
一、软件安装
首先通过appstore下载安装Xcode开发工具,当前编写文档时最新版本为4.5.1
二、通过Xcode工具编写运行测试脚本
说明:如果是在IOS模拟器上运行测试用例,需要有被测试应用的源代码才有权限把应用安装到模拟器中,当前示例中使用了自己编写的一个简单Iphone应用,大家也可以直接在网上搜索一个开源的应用即可。
1、当你有了一个应用的源代码之后,在Xcode工具中,首先选中被测应用,然后点击菜单栏中的“Product-Profile”,则会弹出Instruments工具,在弹出的工具中选择IOS Simulator-》Automation,然后点击Profile
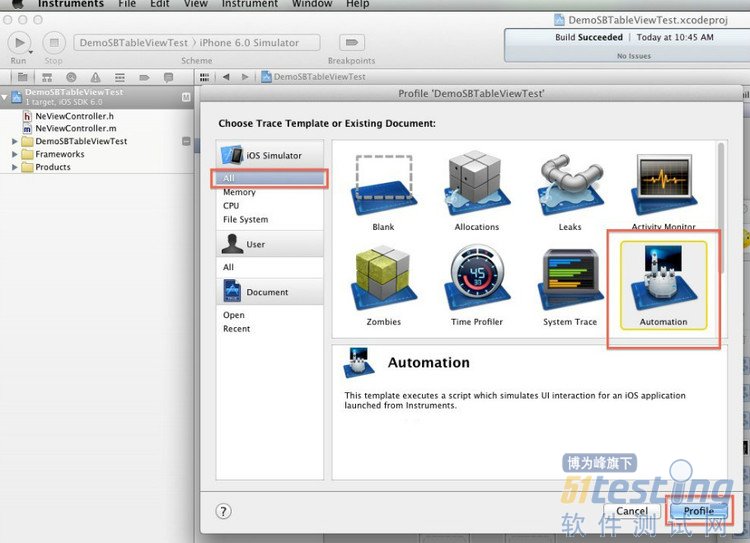
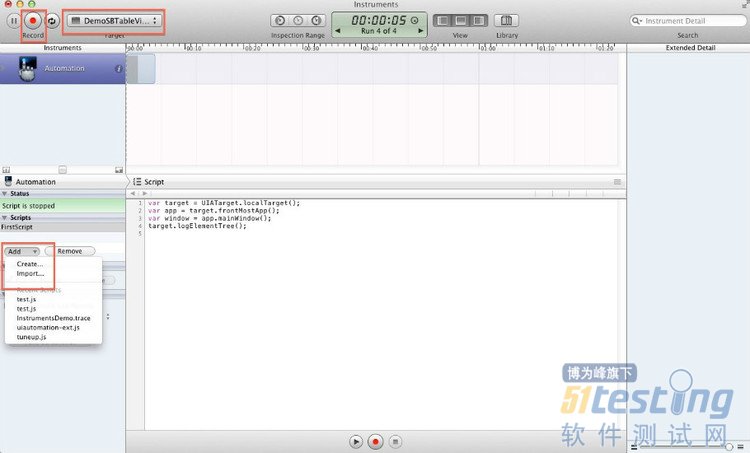
2、在弹出的Automation工具中选择需要测试的项目,同时在Add-》Create 添加测试脚本,点击Create后,在中间区域会出现编写测试脚本的区域,在中间添加以下脚本
//获取当前window对象
var target = UIATarget.localTarget();
var app = target.frontMostApp();
var window = app.mainWindow();
//打印除当前界面的控件数信息
target.logElementTree(); |
具体的API参考官方文档:http://developer.apple.com/library/ios/#documentation/DeveloperTools/Reference/UIAutomationRef/_index.html
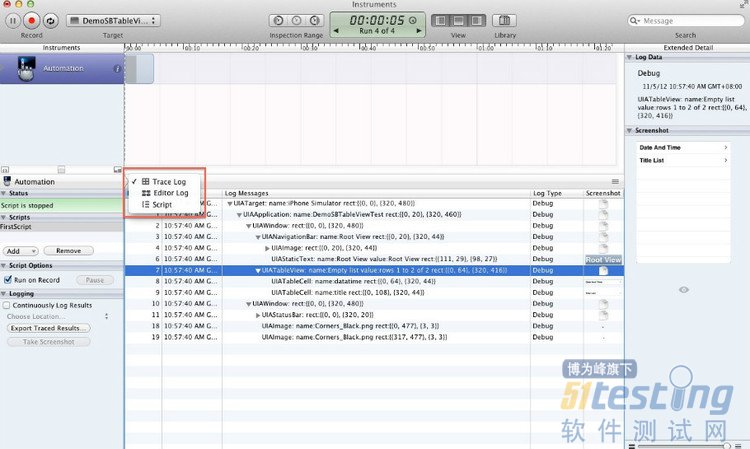
3、点击左上角的Record按钮则开始运行测试用例,运行完成后在工具的中间位置,原来编写代码的地方会出现运行结果的log日志,我们在刚才的代码中编写了target.logElementTree(),这句API会打印出当前页面的控件信息,可以在日志中看到树形结构的控件,点击可以查看控件的一些属性,这个API在编写代码的过程中也会比较有用。
另外如果想切换到编写代码的页面,可以点击图中红框处的进行切换。
注意:通过点击Record来运行测试用例时,代码执行完成后不会自动停止,所以需要手工的点击一下左上角的Stop按钮来停止运行。
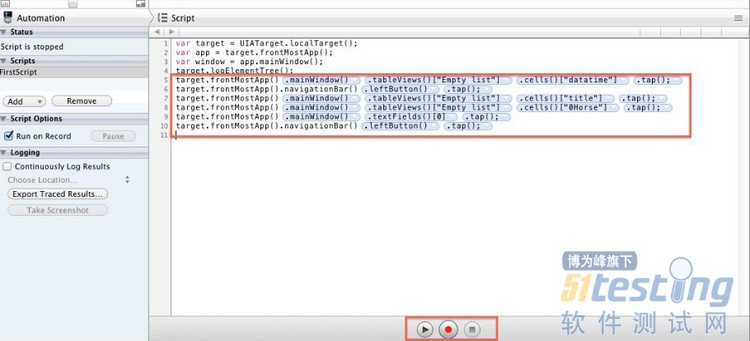
4、录制回放功能
如果你是第一次编写自动测试脚本,可能很多API都不知道,这时候你可以先使用一下UIAutomation的录制回访功能,参考一下大概是怎么来编写测试用例的,当然你也会发现通过录制回访会有很多重复的代码,当你熟悉之后就可以不用录制回访来编写脚本了。
首先你切换到编写脚本的界面,这时候会看到中间的下方会有一个红色按钮,你点击一下就开始录制了,这时候会自动帮你在模拟器中启动起来被测应用,然后你在模拟器上继续点击操作的步骤都会被记录下来。
中间红色区域就是自动生成的代码,你可以点击代码中的箭头能看到不同的API,因为查找到一个元素可以使用不同的路径,对你属性了解API会有些帮助。
录制完成后点击红色按钮旁边的方块形停止按钮,录制就停止了,想要运行的话还是点击左上角的Record按钮就再次运行录制结果了。
三、编写测试用例进阶篇
通过上面你应该了解了大概怎么来使用UIAutomation工具以及编写简单的测试脚本,当时编写的也不算是一个测试用例,最起码的断言操作都没有,那么这一篇我们来将一下如何来编写一个真正的测试用例。
1、元素识别
如果要编写测试用例,我们首先想到要操作的控件元素应该如何去识别找到它呢,第二节我们简单说了一下通过脚本输出控件Log是一种方式可以识别到控件,还有另外一种方式是使用设备自带的Accessibility Inspector功能
在模拟器上,你还可以激活Accessibility 的检测器。启动模拟器,找到“Settings > General > Accessibility > Accessibility Inspector”,然后将它设为“打开”状态。
此时在模拟器上会出现一个覆层,你进入需要测试的应用,鼠标点击相应的控件,如下图所示会看到一些信息,Label就是这个控件的id属性,Traits就是这个控件的类型,Frame就是这个控件的位置以及大小{{36,295},{43,21}},其中第一个位置{36,295}是该控件的左上角的坐标,{43,21}则是这个控件的宽度和高度,通过这两个参数可以算出控件的具体坐标位置。
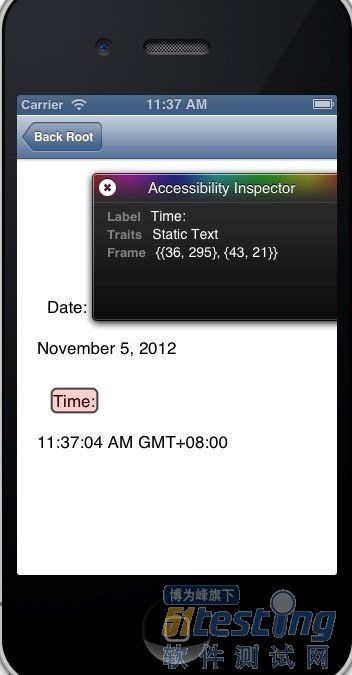
2、编写测试用例
var testName = "FirstTest";
UIALogger.logStart(testName);
var target = UIATarget.localTarget();
var app = target.frontMostApp();
var window = app.mainWindow();
app.logElementTree();
window.tableViews()[0].cells()[0].tap();
target.delay(3);
var date = window.elements()["date"];
UIALogger.logMessage( date );
if (date){
