供磁盘系统的吞吐率。
决定工作负载的平衡要平衡网络服务器上的负载,需要了解服务器磁盘驱动器的繁忙程度。使用 Physical Disk\ %Disk Time 计数器,该计数器显示驱动器活动时间的百分比。如果 % Disk Time 较高(超过90%),请检查 Physical Disk\ Current Disk Queue Length 计数器以查看正在等待磁盘访问的系统请求数量。等待 I/O 请求的数量应当保持在不大于组成物理磁盘的主轴数的 1.5 到2倍。
尽管廉价磁盘冗余阵列 (RAID) 设备通常有多个主轴,大多数磁盘有一个主轴。硬件 RAID设备在“系统监视器”中显示为一个物理磁盘;通过软件创建的 RAID 设备显示为多个驱动器(实例)。可以监视每个物理驱动器(而不是 RAID)的 Physical Disk 计数器,也可以使用 _Total 实例来监视所有计算机驱动器的数据。
使用 Current Disk Queue Length 和 % Disk Time 计数器来检测磁盘子系统的瓶颈。如果Current Disk Queue Length 和 % Disk Time 的值始终较高,可以考虑升级磁盘驱动器或将某些文件移动到其他磁盘或服务器。
测试是应用程序生命周期里至关重要的一步,应用程序在进行最后的部署之前,需要通过测试来确保它的负载管理能力以及在特殊情况下的工作条件和工作加载情况。
网络上许多开源的Java测试工具,然而真正经得起时间和实践考验的不多,本文例举了Java里的四大开源测试工具,这四个工具主要专注于前端测试,并且得到了测试人员和QA团队的广泛使用。

Apache JMeter——JMeter是一款开源的纯Java测试工具,其主要用于负载测试和性能测试。QA团队使用它来查找和发现相关的性能和负载管理问题,尤其是Web应用程序的性能问题。它可以用于对静态的和动态的资源(文件、Servlet、Perl脚本、Java对象、JDBC数据库连接和查询、FTP、HTTP、JMS、通用的TCP连接、LDAP和OS本地进程访问等)的性能进行测试。它可以用于对服务器,网络或对象模拟繁重的负载来测试它们的强度或分析不同压力类型下的整体性能。
Jmeter架构提供了“out of the box”功能。此外,它还支持各种插件,这些插件可以实现其独特的创新功能,用户可以根据自己的需求进行自定义配置,添加相应地插件。
Selenium——Selenium是一个开源的自动化测试工具,其主要用于Web应用程序的自动化测试,与其它测试工具不同的是,它可以在许多平台和操作系统上运行,可以直接在浏览器下运行,并且支持所有流行的测试框架和编程语言,如C++、Java、Python、Per和Ruby等。
Sahi——Sahi是另一个开源的自动化Web测试工具,Sahi可以专门测试动态的AJAX应用程序,还带有非常出色的自动播放效果机制。其主要特点是:独立的平台和浏览器、出色的刻录机、无需等待、无需XPath、内置Java异常交互报告。
Robotium——Robotium是一款测试Android应用程序的开源自动化测试框架,应该说,Robotium是开发者们最常用的一款开源工具。主要针对Android平台的应用进行黑盒自动化测试,它提供了模拟各种手势操作(点击、长按、滑动等)、查找和断言机制的API,能够对各种控件进行操作。Robotium无需测试应用程序源码,并且安装简单、容易编写测试用例。当然,它还可以测试基于浏览器的一些Android应用程序,但前提是有些限制条件。
各位开发者,你们使用哪一款工具呢?