
【功能】
WebScarab是一个用来分析使用HTTP和HTTPS协议的应用程序框架。其原理很简单,WebScarab可以记录它检测到的会话内容(请求和应答),并允许使用者可以通过多种形式来查看记录。WebScarab的设计目的是让使用者可以掌握某种基于HTTP(S)程序的运作过程;可以用它来调试程序中较难处理的bug,也可以帮助安全专家发现潜在的程序漏洞。
【适用对象】
分析使用HTTP和HTTPS协议的应用程序框架
1.1.1 工具安装
WebScarab需要在
java环境下运行,因此在安装WebScarab前应先安装好java环境(JRE或JDK均可)。
安装好jdk后,右击安装文件:webscarab-installer-20070504-1631.jar 选择“打开方式”如下图:
然后进入安装界面,下一步下一步安装即可。
1.1.2 功能原理
webscarab工具的主要功能:它可以获取客户端提交至服务器的http请求消息,并以图形化界面显示,支持对http请求信息进行编辑修改。
原理:webscarab工具采用
web代理原理,客户端与web服务器之间的http请求与响应都需要经过webscarab进行中转,webscarab将收到的http请求消息进行分析,并将分析结果图形化显示,如下图:
可以用于验证当客户端对输入有限制时(如长度限制、输入字符集的限制等),可以使用此种方法绕过客户端验证服务端是否对输入有限制。
1.1.3 工具使用
下面将主要介绍如何使用webscarab工具对post请求进行参数篡改
1、 运行WebScarab
WebScarab有两种显示模式:Lite interface和full-featured interface,可在Tools菜单下进行模式切换,需要重启软件生效,修改http请求信息需要在full-featured interface下进行。
2、 点击Proxy标签页->Manual Edit标签页
3、 选中Intercept requests
在Methods中列举了http1.1协议所有的请求方法,用来选择过滤,如我们选择了post,那WebScarab只能对post请求的http消息进行篡改。
4、 打开IE浏览器的属性,进入连接》局域网设置,在代理地址中配置host为127.0.0.1或localhost,port为8008
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
快速上手
如果你对
Selenium 自动化测试已经非常熟悉,你仅仅需要一个快速上手来使程序运行起来。本章节的内容能满足不同的技术层次,但是如果你仅仅需要一个可以快速上手的指引,那么就显得有点多。如果是这样,你可以参考 Selenium Wiki 的相关
文章。
什么是 Selenium-Grid ?
Selenium-Grid 允许你在多台机器的多个浏览器上并行的进行测试,也就是说,你可以同时运行多个测试。本质上来说就是,Selenium-Grid 支持分布式的测试执行。它可以让你的测试在一个分布式的执行环境中运行。
何时需要使用
通常,以下两种情况你都会需要使用 Selenium-Grid。
在多个浏览器中运行测试,在多个版本的浏览器中进行测试,或在不同
操作系统的浏览器中进行测试。
减少测试运行时间。
Selenium-Grid 通过使用多台机器并行地运行测试来加速测试的执行过程。例如,如果你有一个包含100个
测试用例的测试套件,你使用 Selenium-Grid 支持4台不同的机器(虚拟机或实体机均可)来运行那些测试,同仅使用一台机器相比,你的测试所需要的运行时间大致为其 1/4。对于大型的测试套件和那些会进行大量数据校验的需要长时间运行的测试套件来说,这将节约很多时间。有些测试套件可能要运行好几小时。另一个需要缩短套件运行时间的原因是开发者检入(check-in)AUT 代码后,需要缩短测试的运行周期。越来越多的团队使用
敏捷开发,相比整夜整夜的等待测试通过,他们希望尽快地看到测试反馈。
Selenium-Grid 也可以用于支持多执行环境的测试运行,典型的,同时在多个不同的浏览器中运行。例如,Grid 的虚拟机可以安装测试必须的各种浏览器。于是,机器 1 上有 ie8,机器 2 上有 ie9,机器 3 上有最新版的 chrome,而机器 4 上有最新版的 firefox。当测试套件运行时,Selenium-Grid 可以使测试在指定的浏览器中运行,并且接收每个浏览器的运行结果。
另外,我们可以拥有一个装有多个类型和版本都一样的浏览器 Grid。例如,一个 Grid 拥有 4 台机器,每台机器可以运行 3 个 firefox 12 实例,形成一个 firefox 的服务农场。当测试套件运行时,每个传递给 Selenium-Grid 的测试都被指派给下一个可用的 firefox 实例。通过这种方式,我们可以使得同时有 12 个测试在并行的运行以完成测试,显著地缩短了测试完成需要的时间。
Selenium-Grid 非常灵活。以上两个例子可以联合起来使用,这样可以就可以使得不同类型和版本的浏览器有多个可运行实例。使用这样的配置,既并行地执行测试,同时又可以测试多个浏览器类型和版本。
Selenium-Grid 2.0
Selenium-Grid 2.0 是在编写本文时(5/26/2012)已发布的最新版本。它同版本 1 有很多不同之处。在 2.0 中,Selenium-Grid 和 Selenium-RC 服务端进行了合并。现在,你仅需要下载一个 jar 包就可以获得它们。
Selenium-Grid 1.0
版本 1 是 Selenium-Grid 的第一个发布版本。如果你是一个 Selenium-Grid 新手,你应该选择版本 2 。新版本已经在原有基础上进行了更新,页增加了一些新特性,并且支持 Selenium-WebDriver。一些老的系统可能仍然在使用版本 1.关于 Selenium-Grid 版本 1 的信息可以参考 Selenium-Grid website
Selenium-Grid 的 Hub 和 Nodes 是如何
工作的?
