
Date类
在JDK1.0中,Date类是唯一的一个代表时间的类,但是由于Date类不便于实现国际化,所以从JDK1.1版本开始,推荐使用Calendar类进行时间和日期处理。这里简单介绍一下Date类的使用。
1、使用Date类代表当前系统时间
Date d = new Date();
System.out.println(d); |
使用Date类的默认构造方法创建出的对象就代表当前时间,由于Date类覆盖了toString方法,所以可以直接输出Date类型的对象,显示的结果如下:
Sun Mar 08 16:35:58 CST 2009
在该格式中,Sun代表Sunday(周日),Mar代表March(三月),08代表8号,CST代表China Standard Time(中国标准时间,也就是北京时间(东八区))。
2、使用Date类代表指定的时间
Date d1 = new Date(2009-1900,3-1,9);
System.out.println(d1); |
使用带参数的构造方法,可以构造指定日期的Date类对象,Date类中年份的参数应该是实际需要代表的年份减去1900,实际需要代表的月份减去1以后的值。例如上面的示例代码代表就是2009年3月9号。
实际代表具体的年月日时分秒的日期对象,和这个类似。
3、获得Date对象中的信息
Date d2 = new Date();
//年份
int year = d2.getYear() + 1900;
//月份
int month = d2.getMonth() + 1;
//日期
int date = d2.getDate();
//小时
int hour = d2.getHours();
//分钟
int minute = d2.getMinutes();
//秒
int second = d2.getSeconds();
//星期几
int day = d2.getDay();
System.out.println("年份:" + year);
System.out.println("月份:" + month);
System.out.println("日期:" + date);
System.out.println("小时:" + hour);
System.out.println("分钟:" + minute);
System.out.println("秒:" + second);
System.out.println("星期:" + day); |
使用Date类中对应的get方法,可以获得Date类对象中相关的信息,需要注意的是使用getYear获得是Date对象中年份减去1900以后的值,所以需要显示对应的年份则需要在返回值的基础上加上1900,月份类似。在Date类中还提供了getDay方法,用于获得Date对象代表的时间是星期几,Date类规定周日是0,周一是1,周二是2,后续的依次类推。
4、Date对象和相对时间之间的互转
Date d3 = new Date(2009-1900,3-1,10);
long time = 1290876532190L;
//将Date类的对象转换为相对时间
long t = d3.getTime();
System.out.println(t);
//将相对时间转换为Date类的对象
Date d4 = new Date(time);
System.out.println(d4); |
使用Date对象中的getTime方法,可以将Date类的对象转换为相对时间,使用Date类的构造方法,可以将相对时间转换为Date类的对象。经过转换以后,既方便了时间的计算,也使时间显示比较直观了。
Calendar类
从JDK1.1版本开始,在处理日期和时间时,系统推荐使用Calendar类进行实现。在设计上,Calendar类的功能要比Date类强大很多,而且在实现方式上也比Date类要复杂一些,下面就介绍一下Calendar类的使用。
Calendar类是一个抽象类,在实际使用时实现特定的子类的对象,创建对象的过程对程序员来说是透明的,只需要使用getInstance方法创建即可。
1、使用Calendar类代表当前时间
Calendar c = Calendar.getInstance();
由于Calendar类是抽象类,且Calendar类的构造方法是protected的,所以无法使用Calendar类的构造方法来创建对象,API中提供了getInstance方法用来创建对象。
使用该方法获得的Calendar对象就代表当前的系统时间,由于Calendar类toString实现的没有Date类那么直观,所以直接输出Calendar类的对象意义不大。
2、使用Calendar类代表指定的时间
Calendar c1 = Calendar.getInstance();
c1.set(2009, 3 - 1, 9);
使用Calendar类代表特定的时间,需要首先创建一个Calendar的对象,然后再设定该对象中的年月日参数来完成。
set方法的声明为:
public final void set(int year,int month,int date)
以上示例代码设置的时间为2009年3月9日,其参数的结构和Date类不一样。Calendar类中年份的数值直接书写,月份的值为实际的月份值减1,日期的值就是实际的日期值。
如果只设定某个字段,例如日期的值,则可以使用如下set方法:
public void set(int field,int value)
在该方法中,参数field代表要设置的字段的类型,常见类型如下:
Calendar.YEAR——年份
Calendar.MONTH——月份
Calendar.DATE——日期
Calendar.DAY_OF_MONTH——日期,和上面的字段完全相同
Calendar.HOUR——12小时制的小时数
Calendar.HOUR_OF_DAY——24小时制的小时数
Calendar.MINUTE——分钟
Calendar.SECOND——秒
Calendar.DAY_OF_WEEK——星期几 |
后续的参数value代表,设置成的值。例如:
c1.set(Calendar.DATE,10);
该代码的作用是将c1对象代表的时间中日期设置为10号,其它所有的数值会被重新计算,例如星期几以及对应的相对时间数值等。
3、获得Calendar类中的信息
Calendar c2 = Calendar.getInstance();
//年份
int year = c2.get(Calendar.YEAR);
//月份
int month = c2.get(Calendar.MONTH) + 1;
//日期
int date = c2.get(Calendar.DATE);
//小时
int hour = c2.get(Calendar.HOUR_OF_DAY);
//分钟
int minute = c2.get(Calendar.MINUTE);
//秒
int second = c2.get(Calendar.SECOND);
//星期几
int day = c2.get(Calendar.DAY_OF_WEEK);
System.out.println("年份:" + year);
System.out.println("月份:" + month);
System.out.println("日期:" + date);
System.out.println("小时:" + hour);
System.out.println("分钟:" + minute);
System.out.println("秒:" + second);
System.out.println("星期:" + day); |
使用Calendar类中的get方法可以获得Calendar对象中对应的信息,get方法的声明如下:
public int get(int field)
其中参数field代表需要获得的字段的值,字段说明和上面的set方法保持一致。需要说明的是,获得的月份为实际的月份值减1,获得的星期的值和Date类不一样。在Calendar类中,周日是1,周一是2,周二是3,依次类推。
4、其它方法说明
其实Calendar类中还提供了很多其它有用的方法,下面简单的介绍几个常见方法的使用。
a、add方法
public abstract void add(int field,int amount)
该方法的作用是在Calendar对象中的某个字段上增加或减少一定的数值,增加是amount的值为正,减少时amount的值为负。
例如在计算一下当前时间100天以后的日期,代码如下:
Calendar c3 = Calendar.getInstance();
c3.add(Calendar.DATE, 100);
int year1 = c3.get(Calendar.YEAR);
//月份
int month1 = c3.get(Calendar.MONTH) + 1;
//日期
int date1 = c3.get(Calendar.DATE);
System.out.println(year1 + "年" + month1 + "月" + date1 + "日"); |
这里add方法是指在c3对象的Calendar.DATE,也就是日期字段上增加100,类内部会重新计算该日期对象中其它各字段的值,从而获得100天以后的日期,例如程序的输出结果可能为:
2009年6月17日
b、after方法
public boolean after(Object when)
该方法的作用是判断当前日期对象是否在when对象的后面,如果在when对象的后面则返回true,否则返回false。例如:
Calendar c4 = Calendar.getInstance();
c4.set(2009, 10 - 1, 10);
Calendar c5 = Calendar.getInstance();
c5.set(2010, 10 - 1, 10);
boolean b = c5.after(c4);
System.out.println(b); |
