
质量管理是一种组织行为,是为达到一定目标而需要一个群体去努力实现的。去末追本,他的实质和我们个体去实现一件事情没有本质的区别。
简单的说,我们要去做一件事情必须有以下要素:目标,动力,行动和达到目标以后的收获。一个很简单的问题,但却在质量管理过程中被抛弃的问题。我们质量管理的目标是保证产品质量;动力是高质量的产品在市场中的竞争优势;动力就是质量管理;而收获当然是利润了。
老板的利润=市场的收益-研发的成本
研发的成本=人力成本+资源投入成本
所以老板的利润=市场收益-(人力成本+资源投入成本)
假设,市场收益一定,那么增加利润的手段是有减少人力成本和资源投入。人力成本通过减少雇佣人数,压低个人的薪资待遇,尽量不支付除基本工资以外的任何费用等。表现为加班严重,一个人做两个人的活,平时一切都好商量除了涨工资,员工得不到正常的奖金福利待遇,得不到任何培训机会等等。而资源投入一般不会被消减,因为这是保证赚钱的工具。那么众位打工的,自己为什么幸苦的工作却得到那么少的报酬,就是这样造成的。
我们不要怪罪老板,因为他也迫不得已。要想在市场竞争中取得优势,唯一的途径就是成本的优势。
我不是社会学家,但我知道根源所在,不知道别人是否认可。众所周知,我们国家的经济主要为手工制造和原始材料加工,这些初级产品没有任何质量优势,而唯一的优势就是价格。这也是中国获得世界工厂“美誉”的前提,他所利用的就是国内廉价的劳动力和生产成本。举了例子:一双美国某一品牌的运动鞋材料成本为三美元,各种税务成本1美元,但在美国生产地人力成本却需要10美元以上,那么这双鞋的成本为14美元。如果生产线在中国大陆呢?材料成本不变3美元,税务成本肯定少于1美元,而在中国的人力成本最多不过2美元,那么这双鞋的成本就是不足6美元。
道理就是这么简单。中国的经济就是靠着廉价的劳动力发展起来的。我绝对没有说错。
言归正传,在我们软件的质量管理中,所最可能压缩成本的也就是人力成本,这也是为什么公司只招会干实活的人,而不愿意招质量管理人员的原因。在老板看来,多个会干活的人可以多赚钱,而多个质量管理的人,只会给公司增加额外的投入,所以只要目前的管理能够维持下去,那么就没有必要改变它。另外,质量管理是一个漫长的过程,不可能立竿见影,这也是公司缺少动力的原因之一。
所谓质量管理人员的尴尬,在很长的一段时间内将继续持续下去,而想走质量管理这条路得人,必须慎重,因为现在还没有它生存的土壤----公司没有做它的动力。
版权声明:本文出自 kuailederen 的51Testing软件测试博客:http://www.51testing.com/?117068
原创作品,为经作者允许请勿转载,否则将追究法律责任。
这是第一次写博客,是有关JAVA页面设计当中的布局管理器,可能大多数人会选择使用 NetBeans 或者是Eclipse 的组件来实现可视化拖拽组件来达到自己页面设计布局,因为是第一次做界面,总结一下,以供以后复习能用到。
JAVA中Layout Mananager这次界面中主要用到的有BorderLayout、FlowLayout、GridLayout、GridLayBagout
1、BorderLayout是JFrame中的默认布局方式,如果你没有在容器类明确的定义布局方式,它将是默认的布局方式,当你想在容器中添加组件的时候,默认添加到中央的位置,所以第二个组件会遮住第一个组件,下面是BorderLayout 一个小小的例子;
import javax.swing.*;
import java.awt.*;
public class BorderLayout1 {
public BorderLayout1(){
JFrame frame=new JFrame();
frame.add(BorderLayout.NORTH,new JButton("North"));
frame.add(BorderLayout.SOUTH,new JButton("South"));
frame.add(BorderLayout.WEST,new JButton("West"));
frame.add(BorderLayout.EAST,new JButton("East"));
frame.add(BorderLayout.CENTER,new JButton("Center"));
frame.setVisible(true);
frame.setSize(400,200);
}
public static void main(String[] args) {
new BorderLayout1();
}
} |
总结:在整体的界面当中没有很规范能够使用这种布局方式,需要和其他的布局方式进行搭配才能够达到自己想要的界面布局效果。
2、FlowLayout 设置流布局以后你所要添加的组件就会按照顺序排列在容器里面,能保证没有组件会被阻挡起来,当时当你拉动界面的时候会很不满意,组将也同样会想水一样流动起来,如果有使用流布局的容器能够固定大小是最好不过的了,例子如下:
import javax.swing.*;
import java.awt.*; public class FlowLayout1{
public FlowLayout1() {
JFrame frame=new JFrame();
frame.setLayout(new FlowLayout());
for(int i = 1; i <=5; i++)
frame.add(new JButton("Button " + i));
frame.setVisible(true);
frame.setSize(500,100);
}
public static void main(String[] args) {
new FlowLayout1();
}
} |
3、GridLayout 表格布局能将你的组将整齐的摆放在容器当中,当组件的数量超出表格的数量的时候,表格会自动添加来满足组件的数量要求,同BorderLayout 相同,完整的界面一般不会是整齐的表格样式,所以这种布局方式和其他的搭配起来才能够真正的达到你想要的界面效果,下面是个小例子:
import javax.swing.*;
import java.awt.*; public class GridLayout1 {
public GridLayout1() {
JFrame frame=new JFrame();
frame.setLayout(new GridLayout(3,2)); //3行2列的表格布局
for(int i = 0; i < 7; i++)
frame.add(new JButton("Button " + i));
frame.setVisible(true);
frame.setSize(500,300);
}
public static void main(String[] args) {
new GridLayout1();
}
} |
4、GridBagLayout 这个布局方式是最复杂的,它动态的给每一个组件精确的进行位置的约束,为此还专门有个约束的对象GridBagConstraints,总共有11个参数能够对组件进行约束; GridBagConstraints(int gridx,int gridy,int gridwidth,int gridheight,double weightx,double weighty,int anchor,int fill, Insets,int ipadx,int ipady);
gridx和gridy是组件在网格中的位置,这位置的计算方法非常有趣,类似与直角坐标系里面的位置分布;
gridwidth和gridheight 这俩个参数是设置组件在表格当中的大小的,设置的时候要小心一点,自己要有一个界面的草图在旁边参考;
weightx和weighty参数可以设置当你的窗口被拉大(或拉小)的时候,组件所按照什么比例进行缩放,数字越大,组件变化的会越大;
anchor 参数是有两个组件,相对小的的组件应该放在哪里;
fill 参数是当组件所处的动态表格里面有空余的位置的时候,组件将按什么方向填充,这个参数在界面中比较关键一点;
Insets 参数是一个小的对象,其中也有4个不同的参数,分别是上,左,右,下来设置组件之间的间距;
ipadx和ipady是组件边框离组件中心的距离,对有些组件来说这个参数是没有必要的;
感觉有很多的参数来设置一个组件,还有专门的约束对象,其实每次并不是哪一个参数都要重新设置的,下面是一个例子
import javax.swing.*;
import java.awt.*; public class GridBagLayout1 {
public GridBagLayout1(){
JFrame frame =new JFrame();
GridBagLayout grid=new GridBagLayout();
GridBagConstraints c1=new GridBagConstraints();
frame.setLayout(grid);
//为button1进行约束
c1.gridwidth=2; c1.gridheight=1;
c1.insets=new Insets(5,5,0,0); //和上面的组件间距为5,右边为间距5
JButton button1=new JButton("button1");
grid.setConstraints(button1,c1);
frame.add(button1);
//为button2进行约束
c1.fill=GridBagConstraints.HORIZONTAL;
JButton button2=new JButton("button2");
grid.setConstraints(button2,c1);
frame.add(button2);
//为button3进行约束
c1.gridx=0; c1.gridy=1; //动态表格(0,1)位置
c1.gridwidth=4; //组件长占4个单元格,高占一个单元格
JButton button3=new JButton("button3");
grid.setConstraints(button3,c1);
frame.add(button3);
frame.setVisible(true);
frame.setSize(200,150);
}
public static void main(String[] args) {
new GridBagLayout1();
} } |
下面是学校实验里面的一个聊天界面的实现,里面综合了上面讲到的几种布局方式:
import javax.swing.*;
import java.awt.*; public class ChatDisplay extends JPanel{
private JPanel interfacePanel;
private JPanel userPanel;
private JLabel userLabel;
private JComboBox userComboBox;
private JLabel messageLabel;
private JButton sendButton;
private JTextField messageText;
private JTabbedPane textTabbedPane;
private JScrollPane publicScrollPane;
private JTextPane publicTextPane;
private JScrollPane privateScrollPane;
private JTextPane privateTextPane;
public ChatDisplay(){
interfacePanel=new JPanel();
interfacePanel.setLayout(new BorderLayout(10,10));
//两个菜单项
//实例化菜单与菜单项
JMenu[] menus={ new JMenu("File"),new JMenu("Action")};
