
想当年毕业设计就是测试驱动开发,所以从刚入行开始就对单元测试、测试驱动开发有比较深入的认识,刚开始一直作为敏捷开发的忠实粉丝。但是几年工作下来,我开始对单元测试持矛盾的态度:单元测试当然是一种很好的创举,但是具体使用当中,它却经常会产生副作用。这当然不是因为单元测试这一思想有问题,而是实践这一思想的人的问题。
当前很多公司使用单元测试的怪现象:
很多公司为了说出去好看——我们的开发遵循敏捷开发,拥有近100%的单元测试覆盖率,所以代码质量有非常可靠的保障。但是实际上,单元测试都是软件已经开发完成之后加上去的,而且经常还是由专门分配的几个人去写单元测试的,而这几个人根本不熟悉需求,甚至根本没有参与开发过程,或者参与得很少,而分配给他们写单元测试代码的时间当然也很紧张,因为这也是需要成本的。所以,最终导致的结果就是——为了达到覆盖率目标,为每个方法(不管有无必要)加上单元测试,简单看一下这个方法,然后从对这个方法的肤浅理解出发,即开始动手,写一个或很少的几个测试用例,这样单元测试覆盖率100%的要求就达到了,可是这样的单元测试有用吗?答案不言自明。
这种怪现象一般可能具备哪些特征呢?
1、整个开发过程完全之后写单元测试——这是单元测试的时机问题
2、由非开发过程的参与者写单元测试——这是单元测试的执行者的角色问题
3、由不了解需求的人员写单元测试——这也是单元测试的执行者的角色问题
那么,这种行为会带来哪些副作用呢?
1、这浪费了时间和人力成本
2、这会带来负面的情绪影响
这些人是带着抵触的厌烦的情绪投入工作的,因为明知这样的工作是无用功,仅仅是面子工程,却不得已而为之,自然没有兴趣没有热情,而这一情绪会横向和纵向地散发,从而给团队带来负面的影响。
3、这些单元测试代码毫无用处,甚至产生负作用
对于后来者来说,这种单元测试代码没有任何作用,因为写作者本就是在不了解需求的基础上仓促写就的,那么自然对后来者理解需求没有任何益处;而且如果后来者相信的这份单元测试代码,没有充分地调查具体的实现代码,还会因此产生误解。
单元测试到底要怎么写?何时写?
这是一个很值得探究的问题,但是有十足的必要。
在网上上看到“如何控制单元测试的粒度”这篇文章,文章是从StackOverflow上的一个问题开始引入的。
这个问题是:
TDD需要花时间写测试,而我们一般多少会写一些代码,而第一个测试是测试我的构造函数有没有把这个类的变量都设置对了,这会不会太过分了?那么,我们写单元测试的这个单元的粒度到底是什么样的?并且,是不是我们的测试测试得多了点?
问题的最佳答案是:
老板为我的代码付报酬,而不是测试,所以,我对此的价值观是——测试越少越好,少到你对你的代码质量达到了某种自信(我觉得这种的自信标准应该要高于业内的标准,当然,这种自信也可能是种自大)。如果我的编码生涯中不会犯这种典型的错误(如:在构造函数中设了个错误的值),那我就不会测试它。我倾向于去对那些有意义的错误做测试,所以,我对一些比较复杂的条件逻辑会异常地小心。当在一个团队中,我会非常小心的测试那些会让团队容易出错的代码。
看了这个最佳答案,给人感觉对单元测试持一定的否定态度和不感冒态度。但是知道这一最佳答案的回答者是谁吗?是Kent Beck。对,正是那位极限编程、测试驱动开发和单元测试以及JUnit的创造者Kent Beck。Kent Beck的答案,正好回答了单元测试该怎么写、要写到什么程度、何时应该写这几个问题。我的一些观点:
对于如何进行单元测试,有这么几个观点:
一、单元测试的时机很重要
无非两种:
一是在具体实现代码之前,这就是所谓的测试驱动开发;
二是与具体实现代码同步进行,正是大部分人采用的方式。
那种事后单元测试,基本是没用的。当然有一种例外:要对没有单元测试的既有代码进行维护和改造,这时候需要为既有代码追加单元测试,但是这也得建立在充分调查理解需求的基础上才能进行。
二、单元测试的执行者的角色
单元测试应当由具体实现代码的开发者进行,也就是说每个开发人员都应当同时对自己负责具体实现代码和单元测试代码负责。
这里也存在同第一条中的例外的情况。
三、单元测试应当突出重点
应当对那些重点部分重点关照,主要有:
1、逻辑复杂的
2、容易出错的
3、不易理解的,即使是自己过段时间也会遗忘的,看不懂自己的代码,单元测试代码有助于理解代码的功能和需求
4、后期需求变更可能性相对比较大的,这样后期需求更变修改代码之后就不用太担心写的代码对不对以及是否破坏既存代码逻辑了
四、单元测试也应注重质量,不要写无用的单元测试代码
写没有实际用处的单元测试不如不写,正如注释,写没有意义的注释也不如不写。
最后要说的是:
那种为了单元测试而单元测试的愚蠢行为应当立即停止。
那种只是想把单元测试作为一项面子工程的行为更应当停止(官场的种种坏习惯不应该在思想纯洁的程序员当中流行)。
那些对单元测试没有深入理解,只是希望今后能冠以“单元测试覆盖率100%”荣誉头衔的团队,应该立即停止这种想法。
单元测试不应当过于重视覆盖率,而应该在需要的时候写单元测试。何时写,怎么写,都需要建立在开发者已经对单元测试有深刻理解的基础上。
单元测试也是一把双刃剑,要用得好它才能发光发热,产生强大的正能量,请不要把它当作“龙泉宝剑”挂在自家的玄关辟邪。
如何能够提高自己的测试用例?我的一些经验,仅针对游戏测试人员。
测试用例一直是我早期测试过程中比较大的障碍,在写测试用例的时候,相信大家都知道,我们最怕的就是一些不容易想到的边界的遗漏,尤其对于新手或者缺乏游戏经验的人来说更是容易顾了这头忘了那头,如何能够保证自己写的测试用例尽可能的完善呢?我想就我的一些经验来抛砖引玉,与大家分享。
(1)游戏经验,刚接触测试工作的时候,我对网游(尤其MMORPG)其实一窍不通,在写用例的时候很难靠自己纯粹的想象来去覆盖到每一个边界,写的用例也是漏洞百出,有时候甚至连主流程也会遗漏,但是对MMORPG(由于产品的原因,当时选择了wow)有一定的了解后,写用例的效率明显提高很多,写的过程中自然而然会想到很多边界,因此我觉得很有必要去熟悉自己的产品,与此同时,可以选择一款市面上比较成功又与自己产品类似的游戏作为长期的体验。
(2)用例走读的总结(边界情况的总结),这个过程对于新手测试人员帮助其实非常大的,走读一次总结一次,每个人对问题的看法都存在差异,把一些通用的边界(自己经常遗漏的)汇总起来,以及一些通用的测试用例概括一下(例如对物品的测试、界面的通用测试等等),经常翻阅一下,接下来写用例的时候至少不会在这个边界出问题,当走读的次数多了,对游戏有一定的认识以后,会发现走读的过程中从用例中暴露出来的问题也会越来越少,只不过用例走读是一项挺耗时的工作,时间若是允许的话,走读用例还是非常有必要的。
(3)边测试边补充用例,这个过程我想大多数测试人员都是这样执行的,我也不做过多的补充,只是一些特殊情况下容易遗忘,比方说过了一两个月,策划更改了一些玩法,还是很有必要将这些用例补充进去的,在用例的备注中最好写上修改日期。还有一点就是对一些经常出BUG的边界多多留意,在我测试的很多系统中经常会遇见同一个问题:A玩家在转场景的过程中遇到的一些操作,从而引起BUG,比方说转场景过程中被踢出队伍,A玩家是否依然可以进一些只有组队状态下才能进的场景?转场景过程中其他玩家提交一个加全服BUFF的物品,A是否会加到?等等,诸如此类。
(4)业余多看一些其他同事写的优秀用例,尤其是一些自己经常测试的系统,学习别人是如何进行分块的,这样分块是否能够让整个用例看起来非常的清晰?个人感觉,分块分好了,用例也就成功一半了,基于每个小块的考虑边界怎么都比基于整体考虑边界来的明了。
欢迎大家补充~
从事API相关的工作很有挑战性,在高峰期保持系统的稳定及健壮性就是其中之一,这也是我们在Mailgun做很多压力测试的原因。
这么久以来,我们已经尝试了很多种方法,从简单的ApacheBench到复杂些的自定义测试套。但是本贴讲述的,是一种使用python进行“快速粗糙”却非常灵活的压力测试的方法。
使用python写HTTP客户端的时候,我们都很喜欢用 Requests library。这也是我们向我们的API用户们推荐的。Requests 很强大,但有一个缺点,它是一个模块化的每线程一个调用的东西,很难或者说不可能用它来快速的产生成千上万级别的请求。
