
摘要: 9.5.4 验收测试方案索引目录结构 也许,有很多测试同行非常关心测试方案的编写内容,这里以我的方案为样本,给大家做一些介绍。 以下内容为某项目的验收测试方案索引目录结构。 1. 引言 1.1 编写目的 1.2 项目背景 1.3 预期读者 1.4 参考文档 1.5 名词定义 1.5.1 验收测试 ...
阅读全文
中国软件测试专家访谈录(1)
中国软件测试专家访谈录(2)
中国软件测试专家访谈录(3)
第三章 人是软件测试的中心
简单的职业经历
蔡:请介绍一下你的职业经历。你是一直在华为工作?
邰:对,我的职业经历很简单。硕士研究生毕业后,在华为从事软件测试工作11年。
旁观者说:从职业发展的角度来说,长期在一家公司工作和服务于不同的公司各有好处。换多家公司,可以接触到不同的项目和不同团队,见多识广。长期在一家公司服务,有利于经验和人脉方面的积累,增加获得更高职位的可能性。
我本科和研究生的专业是机械电子,都是在天津大学上的。2001年3月,我研究生毕业,当年4月9日,我进入华为工作,到今年(2012年)的4月9日离开华为,整整11年。
蔡:真是不容易,在一家公司服务了11年。这11年是一段丰富的经历,给我们介绍一下吧。
邰:回过头来看,这11年可以分为两个阶段。2001年到2008年做具体产品的测试。在这个阶段里,从测试执行,到测试设计,再到团队管理,也是一个逐步提升的过程。
旁观者说:有一个问题,也简单,也残酷,就是回顾自己的职业经历,问自己:它是不是一个逐步提升的过程?如果没有了提升,可能就是处于停滞状态了。
从2008年开始,我的工作内容发生了转变:从"负责某个具体产品的测试"转变到"负责帮助其他测试人员更好地做好他们的测试工作"上来。
当时正好我所在的测试部(华为上海研究所)和来自华为瑞典研究所的高端测试专家有一个TPI(Test Process Improvement)合作项目,而我也希望自己能够从管理路线转到技术路线上来,希望自己在做了七、八年的软件测试之后,能够系统地、深入地思考一下怎样把测试工作做得更好。我很幸运地参与了这个合作项目,并自此开始了测试理论方面的研究。
TPI的工作就是对现有的测试工作做评估,并给出评估报告,然后各利益相关人再根据评估报告以及项目上下文开展具体的测试改进实施。说实话,在参与这个合作项目之前,没有想过要做测试理论方面的工作和研究,身边也没有这个氛围。和来自瑞典研究所的专家接触后,才意识到了测试理论与测试实践相结合的重要性。
TPI合作项目持续了一年多,我从中受益匪浅。TPI项目结束后,我选择了一个当时问题比较多的领域"测试设计领域",继续开展更深入的调查和研究,提出了一套测试分析和测试设计的框架:MFQ&PPDCS ,该论文在葡萄牙的ICSEA2009会议上得到发表。基于这篇论文,我开发了相关的培训课程,在公司内部讲过十几次,让更多的同事了解了自己的主张。
旁观者说:职业发展的路都是一步一步走的,我相信,在公司内部的培训经历对于邰晓梅后来成为独立测试咨询顾问是有帮助的。
2008年,我代表部门参加了ISTQB -FL的培训,觉得它不错,把测试方面的知识做了系统化的梳理。参考ISTQB大纲,结合华为的工作经验,我开发出了"软件测试基础"这门课程。参加这门课程的人来自于各个产品线,而不仅仅局限于我所在的无线产品线。我从事测试工程领域的研究后,经常会收到来自不同部门不同地域的求助邮件或者咨询电话,有的时候可能都分不清楚对方来自哪里。但是,没有关系,我愿意给大家提供测试方面的咨询和服务。能够被人所信任、所依赖,是价值的体现。
旁观者说:有的人可能怕做多了,心想这又不是我的职责范围;有的人则愿意为别人提供服务,被别人需要。
2010年和2011年,我到美国参加了三次StarWest/StarEast会议,收获非常大。回来后我做了详细的总结,觉得光是把从大会上学到的技术分享给大家,并不充分,我希望更多的同事也能感受到参会的氛围,感受到测试工作的激情,于是就开始组织策划公司内部的软件测试会议,这样的会议共举办了两届,每年参加的人数大概有250人。
11年华为工作经历中印象深刻的事情
蔡:在一家公司能持续工作11年,挺不容易的。在这11年里,有哪些给你留下深刻印象的项目或者事情呢?
测试并不只是发现bug
邰:这方面的事情自然很多,我举个例子吧。大概在2005年的时候,我带一个测试组做一个小型产品的测试。这款产品的主要功能是配置和维护,功能并不算复杂,但是是新开发的产品,从零做起。我们测试组有十几个人,大家的干劲都比较高。这是我第一次独立带团队做测试,也是既兴奋又紧张。我很看重这个项目,从计划、人员配置到团队氛围等,我都处处留意。
在我的带领下,我们测试组每天都能发现很多缺陷,开发改不过来了,因为新增的bug数量大于开发每天所能解决的数量,再加上开发团队还要做新功能,这样,就出现了测试压倒开发的"态势"。
旁观者说:测试压倒开发,与开发压倒测试一样,不是好的项目状态。二者应当势均力敌,互相制约,互相推动和促进,做出一个好的产品来。
整个项目进行期间,测试团队不可谓不努力,但是绩效却不好,也算不上快乐。这其中的原因是什么呢?当时百思不得其解。现在回过头来看,至少有两个方面是可以从中吸取教训的。
第一,当时的理念认为测试就是提问题单。现在很多人都知道,这是不对的,测试并不仅仅是发现bug,预防bug也非常重要。
第二,没有把开发和测试视作一个完整的团队,而是开发和测试分隔得太"开"。
在产品bug非常多的时候,我们没有想到去做缺陷分析,采取一些预防措施,没有问:"这类缺陷怎么又出现了?我们能不能走到开发前期,去了解测试做哪些工作,可以帮助预防这类缺陷?甚至测试能不能帮助开发解决一些bug?因为未修复的bug已经堆积很多了"等这样的问题,不认为这些也是自己的工作职责。由于缺乏"预防测试(Preventive Testing)、完整团队(Whole Team)"的思想,测试只是一味地发现缺陷,而大量的缺陷意味着产品质量并不高,测试人员难免会有挫败感。
旁观者说:在实际的项目中,有的时候其实也能发现流程或者工作方法方面的一些问题,但是往往因为疲于应对工作,下不了决心来做改进。项目结束后的总结过程是很有必要的,让我们更加清晰地看到不足,制定出具体的改进办法。
更多的启发
如果深入思考,这个案例可以带给我们更多的启发。
第一,如果一个产品或项目有大量的bug暴露出来,作为项目管理者要注意了,这意味着项目本身有很大的改进空间,产品的质量不容乐观。
处理bug是很费时间的:测试提交一个bug,开发打回,说这不是bug;测试再打过去,证明这就是一个bug;开发修改后,不经过单元测试,就打给测试去验证;如果测试验证没有通过,还要打回给开发,开发重新修复,测试再重新验证……可以想象,成千上万个bug,如果每一个都要走这样的流程,单是解决掉这些bug就要耗费多么大的精力!每一个bug就是对系统的一次change,软件系统本身已经很复杂了,再加上成千上万次change,系统变得更加复杂,潜藏的缺陷有可能更多!
旁观者说:对于全新的功能,我在自己的团队有一个提法:剥笋子。软件的功能都是逐步完善的,在初期很容易发现这样、那样不对的地方,这个时候不要开过多的bug,而应该像剥笋一样一层一层来。先提交最主要的几个bug,开发修改了以后,测试人员得到新的build,再基于新的build提交另几个主要的bug。bug分清楚主次,提交的时间分先后,能够提高bug的有效性,也方便开发人员解决问题,提高研发效率。
第二,测试流程只起到辅助性的作用。
当时公司已经有了非常不错的测试流程,有很多测试工程方法可以使用,有很多测试文档模板可以选用,我认为只要认真遵守流程规范,就一定能做好测试。在某一个时间点,应该采用什么样的模板、出具什么样的测试文档、使用哪些测试工程方法、开展哪些测试活动、做哪些测试总结和缺陷分析等,我都一一照做,花了不少的时间。但是,遗憾的是,我虽然努力了,却没有抓住事情的本质,忘记了我们的第一目标是要得到一个可发布的高质量软件,而不是找到尽可能多的bug。
旁观者说:测试团队天生有想发现更多bug的倾向,有的时候绩效考核会起到推波助澜的作用。但是的确,按时发布质量达到标准的软件产品是任何"参战部队"的最重要的目标。
实际上,我现在认为,测试流程是一种启发式(Heuristics),遵守了流程,测试不一定就做得好;不遵守流程,测试也不一定就做不好。测试流程起到的更多的是一个辅助性的作用,而不是决定性的作用。所有的启发式都可以帮助我们思考。我们要学会应用(Apply)测试流程,而不是遵守(Follow)测试流程。
旁观者说:让测试流程为我所用,而不是机械地遵循。
第三,做任何测试工作,首先要做的是Know Your Mission(知道你的任务所在)。
测试是一种服务,为我们的客户(包括其他各种角色和最终的客户)提供质量相关的信息。当我们接收到一个测试任务时,首先要做的就是了解客户是谁,客户期望得到什么价值,希望测试为其提供什么样的服务。有的朋友可能有这样的工作习惯,不管软件大小或者功能大小,一上来就动手测试,迫不及待地想提交bug。可是,如果不知道客户的期望是什么,则容易出现偏差。要了解客户在哪里,期望的价值在哪里。
旁观者说:我很赞同测试是服务的提法。记得几年前在一家企业做演讲,当我提出测试是一种服务的时候,就有朋友表示不理解,认为服务人员的地位太低了,这么说是看低了软件测试。
在社会生活中,从事服务的人员没有得到足够的尊重。其实每一个人都是平等的,只是从事的职业不一样而已。说测试是一种服务,并不意味着测试低人一等。在大的研发体系中,软件测试这支力量扮演的是服务的角色,为提高研发效率和提高产品质量而奋斗。
对测试认识的三个阶段
蔡:谢谢你的分享。虽然你的工作经历比较单纯,但我相信你在华为工作的11年当中,对软件测试的认识应该是变化和逐步提高的。
以bug、流程、人为中心
邰:是,我对软件测试的认识是有变化的。
在2008年之前,虽然我也一直在做测试工作,但是我的确思考不多。现在回过头来看,如果在成长的道路上有人时不时地指点一下,那真是一件值得庆幸的事,会进步很快。从2008年开始,我会经常浏览测试类的博客、网站,参加各种会议,多做交流,对测试的认识有明显上升。
旁观者说:找到自己的导师,虚心请教。有的时候经验丰富的人一句话,就能让自己少折腾几个月。
到现在为止,我对测试的认识可以大体划分为三个阶段。
第一阶段,以bug为中心。认为测试就是找bug,bug越多越好。这可称为原始阶段。在这个阶段里,一般都是拿到软件就开测,流程不一定规范,也没有想到要规范,只是找bug。
第二阶段,以流程为中心。在测试工作中,认为应该先定义各种测试流程和规范,认为只要follow这些流程和规范,就可以更有效、更高效地找bug,就可以做好测试。
第三阶段,以人为中心。认为测试是以人为中心。我现在也还在这个阶段。不再以流程为中心,把流程、模板放到边上,而把人放在中心的位置上。把测试工程师的能力和潜能发挥出来,这是比流程更重要的事情。
旁观者说:团队的核心就是人,团队管理者的主要工作始终是调动和保持员工的工作积极性。
注意:这三个阶段对于我个人而言是个顺序认知的过程,但不意味着每个组织都要串行依次经历这三个阶段,也就是说,不一定要先建立测试流程,才谈测试以人为中心的事情。
软件测试在没有规范的时候也能做,也能找到一些问题,有了规范之后你的测试看起来就会正式一些,但如果想把测试做好,就应该以人为中心。最近国内开始流行的探索性测试,就是以人为中心,充分发挥人的各项技能。
研究软件测试思维
认识到测试以人为中心后,我开始研究"软件测试思维"相关课题,这是一个很大的课题,不仅涉及测试领域的知识,还可以从心理学、社会学、人类学等很多领域获得启发,这个课题的研究我也是刚刚起步,目前开发了"认识你的测试思维"这门课程,旨在帮助学员认识自己的测试思维,以实现改进和提高。
我通过和不同的测试人员开展结对测试发现,在外部条件都相近的情况下,例如,在相同的时间内,相同的测试对象和测试环境,甚至相同的测试用例,不同的人却得到不同的测试结果。在测试工作当中,测试思维扮演着重要的角色。但是,对于大多数人来说,测试思维--你测试时是如何思考的--是在潜意识下发生,很难用语言表达的,所以为了提高测试思维,首先得认识当前的测试思维。
测试深度图
为了把看不见的东西可视化地表现出来,我提出了"测试深度图(Test Depth Graph)"的概念。通过这张图,可以展现出学员测试思维的特点,例如,是擅长深入思考(Focused Thinking)还是擅长广度思考(Defocused Thinking)等。在观察的过程中,我会告诉学员,哪些地方他(她)做得很好,这样他(她)就会得到激励,对测试工作更有信心。对于不足,我也会提起,这样他(她)在下次遇到类似场景时就会有意识地提醒自己,去做改进。这样的事情反复几次,一个人在测试思维方面就会得到提高。
旁观者说:表扬就是一种正面的引导。
蔡:对这三个阶段的认识的跨越你都是在一家公司,你的职业生涯比较顺利。
邰:是,我比较幸运,相对还是比较顺利的。刚进华为时,我告诉自己,两年后我就离开。过了两年,我发现有很多东西要去学习。就这样,年复一年,不断地觉得有新的值得去学习的东西,我也在一路不断成长。当你一直在学习一直有收获的时候,就会感觉很充实。我喜欢这种充实的感觉。
重点测试技术
蔡:请你给大家介绍一下你认为重要的测试方面的技术,或者新技术。
邰: 所谓的新技术,是有context(上下文)的。例如ReqBT(Requirements Based Testing,基于需求的测试),我邀请了Richard Bender在ChinaTest 2012上做了介绍,有的朋友可能会认为这是测试新技术,其实作者提出来已经30多年了。新与不新,是个相对的概念,有的人感觉比较新,有的人则早就接触过了。
不同的公司也有不同的情况。对于有些公司来说,在时间、资源等很有限的情况下,ReqBT这样偏"重"型的方法可能就不适合,他们可能更需要类似于RST(Rapid Software Testing,快速软件测试)这样偏"轻"型的方法,RST是James Bach和Michael Bolton讲述的一门课程,侧重于如何在测试进度紧张、测试资源有限等条件下快速而有效地开展测试工作。所以,技术的应用或者重要与否取决于项目上下文。
人也是有上下文的。不同资历的人,看法会不一样。当然,如果只是年资的增长但是见识没有增长,这是自己要认真思考的问题。对于培养测试新手而言,我的观点是,并不一定一开始就要学习系统的软件测试知识,或者去学习测试新技术,而应当是多实践并且多思考。给他们一个测试任务,让他们去做。这对于新手来说肯定是个挑战,但是在这种情况下他们也会发挥自己的各项能力去做。当然,指导者也不是撒手不管,可以和他们一起结对测试,发现他们的不足,指导他们去做测试。通过实践,新人对软件测试的认识和兴趣都会得到提高,然后再去教他们测试理论知识,例如等价类边界值等,效果会更好。
旁观者说:邰晓梅这里提出来一个新的观点:对于软件测试,可以走先实践、后理论的学习路子。这里有新意,值得参考。对于公司内部转岗的情况,可以尝试一下这种做法,先直接做测试,然后慢慢回过头来学习理论。对于刚毕业的大学生朋友,因为需要找一份测试工作,先学习测试理论会有利于通过面试。
如何学习软件测试
蔡:你对于正在学习软件测试的朋友有哪些建议?
多实践,多思考
邰:我强调的是,不管你是在学校里,还是在公司里,要多交流,多实践。如果条件允许,最好找一个导师,项目里的最好,可以面对面交流,这对成长有很大的帮助。从我个人的体会来说,人与人之间传递信息最有效的方式就是面对面的交流,比看文档、读书、参加培训效果更好。
旁观者说:寻找导师,向周围的人学习。如果真能找到一位师傅,建立一种或密切或松散的师徒关系,收获往往很大。除了技术方面,思维方式和做事风格都是对人有很大影响的几个方面。
找导师往往很难,因为这是要双方愿意的事情。每个人对自己的师傅有一定的期望,有的时候你看准了一位师傅对方也不一定愿意来指点你。虚心请教,有利于学习和找到导师。
多实践,多思考。如果工作了七、八年,在软件测试方面的进步却并不明显,这是值得反思的:是不是自己思考不多?
三步法
如果你想学习软件测试,甚至成为测试的牛人,我们可以应用前面提到的Know Your Mission的方法思考这个问题。
第一步,请你描述自己的目标,你想成为什么样的人?是想写软件测试方面的著作,还是要得到公司的认可?目标要定下来。
第二步,如果想要实现这些目标,需要具备哪些技能和知识?也许你需要了解测试设计技术,也许你需要在某个方面很强,比如测试自动化、安全性测试、性能测试等。
第三步,如何掌握这些知识和技能?也许你要去学习一些相关的测试课程,浏览相关的网站,阅读一些测试书籍,思考总结自己的测试经验等。
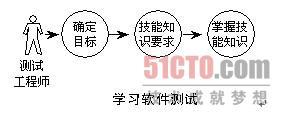
归纳起来,这是一个What'What'What(目标是什么-需要什么技能和知识-做些什么以获取这些知识和技能)的过程。这3个What是一个迭代的过程,刚开始的时候对每一个What的认知少一点没有关系,循环执行这个过程,就会一步步贴近你的目标。
旁观者说:定一个目标何其容易,愿意一步一步、一天一天去实现它又何其难啊!
