全表扫描是
Oracle访问
数据库表是较为常见的访问方式之一。很多朋友一看到
SQL语 句执行计划中的全表扫描,就要考虑对其进行修理一番。全表扫描的存在,的确存在可能优化的余地。但事实上很多时候全表扫描也并非是最低效的,完全要看不同 的情形与场合,任一方式都是有利有弊的,也就是具体情况要具体分析。本文描述了什么是全表扫描以及何时发生全表扫描,何时全表扫描才低效。
本文涉及到的相关链接:
高水位线和全表扫描
启用 AUTOTRACE 功能
Oracle 测试常用表BIG_TABLE
Oracle db_file_mulitblock_read_count参数
1、什么是全表扫描?
全表扫描就是扫表表中所有的行,实际上是扫描表中所有的数据块,因为Oracle中最小的存储单位是Oracle block。
扫描所有的数据块就包括高水位线以内的数据块,即使是空数据块在没有被释放的情形下也会被扫描而导致I/O增加。
在全表扫描期间,通常情况下,表上这些相邻的数据块被按顺序(sequentially)的方式访问以使得一次I/O可以读取多个数据块。
一次读取更多的数据块有助于全表扫描使用更少的I/O,对于可读取的数据块被限制于参数DB_FILE_MULTIBLOCK_READ_COUNT。
2、何时发生全表扫描?
a、表上的索引失效或无法被使用的情形(如对谓词使用函数、计算、NULL值、不等运算符、类型转换)
b、查询条件返回了整个表的大部分数据
c、使用了并行方式访问表
d、使用full 提示
e、统计信息缺失时使得Oracle认为全表扫描比索引扫描更高效
f、表上的数据块小于DB_FILE_MULTIBLOCK_READ_COUNT值的情形可能产生全表扫描
3、演示全表扫描的情形
a、准备演示环境
scott@ORA11G> select * from v$version where rownum<2;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production
--创建表t
scott@ORA11G> CREATE TABLE t
2 AS
3 SELECT rownum AS n, rpad('*',100,'*') AS pad
4 FROM dual
5 CONNECT BY level <= 1000;
Table created.
--添加索引
scott@ORA11G> create unique index t_pk on t(n);
Index created.
scott@ORA11G> alter table t add constraint t_pk primary key(n) using index t_pk;
Table altered.
--收集统计信息
scott@ORA11G> execute dbms_stats.gather_table_stats('SCOTT','T',cascade=>true);
PL/SQL procedure successfully completed.
scott@ORA11G> set autot trace exp;
scott@ORA11G> select count(*) from t; --->count(*)的时候使用了索引快速扫描
Execution Plan
----------------------------------------------------------
Plan hash value: 454320086
----------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | INDEX FAST FULL SCAN| T_PK | 1000 | 2 (0)| 00:00:01 |
----------------------------------------------------------------------
scott@ORA11G> set autot off;
scott@ORA11G> alter table t move; --->进行move table
Table altered.
-->move 之后索引失效,如下所示
scott@ORA11G> @idx_info
Enter value for owner: scott
Enter value for table_name: t
Table Name INDEX_NAME CL_NAM CL_POS STATUS IDX_TYP DSCD
------------- -------------- -------------------- ------ -------- --------------- ----
T T_PK N 1 UNUSABLE NORMAL ASC
b、索引失效导致全表扫描
scott@ORA11G> set autot trace exp;
scott@ORA11G> select count(*) from t;
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 7 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| T | 1000 | 7 (0)| 00:00:01 |
-------------------------------------------------------------------
scott@ORA11G> set autot off;
scott@ORA11G> alter index t_pk rebuild; -->重建索引
Index altered.
scott@ORA11G> @idx_info
Enter value for owner: scott
Enter value for table_name: t
Table Name INDEX_NAME CL_NAM CL_POS STATUS IDX_TYP DSCD
-------------- ---------------- -------------------- ------ -------- --------------- ----
T T_PK N 1 VALID NORMAL ASC
c、返回了整个表的大部分数据使用了全表扫描
scott@ORA11G> select count(pad) from t where n<=990;
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 105 | 7 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 105 | | |
|* 2 | TABLE ACCESS FULL| T | 991 | 101K| 7 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("N"<=990)
--返回小部分数据时,使用的是索引扫描
scott@ORA11G> select count(pad) from t where n<=10;
Execution Plan
----------------------------------------------------------
Plan hash value: 4270555908
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 105 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 105 | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T | 10 | 1050 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T_PK | 10 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("N"<=10)
d、使用并行方式访问表时使用了全表扫描
scott@ORA11G> select /*+ parallel(3) */ count(pad) from t where n<=10;
Execution Plan
----------------------------------------------------------
Plan hash value: 3126468333
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 105 | 3 (0)| 00:00:01 | | | |
| 1 | SORT AGGREGATE | | 1 | 105 | | | | | |
| 2 | PX COORDINATOR | | | | | | | | |
| 3 | PX SEND QC (RANDOM) | :TQ10000 | 1 | 105 | | | Q1,00 | P->S | QC (RAND) |
| 4 | SORT AGGREGATE | | 1 | 105 | | | Q1,00 | PCWP | |
| 5 | PX BLOCK ITERATOR | | 10 | 1050 | 3 (0)| 00:00:01 | Q1,00 | PCWC | |
|* 6 | TABLE ACCESS FULL| T | 10 | 1050 | 3 (0)| 00:00:01 | Q1,00 | PCWP | |
----------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
6 - filter("N"<=10)
Note
-----
- Degree of Parallelism is 3 because of hint
--Author : Robinson
--Blog :http://blog.csdn.net/robinson_0612
e、使用full提示时使用了全表扫描
scott@ORA11G> select /*+ full(t) */ count(pad) from t where n<=10;
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 105 | 7 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 105 | | |
|* 2 | TABLE ACCESS FULL| T | 10 | 1050 | 7 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("N"<=10)
f、统计信息缺失导致全表扫描的情形
scott@ORA11G> exec dbms_stats.delete_table_stats('SCOTT','T');
PL/SQL procedure successfully completed.