Treq on Twisted简介
为解决这个问题我们引入了Treq(Github库)。Treq是一个HTTP客户端库,受Requests影响,但是它运行在Twisted上,具有Twisted典型的强大能力:处理网络I/O时它是异步且高度并发的方式。
Treq并不仅仅限于压力测试:它是写高并发HTTP客户端的好工具,比如网页抓取。Treq很优雅、易于使用且强大。这是一个例子:
>>> from treq import get
>>> def done(response):
... print response.code
... reactor.stop()
>>> get("http://www.github.com").addCallback(done)
>>> from twisted.internet import reactor
>>> reactor.run()
200 |
简单的测试脚本
如下是一个使用Treq的简单脚本,用最大可能量的请求来对单一URL进行轰炸。
#!/usr/bin/env python
from twisted.internet import epollreactor
epollreactor.install()
from twisted.internet import reactor, task
from twisted.web.client import HTTPConnectionPool
import treq
import random
from datetime import datetime
req_generated = 0
req_made = 0
req_done = 0
cooperator = task.Cooperator()
pool = HTTPConnectionPool(reactor)
def counter():
'''This function gets called once a second and prints the progress at one
second intervals.
'''
print("Requests: {} generated; {} made; {} done".format(
req_generated, req_made, req_done))
# reset the counters and reschedule ourselves
req_generated = req_made = req_done = 0
reactor.callLater(1, counter)
def body_received(body):
global req_done
req_done += 1
def request_done(response):
global req_made
deferred = treq.json_content(response)
req_made += 1
deferred.addCallback(body_received)
deferred.addErrback(lambda x: None) # ignore errors
return deferred
def request():
deferred = treq.post('http://api.host/v2/loadtest/messages',
auth=('api', 'api-key'),
data={'from': 'Loadtest <test@example.com>',
'to':'to@example.org',
'subject': "test"},
pool=pool)
deferred.addCallback(request_done)
return deferred
def requests_generator():
global req_generated
while True:
deferred = request()
req_generated += 1
# do not yield deferred here so cooperator won't pause until
# response is received
yield None
if __name__ == '__main__':
# make cooperator work on spawning requests
cooperator.cooperate(requests_generator())
# run the counter that will be reporting sending speed once a second
reactor.callLater(1, counter)
# run the reactor
reactor.run() |
输出结果:
2013-04-25 09:30 Requests: 327 generated; 153 sent; 153 received
2013-04-25 09:30 Requests: 306 generated; 156 sent; 156 received
2013-04-25 09:30 Requests: 318 generated; 184 sent; 154 received |
“Generated”类的数字代表被Twisted反应器准备好但是还没有发送的请求。这个脚本为了简洁性忽略了所有错误处理。为它添加超时状态的信息就留给读者作为一个练习。
这个脚本可以当做是一个起始点,你可以通过拓展改进它来自定义特定应用下的处理逻辑。建议你在改进的时候用 collections.Counter 来替代丑陋的全局变量。这个脚本运行在单线程上,想通过一台机器压榨出最大量的请求的话,你可以用类似 mulitprocessing 的技术手段。
愿你乐在压力测试!
本文出自:http://www.oschina.net/translate/stress-testing-http-with-twisted-python-and-treq
不管是什么程序开发都可能会出现各种各样的异常。可能是程序错误,也可能是业务逻辑错误。针对这个各个开发人员都有自己的处理方式,不同的风格增加了业务系统的复杂度和维护难度。所以定义好一个统一的异常处理框架还是需要的。我们开发框架采用java实现,java中的异常一般分为两种,检查异常和运行时异常。检查异常(checked exception)有可能是程序的业务异常,这种异常一般都是开发人员自定义的、知道什么时候会抛出什么异常并进行捕捉处理。也可以是系统的异常,不捕捉编译不会通过,如 IOException、SQLException、ClassNotFoundException , 这种是必须要捕捉的并且大多都是继承Exception。 运行时异常一般都是系统抛出来的异常,这种异常不捕捉处理也不会报编译错误,如NullPointerException,ClassCastException。运行异常都是继承至RuntimeException。不管是检查异常还是运行时异常都是继承至Exception。另外还有一种异常是系统错误Error,这种异常是系统出现了故障抛出来的不能捕捉,如OutOfMemoryError。Exception和Error都是继承至Throwable。
了解了java的异常体系后,我们设计一下web框架的异常处理格式。在以往EJB时代的J2ee系统,一般是标准的三层架构:web层、业务逻辑层、数据访问层,并且每一层都分别部署在不同的机器集群中。这样我们的异常一般分为三个,WebException、BizException、DAOException分别映射到web层、业务逻辑层、数据访问层。并且这些异常都要设计的串行化可以跨机器传递生成异常链。这样的好处是看到异常链知道从哪儿抛出来的错误,比较清晰明了。

随着后面spring的推出,java的开发越来越轻量级很多时候一台服务器可以同时部署三层并集群化,架构模式也慢慢由充血模式演变为贫血模式,再也没有了厚重的实体Bean和有状态会话Bean。针对现在轻量级的框架,异常结构如何设计呢?
先看看我们这个异常结构需要解决的问题是什么?