Grid 由一个中心和一到多个节点组成。两者都是通过 selenium-server.jar 启动。在接下来的章节中,我们列出了一些例子。
中心接收要执行的测试信息,包括在哪些平台和浏览器执行等。它知道每个注册了的节点的配置。根据测试信息,它会选择符合需求的节点进行测试。一旦选定了一个节点,测试脚本就会初始化 Selenium 命令,并且由重心发送给选定的要运行测试的节点。这个节点会启动浏览器,然后在浏览器中执行这个 AUT 的 Selenium 命令。
我们提供了一些图标来演示其原理。第二张图标是用以说明 Selenium-Grid 1 的,版本 2 也适用并且对于我们的描述是一个很好的说明。唯一的区别在于相关术语。使用“Selenium-Grid 节点”替换“Selenium Remote Control”即符合我们对 Selenium-Grid 2 的描述。
下载
下载过程很简单。从 SeleniumHq 站点的下载页面下载 Selenium-Server jar 包。你需要的链接在“Selenium-Server (以前是 Selenium-RC)”章节中。
将它存放到任意文件夹中。你需要确保机器上正确的安装了
java。如果 java 没有正常运行,检查你系统的 path 变量是否包含了 java.exe 的路径。
启动 Selenium-Grid
由于节点对中心有依赖,所以你通常需要先启动一个中心。这也不是必须的,因为节点可以识别其中心是否已经启动,反之亦然。作为教程,我们建议你先启动中心,否则会显示一些错误信息,你应该不会想在第一次使用 Selenium-Grid 的时候就看到它们。
启动中心
通过在命令行执行以下命令,可以启动一个使用默认设置的中心。所有平台可用,包括 Windows Linux, 或 MacOs 。
java -jar selenium-server-standalone-2.21.0.jar -role hub
我们将在接下来的章节中解释各个参数。注意,你可能需要修改上述命令中 jar 包的版本号,这取决于你使用的 selenium-server 的版本。
启动节点
通过在命令行执行以下命令,可以你懂一个使用默认设置的节点。
java -jar selenium-server-standalone-2.21.0.jar -role node -hub http://localhost:4444/grid/register
该操作假设中心是使用默认设置启动的。中心用于监听请求使用的默认端口号为 4444,这就是为什么端口 4444 被用于中心 url 中。同时“localhost”假定你的节点和中心运行在同一台机器上。对于新手来说,这是最简单的方式。如果要在两台不同的机器上运行中心和节点,只需要将“localhost”替换成中心所在机器的 hostname 即可。
警告: 确保运行中心和节点的机器均已关闭防火墙,否则你将看到一个连接错误。
配置 Selenium-Grid
默认配置
JSON 配置文件
通过命令行选项配置
中心配置
通过指定 -role hub 即以默认设置启动中心:
java -jar selenium-server-standalone-2.21.0.jar -role hub
你将看到以下日志输出:
Jul 19, 2012 10:46:21 AM org.openqa.grid.selenium.GridLauncher main
INFO: Launching a selenium grid server
2012-07-19 10:46:25.082:INFO:osjs.Server:jetty-7.x.y-SNAPSHOT
2012-07-19 10:46:25.151:INFO:osjsh.ContextHandler:started o.s.j.s.ServletContextHandler{/,null}
2012-07-19 10:46:25.185:INFO:osjs.AbstractConnector:Started SocketConnector@0.0.0.0:4444
指定端口
中心默认使用的端口是 4444 。这是一个 TCP/IP 端口,被用于监听客户端,即自动化测试脚本到 Selenium-Grid 中心的连接。如果你电脑上的另一个应用已经占用这个接口,或者你已经启动了一个 Selenium-Server,你将看到以下输出:
10:56:35.490 WARN - Failed to start: SocketListener0@0.0.0.0:4444
Exception in thread "main" java.net.BindException: Selenium is already running on port 4444. Or some other service is.
如果看到这个信息,你可以关掉在使用端口 4444 的进程,或者告诉 Selenium-Grid 使用一个别的端口来启动中心。-port 选项用于修改中心的端口:
java -jar selenium-server-standalone-2.21.0.jar -role hub -port 4441
即使已经有一个中心运行在这台机器上,只要它们不使用同一个端口,就能正常工作。
你可能想知道哪个进程使用了 4444 端口,这样你就可以让中心使用这个默认端口。使用以下命令可以查看你机器上所有运行程序使用的端口:
netstat -a
Unix/Linux, MacOs 和 Windows 均支持此命令,只是在 Windows 中 -a 参数为必须的。基本上,你需要显示进程 id 和端口。在 Unix 中,你可以通过管道 “grep” 输出那些你关心的端口相关的条目。
节点配置
时间参数
获取命令行帮助
Selenium-Server 提供了一个可选项列表,每个选项都有一个简短的描述。目前(2012夏),命令行帮助还有一些奇怪,但是如果你知道如何去找、如何解读信息会对你很有帮助。
Selenium-Server 提供了两种不同的功能,Selenium-RC server 和 Selenium-Grid。它们是两个不同的团队编写的,所以每个功能的命令行帮助被放置在不同的地方。因此,对于新手来说,在初次使用任意一个功能时,帮助都不是那么显而易见。
如果你仅传递一个 -h 选项,你将看到 Selenium-RC Server 的可选项而不是 Selenium-Grid 的。
java -jar selenium-server-standalone-2.21.0.jar -h
上述代码将显示 Selenium-RC server 选项。如果你想看到 Selenium-Grid 的命令行帮助,你需要先使用 -hub 或 -node 选项告诉 Selenium-Server 你想看的是关于 Selenium-Grid 的,然后再追加 -h 选项。
java -jar selenium-server-standalone-2.21.0.jar -role node -h
对于这个问题,你还可以给 -role node 传递一个垃圾参数:
java -jar selenium-server-standalone-2.21.0.jar -role node xx
你将先看到 “INFO...” 和一个 “ERROR”,在其后你将看到 Selenium-Grid 的命令行选项。我们没有列出这个命令的所有输出,因为它实在太长了,这个输出的最初几行看起来如下:
Jul 19, 2012 10:10:39 AM org.openqa.grid.selenium.GridLauncher main INFO: Launching a selenium grid node org.openqa.grid.common.exception.GridConfigurationException: You need to specify a hub to register to using -hubHost X -hubPort 5555. The specified config was -hubHost null -hubPort 4444 at org.openqa.grid.common.RegistrationRequest.validate(RegistrationRequest.java:610) at org.openqa.grid.internal.utils.SelfRegisteringRemote.startRemoteServer(SelfRegisteringRemote.java:88) at org.openqa.grid.selenium.GridLauncher.main(GridLauncher.java:72) Error building the config :You need to specify a hub to register to using -hubHost X -hubPort 5555. The specified config was -hubHost null -hubPort 4444 Usage : -hubConfig: (hub) a JSON file following grid2 format. -nodeTimeout: (node) <XXXX> the timeout in seconds before the hub automatically ends a test that hasn't had aby activity than XX sec.The browser will be released for another test to use.This typically takes care of the client crashes. |