scott@ORA11G> select count(pad) from t where n<=10;
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 65 | 7 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 65 | | |
|* 2 | TABLE ACCESS FULL| T | 10 | 650 | 7 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("N"<=10)
Note
-----
- dynamic sampling used for this statement (level=2)
--上面的执行计划使用了全表扫描,而且提示使用了动态采样,也就是缺乏统计信息
--表上的数据块小于DB_FILE_MULTIBLOCK_READ_COUNT值的情形可能产生全表扫描的情形不演示
4、全表扫描何时低效?
| --先来做几个实验
a、演示表上的相关信息
scott@ORA11G> @idx_info
Enter value for owner: scott
Enter value for table_name: big_table Table Name Index Name CL_NAM CL_POS Status IDX_TYP DSCD
------------------------- ------------------------- --------- ------ -------- --------------- ----
BIG_TABLE BIG_TABLE_PK ID 1 VALID NORMAL ASC scott@ORA11G> @idx_stat
Enter value for input_table_name: big_table
Enter value for owner: scott AVG LEAF BLKS AVG DATA BLKS
BLEV IDX_NAME LEAF_BLKS DST_KEYS PER KEY PER KEY CLUST_FACT LAST_ANALYZED TB_BLKS TB_ROWS
---- -------------- ---------- ---------- ------------- ------------- ---------- ------------------ ---------- ----------
1 BIG_TABLE_PK 208 100000 1 1 1483 20130524 10:45:51 1515 100000 --数据库参数设置
scott@ORA11G> show parameter optimizer_index_ NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_index_caching integer 0
optimizer_index_cost_adj integer 100
scott@ORA11G> show parameter optimizer_mode NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_mode string ALL_ROWS
b、查询返回20%数据行的情形
scott@ORA11G> alter system flush buffer_cache;
scott@ORA11G> select sum(object_id),avg(object_id) from big_table where id between 20000 and 40000;
Execution Plan
----------------------------------------------------------
Plan hash value: 3098837282 -- 执行计划中,使用了索引范围扫描
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 18 | 341 (0)| 00:00:05 |
| 1 | SORT AGGREGATE | | 1 | 18 | | |
| 2 | TABLE ACCESS BY INDEX ROWID| BIG_TABLE | 20046 | 352K| 341 (0)| 00:00:05 |
|* 3 | INDEX RANGE SCAN | BIG_TABLE_PK | 20046 | | 43 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("ID">=20000 AND "ID"<=40000)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
351 consistent gets
351 physical reads
0 redo size
427 bytes sent via SQL*Net to client
349 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed scott@ORA11G> alter system flush buffer_cache;
scott@ORA11G> select /*+ full(big_table) */ sum(object_id),avg(object_id) from big_table where id between 20000 and 40000; Execution Plan
----------------------------------------------------------
