摘要:软件测试时保证软件质量的重要手段,如何组织软件测试,耗费最少的时间与最小的
工作量完成软件测试,试软件质量满足用户要求,是软件研发单位需要解决的问题。本文结合工程实践,从软件的可测试性以及测试组织等方面探讨提高软件测试效率的方法。
关键词:可测试性;软件测试;测试人员;
引言
自从上世纪七八十年代全面爆发软件危机起,软件产业的发展过程中始终伴随着巨大的管理难题。整个软件产业存在着软件代价高、难于控制开发进度、软件工作 量估计困难、质量低,以及软件修改、维护困难等问题。而要解决这些问题,在很大程度上取决于提高软件的设计、开发和测试质量。
随着软件开发规 模的增大,软件的质量问题越来越突出。软件测试是提高软件质量的有效途径在软件测试工作中投入的人力、物力、财力逐渐加大,国外有些软件公司的测试人员和 开发人员的比例甚至达到1:1或者2:1的程度,因此如何提高软件测试效率是每个软件研发单位和研发项目面临的严峻问题。
本文结合工程实践,从软件的可测试性和软件测试组织两个方面进行分析,探讨提高软件测试效率的方法。
1、影响软件测试效率的因素
影响软件测试效率的因素很多,文本只论述被测软件质量和软件测试组织对软件测试效率的影响。
通过软件测试可以发现软件中的某些问题,软件中存在的某些潜在问题由于受测试工具、测试方法和测试时间的限制而无法发现,测试中发现的问题最终需要通过 软件开发人员进行纠正,从某种角度来看,软件测试并不能从根本上提高软件质量,软件质量的高低直接取决于软件开发人员的设计与编程水平,好的软件开发人员 编写完成的软件具有问题少、易维护等特点,但是有时会出现修改完成了一个软件缺陷,同时又引入多个软件缺陷的情况,需要经过多轮回归测试才能够完成问题归 零。所以,虽然软件测试时提高质量的有效途径,但提高软件开发人员的水平,提高反映软件设计质量和开发质量的软件的可测试性是提高软件质量的根本途径。
软件测试人员对项目需求的理解程度,对测试理论、测试工具和测试方法的掌握程度,以及对测试软件模块在项目中的重要程度和成熟程度的认识,对软件测试效率同样有很大的影响,所以在工程中需要合理组织软件测试,提高软件测试效率。
2、软件的可测试性
2.1 可测试性软件的特征
可测试软件具有以下特征:
(1)可操作性。可操作性是指:被测软件的错误很少,可以避免重复测试的开销;没有阻碍测试连续执行的错误;在软件设计时应允许在开发阶段进行部分测试活动。
(2)可观察性。
可观察性包括:每个输入有唯一的输出;系统状态和变量可见,或在运行中可查询;过去的系统状态和变量可见,或在运行中可查询;所有影响输出的因素都可见;容易识别错误输出;自动报告内部错误;可获取源代码;
(3)可控制性。可控制性是指:所有可能的输出都产生于某种输入组合;通过某种输入组合,所有代码都可能被执行;软件测试人员可直接控制软件和硬件的状态及变量;输入和输出格式保持一致且有规范的构成;能够便利地对测试进行说明,以及方面地执行和重构测试。
(4)可分解性。软件系统由众多独立模块构成。每个软件模块均可独立进行测试。
(5)简单性。简单性包括功能简单性、结构简单性、代码简单性。
(6)稳定性。软件的变化是不经常的,变化时可控制的,软件的变化不形象已有的测试,失效后能够得到良好的回复。
(7)易理解性。易理解性包括:设计能够被很好的理解;内部、外部和共享构件之间的依赖性能够很好地被理解;测试人员可方便的获取技术文档,并及时掌握设计更改清空;技术文档组织合理,明确详细。
2.2 提高软件可测试性的途径
在实际工作中,可通过以下几个途径提高软件的可测试性:减少并控制需求的变更;加强软件可测试性的设计;重视并规范技术文档的编写。
2.2.1 减少并控制需求的变更
用户需求可以分为如下三个层次:基本需求、预期需求和扩展需求三类。七宗预期需求是明示的。而基本需求和扩展需求是非明示的。所谓扩展需求是指这些特征 在用户的期望范围之外,并且当其存在时将是非常令人满意的。由于种种原因,软件的需求不确定性事客观存在的,是不可避免的,软件规模越大,研制周期越长, 需求的不确定性就越大。软件需求不确定性原因主要包括:用户在表述需求时常常带有不确定性与模糊性;随着开发进程的推进,用户对所建应
用系统的理解不断深入,对原来模块或是非明示的需求有了新的认识。随时会提出需求的变更;由于开发人员的领域知识的局限性,导致引发对需求的误解;用户需求的获取过程与描述形式往往采用非形式化的自然语言,以及自然概念中存在的本质矛盾,使需求的规范描述发生困难。
识别项目需求
识别项目需求是项目成功的关键,为了减少需求的不确定性,首先应充分认识确定需求的重要性,通过与用户的沟通,使用户能充分认识到软件需求变更对软件质 量、进度和成本的影响,积极参与到确定软件需求的活动中,达到现有进行软件设计前尽量确定软件需求的目的。同时在识别项目需求时,除了用户明示的需求外, 还需关注用户基本需求,用户基本需求常常体现在项目的领域知识、项目所在行业的相关标准等方面。实践证明,开发人员对领域知识掌握的程度直接影响到项目需 求的确定,开发人员通过对领域知识的积累有助于项目需求的确定。
需求文档化及需求评审 按照软件工程化需求,用户应该向研制方正是提交需求文档,研制方根据用户需求进行需求分析形成产品需求,用户需求及产品需求均需文档化并经过评审,以尽早发现不合理的需求。
需求管理、需求变更的控制
在系统研制过程中应对需求进行管理,首先建立需求库以及需求跟踪矩阵,在需求跟踪矩阵中反映研制跟阶段工作产品与需求的对应关系,并对需求进行需求的双向跟踪。
采用软件需求管理工具
采用需求管理工具,可以提高需求管理工作流程的自动化程度,使需求管理可以在项目实施过程中得到有效地推行。需求管理工具可以在整个项目生命周 期内,帮助团队有效地协作,将需求的变更信息及时传送到团队的每个成员,可以使跨项目团队的所有成员都能掌握必要的需求详细信息,并对软件项目规划、项目 跟踪与监督实施管理。
2.2.2 加强软件可测试性设计
在项目设计阶段应注重对软件可测试性的设计。项目负责人可根据项目具体情况对软件可测试性提出具体要求,对软件注视率、软件模块规模、模块圈复 杂度、基本圈复杂度、操作数的个数以及过程出口个数等进行规定,在软件设计以及编程阶段严格按照规范执行,可有效地提高软件测试效率。实践证明,如果在项 目设计阶段不进行软件可测试性的设计,待软件完成后再根据可测试性要求对软件进行修改完善常常需要花费巨大的人力和物力,同时大量的修改对软件质量也会带 来不利影响。
2.2.3 重视并规范技术文档的编写
技术文档不仅是开发人员进行信息交流的手段,也是测试人员进行测试的依据。所以软件相关文档应描述明确详细,组织合理,并根据需求和设计的变更 及时更新。同时为了给独立测试人员提供更多的信息,在技术文档中可增加各软件模块的重要程度、重用性以及测试历史等信息,使得独立测试人员可以合理分配经 理,对重要软件进行重点测试,减少不必要的重复劳动,提高测试效率。
3、软件测试方法与组织
3.1 软件测试方法
软件模块级测试分为白盒测试和黑盒测试。黑盒测试注重于测试软件的功能性需求,试图发现功能缺陷或遗漏、界面错误、数据结构或外部数据库访问错 误、性能错误以及初始化和中止等类型的错误。百合测试依赖对程序细节的严密检验,对软件的逻辑路径进行测试,在不同的程序点检验“程序的状态”以判定预期 状态或待验证状态与真实状态是否项目。在软件测试中,常常结合黑盒与白盒两种测试方法,相互补充。
3.2 软件测试人员
软件测试可以有软件开发人员、独立测试人员或者用户进行。在组织软件测试时,可根据不同人员的得点进行组织,使得各类测试相互补充。软件开发人员熟悉软件需求以及被测软件,清除各软件模块的重要程度和相互关系,了解各
软件模块以前的测试及修改等历史情况,可以有针对性地进行测试;软件开发人员和用户交流较为方便,在测试中能够发现与需求不一致的软件错误。但 是开发人员急于证明他们的程序是毫无错误的,是按照用户的需求开发的,而且完全能够按照预定的进度和预算完成,这将影响开发人员完成相关测试任务。
