
Linux/Unix shell脚本中调用或执行SQL,RMAN 等为自动化作业以及多次反复执行提供了极大的便利,因此通过Linux/Unix shell来完成Oracle的相关工作,也是DBA必不可少的技能之一。本文针对Linux/Unix shell脚本调用sql, rman 脚本给出了相关示例。
一、由shell脚本调用sql,rman脚本
1、shell脚本调用sql脚本
#首先编辑sql文件
oracle@SZDB:~> more dept.sql
connect scott/tiger
spool /tmp/dept.lst
set linesize 100 pagesize 80
select * from dept;
spool off;
exit; #编辑shell脚本文件,在shell脚本内调用sql脚本
oracle@SZDB:~> more get_dept.sh
#!/bin/bash # set environment variable if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi export ORACLE_SID=CNMMBO
sqlplus -S /nolog @/users/oracle/dept.sql #注意此处执行sql脚本的方法 -S 表示以静默方式执行
exit #授予脚本执行权限
oracle@SZDB:~> chmod 775 get_dept.sh -->执行shell脚本
oracle@SZDB:~> ./get_dept.sh DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON |
2、shell脚本调用rman脚本
#首先编辑RMAN脚本
oracle@SZDB:~> more rman.rcv
RUN {
CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 7 DAYS;
CONFIGURE BACKUP OPTIMIZATION ON;
CONFIGURE CONTROLFILE AUTOBACKUP ON;
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '/users/oracle/bak/%d_%F';
ALLOCATE CHANNEL CH1 TYPE DISK MAXPIECESIZE=4G;
ALLOCATE CHANNEL CH2 TYPE DISK MAXPIECESIZE=4G;
SET LIMIT CHANNEL CH1 READRATE=10240;
SET LIMIT CHANNEL CH1 KBYTES=4096000;
SET LIMIT CHANNEL CH2 READRATE=10240;
SET LIMIT CHANNEL CH2 KBYTES=4096000;
CROSSCHECK ARCHIVELOG ALL;
DELETE NOPROMPT EXPIRED ARCHIVELOG ALL;
BACKUP
DATABASE FORMAT '/users/oracle/bak/%d_FULL__%U';
SQL 'ALTER SYSTEM ARCHIVE LOG CURRENT';
BACKUP ARCHIVELOG ALL FORMAT '/users/oracle/bak/%d_LF_%U' DELETE INPUT;
DELETE NOPROMPT OBSOLETE;
RELEASE CHANNEL CH1;
RELEASE CHANNEL CH2;
} #编辑shell脚本文件,在shell脚本内调用rman脚本
oracle@SZDB:~> more rman_bak.sh
#!/bin/bash # set environment variable if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi export ORACLE_SID=CNMMBO
$ORACLE_HOME/bin/rman target / cmdfile=/users/oracle/rman.rcv log=/users/oracle/bak/rman.log
exit #授予脚本执行权限
oracle@SZDB:~> chmod 775 rman_bak.sh #执行shell脚本
oracle@SZDB:~> ./rman_bak.sh |
二、嵌入sql语句及rman到shell脚本
1、直接将sql语句嵌入到shell脚本
oracle@SZDB:~> more get_dept_2.sh
#!/bin/bash
# Author : Robinson Cheng
# Blog : http://blog.csdn.net/robinson_0612 # set environment variable if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi export ORACLE_SID=CNMMBO
sqlplus -S /nolog <<EOF #EOF在此表示当输入过程中碰到EOF后,整个sql脚本输入完毕
connect scott/tiger
spool /tmp/dept.lst
set linesize 100 pagesize 80
select * from dept;
spool off;
exit; #退出sqlplus 环境
EOF
exit #推出shell脚本 #授予脚本执行权限
oracle@SZDB:~> chmod u+x get_dept_2.sh #执行shell脚本
oracle@SZDB:~> ./get_dept_2.sh DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON |
2、直接将sql语句嵌入到shell脚本(方式二,使用管道符号>代替spool来输出日志)
oracle@SZDB:~> more get_dept_3.sh
#!/bin/bash # set environment variable if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi export ORACLE_SID=CNMMBO
sqlplus -S /nolog 1>/users/oracle/dept.log 2>&1 <<EOF
connect scott/tiger
set linesize 80 pagesize 80
select * from dept;
exit;
EOF
cat /users/oracle/dept.log
exit #另一种实现方式,将所有的sql语句输出来生成sql脚本后再调用
oracle@SZDB:~> more get_dept_4.sh
#!/bin/bash # set environment variable if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi export ORACLE_SID=CNMMBO
echo "conn scott/tiger
select * from dept;
exit;" >/users/oracle/get_dept.sql
sqlplus -silent /nolog @get_dept.sql 1>/users/oracle/get_dept.log 2>&1
cat get_dept.log
exit |
3、将rman脚本嵌入到shell脚本
oracle@SZDB:~> more rman_bak_2.sh
#!/bin/bash # set environment variable if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi export ORACLE_SID=CNMMBO
$ORACLE_HOME/bin/rman log=/users/oracle/bak/rman.log <<EOF
connect target /
RUN {
CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 7 DAYS;
CONFIGURE BACKUP OPTIMIZATION ON;
CONFIGURE CONTROLFILE AUTOBACKUP ON;
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '/users/oracle/bak/%d_%F';
ALLOCATE CHANNEL CH1 TYPE DISK MAXPIECESIZE=4G;
ALLOCATE CHANNEL CH2 TYPE DISK MAXPIECESIZE=4G;
SET LIMIT CHANNEL CH1 READRATE=10240;
SET LIMIT CHANNEL CH1 KBYTES=4096000;
SET LIMIT CHANNEL CH2 READRATE=10240;
SET LIMIT CHANNEL CH2 KBYTES=4096000;
CROSSCHECK ARCHIVELOG ALL;
DELETE NOPROMPT EXPIRED ARCHIVELOG ALL;
