
顾名思义,慢查询日志中记录的是执行时间较长的 query
可以设一个阀值、将运行时间超过该值的所有SQL语句都记录到慢查询日志文件中
该阀值可以通过参数long_query_time来设置、默认是10秒
这里需要一点、对于运行时间正好等于long_query_time的情况、并不会被记录
因为、在源代码里是判断大于long_query_time、而非大于等于
mysql> show variables like 'log_slow_queries';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| log_slow_queries | ON |
+------------------+-------+
1 row in set (0.00 sec) mysql> show variables like 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec) |
另一个和慢查询日志相关的参数是log_queries_not_using_indexes
如果运行的SQL没有使用索引、则MySQL同样会将这条语句记录到慢查询日志文件
mysql> show variables like 'log_queries_not_using_indexes';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| log_queries_not_using_indexes | OFF |
+-------------------------------+-------+
1 row in set (0.00 sec) |
在这里、我没有开启、但有点需要提醒、如果在线修改该参数、虽然没有报错、但是不会生效
MySQL 还提供了专门用来分析满查询日志的工具程序 mysqldumpslow、用来帮助MySQL DBA解决可能存在的性能问题
例子、获得 TOP-5 SQL语句:
[mysql@localhost bin]$ ./mysqldumpslow -s al -n 5 /home/mysql/mysql/log/slow.log Reading mysql slow query log from /home/mysql/mysql/log/slow.log
Count: 1 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0), 0users@0hosts |
更多用法、请咨询 ./mysqldumpslow --help
从5.1.6版本开始,慢查询日志即可以是个文件,也可以保存在数据库中的指定表
参数log_output指定了慢查询输出的格式、默认为file、你也可以将它设为table
参数log_output是动态的、并且是全局的、我们能够在线进行变更
mysql> show variables like 'log_output';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_output | FILE |
+---------------+-------+
1 row in set (0.00 sec) mysql> set global log_output='TABLE';
Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'log_output';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_output | TABLE |
+---------------+-------+
1 row in set (0.00 sec) mysql> select sleep(15);
+-----------+
| sleep(15) |
+-----------+
| 0 |
+-----------+
1 row in set (15.02 sec) mysql> select * from mysql.slow_log\G;
*************************** 1. row ***************************
start_time: 2013-04-14 01:22:29
user_host: root[root] @ localhost []
query_time: 00:00:15
lock_time: 00:00:00
rows_sent: 1
rows_examined: 0
db: test
last_insert_id: 0
insert_id: 0
server_id: 1
sql_text: select sleep(15)
1 row in set (0.00 sec) |
在这个例子里、我设置了睡眠15秒、那么这句SQL就会被记录到slow_log表
需要注意的是,慢查询日志中有可能记录到与用户权限或密码相关的语句,因此慢查询日志文件的保存也要注意安全
关于即将要落实的测试环境搭建接手工作,自己作了一些比较简单的分析,画了一张Freemind思维导图,希望能在工作落实之前帮助自己从全局上去控制工作落实的一些边边角角,弄清楚自己该做什么,有针对性地去处理它,更加出色的完成这项工作。
思维导图如下:
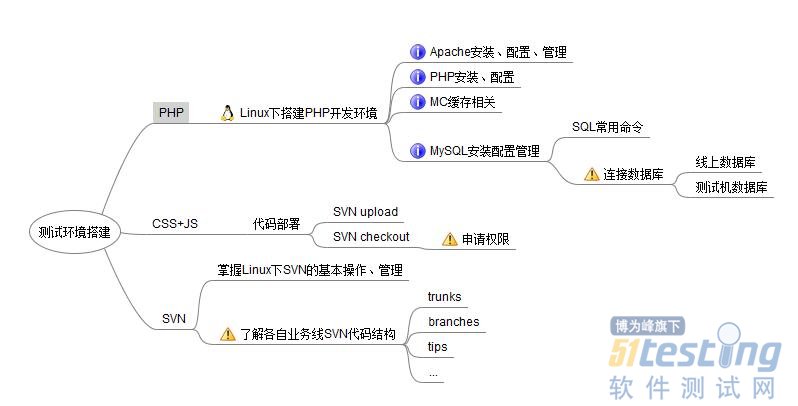
这张图是比较简单的,相信看起来不会太难理解。下面结合自己的理解,讲解一些这个“测试环境搭建”具体落实到了哪些点上,那些点就是我应该去了解、学习并掌握的地方。
总的来说,测试环境搭建包括了三个大的模块:PHP、CS、JS。
1、PHP测试环境的搭建
据我所了解,平台这边搭建PHP的机器安装的都是纯Linux操作系统,没有desktop。既然如此,无论搭建PHP环境,还是CSS或者JS环境也好,都是在Linux操作系统下进行的,因此掌握Linux的基本操作命令,熟悉Linux的文件目录结构对于本工作来说,算是一个比较基础性的工作。这个掌握不好,下面的工作应该举步维艰吧。
以前在自己的本本上搭建过PHP的开发环境,知道PHP的环境搭建比较麻烦,当然了,我是自己单独安装的各种软件,没有直接使用wamp,因为个人觉得单独安装配置虽然比较麻烦,但是亲身经历过的事情印象会更加深刻。写到这里,突然就想到了一个问题:平台开发人员部署PHP代码的机器是单独安装Apaceh+MySQL+PHP,还是使用的Xamp呢?
暂且以单独安装为标准来说明吧。
单独安装各软件,熟悉和掌握Apache、MySQL、PHP的安装、配置和管理也是很重要的。之前在跟建强学习JS测试环境搭建的过程中,就是因为自己不懂Apache的配置,没有完全搞清楚他们对服务器做了哪些修改,导致工作没有方向,调试一直出错。
在使用MySQL的使用,不可避免地会涉及到数据库方向的操作和管理,包括:基本的SQL命令,数据库的连接和管理,同时还要弄清楚连接的数据库是否为线上数据库。
在环境搭建的过程中可能还会涉及到MC缓存的一些相关配置管理,这个我暂时不是很确定,对MC也不够了解,这块暂时保留意见,等待确认。
2、CSS+JS测试环境的搭建
这两个的测试环境搭建起来就没有PHP那么复杂和繁琐了。
我总结了一些这两部分,认为在这两部分的工作中存在很多类似的工作,觉得可以合并,所以这两部分就放在一起说了。之前在学习环境搭建的过程中了解到,CSS部门使用的代码目录和JS使用的代码目录,他们的路径是一样的。
这两部分的工作其实比较的简单:首先,要弄清楚他们设置的Apache根目录,以及他们对Apache做出的其他配置更改;然后搞清楚他们代码部署到哪个文件下面;最后就是代码checkout和upload。
以上三部分的代码都部署好了之后就是联调的过程了。在WEB系统联调的过程中,Firebug是一个很重要的调试工具,它能够很清晰的反馈给你哪些JS文件没有加载进来,哪些CSS文件加载失败等等,因此学习和了解Firebug也是同样重要的。
通过上面的分析,可以知道哪些地方需要学习和掌握的,总结如下:
1)Linux基本操作命令,Linux文件目录结构
2)SVN的基本知识,Linux下SVN常用命令,各部门SVN的目录结构以及对应权限
3)Linux下Apache安装,配置和管理
4)Linux下PHP安装,配置和管理
5)Linux下MySQL安装,配置和管理
6)MC缓存学习
任务还是略重的,加油!