常见错误
Unable to acess the jarfile
Unable to access jarfile selenium-server-standalone-2.21.0.jar
无论是启动中心还是节点都有可能产生这个错误。这意味着 java 无法找到 selenium-server jar 包。你需要从 selenium-server-XXXX.jar 文件存放在目录运行命令或者指定 jar 包的完整路径。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一、体系架构
1.C/S:客户端+服务器端,如QQ、单机版记事本、office等,所用语言:VB、C++、C、C#、JAVA、PB、D…等数组语言,C和S都是自己测,且复杂度较高。扩展性差。
补:软件质量包括五种质量:内部质量、外部质量、过程质量、使用质量、情感质量(从使用质量提取出来的,易用性的、用户体验的老师称为情感质量)。
B/S:浏览器+服务器,S如tomcat、IIS,所用语言:HTML、ASP、PHP、JSP等脚本语言,B和S都是成熟的产品,不需测。范围广。扩展性好,便于用户访问,但是安全性较差。可看到后缀,根据后缀知道其架构,即知道什么语言开发,可能使用的服务器是什么,可能使用的
数据库是什么,可能使用的服务器的
操作系统是什么。便于测试。
机房包括:HTTP(只做请求的转发,不做请求的具体处理,做负载均衡的)、
Web Server(网络服务)、APP Server(应用服务)、DB Server(数据库服务器)。
嵌入式应用系统:如投影仪,里面装有数控类的代码,也是程序,对其需用模拟器来进行测试,称为嵌入式系统。
如今很多企业都是C/S和B/S合并起来做,核心关键的用B/S做,对外公布的用C/S做,两者之间留接口即可。涉及军工类的都是C/S架构。
2.web服务器:在B/S架构开发平台:J2EE(Java开发,包括:J2EE企业级,是C/S系统;J2ME微型平台,是嵌入式系统;J2SE标准平台,是桌面型系统、.net(C#,
微软开发,是站点开发,应用于电子商务)、LAMP(php开发,Linux+Apache+MySQL+php)
SUN: 后台Java,前台jsp
常用的web服务器:Apache、Tomcat、IIS、jboss、Resin、weblogic、WebSphere
3.DB Server数据库服务器:全部基于
SQL语言(结构化查询语言),包括:
MySQL、SQLServer、
Oracle、Sybase、DB2(后三者过了安全认证即五星认证,较厉害)
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
karma作为angular测试runner出现,如果你使用过karma一定感受到这很不错的javascript测试runner。简单干净的配置文件karma.config.js,以及karma init一些快捷的配置command。以及整套
测试套件,如html2js,coverage。对于angular单元测试karma就是一个全生态的测试套件,能够简洁快速的搭建整个测试流程。
本文将尝试运用karma作为jQuery单元测试runner。对于jQuery这种DOM操作的框架,有时难于分离view逻辑,以及ajax这种外部资源的mock,所以比较难于实施对jQuery程序的TDD开发。
jasmime测试套件
对于jasmine测试框架为了解决这些问题有两个插件jasmine-jquery和jasmine-ajax。
jasmine-jquery
jasmine-jQuery主要解决加载测试所需的DOM元素,为
单元测试构建前置环境。jasmine-jQuery加载DOM方法:
jasmine.getFixtures().fixturesPath = 'base path';
loadFixtures('myfixture.html');
jasmine.getFixtures().load(...);
这里的loadFixtures需要真实ajax获取html fixtures所以我们需要提前host html fixtures。jasmine-jQuery还框架了一些有用的matchers,如toBeChecked, toBeDisabled, toBeFocused,toBeInDOM……
jasmine-ajax
jasmine-ajax则是对于一般ajax测试的mock框架,其从底层xmlhttprequest实施mock。所以让我们能很容易实施对于jQuery的$.ajax,$.get…mock。如
beforeEach(function() { jasmine.Ajax.requests.when = function (url) { return this.filter("/jquery/ajax")[0]; }; jasmine.Ajax.install(); }); it("jquery ajax success with getResponse", function() { var result; $.get("/jquery/ajax").success(function(data) { result = data; }); jasmine.Ajax.requests.when("/jquery/ajax").response({ "status": 200, "contentType": 'text/plain', "responseText": 'data from mock ajax' }); expect(result).toEqual('data from mock ajax'); }); afterEach(function() { jasmine.Ajax.uninstall(); }); |
对于jasmine-ajax是实施mock之前一定需要jasmine.Ajax.install(),以及测试完成后需要jasmine.Ajax.uninstall();jasmine-ajax在install后会把所有的ajax mock掉,所以如果有需要真实ajax的需要在install之前完成,如jasmine-jQuery加载view loadFixtures。
运用karma runner
我们已经了解了jasmine测试的两个框架jasmine-jQuery和jasmine-ajax,所以运用karma作为runner,我们需要解决的问题就是把他们和karma集成在一起。
所以分为以下几步: 1:karma中引入jasmine-jQuery和jasmine-ajax(可以利用bowerinstall) 2:host 测试的html fixtures。 3:加载html fixtures 与install ajax之前。
对于host 文件karma提供了pattern模式,所以karma配置为:
files: [ { pattern: 'view/**/*.html', watched: true, included: false, served: true }, 'bower_components/jquery/dist/jquery.js', 'bower_components/jasmine-jquery/lib/jasmine-jquery.js', 'bower_components/jasmine-ajax/lib/mock-ajax.js', 'src/*.js', 'test/*.js' ], |
这里需要注意karma自带的jasmine是低版本的,所以我们需要npm install karma-jasmine@2.0获取最新的karma-jasmine插件。
我们就可以完成了karma的配置,我们可以简单测试我们的配置:demo on github.