BACKUP
DATABASE FORMAT '/users/oracle/bak/%d_FULL__%U';
SQL 'ALTER SYSTEM ARCHIVE LOG CURRENT';
BACKUP ARCHIVELOG ALL FORMAT '/users/oracle/bak/%d_LF_%U' DELETE INPUT;
DELETE NOPROMPT OBSOLETE;
RELEASE CHANNEL CH1;
RELEASE CHANNEL CH2;
}
EXIT;
EOF
exit #授予脚本执行权限
oracle@SZDB:~> chmod u+x rman_bak_2.sh #执行shell脚本
oracle@SZDB:~> ./rman_bak_2.sh
RMAN> RMAN> 2> 3> 4> 5> 6> 7> 8> 9> 10> 11> 12> 13> 14> 15> 16> 17> 18> 19> 20> 21> RMAN> oracle@SZDB:~> |
这两天各种看职位要求,各种总结研究最后找到自己的发展目标了。至少是一个可以作为短期的发展目标—>做白盒测试。基调找到了之后就要确定学习计划。现在什么都要讲究敏捷Agile,我也来一个敏捷学习计划吧。以半个月为期限,随时研究随时调整。
学习目的:想要做白盒测试-->写测试代码-->需要知道自动化测试框架
百度百科看得云里雾里的,突然发现还是要追根究底的,这样就带来以下的问题:
为什么要进行自动化测试?
之前很长时间做的都是手工测试,虽然也有将手工测试用例转化为自动化测试用例过,但是个人的认识是自动化测试是用在为产品后期维护进行测试的目的上。我接触到的自动化测试分两个方面:一个是性能测试(LR),一个是自动化测试(XACC)。我个人的理解想要做这两样测试的话必须软件的界面都很成熟了,变动不大了。比如在产品后期交付界面比较稳定不会做大的调整的过程中,为了进一步的提高软件性能可以进行性能测试,为了保证每一个版本的基础功能不受其他代码变动的影响也可以在后期版本中运行自动化测试。既然要打翻从新学习就要了解一下网上现在都是什么情况?总结起来跟我之前的理解不冲突。
软件自动化测试是测试工作的一部分,是对手工测试的一种补充。自动化测试是相对手工测试而存在的,主要是通过所开发的软件测试工具、脚本等来实现,具有良好的可操作性、可重复性和高效率等特点。
手工测试局限性:
1、手工测试不能覆盖所有代码路径。
2、基本的功能性测试用例在每一轮测试中都不能少。由于工作量往往较大,属于重复性的、非智力性的和非创造性,并要求准确细致,使用机器比人类更有优势。
3、许多死锁、资源冲突、多线程等有关的不正确 ,通过手工测试很难捕捉到。
4、系统压力、性能测试,须要模拟大数据或大并发用户等各种测试场景,很难通过手工测试执行。
5、系统可靠性测试,须要模拟系统长时间运行,以验证系统能否稳定运行,难以通过手工测试执行。
6、如果有大量(几千)的测试用例,须要在短时间内(1天)完成,手工测试几乎不可能做到。
自动化测试主要优点:
1、避免重复工作:对于功能已经完整和成熟的软件,每发布一个新的版本,其中大部分功能和界面都和上一个版本相似或完全相同,这部分功能特别适合于自动化测试,从而可以让测试达到测试每个特征的目的。
2、提高测试效率:DCC版本的发布周期往往比较短,也就是开发周期只有短短的几个月,而在测试期间是每天/每2天都要发布一个版本供测试人员测试,一个系统的功能点有几千个上万个,人工测试是非常的耗时和繁琐,这样必然会使测试效率低下。
3、保证每次测试地一致性和可重复性:由于每次自动化测试运行的脚本是相同的,所以每次执行的测试具有一致性,人是很难做到的。由于自动化测试的一致性,很容易发现被测软件的任何改变。
4、更好的利用资源--周未/晚上。理想的自动化测试能够按计划完全自动的运行,在开发人员和测试人员不可能实行三班倒的情况下, 自动化测试可以胜任这个任务, 完全可以在周末和晚上执行测试。这样充分的利用了公司的资源,也避免了开发和测试之间的等待。
5、解决测试与开发之间的矛盾:通常在开发的末期,进入集成测试阶段,由于每发布一个版本的初期,测试系统的错误比较少,这时开发人员有等待测试人员测试出错误的时间。事实上在叠代周期很短的开发模式中,存在更多的矛盾,但自动化测试可以解决其中的主要矛盾。
6、节省人力资源:将烦琐的任务转化为自动化测试。大量重复的测试是非常繁琐的,并且需要消耗大量的人力才能够完成。自动测试能够很好的解决这个问题,不需要繁琐的劳动,不需要大量的人员。
7、增加软件信任度:只有经过大量测试案例测试过的版本才是可靠的,而只有使用自动测试才能够保证在段时间内完成大量的测试案例。
8、缩短软件开发测试周期,可以让产品更快投放市场。
9、提高软件测试的准确度和精确度,添加软件信任度。
10、软件测试工具使测试工作相比较容易,但能产生更高质量的测试结果。
11、手工不能做的事情,自动化测试能做,如压力、性能测试。
自动化测试局限性:
1、不能取代手工测试
2、手工测试比自动测试发觉的缺陷更多
3、对测试质量的依赖性极大
4、测试自动化不能提高有效性
5、测试自动化可能会制约软件开发。
6、工具本身并无想象力,不能主动发觉缺陷
7、手工测试比测试工具更优越的另一个方面是可以处理意外事件。虽然工具也可以处理部分异常事件,但是对真实的突发事件和不能由软件处理的疑问就无能为力。
自动化测试需要知道:
1、一种测试工具不完全适用于所有测试
2、自动测试不一定减轻工作量
3、测试进度可能不一定缩短
4、测试工具不一定易于运用
5、自动化测试的普遍使用 存在局限
6、测试覆盖率不会达到百分之百
后面的文章会解决下面的问题:
1、什么是自动化测试框架?
2、测试框架的作用?
3、一般测试框架的分类?
4、我究竟要怎么学?
什么是测试过程的版本控制?
● 对象:开发人员提交给测试人员的产品版本
● 定义:是对测试版本有明确的标识、说明、并且测试版本的交付是在项目管理人员的控制之下。
● 作用:在于能跟踪记录整个测试过程,包括测试本身和相关文档,以便对不同阶段的待测试软件有相关文档进行标识和差别分析,便于协调和管理测试工作。
如何有效的控制测试版本?
● 制定合理的版本发布计划,并加强版本控制管理
● 强化测试准入条件
● 强化BUG管理
● 做好版本控制的文档管理工作
● 积极解决问题的态度
制定合理的版本发布计划,并加强版本控制管理
软件版本的发布应有计划的执行,在项目开发计划中明确发布版本的时机和版本更新的策略,简单的说就是明确在什么条件下可以发布测试初始版本;什么条件时进行主版本、子版本的更新。这样可以避免频繁的发布测试版本和随意修改版本号给测试带来的混乱。
强化测试准入条件
软件测试的启动是有条件的,在开发人员发布测试版本时,应有相应的文档支持如自测报告、软件版本说明等等,这是前提,不满足这个前提,测试活动不应启动。
软件版本说明可以使测试人员了解当前版本的具体内容和与上一版本的差异。
自测报告对版本质量的一个保证,避免出现版本质量太差的情况。
强化BUG管理
充分使用TD测试管理工具,做好BUG管理工作。首先,在提交BUG时,应完整填写BUG的详细内容,如发现版本、对应人员、发现的模块等等;其次,在开发修改BUG时,应注明修复问题的信息;最后,在测试人员关闭BUG时,应填写选择关闭BUG的版本号。这有利于分析不同版本和不同模块的BUG走势。
BUG提交界面
做好版本控制的文档管理
在每次提交测试版本,执行测试时都会生成相应的文档以便来记录版本信息和测试记录及测试结果等等,管理好这些文档,不仅有助于跟踪和监测测试版本的执行,而且也便于对测试活动的追溯。
积极解决问题的态度
无论是开发人员还是测试人员,在版本控制过程中都应有积极的态度,遇到问题及时沟通,以高效的方式来解决问题。
版本控制的评价标准是什么?
● 对软件测试的版本控制来说,衡量其效果的标准可归根结底为两点:效率和质量。
● 如果版本控制最终使软件测试效率得到提高、使软件质量得到提升,那就是成功的。反之,则是失败的。
对象识别(Object Identification)
对象识别是实现测试脚本的关键部分。QTP不能随意的录制对象,它在记录对象的一组属性时是遵循一定结构的。我们可以更改这些属性,以适应应用程序。更改设置可以在 Tools->Object Identification…
有三种类型的属性可以被QTP用来识别对象:
● 强制属性 - 强制属性总是被捕捉并保存,即使没有其中的一些属性,对象也能识别也不例外。
● 辅助属性 - 假如强制属性不足以唯一识别某对象,那么可以依次添加辅助属性,直到对象可以唯一识别。
● 顺序标识符 - 一旦在使用了强制属性和辅助属性后,对象仍然不能唯一识别,那么可以使用序数识别。有三种类型的序数识别:
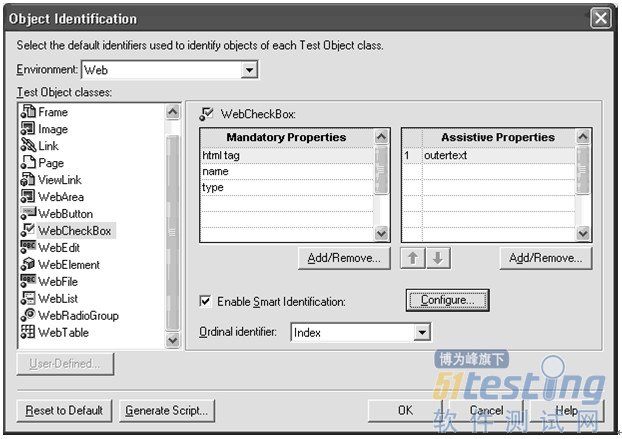
图3-8 对象识别设置
图3-8 显示了WebCheckBox的强制属性和辅助属性。
小提示:这些设置是常规的全局设置,并不基于任何脚本。我们可以根据需要添加和删除。
用户定义的对象
QTP使用窗体的类名来识别对象的类型。假如我们的应用程序没有使用标准的窗体类,那么QTP就可能无法正确识别对象。Windows的搜索对话框有一些CheckBox放在了自定义的控件内,当我们试图添加他们到QTP对象库中时,它们只能被识别为WinObject,如图3-9所示。这是由于Qtp不能把这些CheckBox识别成一般的测试对象。