1、规范大家的异常处理方式。
2、简化异常处理。
3、区分业务异常和系统异常,业务异常需要业务逻辑支持,系统异常需要记录log。
4、友好的异常展示。
5、异常结构可扩展。
针对这些点,我的想法是开发可以使用三个类:SDKException、BizException、BizSystemException。SDKException是处理的基础类,可以在里面封装一些异常处理的基本函数。BizException是业务逻辑处理异常,一般这类异常是不需要记录log,只是展示给页面显示并提示给用户。如你的用户名、密码为空等错误。BizSystemException是业务系统异常,这类异常一般需要捕捉并记录log,比如数据库的主键冲突、sql语句错误等。按照三层架构的话,我们不可能对每一层都捕捉并且记录log,会造成重复log。可以从DAO层把捕捉到的数据库异常转换为BizSystemException抛出,如果有BizException也抛出。业务逻辑层对于BizSystemException、BizException不处理直接抛出。所有处理都在web层进行集中处理,如果是BizException,根据错误码和错误消息显示给用户对应的页面和错误消息。如果是BizSystemException告知用户系统错误,并把错误结果记入log。如果是其他异常和BizSystemException一致。这样就减少了异常处理的复杂度,开发也不用关心什么检查异常,运行时异常。

如果是ajax请求在做web层时,把返回的jsp变成json格式或者流格式输出即可,不影响异常框架。如采用struts2结构的代码:
public String testAjax()
{
try
{
genAjaxDataStr(0, "{}");
} catch (BizException e)
{
getRequest().setAttribute(this.ERRORMESSAGE, e.getErrorMessage());
return this.ERRORJSON;
} catch (BizSystemException e)
{
getRequest().setAttribute(this.ERRORMESSAGE, this.SYSTEMERROR);
return this.ERRORJSON;
} catch (Exception e)
{
this.errorTrace("test", e.getMessage(), e);
getRequest().setAttribute(this.ERRORMESSAGE, this.SYSTEMERROR);
return this.ERRORJSON;
}
return this.NONE;
} |
这样前台就能根据我们的异常显示对应的错误页面了,并能把系统知道的和未知的异常记入log。
针对struts2还有个问题,在开发模式时,struts2和webwork的异常打印在页面,我们可以根据页面输出进行调试。一但部署在生产环境,需要将这个模式关闭,log就没有了。
| <constant name="struts.devMode" value="false" /> |
为了记录一些未知的错误,需要做以下步骤:
1、将全局的异常映射页面从struts2的包定义里去掉。如果不去掉,在webwork不会抛出异常也就找不到出了什么问题。
2、扩展struts的DispatcherFilter捕捉未知的异常并记录入log。
<global-exception-mappings>
<exception-mapping exception="com.linktong.sdk.biz.exception.BizException"
result="checkedException" />
</global-exception-mappings> |
这样,基本的异常框架就搭建完成。更进一步需要做的是:
1、分布式全局错误码体系,保证所有机器都共用一套错误码。
2、分布式部署,异常传递。可以采用hessian序列化错误码的机制,不用传输整个异常链节省带宽。
3、集中logger服务处理,所有机器的log统一发送到集中服务器处理。logger框架和log4j也有服务器的机制。
针对web框架、分布式部署、log服务器再讨论:)
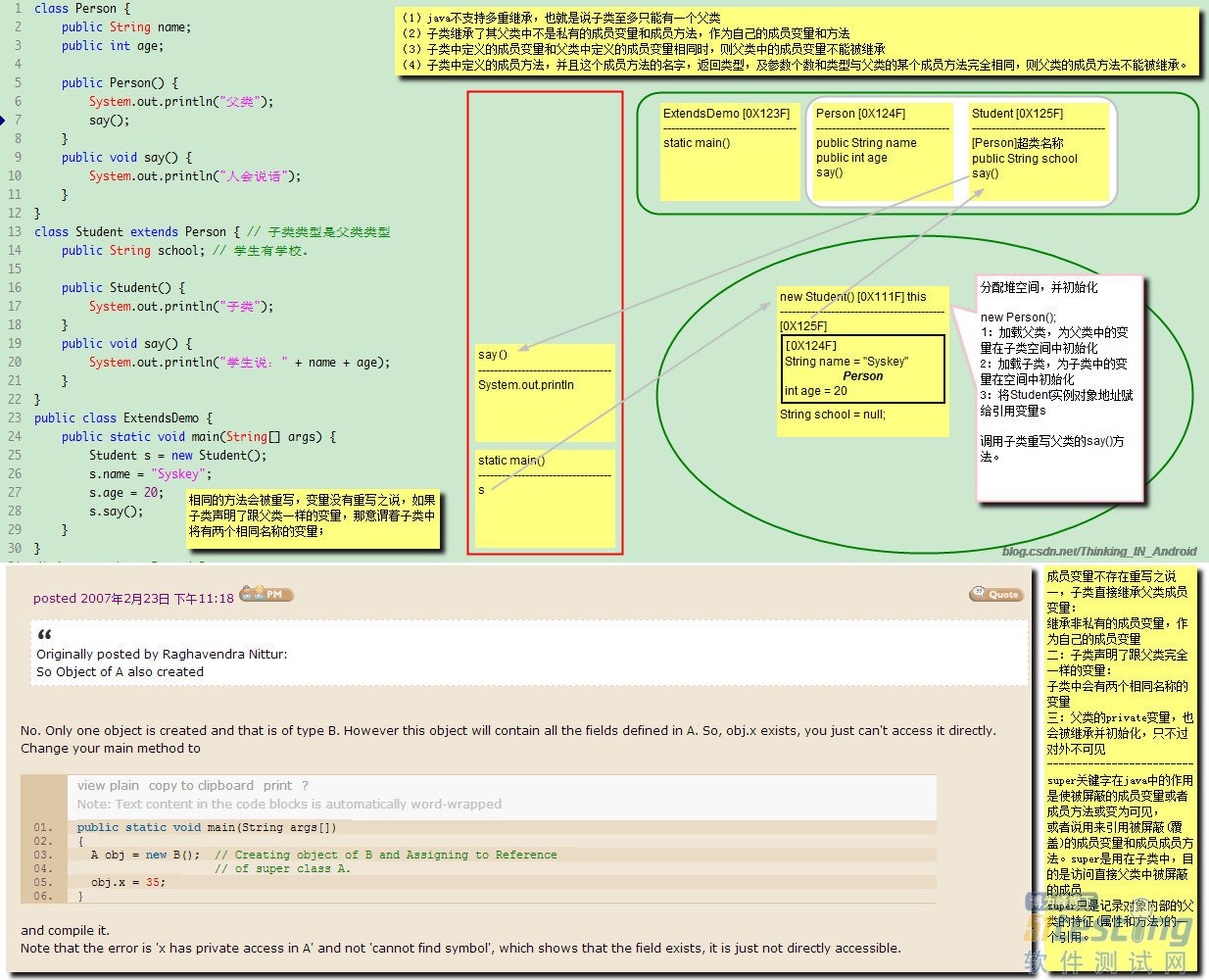
继承的基本概念:
(1)Java不支持多继承,也就是说子类至多只能有一个父类。
(2)子类继承了其父类中不是私有的成员变量和成员方法,作为自己的成员变量和方法。
(3)子类中定义的成员变量和父类中定义的成员变量相同时,则父类中的成员变量不能被继承。
(4)子类中定义的成员方法,并且这个方法的名字返回类型,以及参数个数和类型与父类的某个成员方法完全相同,则父类的成员方法不能被继承。
分析以上程序示例,主要疑惑点是“子类继承父类的成员变量,父类对象是否会实例化?私有成员变量是否会被继承?被继承的成员变量在哪里分配空间?”