在该示例代码中对象c4代表的时间是2009年10月10号,对象c5代表的时间是2010年10月10号,则对象c5代表的日期在c4代表的日期之后,所以after方法的返回值是true。
另外一个类似的方法是before,该方法是判断当前日期对象是否位于另外一个日期对象之前。
c、getTime方法
public final Date getTime()
该方法的作用是将Calendar类型的对象转换为对应的Date类对象,两者代表相同的时间点。
类似的方法是setTime,该方法的作用是将Date对象转换为对应的Calendar对象,该方法的声明如下:
public final void setTime(Date date)
转换的示例代码如下:
Date d = new Date();
Calendar c6 = Calendar.getInstance();
//Calendar类型的对象转换为Date对象
Date d1 = c6.getTime();
//Date类型的对象转换为Calendar对象
Calendar c7 = Calendar.getInstance();
c7.setTime(d);
5、Calendar对象和相对时间之间的互转
Calendar c8 = Calendar.getInstance();
long t = 1252785271098L;
//将Calendar对象转换为相对时间
long t1 = c8.getTimeInMillis();
//将相对时间转换为Calendar对象
Calendar c9 = Calendar.getInstance();
c9.setTimeInMillis(t1); |
在转换时,使用Calendar类中的getTimeInMillis方法可以将Calendar对象转换为相对时间。在将相对时间转换为Calendar对象时,首先创建一个Calendar对象,然后再使用Calendar类的setTimeInMillis方法设置时间即可。
应用示例
下面以两个简单的示例介绍时间和日期处理的基本使用。
1、计算两个日期之间相差的天数
例如计算2010年4月1号和2009年3月11号之间相差的天数,则可以使用时间和日期处理进行计算。
该程序实现的原理为:首先代表两个特定的时间点,这里使用Calendar的对象进行代表,然后将两个时间点转换为对应的相对时间,求两个时间点相对时间的差值,然后除以1天的毫秒数(24小时X60分钟X60秒X1000毫秒)即可获得对应的天数。实现该示例的完整代码如下:
import java.util.*;
/**
* 计算两个日期之间相差的天数
*/
public class DateExample1 {
public static void main(String[] args) {
//设置两个日期
//日期:2009年3月11号
Calendar c1 = Calendar.getInstance();
c1.set(2009, 3 - 1, 11);
//日期:2010年4月1号
Calendar c2 = Calendar.getInstance();
c2.set(2010, 4 - 1, 1);
//转换为相对时间
long t1 = c1.getTimeInMillis();
long t2 = c2.getTimeInMillis();
//计算天数
long days = (t2 - t1)/(24 * 60 * 60 * 1000);
System.out.println(days);
}
} |
2、输出当前月的月历
该示例的功能是输出当前系统时间所在月的日历,例如当前系统时间是2009年3月10日,则输出2009年3月的日历。
该程序实现的原理为:首先获得该月1号是星期几,然后获得该月的天数,最后使用流程控制实现按照日历的格式进行输出即可。即如果1号是星期一,则打印一个单位的空格,如果1号是星期二,则打印两个单位的空格,依次类推。打印完星期六的日期以后,进行换行。实现该示例的完整代码如下:
import java.util.*;
/**
* 输出当前月的日历
*/
public class DateExample2{
public static void main(String[] args){
//获得当前时间
Calendar c = Calendar.getInstance();
//设置代表的日期为1号
c.set(Calendar.DATE,1);
//获得1号是星期几
int start = c.get(Calendar.DAY_OF_WEEK);
//获得当前月的最大日期数
int maxDay = c.getActualMaximum(Calendar.DATE);
//输出标题
System.out.println("星期日 星期一 星期二 星期三 星期四 星期五 星期六");
//输出开始的空格
for(int i = 1;i < start;i++){
System.out.print(" ");
}
//输出该月中的所有日期
for(int i = 1;i <= maxDay;i++){
//输出日期数字
System.out.print(" " + i);
//输出分隔空格
System.out.print(" ");
if(i < 10){
System.out.print(' ');
}
//判断是否换行
if((start + i - 1) % 7 == 0){
System.out.println();
}
}
//换行
System.out.println();
}
} |
关于时间和日期的处理就介绍这么多,更多的实现方法还需要根据具体问题进行对应的实现。
摘要: 9.5.10 验收测试方案的“项目实施阶段”部分 “项目实施阶段”索引段落内容主要描述了项目实施各个阶段进入的标准、主要活动、交付物和退出标准。 示范性文档编写内容介绍如下。 6. 项目实施阶段 6.1 项目实施阶段描述 根据我方测试方法论和某单位的要求进行项目实施。 6.1.1 测试计划阶段 对整个测试工作做一个高层次规划...
阅读全文
这篇文章是继上一篇“windows性能监视器常用计数器”之后再次介绍关于windows操作系统中的性能监视器。这次我们从软件测试的性能测试角度去看windows提供的性能监视器。
性能计数器(counter)是描述服务器或操作系统性能的一些数据指标。计数器在性能测试中发挥着“监控和分析”的关键作用,尤其是在分析系统的可扩展 性、进行性能瓶颈的定位时,对计数器的取值的分析非常关键。但必须说明的是,单一的性能计数器只能体现系统性能的某一个方面,对性能测试结果的分析必须基于多个不同的计数器。
与性能计数器相关的另一个术语是“资源利用率”。该术语指的是系统各种资源的使用状况。为了方便比较,一般用“资源的实际使用/总的资源可用量”形成资源利用率的数据,用以进行各种资源使用的比较。
性能测试之内存篇(windows)
要监视内存不足的状况,请从以下的对象计数器开始:
· Memory\ Available Bytes
· Memory\ Pages/sec
Available Bytes剩余的可用物理内存,单位是兆字节(参考值:>;=10%)。表明进程当前可使用的内存字节数。Pages/sec 表明由于硬件页面错误而从磁盘取出的页面数,或由于页面错误而写入磁盘以释放工作集空间的页面数。
如果 Available Bytes 的值很小(4 MB 或更小),则说明计算机上总的内存可能不足,或某程序没有释放内存。如果 Pages/sec 的值为 20 或更大,那么您应该进一步研究页交换活动。Pages/sec 的值很大不一定表明内存有问题,而可能是运行使用内存映射文件的程序所致。
操作系统经常会利用磁盘交换的方式提高系统可用的内存量或是提高内存的使用效率。下列四个
指标直接反映了操作系统进行磁盘交换的频度。
Page Faults/sec
当处理器在内存中读取某一页出现错误时,就会产生缺页中断,也就是 page Fault。如果这个页
位于内存的其他位置,这种错误称为软错误,用Transition Fault/sec 来衡量;如果这个页位于硬盘上,必须从硬盘重新读取,这个错误成为硬错误。硬错误会使系统的运行效率很快将下来。Page Faults/sec这个计数器就表示每秒钟处理的错误页数,包括硬错误和软错误。
Page Input/sec
表示为了解决硬错误而写入硬盘的页数(参考值:>;=Page Reads/sec)
Page Reads/sec
表示为了解决硬错误而从硬盘上读取的页数。(参考值: <;=5)
Pages/sec
表示为了解决硬错误而从硬盘上读取或写入硬盘的页数(参考值:00~20)
必须同时监视 Available Bytes、Pages/sec 和 Paging File % Usage,以便确定是否发生这种情况。如果正在读取非缓存内存映射文件,还应该查看缓存活动是否正常。
Cathe Bytes
文件系统的缓存(默认为50%的可用物理内存)
内存泄露
· Memory\Available Bytes
· Memory\ Committed Bytes
如果您怀疑有内存泄露,请监视 Memory\Available Bytes 和 Memory\ Committed Bytes,以观察内存行为,并监视你认为可能在泄露内存的进程的 Process\ Private Bytes、Process\ Working Set 和Process\ Handle Count。如果您怀疑是内核模式进程导致了泄露,则还应该监视 Memory\ Pool Nonpaged Bytes、Memory\ Pool Nonpaged Allocs 和 Process(process_name)\ Pool Nonpaged Bytes。
private Bytes
进程无法与其他进程共享的字节数量。该计数器的值较大时,有可能是内存泄露的信号
检查过于频繁的页交换
由于过多的页交换要使用大量的硬盘空间,因此有可能将导致将页交换内存不足,这容易与导致页交换的磁盘瓶颈混淆。因此,在研究内存不足不太明显的页交换的原因时,您必须跟踪如下的磁盘使用情况计数器和内存计数器:
· Physical Disk\ % Disk Time
· Physical Disk\ Avg.Disk Queue Length
例如,包括 Page Reads/sec 和 % Disk Time 及 Avg.Disk Queue Length。如果页面读取操作速率很低,同时 % Disk Time 和 Avg.Disk Queue Length的值很高,则可能有磁盘瓶径。但是,如果队列长度增加的同时页面读取速率并未降低,则内存不足。
要确定过多的页交换对磁盘活动的影响,请将 Physical Disk\ Avg.Disk sec/Transfer 和 Memory\ Pages/sec 计数器的值增大数倍。如果这些计数器的计数结果超过了 0.1,那么页交换将花费百分之十以上的磁盘访问时间。如果长时间发生这种情况,那么您可能需要更多的内存。
研究程序的活动
接下来,检查正在运行的程序导致的过多的页交换。如果可能,请停 止具有最高工作集值的程序,然后查看页交换速率是否有显著变化。如果您怀疑存在过多的页交换,请检查 Memory\ Pages/sec 计数器。该计数器显示由于页面不在物理内存中而需要从磁盘读取的页面数。(注意该计数器与 Page Faults/sec 的区别,后者只表明数据不能在内存的指定工作集中立即使用。)
性能测试之处理器篇(windows)
监视“处理器”和“系统”对象计数器可以提供关于处理器使用的有价值的信息,帮助您决定是否存在瓶颈。需要包含下列内容:
Processor\ % Total Processor Time 获得处理器整体使用情况。
该计数值用于体现服务器整体的处理器利用率,对多处理器的系统而言,该计数值体现的是所有CPU的平均利用率。如果该值的数值持续超过90%,则说明整个系统面临着处理器方面的瓶颈,需要通过增加处理器来提高性能。
要注意的是,由于操作系统本身的特性,在某些多CPU系统中,该数据本身并不大,但此时CPU之间的负载状况极不均衡,此时也应该视作系统产生了处理器方面的瓶颈。
监视 Processor\ % Processor Time、Processor\ % User Time 和 % Privileged Time 以获得详细信息。
Processor\ % User Time是指系统的非核心操作消耗的CPU时间,如果该值较大,可以考虑是否通过优化算法等方法降低这个值。如果该服务器是数据库服务 器,Processor\ % User Time大的原因很可能是数据库的排序或是函数操作消耗了过多的CPU时间,此时可以考虑对数据库系统进行优化。
System\ Processor Queue Length 用于瓶颈检测。
%Total Processor Time
系统中所有处理器都处于繁忙状态的时间百分比,对于多处理器系统来说,该值可以反映所有处理器的平均繁忙状态,该值为100%,如果有一半的处理器为繁忙状态,该值为50%
File Data Operations/sec
计算机对文件系统进行读取和写入操作的频率,但是不包括文件控制操作
Process Queue Length
线程在等待分配CPU资源所排队列的长度,此长度不包括正在占有CPU资源的线程。如果该队列的长度大于处理器个数+1,就表示处理器有可能处于阻塞状态(参考值:<;=处理器个数+1)
%Processor Time
CPU利用率,该计数器最为常用,可以查看处理器是否处于饱和状态,如果该值持续超过 95%,就表示当前系统的瓶颈为CPU,可以考虑增加一个处理器或更换一个性能更好的处理器。(参考值:<;80%)
%Priviliaged Time
CPU在特权模式下处理线程所花的时间百分比。一般的系统服务,进城管理,内存管理等一些由操作系统自行启动的进程属于这类
%User Time
与%Privileged Time计数器正好相反,指的是在用户状态模式下(即非特权模式)的操作所花的时间百分比。如果该值较大,可以考虑是否通过算法优化等方法降低这个值。如果该服务器是数据库服务器,导致此值较大的原因很可能是数据库的排序或是函数操作消耗了过多的CPU时间,此时可以考虑对数据库系统进行优化。
%DPC Time
处理器在网络处理上消耗的时间,该值越低越好。在多处理器系统中,如果这个值大于50%并且%Processor Time非常高,加入一个网卡可能会提高性能。
观察处理器使用情况的值
要测量处理器的活动,请查看 Processor\ % Processor Time 计数器。该计数器显示处理器忙于执行非空闲线程所耗时间的百分比。
检查处理器使用时,请考虑计算机的角色和所完成工作的类型。根据计算机进行的工作,较高的处理器值意味着系统正有效地处理较重的工作负载或正在努力维持。例如,如果正在监视用户的计算机,并且该计算机用于计算,计算程序可能容易使用 100% 的处理器时间。即使这会造成该计算机中其他应用程序的性能受到影响,但可以通过改变负载来解决。
另一方面,在处理许多客户请求的服务器计算机中,100% 左右的值表示这些过程在队列中,正在等待处理器时间,并且造成瓶颈。如此持续高层次的处理器使用对服务器而言是无法接受的。
考察处理器瓶颈
进程的线程所需要的处理器周期超出可用周期时,处理器瓶颈将逐步显示出来。可以建立较长的处理器队列,并且系统响应会受到影响。处理器瓶颈两种常见的原因是 CPU 限制程序和产生过多中断的驱动程序或子系统组件。
要决定是否由于对处理器时间的要求较高而存在处理器瓶颈,请查看 System\ Processor Queue Length 计数器。队列中包含两个或更多的项目则表明存在瓶颈。如果多个程序进程竞争大多数处理器时间,安装更快速的处理器会提高吞吐量。如果正在运行多线程的进程,附加处理器会有所帮助,但是请注意,附加处理器可能只有有限的益处。
此外,跟踪计算机的服务器工作队列当前长度的 Server Work Queues\ Queue Length 计数器会显示出处理器瓶颈。队列长度持续大于 4 则表示可能出现处理器拥塞。此计数器是特定时间的值,而不是一段时间的平均值。
要决定中断活动是否造成瓶颈,请观察 Processor\ Interrupts/sec 计数器的值,该计数器测量来自输入/输出 (I/O) 设备的服务请求的速度。如果此计数器的值明显增加,而系统活动没有相应增加,则表明存在硬件问题。
也可以对生成中断的磁盘驱动器、网卡和其他设备活动的间接指示器监视 Processor\ % Interrupt Time 时间。
注意
要检测可能影响处理器性能的硬件问题,例如 IRQ 冲突,请观察 System\ File Control Bytes/second 的值。
监视多处理器系统
要观察多处理器计算机的效率,请使用下列附加计数器。
计数器
说明
Process\ % Processor Time
过程的所有线程在每个处理器上的处理器时间总和。
Processor(_Total)\ % Processor Time
计算机中所有处理器的处理器活动的度量。
“N[{y8_0此计数器采样间隔期间的所有处理器平均非空闲时间的总和,并用处理器数目除以该和。51Testing软件测试网
t#e_5I:N2y8@"a:X:Y
例如,如果所有处理器平均忙半个采样间隔,则显示 50%。如果半数处理器忙整个间隔,而其他的处理器空闲,则也显示 50%。
Thread\ % Processor Time
线程的处理器时间数
性能测试之磁盘篇(windows)
监测对象:PhysicalDisk
如果分析的计数器指标来自于数据库服务器、文件服务器或是流媒体服务器,磁盘I/O对这些系统来说更容易成为瓶颈。
每磁盘的I/O数可用来与磁盘的I/O能力进行对比,如果经过计算得到的每磁盘I/O数超过了磁盘标称的I/O能力,则说明确实存在磁盘的性能瓶颈。
下表给出了每磁盘I/O的计算公式:
RAID类型
计算方法
RAID0
(Reads+Writes)/Number of Disks
RAID1
(Reads+2*Writes)/2
RAID5
[Reads+(4*Writes)]/Number of Disks
RAID10
[Reads+(2*Writes)]/Number of Disks
%Disk Time
表示磁盘驱动器为读取或写入请求提供服务所用的时间百分比,如果只有%Disk Time比较大,硬盘有可能是瓶颈
Average Disk Queue Length
表示磁盘读取和写入请求提供服务所用的时间百分比,可以通过增加磁盘构造磁盘阵列来提高性能(<;=磁盘数的2倍)
Average Disk Read Queue Length
表示磁盘读取请求的平均数
Average Disk write Queue Length
表示磁盘写入请求的平均数
Average Disk sec/Read
磁盘中读取数据的平均时间,单位是s
Disk Bytes/sec 提供磁盘系统的吞吐率。
决定工作负载的平衡
要平衡网络服务器上的负载,需要了解服务器磁盘驱动器的繁忙程度。使用 Physical Disk\ % Disk Time 计数器,该计数器显示驱动器活动时间的百分比。如果 % Disk Time 较高(超过 90%),请检查 Physical Disk\ Current Disk Queue Length 计数器以查看正在等待磁盘访问的系统请求数量。等待 I/O 请求的数量应当保持在不大于组成物理磁盘的主轴数的 1.5 到 2 倍。
Average Disk sec/Transfer
磁盘中写入数据的平均时间,单位是s
计数器反映磁盘完成请求所用的时间。较高的值表明磁盘控制器由于失败而不断重试该磁盘。这些故障会增加平均磁盘传送时间。一般来说,定义该值小于15ms最为优异,介于15-30ms之间为良好,30-60ms之间为可以接受,超过60ms则需要考虑更换硬盘或硬盘的 RAID方式了
Average Disk Bytes/Transfer
值大于 20 KB 表示该磁盘驱动器通常运行良好;如果应用程序正在访问磁盘,则会产生较低的值。例如,随机访问磁盘的应用程序会增加平均 Disk sec/Transfer 时间,因为随机传送需要增加搜索时间。
性能测试之网络篇(windows)
监测对象:Network Interface
网络分析是一件技术含量很高的工作,在一般的组织中都有专门的网络管理人员进行网络分析,对测试工程师来说,如果怀疑网络是系统的瓶颈,可以要求网络仍有来写真进行网络方面的检测。
Network Interface\Bytes Total/sec为发送和接收字节的速率(包括帧字符在内)。可以通过该计数器的值判断网络连接速度是否是瓶颈,具体操作方法是用该计数器的值与目前的网络带宽进行比较。
Byte Total/sec
表示网络中接受和发送字节的速度,可以用该计数器来判断网络是否存在瓶颈(参考值:该计数器和网络带宽相除,<;50%)
性能测试之进程篇(windows)
查看进程的%Processor Time值
每个进程的%Processor Time反映进程所消耗的处理器时间。用不同进程所消耗的处理器时间进行对比,可以很容易的看出具体是哪个进程在性能测试过程中消耗了最多的处理器时间,从而可以据此针对应用进行优化。
查看每个进程产生的页面失效
可以用每个进程产生的页面失效(通过Process\Page Failures/sec计数器获得)和系统的页面失效(可通过Memory\Page Failures/sec计数器获得)的比值,来判断哪个进程产生了最多的失效页面,这个进程要么是需要大量内存的进程,要么是非常活跃的进程,可以对其进行中的分析。
了解进程的Process\Private Bytes
Process\Private Bytes是指进程所分配的无法与其他进程共享的当前字节数量。该计数器主要用拉判断进程在性能测试过程中有无内存泄漏。
例如:对于一个IIS之上的web应用,我们可以重点监控inetinfo进程的Private Bytes,如果在性能测试过程中,该进程的Private Bytes计数器值不断增加,或是性能测试停止后一段时间,该进程的Private Bytes仍然持续在高水平,则说明应用存在内存泄漏。
(备注:进程分析方法用到的计数器主要有:Process\%Processor Time、Page Failures/sec、Page Failures/sec、Private Bytes)
相关链接:
① 内存映射文件机制
内存映射文件是利用虚拟内存把文件映射到进程的地址空间中去,在此之后进程操作文件,就像操作进程空间里的地址一样了,省去了读和写I/O的时间。
比如使用memcpy等内存操作的函数。这种方法能够很好的应用在需要频繁处理一个文件或者是一个大文件的场合,这种方式处理IO效率比普通IO效率要高。
利用内存映射文件您可以认为操作系统已经为您把文件全部装入了内存,然后您只要移动文件指针进行读写即可了。这样您甚至不需要调用那些分配、释放内存块和文件输入/输出的API函数,另外您可以把这用作不同的进程之间共享数据的一种办法。运用内存映射文件实际上没有涉及实际的文件操作,它更象为每个进程保留一个看得见的内存空间。至于把内存映射文件当成进程间共享数据的办法来用,则要加倍小心,因为您不得不处理数据的同步问题,否则您的应用程序也许 很可能得到过时或错误的数据甚至崩溃。
内存映射文件本身还是有一些局限性的,譬如一旦您生成了一个内存映射文件,那么您在那个会话期间是不能够改变它的大小的。所以内存映射文件对于只读文件和不会影响其大小的文件操作是非常有用的。当然这并不意味着对于会引起改变其大小的文件操作就一定不能用内存影射文件的 方法,您可以事先估计操作后的文件的可能大小,然后生成这么大小一块的内存映射文件,然后文件的长度就可以增长到这么一个大小。我们的解释够多的了,接下来我们就看看实现的细节:
调用CreateFile打开您想要映射的文件。
调用CreateFileMapping,其中要求传入先前CreateFile返回的句柄,该函数生成一个建立在CreateFile函数创建的文件对象基础上的内存映射对象。
调用MapViewOfFile函数映射整个文件的一个区域或者整个文件到内存。该函数返回指向映射到内存的第一个字节的指针。
用该指针来读写文件。
调用UnmapViewOfFile来解除文件映射。
调用CloseHandle来关闭内存映射文件。注意必须传入内存映射文件的句柄。
调用CloseHandle来关闭文件。注意必须传入由CreateFile创建的文件的句柄。
虚拟化技术的应用可以帮助用户通过服务器整合,实现在同一台物理服务器上运行多个软件应用,甚至可以运行在不同的操作系统上,用更少的服务器获得更高的整体性能,提高计算机性能的利用率。伴随着用户对于服务器的整合需求的不断增多和处理器性能的不断提升,特别是多核时代到来后,虚拟化应用也逐渐从原有的大型机移植到了x86架构的服务器上。由于虚拟化技术拥有高效、节能、节省空间、省电等多种优势,无论是大型企业数据中心整合还是中小型企业的经济型服务器选型,虚拟化都在其中扮演着重要的角色。事实上,实施服务器虚拟化可以让客户获得更大的收益。虚拟化技术能够为公司节约大量的成本、降低系统管理成本、节约人力、提高老业务系统的性能,还降低新系统的开发部署成本。
可见,在商用环境中,已经有越来越多的客户选择了英特尔多核技术的服务器,并且已经开始广泛采用虚拟化技术来降低数据中心整合的成本。然而,在选择实现最佳运作的服务器平台的时候,特别是虚拟化的应用层面比较上,至今没有统一的计算标准来衡量和反映虚拟化所带来的性能提升和IT基础建设整体拥有成本(TCO)的改善。
然而,虚拟化的发展离不开虚拟化性能基准测试的完善。因为,目前许多企业的IT管理人员还只是停留在学习阶段,有些人对虚拟化一无所知,因此,基准评测的建立可以帮助用户更好地了解虚拟化。“通过基准评测,用户在采购过程中可以更好地进行比较,从而降低采购风险,这实际上也会促进虚拟化市场的发展。”
目前,IBM、Intel、VMware等相关厂商都对虚拟化性能测试基准的发展表示非常关注,并且都采取了相应的措施。Intel在2006年年底与IBM合作,共同推出了vConsolidate,VMware也在最近退出了VMmark。我们认为两者在大的目标和设计理念方面是非常相似的。细节方面,两个测试在各个虚拟机的负载选择方面有所不同。由于虚拟化是一个非常新的领域,在测试基准方面以前一直是一个空白。
vConsolidate评测工具通过真实地模拟典型虚拟化部署环境中的负载来达到测试服务器虚拟化性能的目的。vConsolidate是一项整合性能指标评测,包括四个同时运行的不同性能指标评测。其中包含面向数据库、Web、Java和邮件的性能指标评测组件。
vConsolidate是一项整合性能指标评测,包括四个同时运行的不同性能指标评测。其中包含面向数据库、Web、Java和邮件的性能指标评测组件。由于该评测面向虚拟环境,因而每个组件均在其自己单独的虚拟机和操作系统中运行。除了上述四个性能指标评测组件之外,还有第五台虚拟机未运行性能指标评测,由此来模拟闲置的VM。这五台虚拟机构成了一个整合堆栈单元(CSU)。
vConsolidate堆栈的构建模块包括五台不同的虚拟机(数据库、Web、邮件、Java和闲置)。为了运行单个的整合堆栈单元,需要将三台客户机与被测服务器(SUT)相连接。其中两台客户机生成负载(一个用于Web,另一个用于邮件),第三台客户机来控制运行环境。Java和数据库组件具有低消耗的独立驱动程序,不需要运行外部客户机。注意,随着更多CSU的增加,所需的客户机将以“三个”为单位递增。
vConsolidate所用的四个组件工作负载分别为:Sysbench(数据库)、WebBench*(Web)、LoadSim(邮件)和Specjbb2005*(Java)。工作负载的存储跨整个测试配置进行分布。Web客户机包含WebBench客户机程序。邮件客户机包含:Microsoft Outlook、LoadSim和WebBench控制器程序。服务器包含虚拟化软件,在此为VMware ESX Server。单个VM包含各自的工作负载。这些VM文件可以本地存储到服务器上,或者如同我们的配置一样存储到外部存储域网络上。
作为虚拟化技术的测试基准系统,VMmark的诞生也是为了帮助用户在解决:“当前的服务器硬件上,可以划分几个虚拟机?”等问题。通过VMmark,服务器供应商就可以公布出每台服务器的得分,进而得出每台服务器所能支持的最大工作负载数,也就是这台服务器上的虚拟机的总体性能,这可以帮助用户决定他们需要多大的服务器硬件来运行他们当前的企业级工作负载。
作为虚拟化技术的测试基准系统,VMmark目前包括六种主要的工作负载:文件服务器、邮件服务器、Web服务器、备用服务器、OLTP数据库和Java顺序登录系统。这些应用当中,一半运行在Windows上,另一半运行在Linux上。这六个工作负载的表现被VMware称为“砖瓦(tile)”。最终的得分就取决于机器最终能够运行多少块砖瓦。“不幸的是,尽管我们能够非常简单地在VMmark系统当中加入例如Exchange电子邮件服务器以及其他Windows上的工作负载,但因为微软公司的许可限制,VMmark当中并没有包括这些非常常见的应用。”戴尔公司和Sun公司的公布了基于beta版VMmark的基准测试值,但VMware公司是与IBM、惠普、富士通-西门子以及其他硬件供应商在VMmark上合作。
而SPEC(Standard Performance Evaluation Corp.标准性能评估机构)也在去年成立了一个工作组,讨论是否需要针对虚拟化应用建立基准评测。如果需要,预计三个月后就能提供全新的评测方法和指标体系。
SPEC是一个全球性的、权威的第三方非赢利性组织,旨在联合许多高科技领域的顶尖级企业共同建立公平的标准,以评测各种技术的性能。目前,SPEC已经推出一系列针对服务器、软件应用、高性能计算系统的基准评测。
目前,WEB服务器、EMAIL服务器或数据库应用都有着各自不同的基准评测。但是,如果这些应用同时在一台虚拟服务器上跑,基准评测的程序和方法就要重新考虑和设计。而SPEC所要做的事情就是集合英特尔、AMD、富士通西门子、Vmware和其他主要厂商的代表和一些最终用户来共同建立一套简单、高效的度量标准,来量化评价虚拟服务器系统,以便作为用户做虚拟化解决方案选型的依据。
那么,基准是如何测量虚拟化的,它看起来什么样子?SPEC主席Walter Bays给出了如下答案。
基准如何测量一个服务器在虚拟化上表现得有多好?
Walter Bays:有一些东西是我们努力要找出来的。在这个基准中,每个人关心的内容都不一样,不论是终端用户还是会员,因为你可以从硬件为中心的视角出发,了解你感兴趣的那些地方,例如当有人在虚拟化环境中进行操作的时候,什么是最好的处理方法。然后你就看到软件公司力图从这个出发点开始竞争。你有一个独特的服务器;那么对于它来说什么是最好的虚拟化软件?
那是否意味着会有多个虚拟化基准呢?
Bays:我想很可能是同一个基准,但是正如看到的结果,你可以辨别它们是针对软件或者是硬件的性能。我期望它的工作方式就像SPECjAppServer基准。你可以看到硬件公司有他们自己的软件进行测试,但是他们也有第三方的测试软件。然后你还会看到软件公司也会基于某个范围的硬件产品进行测试。
希望就是,如果你同时有硬件供应商和软件供应商都想展示一下他们在一定范围的配置下能够做什么,那么终端用户就会得到他们真正需要的底线信息。
中国软件测试专家访谈录(1)
把握软件的质量
蔡:如何把握软件产品的质量?
郑:不管软件产品规模是大还是小,结构是简单还是复杂,对它们质量的评估都不是一件容易的事情。尽管很难,但是产品质量的评估仍然是必需的,因为它也涉及软件版本是否能够发布。
软件发布之前做评估
根据我和公司内的实践经验,可以从下面两个方面进行评估。
第一,软件产品发布之前的质量评估,具体的度量指标包括:
缺陷,包括发现的总的缺陷分布趋势、缺陷在不同功能模块中的分布等。例如,总的缺陷分布趋势图。
测试通过率,主要包括计划的测试用例执行进度、通过的测试用例数目、失败的测试用例数目、被阻塞的测试用例数目等。我们项目中定义的测试通过率是95%。
测试覆盖率,包括测试对系统需求的覆盖率、对测试类型的覆盖率。例如,我们项目中定义的需求覆盖率必须达到100%,测试类型覆盖率也必须达到100%。
信心,负责这个模块的测试人员对质量的主观感受。可能有的人觉得很奇怪,怎么主观感受也可以作为产品质量的评估?因为负责功能模块测试的工程师是最了解他们的测试对象的。
旁观者说:可以设计一个信心指数,例如1~10,然后通过各种数据来支持这个指数。
软件发布之后做评估
第二,软件产品发布之后的质量评估。我们目前采用的度量指标是缺陷检测百分比DDP(Defect Detected Percentage),其计算公式如下:
客户现场发现的缺陷数 /(发布前测试团队发现的缺陷数 + 客户现场发现的缺陷数)* 100%
我们一般统计产品发布之后6个月内在客户现场发现的缺陷数。不同的公司与项目,采用的统计时间范围会有所不同。
旁观者说:统计客户发现的bug是有意义的,一是可以据此对客户做一些分析,例如,经常使用的功能、满意度等;二是可以用于反思之前的测试活动,以求改进。
测试团队为软件发布提供质量信息
还有一个问题是测试团队非常关心的:谁来决定软件产品的发布?从我的角度而言,我认为由测试团队决定软件产品是否发布是不合适的。
软件产品是否可以发布,需要有不同角色的成员参与进来,根据公司定义的判定准则进行评估,同时平衡产品质量、市场机会、产品战略以及成本等多个因素。测试团队在这个过程中主要的作用是尽量多地提供软件产品的质量信息、风险信息等,以帮助管理层做出是否发布的决定。任何一个单方面做决定都可能是不全面的。例如,测试人员觉得质量还不够好,发布有风险;但是市场机会要求我们发布,如果再等一段时间就会减弱市场机会,甚至丧失机会,这个时候就需要考虑哪个因素有更高的优先级。
旁观者说:赞同。软件发布与否应当综合各种因素来考虑,而不仅仅是某个角色说了算。
新人如何学习软件测试
蔡:对于软件测试的新手,包括刚进入这个行业的,也包括正在学习、准备进入的,你有什么建议和经验分享?
郑:对于软件测试的新手,假如希望在测试行业有所发展,根据我的经验可以从下面几个方面入手。
1、了解你的测试对象。你首先要知道软件产品是干什么的,其实现的主要功能是什么,其工作的基本原理和流程等。比如,我一直从事通信产品,除了产品本身的需求资料外,还花了大量的时间学习和钻研各种通信产品相关的国际标准和行业标准,例如路由协议、IPv6等。
2、多向有经验的人学习。在刚刚入门测试行业的时候,我们应该抱着向各位前辈学习的态度,通过各种形式向有经验的人员学习,例如,参加培训、个人交流等。根据测试的特点,学习主要从两个方面入手。
(1)我们应该积极参加项目团队中的领域知识培训和交流,也可以直接向系统人员和开发人员询问产品是如何工作的,具体如何实现等问题,以更快地熟悉和掌握产品知识。
(2)测试人员向测试团队中的前辈学习,包括他们在产品知识、测试过程、测试技术与方法等方面的经验。他们是测试新人学习的最直接的对象,看看他们是如何掌握产品知识的,如何快速有效地找到bug的。
3、多实践,不要怕失败。不管是测试领域的知识,还是测试技能,或者是测试思想和方法,测试新人都需要勇敢地去实践,许多经验、思想和收获来自于失败的经验教训。
旁观者说:如果真是要丢脸的话,越早越好,越晚越被动。
4、勤奋。在我的经验中,勤奋总是占有非常重要的地位。只要你设定的方向是正确的,想要达到目标,勤奋将是不可或缺的基础。特别是觉得自己在某方面基础不好,勤奋可以弥补这方面的不足,我当时入门软件测试就是这么走过来的。你看到有的人很牛,测试经验丰富,各方面都懂,那是表象,其实他(她)在背后花了很多时间,你在玩游戏、看电视的时候,他(她)在看书、总结、写文章。如果我们能够坚持,每天坚持,这样一段时间后你就会发现自己与以前大不相同了。
旁观者说:我很相信一句话:天道酬勤。
如何面对职业发展的迷茫
蔡:你对在软件测试行业工作了三五年的朋友有什么建议吗?有的朋友对我说,他觉得有些迷茫。
问自己三个问题
郑:在软件测试行业工作几年之后,免不了会产生各种不同的迷茫:软件测试有前途吗?软件测试有技术含量吗?将来是做技术还是做管理?我自己在2005年准备换工作的时候,就对是做技术呢,还是去找测试管理的职位有过迷茫。尽管现在已经选择技术方向很多年了,有时候还是会迷茫:测试技术真的能顺利走下去吗?
在面对这些迷茫的时候,我就会问自己:
(1)你喜欢做技术还是做管理?我喜欢做技术。
(2)你的目标是什么?我希望将来成为测试专家。
(3)目前的工作和活动能帮助你达成这个目标吗?是的。
旁观者说:简单直接的三个问题,就像程咬金的三板斧,蛮有威力的,你可以试试。
基于这些问题的内心回答,我会不断给自己加油,并鼓励自己继续往前走。我几乎每天都会反省自己当天的工作,有了哪些收获,有了什么总结,多少时间又被浪费了等。通过这样的形式,不断提升自己的信心,提高学习的效率和有效性。
旁观者说:能够做到每天反省和总结,不简单,值得学习。孔子说,吾三省吾身。或许可以这样说,无论做什么事情,比如锻炼、减肥、写日记、练字、学习等,如果能够坚持每天做,都了不起。
分享周围几个朋友在职业发展方面的例子
我与大家分享一下我对下面几个迷茫问题的建议。
1、到底是做技术还是做管理工作?希望读者可以从我前面的工作经历中得到一些启发:做自己喜欢做的事情,勤奋加坚持,你会发现你可以逐步走向成功,不管是做技术还是做管理。
2、软件测试有前途吗?这个问题应该是每个测试从业人员所关心的话题。假如大家因为这个问题而觉得迷茫,我和大家分享我周围几个朋友的例子,测试同样可以成就你的未来。
(1)以前公司的某个测试部门经理,现在是某公司重庆研究所的所长。测试的职业发展也可以是有高度的,而不是说测试经理就是测试人员的终极目标。
(2)以前公司的某位测试工程师,在2005年换工作的时候,找到的职位是产品经理。测试人员的优势是对软件产品的工作原理、工作环境与客户最关注什么等有充分的了解,因此产品经理是你可以努力的一个方向。
(3)以前公司的某位测试工程师,首先从事测试工作,在换工作的时候应聘了软件开发的工作,在第二次跳槽的时候选择了项目经理的职位。由于有明确的职业规划,在对测试与开发有了深入了解之后,再加上项目管理的知识、技能与经验,测试人员成为项目经理是可以的。
(4)另外,在我们周围有不少独立的测试专家、咨询师等,他们不断出书、写文章,参加各种大会做报告,受邀为公司开展企业咨询工作等,这同样是你可以选择的一条路。
旁观者说:他山之石,可以攻玉。上面几个例子虽然简单,但是仍有可借鉴的地方。
要懂得如何思考和分析
3、软件测试有技术含量吗?很多人都认为软件开发有技术含量,而软件测试就是点点鼠标,按照需求检查工作产品,所以没有什么技术含量。实际情况是这样吗?这让我想起了一个故事:某公司的发电机出现了故障,请了一位经验丰富的工程师进行维修,他在机器上东敲敲、西敲敲,在某个地方画了一个圈,将其中的一个线圈换掉后发电机就正常工作了。收取了1000美元的费用。公司老总觉得费用太贵,不就是换了一个线圈吗?维修工程师回答说:“换个线圈只要1美元,找到哪里的线圈更换需要999美元。”很多人只是看到了表象,测试人员坐在那里点点鼠标,提交了一个缺陷。但是技术含量不是测试人员点点鼠标,而是测试人员为什么点鼠标,鼠标点在哪里,要点几次,即测试人员是如何思考的、如何分析的。这才是人与人之间的最大不同,也是测试人员真正的价值所在。优秀的测试人员与平庸的测试人员之间的最大区别在于前者更懂得如何思考和分析。
旁观者说:努力成为专家型的人才,符合个人利益,也符合公司利益,双赢。
如何做好测试用例的设计
蔡:如何做好测试用例的设计呢?
郑:测试用例设计是每个测试从业人员最主要的测试活动之一。为了做好测试用例的设计,我们必须考虑下面几个因素。
明确参考输入
第一,做好测试用例设计,需要首先明确它有哪些参考输入。以我为例,我是做系统测试的,因此测试对象的需求规格说明是最主要的测试设计参考。但是实际面临的问题是需求常常不完善,因此纯粹依赖于需求规格说明肯定是不全面的。根据我的经验,下面的这些输入也应该经常考虑:用户需求、开发文档、标准与规范、测试经验知识库等。
测试经验知识库是测试人员以前做类似项目的测试经验、收集与分析的缺陷类型分类等,都是开展测试用例设计的基础。例如,我们的测试用例模板中的测试类型定义,除了参考ISO 9126质量模型 ,其中的重要输入就是以前项目的测试经验和缺陷分类分析。
旁观者说:有多少公司收集和存储了项目的历史数据?又是否做了分析和利用?
关注功能之间的交互
第二,做好测试用例设计,除了考虑被测对象功能之外,也需要关注被测功能与其他功能模块之间的交互。由于每个测试人员负责各自的功能模块,往往会导致整个测试对象不同功能模块之间的接口、相互作用和耦合等分析不够充分,而这些是影响测试对象质量的重要因素。例如,在我们当前的项目中,通用的交互测试点有主备倒换、内存使用、内存泄漏、CPU使用、数据备份/恢复、版本升级、系统重启等。
旁观者说:相对于开发人员来说,功能交互是测试人员的优势,我们要在这方面好好发挥。
采用合适的设计技术与方法
第三,有了测试用例设计的输入与交互分析之后,采用合适的测试用例设计技术与方法,有助于做好测试用例的分析。根据《软件测试设计》中提出的“问题驱动的软件测试设计”观点,可以从下面四个方面考虑进行测试设计,以解决测试设计中面临的问题。
1、挑战1:被测对象的逻辑组合和输入数据的组合是非常庞大的,而穷尽测试是不可能的。经典测试设计中的一些技术与方法,在保证测试覆盖率与质量的情况下,对减少测试用例的数目是非常有效的。例如,在项目测试中引入了“组合测试”技术。
2、挑战2:软件产品的不同利益相关者对产品的质量要求是不一样的,如何满足他们各自的质量要求?基于质量特性的测试设计有助于我们选择合适的质量特性。测试设计中要求100%的测试类型覆盖率,可以更好地满足不同利益相关者对质量的不同要求。
3、挑战3:测试时间与资源总是非常有限的,如何平衡测试时间、成本与质量之间的关系是每个测试人员都需要考虑的。基于风险的测试设计可以帮助我们有效地解决这个问题。例如,先给模块确定测试优先级,然后分析每个模块存在的主要风险,并按照不同风险级别开展测试设计活动,以尽快尽早发现严重程度高的缺陷。
4、挑战4:测试人员面对的需求经常是不完善的、经常变更的。除了前面提到的完善测试用例设计的参考输入之外,基于经验的测试设计也可以帮助测试人员在这种情况下做得更好。例如,根据以前发现的缺陷和用户现场反馈的缺陷,进行缺陷分类分析和评估。另一个策略是更多地采用探索性测试,更好地发挥测试人员的主观能动性与分析能力。
做好评审
第四,在测试用例设计过程中,发挥团队的力量分析和评审测试点,其得到的效率和有效性会更好。例如,通过在测试分析与设计过程中应用思维导图 工具,帮助我们拓宽测试思路,增加测试条目。测试团队的放射性思维可以很好地帮助我们提升测试用例设计的效率和有效性。
测试用例的颗粒度没有严格的标准,我的观点是只要它们满足测试目的,符合产品特点、开发特点和测试过程等要求,有助于我们更好地发现缺陷和开展测试活动,测试用例的颗粒度就是合适的。
如何做好测试用例的评审
蔡:测试用例的评审一直是个问题。如何做好评审呢?
郑:测试用例是测试人员最重要的输出之一,也是后续开展测试执行与评估的基础。评审应该是开发过程中比较有争议的关键域,现实中存在矛盾:不做评审,这又是一个强制活动;开展评审吧,效果很一般,甚至得不到有用的评审建议,浪费时间。
结合我自己在评审方面的经验教训,做好测试用例的评审,下面是我的几个建议。
合适的评审团人选
第一,选择合适的人参与测试用例评审。例如,我们在做测试用例评审的时候,强制参与的评审人员有该功能的系统人员(他定义具体的需求)、开发人员以及测试架构师等。每个人参与测试用例评审的关注点是不一样的,例如,测试架构师关注测试类型的覆盖率方面,而开发人员和系统人员关注测试用例是否覆盖业务场景与不同功能模块之间的交互等。另外,语法、拼写、排版等方面的问题应该关注,但不应该是评审的重点。
管理层的支持
第二,管理层的支持。有效的评审是需要时间与资源的。例如,在我们公司的火车开发模型下,针对测试用例的评审是强制的,而且定义了评审的入口准则与出口准则;而且在做项目计划的时候,测试用例评审作为一个重要的活动,也相应地进行了工作量的估算和时间进度安排,这些都需要管理层的支持。
做好准备
第三,评审人员的准备,这是有效评审的关键所在。例如,我们针对测试用例的评审,定义了评审检查表,包括:测试类型覆盖、系统需求覆盖、测试用例模板符合程度检查等,这有助于有效开展测试用例的评审,也可以集中评审的重点。
旁观者说:即使我们要求不了别人,至少可以要求自己,评审前做些准备。
宣传评审的价值
第四,让更多的人明白测试尽早介入(评审)的意义。很多时候,大家不愿意积极参与评审,除了时间和资源方面的原因,主要是大家对评审的优点没有直观的感觉和定量的数据。例如,提高质量、降低成本、加快进度与过程改进等。只有认可了这些优点,大家参与评审才能更加自觉、有效。
我举一个写作的例子。我与马均飞在写作《软件测试管理》与《软件测试设计》过程中,对书稿进行交叉评审。评审过程中的讨论与交流,不仅使得我们对写作内容有更多的理解并达成一致,而且可以使内容更加全面、完善。评审取得成功的主要因素包括:选择合适的评审人员、每个人准备充分、时间与资源有保证,特别是认识到评审对作品(产品)的重要意义!
(未完待续)
测试用例优先级
在有限的测试资源和时间的情况下,尽早尽快在测试对象查找出尽可能多的缺陷很大程度上是由如何制定测试用例优先级决定的,因此测试用例优先级在一个测试项目中至关重要。
一 测试优先级的划分
1.测试时间和资源有限,可能无法执行所有的测试用例,穷尽测试是不可能的。
2.首先执行最重要的测试用例,尽早尽快的发现尽可能多的缺陷,或者优先测试用户最需要的功能
3.测试用例优先级的划分和测试执行顺序的确定,取决于项目的特征,应用领域和客户的要求。
4.即使测试过早结束,也能保证在该时刻测试工作能达到最好的效果。
5.最重要的测试用将首先被执行,这样可以保证尽早发现最重要的问题。
二 测试优先级划分准则
1.使用频率或失效的概率:
系统的某些特定的被经常使用的功能优先级更高(若该功能包含了故障,其在被频繁使用而导致的概率将会很高,故该功能的用例具有更高的优先级)。
2.失效的风险
高风险失效的用例应该比低风险失效的用例具有更高的优先级(用户或客户在使用时,高风险失效导致的后果和造成的损失将更加严重)。
3.失效的可见性
失效对用户的可见性,是划分测试优先级的更进一步准则(尤其在交互系统中,用户可减的失效,例如:界面错误,会导致用户对产品的极度不信任)。
4.需求的优先级
系统对使用的用户来说,各个功能的重要性不同,某些不重要的功能对用户来说缺失该功能是致命的,但是有些功能,即使缺失,用户也是可以接受的。
5.质量特性
质量特性对用户也有不同的重要性,因此验证与重要质量特性是否一致的用例具有更高的优先级。
6.开发人员角度
能够导致系统或组件崩溃的测试用例具有更高的优先级。
7.测试对象的复杂性
复杂的程序的组件需要加强测试,因为开发人员可能在该位置引入更多的缺陷;但不是说简单的程序组件就可以忽视,该部分缺陷往往由于开发人员的粗心导致。
8.高项目风险的失效
存在高项目风险的缺陷应该尽早被发现(该类失效会导致大量的修正工作,并导致项目时间的明显延迟)。
9.缺陷的集群效应
在先前发现缺陷的位置可能会存在更多的缺陷。
三 划分测试优先级的优点
1.为每个测试用例划分测试优先级,在有限的时间和测试资源条件下,可以首先执行测试优先级高的用例,从而达到成本,质量的平衡。
2.根据前面版本测试的缺陷分布的情况,合理制定优先级策略,可以高效分配测试资源。
关于,selenium 命令这一部分,为了便于像我一样的菜鸟理解,我采用通过例子讲命令的方式。边学边总结吧!相互学习。呵呵。
菜鸟Selenium 命令通常被称为selenese,有一系列运行测试案例所需的命令构成。
----// Actions
----// Actions
Actions描述了用户所会作出的操作。
Action 有两种形式: action和actionAndWait, action会立即执行,而actionAndWait会假设需要较长时间才能得到该action的相响,而作出等待,open则是会自动处理等待时间。
================= 例1 ================================================

操作说明:
打开谷歌首页,输入“selenium 环境配置”字段,点击“搜索”按钮。
命令说明:
open
open(url)
- 在浏览器中打开URL,可以接受相对和绝对路径两种形式
- 注意:该URL必须在与浏览器相同的安全限定范围之内
Highlight(locator)
- 暂时将指定元素的背景色改变为黄色,有利于调试。
pause
pause(millisenconds)
- 根据指定时间暂停Selenium脚本执行
- 常用在调试脚本或等待服务器段响应时
type
type(inputLocator, value)
- 模拟人手的输入过程,往指定的input中输入值
- 也适合给复选和单选框赋值
click
click(elementLocator)
- 点击连接,按钮,复选和单选框
- 如果点击后需要等待响应,则用"clickAndWait"
- 如果是需要经过JavaScript的alert或confirm对话框后才能继续操作,则需要调用verify或assert来告诉Selenium你期望对对话框进行什么操作。
goBack()
模拟点击浏览器的后退按钮
close()
模拟点击浏览器关闭按钮
=============== 例2 =======================================
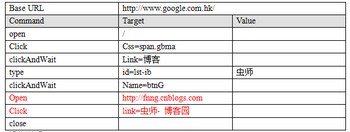
操作说明:
打开谷歌搜索首页,在左上边的选项中选择“更多”,在下拉列表中选择“博客”,然后在搜索栏内输入“虫师”,点击搜索按钮,然后打开我的博客(通过我url的方式)
命令说明:
其实本例中并没有出现新命令,但有一个问题。在搜索的结果中,标红的两行作用是一样的,都能打开我的博客。
click通过页面的字符匹配,点击链接,但打开的新窗口中只有地址栏;用click的方式,如果页面发生变动,没匹配到我想到我输入的关键字,页脚本就会失败。
open直接通过链接跳转,但又失去了前面搜索操作的意义。-----当然,这里只是把它作为一个问题提出来。真实项目中,可能我们是不会遇到这种情况的。
用兴趣的话将上面的例子验证一下,算是对第一个例子的理解和加强吧!
=============== 例3 =======================================
这个例子录制的是开心网的注册页面,这不是一个完整的注册,因为最后一项要求输入验证码。所以,就算录制完成,也无法正常回放,这里只是为了讲解几个命令。(*^__^*) 嘻嘻……
可能通过上面的表格,你依然觉得不够直观。那么,看看下面的截图呢!?

相信截图还是很清晰的说,那就根据上面的截图讲解了。。
操作说明:
打开开心网注册页面, 填写email地址,输入密码,重复密码,输入姓名,选择性别(男女)选择出生年、月、日,选择权限(都谁可以访问我的页面)
命令说明:
select
select(dropDownLocator, optionSpecifier)
- 根据optionSpecifier选项选择器来选择一个下拉菜单选项
- 如果有多于一个选择器的时候,如在用通配符模式,如"f*b*",或者超过一个选项有相同的文本或值,则会选择第一个匹配到的值
陌生的命令就这一个啦,关于命令target部分(就是id=...),我们可以通过firefox的插件firebug工具,进行查看页面元素,前面有讲解,这里就不多说了。
下面的命令我还没有找到合适的例子做演示,所以,先罗列出来,有时间在做演示。
·fireEvent
fireEvent(elementLocatore,evenName)
模拟页面元素事件被激活的处理动作
| fireEvent | textField | focus |
| fireEvent | dropDown | blur |
·waitForCondition
waitForCondition(JavaScriptSnippet,time)
- 在限定时间内,等待一段JavaScript代码返回true值,超时则停止等待
| waitForCondition | var value="/selenium.getText(""foo"); value.match(/bar/); | 3000 |
·waitForValue
waitForValue(inputLocator, value)
- 等待某input(如hidden input)被赋予某值,
- 会轮流检测该值,所以要注意如果该值长时间一直不赋予该input该值的话,可能会导致阻塞
| waitForValue | finishIndication | isfinished |
| | | |
·store,stroreValue
store(valueToStore, variablename)
保存一个值到变量里。
该值可以由自其他变量组合而成或通过JavaScript表达式赋值给变量
把指定的input中的值保存到变量中
| storeValue | userName | userID |
| type | userName | $.{userID} |
·storeText, storeAttribute
storeText(elementLocator, variablename)
把指定元素的文本值赋予给变量
| storeText | currentDate | expectedStartDate |
| verifyValue | startDate | $.{expectedStartDate} |
·storeAttribute(.{}elementLocator@attributeName,variableName.{})
把指定元素的属性的值赋予给变量
| storeAttribute | input1@class | classOfInput1 |
| verifyAttribute | input2@class | $.{classOfInput1} |
·chooseCancel.., answer..
chooseCancelOnNextConfirmation()
- 当下次JavaScript弹出confirm对话框的时候,让selenium选择Cancel
- 如果没有该命令时,遇到confirm对话框Selenium默认返回true,如手动选择OK按钮一样
| chooseCancelOnNextConfirmation | | |
- 如果已经运行过该命令,当下一次又有confirm对话框出现时,也会同样地再次选择Cancel
- 在下次JavaScript弹出prompt提示框时,赋予其anweerString的值,并选择确定
answerOnNextPrompt Kangaroo
| answerOnNextPrompt | Kangaroo | |
关于selenium 命令,这一部分,我学的比较仔细,所以,也想讲的仔细点。关于后面,还会说到:
* 验证页面元素
* 定位页面元素
* 文字范本匹配
相关文章:
菜鸟学自动化测试(一)----selenium IDE
菜鸟学自动化测试(二)----selenium IDE 功能扩展
在Linux系统下,写的应用程序,每次重新启动时,经常会有启动不成功的情况,困惑了好久。
后来在网上搜索到一篇文章,试了一下,问题解决了。原来的脚本是用kill -9 命令来杀死java应用进程,-9比较暴力,会造成资源释放不掉的问题。根据文章提示,修改为 -15,问题解决
在linux/unix下,你会怎么中止一个java应用或进程?
多数人可能会回答 kill -9 pid,这是一种在多数情况下正确的做法。不过本文打算阐述使用kill -9带来的一些问题,并给出另一种标准的kill方式。
标准中断信号
在Linux信号机制中,存在多种进程中断信号(Linux信号列表 )。其中比较典型的有 SIGNKILL(9) 和 SIGNTERM(15).
SIGNKILL(9) 和 SIGNTERM(15) 的区别在于:
SIGNKILL(9) 的效果是立即杀死进程. 该信号不能被阻塞, 处理和忽略。
SIGNTERM(15) 的效果是正常退出进程,退出前可以被阻塞或回调处理。并且它是Linux缺省的程序中断信号。
由此可见,SIGNTERM(15) 才是理论上标准的kill进程信号。
那使用 SIGNKILL(9) 又有什么错呢?
SIGNKILL(9) 带来的问题
先看一段程序
Java代码
/**
* Shutdown Hook Presentation
*
*/
public class ShutdownHookTest {
private static final void shutdownCallback() {
System.out.println("Shutdown callback is invoked.");
}
public static void main(String[] args) throws InterruptedException {
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
shutdownCallback();
}
});
Thread.sleep(10000);
}
}
/**
* Shutdown Hook Presentation
*
*/
public class ShutdownHookTest {
private static final void shutdownCallback() {
System.out.println("Shutdown callback is invoked.");
}
public static void main(String[] args) throws InterruptedException {
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
shutdownCallback();
}
});
Thread.sleep(10000);
}
} |
在上面这段程序中,我使用Runtime为当前java进程添加了一个ShutdownHook,它的作用是在java正常退出时,执行shutdownCallback()这个回调方法。 此时,如果你试验过在java进程未自动退出前,执行 kill -9 pid,即发送 SIGNKILL 信号,会发现这个回调接口是不会被执行的。这是SIGNKILL信号起的作用。
对于我这个简单的测试用例来说,不被执行也无大碍。但是,如果你的真实系统中有需要在java进程退出后,释放某些资源。
而这个释放动作,因为SIGNKILL被忽略了,那就可能造成一些问题。
所以,推荐大家使用标准的kill进程方式,即 kill -15 pid。
如何查看Linux操作系统版本? 1. 查看内核版本命令:
chen@mylinuxserver:~> cat /proc/version
Linux version 2.6.5-7.244-smp (geeko@buildhost) (gcc version 3.3.3 (SuSE Linux)) #1 SMP Mon Dec 12 18:32:25 UTC 2005 |
/proc 目录的作用?
chen@mylinuxserver:/proc> uname -a
Linux mylinuxserver 2.6.5-7.244-smp #1 SMP Mon Dec 12 18:32:25 UTC 2005 i686 i686 i386 GNU/Linux
chen@mylinuxserver:/proc> uname -r
2.6.5-7.244-smp |
uname命令的作用?
2. 查看Linux版本:
1) 登录到服务器执行 lsb_release -a ,即可列出所有版本信息,例如:
chen@mylinuxserver:/proc> lsb_release -a
LSB Version: core-2.0-noarch:core-3.0-noarch:core-2.0-ia32:core-3.0-ia32:graphics-2.0-ia32:graphics-2.0-noarch:graphics-3.0-ia32:graphics-3.0-noarch
Distributor ID: SUSE LINUX
Description: SUSE LINUX Enterprise Server 9 (i586)
Release: 9
Codename: n/a |
注:这个命令适用于所有的linux,包括Redhat、SuSE、Debian等发行版。
2) 登录到linux执行cat /etc/issue,例如如下:
chen@mylinuxserver:/proc> cat /etc/issue
Welcome to SUSE LINUX Enterprise Server 9 (i586) - Kernel \r (\l). |
3) 登录到linux执行cat /etc/redhat-release ,例如如下:
chen@mylinuxserver:/proc> cat /etc/*release*
LSB_VERSION="core-2.0-noarch:core-3.0-noarch:core-2.0-ia32:core-3.0-ia32"
cat: /etc/lsb-release.d: 是一个目录
SUSE LINUX Enterprise Server 9 (i586)
VERSION = 9
PATCHLEVEL = 3 |
今天给大家介绍一个小的性能测试工具,微软的WAS,很容易上手。
Webstress是比较简单易用的工具,由于不能进行参数设定,只适合模拟一些固定的网络地址连接的压力测试,推荐使用Loadrunner。目前微软已经不进行版本升级了。
手动创建一个脚本
————————
File->new (Ctrl + N)->Manual
在[Server]中输入服务器名称或地址及注释
选择HTTP传递的方法(Get Head Post)
输入测试路径(Path)
修改所属组(Group 可选项)
OK
录制一个脚本
——————
File->new (Ctrl + N)->Record
设定默认浏览器并清除Cache
选择需要录制记录的项目点击Next->Finish
访问测试地址及待测试链接
修改各链接所属组(Group)可选项
点击Stop Recording
——————
Script Edit Tree
item delay可以认为是Thinking time单位(ms)
Group 更真实的模拟实际运行,交错同时点击
Verb (Post Get Head)
——————————
并发连接设置( Concurrent Requests )
Script Tree->Setting
Stress level (threads)创建客户端的数目
Stress multiplier (sockets per thread) 每个线程并发的数目
Total Concurrent Requests = Stress level (threads) x Stress multiplier (sockets per thread) = Total Number Sockets
-————————
请求延迟设置(Request Delay)
Script Tree->Setting
用于模拟协调实际带宽
单位(ms)
————
设置带宽(Bandwidth)
Script Tree->Setting-> Bandwidth
——————
数据分析
Number of hits:测试间隔内虚拟用户点击页面的总次数
Requests per second:每秒客户端的请求次数
Threads:线程数,即虚拟用户并发量
Socket Errors Connect:Socket错误连接次数
Socket Errors Send:Socket错误发送次数
TTFB Avg:从第一个请求发出到测试工具接收到服务器应答数据的第一个字节之间的平均
时间
TTLB Avg:从第一个请求发出到测试工具接收到服务器应答数据的最后一个字节之间的平
均时间
备注
1.不能进行实际真实模拟数据添加,用于测试Web Page Download Performance
2.缓存因素影响测试记录准确性
3.调整 Webtool 服务“管理工具”->“服务” 设置为手动
4.测试数据WAS目录下的WAS.mdb