图3-9 搜索窗口中的CheckBox识别成了WinObject
因此我们需要在QTP设置中,把这个CheckBox映射成WinCheckBox.打开Tools->Object Identification ,然后选择标准Windows环境,点击User Defined按钮,就会弹出映射对话框。点击手型按钮,然后点击CheckBox后,类名就被添加,并且我们可以映射到CheckBox,如图3-10所示。点击Add按钮添加这个映射。

3-10用户自定义对象映射
映射后,QTP便可识别这个对象为WinCheckBox,如图3-11所示。
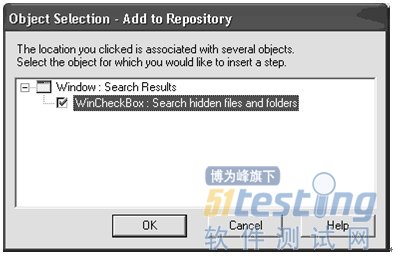
图3-11 用户自定义对象识别为Checkbox
对象库的不足
作者认为QTP 8.x的对象库有一些不足:
● 对象库管理器不允许批量更新对象属性到脚本。
● 其他对象下面的对象不能被删除或复制。
● 当一个框体(frame)被加入到了被测的应用程序中时,那么整个测试脚本都要重新录制。
● 当重新录制一个页面或者窗体时,完全一样的对象经常会重复添加,因此,会创建很多相同的页面或窗体:Page_1, Page_2诸如此类。有时候这个问题可以通过更改Web设置来解决,
打开Tools->Options…Web(Tab)->Page/Frame Options…然后更改设置如图3-12所示
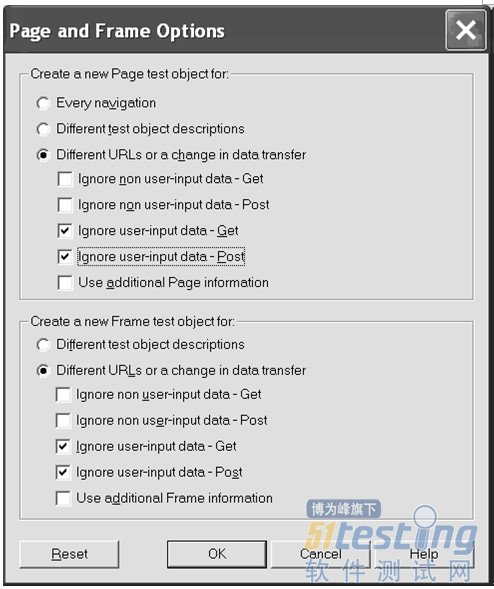
图3-12页面和框体选项
小提示:以上所述的大多数的不足在 QTP9.x中已经得到解决。
(未完待续)
版权声明:51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像。51testing软件测试网欢迎与业内同行进行有益的合作和交流,如果有任何有关内容方面的合作事宜,请联系我们。
相关链接:
QTP自动化测试权威指南 连载(一)
QTP自动化测试权威指南 连载(二)
Perl 提供测试的基础模块是Test::More ,该包能提供测试用例的执行以及测试的断言。Test::Unit测试框架以及Test::Nginx测试框架都是基于该模块创建的。接下来介绍该模块常用的使用。
1、导入包的方式
use Test::More;
同时Test::More需要事先申明需要测试的 testcase 的个数,声明方式如下:
use Test::More tests => 2;
这表示在该模块中有两个测试用例被执行。
有时候,你不知道有多少测试用例会被执行,可以用这个方法:
use Test::More; # see done_testing()
……
执行测试用例
……
done_testing(); or done_testing($number_of_tests_run);
2、常用 Test::More 断言方法:
ok
| ok($succeeded, $test_name); |
该方法用来判断测试成功或者失败。第一个参数为判断参数,第二个参数为测试用例的名字。当$succeeded 为定义变量的变量非0、非空或者,则为成功,否则为失败。使用方式如下:
ok( $exp{9} == 81, 'simple exponential' );
ok( Film->can('db_Main'), 'set_db()' );
ok( $p->tests == 4, 'saw tests' );
ok( !grep !defined $_, @items, 'items populated' ); |
is/isnt
is ( $got, $expected, $test_name );
is ( $got, $expected, $test_name ); |
is() 和 isnt()函数与ok()函数的功能类似。is() 和 isnt()对是对比两个参数是否相等,若相等该测试用例就成功,否则失败。isnt()函数与is()论断结果相反。用法:
# Is the ultimate answer 42?
is( ultimate_answer(), 42, "Meaning of Life" );
# $foo isn't empty
isnt( $foo, '', "Got some foo" ); |
相当于ok()函数:
ok( ultimate_answer() eq 42, "Meaning of Life" );
ok( $foo ne '', "Got some foo" ); |
注意:undef 只会匹配undef。
Like/ unlike
like( $got, qr/expected/, $test_name );
unlike( $got, qr/expected/, $test_name ); |
该函数和ok()函数类似,不同的是第二个参数可以为正则表达式qr/expected/。unlike()为like()函数的相反结果。用法:
| like($got, qr/expected/, 'this is like that'); |
类似于:
| ok( $got =~ /expected/, 'this is like that'); |
cmp_ok
| cmp_ok( $got, $op, $expected, $test_name ); |
cmp_ok()函数类似于ok() 和 is()。该方法还提供加入比较操作符的功能,用法。
cmp_ok( $got, 'eq', $expected, 'this eq that' );
cmp_ok( $got, '==', $expected, 'this == that' );
cmp_ok( $got, '&&', $expected, 'this && that' ); |
3、常用显示测试诊断结果的方式:
当测试用例运行失败的时候,经常是需要测试人员去debug排查失败的原因。该框架提供一些方法来提供只有当测试失败的时候才打印出失败信息的方式。
diag
| diag(@diagnostic_message); |
该函数保证打印一个诊断信息时不会干扰测试输出. 保证只有测试失败的时候才打印出信息。使用方式如下:
ok( grep(/foo/, @users), "There's a foo user" ) or
diag("Since there's no foo, check that /etc/bar is set up right"); |
explain
| my @dump = explain @diagnostic_message; |
该函数通过一种人可以阅读的格式输出任何引用指向的内容。通常和diag()函数一起使用。
相关链接:
Nginx 单元测试自动化浅析之一-Test::Nginx源码分析和使用
项目背景简介
该系统以用户体验性能测试及问题定位为目的,该系统为B/S结构、J2EE架构,应用服务器为Tomcat 6.5,数据库为Oracle 10g。该系统的使用对象为公司的内部人员,网络环境为100兆局域网。
用户体验性能是指最终用户对系统使用的一种性能评价,主要是用户对前端性能的一种主观评价。用户体验性能直接影响用户对网站的满意度,同时也影响到网站的商业价值。
用户体验性能瓶颈定位技术思路
该项目引入应用性能管理工具dynaTrace协助问题的快速定位,并结合Javascript Agent的使用,实时获取用户体验性能指标并定位前端性能问题的根本原因。该工具由Server、Analysis、Collector、Agent、Client等五部分组成。
该项目采用Compuware对用户体验性能测试所采纳的完整解决方案,对Web Server 或者Java 应用程序植入Javascript Agent。通过它实时捕获用户在页面的所有行为及页面的响应情况,如访问的浏览器型号及版本、操作系统平台、IP地址;用户在访问过程中的所有页面操作的性能指标,例如访问的URL、点击的按钮、Javascript、渲染等。dynaTrace Server收集并分析Javascript Agent捕获的数据,分析最终用户体验的性能指标及数据的相关性。
用户体验性能测试及问题定位步骤
用户体验性能测试
用户体验性能测试的过程中,从用户端实时监控其性能指标如:响应时间、连接成功率等,并识别潜在性能问题。兼顾不同位置、不同连接条件下的访问效果,检查用户对程序处理细节的用户体验,如系统中登录、查询、统计等操作并快速完成响应。确保上述问题能在最短时间内修复。用户体验性能指标示意图1如下。

图 1 用户体验性能指标(响应时间、连接成功率)
同样在用户体验性能测试过程中对实时监控收集的日志进行分析,如visits图显示网站的所有访问信息,包括发起访问的IP及使用的浏览器型号。visits可以以七种不同维度分组显示,方便系统的测试人员或者运营人员能快速准确的定位到指定的用户访问。部分分组示意图如下所示。
1)visits by User-experience
以访问的满意度分类,三类为满意的【satisfied visits】、容忍的【tolerated visits】、沮丧的【frustrated visits】。如图2所示。

图 2 visits by User-experience
2)visits by browser
显示不同的浏览器,支持桌面电脑、平板电脑、智能手机的主流浏览器。如图3所示。
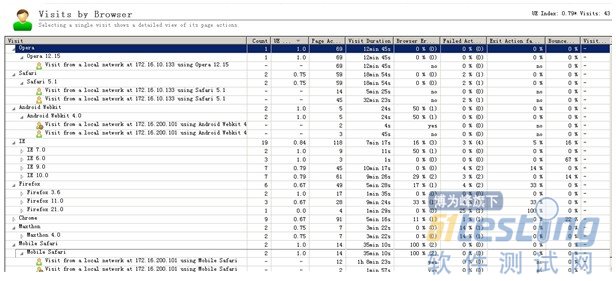
图 3 visits by browser
3)visits by client-type

图 4 visits by client-type
4)visits by OS
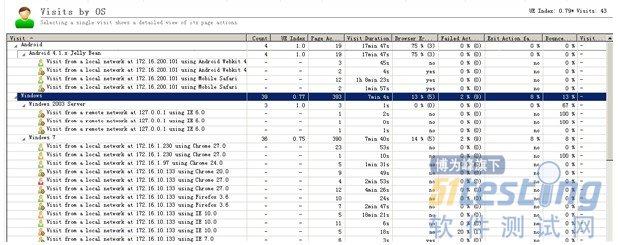
图 5 visits by OS
用户体验性能问题定位
1)故障描述
用户投诉在对该系统进行访问的过程中,操作一个文件导出时中出现了一个页面异常,如图6所示。
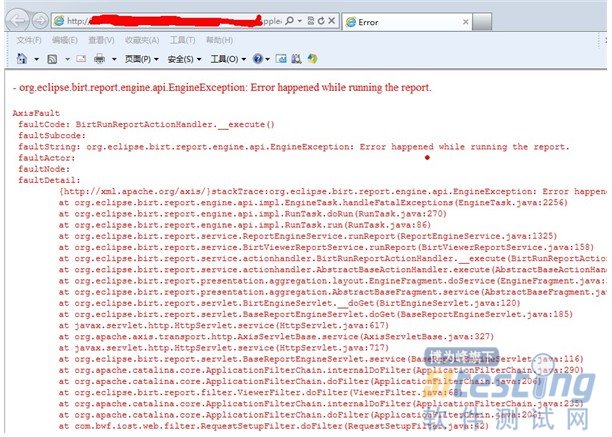
图 6 页面异常
2)通过visits快速定位投诉用户
投诉的用户使用的IP为172.16.200.2,浏览器为 IE9。根据用户提供的信息。快速定位到该用户的访问信息。并能看到此用户访问的体验性能较差,如图7所示。