测试html fixtures加载:
describe('console html content', function() { beforeEach(function() { jasmine.getFixtures().fixturesPath = 'base/view/'; loadFixtures("index.html"); }); it('index html', function() { expect($("h2")).toBeInDOM(); expect($("h2")).toContainText("this is index page"); }); }) |
测试mock ajax:
describe('console html content', function() { beforeEach(function() { jasmine.Ajax.requests.when = function(url) { return this.filter("/jquery/ajax")[0]; }; jasmine.Ajax.install(); }); it('index html', function() { expect($("h2")).toBeInDOM(); expect($("h2")).toContainText("this is index page"); }); it("ajax mock", function() { var doneFn = jasmine.createSpy("success"); var xhr = new XMLHttpRequest(); xhr.onreadystatechange = function(args) { if (this.readyState == this.DONE) { doneFn(this.responseText); } }; xhr.open("GET", "/some/cool/url"); xhr.send(); expect(jasmine.Ajax.requests.mostRecent().url).toBe('/some/cool/url'); expect(doneFn).not.toHaveBeenCalled(); jasmine.Ajax.requests.mostRecent().response({ "status": 200, "contentType": 'text/plain', "responseText": 'awesome response' }); expect(doneFn).toHaveBeenCalledWith('awesome response'); }); it("jquery ajax success with getResponse", function() { var result; getResponse().then(function(data){ result = data; }); jasmine.Ajax.requests.when("/jquery/ajax").response({ "status": 200, "contentType": 'text/plain', "responseText": 'data from mock ajax' }); expect(result).toEqual('data from mock ajax'); }); it("jquery ajax error", function() { var status; $.get("/jquery/ajax").error(function(response) { status = response.status; }); jasmine.Ajax.requests.when("/jquery/ajax").response({ "status": 400 }); expect(status).toEqual(400); }); afterEach(function() { jasmine.Ajax.uninstall(); }); }) |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一周时间过去了,断断续续学习selenium也有几个小时了;今天细想一下学习效率不高的原因在哪,总结出以下几点: 1、求“进”心切——总想一步到位,搭建好环境,开始动手写用例。
2、学习深度不够——同样想着快速浏览一遍某大神、高手的日志,教程什么的很立即动手复制,其实很多基础环境不一样,无法全部照搬。
3、学习时间太少——这个是最为关键的点,统计一下,一周下来,花在学习Selenium上的时间不过3-5小时,而且时间分布在12点到2点之间,效率也最低下。
两天前弄出来的SELENIUM IDE for firefox已经可以进行录制回放功能,做一些最为简单的单线流程录制。但一直无法将用例转换的JAVA代码编译通过,报错也无法定位与解决,被阻塞了两天时间 。
Java for selenium 做WEB测试应具有的知识体系,大致如下(自己感受):
2、selenium的JAVA API及selenium基本知识(摸不着北)
通过分析上述的几点要求后,发现自己在基础上还是非常薄弱,不能一味的追求快;而是需要一边夯实基础、一边开阔视野、一边提升;推动整体向前进步。
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"> <head profile="http://selenium-ide.openqa.org/profiles/test-case"> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> <link rel="selenium.base" href="http://www.baidu.com/" /> <title>hyddd</title> </head> <body> <table cellpadding="1" cellspacing="1" border="1"> <thead> <tr><td rowspan="1" colspan="3">hyddd</td></tr> </thead><tbody> <tr> <td>open</td> <td>/</td> <td></td> </tr> <tr> <td>click</td> <td>id=kw1</td> <td></td> </tr> <tr> <td>type</td> <td>id=kw1</td> <td>hyddd</td> </tr> <tr> <td>click</td> <td>id=su1</td> <td></td> </tr> </tbody></table> </body> </html> |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
通常我们通过终端连接到
linux系统后执行ulimit -n 命令可以看到本次登录的session其文件描述符的限制,如下:
$ulimit -n
1024
当然可以通过ulimit -SHn 102400 命令来修改该限制,但这个变更只对当前的session有效,当断开连接重新连接后更改就失效了。