测试就是学习
我主张的一个观点是,Testing is learning(测试即学习)。谁的学习能力强,谁就可以快速地了解被测对象,快速地了解哪些区域bug比较多、风险比较高,从而把测试做得很好。一个人要想成为测试高手,需要具备很强的学习能力。如果只是资历高,但学习能力差,会很麻烦的。
(未完待续)
ConfigParser 是Python自带的模块, 用来读写配置文件, 用法及其简单。 直接上代码,不解释,不多说。
配置文件的格式是: []包含的叫section, section 下有option=value这样的键值
配置文件 test.conf
[section1]
name = tank
age = 28 [section2]
ip = 192.168.1.1
port = 8080 |
Python代码
# -* - coding: UTF-8 -* -
import ConfigParser conf = ConfigParser.ConfigParser()
conf.read("c:\\test.conf") # 获取指定的section, 指定的option的值
name = conf.get("section1", "name")
print(name)
age = conf.get("section1", "age")
print age #获取所有的section
sections = conf.sections()
print sections #写配置文件 # 更新指定section, option的值
conf.set("section2", "port", "8081") # 写入指定section, 增加新option的值
conf.set("section2", "IEPort", "80") # 添加新的 section
conf.add_section("new_section")
conf.set("new_section", "new_option", "http://www.cnblogs.com/tankxiao") # 写回配置文件
conf.write(open("c:\\test.conf","w")) |
相关文章:
Python自动化测试 (一) Eclipse+Pydev 搭建开发环境
业内但凡玩过QTP的,多半都知道songfun的名字,多少读过几篇我写的关于QTP的文章。然而今天,作为捧红它的一员,我决定亲自推翻它,让它从神坛走下。
前面博文说了QTP已死,这里要谈谈最近势头正劲的 SilkTest 。
众所周知,自动化测试工具曾几何时三足鼎立,Mercury QTP/WinRunner系、IBM RobotJ (RFT)系、Borland Segue SilkTest系,但是几年下来,QTP在国内和国外都将同类工具远远甩在身后几条街。即使后起之秀Web界翘楚Selenium也只能将超越QTP作为自己终身己任,以至于连名字上都要以 Selenium(硒) 克一下它的偶像 Mercury(汞,硒解汞毒)。
但是时过境迁,SilkTest 已经不再是当年的那个SilkTest,QTP也不再是当年的QTP。2013年的自动化测试工具因为QTP的裹足不前和SilkTest 的浴火重生变得有了味道。
好吧,一定有人要站出来说QTP现在的市场份额在国内的仍然有60%,SilkTest还远未成气候,而Selenium只能进行B/S的自动化,不可能取代之……我只想说,这几年以来QTP并无太大建树,除了界面更加华丽,兼容性更差,更耗资源,内核未做更新,就是多了一些华而不实噱头级别的功能特性和某几个小功能——真的一直没有太大变化,按照这样的趋势,QTP很有可能成为下一个WinRunner。
好吧,最近网站和论坛正在热捧 WinRunner,好多朋友连这个名字都没听过,跑个题,告诉大家 曾经的WinRunner就像今天的QTP一样统领自动化领域的武林,如果大家去看国外最大的SQAForum就会看到它的历史回帖数在今天仍然跻进 Top 3,但是如果你去 bbs.51testing.com 的论坛看看它目前的人气那真是令人嗟叹,整个季度的回帖数不足10篇!
QTP可能会变成下一个WinRunner,作为使用了QTP 十年之久的我从感情上有些舍不得,但是必须面对的要去面对,我们应该拥抱变化。
好吧,闲话少说,以下横向PK两大商业级自动化测试工具:
(一)编程语言:
QTP一直以来都使用 VBScript. 作为自己的引擎,这在一定程度上降低了学习的成本,确实吸引了很多初学者来学习和使用QTP。
但 VBScript. 不是一个纯粹的面向对象编程语言,除了可以封装Class,是不能继承和多态的。直接一点说,这样天生缺陷是的QTP的重用性从骨子里就很差,执行效率还很低!
而SilkTest呢,可以支持 .Net, C#, Java, 以及它自身的 4Test,这本身就可以吸引一大批编程基础扎实的开发人员参与到自动化的实施过程中,而它强大的面向对象基因,强大的重用性,强大的维护性(甚至可以轻而易举进行版本管理,学过QTP的同学都知道,QTP所谓的简单只是入门简单,后期维护是非常恐怖的),极高的开发效率更是远超QTP。
(二)检查点(Checkpoint)
QTP的检查点一向不伦不类,好像基于对象库(因为是在对象库中才能看属性),又好像脱离于对象库(因为不是所有的检查点都可以进行对象模式的维护管理,而Checkpoints和Test Objects是并列节点不是归属关系),这在开发过程中被很多朋友直接抛弃,改用其他手段做验证(比如经典的 GetRoProperty)。
而SilkTest呢,直接通过代码秀出自己要检查的对象的属性等信息,简单易懂不说,维护方便很多——毕竟,难道你喜欢一边在Expert View里编程一边在对象库里看对象吗?累不累啊?
(三)“录制/回放”
QTP的录制分为:标准录制模式、低级别录制模式(WinObject对象模式)、模拟录制模式(模拟鼠标运动轨迹)。在视图上采用了业务专家(SME)的 Keyword View和编程人员的 Expert View。
总体来说还算不错,除了专家视图模式下的编程功能太坑爹。
而SilkTest呢,有 SilkWorkBench、Silk4J、Silk4Net、SilkClassic等一堆的IDE,支持VB.Net、C#、Java等IDE,真的觉得假如你是团队化开发自动化测试脚本的话,SilkTest的优势要比 QTP明显很多。
(四)脚本
QTP的脚本我一直不喜欢,因为不是纯文本。它在创建工程的时候(QTP中的工程叫Test,而不叫 Project),会生成一堆的资源文件,比如ObjectRepository.bdb、Resource.mtr,还有截图目录SnpaShots目录,而脚本代码放在 Script.mts 中,还偏偏在代码行后附着了 Active Screen关联的图片信息。
另外启动信息非要整在 Action0 这个目录里面,这种规划思路很不好,过度分离的结果是你维护的时候不得不关注一大堆地方。
而SilkTest呢,就是单一的脚本文件,我即使不开工具也可以直接修改。简单即美,难道不是么?
(五)异常捕获、场景恢复
QTP的场景设计也很复杂,又是独立于脚本(脚本里看不到),在脚本外进行配置(类似resource),需要开发者思路很清晰的规划它可能在什么地方出现什么错误、怎么处理,最糟糕的是可读性极差,假如你在场景里面还有Function Call还得再配一个外部qfl或vbs文件,而如果引发了迭代还要在另一个Settings中做迭代设置,否则你场景恢复的时候可能莫名其妙的调起了好几遍自己的应用。一句话,真的很坑爹,不是一般的高手搞不定它。
而SilkTest呢,开箱即用,真正的 7*24小时支持。
(六)插件支持(Add-ins)
QTP每个编程语言都需要一个插件,通过插件来识别对象。而有时候这种插件加载显得很不灵活,比如你勾选插件进去以后居然没法再添加,这什么易用性啊?
而SilkTest呢,不需要安装这个那个插件。一句话:哪儿那么多麻烦啊。
(七)Web 2.0支持
QTP对于 Web 2.0 的支持,我连写的欲望都没有,因为实在太差了! 什么Ajax/DHTML,什么Flex,全部都不认(或者干脆整个窗口认为ActiveX),……
可以说,QTP曾几何时打败 WinRunner的 关键就是Web 1.0 的支持超强,可如今死在了自己的最强绝学上。这也是为什么后来给了 Selenium 以可趁之机的地方!
但是 Selenium 的强项在于纯HTML/JS应用,对于 Flex基本无能为力。
而反观 SilkTest,全面支持 Ajax/DHTML,Flex/Adobe Air,全面支持 .Net 4.0,即使 Adobe公司自己也是选择SilkTest作为它的自动化测试工具哦!
(八)参数化、数据驱动
QTP号称自己采用 Keyword-Driven,一种在Data-Driven基础上派生的更高级的扩展驱动理念,而事实上是QTP 直接把数据驱动的框架内嵌在自己的DataTable上,以 DataTable Object的内核结合Action迭代驱动脚本运行。这意味着号称自己是共产主义社会,但其实在封建主义社会。这么说已经很客气了,事实上DataTable并不好用,在实际项目中应用不多,一般往往采用外部文件(文本、csv/excel格式、数据库、XML)做配置,扩展性比DataTable好多了。
而且坑爹的是,我还要爆料一下,QTP从诞生到现在,DataTable对象的SetNextRow 一直都有指针重置的Bug,我一般都推荐用SetCurrentRow。
而SilkTest呢,有自己的Data Driven向导,直接操作、快速完成,还支持直接从数据库里面查询测试数据。是不是很霸气侧漏呢?!