图 7 投诉的用户访问信息
3)通过dynaTrace定位其根本原因
进一步钻取到投诉的用户所操作的详细信息。用户访问的主要页面操作,如图8所示。其中的一个页面操作是用户非常不满意的,并显示出现了失败的事务。

图 8 页面操作图
钻取到发生失败事务页面操作的性能索引图发现程序执行过程中出现了异常,如图9所示。

图 9 页面操作的性能索引图
出现的异常如图10所示。

图 10 exceptions
进一步钻取异常的详细信息,异常显示是由于一个文件的不存在导致。如图11所示。
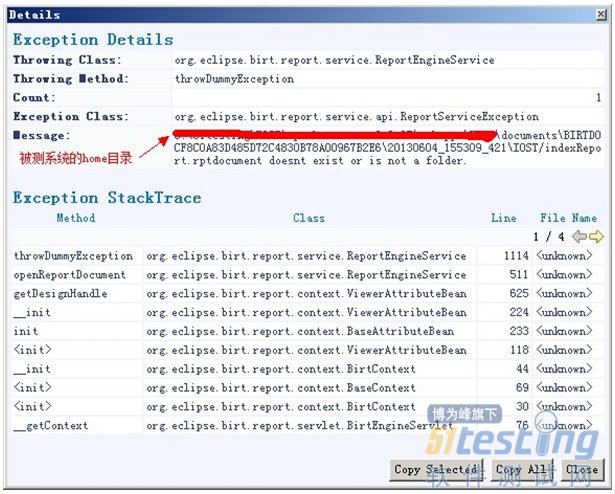
图 11 exception details
将异常的详细日志发送给研发人员,协助研发人员快速定位到问题的原因。
解决方案效果
本项目通过dynaTrace后台监控和Javascript Agent前端监控的结合,实时获取用户体验性能指标和监控数据。通过监控日志快速定位投诉用户所遇问题的根本原因,为客户减少商业流失。
更多解决方案>> www.51testing.cn
版权声明:51Testing软件测试网原创,拥有文章的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像。51testing软件测试网欢迎与业内同行进行有益的合作和交流,如果有任何有关内容方面的合作事宜,请联系我们。
摘要:本文将介绍持续集成在互联网软件项目中的应用及案例分析,主要针对互联网行业软件项目过程中的软件测试效率和质量的研究与实践;在当前Web2.0时代,笔者抓住互联网行业的软件测试特性,在软件项目的开发过程中运用持续集成构建的思想来统一规范、流程和管理,不仅提升项目在提测之前的软件版本质量,也有利于软件项目过程的效率和质量风险控制。在浅谈持续集成及工具在项目中的应用同时,也结合笔者从事互联网软件测试的工作经验,进一步阐述与总结在软件测试过程的持续集成带来的益处与不足。
笔者会先介绍当前互联网的软件测试与传统的软件测试区别与联系,然后针对互联网软件测试的特性再结合持续集成工具思想的运用,最后将比较详细的介绍Hudson持续集成构建平台在项目中的实践与分析,从而解决了在多个项目并行开发的软件项目中应该如何应用持续集成以保持项目整理开发过程的高质量和高效率问题。
关键词:软件测试;持续集成;自动化测试;
一、引言
在互联网信息时代,随着Internet的快速增长及Web应用的不断发展,使其快速渗透到商业、电子商务、军事、工业、教育等领域和个人生活的各个方面,对我们的生活及工作产生了深远的影响。在当今市场需求和Internet技术进步的不断推动下,Web应用日益增加,互联网的软件规模不断扩大,复杂性增加,操作易用性降低,面对互联网的用户也越来越多,因此软件的质量越来越成为人们共同关注的问题,作为保证软件质量和可靠性的重要手段,软件测试已成为互联网软件项目开发过程的重要环节。
在整个软件生命周期中每个环节都存在软件测试的活动,软件测试伴随着软件开发,以检验每一个阶段性的成果是否符合质量要求和达到预先定义的目标,尽可能早的发现问题并修复问题已成为当前互联网时代软件开发与测试过程的目的,也就孕育了要提高上游软件质量,发挥测试工程师在软件项目需求、设计阶段参与的重要性。互联网的信息和产品更新速度较传统软件产品是非常之快的,保证好软件系统的质量和稳定性,运用敏捷的测试思维、测试工具来改变传统的测试方法和测试观念,正是在互联网软件实施过程中必须面对的。针对互联网软件开发的特点,笔者结合多年的软件测试经验与测试策略、工具,总结一些比较适用的方法、流程和工具综合运用到互联网软件开发与测试过程中,综合运用持续集成构建的思想进一步保证软件质量和提升开发效率。
二、 现状分析
目前在互联网软件开发测试过程中,存在效率低下、质量不高的情况,具体可以总结成以下几个方面:
第一、RD编写的代码质量不高
开发工程师在编码阶段,经常犯一些比较低级的错误,致使提测版本的代码质量较低,如空指针异常、重复犯错及违背编码规范等,常常会被在冒烟测试阶段退回而重新开发,增加提测版本质量和效率的风险,也影响到项目整体开发进度。
第二、单元测试流程不规范,质量和覆盖率较低
为了提高上游代码质量,在开发过程增加了单元测试流程和规范,各部门产品线统一推广与执行,实施一段时间后发现流程在各产品线执行执行的比较混乱,存在一些流程和规范细节问题,执行出现脱节,导致单元测试的代码质量与代码覆盖率下降,在某些项目过程中暴露的非常明显,较严重地影响了项目进度和质量。
第三、测试方法单一,测试策略陈旧,测试过程的效率和质量低下
项目过程,测试工程师从立项前的需求讨论到立项后的需求、DEMO、设计评审和TC编写几乎全程参与,一定程度提升测试工程师在项目研发过程的地方和影响力,另外也带来了测试方法单一和测试策略陈旧的问题,全靠手工测试已成为项目测试过程的瓶颈,往往就导致项目、需求排队现象,进一步分析说明了我们的测试产出比低下,效率不高。
必须改变整个项目过程的测试方法,引入新的测试工具和测试策略,必须发挥自动化的力量缓解手工测试的瓶颈和解决效率低下的问题。
第四、上线后出现故障频繁,bugfix需求增多
项目和小需求在互联网行业中更新非常快,如果过程没有更好的控制软件风险的话,上线后的需求就会出现很多故障,导致用户大量投诉,后续修复的工作量将投入很多资源去支持,一定程度上浪费了精力和物力,降低了生成率。
尤其是在大项目和新增需求发布上线后,故障的频繁让开发、测试心惊胆战,不仅要处理手中新的需求,还要跟进线上故障的bugfix需求,使工程师的精力分散,增加了质量的风险。如何把故障减少下来,如何提升测试阶段和开发前期的质量,已摆在工程师及主管们面前。
第五、无数据支撑来度量和评估开发和测试人员的质量和效率
软件过程度量目前实施的还不规范,无基本度量的数据来支撑说明存在的问题,只能通过某阶段某现象说明有问题存在,但无法给一个标准去度量和评估,这样给软件开发和测试过程的质量和效率评估带来很多不便,如何收集过程数据,如何制定度量标准,还需要进一步在软件开发过程进行分析与梳理。软件过程度量也是为保证软件质量的纽带,其实这个专题研究的内容也是比较广的,从软件工程上来讲,测试过程改进有很多模型参考,这里不展开说明。
三、互联网软件测试特性
在基于互联网软件系统开发过程中,通常就是以Web系统为基础,按照B/S的访问方式为主,包含客户端浏览器、Web应用服务器、数据库服务器的软件系统,首先从技术实现上来说,一般的Web系统结构,不论是.NET还是J2EE框架,都是多层框架设计,有用户操作界面层、业务逻辑层、数据驱动层;其次从结构上来讲,都是有客户端部分、传输网络部分和服务端部分。
1、系统架构
一个比较典型的互联网软件系统的结构示意图如图-1,前端的用户浏览器,通过网络访问应用服务器及数据库服务器传回的数据。

