
要使你的应用程序能够被各种有障碍的人使用,测试是很重要的一部分。参照design和development来进行开发是很重要的一步,但是辅助功能测试能够帮助你发现设计和开发过程中不明显的问题。
这份辅助功能测试清单将带领你浏览辅助功能测试的各个重要方面,包括整体的目标、必需的测试步骤、推荐的测试方式以及特殊的考虑。文档同时讲述了如何在android设备上启用辅助功能。
测试目标
辅助功能测试应该有下列高层次的目标:
在没有明显的帮助的情况下启动和使用应用程序
应用中的任务流程都能够很容易地导航并且会提供清晰适当的反馈
必需的测试
要保证最低级别的辅助功能必须完成下列测试项。
1. 方向键(Directional controls):确认应用能够在无触摸屏的情况下操作,尝试在只使用方向键的情况下完成应用中的主要任务。使用模拟器中的键盘及方向盘,或者在4.1以上的设备中使用手势导航来操作设备。注意:手势允许用户获得屏幕上几乎任何内容的焦点,而键盘和方向盘只可以获取输入区域和按钮的焦点。
2.对话语音提示:确保提供信息或者允许用户操作的UI控件在TalkBack is enabled并且该控件获得焦点时都有清晰准确的语音描述。用户可以使用定向控制在应用的布局间移动焦点。
3.触控浏览提示:确保提供信息或者允许用户操作的UI控件在Explore by Touch is enabled时都有清晰准确的语音描述。每个地方的内容或者控件都应该有语音描述。
4.触控区大小:所有用户可以选择和执行操作的控件在长度和宽度上都应该至少有48dp(大约9mm),正如Android Design中推荐的做法。
5.语音提示下使用手势:确保应用中使用的手势,如缩放图片,滑动列表,页面间切换等在TalkBack is enabled的情况下能继续正常工作。如果这些手势不起作用,你应该为这些动作提供一个替代的操作方式。
6.不应该只有声音反馈:声音反馈必须同时有另外一套反馈机制来供耳聋用户使用。例如,收到短信后发出声音提醒的同时应该也发送一条系统通知,震动反馈或者其它的视觉提醒。
测试建议
为了保证应用的无障碍,下列测试项都是推荐测试的。如果没有测试这些,应用的整体无障碍以及质量都可能受到影响。
1.重复语音提示:密切相关的控件(比如一个列表中有多项内容的一栏)不应该重复相同的语音提示。例如,在一个包含联系人图片、姓名、职位的联系人列表中,不应该对每一项都只是重复地提示"Bob Smith"。
2.语音提示过多或者过少:密切相关的控件应该提供适当的语音提示以保证用户明白并能操作屏幕上的元素,太多或者太少提示会让用户难以理解及使用控件。
特殊情况及考虑:
下面描述了为了保证应用的无障碍需要测试的特殊情况,其中可能有一些或者没有或者全部适用于你的应用。你应该确保对照下面列表检查一遍以查看这些特殊情况是否会发生并采取适当的措施。
1.检查开发者特殊情况以及考虑:检查无障碍功能开发的special cases并且测试需要测试的情况。
2.为功能有改变的控件作出提示:如果由于应用流程导致按钮或者其它控件改变了功能,那么必须为控件的当前功能作出适当的语音提示。例如,一个按钮的功能由播放视频变为暂停视频,那么必须作出适当的语音提示来表明当前的状态。
3.视频播放和字幕:如果一个应用提供视频播放,那么确保它支持字幕并提供字幕以帮助听障人士。视频的播放控制必须明确地标明字幕是否可用并且提供方便的方式启用字幕。
测试无障碍功能
对无障碍特性如语音提示、触控浏览提示、辅助手势进行测试需要你的测试设备进行设置,下面描述如何打开这些特性。
测试语音提示
android设备上的语音提示能够在你浏览应用时读出屏幕内容,通过启用该特性,你可以测试视障人士使用应用时的体验。
android设备上用户可听见的反馈主要由对话无障碍服务以及触控浏览的系统功能。对话无障碍服务一般在大多数的android设备中预装,也可以免费从GooglePlay下载,触控浏览的系统功能可以在android 4.0及以上的设备上使用。
用语音反馈来测试
对讲无障碍服务是这样工作的,当用户移动焦点到一个控件上时它会读出控件的内容。测试焦点导航和语音提示时,该服务作为其中的一部分也应该被开启。
要打开对讲无障碍服务:
1.启动“setting"应用程序。
2.找到"Accessibility"项并选择它。
3.启用"Accessibility"。
4.启用"TalkBack"。
用触控浏览来测试
触控浏览这个系统功能在android 4.0及以上的设备可用,它会开启一种特殊的辅助模式,用户可以在应用界面上拖动手指然后听到屏幕上的内容。该功能不需要平面上的元素获得焦点,而是监听手指在界面控件上的停留时间。
要打开触控浏览功能:
1.启动“setting"应用程序。
2.找到"Accessibility"项并选择它。
