
1.概述及性能需求:
在智能交通系统中,前端摄像机拍到过车的照片后会把相关信息传到接入服务器,然后入库。现在要测试接入服务器的性能, 是否达到需求规格中要求的100条/秒的接入速度
2.测试环境搭建:
测试工具使用LoadRunner,用12台PC机作为压力机,一台应用服务器,部署接入服务器主程序,一台数据库服务器,考虑到过车数据中包含图片,加压后数据量大,对网络速度要求高,所以直接通过千兆交换机相连。
服务器设置:打开最大文件链接数
ulimit -n 65535
随着存放的图片越来越多,为避免服务器空间被占满,设置定时删除命令:
crontab -e
30 */1 * * * rm -rf /pic/2013/06/* |
就是每小时30分,每隔一小时删除一次图片。
3.测试脚本录制与调试
测试时是通过开发的WINDOWS终端程序模拟前端设备发送过车程序,所以录制协议选择Windows Sockets,应用类型选:Win32 Applications,录制后,插入事务,再参数化,设置迭代次数
部分代码如:
#include "lrs.h"
Action()
{
lr_think_time(6);
lr_start_transaction("send");
lrs_send("socket1", "buf4", LrsLastArg);
lrs_receive("socket1", "buf5", LrsLastArg);
lr_end_transaction("send", LR_AUTO);
return 0;
} |
4.测试过程
测试时使用其中一台PC机作为控制机,另外11台PC机作为压力机,同时向接入服务器发送数据。测试过程序中,发现程序存在内存泄漏、处理速度慢等问题,经开发优化后,最后测试结果达到了需求规格中指定的处理速度。
5.性能监控分析
监控服务器状态可使用nmon工具,使用Linux命令也可以收集到一些性能数据,如:
#!/bin/sh
while [ "XX" = "XX" ]
do
ps aux|grep Alarm|grep -v grep >> xnjk.log
sleep 60
done |
事务响应时间、每秒通过事务数,通过率等过程记录可以通过loadrunner进行监控,数据库性能可以使用AWK进行监控。
6.测试结束后,根据测试数据编写测试报告,提出自己的意见。
本文出自 pengpengfly 的51Testing软件测试博客:http://www.51testing.com/?394182
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
版权声明:本文欢迎转载,转载时请务必以超链接形式标明文章原始出处、作者信息和本声明,否则将追究法律责任
13.13 Web Services协议脚本应用
13.13.1 Web Services简介
Web Service是基于网络的、分布式的模块化组件,它执行特定的任务,遵守具体的技术规范,这些规范使得Web Service能与其他兼容的组件进行互操作。Internet Inter-Orb Protocol(IIOP)都已经发布了很长时间了,但是这些模型都依赖于特殊对象模型协议,而Web Services利用SOAP和XML对这些模型在通信方面作了进一步的扩展以消除特殊对象模型的障碍。Web Services主要利用HTTP和SOAP协议使商业数据在Web上传输,SOAP通过HTTP调用商业对象执行远程功能调用,Web用户能够使用SOAP和HTTP通过Web调用的方法来调用远程对象。
客户根据WSDL描述文档,会生成一个SOAP请求消息,请求会被嵌入在一个HTTP POST请求中,发送到Web服务器来。Web Services部署于Web服务器端,Web服务器把这些请求转发给Web Services请求处理器。请求处理器解析收到的请求,调用Web Services,然后再生成相应的SOAP应答。Web服务器得到SOAP应答后,会再通过HTTP应答的方式把信息送回到客户端。
下面针对Web Services中的一些重要名词进行讲解。
(1)UDDI,英文为“Universal Description, Discovery and Integration”,可译为“通用描述、发现与集成服务”。UDDI是一个独立于平台的框架,用于通过使用Internet来描述服务,发现企业,并对企业服务进行集成。任何规模的行业或企业都能得益于UDDI,UDDI使用W3C和IETF*的因特网标准,比如XML、HTTP和DNS协议。在UDDI之前,还不存在一种Internet标准,可以供企业为它们的企业和伙伴提供有关其产品和服务的信息。也不存在一种方法,来集成到彼此的系统和进程中。那么UDDI有什么样的用途呢?举个例子来讲,假如航空行业发布了一个用于航班预订的UDDI标准,航空公司就可以把它们的服务注册到一个UDDI目录中。然后旅行社就能够搜索这个UDDI目录以找到航空公司预订界面。当此界面被找到后,旅行社就能够立即与此服务进行通信,这是由于它使用了一套定义良好的预订界面。
(2)WSDL英文为“Web Services Description Language”,可译为网络服务描述语言。它是一种使用XML编写的文档,可描述某个Web Service。它可规定服务的位置,以及此服务提供的操作(或方法)。WSDL文档仅仅是一个简单的XML文档,它包含一系列描述某个Web Service的定义。
以下WSDL文档的简化的片段是后续将会讲到的,这里我们先拿出来分析一下:
<message name="getTermRequest">
<part name="term" type="xs:string"/>
</message>
<message name="getTermResponse">
<part name="value" type="xs:string"/>
</message>
<portType name="glossaryTerms">
<operation name="getTerm">
<input message="getTermRequest"/>
<output message="getTermResponse"/>
</operation>
</portType>
<?xml version="1.0" encoding="utf-8"?>
<definitions xmlns=http://schemas.xmlsoap.org/wsdl/
xmlns:xs=http://www.w3.org/2001/XMLSchema name="IMyHelloservice"
targetNamespace=http://tempuri.org/ xmlns:tns=http://tempuri.org/
xmlns:soap=http://schemas.xmlsoap.org/wsdl/soap/
xmlns:soapenc=http://schemas.xmlsoap.org/soap/encoding/
xmlns:mime=http://schemas.xmlsoap.org/wsdl/mime/>
<message name="Welcome0Request">
<part name="name" type="xs:string" />
</message>
<message name="Welcome0Response">
<part name="return" type="xs:string" />
</message>
<portType name="IMyHello">
<operation name="Welcome">
<input message="tns:Welcome0Request" />
<output message="tns:Welcome0Response" />
</operation>
</portType> |
<binding name="IMyHellobinding" type="tns:IMyHello">
<soap:binding style="rpc" transport="http://schemas.xmlsoap.org/soap/http" />
<operation name="Welcome">
<soap:operation soapAction="urn:MyHelloIntf-IMyHello#Welcome" style="rpc" />
<input message="tns:Welcome0Request">
<soap:body use="encoded" encodingStyle=http://schemas.xmlsoap.org/soap/encoding/
namespace="urn:MyHelloIntf-IMyHello" />
</input>
<output message="tns:Welcome0Response">
<soap:body use="encoded" encodingStyle=http://schemas.xmlsoap.org/soap/encoding/
namespace="urn:MyHelloIntf-IMyHello" />
</output>
</operation>
</binding>
<service name="IMyHelloservice">
<port name="IMyHelloPort" binding="tns:IMyHellobinding">
<soap:address location=http://localhost:5678/soap/IMyHello />
</port>
</service>
</definitions> |
我们可以将该WSDL 文档分成三部分。
第一部分:声明部分内容
<xml version="1.0" encoding="utf-8"?>
<definitions xmlns="http://schemas.xmlsoap.org/wsdl/"
xmlns:xs="http://www.w3.org/2001/XMLSchema" name="IMyHelloservice"
targetNamespace="http://tempuri.org/" xmlns:tns="http://tempuri.org/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:soapenc="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:mime="http://schemas.xmlsoap.org/wsdl/mime/"> |
第二部分:
<message name="Welcome0Request">
<part name="name" type="xs:string" />
</message>
<message name="Welcome0Response">
<part name="return" type="xs:string" />
</message>
<portType name="IMyHello">
<operation name="Welcome">
<input message="tns:Welcome0Request" />
<output message="tns:Welcome0Response" />
</operation>
</portType>
<binding name="IMyHellobinding" type="tns:IMyHello">
<soap:binding style="rpc" transport="http://schemas.xmlsoap.org/soap/http" />
<operation name="Welcome">
<soap:operation soapAction="urn:MyHelloIntf-IMyHello#Welcome" style="rpc" />
<input message="tns:Welcome0Request">
<soap:body use="encoded" encodingStyle=http://schemas.xmlsoap.org/soap/encoding/
namespace="urn:MyHelloIntf-IMyHello" />
</input>
<output message="tns:Welcome0Response">
<soap:body use="encoded" encodingStyle=http://schemas.xmlsoap.org/soap/encoding/
namespace="urn:MyHelloIntf-IMyHello" />
</output>
</operation>
</binding> |
在这部分内容中,<portType> 元素把 " IMyHello" 定义为某个端口的名称,把 " Welcome " 定义为某个操作的名称。操作 " Welcome " 拥有一个名为 " Welcome0Request " 的输入消息,以及一个名为 " Welcome0Response " 的输出消息。<message> 元素可定义每个消息的部件,以及相关联的数据类型。从上面的文档您不难发现,其主要有以下元素的元素来描述某个web service ,参见表13-5。
表13-5 WSDL 文档结构表
元 素 | 定 义 |
<portType> | Web Service 执行的操作 |
<message> | Web Service 使用的消息 |
<types> | Web Service 使用的数据类型 |
<binding> | Web Service 使用的通信协议 |
<portType> 元素是最重要的WSDL元素。它可描述一个 Web Service、可被执行的操作,以及相关的消息。可以把<portType>元素比作传统编程语言中的一个函数库(或一个模块、或一个类)、<message>元素定义一个操作的数据元素。每个消息均由一个或多个部件组成。可以把这些部件比作传统编程语言中一个函数调用的参数、<types>元素定义Web Service使用的数据类型。为了最大程度的平台中立性,WSDL使用XML Schema语法来定义数据类型、<binding>元素为每个端口定义消息格式和协议细节。binding元素的name属性定义binding的名称,而type属性指向用于binding的端口,在这个例子中是“ImyHello”端口。
soap:binding元素的style属性可取值“rpc”或“document”。在这个例子中我们使用rpc、transport属性定义了要使用的SOAP协议,在这个例子中我们使用HTTP。operation元素定义了每个端口提供的操作符,对于每个操作,相应的SOAP行为都需要被定义。同时您必须对输入和输出进行编码。在这个例子中我们使用了“encoded”。