图-1
2、互联网软件测试特点
1)不断创新,改变易用性,留住用户
在互联网软件开发过程中,我们往往关注点会集中在用户体验、软件的创新及能为用户带来的价值,所以必须建立在用户体验基础上进行创新,留住用户,改变易用性,是互联网软件开发与测试的首要特点。
2)采用敏捷的开发测试思维,快速实现新功能,快速修复线上bug
基于创新的思维决定了我们在互联网行业的软件开发过程中,必须采取小步快走、版本微创新和快速获取用户反馈,只有这样才能体验客户第一,改变软件服务的对象观念。第二个互联网软件开发测试的特点就是快,行业觉得要快速实现新功能并快速发布,快速修复线上存在的问题。
在很多互联网公司,开发和测试团队往往是技术团队的主力军,信息更新快捷和项目需求发布的频繁,很多程度上与传统软件开发和测试过程分离开来,组成比较小的团队进行软件开发与测试,这样有利于处理需求的响应速度的提升,也有利软件开发过程的风险和资源管理。
3)采用的工具协助敏捷开发测试过程,提出了自动化测试
大家知道,如果缩短软件开发和测试过程的时间,在保证需求质量的前提下,我们必须提供我们的过程效率,那么如何提高呢?这里就引起在互联网软件项目中的自动化测试,尤其在软件测试过程,自动化测试不仅仅是测试技能的提升,更是能给测试工程师乃至整个研发团队带来质的价值和创新,是真正提高了整个研发过程的效率。自提出自动化测试以后,工程师不断研究与实践,发现自动化脚本与更新维护成本非常大,久而久之维护的工作量已超出预期评估时间,这样导致要花大量的资源投入自动化维护,增加成本,经过大量项目实践与分析,在互联网行业的自动化不能是单纯的基于页面UI功能自动化,必须基于架构进行分层设计自动化,深化自动化技术和平台化的服务,做到持续集成才更有效。
3、敏捷测试思维
通过了解互联网系统架构和软件开发测试过程,我们必须改变以往的测试思维和测试策略,抓住Web软件测试的特点综合选取更适合的方法去运用,直到提出持续集成构建,才在项目中慢慢推广应用起来,其实就是采用敏捷的开发过程和测试思维相结合,把软件开发整个过程质量控制提到上游。
四、持续集成介绍
1、持续集成是什么
大师Martin Fowler对持续集成是这样定义的: 持续集成是一种软件开发实践,即团队开发成员经常集成它们的工作,通常每个成员每天至少集成一次,也就意味着每天可能会发生多次集成。每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽快地发现集成错误。许多团队发现这个过程可以大大减少集成的问题,让团队能够更快的开发内聚的软件。
在敏捷开发与测试中,持续集成是极限编程十二实践之一(1999年Kent Beck编写的《解析极限编程》),最初被使用极限编程方法的开发人员所推捧,并在过去的几年中得到广泛应用,成为业界广为人知的软件开发实践。该实践用于解决软件开发过程中一个具体且重要的问题,即“确保当某个开发人员完成新的功能或修改代码后,整个软件仍旧能正常工作。”
简单来说,持续集成是频繁、持续的在多个团队成员的日常工作中进行集成、验证并反馈。一个典型的持续集成周期基本包含如下几个步骤:
1)持续集成服务器不断从版本代码库的服务器上检查代码状态,看代码是否有更新;
2)若发现代码有最新的提交,集成服务器就会从版本代码库服务器下载最新的代码;
3)等代码完成更新结束后,持续集成服务器调用自动化编译脚本进行代码编译;
4)运行所有的自动化测试;
5)进行代码分析
6)输出可执行的软件,提高给测试人员进行最后的测试与验证
7)通过测试工程师的测试与验证,最后发布集成到发布
通过上面的持续集成构建步骤我们不难知道,其实持续集成就是一个循环、多次运用、统一检查的过程,如图-2所示描述

图-2
2、持续集成模式
根据持续集成在项目中的运用与分析,从基础搭建模式到企业级的解决方案模式,基本可以分成下面三种模式,它们分别是递增的关系,在软件开发中随着系统的复杂度和测试件的可测性不断改进的过程,最理想的持续集成达到是统一化、流程化和服务化的过程。
1)基础模式
目前,有很多种持续集成工具,其中不乏开源产品,如Maven、Hudson平台。项目伊始,我们可以建立自己的持续集成服务器,整个项目的持续集成基础结构如图-3所示:
图-3
并发多个工程师进行代码开发,每个工程师有独立的开发环境和开发分支,然后统一提交到中央代码库,最后进行统一集成编译。
2)阶段式模式
在基础模式的框架基础上,我们增加软件开发过程单元测试、静态代码检查、UI功能自动化检查,如图-4
阶段模式的持续集成较集成提升了很多,在集成server中增加了很多构建套件,综合利用持续集成的特点进行统一管理。

图-4
3)管道模式
阶段式持续集成重复任务多,而过程化集成的管理复杂性太高了,任何过程化上的变化都要修改已经写好的脚本,而这些脚本维护比较困难。既然以上两种模式都不灵了,所以就引出了高级模式就是管道式的持续集成模式。
管道式持续集成形式上与过程化持续集成相类似,但却在概念上有显著不同。在管道式持续集成中,所有的过程单元都运行在同一管道的上下文中,即各单元所使用的原材料都是完成相同的,即代码基线相同。当持续集成服务器发现有新的代码时,会创建新的一个管道,所有的过程单元都在这一个管道中运行,包含编译打包、单元测试、功能测试、性能测试和自动化测试。而每个单元产生的产物也在该管道中有效。如图-5所示:
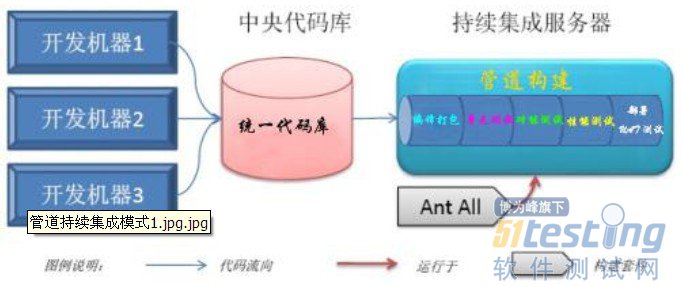
图-5
不难看出管道模式的持续集成综合了基础模式和阶段模式的优点,在管道式中,每次构建都会试图从管道的一端走到另一端。因此,你不会遗漏任何一个版本的成功产品代码,基本上可以使项目研发过程全部自动化了。
3、持续集成流程
一般在互联网软件开发和测试过程中,增加了持续集成构建,在开发和测试环节会进行多次集成与构建,做的比较好的公司,如google,微软等,可以集单元测试、功能自动化测试等集成在一起构建,做到分支代码变更脚本通知一条龙智能流程化和服务化,可见下图-6流程所示。
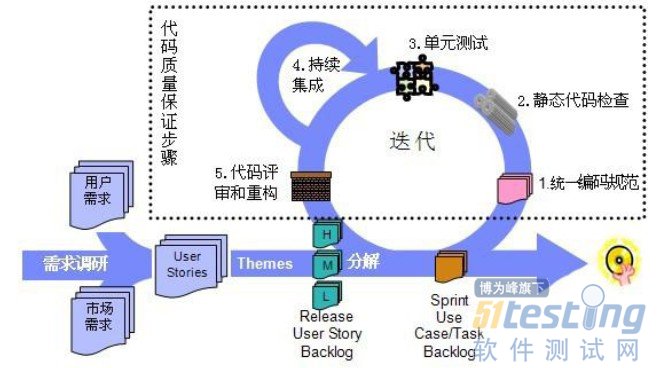
图-6
4、持续集成优点
通过上述概念和模式的阐述,让读者很容易发现持续集成最大的优点就是降低风险,提高项目研发过程的效率和质量,迎合在互联网时代信息快速更新的现象。持续集成本身并不能帮助开发工程师找到bug,它是通过不断的测试和反馈来尽早的发现缺陷,问题发现的越早处理问题的成本就越小越容易解决,由于无法证明通过了测试的代码是无bug存在的,所以持续集成中的测试非常重要,好的测试能够更多更快的发现当前版本中的错误。
往往在开发和测试过程中,软件的缺陷是累积性的,当缺陷很多时,就很难发现它们,利用持续集成构建的思想,在项目过程中可以尽早的发现缺陷,最大限度的降低了我们在项目后期发现缺陷的可能性和偶然性。
每成功构建运行一次就意味着之前做的代码提交可以成功集成,没有与他人提交的分支代码发生冲突,没有带来新的缺陷,有利于开发人员对项目保持自信心和提高工程师的工作激情。
持续集成在项目中的频繁部署将会使最终部署的难度降到最小,用户能够看到频繁上线的软件,并做及时的沟通反馈,有助于增强互联网模式下用户的信心和动力,也有助于Web产品化和服务化朝着正确的方向快速发展。
5、持续集成构建分析及工具
在敏捷的软件开发和测试团队中,我们所要做的只不过是:不断的回顾、找出问题与瓶颈、不断地重构。通过不断重构持续集成基础结构以及自动化构建脚本,使其达到我们对“反馈时间”和“判断质量准确性”的要求。另外,我们已将“持续集成”扩展到整个软件开发周期,涵盖了持续部署及发布。在上面的配置文件中,不难看出在管道模式中的两个Stage分别名为 “UAT”测试和交付的“Production”,它们一个用于部署新版本到我们自己的持续集成服务器,另一个用于部署新版本到一个公用的持续集成服务器。部署 ‘UAT’的频率为两天到一周之间,‘Production’的频率基本都是一周。这样,我们可以得到快速反馈,改进自己的产品,同时其它团队可以尽早地使用我们开发的新功能。
目前业界主流的持续集成工具主要有:Apache Continuum,CruiseControl,Hudson,Maven,LuntBuild等等,开源工具使用的比较多是Hudson框架。
五、Hudson介绍
1、Hudson简介
是一个功能强大的持续集成框架,可以持续构建和测试软件项目,并监控持续集成中生成的报告,属于开源框架,可以进行多元化插件开发与集成。
框架的优点是基于WAR包,安装部署非常简单,提供了功能完善的Web管理界面和强大的报告输出功能,另外就是有丰富的插件支持,并支持自动化安装,便于维护。
2、核心应用
由于是开源框架,在项目实践中可以不断完善我们持续集成过程存在的问题,可以集成更多的插件解决我们想要自助的集成模式。
目前在笔者参与的项目中的核心应用主要有几个部分:
1)静态代码检查(Findbugs工具)
2)单元测试(Junit)
3)代码覆盖率检查(Cov)
3、安装与配置
开源框架,有便利的安装指南,安装起来非常快捷,主要步骤有:
● 下载Hudson WAR包
● 部署到Jboss服务中
● 安装Html Report Plugin插件
● 安装Cobertura Plugin插件
● 安装Findbugs Plugin插件
● 创建分组视图和用户权限
配置也比较简单,主要配置插件和SVN代码及环境相关的条件,我们先看下配置插件,见下图所示:
Cobertura配置(图-7)