UIALogger.logPass( testName );
}
else{
UIALogger.logFail( testName );
} |
上面是使用了UIAutomation自带的一些API完成了一个自动测试用例的编写,包括了元素查找以及断言操作,但是如果你编写多个测试用例的话会发现一些问题,比如一些代码会有重复,用例组织不是很好,断言操作不方便。
3、tuneup介绍
下面为大家介绍一个开源的基于UIAutomation扩展的JS库tuneup,这个js扩展库是方便大家来编写测试用例。
Tuneup开源地址:https://github.com/alexvollmer/tuneup_js
如何来使用,首先你可以在电脑上新建一个测试用例目录,比如文件夹名称就叫Demo,下面可以新建一个lib子文件夹,存放需要用到的一个扩展库,你下载的tuneup目录内容可以都放到lib目录下,在demo文件夹下新建一个测试用例的js文件,测试代码中只需要把tuneup使用import引用进来就可以使用了,通过tuneup编写的测试用例如下。
#import "lib/tuneup/tuneup.js"
var target = UIATarget.localTarget();
var app = target.frontMostApp();
/* Second是测试用例的注释,可以填写用例的用途,以及编写人等信息 */
test("Second", function(target, app) {
var window = app.mainWindow();
app.logElementTree();
window.tableViews()[0].cells()[0].tap();
var date = window.elements()["date"];
assertNotNull(date,"进入日期详情页面,date属性没找到!"); }); |
四、通过命令行运行测试用例
为了能够实现自动定时运行测试脚本,编写完成的测试用例我们希望是能够通过命令行的方式来启动运行的,那么下面我们介绍一下如何通过命令行来启动运行我们编写好的测试用例。
instruments -t /Applications/Xcode.app/Contents/Applications/Instruments.app/Contents/PlugIns/
AutomationInstrument.bundle/Contents/Resources/Automation.tracetemplate
"/Users/ios/Library /Application Support/iPhone Simulator/6.0/Applications/D02EF837-94F7-457A-989A-A654FC034803 /
DemoSBTableViewTest.app"
-e UIASCRIPT /AutoTest/workspace/IosDemo/test.js
-e UIARESULTSPATH /AutoTest/workspace/IosDemo/lib/ |
上面是通过命令行来运行测试用例的脚本,
-t 后面的参数为Automation.tracetemplate的路径,不用修改,Xcode4.5以后的版本路径都是这个,如果是Xcode4.5以前的路径会不一样
“/User***.app” 这个参数为被测程序的绝对路径,模拟器中安装的应用都可以在本地硬盘中找到
-e UIASCRIPT 指定执行的js脚本
-e UIARESULTSPATH 指定输出结果存放的路径
五、后续基于UIAutomation扩展需要的改进点
1、输出的用例运行结果存在给定的xml文件中, 后续需要解析xml文件,解析成testng的格式,方便后续和Jenkins等持续集成平台整合
2、查找定位元素,只能按照控件层级,一级一级往下找,使用起来有些不方便,需要再次封装一下
3、需要加入外围的一些控制,使整个自动化测试运行完全自动化,另外还需要加入一些失败重跑机制,UI的自动化一般都会存在一些不稳定的因素。
下面是一平安银行的软件测试笔试题目,看你能做出多少题?
单选题
1、下列哪一个不是UML的动态图?(该题为必答题) 4
活动图
序列图
状态图
用例图
2、下面有关系统并发访问数估算数据那个最有效:(该题为必答题) 1
高峰时段平均每秒请求数80
同时在线用户数100
高峰时段日处理业务量100000
平均每秒用户请求数50
3、EJB组件的包文件的扩展名是:(该题为必答题) 1
.ear
.war
.jar
.rar
4、关于进程的叙述哪一项是不正确的(该题为必答题) 1
可同时执行的进程是指若干进程同时占用处理器
一个进程的工作没有完成之前,另一进程就可开始工作,则称这些进程具有并发性
一个进程独占处理器时其执行结果只取决于进程本身
进程并发执行时其执行结果与进程执行的相对速度有关
5、在数据库中,产生数据不一致的根本原因是(该题为必答题) 1
数据冗余
未对数据进行完整性控制
数据存储量太大
没有严格保护数据
6、评估下面的一组SQL语句:
CREATE TABLE dept (deptno NUMBER(2), dname VARCNAR2(14), 1oc VARCNAR2 (13)); ROLLBACK; DESCRIBE DEPT
下面关于该组语句的哪个描述是正确的?(该题为必答题) 3
DESCRIBE DEPT语句将返回一个错误ORA-04043: object DEPT does not exist.