如果想永久变更需要修改/etc/security/limits.conf 文件,如下:
vi /etc/security/limits.conf
* hard nofile 102400
* soft nofile 102400
保存退出后重新登录,其最大文件描述符已经被永久更改了。
这只是修改用户级的最大文件描述符限制,也就是说每一个用户登录后执行的程序占用文件描述符的总数不能超过这个限制。
系统级的限制
它是限制所有用户打开文件描述符的总和,可以通过修改内核参数来更改该限制:
sysctl -w fs.file-max=102400
使用sysctl命令更改也是临时的,如果想永久更改需要在/etc/sysctl.conf添加
fs.file-max=102400
保存退出后使用sysctl -p 命令使其生效。
与file-max参数相对应的还有file-nr,这个参数是只读的,可以查看当前文件描述符的使用情况。
直接修改内核参数,无须重启系统。
sysctl -w fs.file-max 65536
或者
echo "65536" > /proc/sys/fs/file-max
两者作用是相同的,前者改内核参数,后者直接作用于内核参数在虚拟文件系统(procfs, psuedo file system)上对应的文件而已。
可以用下面的命令查看新的限制
sysctl -a | grep fs.file-max
或者
cat /proc/sys/fs/file-max
修改内核参数
/etc/sysctl.conf
echo "fs.file-max=65536" >> /etc/sysctl.conf
sysctl -p
查看当前file handles使用情况:
sysctl -a | grep fs.file-nr
或者
cat /proc/sys/fs/file-nr
825 0 65536
另外一个命令:
lsof | wc -l
下面是摘自kernel document中关于file-max和file-nr参数的说明
file-max & file-nr: The kernel allocates file handles dynamically, but as yet it doesn't free them again. 内核可以动态的分配文件句柄,但到目前为止是不会释放它们的 The value in file-max denotes the maximum number of file handles that the Linux kernel will allocate. When you get lots of error messages about running out of file handles, you might want to increase this limit. file-max的值是linux内核可以分配的最大文件句柄数。如果你看到了很多关于打开文件数已经达到了最大值的错误信息,你可以试着增加该值的限制 Historically, the three values in file-nr denoted the number of allocated file handles, the number of allocated but unused file handles, and the maximum number of file handles. Linux 2.6 always reports 0 as the number of free file handles -- this is not an error, it just means that the number of allocated file handles exactly matches the number of used file handles. 在kernel 2.6之前的版本中,file-nr 中的值由三部分组成,分别为:1.已经分配的文件句柄数,2.已经分配单没有使用的文件句柄数,3.最大文件句柄数。但在kernel 2.6版本中第二项的值总为0,这并不是一个错误,它实际上意味着已经分配的文件句柄无一浪费的都已经被使用了 |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
《动态网站设计十八般武艺 --ASP 篇》一文从第一期至今已和朋友们一起度过了大半个年头,相信通过在这一段时间中的
学习、实践到再学习、再实践,大家已经能够熟练运用 ASP 的内建对象、 ActiveX 组件去编写一些基本的 ASP 应用程序。从我收到的朋友们的来信中可以明显的感觉到,大家的 ASP 功力正不断地提升。最近很多朋友来信希望我写一些 ASP 在现实运用中的实例。因此,从本期开始我决定将《动态网站设计十八般武艺 --ASP 篇》的定位从介绍和学习 ASP 基础知识转向到 ASP 实际运行的探讨和深化。应朋友们的要求,在本期中我将给大家着重谈一谈“ADO 存取
数据库时如何分页显示”的问题。
什么是 ADO 存取数据库时的分页显示?如果你使用过目前众多网站上的电子公告板程序的话,那你应该会知道电子公告板程序为了提高页面的读取速度,一般不会将所有的帖子全部在一页中罗列出来,而是将其分成多页显示,每页显示一定数目的帖子数,譬如 20 条。这就是数据库查询的分页显示,如果你还不明白,去看看 yahoo 等搜索引擎的查询结果就会明白了。
那么究竟如何才能做到将数据库的查询结果分页显示呢?其实方法有很多,但主要有两种:
一、将数据库中所有符合查询条件的记录一次性的都读入 recordset 中,存放在内存中,然后通过 ADO Recordset 对象所提供的几个专门支持分页处理的属性: PageSize( 页大小 )、 PageCount( 页数目 ) 以及 AbsolutePage( 绝对页 ) 来管理分页处理。
二、根据客户的指示,每次分别从符合查询条件的记录中将规定数目的记录数读取出来并显示。
两者的主要差别在于前者是一次性将所有记录都读入内存然后再根据指示来依次做判断分析从而达到分页显示的效果,而后者是先根据指示做出判断并将规定数目的符合查询条件的记录读入内存,从而直接达到分页显示的功能。
我们可以很明显的感觉到,当数据库中的记录数达到上万或更多时,第一种方法的执行效率将明显低于第二种方法,因为当每一个客户查询页面时都要将所有符合条件的记录存放在服务器内存中,然后在进行分页等处理,如果同时有超过 100 个的客户在线查询,那么 ASP 应用程序的执行效率将大受影响。但是,当服务器上数据库的记录数以及同时在线的人数并不是很多时,两者在执行效率上是相差无几的,此时一般就采用第一种方法,因为第一种方法的 ASP 程序编写相对第二种方法要简单明了得多。
在这里作者就以我们常见的 ASP BBS 程序为例,来给大家分析一下如何在 BBS 程序里实现分页显示功能,由于我们一般使用的 BBS 程序的数据库记录数和同时访问的人数都不会太多,所以以下程序实例是使用的先前所介绍的第一种分页显示方法。
进行 ADO 存取数据库时的分页显示,其实就是对 Recordset 的记录进行操作。所以我们首先必须了解 Reordset 对象的属性和方法:
BOF 属性:目前指标指到 RecordSet 的第一笔。
EOF 属性:目前指标指到 RecordSet 的最后一笔。
Move 方法:
移动指标到 RecordSet 中的某一条记录。
AbsolutePage 属性:设定当前记录的位置是位于哪一页 AbsolutePosition 属性:目前指标在 RecordSet 中的位置。
PageCount 属性:显示 Recordset 对象包括多少“页”的数据。
PageSize 属性:显示 Recordset 对象每一页显示的记录数。
RecordCount 属性:显示 Recordset 对象记录的总数。
下面让我们来详细认识一下这些重要的属性和方法
一、 BOF 与 EOF 属性
通常我们在 ASP 程序中编写代码来检验 BOF 与 EOF 属性,从而得知目前指标所指向的 RecordSet 的位置,使用 BOF 与 EOF 属性,可以得知一个 Recordset 对象是否包含有记录或者得知移动记录行是否已经超出该 Recordset 对象的范围。
如:
< % if not rs.eof then ... %>
< % if not (rs.bof and rs.eof) %>
若当前记录的位置是在一个 Recordset 对象第一行记录之前时, BOF 属性返回 true,反之则返回 false。
若当前记录的位置是在一个 Recordset 对象最后一行记录之后时, EOF 属性返回 true,反之则返回 false。
BOF 与 EOF 都为 False:表示指标位于 RecordSet 的当中。
BOF 为 True:目前指标指到 RecordSet 的第一笔记录。 EOF 为 True:目前指标指到 RecordSet 的最后一笔记录。
BOF 与 EOF 都为 True:在 RecordSet 里没有任何记录。
二、 Move 方法
您可以用 Move 方法移动指标到 RecordSet 中的某一笔记录,语法如下:
rs.Move NumRecords,Start
这里的“rs”为一个对象变量,表示一个想要移动当当前记录位置的 Recordset 对象;“NumRecords”是一个正负数运算式,设定当前记录位置的移动数目;“start”是一个可选的项目,用来指定记录起始的标签。
所有的 Recordset 对象都支持 Move 方法,如果 NumRecords 参数大于零,当前记录位置向末尾的方向移动;如果其小于零,则当前记录位置向开头的方向移动;如果一个空的 Recordset 对象调用 Move 方法,将会产生一个错误。
MoveFirst 方法:将当前记录位置移至第一笔记录。
MoveLast 方法:将当前记录位置移至最后一笔记录。
MoveNext 方法:将当前记录位置移至下一笔记录。 MovePrevious 方法:将当前记录位置移至上一笔记录。
Move [n] 方法:移动指标到第 n 笔记录, n 由 0 算起。
三、 AbsolutePage 属性
AbsolutePage 属性设定当前记录的位置是位于哪一页的页数编号;使用 PageSize 属性将 Recordset 对象分割为逻辑上的页数,每一页的记录数为 PageSize( 除了最后一页可能会有少于 PageSize 的记录数 )。这里必须注意并不是所有的数据提供者都支持此项属性,因此使用时要小心。
与 AbsolutePosition 属性相同, AbsolutePage 属性是以 1 为起始的,若当前记录为 Recordset 的第一行记录, AbsolutePage 为 1。可以设定 AbsolutePage 属性,以移动到一个指定页的第一行记录位置。
四、 AbsolutePosition 属性
若您需要确定目前指标在 RecordSet 中的位置,您可以用 AbsolutePosition 属性。
AbsolutePosition 属性的数值为目前指标相对於第一笔的位置,由 1 算起,即第一笔的 AbsolutePosition 为 1。
注意 , 在存取 RecordSet 时,无法保证 RecordSet 每次都以同样的顺序出现。
若要启用 AbsolutePosition,必须先设定为使用用户端 cursor( 指针 ), asp 码如下:
rs2.CursorLocation = 3
五、 PageCount 属性
使用 PageCount 属性,决定 Recordset 对象包括多少“页”的数据。这里的“页”是数据记录的集合,大小等于 PageSize 属性的设定,即使最后一页的记录数比 PageSize 的值少,最后一页也算是 PageCount 的一页。必须注意也并不是所有的数据提供者都支持此项属性。
六、 PageSize 属性
PageSize 属性是决定 ADO 存取数据库时如何分页显示的关键,使用它就可以决定多少记录组成一个逻辑上的“一页”。设定并建立一个页的大小,从而允许使用 AbsolutePage 属性移到其它逻辑页的第一条记录。 PageSize 属性能随时被设定。
七、 RecordCount 属性
这也是一个非常常用和重要的属性,我们常用 RecordCount 属性来找出一个 Recordset 对象包括多少条记录。如: < % totle=RS.RecordCount %>
在了解了 Recordset 对象的以上属性和方法后,我们来考虑一下,如何运用它们来达到我们分页显示的目的。首先,我们可以为 PageSize 属性设置一个值,从而指定从记录组中取出的构成一个页的行数;然后通过 RecordCount 属性来确定记录的总数;再用记录总数除以 PageSize 就可得到所显示的页面总数;最后通过 AbsolutePage 属性就能完成对指定页的访问。好象很并不复杂呀,下面让我们来看看程序该如何实现呢?{上海治疗阳痿医院}
我们建立这样一个简单的 BBS 应用程序,它的数据库中分别有以下五个字段:“ID”,每个帖子的自动编号;“subject”,每个帖子的主题;“name”,加帖用户的姓名; “email”,用户的电子邮件地址;“postdate”,加帖的时间。数据库的 DSN 为“bbs”。我们将显示帖子分页的所有步骤放在一个名为“ShowList()”的过程中,方便调用。程序如下:
\'----BBS 显示帖子分页----
< % Sub ShowList() %> < % PgSz=20 \'设定开关,指定每一页所显示的帖子数目,默认为20帖一页 Set Conn = Server.CreateObject("ADODB.Connection") Set RS = Server.CreateObject("ADODB.RecordSet") sql = "SELECT * FROM message order by ID DESC" \'查询所有帖子,并按帖子的ID倒序排列 Conn.Open "bbs" RS.open sql,Conn,1,1 If RS.RecordCount=0 then response.write "< P>< center>对不起,数据库中没有相关信息!