3.启用"TalkBack"。在android 4.1及以上设备中,系统会弹出一条消息让用户启用"Explore by Touch",在之前版本中,你必须按照下列步骤继续。
4.返回"Accessibility"项并启用"Explore by Touch"项。注意你必须先启用"TalkBack",否则该选择不可用。
测试焦点导航
焦点导航指的是使用方向键在应用中的单个元素间切换焦点,视力不好或者手不方便的用户通常使用这种导航模式而不是触控导航。作为无障碍测试的一部分,你应该确保你的应用能够在只有方向键的情况下可以使用。
你可以只使用焦点的控制来测试应用的跳转,尽管你的设备可能没有方向键。Android Emulator模拟了一个方向控制器,你可以用它来测试跳转。你也可以使用例如Eyes-Free Keyboard这样的软件来模拟方向控制器。
测试手势导航
手势导航是一种无障碍导航模式,它允许用户用特定的gestures来操作设备,该模式在android 4.1及以上的设备上可用。
要打开手势导航:
同时启用"TalkBack"和"Explore by Touch",这样手势导航也会自动启用。
你可以通过如下路径改变手势设置:Settings-->Assessibility-->TalkBack-->Settings-->Manager shortcut gestures。
1.Test run failed:Instrumentation run failed due to 'java.lang.ClassNotFoundException'
原因是找不到单元测试的类,后来经过仔细看代码及网上查找终于解决,现在记录下来便于以后查找解决办法,问题简单下次就记得了,但是做的项目多了,问题也多了就易忘记或遗漏,好记性不如烂笔头真的一点不错。从头再来,遇到问题就记录下来。
解决方法:打开androidmanifest.xml文件在<activity> **** </activity>之间加上配置
<!-- 单元测试配置 -->
<uses-library android:name="android.test.runner" /> |
别忘了导入junit4包
2. Caused by: java.lang.ClassNotFoundException: android.test.InstrumentationTestRunner in loader dalvik.system.PathClassLoader[/data/app/tyrj.lr.sqliteapply-1.apk:
解决办法:在androidmanifest.xml文件的</application>标签之前加上
<instrumentation
android:name="android.test.InstrumentationTestRunner"
android:targetPackage="tyrj.lr.sqliteapply" > |
这里的包设置和此xml文件的最上面的Package设置相同
</instrumentation>
3.android.content.res.Resources$NotFoundException: String resource ID
在执行sqlite查询数据操作时出现错误,通过错误信息找到错误代码行,原来是利用cursor游标获得Int 类型的数据没有转换,编译器没通过,不能得到游标获取到的值。
错误行: int id = cursor.getColumnIndex("id");
int age = cursor.getColumnIndex("age");
解决:
int id = cursor.getInt(cursor.getColumnIndex("id"));
int age = cursor.getInt(cursor.getColumnIndex("age")); |
这两天出现的错误可不少,一些知识都忘了,哎真是一天不学习就忘得一干二净,这样的小错误一而再再而三的错,希望记载下来,以后出现的错误就不再错了,祈祷!!!
第一步:首先在AndroidManifest.xml中加入下面红色代码:
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="cn.itcast.action“ android:versionCode="1“ android:versionName="1.0">
<application android:icon="@drawable/icon" android:label="@string/app_name">
<uses-library android:name="android.test.runner" />
....