图-7
Findbugs的配置(图-8)

图-8
在Hudson持续集成平台中创建一个Job(图-9)
图-9
下面是配置代码库,以Svn代码库代码管理为例(图-10)

图-10
后续进行配置定制执行任务和执行shell脚本,然后完成生成单元测试报告和生成代码覆盖率报告的配置,最后完成生产bug扫描报告和自动发生邮件提醒的配置,当然也开源插件集成到自动发到手机提醒。都配置完成后就可以进行build 运行查看配置信息的报告,如果都通过自己在项目中需求的话,基本配置就完成了,后续在项目中就能发挥Hudson平台进行持续集成带给我们价值。
六、 Hudson在项目中的应用
可以看出,持续集成的关键在于完成的自动化、完成的流程化,需要借助相关工具和平台才能完成,所以持续集成环境的搭建需要花费比较大的精力,但是环境一旦搞定后,只需要花费很短的时间去维护,而且可以给我们项目开发和测试的效率带来很大的回报。根据持续集成的重要实践,下面以笔者工作中的实例,主要是在Hudson平台进行持续集成进行应用和分析,在项目中的持续集成流程,详见下图-11说明

图-11
下面以当前正在开发的一个项目(项目名称为Campaign)为例说明Hudson在项目中的应用及分析,如图-12所示:
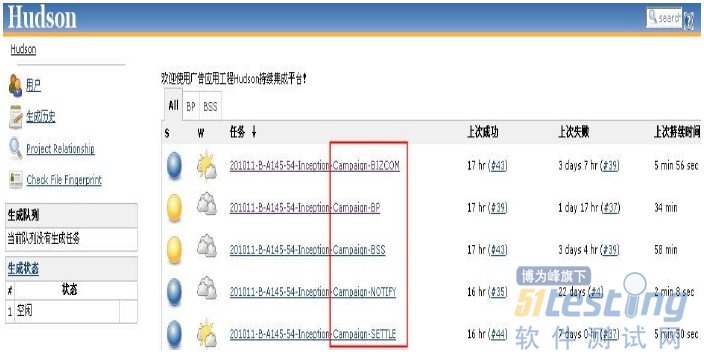
图-12
从Hudson持续平台上截图中可以看到,目前这个项目并行有5条分支(应用)在开发,平台上很清晰的记录了每个应用开发过程构建集成的记录信息,如成功、失败和持续的Time,图中s列颜色分别代表了:蓝色-集成构建通过,黄色-集成构建(冒烟失败)不通过,还有一种红色-集成构建过程编译失败或发生错误。
下面分别拿不通过和通过的两个应用分支来看(Campaign-Bss和Campaign-Settle)
(一)先看Campaign-Bss(图-13)分支集成情况:
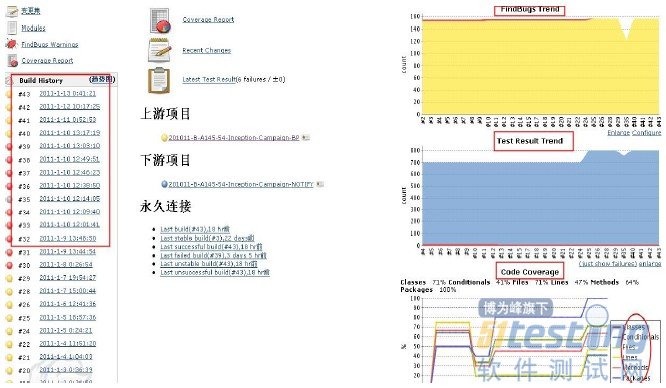
图-13
图-13中标红圈起来的我们一一说明和分析下:
● 左侧表示:持续集成的历史记录,可以看出有红色编译失败或错误阶段到黄色冒烟失败的build history记录
● 右侧表示:插件集成后检查,如Findbugs(静态代码)检查、静态代码检查,单元测试和UI自动化覆盖率检查。图-13中覆盖率的图很明显随着Build次数覆盖率是提高的,也就是说最后的Build覆盖率肯定比前一次要好,质量要高,直到达到约定的提测条件时且主干无failed的情况下才通过(主干无failed是只单元测试脚本在研发过程中可能有变更,如添加、修改和删除,有运行失败的风险,所以要求研发工程师要保证单元测试脚本每次Build后必须是100%Pass)
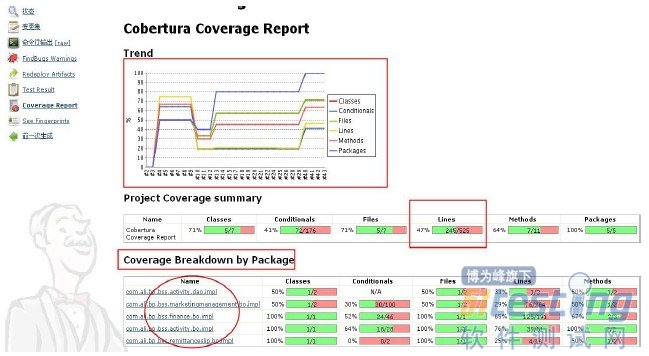
图-14
● 进一步查看Coverage Report 我们不难发现更详细的信息展现在我们眼前,如图-14所示,比较详细的输出了工程包摘要,如Lines(代码行覆盖)这里统计代码行共计525行,完成覆盖245行,所以结果统计是Lines为47%
● 分析下下面圈起的信息是显示代码框架中(接口)实现类、方法的名称(如dao层和bo业务的接口实现类等信息),其中com.ali.bp.bss.activity.dao.impl 在Conditionals为N/A(说明开发还未提交代码集成),可以通过下面名称详细查看代码覆盖率覆盖的情况
(二)再看Campaign-Settle(图-15)分支集成情况:
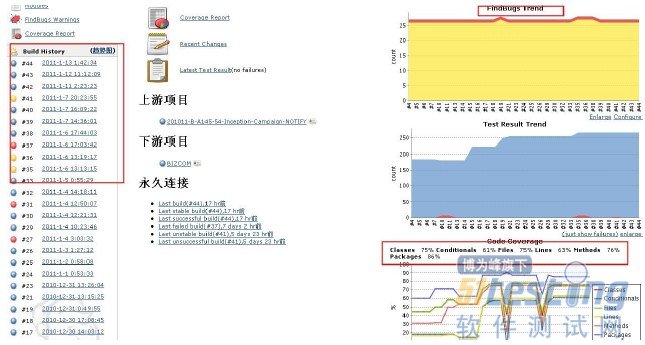
图-15
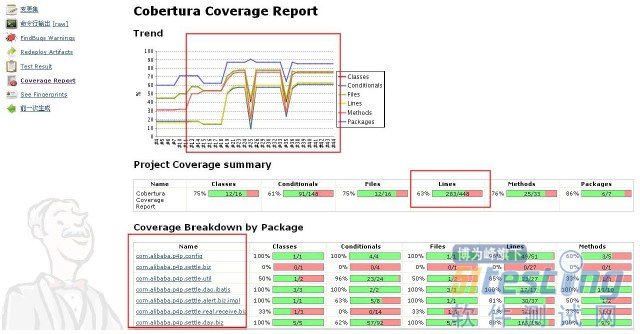
图-16
Campaign-Settle分支集成通过后,总体无Findbugs增加,Lines覆盖率为63%,从图-15和图-16中不难看出比Campaign-Bss分支集成后的质量要好。
通过这个项目的案例我们来做个小结与分析,从上面(一)和(二)持续集成分析报告来看,(二)的结果最终是集成成功且冒烟通过,而(一)被测试退回重新修复问题再等待集成验证。我们通过Hudson这样的一个持续集成平台,规范了研发过程的集成测试流程,让测试协助开发一起提升整个研发过程的质量和效率,提高软件系统的上游质量。
很明显目前我们在项目中运用的持续集成还没有到达管道模式的一体化平台,像UI功能自动化当前是在另外一个系统上运行,如果没有通过在Hudson平台配置的话,在持续集成平台中是看不到运行结果报告的,另外还有一些插件有待后续进一步研究与实践,像在C++框架模式如何实现Hudson持续集成目前还是调试实践中,当然业绩也有很多好的关于持续集成的平台与案例学习与借鉴,还是希望能通过项目实践证明持续集成能真正解决当前互联网行业软件开发模式存在的一些问题。
七、结束语
结合笔者在互联网行业工作经验,浅谈了在前端基于java应用的软件测试过程中,我们运用敏捷的开发和测试思想,采用Hudson持续集成构建平台,整体打破了传统测试思维,经过多个项目的实践证明,采用持续集成提升了软件开发和测试过程的质量和效率,提高了互联网软件生产效能。
我们说持续集成并不是一蹴而就的工作,要想真正做到管道的持续集成构建模式,需要在项目过程中不断积累经验来提升与改进,当然实施持续集成也是需要根据团队的实际情况来实施,但这并不能成会“偷赖”的另一个说法。俗语道“没有做不到,只有想不到”,只要不断反思、重构与实践总结,在互联网软件测试过程中创新每天都会出现。
下图是一张 SpecDD的基本结构图:

从图上我们可以清楚地看到,测试是贯穿于SpecDD整个过程的,从需求到开发到大规模测试,无一不显现着测试的影子。
不过虽然测试贯穿整个过程,但是其实是不同类别的测试,比如需求阶段的叫做“设计测试“,开发阶段的“验证测试”,而产品进入大规模测试阶段叫做“Full Cycle Testing”,而我今天想讲的 Floater QA,即使是属于开发阶段的测试,下面来主要介绍一下:
从英文上分析 Floater QA的意思大约是流浪的QA,引申开来大致就是这个QA不会去固定做一个工作,而是会参与很多地方的测试,哪里有需要就会去哪里。(以下简称FQA)
那这个FQA有哪些地方需要去参与呢?
● 参与测试用例的编写
● 参与功能最初的验证性测试,修改测试用例,并且给出改善建议
● 与开发人员与项目经理紧密合作解决所有阻碍下一步测试的问题
为什么需要有FQA这么一种QA的设置呢?
因为在实际的软件开发过程中,我们可能会经常遇到一种情况,一个功能或者一个产品给QA去测试的时候,由于开发不可能把所有地方都测试过,所以一旦发现严重的问题,这些问题会阻碍QA去进一步的测试,但是开发不一定每次都是能第一时间去修复它,那也就使得对于这个功能的测试会因此暂停。如果这种问题不断累积的话,我们会发现一个更加严重的问题:开发很忙,因为有很多功能需要去做;而QA需要测试的功能也很多,但是却发现很多没法测试下去。
所以引入FQA这么一类人,他们跟开发与项目经理合作最紧密:
1、当功能还在开发的时候,先去写测试用例
2、当功能开始有Build可以测试的时候,FQA首先去介入测试,他的测试其实是为后面的正规测试做准备,所以要确保该功能基本功能能够工作正常,符合设计文档,发现了问题,需要直接面对面与开发沟通,快速修复,如果这个最初的测试无法通过FQA的测试,那意味着这个功能的开发部分工作还没有结束,无法让正式的QA团队去进行测试。(平常情况下,开发人员为了改进度,可能草草跑了一下功能就说做好了,导致以后发现很多问题,进而影响其他功能,影响整个进度,而FQA的出现,能让这种情况较少出现)
3、FQA测试完成后,开发人员可以正式把这个功能打到“待测试的状态”,让正轨的测试人员在各种的环境下进行更加细致的测试和性能测试。
4、FQA测试的同时需要根据需要更新测试用例,让之后的正规QA测试可以做些参考。
所以,用一句话形容FQA的作用就是:帮助开发人员去高质量完成开发工作,帮助测试人员去顺利进行测试工作,帮助产品的开发能够在可控的范围下进行。
相关链接:
什么是SpecDD?
敏捷开发中的测试——SpecDD模型
第三章对象库
QTP在对象库(OR)里为每一个被测对象存储了一个对象定义。该定义包含了一些用来唯一识别运行时对象的参数值。QTP Object Repository Manager 是用来查看和修改对象库中的对象及其属性的。
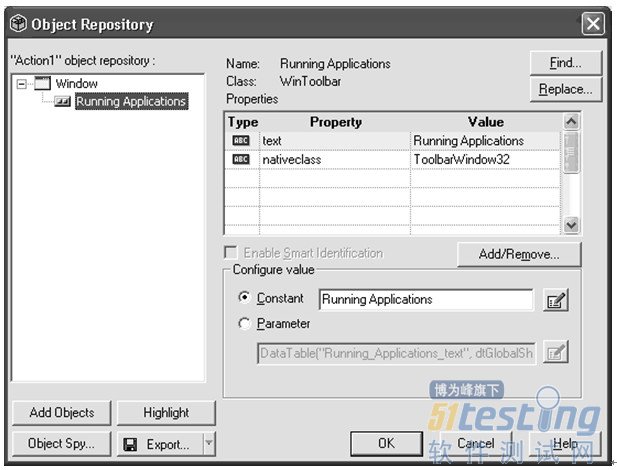
图 3-1. Object Repository Manager
图3-1,展示了一个简单的对象库。这个对象库有一个WinToolbar对象,包含了一个可以用来识别的逻辑名"Running Applications"和两个属性:"Text" 和"nativeclass" .我们可以点击"Add/Remove"按钮来添加或者删除属性。图3-2显示了从Object Identification打开的Add/Remove Properties对话框,它可以用来添加或删除任意的属性。
提示:在对象库的树视图中选择一个对象后,点击'Highlight'按钮,应用程序(必须是打开的)中的对象将会高亮显示。同样,在代码中也可以实现高亮:Window("Window").WinToolbar("Running Applications").Highlight.
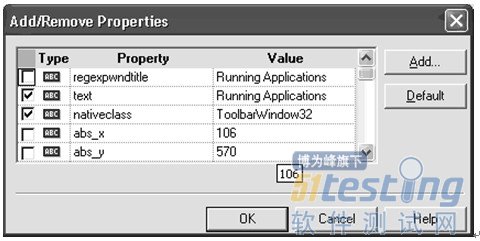
图3-2.Add/Remove Properties
对象是如何被添加到对象库的?
对象可以通过两种方式添加到对象库:
● 通过录制与被测应用程序的交互过程添加。
● 手工添加一个或多个对象。
我们可以点击"Add Objects"按钮,然后点击我们要添加的对象,通过这种方式,我们便可以手工添加对象到对象库中。
注意:假如我们要添加的对象是在鼠标点击之后才出现,那么我们可以先按下Ctrl键,然后再去点击。这个方法可以让我们临时屏蔽对象选择模式,从而进行鼠标操作。一旦我们准备好了要添加的对象,就可以放开Ctrl键,进行添加了。
如果我们需要在应用程序间切换,可以先按住Ctrl+ALT键去屏蔽对象选择模式,然后使用例如Alt+Tab键来在不同的应用程序间切换,完成切换后,再次按下Ctrl+ALT键后便可进入对象选择模式并添加对象了。
对象一旦被选中,便会在对象选择窗口中出现
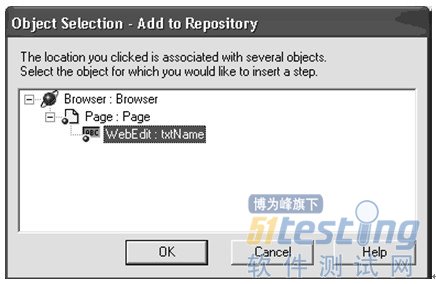
图3-3.对象选择
本对象选择窗口显示了Web页面上的完整的对象结构。选择你需要添加的对象然后点"OK"键就可以了。
小提示:对象选择窗口显示的对象可能会和录制到对象库的不一致。QTP只保留能识别对象的必须的对象结构,这样就可以在测试脚本使用对象时,减少代码的长度。
如果我们选择一个Page对象,然后继续,QTP就会询问我们是否要添加它的子对象。