< /center>< /P>" else RS.PageSize = Cint(PgSz) \'设定PageSize属性的值 Total=INT(RS.recordcount / PgSz * -1)*-1 \'计算可显示页面的总数 PageNo=Request("pageno") if PageNo="" Then PageNo = 1 else PageNo=PageNo+1 PageNo=PageNo-1 end if ScrollAction = Request("ScrollAction") if ScrollAction = " 上一页 " Then PageNo=PageNo-1 end if if ScrollAction = " 下一页 " Then PageNo=PageNo+1 end if if PageNo < 1 Then PageNo = 1 end if n=1 RS.AbsolutePage = PageNo Response.Write "< CENTER>" position=RS.PageSize*PageNo pagebegin=position-RS.PageSize+1 if position < RS.RecordCount then pagend=position else pagend= RS.RecordCount end if Response.Write "< P>< font color=\'Navy\'>< B>数据库查询结果:< /B>" Response.Write "(共有"&RS.RecordCount &"条符合条件的信息,显示"&pagebegin&"-"&pagend&")< /font>< /p>" Response.Write "< TABLE WIDTH=600 BORDER=1 CELLPADDING=4 CELLSPACING=0 BGCOLOR=#FFFFFF>" Response.Write "< TR BGCOLOR=#5FB5E2>< FONT SIZE=2>< TD>< B>主题< /B>< /TD>< TD>< B>用户< /B>< /TD>< TD>< B>Email< /B>< /TD>< TD>< B>发布日期< /B>< /TD>< /FONT>< TR BGCOLOR=#FFFFFF>" Do while not (RS is nothing) RowCount = RS.PageSize Do While Not RS.EOF and rowcount >0 If n=1 then Response.Write "< TR BGCOLOR=#FFFFFF>" ELSE Response.Write "< TR BGCOLOR=#EEEEEE>" End If n=1-n %> < TD>< span style="font-size:9pt">< A href=\'view.asp?key=< % =RS("ID")%>\'>< % =RS("subject")%>< /A>< /span>< /td> < TD>< span style="font-size:9pt">< % =RS("name")%>< /A>< /span>< /td> < TD>< span style="font-size:9pt">< a href="mailto:< % =RS("email")%>">< % =RS("email")%>< /a>< /span>< /TD> < TD>< span style="font-size:9pt">< % =RS("postdate")%>< /span>< /td> < /TR> < % RowCount = RowCount - 1 RS.MoveNext Loop set RS = RS.NextRecordSet Loop Conn.Close set rs = nothing set Conn = nothing %> < /TABLE> < FORM METHOD=GET ACTION="list.asp"> < INPUT TYPE="HIDDEN" NAME="pageno" VALUE="< % =PageNo %>"> < % if PageNo >1 Then response.write "< INPUT TYPE=SUBMIT NAME=\'ScrollAction\' VALUE=\' 上一页 \'>" end if if RowCount = 0 and PageNo < >Total then response.write "< INPUT TYPE=SUBMIT NAME=\'ScrollAction\' VALUE=\' 下一页 \'>" end if response.write "< /FORM>" End if %> < % End Sub %> |
相信大家都应该能完全读懂上面的程序,因此作者就不在此详细解释了。值得注意的是在这段程序中运用了一个小技巧
< INPUT TYPE="HIDDEN" NAME="pageno" VALUE="< % =PageNo %>">
,这是用来在每次调用该 ASP 文件时传递数据的“暗道”,由于我们需要在每次调用程序时传递代表当前页码的参数,可能大家会想到使用 session,但是从节省系统资源和通用性来讲,用这样一个隐藏的 form 来传递数据将会达到更好的效果。
好了,又到了说再见的时候了,如果你没完全看懂本篇中所列的程序,那你必须加把油,看一看 VbScript 的语法;
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
这个bug出现在一年前,当时自己大学还没毕业,刚刚进入一家公司实习。那个时候还没有用seajs或者requirejs那样的模块化管理的库,也没有用一个自执行的函数将要执行的代码包裹起来,于是bug就在这样的一个场景下诞生了。当时自己定位了比较久,也不知道status是window下的一个属性,所以请了高手帮忙定位,高手也是定位了半天才定位出来,只是凑巧将status换了一个名字就正常了,后来我问高手原因,他当时也答不出来,后来就一直没管它了,也忘记了。就在前几天,群里有人在讨论一些bug以及要注意的一些坑,我突然想起了一年前自己遇到过的坑,于是提了出来,在各位高手的讨论下终于搞懂了这个bug出现的原因以及原理,于是记录下,方便那些跟我一样做开发的同学能够绕过这些坑,少走弯路。
1.场景再现(为了方便最简化代码,当时的情景不像下面这么直白的提示错误):
咦,为什么这里status是一个数组,为什么会提示它没有push函数呢,这到底是为什么呢?这个bug对于当时初出茅庐的我来说简直就是一个大挑战,那个时候对调试还不熟,看到bug那个小心脏顿时就有点受不了了,紧张啊,抓狂啊随之而来。因为当时代码量比较多,所以当时不能一下子定位到这里的问题。
2.讨论
我们看到就因为变量名不同,却一个出错一个正常,难道不能将一个数组赋值给status吗?
我们看到将一个数组赋值给status是完全没有问题的,它是数组类型。既然是数组为什么就没有push方法呢?这个时候我们不防打印下status的类型
我们看到我们将一个数组赋值给status,按理说应该是object类型,可是这里却是string类型,string类型没有push方法,这时我们对于为什么报错就没有那么疑惑了。按这样理解的话,就是在给status赋值时确实是将一个数组赋给了它,但是就是在读取status时浏览器强制将status转化成了字符串。我们不防在chrome控制台看看。
看来我们的猜测是对的,赋值成功,在取值的时候将status强制转化为了字符串,那要是将一个对象赋值给status在读取status的时候是不是也会将status转化为json格式的字符串呢?