</application>
<uses-sdk android:minSdkVersion="6" />
<instrumentation android:name="android.test.InstrumentationTestRunner"
android:targetPackage="cn.itcast.action" android:label="Tests for My App" />
</manifest> |
上面targetPackage指定的包要和应用的package相同。
第二步:编写单元测试代码(选择要测试的方法,右键点击“Run As”--“Android Junit Test” ):
import android.test.AndroidTestCase;
import android.util.Log;
public class XMLTest extends AndroidTestCase {
public void testSomething() throws Throwable {
Assert.assertTrue(1 + 1 == 3);
}
} |
简而言之,数据库是面向事务的设计,数据仓库是面向主题设计的。
数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计是有意引入冗余,采用反范式的方式来设计。
数据库是为捕获数据而设计,数据仓库是为分析数据而设计,它的两个基本的元素是维表和事实表。维是看问题的角度,比如时间,部门,维表放的就是这些东西的定义,事实表里放着要查询的数据,同时有维的ID。
单从概念上讲,有些晦涩。任何技术都是为应用服务的,结合应用可以很容易地理解。以银行业务为例。数据库是事务系统的数据平台,客户在银行做的每笔交易都会写入数据库,被记录下来,这里,可以简单地理解为用数据库记帐。数据仓库是分析系统的数据平台,它从事务系统获取数据,并做汇总、加工,为决策者提供决策的依据。比如,某银行某分行一个月发生多少交易,该分行当前存款余额是多少。如果存款又多,消费交易又多,那么该地区就有必要设立ATM了。
显然,银行的交易量是巨大的,通常以百万甚至千万次来计算。事务系统是实时的,这就要求时效性,客户存一笔钱需要几十秒是无法忍受的,这就要求数据库只能存储很短一段时间的数据。而分析系统是事后的,它要提供关注时间段内所有的有效数据。这些数据是海量的,汇总计算起来也要慢一些,但是,只要能够提供有效的分析数据就达到目的了。
数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它决不是所谓的“大型数据库”。那么,数据仓库与传统数据库比较,有哪些不同呢?让我们先看看W.H.Inmon关于数据仓库的定义:面向主题的、集成的、与时间相关且不可修改的数据集合。
“面向主题的”:传统数据库主要是为应用程序进行数据处理,未必按照同一主题存储数据;数据仓库侧重于数据分析工作,是按照主题存储的。这一点,类似于传统农贸市场与超市的区别—市场里面,白菜、萝卜、香菜会在一个摊位上,如果它们是一个小贩卖的;而超市里,白菜、萝卜、香菜则各自一块。也就是说,市场里的菜(数据)是按照小贩(应用程序)归堆(存储)的,超市里面则是按照菜的类型(同主题)归堆的。
“与时间相关”:数据库保存信息的时候,并不强调一定有时间信息。数据仓库则不同,出于决策的需要,数据仓库中的数据都要标明时间属性。决策中,时间属性很重要。同样都是累计购买过九车产品的顾客,一位是最近三个月购买九车,一位是最近一年从未买过,这对于决策者意义是不同的。
“不可修改”:数据仓库中的数据并不是最新的,而是来源于其它数据源。数据仓库反映的是历史信息,并不是很多数据库处理的那种日常事务数据(有的数据库例如电信计费数据库甚至处理实时信息)。因此,数据仓库中的数据是极少或根本不修改的;当然,向数据仓库添加数据是允许的。
数据仓库的出现,并不是要取代数据库。目前,大部分数据仓库还是用关系数据库管理系统来管理的。可以说,数据库、数据仓库相辅相成、各有千秋。
补充一下,数据仓库的方案建设的目的,是为前端查询和分析作为基础,由于有较大的冗余,所以需要的存储也较大。为了更好地为前端应用服务,数据仓库必须有如下几点优点,否则是失败的数据仓库方案。
1.效率足够高
客户要求的分析数据一般分为日、周、月、季、年等,可以看出,日为周期的数据要求的效率最高,要求24小时甚至12小时内,客户能看到昨天的数据分析。由于有的企业每日的数据量很大,设计不好的数据仓库经常会出问题,延迟1-3日才能给出数据,显然不行的。
2.数据质量
客户要看各种信息,肯定要准确的数据,但由于数据仓库流程至少分为3步,2次ETL,复杂的架构会更多层次,那么由于数据源有脏数据或者代码不严谨,都可以导致数据失真,客户看到错误的信息就可能导致分析出错误的决策,造成损失,而不是效益。
3.扩展性
之所以有的大型数据仓库系统架构设计复杂,是因为考虑到了未来3-5年的扩展性,这样的话,客户不用太快花钱去重建数据仓库系统,就能很稳定运行。主要体现在数据建模的合理性,数据仓库方案中多出一些中间层,使海量数据流有足够的缓冲,不至于数据量大很多,就运行不起来了。
摘要: 13.13.2 Delphi Web Services样例程序 1.服务端 为了使读者朋友对Web Services程序的开发过程有一个较清晰的认识,这里作者用Delphi给大家做一个简单样例程序。服务端用来提供对外服务接口,只有服务端运行后,其提供的服务接口才能被其他应用所调用,这里我们把调用其服务接口的程序统一叫客户端。 首先,选择“SOAP Server App...