第三部分:
service是一套<port>元素。在一一对应形式下,每个<port>元素都和一个location关联。如果同一个<binding>有多个<port>元素与之关联,可以使用额外的URL地址作为替换。
一个WSDL文档中可以有多个<service>元素,而且多个<service>元素十分有用,其中之一就是可以根据目标URL来组织端口。这样,我就可以方便地使用另一个<service>来重定向我的股市查询申请。我的客户端程序仍然工作,因为这种根据协议归类的服务不随服务而变化。多个<service>元素的另一个作用是根据特定的协议划分端口。例如,我可以把所有的HTTP端口放在同一个<service>中,所有的SMTP端口放在另一个<service>里。
后续内容请从书籍获得……
(未完待续)
版权声明:51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像。51testing软件测试网欢迎与业内同行进行有益的合作和交流,如果有任何有关内容方面的合作事宜,请联系我们。
相关链接:
精通软件性能测试与LoadRunner最佳实战 连载十一
13.13 Web Services协议脚本应用
13.13.1 Web Services简介
Web Service是基于网络的、分布式的模块化组件,它执行特定的任务,遵守具体的技术规范,这些规范使得Web Service能与其他兼容的组件进行互操作。Internet Inter-Orb Protocol(IIOP)都已经发布了很长时间了,但是这些模型都依赖于特殊对象模型协议,而Web Services利用SOAP和XML对这些模型在通信方面作了进一步的扩展以消除特殊对象模型的障碍。Web Services主要利用HTTP和SOAP协议使商业数据在Web上传输,SOAP通过HTTP调用商业对象执行远程功能调用,Web用户能够使用SOAP和HTTP通过Web调用的方法来调用远程对象。
客户根据WSDL描述文档,会生成一个SOAP请求消息,请求会被嵌入在一个HTTP POST请求中,发送到Web服务器来。Web Services部署于Web服务器端,Web服务器把这些请求转发给Web Services请求处理器。请求处理器解析收到的请求,调用Web Services,然后再生成相应的SOAP应答。Web服务器得到SOAP应答后,会再通过HTTP应答的方式把信息送回到客户端。
下面针对Web Services中的一些重要名词进行讲解。
(1)UDDI,英文为“Universal Description, Discovery and Integration”,可译为“通用描述、发现与集成服务”。UDDI是一个独立于平台的框架,用于通过使用Internet来描述服务,发现企业,并对企业服务进行集成。任何规模的行业或企业都能得益于UDDI,UDDI使用W3C和IETF*的因特网标准,比如XML、HTTP和DNS协议。在UDDI之前,还不存在一种Internet标准,可以供企业为它们的企业和伙伴提供有关其产品和服务的信息。也不存在一种方法,来集成到彼此的系统和进程中。那么UDDI有什么样的用途呢?举个例子来讲,假如航空行业发布了一个用于航班预订的UDDI标准,航空公司就可以把它们的服务注册到一个UDDI目录中。然后旅行社就能够搜索这个UDDI目录以找到航空公司预订界面。当此界面被找到后,旅行社就能够立即与此服务进行通信,这是由于它使用了一套定义良好的预订界面。
(2)WSDL英文为“Web Services Description Language”,可译为网络服务描述语言。它是一种使用XML编写的文档,可描述某个Web Service。它可规定服务的位置,以及此服务提供的操作(或方法)。WSDL文档仅仅是一个简单的XML文档,它包含一系列描述某个Web Service的定义。
以下WSDL文档的简化的片段是后续将会讲到的,这里我们先拿出来分析一下:
<message name="getTermRequest">
<part name="term" type="xs:string"/>
</message>
<message name="getTermResponse">
<part name="value" type="xs:string"/>
</message>
<portType name="glossaryTerms">
<operation name="getTerm">
<input message="getTermRequest"/>
<output message="getTermResponse"/>
</operation>
</portType>
<?xml version="1.0" encoding="utf-8"?>
<definitions xmlns=http://schemas.xmlsoap.org/wsdl/
xmlns:xs=http://www.w3.org/2001/XMLSchema name="IMyHelloservice"
targetNamespace=http://tempuri.org/ xmlns:tns=http://tempuri.org/
xmlns:soap=http://schemas.xmlsoap.org/wsdl/soap/
xmlns:soapenc=http://schemas.xmlsoap.org/soap/encoding/
xmlns:mime=http://schemas.xmlsoap.org/wsdl/mime/>
<message name="Welcome0Request">
<part name="name" type="xs:string" />
</message>
<message name="Welcome0Response">
<part name="return" type="xs:string" />
</message>
<portType name="IMyHello">
<operation name="Welcome">
<input message="tns:Welcome0Request" />
<output message="tns:Welcome0Response" />
</operation>
</portType> |
<binding name="IMyHellobinding" type="tns:IMyHello">
<soap:binding style="rpc" transport="http://schemas.xmlsoap.org/soap/http" />
<operation name="Welcome">
<soap:operation soapAction="urn:MyHelloIntf-IMyHello#Welcome" style="rpc" />
<input message="tns:Welcome0Request">
<soap:body use="encoded" encodingStyle=http://schemas.xmlsoap.org/soap/encoding/
namespace="urn:MyHelloIntf-IMyHello" />
</input>
<output message="tns:Welcome0Response">
<soap:body use="encoded" encodingStyle=http://schemas.xmlsoap.org/soap/encoding/
namespace="urn:MyHelloIntf-IMyHello" />
</output>
</operation>
</binding>
<service name="IMyHelloservice">
<port name="IMyHelloPort" binding="tns:IMyHellobinding">
<soap:address location=http://localhost:5678/soap/IMyHello />
</port>
</service>
</definitions> |
我们可以将该WSDL 文档分成三部分。
第一部分:声明部分内容
<xml version="1.0" encoding="utf-8"?>
<definitions xmlns="http://schemas.xmlsoap.org/wsdl/"
xmlns:xs="http://www.w3.org/2001/XMLSchema" name="IMyHelloservice"
targetNamespace="http://tempuri.org/" xmlns:tns="http://tempuri.org/"
xmlns:soap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:soapenc="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:mime="http://schemas.xmlsoap.org/wsdl/mime/"> |
第二部分:
<message name="Welcome0Request">
<part name="name" type="xs:string" />
</message>
<message name="Welcome0Response">
<part name="return" type="xs:string" />
</message>
<portType name="IMyHello">
<operation name="Welcome">
<input message="tns:Welcome0Request" />
<output message="tns:Welcome0Response" />
</operation>
</portType>
<binding name="IMyHellobinding" type="tns:IMyHello">
<soap:binding style="rpc" transport="http://schemas.xmlsoap.org/soap/http" />
<operation name="Welcome">
<soap:operation soapAction="urn:MyHelloIntf-IMyHello#Welcome" style="rpc" />
<input message="tns:Welcome0Request">
<soap:body use="encoded" encodingStyle=http://schemas.xmlsoap.org/soap/encoding/
namespace="urn:MyHelloIntf-IMyHello" />
</input>
<output message="tns:Welcome0Response">
<soap:body use="encoded" encodingStyle=http://schemas.xmlsoap.org/soap/encoding/
namespace="urn:MyHelloIntf-IMyHello" />
</output>
</operation>
</binding> |
在这部分内容中,<portType> 元素把 " IMyHello" 定义为某个端口的名称,把 " Welcome " 定义为某个操作的名称。操作 " Welcome " 拥有一个名为 " Welcome0Request " 的输入消息,以及一个名为 " Welcome0Response " 的输出消息。<message> 元素可定义每个消息的部件,以及相关联的数据类型。从上面的文档您不难发现,其主要有以下元素的元素来描述某个web service ,参见表13-5。
表13-5 WSDL 文档结构表
元 素 | 定 义 |
<portType> | Web Service 执行的操作 |
<message> | Web Service 使用的消息 |
<types> | Web Service 使用的数据类型 |
<binding> | Web Service 使用的通信协议 |
<portType> 元素是最重要的WSDL元素。它可描述一个 Web Service、可被执行的操作,以及相关的消息。可以把<portType>元素比作传统编程语言中的一个函数库(或一个模块、或一个类)、<message>元素定义一个操作的数据元素。每个消息均由一个或多个部件组成。可以把这些部件比作传统编程语言中一个函数调用的参数、<types>元素定义Web Service使用的数据类型。为了最大程度的平台中立性,WSDL使用XML Schema语法来定义数据类型、<binding>元素为每个端口定义消息格式和协议细节。binding元素的name属性定义binding的名称,而type属性指向用于binding的端口,在这个例子中是“ImyHello”端口。
soap:binding元素的style属性可取值“rpc”或“document”。在这个例子中我们使用rpc、transport属性定义了要使用的SOAP协议,在这个例子中我们使用HTTP。operation元素定义了每个端口提供的操作符,对于每个操作,相应的SOAP行为都需要被定义。同时您必须对输入和输出进行编码。在这个例子中我们使用了“encoded”。
第三部分:
service是一套<port>元素。在一一对应形式下,每个<port>元素都和一个location关联。如果同一个<binding>有多个<port>元素与之关联,可以使用额外的URL地址作为替换。
一个WSDL文档中可以有多个<service>元素,而且多个<service>元素十分有用,其中之一就是可以根据目标URL来组织端口。这样,我就可以方便地使用另一个<service>来重定向我的股市查询申请。我的客户端程序仍然工作,因为这种根据协议归类的服务不随服务而变化。多个<service>元素的另一个作用是根据特定的协议划分端口。例如,我可以把所有的HTTP端口放在同一个<service>中,所有的SMTP端口放在另一个<service>里。
后续内容请从书籍获得……
(未完待续)
版权声明:51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像。51testing软件测试网欢迎与业内同行进行有益的合作和交流,如果有任何有关内容方面的合作事宜,请联系我们。
相关链接:
精通软件性能测试与LoadRunner最佳实战 连载十一
中国软件测试专家访谈录(1)
中国软件测试专家访谈录(2)
中国软件测试专家访谈录(3)
中国软件测试专家访谈录(4)
如何把握软件质量
蔡:如何把握一个软件的质量呢?