Plan hash value: 599409829 ---- 使用了提示执行为全表扫描
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 18 | 413 (1)| 00:00:05 |
| 1 | SORT AGGREGATE | | 1 | 18 | | |
|* 2 | TABLE ACCESS FULL| BIG_TABLE | 20046 | 352K| 413 (1)| 00:00:05 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("ID"<=40000 AND "ID">=20000)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
1486 consistent gets
1484 physical reads
0 redo size
427 bytes sent via SQL*Net to client
349 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed --注意对比上面两次操作中的consistent gets与physical reads
c、查询返回30%数据行的情形
scott@ORA11G> alter system flush buffer_cache;
scott@ORA11G> select sum(object_id),avg(object_id) from big_table where id between 20000 and 50000;
Execution Plan
----------------------------------------------------------
Plan hash value: 599409829 --->尽管返回数据的总行数为30%,而此时优化器使用了全表扫描
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 18 | 413 (1)| 00:00:05 |
| 1 | SORT AGGREGATE | | 1 | 18 | | |
|* 2 | TABLE ACCESS FULL| BIG_TABLE | 30012 | 527K| 413 (1)| 00:00:05 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("ID"<=50000 AND "ID">=20000)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
1486 consistent gets
1484 physical reads
0 redo size
427 bytes sent via SQL*Net to client
349 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed --下面使用提示来强制优化器走索引扫描
scott@ORA11G> alter system flush buffer_cache;
scott@ORA11G> select /*+ index(big_table big_table_pk) */ sum(object_id),avg(object_id)
2 from big_table where id between 20000 and 50000; Execution Plan
----------------------------------------------------------
Plan hash value: 3098837282
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 18 | 511 (1)| 00:00:07 |
| 1 | SORT AGGREGATE | | 1 | 18 | | |
| 2 | TABLE ACCESS BY INDEX ROWID| BIG_TABLE | 30012 | 527K| 511 (1)| 00:00:07 |
|* 3 | INDEX RANGE SCAN | BIG_TABLE_PK | 30012 | | 64 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("ID">=20000 AND "ID"<=50000)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
526 consistent gets
526 physical reads
0 redo size
427 bytes sent via SQL*Net to client
349 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
--注意观察每一次测试时所耗用的物理读与逻辑读
--从上面的测试可以看出,当表上所返回的数据行数接近于表上的30%时,Oracle 倾向于使用全表扫描
--而对于表上所返回的数据行数接近于表上的30%的情形,我们给与索引提示,此时比全表扫描更高效,即全表扫描是低效的
--笔者同时测试了数据返回总行数接近80%的情形以及创建了一个百万记录的进行对比测试
--大致结论,如果查询所返回的数据的总行数仅仅是表上数据的百分之八十以下,而使用了全表扫描,即可认为该全表扫描是低效的
--注:
--具体情况需要具体分析,如果你的表是千万级的,返回总数据的百分之零点几都会导致很大的差异
--其次,表上的索引应具有良好的聚簇因子,如不然,测试的结果可能有天壤之别