独立测试人员应具备较强的测试理论水平和测试经验,熟练掌握软件测试工具,并知悉被测软件的功能需求才能够对软件进行系统全面的测试。但独立测 试人员有时会缺乏相应领域的专业知识,主要测试依据是用户的技术要求以及开发人员在软件研制过程中形成的文档,一方面这些文档中缺乏对用户基本需求的描 述;另一方面,独立测试人员常常需通过开发人员来进行需求的解释,因此在软件测试中优势无法发现软件不满足需求方面的错误,但这种错误往往从用户角度看来 是最严重。同时,独立测试人员由于对各软件模块的重要性及相互关系了解不深,有时会影响测试效率。
在条件允许的情况下,软件完成后可提交用户试用,用户在试用中根据实际使用需求进行操作,其中包括各种正常操作流和非正常操作流。用户试用可有 效验证软件是否满足用户用户需求,同时在用户试用中对软件的可靠性等方面也同步进行了测试。因为用户试用方式同实际使用方式非常接近,所以通过用户试用获 得好评的软件基本可以满足今后的实际使用要求。
3.3 提高软件测试效率的方法
为了提高软件测试效率,测试人员需要熟悉掌握软件涉及的领域知识,了解软件各项功能的重要程度和成熟程度,掌握测试理论和工具;用户是炎症需求正确性的主导力量,应允许发挥用户的积极作用。
在组织软件测试时,可通过以下几个方面提高软件测试效率:
(1)根据不同测试人员的特点进行测试分工,单元测试应以软件开发人员为主进行,以保证每个单元能够完成设计的功能。在很多情况下,集成测试也可以开发人员为主进行。当软件体系结构完成后,独立测试人员机构计入;
(2)软件测试人员应注重与用户沟通,及早发现需求分析、理解不合理的问题,避免今后花费大量的资源和时间进行修改;
(3)对于软件开发人员,需加强测试方法的培训,提高自我测试的效率;
(4)在选择独立测试人员是,尽量选择比较熟悉了解被测试软件相关领域知识的人员;
(5)独立测试人员应该在软件开发的需求阶段就参与项目的研制,以便更好地制定测试计划、确定测试目标以及便携测试用例。通过找出项目中关键的 模块和错误率高的模块,可使用测试首先集中在重要的部分,避免发生把过多的时间花费在非重要模块的测试而没有时间测试重要的模块的情况;
(6)被测试软件在测试中发现了问题,需要进行有组织的分析研究,然后权衡利弊进行规范化修改,避免反复修改,反复测试;
(7)规范软件配置管理,通过管理及技术手段,对软件和文档版本进行控制,保障软件测试的有效性。
4、结束语
实践证明,通过提高被测软件的可测试性,以及合理组织软件测试工作,可以有效地提高软件测试效率。随着软件测试的重要性得以承认,软件测试阶段 在整个软件开发周期中占得比重也日益增大。为了将缺陷和错误消灭在萌芽之中,软件测试将逐步发展成为软件开发每一阶段都要进行而且需要反复进行的活动。软 件测试中大量的工作是机械的、重复的、枯燥的和非智力的,但逐步加强软件自动化测试的研究与推广将是今后软件产业的发展趋势。
公司的规模不大,做的项目不多,每个项目组的成员也少,最多的也就是四、五个人,目前的几个项目问题多多,各方面的问题都有,但是开发流程上的问题应该是最严重的。
这几天在考虑公司的开发流程可以做哪些改进,考虑的结果如下,自己的一点看法,如果有不合理的地方希望大家能给我指出来,帮助我改进,谢谢!
公司现有开发流程改进可以做的地方:
一、开发
1、开发时的模块划分不是简单的按照功能模块划分;必须按照面向对象的方法进行设计并拆分;
现在的划分方法是:按照程序的功能划分模块,基本信息给A做,库存管理给B做,业务模块给C做,报表模块给D做……
这种划分方法造成的结果是大家的开发是各自为战的,并且开发通常是面向过程的,程序很难进行自动化的测试;另一个就是代码的重用只能做到函数级的,对于一些业务逻辑的全面封装很困难;当然这些问题也跟开发工具有关,PB做OO开发要比做过程化的开发要困难。
模块的划分必须按照OO的概念进行,即必须把业务逻辑部分独立出来,这一部分必须是仅仅包含逻辑,而不考虑展现的问题;在其他的功能部分全部都是使用逻辑部分的功能进行数据处理;
这样做的好处是显而易见的:
1)代码的重用可以提高一级;
2)对于业务逻辑的修改可以封闭在业务逻辑部分,而对于展现部分的改动不会太大;
3)是在封装后的业务逻辑模块可以通过自动化测试工具(NUnit、DUnit等)进行单元测试,可以保证单元级的代码质量;
2、在开发过程中对业务逻辑部分使用测试驱动开发,要求对业务逻辑类必须先写出测试类,在开发过程中始终以测试对开发进行检验,以保证业务逻辑的正确性。
二、开发过程
1、开发过程必须使用配置管理系统,并且最好使用支持并行开发的SCM系统,比如CVS、SVN等;
2、对配置管理系统不能再作为单纯的源代码控制系统来使用,对于标签、分支等等功能都应该使用起来,这对于开发的管理是很有好处的;
3、推行每日构建,在每日构建后对业务逻辑部分进行自动化的单元测试,对于构建或测试失败的要立即解决,以免将错误拖延的太久,造成解决问题的代价过高;
4、Bug管理系统必须使用起来,目前使用Excel文件进行Bug管理的方法有诸多的缺陷,不是一个很好的办法;使用Bugzilla、Mantis等等Bug管理系统有助于对系统存在的问题进行跟踪管理,也有助于对开发过程的跟踪;
5、开发人员必须每天记录工作日志,工作日志不应该是单纯的是“今天做了什么模块,解决了什么问题”的垃圾信息,也不应该是给领导的工作汇报;工作日志更多的应该是大家在开发过程中遇到的问题、解决过程、心得等等的交流;我想通过建立一个内部的多人 Blog 用来记录工作日志比较好;
三、流程改进中存在的问题
1、客户的需求总是在不停的变动,甚至在核心业务的流程上有有可能更改;对于这种需求变更无论怎样设计,其更改都不可能会少,需要想办法尽量减少这中需 求变更对系统的影响;另一个就是在前期的需求调研中对用户的需求了解应该能够达到一定的深度,否则象目前项目在开发第二版的时候不得不推翻第一版的情况很 有可能会再次重演;
2、系统必须有OO的设计,这方面大家的经验都很欠缺,而且欠缺的不仅仅是经验,更重要的还有OO的思想;
3、开发工具的问题,虽然公司在逐渐向VS.Net转移,但是目前大家比较熟的开发工具是PB,而且目前的一些业务项目仍然是CS结构,无法使用 VS.Net开发;继续沿用 PB 则上面所说的全部都是一句空话;而如果改用Delphi,其转移难度仍然很大,转移的代价是否合算也是个问题;
MySQL 一些基本操作 ALTER TABLE:添加,修改,删除表的列,约束等表的定义。
查看列:desc 表名;
修改表名:alter table t_book rename to bbb;
添加列:alter table 表名 add column 列名 varchar(30);
删除列:alter table 表名 drop column 列名;
修改列名MySQL: alter table bbb change nnnnn hh int;
修改列名SQLServer:exec sp_rename't_student.name','nn','column';
修改列名Oracle:lter table bbb rename column nnnnn to hh int;
修改列属性:alter table t_book modify name varchar(22);
sp_rename:SQLServer 内置的存储过程,用与修改表的定义。
mysql修改、删除数据记录:
mysql数据库相信很多人都接触过,在进行mysql数据库的操作的时候,有人就希望删除或者修改mysql数据库中的一些数据记录。DELETE 和UPDATE 语句令我们能做到这一点。
用update修改记录:
UPDATE tbl_name SET 要更改的列
WHERE 要更新的记录:
这里的 WHERE 子句是可选的,因此如果不指定的话,表中的每个记录都被更新。
例如,在pet表中,我们发现宠物Whistler的性别没有指定,因此我们可以这样修改这个记录:
mysql> update pet set sex=’f’ where name=” Whistler”;
用delete删除记录:
DELETE 语句有如下格式:
DELETE FROM tbl_name WHERE 要删除的记录
WHERE 子句指定哪些记录应该删除。它是可选的,但是如果不选的话,将会删除所有的记录。这意味 着最简单的 DELETE 语句也是最危险的。
这个查询将清除表中的所有内容。一定要当心!
为了删除特定的记录,可用 WHERE 子句来选择所要删除的记录。这类似于 SELECT 语句中的 WHERE 子句。
mysql> delete from pet where name=”Whistler”;
可以用下面的语句清空整个表:
mysql>delete from pet;
总结
本节介绍了两个SQL语句的用法。使用UPDATE和DELETE语句要十分小心,因为可能对你的数据造成危险。尤其是DELETE语句,很容易会删除大量数据。使用时,一定小心。
MySQL InnoDB 管理和备份二进制日志
(一)二进制日志的重要性
如果有某个时间点的数据备份和所有从那时以后的二进制日志就可以重放自从上次全备以来的二进制日志并“前滚”所有的变更
(二)二进制日志配置的最佳实践
对于 InnoDB 如果仅是启用二进制日志是不够、还需要其他措施来保证安全:
推荐配置如下:
● sync_binlog = 1
表示采用同步写磁盘的方式来写二进制日志、这时写操作便绕开了OS的缓冲
该默认值为0
● innodb_support_xa = 1
确保二进制日志和InnoDB 数据文件的同步
(三)影响二进制日志备份策略的因素
如下图:
(四)二进制日志的格式
二进制日志的粒度是事件、每个事件都有固定的事件头、含:When、What、Who等
因其格式为二进制不可看、我们可借助 mysqlbinlog 查看其内容
下面是一个例子:
[mysql@even data]$ mysqlbinlog -vv mysql-bin.000023
/*!40019 SET @@session.max_insert_delayed_threads=0*/;
/*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#130515 12:35:29 server id 2 end_log_pos 107 Start: binlog v 4, server v 5.5.16-log created 130515 12:35:29 at startup
# Warning: this binlog is either in use or was not closed properly.
ROLLBACK/*!*/;
BINLOG '
kRCTUQ8CAAAAZwAAAGsAAAABAAQANS41LjE2LWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAACREJNREzgNAAgAEgAEBAQEEgAAVAAEGggAAAAICAgCAA==
'/*!*/;
# at 107
#130515 12:37:47 server id 2 end_log_pos 255 Query thread_id=3 exec_time=0 error_code=0
SET TIMESTAMP=1368592667/*!*/;
SET @@session.pseudo_thread_id=3/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=0/*!*/;
SET @@session.auto_increment_increment=2, @@session.auto_increment_offset=2/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
alter database db_rocky character set = utf8mb4 COLLATE = utf8mb4_unicode_ci
/*!*/;
DELIMITER ;
# End of log file
ROLLBACK /* added by mysqlbinlog */;
/*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; |
这里列了 2 个事件、来看第二个事件:
# at 107
#130515 12:37:47 server id 2 end_log_pos 255 Query thread_id=3 exec_time=0 error_code=0 |
第一行表示该事件的起始位置:at 107
第二行包含如下几项:
● 事件的日期和时间:130515 12:37:47
● 服务器 ID、这对于防止复制之间无限循环和其他问题是非常有必要的
● 下一个事件的开始位置:end_log_pos 255
注意了:该值通常是不正确的。因为主库会复制事件到一个缓冲区、但这样做时MySQL并不知道下个日志事件的位置
● 事件类型、这里是 Query
● 执行改事件的线程 ID、这点对审计蛮重要的
● 语句的时间戳和写入二进制日志的时间差:exec_time
该值在复制落后的备库上会有很大偏差
● 事件产生的错误代码
(五)清除老的二进制日志的方法
不要用 rm 删除日志、否则、将会导致 mysql-bin.index 状态文件与磁盘上的不一致
应该用类似下面的 cron 命令:
0 0 * * * /usr/bin/myql -e "PURGE MASTER LOGS BEFORE CURRENT_DATE - INTERVAL N DAY"
在把jdk安装到计算机中之后,我们来进行设置使
java环境能够使用。 首先右键点我的电脑。打开属性。然后选择“高级”里面的“
环境变量”,在新的打开界面中的系统变量需要设置三个属性“JAVA_HOME”、“path”、“classpath”,其中在没安装过jdk的环境下。path属性是本来存在的。而JAVA_HOME和classpath是不存在的。
一:点“新建”,然后在变量名写上JAVA_HOME,顾名其意该变量的含义就是java的安装路径,呵呵,然后在变量值写入刚才安装的路径 “C:\jdk1.6”。(注:如果安装的路径不是磁盘C或者不是在jdk1.6这个文件夹,可对应修改。以下文字都是假定安装在C:\jdk1.6里 面。)
二:其次在系统变量里面找到path,然后点编辑,path变量的含义就是系统在任何路径下都可以识别java命令,则变量值为 “.;%JAVA_HOME%\bin”,(其中“%JAVA_HOME%”的意思为刚才设置JAVA_HOME的值),也可以直接写上“C: \jdk1.6\bin”
三: 最后再点“新建”,然后在变量名上写classpath,该变量的含义是为java加载类(class or lib)路径,只有类在classpath中,java命令才能识别。其值为“.;%JAVA_HOME%\lib \dt.jar;%JAVA_HOME%\lib\toos.jar (要加.表示当前路径)”,与相同“%JAVA_HOME%有相同意思”
以上三个变量设置完毕,则按“确定”直至属性窗口消失,下来是验证看看安装是否成功。先打开“开始”-> “运行”,打入“cmd”,进入dos系统界面。然后打“java -version”,如果安装成功。系统会显示java version jdk“1.6.0”。
确保安装在C盘文件名为jdk1.6,环境变量直接复制就可以了,在dos界面中输入javac来查看该命令是否合法,同样输入java来查看该命令是否合法
这样环境变量就设置好了,下面进行对PATH,CLASSPTH,JAVA_HOME的讲解
以下为置JAVA_HOME,CLASSPATH,PATH的目的:
1、设置JAVA_HOME:
一、为了方便引用,比如,你JDK安装在C:\Program Files\Java\jdk1.6.0目录里,则设置JAVA_HOME为该目录路径, 那么以后你要使用这个路径的时候, 只需输入%JAVA_HOME%即可, 避免每次引用都输入很长的路径串;
二、归一原则, 当你JDK路径被迫改变的时候, 你仅需更改JAVA_HOME的变量值即可, 否则,你就要更改任何用绝对路径引用JDK目录的文档, 要是万一你没有改全, 某个程序找不到JDK, 后果是可想而知的----系统崩溃!
三、第三方软件会引用约定好的JAVA_HOME变量, 不然, 你将不能正常使用该软件, 以后用JAVA久了就会知道, 要是某个软件不能正常使用, 不妨想想是不是这个问题.
2、设置CLASSPATH:
这是一个很有趣,当然也比较折磨初学者的问题, 这个变量设置的目的是为了程序能找到相应的“.class”文件, 不妨举个例子: 你编译一个JAVA程序---A.java, 会得到一个A.class的类文件,你在当前目录下执行java A, 将会得到相应的结果(前提是你已经设置CLASSPATH为“.”). 现在, 你把A.class移到别的目录下(例如:“e:\”), 执行java A, 将会有NoClassDefFindError的异常,原因就是找不到.class文件, 现在你把CLASSPATH增加为:“.;e:\”再运行java A, 看看会有什么结果~~:)~~~, 一切正常, java命令通过CLASSPATH找到了.class文件!
3、设置PATH:
道理很简单, 你想在任何时候都使用%JAVA_HOME%\bin\java 等来执行java命令吗, 当然不会, 于是, 你可以选择把 %JAVA_HOME%\bin添加到PATH路径下, 这样, 我们在任何路径下就可以仅用java来执行命令了.(当你在命令提示符窗口输入你个代码时,操作系统会在当前目录和PATH变量目录里查找相应的应用程序, 并且执行.)
经常遇到PL/SQL Developer等依赖Client的工具无法连接
Oracle数据库服务器的问题。至今也没完全理清楚,先发个帖总结一下目前的方法,后面会不断完善。
方法一:
重启Oracle服务器端相关服务,包括...TNSListener,所用的数据库实例的服务。可直接在Windows的“服务”中重启。或者(可使用的命令):
lsnrctl stop
lsnrctl start
lsnrctl reload
sqlplus / as sysdba;
startup; |
这个方法试过多次有效,但原因未知,求真相。
方法二:
使用Net Configuration Assist配置服务器端和客户端。
Oracle服务器端需要设置listener(监听程序),设置结果影响listener.ora(...\db_1\NETWORK \ADMIN)。Client端(客户端)需要配置“本地Net服务名配置”,可能影响tnsnames.ora和sqlnet.ora两个文件。若是 Oracle Client,则文件位置是...\client_1\NETWORK\ADMIN
方法三:
若装有Oracle Client,则可使用Enterprise Manager Console添加数据库连接,会修改tnsnames.ora文件(...\client_1\NETWORK\ADMIN)。
方法四:
查看sqlnet.ora中是否有NAMES,DIRECTORY_PATH等,可能与此有关。
# sqlnet.ora Network Configuration File: C:\oracle\product\10.2.0\db_1\network\admin\sqlnet.ora
# Generated by Oracle configuration tools. # This file is actually generated by netca. But if customers choose to
# install "Software Only", this file wont exist and without the native
# authentication, they will not be able to connect to the database on NT. SQLNET.AUTHENTICATION_SERVICES= (NTS) NAMES.DIRECTORY_PATH= (TNSNAMES, EZCONNECT) |
注意:
1、Enterprise Manager Console与Net Configuration Assist添加的数据库连接描述符不同,前者为...CONNECT_DATA=(SID=...)(SERVER=...)...,后者为... (SERVICENAME=...)...。
2、Enterprise Manager Console中删除一条连接后,tnsnames.ora中的描述字符串不会自动删除;Net Configuration Assist中删除一条本地Net服务配置后,tnsnames.ora文件中对应的描述字符串会自动删除。
3、若安装配置OWB(Oracle Warehouse Builder),则文件位置是...\client_1\NETWORK\ADMIN
内存映射结构: 1、32位地址线寻址4G的内存空间,其中0-3G为用户程序所独有,3G-4G为内核占有。
2、struct page:整个物理内存在初始化时,每个4kb页面生成一个对应的struct page结构,这个page结构就独一无二的代表这个物理内存页面,并存放在mem_map全局数组中。
3、段式映射:首先根据代码段选择子cs为索引,以GDT值为起始地址的段描述表中选择出对应的段描述符,随后根据段描述符的基址,本段长度,权限信息等进行校验,校验成功后。cs:offset中的32位偏移量直接与本段基址相累加,得出最终访问地址。
0-3G与mem_map的映射方式:
因linux中采用的段式映射为flat模式,所以从逻辑地址到线性地址没有变化。从段式出来进入页式,每个用户进程都独自拥有一个页目录表 (pdt),运行时存放于CR3。 CR3(页目录) + 前10位 => 页面表基址 + 中10位 => 页表项 + 后12位 => 物理页面地址
3G-4G与mem_map的映射方式:
分为三种类型:低端内存/普通内存/高端内存。
低端内存:3G-3G+16M 用于DMA __pa线性映射
普通内存:3G+16M-3G+896M __pa线性映射 (若物理内存<896M,则分界点就在3G+实际内存)
高端内存:3G+896-4G 采用动态的分配方式
4、高端内存(假设3G+896为高端内存起址)
作用:访问到1G以外的物理内存空间。
线性地址共分为三段:vmalloc段/kmap段/kmap_atomic段(针对与不同的内存分配方式)
从内存分配函数的结构来看主要分为下面几个部分:
a.伙伴算法(最原始的面向页的分配方式)
alloc_pages 接口:
struct page * alloc_page(unsigned int gfp_mask)--分配一页物理内存并返回该页物理内存的page结构指针。
struct page * alloc_pages(unsigned int gfp_mask, unsigned int order)--分配 个连续的物理页并返回分配的第一个物理页的page结构指针。
<释放函数:__free_page(s)>
内核中定义:#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
最终都是调用 __alloc_pages.
其中MAX_ORDER 11,及最大分配到到页面个数为2^10(即4M)。
分配页后还不能直接用,需要得到该页对应的虚拟地址:
void *page_address(struct page *page);
低端内存的映射方式:__va((unsigned long)(page - mem_map) << 12)
高端内存到映射方式:struct page_address_map分配一个动态结构来管理高端内存。(内核是访问不到vma的3G以下的虚拟地址的) 具体映射由kmap / kmap_atomic执行。
get_free_page接口:(alloc_pages接口两步的替代函数)
unsigned long get_free_page(unsigned int gfp_mask)
unsigned long __get_free_page(unsigned int gfp_mask)
Unsigned long __get_free_pages(unsigned int gfp_mask, unsigned int order)
<释放函数:free_page>
与alloc_page(s)系列最大的区别是无法申请高端内存,因为它返回到是一个线性地址,而高端内存是需要额外映射才可以访问的。
b.slab高速缓存(反复分配很多同一大小内存) 注:使用较少
kmem_cache_t* xx_cache;
创建: xx_cache = kmem_cache_create(“name”, sizeof(struct xx), SLAB_HWCACHE_ALIGN, NULL, NULL);
分配: kmem_cache_alloc(xx_cache, GFP_KERNEL);
释放: kmem_cache_free(xx_cache, addr);
内存池
mempool 不使用。
c.kmalloc(最常用的分配接口) 注:必须小于128KB
GFP_ATOMIC 不休眠,用于中断处理等情况
GFP_KERNEL 会休眠,一般状况使用此标记
GFP_USER 会休眠
__GFP_DMA 分配DMA内存
kmalloc/kfree
d.vmalloc/vfree
vmalloc采用高端内存预留的虚拟空间来收集内存碎片引起的不连续的物理内存页,是用于非连续物理内存分配。
当kmalloc分配不到内存且无物理内存连续的需求时,可以使用。(优先从高端内存中查找)
e.ioremap()/iounmap()
ioremap()的作用是把device寄存器和内存的物理地址区域映射到内核虚拟区域,返回值为内核的虚拟地址。使用的线性地址区间也在vmmlloc段
注:
vmalloc()与 alloc_pages(_GFP_HIGHMEM)+kmap();前者不连续,后者只能映射一个高端内存页面
__get_free_pages与alloc_pages(NORMAL)+page_address(); 两者完全等同
内核地址通过 __va/__pa进行中低内存的直接映射
高端内存采用kmap/kmap_atomic的方式来映射
个人总结如下:
a.在<128kB的一般内存分配时,使用kmalloc
允许睡眠:GFP_KERNEL
不允许睡眠:GFP_ATOMIC
b.在>128kB的内存分配时,使用get_free_pages,获取成片页面,直接返回虚拟地址(<4M)(或alloc_pages + page_address)
c.b失败,
如果要求分配高端内存:alloc_pages(_GFP_HIGHMEM)+kmap(仅能映射一个页面)
如果不要求内存连续: 则使用vmalloc进行分配逻辑连续的大块页面.(不建议)/分配速度较慢,访问速率较慢。
d.频繁创建和销毁很多较大数据结构,使用slab.
e.高端内存映射:
允许睡眠:kmap (永久映射)
不允许睡眠:kmap_atomic (临时映射)会覆盖以前到映射(不建议)
近半年在做分布式系统开发的同时,也做了不少的
测试工作,软件工程教科书上描述软件项目的流程,基本上都会提到
单元测试、集成测试、压力测试等名词,但对这些词汇一直停留在理论认识阶段。研究生阶段做的项目,因为要求不高,基本上也没做什么测试工作;去年在实习的时候,因为时间有限,主要接触单元测试和系统
功能测试;直到现在才把这些词汇都近距离的感受了一下。
单元测试
分布式系统的开发工作通常会被划分成多个模块,由不同的开发人员分别编写程序,所以代码的单元测试工作通常是针对单个模块进行的。如果模块是独立的,并 且功能集足够小,单元测试是很容易做的,构造一组case,尽量覆盖所有的分支基本上就OK。但实际上分布式系统里很少有完全独立的模块,大部分的模块都 会跟其他的模块有依赖关系或是网络通信等。
对于有依赖的模块的单元测试,理想情况下,依赖的模块都已经准备好,并且被测试过没有问题 (这个实际上是做不到的,而且模块间有时还会存在相互依赖的情况),这种理想情况会严重影响开发效率,使得有依赖的模块就只能串行开发测试。另外,如果依 赖的模块在安装、部署上需要花费很长的时间(比如是一个配置比较麻烦的server),那么每次单元测试都需要把server部署起来,测试成本是很高的。
实际单元测试的过程中,我们经常会把依赖其他模块的地方用简单的代码代替,也就是做mock。最直观的mock方式就是通过宏来控制,即如果是以 DEBUG模式运行,执行某段简单的代码(mock),如果非DEBUG模式运行,则执行实际的代码逻辑。比如通过下面一段代码把“从网络上获取数据”在 DEBUG模式运行时替换为“从本地内存获取数据”,那么在执行单元测试时,我们就不需要依赖网络的对端来提供数据,从而方便的测试代码逻辑。而实际 fetch_data_from_network()的测试可延迟到功能测试阶段。
#ifndef DEBUG_MODE
fetch_data_from_network();
#else
fetch_data_from_local_memory();
#fi |
使用宏来控制有时会使得代码读起来很混乱,如果是使用C++开发(或其他面向对象编程语言),更好的方式是借助多态的性质来做mock,如下面一段代 码,DataManager是一个负责管理数据的类,它需要从网络上其他的服务里获取数据,MockDataManager是一个继承自 DataManager的类,它从本地内存获取数据,在测试时,我们可以将DataManager的实例换成MockDataManager的实例来运行 (必须是指针或是引用),这样思路跟前面的思路其实是一样的,只不过借助多态,更清晰明了,需要做的事情更少。google test和google mock是开源的测试、以及mock框架,使用他们会使你的测试工作更简单,更有趣。
class DataManager {
public:
DataManager();
~DataManager();
virtual int fetch_data()
{
fetch_data_from_network();
}
...
}; class MockDataManager : public DataManager {
public:
virtual int fetch_data()
{
fetch_data_from_local_memory();
}
}; |
测试久了之后,你会发现测试的工作量往往跟代码结构的设计有很大的关系,如果代码结构本身毫无章法,再加进去一堆为单元测试而写的代码逻辑,只会令代码 看起来更加糟糕;如果设计之初就考虑测试需求,尽量把业务与逻辑层次分开降低模块间依赖性,把可能需要mock测试的地方设计为虚基类等,在做测试的时候 需要做的工作就会很少,而且测试新增代码不会打乱现在的代码逻辑结构。
什么是需求 需求是产品必须完成的事以及必须具备的品质。
功能性需求
功能性需求是产品必须完成的那些事,要求一定的功能和品质。
例子:培训机构的班主任可以给所在班级学员打考勤
非功能性需求
非功能性需求是产品必须具备的属性或品质。诸如观感、可用性、安全性和法律限制等。
例子: 平台用户数为5万人,每天登录用户数为10000左右,网络的带宽为100M带宽。在工作时间根据资料名称条件进行搜索,可以在3秒内得到搜索结果。
这类需求通常在产品的功能确定之后(但并非总是如此)。也就是说,一旦知道了产品要做的事情,就可以确定它的行为方式,它需要具备什么品质以及它的响应速度、可用性、可读性和安全性。
限制条件
限制条件是全局性的需求。它们可以是对项目本身的限制,或是对产品最终设计的限制。
例子:南京平台必须在2010年开学的第一学期上线
客户是在说,如果顾客不能在给定的时间前使用该产品,那么它就没有什么用了。其效果是,需求分析师必须对需求进行限制,只包括那些在最后期限前能够提供最大价值的需求。
需求分析的重要性
背景:冯大勇吃鱼时嗓子被鱼刺卡住了。现在正坐在椅子上候诊。
大夫:(在桌上拿起一份挂号单,大声的喊)冯大勇!
冯大勇:(病怏怏的样子,边走边咳嗽)我是。
大夫:怎么了?(低头整理手中的资料,自言自语,并打手势,示意冯大勇坐下)
冯大勇:我...(咳嗽)...我今天...(咳嗽)
大夫:不用说了,我知道了。(从桌子下面拿出一个大盒子,放在桌子上)我看你适合吃这种药。这是本院独家开创的哮喘新药“咽喉糖浆”,疗程短,见效快,一个疗程吃3盒,平均每天只需花费3块钱。给你先开6盒吧!(边说边开药方)
冯大勇非常惊讶地瞪大眼睛并止不住地弯腰大声咳嗽,以至于把鱼刺都咳出来了。冯大勇从口里掏出一条巨型鱼刺,递给医生。医生见到鱼刺先是吃惊,而后又非常尴尬。
医生不了解病人的需求就用药,是草菅人命;销售员不了解客户的需求就进行推销,不仅自己要徒劳无功地浪费很多口舌,更重要的是完不成销售的目标。给客户 推销软件产品,也相当于医生给病人治病,应当首先充分、全面地了解客户的需求所在、期望所在,然后才能带给他一个完美的解决方案。
需求分析没有做好的后果一般会有下列现象:
1、浪费时间和资源来满足用户并不需要的需求(过度实现一些功能);
2、开发出来的产品技术上先进,但不满足用户需求;
3、总是需要比较长的时间来达成对产品设计的共识;
4、在产品设计,开发和测试工作中对于用户需求的解释不一致;
5、员工会厌倦因需求不断被重新解释而导致的返工;
6、未说明的或不正确的需求会导致员工与用户间的不满;
7、不稳定的产品,用户的不满意对我们未来的市场造成损失;
8、浪费时间,增加成本,使得在一些投标的项目中不能低价;
1、如果你在编码的时候发现某几行有误,那么改掉这几行就行了。而如果在编码阶段发现需求有误,那么你很可能需要改变所有代码来适应新的需求
2、在需求阶段消除问题的代价最小,而如果需求问题等到产品发布出去后才发现的话,那修复的成本就会N倍的增加。
3、稳定的需求是软件开发的关键。有了稳定的需求,软件开发工作可能从结构设计到详细设计到代码到测试都会平稳顺利的进行。
为什么要做需求分析
1、“决策性”--要不要做这个产品,通过对市场需求的分析来决策项目是否需要立项;
2、“方向性”--良好的需求分析可以对项目人员明确方向,让项目成员知道下面应该如何实施;
3、“策略性”--既然知道了为什么要做需求分析,就需要了解什么是需求分析,及如何做。需求分析并不是简单的对与错,比如说做一个产品,“做技术最先进的软件,还是做最好卖的软件”,这个需求有错吗,没有,只能说需要从不同的地方去考虑,去定位。
如何进行需求分析 “ 需求分析”不代表“用户要求什么就是什么”也不代表“我们能做什么就做什么”,做为需求人员,在进行需求分析的时候,首先应该明白用户的需求,然后再加上 自己的分析处理过程,知道哪些我们现在能做,哪些我们做不了,哪些我们咬咬牙齿能做,需求人员在做需求分析的时候不能一味的成为客户的传话筒,要有自己的 分析。
一般可以从三个方面去考虑:
1、功能需求--产品应该完成哪些功能,即向用户提供的功能,一般来说这个都是比较硬性的标准;
2、非功能性需求--用户可能不能明确告诉你的一些需求,比如说性能达到什么要求,可靠性方面,响应时间,扩展性,性能方面等,这块的内容并不 是说用户需要,而是说不知道需要做成什么样的,我们不能不做,做了只会对自己受益。要不然等到后期用户使用感觉这慢,那不爽,那倒霉的还是是自己;
3、限制条件--在需求分析中需要考虑一些条件约束,规则等,比如客户的约束,行业的约束,法律的约束以及自己的约束等,这些都需要在需求分析考虑清楚,要不然做出一款白人狂殴黑人的游戏给黑人玩,那就惨了……
测试需求分析的步骤
1 、 熟悉需求背景及商业目标:
a) 了解清楚项目发起的原因,是为了解决用户的什么问题。
b) 当前的解决方案是不是最优的,为什么会这样做?
2 、业务模型法:
a) 考虑本项目与外部系统的交互,划分系统边界(除了本项目的需求中要求做的事情,其他的都可以是外部系统,本系统和外部系统之间的交互就是系统的边界),可以参考系统分析说明书。
b) 确定测试范围和关注点。系统的边界是测试的重点,特别需要关注边界交互时的数据交互。
3 、业务场景法:
a) 考虑用例的调用者;考虑每一个用例提供的服务是供哪些外部用例或者系统调用,找出所有的调用者。调用的前提、约束都要考虑。每一个调用都可以考虑成一个大的业务流程。(一般和外部有交互的用例出错的概率比较大,需要重点关注)
b) 考虑系统内部各个用例之间的交互,形成内部业务流程图。需要分析每个用例之间的约束关系、执行条件,组织出各种业务流程图。
4 、功能分解法
a). 业务功能:与用户实际业务直接相关的功能 或细节。
b). 辅助功能:辅助完成业务功能的一些功能或者是细节,比如,设置过滤条件。
c). 数据约束:功能的细节,主要是用于控制在执行功能时,数据的显示范围、数据之间的关系等。
d). 易用性需求:功能的细节,产品中必须提供了,便于功能操作使用的一些细节,比如快捷键就是典型的易用性需求。
e). 编辑约束:功能的细节,在功能执行时,对输入数据项目的一些约束性条件,比如只能输入数字。
f). 参数需求:功能的细节,在功能中,需要根据参数设置不同,进行不同处理的细节。
g). 权限需求:功能的细节,这里的权限是指在功能的执行过程,根据根据不同的权限进行不同处理的,不包括直接限制某个功能的权限。
一个有趣的例子 某日,老师在课堂上想考考学生们的智商,就问一个男孩:“树上有十只鸟,开枪打死一只,还剩几只?”
男孩反问:“是无声枪么?”
“不是。”
“枪声有多大?”
“80~100分贝。”
“那就是说会震的耳朵疼?”
“是。”
“在这个城市里打鸟犯不犯法?”
'不犯。“
“您确定那只鸟真的被打死啦?”
“确定。”老师已经不耐烦了,“拜托,你告诉我还剩几只就行了,OK?”
“OK。鸟里有没有聋子?”
“没有。”
“有没有关在笼子里的?”
“没有。”
“边上还有没有其他的树,树上还有没有其他鸟?”
“没有。”
“方圆十里呢?”
“就这么一棵树!”
“有没有残疾或饿的飞不动的鸟?”
“没有,都身体倍棒。”
“算不算怀孕肚子里的小鸟?”
“都是公的。”
“都不可能怀孕?”
“………,决不可能。”
“打鸟的人眼里有没有花?保证是十只?”
“没有花,就十只。”
老师脑门上的汗已经流下来了,下课铃响起,但男孩仍继续问:“有没有傻的不怕死的?”
“都怕死。”
“有没有因为情侣被打中,自己留下来的?”
“笨蛋,之前不是说都是公的嘛!”
“同志可不可以啊!”
“…………,性取向都很正常!”
“会不会一枪打死两只?”
“不会。”
“一枪打死三只呢?”
“不会。”
“四只呢?”
“更不会!”
“五只呢?”
“绝对不会!!!”
“那六只总有可能吧?”
“除非你他妈的是猪生的才有可能!”
“…好吧,那么所有的鸟都可以自由活动么?”
“完全可以。”
“它们受到惊吓起飞时会不会惊慌失措而互相撞上?”
“不会,每只鸟都装有卫星导航系统,而且可以自动飞行。”
“恩,如果您的回答没有骗人,”学生满怀信心的回答,“打死的鸟要是挂在树上没掉下来,那么就剩一只,如果掉下来,就一只不剩。”
老师当即倒!
举例说明如何进行测试需求分析 先看一段关于日志文件的需求描述如下:“软件要将所有的访问者都要记录下来,对每次访问要记录访问开始时间、访问结束时间、访问者的IP地址这三个信息作为一条日志记录。要求以天为单位每天生成一个访问记录日志文件。
在这段需求描述中,我们首先要想象自己是日志模块的开发者,根据这段需求描述,是否能够开发出日志模块来呢?日志文件要记录的信息内容上面都提到了:访问开始时间、结束时间、IP地址。乍一看好像可以根据这个需求描述进行开发。
但仔细来分析一下这段需求的话,就会发现并不是想象的那样乐观。先找出需求中涉及的三个显性元素:
1、访问者
2、访问记录
3、日志文件
首先对访问者和访问记录这两个元素进行分析,先看访问者有那些属性,除了描述中提及的访问时间和IP地址外,访问者还有那些属性呢?显然访问者 的访问内容是最重要的属性,仅记录访问时间和访问者的IP地址是否足够呢,从日志能分析出什么有用的信息呢?从时间信息上最多只能看出那段时间访问的人数 较多,得到用户的时间分布规律,但很难对用户的行为有深入的分析,只有知道访问者在访问那些内容才能得到更有价值的信息。象Web服务器软件要记录下访问 的URL信息以便知道访问者访问的内容,所以访问记录中遗漏了关于访问内容的信息。
从访问记录这个元素来分析,访问记录主要属性是记录格式,每条记录是以什么格式来记录呢?没有描述出来。有经验的开发者就知道日志记录格式是一 个很重要的问题,因为日志记录的分析一般是需要使用专门的分析软件或者写专门的分析程序来分析的。如何设计合理的记录格式来利用已有的日志分析软件来进行 分析是首要考虑的问题。
再对日志文件这个元素进行分析,先看看日志文件有那些属性,首先日志文件具有文件名,还有存放位置,文件格式,文件内容、文件创建时间、文件大小、文件权限等属性。
需求描述中提到了每天要生成一个日志文件,从文件创建时间属性来看,每天有24小时,到底从什么时候开始创建文件,从0点开始还是从几点开始,没有描述出来。
---从文件名属性来看,如何命名日志文件,需求中也没有提及。从存放位置属性来看,日志文件存放在什么地方也没有说明。是不是所有的日志文件都存放在应用程序同一子目录下?
---从文件格式属性来看,首先日志文件是以文本方式存储还是以二进制格式存储?再者,文件的内容是以何种格式记录,每条访问记录间如何分隔,是以回车换行作为分隔还是以其他字符作为分隔?都没有描述。
---从文件内容属性来分析,除了存放上述描述的内容外,是否还可以保存其他内容,如果不能保存其他内容的话,需求描述中应该加上一句”日志文件中只能存储访问记录信息,不得储存其他记录信息“。
---从文件大小属性来分析,日志文件的大小有没有限制?如果某天处于访问高峰期,访问特别多,是否需要将日志文件分拆成多个是一个需要考虑的问题。
---从文件权限属性来分析,日志文件是否机器上的所有用户都可以访问还是只有特定的用户可以访问?文件是否需要设置权限是一个需要考虑的问题。
所以在对上述需求描述进行分析后,你会发现需求描述中有很多的问题没有描述清楚。也许有人会有疑问,如果将所有上面说到的问题都描述出来的话会 不会工作量太大了?仅从需求分析的角度来讲,需求规格描述得较细的话确实会增大很多工作量,但从整个开发过程来看,需求描述完整的话,后续阶段的开发产生 歧义和遗漏的可能性就很小,实际上后续阶段节约的时间会大大超过需求所多花的时间。
测试人员在需求阶段应做哪些工作
1)首先,测试用例和测试工作本身是不断完善的,在开发过程的初期,可以认为是需求阶段,或者没有规范需求工作的设计阶段。如果有一个比较明确的需求文档,可以在这个阶段检查完了需求文档以后开始设计测试用例。这里,对于需求文档的检查主要是两个方面:
---检查需求文档描述的正确性,测试人员要对于真实的系统所涉及的业务非常熟悉,比如一个简单的财务软件,那么测试人员本身就要对会计工作熟 悉,财务制度熟悉,在检查需求文档的时候不要迷信所谓的”都是用户真实的需求“,这里存在两个问题,一是用户是否真的能正确地描述自己的需求,二是需求人 员是否真的能正确地理解需求。另外,还有一个用户的需求是否符合行业规范的问题,如果不符合,那么是否要确认--这里存在一个隐患,用户可能会在开发的后 期突然要求他们自己要走行业规范,让你的需求变动,所以要事先明确好。
---检查需求文档描述的准确性。主要是考虑文档中是否存在描述的模糊的地方,对于自己不清楚的问题一定要明确。这个时候是要保证需求的可测试性--我的意思是说保证需求是可以完全为测试工作服务的。
2)那么在检查完了需求之后,就可以开始设计测试用例了,在这个阶段因为没有开始设计工作,所以对于测试用例的考虑不能仅仅从界面出发,而应该从业务角度出发,从实际业务出发来设计测试用例。
当然,这个阶段所设计的测试用例是不够完善的,只能涵盖某些内容,但是我认为这些用例不仅仅全部都是功能测试用例,而且在整个项目中都将有效。 。
3)不过,当缺少需求文档时,那就要发挥测试人员自己的能动性了,要主动的工作,而不是被动的等待。要自己尝试着去熟悉实际业务,要尽量通过自己所能想到的方法来开展工作。
已经有一年半的
功能测试经验,不满于现状,决定换个跑道,历经一个月的时间,申请辞职、
面试、正式辞职、上岗,一气合成,投了五百份简历,得到五个面试通知,最终两个offer二选一,通过此过程受益匪浅,下面从几个方面总结一下,为正在找
工作和打算换工作的朋友做个参考。
1、辞职
人各有志,好男儿志在四方,干的开心就干,没有发展前途就撤,当然要慎重决定,不要进入职场跳 蚤的恶性循环;一般正规的单位辞职都需要提前一个月申请,因为劳动法有相关规定;提前一个月申请辞职,不管领导批准与否,一个月后你就可以离职并且不用承 担任何法律责任,公司不得拖欠工资,并且在半个月内把你的相关保险转出,用人单位不能违背劳动者的意志强迫他上班;申请辞职后一个月内未经公司同意就走, 或者裸辞(说走咱就走型的),可能会承担法律责任或者一个月薪水的经济赔偿;具体规定参见劳动法;所以辞职的时间要把控好了。
我是从以下几点考虑的:首先,手头重要项目定版了,突然撤退落个撂挑子的名声不好,再说项目定版了多有成就感;其次,发了上个月工资再申请辞职,不排除公司会有各种下三滥的手段来拖欠你的血汗钱,一般公司都会压一段时间的工资,即便要扣钱也是在这几天上做文章了; 再者考虑找工作的时间,现在是否好找工作,辞职后歇上半年有点吃不消,一般三四月份是跳槽的高峰期,不过此时段大牛横行,竞争压力非常大,公司一般都招上 手就能干活的人,外包公司更甚,其他时段可能会招储备性人才,有时间培养你,所以有人说想跳槽就别等年终奖十月份就跳;除了以上三点有人可能还会考虑年假 是否休了(不休白不求,白休谁不休)或者年终奖是否发了,情况因人而异,自己掌控。
2、投简历
在你提出辞职申请到正式离职的一个月时间内(因涉及到具体交接内容或者其他情况,此时间各有不同),是投简历的最好时机;对于软件行业,个人觉得跑招聘 会为下策,劳民伤财没有效果,网上投简历才是王道;北京比较火的招聘网就是“智联招聘”和“前程无忧”了,此处需要严重强调:千万别吊死在“智联招聘” 上,由于智联的名气比较大,界面更友好等原因,所以很多人只知道在智联投简历,殊不知智联的一个岗位有大几百甚至几千人竞争,据我了解用人单位每下载一份 简历可能需要十块大洋之多(也有包年套餐等,此数据没有经过考证),所以单位需要筛选后查看,可想而知你的简历投出去之后一般都石沉大海了,除非你是那个 分子,枪林弹雨总有活下来的;而“前程无忧”的确是个不错的招聘网站,职位不比智联少,但是竞争压力貌似没有智联大,笔者好几个面试通知都是通过“前程无 忧”获得的;
关于投简历怎么投这里要说一句,最好投跟自己能力相近或偏高的符合自己求职意向的,盲目投简历没什么效果,别抱着中五百万的心情去投简历;再者一定得多投,每天都有好多工作更新,有的朋友反映没有接到面试电话,一问只投了几十份简历,这个东西也是有概率的;还有一个途径就是软件测试论坛,常泡论坛的都知道论坛当中有关于招聘的版面,上边不乏有好的单位。
3、面试
面试似乎是求职过程中最重要的环节了,一旦接到用人单位的面试通知,那么恭喜你可以去面试了,公司从茫茫人海中选择你去面试不是没事闹着玩的,都是经过 一番筛选的,要认真对待每一次面试;给面试官的第一印象非常重要,如果你胡子拉碴头发半年没理,鼻毛外翘,那么面试定将草草结束,一句“回去等通知吧”把 你打发了,一屋不扫何以扫天下;精神饱满穿衣得体,在约定面试时间前一刻钟到达即可,出门之前计划好时间,尤其是天朝爱堵车,不要迟到也不要到的太早,太 早人家还没准备好呢,另外要把路线理清楚,邀请你面试地址都会写得很清楚,尽量不要打电话问路,连地址都找不到你还找什么bug呢?彬彬有礼,在没有允许 你坐下之前千万不要坐,别把自个不当外人;去之前对将要面试的岗位做出分析,猜测一下面试官会提出什么的问题,心里好有个底,一般会问对测试的看法领悟、 做过的项目、离职原因等等,回答问题的时候不要紧张,不必急于作答,想清楚以后条理清晰的说出一二三,注意谈吐,面试官不仅看你掌握的专业知识更会注意你 的逻辑表达能力;
我感觉会有一半以上的公司会安排笔试(笔试跟初次面试一起安排),笔试内容无非是测试理论、行业知识(比如银行的或许出关于银行的业务知识)、测试工具、c语言、sql等(一般会出好多软件评测师的题),注意笔试当中不会的题要记下来回去研究(用手机拍 下来),万一下家公司出了相同的题你还不会你都想抽自己,再说掌握点知识也没坏处;总体来说面试的决定性因素大于笔试; 再强调一次千万不要紧张,不要想着我真的很喜欢这家公司,我除了这家公司哪里都不想去,这无形当中增加了你的心里负担;要抱着菜场买菜的心理,这家不行去 下家,后边好工作多着呢,此处不留爷自有留爷处;话说回来,即便是你最初特别想去的公司,或许过几天你又不想去了,不要被自己的感觉骗了; 面试结束后一般两三天内就可以知道初试的结果了,如果两天内没有回信,打电话问一下也是可以的,好决定下一步的安排,每个公司的面试周期都不一样所以问一 下也没什么不妥;不过从面试聊天当中也能猜个七八成,比如谈的很投机、相见恨晚、面试官很着急担心你被别的公司录抢了,或者稍带不屑的告诉你回家等通知 吧,都给了你很多暗示。
4、复试
如果企业决定让你复试,说明你已经通过了技术 关,已经很有戏了,复试主要跟人事经理谈,谈的主要内容是公司的发展状况、企业理念、福利待遇、你的职业规划、理想等等,最主要的就是薪资的谈判,要价是 个技术活,我个人建议薪资不要要的太高也不要太低,高了有点好高骛远不切实际也不可能得到,低了对不起自己也没有跳槽的意义,要价就根据自己的学历、工作 经验、年限、行业的薪资情况来决定要多少;hr一般会跟你砍价,这个环节其实就跟商场买衣服一样,他觉得你要的价格小于或等于你的能力,这就成交了。
5、offer的抉择
如果你同时获得了两个以上的offer,那么恭喜你权利反转了(hr也有屌丝的时候),个人觉得offer的抉择从以下几个方面来打分最终决定去哪家,需要注意的是想好了再答复,反复就不好了。
看发展:有没有性能与自动化测试?大行业发展怎么样?测试体系是否完整,是否有学习空间?
看待遇:待遇是个硬道理,某个企业的待遇有绝对优势并且发展不错,那么基本就可以决定去这家了;不过你的水平在那里放着呢,hr的水平也都差不多,所以你值多少基本相差不大,总之待遇这块很重要。
看福利:企业的福利待遇取决于企业的性质,经营的状况等因素,好的公司保险公积金都是全额缴纳的,还有各种补助。
看地点:比如一个在开发区大兴,一个在三环,由个人喜好与住址决定。
看延续性:对比各个offer跟你做过的工作的延续性大不大,你是否还想在这个领域更进一步发展?业务是否跟你所学专业挂钩?
看爱好:俗话说爱好是最好的老师......此处略去78个字......
通过一个月歇斯底里的奔波,终于入职了,通过求职这个过程感觉有不小的提高,但是建议不要频繁跳槽,不利于沉淀而且光跟试用期较劲了;建议几个月更新一 次简历,不是为了找工作,是给自己立一个标杆,把自己的所学所得记录下来,步步为营督促自己不断学习;发现自己的缺点和竞争点,知道自己缺什么?补什么! 废话不多说了,好好工作才是正道!
3、安装完成后,系统会自动打开“Loadrunner License Information”窗口:
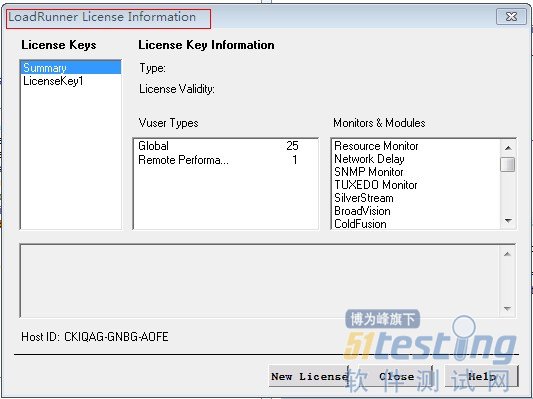
并提示你的“license”只有十天的使用期。

此时,可以启动Loadrunner了。
三、破解篇
1、下载破解文件,此处我们使用已经下载好的文件“lm70.dll”和“mlr5lprg.dll”。
2、将“lm70.dll”,“mlr5lprg.dll”这两个文件复制并粘贴到LR11安装目录下的bin文件 夹下,一般是C:\Program Files\Mercury\LoadRunner\bin。复制时注意要先将loadrunner关闭,否则会出现复制出错的提示。
3、复制后启动loadrunner,如下图选择“CONFUGURATION—>loadrunner license”。

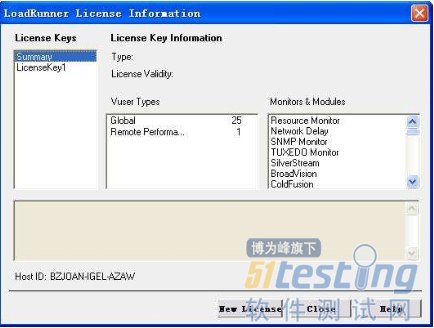
成功:
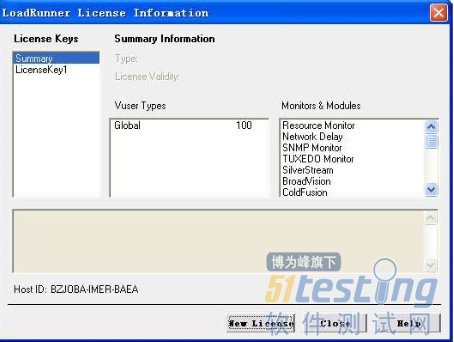
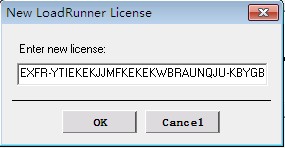
继续点击“New License”,输入web-10000的注册码:AEABEXFR-YTIEKEKJJMFKEKEKWBRAUNQJU-KBYGB。
再次成功。
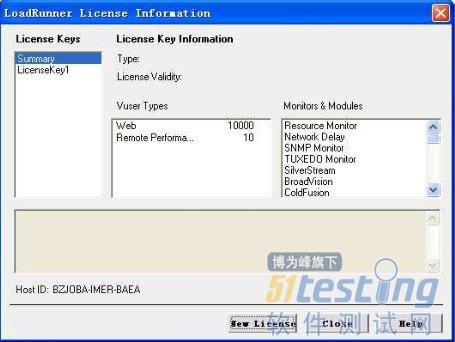
到此,安装,破解工作就全部完成了。