邰:软件测试的目的是什么?不仅是找bug,而是要随时提供质量相关的信息。质量是什么?我比较喜欢的一个定义是RST课程里给出的:Quality is the value to someone who matters。做测试,首先要找到这个someone是谁,以及这个someone重视的value是什么。
问题里提到的"把握"软件产品的质量,我觉得这个词用得很好,测试就像一把尺子,我们可以通过测试衡量一个产品的质量,但不能"改变"一个产品的质量。也许测试间接地提升了产品的质量,但那不是测试本身最主要的目的。
如何把握一个产品的质量?对这个问题,我们仍然可以应用Know Your Mission的思路来回答。
第一,找到这个问题的客户是谁。是开发团队?运维团队?最终的用户?还是其他项目管理者?
第二,明白客户在意的价值是什么,明白客户希望测试提供什么样的信息。
第三,制定测试策略,考虑如何开展测试以便尽可能提供实时准确的质量相关信息给客户。

如果不思考这些问题,一上来就开始测试,例如,测试了100个用例,这能说明什么?说明被测系统的质量如何?我们知道,测试域是无穷尽的,这个数据只是part(部分),而不是整体,意义并不大。测试工程师要具有全局的视角,首先找到客户关心的value,然后据此开展测试。当你知道要开展哪些测试活动后,如果此时发现测试时间不够,没有关系,你可以按照风险的大小程度开展测试,先测试风险高的。这样,测试人员不仅可以告诉别人已经测了什么,还可以告诉别人哪些还没有测,哪些缺陷还没有修复,哪些地方还存在潜在风险。这种信息对于决策者更为重要,要想把握一个产品的质量,一定要有全局的视角。
旁观者说:对于测试人员来说,不但要尝试着站在客户的立场去使用软件,而且要了解客户在意的是什么,了解什么对于客户完成他(她)的工作是重要的,这些都是测试的重点。否则,在软件测试中平均用力,事倍功半。
质量度量过程中的数据分析
蔡:我同意你的观点,在把握软件质量的时候的确是要有全局的观点。那么,在具体做的时候,需不需要定义一些度量指标呢?
邰:需要的。定义度量指标有很多种方法,比如头脑风暴(Broadband Delphi)、GQM(Goal-Question-Metric)等。大家可以到网上找一些,然后选择一些符合自己要求的度量指标。在选择度量指标的时候,大家要明确自己的目标。你关心的是什么?是bug相关的指标,还是人员相关的指标,抑或是流程相关的指标?不要拿来就用,要多思考。
我这里倒是想要就度量过程中的数据分析谈一谈。大家知道,决定了度量方法后,就要开始收集数据。作为一个测试管理者,在面对度量结果,对这些统计数据进行分析的时候,"要更像一名测试人员"--我的意思是,管理者此时要充分发挥自己作为一名测试工程师的长处,要挑剔地思考(Critical Thinking),多疑多问,去挖掘这些数字背后的真实现象,而不仅仅是凭表面的一些数字就下结论,这种做法和Rick Craig提到的"Meta-Measure"这个词的含义很像,也就是说,去度量你的度量项。
旁观者说:不满足于已经得到的,多问几个为什么。
当我们看到产品的bug数连续很多天下降时,不要光顾着高兴。在高兴之前,多问几个问题,有哪些原因可能导致缺陷趋势下降了:是产品变好了?还是测试工作受到什么方面的阻碍导致有些地方没有办法测试?抑或是测试用例的有效性变低了?有没有测试人员积极性下降的因素在里面?等等。
无论对于测试管理者还是普通的测试人员,都要学会多问问题,挑剔地思考,逆向地思考,问各种各样的问题。James Bach在"Critical Thinking For Testers"这门课程里讲了一个简单易用的三步法,当你需要挑剔地思考时,只要问自己三个问题:
第一步,Huh?(嗯?)就是问:你说什么?你是说你执行了100个用例而且全部pass?在得到数据时要做一个确认,确保自己听到的是对方所要表达的意思。这一步可以避免交流中的误会和传递错误信息。
第二步,Really?(真的吗?)反问对方,这是不是真的?这个过程可以去伪存真。
第三步,So?(接下来怎么做?也许事实比你认为的还要严重。)和对方一起分析,基于这条信息,接下去我们需要做些什么。
旁观者说:简单实用的三步,做好确认,展开深入的思考。
所以,总结下来,测试度量要做,测试数据要收集,但当我们面对这些度量统计数据时,把它们当做Heuristics,我们不会完全Follow这些数据,而是试图去Apply这些数据,再加上我们挑剔地思考,做正确的数据分析,让这些数据为我所用。
做一个好的协调者
蔡:如何做一个优秀的测试管理者呢?
邰:这个问题很大,我没有全面地想过这个问题,这里我只想谈一点:一个好的测试管理者一定是一个非常好的协调者。他(她)对内协调测试团队,对外代表测试团队做各种沟通。
你知道,测试行业的特殊性之一就是总会有一些测试人员对自己的职业有困惑,有职业危机感,没有信心。团队的管理者应当在团队里建立积极向上的氛围,宣扬和培养正面的职业认识。软件测试是一个非常有挑战性、富有激情、充满乐趣的职业,值得为之奋斗,这是对内协调很重要的一个方面。
旁观者说:团队的管理者应当是团队的核心,成为团队的精神领袖。
对外协调就更难了,因为在测试团队之外,有不少人并不了解测试。测试团队怎么做测试他们并不关心,但是产品一旦出了问题,就会来指责测试。测试管理者应当做好对外协调,让测试团队之外的人了解和理解测试,进而理解测试团队,这会方便测试工作的开展。
比如,测试的基本原则之一"穷尽测试是不可能的"。但是,有的测试之外的管理者并不是这么认为的,而是认为测试应该抓住所有的bug。测试管理者应当通过各种方法让他们对测试有正确的期待。我讲课的时候,如果有测试之外的人来听,例如开发经理、一线的开发人员等,我会很欢迎他们,因为这会帮助他们更多地了解测试。
旁观者说:对于测试团队之外的人对测试的误解,管理者要做好解释工作。如果有的人很没有礼貌,轻视测试人员,这个时候测试团队管理者强势一些也是好事。对于虚心想来了解测试工作的,则给予耐心和友好的帮助与解释。
当然,我们不能坐等别人改变想法,而是应当积极地去与他们密切合作,在合作中增进相互了解。其实,测试外部的角色都是"测试的客户",我们为他们提供测试服务。像敏捷里提倡的,"与客户合作胜过合同谈判",测试管理者要想办法让这些"测试的客户"参与到测试工作中来,与他们紧密合作。实际上,我们别无选择,测试必须与其他角色紧密合作。大家知道,穷尽测试是不可能的,我们必须基于风险来开展测试。但是,谁更了解风险信息呢?我们应该看到,测试外部的人可能更了解客户,更了解需求,更了解风险所在,例如做需求设计的人,做开发的人,做售前、售后支持的人,销售人员,经验丰富的项目经理等,我们应该向他们学习,邀请他们和我们一起做产品的风险分析,帮助我们决策哪里可以测试得更深入一些,哪里可以测试得浅一些,让"测试的客户"参与到测试中来。
旁观者说:利用一切可以利用的力量,做好测试工作,就像统战工作。
如何提高测试分析能力
蔡:你刚才也提到了,你是很看重测试设计的,我也认为测试设计能力是测试工程师的核心能力之一。那么,一位测试工程师应该如何提高自己的测试设计能力呢?
邰:简单点说,其实不是如何去提高测试设计能力,而是如何去提高他们的分析能力。拿到需求后,如何得到有效的测试用例?这中间有个很重要的步骤就是分析。我们需要使用某种方法或手段去分析被测对象,真正了解被测对象,不仅能了解需求文档中描述的内容,还能挖掘出文档中没有提到的或者写错的内容,这都需要很强的分析能力。经过分析,你就会清楚,针对这样的一个被测对象,应该从哪些方面对其开展测试会比较好,这样你就明确了这次测试任务的测试目标,确定了测试点。接下来,你如何达成这个测试目标,如何测试这些测试点,就是测试设计的工作了。
测试工程师具备了分析能力,测试就会做到有的放矢。如果什么都是拍脑袋,临时决定,这样做缺乏全局观,看到的是部分,而不是整体。得到的结果也是部分,不是整体。
蔡:那么,具体如何提高分析能力呢?
邰:你知道,分析能力不是知识,而是一种skill(技能)。知识的提高可以通过看书、参加培训来实现,技能的提高只能靠多实践。我建议大家多拿一些需求来练习。例如,如果是学习Model Based Testing(基于模型的测试),就拿需求来多练习建模,甚至针对同一个需求用多种模型建模,去比较这之间的差异。如果可能的话,多个人一起学习,可以拿自己的model和别人的做比较,当然,如果能得到有经验的人从旁指点就更好了。这样的练习做多了,就会形成自己的分析型思维。
旁观者说:学习既要个人独自的努力,也要公开讨论,二者各有好处。
招聘测试工程师时的要求
蔡:你负责招聘的时候,对于测试工程师有什么要求?
邰:回想过去招聘的时候,我觉得有的时候没有招对人。如果我现在做招聘的话,我会重点考察面试者是否具备测试人员必备的一些测试技能。
比如,给面试者一个小程序去测试,或者给他一个小游戏去玩,或者问他一些问题,观察他的反应,这个过程可以体现面试者的测试思维。再比如,观察面试者的问问题的能力、逻辑思考的能力、逆向思考的能力、观察是否细致等。
还可以给面试者一个有些挑战性的任务,观察候选人的学习能力、分析能力、解决问题的能力,以及是否有面对挑战的激情。如果一遇到问题,就不知道怎么做,或者没有兴趣去解决问题,原地待命,等待领导,这样的人不适合做测试。
有一点需要分清楚的是,有测试经验并不等于具备测试思维,因为二者是两回事。
旁观者说:我在面试中比较看重发散思维能力。
在面试中,我不会问“什么是等价类”之类的直白的理论问题,因为没有意义。候选人即使不会,也会很快学会。
敏捷让测试如鱼得水
蔡:现在敏捷已经流行开来,很多公司采用了这种软件研发方法。你对软件测试如何适应敏捷有什么建议?