本文出自:http://my.oschina.net/itesting/blog/86350
最近做项目需要查看数据用户表的大小,包括记录条数和占用的磁盘空间数目。在网上找了很久其中查看MSSQL数据库每个表占用的空间大小相对还可以。
不过它的2、3中方法返回的数据比较多,有些是我们不关心的数据,我在AdventureWorks2012数据上做的测试。其中第二种方法代码如下:
View Code if not exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[tablespaceinfo]') and OBJECTPROPERTY(id, N'IsUserTable') = 1)
create table tablespaceinfo --创建结果存储表
(nameinfo varchar(50) ,
rowsinfo int , reserved varchar(20) ,
datainfo varchar(20) ,
index_size varchar(20) ,
unused varchar(20) ) delete from tablespaceinfo --清空数据表 declare @tablename varchar(255) --表名称 declare @cmdsql varchar(500) DECLARE Info_cursor CURSOR FOR
select o.name
from dbo.sysobjects o where OBJECTPROPERTY(o.id, N'IsTable') = 1
and o.name not like N'#%%' order by o.name OPEN Info_cursor FETCH NEXT FROM Info_cursor
INTO @tablename WHILE @@FETCH_STATUS = 0
BEGIN if exists (select * from dbo.sysobjects where id = object_id(@tablename) and OBJECTPROPERTY(id, N'IsUserTable') = 1)
execute sp_executesql
N'insert into tablespaceinfo exec sp_spaceused @tbname',
N'@tbnamevarchar(255)',
@tbname = @tablename FETCH NEXT FROM Info_cursor
INTO @tablename
END CLOSE Info_cursor
DEALLOCATE Info_cursor
GO
--itlearner注:显示数据库信息
sp_spaceused @updateusage = 'TRUE'
--itlearner注:显示表信息
select *
from tablespaceinfo
order by cast(left(ltrim(rtrim(reserved)) , len(ltrim(rtrim(reserved)))-2) as int) desc |
运行效果如图:
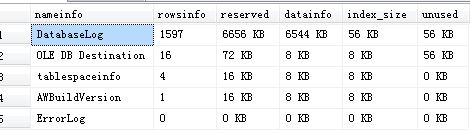
很显然这个返回结果是错误的。但是它提供了一种思路,修改后的SQL语句如下:
View Code IF NOT EXISTS ( SELECT *
FROM sys.tables
WHERE name = 'tablespaceinfo' )
BEGIN
CREATE TABLE tablespaceinfo --创建结果存储表
(
Table_Name VARCHAR(50) ,
Rows_Count INT ,
reserved INT ,
datainfo INT ,
index_size INT ,
unused INT
)
END
DELETE FROM tablespaceinfo
--清空数据表 CREATE TABLE #temp --创建结果存储表
(
nameinfo VARCHAR(50) ,
rowsinfo INT ,
reserved VARCHAR(20) ,
datainfo VARCHAR(20) ,
index_size VARCHAR(20) ,
unused VARCHAR(20)
)
DECLARE @tablename VARCHAR(255)
--表名称 DECLARE @cmdsql NVARCHAR(500) DECLARE Info_cursor CURSOR
FOR
SELECT '[' + TABLE_SCHEMA + '].[' + TABLE_NAME + ']' AS Table_Name
FROM [INFORMATION_SCHEMA].[TABLES]
WHERE TABLE_TYPE = 'BASE TABLE'
AND TABLE_NAME <> 'tablespaceinfo' OPEN Info_cursor FETCH NEXT FROM Info_cursor
INTO @tablename WHILE @@FETCH_STATUS = 0
BEGIN
SET @cmdsql = 'insert into #temp exec sp_spaceused ''' + @tablename
+ ''''
EXECUTE sp_executesql @cmdsql
FETCH NEXT FROM Info_cursor
INTO @tablename
END CLOSE Info_cursor
DEALLOCATE Info_cursor
GO
--itlearner注:显示数据库信息
--sp_spaceused @updateusage = 'TRUE'
--itlearner注:显示表信息
UPDATE #temp
SET reserved = REPLACE(reserved, 'KB', '') ,
datainfo = REPLACE(datainfo, 'KB', '') ,
index_size = REPLACE(index_size, 'KB', '') ,
unused = REPLACE(unused, 'KB', '') INSERT INTO dbo.tablespaceinfo
SELECT nameinfo ,
CAST(rowsinfo AS INT) ,
CAST(reserved AS INT) ,
CAST(datainfo AS INT) ,
CAST(index_size AS INT) ,
CAST(unused AS INT)
FROM #temp
DROP TABLE #temp
SELECT Table_Name ,
Rows_Count ,
CASE WHEN reserved > 1024
THEN CAST(reserved / 1024 AS VARCHAR(10)) + 'Mb'
ELSE CAST(reserved AS VARCHAR(10)) + 'KB'
END AS Data_And_Index_Reserved ,
CASE WHEN datainfo > 1024
THEN CAST(datainfo / 1024 AS VARCHAR(10)) + 'Mb'
ELSE CAST(datainfo AS VARCHAR(10)) + 'KB'
END AS Used ,
CASE WHEN Index_size > 1024
THEN CAST(index_size / 1024 AS VARCHAR(10)) + 'Mb'
ELSE CAST(index_size AS VARCHAR(10)) + 'KB'
END AS index_size ,
CASE WHEN unused > 1024 THEN CAST(unused / 1024 AS VARCHAR(10)) + 'Mb'
ELSE CAST(unused AS VARCHAR(10)) + 'KB'
END AS unused
FROM dbo.tablespaceinfo
ORDER BY reserved DESC
|
运行结果如图:

同时他的第三种方法返回的数据太多,很多是我们不怎么关心的,原SQL语句如下:
View Code SELECT OBJECT_NAME(id) tablename ,
* reserved / 1024 reserved ,
RTRIM(8 * dpages / 1024) + 'Mb' used ,
* ( reserved - dpages ) / 1024 unused ,
* dpages / 1024 - rows / 1024 * minlen / 1024 free ,
rows
FROM sysindexes
WHERE indid = 1
ORDER BY reserved DESC |
运行结果如图:

这里面包含一些索引信息,其实我们只关心表占用磁盘信息,修改后的SQL语句如下:
View Code SELECT OBJECT_NAME(id) tablename ,
CASE WHEN reserved * 8 > 1024 THEN RTRIM(8 * reserved / 1024) + 'MB'
ELSE RTRIM(reserved * 8) + 'KB'
END DataReserve ,
CASE WHEN dpages * 8 > 1024 THEN RTRIM(8 * dpages / 1024) + 'MB'
ELSE RTRIM(dpages * 8) + 'KB'
END Used ,
CASE WHEN 8 * ( reserved - dpages ) > 1024
THEN RTRIM(8 * ( reserved - dpages ) / 1024) + 'MB'
ELSE RTRIM(8 * ( reserved - dpages )) + 'KB'
END unused ,
CASE WHEN ( 8 * dpages / 1024 - rows / 1024 * minlen / 1024 ) > 1024
THEN RTRIM(( 8 * dpages / 1024 - rows / 1024 * minlen / 1024 )
/ 1024) + 'MB'
ELSE RTRIM(( 8 * dpages / 1024 - rows / 1024 * minlen / 1024 ))
+ 'KB'
END FREE ,
rows AS Rows_Count
FROM sys.sysindexes
WHERE indid = 1
AND status = 2066 -- status='18'
ORDER BY reserved DESC |
运行结果如下:

有不对的地方欢迎大家拍砖!
看了zjeagle的回复很好,于是把他的回复贴在下面:
exec sp_MSForEachTable
@precommand=N' create table ##(id int identity,表名 sysname,字段数 int,记录数 int,保留空间 Nvarchar(10),使用空间 varchar(10),索引使用空间 varchar(10),未用空间 varchar(10))',
@command1=N'insert ##(表名,记录数,保留空间,使用空间,索引使用空间,未用空间) exec sp_spaceused ''?'' update ## set 字段数=(select count(*) from syscolumns where id=object_id(''?'')) where id=scope_identity()',
@postcommand=N'
select * from ## order by convert(INT,replace(保留空间,"KB","")) desc drop table ##' |
最近工作中发现有些测试人员经常因为任务杂乱,在版本测试周期快结束的时候才发现有些重要的任务没做完,发现测试人员对自己任务的完成度掌控的不是很好,特别是新手,容易出现丢三落四的情况,为了避免这种事情发生,摸索出来一套出入口自检条件,让执行人员自己跟踪自己的任务。
在版本测试过程中,使用出入口条件来度量测试过程,可以更加清晰明了的跟踪到每个人员的任务完成情况,提高管理效率。
出入口条件用表格的形式放在测试人员的日报中。
以下为举例:
| 自检项 | 状态 | 详细 |
入口条件 | 已经把本轮需要用的测试环境都准备好 | 否 | 开发人员**正在使用iXIA环境做强化测试,预计明天释放 |
| 已经阅读过详细的测试策略 | 是 |
|
| 已经分配到测试用例 | 是 |
|
| 已经核对过测试用例和测试策略 | 是 | **测试场景用例分错了,和策略不符,已经只会测试经理修改完成 |
| 已经拿到测试软件的正确版本 | 否 | 开发因上轮强化性能问题正在做最后修改,测试经理知会明天转测 |
|
|
|
|
出口条件 | 已经把发现的问题全部确认完毕 | 否 | 闭路开关无法初始化的问题因开发人员请假,明早过来第一时间找他确认 |
| 已经把专项测试做完并且把数据归档 | 是 | 已经归档到SVN的 \测试\过程数据\2.0\专项测试\ 路径下 |
| 已经清理好测试环境
| 是 |
|
| 已经把本轮无法执行的用例上报 | 是 | 已经只会测试经理,都已经修改完毕 |
| 已经把测试用例全部执行完成 | 是 |
|
从以上表格中我们可以很详细的看到每轮测试例行流程的执行情况,测试经理可以很明了的掌握测试执行进度,执行人员也可以跟踪到自己的每个任务完成情况,一举多得。
版权声明:本文出自 oydeqq 的51Testing软件测试博客:http://www.51testing.com/?240017
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
你已经努力开发你的 Web 应用,也许这没有什么伟大的,但它是众多维持我们每日生活的方法中的一员,并且,或许它会改变世界。
无论怎样,你知道它需要做一些测试,而且不止一次。测试工作应该贯穿于软件开发过程的每一个阶段,乃至软件发布之后。认识到测试者的工作永远不会停止有点让人头疼,令人欣慰的是每一轮测试和矫正都会提高软件质量。
应用故障有两个原因:开发人员没有做负载测试,或者更糟糕的是,他们花了时间来做负载测试,但是没有做好充分的准备。没有充足的预备工作,负载测试不可能发现它应该发现的所有问题。
那么,怎么才能准备一次最佳的负载测试呢?
好吧,这里给出一些建议,一旦你准备开始负载测试,我们也给你提供了一个易用的高级测试工具来进行它——当然,它是可以免费下载的。
1、什么是你真正需要了解的?
确定你想了解你的应用或系统的哪些方面。每种类型的测试的运行方式都不同,且着眼于应用的不同方面。因此,基于不同的需求,你需要运行不同的测试。例如:
● 如果希望找到你的应用程序在很少或根本没有负载情况下的执行基准,你将运行单用户测试。
● 如果想确定系统在正常负载下的执行情况,你将运行负载测试。
● 如果想确定你的应用程序停止响应或响应缓慢导致不能正常工作的临界点,你需要运行负载测试。
● 如果想了解你的应用程序是否有内存泄露问题,你要运行耐力测试。
2、确定用户数量
如果要加载测试,你会模拟多少虚拟用户呢?要回答这个问题,你要估计大概多少并发用户可能访问你的网站,这取决于一天中的时间。很多测试者只是猜测,相反,你需要跟你的设计师和营销人员谈谈并看看性能说明。你甚至可能要问他们设计的应用程序支持多少并发用户,然后设计这么多用户及比这更多用户的测试。
● 注意:你还要安排当实际用户减少或消除时的测试。
3、研究你的分析
不要假装知道客户如何用你的应用程序。真正了解用户的唯一途径是研究历史(如分析)。通过研究你的分析,你可以创建实际上代表用户的测试--而不是你认为的代表用户的测试。在这方面,分析是测试人员最好的朋友!
4、组建你的团队
你需要许多人参与到测试中来:开发人员,网络工程师,数据库管理员,企业主-举例来说。所有这些人都有着特定的权利来使应用变完美,每个人将从不同的角度定位问题。正确的解决方案将不会直接从众多中的一个里直接获得,而将从两个或多个综合得出。确保团队中的每个成员都是对测试有用的:
● 确保他们在特定领域的专业程度
● 提供稳定的反馈
● 产生对应用质量和性能的归属感
5、准备你的浏览器
使用测试软件使你尽可能地接近你的真实用户的体验。你应该能够在你选择的浏览器中记录你的测试场景,但你也需要预估你的用户将会使用的其它浏览器。考虑你的产品使用率高的国家和地区,调查那里使用率最高的浏览器。你将安装这些浏览器在你开始测试时。然后你需要确保你的负载测试软件尽可能真实地模拟用户的行为。这包括:
● 多线程处理
● 思考时间
● 混合并发场景
● 复杂场景
● 参数化
● 从多个代理进程产生负载(网络/云)
6、准备测试你的应用
虽然在分阶段环境中测试你的应用很有价值,由于很多原因,它也会在你的测试中留下一些漏洞。
● 分阶段环境并不总是产品的真正副本
● 分阶段环境只能从内部防火墙访问
● 可能有一些针对你正在收集信息的相同系统的测试
7、预留时间分析结果
你应该准备花些时间以组为单位分析测试结果(记得在测试过程中存在的所有的那些人吗?)。要仔细看结果,确保真正理解瓶颈、错误、弱点且有有效的补救措施,确保涉及每个人并安排足够的时间。
8、预留时间修改
在计划表中也要留一定的时间去实现那些确定需要修改的测试!从时间方面考虑,不同的补救成本也不一样。在时间和金钱方面,像实现缓存策略、重构代码、数据库优化以及硬件升级等这样的补救措施需要更大的实现成本。举个例子,添加额外的硬件需要花时间下订单、收货、测试硬件、安装软件和数据、测试、加到网络中并做更多测试。这可能花费数周或几个月。
9、计划一个敏捷测试方法
一旦纠正,又是再次测试的时候了。俗话说得好,测试是一个过程,而不是目的。每次发现并纠正一个瓶颈,另一个问题又出现了。所以计划一个敏捷测试方法是很重要的,从而可以使性能测试贯穿开发周期的每一步。附加测试应按以下执行:
● 代码何时被修改或更新
● 新硬件何时被引入
● 修改何时被添加到应用服务器或 DB 服务器
● 流量峰值预计在何时
深呼吸一下,然后放松!你已经完成了绝大部分艰苦的工作。现在你已花时间作了准备,对你的应用作负载测试将有助于你持续改进你的产品和业务。
原文链接:http://www.oschina.net/translate/9-tips-to-prepare-your-app-for-optimal-load-testing
自从加入37Signals公司以来,我一直在努力改善企业的监控基础设施。我们的主要监控方案采用的是Nagios,它与老款沃尔沃倒有几分神似——也许外观不够漂亮、也许速度不够惊人,但它易于使用、而且绝不会让人束手无策。
下面聊几句背景信息。2009年1月时,我们拥有350项Nagios服务。而到了2010年9月,我们所使用的服务数量上升至797项,目前则已经达到7566项之巨。在数字迅猛增长的同时,我们还大幅降低了故障警报的出现频率,现在几乎很少会有管理员会被大半夜拉起来处理紧急情况。当然,整个过程也出现过一些波折,但这一切都是为了实现更好的监控效果。在本文中,我希望与大家分享一些在使用Nagios过程中总结出的实用提示,进而帮助各位在扩展及改进监控系统时获得一些引导。
与37signals公司中的大多数方案一样,我们的Nagios环境也由Chef平台牢牢掌控。当新的主机配置完成后,它们会被自动添加到监控系统当中。一年多之前,我们只能以自动化方式监控主机上的少数事务:磁盘使用率、负载以及内存等。
扩大监控范围
为了扭转局面,我们做的第一件事就是安装Check_MK。Check_MK是一款Nagios插件,能够自动清查主机、收集性能数据,并且提供了一套更友善的UI。在Check_MK的帮助下,我们现在能够以自动化方式在每台主机上监控20项指标;由Postfix队列发往开放TCP连接的所有信息都能受到监控。Check_MK还提供了一套非常实用的后端,即mk_livestatus,允许我们向Nagios查询实时主机、服务信息以及即将发送的处理指令。举例来说,我们利用Livestatus来训练Campfire机器人接收警报并设定停机时间。通过Tally,现在我们几乎可以通过Campfire完成全部Nagios交互工作。
我们还逐步在Nagios中添加了大量针对特定应用程序的监控方案——我们利用statsd追踪响应时间、错误代码及其它各种有助于衡量应用程序性能的指标,此外MySQL、Redis以及Memcached统计数字也被纳入了进来。要想在客户发现问题前将其消灭在萌芽阶段,这些监控手段是必不可少的。额外检查项目的加入使我们对系统运行状态有了更为直观的了解,但凡事有利就有弊:由于监控方案的大幅加强,我们安装并运行Nagios的主机在性能方面承受着很大压力。
存在的问题
对于中小型使用环境而言,Nagios的开箱即用效果非常突出;但我们很快发现了一些局限性,而这给我们带来不小的麻烦。首先,由于Nagios常常拿不出足够的资源执行检查工作,因此在设定检查与执行检查之间往往存在45秒的延迟。为了降低这种延迟,我们对安装配置做出了大量调整,其中一项效果明显,直接将平均延迟时间压缩至0.3秒以内。遗憾的是由此带来的主机负载也同样明显——Nagios在给定时段中的检查活动数量受到影响,延迟检查出于资源节约考虑而被自动忽略掉了。在放开这一性能瓶颈后,我们的负载强度由5%上升到30%左右(我们的主监控服务器采用两块至强E5530处理器)。
最后,我决定在负载失控之前进行检查数量缩减。经过实践,我们发现缩减使用频率最高的check_mk代理检查对于负载的影响微乎其微,但将其它几项活动检查的执行频繁降低一半则大大减轻了主机负载——由30%下降至10%以下。由此我们可以看出,主动服务才是节约性能的最大敌人,必须不惜一切代价予以消除。
Nagios服务上手指南
● 主动服务是指那些由可执行shell脚本所定义、能够由Nagios直接执行的检查项目。这项服务需要进行时间间隔设定,进入调度程序后会根据进程启用情况自动执行。Nagios必须进行shell释放、执行检查脚本、等待结果、分析结果、将结果添加到命令缓冲区然后处理结果等一系列工作,且在整个检查过程中该线程会保持运行并不能用于任何其它工作。
● 被动服务是指那些由Nagios(例如check_mk代理检查)或其它机制所触发、但不会被Nagios服务器主动启用的检查项目。在存在被动检查结果时,外部进程会直接将结果添加至命令缓冲区中,并由Nagios将其作为主动检查结果进行处理。Nagios并不会对此类检查进行调度或者利用资源加以执行,因此这些检查所占用的资源也少得多。
我们的大多数主动服务都会向内部仪表板应用发送HTTP请求,旨在获取前文提到过的应用及数据库指标。由于Nagios主动检查指标的方案会占用过多硬件资源,我们决定定期通过网页接口推送来自Statsd的更新信息(这一机制由Slanger库实现)。要做到这一点,我们在Chef上创建一个配置文件,其中包含我们所需要的指标、相关阈值以及简洁的后台订阅描述。这样检查结果数据就会定期被发送至Livestatus处,并被添加到命令缓冲区中进行处理。我们还将这些来自仪表板的推送检查与其它脚本检查加以整合。
结果汇总
与我们的预期一致,将服务转为被动属性大大降低了Nagios的CPU使用率,具体情况如下图所示:
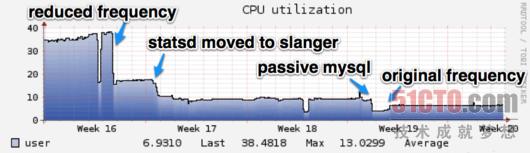
总而言之,我们将主动服务的数量由1900降低到745。幸存下来的检查项目大多必须采取主动状态——例如ping检查、Check_MK代理以及应用程序HTTP检查等。因为只有这样我们才能在项目出现问题时及时得到警告。
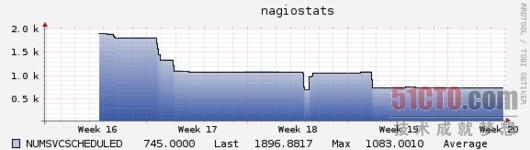
从某种程度来说,这只是种负载转移过程——某些负载被转嫁到其它主机当中,并通过检查脚本或者后台推送程序将结果传递给Nagios。不过这种收益还是相当显著且顺理成章的(将负载分摊到服务器闲置资源中),我们还通过对检查脚本的重新编写改装最系统全局执行效率、消除了成千上万HTTP请求所带来的资源占用。更重要的是,我们在恢复原有检查间隔的同时还添加了一些新的监控项目,并且始终将负载控制在3%、延迟控制在0.5秒以下。
希望我在打理监控基础设施方面的经验能帮助大家找到实际问题的解决办法。过去那种“添加其它可执行脚本”的方式实在太过狭隘,其实我们完全能以其它方式更好地搞定难题。从某种意义上说,即使各位的监控系统并没有出问题,这篇文章也能在进一步提升性能表现方面有所借鉴。

Java性能问题被冠以某种黑暗魔法的称谓。一部分是因为其平台的复杂性,在很多情况下,无法定位其性能问题根源。然而,在以前对于 Java性能的技巧,有一种趋向:认为其由人们的智慧,经验构成,而不是应用统计和实证推理。在这篇文章中,我希望去验证一些最荒谬的技术神话。
1、Java运行慢
在所有最过时的Java性能谬论当中,这可能是最明显的言论。
是的,在90年代和20年代初期,Java确实有点慢。
然而,在那之后,我们有超过10年的时间来改进虚拟机和JIT技术,现在Java整个体系的性能已经快的令人惊讶。
在6个单独的web性能测试基准中,Java框架占据了24个当中的22个前四的位置。
JVM性能分析组件的使用不仅优化了通用的代码路径,而且在优化那些严重领域也很有成效。JIT编译代码的速度在大多数情况下跟C++一样快了。
尽管这样,关于Java运行慢的言论还是存在,估计是由于历史原因造成的偏见,这个偏见来自当时那些使用Java早期版本的人们。
我们建议,在匆忙下结论之前先保留意见和评估一下最新的性能结果。
2、单行java代码意味着任何事都是孤立的
考虑以下一小段代码:
MyObject obj = new MyObject();
对一个Java开发者而言,很明显能看出这行代码需要分配一个对象和运行一个对应的构造方法。
从这来看,我们可以开始推出性能边界。我们知道有一些精确数量的工作必须继续,因此基于我们的推测,我们可以计算出性能影响。
这儿有个认知偏见,那就是根据以往的经验,任何工作都需要被做。
实际上,javac和JIT编译器都可以优化无效代码。就拿JIT编译器来说,代码甚至可以基于数据分析而被优化掉,在这种情况下,该行代码将不会被运行,因此它就不会有什么性能方面的影响。
而且,在一些Java虚拟机(JVM)中,例如JRockit中,即使代码路径没有完全失效,JIT编译器为了避免分配对象甚至可以执行分解对象操作。
这段文字在这里的意义就是当处理Java性能方面的问题时,上下文很重要。而且过早的优化可能会产生意料之外的结果。所以为了获得最好的结果,不要试图过早的优化。与其不断构建你的代码不如用性能调整技术去定位并且改正代码性能的潜在危险区。
3、一个微基准测试意味着你认为它是什么
正如以上看到的,推理一小段程序比分析应用程序的整体性能更不准确。尽管如此,开发者还是喜欢写为基准测试。有些人似乎从摆弄平台的某些低层次方面获取无穷无尽的内心快感。
理查德·费曼曾说:“第一个原则是,不要欺骗自己,而且自己是最容易被骗的人”。没有比编写Java为基准测试更切合这个的例子了。
写好微基准测试是极其困难的。Java平台很复杂,而且很多微基准测试只对测量瞬态效应或平台的其他意外方面有效。
例如,一个想当然的微基准测试频繁地在测量子系统时间或垃圾回收,而不是在试图捕捉效果时结束。
只有当开发者和团队有真正基准需求的时候才需要写微基准测试。这些基准测试应该打包到项目(包括源代码)随项目一起发布,并且这些基准测试应该是可重现的并可提供给他人审阅和进一步的审查。
Java平台的许多优化结果都指的是只运行单一基准测试用例时所得到的统计结果。一个单独的基准测试必须要多次运行才能得到一个比较趋近于真实答案的结果。
如果你认为到了必须要写微基准测试的时候,首先请读一下Georges, Buytaert, Eeckhout所著的”Statistically Rigorous Java Performance Evaluation”。如果没有统计学的知识,你会很容易误入歧途的。
网上有很多好的工具和社区来帮助你进行基准测试,例如Google的Caliper。如果你不得不写基准测试时,不要埋头苦干,你需要从他人那里汲取意见和经验。
4、算法慢是性能问题的最普遍原因
在程序员(和普通大众)中普遍存在一个错误观点就是他们总是理所当然地认为自己所负责的那部分系统才是最重要的。
就Java性能这个问题来说,Java开发者认为算法的质量是性能问题的主要原因。开发者会考虑如何编码,因此他们本性上就会潜意识地去考虑算法。
实际上,当处理现实中的性能问题时,算法设计占用了解决基本问题不到10%的时间。
相反,相对于算法,垃圾回收,数据库访问和配置错误会更可能造成程序缓慢。
大多数应用程序处理相对少量的数据,因此即使主算法有缺陷也不会导致严重的性能问题。因此,我们得承认算法对于性能问题来说是次要的;因为算法带来的低效相对于其他部分造成的影响来说是相对较小的,大多的性能问题来自于应用程序栈的其他部分。
因此我们的最佳建议就是依靠经验和产品数据来找到引起性能问题的真正原因。要动手采集数据而不是凭空猜测。
5、缓存能解决一切问题
“关于计算机科学的每一个问题都可以通过附加另外一个层面间接的方式被解决”
这句程序员的格言,来至于David Wheeler(幸亏有因特网,至少有另外两位计算机科学家),是惊人的相似,特别是在web开发者中。
通常出现这种谬论是因为当面对一个现有的,理解不够透彻的架构时出现的分析瘫痪。
与其处理一个令人生畏的现存系统,开发者经常会选择躲避它通过添加一个缓存并且抱着最大的希望。当然,这个方法仅仅使整个架构变的更复杂,并且对试图理解产品架构现状的下一位开发者而言是一件很糟糕的事情。
夸大的说,不规则架构每次被写入一行和一个子系统。然而,在许多情况下,更简单的重构架构会有更好的性能,而且它们几乎也更易于被理解。
因此当你评估是不是需要缓存时,计划去收集基本用法统计(缺失率,命中率等)去证明实际上缓存层是个附加值。
6、所有应用都要考虑到STW
(译注:“stop-the-world” 机制简称STW,即,在执行垃圾收集算法时,Java应用程序的其他所有除了垃圾收集帮助器线程之外的线程都被挂起)
Java平台的一个存在事实是,所有应用线程必须周期性的停止以便让垃圾搜集器GC运行。这有时被夸大为严重的弱点,即使是在缺少真实证据的情况下。
实证研究已经说明,人类通常无法察觉到频率超过每200毫秒一次的数字数据的变化(例如价格变动)。
因此对以人类作为首要用户的应用,一条有用的经验就是200毫秒或低于200毫秒的 Stop-The-World (STW)停顿通常无需考虑。有些应用(例如视频流)需要比这个更低的GC波动,但是很多GUI应用不是的。
有少数应用(比如低延迟交易,或者机械控制系统)对200毫秒停顿是不可接受的。除非你的应用属于那个少数,否则你的用户察觉到任何由垃圾回收带来的影响是不太可能的。
值得注意的是,在具有比物理内核更多应用线程的系统中,操作系统任务计划将会干涉对CPU的时间分片访问。Stop-The-World听起来吓人,但实际上,每个应用(无论是不是JVM)都必须处理对稀缺计算资源的内容访问。
如果不做测量,JVM的方法对应用性能带来的额外影响具有何等意义将无法看清。
总体来说,判断停顿的次数实际对应用的影响是通过打开GC日志的办法。分析此日志(或者手工,或者用脚本或工具)来确定停顿的次数。然后再判定这些是否确实给你的应用域带来问题。最重要的是,问自己一个最尖锐的问题:有用户确实抱怨了吗?
7、手工处理的对象池对很大范围内的应用都是合适的
对Stop-The-World停顿的坏感觉引起一个常见的应对,即在java堆的范围内,为应用程序组发明它们自己的内存管理技术。经常这会归结为实现一个对象池(或甚至是全面引用计数)的方法,并且需要让任何使用了领域对象的代码参与进来。
这种技术几乎总是被误导。它通常具有自身久远以前的根源,那时对象定位代价昂贵,突然的变化被认为是不重要的。但现在的世界已经非常不同。
现代的硬件具有难以想象的定位效率;近来桌面或服务器硬件的内存容量至少达到了2到3GB。这是一个很大的数字;除了专业的使用情形,让实际的应用充满那么大的容量不是很容易。
对象池一般很难正确的实现(特别是有多个线程在工作的时候),并且有几个消极的要求使得把它作为一般场景使用成为一个艰难选择:
● 所有接触到代码的开发者都必须清楚对象池并正确的处理它
● “对池清醒”代码与“对池不清醒”代码之间的界限必须要通晓并明文规定
● 所有这些附加的复杂性必须保持最新,并定期评估
● 如果这里任何地方失败了,无声损坏的风险(类似C中的指针重用)将被再次引入
总之,只有在GC停顿不能被接受,而且在调试与重构过程中聪明的尝试也不能缩减停顿到可接受水平的时候,对象池才可以使用。
8、在GC中CMS总是比Parallel Old更好
Oracle JDK默认使用一个并行的,全部停止(stop-the-world STW)垃圾收集器来收集老年代的垃圾。
另外一个选择是并发标记清除(CMS)收集器。这个收集器允许程序线程在大部分的GC周期中仍然继续工作,但它需要付出一些代价和带来一些警告。
允许程序线程和GC线程一起运行不可避免地导致对象表的变异同时又影响到对象的活跃性。这不得不在发生后进行清楚,所以CMS实际上有两个STW阶段(通常非常短)。
这会带来一些后果:
1)所有程序线程不得不放进一个安全点并且在每次完全收集时停止两次;
2)在收集并发运行地同时,程序吞吐量会减少(通常是50%)
3)在JVM从事通过CMS来收集垃圾的总体数据上(包括CPU周期)比并行收集更加高的。
依据程序的情况这些成本或者是值得的或者又不是。但并没有免费的午餐。CMS收集器是一个卓越的工程品,但它不是万能药。
所以在介绍前,CMS是你正确的GC策略,你得首先考虑Parallel Old的STW是不可接收的和不能调和的。最后,(我不能足够地强调),确定所有的指标都从相当的生产系统上得到。
9、增加堆内存会解决你内存溢出的问题
当一个应用程序崩溃,GC中止运行时,许多应用组会通过增加堆内存来解决问题。在许多情况下,这可以很快解决问题,并争取时间来考虑出一个更深的解决方案。然而,在没有真正理解性能产生的根源时,这种解决策略实际上会使情况更糟糕。
试想一下,一个编码很烂的应用构造了非常多的领域对象(生命周期大概维持2,3秒)。如果内存分配率足够高,垃圾回收就会很快地执行,并把这些领域对象放到年老代。一旦进入了老年代,对象就会立即死去,但直到下一次完全回收才会被垃圾回收器回收。
如果这个应用增加其堆内存,那么我们能做的是增加空间,为了存放那些相对短期存在,然后消逝的领域对象。这会使得 Stop-The-World 的时间更长,对应用毫无益处。
在改变堆内存和或其他参数之前,理解一下对象的动态分配和生命周期是很有必要的。没做调查就行动,只会使事情更糟。在这里,垃圾回收器的老年分布信息是非常重要的。
总结
当说道Java性能调优时直觉通常会误导人。我们需要经验数据和工具来帮助我们具象化和了解平台的特性。
垃圾收集也许提供了这方面最好的例子。GC子系统对于调优和生产数据指导调整有惊人的潜力,但对于生产程序它是很难去不借助工具来让产生的数据有意义。
运行任何Java进程,默认都应该最少有这些标记:
-verbose:gc(打印GC日志)
-Xloggc:(更全面的GC日志)
-XX:+PringGCDetail(更详细的输出)
-XX:+PrintTenuringDistribution(显示由JVM设定的保有阈值)
然后使用工具来分析日志——手写脚本和一些生成图,或一个可视化工具如(开源的)GCViewer或JClarity Censum。
自己给公司同事写的一点入门小知识,希望对新同行有些帮助。
上次性能测试培训后,不少同事反馈性能测试的一些基本概念还是难以理解,所以我在这里把那些看起来比较虚无缥缈的概念实例化生活化一下,一来仅供大家参考,二来当做自己的一个简单总结。
● 什么是性能测试?
性能测试可以用资本家模型来描述。资本家自然是希望工人们多干活少拿工资,同样性能测试也是要求系统多干活少损耗。又要马儿跑得快又想马儿少吃草。
不少前辈总结过,性能测试是在时间和空间上寻找最佳结合点。马儿跑得快是指时间,不吃草是指空间。性能测试则是寻找时间和空间之间的一个平衡点。
上述为最朴素和广义的性能测试。
● 性能测试的观点
性能测试有如下几个观点可以进行关注:
用户的观点:用户的观点很简单,系统快而稳定!所以如果从用户观点进行性能测试的话,那么性能测试的最终效果表现为提高用户体验。大部分门户网站的性能测试就是从用户的观点来编写测试用例和脚本的。
系统的观点:系统观点也不难。在已有得性能硬件软件条件下,进行系统测试从而获取系统的短板,短板可能是硬件瓶颈,也可能是软件的缺陷。系统观点的最终测试效果表现为优化系统软硬件,消除系统的显式瓶颈。
开发的观点:开发的观点与系统观点差不多,但是开发观点对软件关注得更为投入。以开发观点进行性能测试,则性能测试的介入时间会比以上两种观点都要来得早。比如系统数据库设计完毕之后,就可以立即利用性能测试来测试数据库设计上的瓶颈,而不像上述两种测试观点一样,必须系统功能测试稳定之后方可进行。
综上所述,从用户的观点去进行性能测试是满足用户需求的最好手段;而从系统角度去进行性能测试则可以确定系统的性能指标。而从开发的观点去进行性能测试则对开发过程很有帮助,也会降低后续出现性能瓶颈的风险。
● 性能测试的几种常见方法
负载测试:负载测试是用户观点的测试行为。简单说来就是负载测试就是让系统在一定得负载压力下进行正常的工作,观察系统的表现能否满足用户的需求。
用户的需求从何而来?需求分析——特指性能测试的需求分析。由此看来需求分析是相当重要的。
负载测试是站在用户的角度去观察在一定条件下软件系统的性能表现。
负载测试的预期结果是用户的性能需求得到满足。此指标一般体现为响应时间、交易容量、并发容量、资源使用率等。
负载测试也是最常用的性能测试方法,因此也有不少人将负载测试混淆为性能测试。
压力测试:压力测试的关键字就是“极端”。通过对系统的极端加压,从而观察系统的所表现出来性能问题。再对此性能问题进行分析,从而达到系统优化的目的。所以压力测试就是一定要让系统出问题,如果系统没有出问题,那么压力测试的手段和方法就肯定存在问题。
并发测试:验证系统的并发能力。通过一定的并发量观察系统在该并发量的情况下所表现出来的行为特征,确定系统是否满足设计的并发需要。并发测试是系统观点的测试行为。
基准测试:顾名思义,基准测试要有一个基准点,也就是说供比较基点。当软件系统中增加一个新的模块的时候,需要做基准测试,以判断新模块对整个软件系统的性能影响。按照基准测试的方法,需要打开/关闭新模块至少各做一次测试。关闭模块之前的系统各个性能指标记下来作为基准(Benchmark),然后与打开模块状态下的系统性能指标作比较,以判断模块对系统性能的影响。
稳定性测试:很简单,长时间进行负载测试,从而观察系统的稳定性。
可恢复性测试:测试系统能否快速地从错误状态中恢复到正常状态。比如,在一个配有负载均衡的系统中,主机承受了压力无法正常工作后,备份机是否能够快速地接管负载。可恢复测试通常结合压力测试一起来做。
好吧,如果以上概念仍然过于“神乎其技”让人如同满文**过生日一般如坠云里雾里,下面我将会以打比方的方式让大家更好的理解上述内容。
《西游记》中有一场景叫做:“猪八戒背媳妇”,下面我们就以这个来打比方向大家描述几种性能测试方法的异同点。
我们将猪八戒同志作为性能测试的被测试对象。
负载测试:猪同志身上背着的高小姐可以被视为加在“猪八戒人猪混合系统”上的负载。当然了,猪八戒身强体壮,背个高小姐应该是问题不大的。负载测试就是让猪八戒背着高小姐走路(这里的走路就是一定得系统行为,通常这种系统行为通过脚本来进行模拟),我们观察猪八戒的生理和心理指标是否存在异常从而断定“猪八戒人猪混合系统”的瓶颈所在。如果猪八戒背着背着腰酸背疼腿抽筋,那么猪无能同志可能是缺钙了,需要补钙;如果他背着背着头晕眼花四肢麻木,那么猪同志应该是脂肪肝、酒精肝三高患者的杰出代表,这就证明猪八戒需要减肥了。如果猪八戒背着小媳妇身轻如燕、健步如飞,那么我们可以判断猪八戒同志是个好同志,“猪八戒人猪混合系统”是个好系统。当然,这只是在没有测试标准的衡量基础上得到的结论,为了更进一步的测试“猪八戒人猪混合系统”,我们需要给这个系统一些指标,这个指标举例如下:背着体重为45公斤的高小姐走上一段山路十八弯总长为10公里的羊肠小道,在此过程中猪八戒同志的平均时速不能低于8km/h,其心跳不能快于60次/秒。好吧,再进行一次测试,我们发现在测试过程中猪八戒同志依然健步如飞,身轻如燕,但是其心跳却高于60次/秒。于是在猪八戒同志心跳高于60次/秒的那一刻,我们可以停止测试,帮猪八戒同志找出瓶颈,待此瓶颈问题被解决后,我们再对其进行测试。当然,如果猪八戒一背上高小姐就显得异常吃力,举步维艰,那么我们可以认为高小姐应该减肥了(负载过大),我们应该让高小姐节食一段时间,体重达到正常标准后再进行测试。以上就是负载测试的一个通俗例子。
压力测试:还是猪八戒同志背媳妇。我们发现他一次背一个媳妇异常轻松,于是乎我们必须加大负载,让猪八戒在极端的情况下进行背媳妇活动。我们可以让猪八戒同志一次背10个媳妇,当然这并不符合一夫一妻制,因此我们选择让猪八戒同志来背孙悟空同学。孙同学是石头里蹦出来的,所以密度大,质量大,符合极端负载的标准。
测试开始了,猪同志背上孙同学立即大汗淋漓、哭爹喊娘。好了,极端负载的条件达到。我们可以观察猪八戒的表现以确定猪八戒同志全身最薄弱的部位了。如果我们发现猪八戒同志腹部力量不足从而导致背孙同学极度吃力,那么我们可以让猪八戒去练腹肌,让他的腹部力量得到增强。这样我们也找到了系统的瓶颈,对系统进行了优化。
如果猪八戒背上孙悟空依然轻轻松松,神情自若,那么我们可以猜测猪八戒背的孙同学不是孙悟空而是孙尚香。于是我们可以选择更大的负载进行测试。
压力测试一定要测出来问题,否则我们有理由认为压力负载过小,不符合测试要求。
并发测试:主要是测试猪八戒一次能背几个媳妇。如果“猪八戒人猪混合系统”的设计目标是“一次至少背上三到四个高小姐”的话,我们就有尺度来衡量猪八戒的表现是否达标。
基准测试:如果猪八戒同志在被高小姐的时候没有服用任何的违禁药品,那么我们可以将此次的测试结果作为一个基点,然后让猪八戒同志喝点红牛或者是学习满文**同学嗑点小药,然后进行同样的负载测试,查看****或者是喝红牛对猪八戒背高小姐这个行为是否产生了利弊影响。这里的****可以值得是软件更换了一种新算法,也可以理解系统更换了新的中间件。当然我们也可以不让猪八戒同志背高小姐,而换成是让孙悟空同学背高小姐,观察这两次测试的测试结果,从而确定究竟那一种系统更能胜任“背高小姐”这个重任。
稳定性测试:让猪八戒背高小姐背上七七四十九天,观察猪同学的表现。若“猪八戒人猪混合系统”的设计要求为至少能连续背高小姐走上49天,而实际猪八戒只走了36天的话,我们可以认为“猪八戒人猪混合系统”不达标,需要优化。
可恢复性测试:先让猪八戒背孙悟空同志走上半天,此时猪八戒已经累得接近崩溃,然后再让猪八戒背上高小姐,查看猪八戒是否能从疲劳中恢复,从而担当起背高小姐的重任。
性能测试的概念还有很多,不过今天时间有限,仅举几个例子让大家了解一下性能测试的基础概念。如果您对以上内容有任何疑议,欢迎斧正指导。
本文首发于7dtest论坛:http://www.7dtest.com/site/thread-2177-1-1.html
有很多人在谈论HTTP服务器软件的性能测试,也许是因为现在有太多的服务器选择。
这很好,但是我看到有人很多基本相同的问题,使得测试结果的推论值得怀疑。在日常工作中花费了很多时间在高性能代理缓存和源站性能测试方面之后,这里有我认为比较重要的一些方面来分享。
希望能抛砖引玉。
0、一致性
最最重要的是,每次都测试同一个时间点。因为系统发生的每个改变,无论是OS升级还是运行了其它消耗带宽和CPU的应用,都会影响测试的结果,所以一定要把测试环境固定下来。
也许,有人会说那就把测试放虚拟机里做吧,听起来不错。但是,这种方式加多了一个抽象层(而且宿主机上也跑了更多的进程),如果说这样就能得到更加一致的结果,我是无论如何也不会相信的。我觉得,最好的办法是为测试准备一套专用硬件。如果做不到这个,那么一定要把所有测试放在同一个会话里,不要去比较不同会话里的测试结果。
1、每台机器,各司其职
人们常常会犯另一个错误,他们把负载生成器和被测试的服务器放在同一台机器上。这样做将导致产生不可靠的测试结果,因为,负载生成器实际上是「窃取」了一部分资源,而且这部分资源的量还会随着服务器处理负载情况的变化而变化。
最好的做法是,为测试主体和负载生成器分配不同的硬件,而且将它们放在封闭的网络上。这样做的代价并不是太高,我们并不需要非常高精尖的配置,只需要确保一致性就好。
所以,如果有人跟你说,他们的测试是在localhost上做的,或者拒绝透露测试用了几台机器,那么你尽可以忽略他们的结果。因为,这样的结果,往好了说,只有最基本的定性作用,往坏了说,甚至可能会误人子弟。
2、检查网络
在测试前,一定要知道你的网络有多大容量,这样,你才会知道,什么时候是你测试的服务器制约了测试,什么时候是网络制约了测试。
一种方法是通过iperf:
qa1:~> iperf -c qa2 ------------------------------------------------------------ Client connecting to qa2, TCP port 5001 TCP window size: 16.0 KByte (default) ------------------------------------------------------------ [ 3] local 192.168.1.106 port 56014 connected with 192.168.1.107 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 1.10 GBytes 943 Mbits/sec |
从上面的输出中可以看到,我的千兆网可以达到943Mbps的速度(之所以不到1000Mbps,是由于TCP的开销)。
知道网络容量后,我们需要确保它不会成为制约测试的因素。有几种方法,最简单的是记录当前使用的带宽。例如,httperf可以像这样展示当前的带宽用量:
| Net I/O: 23399.7 KB/s (191.7*10^6 bps) |
上例表明,我们目前只用了192Mbps。
记住,我们在负载产生工具中看到的数字并没有包括TCP开销,而且,如果我们的负载在整个测试期间并不固定,那么突发带宽一定会有超过平均值的时候。而且除了带宽以外还有其它的问题,例如,廉价的网卡和交换机很有可能会被大量的数据包淹没。
基于以上的种种原因,我们最好不要让测试的带宽逼近网络的可用带宽,最好是不要超过某个比例,比如2/3。对网络(包括网卡和交换机)错误和峰值速率进行监控也是一个很好的办法。
3、去除OS限制
同样,我们还需要确保OS不会对服务器的表现构成限制。
TCP参数的调整颇为重要,但它会对所有测试主体产生相同的影响。更为重要的是,不要让你测试的服务器用光文件描述符(file descriptor)。
4、避免压测客户端
现代高性能服务器使得容易将负载产生器的限制当作服务器的能力。所以,认真检查以确保你的客户端没有用爆CPU,如果有任何怀疑,就使用更多客户端压力来验证(autobench可以让这件事更简单)。
确保负载产生器的硬件优于要测试的服务端硬件,也很有帮助;比如,使用4核心的i5-750服务器产生负载,将服务器运行在较慢的双核i3-350服务器上,而且经常只用两个核心之一。
另外一个需要注意的因素是客户端错误,尤其是临时端口(ephemeral ports)用尽。处理这个问题有很多策略,扩大服务器的可用端口范围,或设置多个网络接口,确认由客户端使用它们(有时需要一些技巧)。也可以优化TIME_WAIT时间(只有是测试环境就没问题),或仅仅使用HTTP长连接和激进的客户端超时策略,确保连接速率不会用尽端口数。
我喜欢httperf的一个原因是它在结束时提供了错误的概要:
Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0
Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0 |
这里,服务器的问题位于第一行(比如由于服务器端超过--timeout设置的超时时间而造成的请求超时,或拒绝连接,或连接重置),客户端错误(如文件描述符用尽或地址用尽)在第二行。
在测试本身出错时,这能够帮你及时了解。
5、过载时的容量并不是真正的容量
产生尽可能大的负载,扔给服务器,这是许多负载产生工具的工作模式。
这种方法对于检查服务器在过载情况下的表现也许不错,但它并不能真正帮我们确定服务器的容量。因为,许多服务器在过载的情况下都会损失一部分的容量。
更好的方法是逐步加大负载,直到服务器达到容量上限,出现性能下降为止。我们可以把结果绘制成一条先抵达峰值、随后下降的曲线,而下降的程度意味着服务器应对过载时的表现情况。
autobench是其中的一种方法,我们可以设置测试的范围,然后就可以得到这样一张图:
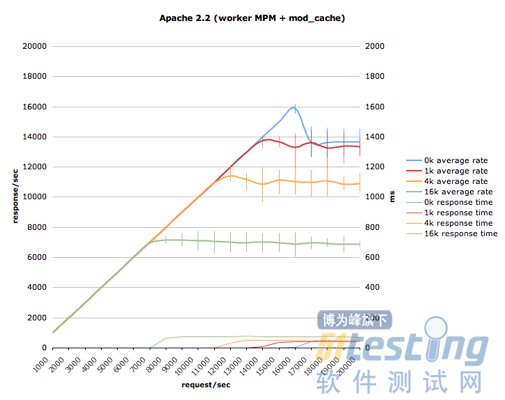
可以看到,在响应消息最小时,服务器的处理峰值为16,000响应/秒,但在过载情况下快速衰落至14,000响应/秒。而在响应消息更大时,过载情况下的衰落并没有这么多,但可以看到错误条不停弹出来,说明了服务器的紧张境况。
6、30秒的测试不算测试
由于处于应用、OS与网络栈各层的缓冲区需要一定的稳定时间,所以30秒的测试很可能不准确。如果你的测试数据是要正式发布的,请至少测试3分钟,或者更长一些,比如5到10分钟。
7、不要仅仅测试Hello World
如果要测试服务器的响应是否迅速,用4字节的响应消息过于局限,意义不大,4k甚至100k才更有现实意义。
另外一个需要测试的是服务器在面对大量空闲连接时的表现,比如10,000个连接。这对现代的成熟服务器来说本来不算什么,但往往会导致一些你想象不到的问题。
当然,以上仅仅只是两个例子而已。
8、仅仅平均值是不够的
如果有人告诉你,服务器可以每秒产生1000个响应,平均时延为5ms,听起来是不是很棒?但是,如果这1000个响应里,有些需要100ms呢?或者,如果说在整个测试的10%时间里,由于垃圾收集的关系,只能达到500个响应/秒的速度,你怎么看?
平均值是个快速指标,但是,仅此而已。有许多重要的信息,包含在时间线和直方图(histogram)中,但平均值并没有提供。如果你的测试工具不提供时间线和直方图,那么还是换一个吧(开源的话,还可以选择提交一个patch)。
httperf可以显示:
Total: connections 180000 requests 180000 replies 180000 test-duration 179.901 s Connection rate: 1000.0 conn/s (99.9 ms/conn, <=2 concurrent connections)
Connection time [ms]: min 0.4 avg 0.5 max 12.9 median 0.5 stddev 0.4
Connection time [ms]: connect 0.1
Connection length [replies/conn]: 1.000 Request rate: 1000.0 req/s (.9 ms/req)
Request size [B]: 79.0 Reply rate [replies/s]: min 999.1 avg 1000.0 max 1000.2 stddev 0.1 (35 samples)
Reply time [ms]: response 0.4 transfer 0.0
Reply size [B]: header 385.0 content 1176.0 footer 0.0 (total 1561.0)
Reply status: 1xx=0 2xx=0 3xx=0 4xx=1800 5xx=0 |
可以看到,它不仅显示了响应速度的平均值,还显示了最小值、最大值和标准差(deviation)。连接时间也是这样。
9、把相关信息全部发布出来
如果只是给出一个结果,而不给出重现它的必要信息,那么往好了说,这个结果只是一个全凭大家靠信仰来相信的没有用的结论,往坏了说,它甚至有故意误人子弟之嫌(译者注:各种数据库的宣传式的benchmark表示纷纷中枪)。所以,如果要发布测试结果,记得要把测试的相关上下文也一起发布,不光是测试所用的硬件,还应包括OS版本与配置、网络设置、服务器与负载产生器的版本与配置、所用的负载,甚至必要时还要加上源代码。
理想情况下,我们可以采用代码库(比如github)的形式,使任何人都能以最小的代价(用自己的硬件)重现你的结果。
10、尝试不同工具
看到这里,你也许会以为我只认httperf和autobench这两个工具。我很喜欢全能型选手,可惜httperf不是。对于现代的一些服务器来说,httperf太慢了,也许是由于它缺乏事件循环的缘故。httperf只能以每秒50到500个请求的速度测试一些PHP应用,但无论如何也做不到以每秒上万个请求的速度去测试那些现代的web服务器。
而且,如果只认准一个工具的话,可能会由于客户端与服务器之间一些奇怪的交互,导致对某个实现特别不利的情况发生。例如,有些工具建立持久连接的方式对一些服务器不够友好,导致它们的测试结果不佳。
而我之所以喜欢httperf,上文中也已经提过,由于它有很详细的统计信息和错误报告,而且可以自定义负载速率,让我们可以更清晰地了解我们的服务器。我希望其它工具也能输出同样详细的信息。
我最近还用了siege,虽然在信息方面还比不上httperf那么详细,不过也很好用,尤其速度真叫一个快。
原文链接:http://www.oschina.net/translate/http_benchmark_rules
跟踪标记是什么?