ROLLBACK语句将释放DEPT占用的存储空间
DESCRIBE DEPT语句将显示DEPT表的结构描述内容
DESCRIBE DEPT语句将只有在ROLLBACK之前引入一个COMMIT语句时,才会显示DEPT表的结构描述内容
7、Oracle中VARCHAR2类型的最大长度是:(该题为必答题) 1
4000
3000
1000
2000
8、在下面哪个场景中,索引将是最有用的?(该题为必答题) 1
被索引的列作为表达式的一部分
被索引的列包含不同范围的值
被索引的列用于FROM子句
被索引的列被声明为NOT NULL
9、下列四项中,不属于关系数据库特点的是( ) (该题为必答题) 4
多用户访问
数据独立性高
数据共享性好
数据冗余小
10、关于sleep() 和 wait() 的区别描述错误的是(该题为必答题) 2
wait是Object类的方法
sleep会释放对象锁
对此对象调用wait方法导致本线程放弃对象锁
sleep是线程类(Thread)的方法
11、以下哪行代码会进行对象垃圾回收 (该题为必答题) 2
1.public class MyClass{
2. public StringBuffer aMethod(){
3. StringBuffer sf = new 4.StringBuffer(“Hello”);
5. StringBuffer[] sf_arr = new StringBuffer[1];
6. sf_arr[0] = sf;
7. sf = null;
8. sf_arr[0] = null;
9. return sf;
}
} |
第8行
第7行
第5行
第3行
12、以下循环执行()次(该题为必答题) 1
public class Test{
public static void main(String[] args){
int x=-10,k=0;
while(++x<0){
k++;
}
System.out.println(k);
}
} |
9
10
11
无限
13、如果存在事务上下文,方法调用使用当前事务上下文,如果不存在,则不创建新的事务上下文。这种事务属性在EJB中应该配置为:(该题为必答题) 2
Never
Supports
Mandatory
Required
Mandatory-当使用这个值时,bean方法被调用时必须有一个事务已经处在运行中.
Never-如果在现有事务中调用此bean,容器将抛出java.rmi.RemotException.
Required-bean方法必须总是在事务上下文中执行.
RequiresNew-当方法被调用的时候,bean总会需要启动一个新的事务
Supports可以参与到正在运行的事务中,但这个事务并不是必须的.
Not Supported-该值意味着在事务中bean或者方法根本不能被调用.
14、在Java中,负责对字节代码解释执行的是(该题为必答题) 3
编译器
应用服务器
虚拟机
垃圾回收器
15、在划分了等价类后,首先需要设计一个案例覆盖()有效等价类(该题为必答题) 2
等价类数量-1个
尽可能多的
2个
1个
16、压力测试属于( )阶段(该题为必答题) 1
系统测试
集成测试
用户验收测试
单元测试
17、可靠性测试属于( )阶段(该题为必答题) 2
用户验收测试
系统测试
集成测试
单元测试
18、系统测试阶段的测试对象不包括()(该题为必答题) 2
硬件系统
源程序
软件系统
文档
19、下面哪个描述属于功能需求()(该题为必答题) 4
系统要求能够连续运行1000小时
系统应按J2EE架构进行设计
90%的响应时间小于2秒钟
随机选择5%的用户发送广告消息
20、使用瀑布模型术语,在软件测试V模型中,对应“需求分析”的测试阶段是()(该题为必答题) 1
系统测试
集成测试
用户验收测试
单元测试
21、“均匀分散、齐整可比”这个描述与哪种测试方法一般知识有关:( )(该题为必答题) 1
正交法
决策表
因果图
等价类分析法
22、以下状态迁移图(中括号表示状态,箭头表示边):
[a]->[b],[b]->[c],[b]->[d],[c]->[d],[b]->[e]
则覆盖所有边至少需要()个案例(该题为必答题) 1
3
2
4
1
23、测试系统长时间运行的表现,以期发现一些资源泄露等问题。这种测试类型一般知识是(该题为必答题) 4
强度测试
基准测试
负载测试
稳定性测试
24、软件测试方法一般知识中,___称为功能测试,___测试称为结构测试(该题为必答题) 4
灰盒测试白盒测试
白盒黑盒
黑盒测试灰盒测试
黑盒测试白盒测试
25、项目中的技术风险是通常是通过()方法来缓解的(该题为必答题) 4
架构原型验证
技术文档
代码复审
单元测试
26、软件设计的主要任务是设计软件的结构、模块和过程,其中软件结构设计的主要任务是要确定(该题为必答题) 3
模块的具体功能
模块间的操作细节
模块间的组成关系
模块间的相似性
27、文件系统与()密切相关,它们共同为用户使用文件提供方便(该题为必答题) 3
设备管理
作业管理
处理器管理
存储管理
28、文件的存取方式与文件的物理结构有关,可能有如下的文件物理结构:
Ⅰ.顺序结构Ⅱ.线性结构
Ⅲ.链接结构Ⅳ.索引结构
而常见的文件物理结构是(该题为必答题) 3
Ⅰ、Ⅱ和Ⅳ
Ⅰ、Ⅲ和Ⅳ
Ⅰ、Ⅱ和Ⅲ
Ⅱ、Ⅲ和Ⅳ
29、要想在你的视图上成功的执行查询需要做什么?(该题为必答题) 3
基础表必须在同一个用户模式中
基础表中必须有数据
只能在基础表中有select权限
在视图中需要有select权限
30、数据库中只存放视图的?(该题为必答题) 3
对应的数据
操作
定义
限制
31、在视图上不能完成的操作是(该题为必答题) 1
在视图上定义新的基本表
在视图上定义新视图
更新视图
查询
32、“|DF|A3″.split(“|”).length的结果是()(该题为必答题) 5
5
4
6
7
3
33、下列关于Perl语言说法不正确的是()(该题为必答题) 1
Perl是脚本语言,因此运行速度较慢
Perl的脚本不支持动态加载
Perl比较擅长就是分析处理日志文件
Perl不需要编译器和链接器来运行代码
34、下列代码哪几行会出错:(该题为必答题) 2
1) public void modify() {
2) int I, j, k;
3) I = 100;
4) while ( I > 0 ) {
5) j = I * 2;
6) System.out.println (” The value of j is ” + j );
7) k = k + 1;
8) I–;
9) }
10) } |
line 6
line 7
line 8
line 4
35、关于finally块中的代码描述正确的是:(该题为必答题) 3
异常发生时才被执行
如果try块后没有catch块时,finally块中的代码才会执行
finally块可以不写
异常没有发生时才被执行
36、在面向对象数据模型中,子类不但可以从其超类中继承所有的属性和方法,而且还可以定义自己的属性和方法,这有利于实现(该题为必答题) 1
可扩充性
可靠性
可移植性
安全性
37、关于自动化测试与手工测试的比较,正确的是()(该题为必答题) 3
自动化测试能做的,手工测试不能做
手工测试能做的,自动化测试都能做
谁也不能完全代替对方
自动化测试能做的,手工测试都能做
38、假设i是小于10的整型变量,则表达式 i-10+10==i 的运行结果()(该题为必答题) 3
等于-i
等于i
可能为真,也可能为假
一定为真
39、运用正交设计法可以覆盖()(该题为必答题) 2
所有逻辑分支
所有因素之间的组合
任意两个因素之间的组合
所有数据流
40、采用自顶向下集成的测试方法,需要编写()。 (该题为必答题) 2
客户端程序
驱动程序
条件桩
测试桩
41、功能测试也叫做()(该题为必答题) 1
FVT
ST
PT
UAT
42、使用录制模式产生的自动化脚本,与人工编写的脚本相比,后期维护成本通常()(该题为必答题) 2
不能比较
较高
较低
没有差别
43、某项测试有6个因素,均为布尔量,使用判定表方法,判定表有()行(该题为必答题) 1
2^B194
B194^2
POWER(B194,B194)
6