邰:对于这个问题,我觉得可能换一种问法更好,并不是“软件测试如何适应敏捷”,而是“软件测试如何适应瀑布模型的?”
我在了解了敏捷之后,觉得这才是软件测试应该处于其中的开发模式。敏捷中的很多理念把测试的本质充分发挥出来。
“个体和交互胜过流程和工具”强调的是以人为中心,而不是以流程和工具为中心。测试中以人为中心,强调的就是通过个人技能的发挥、通过与其他角色有效的沟通获得有价值的信息,做高效的测试,这比一味地遵守流程和规范重要得多。
“可以工作的软件胜过面面俱到的文档”,这当然是测试想要做到的。以前测试没有办法在项目早期就拿到可以工作的软件开展测试,敏捷以后,测试不用等那么久了,我们可以尽早开展测试了。
“与客户合作胜过合同谈判”,这也是测试人员一直希望做到的。以前我们想找到客户,想了解客户到底在意哪些方面,我们希望站在客户角度测试,可是很难做到,测试和客户的距离太远,我们只能把自己假象成客户去测试。现在客户和我们紧密合作,我们有很多机会和客户接触,了解客户真实的需求,我们可以开展更有针对性的测试。
“响应变化胜过遵循计划”,这也是测试提倡的。测试要基于风险,而风险是一直在变化的,我们必须拥抱变化、响应变化,而不是只知道遵循一个事先制订好的测试计划,我们的被测对象一直处于变化中,我们要找的bug也不是按照计划出现的,我们必须基于风险、调整测试,准备随时、随地发现各种类型的bug。
在我看来,敏捷让软件测试如鱼得水。所以,倒是以前在瀑布模型的时候测试需要去“适应”。
旁观者说:敏捷的好处前面邰晓梅已经说得比较细了,我这里再来补充几点个人的认知,尝试让读者朋友们得到一个全面的认识。
(1)敏捷中仍然需要编写和保留一定的重要的文档,例如主要功能的设计。有的团队在实施敏捷的时候打着敏捷的旗号不写文档了,项目信息都存在组员的脑袋里。这样做的风险是,每个人对于应该做成什么样子可能有不同的理解,而且当有员工流动的时候会有比较大的挑战。
(2)客户的参与在国内是双刃剑。有的客户做事并不专业,认为自己是甲方就随便更改需求,直接给研发团队下指令,导致研发团队疲于奔命。最好是既让客户参与,又让客户与研发团队保持适当距离,避免干扰。
(3)是响应变化,还是遵循计划,需要单独分析,看优先级。
开发和测试会融合吗
蔡:根据经典的敏捷理论,在敏捷中就不再区分开发和测试了,你觉得这两个角色在将来会融合吗?
邰:这要看情况。有的公司开发人员很强,他们去做测试也能做得很好,有的公司则不是这样。所以我想,不需要把开发和测试在角色上鲜明地分开,说开发人员和测试人员,这不是问题的关键,而是可以把它们从工作上分开:有开发类的工作和测试类的工作。从这个角度看,测试类的工作一定会存在,至于是谁去做,就要看实际情况和能力了,这在ISTQB里称为测试的独立性(Independence of Testing),可以是开发人员做测试,他们可以把测试做得很好;也可以是专业的测试人员去做测试;还可以是独立的第三方测试团队去做。
不管谁来做测试,都要保持一定的测试独立性,毕竟测试有其特有的思维方式。这里的独立性指的是精神上的独立,而不是物理上的独立(测试人员属于专门的测试团队,有自己单独的办公区域等)。
旁观者说:保持测试力量的独立的确重要,这有利于测试人员做出质量方面的判断。至于是否保持独立的测试团队,可根据测试团队的成熟程度而定。一般来说,我推荐成立独立的测试小组,让测试工程师有归属感。
对于软件测试行业前景的看法
蔡:对于测试行业的前景你怎么看?
邰:我认为测试从业人员面临的挑战会越来越大。现在测试环境越来越复杂,例如云计算环境、复杂的网络环境,被测对象也越来越复杂,bug也隐藏得越来越深,测试人员要充分了解测试环境和测试对象。
不管是测试新人还是有多年经验的测试工程师,都有必要认识自己的测试思维,不断有意识地提升自己的测试技能。
书籍推荐
1、《Secrets of A Buccaneer Scholar》,作者James Bach,中文版书名为《学习要像加勒比海盗》。这是一本关于自我教育的书,也是James本人最满意的一本著作,书虽然很薄,但James花了二、三十年时间才终于写成,书中每一篇都是精华,记录了James对自我教育、自我学习方面的认识和经验,测试即学习,相信本书能让很多爱学习的人深受启发。
2、《Lessons Learned in Software Testing》,作者Cem Kaner, James Bach, Bret Pettichord, 中文版书名为《软件测试的经验与教训》。本书堪称软件测试的“红宝书”,书中以293条经验教训的形式阐述了上下文驱动测试学派(Context-Driven School)的各种启发式(Heuristics)的观点,内容涵盖了测试认知、测试技术、测试管理、测试职业等方方面面,本书可以作为测试人员的参考宝典,随时翻阅。
3、《Essential Software Test Design》,作者Torbjorn Ryber。这是一本关于测试设计的书,书中以测试分析设计4步法的方式讲述了常用的十几种测试设计技术的应用,并辅以实例。
4、《XUnit Test Patterns:Refactoring Test Code》,作者Gerard Meszaros,中文版书名为《XUnit测试模式:测试代码重构》。对于从事单元测试的人来说,这是一本难得的好书,书中谈到了很多测试代码的坏味道,以及大量已经被证明的好的测试模式,使得测试代码更易编写和维护。
小结
邰晓梅在这次采访中和我们分享了很多宝贵的经验,总结如下:
1、能够被人所信任、所依赖,是价值的体现。
2、测试并不仅仅是发现bug,预防bug也非常重要。
3、开发和测试是一个完整的团队,不要把开发和测试分隔得太“开”。
4、如果一个产品或项目有大量的bug暴露出来,作为项目管理者要注意了,这意味着项目本身有很大的改进空间,产品的质量不容乐观。
5、测试团队的第一目标是要得到一个可发布的高质量软件,而不是找到尽可能多的bug。
6、我们要学会应用(Apply)测试流程,而不是遵守(Follow)测试流程。
7、做任何测试工作,首先要做的是Know Your Mission(知道你的任务所在)。
8、如果不知道客户的期望是什么,则容易出现偏差。要了解客户在哪里,期望的价值在哪里。
9、测试要以人为中心。不再以流程为中心,把流程、模板放到边上,而把人放在中心的位置上。把测试工程师的能力和潜能发挥出来,这是比流程更重要的事情。
10、年复一年,不断地觉得有新的值得去学习的东西,我也在一路不断成长。当你一直在学习一直有收获的时候,就会感觉很充实。我喜欢这种充实的感觉。
11、对于培养测试新手而言,我的观点是,并不一定一开始就要学习系统的软件测试知识,或者去学习测试新技术,而应当是多实践并且多思考。给他们一个测试任务,让他们去做。这对于新手来说肯定是个挑战,但是在这种情况下他们也会发挥自己的各项能力去做。当然,指导者也不是撒手不管,可以和他们一起结对测试,发现他们的不足,指导他们去做测试。通过实践,新人对软件测试的认识和兴趣都会得到提高,然后再去教他们测试理论知识,例如等价类边界值等,效果会更好。
12、人与人之间传递信息最有效的方式就是面对面的交流,比看文档、读书、参加培训效果更好。
13、如何成为测试牛人:① 描述你的目标;② 如果要实现这些目标,要掌握哪些技能和知识?③ 如何掌握这些技能和知识?
