
为什么选python?
之前的菜鸟系列是基于java的,一年没学其实也忘的差不多了,目前所测的产品部分也是python写的,而且团队也在推广python ,其实就测试人员来说,python也相当受欢迎。易学,易用。翻翻各测试招聘,python出现的概率也颇高。
平台搭建:
前一篇中已经介绍,如果你也想体验一下自动化魅力,那就赶快搭建自己的环境吧~!
selenium + python自动化测试环境搭建
第一个脚本:
下面看看python 穿上selenium webdriver 是多么的性感:
# coding = utf-8 from selenium import webdriver
browser = webdriver.Firefox()
browser.get(http://www.baidu.com)
browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
browser.quit() |
怎么样?相信不懂代码的人都能看懂,但还是请容我在这里啰嗦一下每一句的含义:
# coding = utf-8
可加可不加,开发人员喜欢加一下,防止乱码嘛。
from selenium import webdriver
要想使用selenium的webdriver 里的函数,首先把包导进来嘛
browser = webdriver.Firefox()
我们需要操控哪个浏览器呢?Firefox ,当然也可以换成Ie 或 Chrome 。browser可以随便取,但后面要用它操纵各种函数执行。
browser.find_element_by_id("kw").send_keys("selenium")
一个控件有若干属性id 、name、(也可以用其它方式定位),百度输入框的id 叫kw ,我要在输入框里输入 selenium 。多自然语言呀!
browser.find_element_by_id("su").click()
搜索的按钮的id 叫su ,我需要点一下按钮( click() )。
browser.quit()
退出并关闭窗口的每一个相关的驱动程序,它还有个类似的表弟。
browser.close()
关闭当前窗口 ,用哪个看你的需求了。
添加休眠
什么?你说刚才太快没看清浏览器的操作过程。请time出马,让他跑慢点。
# coding = utf-8 from selenium import webdriver
import time #调入time函数 browser = webdriver.Firefox() browser.get(http://www.baidu.com)
time.sleep(0.3) #休眠0.3秒
browser.find_element_by_id("kw").send_keys("selenium")
browser.find_element_by_id("su").click()
time.sleep(3) # 休眠3秒
browser.quit() |
time.sleep() 函数随意插,哪里太快插哪里,再也不用担心看不清脚本的运行过程了。
其实,这个函数的真正用途不是给我们看脚本的运行过程的,有时候网络原因,或页面加载慢。假设搜索框输入框输入了selenium ,搜索按钮还没加载出来,那么脚本就报错。在适当的位置加入time.sleep()有助于减少网络原因造成的脚本执行失败;
输出
什么?在运行脚本的时候,上了个厕所,你都不知道刚才的脚本是否运行成功了。把刚才访问页面的title 打印出来。
# coding = utf-8 from selenium import webdriver driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
print driver.title # 把页面title 打印出来
driver.quit() |
虽然我没看到脚本的执行过程,但我在执行结果里看到了
说明页面正确被我打开了。
更多内容,关注更新.....
为了防止用户的重复登录,在一开始想到的一种方法:
在用户表中添加一个字段,登录后写1,退出后写0.这样子在用户登录进行检查的时候判断这个字段是否为0,如果是0那么就可以登录;但是这样子就又带来了新的问题,如果在用户正在登录的过程中突然断电,那么表中写入的是1,也就是说用户在以后的登录中都不能能够登录系统了。
另外一种方法:在SQL Server中建立全局临时表,如果用户没有登录就建立一个临时表来存放用户,如果已经登录那么就提醒用户此账号已经登录;临时表相比较上面一个方法的好处就在于:当系统与SQL Server数据库的连接断开以后,临时表是可以被系统自动收回的,这样子用户下次登录的时候会再次建立一个临时表并且可以登录成功!
依据第二种思路我们建立一个存储过程:
create proc PROC_FindTemptable
/*
* 寻找以操作员工号命名的全局临时表
* 如无则将out参数置为0并创建该表,如有则将out参数置为1
* 在connection断开连接后,全局临时表会被SQL Server自动回收
* 如发生断电之类的意外,全局临时表虽然还存在于tempdb中,但是已经失去活性
* 用object_id函数去判断时会认为其不存在.
*/
@View_userID char(20),--输入参数 操作员账号
@outResult int out --输出参数( 0:没有登录 1:已经登录)
as
declare @View_sql varchar(100)
--object_id函数判断操作员账号不存在(没有的登录)
if OBJECT_ID ('tempdb.dbo.##'+@View_userID )is null
begin
--创建临时表
set @View_sql ='create table ##'+@View_userid+'(userid char(20))'
exec(@View_sql)
--out参数设置为0(账号没有登录)
set @outResult =0
end
--账号存在
else
--out参数为1
set @outResult =1
--在这个过程中,我们看到如果以用户工号命名的全局临时表不存在时过程会去创建一张并把out参数置为0,如果已经存在则将out参数置为1。
--这样,应用程序中调用该过程时,如果取得的out参数为1时,我们可以毫不客气地跳出一个message告诉用户说”对不起,此工号正被使用!” |
在系统中调用存储过程来实现用户登录的代码:将与数据库的连接和执行存储过程写在一个函数中,然后在客户端调用即可!
Public Function ExecuteProcTestID(ByVal strID As String, ByVal strProc As String) As Integer
Dim myConnection As New SqlConnection(CmdString) '定义连接
Dim Cmd As New SqlCommand '表示SQL命令语句的执行
'连接数据库将存储名称和参数传递给cmd
Cmd.Connection = myConnection
'指明为存储过程
Cmd.CommandType = CommandType.StoredProcedure
Cmd.CommandText = strProc Cmd.Parameters.Add("@View_userID", SqlDbType.VarChar, 20).Value = strID
Cmd.Parameters.Add("@outResult", SqlDbType.VarChar, 20).Direction = ParameterDirection.Output Try
'执行存储过程
Cmd.ExecuteNonQuery()
Return Cmd.Parameters(1).Value()
Catch e As Exception
Return False
End Try
End Function |
8.2.3 Windows操作系统任务、进程关闭技术
前面8.2.2小节向大家介绍了如何监控正在运行的应用和进程的一些方法,本节将介绍在进行性能测试时,为保证与被测试系统数据的准确性,如何关闭一些无用的应用和进程的方法。打开Windows的任务管理,选中要关闭的进程,然后单击“结束进程”按钮,弹出“任务管理器警告”对话框,单击“是”则结束选定的进程,如图8-8~图8-9所示。
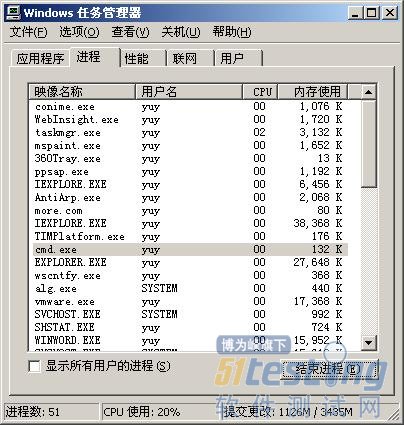
图8-8 “Windows任务管理器”对话框信息
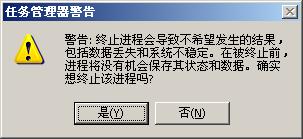
图8-9 “任务管理警告”信息提示框
此外,还可以通过使用Windows的命令行来关闭运行在本地或远程计算机上的所有任务的应用程序和服务列表,并带有进程ID(PID),使用tasklist命令。为了帮助大家使用这个命令,可以输入tasklist/?来查看该命令的帮助信息,显示的信息如下所示:
taskkill [/S system [/U username [/P [password]]]]
{ [/FI filter] [/PID processid | /IM imagename] } [/F] [/T] 描述:
这个命令行工具可用来结束至少一个进程。
可以根据进程 id 或图像名来结束进程。 参数列表:
/S system 指定要连接到的远程系统。
/U [domain\]user 指定应该在哪个用户上下文执行这个命令。