44、软件测试的目的是( )(该题为必答题) 4
发现软件开发中出现的错误
避免软件开发中出现的错误
修改软件中出现的错误
尽可能多的发现软件缺陷,并确保得以修复
45、黑盒测试也称为功能测试。黑盒测试不能发现(该题为必答题) 4
输入是否正确接收
终止性错误
界面是否有错误
是否存在冗余代码
46、如下参数中不能用于进程间通信的是(该题为必答题) 1
信件
信号量
口令
消息
47、操作系统具有进程管理、存储管理、文件管理和设备管理的功能,在以下有关的描述中,哪一个是不正确的(该题为必答题) 3
存储管理主要是管理内存资源
文件管理可以有效地支持对文件的操作,解决文件共享、保密和保护问题
进程管理主要是对程序进行管理
设备管理是指计算机系统中除了CPU和内存以外的所有输入、输出设备的管理
48、下列关于描述XML和HTML的差异不正确的是(该题为必答题) 3
解析XML的性能优于HTML
XML与HTML互补
XML的语法比HTML严格
XML扩展性比HTML强
49、下面是有关子类调用父类构造函数的描述正确的是(该题为必答题) 4
创建子类对象时,先调用子类自己的构造函数,然后调用父类的构造函数
子类必须通过super关键字调用父类没有参数的构造函数
子类定义了自己的构造函数,就不会调用父类的构造函数
如果子类的构造函数没有通过super调用父类构造函数,那么子类会先调用父类不含参数的构造函数,再调用子类自己的构造函数
50、下面( )是有效明确的功能需求(该题为必答题) 2
两年内存储数据量不超过100G
登录后显示公告栏
界面美观大方
长时间操作后提醒用户休息
当项目需要你的时候,开发人员可能充当不同的角色。比如身边的测试人员说,我不会压力测试。但是现在客户又需要压力测试,那怎么办呢?到底怎么办呢?做为就技术人员的你,这个时候就的勇敢的站出来- 开始研究loadrunner,对框架进行压力测试。
Loadrunner 简介:
LoadRunner,是一种预测系统行为和性能的负载测试工具。通过以模拟上千万用户实施并发负载及实时性能监测的方式来确认和查找问题,LoadRunner能够对整个企业架构进行测试。通过使用 LoadRunner,企业能最大限度地缩短测试时间,优化性能和加速应用系统的发布周期。 LoadRunner是一种适用于各种体系架构的自动负载测试工具,它能预测系统行为并优化系统性能。(摘自:百度知道)
LoadRunner 在网络上以及HP已经提供了相当多的的技术资料。网络上也有很多这方面的资料。至于详细的使用说明本文将不再一一阐述。
本文重点只是给大家分享我在使用loadrunner过程中曾经被困扰过的环节。
一、安装:
loadrunner 的安装需要注意:如你您是XP系统可以安装 loadrunner9.5如果想录制IE8脚本,您需要安装IE8插件。注:这个我自己没试
过,只是有安装过XP的同事有提及。具体的插件安装包,百度一下很容易找到。需要着重强调的是,如果您是win7操作系统,我亲身经历的感受就是装了loadrunner9.5 再装IE8插件,loadrunner 依然还存在各种问题、各种不稳定。网络上有文章指出将Loadrunner9.50升级至
9.5.1或者9.5.2然后在装HP的IE8补丁。最后google了下发现loadrunner最新版本是11。且可以支持WIN7。最后就没在折腾9.5.0版本。直接装上了11版本.
二、网络环境:
当我们使用Loadrunner录制脚本的时候,特别是通过IE录制脚本,要密切注意。安装loadrunner的机器的IE是否开启了代理设置
如果开启,Loadrunner11 在录制脚本的时候会出现各种不稳定。这个问题当时困扰了我很久。
三、录制脚本:
录制脚本属loadrunner 重要环节之一。这里挑出几条个人认为比较重要的来和大家分享:
1、参数设定
我们第一次录制脚本成功后生成C脚本内中的参数都是由web表单客户实际操作的业务数据,但是这些数据都是“硬编码”。简单的说我们把这脚本运行时,会将之前录入的内容插入到数据库内(假设数据校验都是合法)。可是我们的实际压力测试时不可能将录制的脚本只运行一次。实际会根据各种场景各种场合进行策略性的执行已录制脚本。同时我们也需要准备充分的数据集(比如File Parameter)让脚本来执行。这些都可以在脚本内使用Parameter 来替换,比如以下脚本:
web_submit_data("GetProvinceAutoInputData",
"Action=http://192.168.0.1:8080/MasterData/GetProvinceAutoInputData",
"Method=POST",
"RecContentType=application/json",
"Referer=http://192.168.0.1:8080/MasterData/BasCity",
"Snapshot=t14.inf",
"Mode=HTML",
ITEMDATA,
"Name=assemblyName", "Value=", ENDITEM,
"Name=sortFields", "Value=", ENDITEM,
"Name=displayFields", "Value=ProvinceCode;ProvinceName", ENDITEM,
"Name=displayLabels", "Value=鐪佷唤缂栫爜;鐪佷唤鍚嶇О", ENDITEM,
"Name=queryFieldName", "Value=ProvinceName", ENDITEM,
"Name=recordsPerPage", "Value=5", ENDITEM,
"Name=filter", "Value=", ENDITEM,
"Name=parentFieldName", "Value=", ENDITEM, |
其中第14行中“Value=5”这里的5 是由UI段传入的。我们可以通过LoadRunner的参数将其替换,选中5点击右键选择Replace whith a parameter 输入parameter name、parameter type. name值可以取一个容易识别业务的名词。type的选项有13种,其中包括随机参数、自增长参数、文件参数等,这里不做一一介绍,具体的请查看相关文档。通过设置参数,我们就可以在脚本多次运行时候使用不同的业务数据模拟真实的用户操作和并发。
2、loadrunner file parameter 列之间互相依赖
这里提一下file parameter ,试想如果我们有20个用户去录入用户订单(order)。同时维护好订单明细(orderDetails)。假设
订单号是由用户自己输入的且是不能重复的。那么我们需要为这个场景准备录入数据。同时假设20人在某一段时间内录入20个订单
每人录入一个。这里以file parameter来处理录入数据。数据结构如下
OrderCode OrderPrice Operator
0001 100 user1
0002 200 user3
0003 300 user4
0004 400 user5
0005 600 user6
..... |
以上文件在Loadruner中是以dat文件来保存,默认以notepad 打开。数据设置非常简单,唯一需要指出的是参数依赖。
比如我们选择这个file parameter作为某一个业务参数。只能选择order表中的一个列,而不是所有table。所以这里涉及到
table中列的互相依赖。假设一个用户用0001 OrderCode 那么这个用户必然会用到 100 的price和 user1的operator。
列之间互相依赖可以有Vuser -> Parameter List 进入修改界面。通过select next row 栏目选择 same line as 字段名
这样该列就能实现以上所述的列之间的依赖。
3、Loadrunner运行后参数返回值
继续参考Order 和 OrderDetail 例子,假设当Order保存后,应用程序自动生成 一个OrderId,且该OrderId为GUID。
也就是说该OrderId是我们事先无法预知的,也就无法准备该值来进行压力测试。我们以LoadRunner的的录制脚本来讲解这个场景下如何使用LoadRunner。