JMenuItem[] items={new JMenuItem("Save"),new JMenuItem("Exit")};
menus[0].add(items[0]);
menus[0].add(items[1]);
//实例化菜单棒,添加菜单项至菜单棒
JMenuBar mb = new JMenuBar();
mb.add(menus[0]);
mb.add(menus[1]);
//设置菜单条的位置在界面的最上方
interfacePanel.add(mb,BorderLayout.NORTH);
//界面中央的信息面板
//实例化共有和私有的文本域 、 滚动面板、设置不可读
publicTextPane=new JTextPane();
publicScrollPane=new JScrollPane(publicTextPane);
publicTextPane.setEditable(false); privateTextPane=new JTextPane();
privateScrollPane=new JScrollPane(privateTextPane);
privateTextPane.setEditable(false);
//实例化动态选项卡
textTabbedPane=new JTabbedPane();
textTabbedPane.addTab("public",publicScrollPane);
textTabbedPane.addTab("private",privateScrollPane);
textTabbedPane.setTabPlacement(JTabbedPane.BOTTOM);
interfacePanel.add(textTabbedPane,BorderLayout.CENTER);
//界面底部的用户面板
//实例化并初始化化各组件
userPanel =new JPanel();
userLabel=new JLabel(" Send to :");
userComboBox=new JComboBox();
String users[]={"Public","ClientB","CientA"};
userComboBox.addItem(users[0]);
userComboBox.addItem(users[1]);
userComboBox.addItem(users[2]);
messageLabel=new JLabel("Message:");
messageText=new JTextField(22);
sendButton=new JButton("Send");
//为下面的uesePanel面板进行布局
//userPanel 设置为两行一列的网格布局,两行分别放两个面板,userPanel2.与userPanel
userPanel.setLayout(new GridLayout(2,1));
JPanel userPanel2 =new JPanel();
JPanel userPanel3 =new JPanel();
userPanel.add(userPanel2 );
userPanel.add(userPanel3); //第一行的面板 userPanel2 采用网格精准定位布局,并添加一个标签与组合框
userPanel2.add(userLabel);
userPanel2.add(userComboBox);
GridBagLayout gridbag=new GridBagLayout();
userPanel2.setLayout(gridbag);
//对第一行第二个组件组合框进行布局约束,实例化一个对象C
GridBagConstraints c=new GridBagConstraints();
//当组合框被拉伸后所按的的比例
c.weightx=1;
c.weighty=1;
//当组件框所占的单位行数还有剩余的时候,组件的填充方式为水平
c.fill=GridBagConstraints.HORIZONTAL;
//组件与组件之前的距离,参数依次为上 左 下 右
c.insets=new Insets(0,10,0,5);
//将布局约束添加在组合框上
gridbag.setConstraints(userComboBox,c); //第二行的面板 userPanel3采用流布局,添加一个标签,一个输入文本的框,一个发送按钮
userPanel3.setLayout(new FlowLayout());
userPanel3.add(messageLabel);
userPanel3.add(messageText);
userPanel3.add(sendButton);
//放置在页面下方,并添加面板到用户面板中去
interfacePanel.add(BorderLayout.SOUTH,userPanel);
JFrame frame=new JFrame();
frame.add(interfacePanel);
frame.setVisible(true);
frame.setSize(410,400);
}
public static void main(String[] args) {
new ChatDisplay();
}
}; |
界面效果如下:
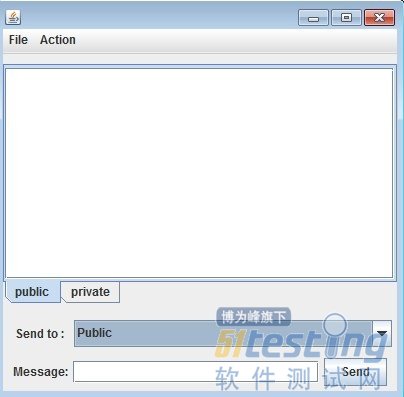
应该总结一下,简单的界面实现,首先需要自己画一个草图,将自己需要的组件都放进去,然后开始敲键盘,复杂一点的界面,借助一点工具是必然的,这样可以省去很大的一部分时间,专注在功能的实现上面。
代码审查是一个好东西,从理论上说,它可以即时(就在代码编写的当天下午)的review代码,以最小的成本发现潜在的隐患,把问题消灭在萌芽状态;同时由于还有至少另外一个人看懂过这部分代码,项目就不会严重依赖于某个个人。但是,在管理中非常忌讳的是一听到先进的东西,就赶紧照搬到企业中,也不管各种配套措施和前提条件是否具备。如同中国的教育产业化。当然也忌讳固步自封,不思进取。
那么,代码审查的前提条件是什么呢?