/P [password] 为提供的用户上下文指定密码。如果忽略,提示输入。
/F 指定要强行终止进程。
/FI filter 指定筛选进或筛选出查询的任务。
/PID process id 指定要终止的进程的PID。
/IM image name 指定要终止的进程的图像名。通配符‘*’可用来指定所有图像名。
/T Tree kill: 终止指定的进程和任何由此启动的子进程。
/? 显示帮助/用法。 筛选器:
筛选器名 有效运算符 有效值
----------- --------------- --------------
STATUS eq, ne 运行 | 没有响应
IMAGENAME eq, ne 图像名
PID eq, ne, gt, lt, ge, le PID 值
SESSION eq, ne, gt, lt, ge, le 会话编号
CPUTIME eq, ne, gt, lt, ge, le CPU 时间,格式为
hh:mm:ss。
hh-时,
mm-钟,ss-秒
MEMUSAGE eq, ne, gt, lt, ge, le 内存使用,单位为 KB
USERNAME eq, ne 用户名,格式为
[domain\]user
MODULES eq, ne DLL 名
SERVICES eq, ne 服务名
WINDOWTITLE eq, ne 窗口标题 注意: 只有带有筛选器的情况下,才能跟 /IM 切换使用通配符 ‘*’。 注意: 远程进程总是要强行终止,不管是否指定了 /F 选项。 例如:
TASKKILL /S system /F /IM notepad.exe /T
TASKKILL /PID 1230 /PID 1241 /PID 1253 /T
TASKKILL /F /IM notepad.exe /IM mspaint.exe
TASKKILL /F /FI "PID ge 1000" /FI "WINDOWTITLE ne untitle*"
TASKKILL /F /FI "USERNAME eq NT AUTHORITY\SYSTEM" /IM notepad.exe
TASKKILL /S system /U domain\username /FI "USERNAME ne NT*" /IM *
TASKKILL /S system /U username /P password /FI "IMAGENAME eq note*" |
为了使大家对该命令的使用有更深刻的认识,这里给大家举几个例子进行说明。
1.示例一
如果应用Tasklist命令查到“Foxmail”应用的进程如
图8-10所示,现在要终止“Foxmail.exe”这个应用进程,可以在控制台执行“taskkill /im foxmail.exe”命令以后,显示如图8-11所示信息,当然也可以应用“taskkill/pid 2912”命令来关闭“Foxmail.exe”程序,如图8-12所示。那么这两条命令有什么区别呢?如果应用程序“TEST”打开了若干个进程,则“Taskkill/IM TEST.exe”命令将关闭该程序的全部进程;而“Taskkill/PID对应pid值”则只关闭该PID所对应的进程。

图8-10 用Tasklist命令显示Foxmail.exe进程的相关信
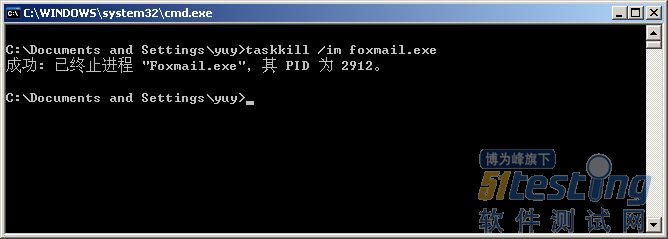
图8-11 用Taskkill命令关闭Foxmail.exe进程的相关信息

图8-12 用Taskkill命令关闭2912进程的相关信息
2.示例二
如果需要终止远程计算机上的某个进程,可以执行命令“taskkill/s 192.168.0.102/u administrator/p beco/im winrar.exe”,这里要关闭的进程IP地址为“192.168.0.102”,因为访问这台远程计算机需要用户名和密码,所以加入了“/p administrator/p beco”,“administrator”、“beco”为远程计算机的用户名和密码,“/im winrar.exe”为要关闭的远程计算机上的应用进程图像名,命令执行完成后,显示如图8-13所示信息。命令执行完毕以后,可以查看远程计算机的winrar应用就被关闭了。

图8-13 用Taskkill命令关闭远程计算机应用进程的相关信息
3.示例三
如果要同时关闭几个进程实例,例如,启动了两个记事本程序和一个电驴程序应用,如图8-14所示。接下来,运行tasklist命令查看所有的任务进程,如图8-15所示信息,可以看到有3个应用进程:2个notepad.exe和1个emule.exe的图像名。如果现在要关闭记事本和电驴程序应用,则可以执行命令“taskkill/im emule.exe/im notepad.exe”,执行完成后,显示如图8-16所示信息。

图8-14 记事本和电驴程序
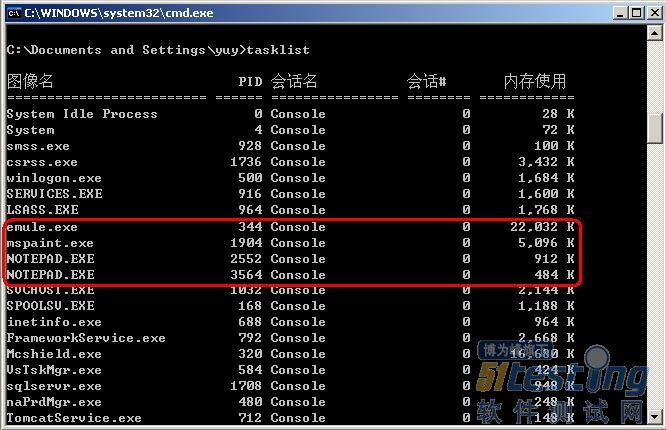
图8-15 tasklist显示所有进程信息

图8-16 taskkill关闭记事本和电驴程序
4.示例四
如果需要批量关闭任务进程,可以使用条件过滤组合,即方便又快捷。这里以关闭记事本进程为例,从图8-17可以看出,记事本的3个实例,pid分别为3544、3556、3568,这时,可以用命令“taskkill/f/fi"pid gt 3543"/fi"pid lt 3570"”来关闭这3个实例。其中命令行中的“gt”和“lt”分别代表“大于”和“小于”,即要关闭pid>3542且pid<3570的任务进程。

图8-17 taskkill过滤参数的应用
8.2.4 Linux操作系统任务、进程监控技术介绍
Linux的发展潜力巨大,一方面,Linux在各行各业中的应用也得到了很好的推广,它的应用已经非常成熟。国际上,如当今世界最大的搜索引擎公司Google应用了1万多台Linux服务器;在国内,电信、银行、文化部、铁路、电力、教育、民航等各大领域也应用了Linux。基于Linux内核的操作系统有很多,这里不给大家逐一介绍,关于Linux部分的样例内容以RedHat 9为例,本书也将它作为讲解的主要操作系统。像Windows操作系统一样,Linux操作系统同样可以对进程、CPU、内存、硬盘等进行监控,因为Linux是开源的,越来越多的组织机构和个人不断地去完善、发展这个操作系统,可以说Linux各个方面不逊色于Windows操作系统。
在给大家介绍Linux进程监控之前,先了解一下有关Linux进程的一些基础知识。
1.Linux进程概念
Linux进程中最知名的属性就是它的进程号(Process Idenity Number,PID)和它的父进程号(parent process ID,PPID)。PID、PPID都是非零正整数。一个PID唯一地标识一个进程。一个进程创建新进程称为创建了子进程(child process)。相反地,创建子进程的进程称为父进程。所有进程追溯其祖先最终都会落到进程号为1的进程身上,这个进程叫做init进程。它是内核自举后第一个启动的进程。init进程的作用是扮演终结父进程的角色。因为init进程永远不会被终止,所以系统总是可以确信它的存在,并在必要的时候以它为参照。如果某个进程在它衍生出来的全部子进程结束之前被终止,就会出现必须以init为参照的情况。此时那些失去了父进程的子进程就都会以init作为它们的父进程。
2.Linux进程在运行中的3种状态
执行(Running)状态:CPU正在执行,即进程正在占用CPU。
就绪(Waiting)状态:进程已经具备执行的一切条件,正在等待分配CPU处理时间。
停止(Stoped)状态:进程不能使用CPU。
3.理解Linux下进程的结构
Linux中一个进程在内存里由3部分的数据组成,就是“数据段”、“堆栈段”和“代码段”,基于I386兼容的中央处理器都有上述3种段寄存器,以方便操作系统的运行,如图8-18所示。

图8-18 Linux进程的结构
代码段是存放了程序代码的数据,假如计算机中有数个进程运行相同的一个程序,那么它们就可以使用同一个代码段。而数据段则存放程序的全局变量、常数以及动态数据分配的数据空间。堆栈段存放的就是子程序的返回地址、子程序的参数以及程序的局部变量。堆栈段包括进程控制块PCB(Process Control Block)中。PCB处于进程核心堆栈的底部,不需要额外分配空间。
4.Linux进程的种类
Linux操作系统包括3种不同类型的进程,每种进程都有自己的特点和属性。
● 交互进程:由一个Shell启动的进程。交互进程既可以在前台运行,也可以在后台运行。
● 批处理进程:这种进程和终端没有联系,是一个进程序列。
● 监控进程:也称守护进程,Linux系统启动时启动的进程,并在后台运行。
(未完待续)
版权声明:51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像。51testing软件测试网欢迎与业内同行进行有益的合作和交流,如果有任何有关内容方面的合作事宜,请联系我们。
相关链接:
精通软件性能测试与LoadRunner最佳实战 连载一
精通软件性能测试与LoadRunner最佳实战 连载二
精通软件性能测试与LoadRunner最佳实战 连载三
精通软件性能测试与LoadRunner最佳实战 连载四
摘要: 8.2.5 Linux操作系统进程监控技术 Linux在进程监控方面同样出色,不仅可以通过图形用户界面的管理工具,还可以用命令方式显示进程相关信息。像“Windows的任务管理器”一样,在RedHat 9中可以通过单击“系统工具”→“系统监视器”,启动“系统监视器”,...
阅读全文
摘要: 8.2.5 Linux操作系统进程监控技术 Linux在进程监控方面同样出色,不仅可以通过图形用户界面的管理工具,还可以用命令方式显示进程相关信息。像“Windows的任务管理器”一样,在RedHat 9中可以通过单击“系统工具”→“系统监视器”,启动“系统监视器”,...
阅读全文
导读:本文不讨论单元测试是什么,或者它之于一个工程的利弊,我认为单元测试是一个开发者保证产出代码质量的有效工具。本文从使用者的角度对比当下比较流行的两款单元测试框架,给大家提供一些选用建议。如果你还不甚了解单元测试在工程中所起到的作用,或者还不知道TDD的开发模式,可参考:Test-Driven Development和Unit Testing。
本文对比两个iOS开发中常见的单元测试框架:OCUnit,被官方集成进XCode 4.x版本中;GHUnit,被推荐最多的测试框架,带GUI界面。初窥两款测试框架非常相似,而上手使用就会发现其中的区别。细节上的区别使两款框架在不同角度各有优劣。
OCUnit
OCUnit是XCode 4.x集成的单元测试框架,OCUnit中的测试分为两类,一类称为Logic Tests,另一类称为Application Tests。Logic Tests更倾向于所谓的白盒测试,用于测试工程中较细节的逻辑;Application Tests更倾向于黑盒测试,或接口测试,用于测试直接与用户交互的接口。
·添加单元测试
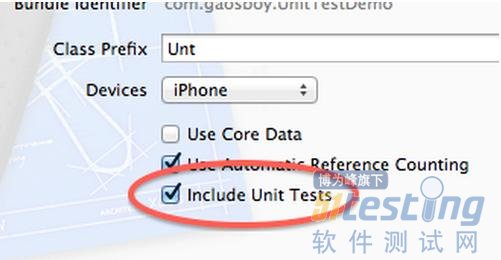
OCUnit是XCode集成的,所以其与工程的结合理应是最好的,添加到工程中的成本也理应最低。使用XCode创建新工程的流程中就有一个“Include Unit Tests”的选项(如图1),新的工程就会自动生成一个Logic Tests。
向已存在的工程中添加OCUnit Logic Tests也不复杂,只需要添加一个类型为:“Cocoa Touch Unit Testing Bundle”的Target即可(如图2)。
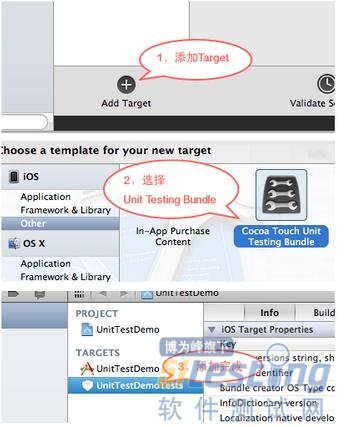
图2,向已存在的工程中添加OCUnit测试
向已有工程中添加一个测试Target时,XCode会自动生成一个Scheme,运行单元测试用例和Build原工程需要切换不同的Scheme。如果认为切换Scheme非常麻烦,也可以在添加Target之前,在“Manage Scheme”菜单中取消“Autocreate schemes”(如图3)。
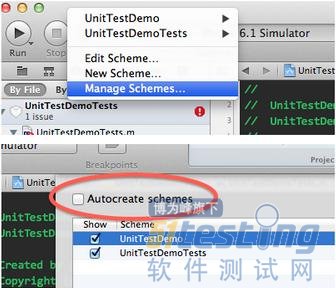
图3,添加Target不创建Scheme
Application Tests要基于Logic Tests做一些修改。一般来说一个工程既需要Logic Tests也需要Application Tests,所以建议按照上述方法添加一个单独的Target,然后执行以下操作(如图4):
1. 在Build Settings中搜索“bundle loader”,设置为:$(BUILT_PRODUCTS_DIR)/APP_NAME.app/APP_NAME(APP_NAME是应用名)
2. 再搜索“test host”,设置为:$(BUNDLE_LOADER)
3. 在Build Phases-Target Dependencies中添加依赖,选择主程序Target
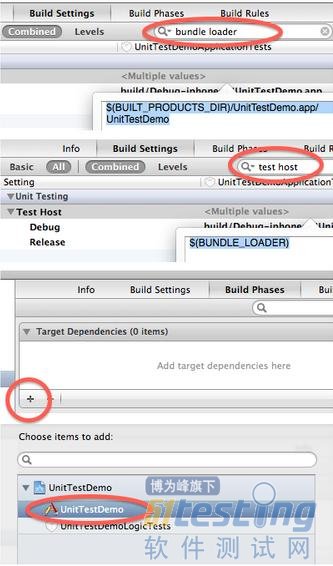
图4,添加一个Application Tests
·创建测试用例
OCUnit的测试用例最常用的方法有三个
1. - (void)setUp:每个test方法执行前调用
2. - (void)tearDown:每个test方法执行后调用
3. - (void)testXXX:命名为XXX的测试方法
添加Target之时XCode已经自动创建了一个测试用例类:UnitTestDemoTests,其中UnitTestDemo是工程的名字,该类中已经包含了setUp,tearDown和testExample三个方法。
通过command+n,选择“Objective-C test case class”创建一个新的测试用例类(如图5)。通过XCode创建的测试用例类是一个继承自SenTestCase(OCUnit由SEN:TE公司开发,因此基类命名为SenTestCase)的空类,需要模仿UnitTestDemoTests编写测试方法。
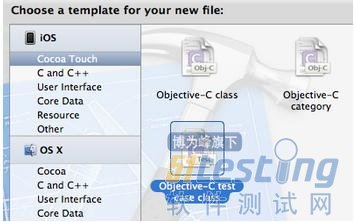
图5,创建一个测试用例类
开发者可以自己实现无返回值,且命名规则为testXXX的实例方法,并使用框架提供的大量断言方法。
Logic Tests与Application Tests的区别主要在setUp方法,Logic Tests只需在setUp方法中初始化一些测试数据,而Application Tests需要在setUp方法中获取主应用的AppDelegate,供test方法调用。
值得注意的是,OCUnit的test bundle是侵入主应用的,因此在使用过程中要十分注意,不要让单元测试的资源覆盖主应用资源,造成诡异的Bug。
·运行测试
由于OCUnit是集成在XCode中的框架,因此在XCode中运行也比较方便。切换到单元测试的scheme(如果与工程共用scheme则无需切换),Product->Test(或直接使用快捷键command+u),框架会自动查找所有工程中SenTestCase的子类,运行其中全部命名类似testXXX的无返回值方法。
·测试反馈
OCUnit的失败方法会通过Console和XCode Issues两个位置反馈,通过XCode Issues可以直接定位到出现错误的单元测试代码行。Issue的提示信息就是在单元测试断言方法中定义的description。
GHUnit
GHUnit是一款Objective-C的测试框架,除了支持iOS工程还支持OSX的工程,但OSX不在本文的讨论范围。GHUnit不同于OCUnit,它提供了GUI界面来操作测试用例,而且也不区分Logic Tests和Application Tests。
·添加单元测试
与集成进XCode的OCUnit相比,GHUnit的添加过程略显复杂。首先在上下载GHUnit的框架包,当前的For iOS的最新版本是0.5.6,解压后是一个GHUnitIOS.framework的文件夹。
打开已经存在的工程,添加一个EmptyApplication Target,并在新Target中添加刚刚下载的GHUnitIOS.framework(如图6、7)。
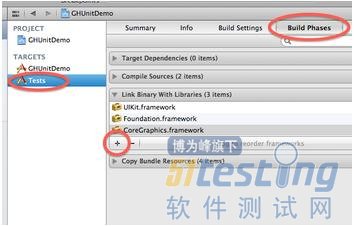
图6,在新Target中添加GHUnitIOS.framework
在Build Phases中添加非官方框架并不会把框架文件拷贝到工程目录,而是只做一个链接,所以建议在添加之前先把框架拷贝到工程目录下。
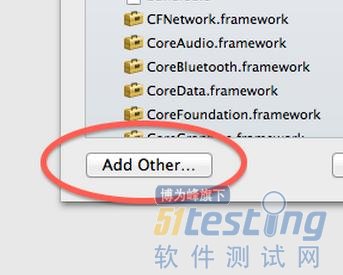
图7,选择GHUnitIOS.framework
接下来用相同的方法添加框架依赖的其他库:“QuartzCore.framework”。
在Build Settings中搜索“linker flags”,设置Other Linker Flags - Debug - 添加一个支持全架构和全版本SDK的标示“-ObjC -all_load”(如图8)。
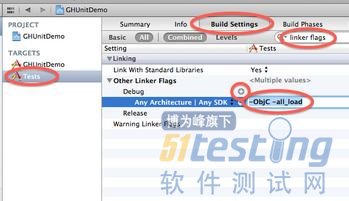
图8,设置linker flags
删除Tests Target中的AppDelegate(.h和.m一起删除)。修改main函数,支持GHUnitIOS,导入GHUnitIOSAppDelegate代替原来的AppDelegate,修改UIApplicationMain的参数(如图9)。
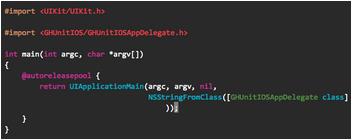
图9,修改main函数
至此已经完成了GHUnit的添加,选择新建Target同时创建的scheme,直接Build and Run即可在设备或Simulator中启动一个新的App(如图10),即该单元测试的App。
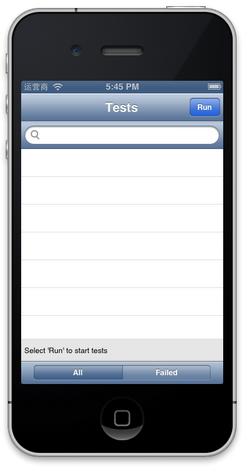
图10,单元测试App
创建测试用例
创建GHUnit测试用例与创建OCUnit测试用例相似。
新建一个Objective-C Class文件,继承自GHTestCase,在XCode生成的.h文件中不会导入GHUnit.h文件,需要开发者自行导入“#import <GHUnitIOS/GHUnit.h>”。
GHUnit框架提供断言方法比OCUnit更加丰富,开发用例也就可以做的更加细致,更有利查找/定位错误。
测试方法的命名规则与OCUnit一样,是以test开头的无返回值方法:- (void)testXXX。而常用的方法除了上述提到的setUp和tearDown,GHUnit还提供了setUpClass和tearDownClass两个方法,在该用例运行前和结束后调用。另外,刚刚提到GHUnit不区分Logic Tests和Application Tests,所以在setUp和tearDown方法中也就不存在设置的区分。
·运行测试
运行GHUnit需要分两步,首先编译并安装单元测试App到设备或Simulator里(如图11),创建了两个用例,每个用例中分别有一个方法。
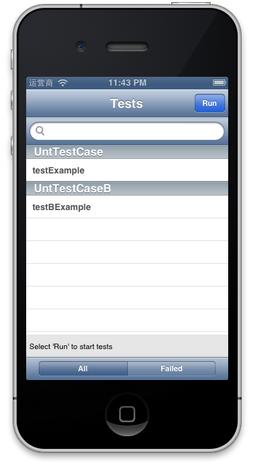
图11,两个用例的GHUnit App
在App中可以通过点击右上角的Run按钮运行全部用例,框架会查找所有以testXXX命名的无返回值方法,并执行。或点击TableView中的某个Cell运行单独的测试方法。
·测试反馈
断言失败测试未通过的方法在App中会标记为红色,并给出每一个方法的运行时间。在Console中会打印出详细的出错信息,包括:异常类型,出错文件,位置,以及断言方法中指定的出错原因。更重要的是,出错时的程序堆栈内容(如图12)。
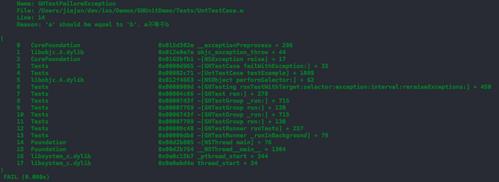
图12,未通过测试的方法,Console中的内容
GHUnit通过Console中的内容给开发者提供帮助,可以快速定位程序出错的位置,这一点比OCUnit做的要好。
总结
GHUnit在安装上确实显得有些麻烦,无法跟集成在XCode里的OCUnit相比。 但从开发者的角度讲,我更喜欢GHUnit带来的体验,GUI的操作界面可以脱离IDE单独运行,支持运行单一测试方法和运行全部用例的,打印出错堆栈可以更快定位到问题所在。
本文简单介绍了两款框架的安装与入门,可以初步了解其各自特点,在接下来的文章中将会更加详细的介绍如何使用框架进行单元测试,以及框架中的一些高级功能。此外,后续还将向大家介绍另外的与这两款框架区别更加明显的单元测试框架。