首先请先参考Loadrunner web_reg_save_param 这个函数参数说明:
语法:int web_reg_save_param(const char *ParamName, <list of Attributes>, LAST);
参数说明:
ParamName:存放得到的动态内容的参数名称
list of Attributes:其它属性,包括:Notfound, LB, RB, RelFrameID, Search, ORD, SaveOffset, Convert, SaveLen。属性值不分大小写
Notfound: 当在返回信息中找不到要找的内容时应该怎么处理
Notfound=error:当在返回信息中找不到要找的内容时,发出一个错误讯息。这是缺省值。
Notfound=warning:当在返回信息中找不到要找的内容时,只发出警告,脚本也会继续执行下去不会中断。
LB( Left Boundary ):返回信息的左边界字串。该属性必须有,并且区分大小写。
RB( Right Boundary ):返回信息的右边界字串。该属性必须有,并且区分大小写。
RelFrameID:相对于URL而言,欲查找的网页的Frame。此属性质可以是All或是数字,该属性可有可无。
Search:返回信息的查找范围。可以是Headers,Body,Noresource,All(缺省)。该属性质可有可无。
ORD:说明第几次出现的左边界子串的匹配项才是需要的内容。该属性可有可无,缺省值是1。如为All,则将所有找到的内容储存起来。
SaveOffset:当找到匹配项后,从第几个字元开始存储到参数中。该属性不能为负数,缺省值为0。
SaveLen:当找到匹配项后,偏移量之后的几个字元存储到参数中。缺省值是-1,表示一直到结尾的整个字串都存入参数。
Convert:可取的值有以下两种:
HTML_TO_URL:将 HTML-encoded 资料转成 URL-encoded 资料格式
HTML_TO_TEXT:将 HTML-encoded 资料转成纯文字资料格式
ok,现在开始在录制脚本内使用这个函数:
//定义这个主表将要生成的ID,具体参数含义参考上文中的web_reg_save_param 参数说明,这里就不再解释了。
web_reg_save_param("Id","LB=Id\":\"", "RB=\"}","Notfound=warning","Search=Body", LAST);
//http服务端保存脚本
web_custom_request("SaveOrder",
"URL=http://192.168.0.1:8080/Order/SaveTmsOrder",
"Method=POST",
"Resource=0",
"RecContentType=application/json",
"Referer=http://192.168.0.1:8080/Order/TmsOrder",
"Snapshot=t10.inf",
"Mode=HTML",
"Body=TnNo=&TnTypeCode=OUTBOUND&FeeTypeCode=AUTO+CALCULATION&ShipperName=%E5%8C%97%E4%BA%AC%E4%BB%93%E5%BA%93&ShipperCode=BJ&ShipperId=0569ccc3-6625-4ffb-b659-2e4fb3b10bc5&ShipperNameEn=BJ&ShipperTypeCode=&ShipperTypeName=&ShipperOfficeCode=BJ&ShipperOfficeName=%E5%8C%97%E4%BA%AC%E4%BB%93%E5%BA%93&ShipperAttribute=0&OriginCityCode=Beijing&OriginCityName=beijing"
"ConsigneeName={ConsigneeName}&"
"ConsigneeCode={ConsigneeCode}&"
........ //在loadrunner 的控制台输出 服务端返回的ID
lr_output_message("%s",lr_eval_string("{Id}")); |
下面如果还有其他地方需要用到这个Id,请使用 "Value={Id}"。
小结:
文中只是提到了本人在实际压力测试中使用loadrunner过程中的一些心得,当然功能强大的Loadrunner 远不止这么一点功能可以来让我们挖掘。比如loadrunner事务的使用、对事务插入集合点等。强大的图标分析器等等
这些就留给读者自己去实践了。
摘要: 简介:在作为系列的最后一篇覆盖的部分是缺陷生命周期的最后一个环节,缺陷的验证。本文主要描述了如何通过 Rational Team Concert(RTC)、Rational Quality Manager(RQM)及 IBM Workload Deployer(IWD)实现缺陷验证的自动化,而且笔者通过一个 RTC web 插件来展现自动...
阅读全文
摘要: entrySet遍历key+value(写法1):Iterator<Entry<String, String>> iter = map.entrySet().iterator(); Entry<String, String> entry; while (iter.hasNext()) { &nbs...
阅读全文
最近负责在上海设立研发中心,准备打造一支适用于敏捷开发的团队,对于团队建设中有几点想法,写出来和大家讨论。
(1) 关于开发手法
敏捷开发讨论中,很多都会去讨论采用XP,还是Scrum,或是其他的开发手法。我们的观点是适合整个开发团队的才是最好的,毕竟开发技术人员是整个敏捷开发的灵魂,开发团队在学习,了解了各种敏捷开发手法之后,实践之后形成稳定的开发速度和质量。
(2) 敏捷开发的核心价值
团队采用敏捷开发,是为了尽快将核心的功能交付市场,加快对市场反馈的对应速度,进一步提高系统的核心竞争力。其实这是从市场的角度来阐述敏捷开发的价值,从技术开发人员角度来讲,如果变化是不可避免的话,如何避免开发进入无休无止的系统式样修改,出现bug,修改的恶性循环之中,这样的过程对于每个开发人员来说都是一个噩梦,整个过程都处于改了一个地方不知道什么地方会受影响而出现不可预测的问题的恐惧之中,直至最后进度的延期和低劣的质量只是客户对我们丧失信心,使得开发人员感到沮丧。
敏捷开发原则,很好的帮助技术人员去回避这样的恶性循环,让技术人员能更好的专注于开发。我们来看几条敏捷开发的实践,都能体会到这些实践都是能让技术人员更好的降低团队出现上述恶性循环的风险
- 客户作为团队成员
只要当团队的每个技术人员都能很好的理解问题域的时候,才可能敏锐的洞察哪些应该抽取,隔离的事物。相对于传统团队,需求分析员,设计人员,编程人员,测试人员各司其职,编程几乎是在完全不理解的状态下的填空状态,怎么可能考虑哪个依存需要倒置,哪个需要做借口隔离。
此次公司的开发项目是公司的互联网项目,项目所实现的核心价值很容易由开发团队制定,这符合了敏捷开发的基本条件。
- 测试优先
不用说也明白,有了测试的系统,才是可能拥抱变化的基础。写测试逻辑的过程,其实是对设计的一次检验,能否简洁的测试,反应了系统对于变化的对应能力的一个指标。
- 重构
其实重构的标准很简单,第一是出现重复的代码,第二是代码的可读性。系统在不断微小的重构之中,防止系统的腐化,而测试优先保证了重构的可能性。
(3)工具的使用
在开发中能很好的运用工具,也是敏捷开发是否能成功的很关键的部分。现在我们主要使用以下工具(服务)
- Yammer
是一款企业内SNS软件。主要用来做用户素材分析。在没有用户需求不明确的时候,在Yammer上和开发人员,管理人员,业务人员一起深度讨论,直到用户素材变得明了清晰。
- Pivotal Tracker
一款很好的Ticket驱动的敏捷开发管理服务,在用户素材明确之后,登入到Pivotal Tracker,然后由开发人员做任务计划。
- github
源文件管理,可很好的和Pivotal Tracker联动,关联Pivotal Tracker的用户素材,便于code review.