第一个条件就是要有统一的编码规范,如果一个软件公司这一点都没有做到,那就是彻底的土匪军,代码审查这种正规军的做法就不要考虑了,先把编码规范建立并培训普及起来。
第二个条件就是开发人员要比较多,多到至少一个模块有两个人在做;或者至少每一个模块除了开发者之外,还有一个熟悉理解该模块的人。为什么需要这样,其实很简单,代码审查的目的是要能看懂并真正理解代码和潜在的设计思路,试想如果都看不懂又如何发现问题和以后可能的顶替呢?在一个项目,每个人负责N多个模块,各个模块之间功能、设计、算法差别又很大,如果强制规定必须进行代码审查,那岂不是要求大家都在学习别的模块,并努力发现不符合编码规范(例如没有必要的空行等)的小错误,以应付要求。另外,在这种项目中,每个人的任务都是满满的,谁也不会有兴致和时间去学习另一个陌生的模块。
那么,在不具备第二个条件的软件企业/项目中,是否就无法进行代码审查了呢?也不尽然。在我同事所带领的一个项目中,就采用了另一种方式来进行代码审查,也取得了预想的效果(虽然不是正规意义上代码审查的效果)。在这个项目中,除了项目经理外,其他几个开发工程师都是刚毕业的新员工,所开发的产品已经发展很多个版本,产品规模巨大,模块众多,项目开发人员又不多。如果按照正规意义上的代码审查,结果是预想而知的。那么,该项目经理就采取了另一种形式,就是定期把几个开发工程师召集在一起,来阅读和分析某个开发工程师最近完成的一个小功能,通过对该功能的分析和代码的阅读,项目经理给出点评,变相起到了一种设计培训和代码规范培训的作用。
所以代码审查可以分为两种方式、对应两种目的。
第一种方式是任何软件项目都可以、且应该做的,就是在开发之前或者前期,由有经验者和开发工程师一起来阅读一段代码,有经验者评点这段代码,指出设计上和代码实现上好的或者可以改进的地方,开发工程师可以提出一些疑问,共同讨论;这样主要起到培训和代码规范的目的。这种审查方式不用经常进行,开发初期、尤其是部分开发工程师水平还有待提高时,做3-5次就可以了。投入不大,效果明显。
第二种方式是主要发现代码中存在的隐患和问题为主,一般在开发阶段,每天下午四五点之后,由开发工程师之间,交换检查当天编写完成的代码,检查完毕后,再提交到代码库中。这种方式投入成本高、且必须每个模块都至少有两个人比较熟悉,否则就发现不了存在的隐患和逻辑错误,只能做代码规范层面的检查。但如果一个项目团队拥有了足够的资源保证,就完全可以做到每天进行这样的审查;这种审查可以在第一时间review编写(增删改)的代码,对于提高代码质量,发现并解决潜在的问题有极大的好处,可以大大降低在后期测试或者用户使用中发现缺陷的概率,减少维护的开销,提高产品的品质;从整体上看反而会减少工作量,缩短开发周期。
WebDriver启动的时候很容易无限挂起,直到外围框架设定的超时时间达到而退出运行,给测试运行带来很大的困扰。而实际上WebDriver有一组timeout的设置方法,启动时的挂起属于页面加载的范畴,所以可以考虑用timeouts().pageLoadTimeout()来重新启动一个有效的实例来执行测试。
Java代码:
* Description: catch page load timeout Exception and restart a new session.
* 内容描述:通过页面跳转是否超时来测试WebDriver启动时是否发生挂死异常。
*
* @param driver RemoteWebDriver object.
* @param browser the browser mode.
* @param testUrl the url used to navigate by the driver.get method.
* @throws Exception
*/
private boolean hasLoadPageSucceeded(RemoteWebDriver driver, String browser, String testUrl) throws Exception {
try {
driver.manage().timeouts().pageLoadTimeout(5, TimeUnit.SECONDS);
driver.get(testUrl);
return true;
} catch (TimeoutException te) {
LOG.error("******************本次启动WebDriver异常挂起******************");
setBuildEnvChoice(browser);
driverObjectInitalize();
return false;
}
}
/**
* Description: catch page load timeout Exception and restart a new session.
* 内容描述:循环一定次数测试WebDriver启动是否挂死。
*
* @param driver RemoteWebDriver object.
* @param browser the browser mode.
* @param testUrl the url used to navigate by the driver.get method.
* @param repeatTimes retry times.
* @throws Exception
*/
private void driverStatusTest(RemoteWebDriver driver, String browser, String testUrl, int repeatTimes) throws Exception {
int index = 0;
boolean suspended = true;
while (index < repeatTimes && suspended){
suspended = !hasLoadPageSucceeded(driver, browser, testUrl);
index ++;
}
if (index == repeatTimes && suspended){
throw new RuntimeException("can not start webdriver successfully, it's suspended!");
}
}
/**
* Description: start webdirver after capability settings completed.
* 内容描述:在做好配置之后创建WebDriver实例。
*
* @throws Exception
*/
private String driverObjectInitalize() throws Exception{
if (USE_DRIVERSERVER){//是否使用IEDirverServer
driver = new RemoteWebDriver(service.getUrl(), capability);
return service.getUrl().toString();
}else{
URL url = new URL("http://localhost:" + server.getPort() + "/wd/hub");
driver = new RemoteWebDriver(url, capability);
return "http://localhost:" + server.getPort() + "/wd/hub";
}
}
/**
* Description: start webdirver
* 内容描述:启动WebDriver实例。
*
* @param browser the browser mode
* @throws RuntimeException
*/
protected void startWebDriver(String browser) {
try {
setBrowserMode(browser);
String url = driverObjectInitalize();//about:blank is useless on some machines.
driverStatusTest(driver, browser, url, 2);
driver.manage().timeouts().implicitlyWait(maxWaitfor, TimeUnit.SECONDS);
driver.manage().timeouts().setScriptTimeout(maxWaitfor, TimeUnit.SECONDS);
driver.manage().timeouts().pageLoadTimeout(maxLoadTime, TimeUnit.SECONDS);
} catch (Exception e) {
LOG.error(e);
throw new RuntimeException(e);
}
}
/**
* Description: set browser mode on local machines: do not close browsers already opened.
* 内容描述:选择在本机执行,有人工干预,无需杀掉浏览器进程。
*
* @throws Exception
*/
private void setBrowserMode(String browser) throws Exception{
if (browser.toLowerCase().contains("ie") || browser.toLowerCase().contains("internetexplorer")) {
capability = DesiredCapabilities.internetExplorer();
} else if (browser.toLowerCase().contains("ff") || browser.toLowerCase().contains("firefox")) {
capability = DesiredCapabilities.firefox();
} else if (browser.toLowerCase().contains("chrome")) {
capability = DesiredCapabilities.chrome();
} else if (browser.toLowerCase().contains("safari")) {
capability = DesiredCapabilities.safari();
} else if (browser.toLowerCase().contains("opera")) {
capability = DesiredCapabilities.opera();
} else if (browser.toLowerCase().contains("htmlunit")) {
capability = DesiredCapabilities.htmlUnit();
} else {
throw new IllegalArgumentException("you are using wrong mode of browser paltform!");
}
} |
上面的文档给出的解决方案只是能够部分地解决工具问题,但有时候这种hang死会发生在timeouts().pageLoadTimeout()发生作用之前。也就是说,这需要更为彻底的方法去解决这个问题,我想到最简单的方式是用独立的守护线程去看守,具体代码如下:
[html] view plaincopyprint?private final int DRIVER_STATUS_TEST_TIMES = 2;
private final int DRIVER_START_TIMEOUT = 30000;
/**
* Description: start webdirver
* 内容描述:启动WebDriver实例。
*
* @param browserMode the browser mode
*/
private void startWebDriver(String browserMode){
try {
setBuildEnvChoice(browserMode);
initalizeWebDriver(DRIVER_START_TIMEOUT);
//the address "about:blank" is sometimes useless.
ensureWebDriverStatus(browserMode, getServerAddress(), DRIVER_STATUS_TEST_TIMES);
setPageLoadTimeout(maxLoadTime);
setElementLocateTimeout(maxWaitfor);
setScriptingTimeout(maxWaitfor);
actionDriver = new Actions(driver);
ASSERT = new StarNewAssertion(driver, LOG_ABS, className, logger, devidor);
pass("webdriver new instance created");
} catch (Exception e) {
LOG.error(e);
throw new RuntimeException(e);
}
}
/**
* Description: start webdirver using browser iexplore
* 内容描述:默认选择IE模式创建WebDriver实例。
*/
protected void startWebDriver() {
startWebDriver("ie");
}
/**
* Description: start webdirver after capabilities settings completed.
* 内容描述:在做好配置之后创建WebDriver实例。
*/
private void initalizeWebDriver() {
WebDriverListener listener = new WebDriverListener(LOG_ABS, className, logger, devidor);
if (USE_DRIVERSERVER) {// 是否使用IEDirverServer
driver = new EventFiringWebDriver(new RemoteWebDriver(service.getUrl(), capabilities)).register(listener);
} else {
try {
URL url = new URL("http://localhost:" + server.getPort() + "/wd/hub");
driver = new EventFiringWebDriver(new RemoteWebDriver(url, capabilities)).register(listener);
} catch (MalformedURLException e) {
throw new RuntimeException("illegal url!");
}
}
}
/**
* Description: start and see if webdirver start successfully.
* 内容描述:创建并且判断WebDriver实例是否启动成功。
*
* @param timeout timeout for start webdriver.
* @param redoCount retry times for start webdriver.
* @throws Exception
*/
private void initalizeWebDriver(long timeout, int redoCount) throws Exception {
for (int i = 0; i < redoCount; i++) {
Thread thread_start = new Thread(new Runnable() {
public void run() {// 用一个独立的线程启动WebDriver
initalizeWebDriver();
}
});
thread_start.start();
waitFor(thread_start, timeout);//为启动WebDriver设定超时时间
if (!thread_start.isAlive()) {
return;
} else {
thread_start.interrupt();
consoleError("start Webdriver failed 【" + i + "】 times!");
}
if (thread_start.isAlive() && i == redoCount){// 如果最终没能启动成功则抛出错误
thread_start.interrupt();
throw new RuntimeException("can not start webdriver, check your platform configurations!");
}
}
} |
下面就让我们来看看敏捷流程如何将瀑布式流程的问题逐一破解:
● 瀑布式流程问题之一:
版本发布的时间越来越长。在敏捷流程中,版本是由一系列增量集成在一起组成的,这些增量通过一个一个迭代按顺序开发。我们还可以在任意时间停止迭代。一旦发现产品的价值已经达到最大,尤其是发现软件里过半的功能很少被使用的时候,就可以停止迭代。我们还可以在到达交付期限或者预算上限的时候,停止迭代并发布软件。我们只会开发并积累有价值的增量。
● 瀑布式流程问题之二:
无法按时发布。在敏捷流程中,版本的发布延迟最多不会超过30天,因为每个迭代的最长期限就只有30天。当到达交付期限的时候,就可以交付累积的增量。由于不会在迭代中开发低价值的功能,因此可以比以往更早地发布完整的系统。在传统开发流程中,常用功能占所有功能总数的不到一半。而在敏捷流程中,我们根本不会在不常用的功能上浪费时间。
● 瀑布式流程问题之三:
在版本发布的最后阶段让软件稳定的时间越来越长。在敏捷流程中,每个迭代所产生的增量都是完整和可用的,后续迭代所产生的增量都会包含之前所有迭代产生的增量,因此任何迭代产生的增量都是完成且可用的。也就是说,没有软件稳定化时期,因为软件一直保持稳定。
● 瀑布式流程问题之四:
做计划的时间越来越长,而且不准确。在敏捷流程中我们不再做大而全的计划,而只是设定最终目标,然后确定为了达到该目标所需的高价值功能和特性,同时还会确定交付日期以及估算成本。这样在第一个迭代开始前做计划所需的时间通常只有瀑布式或预测型流程的20%。我们只会为即将到来的迭代的需求做详细的计划,因此我们把每个迭代的计划称为“及时雨计划”。另外值得注意的是,需求是涌现的,在评审迭代产生的软件增量的时候,我们可能会发现下一个迭代需要实现的最佳需求。
● 瀑布式流程问题之五:
在发布期间很难进行改变。版本发布中期的概念在迭代增量式项目中已经不复存在了。我们能够以最小的代价,在每个迭代开始前发现或者提出需求。
● 瀑布式流程问题之六:
质量持续恶化。在敏捷流程中,每个迭代产生的增量都是完整可用的。因此,增量必然已经通过质量测试。而后续迭代产生的增量同样要满足相同的质量要求,也就是说我们再也不必在项目的最后阶段为了赶上交付期限而牺牲质量,因为质量始终伴随着这个软件的整个开发过程。
● 瀑布式流程问题之七:
拼命竞赛进度使员工士气受挫。版本稳定化阶段已经不再需要了,因此加班的“死亡之旅”也随之而去。
这几天看了看《硝烟中的Scrum和XP》,其中作者将产品质量分为两种——“外部质量”和“内部质量”。作者认为,在项目工期紧的时候,外部质量是可以妥协的。而内部质量是不容妥协的。但是,哪些问题属于内部质量呢?
作者并没有详细的论述这个问题。下面,我列出了一些常见的场景和划分。你怎么看待这个问题呢?
外部质量
● 可扩展性
我一直认为,一个没有明确的目标的可扩展性设计往往会变成过度设计。因此,我觉得可扩展性相关的质量问题应该作为外部质量看待。敏捷中强调 做的刚够就好。
● 功能不完整的实现
有些时候,对某个功能模块的实现中存在 明显的 功能不完整。这一点我认为也是外部质量。因为,我们采用迭代式开发的目的就是可以逐渐的完成这个功能。但是,我认为这种功能不完整应该是 显而易见 的。否则,我认为就属于内部质量中的“逻辑严整性”和“语义清晰性”的问题了。
● 性能
性能优化往往会牺牲架构的简单性和代码的可维护性。而且,我个人认为从实际的产品角度来看,性能只有“能够接受”和“不能接受”的差别,而没有“好”和“不好”的差别。因此,我认为它是产品是否能够验收的一个重要指标。但不是一个我们应该时刻关注的质量问题。
内部质量
● 代码规范
混乱的代码意味着更加难以维护。划分外部质量和内部质量的一个重要标准是:对产品的可维护性有很大影响的质量问题应该称之为内部质量。因此,我认为代码规范为“内部质量”。
● 设计和实现的逻辑严整性
例如:你设计了一个集合类,就应该确保集合的基本增删改操作正确。你可以在集合的删除操作中抛出“NotSupportException”或断言错误以标示该集合是一个只增集合。但是,你不能通过忽略删除方法的实现来达到同样的目的。
另外一个逻辑严整性问题的例子是:Equals方法和GetHashCode方法实现上。你可以同时不实现这两个方法。如果实现,就一定要实现正确。不能因为目前没有需求将该对象作为Hashtable的Key,而忽略GetHashCode的实现。
一个逻辑上不严整的设计往往会对将来使用该模块的开发人员造成误导。 最终造成可维护性问题。因此参考上面的原则,我认为这一条应该归为“内部质量”。
● 语义清晰性
这一条和“逻辑严整性”类似。不能在方法命名等地方出现语义上的不清晰。对将来的使用者造成误导。
关于划分原则的思考
● 对产品未来可维护性有影响的点应该归为内部质量
正因为“可维护性”往往是一个不易被觉察的问题,我才觉得可维护性是团队最应该关注的质量问题。是不能够放弃的底线。相对而言,“可扩展性”和“可维护性”如此相似,却恰恰相反,它看起来如此美妙。但,过度设计往往都是因为对“可扩展性”的追求而导致的。它反而是我们程序员应该时刻警惕的东西。
● 内部质量往往比较虚,而那些清晰明确的问题或目标个人认为归为“外部质量”比较好。
人的精力是有限的,正因为这种有限性,让我们需要建立一些简单的原则来帮助我们将精力放在更重要的问题上。尽可能减少我们关注的范围,会让我们在这个范围内做的更好。因此,我觉得应该尽可能的将那些显而易见的问题排除出“内部质量”问题之外。这样,我们才能够更好的控制“内部质量”。那些显而易见的问题,其实,往往都不是问题。
● 性能
这一点我一直很犹豫,因为往往一个不好的架构会导致难以修复的性能问题。但是,就这个话题而言。我还是更加倾向于将性能看做是外部质量。因为它往往是显而易见的。产品的Master,Customer等等很多人会关注与这个问题上。很多时候,在产品前期准备的时候就已经提出了明确的性能要求。因此,它是一个重要的产品测量点,但是,不是“内部质量”。
摘要: 在做页面自动化(以使用selenium为例)的时候,很常见的一个场景就是输入密码。往往对于输入框都使用WebElement的sendKeys(CharSequence... keysToSend)的方法。 Java代码1./**2. * Use this method to simulate typing into an element, which may set it...
阅读全文
本文主要介绍使用LoadRunner手工编写Windows Socket协议测试脚本的方法。
通过LoadRunner编写Windows Socket协议测试脚本,总体说来,比较简单。就像把大象放进冰箱一样,总共分三步:
第一步:把冰箱门打开
//建立到服务端的连接 rc = lrs_create_socket("socket0", "TCP", "LocalHost=0", "RemoteHost=128.64.64.23:8988", LrsLastArg);
if (rc==0)
lr_output_message("Socket was successfully created ");
else
lr_output_message("An error occurred while creating thesocket, Error Code: %d", rc); |
第二步:把大象装进去
lrs_send("socket0", "buf0", LrsLastArg); //往"socket0"发送"buf0"中的数据lrs_receive("socket0", "buf1", LrsLastArg);//将"socke0"中返回的数据存放到"buf1"中 |
第三步:把冰箱门带上
//关闭连接
lrs_close_socket("socket0"); |
整个脚本关键是在第二步,要把这么一头大象装到冰箱里可不是件容易的事情,我们要对传送的数据做一些处理才行。LR会把你发送的数据包内容写到data.ws这个文件中,那么我们在此也同样应该把数据写到data.ws中去。假设我要发送的是“00100312303456”这一串字符,那么我就直接把它写到data.ws中,脚本如下:
| ;WSRData 2 1 send buf0 10 "00100312303456" //注意要加"" recv buf1 128 -1 |
运行脚本,可以看到执行成功。在日志信息中可以打印出发送的BUFFER和接收到的BUFFER内容。
接下来,我们要对发送的字符串进行参数化,让脚本每次发送的字符串都不一样,怎么做呢?有两种方法可以实现:
直接参数化。在data.ws中直接进行参数化,要注意的是默认的参数名称符号是尖括号(<>),和HTTP协议的大括号({})不同。脚本如下:
send buf0 106
"<string>" //string是自定义的参数名 |
第二种方法则麻烦一点,下面重点做个介绍。
事情是这样的:如果我要发送的数据是很通过简单的方法拼接起来,最简单的例子,如“用户名(假设是123)+密码(假设是456)”,在这种情况下,使用第一种方法就够用了,我可以设置两个参数<username>和<password>,写成下面的方式就可以了。
send buf0 106
"<username><password>" |
但是情况稍微复杂一些,发送的数据格式还需要加上字符串的长度,比如在上面的例子中,需要这样表示:00100312303456。
前四位0010是表示后面发送的字符串总长度是10,后面的03则表示用户名有3位,再后面的123才是真正的用户名,再后面的03456也是同样的道理。而每次发送的用户名长度不同,字符串也就不同,比如用户名如果是1234,那么我的报文就应该是这样“001104123403456”这样一来,我就不能通过简单地拼接的方式来发送了,而需要再对它进行一些处理:
char data[200];
char length[20]; len = strlen(lr_eval_string("{usermame}"));
sprintf(length,"%d",len);
strcat(data,length);
strcat(data,"{username}"); //然后,再通过lrs_save_param_ex函数把该数据保存到data_param参数中。 lrs_save_param_ex("socket0", "user", data, 0, strlen(data),NULL, "data_param"); //最后,在data.ws文件中使用data_param参数发送数据包:
send buf0 "<data_param>" |
本文转载自:http://lovesoo.org/how-to-use-loadrunner-to-write-socket-protocol-script.html
相关链接:
LoadRunner录制Socket协议脚本乱码调研
最近在测试过程中使用LoadRunner录制Socket协议脚本,在data.ws中,中文参数显示为乱码,直接影响到参数化等操作,导致压力测试无法继续下去。本文对录制脚本的乱码问题进行了相关调研。
使用LoadRunner录制的脚本如下:
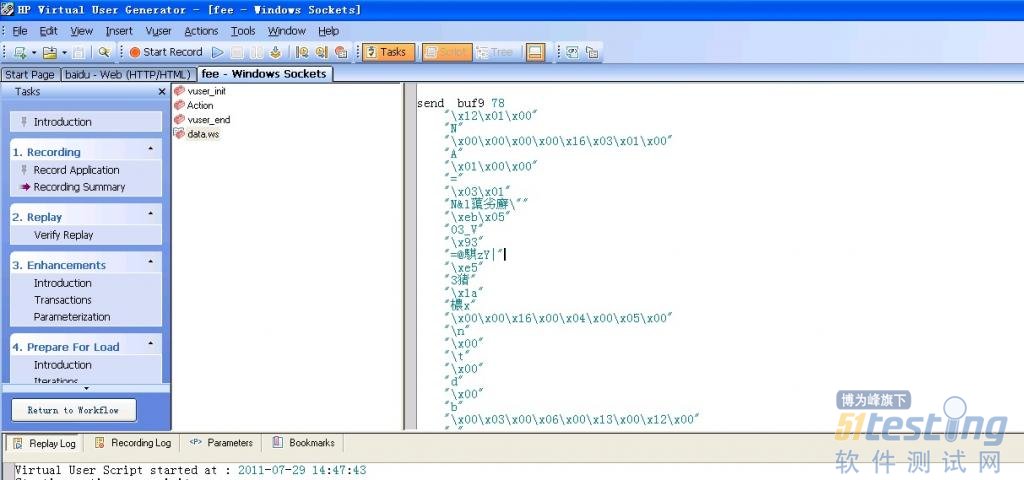
通过在网上搜索资源,查询到几种解决方案如下:
■ 方法一:通过字符串编码转换的函数修改脚本中的乱码;
通过一个字符串编码转换的函数lr_convert_string_encoding
在LoadRunner中,为我们提供了一个字符串编码转换的函数lr_convert_string_encoding,它可以把字符编码转换为UTF-8格式。
测试组人员通过对比发现,这个函数是在录制的脚本中出现乱码时使用的,例如:
web_custom_request("CALL-H001I",
"EncType=text/xml; charset=UTF-8",
"BodyBinary=CALLH001I1040浣忔埧01
鏆傛棤鍙风爜1
11000000
1000000.00A110102641122043#1闇嶈景榫"
"""x99"
"10001鍘﹂棬100 |
但本次遇到的问题是在录制结束后,data.ws文件的中文参数显示为乱码。问题仍然得不到解决。
■ 方法二:录制选项中的Support charset选中UTF-8再重新录制
这种方法是在录制前,将录制选项的Support charset选中UTF-8后进行录制,这种方法主要适用于WEB页面录制时的场景。在录制使用Socket协议时,录制选项中没有Support charset,导致问题也不能解决。
■ 方法三:更改服务器操作系统的语言
将操作系统语言修改为英语,重启机器后,重新录制脚本,乱码问题即可解决。
但实际情况是,将操作系统语言改为英语后,重启机器,重新录制脚本,乱码只是变换了一种形式而已(且文件名称或目录中有中文时会显示成“??”),问题仍然无法解决。
■ 最终解决方法
网上也有资料说这个问题无法解决(汗!!!),因为录制Socket协议是LoadRunner直接监控TCP这一层的数据流,任何数据,虽然在最顶层应用层时是可见数据,但是一旦到了TCP层,均被封包成二进制。
所以呢,看来要用LoadRunner来测试Socket,还是得通过手写脚本的方式来实现。方法呢,其实很简单。看下一篇吧!