阅读全文
近期在做项目的性能测试和性能优化,先了解与性能相关的一些概念。
一.系统吞度量要素:
一个系统的吞度量(承压能力)与request对CPU的消耗、外部接口、IO等等紧密关联。
单个reqeust 对CPU消耗越高,外部系统接口、IO影响速度越慢,系统吞吐能力越低,反之越高。
系统吞吐量几个重要参数:QPS(TPS)、并发数、响应时间
QPS(TPS):每秒钟request/事务 数量
并发数: 系统同时处理的request/事务数
响应时间: 一般取平均响应时间
(很多人经常会把并发数和TPS理解混淆)
理解了上面三个要素的意义之后,就能推算出它们之间的关系:
QPS(TPS)= 并发数/平均响应时间
一个系统吞吐量通常由QPS(TPS)、并发数两个因素决定,每套系统这两个值都有一个相对极限值,在应用场景访问压力下,只要某一项达到系统最高值,系统的吞吐量就上不去了,如果压力继续增大,系统的吞吐量反而会下降,原因是系统超负荷工作,上下文切换、内存等等其它消耗导致系统性能下降。
决定系统响应时间要素
我们做项目要排计划,可以多人同时并发做多项任务,也可以一个人或者多个人串行工作,始终会有一条关键路径,这条路径就是项目的工期。
系统一次调用的响应时间跟项目计划一样,也有一条关键路径,这个关键路径是就是系统影响时间;
关键路径是有CPU运算、IO、外部系统响应等等组成。
二.系统吞吐量评估:
我们在做系统设计的时候就需要考虑CPU运算、IO、外部系统响应因素造成的影响以及对系统性能的初步预估。
而通常境况下,我们面对需求,我们评估出来的出来QPS、并发数之外,还有另外一个维度:日PV。
通过观察系统的访问日志发现,在用户量很大的情况下,各个时间周期内的同一时间段的访问流量几乎一样。比如工作日的每天早上。只要能拿到日流量图和QPS我们就可以推算日流量。
通常的技术方法:
1. 找出系统的最高TPS和日PV,这两个要素有相对比较稳定的关系(除了放假、季节性因素影响之外)
2. 通过压力测试或者经验预估,得出最高TPS,然后跟进1的关系,计算出系统最高的日吞吐量。B2B中文和淘宝面对的客户群不一样,这两个客户群的网络行为不应用,他们之间的TPS和PV关系比例也不一样。
A)淘宝
淘宝流量图:
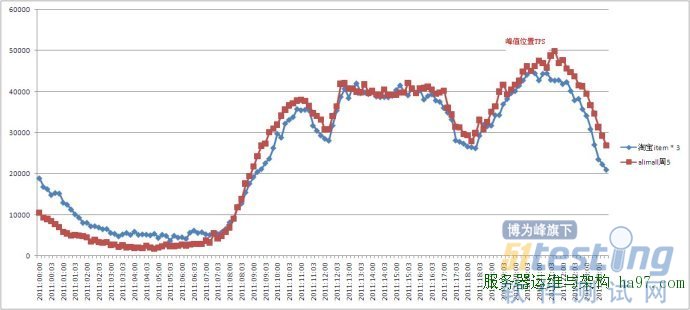
淘宝的TPS和PV之间的关系通常为 最高TPS:PV大约为 1 : 11*3600 (相当于按最高TPS访问11个小时,这个是商品详情的场景,不同的应用场景会有一些不同)
B) B2B中文站
B2B的TPS和PV之间的关系不同的系统不同的应用场景比例变化比较大,粗略估计在1 : 8个小时左右的关系(09年对offerdetail的流量分析数据)。旺铺和offerdetail这两个比例相差很大,可能是因为爬虫暂的比例较高的原因导致。
在淘宝环境下,假设我们压力测试出的TPS为100,那么这个系统的日吞吐量=100*11*3600=396万
这个是在简单(单一url)的情况下,有些页面,一个页面有多个request,系统的实际吞吐量还要小。
无论有无思考时间(T_think),测试所得的TPS值和并发虚拟用户数(U_concurrent)、Loadrunner读取的交易响应时间(T_response)之间有以下关系(稳定运行情况下):
TPS=U_concurrent / (T_response+T_think)。
并发数、QPS、平均响应时间三者之间关系
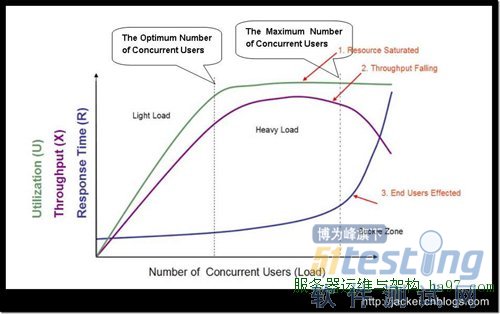
软件性能测试的基本概念和计算公式
一、软件性能的关注点
对一个软件做性能测试时需要关注那些性能呢?
我们想想在软件设计、部署、使用、维护中一共有哪些角色的参与,然后再考虑这些角色各自关注的性能点是什么,作为一个软件性能测试工程师,我们又该关注什么?