(九)平台支持
QTP只能运行在 Windows上,而且对于不同Windows的兼容也有问题,比如我几年前提及的OCR识别验证码技术,现在已经没落了。
而SilkTest呢,通过SilkBean支持 Java的应用,可以在Linux平台上回放哦!
(十)分布式、云计算
QTP本身带有Remote Agent,可以远程调度,但是它的商业意图过度明显,因为这个远程调用是通过Quality Center/ALM来完成的,哥们你知道意味着什么吗?意味着你要去迪拜旅游得自己买个直升机,我擦。。。
Selenium 有 Grid,而SilkTest原生支持,它通过Runtime&Agent技术实现。都明显强过QTP!
(十一)对象库、对象存储
QTP可以说是成也对象库,败也对象库。QTP用单独的文件存储对象库,本地对象库放在ObjectRepository.bdb文件里,共享对象库放在 XXXX.tsr 文件里。管理起来很复杂,有些人看我介绍过高阶的对象库管理,一致都表示很晕。因为对象库的比较、合并、参数化全部都得额外的对象库管理器里去实现,而且实现参数化还要做映射,弄完之后满身的汗。。。
而SilkTest呢,可以直接通过编辑器编辑,是不是灰常的爽?!
(十二)采购成本、ROI
得说“ROI(投资回报率)”的问题了。
QTP以前根据插件收费,后来整合起来销售,美其名曰打包赠送。等于你就是先买个铁钉,人家卖你一套家具让你自己拔出来。
SilkTest不一样,提供了 RunTime的 License模式,降低了采购成本,什么意思呢,就是你买的时候可以分的,看你是编写脚本,还是只是运行脚本,等于说你买个套餐,居然还可以单点套餐里的东西——靠,这还叫套餐吗?没见过这么好的销售啊,哈哈。
(十三)自动化框架
QTP的天生劣势使得它的自动化框架部署非常困难和麻烦,这也是几年前很多人在网上争论不休的原因,大家都说不出一个真正被认可的很实用可以大面积推广的成熟框架。
这点上,跟 Selenium、SilkTest 这种工具本身的设计理念就有很大差异。
试想,你把自己的工具捆绑在QC上、自己的工具上,你怎么拥抱开源?没有开源,你自己的东西怎么集成别人的东西?没有集成,你的自动化能叫框架吗?这不搞笑吗?撑死了就是个半自动化框架。
(十四)成功案例
QTP名气相当大,国内外都是!但是真正成功实施的用户很少,给客户带来的收益很低。
为什么?因为它虽然上手非常快,但是管理维护非常麻烦,没有成熟的 framework 。比如建设银行2007年就开始使用QTP做自动化,迄今没有形成成熟成型的自动化测试体系,一直在通过外部程序控制QTP执行还是QC控制QTP之间徘徊。
而SilkTest呢,它的不足在于不支持 VBScript,哈哈,不够简单,这直接造成了门槛偏高,等于做测试的人一定、必须精通编程,而不能只是能改改脚本那么初级。但是,只要你迈过了前期这个槛,就会发现它的精妙和强大之处。它内置的设计框架,管理比QTP简单非常多,后期收益大,试想,连 Adobe/SAP/Oracle这样的大公司都在拥抱 SilkTest,你觉得它们都是傻瓜吗?而 国际上有几个巨头在使用QTP呢?呵呵,Google用吗?微软用吗?Facebook用吗?呵呵呵……
所以啊,玩QTP其实就是一场空,你玩QTP顶多只是QTP(因为你会VBScript还是做不了JUnit/TestNG/HTMLUnit/Selenium/JMeter等测试,而你会Java以后就能做所有的测试包括SilkTest和Selenium了),用它抢抢票、灌灌水还是可以的,可是,你既然都要花那么多时间学一个工具,为什么不顺便在学自动化工具的同时把编程学会了,一举两得,顺便还拿到了高薪,对不?
好了,说了这么多,大家应该明白了吧?
有要拍砖的尽管来,但是别搞人身攻击!呵呵呵
版权声明:本文出自songfun 的51Testing软件测试博客:http://www.51testing.com/?songfun
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
版权声明:本文欢迎转载,转载时请务必以超链接形式标明文章原始出处、作者信息和本声明,否则将追究法律责任。
通过上一节的学习,相信我们已经会selnium IDE的基本使用了,为了使selenium 更强大,其实selenium 还提供了良好的扩展能力。
----//用户扩展
用户扩展就是使用javaScript文件来创建定制化特性,添加新功能,通常情况下这种扩展就是定制化命令,但扩展并不仅限于命令。
这里有一些列的扩展:http://wiki.openqa.org/display/SEL/Contributed+User-Extensions
1.下面我们利用扩展的方式,产生一个用户随机数字
为了使用用户扩展,我们需要一个创建一个文件,当然也可以从上面的链接中下载。文件名为:user-extention.js
//产生随机数
Selenium.prototype.doStoreRandom = function(variableName){
random = Math.floor(Math.random()*10000000);
storedVars[variableName] = random;
}
//弹出框
Selenium.prototype.doDisplayAlert = function(value, varName) {
alert(value);
}
//在控件中输入当前日期
Selenium.prototype.doTypeTodaysDate = function(locator){
var dates = new Date();
var day = dates.getDate();
if (day < 10){
day = '0' + day;
}
month = dates.getMonth() + 1;
if (month < 10){
month = '0' + month;
}
var year = dates.getFullYear();
var prettyDay = day + '/' + month + '/' + year;
this.doType(locator, 'dddddd');
} |
将上面代码复制到一个记事本里,并另存为一个:user-extention.js的文件
在selenium IDE 中导入此文件,如下图:

选中文件后,点击“确定”按钮。你必须关闭再重启selenium IDE,以便于扩展文件被读取。任何扩展的改变,都要求关闭和重启selenium IDE.
2.转换代码形式
选择Options 菜单下的Format,允许你选择一种语言来保护和战士测试案例。默认是HTML格式。
如果你使用selenium RC 运行测试案例。这个特性可以帮助你将测试案例翻译成编程语言。
我们可以选择“文件”----Export test Case As...来转换我们需要的语言格式。具体实例请参考《selenium RC 环境搭建》

3.在不同浏览器上执行selenium IDE测试。
selenium IDE只能在friefox上运行,但是通过selenium IDE 开发的自动化测试,可以在其他浏览器上运行。只要使用一条简单的命令唤醒 selenium RC 服务器就可以了。
如果浏览器不被直接支持,那么通过使用" *custom "运行模式,你依然可以在浏览器上运行selenium 测试案例。
| cmd=getNewBrowserSession&1=*custom c:\Program Files\Mozilla Firefox\MyBrowser.exe&2=http://fnng.cnblogs.com |
如下一段代码:
package com.example.tests; import com.thoughtworks.selenium.*;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.util.regex.Pattern; public class test extends SeleneseTestCase {
@Before
public void setUp() throws Exception {
selenium = new DefaultSelenium("localhost", 4444, "*chrome", http://fnng.cnblogs.com/);
//可以用下面一行的代码来替换上面一行代码
//cmd=getNewBrowserSession&1=*custom c:\Program Files\Mozilla Firefox\MyBrowser.exe&2=http://fnng.cnblogs.com
//如果是IE浏览器的话,可以直接修改浏览器名称,代码如下:
//selenium = new DefaultSelenium("localhost", 4444, " *iexplore", http://fnng.cnblogs.com/); 这种方式更为简便。 selenium.start();
} @Test
public void testTest() throws Exception {
selenium.open("/");
selenium.click("id=homepage1_HomePageDays_DaysList_DayItem_0_DayList_0_TitleUrl_0");
selenium.waitForPageToLoad("30000");
} @After
public void tearDown() throws Exception {
selenium.stop();
}
} |
如何配置java环境来验证我面的一段代码,请参考,我的《selenium RC 环境搭建》
注意:如果通过这种方式启动浏览器,你必须手动配置浏览器,以便将selenium Server 作为代理,通常这仅仅意味着打开你的浏览器参数文件,并指明“localhost:4444”作为HTTP代理。但是,不同浏览器的指令可能完全不一样,这就需要从你的浏览器支持文档中寻找更多细节。
相关文章:
菜鸟学自动化测试(一)----selenium IDE
1.进程并发执行时若不满足Bernstein条件时会出现什么结果?
程序执行结果会不可避免的失去封闭性和可在线性。
2.一个作业从提交到运行结束通常经历那几个阶段?
经历提交、收容、执行和完成四个状态。
3.段页式管理注意缺点是什么?有什么改进办法?
段页式管理的主要缺点是对内存中指令或者是数据进行一次存取的话,至少需要访问三次以上内存,
地址变换速度太慢。
改进办法:采用联系寄存器的方式提高CPU的访问速度。
4.常用的文件物理结构有哪几种?试比较他们的优劣。
常用的文件物理结构有:
1)连续文件:实现简单,支持直接存储,不便于文件的动态增加、删除。
2)串联文件:便于文件的动态增加、删除,但不支持文件的直接存储。
3)索引文件:采用索引表,便于文件的动态增加、删除,可支持直接存储。
5.常用的文件存取方法有哪几种?哪一种比较适合于DBMS?
常用的文件存取方法:
(1)顺序存取法
(2)随机存取法
(3)按键存取法
按键存取法比较适合于DBMS
6.设备管理的目标和功能是什么?
设备管理的目标是选择和分配输入/输出设备以便进行数据传输操作;
控制输入/输出设备和CPU之间交换数据;为用户提供一个友好的透
明接口等。
设备管理的功能是:提供进程管理的接口;进行设备分配;实现设备和设备
、设备和CPU等之间的并行操作;进行缓冲器管理。
上一篇文章简单介绍了OCUnit和GHUnit两款iOS开发中较为常见的单元测试框架,本文进一步介绍单元测试中的另一利器——匹配引擎(Matcher Engine)。匹配引擎可以替代断言方法,配合单元测试引擎使用,测试用例可以更多样化,更细致。
传统断言提供的方法数量和功能都有限,以导读中提到的两款框架为例,即使是断言相对丰富的GHUnit也只是提供了38种断言方法,范围仅涵盖了逻辑比较,异常和出错等少数几方面,仍然很单一。而使用匹配引擎代替断言,可能性就大大丰富了,除了普通断言支持的规则,一般的引擎还默认提供了包含,区间,继承关系等。更重要的是,使用匹配引擎开发者可以自行开发匹配规则,引入与业务相关的逻辑判断。
本文要介绍两款匹配引擎,一款就是Hamcrest的Objective-C实现——OCHamcrest,另一款则是专为Objective-C/Cocoa而生的后来者——Expecta。接下来将结合GHUnitTest,介绍两款匹配引擎如何在单元测试中发挥作用(有关GHUnitTest参考《iOS开发中的单元测试(一)》。
OCHamcrest
介绍匹配引擎必须要提Hamcrest,几乎已经成为匹配引擎的代名词。官网首页上的一句话表明了它的身世:“Born in Java, Hamcrest now has implementations in a number of languages.”。这款诞生于Java的匹配引擎现在还支持除Java的Python、Ruby、PHP、Erlang和Objective-C。
加入工程
在iOS工程中使用OCHamcrest需要先获取OCHamcrestIOS.framework,可以从Quality Coding直接下载,或在Github上获取源码编译。注意:Github上托管的OCHamcrest工程以Submodule的形式关联源代码,因此如果使用命令行方式clone工程,需要执行“git submodule update --init”。
下载源码后,进入Source目录,执行MakeDistribution.sh脚本,将会在Source/build/Release下生成OCHamcrest.framework、OCHamcrestIOS.framework和OCHamcrest.framework.dSYM , OCHamcrestIOS.framework就是iOS工程中需要用到的框架,如图1。

图1,从源码编译生成 OCHamcrestIOS.framework
打开已经安装了GHUnitTest的工程,把OCHamcrestIOS.framework添加到单元测试的Target中。在需要使用匹配引擎的用例中,定义“HC_SHORTHAND”并导入“<OCHamcrestIOS/OCHamcrestIOS.h>”(如图2)。
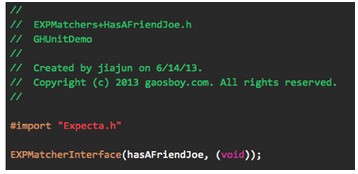
图2,把OCHamcrestIOS.framework导入工程
至此OCHamcrest已经安装完成,可以再测试用例中使用匹配规则代替GHUnitTest的断言方法。
预定义规则
OCHamcrest针对不同的数据类型提供了大量的预定义匹配规则,大大丰富了断言的类型。支持的数据类型包括:对象、容器、数值和文本,此外还提供了专门的逻辑匹配规则。
以文本(一般就是NSString)为例,OCHamcrest提供了6种针对对象的匹配规则:
IsEqualIgnoringCase,该文本是否与给出的文本相同(忽略大小写);
IsEqualIgnoringWhiteSpace,该文本是否与给出的文本相同(忽略空格);
StringContains,该文本是否包含给出的文本片段;
StringContainsInOrder,该文本是否按照先后顺序包含给出的若干文本片段;
StringEndsWith,该文本是否以给出的文本片段结尾;
StringStartsWith,该文本是否以给出的文本片段开头。 |
另外,再举OCHamcrest为对象(NSObject和NSObject的子类)预定义的8条规则:
ConformsToProtocol,该对象是否遵循了给出的协议,或者说是否实现了给出的Delegate;
HasDescription,允许使用文本规则对给出的一段文本与该对象的描述进行匹配;
HasProperty,该对象是否含有给出的属性;
IsInstanceOf,是给出的类的实例,或是给出的类子类的实例;
IsTypeOf,是给出的类的实例,不同于IsInstanceOf,无法匹配子类实例;
IsNil,为空;
IsSame,与给出的对象是同一个实例。 |
撰写用例
OCHamcrest提供了匹配规则和相应的断言方法,配合单元测试框架(本文以GHUnit为例, 在《iOS开发中的单元测试(一)》中已经介绍了如何安装GHUnit框架并撰写用例)的驱动机制即可撰写用例。本文以联合使用上述提到的StringStartsWith和HasDescription规则为例。
首先,定义一个用于示例的类“Man”(如图3),有属性friends,当friends为空,其description为“Man without any friend, so sorry.”,反之为“Nice persion with [friends count] friend(s).”。(使用Foo或Bar这样的示例会显得很没情怀吧 ;-|)
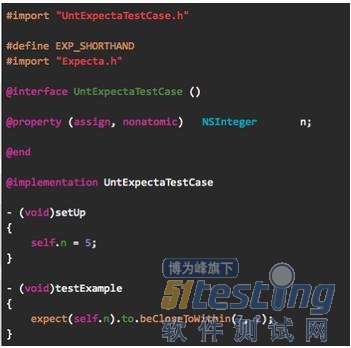
图3,用于测试的类:Man
用例中判断某Man实例的description是否以Nice开头(这是不是一个友善的人),如图4。
图4,测试用例两则
UntTestCase是GHTestCase的子类,引入<OCHamcrestIOS/OCHamcrestIOS.h>并定义HC_SHORTHAND表示使用OChamcrest。setUp方法在每个测试方法执行之前初始化一个Man实例;testANiceMan方法向Man实例的friends属性中加入两个值,因此该实例的description将返回“Nice man ....”;使用OCHamcrest提供的断言方法assertThat与匹配规则配合,判断该实例的description是否以“Nice”开头;testNotANiceMan方法则直接测试一个未经过加入friends的实例测试。
上述测试,testANiceMan方法顺利通过,testNotANiceMan不会通过,直接报出错误堆栈,并打印在匹配规则中预先定义好的出错信息(如图5)。
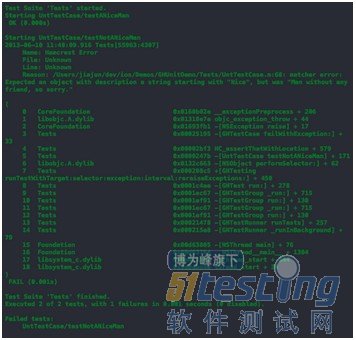
图5,测试结果
辅助方法
Syntactic Sugar是一种提高匹配规则和断言可读性的方案,让一个匹配和断言看起来更像是一句自然语言的话,而非多个函数的堆砌,对实际的匹配运算不产生任何影响。例如,没有加Sugar的匹配:
| assertThat(foo, equalTo(bar)); |
加Sugar可以是:
| assertThat(foo, is(equalTo(bar))); |
除了Sugar,OCHamcrest还提供了describedAs方法,用于辅助断言方法,自定义出错文案,例如:
| assertThat(foo, describedAs(@”foo should be equal to bar”, equalTo(bar), nil)); |
自定义规则
OCHamcrest官方给出的自定义匹配规则示例是:onASaturday,判断一个NSDateComponents实例是否为星期六。本文以上一节使用的Man对象为例,匹配某Man实例是否有一个名为“Joe”的好友,规则命名为:hasAFriendJoe。
自定义匹配规则包括两部分,一个Macher类和一个用OBJC_EXPORT方式定义的函数。
自定义Macher类都是HCBaseMatcher的子类(如图6),接口中定义的类初始化方法供匹配方法hasAFriendJoe调用,其实现则通过调用接口中定义的另一个实例方法。

图6,HasAFriend接口和匹配方法hasAFriendJoe定义
在HasAFriend中需要引入<OCHamcrestIOS/HCDescription.h>,并重写父类中的matches:和describeTo:方法(如图7)。在maches:方法中实现匹配逻辑,匹配成功则返回YES,否则返回NO;describeTo是失败后的描述;hasAFriendJoe方法只需要调用类方法初始化匹配规则类即可。匹配规则定义后,可以配合断言方法使用,如上一节所示的assertThat方法:
assertThat(self.man, hasAFriendJoe());
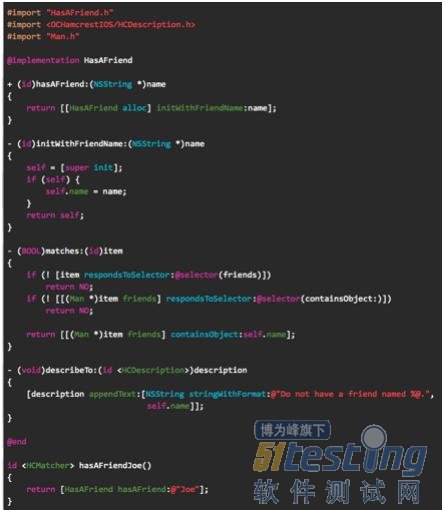
图7,规则实现
Expecta
Expecta专为Objective-C/Cocoa而生,相比OCHamcrest,其优化了匹配的语法,测试用例的可读性更高。此外,Expecta对匹配对象类型没有强制要求,允许任意类型的数据进行匹配。在OCHamcrest中每一条匹配规则都是一个方法,规则联合使用也需要以参数形式传递。在Expecata中联合规则的语法是以点号连接,借助Sugar介词可以把一个联合规则拼装成一句符合自然语法的句子,例如:
OCHamcrest —— assertThat(@"foo", is(equalTo(@"foo")));
Expecta —— expect(@"foo").to.equal(@"foo"); |
· 加入工程
Expecta提供了CocoaPods的源,可以通过定义依赖引入:
dependency 'Expecta', '~> 0.2.1'
dependency 'Specta', '~> 0.1.7' # specta bdd framework |
或者从github上获取源代码,编译出Library,引入XCode工程。下载源码后,进入工程目录,运行rake,编译工程。编译完成后,把products目录拷贝到工程中(如图8),在iOS/MacOSX工程中加入响应的.a文件(如图9)。在Build Settings的Other Linker Flags中加入-ObjC参数(在《iOS开发中的单元测试(一)》中添加GHUnit一节介绍了如何添加-ObjC的参数)。与OCHamcrest类似,在测试用例中定义EXP_SHORTHAND,并引入“Expecta.h”(如图10)。
图8,加入编译后的头文件列表

图9,加入Library文件
图10,用例中引入Expecta.
· 预定义规则
Expecta提供的预定义规则只有20条,远远少于OCHamcrest提供的预定义规则。由于Expecta的匹配规则对匹配对象没有要求,因此没有提供像OCHamcrest中针对某种对象的特定规则。
在Expecta的github首页可以看到全部预定义规则列表。举几个较有特点的规则为例:
expect(x).to.beCloseToWithin(y, z),x距离y的距离小于z
expect(x).to.beTruthy(), x是否为真(或非空);
expect(x).to.beFalsy(),x是否为假(或空/零);
expect(^{ /* code */ }).to.raiseAny(),该Block是否抛出异常;
expect(^{ /* code */ }).to.raise(@"ExceptionName"),该Block是否抛出给定名字异常。 |
此外,通过.notTo或.toNot对规则取反进行匹配,如:expect(x).notTo.equal(y)。
通过.will或.willNot进行异步匹配,即在超时时间(默认超时1秒,也可通过[Expecta setAsynchronousTestTimeout:x]设定)之前满足匹配规则即可,如:expect(x).will.beNil()。
· 撰写用例
Expecta不使用类似assertThat类似的辅助断言方法,而是直接使用expecta.语法匹配。
仍然以GHUnit测试用例为例,测试一个数字n,是否在5附近,距离小于2,即处在[3,7]区间内(如图11)。
图11,Expecta测试用例
Expecta不支持匹配规则的联合使用。
· 辅助方法
Expecta也有语法Sugar:to。
· 自定义规则
Expecta的自定义规则有两种方式,静态规则和动态规则。
定义静态规则:
Expecta的匹配规则不是一个类,是通过框架提供的宏定义来实现的,操作比定义OCHamcrest规则简单不少。仍以OCHamcrest中的判断一个Man实例是否有名为“Joe”的好友。
通过EXPMatcherInterface()方法定义,该方法有两个参数,规则名和规则参数列表。示例如图12。
图12,扩展规则hasAFriendJoe定义
EXPMacherInterface第二个参数允许通过这样的方式定义列表:(NSString *Foo, int bar)。
在实现中,用EXPMatcherImplementationBegin和EXPMatcherImplementationEnd标示规则实现的头尾。并定义prerequisite、match、failureMessageForTo和failureMessageForNotTo四个Block,分别返回与判断结果,匹配结果,正向匹配出错原因和反相匹配出错原因(如图13)。由于Expecta框架不支持ARC,因此需要在Build Settings中对该.m文件添加 -fno-objc-arc参数。在测试用例中可以通过如下语法调用:
| expect(self.man).hasAFriend(@"Joe"); |
或反相匹配:
expect(self.man).notTo.hasAFriend(@"Joe"); |
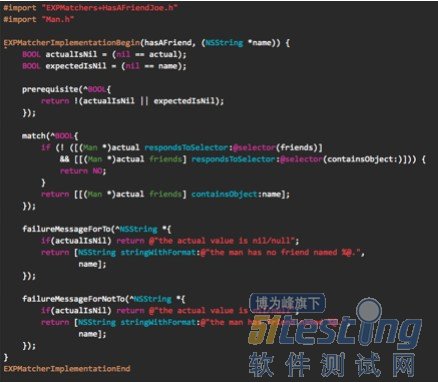
图13,Expecta自定义规则实现
定义动态规则:
动态规则是本质上并不是一段逻辑匹配,而是通过Expecta的语法对匹配对象的属性进行是否为真的断言。例如:
@interfaceLightSwitch:NSObject
@property(nonatomic,assign,getter=isTurnedOn)BOOLturnedOn;
@end
@implementationLightSwitch
@synthesizeturnedOn;
@end |
可以写出如下断言:
建立动态规则:
EXPMatcherInterface(isTurnedOn, (void)); |
就可以通过以下断言判断turendOn属性的真假:
expect(lightSwitch).isTurnedOn(); |
总结
整体看两款匹配引擎,Expecta小巧,敏捷,提供了多种灵活的匹配方式,OCHamcrest从Hamecrest体系继承而来,形式更加中庸,提供的机制更完善。从开发者的角度看,Expecta更好玩,而OCHamcrest更实用,在实验性的项目中我会偏向选择Expecta,而较正式的项目则会使用OCHamcrest。
OCHamcrest结合上一篇《iOS开发中的单元测试(一)》中介绍的单元测试框架GHUnit可以给开发者提供一个完整的单元测试方案,建议开发者在自己的项目中引入这样的质量自控机制,写出健壮的代码。
通过两篇文章介绍了单元测试框架和匹配引擎的一些基础知识,在接下来的文章中,我将结合一个项目,从实战角度详细记述如何开发带有单元测试的iOS项目。
相关文章:
iOS开发中的单元测试(一)
C#之所以容易让人感兴趣,是因为安装完Visual Studio, 就可以很简单的直接写程序了,不需要做如何配置。 对新手来说,这是非常好的“初体验”, 会激发初学者的自信和兴趣。
而有些语言的开发环境的配置非常麻烦, 这让新手有挫败感,没有好的“初体验”,可能会对这门语言心存敬畏, 而失去兴趣。
作为一个.NET程序员, 用惯了Visual Studio。 Visual Studio的强大功能,比如智能提示,自动完成等,可以大量减少我们的记忆量和工作量。如果没有智能提示, 那要疯掉了。 现在年纪大了,根本记不住那些函数名, 必须要依赖IDE的智能提示。
学习Python, 第一件最重要的事,就是选择一款IDE, 最好是能拥有Visual Studio那样的功能。
本文重点介绍为什么使用Eclipse+pydev插件来写Python代码, 以及在Mac上配置Eclipse+Pydev 和Windows配置Eclipse+Pydev
阅读目录
1.好的IDE起码有这些功能
2.编辑器:Python 自带的 IDLE
3.编辑器: VI
4.编辑器: Eclipse + pydev插件
5.安装Python
6.安装JAVA JDK
7.下载Eclipse
8.pydev插件介绍
9.在Eclipse中安装pydev插件
10.配置pydev解释器
11.开始写个代码
好的IDE起码有这些功能
1. 智能提示,(这样不需要记忆函数名,已经类库,通过智能提示就能调用出来, 而且不会把函数名弄错。)
2. 下断点调试 (写程序的过程中,必须可以下断点,查看变量, 一步一步执行。 这样就容易去阅读别人写的代码)
3. 自动完成功能 (可以加快写代码的速度)
4. 语法错误提示,(脚本语言是一步一步执行的, 直到执行才会直到语法错误。 如果IDE能及时发现编译过程中出现的语法错误)
5. 容易阅读代码,(从一个文件, 到另一个文件,支持阅读后退,查看定义什么的。)
编辑器:Python 自带的 IDLE
简单快捷, 学习Python或者编写小型软件的时候。非常有用。
编辑器: VI
必须掌握的, 万能编辑器。 可以做很多程序的开发, ruby, Python都可以。 支持Windows和Mac. 我的80%同事都是用这个写代码。看着他们的屏幕,满屏的代码,很有程序员的感觉。
不知道为什么, 我个人不是很习惯。 可能是习惯了Visual Studio 这样的图形界面。
但是这个的基本操作还是要会的。 比如要编辑一个文件的时候, 可以用VI来编辑。 方便快捷。 用VI来做大型的开发, 我个人不是很习惯
编辑器: Eclipse + pydev插件
1. Eclipse是写JAVA的IDE, 这样就可以通用了,学习代价小。 学会了Eclipse, 以后写Python或者JAVA 都可以。
2. Eclipse, 功能强大。
3. Eclipse跨平台, 可以在Mac上和Windows运行
安装Python
下载地址:http://www.python.org/
Python 有 Python 2 和 Python 3 两个版本。 语法有些区别。 保险起见, 我安装Python 2.7.5
安装JAVA JDK
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
Eclipse 需要这个安装好JAVA JDK后才能运行
下载Eclipse
http://www.eclipse.org/downloads/ 到这下载。
下载完后,解压就可以直接使用, Eclipse不需要安装。
pydev插件介绍
pydev插件的官方网站: http://www.pydev.org/
在Eclipse中安装pydev插件
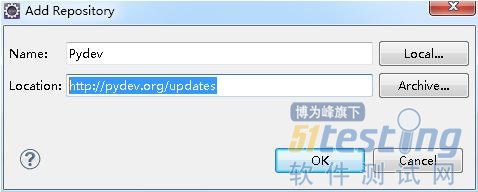
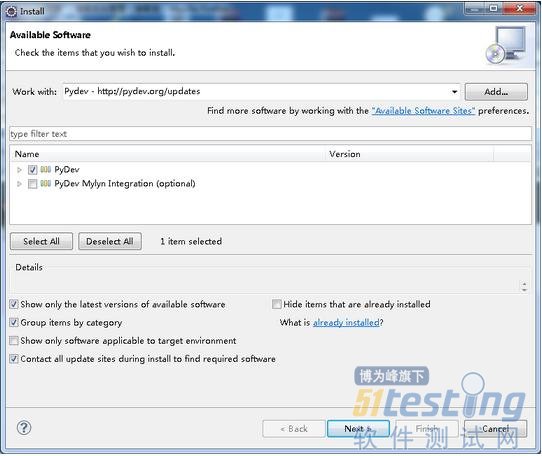
启动Eclipse, 点击Help->Install New Software... 在弹出的对话框中,点Add 按钮。 Name中填:Pydev, Location中填http://pydev.org/updates
然后一步一步装下去。 如果装的过程中,报错了。 就重新装。
配置pydev解释器
安装好pydev后, 需要配置Python解释器。
在Eclipse菜单栏中,点击Windows ->Preferences.
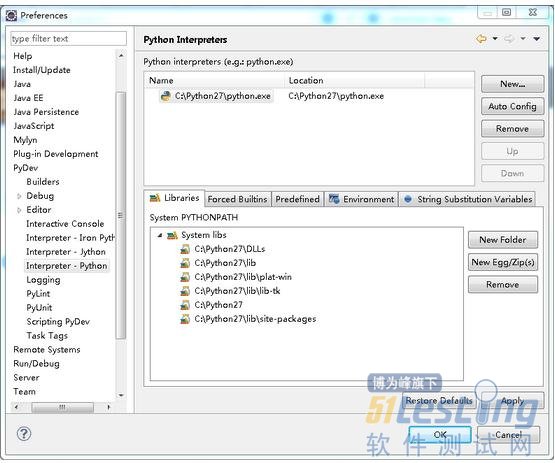
在对话框中,点击pyDev->Interpreter - Python. 点击New按钮, 选择python.exe的路径, 打开后显示出一个包含很多复选框的窗口. 点OK
如果是Mac系统, 点击“Auto Config” 按钮
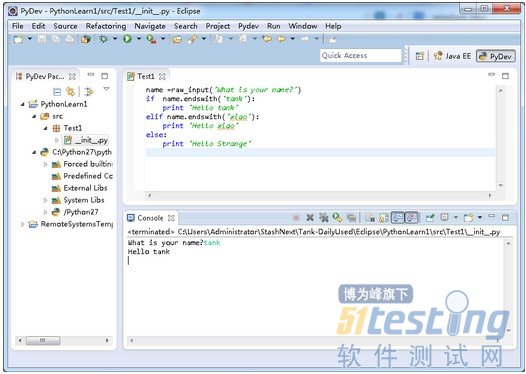
开始写代码
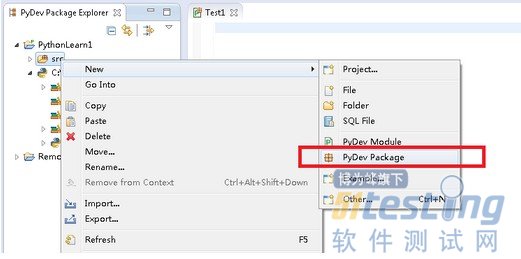
启动Eclipse,创建一个新的项目, File->New->Projects... 选择PyDev->PyDevProject 输入项目名称.
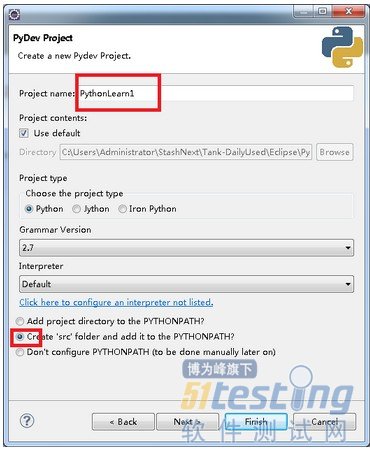
新建 pyDev Package. 就可以写代码了。
----//前言
对于,我们做测试的新手来说,自动化测试一直是一个比较高级的领域,当然是相对于手工测试来说。最近,对自动化测试产生了兴趣。不,具体点应该是对selenium工具产生了兴趣。为什么不是QTP呢,之前,QTP也有学习,后来还买了本《QTP自动化测试进阶指南》,看了几天,不知为什么看不下去。嗯!我一直偏爱于开源的技术和工具。最早用LR做性能测试,后来发现了JMeter那个小工具后,基本上能用JMeter解决的问题,就不在用LR了。开源的东西好处多多,当然了不足也多多。这里就不啰嗦了。呵呵。
下面说说selenium吧!想学一样东西,找相关学习资料是第一步。说说我觉得比较好的资料:《selenium私房菜系列》、selenium官方文档、《selenium 1.0 testing tools 》。不过,我还是买了一本书,我把在当当网的评论贴过来。
"本来想买,后来听朋友说,内容行间距很大,有凑页数的意思,前面部分是在翻译(selenium)官网的文档,包括后面也?有真正写出作者公司的实战经验。打开一看基本和朋友说的一样。为什么后来又要买了,有几分无奈在里面。selenium 的中文资料并不多,网上的都是零散的皮毛,本人英语很差,所以,英文的资料看起来太吃力。《selenium 1.0 testing tools 》其实是一本很好的书,可惜没有中文的,其实可以慢慢啃,但selenium 2.0都出来了,selenium RC 已经被selinum server替代,又加了很多新技术,跟不上啊。所以,只能选了这本书,希望对我有所帮助。" 下面我的笔记也算是基于《零成本实现web自动化测试---基于seleinum与Bromine》这本书的。
----//认识IDE面板
关于selenium IDE的安装,请参考我的上一篇文章《selenium RC 配置》
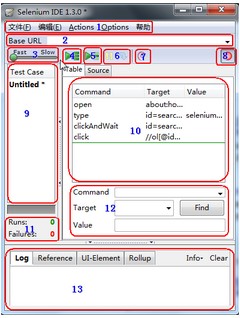
为了方便简洁,我们就按照上图的数字标记介绍:
1、文件:创建、打开和保存测试案例和测试案例集。编辑:复制、粘贴、删除、撤销和选择测试案例中的所有命令。Options : 用于设置seleniunm IDE。
2、用来填写被测网站的地址。
3、速度控制:控制案例的运行速度。
4、运行所有:运行一个测试案例集中的所有案例。
5、运行:运行当前选定的测试案例。
6、暂停/恢复:暂停和恢复测试案例执行。
7、单步:可以运行一个案例中的一行命令。
8、录制:点击之后,开始记录你对浏览器的操作。
9、案例集列表。
10、测试脚本;table标签:用表格形式展现命令及参数。source标签:用原始方式展现,默认是HTML语言格式,也可以用其他语言展示。
11、查看脚本运行通过/失败的个数。
12、当选中前命令对应参数。
13、日志/参考/UI元素/Rollup
日志:当你运行测试时,错误和信息将会自定显示。
参考:当在表格中输入和编辑selenese命令时,面板中会显示对应的参考文档。
UI元素/Rollup:参考帮助菜单中的,UI-Element Documentation。
----//编辑命令
selenium为我们录制的脚本不是100%符合我们的需求的,所以,编辑录制的脚本是必不可少的工作。
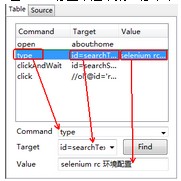
1. 编辑一行命令或注释。
在Table标签下选中某一行命令,命令由command、Target、value三部分组成。可以对这三部分内容那进行编辑。
2. 插入命令。
在某一条命令上右击,选择“insert new command”命令,就可以插入一个空白,然后对空白行进程编辑。
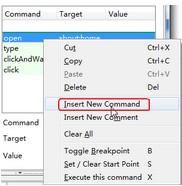
3. 插入注解
以上面同样的方式右击选择“insert new comment”命令插入注解空白行,本行内容不被执行,可以帮助我们更好的理解脚本,插入的内容以紫色字体显示。
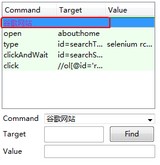
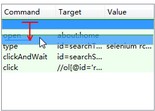
4. 移动命令或注解
有时我们需要移动某行命令的顺序,我们只需要左击鼠标拖动到相应的位置即可。
----//录制我们的第一个脚本
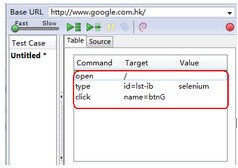
我们的录制流程:
用火狐浏览器,打开一个新的标签-----输入谷歌网址(http://www.google.com.hk/)----在搜索框输入:selenium----点击“google搜索”按钮。
注:注意开启和关闭selenium IDE面板上的红色圆形的录制按钮。
录制的脚本:
----//调试脚本
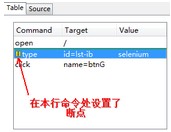
1. 设置断点。
要设置断点,先选择一行命令,点击鼠标右键,在下拉菜单中选择“Toggle Breakpoint”命令,点击“运行”按钮,脚本会运行到断点处停止。用过myecilpse的debug功能来调试脚本的同学懂的!
2. 通过页面源代码来调试脚本
很多情况下,调试自动化测试案例都离不开查看页面源代码,我们可以借助firefox的firebug工具,关于firebug的安装(浏览器菜单栏---工具---查看组件---搜索firebug---安装并重启浏览器即可)。
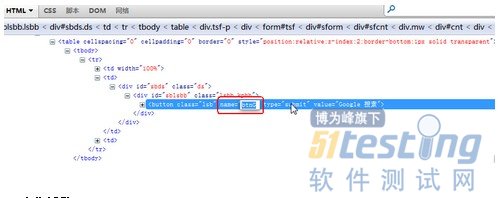
如:我们不确定或想获得谷歌搜索按钮的属性。在按钮上右击---查看元素
在浏览器下方打开的firebug工具里面,就可以查看按钮代码了。
3. 定位辅助
当selenium IDE录制脚本时,它会存储额外的信息,支持用户挑选其他格式的定位器来代替默认格式的定位器,这种特殊性对于学习定位器很有用。
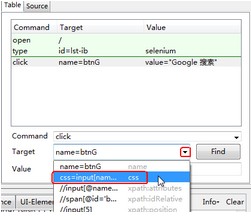
我们可以选择其他的命令来代替“name=btnG” 命令,当然,脚本依然是可以运行的。
关于 selenium IDE一些基础的东西就将这些。下一篇内容在准备中。
结束
selenium 是一个web的自动化测试工具,不少学习功能自动化的同学开始首选selenium ,相因为它相比QTP有诸多有点:
* 免费,也不用再为破解QTP而大伤脑筋
* 小巧,对于不同的语言它只是一个包而已,而QTP需要下载安装1个多G 的程序。
* 这也是最重要的一点,不管你以前更熟悉C、 java、ruby、python、或都是C# ,你都可以通过selenium完成自动化测试,而QTP只支持VBS
* 支持多平台:windows、linux、MAC ,支持多浏览器:ie、ff、safari、opera、chrome
* 支持分布式测试用例的执行,可以把测试用例分布到不同的测试机器的执行,相当于分发机的功能。
关于selenium的基础知识与java平台的结合,我之前写过一个《菜鸟学习自动化测试》系列,最近学python,所以想尝试一下selenium的在python平台如何搭建;还好这方法的文章很容易,在此将搭建步骤整理分享。
搭建平台windows
准备工具如下:
-------------------------------------------------------------
下载python
http://python.org/getit/
下载setuptools 【python的基础包工具】
http://pypi.python.org/pypi/setuptools
下载pip 【python的安装包管理工具】
https://pypi.python.org/pypi/pip
-------------------------------------------------------------
因为版本都在更新,pyhton选择2.7.xx ,setuptools 选择你平台对应的版本,pip 不要担心tar.gz 在windows下一样可用。
安装步骤:
1、python的安装 ,这个不解释,exe文件运行安装即可,既然你选择python,相信你是熟悉python的,我安装目录C:\Python27
2、setuptools 的安装也非常简单,同样是exe文件,默认会找到python的安装路径,将安装到C:\Python27\Lib\site-packages 目录下
3、安装pip ,我默认解压在了C:\pip-1.3.1 目录下
4、打开命令提示符(开始---cmd回车)进入C:\pip-1.3.1目录下输入:
C:\pip-1.3.1 > python setup.py install
(如果提示python不是内部或外部命令!别急,去配置一下环境变量吧)
修改我的电脑->属性->高级->环境变量->系统变量中的PATH为: 变量名:PATH 变量值:;C:\Python27 |
5、再切换到C:\Python27\Scripts 目录下输入:
C:\Python27\Scripts > easy_install pip
6、安装selenium,(下载地址: https://pypi.python.org/pypi/selenium )
如果是联网状态的话,可以直接在C:\Python27\Scripts 下输入命令安装:
C:\Python27\Scripts > pip install -U selenium
如果没联网(这个一般不太可能),下载selenium 2.33.0 (目前的最新版本)
并解压把整个目录放到C:\Python27\Lib\site-packages 目录下。
7、下载并安装(http://www.java.com/zh_CN/download/chrome.jsp?locale=zh_CN)什么?你没整过java,参考其它文档吧!这不难。
8、 下载selenium 的服务端(https://code.google.com/p/selenium/)在页面的左侧列表中找到
selenium-server-standalone-XXX.jar
对!就是这个东西,把它下载下来并解压;
在selenium-server-standalone-xxx.jar目录下使用命令 java -jar selenium-server-standalone-xxx.jar启动(如果打不开,查看是否端口被占 用:netstat -aon|findstr 4444)。
恭喜~! 你前期工作已经做了,上面的步骤确实有些繁琐,但是并不难,不过我们已经完成成了,下面体验一下成果吧! 拿python网站上的例子:
from selenium import webdriver from selenium.common.exceptions import NoSuchElementException from selenium.webdriver.common.keys import Keys import time browser = webdriver.Firefox() # Get local session of firefox browser.get("http://www.yahoo.com") # Load page assert "Yahoo!" in browser.title elem = browser.find_element_by_name("p") # Find the query box elem.send_keys("seleniumhq" + Keys.RETURN) time.sleep(0.2) # Let the page load, will be added to the API try: browser.find_element_by_xpath("//a[contains(@href,'http://seleniumhq.org')]") except NoSuchElementException: assert 0, "can't find seleniumhq" browser.close()
(运行过程中如果出现错误:
WebDriverException: Message: u'Unexpected error launching Internet Explorer.
Protected Mode settings are not the same for all zones. Enable Protected Mo
de must be set to the same value (enabled or disabled) for all zones.'
更改IE的internet选项->安全,将Internet/本地Internet/受信任的站定/受限制的站点中的启用保护模式全部去 掉勾,或者全部勾上。)
-----------------------------------------
selenium + python的一份不错文档
http://selenium.googlecode.com/git/docs/api/py/index.html
====================================如果想通过其它浏览器(IE Chrome)运行脚本==========================================
安装Chrome driver
chrome driver的下载地址在这里。
1. 下载解压,你会得到一个chromedriver.exe文件(我点开,运行提示started no prot 9515 ,这是干嘛的?端口9515被占了?中间折腾了半天),后来才知道需要把这家伙放到chrome的安装目录下...\Google\Chrome\Application\ ,然后设置path环境变量,把chrome的安装目录(我的:C:\Program Files\Google\Chrome\Application),然后再调用运行:
# coding = utf-8 from selenium import webdriver driver = webdriver.Chrome() driver.get('http://radar.kuaibo.com') print driver.title driver.quit()又报了个错:
Chrome version must be >= 27.0.1453.0\n (Driver info: chromedriver=2.0,platform=Windows NT 5.1 SP3 x86)
说我chrome的版本没有大于27.0.1453.0 ,这个好办,更新到最新版本即可。
安装IE driver
在新版本的webdriver中,只有安装了ie driver使用ie进行测试工作。
ie driver的下载地址在这里,记得根据自己机器的操作系统版本来下载相应的driver。
暂时还没尝试,应该和chrome的安装方式类似。
记得配置IE的保护模式
如果要使用webdriver启动IE的话,那么就需要配置IE的保护模式了。
把IE里的保护模式都选上或都勾掉就可以了。