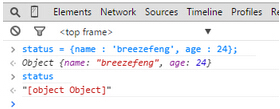
我们看到,浏览器并没有按我们的预期将它转化为一个json格式的字符串,而是转化为[object Object]这样的东东,这不是我们经常用来判断变量的类型吗?一般我们会调用Object.prototype.toString.call(变量)来查看变量类型,因为使用typeof太不靠谱。于是我们猜到在将status转化为字符串的时候是调用了toString方法。
难道status只能是字符串吗?想想status当初设计出来的初衷,它就是为了临时在状态栏展示一些用户信息,所以必须是字符串。这样理解的话就顺理成章了。
所以我们看到使用status来定义变量是不可行的,除非定义的status是string类型,但是有的人就说,经常用status,没啥问题啊。
看,用得挺好的,妥妥的啊。
我们再来看另外一种情况。
xx,报错了,咋回事?在项目中,由于我们的疏忽,有时候定义的变量忘记写var关键字都是时常有的事,在一个代码量很庞大的应用中,定位这样的一个bug肯定需要花费不少时间,而且很容易让人抓狂。
上面那种情况将一个数组赋值给status并调用push方法为啥不出错,这里就涉及到javascript变量作用域的问题了,因为一个自执行函数就是一个作用域,系统在查找这个变量时是先在这个作用域内进行查找,找不到就往上一层作用域中查找,直到作用域的最前端,没有找到就报错提示变量is not defined。这里因为在当前作用域中申明了变量status,所以不会去window环境下去查找status变量,所以是ok的,但是下面这种情况因为没有使用var进行变量的申明,所以status就会成为window下的变量,而status又是window下的一个固有属性,取值的时候只能是string类型,从而没有push方法,最终报错。
所以,为了不给自己制造那么多麻烦,在定义变量时应该尽量避免使用javascript中的关键字、保留字和window下的固有属性进行命名,这些都是坑,实际项目中应该多注意避免。
从以上分析中,我们看到全局的status可以设置,但是读取的时候却调用了toSting方法返回了字符串,这里我们可以利用es5提供的Object.defineProperty来模拟一下这种行为。代码如下:
var a = {}; Object.defineProperty(a, 'm', (function () { var _a = 'xx'; return { get : function () { return _a.toString(); }, set : function (v) { _a = v; } }; })()); |
利用Object.defineProperty方法,可以对一个变量或者属性进行监控,当直接赋值给变量的时候就会调用set方法,当直接读取变量的时候就会将调用tostring方法将变量转化为字符串。
我们看到我们模拟的行为和status默认的行为一模一样。
一年前遇到的bug今天才豁然开朗,这让我意识到针对任何一个小的bug都不应该放过,而要报着打破沙锅问到底的态度去探究,这样才可以看到别样的风景以及让自己更加专业。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
总体是利用
TestNG里面的IRetryAnalyzer、TestListenerAdapter接口来实现相关问题
1、定义一个自己的retryanalyzer
import org.testng.ITestResult; import org.testng.util.RetryAnalyzerCount; //这里集成自抽象类RetryAnalyzerCount,该抽象类实现了IRetryAnalyzer public class TestRetryAnalyzer extends RetryAnalyzerCount{ public TestRetryAnalyzer(){ setCount(1); } @Override public boolean retryMethod(ITestResult arg0) { // TODO Auto-generated method stub return true; } } |
2、定义自己的监听器,集成自TestListenerAdapter
import java.util.ArrayList; import java.util.Collections; import java.util.List; import org.testng.IResultMap; import org.testng.ITestContext; import org.testng.ITestResult; import org.testng.Reporter; import org.testng.TestListenerAdapter; import org.testng.ITestNGMethod; import org.testng.collections.Lists; import org.testng.collections.Objects; public class RetryTestListener extends TestListenerAdapter { private List<ITestNGMethod> m_allTestMethods = Collections.synchronizedList(Lists.<ITestNGMethod>newArrayList()); private List<ITestResult> m_passedTests = Collections.synchronizedList(Lists.<ITestResult>newArrayList()); private List<ITestResult> m_failedTests = Collections.synchronizedList(Lists.<ITestResult>newArrayList()); private List<ITestResult> m_skippedTests = Collections.synchronizedList(Lists.<ITestResult>newArrayList()); private List<ITestResult> m_failedButWSPerTests = Collections.synchronizedList(Lists.<ITestResult>newArrayList()); private List<ITestContext> m_testContexts= Collections.synchronizedList(new ArrayList<ITestContext>()); private List<ITestResult> m_failedConfs= Collections.synchronizedList(Lists.<ITestResult>newArrayList()); private List<ITestResult> m_skippedConfs= Collections.synchronizedList(Lists.<ITestResult>newArrayList()); private List<ITestResult> m_passedConfs= Collections.synchronizedList(Lists.<ITestResult>newArrayList()); public synchronized void onTestFailure(ITestResult arg0) { m_allTestMethods.add(arg0.getMethod()); m_failedTests.add(arg0); } @Override public void onFinish(ITestContext context) { for(int i=0;i<context.getAllTestMethods().length;i++){ System.out.println("~~~~~~~~~~"+context.getAllTestMethods()[i].getCurrentInvocationCount()); if(context.getAllTestMethods()[i].getCurrentInvocationCount()==2){ System.out.println("~~~~~~~~~~~~~~~~~"+context.getAllTestMethods()[i].getParameterInvocationCount()); System.out.println(context.getAllTestMethods()[i].ignoreMissingDependencies()); if (context.getFailedTests().getResults(context.getAllTestMethods()[i]).size() == 2 || context.getPassedTests().getResults(context.getAllTestMethods()[i]).size() == 1){ context.getFailedTests().removeResult(context.getAllTestMethods()[i]); } } } } ... } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
1.LR12是11.52的完成版本,确实觉得整体舒服多了,用起来不是那么别扭了,有些菜单的优化还是不错的
2.对于win8.1和ie11支持确实很好,采用了新的证书策略,效果不错
3.trueclient的录制模式还是和以前差不多
4.对于
手机端的模拟测试多了不少的平台,包括nexus7之类的平台也有了
5.录制支持chrome了,但是我用最新的33还是出现了无响应的问题,不过奇怪的是UFT12对chrome33这样的最新版本支持的很好。
6.提供了直接的端口代理录制模式,用起来很方便直接修改应用的代理地址到LR配置的地址就行了,但是用IE11走代理模式出现了请求录制成功,但返回的页面没有出现的情况,就是请求出去了,但是没返回到浏览器中的情况,实际就是还是没法用啊。
7.runtime setting的这类跟踪调试功能貌似增强了。
总结:
如果你已经习惯用lr11.52了,那么12还是非常值得升级的版本,确实很多地方人性了。
如果你还是传统用户,个人觉得11还是一个最合适的版本,至少用起来还是比12快不少。我的虚拟机是i7 930 2X2+4G内存+raid0硬盘,应该不算很差了。
如果某些特殊的东西实在LR11不支持,你可以试试LR12.
如果你还不知道怎么“
学习版”的话,LR12的默认50个用户策略和可能一直免费的License,会让你少处理很多东西。
如果你是新学LR,个人还是建议你用老版本,因为LR12真没啥学习资料。
如果你是老手,用LR12就和普通的一样,道理明白了新版本真没啥新意。
ps.貌似有个bug就是默认装完了第一次用Load generator的时候系统自动选的是localhost但是其实是没有这个负载生成机的,需要自己去列表里面添加一个再选择了才能跑负载。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters