其实大家都知道sql语句的错误信息都可以在sys.messages表里面找到
如:

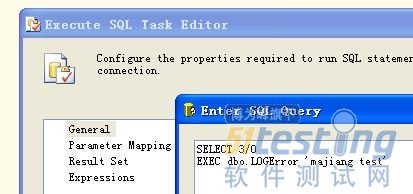
如果在执行语句在try...catch中,我们可以通过以下方法获取错误信息。sql语句如下:
BEGIN TRY
SELECT 3 / 0
END TRY
BEGIN CATCH
DECLARE @errornumber INT
DECLARE @errorseverity INT
DECLARE @errorstate INT
DECLARE @errormessage NVARCHAR(4000)
SELECT @errornumber = ERROR_NUMBER() ,
@errorseverity = ERROR_SEVERITY() ,
@errorstate = ERROR_STATE() ,
@errormessage = ERROR_MESSAGE() SELECT @errornumber ,
@errorseverity ,
@errorstate ,
@errormessage RAISERROR (
@errormessage, -- Message text,
@errorseverity, -- Severity,
@errorstate, -- State,
@errornumber
);
END CATCH
View Code |
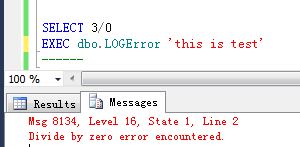
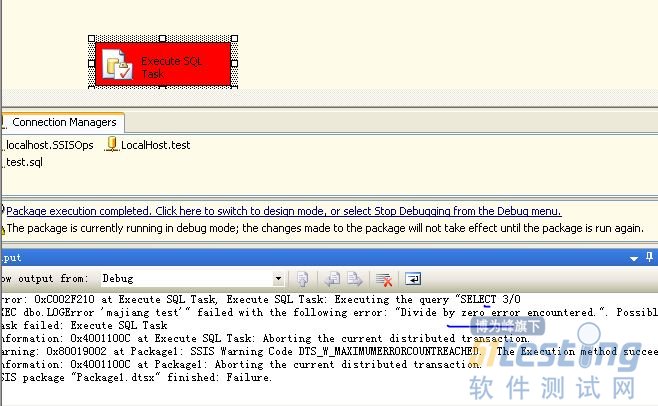
当然我这里是故意用RAISERROR再次抛出错误信息,运行结果如下:

现在我们来定义一个存储过程,其目的就是往本地文件中写入信息。
sql脚本如下:
CREATE Proc [dbo].[UCreateOrAppendTextFile](@Filename VarChar(100),@Text nVarchar(4000))
AS
DECLARE @FileSystem int
DECLARE @FileHandle int
DECLARE @RetCode int
DECLARE @RetVal int
DECLARE @CreateOrAppend int
EXECUTE @RetCode = sp_OACreate 'Scripting.FileSystemObject' , @FileSystem OUTPUT
IF (@@ERROR|@RetCode > 0 Or @FileSystem < 0)
RAISERROR ('could not create FileSystemObject',16,1)
EXECUTE @RetCode = sp_OAMethod @FileSystem , 'FileExists', @RetVal out, @FileName
IF (@@ERROR|@RetCode > 0)
RAISERROR ('could not check file existence',16,1)
-- If file exists then append else create
SET @CreateOrAppend = case @RetVal when 1 then 8 else 2 end
EXECUTE @RetCode = sp_OAMethod @FileSystem , 'OpenTextFile' , @FileHandle OUTPUT , @Filename, @CreateOrAppend, 1
IF (@@ERROR|@RetCode > 0 Or @FileHandle < 0)
RAISERROR ('could not create File',16,1)
EXECUTE @RetCode = sp_OAMethod @FileHandle , 'WriteLine' , NULL , @text
IF (@@ERROR|@RetCode > 0 )
RAISERROR ('could not write to File',16,1)
EXECUTE @RetCode = sp_OAMethod @FileHandle , 'Close'
IF (@@ERROR|@RetCode > 0)
RAISERROR ('Could not close file ',16,1)
EXEC sp_OADestroy @filehandle
IF (@@ERROR|@RetCode > 0)
RAISERROR ('Could not destroy file object',16,1)
EXEC sp_OADestroy @FileSystem
----------------------------------------
然后执行该存储过程:
exec UCreateOrAppendTextFile 'C:\Error.log','hello majaing'
如果遇到以下错误则说明Ole Automation Procedures没有启用
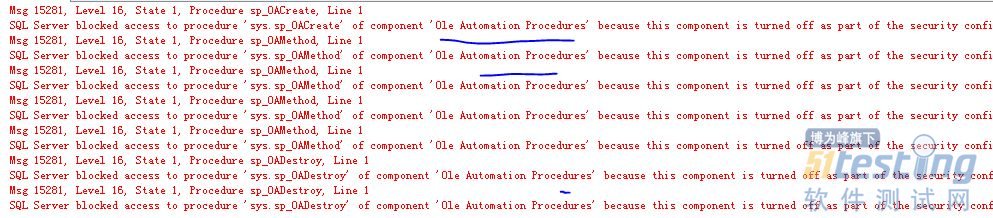
需要执行以下SQL:
go
sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
sp_configure 'Ole Automation Procedures', 1;
GO
RECONFIGURE;
GO |
运行即如果如图:

当然这里运行存储过程之前必须保证 文件是存在的。
最后封装一个存储过程获取错误信息,其脚本如下:
CREATE PROCEDURE LOGError(@msg nvarchar(400))
as
declare @text nvarchar(400)
SELECT @text=text FROM sys.messages WHERE language_id=1033 AND message_id=@@ERROR
if len(@text)>1
begin
set @msg=@msg +' : '+@text
EXEC dbo.UCreateOrAppendTextFile 'C:\Error.log',@msg
end |
执行存储过程及结果如下:
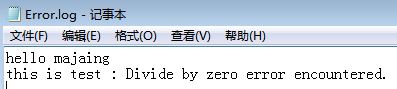
以上存储过程在MSSQL2005、2012中测试通过。
大家都知道目前在文件系统中事务的实现还是比较复杂的,虽然在win7后我们可以用C#实现文件的事务,但是微软的分布式事务Distributed Transaction Coordinator(msdtc)目前也还不支持文件事务。
这里说说为什么有这样的需求吧:目前需要一个项目用SSIS做数据迁移,其中很大部分都是用sql语句实现的, 如 insert into ....select ... from xxxx.其中原数据库中难免有什么脏数据导致插入失败,于是我在SSIS中使用msdtc服务,保证数据的一致性。虽然SSIS也有错误处理,但是它只 能记录那个sql语句有问题,而不能记录具体问题。于是我想到把错误信心记录报数据库表里面,可是当遇到问题时事务会回滚,表里面根本就没有错误信息。于 是乎 只能报错误信息记录到文件中了。
如:

有不对的地方还请大家拍砖哦!
1.2 关于虫子的故事 在熟悉了公司的结构、开发流程,参与了部门例会之后,小白要开始从事具体的软件测试工作了,对于他来说,这一领域陌生而令人兴奋。
在刚上班的一周内,小白不断地听到周围的测试工程师高兴得喊道:“又发现Bug了!”,看着他们那兴奋的样子,小白也有点跃跃欲试,想赶紧在捉虫的战场上大展身手。那么,什么是Bug呢,它为什么这么重要,发现Bug为什么这样兴奋?
1.2.1 虫子的来世今生
在本章的序幕部分,我们已经了解了很多由于软件代码的问题使得事情失败的案例了。它们有的后果真的很严重,甚至能够造成对生命的威胁。这肯定不是软件设计者和开发者想要达到的目标,因此,出现这样的情况可以说是软件的错误。
细细的分起来,软件的错误有如下几个词语来描述:
缺陷、偏差、错误、问题、事故、异常。在这一堆词语当中,除了偏差之外,其他的词语所造成的后果给人的感觉都相当严重。所谓偏差,就是软件在使用过程中,和软件设计说明(product specification)所不一致的行为。
那么为什么将这样的软件问题称为Bug呢?这里面还有一个故事。
【史上第一个软件Bug】
该词的原意是“臭虫”或“虫子”。1947年9月9日,正值计算机刚刚被发明的时候,哈佛大学的某个计算机实验室正在做实验。由于当时的原始计算机由很 多庞大且昂贵的真空管组成,运行时会产生光和热,在下午15点45分的时候,一个飞蛾(英文是Moth)钻入了真空管内,导致整个计算机无法工作。当把这 只小虫子从真空管中取出后,计算机又恢复正常。后来,虫子的泛称Bug这个名词就沿用下来,而那个被拍死的飞蛾也成为了历史上发现的第一个Bug。
【Bug渗透到日常生活中】
一般来说,拥有一定知识产权的产品的错误都能称之为Bug。这方面有一个我们比较熟悉的例子就是电影。影迷们经常议论某热门电影中出现了所谓的“穿帮” 镜头,比如在描述古代武侠的影片中天空掠过一架飞机,主角刚才是右脸有伤痕,过一会变成左脸等。这样的镜头也可以说是Bug,甚至还有专门的网站来记录这 些影迷的细心发现,比如http://www.chinabug.net。
1.2.2 软件Bug的5个要素
前文笼统解释了软件Bug是软件的错误或者偏差。那么在具体的工作中,小白如何判断软件的行为是Bug呢?说来简单,根据软件设计阶段形成的功能说明 书,英文为Specification Document,一般简称Spec。对于具体的判断标准,经理介绍了如下5个要素:
软件没有实现说明书中所列出的功能。
软件出现了说明书中提到不应出现的事情。
软件实现了说明书中没有提到的功能。
软件没有实现说明书中没有提到但应该实现的功能。
软件非常难于学习、使用,运转速度很慢,用户认为无法达到预期。
为了充分理解上述5个要素,小白自己打开了Windows系统中最简单的一款软件Notepad,也就是我们平时“不屑于”用到的记事本程序,开始了自己的思考。
1.软件没有实现说明书中所列出的功能
对于“软件没有实现说明书中所列出的功能是Bug”这一点是比较好理解的。如果打开记事本软件,却无法在其中输入汉字,或者输入了文本,无法保存成文件,那么肯定是一个很重要的Bug。
2.软件出现了说明书中提到不应出现的事情
对于第2点,“软件出现了说明书中提到不应出现的事情也是Bug”,这一点和小白的性能测试工作有相对更紧密的关系。小白要测试的是公司的网站,它要求用户在浏览网站时显示页面尽可能地快,如果超出5秒钟则认为是不可接受的。这个“超出5秒钟”就是说明书中提到不应该出现的事情,实际出现后肯定是一个Bug,需要开发人员找出哪里耗费了页面显示时间。
在记事本程序中,如果程序保存文件时出现了程序崩溃(Crash)现象,即属于此类。
3.软件实现了说明书中没有提到的功能 软件实现了说明书中没有提到的功能也是Bug这一点可能有点难于理解。一个软件,功能难道不是越多越强大吗?其实不尽然,实现额外的功能有如下几个缺点,如表1-3所示。
表1-3 软件实现说明书中未提到功能所带来的问题
| 缺 点 | 说 明 |
| 代码量增大 | 由于代码可能相互影响,因此这部分额外 的功能可能对其他功能的实现造成影响, 带入新的Bug |
| 增加额外的开发、测试时间 | 在软件项目时间固定的情况下,导致投入 到其他必备功能的开发测试时间减少, 可能影响它们的完成质量 |
| 增加了成本, 与软件的宣传不完全符合 | 虽然用户对于增加功能一般不会有意见, 但可能影响了公司的销售策略和市场定位 |
4.软件没有实现说明书中没有提到但应该实现的功能
小白一般是将网上找到的有用文档保存在随身携带的U盘中。这一次,他在测试记事本程序的时候,同样打算将文件保存在 U盘上,可是由于连日来的文档太多了,优盘已经没有空间,记事本提示无法保存,同时系统托盘有提示说磁盘空间已满。在这种情况下记事本的行为,就属于实现 了说明书中没有提到却应该实现的功能(在磁盘满的情况下,给用户以提示)。如果没有提示,不符合绝大部分用户的使用习惯,也是一个Bug。
5.软件难于使用、性能差
软件是拿来用的,再好的界面使用不方便也不会产生多大效果。一个网站如果半天都打不开,很难想象还会有多少用户会访问它。因此这样的问题也是Bug,而且对于性能测试来说,这一个规则很重要。
1.2.3 发现虫子的危害
既然软件Bug对产品造成了这么多的影响,那么发现它就显得非常重要了。业内人士都认为,在软件生命周期内的不同阶段发现Bug,所节省的成本是不同的,如图1-5所示。

图1-5 软件生命周期内各阶段发现与改正Bug所需成本示意图
从图中可以看出,在产品设计阶段发现Bug要比在产品维护阶段发现好得多,这是很好理解的。
在需求分析阶段,对于用户需求的理解停留在需求文档中,对其中理解不正确的部分只需要修改文档即可以,基本不会产生什么成本。
在软件设计阶段,发现的Bug很多都是设计思想的缺陷。由于尚未开始编码,这样的Bug一般需要进行深入的讨论最终获得一种正确的结论,因此改正成本也不高。
在软件编码阶段和测试阶段,代码通过开发人员和测试人员的努力在进行不断的完善,有关Bug的成本主要花费在项目内部的沟通与时间成本方面。
但是一旦产品发布,在软件维护阶段发现的Bug,其修改成本会非常高昂:一是因为软件成为了系统,与开发阶段重点检 查各模块功能相比更为复杂,寻找代码上的产生Bug根源更加困难。特别是,如果前期工作没有做好的话,甚至软件产品的结构都需要进行大修改;二是因为牵扯 的部门明显增加,比如客户服务部门、产品部署部门、销售部门等都要参与,导致公司内部、公司与客户之间的沟通成本急剧增加;第三点则是影响产品质量与公司 的信誉、未来产品的销售。
【千年虫的问题】
在前几年,有一个著名的虫子把业内搅得不可开交,那就是千年虫问题,也叫做2000年问题。它是指在某些使用了计算 机程序的智能系统(比如一般的计算机系统以及自动控制芯片等)中,由于其中的年份沿用早期的设计,只使用2位十进制数来表示,比如用80代表1980年, 因此当系统进行(或者涉及到)跨世纪的日期处理运算(比如计算1980年到2080年之间的日期)时,就会出现错误的结果,从而引发各种各样的系统功能紊 乱甚至系统崩溃。
从千年虫的实际例子中也可以看出,不考虑硬件上的限制,如果当初在设计日期表示格式的时候能够想得更长远一些,就完 全可以避免这个虫子的发作,从而节省一大笔修改更新软件等的费用(据未经证实的来自美国国际资料公司调查报告表明,光是1995年到1998年,全球捉" 千年虫"的开销就已经达到惊人的1840亿美元)。
1.3 软件测试的定义与分类 前文花费了不少文字来讲述Bug的定义、危害和判断原则,本节将在更广的范围内介绍软件测试的定义与分类。
1.3.1 软件测试的定义
软件测试就是利用一定的方法对软件的质量或者使用性进行判断和评估的过程。这一定义获得了较广泛的认同。
1.3.2 软件测试工程师的工作内容
软件测试是由软件测试工程师来完成的,他们的主要工作内容则是:
寻找软件中的Bug,并且是越早发现越好(原因见1.2节)。
确认Bug的可重复性(Repro)以及Bug产生的步骤。
确认Bug是否被解决(Fixed)。
测试方法、测试计划、测试平台、测试代码、测试用例、测试文档、测试报告的确定、编写和执行。
对于小白这样刚入职的新人来说,主要工作就是前3项以及测试用例的编写了。在1.4节将讲述测试用例的知识。
1.3.3 软件测试的分类
软件测试可以有很多种分类,常见的有如下一些:
黑盒测试(Black box testing);
白盒测试(White box testing);
功能性测试(Functional testing);
兼容性测试(Compatibility testing);
性能测试(Performance testing);
安全测试(Security testing);
压力测试(Stress testing)。
虽然看起来很多很复杂,但是目前,小白所要做的工作就是先熟悉这些名词,这样在阅读众多的技术文档时,了解这些名词属于软件测试的范畴就可以了。
对于软件测试的两个核心,则有必要在第1章详细的介绍。这两个核心分别是测试用例和测试工程师,分别代表了软件测试的两个方面:工具和人。
(未完待续)
相关链接:
捉虫记--大容量Web应用性能测试与LoadRunner实战(连载一)
一、单元测试的意义
单元测试会为我们的质量做保证。编写单元测试就是用来验证这段代码的行为是否与我们期望的一致。有了单元测试,我们可以自信的交付自己的代码,而没有任何的后顾之忧。
我们在编码时,一定会反复调试保证它能够编译通过。如果是编译没有通过的代码,没有任何人会愿意交付给Boss。但代码通过编译,只是说明了它的语法正确;我们却无法保证它的语义也一定正确,没有任何人可以轻易承诺这段代码的行为一定是正确的。
从成本角度考虑,BUG发现越早越好,加强单元测试力度有利于降低缺陷定位和修复难度,从而降低缺陷解决成本,同时加强单元测试也减轻了后续集成测试和系统测试的 负担。据业界统计,如果一个BUG在单元测试阶段发现花费是1的话,到集成测试就变为10,到系统测试就高达100,到实际推向市场量产后就高达 1000,所以,进行充分的单元测试,是提高软件质量,降低开发成本的必由之路。但单元测试在目前国内软件企业中开展得并不好,一方面是由于对单元测试重 视程度不够,测试投入不足,另一方面是由于在单元测试实践方面积累得也不够,单元测试处于一种摸索状态。
单元测试不仅仅是作为无错编码一种辅助手段,在一次性的开发过程中使用,单元测试必须是可重复的,无论是在软件修改,或是移植到新的运行环境的过程中。因此,所有的测试都必须在整个软件系统的生命周期中进行维护。
单元测试与其他测试不同,单元测试可看作是编码工作的一部分,应该由程序员完成,也就是说,经过了单元测试的代码才是已完成的代码,提交产品代码时也要同时提交单元测试代码。测试部门可以对单元测试的过程以及结果作一定程度的审核,作为集成和系统测试准入的一种标准。
二、如何做好单元测试
1)组织结构应该保证测试部门参与单元测试
目前普遍都认为单元测试应该由开发人员开展,这是因为从单元测试的过程看,单元测试普遍采用白盒测试的方法,离不开深入被测对象的代码,同时还需要构造驱动模块、桩函数,因此开展单元测试需要较好的开发知识。从人员的知识结构、对代码的熟悉程度考虑,开发人员具有一定的优势。
单元测试由开发人员进行能带来一些特别的收益。我们知道,在实践中开发人员进行单元测试一般推荐采用交叉测试的方法,例如由被测单元的调用方进行该单元 的测试,即尽量避免对自己的代码进行单元测试。这种交叉的测试安排可以避免测试受开发思路影响太大,局限于原来的思路不容易发现开发过程中制造的问题;二 来也达到一个技术备份或充分交流的目的,这对组织非常有利。即使不采用交叉测试的方法,而安排单元的生产者自行开展单元测试,也是有很大的优越性的,其最 大的优点是快速。在人员紧张的情况下这种自行测试的安排也是不错的选择。
从经验值来看,单元测试投入和编码投入相比基本上是一比一,如果由专职测试队伍来进行单元测试,维持这样庞大的单一任务队伍显然是不合适的,对于一般企业来说也是不小的成本负担。
以上谈的是由开发人员进行单元测试的优点,其中主要是从单元测试的效率角度来考虑。但是从单元测试效果的角度考虑,必须从组织结构上保证测试部门参与单元测试,这是因为:
首先,从目前国内企业普遍现状来看,测试人员质量意识要高于开发人员,测试人员参与单元测试能够提高测试质量。
其次,对被测系统越了解,测试才有可能越深入,测试人员参与单元测试,将使得测试人员能够从代码级熟悉被测系统,这对测试人员后期集成测试和系统测试活动非常有帮助,会很大的提升集成测试和系统测试质量。
测试部门以何种方式参与单元测试,应该结合软件组织的实际情况来定。如果软件组织测试充分,测试人员对开发人员的比例较高,那么可以由测试人员独立承担 部分重要模块的单元测试工作;如果测试资源不足,测试人员对开发人员的比例较低,那么可以采取由测试人员进行单元测试计划、单元测试设计的工作,而单元测 试的实现和执行由开发人员来完成;而如果测试资源非常缺乏或测试人员素质不够全面,连单元测试计划、单元测试设计都无法承担,那么测试部门至少应该参与开 发过程的各相关单元测试文档、单元测试报告的评审,保证单元测试的质量。
2)制订单元测试的过程定义
软件质量的提高需要规范的流程,对软件开发过程进行管理也需要依据规范的过程定义。要提高单元测试的质量,首先要制定规范的单元测试过程,各生产部门可以依据单元测试过程定义开展各自的工作,共同保证单元测试的质量。
单元测试过程的定义需要参照企业的实际情况,例如阶段划分可以分为四个阶段:计划、设计、实现、执行。
其中计划阶段应当考虑整个单元测试过程的时间表,工作量,任务的划分情况,人员和资源的安排情况,需要的和测试方法,单元测试结束的标准等,同时还应当考虑可能存在的,以及针对这些风险的具体处理办法,并输出《单元测试计划》文档,作为项目中整个单元测试过程的指导。
设计阶段需要具体考虑对哪些单元进行测试,被测单元之间的关系以及同其它模块单元之间的关系,具体测试的策略采用哪一种、如何进行单元测试用例的设计、如何进行单元测试代码设计、采用何种工具等,并输出《单元测试方案》文档,用来指导具体的单元测试操作。
实现阶段需要完成单元测试用例设计、脚本的编写,测试驱动模块的编写,测试桩模块的编写工作,输出《单元测试用例》文档、相关测试代码。
执行阶段的主要工作是搭建单元测试环境,执行测试脚本,记录测试结果,如果发现错误,开发人员需要负责错误的修改,同时进行回归测试,该阶段结束需要提交《单元测试报告》。我们可以将设计和实现阶段合并,输出《单元测试用例》文档、相关测试代码。
3)必须制订覆盖率指标和质量目标来指导和验收单元测试
单元测试必须制订一定的覆盖率指标和质量目标,来指导单元测试设计和执行,同时作为单元测试验收的标准。设计用例时,可针对要达到的覆盖率指标 来设计用例,而在测试执行时,可以依据覆盖率分析工具分析测试是否达到了覆盖率指标,如果没达到,需要分析哪些部分没有覆盖到,从而补充用例来达到覆盖率 指标。而单元测试质量目标的制订,需要符合软件企业的实际过程能力,这依赖于软件企业对以前单元测试过程度量数据的积累,不能凭空制造出来。有了以前度量 数据的积累,完全可以了解当前组织的单元测试能力,例如单元测试每千行代码发现的缺陷数是多少。如果单元测试统计结果没有落到这个质量目标范围内,说明单 元测试过程中某些方面存在一些问题,需要对测试过程进行分析后找出问题原因进行改进。
这些指标确定下来后,一定要严格推行。定会有一些人找出各种理由证明覆盖率指标达不到等等,这需要质量部门根据实际情况分析指标是否合理。实际 证明有一个相对简单的标准也比没有标准要好得多,但显然,通过推行硬性指标,单元测试发现的问题数目比没有标准前至少增加了2倍。
4)单元测试者技能的提高
1、加强对单元测试人员的技能
单元测试的质量很大程度上决定于进行单元测试的人的技术水平。如果测试者不具备单元测试的知识,那么应该对测试者进行相关的培训。一个没有做过 单元测试人,不经过培训初次是很难做好单元测试的。单元测试在详细设计阶段结束时开始,但是单元测试相关培训应该尽早准备和计划,培训可以分两个阶段,每 个阶段的内容类似。第一阶段是写单元测试方案前,培训对象为测试方案的写作者和详细设计的写作者,这样可以在设计时多考虑可测试性,培训的内容为单元测试 基本概念、单元测试分析方法、单元测试用例的写作、单元测试标准的明确;第二阶段为单元测试执行前,对象为测试执行者,培训内容为具体单元测试的执行,包 括驱动函数、桩函数的构造、覆盖率测试工具的使用(TrueCoverage、Logiscope等)、利用自动化单元测试框架构造单元测试自动化 (TCL、CppUnit、JUnit等)。培训过程中最好结合实例穿插其中,会比较生动,而且增强理解。
通过以上的系统培训,可以统一单元测试方法、明确单元测试的标准、掌握单元测试基本技能,为后期单元测试的顺利开展扫平道路。
2、必须引入工具进行辅助
单元测试非常需要工具的帮助,特别是覆盖率工具不能缺少,否则用例执行后无法得到测试质量如语句覆盖、路径覆盖等情况,也就无法对被测对象进行 进一步的分析。应用较广的分析覆盖率的工具有Logiscope、TrueCoverage、PureCoverage等,它们的功能有强有弱,可以根据 实际情况采用。
为了提高单元测试的效率,特别是提高进行回归测试时的效率,需要在单元测试中引入自动化。目前常用的方法是采用TCL语言编写扩展指令,构造自己的单元测试自动化。也可以直接采用开源的自动化测试框架如CppUnit、JUnit等。
此外,在单元测试之前,还需要利用PC_Lint对被测代码进行检查,排除代码语法错误,确保进行单元测试的代码已经具备了基本质量,保证单元测试能够顺利进行,提高单元测试执行效率。
3、单元测试者加强对被测软件的全面了解
单元测试的目的除了要发现编码中引入的错误和发现代码与详细设计不一致的地方之外,还有一个目的是为了保证详细设计的质量。因为测试分析和测试用例设计需要依据详细设计来进行,这个过程实际上是对详细设计的重新检视,在这个过程中会发现以前评审中没有发现的问题。
三、我们公司的单元测试 我们公司的单元测试才刚刚起步,质量体系中尚无明确的规范,程序员对单元测试的意识也较淡薄。虽然在推行单元测试上取得了一些进步,但很难落实 到实际的环节上,很多都是走过场的。不少程序员觉得任务大,时间赶,人手少,一接到任务就是先赶代码完成工作量了,这其实是很普遍的现象。而且,绝大部分 程序员从骨子里不喜欢写单元测试,这却是不争的事实。我们公司的开发人员在单元测试上多是走过场,而测试人员也只涉及到存储过程的单元测试,且没有单元测 试用例,测试方法存在误区,导致测试带有随意性,效率低下。
要做好单元测试,还必须充分考虑到公司自身的实际情况。基于我们公司目前的诸多现状,结合项目具体实际情况,在公司某一项目中,对单元测试做了如下理论结合实际的应用。
1、项目经理在项目计划的过程定义文件中明确单元测试作为本项目的过程,确定在单元测试的各个阶段的工作产物;
2、项目经理制定单元测试计划,明确测试目标、测试方法、准入准则、准处准则、单元测试数据、单元测试工具、人力资源计划、进度计划;
3、开发人员在编码前设计测试用例,并且准备单元测试代码及设计文档,项目组组织人员评审,测试人员必须参加;
4、开发人员在编码完成提交产物前,必须做单元测试,可以是自测,也可以是开发人员互测,发现的缺陷必须提交缺陷库,并提交单元测试报告。在人力资源紧张时,可以由测试人员执行单元测试;
5、有了单元测试的缺陷数据,我们就可以分析,一般常见的缺陷有哪些类型,如何改进;还可以发现哪些开发人员的编码质量,为奖惩提供依据。
四、结论和展望
总而言之,单元测试将让我们的开发工作变得更加轻松,让我们对自己的代码更加自信。无论是项目的规模大小,无论是时间紧迫的项目还是时间宽裕的项目,只要代码不是一次写完永不改动,编写单元测试就一定超值。我希望它能成为我们公司编码过程中不可缺少的一部分。
单元测试仅仅是软件质量保证的一个环节,软件的质量由组织、流程和技术三个维度来决定,任何一个维度都不能单独决定软件的质量。好的组织结构可 以保证流程的顺利实施,好的流程能提高软件开发的规范性和可控性,从而提高软件开发的效率和质量,而采用了好的技术和有好的技术的载体--人,则从根本上 保证了软件的质量。
该项目在落实以上措施后,达到了一下效果:
1、在一定承担上提升了软件交付质量;
2、测试部门反映:有效降低集成和系统测试投入的成本;
3、项目执行周期比预期的缩短。
因此,论证了单元测试在软件生产过程中作用。
1、历史与三重迷雾
在“认识软件测试中黑天鹅”一文中,我描述了什么是软件测试中的黑天鹅及其特点,本文将探讨测试中的黑天鹅发生之前、之后、以及正在发生之中的故事。
《黑天鹅》一书的作者Nassim指出“历史是模糊的。你看到了结果,但看不到导致历史事件发生的幕后原因。”其实,测试何尝不是这样,假如把测试看成一个盒子,这个盒子也是模糊的,你看不到盒子里面是什么,整个机制是如何运行的。
书中描述:“对待历史问题,人类思维会犯三个毛病,我称之为三重迷雾。他们是:
1)假想的理解,也就是人们都以为自己知道在一个超出他们认知的更为复杂(或更具随机性)的世界中正在发生什么。
2)反省的偏差,也就是我们只能在事后评价事务,就像只能从后视镜里看东西(历史在历史书中比在经验现实中显得更加清晰和有调理)。
3)高估事实性信息的价值,同时权威和饱学之士本身有缺陷,尤其是在他们进行分类的时候,也就是进行‘柏拉图化’的时候。”
我很容易联想到,这三重迷雾分别对应测试中的黑天鹅发生之前、之后、以及黑天鹅形成之中的故事,即:发生之前的“盲目预测”、发生之后的“假想解释”、以及黑天鹅形成之中的“柏拉图化”。
2、黑天鹅发生之前的“盲目预测”
“第一重迷雾就是我们以为我们生活的这个世界比它实际上更加可理解、可解释、可预测”。打开收音机或电视机,你就会听到或看到,每天都有无数的人在信心满满地预测着各种各样的事情:股市的走势、房价的走势、战争是否会爆发、疾病是否会流行。。。
正向Nassim指出的那样,“几乎所有关心事态发展的人似乎都确信自己明白正在发生什么。每一天都发生着完全出乎他们预料的事情,但他们就是认识不到 自己没有预测到这些事。很多发生过的事情本来应该被认为是完全疯狂的,但在事情发生之后,看上去就没有那么疯狂。这种事后合理性在表面上降低了事件的稀有 性,并使事件看上去具有可理解性。”就拿我所生活的这座城市-上海来说,近来的许多事件都在证实着这点:黄浦江上打捞出数千头病死猪、H7N9的流行,昨 天突然看到一条“上海自来水中添加了XX”的微博更是令人触目惊心,我们内心都预测这些事情不应该发生,可是实际上却发生了。
这种黑天鹅发生之前的“盲目预测”让我想到软件测试中版本发布之前的“测试评估(test evaluation)”。一个产品经过测试团队的集中测试后,发布到用户那里,谁能准确预测是否会出现“黑天鹅”呢?在你的团队,在版本对外发布之前,是否需要测试团队填写一个关于产品质量的测试评估表?下图是测试评估表的一个样例。

这里的特性指的是“测试特性(test feature)”。根据各团队上下文的不同,这个测试特性可能与开发特性直接对应,也可能不与开发特性一一对应,每个测试特性对应一条到多条需求(用户 需求或系统设计需求)。我最常看见的质量评估说明是“XX特性基本功能正常。”有些人会在后面附上所发现的比较严重的bug。这样的描述显然并不令人满 意。
问题是:
每个特性质量的A/B/C/D的结论是否准确? 所有特性的A/B/C/D的结论加一起又如何判别整个系统的质量?是否所有特性的质量都是A或B,版本就可以对外发布,并且发布以后不会出现令人意想不到 的“黑天鹅”现象?测试人员给出的A/B/C/D有多大成分是基于一种feeling给出的?
对于任何一条 需求,开发人员的任务就是实现它,无论是由一个项目组实现,还是多个项目组配合实现。但是,对于测试人员,考虑的事情就复杂一些。我们除了要验证这条需求 本身的功能实现是否正确,还要验证该需求和其它功能之间的交互,还要考虑客户可能使用的各种场景(Scenario),包括各种组网场景、各种参数的配置 等。如果把测试场景和测试特性交互起来,测试就无穷无尽了,并且也没有必要在每一种测试场景下,都验证被测特性的基本功能、异常功能、与其它功能的交互、 非功能属性等各方面。如何设计更有效的、有限数目的用例尽量做到最大的测试覆盖,这属于另外一个话题,本文不做探讨。
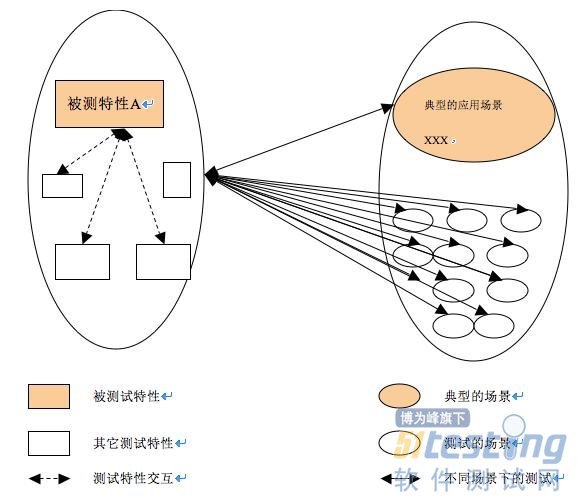
毫无疑问,尽管测试设计人员和测试执行人员精疲力尽的试图覆盖该特性的所有可能的场景,测试人员仍然只覆盖了一小部分的场景下的该特性的部分测试用例,如果没有Fatal的遗留问题,是否该特性的质量就可以评价为A或B,并且认为可以对外发布了呢?这种测试评估工作, 与其说是让测试人员对被测对象的质量进行测试评价,不如说是让测试人员对被测对象进行质量预测,因为测试人员所了解的只是部分信息,而不是全部。 Nassim说“在这些错误的预测和盲目的希望中,有一些愿望的成分,但也有知识的问题。”我更愿意相信,测试人员对产品质量的预测主要是“知识的问 题”,毕竟完整测试是不可能的。
既然测试无法做到完整覆盖,不如在有限的时间和资源内,尽可能覆盖典型的场 景,测试评估中针对已经覆盖到的典型场景进行评估,具体地,James Bach和Michael Bolton在RST(Rapid Software Testing)课程里提出的三步法可以供参考:
● 测试中发现了哪些问题;
● 做了哪些测试活动发现了这些问题;
● 测试活动本身的有效性如何,哪些地方可以改善。
那么对于典型场景之外的其他场景又如何评估呢,这与测试评价之前的那些测试活动息息相关,也就是与黑天鹅正在形成之中的那些故事有关,我们在后面第四部分再探讨。
3、黑天鹅发生之后的“假想解释” 不管怎样,那些你认为不应该发生的“黑天鹅”经常如期而至。很多组织要求缺陷发生后开展缺陷根因分析(RCA)(我总是在尽力避免使用“缺陷回 溯”这个词)。尤其对黑天鹅这样的重要的bug,更要仔细开展缺陷根因分析了。对黑天鹅开展RCA的目的是利用这个黑天鹅,挖掘它带给我们的信息,从而尽 可能在以后的测试中发现更多类似的缺陷,对开发而言则是在以后尽可能避免引入此类的bug。
RCA的目的是做到基于缺陷的过程改进,而不是解释黑天鹅的发生这个动作本身。不要试图去解释所有的黑天鹅,尤其是那些在实验室很难重现的黑天 鹅。我看到有些测试团队,当黑天鹅发生了很紧张,又是一个严重的bug漏测了,赶紧组织人力调查分析,尽快写出一个看起来像样的缺陷分析报告。而阅读这个 RCA报告,很难从中找出真正有力的措施可以有效避免今后这类bug不再漏测。举几个现实中的“RCA现象”:RCA报告中,错误的原因有“人为错误”、 “沟通不畅”、“缺乏相应的测试用例”等;避免漏测的措施有“加强代码走读”、“加强白盒测试”、“提高测试设计能力”、“加强与开发人员的沟通”等。 Nassim发现,“我们的头脑是非常了不起的解释机器,能够从几乎所有事物中分析出道理,能够对各种各样的现象罗列出各种解释,并且通常不能接受某件事 是不可预测的想法。”
我曾对多个团队进行T-RCA(我提出的一个缺陷根因分析的方法)引导,发现一个有趣的现象,尽管各个团队所测试的产品是不同的,但是他们 RCA分析的结论却是惊人的相似,很多团队都存在我上述所列的“RCA现象”。我分析原因大致有二,一是没有找到有效开展RCA的方法,没有找到缺陷发生 的根本原因;二是很多团队使用了比较“细致”的RCA模板,模板里对每一项可能的情况进行了细致的分类,比如该缺陷所处的测试级别、涉及的测试活动、所属 的测试类型、可能的原因分类等等。缺陷根因分析工作仿佛变成了测试人员只要对照模板逐一打钩去筛选就可以了,但实际上RCA是个高度探索性的过程,需要与 缺陷相关的各干系人去沟通,需要从纷繁复杂的种种因素中创造性地找到改进的措施。面对着电脑,填写那些RCA模板中的空白项不是最主要的工作。实际上,某 种程度上讲,过细的RCA模板简化了缺陷分析过程,掩盖了缺陷根因分析过程的复杂性,也比较容易导致分析结果的雷同。《黑天鹅》里的这句话也许可以给我们 更多启示:“我们对周围世界的任何简化都可能产生爆炸性后果,因为它不考虑不确定性的来源,它使我们错误地理解世界的构成。”
4、黑天鹅形成之中的“柏拉图化”
既然,测试中的黑天鹅的发生是个经常性的事件,那么测试的过程不也正处于黑天鹅形成的过程吗?想象一下,当前我们正在测试一个产品,我们了解黑天鹅理论,我们知道这个产品发布给用户后极有可能会冒出“黑天鹅”来,那么我们当前可以采取什么措施呢?
我在“认识软件测试中黑天鹅”一文中解释了什么是“测试的柏拉图化”:只注重外在的形式、尤其是针对具体明确的事情进行简单分类的时候,犯“柏 拉图化”错误的人容易高估他们已经掌握的事实性信息的价值,而对大量的他们还不知晓的并且非常重要的信息视而不见。我是在2006年发现这个“我所不知道 的大量信息的”,也同时发现了之前我所犯的“测试的柏拉图化”的错误,即特别重视诸如“测试用例设计个数、测试用例执行个数、发现的bug数”等这些数 据,也许在这些明确的、外在的形式之外,有更多值得我们思考的东西。
那一年,我负责一个特性(大体就是在手机上通过蜂窝小区广播的形式收看电视)的测试,这个特性是个全新开发的特性,我是第一个、也是当时唯一一 个测试人员,测试任务很紧张,因为这个特性已经定于一、两个月以后在香港某个运营商网络里首次商用。像大多数测试人员一样,我很辛勤地、按照既定方法和策 略测试这个特性,在有限的测试时间里:我熟悉了这个特性、设计了很多测试用例、执行了大量的测试用例、发现了很多bug、对这个特性相关的每一个bug都 了如指掌、通过和开发人员不断地交涉和定位bug还对该特性当前存在的缺陷非常清楚、熟悉这个特性的代码和问题定位手段。当我奔赴香港作为测试人员辅助开 通这个特性的商用之前,研发团队解决了所有严重的缺陷,我很有信心应对各种可能的状况,我几乎认为我对这个特性的了解已经很完整了。
可是,当我抵达用户那里,看到我们的产品在真实网络中的运行环境、配置、使用方式,与用户和当地技术支持人员的各种交流,坐在地铁里看到身边的 人员拿着手机正在开启使用我刚刚参与开通商用的特性,从真实网络环境中获取的大量错误报告和跟踪消息和后台日志。。。短短几天内,有关这个特性的、以前我 所不知道的、大量的信息冲进了我的大脑,我像突然捡到宝藏一样地忙着分析日志、记录bug,生怕遗漏了哪个bug没有记录,然后回到实验室都不知道如何触 发。
我发现了一个重要的事实:这一回,我只用了几天时间,没有设计任何测试用例,没有执行任何测试用例,却在一个我几乎认为没有什么严重缺陷的特性 上,“不费吹灰之力”似的又发现了很多严重的缺陷。而且这些缺陷不是实验室触发的,而是就发生在用户的身上,有些遭到用户的投诉,有些用户还不知晓,换句 话说,这些缺陷都是优先级很高的非常重要的缺陷。
从香港回来,我一直在思考,测试团队如何发现这些重要的缺陷?甚至如何让平常我们在实验室中的测试也能这么高效、这么有效?您可能已经猜到了, 这就是后来备受重视的UBT(Usage Based Testing),或者有的行业叫做TiP(Test in Production),也有人称为Testing-in-the-wild。
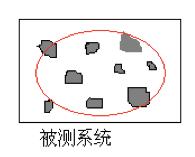
再回到前面曾提到的一个关于测试评估的问题上:假如平常的测试更关注典型场景的测试,那么对于非典型场景如何测试以及如何评估呢?我想UBT是 个不错的选择。既然无法做到全覆盖的测试,就不去做,不要试图在现有的测试模式下,测试设计和测试执行都投入很大精力去覆盖各种场景和交互,因为这样做收 效甚微,依然达不到目的。平常的功能测试只做最普通、最典型、最重要场景下的功能验证,保证每个测试特性的基本功能OK。此外,还要开展UBT或TiP, 主要考虑各种配置和场景,用模拟器模拟真实商用组网环境和业务模型,或者直接在用户使用产品的真实环境中开展测试。
假如被测系统如下图的方框,灰色的小块就是我们平常的功能测试覆盖,可能很多测试团队的做法是试图尽最大能力增加这些灰色小块的覆盖,但依然会 有很多覆盖不到的地方。而UBT就相当于红色的范围,虽然没有针对性的设计测试用例,但由于模拟了可能使用的商用场景和业务,业务之间交互的测试在这种测 试环境下自动进行,潜在的一般的bug都被自动发现(比较难触发的异常bug依然发现不了),如果这样的UBT测试连续执行几天或数周都没有问题,此时测 试的评估中就可以很有信心地写到:在XXX UBT环境下连续运行XX天,没有发现严重问题。 这样,也大大减少了版本发布后“黑天鹅”出现的几率。
5、结论
如果你认同“测试的黑天鹅”就在我们身边,那么:
● 在“测试的黑天鹅”发生之前,不要在信息不完整的情况下对全局做“盲目预测”,因为你只掌握了部分信息,你要做的是更准确地陈述这些“部分信息”;
● 在“测试的黑天鹅”发生之后,不要试图对所有黑天鹅都做“假想解释”,更重要的是从已经发生的黑天鹅身上挖掘更有价值的信息,以减少更多类似黑天鹅事件的发生;
● 在“测试的黑天鹅”形成过程之中,不要犯“测试的柏拉图化”错误,重视你知道的信息,更重视那些你所不知道的大量的更有价值的信息。
本文转载自:http://www.taixiaomei.com/archives/223
相关链接:
软件测试中的黑天鹅(一):认识软件测试中的黑天鹅
面试经历我看大家伙写的都是被面的经历,所以我呢就从另外一个角度来写一写,希望能对后来者有点帮助。
在做测试负 责人的时候,面试过很多人,刚开始面试的时也就是随便问问一些问题,看看面试同学的临场反应,觉得过得去就行,后来面的人多了招的人多了也就总结了一些经 验,比如在面试的时候要问哪些内容,要注意哪些方面,要观察他们说话的语气和反应等等,通过这些一般就能知道被面者对问题理解的程度以及是否诚实等等面试 官想要知道的信息,因为身体语言透露出来的信息比语言更真实。另外面试过程时面试官提的问题千奇百怪各种各样,有一些问题很常见但是想回答的很好非常难, 有一些问题知道的很简单不知道就很难,还有一些问题根本就不是问题,但是实际上都有关联,所以面试的时候一定不要松懈,有些问题其实就是陷阱,面试过程中 千万不能抱着蒙混过关的想法,会就是会,不会就说不会,要知道面试官都是人精,你说的话他们都能知道哪些是真话哪些是忽悠他们的话,当然不排除有一些刚开 始面试啥也不懂的面试官,碰到这样的面试官是你的运气:)
面试之初接触:沟通能力很重要
第一次面试纯粹是被拉过去的,另外一个项目组招测试,但是他们没有相关的测试团队,都是些开发人员,招测试的时候不知道问什么,笔试题倒是列了一堆,给 了我几张做的比较好的卷子让我挨个面一下,给我的说法是“随便看看”,我那时候都是被面过来的,哪里面过别人,还挺紧张,直说不行,万一面砸了可怎么办, 人家就说了你试试,也是为后面的新人面试积累一些经验,反正迟早有这么一天呀,回头告诉一下想法就行。我心一想也是,就带着这么点忐忑和兴奋进了面试室, 结果一进去后完全就不紧张了,因为我看见那家伙非常紧张,我就一下子释然了,这就是位置不一样心态也不一样。认认真真的对着卷子说他那些地方错了那些地方 对了,我估计那小子第一次碰到我这么认真的面试官。
这次的面试我没有问问题,都是根据卷子来讲,但是即便如此我也看出来了这些人中哪些 比较适合做测试哪些比较不适合,因为在沟通的时候能够非常明确的知道对方的沟通能力。沟通能力大家都知道非常重要,尤其是做测试的,要和开发沟通,要和设 计沟通,要和需求沟通,这些沟通在常规的测试流程中无法避免,所以沟通能力非常重要,要能简单明了的让开发知道你在说什么,否则就是鸡同鸭讲。
面试之二接触:态度要端正
小时候老师就告诉我们学习态 度很重要,就算你作业不会写,你也要表现出你端正的态度。同理,在面试的时候保持一个好的态度很重要,这个态度包括两方面,服饰礼仪是一方面,另外就是能 待人接物方面的态度。举个例子,我面过一个男同学,穿着拖鞋就算了,顶着一头乱蓬蓬的头发也算了,回答问题的时候抖腿我也忍了,但是问题不会的时候长时间 保持沉默我就无法忍受了,一个问题如果你想了两分钟没有思路就要直接明说,千万不要一直沉默不语,面试官怎么知道你是在想问题呢还是睡着了。
面试之三接触:诚实真的很重要
前面说了,面试过程时面试官提的问题千奇百怪各种各样,有一些问题很常见但是想回答的很好非常难,比如说“为什么你要离开以前的公司”,有一些问题知道 的很简单不知道就很难,还有一些问题根本就不是问题,其实就是陷阱,所以在面试过程中一定要诚实,会就是会,不会就说不会,可以说面试官都是人精,年纪越 大估计越难对付。千万不要为了你的面子不懂装懂,那样你只会更没面子,因为一句谎话是要用10句谎话来弥补的,这点相信面试过的同学都深有体会。
面试之四接触:不打无准备之战
俗话说知己知彼百战不殆,面试也是一样,一定要准备好,不仅仅是知识要准备好,时间要准备好,材料要准备好,甚至心情也 要准备好。知识要准备好是指准备好测试的理论知识、实践经验、应聘公司的背景要求等等,时间要准备好是指最好提前15分钟到达公司,不要太早当然更不要迟 到,如果迟到要提前半小时通知HR告知迟到原因及多久能到,材料要准备好是指面试的相关材料,比如有些公司需要应聘者自带简历等,心情准备好是说要收拾一 下心情准备面试,不要慌慌张张毛毛躁躁。
面试之五接触:定位要明确
想换工作或 者正在换工作的同学一定要看一看这个例子,不管是想换工作或者正在换工作,你心里要有一杆秤,想换的工作应该是怎样,职位如何,薪资如何等等都要考虑清 楚,不要盲目的换。很多同学一年一跳,甚至一月就跳一次,每次跳的时候要给自己定位好。我曾经面过一个被推荐的“牛人”,9年工作经验,带过项目,我们看 到这样的简历那真是当个宝啊,虽然心里也有点奇怪为什么9年后还在做测试工程师, 而不是更高级一点的。等到面试的时候我一看年纪比我大,皱纹比我多,前辈啊,结果问问题的时候发现他有点心不在焉,那时候我已经有了一点经验,所以就明确 问了一下来这边面试的目的,好吧人家说了本来想应聘的是测试经理的职务,结果没有,就先投了一下这个职位,结果就可想而知,强扭的瓜哪能甜呢,待了一年 半,工作不积极,其他员工相处的也有问题,只好走人。他可能觉得屈才了,我们也觉得不爽,既然决定留下来,那么就应该在其位谋其政,而不是消极怠工,给自 己给他人留下一个不好的印象。
面试之六接触:不会的可以学可以教,但是不能不爱学不想学
谁都喜欢聪明的小孩,但是生活中 聪明的孩子毕竟是少数,我们都是普通人,所以不会或者有点笨不是什么丢脸的事情,面试的时候不怕不会的笨的就怕不爱学习不想学习的。IT行业日新月异,测 试技术更是如此,很难想象一个不爱学习不想学习的人做测试会是什么样的。因此在面试的时候不会做的题不会回答的问题诚实的告诉对方不会,但是你会去学等等 诸如此类的回答。
综上,当我们面试的时候,保持好的沟通能力,端正好态度,明确自己的定位,诚实的说出自己的想法,那么,向着目标开火吧!
原帖地址:http://bbs.51testing.com/thread-961722-1-1.html
版权声明:本文由会员wuliangye首发于51Testing软件测试论坛九周年庆活动。
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
1、引子 这两天无意翻到几个月前的Evernote笔记,看到了当时对团队开发环境的一些想法。可惜后来种种,这一想法未能得到实践,只能将其完善后公诸于众,立此存照,日后有空可以一试。
考虑这套开发环境是因为我们遇到了这些问题:
开发人员的环境并不统一:dev在osx,ubuntu 11.10和ubuntu 12.04上工作,而ux在windows下工作,协调,解决问题不太方便,尤其是一个bug在A的系统出现,却在自己的环境下无法复用。
无法即刻搭建和线上同版本的环境,解决线上问题。小团队节奏很快,当前的工作目录可能和线上版本差几天的代码(diff可能已经是巨量),所以当线上出问题时,將工作环境切换过去非常耗时(尤其是数据库发生变化时)。
为新员工构建开发环境耗时且问题重重。这和第一点有些类似,即在ubuntu下工作的构建开发环境的流程在osx下会break。尤其是后期我们不断有开发人员转换系统到osx下。
当时正好看到一篇关于 vagrant 的文章,感觉这正是我想要的救命稻草。
2、理想的开发环境
我心目中理想的开发环境应该是这样子的:
编辑环境和运行/测试环境分离。这意味着开发人员,不管是dev还是ux,可以使用任何她喜欢的系统进行内容的编辑,而其产出可以无缝地运行在另一个统 一的环境。无缝是很重要的体验,如果分离意味着在两个系统显示地频繁切换,那还不如不分离;在此基础上的统一的环境则让大家在同一个上下文中交流。
开发人员可以同时工作在好几个版本下。在途客圈,一个relase(或者一个scrum)以两周为周期,一周开发,一周测试,然后就上线,如图所示:
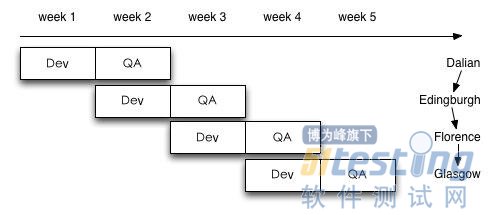
这意味着在任何一周,开发人员同时工作在3个不同的branch上,以week 3第一天为例:Dalian已经部署到线上,Edingburgh交付测试,而Florence正在开发中。开发人员能够无痛地在这三个环境中任意切换, 就像任务调度一样,保存上下文,切换到另一个branch,开始工作。作为小团队,我们不希望甚至不可能将有限的人员切成三份来运作,所以应该通过工具支 持这种开发状态。
能很好地支持持续集成。travis-ci.org 跑跑开源项目还可以,但商业项目就免了,而且其每次构建都rebuild整套环境这个效率太低。
3、构建理想的开发环境
存在的问题和期望的解决方案已经摆出来了,接下来就是如何实现的问题。这种场景是典型的虚拟机大展拳脚的地方,VmWare会很欣慰地摆出VDI + vSphere的解决方案。不过小团队人少钱紧,自然只能寻找免费的替代品,即之前提到的 vagrant。
什么是VAGRANT?
我对它的不太确切的理解是:一套自动化创建,部署和使用虚拟机的工具。vagrant 原生支持virtualbox,这就足够了。通过一系列CLI命令,我们可以很方便地操作虚拟机。
创建并运行虚拟机:
$ vagrant box add lucid32 http://files.vagrantup.com/lucid32.box
$ vagrant init lucid32
$ vagrant up |
登入虚拟机:
打包虚拟机:
| $ vagrant package --vagrantfile Vagrantfile.pkg |
更详细的 vagrant 使用说明请参考其文档,这里就不详细介绍。
如何使用VAGRANT构建理想的开发环境
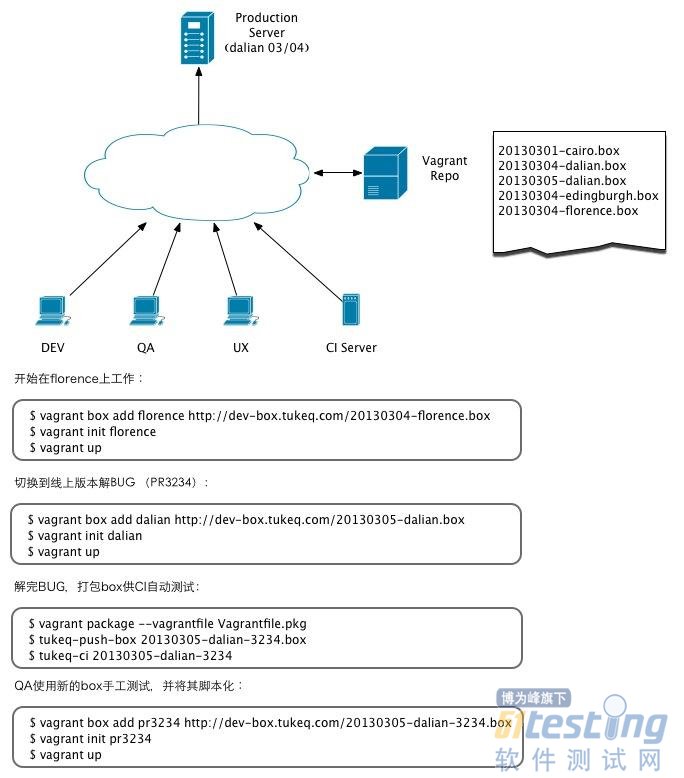
在这个模型中,大家交流的基础是虚拟机。虚拟机随时被创建,随时又销毁,有一个box服务器 vagrant repo 来统一存储所有box并提供上传/下载服务。box服务器提供两类box:
基准box。每天半夜从GitHub pull相应branch的代码,并辅以对应的database,自动打包成一个基准box。每个活跃的branch每天都会有一个新的基准box。基准box保存一周足矣。大家新的一天工作的基础是基准box。
PR box。解决线上问题时,和QA,CI交流使用的box。
任意一个box都是一个沙箱,它包含和线上环境同版本的操作系统,运行环境。同时里面有对应branch的代码库和数据库。数据库采用线上数据 库的一个子集,可以让系统正常运行即可。box和用户的host OS间可以共享目录,比如说代码的目录,这样可以让用户通过host OS上的个性化编辑环境撰写代码。此外,box里的port和host OS的port要能一一映射,这样用户完全具有本地的测试体验。
详细的环境和工作场景参见下图:
适用场景
这样的开发环境能满足本地办公团队,甚至远程办公团队的需要。
同一个地点办公的团队,vagrant repo 服务器可以放在本地,以获得最好的下载速度。
异地办公或者服务于开源项目的松散团队,可以把 bagrant repo 放在一个公网服务器,让参与者都能访问(安全性不在本文讨论)。访问速度的问题可以通过本地缓存来解决,这样在多人下载同一个box时会有近乎本地访问的体验。
4、免责声明
如引文所述,本文想法尚未来得及实践,所以不保证能正常运行,所以 “try it at your own risk”。笔者个人觉得这个想法的靠谱率在90%以上。
我们知道在
Android App测试时,当我们想把应用程序恢复的初始状态,我们通常可以有以下几种做法:
手动
到Setting -> Apps -> 单击我们要测得应用程序 -> 选择Clear data
这样重新启动App的时候,我们的程序就处于初始状态了。
命令行
当然我们也是可以使用命令行来操作的,比如:
| adb shell pm clear my.app.package |
只要把对应的包名,改成你自己的就可以了。
自动化
要是能自动化就更加完美了,这样我们就可以在我们的自动化Case里添加相应的恢复App原始状态的代码了,如此我们就可以保证我们的Case总是在一个一致的测试环境中,岂不更美?
这里我找到了两种方法。
方法一:在VBS脚本中添加代码,完成操作
Set objWsh = CreateObject("Wscript.Shell")
objWsh.Run "adb shell pm clear my.app.package",1, True |
方法二:在Android Test Project中添加相应代码删除私有原始数据
Context context = this.getInstrumentation().getTargetContext().getApplicationContext();
Editor edit = context.getSharedPreferences(m_strPreferencesName, Context.MODE_PRIVATE).edit();
edit.clear();
edit.commit(); |
当然我这里是删除名叫“m_strPreferencesName”的数据,如果我们想删除其他,或者所有的Share Preferences数据都是可以的。
请注意:
虽然Java 有Java.lang.runtime,我们可以通过它在运行时去执行Command命令,完成一些操作,但是在Android里,类似下面的代码就不可以:
try
{
Runtime.getRuntime().exec("adb shell pm clear com.my.package");
}
catch(IOException ex)
{
ex.printStackTrace();
} |
这里不会抛任何异常,而且也不会清除App的数据。
这是因为Andorid的安全机制不允许一个App去删除另一个App的数据。
1】.集成
测试:是在
单元测试的基础上,将所有模块按照设计要求组装成子系统或系统进行的测试活动。
2】.集成测试的两种集成模式:非渐增式集成渐增式集成:自顶向下集成,自底向上集成。
3】.对面向过程的系统采用的集成策略有:自顶向下,自底向上两种。
4】.简述集成测试的过程
1. 构建的确认过程。
2. 补丁的确认过程。
3. 系统集成测试测试组提交过程。
4. 测试用例设计过程。
5. 测试代码编写过程。
6. Bug的报告过程。
7. 每周/每两周的构建过程。
8. 点对点的测试过程。
9. 组内培训过程。
5】.集成测试分析与设计步骤:
1)确定测试需求;2)确定集成策略;3)评估测试风险;4)确定测试优先级;5)确定测试方法;6)集成测试代码设计;7)集成测试用例设计;8)集成测试工具和资源(的准备)。
5.1】.自顶向下集成优点:较早地验证了主要控制和判断点;按深度优先可以首先实现和验 证一个完整的软件功能;功能较早证实,带来信心;只需一个驱 动,减少驱动器开发的费 用;支持故障隔离。缺点:柱的开发量大;底层验证被推迟;底层组件测试不充分。适应 于产品控制结构比较清晰和稳定;高层接口变 化较小;底层接口未定义或经常可能被修改 ;产口控制组件具有较大的技术风险,需要尽早被验证;希望尽早能看到产品的系统功能 行为。
5.2】.自底向上集成优点:对底层组件行为较早验证;[url=]工作[/url]最初可以并行集成,比自顶向下效率高;减少了桩的工作量;支持故障隔离。缺点:驱动的开发工作量大;对高层的验证被推迟,设计上的错误不能被及时发现。适应于底层接口比较稳定;高层接口变化比较频繁;底层组件较早被完成。
5.3】.分层集成适应于有明显层次关系的系统
6】.集成测试有哪些不同的集成方法?简述不同方法的特点。
解:集成测试通常有一次性集成、自顶向下集成、自底向上集成和混合集成4种集成方法。
一次性集成方法需要的测试用例数目少,测试方法简单、易行。但是由于不可避免存在模块间接口、全局数据结构等方面的问题,所以一次运行成功的可能性不 大;如果一次集成的模块数量多,集成测试后可能会出现大量的错误,给程序的错误定位与修改带来很大的麻烦;即使集成测试通过,也会遗漏很多错误进入系统测试。
自顶向下集成在测试的过程中,可以较早地验证主要的控制和判断点;一般不需要驱动程序,减少了测试驱动程序开发和维护的费用;可以和开发设计工作一起并 行执行集成测试,能够灵活的适应目标环境;容易进行故障隔离和错误定位。但是在测试时需要为每个模块的下层模块提供桩模块,桩模块的开发和维护费用大;桩 模块不能反映真实情况,重要数据不能及时回送到上层模块,导致测试不充分;涉及复杂算法和真正I/O的底层模块最易出问题,在后期才遇到导致过多的回归测 试。
自底向上集成可以尽早的验证底层模块的行为;提高了测试效率;一般不需要桩模块;容易对错误进行定位。但是直到最后一个模块加进去之后才能看到整个系统的框架;驱动模块的设计工作量大;不能及时发现高层模块设计上的错误。
混合集成具有自顶向下和自底向上两种集成策略的优点,但是在被集成之前,中间层不能尽早得到充分的测试。
7】.可以思考以下内容并用集成测试计划的模板写下来:
1)确定集成测试对象
2)确定集成测试策略
3)确定集成测试验收标准
4)确定集成测试挂起和恢复条件
5)估计集成测试工作量
6)估计集成测试所需资源
7)进行集成测试任务划分
关联:服务器返回给客户端一些动态变化的值,客户端使用这些值去访问服务器的时候,不能把这些值写死在脚本里面,而应该存放在一个变量里面。
在脚本回放过程中,客户端发出请求,通过关联函数所定义的左右边界值(也就是关联规则),在服务器所响应的内容中查找,得到相应的值,以变量的形式替换录制时的静态值,从而向服务器发出正确的请求,这种动态获得服务器响应内容的方法被称作关联。
以loadrunner自带的示例进行。
启动loadrunner自带的服务器,Start Web Server
点击“HP Web Tours Application”,启动浏览器。
点击“administration”,设置服务器选项。

勾选第三项,“Set LOGIN form's action tag to an error page”。再拉动滚动条到下方,点击“Update”。

点击“Virtual User Generator”,打开脚本录制器。
点击“新建”按钮。
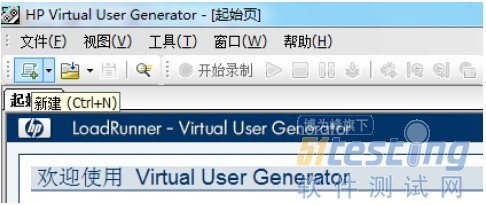
弹出“新建虚拟用户”窗口,选择“新建单协议脚本”,选择协议中的“Web (HTTP/HTML)”,点击“创建”按钮。
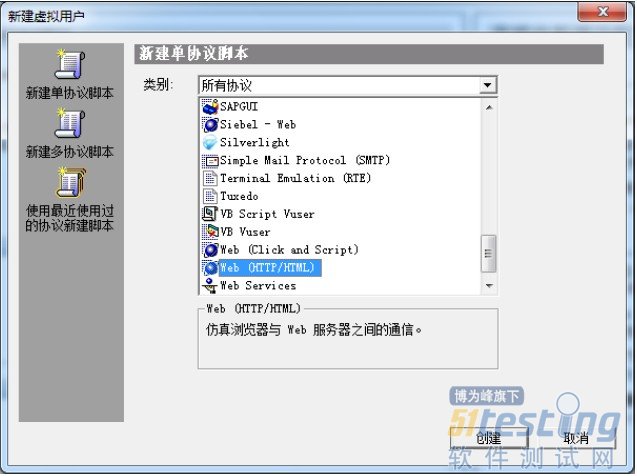
弹出“开始录制”窗口,填写“URL”地址。

点击“选项”按钮,弹出“录制选项”窗口,选择“常规”下“录制”,选择“基于HTML脚本”。
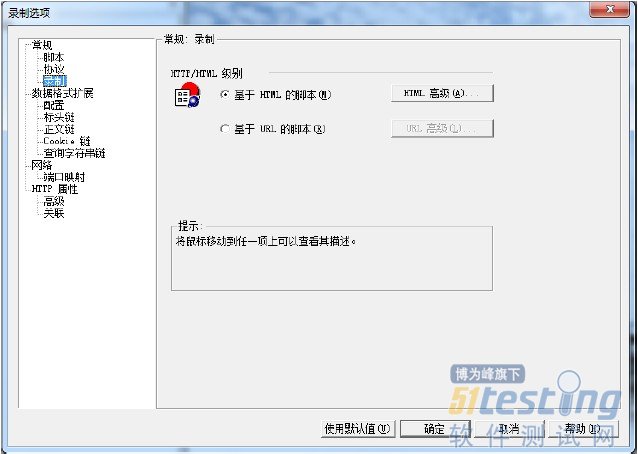
选择“HTTP属性”下“关联”,确保勾选“在录制期间启用关联”,点击确定按钮。
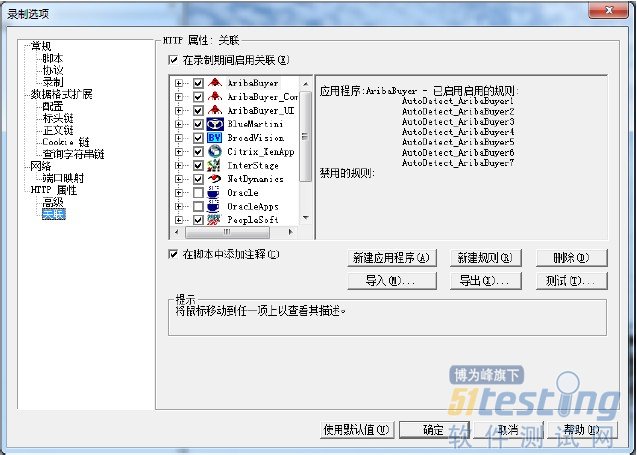
开始录制窗口点击“确定”按钮,开始录制。
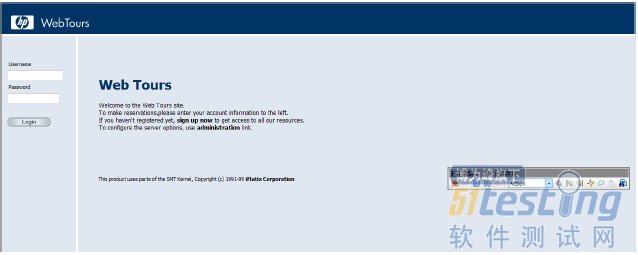
填写用户名“jojo”,密码“bean”。点击登录。

点击“Sign Off”退出登录。
点击“停止”录制按钮,可以查看录制脚本。
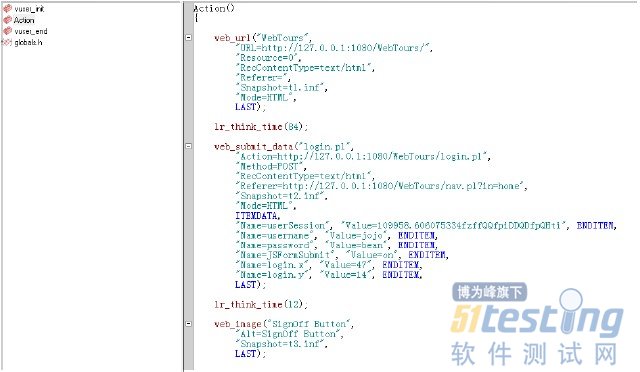
点击“F5”或者回放按钮。

查看“回放脚本”,显示错误。
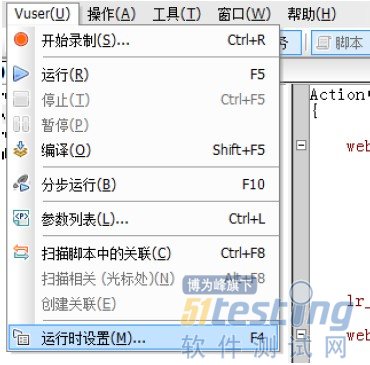
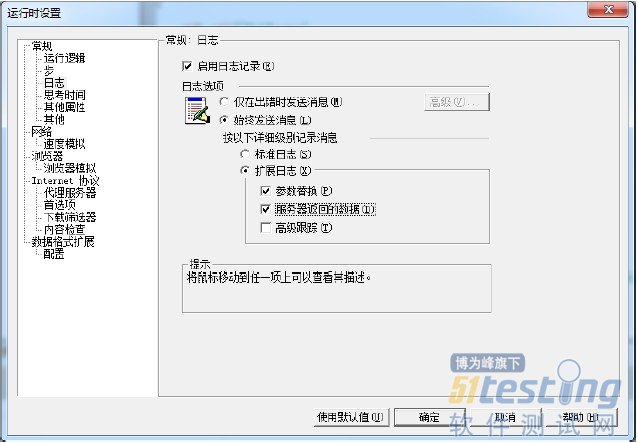
点击“运行时设置”弹出“运行时设置”窗口,勾选“扩展日志”下的“参数替换”和“服务器返回的数据”。
右键选择“插入”,“新建步骤”。
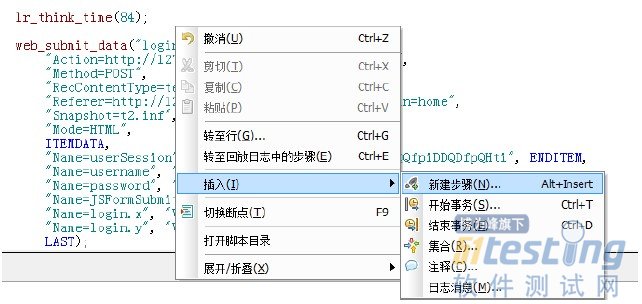
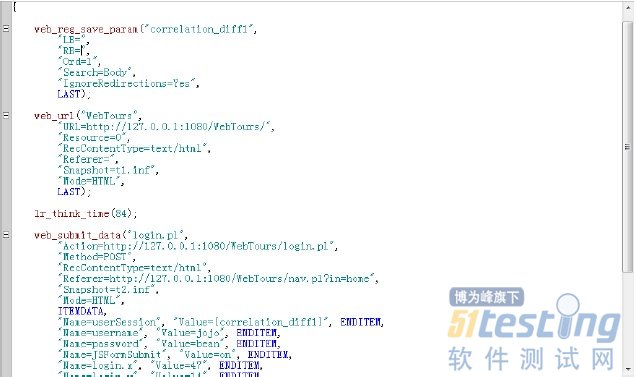
在“添加步骤”的“查找函数”中输入“web_reg_save_param”,点击“确定”按钮。
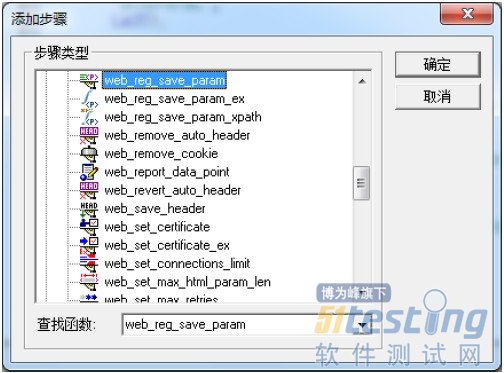
在“将数据保存到参数中”,填写“参数名”,不写“左边界”和“右边界”,因为不知道左右边界,勾选“实例”、“搜索范围”、“忽略重定向”。点击确定按钮。

在action函数中添加这个函数,将userSession的值用函数代替。
点击“运行”按钮,在“回放日志”中查看。
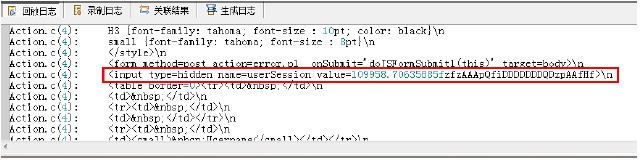
确定左边界为userSession value=,右边界为>。将对应的值天道函数的LB和RB中。

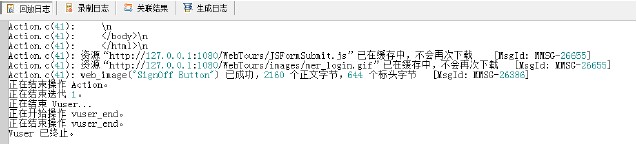
再运行,不再报错。
【常见的质量问题现象】 软件质量问题很大程度上可以从其开发过程上表现出来。在缺乏有效项目管理的团队中,下面的现象我相信是典型的。
一个功能第一次转测的时候,测试人员能够发现N个低级错误型的Bug。接着开发人员”改完”代码后,测试人员进行回归测试继续发现N个Bug。这些Bug有些是第一轮测试中发现的Bug没有修复正确或者完全的,而很大一部分可能是因修改之前的Bug而引入的新Bug。于是,这种现象不断得在第三次、第四次……回归测试中出现。
上面的现象就是典型的返工。返工不仅浪费了时间和人力,也是质量问题的标志。
而最后交付的功能还有若干Bug被发现。因为,测试人员漏测试了。
【原因分析与解决问题的经验分享】
质量问题的产生原因主要有两个因素:个人的因素和项目管理的因素。
人的因素主要有开发人员、测试人员的知识、能力和经验以及工作习惯。
比如,虽然敏捷开 发一直强调测试先行。但是,仍然有很多开发人员习惯于先编码后测试。更为不好的是,很多开发人员习惯于把所有代码都”写好”,然后集中对这些代码进行测 试。这样做的结果往往是一个地方发现的问题往往在其它地方也存在。于是,他不得不重复得修改这些问题。这种情形不仅浪费了他们的宝贵时间。也往往使问题没 有被彻底修正。另外,很多没有计算机专业背景的人被培训机构以高薪为诱惑被培训为测试人员。对于这些测试人员,当被测试的对象的技术性比较鲜明的时候,他 们往往不知怎么测试。
但是,人的因素往往很难短期内有所改善。所以,我将重点从项目管理的角度来分析。
返工和漏测试 是软件质量的两大问题。返工从项目管理的角度看,很大程度上是因为缺乏有效的流程控制。即,在一个功能转测试人员进行测试前,没有检查其质量是否满足一定 的要求——最低质量要求。这一点,其实可以借鉴建筑工程中的材料验收。比如,建设一栋大楼,其所需的钢筋水泥等材料如果我们不在使用它们前检查其质量是否 符合要求。那么,后面才发现它们的质量问题则必然要返工。关于如何进行流程控制,以使被转测的功能符合最低质量要求,可以借鉴下Story演示这个具体实 践。感兴趣的读者可以借鉴下IBM developerWorks网站上的文章:
《敏捷项目管理实战之在敏捷开发中引入Story演示》
http://www.51testing.com/html/63/n-846263.html
当然,质量问题是一个系统性的问题。那么,解决这个问题的方法也必然是要系统性。另外,管理不是照着菜谱做菜。管理者必须要掌握一套质量管理的方法,而非”拷贝”所谓优秀实践。学习优秀实践的意义在于掌握其背后所体现的方法与思想。下面的文章中以这样的一种思路分享了基于“经验过程控制”的质量管理思想,并以作者的项目管理经验为基础分享了另外一些提升项目质量的一些具体实践。
《敏捷项目管理实战之质量管理》
http://www.51testing.com/html/38/n-817638.html