1:虚拟机加载ExtendsDemo类,提取类型信息到方法区。
2:通过保存在方法区的字节码,虚拟机开始执行main方法,main方法入栈。
3:执行main方法的第一条指令,new Student(); 这句话就是给Student实例对象分配堆空间。因为Student继承Person父类,所以,虚拟机首先加载Person类到方法区,并在堆中为父类成员变量在子类空间中初始化。然后加载Student类到方法区,为Student类的成员变量分配空间并初始化默认值。将Student类的实例对象地址赋值给引用变量s。
4:接下来两条语句为成员变量赋值,由于name跟age是从父类继承而来,会被保存在子类父对象中(见图中堆中在子类实例对象中为父类成员变量分配了空间并保存了父类的引用,并没有实例化父类。),所以就根据引用变量s持有的引用找到堆中的对象(子类对象),然后给name跟age赋值。
4:调用say()方法,通过引用变量s持有的引用找到堆中的实例对象,通过实例对象持有的本类在方法区的引用,找到本类的类型信息,定位到say()方法。say()方法入栈。开始执行say()方法中的字节码。
5:say()方法执行完毕,say方法出栈,程序回到main方法,main方法执行完毕出栈,主线程消亡,虚拟机实例消亡,程序结束。
总结:相同的方法会被重写,变量没有重写之说,如果子类声明了跟父类一样的变量,那意味着子类将有两个相同名称的变量。一个存放在子类实例对象中,一个存放在父类子对象中。父类的private变量,也会被继承并且初始化在子类父对象中,只不过对外不可见。
super关键字在java中的作用是使被屏蔽的成员变量或者成员方法变为可见,或者说用来引用被屏蔽的成员变量或成员方法,super只是记录在对象内部的父类特征(属性和方法)的一个引用。啥叫被屏蔽的成员变量或成员方法?就是被子类重写了的方法和定义了跟父类相同的成员变量,由于不能被继承,所以就称作被屏蔽。
说到这里,上面提出的疑惑也就解开了。
本文转载自:http://blog.csdn.net/thinking_in_android/article/details/8874171
相关链接:
图解Java对象初始化过程以及方法调用
图解Java单例模式内存分配
(一)原理
只要用户定义的索引字段中包含了主键中的字段,那么这个字段就不会再被InnoDB自动加到索引中。但如果用户的索引字段中没有完全包含主键字段,InnoDB就会把剩下的主键字段加到索引末尾。
(二)例子
例子一:
CREATE TABLE t (
a char(32) not null primary key,
b char(32) not null,
KEY idx1 (a,b),
KEY idx2 (b,a)
) Engine=InnoDB; |
idx1和idx2两个索引内部大小完全一样,没有区别
例子二:
CREATE TABLE t (
a char(32) not null,
b char(32) not null,
c char(32) not null,
d char(32) not null,
PRIMARY KEY (a,b)
KEY idx1 (c,a),
KEY idx2 (d,b)
) Engine=InnoDB; |
这个表InnoDB会自动补全主键字典,idx1实际上内部存储为(c,a,b),idx2实际上内部存储为(d,b,a)
但是这个自动添加的字段、Server层是不知道的,所以 MySQL 优化器并不知道这个字段的存在。那么如果你有一个查询:
| SELECT * FROM t WHERE d=x1 AND b=x2 ORDER BY a; |
其实内部存储的idx2(d,b,a)可以让这个查询完全走索引。但是由于 Server 层不知道,所以最终MySQL优化器可能选择idx2(d,b)做过滤然后排序a字段或者直接用PK扫描避免排序。
而如果我们定义表结构的时候就定义为KEY idx2(d,b,a),那么MySQL就知道(d,b,a)三个字段索引中都有,并且InnoDB发现用户定义的索引中包含了所有的主键字段,也不会再添加了,并没有增加存储空间。
(三)建议
因此,由衷的建议所有的MySQL DBA建索引的时候都在业务要求的索引字段后面补上主键字段。这没有任何损失,但是可能给你带来意外的惊喜哦。
1.3 从专家到高手
小艾成为软件测试工程师加入项目团队已有一段时间,参加的几个开发项目给他带来了一些实践经验。时常倾听同事的经验介绍,让他有机会对自己所处的水平做出一个合理的判断。随着软件测试基本理论及实践经验的积累,小艾感觉自己跟刚加入时已经有明显的区别。这种区别体现在几个方面,包括对组织结构的认识、对工作内容和工作方法的理解、对测试相关的专业技能的掌握等。软件测试工程师是一个技术背景非常强的职位,因此,技术是这个职位的立足点。尽管没有详细实践过不同的测试,但小艾已经对测试的来龙去脉有了比较系统的了解,对于测试的关键点有了清楚的认识。应该说,小艾逐渐从测试菜鸟成长为一名测试专家。
对于在技术上进一步修炼的方向,小艾依然有自己的疑惑。究竟达到什么样的程度才算是脱离“菜鸟”头衔而成为一名专家呢?专家是否就意味着技术上已经达到了顶峰?优秀的测试工程师应该有哪些标准?
带着这些疑问,小艾又找到他的导师凯文。面对有着类似经历的新人,凯文一直都是知无不言,言无不尽的。这种分享的氛围,使软件开发实验室成为一个非常适合学习和交流的地方。
凯文的解释从区分新手、专家和高手三个级别谈起。
刚开始接触一个新的领域时,对这个领域一无所知或者知之甚少,对于这个领域,我们就是新手。正如之前已经提及的,术业有专攻,同一个人,在一个领域是新手,并不妨碍他在另一个领域是专家。作为测试工程师新手,要成长为专家,需要对测试的相关专业技能进行系统的学习和实践。在开发项目组里,测试团队本身就包括多个角色,对于每种角色,从技能水平上也有新手和专家的区分。新手到专家的学习曲线主要包括学习测试和开发方法、测试计划和测试设计、测试文档的编写、发现和解决问题的一般方法等。在从新手到专家的发展过程中,“准专家”可以在专家的指导下完成特定的测试任务,能发现和解决一些比较常见的问题。随着经验的积累,测试新手可以成长为测试专家。
软件测试的关键考量点是软件的质量,因此,对于软件工程师而言,经验积累是新手成长为专家的过程中不可缺少的环节。当测试新手对测试的相关技能都熟练掌握、经验积累也达到一定程度之后,新手就基本上成长为测试专家。测试专家对相关的测试技能和工具都已经熟练地掌握,能够以标准化的方式策划并完成测试任务。专家的“专业”,主要体现在他对软件质量的控制把握方面的专业。
而高手则是专家更进一步的发展方向。专家的特点表现在对流程的严格把握,通过一种控制力保证软件的质量;而高手则比这走得更远。有一些非常复杂的系统或复杂的应用场景,已经超出了正常流程的控制范围。在这种条件下依然要保证系统能够正常满足需求,于是对测试人员提出了更高的要求。高手的价值就在这种超越一般情形的条件下体现出来了。总体而言,高手对于发现问题、解决问题,有更多超出一般步骤的灵感和直觉,这种灵感和直觉是建立在对系统的深入理解及高手本身强大的洞察力基础上的。