--最后,上面所描述的返回总行数应与执行结果返回的行数有差异,是指多少行参与了sum(object_id) |
5、小表的全表扫描是否高效?
| --使用scott下dept表,仅有4行数据
scott@ORA11G> select * from dept where deptno>10; 3 rows selected. Execution Plan
----------------------------------------------------------
Plan hash value: 2985873453 --->执行计划选择了索引扫描
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 60 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| DEPT | 3 | 60 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | PK_DEPT | 3 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPTNO">10)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets -->使用了4次逻辑读
0 physical reads
0 redo size
515 bytes sent via SQL*Net to client
349 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
3 rows processed -->下面强制使用全表扫描
scott@ORA11G> select /*+ full(dept) */ * from dept where deptno>10; 3 rows selected. Execution Plan
----------------------------------------------------------
Plan hash value: 3383998547
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 60 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| DEPT | 3 | 60 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("DEPTNO">10)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
4 consistent gets -->此时的逻辑读同样为4次
0 physical reads
0 redo size
515 bytes sent via SQL*Net to client
349 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
3 rows processed --下面来看看count(*)的情形
scott@ORA11G> select count(*) from dept; 1 row selected. Execution Plan
----------------------------------------------------------
Plan hash value: 3051237957 --->执行计划选择了索引全扫描
--------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
--------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | INDEX FULL SCAN| PK_DEPT | 4 | 1 (0)| 00:00:01 |
--------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
1 consistent gets -->逻辑读仅为1次
0 physical reads
0 redo size
335 bytes sent via SQL*Net to client
349 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed -->下面强制使用全表扫描
scott@ORA11G> select /*+ full(dept) */ count(*) from dept; 1 row selected. Execution Plan
----------------------------------------------------------
Plan hash value: 315352865
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| DEPT | 4 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
3 consistent gets -->使用了3次逻辑读
0 physical reads
0 redo size
335 bytes sent via SQL*Net to client
349 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
--对于小表,从上面的情形可以看出,使用索引扫描也是比全表扫描高效
--因此,建议始终为小表建立索引 |