首先,开发软件的目的是为了让用户使用,我们先站在用户的角度分析一下,用户需要关注哪些性能。
对于用户来说,当点击一个按钮、链接或发出一条指令开始,到系统把结果已用户感知的形式展现出来为止,这个过程所消耗的时间是用户对这个软件性能的直观印象。也就是我们所说的响应时间,当相应时间较小时,用户体验是很好的,当然用户体验的响应时间包括个人主观因素和客观响应时间,在设计软件时,我们就需要考虑到如何更好地结合这两部分达到用户最佳的体验。如:用户在大数据量查询时,我们可以将先提取出来的数据展示给用户,在用户看的过程中继续进行数据检索,这时用户并不知道我们后台在做什么。
用户关注的是用户操作的相应时间。
其次,我们站在管理员的角度考虑需要关注的性能点。
1、 相应时间
2、 服务器资源使用情况是否合理
3、 应用服务器和数据库资源使用是否合理
4、 系统能否实现扩展
5、 系统最多支持多少用户访问、系统最大业务处理量是多少
6、 系统性能可能存在的瓶颈在哪里
7、 更换那些设备可以提高性能
8、 系统能否支持7×24小时的业务访问
再次,站在开发(设计)人员角度去考虑。
1、 架构设计是否合理
2、 数据库设计是否合理
3、 代码是否存在性能方面的问题
4、 系统中是否有不合理的内存使用方式
5、 系统中是否存在不合理的线程同步方式
6、 系统中是否存在不合理的资源竞争
那么站在性能测试工程师的角度,我们要关注什么呢?
一句话,我们要关注以上所有的性能点。
二、软件性能的几个主要术语
1、响应时间:对请求作出响应所需要的时间
网络传输时间:N1+N2+N3+N4
应用服务器处理时间:A1+A3
数据库服务器处理时间:A2
响应时间=N1+N2+N3+N4+A1+A3+A2
2、并发用户数的计算公式
系统用户数:系统额定的用户数量,如一个OA系统,可能使用该系统的用户总数是5000个,那么这个数量,就是系统用户数。
同时在线用户数:在一定的时间范围内,最大的同时在线用户数量。
同时在线用户数=每秒请求数RPS(吞吐量)+并发连接数+平均用户思考时间
平均并发用户数的计算:C=nL / T
其中C是平均的并发用户数,n是平均每天访问用户数(login session),L是一天内用户从登录到退出的平均时间(login session的平均时间),T是考察时间长度(一天内多长时间有用户使用系统)
并发用户数峰值计算:C^约等于C + 3*根号C
其中C^是并发用户峰值,C是平均并发用户数,该公式遵循泊松分布理论。
3、吞吐量的计算公式
指单位时间内系统处理用户的请求数
从业务角度看,吞吐量可以用:请求数/秒、页面数/秒、人数/天或处理业务数/小时等单位来衡量
从网络角度看,吞吐量可以用:字节/秒来衡量
对于交互式应用来说,吞吐量指标反映的是服务器承受的压力,他能够说明系统的负载能力
以不同方式表达的吞吐量可以说明不同层次的问题,例如,以字节数/秒方式可以表示数要受网络基础设施、服务器架构、应用服务器制约等方面的瓶颈;已请求数/秒的方式表示主要是受应用服务器和应用代码的制约体现出的瓶颈。
当没有遇到性能瓶颈的时候,吞吐量与虚拟用户数之间存在一定的联系,可以采用以下公式计算:F=VU * R /
其中F为吞吐量,VU表示虚拟用户个数,R表示每个虚拟用户发出的请求数,T表示性能测试所用的时间
4、性能计数器
是描述服务器或操作系统性能的一些数据指标,如使用内存数、进程时间,在性能测试中发挥着“监控和分析”的作用,尤其是在分析统统可扩展性、进行新能瓶颈定位时有着非常关键的作用。
资源利用率:指系统各种资源的使用情况,如cpu占用率为68%,内存占用率为55%,一般使用“资源实际使用/总的资源可用量”形成资源利用率。
5、思考时间的计算公式
Think Time,从业务角度来看,这个时间指用户进行操作时每个请求之间的时间间隔,而在做新能测试时,为了模拟这样的时间间隔,引入了思考时间这个概念,来更加真实的模拟用户的操作。
在吞吐量这个公式中F=VU * R / T说明吞吐量F是VU数量、每个用户发出的请求数R和时间T的函数,而其中的R又可以用时间T和用户思考时间TS来计算:R = T / TS
下面给出一个计算思考时间的一般步骤:
A、首先计算出系统的并发用户数
C=nL / T F=R×C
B、统计出系统平均的吞吐量
F=VU * R / T R×C = VU * R / T
C、统计出平均每个用户发出的请求数量
R=u*C*T/VU
D、根据公式计算出思考时间
TS=T/R
1.创建单元测试项目
2.下一步选择针对哪个项目进行单元测试
3.在自动生成的包里,添加测试文件
package cn.itcast.test.test; import cn.itcast.service.PersonService;
import android.test.AndroidTestCase; public class PersonServiceTest extends AndroidTestCase {
public void testSave() throws Exception
{
PersonService service = new PersonService();
service.save("45324");
}
public void testAdd() throws Exception
{
PersonService service = new PersonService();
int res=service.add(1, 2);
assertEquals(6, res);
}
} |
4.执行测试
安全性测试——Buffer overrun
什么是BO?
BO的概念很容易理解,只需要C语言的基本知识就足够了。申请了一段内存,而填入的数据大于这块内存,填入的数据就覆盖掉了这段内存之外的内存了。比如,
void foo(char* input)
{
char buf[100];
strcpy(buf, input);
} |
没有进行长度检查,如果黑客通过操作input,可能重写返回地址,从而产生安全性问题。
为什么BO是一个安全问题?
当copy的数据大于在stack声明的buffer,导致buffer被overwritten,从而产生基于stack的buffer overrun。在stack声明的变量位于函数调用者的返回地址,返回地址被攻击者重写,利用BO执行恶意代码从而控制计算机。
X86 EBP Stack Frame
Highest address
Arguments
Return address
Previous EBP
Saved rigisters
local storageLowest address |
在C语言中,当调用一个函数的时候,在汇编或者机器码的level是如何实现的呢?假设调上边的函数foo的时候,程序的stack将会是下边图表的样子。首先,输入参数会放到栈中去,然后是这个函数执行完的下一个指令的地址,也就是return address, 然后是EBP,再然后就是这个函数的本地变量的内存空间。比如这个函数申请了100个字节的空间。当BO发生的时候,数据就会覆盖掉buf之后的内存,关键的部分是return address可以被覆盖。那么黑客就可以把return address的值修改成这个buf的一个地址,比如起始地址buf[0]的地址,而这个buf里边填入黑客自己的代码。这样当这个函数退出的时候,程序会执行return address所指定的代码,也就是黑客的代码了。
安全性测试
在最高的层次上,安全漏洞发掘方法可被分为白盒、黑盒和灰盒测试方法三大类。测试者可以获得的资源决定了这三种方法的差别。白盒测试需要使用所有可用的资源,包括源代码,而黑盒测试只访问软件的输入和观察到的输出结果。介于两者之间的是灰盒测试,它在黑盒测试的基础上通过对可用的二进制文件的逆向工程而获得了额外的分析信息。
白盒测试包括各种不同的源代码分析方法。可以人工完成也可以通过利用自动化工具完成,这些自动化工具包括编译时检查器、源代码浏览器或自动源代码审核工具。
灰盒测试定义是首先它包括了黑盒测试审核,此外还包括通过逆向工程(RE)获得的结果,逆向工程也被称为逆向代码工程(RCE)。分析编译后得到的汇编指令能够帮助阐明类似的故事,但是要付出更多的努力。在汇编代码层次上进行安全评估而不是在源代码层次上进行安全评估,这种安全评估典型地被称作二进制审核(binary auditing)。二进制审核也被称为是一种”从里向外”的技术:研究者首先识出反汇编结果中令其感兴趣的可能存在的漏洞,然后反向追溯到源代码中以确定漏洞是否可以被别人所利用。
调试器能够显示应用程序正在运行时CPU寄存器的内容和内存状态。Win32平台下的流行调试器包括OllyDbg18,其运行时的一个屏幕快照。此外还有Microsoft WinDbg(也被人称做”wind bag”)19。WinDbg是Windows软件调试工具包20中的一部分,可从Microsoft的网站上免费下载。OllyDbg是一个由Oleh Yuschuk开发的调试器,用户友好性稍好于WinDbg。这两个调试器都允许用户创建自定制的扩展功能组件,有许多第三方插件可用于扩展OllyDbg的功能21。UNIX环境下也有各种各样的调试器,GNU Project Debugger22(GDB)是最流行的也是最容易被移植的调试器。GDB是一个命令行调试器,许多UNIX/Linux产品中都包含这个调试器。
在执行黑盒测试时,源代码是不可用的,通过黑盒测试来执行。可以考虑结合模糊测试来进行。
Fuzz Test
Fuzz Test概念
传统的Fuzz指的是一种黑盒测试技术或随机测试技术,用来发现软件的缺陷(flaws)。模糊测试是这样的一个过程:向产品有意识地输入无效数据以期望触发错误条件或引起产品的故障。这些错误条件可以指导找出那些可挖掘的安全漏洞.
1990年Miller等人发现,通过简单的Fuzz testing可以使运行于UNIX系统上的至少25%的程序崩溃;2002年Aitel通过自己设计实现的Fuzz工具SPIKE成功地发现了多个未知漏洞;安全漏洞困扰了许多流行的客户端应用程序,包括Microsoft的Internet Explorer、Word和Excel,它们中的许多漏洞在2006年通过模糊测试技术被发现。模糊测试技术的有效应用产生了许多新的工具和日益广泛的影响。可见,Fuzz测试在安全领域的重要性。
安全性必须被融入软件开发生命周期(SDLC),而不是到了最后才草率处理。模糊测试可以并且应该是任何完整SDLC的一部分,不仅在测试阶段需要考虑,在开发阶段也同样需要考虑。缺陷被发现得越及时,修补缺陷的成本就越低。
Fuzz技术的原理
Fuzz技术的原理简单,基本的思想是将随机数据作为程序的输入,并监视程序执行过程中产生的任何异常,记录下导致异常的输人数据,从而定位软件中缺陷的位置。
Fuzz 阶段
模糊测试方法的选择依赖不同的因素,可能有很大的变化。没有一种绝对正确的模糊测试方法。模糊测试方法的选择完全取决于目标应用程序、研究者的技能,以及需要测试的数据所采用的格式。然而,无论要对什么进行测试,也不论确定选择了哪种方法,模糊测试总要经历几个基本的阶段。
其中,识别输入:几乎所有可被人利用的漏洞都是因为应用程序接受了用户的输入并且在处理输入数据时没有首先清除非法数据或执行确认例程。
经验介绍
API测试:
Memory Boundary Test for GetPluginVersion:
Buffer is bigger than needed Buffer;
content is setted to be 0xFF before calling the fuction
Input buffer with sizeWChar is bigger than the actual value
Expected Results:The lower bytes of the buffer is the actual vertion information,and other bytes is the setted 0xFF before calling the fuction.
阅读源代码,也可以查找这类Bug,如查看Strcpy,memcopy等函数调用之前,是否有做判断?另外,不安全调用CreateProcess()也会引起漏洞。
借助工具如Prefast,Fxcop等工具进行测试。
AP测试:
黑盒测试:
举例,假设Name域应该接受一个字符串值,Age域应该接受一个整数值。如果用户偶然改变了两个域的实际输入范围并且在Age域输入了一个字符串后会发生什么呢?字符串值会被自动转换为基于ASCII码的整数值吗?是否会显示一条错误报告消息?应用程序会崩溃吗?借助模糊自动化测试实现;
也可以通过工具或源代码检查来进行。
在白盒测试中,基本路径测试方法当然是最优秀的一种测试方法,根据流程图画出控制流图,再画出控制流图的时候,我们要注意两点
一:&&和||组合条件需要拆开,即改成单一条件
二:关于求解路径条数的时候,用判定点来算路径总数是有风险的
1.else语句不存在 2.case 语句也称为判定点,是不稳定的,举个例子,case情况有很多且每种情况没有其他判定,这么算来,总的路径条数就会变少。
所以我建议大家还是使用数圈圈的个数即 N+1 或者也可以为 E-N+2 其中 E 为边的条数,N 为结点个数,两者的值是相等的。
(关于case 如果把它描绘成各个判定点的话,也可以用判定点的个数+1 来进行计算得到,且由case得到的判定像是一个楼梯一样的判定哦!!!)
三:防止犯了先验性错误(极容易犯错,导致路径丢失)这也是我要在这边特别强调的(本人就是在这个问题上纠结了个把个小时,终于找出来了)
为什么会有这种错误呢,因为我们在分析了程序之后,潜意识中把实际代码中,逻辑相互矛盾,不可能出现的路径给排除了!!!到后来会发现怎么总缺少一点。
从程序的环路复杂性可导出程序基本路径集合中的独立路径条数,这是确定程序中每个可执行语句至少执行一次所必须的测试用例数目的上界。从这里我们也可以看出一点,并不是每条测试用例会设计出一个测试用例!!!
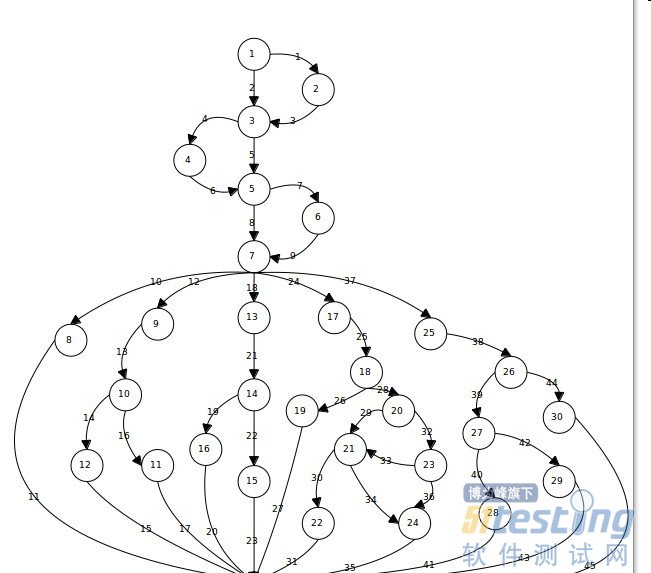
这么讲未必抽象了点,我来举一个今晚我做的实验吧,控制流图已经画出如下所示:
注意路径4 为 我一直被我潜意识排除的那条!!!
因为实际中,我们在设计路径的时候是不该考虑这种情景是否会出现的!!!
而且 我们也可也发现,白盒测试也是很脆弱的了,若没有 2 29 2001 本身这是不符合实际的,但若在白盒测试中没有用到这个用例,也是无法检测出错误来。所以现在业内有些人就开始发问,白盒测试是在浪费时间,它的功能完全可以用黑盒测试来取代,遗憾的是,到现在为止还没有被证明哈!
路径1:1-2-3-4-5-6-7-8-31-33
路径2:1-3-4-5-6-7-8-31-33
路径3:1-3-5-6-7-9-10-12-31-33
路径4:1-3-5-7-8-31-33
(注意:这条路径被我先验性得排除了,以至于一直少了一条,虽然不存在,但在设计用例的时候应该要考虑进去的)
路径5:1-3-5-7-9-10-12-31-32-33
路径6:1-3-5-7-9-10-11-31-32-33
路径7:1-3-5-7-13-16-31-32-33
路径8:1-3-5-7-13-14-15-31-32-33
路径9:1-3-5-7-17-18-19-31-32-33
路径10:1-3-5-7-17-18-20-21-22-31-32-33
路径11:1-3-5-7-17-18-20-21-24-31-32-33
路径12:1-3-5-7-17-18-20-23-21-22-31-32-33
路径13:1-3-5-7-17-18-20-23-21-24-31-32-33
路径14:1-3-5-7-17-18-20-23-24-31-32-33
路径15:1-3-5-7-25-26-27-28-31-32-33
路径16:1-3-5-7-25-26-27-29-31-32-33
路径17:1-3-5-7-25-26-30-31-32-33
对“一把椅子“做一个功能测试
功能测试:
1.能不能供人坐,即能不能供人使用。
2.坐上去是否摇晃。
3.坐人后是否会发出响声。
4.椅子上会不会掉颜色,即坐上去,来回摩擦椅子上的颜色会不会粘到衣服上
5.有水撒到椅子上的时候,用布子或纸擦的时候会不会掉颜色。能不能擦干净水。
6.坐上去会不会有塌陷的感觉。
7.从椅子上离开的时候会不会发出响声。
8.椅子会不会轻易挂到衣服。
9.靠在椅背上的时候会不会,发出响声,椅子会不会摇晃。
10.椅子脏了是能易清理干净。
11.是否只能供一个人坐
性能测试:
1.椅子能承受多大的重量,不会发出响声;能承受多大的重量不被压坏。
2.椅子是否怕水
3.椅子是否怕火
4.椅子是否能在压了重物的情况下,然后摇晃,能坚持不长时间不响\不坏.
5.椅背,用力向后靠椅背,检测椅背的向后的承受能力.
安全性测试:
1.椅子的材质是否与用户说明书或质量保证书上的一样。
2.椅子的材料是否对人体有危害。
3.在撒到椅子上水/饮料等液体的时候,椅子会不会产生什么有害的物质。
4.在椅子被磨损的时候,会不会有划伤或擦伤用户的可能。
5.坐在椅子上的时候,是否安全,例如在只坐到椅子最前端的一部分时,椅子会不会失去平衡等等。
6.在与椅子摩擦的时候,会产生一定的容量,在摩擦的比较厉害的时候,会不会,产生有害的气体或物质。例如,产生难闻的气味等等。
7.在人坐或踩在椅子上时椅子是否稳固,即不摇晃等。
外观/适用性测试(界面/适用性测试):
1.椅子的外观是否美观实用。
2.是否与用户说明书或质量保证书上的一样出现的实物图相同。
3.椅子的气味/扶手/坐垫及靠垫的软硬度是否合适。
4.椅子是否容易挪动。
5.椅子的高度/重量/材质是否合适。
6.椅子的适用场合是否合适。