图 3-4. 对象选择
选择Selected object and all its descendants这个单选按钮,然后点击OK, 页面上所有的对象都会被添加到对象库中去。
提示:对象库不能添加页面上的隐藏对象。
测试对象和运行时对象
测试对象(TO):测试对象是QTP定义的一些类,用它们来代表被测应用的各种对象。
运行时对象(RO):运行时对象是实际的被测应用的对象,是测试执行过程中,TO用来关联的对象。
理解这两种对象类型的区别是非常重要的。可以看成两辆车;车A和车B,QTP能在脚本里用一辆车的测试对象来描述出两辆车A和B。除此之外,每个测试对象也提供了用来和运行时对象交互时相关联的方法和属性。
比如Start,Run和Stop都是汽车对象提供的有用的方法。
TO属性
测试对象的属性是QTP为了识别在测试执行过程中的运行时对象而保留在对象库中的属性。QTP提供GetTOProperties方法来列举对象的所有的TO属性.GetTOProperty和SetToProperty则分别用了读取和修改TO的属性值。
问题 3-1. Test Object 属性的使用
'获取webeidt对象
Set oWebEdit = Browser("").Page("").WebEdit("")
'获取webedit对象封装属性集合
Set TOProps = oWebEdit.GetTOProperties()
Dim i, iCount
iCount = TOProps.Count - 1
'遍历所有封装属性
For i = 0 ToiCount
'获取属性名
sName = TOProps(i).Name
'获取属性值
sValue = TOProps(i).Value
'检查是否为正则表达式
isRegularExpression = TOProps(i).RegularExpression
'显示结果
MsgboxsName&"->" &sValue&"->" &isRegularExpression
Next |
问题 3-2. 运行时改变Test Object 属性
'获取webedit对象
Set oWebEdit = Browser("Browser").Page("Page").WebEdit("txtName")
'获取webedit的name封装属性值
oldName = oWebEdit.GetTOProperty("name")
'变更webedit对象的name封装属性
oWebEdit.SetTOProperty"name","new value"
'获取已修改的属性
newName = oWebEdit.GetTOProperty("name")
MsgBoxnewName |
问题 3-3. 测试中获取运行时对象属性
'x为WebEdit对象运行时的value属性值
x = Browser("").Page("").WebEdit("").GetROProperty("value")
MsgBoxx |
提示:QTP不提供修改运行时对象属性的方法。换言之,没有SetROProperty这个方法。同样, 不同的测试对象都有一个它支持的属性列表,在QTP帮助的对象模型参考中可以找到。
对象库模式
有两种对象库,更确切的说是对象库模式。

图 3-5. 每个Action的对象库设置
每个Action对应的公共对象库
Action的对象库 | 公共对象库 |
若对象还为添加到对象库,那么可以添加到Action对象库。 | 若对象还为添加到对象库,那么可以添加到公共对象库。 |
重命名对象不会影响其他的脚本。当前的脚本会自动更新对象的命名。 | 重命名对象并不会更新所有使用公共对象库的脚本,所以这会有比较大的影响。 |
如果被测对象的属性发生改变,那么需要更改所有脚本。 | 被测对象的属性发生改变,将会更新到所有脚本中。 |
如果不是很多的测试脚本来运行同一个应用程序的情况,可以使用Action对象库。 | 如果有很多不同的脚本都在与相同的对象进行交互,那么建议使用公共对象库。 |
| 公共对象库可能会变的很大,所以需要经常备份以免损坏。 |
对象探测器 (Object Spy)
对象探测器是用来查看对象所支持的方法和属性。启动对象探测功能:Tool->Object Spy…
点击指针按钮,然后选择一个对象。当选择了Test Object Properties按钮,属性标签页中就会显示出所有可得到的TO属性,并且在方法标签页中会显示所有可获得的方法,如图3-6

图 3-6. 对象探测对象属性
若选择了Run-time Object Properties按钮,那么将会显示对象的实际属性或方法,如图3-7
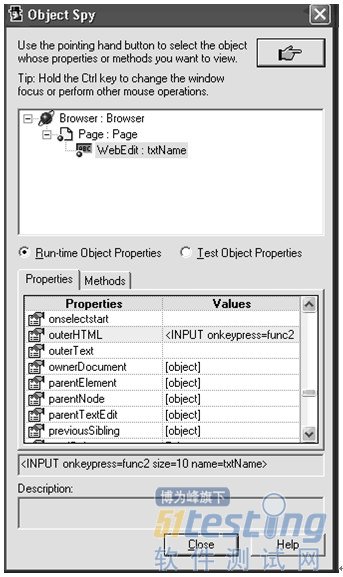
Figure 3-7. 对象探测实际属性
大多数的属性值可以通过GetROProperty方法获得。想要了解对象支持的所有属性,可以参考QTP手册。
'获取对象运行时的outerhtml封装属性值
sOuterHTML = Browser("").Page("").WebEdit("").GetROProperty("outerhtml")
小提示:对象探测器不会显示出任何带有序数识别的属性,例如CreationTime, index or location.
它们只能在添加到对象库以后计算出来。
(未完待续)
版权声明:51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像。51testing软件测试网欢迎与业内同行进行有益的合作和交流,如果有任何有关内容方面的合作事宜,请联系我们。
相关链接:
QTP自动化测试权威指南 连载(一)
在淘宝内网里看到同事发了贴说了一个CPU被100%的线上故障,并且这个事发生了很多次,原因是在Java语言在并发情况下使用HashMap造成Race Condition,从而导致死循环。这个事情我4、5年前也经历过,本来觉得没什么好写的,因为Java的HashMap是非线程安全的,所以在并发下必然出现问题。但是,我发现近几年,很多人都经历过这个事(在网上查“HashMap Infinite Loop”可以看到很多人都在说这个事)所以,觉得这个是个普遍问题,需要写篇疫苗文章说一下这个事,并且给大家看看一个完美的“Race Condition”是怎么形成的。
问题的症状
从前我们的Java代码因为一些原因使用了HashMap这个东西,但是当时的程序是单线程的,一切都没有问题。后来,我们的程序性能有问题,所以需要变成多线程的,于是,变成多线程后到了线上,发现程序经常占了100%的CPU,查看堆栈,你会发现程序都Hang在了HashMap.get()这个方法上了,重启程序后问题消失。但是过段时间又会来。而且,这个问题在测试环境里可能很难重现。
我们简单的看一下我们自己的代码,我们就知道HashMap被多个线程操作。而Java的文档说HashMap是非线程安全的,应该用ConcurrentHashMap。
但是在这里我们可以来研究一下原因。
Hash表数据结构
我需要简单地说一下HashMap这个经典的数据结构。
HashMap通常会用一个指针数组(假设为table[])来做分散所有的key,当一个key被加入时,会通过Hash算法通过key算出这个数组的下标i,然后就把这个<key, value>插到table[i]中,如果有两个不同的key被算在了同一个i,那么就叫冲突,又叫碰撞,这样会在table[i]上形成一个链表。
我们知道,如果table[]的尺寸很小,比如只有2个,如果要放进10个keys的话,那么碰撞非常频繁,于是一个O(1)的查找算法,就变成了链表遍历,性能变成了O(n),这是Hash表的缺陷(可参看《Hash Collision DoS 问题》)。
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的无素都需要被重算一遍。这叫rehash,这个成本相当的大。
相信大家对这个基础知识已经很熟悉了。
HashMap的rehash源代码
下面,我们来看一下Java的HashMap的源代码。
Put一个Key,Value对到Hash表中:
- public V put(K key, V value)
- {
- ......
- //算Hash值
- int hash = hash(key.hashCode());
- int i = indexFor(hash, table.length);
- //如果该key已被插入,则替换掉旧的value (链接操作)
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
- modCount++;
- //该key不存在,需要增加一个结点
- addEntry(hash, key, value, i);
- return null;
- }
|
检查容量是否超标
- void addEntry(int hash, K key, V value, int bucketIndex)
- {
- Entry<K,V> e = table[bucketIndex];
- table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
- //查看当前的size是否超过了我们设定的阈值threshold,如果超过,需要resize
- if (size++ >= threshold)
- resize(2 * table.length);
- }
|
新建一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
- void resize(int newCapacity)
- {
- Entry[] oldTable = table;
- int oldCapacity = oldTable.length;
- ......
- //创建一个新的Hash Table
- Entry[] newTable = new Entry[newCapacity];
- //将Old Hash Table上的数据迁移到New Hash Table上
- transfer(newTable);
- table = newTable;
- threshold = (int)(newCapacity * loadFactor);
- }
|
迁移的源代码,注意高亮处:
- void transfer(Entry[] newTable)
- {
- Entry[] src = table;
- int newCapacity = newTable.length;
- //下面这段代码的意思是:
- // 从OldTable里摘一个元素出来,然后放到NewTable中
- for (int j = 0; j < src.length; j++) {
- Entry<K,V> e = src[j];
- if (e != null) {
- src[j] = null;
- do {
- Entry<K,V> next = e.next;
- int i = indexFor(e.hash, newCapacity);
- e.next = newTable[i];
- newTable[i] = e;
- e = next;
- } while (e != null);
- }
- }
- }
|
好了,这个代码算是比较正常的。而且没有什么问题。
正常的ReHash的过程
画了个图做了个演示。
● 我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
● 最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]这里了。
● 接下来的三个步骤是Hash表 resize成4,然后所有的<key,value> 重新rehash的过程

并发下的Rehash
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。
我们再回头看一下我们的 transfer代码中的这个细节:
- do {
- Entry<K,V> next = e.next; // <--假设线程一执行到这里就被调度挂起了
- int i = indexFor(e.hash, newCapacity);
- e.next = newTable[i];
- newTable[i] = e;
- e = next;
- } while (e != null);
|
而我们的线程二执行完成了。于是我们有下面的这个样子。

注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
● 是执行 newTalbe[i] = e;
● 然后是e = next,导致了e指向了key(7),
● 而下一次循环的next = e.next导致了next指向了key(3)

3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。

4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。

于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
其它
有人把这个问题报给了Sun,不过Sun不认为这个是一个问题。因为HashMap本来就不支持并发。要并发就用ConcurrentHashmap
我在这里把这个事情记录下来,只是为了让大家了解并体会一下并发环境下的危险。
原文链接:http://coolshell.cn/articles/9606.html