摘要:传统的面向故障的测试方法存在限制条件高精确程度与低误报率无法兼得的瓶颈效果,而高误报率直接导致了测试成本的增加和效率的低下。本文在面向故障的测试框架下,深入研究了探索性软件测试方法,对该测试过程进行了量化处理,提取出一系列指标和效应函数,作为所采用的用于优化的遗传算法中的迭代条件,进而寻找出在有限测试成本内的最佳检查点组合,最终实现了既定精确程度的条件下测试成本的优化。
关键词:探索性测试;面向故障;遗传算法;检查点
1、引言:
软件测试是是软件工程的重要组成部分,是保证软件质量、高软件可靠性的关键。软件测试工作的好坏直接决定着软件产品质量的好坏。近年来,随着软件应用范围的扩大,软件复杂度的提高,以及软件设计技术的不断发展,软件开发规模越来越大,处理的问题愈来愈复杂。软件系统的可靠性也变得更为重要,传统的软件测试技术和方法以及测试工具己无法满足大型的、复杂的软件测试需要。软件测试己成为当前软件技术研究的重点和难点。
探索性软件测试是软件测试领域比较前沿的理论,尤其适用于那些要求在短时间内发现被测软件一些重要缺陷或事先没有能够进行详细测试设计的情况。利用探索性测试,能显著提高软件测试的效率。
面向故障的软件测试方法是指测试是针对某些故障的,而不是传统意义上的针对的是整个软件。因为面向故障的方法在测试之前把测试目标定位到一类具体的故障,所以这些故障具有类似的检测难度。
已经有很多文献把遗传算法应用到软件测试中并取得了较好的结果,但是这些应用大多是基于路径覆盖,条件覆盖以及测试数据生成的。在探索性测试方面,J¨org Denzinger把遗传算法应用到系统冗余(错误)行为测试中效果也较明显,他的测试倾向于系统测试,把时间和待测个体(这些个体被看作agent)的动作构建成一个序偶,进而用遗传算法迭代寻找出冗余错误的动作。
传统的面向故障的测试方法存在限制条件高精确程度与低误报率无法兼得的瓶颈效果,而高误报率直接导致了测试成本的增加和效率的低下。本文在面向故障的测试框架下,深入研究了探索性软件测试方法,对该测试过程进行了量化处理,提取出一系列指标和效应函数,作为所采用的用于优化的遗传算法中的迭代条件,进而寻找出在有限测试成本内的最佳检查点组合,最终实现了既定精确程度的条件下测试成本的优化。
2、探索性测试:
探索性测试的创始人James Bach对探索性测试的定义为:了解被测软件,设计测试用例,执行测试同时进行的软件测试技术。也就是说不进行事先计划和设计的一种特殊类型的测试,由有经验的测试人员根据实际情况产生诸如“我这么测结果会怎样?”的灵感来进行测试,这一方式往往能帮助在测试设计之外发现更多的软件错误。
探索性测试往往是测试人员依据测试任务进行主动的、探索性的测试,这就要求探索性测试的实施具备比传统测试更强的测试设计能力,他要根据测试的实际情况,来及时的设计出测试用例,只不过这个测试不需要形成文档而已,但是要给出测试的结果报告,此外,还需要很强的观察能力,思维能力和调动各种资源的能力,如他人的帮助,工具的使用等,特点概括如下:
(1)探索性测试强调测试设计和测试执行的“同时”性。这个“同时”是相对于传统软件测试过程中的“先设计,后执行”来说的。
(2)测试工程师通过测试来不断学习被测试系统。
(3)探索性测试的重点是创造。
运用探索性测试对软件进行测试,首先通过阅读能找到的软件需求和开发文档,学习了解软件的运行环境、了解测试任务、配置测试环境等。准备这些测试计划的同时,根据已经掌握的情况,对被测试系统实施初次的测试用例设计。利用设计出来的测试用例,进行初次的探索性软件测试执行。测试的执行结果,一方面反馈到设计好的测试用例中去,对已有的测试用例进行重新修订;另一方面与原先学习到的系统作比较,加深对原来界定不清问题的理解,进一步的加深对原系统的了解。之后,又可以进一步利用对系统的学习了解成果,设计出新的测试用例,执行测试。如此反复,直至完成原先设定的测试目标。
3、面向故障的软件测试:
面向故障的软件测试方法是指测试是针对某些故障的,而不是传统意义上的针对的是整个软件。因为程序是软件的具体表现,所以为了便于测试,其定义的故障模型必须落实到程序上,也就是说,故障是程序中某个或某几个程序的错误。定义在程序中的故障必须满足下列几个条件:
(1)故障必须是和实际是对应的。也就是说,实际软件中存在大量这种故障,而且所提出的故障模型能覆盖大多数实际存在的故障。
(2)故障必须能引起错误。一旦该故障被执行且产生的变异能传播到程序中的某个输出,则程序的结果必然是错误的,或者说程序的行为是错误的。
(3)故障的个数是可以容忍的。故障的个数一般和程序的规模是线性关系,个数太多,难以实现,以至无法实用。
4、探索性方法的建模和量化:
Andy Tinkham和Cem Kaner, J.D., Ph.D.分析了影响探测型测试人员测试效率的因素,包括过去的经验,个人的技能,知识构架,思维方式,和对待测软件系统的了解程度等。这些因素都会或多或少地影响测试人员的执行测试的质量。
本文构建基于探索型测试的模型,首先定义效用值V,然后把影响因素数量化之后映射到V,用V来描述一个检查点出现故障的可能性,这个值是测试人员从自身的经验技能及对系统的理解程度出发做出的判断,是一个主观上的效用值,用来决策一个检查点是否应当经行测试。即:V=F(E,P,K);
V: Value of testing necessary; E: experience ; P: personnel situation ; K: knowledge of the SUT
(注:检查点:具体确定待测故障后,依据故障检查规则自动或手动找出的可能出现此类故障的地方。)
模型中E表示过去经验,P表示个人的一些情况,涵盖了个人的思维技能知识等方面因素,K表示他对系统的了解程度。在一个测试人员即将开始一次探索性测试时,他的经验和个人情况是相对既定的,之所以把两者独立起来,因为在诸多因素中,经验所占的比重是最大的。但是,对系统的理解程度,是随着学习和测试的不断深入而变化的,这样使得每个检查点的效用值在测试过程中不断变化。各个因素具体的数量化方法,随着所采用的函数F而不同;而F的选择应当在面向具体故障时给予确定。
由于采用遗传算法进行测试,需要给出编码规则和适应度函数。(1)编码是先进行代码解析,根据给定规则,找出可能出错的检查点,各位取值0或1,0表示出错可能性较小不许测试,1则相反,是最后的测试点。由于对软件质量要求不同,所给出的规则可能有不同的严格程度。把所有的检查点放在一起,就得到了一个n位的串,作为染色体串。我们的目标就是对这个串优化,寻找出有限测试成本内的检查点组合。(2)适应度函数: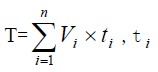 , 是编码串中的位值,取值为0或1;Vi是各位的测试必要值。
, 是编码串中的位值,取值为0或1;Vi是各位的测试必要值。
在模型中,采用遗传算法行进探索性测试。在寻找最佳组合时,设I是给定测每轮计划测试次数,即测试成本,我们的目标是
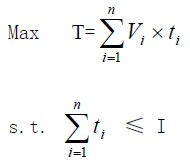
这样该问题就退化为0-1背包问题,可以有多种方法给出近似或确定解,但是为了更好的模拟人类思维进行探索型测试,遗传算法的定向性和随即性是最佳选择。
5、测试流程:
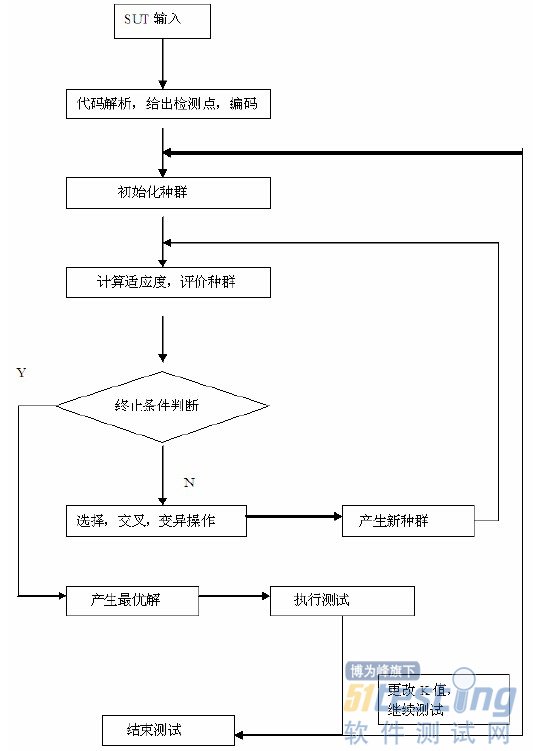
6、实验及结果:
实验采用了PC—lint代码检测工具,针对非法计算故障,对一个用C++编写的大约2万行代码的程序做了两组测试实验。当PC—lint给出警报点时,一般测试方法要对所有警报点进行测试,存在测试成本太高的情况。根据本文所给出的基于探索性测试的方法,可以在保证测试质量的基础上,减少测试成本。下图是实验数据统计
试验一

进行探索性试验时,测试人员的经验知识背景等方面会影响测试的效果,下面实验结果反应了两个经验不同的试验者测试结果的差异。
试验二

PC—lint工具给出的警报点存在误报和漏报的情况,但是一般已能涵盖大部分故障点,所以上述试验不考虑漏报的情况。
7、结束语:
探索性测试要求充分发挥测试人员的个人能力,把自身的经验技能及对系统的学习认知作为参考,灵活地经行测试设计和执行。本文模型把这些方面量化并以此构造适应度函数,理论上能够寻找低代价高覆盖的测试组合。但是在实践中,首先要解决的是检查点生成的任务,这需要一定的经验和理论指导,也是一个很有意义的研究点。另外,遗传算法有一定的缺陷,比如收敛过早等,可以把改进的算法应用到该模型中。
本文作者创新点:采用量化处理的方法对探索性测试进行研究,并结合遗传算法对故障测试进行优化,为软件测试提供了一种新的思路和方法。
本次交流的目的
● 我们许多技术人员往往将测试简单的理解为对产品功能性能的验证。
● 在产品测试中他们简单的对产品需求规格说明书中所述的产品性能、功能进行分类,并按照其预想的用户操作步骤通过黑盒测试的方法来测试产品是否实现设计指标和功能。
● 这种方法会带来严重的缺陷:
1、产品需求规格说明书只会对产品外在指标和功能进行定义,而不会对产品组成的单元/单板、接口等指标功能进行描述。这样的测试可以肯定比较难以发现产品内部的设计缺陷。
2、产品需求规格说明书定义的指标、功能可能列写不充分。根据不充分的需求定义导出的测试用例不能够覆盖基本(正常)事件的测试,导致测试有效性的降低。
3、产品需求规格说明书可能不会对备选事件和异常事件进行描述,即使是一一对应需求规格而设计的测试用例也会造成对备选事件和异常事件的测试遗漏,进一步降低测试有效性。
4、单元测试、集成测试、系统测试所用测试用例完全一样,忽略了不同产品测试阶段所要关注的工作重点,使得产品设计缺陷难以在研发阶段暴露,后续影响量产产品的质量。
本次交流的目的就是增强技术人员对测试工作的理解和认识,便于后续公司测试工作流程的持续改进。
测试的目的和原则
● 一点共识:
→ 为使最终用户对产品满意,就必须保证产品功能性能达到用户需求。而验证产品功能性能否达到用户要求的唯一方法就是持续有效的测试。
● 两种角度:
→ 从用户的角度出发,就是希望通过测试能充分暴露产品中存在的缺陷,以便决定是否买单。
→ 从开发者的角度出发,就是希望测试能表明产品不存缺陷,已经完全正确地实现了用户需求。
● 三个问题:
→ 从情感角度来看,开发者是不愿意自己设计的产品被证明存在设计缺陷。
→ 从应用角度来看,开发者往往是认为用户一定是按照自己设计好的操作模式来对产品进行操作的。
→ 从实施角度来看,开发者总是对能够验证产品已经实现了预期功能的测试项目更加感兴趣。
● 四条结论:
→ 测试不仅仅是为了证明产品能够实现既定功能,还要尽可能多地发现产品中的错误和缺陷。
→ 测试只能证明错误的存在,但不能证明错误不存在。
→ 研发产品质量保证的唯一方法就是尽量大覆盖范围下的有效测试。
→ 测试的有效性是通过符合实际应用条件下的测试用例的设计及实施来保证。
测试实施原则
● 由于惯性思维的存在使得难以发现设计缺陷,因此尽量避免设计人员来测试自己设计的产品,但是单元测试除外。
● 确定预期输出结果是测试用例必不可少的一部分。如果只有测试数据而无预期结果,那么就不容易判断测试结果是否正确。
● 彻底检查每个测试结果。如果不仔细检查测试结果,有些已经测试出来的错误也可能被遗漏掉。
● 对非法的和非预期的输入也要像合法的和预期的输入一样编写测试用例。
● 检查产品是否做了应做的事仅是成功的一半,另一半是看产品是否做了不该做的事。
● 对测试错误结果一定要有一个确认的过程,一般有A测试出来的错误,一定要有一个B来确认,严重的错误可以召开评审会进行讨论和分析。
● 测试后遗留的错误数目往往与已发现的错误数目成比例。因此当A模块找出错误比B模块多得多时,很可能A模块遗留的错误仍比B模块遗留的错误多。
● 回归测试的关联性一定要引起充分的注意,修改一个错误而引起更多的错误出现的现象并不少见。
● 妥善保存一切测试过程文档,测试的重现性往往要靠测试文档。
● 制定严格的测试计划,并把测试时间安排的尽量宽松,不要希望在极短的时间内完成一个高水平的测试。
● “尽早和不断的测试”应该成为一个合格的开发者的座右铭。
总结一下
● 对于测试重要性的理解我们都相差不多,唯一的区别在于对测试所关注问题的不同看法。
● 我们的核心问题是如何提高测试效率。
→ 测试会占用开发周期,特别是测试覆盖率要求越高周期就会越长,这与开发进度要求一定是矛盾的。
→ 开发人员、测试人员较少测试经验,不具备良好的测试技能和测试工具,使得测试进度更加不可保证。
广义的测试
● 测试应该贯穿产品开发周期,测试不仅仅是测试所实现的产品性能与功能,还要测试开发周期中各种设计文档。
● 需求阶段、总体(概要)设计阶段、详细设计阶段所输出的技术文档,包括需求规格说明、总体(概要)设计、详细设计、源程序(SCH、PCB)、用户文档等,都是测试的对象。
测试的分类
● 按测试方法划分,有静态测试和动态测试。
→ 动态测试:使被测试产品或模块有控制地运行,并从多种角度观察运行时的行为,以发现其中的错误。
→ 静态测试:就是指人工评审设计文档,借以发现其中的错误。作为研发质量控制的重要手段,评审经常作为具体实施前的检查手段,其目的是保证设计的正确性、减小设计风险、尽早发现设计缺陷。
● 按测试功能划分,有黑盒测试和白盒测试。
→ 白盒测试:对模块内部是不透明的。从模块/产品的设计、结构上来进行测试,检查模块/产品中的错误。
→ 黑盒测试:对内部透明,仅从使用上来检查功能上是否有错误。
黑盒与白盒
● 黑盒测试是从上到下、从宏观到微观的逐步验证过程,一般止步于单板/功能模块外部功能的测试。
● 白盒测试是从下到上、从微观到宏观的逐步验证过程,一般涉及单板/功能模块内部性能功能及单元间接口的测试。
● 一般采用白盒测试方法来检查产品的基本功能单元内部错误,而采用黑盒测试方法来验证由各功能单元组装而成的产品/系统的功能和性能。
黑盒测试也称功能测试或数据驱动测试,它是在对产品应具功能进行抽象的基础上,将程序划分成功能单元,然后对每个功能单元设计测试用例进行测试。
● 优点:黑盒法测试用例是围绕着产品操作方式和实际应用环境来设计的,每一个测试用例表征着一种产品实际可能发生的应用场景,测试结果非常直观便于理解。
● 缺点:黑盒测试用例的设计不可能做到完全覆盖,因此难以完全触发产品内部所有执行流程/路径,也就难以完全发现深藏在产品内部单元/模块及接口的设计缺限,需要有白盒测试进行补充。
白盒测试也称结构测试或逻辑驱动测试,在知道产品内部工作过程的前提下,按照产品内部的结构,通过测试来检测产品内部动作是否符合详细设计。
● 优点:白盒法测试用例是围绕着产品设计实现角度出发,通过对其内部信号特征、接口功能性能的覆盖性检查来保证设计的正确性。
● 缺点:以详细设计为依据,以覆盖率为最终目标,因此缺乏宏观把握的能力。
→ 能查出详细设计本身所存在的问题,即错误的产品设计。
→ 不可能查出被详细设计所遗漏的功能、性能。
灰盒测试
● 灰盒测试介于黑盒与白盒之间,关注输出对于输入的正确性,同时也关注内部表现,但这种关注不象白盒那样详细、完整,只是通过一些表征性的现象、事件、标志来判断内部的运行状态。
● 灰盒法在用例设计中不关心模块内处理过程,只关心被测对象的输入与输出,这是典型的黑盒思维模式。
● 灰盒法在用例设计时基于对模块内部处理的了解,测试设计可以有针对性的进行,测试过程评估也是白盒法。
模糊测试
● 模糊测试是黑盒法中的一种,其执行过程为:向产品有意识地进行无效输入以期望触发错误条件或引起产品的故障。
● 模糊测试最为形象的说法是:测试过程要做的就是站在后面向目标投掷石头,等待玻璃被打破的声音。就这个意义而言,模糊测试可被归结为黑盒测试。
● 若我们对产品内部有所了解,就可以让石头每次的飞行路线更直接并且更真实。因此,模糊测试也可以应用在灰盒测试中。
● 按测试步骤划分,有单元测试、集成测试、系统测试。
→ 单元测试:也称模块测试。测试的对象是设计的最小单位-功能模块。单元测试的依据是详细设计描述,对模块内所有表达功能/性能的节点设计测试用例,以便发现模块内部的错误。单元测试主要发现详细设计阶段产生的错误。
→ 集成测试:又称联合测试也称组装测试,它是对由各模块组装而成的产品进行测试,主要检查模块间的接口和通信。
→ 系统测试:是把软、硬件和环境连在一起全面的测试,检查系统的功能、性能及其他特征是否与用户的需求一致,它是以需求规格说明书作为依据的测试。系统测试又可细分为功能测试、容量测试、压力测试、使用性测试、安全性测试、性能测试、可靠性测试、恢复测试、强度测试、文档测试以及工序测试。
划分测试的种类并不重要,重要的是,一定要把测试看成是产品设计全生命周期持续不断而不是阶段性的工作。
测试方法的选择
有一种观点认为:
● 在单元测试阶段采用白盒法;
● 在集成测试阶段采用灰盒法;
● 在系统测试阶段采用黑盒法。
测试覆盖范围
● 正确性测试:测试用例中的测试点应首先保证要至少覆盖需求规格说明书中的各项功能。
● 健壮性测试:正确信息输入将产生预期输出, 非法信息输入将导致相应提示或错误处理,而不至于系统/模块崩溃。
● 容错性测试:测试系统/产品的功能单元、接口间出现异常的情况下系统的保护性处理,以及异常结束后系统功能性能的恢复处理。
● 可靠性测试:测试系统/产品在实际应用环境下可保证性能功能有效性的能力。
● 压力测试:测试在大信息量处理情况下的系统/产品正常工作的能力。
● 回归测试:测试上一轮测试所发现缺陷的解决及对系统的潜在影响。
软件测试与硬件测试
● 软件测试:软件不涉及制造加工,因此软件测试的目的仅仅是验证设计的正确性。
● 硬件测试:除了验证设计正确性以外,还要包括制造的准确性,或者一致性测试。
当我们只考虑验证设计正确性的话:
→ 软件测试:发现软件代码语法错误和逻辑错误,衡量软件设计正确性的标准是:软件在某种输入条件下是否按正确时序完成对硬件的操作(如写入/读出寄存器数据)。
→ 硬件测试:发现硬件设计的错误,衡量硬件设计正确性的标准是:硬件系统在某种激励条件下能否保证线路上的信号完整性,即“在需要的时间内信号达到所需要的形状”。
测试的实施
实施测试工作的过程为:
● 制定测试策略
● 测试用例设计
● 执行测试用例
● 缺陷修复过程
● 回归测试
测试策略-定义
依据测试项目的特定环境约束而规定的测试原则、方式、方法的集合,用以描述在测试活动各阶段所采用的测试方法和测试目标。内容主要包括:
→ 资源需求的详细说明。
→ 进度约束下的人力资源角色和职责。
→ 某测试阶段所使用的测试方法和工具。
→ 某测试阶段所需要执行的测试类型。
→ 测试完成和测试成功所采用的评价标准。
测试策略-意义
● 测试策略明确了所有测试阶段、测试技术和项目所使用的测试工具和测试目标,用以指导后续测试工作得有效实施。
● 测试策略的制定还可以使得测试过程中的沟通交流变得更为容易和有效,而它会影响到整个项目组。
测试用例-定义
● 测试用例(Test Case)是为某个特殊目标而编制的一组测试输入、执行条件以及预期结果,以便测试某个功能单元/模块、系统/产品是否满足某些特定需求。
● 测试用例指对特定的功能单元/模块、系统/产品进行测试任务的描述,体现测试方案、方法、技术和策略。内容包括测试目标、测试环境、测试输入、测试步骤、预期结果等,并以文档的形式予以表达。
测试用例-要素
● 用例编号:便于测试用例的管理及测试过程的跟踪。
● 用例标题:清楚表达测试用例的用途。
● 重要级别:定义测试用例的优先级别。
→ 高:确保系统基本功能及主要功能的测试用例
→ 中:确保系统功能的完善方面的测试用例
→ 低:较少使用或辅助功能的测试用例,如提示信息
● 测试输入:定义用例实施中的各种输入条件。
● 操作步骤:对于复杂测试用例,操作时需要分几个步骤完成,这部分内容在操作步骤中详细列出。
● 预期结果:提供测试执行的预期结果,预期结果应该根据产品需求中的输出得出。
● 基本事件:描述该测试用例的基本操作流程,指每个流程都“正常”运作时所发生的事情。基本事件用以测试在正确环境及操作下产品所能实现的性能、功能。
● 备选事件:表示这种行为或流程是可选的或备选的,并不是总要执行。
● 异常事件:表示在发生某些非正常的事件后产品所要执行的响应。
● 正面测试:用于验证被测单元能够执行应该完成的工作。
● 负面测试:用于验证软件不执行其不应该完成的工作。
测试用例设计-白盒法
● 白盒测试是穷举类测试,主要强调的是覆盖率,即测试用例要覆盖单元内部所有处理流程。
● 对软件来讲就是代码路径的覆盖率,对于硬件测试来讲则是检查所有电路节点的响应信号。
● 受到进度和资源的约束,不可能达到完全覆盖率,折衷办法就是选取关键重要的部分进行测试用例的设计。
● 覆盖率由低到高
→ 语句覆盖:检查到模块中每个语句执行情况。
→ 判定覆盖:检查到模块中每个分支/信号流执行情况。
→ 条件覆盖:使判定中的每个条件获得各种可能的结果。
→ 判定/条件覆盖:选择足够的测试用例,使得判定中每个条件取到各种可能的值,并且每个判定取到各种可能的结果。
→ 条件组合覆盖:执行足够的测试用例,使得每个判定中条件的各种可能组合都至少出现一次。
→ 路径覆盖:执行足够的测试用例,使得每条路径至少被执行一次。
● 白盒法实施深度:
→ 白盒法(包括设计文档评审、软件代码检查)工作量应占到测试总工作量的50%。
→ 对测试缺陷进行统计分析,白盒法发现的缺陷要达到总缺陷数的50%以上。
测试用例设计-黑盒法
● 等价分类法:在输入数据中选择一组子集,每个子集选择一个具有“代表性”的测试用例,使这个测试用例可以代表一大类的有同样共性的其他测试用例,这就形成了一个等价类。这样就可使用少数的等价类测试用例能发现较多的错误。
● 等价分类法分为二步:
1、根据功能说明中的输入条件划分等价类;
2、按等价类来选择测试用例。
● 边缘值分析法:与等价分类法的差别主要在于边缘值分析法是着重检查等价类边界上的情况。
→ 若某个输入条件说明了值的范围,则可选择恰好取到边界值的用例;另外再编写一些代表不合理输入数据的用例,它们的值恰好超过边界。
→ 如果一个输入条件指出了输入数据的个数,则为最小个数,最大个数,比最小个数少1,比最大个数多1,分别设计用例。
● 因果图法:因果图法则着重检查输入条件的各种组合情况,消除等价分类法和边缘值分析法没有检查各种输入条件的组合的缺点。
→ 从用自然语言书写的功能说明中找出因(输入条件)和果(输出或程序状态的修改);
→ 通过画因果图将功能说明转换成判定表,然后为判定表的第一列设计测试用例。
→ 因果图法是设计测试用例的一个系统的方法。
● 错误推测法:通过经验或直觉推测程序中可能存在的各种错误,从而有针对性的编写测试用例,这就是错误推测法。
错误推测法没有确定的步骤,很大程度上是凭经验进行的。
测试用例设计
前述概念是随着软件测试的发展而提出并逐渐完善。相对而言,硬件测试并未能够形成一种完善的理论和实施流程,其主要原因在于硬件的多样性以及硬件系统难以独立于软件而单独实现。对于软件测试用例的设计有许多参考文献,这里不再描述。
测试管理小组
● 成立背景:
1、项目组对测试工作不重视,虽然按流程要求进行了测试计划和测试用例的撰写及评审,但是评审有效性差,导致测试用例设计质量差,执行效果不佳。
2、项目组对测试的目的和原则理解偏差,对各测试阶段的中心任务不明确,测试经验欠缺,没有掌握正确的测试方法。
3、公司流程定义模糊,没有对质量节点、阶段出入允许条件进行有效的定义,缺乏详细的工作指南和文档模板。
● 工作职责:
1、负责识别公司研发流程中产品测试相关问题,确定问题的优先级和改进计划。
2、负责组织完善测试工作流程,进行文档模板的建设,撰写测试工作指南。
3、负责组织实施测试流程、测试技能的培训。
4、负责公司在研项目的测试工作阶段评审,并对项目组产品测试进行全程辅导。