先写这些,余下留待一起讨论。
来百度工作有些日子了,在未进入百度之前,由于一直以来百度质量部在业界都是比较低调的,外部的测试同行很少能了解到百度的QA们是如何工作的,如何来应对互联网的研发节奏和质量的平衡。因此我来百度后互联网上经常都有测试工程师找我打听百度的QA是如何做测试的?百度的测试是什么样子?水平如何?对于现在正式QA数已突破1000人的百度质量部所覆盖的工作范围和内容是非常之多的,我也很难用几句话全部描述清楚,因此很想根据我经过这些日子工作对百度质量部的了解,写几篇文章来较详细的给大家分享百度QA是如何工作的。
开篇先说说百度QA们的特点:
从组织结构上百度所有的QA都归属于一个大部门百度质量部统一管理,在一个大部门下的好处是很容易一起跨产品线的协同作战,各种测试技术和测试工具能以最快的速度得到传播,避免重复造轮子的浪费。同时QA们能有一种更强的组织归属感、有着专业的发展通道与空间、关键能交到更多在QA领域与自己志同道合的朋友,扩展视野,所有QA都能从这种大资源池中获益。这一点对所有做测试的人而言更有利于测试专业技能的持续提升。
从我工作所见和感受来看,百度QA有四个主要的工作挑战:职责范围广(覆盖完整的产品生命周期全流程)、 面对产品技术新(如移动互联网、WebOS、推荐引擎)、研发速度快(互联网的节奏)、大数据系统的复杂(百度本质是一个分析处理数据的公司)。这些挑战长期影响着QA日常的工作方式,使得与传统的tester有着工作模式的不同。
百度QA的工作范围覆盖了百度所有形态的产品从基础架构的分布式系统、搜索架构系统、到搜索算法、Web前端、Windows客户端、手机客户端,以及最新的多媒体技术、机器学习等这些前沿的IT业务,因此在这里我能最广泛的接触到各领域测试的QA同行,听听他们的分享,扩展我的测试视野。当然我也有机会到各领域进行测试实战,从我到百度算起,我已在web前端、windows客户端、手机客户端、搜索架构系统、搜索算法、图片搜索领域进行了各种测试实践工作,大大丰富和完善了我的测试技术知识体系,受益不少。
另外百度QA会更完整参与到产品研发流程的周期,从最早的MRD,到设计评审、到产品发布后的效果评测是端到端的参与完整的产品生命周期。与我过去经历最大的区别在于,QA与PM(产品经理)打交道的时间非常多,在整个产品生命周期中几乎是同步一起从头到尾密切配合,同时QA还会为PM设计并开发用于产品评测的平台对产品设计的影响会更多。对于QA与RD的关系,QA不仅只是响应RD提交代码的测试,还会主动去帮助RD如何更好地做好UT(单元测试)、如何做好code review。基于百度QA职责范围的扩大,在百度QA工程师的职责和发展路线上目前来看已大致分为QAD和QAT,至少我在进行职称评定的评审时,已会有意识的区别评估。QAD就是QA中的软件开发者更多侧重测试工具和测试系统的软件开发,我在参加QAD任职评审1对2活动时,基本是以一个对软件开发者和软件产品设计者的角度来进行review,关注其代码质量、软件架构设计思路和产品设计思路的能力。QAT则是标准的Tester,偏重如何尽早的发现更多软件质量问题,要求精通产品的应用场景以及各种测试类型。因此各种风格和兴趣的QA都可以在百度找到自己希望和喜欢的角色,当然有时QAT和QAD也会互换,我个人而言,认为相对而言QAT转QAD容易,QAD转QAT要难些,因为百度的QAT大多具备一定的软件开发能力,平时也会根据工作需求自己做一些自动化测试开发和工具开发的工作。而QAD要转QAT则还需要补充多种测试类型的知识技能,以及产品的业务知识。我在这里目前算是QAT路线,大多时间在思考如何设计更完整的测试避免问题遗漏,以及如何让测试人员在短时间内发现更多的深层次问题,当没有QAD资源来帮助你时,也会自己设计与实现一些小规模的测试系统或测试工具。如果未来某天我的兴趣转换到了QAD的工作内容了也是比较容易获得机会转换的。所以当QA工作的平台足够大时,个人的兴趣也会得到最大化的满足。
在日常的工作中很多百度QA常常还会面对很多新产品技术的挑战,这里的“新”是指新形态的互联网产品(机器学习、推荐系统、多媒体搜索)以及新的软件应用场景(移动互联网和Webos),这些新的被测对象所带来的直接挑战主要是业界很难有现成的完整的测试方案及测试技术,于是不得不逼迫百度的QA比传统软件测试的Tester更加持续地进行测试技术的创新才能满足“新”产品的质保需求。例如:我今年参加的整个百度质量部层面的移动互联网测试技术专项topic组的工作,就不得不去填补诸多业界在移动APP稳定性测试领域、性能测试领域、自动化测试领域技术的空白,否则无法达到真正对高质量用户体验的追求。当业界大多数APP的稳定性测试只依赖Monkey测试工具时,Monkey测试已只占百度最新APP稳定性测试用例类型不到10%的覆盖面,其他90%的稳定性测试方法大多是业界还未知但APP应用又必须要考虑的,否则就会出现“为什么用户会碰到而我无法重现的问题”。当业界还靠移动机型穷尽进行兼容性crash问题的覆盖时,百度的QA已设计实现了基于静态代码自动扫描的兼容性crash问题的快速测试。当很多QA还在为如何在不稳定的2G网络下得到稳定的测试结果而苦恼时,百度QA已靠不到1000元的低成本技术方案很好地解决该问题。同时在完善移动APP测试方案的过程中QA内部还设计开发了不少APP测试工具填补了业界在移动APP测试领域的很多空白。经过我对内部信息的了解,之前官方对外宣传较多的移动云测试MTC只代表了百度QA在移动互联网领域测试技术积累的一部分而不是全部。所以我希望下一步有机会百度质量部能逐渐给业界分享出来,让大家都能受益从而减少移动互联网测试的烦恼和困难。据我在百度的观察我个人总结了一个规律:中国人并不缺创新能力,而是缺逼迫自己去持续创新的压力和平台。正是由于百度QA所处的工作环境和测试对象的特点,逼迫他们不得不去创新,结果QA个人的创新能力在不断提升并形成了创新的习惯。我在这样的环境下,一年下来自己的创新效率感觉比以前也提升了一倍以上,发现原来测试很多领域都有着创新的可能与空间。有朋友问我在百度累吗?我说相比过去身体不累但脑子累因为经常都在思考如何创新地解决所遇到的各种没有现成方案的测试问题。
(第一篇上半部分结束,我会继续编写第一章后面的内容,请各位继续关注)
版权声明:本文出自 架构师Jack 的51Testing软件测试博客:http://www.51testing.com/?293557
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
技术QA是我造出来的词,指的是团队中的自由人,他没有特定的编码任务,只是检查程序代码,并优化代码结构或提出优化代码结构的合理性建议,帮助成员重构其中重复的或低效的代码。
我的建议(包括以前提过的)可以分为三类,一是团队的架构和运营、二是具体技术、三是用人法则。前两个我以前都提过很多,这次我主要提用人法则。
现在项目出现了不少状况,有人员流失,有软件成型困难等,我认为跟用人法则有很大关系。当领导能够因人的不同而赋予不同的角色时,团队的效率、活力、成员的成就感、团队的凝聚力,产品的质量都会很高,反之如果把每个人都当成相同的人来用,所有人都是写代码的程序员,都平均被分配一块任务,我认为会出现成员在接到只能发挥自己三分之一能力的任务时会很没成就感,接到超过自己能力的任务时会很有挫败感,没有成就感的工作会使成员失去向心力,进而流失。我觉得Tony的辞职有这方面的原因,每个人都是不一样的,平均主义行不通,差异化很重要。
微软之所以能够取得今天的成就,我认为有两方面原因,一方面是商业策略的成功,一方面是在软件开发过程中形成了一套合理高效的团队文化,这些经过实践检验的模型和准则统称为MSF(Microsoft Solution Framework)。里面的团队模型包括了开发、测试、用户体验、产品管理、程序管理、发布管理、后勤等如此多截然不同的角色,而各角色间同等重要,因为任何一个出了问题,都会影响到产品的进度和质量。也就是说我想当“技术QA”这个角色并非是想要个官儿当当,因为这个角色并不高人一等,而是跟其它角色平等的,只是分工不同,专业的分工产生高效和优质的劳动。我的意图是做自己擅长的,团队会有更好的成果,自己也能获取成就感,我不是最聪明的,我的自信建立在写过的代码量上,在技术的追求上,以及自我否定精神方面,现有团队中没人比得过我,我达到了俯视现有项目中代码的水平,我能推翻别人,也乐意推翻自己。我担当这个角色,通过读代码,与其他人结队编程等方式,可以在模块划分,接口设计和编码风格方面指导团队成员,编写出健壮的代码,减少Bug,提高质量。这样用于测试的时间将会缩短,成本便会降低,客户满意度会提高, 我觉得你跟Michal和Dawn把道理讲清楚,他们没有理由不支持。
我想当这个角色的第二个原因是,更好的传播知识和应用知识。我以前提过的很多建议基本上在刚开始被否定,但经过解释都被认可,却最终束之高阁无人问津,没有得到贯彻落实。我反省自己,出现这个现象的原因是,“仅仅大概知道”一个新的好的方法,等于0,因为仅仅大概知道,无代码审核机制,人员自己追求技术的主动性又不足(意思不是说大家一点都不重视质量,而是没有达到渴望的程度),最终结果就是不用。知道不重要,做很重要。要能够把好的方法用起来,需要领导的“强力”推广和“深度”的技术沟通,养成代码重构的习惯,当遇到一个新问题时,不是“勤奋”的堆砌,仅仅让代码跑起来完成任务,而是积极研究最佳解决方案,用最少的代码去实现它,“懒惰”的追求“简单性”。研究完后向团队做讲解,经过质疑和完善,得到一个成熟的方案。当遇到一个旧问题时,不是“耐心”的用自己的“笨”方法去实现,而是学习别人已经研究过的成果,用“浮躁”的方式实现它。总之一句话,让质量管理落在实处。
测试的作用只是检查程序的正确性。
一般QA的作用是从管理角度提高产品质量。
技术QA的作用是深入代码内部,在开发的过程中,从技术上提高产品质量,降低Bug率。
所以我认为我们的团队需要技术QA的迫切程度和重要程度超过测试。我们不应该被传统思想所禁锢,应该学会创新思维,积极开创工作新局面。
最后我想说一下代码的问题,我认为如果把软件比做大厦,那么程序员就是地基,软件的架构是柱子,一行行代码是砖瓦。人的作用最重要,起到地基的作用,楼的高度不但决定于人的数量,更决定于人的质量(By the way,质量是可以改进的,但是也是难以改进的,一方面是人的追求不同,他的观念很难被改变,另一方面是智商的限制,比如我再怎么努力也达不到微软的录用标准,成为操作系统的地基)。你所说的用了某种模式可以被认为是某些柱子,但并非所有的柱子,缺少另外一些柱子显然不能支撑起大厦。最重要的是,不能因为一些柱子造好了,就认为砖瓦也是好的。柱子也是代码,从量上说,柱子只是大厦的百分之一,没有柱子就没有大厦没错,但没有砖瓦的大厦只是亭子,只能看不能住。柱子好是必须的,没什么值得炫耀,真正的难点是每块砖瓦都是好的。用破砖烂瓦盖出的只能是危楼,实践证明,它连表面都不会风光。所以我认为,最佳做法是用较少的精力搭出初始架构,之后必须把大多数精力集中在砖瓦上,在开发过程中不断的前进——反省和否定自我——对代码和架构做必要的重构——再前进……周而复始。这种小步快跑的策略也被用于企业的发展。
总结:虽然我不是牛人(牛人都去微软了),但在这个团队中,我有能力当“技术QA”,团队中也急需这个角色。另外,我的心态很好,当不上也不会辞职。
交流是贯穿整个项目之中的,项目收尾阶段,组外之间的交流尤为突出,交流不好,极容易出现问题,作为组长刚开始处理时觉得与组外人员交流很麻烦,因为大家的利益经常是对立,很容易把关系弄僵,但是后来细心观察、思考、实践后,发现一些小技巧,可以巧妙地解决很多问题,又何必大家争得脸红耳赤呢,现在回想起来还是别有一番乐趣的。
交流的前提:调节好自己的情绪
项目中间出了问题,换成谁都得恼火,特别是出现一些比较低级的错误,造成了不必要的损失,这时候你怎么办,马上跑过去,找到当事人,劈头就骂,假如你是别人上级,估计问题不大(其实也有很大问题呀,被骂人很有可能口服心不服)。假如别人跟你是平级或组外人员,再加上责任划分不是很明确,别人本来还有点愧疚感,被你这一骂,逆反的心理起了作用,就跟你吵起来了,大家吵得脸红耳赤,不可开交;等大伙把你们俩拉开的时候,你会发现:好像问题还没解决呀?
出了问题,应该以解决问题为主要目的。情绪一来,火气一大,骂得别人狗血淋头,反过来是你,你受得了吗?在进行交流之前,一定要适当地调节好自己的情绪;是调节情绪再进行交流,而不是心平气和地去和别人交流,因为脾气不是一天两天养成的,一下子达到这境界有可能吗?
说真的,我脾气也不小,特别是刚毕业那一会,几乎是有点属于眼睛容不下沙子,容不了别人犯错。在跟别人吵得脸红耳赤后的两三天,你再回过头看到引发争吵的问题,你会发现那个问题其实也没严重,稍微处理一下就可以解决的事,犯得上吵架吗?(不知道大家有这样的感觉吗?),情绪关键在于调节,以下是我的小方法:
(1)先歇而后行;遇了比较恼火的问题,觉得情绪上不是很好,不要马上去处理,先歇息一下,让其有一小段时间的间隔,比如上午出了点问题,下午再去交流处理,中午就是个间隔;这样做看似是误了些时间,实际则不然;估计你马上过去处理,怒气冲冲了,一般也办不好事情。
(2) 预演骂人;即然有了时间间隔,再加上现在火在心头,可以先预演一下骂人先了,找个没人的地方,阳台,走廊;把你想骂人的话骂出来,想怎么骂就怎么骂,当然最好是在心里或者低声,不要影响到别人。
经过了以上的调节之后,再去跟当事人进行交流,假如这时候还想骂人,那就骂他,经过了调节情绪还是要骂,可见这事比较重要,活该挨骂。不过就我自身,经过了(1)(2)之后,我觉得也没那么严重吧,该怎么处理就怎么处理得了,犯得上骂人吵架吗?就算有责怪也不会是那种骂得狗血淋头的。
关于情绪的小心得:
情绪对工作很重要,情绪好则工作效率高,情绪差则反之;在工作里遇到有些人情绪控制的能力很差,动不动就发火、骂人;这不仅仅是个人的问题,极容易形成怒火传递,例如:上级领导把小组的组长骂了,组长则骂组员,组员只好把怒火发泄在工作上,工作做不好上级领导又火(是不是成了一个循环了?),整个公司充满了火药味,大家一肚子怨气,这又何必呢?做为小组的组长要勇于承担一定的责任,让怒火在组长这一级别止步是很有必要的。
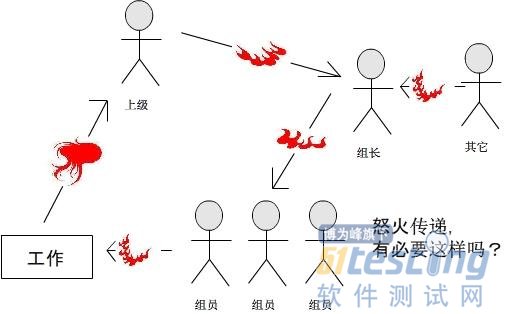
与测试小组的交流
测试小组拿到开发打包的程序,按照设计,需求说明及使用说明书对程序进行相关的测试,测出来的BUG分为如下几个级别(因公司而异):
1、设计中存在功能但产品中没有
2、极其严重的错误导致无法工作
3、一个主要的错误但还可以工作
4、一个普通的错误但还可以工作
5、一个小问题
6、最好能加上的功能
这个BUG级别对开发人员来说比较重要
1、修复错误的时候尽量先修复级别高的。特别是时间紧的时候。还有很多时候都不是把整个程序开发完了再交给测试人员进行测试的,这时候测试人员把BUG表送过来了,但你手上又有任务,这时候只要先把3以上的错误修复即可,即保证了测试能够继续下去,又不会误自己的开发任务。
2、BUG级别是考核开发、测试人员绩效的重要依据,也是之间矛盾产生的根源。测试人员希望找出越多的高级别的错误,这正好表明了程序开发的质量不高,而在程序员这边素有把程序看做自己的孩子这一说法,再加上同一个错误划分级别主观因素比较重,测试人员与开发人员常为了BUG的级别发生争吵(在有些很严格的公司,一定数量某级别的BUG整个软件不能发版,听我一个同学说过,在他公司发生过一个开发人员在拿到BUG表后,直接把测试人员叫出来“单挑”),像这些情况主要是缺少有效的交流造成的,以下是我的做法:
(1)BUG表应先交给开发组组长,组长先过目
一来发现BUG级别划分不当,可与测试组的组长交流,平衡双方的利益,两个同一级别的人讨论下面组员的事,利益冲突不是很大,容易平衡,
二来防止两组组员之间闹矛盾,同一张BUG表由组长交给下面组员,与测试人员直接交给相应的开发人员,效果是完全不同的,前者组员一般是无条件接受,后面则不然。
三来防止两组组员之间作弊,有时两个人员私交太好,会做些小动作,影响组长对组员能力的判断,
四来有利于组长对组员工作的监督,你不知道他的程序出了多少问题,你又怎么知道他修复BUG时在忙些什么呢?
(2)平时多注意融洽感情,不要一见面交流都是工作上的事。像融洽小组内部关系一样,利用空余时间两组可以一起出去活动活动,再则可以在适当的时候请测试小组的人员吃吃便饭,中国俗语:吃了别人的嘴软,拿了别人的手短;这样的话在工作中测试人员说话就客气多了,万事好商量,当然这只为了搞好关系,更有利于开展工作,私下里搞太多小动作也是没必要的,务实才是根本。
与销售人员的交流
假如开发的是产品,在与销售人员的交流主要是对销售人员的培训(这部分的工作可以由开发人员去做,也可以交给测试人员,因公司而异),出现的问题主要有:销售人员在培训时不认真,培训时都说懂了,等去给客户做演示时出了问题就推托是软件的问题,以此推卸责任,到时丢单的责任就说不清了,在培训时,我的做法是:
(1)培训之后一定要进行考核,不及格者有相应处理措施。没有考核就没有压力,没考核,销售人员在下面听课是漫不经心,搞小动作,发短信,玩手机游戏; 一问有问题没,懂了没?个个都说懂,到了客户那就出问题;在培训之前先声明要考核,考核不通过有相应处理措施,这招一出下面的人不但听得认真,问题也多,这才能真正起到培训的作用。
(2)要求销售给客户演示的流程一定要按照之前的规范走,甚至连录入的数据都要求一样。这是确保销售人员在给客户演示时不会出现错误的,特别是程序开发时拖了时间,测试不够深入,这时候连录入的数据都要求与之前练习的一样,因为这时候你不知道程序大概还有多少错误,什么时候会出错,但你只要知道这样操作一定不会出错就够了。
还有个人认为开发人员程序应多与销售人员聊聊天,在闲聊时不仅可以获取到客户的很多想法,还可以从中提高与人交流的技巧,要知道销售人员的主要工作就是与人交流呀!
与客户之间的交流
客户用程序的时候出了问题,当然很着急,人之常情嘛;问题转到开发,去帮客户解决问题,要尽量耐心点并表示一定的歉意,在具体的交流时针对问题有两种大的处理方法。
(1)坦然承认是我方失误,换取客户的理解和信任。
(2)反扯是客户方问题,倒打一耙。
“客户是上帝”,只要说客户用的软件出了问题就应该是我方的失误,采用第一种方法进行处理,其好处也不用我多说了,书上及各种相关的小故事都有很详细的说明;例如:有客户自己电脑中了毒,软件用不了,像这种情况,我们一般也二话不说帮他清毒并弄好防毒的措施。
但客户是上帝,也不能太过份,特别是有些客户是那种得理不饶人,吃硬不吃软的,你跟他说是你的问题,他可就威风了,以此来为难你,让你难堪;遇到这种情况,一律采用方法(2)进行回击,其实软件出了问题,很大部分是客户对软件操作不当,或者环境出了问题,这本来就是有点扯皮的。
在实际操作中我基本上都是使用方法(1)(占99%),毕竟大部分客户都是比较好说话的,相互理解的,再有你责怪我、骂我,有个度我也就接受了。但林子大了,什么样的鸟都有呀,遇到特殊的,方法(2)特殊对待。
相关链接:
工作感言:项目收尾阶段管理