如果说新手到专家的成长过程是一个学习“硬性技能”的过程,那么专家成长为高手则更在于“软性技能”的修为。软性技能的提高,归根结底是思考能力和分析能力的提高。新手可以随着经验积累和技能学习成长为专家,然而,经验的继续积累只是专家成长为高手的其中一部分。专家到高手的修炼,重点在于思考的方法和技巧。
1.3.1 像外行一样思考,像专家一样实践
如果抛开测试的具体技术和实现细节,只是关注测试的目的,那么测试的本质其实就是发现问题和解决问题的过程。在讲述问题分析的方法时,我们介绍过自顶向下和自底向上的方法。作为对一般性问题的分析方法,这两种方法都有助于问题的分析。但对于一些非常规性的问题,这种系统的方法却不一定奏效,可能效率并不高。这时,需要有非常规的方法来应对。
如果让完全没有经验的人员进行测试并发现问题(我们称这个人为外行),遇到问题时,这个人可能有两种应对情形,第一种情形是束手无策,不知发现问题和解决问题都该从何入手;第二种情形是,这个外行不受任何成规的约束,提出一些天马行空的想法。因为没有专业背景的限制,这些想法可能真的不着边际,甚至扰乱了问题本身的解决,然而,这些不着边际的想法有时却能带来令人意想不到的效果,或是从全新的角度发现了问题的本质,或是找到了不同的思路和方法。相对而言,一个普通的专家因为受到许多既有方式的限制,就不太可能得出这种天马行空的点子了。外行以一种随性的方式思考,这种方式往往会带来意外的效果,因为随性的思考方式不会被规则限制。
作为测试人员,在发现和解决问题时,外行的思考方式可以成为有效的切入点。好的切入点是一个不错的开始,然而,真正的实践还是必须以专家的严谨和慎重来验证想法是否正确。像专家一样实践--我们倡导的还是一种小心求证的态度。软件测试是一个非常严谨并且以事实说话的过程,任何假设都必须通过测试实践的检验。
对测试已经有深入了解的人,想做到像外行一样思考,并非易事。测试专家往往下意识地对一个方法的技术可行性做判断,这种下意识能够高效地排除许多不可行的方式方法。但在某些时候,这种下意识却阻碍了创造性灵感的萌生。很多有意义的想法会因为可行性的判断而被扼杀在摇篮之中。像外行一样思考--追求的是一种新的方法或者角度,仅仅考虑某个问题是否可能存在或者某种方法是否能解决问题,不考虑方法是否有理论依据,也避免过多地考虑可行性。
其实,可行性是基于以往的经验做判断,但是谁也不能认定,当前不可行的方法就永远不可行。认为科学已经进步到了终点的想法早已被证明是荒谬的。遇到棘手的问题时,测试高手能够跳出既有的条条框框,像一个外行一样重新审视系统的整体。当然,我们并不认为测试高手是个外行,因为这种“不受约束”的审视其实是建立在对系统的全面深入的理解基础上的,并不是一种纯粹的盲目。在这种大胆假设的前提下,即使是高手,也必须小心地求证假设是否正确。求证过程离不开反复的实验和验证。
面对复杂系统的问题,这种“大胆假设,小心求证”的方法往往能产生神奇的效用。以下是一个真实的例子,在对一个多节点的集群电子商务进行系统测试时,发现在高并发访问的条件下,从应用服务器到数据库的连接数骤然增加,并很快到达连接数的上限。数据库连接数一旦到达上限并且没有及时释放时,新的请求会因为无法获取连接而被阻塞,在表面上看,系统的性能会表现得非常糟糕。
面对这样的问题,一般的问题分析方法可能难以在短时间内找到原因。这时候需要在现有的条件下大胆假设可能有问题的地方。“现有的条件”指的是一些表面的系统运作数据,如应用服务器日志、数据库锁信息、数据连接池信息等。根据这些信息,发现有种特定的操作一旦出现,系统的数据库连接请求会急剧增加。通常情况下,因为存在系统级别的缓存,重复的访问一般不会给系统带来重新计算的负担。然而,问题的表现是,反复的访问似乎对系统产生了明显的性能影响。
这种情况下可以大胆假设系统的缓存设置可能有问题,虽然按照正常流程安装和配置的系统不可能存在缓存的问题。基于这个假设,接着要做的是检查所有和缓存相关的配置内容。检查发现,价格模块的对象缓存并没有设置,而这个设置正常情况下应该是激活的。如果没有价格的对象缓存,那么相同的价格对象都不会被缓存在内存中,而是每次获取的时候都重新计算生成。
在电子商务系统中,价格信息是使用非常频繁的一类信息,因为缺少对象缓存,实际应用就有可能出现不断地查找数据库计算价格的情形,这会导致数据库连接被大量占用。更改设置后重新测试,验证发现使用了价格的对象缓存,数据库的连接数不再出现被异常地大量占用的情况,问题得到解决。发现了对象缓存的设置错误,进一步追寻原因,发现原来是系统安装的过程中配置脚本运行出现了异常,从而导致缓存的创建步骤并没有被执行。如此一来,整个问题的来龙去脉就非常清晰了。解决问题以后,这种看似很复杂的问题,其原因也许很简单。解决这个性能问题的关键在于假设问题的原因是缓存的设置有问题;而验证恰好证实了假设的正确。如果仅仅使用一般的问题分析方法来寻找问题的原因,这种“意外”的问题往往是非常棘手的。
“像外行一样思考,像专家一样实践”的方法是一位著名的计算机学者谈及学术研究时提出的一种方法论。软件测试虽然和学术研究有着明显的差异,但是测试过程中需要发现和解决问题的时候,这种方法论很有借鉴意义。在软件测试中,对待问题同样需要开阔的视野和严谨的求证态度。我们认为,测试专家能够在测试中发现绝大部分的问题并能够使用合理的分析方法找到解决绝大部分缺陷的方案,而高手则能够更进一步,最棘手的问题也能够有效解决。
能否以这种收放自如的思维方式应对测试中遇到问题,是高手和专家的一个重要分野。在大部分情况下,这种分野是不明显的,因为最困难的问题只会占所有问题的很小一部分,而这种问题在测试中不会很容易地暴露。然而这种问题被发现了之后,高手和专家在造诣上的差别就会显现出来。
1.3.2 工欲善其事必先利其器
对于测试工程师而言,虽然发现和解决问题才是体现其价值的事情,然而测试工程师不得不花大部分时间执行测试。
从图1-4中可以发现,对于一个普通的测试工程师来说,执行测试消耗了很大一部分时间,而常规项目 的任务把可用时间的90%都占用了,剩余可以用于提高生产效率的资源变得非常紧缺。而提高生产效率从长远来说又能降低常规项目任务占用时间的比例。
在一个水平较高的开发团队中,设计和代码实现的水平通常是比较高的。在这种团队中,测试的注意力会更多地放在验证和问题解决方面。验证是通过执行测试的方式完成的,真正运行一个场景,查看系统的反馈是否和预期吻合。对于结构复杂的系统和对软件质量要求很高的软件,需要执行多种类型的测试验证各种场景,而每种测试都可能包括大量的测试用例。例如,在电子商务系统一个新版本的开发过程中,功能测试的用例可能多达成千上万,涵盖各种正常或异常的分支场景。对于如此大量的测试用例,执行的工作量之大可想而知。

如果测试工程师的绝大部分时间都被执行所占据,那么可以用来分析解决问题的时间就相对很有限了。开发水平提高不能减小测试的工作量,那么,测试工程师通过什么方法更有效地完成测试任务呢?答案是提高测试效率。对于同一个测试人员,效率的提高有两种外在的表现,第一种方式是使用相同时间完成更多的测试用例执行;第二种方式是对于同一个或同一组测试用例,耗费的时间减少了。
相对于测试新手对测试执行的生疏,测试专家以熟练的执行更快地完成测试任务。提高技能的熟练程度,能够提高效率。通常来说,执行一个测试,需要完成一系列操作步骤,首先需要安装测试环境、准备测试数据,如果是使用自动化操作的方式执行的测试,则需要准备测试脚本或代码;接着需要开启监控测试环境的工具,然后才能开始执行测试用例;执行完毕后,需要收集必要的数据和结果,确认测试是否通过。这一系列步骤的执行效率可以随着熟练的程度得到提高。