网站访问量越来越大,MySQL自然成为瓶颈。因此MySQL 的优化成为我们需要考虑的问题,第一步自然想到的是 MySQL 系统参数的优化,作为一个访问量很大的网站(日20万人次以上)的数据库系统,不可能指望 MySQL 默认的系统参数能够让 MySQL运行得非常顺畅。
(1)、back_log: 要求MySQL 能有的连接数量。当主要MySQL线程在一个很短时间内得到非常多的连接请求,这就起作用,然后主线程花些时间(尽管很短)检查连接并且启动一个新线程。back_log值指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。只有如果期望在一个短时间内有很多连接,你需要增加它,换句话说,这值对到来的TCP/IP连接的侦听队列的大小。你的操作系统在这个队列大小上有它自己的限制。 试图设定back_log高于你的操作系统的限制将是无效。当你观察你的主机进程列表,发现大量 264084 | unauthenticated user |xxx.xxx.xxx.xxx | NULL | Connect | NULL | login | NULL 的待连接进程时,就要加大 back_log的值了。默认数值是50,我把它改为500。
(2)、interactive_timeout: 服务器在关闭它前在一个交互连接上等待行动的秒数。一个交互的客户被定义为对mysql_real_connect()使用 CLIENT_INTERACTIVE 选项的客户。默认数值是28800,我把它改为7200。
(3)、key_buffer_size: 索引块是缓冲的并且被所有的线程共享。key_buffer_size是用于索引块的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写),到你能负担得起那样多。如果你使它太大,系统将开始换页并且真的变慢了。默认数值是8388600(8M),我的MySQL主机有2GB内存,所以我把它改为402649088(400MB)。
(4)、max_connections: 允许的同时客户的数量。增加该值增加mysqld 要求的文件描述符的数量。这个数字应该增加,否则,你将经常看到 Toomany connections 错误。 默认数值是100,我把它改为1024 。
(5)、record_buffer: 每个进行一个顺序扫描的线程为其扫描的每张表分配这个大小的一个缓冲区。如果你做很多顺序扫描,你可能想要增加该值。默认数值是131072(128K),我把它改为16773120 (16M)
(6)、sort_buffer: 每个需要进行排序的线程分配该大小的一个缓冲区。增加这值加速ORDER BY或GROUP BY操作。默认数值是2097144(2M),我把它改为16777208 (16M)。
(7)、table_cache: 为所有线程打开表的数量。增加该值能增加mysqld要求的文件描述符的数量。MySQL对每个唯一打开的表需要2个文件描述符。默认数值是64,我把它改为512。
(8)、thread_cache_size: 可以复用的保存在中的线程的数量。如果有,新的线程从缓存中取得,当断开连接的时候如果有空间,客户的线置在缓存中。如果有很多新的线程,为了提高性能可以这个变量值。通过比较 Connections 和 Threads_created 状态的变量,可以看到这个变量的作用。我把它设置为 80。
(10)、wait_timeout: 服务器在关闭它之前在一个连接上等待行动的秒数。默认数值是28800,我把它改为7200。
注:参数的调整可以通过修改/etc/my.cnf文件并重启 MySQL 实现。这是一个比较谨慎的工作,上面的结果也仅仅是我的一些看法,你可以根据你自己主机的硬件情况(特别是内存大小)进一步修改。
mysql> showglobal status;
可以列出mysql服务器运行各种状态值,另外,查询mysql服务器配置信息语句:
mysql> showvariables;
一、慢查询
mysql> showvariables like ‘%slow%‘;
+------------------+-------+
| variable_name | value |
+------------------+-------+
|log_slow_queries | on |
|slow_launch_time | 2 |
+------------------+-------+
mysql> showglobal status like ‘%slow%‘;
+---------------------+-------+
| variable_name | value |
+---------------------+-------+
|slow_launch_threads | 0 |
| slow_queries | 4148 |
+---------------------+-------+ |
配置中打开了记录慢查询,执行时间超过2秒的即为慢查询,系统显示有4148个慢查询,你可以分析慢查询日志,找出有问题的sql语句,慢查询时间不宜设置过长,否则意义不大,最好在5秒以内,如果你需要微秒级别的慢查询,可以考虑给mysql打补丁:http://www.percona.com/docs/wiki/release:start,记得找对应的版本。
打开慢查询日志可能会对系统性能有一点点影响,如果你的mysql是主-从结构,可以考虑打开其中一台从服务器的慢查询日志,这样既可以监控慢查询,对系统性能影响又小。
二、连接数
经常会遇见”mysql: error 1040: too many connections”的情况,一种是访问量确实很高,mysql服务器抗不住,这个时候就要考虑增加从服务器分散读压力,另外一种情况是mysql配置文件中max_connections值过小:
mysql> show variables like ‘max_connections‘;
+-----------------+-------+
| variable_name | value |
+-----------------+-------+
| max_connections | 256 |
+-----------------+-------+ |
这台mysql服务器最大连接数是256,然后查询一下服务器响应的最大连接数:
mysql服务器过去的最大连接数是245,没有达到服务器连接数上限256,应该没有出现1040错误,比较理想的设置是
最大连接数占上限连接数的85%左右,如果发现比例在10%以下,mysql服务器连接数上限设置的过高了。
三、key_buffer_size
key_buffer_size是对myisam表性能影响最大的一个参数,下面一台以myisam为主要存储引擎服务器的配置:
mysql> show variables like‘key_buffer_size‘;+-----------------+------------+
| variable_name | value |
+-----------------+------------+
| key_buffer_size | 536870912 |
+-----------------+------------+ |
分配了512mb内存给key_buffer_size,我们再看一下key_buffer_size的使用情况:
mysql> show global status like ‘key_read%‘;
+------------------------+-------------+
| variable_name | value |
+------------------------+-------------+
| key_read_requests | 27813678764 |
| key_reads | 6798830 |
+------------------------+-------------+ |
一共有27813678764个索引读取请求,有6798830个请求在内存中没有找到直接从硬盘读取索引,计算索引未命中缓存的概率:
key_cache_miss_rate = key_reads / key_read_requests * 100%
比如上面的数据,key_cache_miss_rate为0.0244%,4000个索引读取请求才有一个直接读硬盘,已经很bt了,key_cache_miss_rate在0.1%以下都很好(每1000个请求有一个直接读硬盘),如果key_cache_miss_rate在0.01%以下的话,key_buffer_size分配的过多,可以适当减少。
mysql服务器还提供了key_blocks_*参数:
mysql> show global status like ‘key_blocks_u%‘;
+------------------------+-------------+
| variable_name | value |
+------------------------+-------------+
| key_blocks_unused | 0 |
| key_blocks_used | 413543 |
+------------------------+-------------+ |
key_blocks_unused表示未使用的缓存簇(blocks)数,key_blocks_used表示曾经用到的最大的blocks数,比如这台服务器,所有的缓存都用到了,要么增加key_buffer_size,要么就是过渡索引了,把缓存占满了。比较理想的设置:
key_blocks_used / (key_blocks_unused + key_blocks_used) * 100% ≈ 80% |
四、临时表
mysql> show global status like ‘created_tmp%‘;
+-------------------------+---------+
| variable_name | value |
+-------------------------+---------+
| created_tmp_disk_tables | 21197 |
| created_tmp_files | 58 |
| created_tmp_tables | 1771587 |
+-------------------------+---------+ |
每次创建临时表,created_tmp_tables增加,如果是在磁盘上创建临时表,created_tmp_disk_tables也增加,created_tmp_files表示mysql服务创建的临时文件文件数,比较理想的配置是:
created_tmp_disk_tables /created_tmp_tables * 100% <= 25%比如上面的服务器created_tmp_disk_tables / created_tmp_tables * 100% = 1.20%,应该相当好了。我们再看一下mysql服务器对临时表的配置:
mysql> show variables where variable_name in (‘tmp_table_size‘,‘max_heap_table_size‘);
+---------------------+-----------+
| variable_name | value |
+---------------------+-----------+
| max_heap_table_size | 268435456 |
| tmp_table_size | 536870912 |
+---------------------+-----------+ |
只有256mb以下的临时表才能全部放内存,超过的就会用到硬盘临时表。
五、open table情况
mysql> show global status like ‘open%tables%‘;
+---------------+-------+
| variable_name | value |
+---------------+-------+
| open_tables | 919 |
| opened_tables | 1951 |
+---------------+-------+ |
open_tables表示打开表的数量,opened_tables表示打开过的表数量,如果opened_tables数量过大,说明配置中table_cache(5.1.3之后这个值叫做table_open_cache)值可能太小,我们查询一下服务器table_cache值:
mysql> show variables like ‘table_cache‘;
+---------------+-------+
| variable_name | value |
+---------------+-------+
| table_cache | 2048 |
+---------------+-------+ |
比较合适的值为:
open_tables / opened_tables * 100% >= 85%
open_tables / table_cache * 100% <= 95% |
六、进程使用情况
mysql> show global status like ‘thread%‘;
+-------------------+-------+
| variable_name | value |
+-------------------+-------+
| threads_cached | 46 |
| threads_connected | 2 |
| threads_created | 570 |
| threads_running | 1 |
+-------------------+-------+ |
如果我们在mysql服务器配置文件中设置了thread_cache_size,当客户端断开之后,服务器处理此客户的线程将会缓存起来以响应下一个客户而不是销毁(前提是缓存数未达上限)。threads_created表示创建过的线程数,如果发现threads_created值过大的话,表明mysql服务器一直在创建线程,这也是比较耗资源,可以适当增加配置文件中thread_cache_size值,查询服务器thread_cache_size配置:
mysql> show variables like ‘thread_cache_size‘;
+-------------------+-------+
| variable_name | value |
+-------------------+-------+
| thread_cache_size | 64 |
+-------------------+-------+ |
示例中的服务器还是挺健康的。
七、查询缓存(query cache)
mysql> show global status like ‘qcache%‘;
+-------------------------+-----------+
| variable_name | value |
+-------------------------+-----------+
| qcache_free_blocks | 22756 |
| qcache_free_memory | 76764704 |
| qcache_hits | 213028692 |
| qcache_inserts | 208894227 |
| qcache_lowmem_prunes | 4010916 |
| qcache_not_cached | 13385031 |
| qcache_queries_in_cache | 43560 |
| qcache_total_blocks | 111212 |
+-------------------------+-----------+ |
mysql查询缓存变量解释:
qcache_free_blocks:缓存中相邻内存块的个数。数目大说明可能有碎片。flush query cache会对缓存中的碎片进行整理,从而得到一个空闲块。
qcache_free_memory:缓存中的空闲内存。
qcache_hits:每次查询在缓存中命中时就增大
qcache_inserts:每次插入一个查询时就增大。命中次数除以插入次数就是不中比率。
qcache_lowmem_prunes:缓存出现内存不足并且必须要进行清理以便为更多查询提供空间的次数。这个数字最好长时间来看;如果这个数字在不断增长,就表示可能碎片非常严重,或者内存很少。(上面的 free_blocks和free_memory可以告诉您属于哪种情况)
qcache_not_cached:不适合进行缓存的查询的数量,通常是由于这些查询不是 select 语句或者用了now()之类的函数。
qcache_queries_in_cache:当前缓存的查询(和响应)的数量。
qcache_total_blocks:缓存中块的数量。
我们再查询一下服务器关于query_cache的配置:
mysql> show variables like ‘query_cache%‘;
+------------------------------+-----------+
| variable_name | value |
+------------------------------+-----------+
| query_cache_limit | 2097152 |
| query_cache_min_res_unit | 4096 |
| query_cache_size | 203423744 |
| query_cache_type | on |
| query_cache_wlock_invalidate | off |
+------------------------------+-----------+ |
各字段的解释:
query_cache_limit:超过此大小的查询将不缓存
query_cache_min_res_unit:缓存块的最小大小
query_cache_size:查询缓存大小
query_cache_type:缓存类型,决定缓存什么样的查询,示例中表示不缓存 select sql_no_cache 查询
query_cache_wlock_invalidate:当有其他客户端正在对myisam表进行写操作时,如果查询在query cache中,是否返回cache结果还是等写操作完成再读表获取结果。
query_cache_min_res_unit的配置是一柄”双刃剑”,默认是4kb,设置值大对大数据查询有好处,但如果你的查询都是小数据查询,就容易造成内存碎片和浪费。
查询缓存碎片率 = qcache_free_blocks /qcache_total_blocks * 100%
如果查询缓存碎片率超过20%,可以用flush query cache整理缓存碎片,或者试试减小query_cache_min_res_unit,如果你的查询都是小数据量的话。
查询缓存利用率 = (query_cache_size -qcache_free_memory) / query_cache_size * 100%
查询缓存利用率在25%以下的话说明query_cache_size设置的过大,可适当减小;查询缓存利用率在80%以上而且qcache_lowmem_prunes> 50的话说明query_cache_size可能有点小,要不就是碎片太多。
查询缓存命中率 = (qcache_hits - qcache_inserts) /qcache_hits * 100%
示例服务器查询缓存碎片率= 20.46%,查询缓存利用率= 62.26%,查询缓存命中率= 1.94%,命中率很差,可能写操作比较频繁吧,而且可能有些碎片。
八、排序使用情况
mysql> show global status like ‘sort%‘;
+-------------------+------------+
| variable_name | value |
+-------------------+------------+
| sort_merge_passes | 29 |
| sort_range | 37432840 |
| sort_rows | 9178691532 |
| sort_scan | 1860569 |
+-------------------+------------+ |
sort_merge_passes 包括两步。mysql 首先会尝试在内存中做排序,使用的内存大小由系统变量 sort_buffer_size 决定,如果它的大小不够把所有的记录都读到内存中,mysql 就会把每次在内存中排序的结果存到临时文件中,等 mysql 找到所有记录之后,再把临时文件中的记录做一次排序。这再次排序就会增加 sort_merge_passes。实际上,mysql 会用另一个临时文件来存再次排序的结果,所以通常会看到 sort_merge_passes 增加的数值是建临时文件数的两倍。因为用到了临时文件,所以速度可能会比较慢,增加 sort_buffer_size 会减少 sort_merge_passes 和创建临时文件的次数。但盲目的增加 sort_buffer_size 并不一定能提高速度,见 how fast can you sort data with mysql?(引自http://qroom.blogspot.com/2007/09/mysql-select-sort.html,貌似被墙)
另外,增加read_rnd_buffer_size(3.2.3是record_rnd_buffer_size)的值对排序的操作也有一点的好处,参见http://www.mysqlperformanceblog.com/2007/07/24/what-exactly-is-read_rnd_buffer_size/
九、文件打开数(open_files)
mysql> show global status like ‘open_files‘;
+---------------+-------+
| variable_name | value |
+---------------+-------+
| open_files | 1410 |
+---------------+-------+
mysql> show variables like ‘open_files_limit‘;
+------------------+-------+
| variable_name | value |
+------------------+-------+
| open_files_limit | 4590 |
+------------------+-------+ |
比较合适的设置:open_files / open_files_limit * 100%<= 75%
十、表锁情况
mysql> show global status like ‘table_locks%‘;
+-----------------------+-----------+
| variable_name | value |
+-----------------------+-----------+
| table_locks_immediate | 490206328 |
| table_locks_waited | 2084912 |
+-----------------------+-----------+ |
table_locks_immediate表示立即释放表锁数,table_locks_waited表示需要等待的表锁数,如果table_locks_immediate /table_locks_waited > 5000,最好采用innodb引擎,因为innodb是行锁而myisam是表锁,对于高并发写入的应用innodb效果会好些。示例中的服务器table_locks_immediate/ table_locks_waited = 235,myisam就足够了。
十一、表扫描情况
mysql>showglobalstatuslike‘handler_read%‘;
+-----------------------+-------------+
|variable_name|value|
+-----------------------+-------------+
|handler_read_first|5803750|
|handler_read_key|6049319850|
|handler_read_next|94440908210|
|handler_read_prev|34822001724|
|handler_read_rnd|405482605|
|handler_read_rnd_next|18912877839|
+-----------------------+-------------+ |
各字段解释参见http://hi.baidu.com/thinkinginlamp/blog/item/31690cd7c4bc5cdaa144df9c.html,调出服务器完成的查询请求次数:
mysql> show global status like ‘com_select‘;
+---------------+-----------+
| variable_name | value |
+---------------+-----------+
| com_select | 222693559 |
+---------------+-----------+ |
计算表扫描率:
表扫描率= handler_read_rnd_next / com_select
如果表扫描率超过4000,说明进行了太多表扫描,很有可能索引没有建好,增加read_buffer_size值会有一些好处,但最好不要超过8mb。
后记:
文中提到一些数字都是参考值,了解基本原理就可以,除了mysql提供的各种status值外,操作系统的一些性能指标也很重要,比如常用的top,iostat等,尤其是iostat,现在的系统瓶颈一般都在磁盘io上,关于iostat的使用
网站访问量越来越大,MySQL自然成为瓶颈。因此MySQL 的优化成为我们需要考虑的问题,第一步自然想到的是 MySQL 系统参数的优化,作为一个访问量很大的网站(日20万人次以上)的数据库系统,不可能指望 MySQL 默认的系统参数能够让 MySQL运行得非常顺畅。
(1)、back_log: 要求MySQL 能有的连接数量。当主要MySQL线程在一个很短时间内得到非常多的连接请求,这就起作用,然后主线程花些时间(尽管很短)检查连接并且启动一个新线程。back_log值指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。只有如果期望在一个短时间内有很多连接,你需要增加它,换句话说,这值对到来的TCP/IP连接的侦听队列的大小。你的操作系统在这个队列大小上有它自己的限制。 试图设定back_log高于你的操作系统的限制将是无效。当你观察你的主机进程列表,发现大量 264084 | unauthenticated user |xxx.xxx.xxx.xxx | NULL | Connect | NULL | login | NULL 的待连接进程时,就要加大 back_log的值了。默认数值是50,我把它改为500。
(2)、interactive_timeout: 服务器在关闭它前在一个交互连接上等待行动的秒数。一个交互的客户被定义为对mysql_real_connect()使用 CLIENT_INTERACTIVE 选项的客户。默认数值是28800,我把它改为7200。
(3)、key_buffer_size: 索引块是缓冲的并且被所有的线程共享。key_buffer_size是用于索引块的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写),到你能负担得起那样多。如果你使它太大,系统将开始换页并且真的变慢了。默认数值是8388600(8M),我的MySQL主机有2GB内存,所以我把它改为402649088(400MB)。
(4)、max_connections: 允许的同时客户的数量。增加该值增加mysqld 要求的文件描述符的数量。这个数字应该增加,否则,你将经常看到 Toomany connections 错误。 默认数值是100,我把它改为1024 。
(5)、record_buffer: 每个进行一个顺序扫描的线程为其扫描的每张表分配这个大小的一个缓冲区。如果你做很多顺序扫描,你可能想要增加该值。默认数值是131072(128K),我把它改为16773120 (16M)
(6)、sort_buffer: 每个需要进行排序的线程分配该大小的一个缓冲区。增加这值加速ORDER BY或GROUP BY操作。默认数值是2097144(2M),我把它改为16777208 (16M)。
(7)、table_cache: 为所有线程打开表的数量。增加该值能增加mysqld要求的文件描述符的数量。MySQL对每个唯一打开的表需要2个文件描述符。默认数值是64,我把它改为512。
(8)、thread_cache_size: 可以复用的保存在中的线程的数量。如果有,新的线程从缓存中取得,当断开连接的时候如果有空间,客户的线置在缓存中。如果有很多新的线程,为了提高性能可以这个变量值。通过比较 Connections 和 Threads_created 状态的变量,可以看到这个变量的作用。我把它设置为 80。
(10)、wait_timeout: 服务器在关闭它之前在一个连接上等待行动的秒数。默认数值是28800,我把它改为7200。
注:参数的调整可以通过修改/etc/my.cnf文件并重启 MySQL 实现。这是一个比较谨慎的工作,上面的结果也仅仅是我的一些看法,你可以根据你自己主机的硬件情况(特别是内存大小)进一步修改。
小结
在这次采访中,郑文强和大家分享了很多宝贵的经验,摘要如下:
1、勤奋学习能够弥补基础的不足。
2、在决定发展方向的时候,不要生活在别人的期望中,而是要知道自己想做什么,擅长做什么。
3、去做自己喜欢的,还是去做人家喜欢的?最终我选择了前者。从目前的结果看,感觉到自己在公司内部可以做的事情更多了,参与的活动也在增加。不管对公司还是对个人,体现的价值都是在不断增加的。
4、把好的测试理论、测试思想与工作实践结合起来。
5、坚持去做自己喜欢的工作,不断积累、总结和分享。
6、认清楚自己,明确自己的优点和不足。
7、让跳槽符合自己的发展方向。
8、分享并不会导致“教会了徒弟,饿死了师傅”,因为学习是一个过程。另一方面,同事会因为你的分享而感谢和尊重你。
9、作为测试的负责人,不要期望自己在所有的方面都比其他人强,你的定位应该是为整个测试团队服务的角色。如果你能在团队内带头分享你的知识与经验,也一定能带动其他人的分享,更好地做好测试团队的知识与技能的储备,有利于测试经理更好地分配测试工作,并做好备份工作。
10、与脚本化测试相比,探索性测试更强调测试人员的思维自由度与主观能动性。然而,探索性的自由,并不代表它是不做准备的,它也不是随机的。好的探索性测试依赖于测试人员综合应用测试策略、测试技术与方法的能力,例如,获取测试数据,掌握测试设计技术,建立失效模式,创建测试模型等。口号式的探索性测试并不能帮助测试人员成功。
11、我几乎每天都会反省自己当天的工作,有了哪些收获,有了什么总结,多少时间又被浪费了等。通过这样的形式,不断提升自己的信心,提高学习的效率和有效性。
12、软件发布与否应当综合多个方面的因素来考虑,而不仅仅是测试的意见。
13、要想获得成功,勤奋是不可或缺的。
14、多实践,不要怕失败。不管是测试领域的知识,还是测试技能,或者是测试思想和方法,测试新人都需要勇敢地去实践,许多的经验、思想和收获来自于失败的经验教训。
15、面对职业发展迷茫的时候问自己喜欢做什么,目标是什么,当前的工作和活动是否能帮助自己达成这个目标。
16、从形式、覆盖率和有效性方面来评估测试用例的质量。
17、成为测试牛人的三个步骤:制订目标,明确技能目标,立即行动。
18、在参见面试前做好准备,并在面试过程中保持坦诚。
19、软件测试行业的发展前景乐观,同时测试工程师会面对不少的挑战。测试人员要提高自己的技能水平和价值。
20、软件测试行业将持续往前发展,而测试从业人员能否在这个平台中同步前进,这依赖于测试人员自己的不断积累、不断实践与不断交流。要发展,测试人员同样需要走出去,了解当前的测试热点、测试发展趋势、测试理念与思想的趋势等。
(未完待续)
国软件测试专家访谈录(1) 中国软件测试专家访谈录(2)
根据形式、覆盖率和有效性来评估测试用例的质量
蔡:如何评估测试用例的质量?
郑:测试用例质量的评估,我主要考虑下面三个方面。
1、根据测试用例的形式评估其质量,主要包括:
(1)测试用例与需求规格说明中需求条目的可追溯性。例如,每个需求条目至少有1个测试用例与之对应。
(2)测试用例有无明确的期望结果。
(3)是否满足公司内部定义的测试用例模板。
2、根据测试用例覆盖率评估其质量,主要包括:
(1)需求的覆盖率。例如,我们主要负责系统测试级别,因此测试用例的需求覆盖率要求必须达到100%。
(2)质量特性的覆盖率。例如,我们在测试用例模板中采用测试类型的概念,要求每个功能的测试用例必须100%覆盖所有的测试类型。
(3)测试平台的覆盖率。例如,针对我们目前的通信产品,每个功能都需要在不同平台上运行;再如,不同的网元类型、接口类型、业务类型等。测试用例对这些平台的覆盖率也要求达到100%。
3、根据测试用例的有效性评估其质量,主要包括:
(1)测试用例的缺陷发现率。我们采用的计算方法是,系统测试发现的缺陷数目除以执行的测试用例数目(百分比)。
(2)脚本化测试的缺陷发现率。我们采用的计算方法是,根据测试用例步骤发现的缺陷数目除以总发现的缺陷数目(百分比)。如果这个百分比很低,则说明设计的测试用例的有效性方面比较差,不少bug是通过探索性测试发现的。
(3)遗漏到用户现场的缺陷率。我们采用的计算方法是,6个月内用户现场反馈的缺陷数目,除以系统测试级别发现的缺陷数目与6个月内用户现场反馈的缺陷数目之和(百分比)。
每个公司和测试团队在评估测试用例质量方面都会存在不同的度量指标,我们的要求是这些度量指标要简单容易收集,并且有利于改进测试过程和测试团队的测试能力,但切记不会做针对测试人员个人的能力与绩效的评估。
旁观者说:从不同的侧面去做度量,是一个更好的办法。这种办法可以在工作的很多方面得到应用。
成为测试牛人的三个步骤
蔡:有网友提到一个问题,如何成为测试牛人?
郑:不管是测试管理方向还是测试技术方向,都是可以成为测试牛人的。要成为测试牛人,你要有成为测试牛人的强烈要求。根据我的经验,下面的步骤有助于你成为某个领域内的专家。
第一步,制订目标:你希望成为哪个领域的测试牛人?例如,测试技术方面的牛人、测试自动化方面的牛人。
第二步,技能要求:要达到所制订的目标,你需要具备哪些方面的技能?以我自己为例,希望自己成为测试技术专家,我主要从下面几个方面不断积累经验与技能。
(1)深入了解测试对象的背景知识与业务功能。例如,我是做宽带接入产品的,除了测试对象的功能之外,我利用空闲的时间学习了VPN、MPLS、IPv6、IP路由交换协议等。
(2)深入了解我公司所采用的开发模型与测试流程,即需要清楚地知道在测试生命周期中,什么阶段需要做什么事情,有哪些输入与输出。
(3)测试人员要深入了解各种软件测试技术与方法。例如,我们采用敏捷开发,在面向业务的测试过程中,探索性测试与测试人员的结对测试是我们经常采用的测试方式,不仅可以有效发挥测试团队的主观能动性与及时分析反馈能力,而且可以更好地分配资源与加强测试团队内部的技能共享。
(4)培养测试人员的各种软技能,例如,沟通与合作。对我而言,在业余时间喜欢看各种类型的书籍,例如,沟通、管理、心理学、演讲、理解与记忆、经济学、思维等。广泛涉猎各种知识,可以帮助我更好地提高软技能。
第三步,立即行动。
“千里之行,始于足下”,坚实走出每一步,坚持走出每一步,成功就在前面等你。
旁观者说:没有行动,再好的目标也仅仅是纸上的目标。

面试中的考量
蔡:你的测试经验很丰富,肯定参加和主持过不少的测试职位的面试。你在面试中看重什么?
郑:在面试过程中,我主要会从下面几个方面进行考量。
第一,会详细了解职位候选人在测试对象的产品背景知识与业务知识方面是否满足职位的要求。
第二,考察应聘者在测试流程、测试技术与方法等方面是否有所了解,结合测试项目和产品的特点,判断他所掌握的这些技能是否有助于测试团队的测试能力改进。例如,我们一直做的是系统测试工作,时间与资源经常非常紧张,除了基本功能的验证之外,测试中很多的精力放在用户业务的考察上,因此应聘者了解基于场景的测试、基于风险的测试等技能是受欢迎的。
第三,考察候选人在性格特征、为人处世等方面是否符合企业文化和团队氛围。
同时,员工的上进心与学习能力也很重要。例如,两个候选人,一个有一年工作经验,另一个有三年工作经验。只要有上进心,有一年工作经验的那位候选人在半年后就能做与有三年工作经验的那位朋友一样的事情,甚至做得更好。
旁观者说:这里也揭示了一个残酷的事实:如果没有高人一等的技能,年资有的时候会在找工作的时候帮倒忙(暂且称为年资拐点)。我们要尽可能延迟年资拐点的出现。
当然,面试中获取每个候选人真实的信息并不是一件容易的事情,我自己会从候选人的日常时间安排、个人兴趣爱好和业余时间计划等方面收集与分析信息。
基于我面试的经验,下面是我给测试职位应聘者的两条建议。
1、面试前做好充足的准备工作。
2、面试过程中,应聘者诚实很重要。面试过程中有些问题不会,可以直接回答不懂或者没有经验,切记不要不懂装懂。没有一个人是完人,面试官可以接受存在不足的候选人,但不会接受明显撒谎的人。
旁观者说:对,坦诚其实是面试中最好的态度。
软件测试行业的发展前景
蔡:对软件测试行业的发展前景,你怎么看?
郑:我是2001年开始从事软件测试工作的,从我个人的整个从业经历来说,软件测试行业一直在往专业化、系统化、正规化方向发展,因此软件测试应该是一直在往上走的趋势。针对软件测试行业的发展,可以从行业本身与测试从业人员两个方面进行分析。
软件测试行业前景乐观
首先,我国的软件测试行业相对欧美国家,现在还是处于很年轻的阶段。借鉴美国等软件测试的历史发展经验,测试行业发展的前景还是乐观的。在欧美国家,软件测试行业中经常可以看到有30年甚至40年测试经验的从业人员;而在国内,像我这样有11年软件测试经验的人都算是“很老的”测试人了。因此,欧美国家中30/40年的软件测试经验,可以说明这个行业能够提供机会,让他们一直做下去,而且做得不错。我相信这个现象同样适用于我国的软件测试行业。
旁观者说:有的朋友说,咱们国家的IT公司不养年纪大的人,你看身边哪有年纪大的?对于这一点不必悲观。之所以现在IT公司里没有年纪大的员工,主要是因为我们的IT行业太年轻。只要IT行业持续发展,公司规模增大,慢慢就会出现白发斑斑的IT工程师。
其次,客户对软件产品的质量要求越来越高。尽管说软件产品的质量是构建进去的,而不是测试出来的,但是软件测试对提高产品质量是建设性的,因此测试在研发中的不可或缺性将会不断得到提升。这对软件测试行业而言是利好消息。
旁观者说:社会对软件的依赖和对软件质量要求的提高,是软件测试行业发展的基础。从这个方面来说,测试从业人员可以去培育和引导社会对软件质量的要求。
第三,2012年的软件测试很热闹,除了在上海成功举行了中国第一届软件测试大会之外,在北京、上海等地轮番上阵了ISTQB测试沙龙、测试专题讨论、软件测试俱乐部沙龙等民间测试活动,并且参与的测试从业人员都是几百人的量级。这样的现象在前几年是不可想象的,这从另一个侧面反映了测试行业的蓬勃发展。
测试人员要提升自己的技能水平和价值
蔡:测试工程师将来会遇到哪些挑战呢?
郑:测试行业前景看好并不代表每个测试从业人员都有好的前景,这依赖于测试人员如何提升自己的测试技能与提供的测试价值。今后一段时间测试业界内的热点是:
1、自动化测试与手工测试之争。随着软件测试成熟度的提高,加强自动化测试将是一个合理的趋势,这对于测试从业人员而言是一个发展方向。但是自动化测试并不能代替手工测试,因为自动化测试的基础来自于测试人员的思维与设计,测试从业人员应该将自动化测试作为一个提高测试效率的手段,而不应该是最终的目标。自动化测试工具并不能保证项目的成功,但是可以帮助优秀的测试人员更加出色地工作。
2、探索性测试与脚本化测试之争。测试从脚本化测试的关注过程,到探索性测试更关注测试人员的思维与主观能动性,并不能说明两者之间谁好谁坏,或者谁替代谁的问题。测试人员需要做的是如何平衡两者之间的关系,如何更好地发挥两者各自的优势,弥补各自的不足。
3、敏捷开发模式下的敏捷测试。敏捷测试更强调整体团队运作,强调将质量构建进产品而不是在生产出来之后再进行测试,强调自动化测试,以及同时强调面向技术的测试与面向业务的测试。敏捷测试要求测试人员掌握熟悉范围之外的新技能,例如,测试驱动开发、持续集成。
软件测试行业将持续往前发展,而测试从业人员能否在这个平台中同步前进,这依赖于测试人员自己的不断积累、不断实践与不断交流。要发展,测试人员同样需要走出去,了解当前的测试热点、测试发展趋势、测试理念与思想的趋势等。
旁观者说:博取各家所长,兼容并蓄。
书籍推荐
1、《软件测试艺术》:软件测试的经典著作,展示了测试大师Glenford Myers多年的软件测试思想和技术。书中探讨了代码检查、走查与审查、测试用例的设计、单元测试、系统测试、极限测试等主题,是测试人员入门的一本优秀教材。
2、《软件测试经验与教训》:本书分享了3位作者多年的测试经验,知道成功的测试需要什么。书中汇总了293条测试经验建议,阐述了如何做好测试工作,如何管理测试,以及如何澄清有关软件测试的常见误解。读者可以将这些经验用于自己的测试工作中,避免一些容易犯的错误,提高测试效率与有效性。
3、《A Practitioners Guide to Software Test Design》:关注测试用例设计的一本著作,其中包括了白盒测试技术、黑盒测试技术与基于经验的测试技术。每个测试技术本身都结合了技术原理、案例分析和优缺点分析,是每个测试人员了解和应用测试用例设计的一本好书。
4、《赢在测试:软件测试先行者之道》:蔡为东写的这本书,汇集了多名测试行业的测试精英,其中描述了他们是如何认识测试,发展测试,规划测试,以及如何在测试行业中取得成功的,为测试从业人员的职业发展提供了参考方向。这本书为处于迷茫阶段的测试人员规划自己的测试职业发展,提供了许多现实可行的方向。
5、《思维导图:大脑使用说明书》:要想在测试领域有所建树,测试人员持续不断地学习与积累是非常重要的,而如何有效地阅读与学习将是决定成败的一个关键。思维导图是一个简单易学的革命性思维工具,它可以帮助你提高记忆力和理解力,激发想象力,更好地制订生活和工作计划。
小结
在这次采访中,郑文强和大家分享了很多宝贵的经验,摘要如下:
1、勤奋学习能够弥补基础的不足。
2、在决定发展方向的时候,不要生活在别人的期望中,而是要知道自己想做什么,擅长做什么。
3、去做自己喜欢的,还是去做人家喜欢的?最终我选择了前者。从目前的结果看,感觉到自己在公司内部可以做的事情更多了,参与的活动也在增加。不管对公司还是对个人,体现的价值都是在不断增加的。
4、把好的测试理论、测试思想与工作实践结合起来。
5、坚持去做自己喜欢的工作,不断积累、总结和分享。
6、认清楚自己,明确自己的优点和不足。
7、让跳槽符合自己的发展方向。
8、分享并不会导致“教会了徒弟,饿死了师傅”,因为学习是一个过程。另一方面,同事会因为你的分享而感谢和尊重你。
9、作为测试的负责人,不要期望自己在所有的方面都比其他人强,你的定位应该是为整个测试团队服务的角色。如果你能在团队内带头分享你的知识与经验,也一定能带动其他人的分享,更好地做好测试团队的知识与技能的储备,有利于测试经理更好地分配测试工作,并做好备份工作。
10、与脚本化测试相比,探索性测试更强调测试人员的思维自由度与主观能动性。然而,探索性的自由,并不代表它是不做准备的,它也不是随机的。好的探索性测试依赖于测试人员综合应用测试策略、测试技术与方法的能力,例如,获取测试数据,掌握测试设计技术,建立失效模式,创建测试模型等。口号式的探索性测试并不能帮助测试人员成功。
11、我几乎每天都会反省自己当天的工作,有了哪些收获,有了什么总结,多少时间又被浪费了等。通过这样的形式,不断提升自己的信心,提高学习的效率和有效性。
12、软件发布与否应当综合多个方面的因素来考虑,而不仅仅是测试的意见。
13、要想获得成功,勤奋是不可或缺的。
14、多实践,不要怕失败。不管是测试领域的知识,还是测试技能,或者是测试思想和方法,测试新人都需要勇敢地去实践,许多的经验、思想和收获来自于失败的经验教训。
15、面对职业发展迷茫的时候问自己喜欢做什么,目标是什么,当前的工作和活动是否能帮助自己达成这个目标。
16、从形式、覆盖率和有效性方面来评估测试用例的质量。
17、成为测试牛人的三个步骤:制订目标,明确技能目标,立即行动。
18、在参见面试前做好准备,并在面试过程中保持坦诚。
19、软件测试行业的发展前景乐观,同时测试工程师会面对不少的挑战。测试人员要提高自己的技能水平和价值。
20、软件测试行业将持续往前发展,而测试从业人员能否在这个平台中同步前进,这依赖于测试人员自己的不断积累、不断实践与不断交流。要发展,测试人员同样需要走出去,了解当前的测试热点、测试发展趋势、测试理念与思想的趋势等。
(未完待续)
摘要: 9.1 基于不同用户群的性能测试 随着互联网的蓬勃发展,软件的性能测试已经越来越受到软件开发商、用户的重视。如:一个网站前期由于用户较少,随着使用用户的逐步增长,以及宣传力度的加强,软件的使用者可能会成几倍、几十倍甚至几百倍数量级的增长,如果不经过性能测试,通常软件系统在该情况下都会崩溃掉,所以性能测试还是非常重要的。不管是软件企业自身进行性能测试,还是企业聘请第三方做性能测试,这里...
阅读全文