14、软件测试的目的是什么?不仅是找bug,而是要随时提供质量相关的信息。质量是什么?我比较喜欢的一个定义是RST课程里给出的:Quality is the value to someone who matters。做测试,首先要找到这个someone是谁,以及这个someone重视的value是什么。
15、作为一个测试管理者,在面对度量结果,对这些统计数据进行分析的时候,“要更像一名测试人员”--我的意思是,管理者此时要充分发挥自己作为一名测试工程师的长处,要挑剔地思考(Critical Thinking),多疑多问,去挖掘这些数字背后的真实现象。
16、测试度量要做,测试数据要收集,但当我们面对这些度量统计数据时,把它们当做Heuristics,我们不会完全Follow这些数据,而是试图去Apply这些数据,再加上我们挑剔地思考,做正确的数据分析,让这些数据为我所用。
17、一个好的测试管理者一定是一个非常好的协调者。他(她)对内协调测试团队,对外代表测试团队做各种沟通。
18、经过分析,你就会清楚,针对这样的一个被测对象,应该从哪些方面对其开展测试会比较好,这样你就明确了这次测试任务的测试目标,确定了测试点。接下来,你如何达成这个测试目标,如何测试这些测试点,就是测试设计的工作了。
19、分析能力不是知识,而是一种skill(技能)。知识的提高可以通过看书、参加培训来实现,技能的提高只能靠多实践。
20、在我看来,敏捷让软件测试如鱼得水。
21、不需要把开发和测试在角色上鲜明地分开,说开发人员和测试人员,这不是问题的关键,而是可以把它们从工作上分开:有开发类的工作和测试类的工作。从这个角度看,测试类的工作一定会存在,至于是谁去做,就要看实际情况和能力了。
22、不管谁来做测试,都要保持一定的测试独立性,毕竟测试有其特有的思维方式。这里的独立性指的是精神上的独立,而不是物理上的独立。
(连载完)
最近开始正式的学习Go语言,奉行我学习一项新技术的步骤和原则( 笔记 + 单元测试 + demo )。首先学习了开发环境的配置,并立即搭建了单元测试的环境,这样可以一边写笔记,一边进行测试和学习,从而加强理解。
这里简单介绍Go中的测试环境搭建方法,大家可以参考着搭建并测试学习。
Go中的测试方式
Go语言中自带有一个轻量级的测试框架(testing) 和 go test 命令来实现单元测试、性能测试 和 示例。一般来说,一个 xxx.go 文件对应的 xxx_test.go 文件就是其对应的单元测试文件,往往在同一个目录下(参见 %GOROOT%\src\pkg 下的各文件)。
_test.go中有三种测试方式(具体可以参见 go help testfunc ):
1.单元测试, 代码示例为:
func TestXxx(t *testing.T) {
单元测试代码, 通过 t.Error 等实现断言
}
2.性能测试,代码示例为:
func BenchmarkXxx(b *testing.B) {
for i := 0; i < b.N; i++ {
目标代码,会重复运行N次
}
}
3.示例 -- 代码示例为:
func ExampleXxx() {
示例语句,往标准输出中输出信息,然后下面会通过 Output 的注释指明会输出的文字,框架会进行比较
//Output: 示例输出
} |
针对本人的学习笔记需要,当前情况下只使用单元测试来记录各种学习笔记。
下面是我针对切片(Slice)的测试代码,从中可以验证文档中说的一些重要信息,比如:可随时动态增减元素,扩充时会重新分配并复制内存(类似于 std::vector) 等
func TestSlice(t *testing.T) {
//方法1:直接创建一个保存有10个整数的slice
intSlice := make([]int, 10, 15) //{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
for idx := 0; idx < len(intSlice); idx++ {
intSlice[idx] = idx + 1
}
GOUNIT_ASSERT(t, len(intSlice) == 10, "make创建的slice长度")
GOUNIT_ASSERT(t, cap(intSlice) == 15, "make创建的slice容量") //从尾端向数组切片中追加元素
newIntSlice := append(intSlice, 11, 12, 13)
GOUNIT_ASSERT(t, len(intSlice) == 10, "append后原来的Slice不变")
GOUNIT_ASSERT(t, len(newIntSlice) == 13, "append后新的Slice")
GOUNIT_ASSERT(t, cap(newIntSlice) == 15, "cap(newIntSlice) == 15")
GOUNIT_ASSERT(t, &newIntSlice != &intSlice, "append返回新的切片")
GOUNIT_ASSERT(t, &newIntSlice[0] == &intSlice[0], "底层的数组是同一个") newIntSlice[0] = 99
GOUNIT_ASSERT(t, newIntSlice[0] == intSlice[0], "未进行内存扩充的情况下新旧Slice指向同一个底层数组") newAddressIntSlice := append(intSlice, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20)
GOUNIT_ASSERT(t, cap(newAddressIntSlice) == 30, "扩充后的长度,目前实现采用容量翻倍的方式")
newAddressIntSlice[0] = 199
GOUNIT_ASSERT(t, &newAddressIntSlice[0] != &intSlice[0], "进行了内存扩充,底层数组不再一样")
GOUNIT_ASSERT(t, newAddressIntSlice[0] != intSlice[0], "进行了内存扩充,底层数组不再一样") //方法2:先创建一个array,然后基于该array创建slice
intArray := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
intSliceFromArray := intArray[0:5] //[:]--基于全部元素, [5:]--从第5个元素开始的所有元素
GOUNIT_ASSERT(t, len(intSliceFromArray) == 5, "array[n:m]创建的slice长度")
GOUNIT_ASSERT(t, cap(intSliceFromArray) == 10, "array[n:m]创建的slice容量")
GOUNIT_ASSERT(t, cap(intArray) == 10, "数组的容量") //下面代码会在运行时抛出"index out of range"的异常(panic) -- 因为该slice长度是5(即0~4)
//intSliceFromArray[5] = 10 //在slice后追加slice,注意最后的三个点
S3 := append(newIntSlice, intSliceFromArray...)
GOUNIT_ASSERT(t, len(S3) == 18 && cap(S3) == 30, "在slice后追加slice") //copy函数,如两个切片不一样大,会按照较小的切片的元素个数进行复制
var newS = make([]int, 3)
nCopy := copy(newS, intSlice[0:5])
GOUNIT_ASSERT(t, nCopy == 3, "只复制3个元素")
} |
最近开始正式的学习Go语言,奉行我学习一项新技术的步骤和原则( 笔记 + 单元测试 + demo )。首先学习了开发环境的配置,并立即搭建了单元测试的环境,这样可以一边写笔记,一边进行测试和学习,从而加强理解。
这里简单介绍Go中的测试环境搭建方法,大家可以参考着搭建并测试学习。
Go中的测试方式
Go语言中自带有一个轻量级的测试框架(testing) 和 go test 命令来实现单元测试、性能测试 和 示例。一般来说,一个 xxx.go 文件对应的 xxx_test.go 文件就是其对应的单元测试文件,往往在同一个目录下(参见 %GOROOT%\src\pkg 下的各文件)。
_test.go中有三种测试方式(具体可以参见 go help testfunc ):
1.单元测试, 代码示例为:
func TestXxx(t *testing.T) {
单元测试代码, 通过 t.Error 等实现断言
}
2.性能测试,代码示例为:
func BenchmarkXxx(b *testing.B) {
for i := 0; i < b.N; i++ {
目标代码,会重复运行N次
}
}
3.示例 -- 代码示例为:
func ExampleXxx() {
示例语句,往标准输出中输出信息,然后下面会通过 Output 的注释指明会输出的文字,框架会进行比较
//Output: 示例输出
} |
针对本人的学习笔记需要,当前情况下只使用单元测试来记录各种学习笔记。
下面是我针对切片(Slice)的测试代码,从中可以验证文档中说的一些重要信息,比如:可随时动态增减元素,扩充时会重新分配并复制内存(类似于 std::vector) 等
func TestSlice(t *testing.T) {
//方法1:直接创建一个保存有10个整数的slice
intSlice := make([]int, 10, 15) //{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
for idx := 0; idx < len(intSlice); idx++ {
intSlice[idx] = idx + 1
}
GOUNIT_ASSERT(t, len(intSlice) == 10, "make创建的slice长度")
GOUNIT_ASSERT(t, cap(intSlice) == 15, "make创建的slice容量") //从尾端向数组切片中追加元素
newIntSlice := append(intSlice, 11, 12, 13)
GOUNIT_ASSERT(t, len(intSlice) == 10, "append后原来的Slice不变")
GOUNIT_ASSERT(t, len(newIntSlice) == 13, "append后新的Slice")
GOUNIT_ASSERT(t, cap(newIntSlice) == 15, "cap(newIntSlice) == 15")
GOUNIT_ASSERT(t, &newIntSlice != &intSlice, "append返回新的切片")
GOUNIT_ASSERT(t, &newIntSlice[0] == &intSlice[0], "底层的数组是同一个") newIntSlice[0] = 99
GOUNIT_ASSERT(t, newIntSlice[0] == intSlice[0], "未进行内存扩充的情况下新旧Slice指向同一个底层数组") newAddressIntSlice := append(intSlice, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20)
GOUNIT_ASSERT(t, cap(newAddressIntSlice) == 30, "扩充后的长度,目前实现采用容量翻倍的方式")
newAddressIntSlice[0] = 199
GOUNIT_ASSERT(t, &newAddressIntSlice[0] != &intSlice[0], "进行了内存扩充,底层数组不再一样")
GOUNIT_ASSERT(t, newAddressIntSlice[0] != intSlice[0], "进行了内存扩充,底层数组不再一样") //方法2:先创建一个array,然后基于该array创建slice
intArray := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
intSliceFromArray := intArray[0:5] //[:]--基于全部元素, [5:]--从第5个元素开始的所有元素
GOUNIT_ASSERT(t, len(intSliceFromArray) == 5, "array[n:m]创建的slice长度")
GOUNIT_ASSERT(t, cap(intSliceFromArray) == 10, "array[n:m]创建的slice容量")
GOUNIT_ASSERT(t, cap(intArray) == 10, "数组的容量") //下面代码会在运行时抛出"index out of range"的异常(panic) -- 因为该slice长度是5(即0~4)
//intSliceFromArray[5] = 10 //在slice后追加slice,注意最后的三个点
S3 := append(newIntSlice, intSliceFromArray...)