如果要通过提高熟练程度来提升测试的执行效率,提升的空间是有限的。对于测试高手而言,进一步提高效率,考虑的方向应该是减少对测试的人工干预,让测试自动完成。在工业化的测试条件下,自动化水平的高低,在很大程度上衡量了一个测试团队的水平。测试自动化指的是通过编写程序完成执行测试用例的所有或部分步骤。自动化的优势是减少人工的干预,把团队中最宝贵的资源--人释放出来;同时,由于自动化是使用程序的方式实现的,因此可以保证每次执行自动化测试程序的条件是一致的,避免了人为因素引起的不一致,影响某些缺陷的可重现性。测试自动化把许多烦琐的步骤交给程序来完成,测试的执行对人的依赖也得到减弱,从这个角度来说,自动化可以提高测试的质量。
自动化测试工具是测试工程师提高效率的利器。对于不同的测试方法,已经有一批针对性很强的自动化工具可供使用。针对基于Java的单元测试,JUnit是最常用的测试框架。通过对JUnit进行扩展,还可以实现单元测试调度和自动结果收集等功能。功能测试的测试目标是端对端(End-to-End)的用例场景,在测试基于浏览器的网络应用程序时,常用的自动测试工具有IBM Rational Functional Tester(RFT)、Selenium、JMeter等。对于胖客户端的应用程序功能测试,IBM Rational Functional Tester也可以提供不错的支持。系统测试的过程需要模拟更复杂的用例场景,如不同行为的虚拟用户并发地访问用户界面,这种测试用例通常来说只能使用自动化测试工具来执行。
有一类性能测试工具使用结构化代码来模拟并发的用户行为。自动化测试工具构造测试代码的一种常用方法是录制操作步骤。当人工对界面进行操作时,录制程序可以完整地记录整个操作过程,录制完成后,测试程序员再对录制的内容进行标准化修改,修改后的测试代码就能够满足标准的测试场景要求。具备这种功能的系统测试工具很多,如IBM Rational Performance Tester、Borland Silk Performer、Load Runner等。
对于要记录测试页面响应时间的性能测试用例,可以使用Firebug、IBM Page Detailer等工具。对于安装测试,系统安装的过程可以使用安装测试脚本来自动完成,测试脚本同时可以验证系统安装的每个步骤结果是否正确。类似地,构建测试也有自动化构建测试工具完成构建的流程。作为一个成熟的团队,为了适应产品的特点,在使用一款自动化测试工具前,往往还得对工具进行定制,使工具更符合特定的测试需求。在测试创新的章节,我们还会讲述关于自动化工具定制开发的内容。
然而,自动化也会给团队带来额外的负担。如果要追求全局的自动化,那么一个完善的自动化测试框架必不可少,但是搭建自动化框架本身就是一个规模不小的工程。软件开发和测试方式随着技术的革新不断变化,这种变化有可能导致原有的自动化框架不再适用。另外,即使有完善的自动化测试框架,测试人员依然得完成基于自动化框架开发的测试用例,测试完成后,也还要对这些自动化执行资源进行维护。如果自动化框架实现的是部分自动化,那么执行过程中有些步骤还是需要人的参与,并不能完全脱离人工干预。可以说,没有经过深思熟虑而仓促上马的自动化执行方案,也许不但不能提高执行效率,反而会增加测试团队的负担。
脱离人工干预的程序控制在执行效率上的优越性很明显,因此在允许的条件下,一个测试团队应该有逐步实现测试自动化的目标和路线图。在初期,可以仅仅使用有针对性的自动化测试工具辅助测试,而随着自动化测试经验的积累,可以基于这些工具开发集成化的自动化测试框架。在实现提高效率目的的同时,也降低了“过度自动化”的风险。
小艾所在的测试团队,正是沿着这种方式逐步完成了手工测试到自动化测试的转变。当然,由于许多测试有着明确的需求,手工测试和人工干预不可能被自动化完全取代;而不同的测试种类,使用的自动化策略也可能完全不一样。
提高效率的方式多种多样,提高熟练程度和测试自动化是比较常见的两种方式。除了完成测试任务,提高测试的效率和质量,同样是测试工程师的一个重要任务。测试高手区别于一般测试人员的关键在于测试高手更善于运用创新,在实践中不断提高。
1.3.3 从拿来主义到创新
小艾所在的电子商务系统,从技术和功能上而言,几年来的变化非常明显。早期的版本采用标准的Java EE技术,业务逻辑是通过命令模式实现的。随后,基于服务的架构开始流行,服务的灵活性的确有利于提高系统的适应能力,于是,系统的实现开始从基于命令转变为基于服务。系统的前端的早期实现主要是基于JSP的标准界面,而随着Web 2.0的兴起,许多新的前端元素逐渐被加入到前端界面中,如Ajax,Remote Widget等技术的使用,使系统的前端可扩展性和可操作性得到很大的提升。早期的电子商务系统实现的功能比较单一,而随着社交化应用的流行,越来越多的社交元素被集成到电子商务系统中,系统的复杂性进一步提高。除了新技术的引入,电子商务系统的核心--中间件的版本同时也在不断更新,在这个过程中,计算机的硬件配置的发展也相当迅速。一个系统似乎从来就没有最终版本。
电子商务领域仅仅是个缩影,整个信息技术领域都是快速发展的,变化之快可用日新月异来形容。一名技术专家,如果不能紧跟技术发展的步伐,那么最终的命运很可能是被技术所抛弃。新的技术常常是伴随着新的业务模式的流行而产生的,除了紧跟技术,有前瞻性的技术专家还应该洞察业务模式的发展。
新技术的出现也对测试提出了新的要求。因为实现的框架变了,测试模型必须做出相应的调整,在新的框架下完成测试需求。前台技术革新了,如果继续使用原来的技术,测试的结果可能不再准确,因此有必要引入新的前台测试技术。随着中间件、系统硬件的升级,测试的基线和指标也必须重新构建。业务在变化,技术在更新,测试技术同样需要创新。
创新不是空想,它是以对现有技术和业务的清晰理解为基础的。对于测试工程师而言,一开始往往需要学习和借鉴现有的经验,如测试的流程、使用的测试技术、分析问题的方法等。随着学习和实践的深入,在特定产品中,特定的需求会逐渐显现。因为是特定的需求,技术上很可能没有现成的解决方案,这种需求就会被作为创新的目标。有了明确的目标,就可以开始寻找新的解决办法,寻找的过程就是一个创新的过程。
刚才看到一则关于TDD的新闻,挺雷的......然后又想起以前跟别人解释关于为什么在Spring里需要先写个接口XXXInterface,然后再写实现类XXXInterfaceImpl的问题。写一点自己的想法,关于单元测试。
一个情景:
一个User类,提供一个静态方法:(这里不讨论框架或者异常控制流程的正确性)
public class User{ public static User login(String username,String password) throw LoginException{
//取得DAO
//查询是否存在用户,如果存在,返回User,否则抛出异常
}
//其他全略
} |
下面讨论如何对这个方法进行测试:
单纯对于这个模块进行单元测试:
public class UserTest{ public void testLogin(){
User user = User.login("aaa", "123456");
//对于user的正确性进行判定
}
} |
这样的测试,正确性和速度实际上都保证不了。因为login中引入了数据库的各种操作,各种未知的可能性都是存在的。比如说数据库并未配置正确或者数据库当前无法访问,直接会导致这个测试失败,但测试失败并不意味着User.login方法错了。同时,由于访问数据库造成的速度可能使这么一个简单的测试需要几百毫秒甚至几秒,那么大量的测试用例加在一起,如文中提到的花费个几十分钟是绝对可能的。
实际上这个简单的测试方案违背了单元测试的基本原则:单元测试应该测试独立的单元模块,这个单元不应依赖于其他模块。在这里显然这个Login的方法使用DAO中的一些方法。
下面讨论DAO:
public class UserDAO implements DAO<User>{
//各种方法的实现
} public class DAOFactory{
public DAO getDAO(Class pojoClass){
//获取各种DAO
} public static DAOFactory getInstance(){
//单例工厂
}
} |
一般来说DAO部分都跟上面的差不多(或许是直接注入进User的,但实际原理是一致的):一共两个步骤:1、获取DAO;2、使用DAO。为了不让User的测试受到DAO部分的干扰,就需要使用Mock技术,对DAO对象进行模拟,保证其各种方法的正确性。然后当User类需要获取DAO时,将MockUserDAO代替UserDAO交给它。
public class MockUserDAO implements DAO<User>{
//肯定准确的实现
} |
而DAOFactory由于是单例,其方法getInstance是静态的,所以最后只能靠修改原始代码来实现获得另一个工厂——也就是MockDAOFactory。如果在程序员和单元测试人员不是同一个人的时候,真的是非常麻烦的事情..... (从这个角度上将,我极力反对静态方法)虽说这种情形可以靠反射来进行伪造实例的活动,但是这种解决方案总是有一种黑客的感觉....
另外就是如果DAO不是接口,而只有实现(这并不是不可能的情况,在有通用DAO的前提下,完全可以达到),情况也会很麻烦。由于DAO不是接口,导致无法Mock这个DAO。也许可以使用MockDAO extends DAO的方案,但也许在DAO的构造方法中依旧有着连接数据库,初始化连接池,初始化日志等等的初始化过程,由于其在构造方法中,是无法覆盖掉的。在这种情况下,就只能通过重构来实现测试了。(这也就是即使只有一个实现,也要尽量写一个接口的原因)
单元测试是至关重要的,我个人认为,如果一个团队中的程序员头脑都不错,那么包括getter和setter都应该测试。单元测试的度基本上可以说是宁滥勿缺的。
挺杂乱的,不过只是随想,所以也无所谓。
原文链接:http://my.oschina.net/Jeky/blog/30354
一、引言
很久前接触linux驱动就知道主设备号找驱动,次设备号找设备。这句到底怎么理解呢,如何在驱动中实现呢,在介绍该实现之前先看下内核中主次设备号的管理:
二、Linux内核主次设备号的管理
Linux的设备管理是和文件系统紧密结合的,各种设备都以文件的形式存放在/dev目录下,称为设备文件。应用程序可以打开、关闭和读写这些设备文件,完成对设备的操作,就像操作普通的数据文件一样。为了管理这些设备,系统为设备编了号,每个设备号又分为主设备号和次设备号。主设备号用来区分不同种类的设备,而次设备号用来区分同一类型的多个设备。对于常用设备,Linux有约定俗成的编号,如终端类设备的主设备号是4。
设备号的内部表示
在内核中,dev_t 类型( 在 <linux/types.h>头文件有定义 ) 用来表示设备号,包括主设备号和次设备号两部分。对于 2.6.x内核,dev_t是个32位量,其中高12位用来表示主设备号,低20位用来表示次设备号。
在 linux/types.h 头文件里定义有
typedef __kernel_dev_t dev_t;
typedef __u32 __kernel_dev_t;
主设备号和次设备号的获取
为了写出可移植的驱动程序,不能假定主设备号和次设备号的位数。不同的机型中,主设备号和次设备号的位数可能是不同的。应该使用MAJOR宏得到主设备号,使用MINOR宏来得到次设备号。下面是两个宏的定义:(linux/kdev_t.h)
#define MINORBITS 20 /*次设备号*/
#define MINORMASK ((1U << MINORBITS) - 1) /*次设备号掩码*/
#define MAJOR(dev) ((unsigned int) ((dev) >> MINORBITS)) /*dev右移20位得到主设备号*/
#define MINOR(dev) ((unsigned int) ((dev) & MINORMASK)) /*与次设备掩码与,得到次设备号*/
MAJOR宏将dev_t向右移动20位,得到主设备号;MINOR宏将dev_t的高12位清零,得到次设备号。相反,可以将主设备号和次设备号转换为设备号类型(dev_t),使用宏MKDEV可以完成这个功能。
#define MKDEV(ma,mi) (((ma) << MINORBITS) | (mi))
MKDEV宏将主设备号(ma)左移20位,然后与次设备号(mi)相或,得到设备号
三、主设备号找驱动、次设备号找设备的内核实现
Linux内核允许多个驱动共享一个主设备号,但更多的设备都遵循一个驱动对一个主设备号的原则。
内核维护着一个以主设备号为key的全局哈希表,而哈希表中数据部分则为与该主设备号设备对应的驱动程序(只有一个次设备)的指针或者多个同类设备驱动程序组成的数组的指针(设备共享主设备号)。根据所编写的驱动程序,可以从内核那里得到一个直接指向设备驱动的指针,或者使用次设备号作为索引的数组来找到设备驱动程序。但无论哪种方式,内核自身几乎不知道次设备号的什么事情。如下图所示:
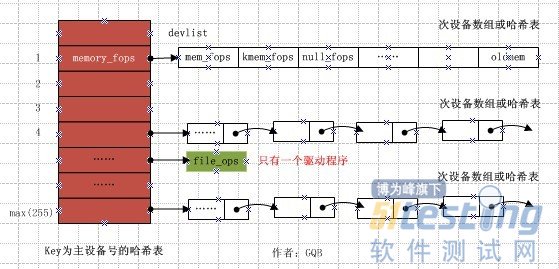
图1:应用程序调用open时通过主次设备号找到相应驱动
作为2011届毕业生,至今倒计还有23天就工作两周年了。时间过得真快,现在回忆,貌似就昨天的事情一样。
目前就职的公司是第二家公司,虽然自认为是稳定分子,但面试过的公司也可说不计其数吧。其实求职就是一个双向的选择,公司有挑选我们的权利,而我们也有挑选公司权利。其中有三家公司面试,让我记忆犹新。
公司A:
历经了笔试+三面,最终还是被淘汰。
笔试题大概有:测试理论,如,画出V型的软件测试模型图、数据库测试包括哪些内容等;数据库的SQL语句考查;网络方面的,如TCP/IP每层所对应的协议以及OSI七层模型所对应的协议内容是什么;编程方面,如用一种编程语言编写输出下面的三角形;性能测试方面,LR的测试流程是什么。当时笔试的题做得感觉也不是很理想。
PS:三角形如下:
1
333
55555
9999999
一面HR,二、三面技术:主要都是围绕简历的项目经验提问,上家公司刚好是电子商务的WEB网站测试,故被问及了:
问题一:对于订单的运费规则计算,有数量、重量、国家等三个因素,你是怎么设计测试场景(测试用例)的?
——当时真的有点词穷,因为上家公司可以说不需要我们写测试用例,没有一套比较规范的测试流程,我们能够保证功能流程不出问题就OK。支支吾吾地也不知道自己说了啥,后来面试官也给了点tips。
后来自个再总结了下:
考虑用因果图的方法进行设计场景,分析输入的各种组合情况,三个条件的话,有8种输入组合。
备注:采用因果图法设计测试用例的步骤:
第一,分析软件规则说明描述中,哪些是原因即输入条件或输入条件的等价类,哪些是结果即输出条件,并给出每个原因和结果赋予一个标识符。
第二,分析软件规格说明中的语义,找出原因与结果之间,原因与原因之间的对于关系,根据这些关系,画出因果图。
第三,由于语法或环境限制,有些原因与原因之间,原因与结果之间的组合情况不可能出现,为表明这些特殊情况,在因果图上用一些记号表明约束或者限制条件。
第四,把因果图转换为判定表。
第五,把判定表的每一列拿出来作为依据,设计测试用例。
问题二:开发人员对一个已经上线的网站系统进行了修改,然后给你两天的时间进行整体测试,你会怎么进行?
——当时回答得也有点糟糕,面完后,再次理的思路:
由于只有两天的时间,比较紧急,所以先了解主要修改了哪些地方,花一点时间整理下测试的思路,再开始进入测试。首先测试下网站系统的整体业务流程是否正常,然后再对网站系统进行模块划分测试,如模块A,模块B,模块C等等。
公司B:
没有笔试,直接技术面试,仍主要是围绕简历的内容进行提问,了解到的内容基本都符合面试官的要求,突然问了个关于:是否可接受出差到客户现场进行测试的问题,我当时迟疑了下,挤出一句“也可以考虑下”,话音刚落,面试官的态度瞬间转变,接下来你懂的,就没什么问题了,我被打道回府,当时心情有小小的失落。
公司C:
公司规模大,在IT行业也算享负盛名。所以当时接到面试通知时,就没抱多大希望,心态很平淡。
历经笔试+三面,在此感谢我的主管,同时感谢每一位让我成长的同事。
笔试题涉及的内容:
一、专业上:数据库、linux系统命令、程序题选择、设计测试用例等。
二、行测:个人职业规划、个人优缺点、爱好等。
面试提及的问题仍多数围绕上家公司的工作情况,现在整理下,貌似都与测试用例有关:
问题1、当需求不明确时,遇到的一些问题不知道是否是bug还是故意这样设计的,你会怎么处理?
——找开发或者提需求的相关人员进行确认。
问题2、你们是怎么设计测试用例的?
——根据需求文档和需求会议讨论的结果,明确测试内容和目的,确定测试用到的方法,最后再进行详细的测试用例设计;同时在设计测试用例的过程中,需考虑设计一些整体的业务流程的用例,或者一些关联模块,需要结合起来设计用例,就不能把他们独立出来设计。
问题3、在设计测试用例的过程中,需要注意哪些问题呢?
——第一,要分析功能模块,根据功能模块来设计测试用例,但要注意一些模块之间的关联关系,不能将他们独立出来设计测试用例,而要把他们的联系起来设计用例;第二,注意一些界面上隐含的功能,例如关系到后台的一些处理。譬如:设计登录模块的测试用例时,需要考虑到,如果我们到数据库里面删除了某个用户信息,那么用这个用户再次登录这个网站系统,是否还能够正常登录。第三点,设计一些正常操作的完整业务流程用例,例如整一个下单流程;第四,关注用户的特殊使用和异常情况,例如考虑网速慢,断网等各种情况。之前我们测试网站的时候就出现过这种情况:在买三送一活动中,由于网速比较慢,会导致用户在提交赠品ID时,如果连续两次快速点击提交按钮,最后会把两个赠品添加到购物车来。
问题4、你觉得测试完后,再补充测试用例有意义吗?
——我觉得有意义,因为补充的测试用例形成了文档,第一,可以方便我们进行回归测试;第二,当这个功能模块进行更新或者升级时,我们可以在原有的测试用例的基础上,进行补充,这样会减少很多的工作量;第三,可以作为一份维护文档,以后有一些新人来接触这个系统时,也可以通过用例,让他们对这个系统有一定的了解。
问题5、举一个比较有意义的测试用例。
——对于这个问题,我至今也觉得挺有难度,不知道是否是提的bug太多,所以很难说哪个是最有意义,对于每个可修复且被修复的bug,对于我们来说,都是有意义的。(PS:这个不是当时回答的内容哈~~)
问题6、测试报告包括哪些内容?
——(PS:当时就按照网上那些定义,作了回答;说句真心话,上家公司领导很少要我们出测试报告)
问题7、你们公司有哪些竞争对手?
——(PS:对于这个问题,还好,曾面试过某家公司,因为答不上来,所以课后做了功课,这次终被用上场了。)
PS:从上面三家公司的面试经历,我觉得求职,心态很重要。
1、不能浮躁,对待笔试要认真(求职测试,一般都有笔试,当你遇到一家没有笔试的公司,你也会觉得似乎有点不太正规,或是要求太低了,就像我第一家公司一样)。
2、要知己知彼,即使不保证百战百胜;对个人简历上写的内容要熟悉,避免自己写了啥,都忘记了,被面试官问及,还一头雾水的,这是求职中不可原谅的;要熟悉做过的项目;了解上家的一些基本情况及即将面试下家公司的基本情况。
3、测试技能再好,面试前,也别忘了复习下测试理论、数据库、linux系统、网络方面等知识,因为笔试题多数会涉及这方方面面的。
4、回答面试官问的非技术性问题,要有一定的技巧,让他相信你对贵公司是有兴趣的,并乐于接受工作安排的,即使自个心里有考虑的成分,但尽量不要表现出来,等有机会拿到offer再考虑,否则是他选择我们,而我们想选择的权利都没了。
5、只要坚持并保持一颗平常心,就没有不可能的事情。在考场上,有存在超常发挥与失常发挥的时候,而在职场上,也存在技术性+机遇性。机遇来了,就看我们能否抓住。
6、最后,求职过程,也要勤于总结哦,面这家不理想,我们还有那家,不灰心,保存良好的心态,积极的孩子,运气总不会太差。
原帖地址:http://bbs.51testing.com/thread-942720-1-1.html
版权声明:本文由会员 li_feibo 首发于51Testing软件测试论坛九周年庆活动。
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。