对于DBA来说,掌握Trace Flag是一个成为SQL Server高手的必要条件之一,在大多数情况下,Trace Flag只是一个剑走偏锋的奇招,不必要,但在很多情况下,会使用这些标记可以让你更好的控制SQL Server的行为。
下面是官方对于Trace Flag的标记:
跟踪标记是一个标记,用于启用或禁用SQL Server的某些行为。
由上面的定义不难看出,Trace Flag是一种用来控制SQL Server的行为的方式。很多DBA对Trace Flag都存在一些误区,认为只有在测试和开发环境中才有可能用到Trace Flag,这种想法只能说部分正确,因此对于Trace Flag可以分为两类,适合在生产环境中使用的和不适合在生产环境中使用的。
Important:Trace Flag属于剑走偏锋的招数,在使用Trace Flag做优化之前,先Apply基本的Best Practice。
如何控制跟踪标记
控制跟踪标记的方式有以下三种:
1、通过DBCC命令
可以通过DBCC命令来启用或关闭跟踪标记,这种方式的好处是简单易用,分别使用下面三个命令来启用,禁用已经查看跟踪标记的状态:
● DBCC TRACEON(2203,-1)
● DBCC TRACEOFF(2203,1)
● DBCC TRACESTATUS
其中,TRACEON和TRACEOFF第二个参数代表启用标志的范围,1是Session Scope,-1是Global Scope,如果不指定该值,则保持默认值Session Scope。
另外,值得说的是,如果你希望在每次SQL Server服务启动时通过DBCC命令控制某些Flag,则使用
EXEC sp_procoption @ProcName = '<procedure name>'
, @OptionName = ] 'startup'
, @OptionValue = 'on'; |
这个存储过程来指定,sp_procoption存储过程会在SQL Server服务器启动时自动执行。
还有一点值得注意的是,不是所有的跟踪标记都可以用DBCC命令启动,比如Flag 835就只能通过启动参数指定。
2、通过在SQL Server配置管理器中指定
这种方式是通过在数据库引擎启动项里加启动参数设置,只有Global Scope。格式为-T#跟踪标记1;T跟踪标记2;T跟踪标记3。
3、通过注册表启动
这种方式和方法2大同小异,就不多说了。
一些在生产环境中可能需要的跟踪标记
Trace Flag 610
减少日志产生量。如果你对于日志用了很多基础的best practice,比如说只有一个日志文件、VLF数量适当、单独存储,如果还是不能缓解日志过大的话,考虑使用该跟踪标记。
参考资料:
http://msdn.microsoft.com/en-us/library/dd425070.aspxhttp://blogs.msdn.com/b/sqlserverstorageengine/archive/2008/10/24/new-update-on-minimal-logging-for-sql-server-2008.aspx
Trace Flag 834
使用 Microsoft Windows 大页面缓冲池分配。如果服务器是SQL Server专用服务器的话,值得开启该跟踪标记。
Trace Flag 835
允许SQL Server 2005和2008标准版使用"锁定内存页",和在组策略中设置的结果大同小异,但是允许在标准版中使用.
Trace Flag 1118
tempdb分配整个区,而不是混合区,减少SGAM页争抢。当apply tempdb的best practice之后,还遇到争抢问题,考虑使用该跟踪标记。
参考资料:http://blogs.msdn.com/b/psssql/archive/2008/12/17/sql-server-2005-and-2008-trace-flag-1118-t1118-usage.aspx
Trace Flag 1204和1222
这两个跟踪标记都是将死锁写到错误日志中,不过1204是以文本格式进行,而1222是以XML格式保存。可以通过sp_readerrorlog查看日志。
Trace Flag 1211和1224
两种方式都是禁用锁升级。但行为有所差别1211是无论何时都不会锁升级,而1224在内存压力大的时候会启用锁升级,从而避免了out-of-locks错误。当两个跟踪标记都启用是,1211的优先级更高。
Trace Flag 2528
禁用并行执行DBCC CHECKDB, DBCC CHECKFILEGROUP,DBCC CHECKTABLE。这意味着这几个命令只能单线程执行,这可能会需要更多的时间,但是在某些特定情况下还是有些用处。
Trace Flag 3226
防止日志记录成功的备份。如果日志备份过于频繁的话,会产生大量错误日志,启用该跟踪标记可以使得日志备份不再被记录到错误日志。
Trace Flag 4199
所有KB补丁对于查询分析器行为的修改都生效,这个命令比较危险,可能扫称性能的下降,具体请参看:http://support.microsoft.com/kb/974006
不应该在生产环境中启用的跟踪标记
Trace Flag 806
在读取过程中对页检查逻辑一致性,在错误日志中就可以看到类似下面的信息:
2004-06-25 11:29:04.11 spid51 错误: 823,严重性: 24 日状态: 2
2004-06-25 11:29:04.11 spid51 I/O 错误 (审核失败) 在读取过程中检测到的偏移量主题 SQL Server\MSSQL\data\pubs.mdf e:\Program 文件中的 0x000000000b0000.
参考资料:http://support.microsoft.com/kb/841776
该跟踪标记会极大的降低性能!!!
Trace Flag 818
检查写一致性
踪标志 818 启用了一个内存中的环形缓冲区,用于跟踪由运行 SQL Server 的计算机执行的最后 2,048 个成功写操作(不包括排序和工作文件 I/O)。发生 605、823 或 3448 之类的错误时,将传入缓冲区的日志序列号 (LSN) 值与最新写入列表进行比较。如果在读操作期间检索到的 LSN 比在写操作期间指定的更旧,就会在 SQL Server 错误日志中记录一条新的错误信息。大部分 SQL Server 写操作以检查点或惰性写入形式出现。惰性写入是一项使用异步 I/O 操作的后台任务。环形缓冲区的实现是轻量的,因此对系统性能的影响可以忽略。
参考资料:http://support.microsoft.com/kb/826433Trace
Flag 1200
返回加锁信息的整个过程,是学习加锁过程很牛逼的标志,示例代码如下:
DBCC TRACEON(1200,-1)
DBCC TRACEON(3604)
DBCC TRACESTATUS
SELECT * FROM AdventureWorks.person.Address
参考资料:http://stackoverflow.com/questions/7449061/nolock-on-a-temp-table-in-sql-server-2008Trace
Flag 1806
禁用即时文件初始化,所有的磁盘空间请求全部使用填0初始化,可能造成在空间增长时产生阻塞。
Trace Flag 3502
在日志中显示有关checkpoint的相关信息。如图1所示。
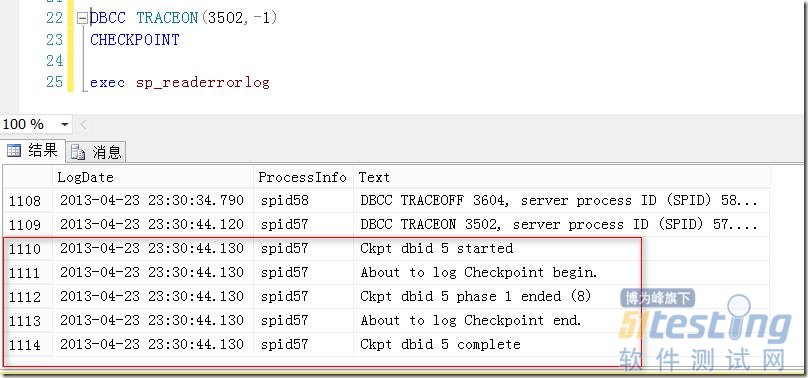
图1.在错误日志中显示Checkpoint
Trace Flag 3505
不允许自动进行checkpoint,checkpoint只能手动进行,是非常危险的一个命令。
小结
跟踪标志是控制SQL Server行为的一种方式,对于某些跟踪标志来说,可以在生产环境中提高性能,而对于另一些来说,用在生产环境中是一件非常危险的事情,只有在测试环境中才能被使用。要记住,跟踪标记对于调优是一种剑走偏锋的手段,只有在使用了所有基本的调优手段之后,才考虑使用跟踪标记。