GOUNIT_ASSERT(t, len(S3) == 18 && cap(S3) == 30, "在slice后追加slice") //copy函数,如两个切片不一样大,会按照较小的切片的元素个数进行复制
var newS = make([]int, 3)
nCopy := copy(newS, intSlice[0:5])
GOUNIT_ASSERT(t, nCopy == 3, "只复制3个元素")
} |
(11)Comment页信息——该页面显示页面的评价相关信息。
HttpWatch 也提供了非常方便的查询和过滤功能,您可以通过单击【Find】按钮,来查
询您关心的相关信息,如图12-19所示。
您可以通过单击【Filter】按钮,来设定过滤条件得到您关心的相关信息,如图12-20所示。
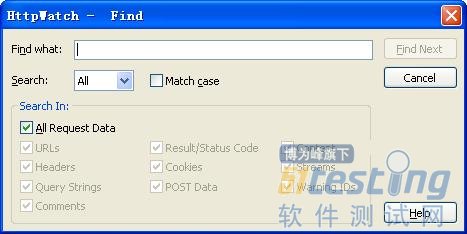
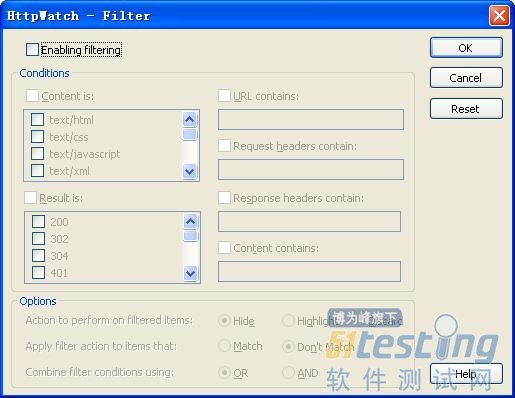
图12-19 Find对话框信息 图12-20 Filter对话框信息
可以通过选择保存相应的文件输出格式将数据信息进行保存,如图12-21所示。
还可以通过选择性地清除Cache和Cookies相关信息等操作,如图12-22所示。
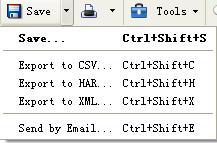

图12-21 Save快捷菜单相关信息 图12-22 Tools快捷菜单相关信息
(4)Cookies页信息。
Cookies页展示了在我们访问百度首页时,服务器将哪些数据信息存放在到了客户端,从图12-9中我们可以看到了,其主要设定了2个Cookie:“BAIDUID”和“BDUT”,键值分别为“D6572EDE2B026FAE0B68BBB375FAD7C3:FG=1”和“6yg771C5C327A86C92969
图12-9 访问百度首页获得的数据信息下半部分——Cookies页信息
2CE95FF7770B35813afe68626e2f”,指定了它们的路径、域、有效期等信息。
(5)Cache页信息。
如图12-10所示,您可以看到针对要考察的URL,在请求前、后相关缓存的一些信息,下面以表格形式给大家介绍一下项目信息项含义,参见表12-5。
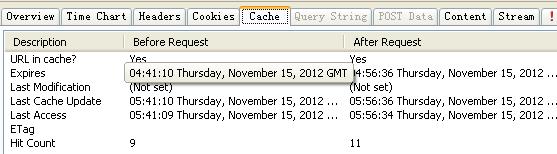
图12-10 访问百度首页获得的数据信息下半部分——Cache页信息
表12-5 服务器端响应返回表头说明
序号 | 信 息 项 | 含 义 |
1 | URL in cache? | 这表明当前选中的URL是否在浏览器缓存中 |
2 | Expires | Web服务器可以指定这个使用Expires表头项,指定当缓存条目将到期的日期/时间 |
3 | Last Modification | 服务器返回last - modified头条目,存储或更新本地缓存,这里没有设置该项 |
4 | Last Cache Update | 最近缓存被更新的日期/时间 |
5 | Last Access | 上一次从缓存读取内容的日期/时间 |
6 | ETag | Etag 是URL的Entity Tag,用于标示URL对象是否改变,区分不同语言和Session等。具体内部含义是使服务器控制的,就像Cookie那样。以前的HTTP标准里有个Last-Modified+If-Modified-Since表明URL对象是否改变。Etag也具有这种功能,因为对象改变也造成Etag改变,并且它的控制更加准确。Etag有两种用法:If-Match/If-None-Match,就是如果服务器的对象和客户端的对象ID(不)匹配才执行。这里的If-Match/If-None- Match都能一次提交多个Etag。If-Match可以在Etag未改变时断线重传。If-None-Match可以刷新对象(在有新的Etag时返回) |
7 | Hit Count | 浏览器从缓存取得内容的次数 |
(6)Query String页信息(如图12-11所示)。

图12-11 访问百度首页获得的数据信息下半部分——Query String页信息
有时候您在浏览页面的时候,经常在地址栏看到类似于“http://www.xxx.com/...? name1=value1&name2=value2&...”的信息。查询字符串(Query String)是用来传递参数的,在该“http://www.xxx.com/...?name1=value1&name2=value2&...”URL中,“name1”、“name2”就是参数,而“value1”和“value2”就是参数的值。当然有些是显式传输的,有一些是隐式传送的。如:访问知名的CSDN网站,您输入用户名和密码信息,其用户名等相关参数和值将被记录,出于安全性方面考虑,作者将关键的信息予以了屏蔽,如图12-12所示,而访问百度首页没有查询字符串,所以显示如图12-11所示。
(7)POST Data页信息(如图12-13所示)。
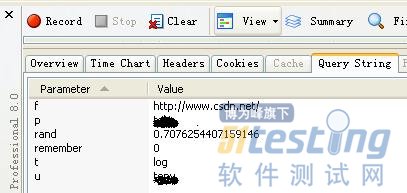
图12-12 登录CSDN-Query String页信息

图12-13 访问百度首页获得的数据信息下半部分——POST Data页信息
“Post Data”是以Post方法传送的相关信息,这里由于百度首页没有应用该方法传送数据,所以无相关信息。下面我们拿“51testing”用户登录为例来进行一下说明,参见图12-14和图12-15所示。

图12-14 51tesing论坛登录界面信息 图12-15 针对51testing论坛登录——POST Data页信息
从图12-14和图12-15我们可以发现相关的输入信息均已被记录,这里鉴于安全方面的考虑,作者将关键的密码相关信息给予了屏蔽。
(8)Content页信息。
如图12-16所示,该页是服务器返回的Http响应相关信息。
(9)Stream页信息。
如图12-17所示,该页分成了2个窗口,左侧为发送请求相关信息,右侧为响应信息。共发送668个字节到119.75.218.77:80,80为端口号,服务器返回响应信息为4300个字节给192.168.0.141:5427,5427为端口号。
(10)Warnings页信息
如图12-18所示,该页显示单个请求的警告,这里出现一个HW1004的警告信息,该信息为“The request content has been cached, but no Last-Modified or ETag header was set. The browser will not be able to re-validate the content using a conditional request。”

图12-16 访问百度首页获得的数据信息下半部分——Content页信息

图12-17 访问百度首页获得的数据信息下半部分——Stream页信息

图12-18 访问百度首页获得的数据信息下半部分——Warnings页信息
以下事例介绍了LoadRunner 关联函数的使用,希望对大家有所帮助。
web_reg_save_param 和关联的使用
1. 作用:保存动态数据。该数据的来源为html源码。
2.使用
顺序:web_reg_save_param();
web_submit_data();
lr_message();
3.web_reg_save_param()的属性
1)在寻找动态数据时,可以对该数据的范围进行限制,通过左边界和右边界进行限制。即:LB,RB两个属性。

来源loadrunner帮助文档
其中LB/IC 是忽略字符的大小写。
2)ORD属性
是将找到的动态变量保存到数组中。默认是ord=1.如果搜索到的字符是多个,并想将他保存在数组里,则ord=all;他们分别保存到pr_1 pr_2 .....。其中pr_count为内部函数,统计数组的个数。
3)search 属性
设置搜索的范围,可以是header,body,header and body,html body。
4)SaveOffset属性
偏移量。从搜索到的字符串中,取子串。默认saveoffset=0.
5) SaveLen 属性
取串的长度。也是从搜索到的字符串中,取子串。
4.例子:
1)
char *pr;
web_reg_save_param("pr","LB=pr","RB="<br>",LAST);
web_submit_data("pr.php
"url=http://"
"TargerFrame="
......
LAST);
lr_message("value: %s",lr_eval_string("{pr}")); |
然后你就可以在运行的log中看到结果。
2)关联的例子
char *pr;
web_reg_save_param("pr","LB=pr","RB="<br>",LAST);
web_submit_data("pr.php
"url=http://"
"TargerFrame="
......
LAST);
i=atoi(pr_count) |
这个函数的作用还是蛮大的。希望能得到大家的关注。
上一篇文章讲了如何打开loadrunner Virtual User Generator并进行录制脚本前的准备工作。
点击选择action 为user-init ,点击ok以后则开始录制脚本。
下面是IE打开需要进行性能测试的web地址。
在初始化时是记录的页面需要的元素,包括一些图片和js之类东西。
因为在这次性能测试中,登录功能并不作为我们测试的功能之一,所以对于登录要求就不是太严格也就没有创建事务。
下图是有init切换到action,如果之前录制过action,则会出现提示是否覆盖之前录制过的action。如下图

查询功能是我们要测试的功能点之一,所以在点击“查询”之前要创建事务,通过事务来查看该功能的相应指标:比如响应时间,事务并发的成功率等。
下图是添加事务
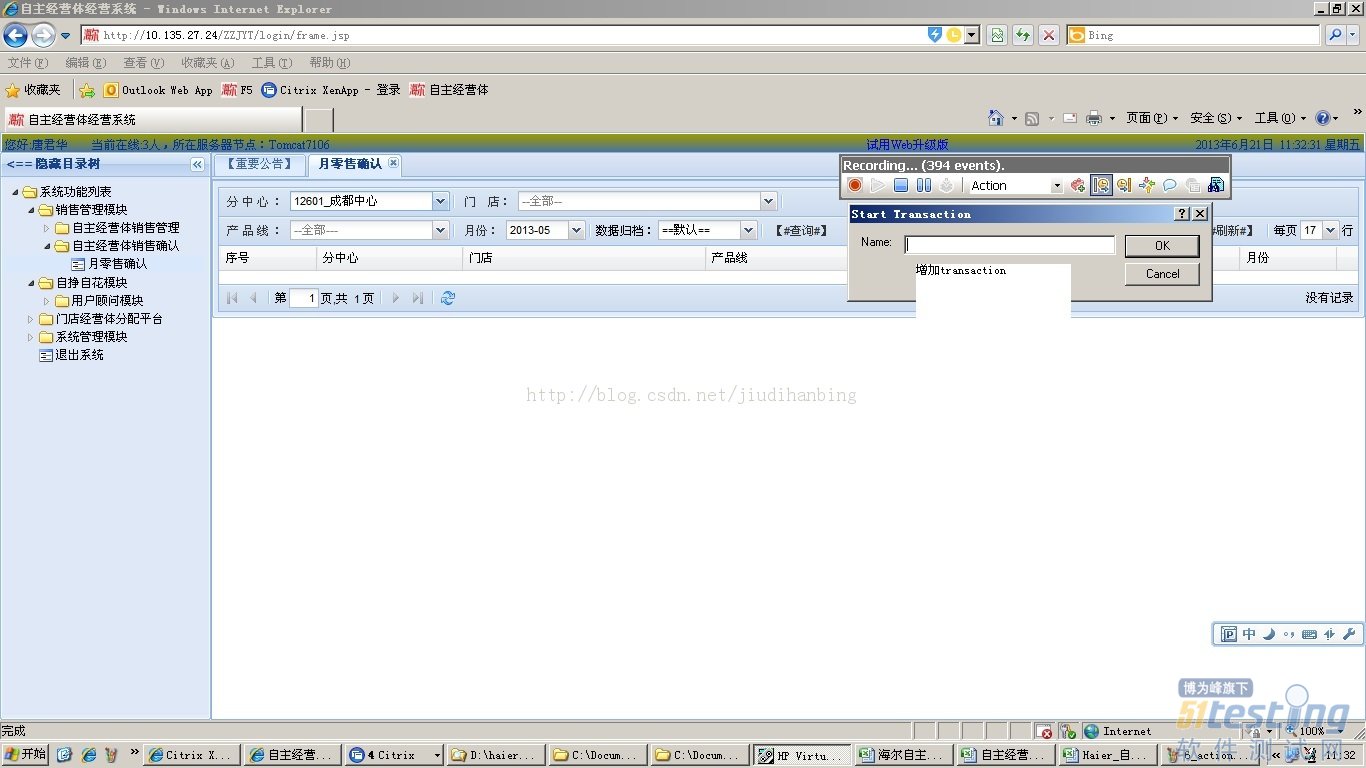
查询完成以后,要立刻结束事务不要在进行其他操作,这样才能准确的记录时间

事务结束以后,该功能的测试就基本完成,剩下的就是退出了。开始的时候是init,结束的则是action了。
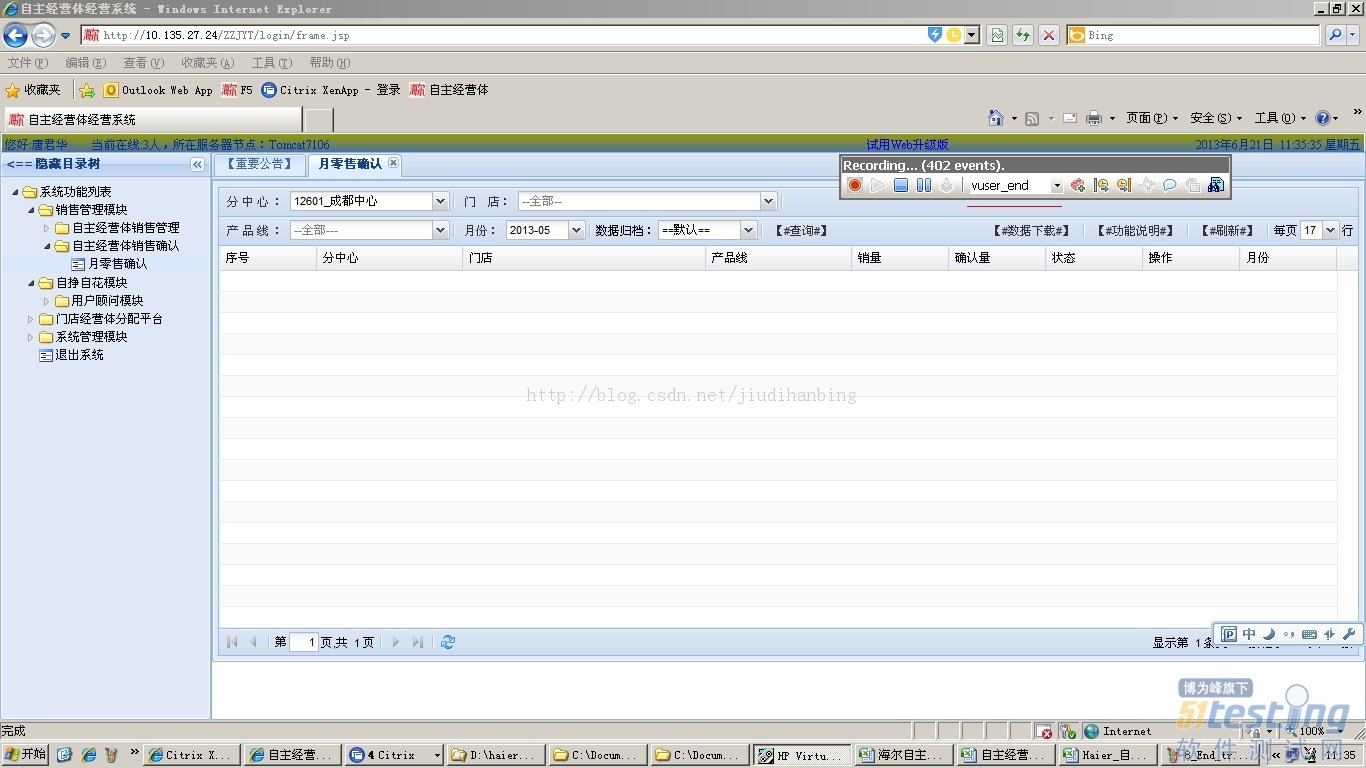
退出系统以后,录制脚本也完成了,停止脚本以后再进行脚本回放来验证录制的脚本是否有问题。
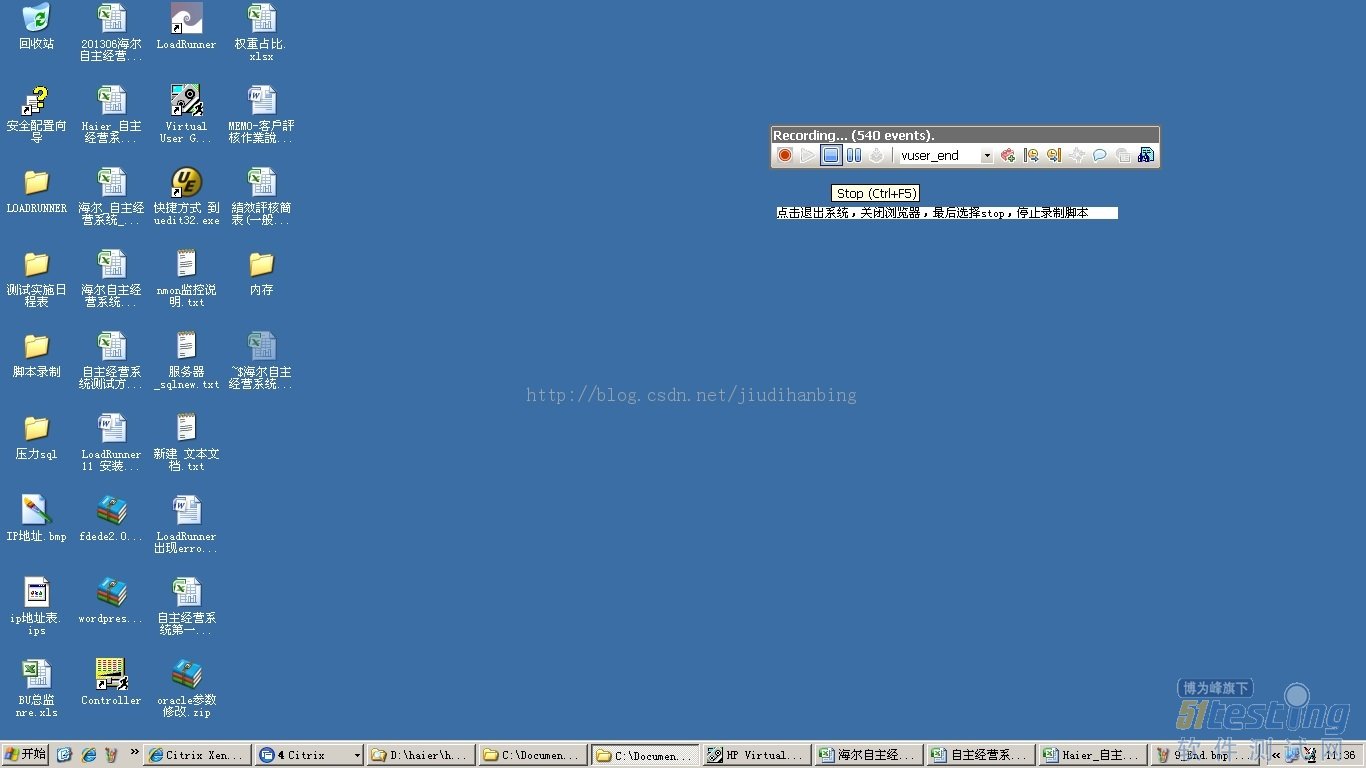
脚本录制完成剩下的就是参数化了,录制脚本还是比较简单的,只要针对相应的功能进行录制就可以了。还有一个参数化在下篇博客中将会写道。
Web性能测试之术语
作为一性能测试工作者,其应该具备更多的技能,大致如下:
掌握常见自动化测试工具的使用;
具备一定的编程能力;
掌握基础的数据可知识;
掌握常见的操作系统知识;
掌握一些WEB应用服务器的使用;
具有综合分析能力,例如通过综合分析测试结果确定系统瓶颈。
在具备了上述各项能力的同时,测试人员还有制定出合适的测试策略和相关方案才算是做好了性能测试的基本条件。再扯了一些人员能力后,下面介绍一些WEB性能测试重要指标,这些术语主要有并发用户、并发用户数量、请求响应时间、事务响应时间、吞吐量、吞吐率、TPS、点击率、资源利用率等。
并发用户:并发一般分两种情况。一种是严格意义的并发,即所有的用户在同一时刻做同一件事情或者操作,这种操作一般指做同一类型的业务。
另外一种并发是广义范围的并发,这种并发与前一种并发的区别是,尽管多个用户对系统发生了请求或者进行了操作,但是这些请求或者操作可以是相同的,也可以是不同的。
并发用户数量:关于用户并发的数量,有两种常见的错误观点。一种错误观点是把并发用户数量理解为使用系统的全部用户的数量,理由是这些用户可能同时使用系统;还有一种比较接近正确的观点是把在在线用户数量理解为并发用户数量。实际上在线用户也不一定会和其他用户发生并发。
并发主要针对Web服务器而言,是否并发的关键是看用户的操作是否对服务器产生了影响。因此用户并发数量的正确理解是,在同一时刻与服务器进行交互的在线用户数量。这些用户的最大特征是和服务器发生了交互,这种交互可以是单向传送数据包,也可以是双向传送数据包。
并发用户平均计算公式:(1)C=NL/T,并发用户数峰值:(2)C1≈C+3√C。公式(1)中,C是平均的并发用户数;n是login
session的数量;L是login session的平均长度;T指考察的时间段长度。公式(2)则给出了并发用户数峰值的计算方式中,其中,C’指并发用户数的峰值,C就是公式(1)中得到的平均的并发用户数。该公式的得出是假设用户的login
session产生符合泊松分布而估算得到的。
请求响应时间:指的是客户端发出请求到得到响应的整个过程的时间。在某些工具中,请求响应时间通常会被称为“TTLB”,即“Time to last byte”,意思是从发起一个请求开始,到客户端收到最后一个字节的响应所耗费的时间。请求响应时间过程的单位一般为“秒”或者“毫秒”。请求响应时间的过程分解如下图所示。
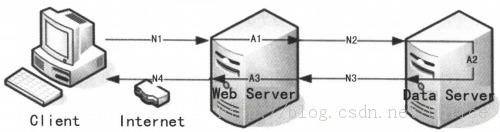
事务响应时间:事务可能由一系列请求组成。事务的响应时间主要是针对用户而言,属于宏观上的概念,是为了向用户说明业务响应时间而提出的。
吞吐量:指的是在一次性能测试过程中网络上传输的数据量的总和。吞吐量/传输时间,就是吞吐率。
吞吐率:单位时间内网络上传输的数据量,也可以指单位时间内处理的客户端请求数量。它是衡量网络性能的重要指标。通常情况下,吞吐率用“请求数/秒”。
TPS:每秒钟系统能够处理的交易或者事物的数量。它是衡量系统处理能力的重要指标。
点击率:每秒钟用户向Web服务器提交的HTTP请求数。这个指标是Web应用特有的一个指标:Web应用是“请求-响应”模式,用户发出一次申请,服务器就要处理一次,所以点击是Web应用能够处理的交易的最小单位,如果把每次点击定义为一个交易,点击率和TPS就是一个概念。容易看出,点击率越大,对服务器的压力也越大。点击率只是一个性能参考指标,重要的是分析点击是产生的影响。
资源利用率:指的是对不同系统资源的使用程度,例如服务器的CPU利用率,磁盘利用率等。资源利用率是分析系统性能指标进而改善性能的主要依据。
希望通过以上术语的介绍,能给读者提供一些帮助。在以后的学习与工作中得以提高。
1 怎样的性能测试结果才是有效的
1.1 错误观点
性能测试工具运行一定用户数都成功,则表示该服务器能支持这么多用户数。这是错误的。
解答:
A. 因为一次有效的测试结果,不只用户都运行成功,同时需要保证访问一个页面或一次交易的响应时间在合理范围。“2-5-8原则”,简单说,就是当用户访问一个页面或一次交易能够在2秒以内得到响应时,会感觉系统的响应很快;当用户在2-5秒之间得到响应时,会感觉系统的响应速度还可以;当用户在5-8秒以内得到响应时,会感觉系统的响应速度很慢,但是还可以接受;而当用户在超过8秒后仍然无法得到响应时,会感觉系统糟透了,或者认为 系统已经失去响应,而选择离开这个Web站点,或者发起第二次请求。
B. 测试场景不一定模拟了真实业务场景,因为浏览器是并发多线程多TCP完成一个页面的,而测试工具基本都是1,2个线程;对服务器的压力是不一样的,真实环境的TCP压力是性能测试工具虚拟环境的几倍。
2 影响WEB服务器性能指标的因素有哪些
为什么性能测试工具,需要提供事务(页面或交易、全脚本)指标、TCP连接、吞吐量、服务器资源监控、请求数/响应数。
1) 硬件资源:如CPU、内存、网卡吞吐量、I/O能力、SWAP交换能力
2) 线程数:这里介绍JAVA的WEB服务器,默认每线程占用的内存为2M,而32为系统JAVA进程(如tomcat、JBoss)占得空间只有2G(一般比这个小),因此线程数有限制;64为无限制线程,但CPU要跟得上
3) TCP连接数:操作系统的TCP连接数理论值一般很大,操作系统对TCP连接设置有默认值(怎么配置,可以网上搜索,这里不介绍);但实际测试中TCP连接在几百,就出现测试的响应时间很长。抓包分析,原来是三次握手的SYN包服务器不及时响应,导致SYN重传(3秒后,9秒后)。
如果SYN丢了,则会重发,但是第一次是3秒后,第2次是在9秒后,如果重发才收到的SYN_ACK,则导致TCP连接超长,从而导致业务响应时间延长。
4) 响应时间:服务器响应时间小,用户体验才好,在大量用户并发的情况下,HTTP响应时间在用户忍受度下才是有效的,一般采用“2-5-8原则”。
5) 软件本身代码性能算法:这个不做介绍,如差的算法、查询数据库时间长等等。
3 测试人员经常遇到的一些常见问题及解答
3.1 为什么使用浏览器访问页面响应很快,1-2秒就完成;而使用测试工具却需要10几秒,甚至几十秒才完成脚本
解答:
A. 这是由于浏览器访问页面响应是并发的,同时并发多个线程(多个Socket),而性能测试工具基本是串行发送请求的。如果一个页面有100个资源(CSS、HTML、JS、图片),需要发送100个HTTP请求,如果使用6个线程(浏览器),则每个大概请求14个HTTP;如果使用一个线程(测试工具),则需要请求100个,时间当然大很多。下图为chrome浏览器调试工具显示的并发情况:
B. 另外浏览器具有缓存功能,如果之前访问了www.qq.com,会把一些图片缓存在浏览器临时目录,下次请求时发送的HTTP请求会带上If-Match或Etag等头域,WEB服务器判断资源没改变则会304响应,而不是回200 OK,这样减少资源的传输,所以时间就小。而有些测试工具是不携带这些头域(包括Loadrunner),因此回的响应是200 OK。所以测试人员默认真实测试时,可以考虑部分有缓存,部分没缓存。
3.2 性能测试工具是怎么模拟WEB虚拟用户
A. 录制
使用浏览器进行正常业务操作,性能测试工具录制下HTTP请求信息。一般需要记录URL与头域、内容、响应码。虽然不同的性能测试工具录制方式不一样(如loadrunner采用Hook,JMeter采用代理或badbody,kylinPET采用网卡抓包与代理),但都能实现录制正常业务的HTTP请求。
测试工具最好能录制出缓存头域,即If-Match或Etag,loadrunner好像不支持录制缓存头域。
B. 模拟用户
根据录制的脚本发送HTTP请求与接收响应,发送前替换参数(实现多用户不同参数值)、接收时关联参数(从接收的响应消息获取参数值,如Cookie、JSessionID)
下面简单列举使用过的性能测试工具是如何模拟的(工具运行一个用户,然后使用wireshark抓包分析得到的结论):
Loadrunner:根据录制脚本发送HTTP请求,如果HTTP请求包括内嵌资源(如图片、CSS、JS),会启动第二个线程执行内嵌资源,即Loadrunner支持同时两个线程两个TCP连接。
kylinPET(国产):可通过配置设置一个线程或者多个线程并发发送HTTP请求,多个线程并发及TCP连接数跟浏览器行为一样。
JMeter:只有一个线程,一个TCP连接
其他工具:本人没用过,请用过的兄弟姐妹可以补充下。通过wireshark抓包分析。
3.3 怎样才能测试出WEB服务器能支持多少真实用户,怎样的服务器调优参数才合理
解答:
这需要性能测试工具可以模拟出真实用户的行为,包括HTTP请求数、每用户并发线程与TCP连接数、思考时间、有无缓存。
为什么需要模拟真实用户的线程数与TCP连接数呢,上面提到过,WEB服务器的线程数与TCP连接数往往很低,这不是提高硬件就能轻松解决的,这也是服务器调优比较复杂的配置。
因此,只有尽最大能力模拟真实用户(浏览器或其它WEB客户端,可能不同浏览器的并发线程与TCP数都不一样)的行为的测试场景,测试结果才最真实,服务器调优才最有意义。
4 怎样才能测试系统支持多少用户
4.1 模拟真实用户的行为
只有模拟用户一样的行为才可以系统支持的测试用户数有效,因此需要模拟一样的并发数、TCP连接数、甚至可以是HTTP请求的时间间隔。用户可以是浏览器、智能手机、智能机顶盒,测试工具模拟他们一样的行为才是最有效的测试。
4.2 测试结果数据在合理范围
4.2.1 用户统计
成功数、失败数、每秒在线数、最大在线数,通过这些指标分析此次测试结果支持的用户数、用户最大数
4.2.2 点击率
每秒平均HTTP请求数、响应数。分析系统的处理能力
4.2.3 事务
事务成功、失败、时间,事务一般是整个脚本运行时间、或者一个页面或一个交易,通过结果分析,得出每个事物的时间是否合理,符合“2-5-8”原则,如果测试结果显示事物时间非常大,则表示系统支持不了此次测试的用户,因为用户的响应时间太大(像火车订票一样,太多用户导致响应时间长,用户无法忍受,则认为这个系统烂)。
当然,还需要查看事务的百分比,分析90%、80%、70%、60%的事务时间是否在合理范围。
4.2.4 TCP连接信息
TCP连接成功数、失败数、TCP三次握手时间。因为此次测试结果可能是由于服务器系统或网络的TCP的丢包与重传才导致延时大的。如果是服务器的原因,服务器收到TCP的SYN而不处理,可以通过调试服务器的TCP配置来优化。
怎么才知道是服务器的问题呢,这个需要性能测试工具能给出TCP连接时间(当前了解只有kylinPET可以支持),如果显示超过3秒,这时需要检查是网络还是服务器问题,可以在服务器端抓包(tcpdump或wireshark)然后分析TCP的SYN信息(个数、时间)
4.2.5 资源占用
服务器的CPU、内存、带宽、I/O是不是已经不足,导致系统上不去是哪个原因,根据原因进行调优或升级。
测试时需要考虑性能测试工具的CPU占用率,如果性能测试工具占用CPU很高,此次测试可能瓶颈是在工具,而导致测试结果是无效的。
原帖地址:http://bbs.51testing.com/thread-980437-1-1.html
版权声明:本文由会员linneiwei首发于51Testing软件测试论坛。
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。