
预取的概念相当简单。我们通常能知道在浏览器运行之前可能需要的资源。预取技术包括将可能需要的页面或资源信息传达给浏览器以便其提前下载,或者在浏览器调用之前将资源下载到浏览器缓存里,这样请求和下载对象这些系统开销可以优先得到处理或以一个无阻碍的方式完成。
预取内容有很多方法,这里有三个简单的选择。
DNS预解析
DNS是实现人类可读的域名(mysite.com)到计算机可读的IP(123.123.123.123)的映射的协议。DNS解析非常快,每次都在100毫秒内,它必须在任何请求发送到服务器之前进行,这就会引起一个对页面整体加载时间有实际影响的级联反应。我们都知道其他一些域名在随后的页面或者用户会话需要加载资源,例如静态内容的二级域名(images.mydomain.com)或第三方内容的域名。有一些浏览器支持使用meta标签来识别需要被解析的域名,这样一来浏览器可以提前解析它们。通过使用下列的标签做到这一点是十分简单的。
<link href="//my.domain.com" rel="dns-prefetch" />
<link href=http://my.domain.com/ rel="prefetch" /> <!– IE9+ –>
添加这一标签使得浏览器可以提前解析DNS,而不是等到资源请求之后才开始解析。对网站上游客可能会访问的其他页面进行DNS预取可能是最有价值的一项技术。Chrome、Firefox以及9.0以上版本的IE浏览器都支持这一特性。
尽管减少几百毫秒看起来微不足道,但汇总起来之后就是一个值得注意的收益。这也是一个安全的优化方法并且易于实现。我很好奇这种技术的使用率,于是我访问了Alexa网站上排名前十万的网站。事实表明只有552个网站(0.55%)目前正在使用DNS预解析技术。这只是成功的一小步,还有更多的网站需利用这种技术。
资源预取
现在,图像占据了很多主流网站总字节数的一大部分。通常,发出请求和下载图像这两个系统开销对性能有显著的影响。不过许多情况下,网站开发人员都知道在什么情况下图像需要不被浏览器过早地检测到,例如通过ajax请求或其他用户在页面操作而加载的图像。资源预取是提前将图像、脚本、样式表或其他资源加载进浏览器。这经常用来处理图像,但也可以处理其他可放在浏览器缓存的资源。
我在这里所提到的三种技术目前为止都是最经典和最常用的。可惜我不能给出一个具体的使用数,因为通过我在访问Alexa时检测到有太多方法可以实现。然而,许多网站没有正确利用这种技术,甚至只预加载一些会引起巨大的用户体验差异的图像。
页面预取/预渲染
页面预取和资源预取十分相似,除了我们实际上让新页面提前自行加载这一点之外。Firefox是第一个使用此技术的浏览器。通过使用下列的标签,你可以提示浏览器预取某个页面(或个别资源)。
<linkrel="prefetch" href="/my-next-page.htm">
在预渲染的情况下,浏览器不仅下载页面还下载页面所需的资源。它也开始在内存里渲染页面(用户不可见),如此一来当页面请求发出时,浏览器就能将页面瞬时呈现给用户。Chrome是首个采用这种技术的浏览器。通过使用下列的标签,你可以提示浏览器预渲染某个页面。
<linkrel="prerender"href=http://mydomain.com/my-next-page.htm>
目前为止,与另外两种技术相比,这一技术目是风险最高并最饱受争议的。只有在十分确定用户接下来将浏览哪一个页面的情况下才能进行预渲染。谷歌在这方面是最有名的例子,在有十足把握的情况下它将会预渲染第一个结果页。在我所访问Alexa排名前十万的网站中,我仅发现有95个这样做的网站。尽管这一技术显然不是针对每一个用例,但我认为更多的网站应充分利用这种技术以便改善用户体验。
缺点
通常情况下,预取往往是一个有争议的话题。很多人认为预取不仅效率低下,还导致了带宽的浪费。它还使用了不必要的客户端资源(特别是在移动设备上)。另外值得一提的是,在某些情况下,由于没有明显的方式去辨别是用户访问页面(并浏览它)还是浏览器在用户不知情的情况下预渲染的,预取或预渲染页面会对分析和日志跟踪造成不良影响。
结论
不管所有这些警告,预取可以算得上是一个巨大的胜利。我们永远不必追求最快,但通过将更多的数据储存在缓存里这一技术,我们能更接近这一目标。通过在用户操作之前发起这些巨量的请求,即使是用最慢的网络访问最慢的网站,我们也能大大提高它的感知性能。如果你尚未确定这样做,在你的网站使用这些技术是值得一试的。结果会有所不同,请确保使用真实的用户测量(如Torbit这一网站)找出你的网站还有多少改善预取的空间。
本文转载自:http://automationqa.com/forum.php?mod=viewthread&tid=1710
写在前面
研究iOS的自动化测试也有些日子了,刚开始的时候,一直苦于找不到什么好的资料,只能从Apple的官网查阅相关的API文档,只可惜,Apple对开发者来说实在是不怎么友好,文档写得相当的粗略,对于初学者来说有一定的难度。
本来是打算自己动手写一篇关于iOS的UI自动化测试的入门级别的介绍性文档的,但想起来后面在具体解决一些问题的时候,收藏一篇很好的Blog,很全面地介绍了如何使用UIAutomation的JavaScript Libraries做iOS程序的自动化测试。如果作者早点看到这篇文章,应该要少走一些弯路,这里没有创意性的把他翻译成中文,希望对你们有一些帮助。
快速入门
自动化测试代码可以“在你的睡着的时候”很好地帮你测试你的应用程序。它可以让你能够快速地跟踪你程序中的回归和性能方面的问题,这样你就不用担心你新增的功能会影响到你之前已经完成开发的程序了。
随着iOS4.0的发布,苹果公司同时发布了一个名为UIAutomation的测试框架,它可以用来在真实设备和iPhone模拟器上执行自动化测试。但官方关于UIAutomation的文档相当的有限,在网络上也没有太多的资源可以查找的。本文将向你展示你如何将UIAutomation整合到你的工作流程当中去。
作为基础知识的准备,你可以先看一下苹果公司关于UIAutomation的文档,另外还有一篇快速入门的介绍苹果Instruments的文档也值得看看,当然,如果你有一个免费的Apple开发者账号的话,你可以看一下WWDC 2010 - Session 306 – 使用Instruments进行用户界面自动化测试的幻灯片或者视频。
除此之外,包括在Xcode中的OCUnit测试框架也可以用来为你的应用程序编写单元测试。
1、第一个UIAutomation测试脚本
● 使用iOS 模拟器
● 使用iOS设备
2、处理UIAElement和元素可访问性(Accessibility)
● UIAElement层次结构
● 模拟用户操作
3、经验分享(让你的生活变得更简单)
● 类库Tune-up介绍
● 导入外部脚本
● 使用强大的命令行
● 使用录制交互功能
● 当遇到问题时,加上“UIATarget.delay(1);”
4、高级交互
● 处理非预期和预期的提示框(alerts)
● 多任务
● 屏幕方向
5、总结
● 有用的链接
● 一个视频
1、你的第一个UIAutomation测试脚本
UIAutomation的功能测试代码是用Javascript编写的。UIAutomation和Accessibility有着直接的关系,你将用到通过标签和值的访问性来获得UI元素,同时完成相应的交互操作。
下面让我们来编写我们的第一段测试代码。
使用iOS模拟器
1)下载示例应用程序TestAutomation.xcodeproj,并打开它。这个项目是一个很简单的包含2个tab的tabbar应用程序。
2)确保选中如下图所示的“TestAutomation > iPhone 5.0 Simulator”模式(或许你已经切换成5.1了,因此它可能是iPhone5.1模拟器)。
3)启动Instruments(Product > Profile),或者通过⌘I。
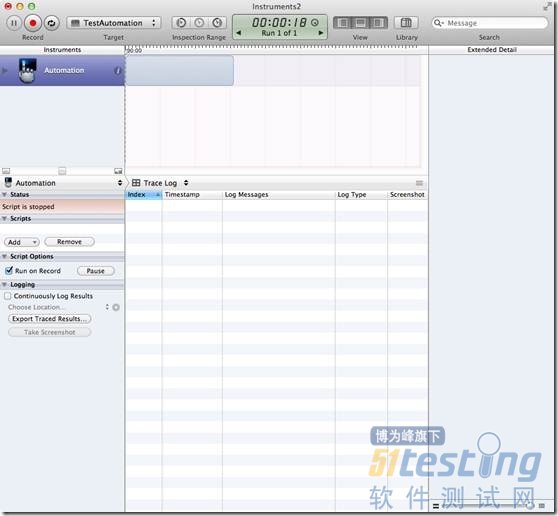
4)选择左边的iOS Simulator,然后再选择Automation模板,然后点击“Profile”。

5)Instruments就已经启动好后,然后直接开始录制了。这里先停止录制,(红包按钮或者⌘R)。
6)在左边的Scripts窗口,点击“Add > Create”创建新的脚本。
7)在脚本编辑器里,输入下面的代码
var target = UIATarget.localTarget();
var app = target.frontMostApp();
var window = app.mainWindow();
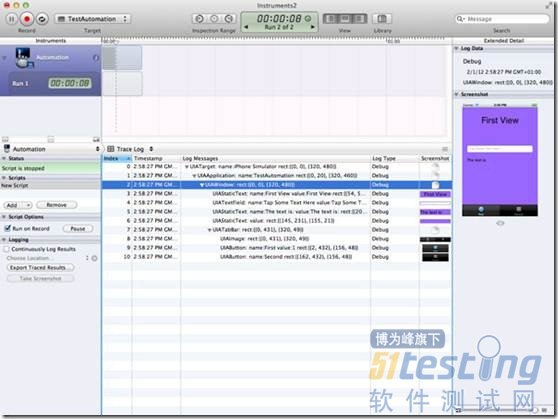
target.logElementTree(); |

8)重新运行这段脚本⌘R(不需要保存)。脚本跑起来后,你可以在日志打完后停止它。
赞一个!我们就这样完成了我们的第一个UIAutomation测试用例。
使用iOS设备
你除了将你的测试用例运行模拟器上,也可以将它运行在一个真实的设备上。不过,自动化测试用例只能运行在支持多任务的:iPhone 3GS,iPad,iOS > 4.0等设备上。遗憾的是不管iPhone 3G的系统版本是什么,都不支持。
下面是如何操作:
1)通过USB接口连接上你的iPhone。
2)选择 “TestAutomation > iOS Device”模式。
3)确保Developper profile设置成Release模式(而不是Ad-Hoc Distribution profile)。默认情况下,profiling是设置成Release模式的(因为没有必要将profile设置成Debug模式)。
4)启动测试 (?I)
5)后面的步骤请参考前面模拟器部分。
2、处理UIAElement和元素可访问性(Accessibility)
UIAElement层次结构
Accessibility和UIAutomation有密切的联系:如果一个控件的Accessibility是可以被访问的,你就可以设置和读取它的值,作相关的操作,而当一个控件的Accessibility不可见时,你就没有办法通过automation访问它。
你可以通过Interface Builder,或者通过在程序里设置isAccessibilityElement属性的方式来设置一个控件的Accessibility或者可被自动化。当你设置container view(即:一个视图包含其它的UIKit元素)的accessibility时,你必须注意。你设置了整个View的accessibility将会“隐藏”它的子视图的accessibility,例如:在示例项目中,你不能将outlet视图设置成可访问的,否则它所有的子控件将都不可以访问了。在任何时候,logElementTree都是你忠实的朋友:它将当前界面的所有可被访问的元素都打印在日志里。
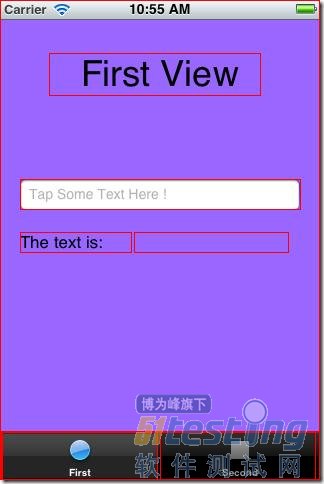
每一个可以被访问的UIKit控件都可以用一个Javascript对象来描述,它就是一个UIAElement。UIAElement有几个属性:name, value, elements, parent。你的主窗口包含很多的控件,它们是以UIKit层次的方式定义的,这些UIKit层次结构对应的是UIAElement的层次树。例如:前面的测试代码中,通过调用logElementTree,我们可以得到如下面所示的树结构:
+- UIATarget: name:iPhone Simulator rect:{{0,0},{320,480}}
| +- UIAApplication: name:TestAutomation rect:{{0,20},{320,460}}
| | +- UIAWindow: rect:{{0,0},{320,480}}
| | | +- UIAStaticText: name:First View value:First View rect:{{54,52},{212,43}}
| | | +- UIATextField: name:User Text value:Tap Some Text Here ! rect:{{20,179},{280,31}}
| | | +- UIAStaticText: name:The text is: value:The text is: rect:{{20,231},{112,21}}
| | | +- UIAStaticText: value: rect:{{145,231},{155,21}}
| | | +- UIATabBar: rect:{{0,431},{320,49}}
| | | | +- UIAImage: rect:{{0,431},{320,49}}
| | | | +- UIAButton: name:First value:1 rect:{{2,432},{156,48}}
| | | | +- UIAButton: name:Second rect:{{162,432},{156,48}}
你可以通过下面的代码来访问文本框:
var textField =
UIATarget.localTarget().frontMostApp().mainWindow().textFields()[0]; |
你可以选择通过从0开始的索引或者这个元素的名称来访问这个元素,例如:你也可以通过下面的代码来访问文本控件。
var textField =
UIATarget.localTarget().frontMostApp().mainWindow().textFields()["User Text"]; |
后一种方式更加清晰明了,应该多使用。你可以通过Interface Builder设置UIAElement的name属性,

或者通过编写代码的方式:
myTextField.accessibilityEnabled = YES;
myTextField.accessibilityLabel = @"User Text"; |
你现在可以看到,通过accessibility属性可以被UIAutomation用来找到不同的控件。这非常的清晰,因为,第一,你只要学习一个测试框架;第二,通过编写自动化测试代码,你同时还可以保证你的程序是可以被访问的。因此,每一个UIAElement对象的子控件可以通过下面的方法进行访问:
buttons(), images(), scrollViews(),textFields(), webViews(), segmentedControls(), sliders(), staticTexts(), switches(), tabBar(),tableViews(), textViews(), toolbar(), toolbars() 等等……
你可以通过如下代码在tabbar上访问第一个tab:
var tabBar = UIATarget.localTarget().frontMostApp().tabBar();
var tabButton = tabBar.buttons()["First"]; |
UIAElement结构层次非常的重要,你以后会常常用到它。而且你还要记住,你可以在随时通过调用UIAAplication的logElementTree来获得它的结构。
| UIATarget.localTarget().frontMostApp().logElementTree(); |
在模拟器上,你还可以激活Accessibility 的检测器。启动模拟器,找到“Settings > General > Accessibility > Accessibility Inspector”,然后将它设为“打开”状态。
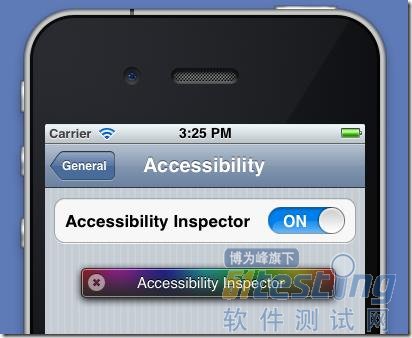
这个彩色的小框框就是Accessibility 检测器了。当它收起来的时候,Accessibility就被关闭了,当它展开的时候,Accessibility就是打开的。你只要点击上面的箭头按钮就可以激活或者屏蔽Accessibility。现在,打开我们的示例程序,激活检测器。

然后,点击文本框,检查UIAElement的name和value属性(其实就是accessibilityLabel和accessibilityValue对应的NSObject类型的值)。这个检测器可以帮助你调试和编写你的测试代码。
模拟用户操作
让我们更进一步,模拟一些用户的交互操作。你可以简单地调用按钮的tap()来作一个点击操作:
var tabBar = UIATarget.localTarget().frontMostApp().tabBar();
var tabButton = tabBar.buttons()["First"];
// Tap the tab bar !
tabButton.tap(); |
你还可以调用UIAButtons的doubleTap(),twoFingerTap()。如果你不想操作具体的某个元素,你也可以直接根据屏幕上指定的坐标点进行操作,你可以这么用:
● 点击:
UIATarget.localTarget().tap({x:100, y:200});
UIATarget.localTarget().doubleTap({x:100, y:200});
UIATarget.localTarget().twoFingerTap({x:100, y:200}); |
● 缩放:
UIATarget.localTarget().pinchOpenFromToForDuration({x:20, y:200},{x:300, y:200},2);
UIATarget.localTarget().pinchCloseFromToForDuration({x:20, y:200}, {x:300, y:200},2); |
● 拖拽与划动:
UIATarget.localTarget().dragFromToForDuration({x:160, y:200},{x:160,y:400},1);
UIATarget.localTarget().flickFromTo({x:160, y:200},{x:160, y:400}); |
注意,当你指定操作的时间间隔的时候,它是有特定的范围的,即:拖拽操作的时间间隔必须大于或者等于0.5秒,小于60秒。
现在,让我们来练习一下:
1)停止Instruments (⌘R)
2)在Scripts窗口里, 移除当前的脚本
3)点击“Add > Import”然后选择TestAutomation/TestUI/Test-1.js(将下面的代码保存到这个路径)
4)点击录制按钮 (⌘R) 然后看看将会发生什么…
下面是Test-1.js代码:
var testName = "Test 1";
var target = UIATarget.localTarget();
var app = target.frontMostApp();
var window = app.mainWindow();
UIALogger.logStart( testName );
app.logElementTree();
//-- select the elements
UIALogger.logMessage( "Select the first tab" );
var tabBar = app.tabBar();
var selectedTabName = tabBar.selectedButton().name();
if (selectedTabName != "First") {
tabBar.buttons()["First"].tap();
}
//-- tap on the text fiels
UIALogger.logMessage( "Tap on the text field now" );
var recipeName = "Unusually Long Name for a Recipe";
window.textFields()[0].setValue(recipeName);
target.delay( 2 );
//-- tap on the text fiels
UIALogger.logMessage( "Dismiss the keyboard" );
app.logElementTree();
app.keyboard().buttons()["return"].tap();
var textValue = window.staticTexts()["RecipeName"].value();
if (textValue === recipeName){
UIALogger.logPass( testName );
}
else{
UIALogger.logFail( testName );
} |
这段脚本先启动待测程序,然后,如果第一个tab没有被选的话就切换到第一个tab,并将上面的文本框的值设成“Unusually Long Name for a Recipe”,接着收起虚拟键盘。这里有一些新的方法值得注意的:UIATarget的delay(Number timeInterval) 方法允许你在两个操作之间做一些等待,UIALogger的logMessage( String message) 方法用来将你想打印的信息输出到日志上去,UIALogger的logPass(String message)方法指明你的测试脚本已经成功的完成测试了。
你还知道了如何访问键盘上的按钮,然后作点击操作:
| app.keyboard().buttons()["return"].tap(); |
由于时间有限且原文太长,先只能翻译到这里,我会尽快的将剩下的部分翻译补上。另外,时间仓促,如有翻译得不准确的地方,也敬请担待。谢谢。
我是一枚潜藏在数据库引擎深处的Bug,躲在一个黑暗的角落很久了,历经多个版本、N轮回归测试的风雨洗礼,我存在,我骄傲。还记得那天,我怀着激动而忐忑的心情等待一位QA新人把我发布出去……
产品发布在即,一位颇有经验的QA在无意间写了一条短小精悍的用例让QA新人来执行一遍,就是这条不起眼的用例,使我原形毕露。这个用例看起来很简单:就是向数据库里插入一条null记录(还记得我们的Mr Null吗?),一条字符串记录;再一条null记录,一条同样的字符串记录……如此反复,来个5000次,然后启用创建数据字典的功能,将这若干条看似规律的记录进行压缩。好歹咱也算经历过风风雨雨的,每天的持续回归测试也没有拿我怎么样,可就在执行这条小用例时,神奇的事情发生了------数据库发生了崩溃。
原因分析:
这个难题先后困扰过好几个人,直到一位研究“炸弹”的开发GG,他对我进行了好好的剖析,终于发现了问题的缘由。具体要从数据库引擎的压缩机制开始讲起:
● 记录压缩:是基于数据字典的压缩。所谓数据字典,就是数据库表所有记录中出现频率最大的字符串集合。压缩时,将记录中与数据字典相同的字符串进行替换,替换为数据字典的下标。由于数据字典的下标一定会远远小于字典所代表的字符串,因此就达到了记录压缩的效果。
● 实现流程:该引擎的数据字典在采集时,是将所有的记录拼成一条长长的字符串流,然后从字符串流中采集出现频率最高的子串,作为数据字典,而拼接记录时并未在记录间添加分隔符。这种一行null记录、一行字符串记录的方式,会使数据库引擎采集的数据字典的长度超过记录的最大长度,导致系统内部验证报错。
解决办法:
知道了问题的本质,解决起来就很方便了,在将记录拼接为长字符串流时,在每个记录的拼接处添加分隔符。不能跨越分隔符采集数据字典,从而保证了数据字典的长度一定小于等于记录的长度限制,问题解决!
经验总结:
● 注意边界问题。问题往往出现在边界情况下,比如最大值/最小值/0值。如果在代码中加入一些边界断言,可以帮助提早发现问题。
● 注意“null”的使用。不论开发还是测试,注意“null”的使用都可以帮助我们少犯一些错误,或者多发现一些问题。
● “杀虫剂困境”的思考。再严密的单一性测试也不可能发现100%的Bug。将不同的测试思路和方法相结合,采用探索式的测试思维或许能帮助发现更多潜在问题。
说了这么多,我得闭嘴了,不低调的Bug是不厚道的,最后把一句很喜欢的佛语送给大家:“你见,或者不见我,我就在那里”,但是我们始终敌不过开发和测试的协同努力。

一、为什么很多公司都说要组建一个自动化测试团队,但极少能建立起来?
● 太过于相信自动化测试,且没有经过严格的自动化测试流程和前期分析设计就草率的进行脚本的开发,最终的结果一定是失败!
● 国内的公司很少有专属的自动化测试团队,往往都是信心十足最后确又虎头蛇尾!这其中也分两种情况:其一,缺乏真正可以做自动化测试的技术人员,每个成员都是在学习阶段,那还谈什么组建自动化测试团队?这最多也就叫兴趣小组?其二,的确有牛人在团队中,但是我们都知道,国内很少有公司会专门组建一个专职做自动化测试的团队,国内现在大多数情况是手动测试和自动化测试并用,那么,自动化测试的优先级肯定没有手工测试那么高,而且项目的任务又多,久而久之,自动化测试的愿景又被搁置于一旁了。
● 其实自动化测试已经做的不错了,但是领导看不到短期内有任何的回报,最后还是搁置了!这其中一方面牵扯到成本问题,另一方面则是领导对自动化测试从意识上就存在误区,没有真正认清什么才是自动化测试的真谛!
二、全职QTP自动化测试工程师的工作内容是什么?问几个心中一直以来的疑问和困惑:
(1)QTP是针对功能测试的,主要是自动化地去做测试,那么它强大的地方在哪儿呢?是它能够发现大量潜在的问题?(似乎没感觉到),还是说可以做到无限重复的执行?我们公司用QTP只是重复运行,用来采集性能数据,所以并不能体会到QTP这款产品“赢”在哪方面。
(2)一个全职的QTP测试人员,每天的工作内容是什么呢?每天修改完善脚本、增加逻辑覆盖率?假如一个成熟的产品有成熟的脚本,那么测试人员只要点一下QTP运行按钮,然后直接拿测试结果?总体来说,还是感觉QTP要求很多,用起来很难且收获也不大。
● 首先回答第一个问题:从这位同行的提问中,推断他对QTP的认识一定停留在录制阶段,他把QTP当成了按键精灵。QTP的强大体现在它是解决自动化测试的最好的工具。其实提问的这位同行对自动化测试概念一定很模糊,他以为自动化测试只是简单地重复工作而没有考虑过验证这个问题。做测试,手工测试是怎么做的?其实说白了,也就是用我们的眼睛来验证,那么QTP就是那个能代替人类眼睛验证的测试工具。就像机器人一样,它不是智能的,它的智能是由人赋予的,所以它能做的操作都是人类事先已经知道的。QTP赢在它的一切,卖的真么贵、市场份儿那么高不是没有道理的,如果去使用其他测试工具一段时间后再回来使用QTP,相信一定会感叹,真实一个好工具啊!
● 接着回答第二个问题:一个全职的QTP人员他要做的事情和开发是一样的,都是一脉相承的。他也要需求、也要框架、也要开发、也要维护等等,修改完善脚本不是每天要做的事情,而是每一个版本发布后要做的事情。如果有一个成熟的产品,用QTP写出了成熟的脚本,那自动化测试的目的不是达到了吗?我们的目的就是每天“点”一下,快速拿到测试结果从而解放人力并可以投入到其他项目的测试中去,这也就是自动化测试的目的和意义。另外,QTP基本上只能发现已知的缺陷,目的是为了保证在新增功能加进来以后老功能不受影响;同时也能够回归以前有问题的功能在修复后是否又重现了。QTP几乎不可能发现新缺陷,那是手工测试阶段做的事情。当然,QTP也真的不是万能的,如它肯定不可能比开源的自动化测试工具更Open、扩展性强等,但是世界上不存在万能的事物!
三、如何才能将QTP自动化测试从无到有地应用到项目中。怎么才能成功实施?有什么成功的要素吗?
这个问题其实问得范围非常广,要回答好很不易,现在分享本人之前自动化测试的一些经验。首先需要了解自动化测试的一个总体实施流程,当接到一个项目之后,需要了解影响自动化测试实施的一些需求,如项目的周期长短、需求变更的频繁度、工具的选择以及工具对测试对象的识别能力等。这样做的目的就是为了确定项目是否适合做自动化测试,并不是每个项目都适合做自动化测试,失败的例子实在是太多了,很大一部分原因就是前期根本没有做充足的分析才会导致后期的被动局面,因此绝对不能忽视前期的这块内容。当这些都确定完成之后,还需要完成一个简单的Demo,用于验证工具对项目中对象的识别能力,这些内容可以归纳在前期的可行性分析方案中。接着需要进行自动化测试设计阶段,这个阶段包括需求分析、自动化用例转化为编写,这里需要注意。不是所有手工测试用例都可以转化为自动化测试用例,有些用例完全不适合做自动化测试,或者说不能用自动化测试完成,也或者需要投入很大的经历才能完成。所以需要在设计阶段就定义好这些可自动化的测试用例,并且还需要定义好公共的用例库以及用例的复杂度。当以上内容都定义完毕后,就可以开始下一步核心工作了,也就是自动化测试框架的开发,其大致包含:创建一些公共的组件、公共函数库、公共对象库、测试用例调度机制、外部配置、错误处理、报表生成等功能,当然,如果不是经验丰富的测试人员,在框架这块处理上是不可能一步到位的,需要后期来适应项目并不断进行改进。一段核心功能完成之后,可以说已经离成功又近了一大步了。最后的工作就是把用例全部完完整整地转化为测试脚本,如果框架搭建的比较牛,这一步实现其实是比较轻松的。当然,一些特殊的难题令当别论,如小部分对象怎么识别不了,那只能通过专家组共同讨论解决方案。
1、自动化测试的优势
(1)回归测试更方便、可靠
(2)可运行更多、更繁琐的测试,且快速、高效
(3)可执行一些对于手工测试来说相当困难或根本做不到的测试
(4)更好地利用资源,使资源的使用更有价值
(5)具有一致性和可重复性的特点
(6)自动化测试脚本完全具有复用性
(7)使软件更有信任度
(8)多环境下测试
2、自动化测试无法做到的事及其劣势分析
(1)永远不可能完全取代手工测试
(2)无法完全保证测试的正确性
(3)手工测试能发现的缺陷远比自动化测试多(手工85%左右,自动化15%左右其中只有1%是新缺陷)
(4)对测试质量的依赖性极大
(5)测试自动化可能会制约软件开发
(6)自动化测试工具是死的,它本身没有任何想象能力
(7)成本投入过高,风险大
(8)自动化测试对测试人员的技术要求较高,对测试工具同样有一定要求
3、何时适合引入自动化测试
(1)项目周期长,系统版本不断
(2)需求变更不频繁
(3)系统中的测试对象基本可以正常识别
(4)系统中不存在大批量第三方控件
(5)需要反复测试,如可靠性测试需要进行上千次的系统测试
4、何时避免展开自动化测试
(1)项目周期短,需求变更频繁
(2)在软件版本还没有稳定的情况下
(3)没有明确的项目测试自动化计划、措施和管理
(4)领导不支持
(5)多数对象无法识别以及脚本维护频繁与艰难,二者有其一,自动化测试注定失败。
版权声明:本文出自 跑跑跑跑 的51Testing软件测试博客:http://www.51testing.com/?591690
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
提高软件开发效率的最有效手段就是一次做对,一次做好,不返工,追求交付零缺陷的目标。“对”就是没有错误,符合需求,“好”就是没有坏味道,易于修改。“做对”保证了产品的外部质量,“做好”保证了产品的内部质量,这样就可以减少软件缺陷、需求变更带来的返工。返工可能发生在生命周期的早期,也可能发生在后期,或者是交付以后,缺陷越早发现,越早解决,返工的工作量越少。有哪些手段可以保证不犯错,少犯错,及时纠错呢?
1、需求阶段
需求调研:
要访谈客户、最终用户与间接用户;
要访谈高层、中层与底层的用户;
要准备好问题单;
采用原型法启发客户需求;
需求描述:
用户故事描述用户需求;
采用用例法描述功能需求;
当用户无法提出非功能性需求时,定义定义非功能性需求的缺省值;
需求确认:
采用多种方法确认需求;
采用需求交底、逆向培训、现场客户等方法确保需求沟通的一致性;
建立需求沟通的平台,确保需求的沟通能传递到每个相关人员;
在需求阶段开始编写系统测试用例,验证需求的可测试性;
建立需求与设计、代码、测试用例之间的跟踪关系;
用户、开发、测试人员参与需求的评审;
需求变更:
基于RTM进行需求变更的影响分析;
需求的变更要通知到相关人员;
对于需求的变更采用结对修改的方法;
人员:
对需求人员进行需求工程的专题培训,要求需求人员掌握需求工程的基本知识,具备基本的技能。
2、设计阶段
需求理解:
和需求人员对需求的理解达成一致;
对需求的拆分、细化,功能的设计要得到需求人员的认可;
设计:
要建立设计到需求的跟踪矩阵,确保设计的完备性;
采用结对设计的方法确保设计的正确性;
需求、设计、开发人员对设计进行技术评审,识别设计中的缺陷;
对设计人员进行培训、上岗资格认证,要求设计人员掌握架构设计、设计原则、设计模式、数据库设计、界面设计的方法;
建立评价设计优劣的准则,包括类的设计、算法设计、数据库设计、界面设计的准则;
对于非功能性需求给出缺省的解决方案;
在设计中采用设计模式提高设计的合理性;
对于界面的设计尽早进行确认;
接口测试要早设计、早实现、早测试;
3、编码阶段
和需求人员对需求的理解达成一致;
和设计人员对设计的理解达成一致;
在写代码之前先做了详细设计,对详细设计做了评审;
结对编程;
测试驱动的开发;
按照编码规范进行编码;
代码的静态检查;
代码评审;
持续集成;
代码重构;
编码人员要掌握常用的设计模式、重构的手法;
4、测试阶段
测试人员参与需求评审,需求人员参与测试用例的评审;
建立测试用例与需求之间的映射关系,追求需求场景的覆盖率;
集成测试用例覆盖每一个接口的输入参数的每种等价类;
定义用例编写规范:
● 用例应覆盖正常操作、异常操作、边界条件
● 用例应该覆盖客户操作场景的各种等价类
● 每个用例应该详细描述出输入、操作步骤、期望的输出
● 区分不同的专项测试制定用例编写规范
● 坚持执行失效模式分析
定义质量目标,并努力达成质量目标:
● 每千行代码的平均测试工作量;
● 每千行代码测试用例的个数;
● 每千行代码发现的缺陷个数;
在客户各种可能的使用环境中进行测试,专人负责测试环境的维护;
针对非功能需求进行测试策略的设计;
先设计测试要点再设计测试用例;
非功能性需求要尽早测试;
先进行冒烟测试,再执行正式的测试;
定义测试结束的量化标准,定义软件交付的最低标准;
针对共性的需求建立复用用例库,每次测试时从中挑选用例,然后再补充完善用例;
尽可能模拟客户的环境进行软件的测试,应进行测试环境的组合设计。
俗话说得好:“千里之堤,毁于蚁穴。”一个小小的漏洞造成一旦被攻击者发现,最终后果有可能是整个网络的瘫痪。而怎么来发现企业网络的安全漏洞呢?需要掌握和采用一些什么关键技术?有什么比较流行和高效的工具可以用来辅助系统管理员来进行漏洞的扫描和发现呢?
企业端口扫描策略
1、端口扫描的目的
对于位于网络中的计算机系统来说,一个端口就是一个潜在的通信通道,也就是一个入侵通道。对目标计算机进行端口扫描,能得到许多有用的信息从而发现系统的安全漏洞。通过其可以使系统用户了解系统目前向外界提供了哪些服务,从而为系统用户管理网络提供了一种参考的手段。
从技术原理上来说,端口扫描向目标主机的TCP/UDP服务端口发送探测数据包,并记录目标主机的响应。通过分析响应来判断服务端口是打开还是关闭,就可以得知端口提供的服务或信息。端口扫描也可以通过捕获本地主机或服务器的流入流出IP数据包来监视本地主机的运行情况,不仅能对接收到的数据进行分析,而且能够帮助用户发现目标主机的某些内在的弱点,而不会提供进入一个系统的详细步骤。一般说来,端口扫描的目的通常是如下的一项或者多项:
1)发现开放端口:发现目标系统上开放的TCP或UDP端口;
2)了解主机操作系统信息:端口扫描可以通过操作系统的“指纹”来推测被扫描操作系统或者应用程序的版本等信息;
3)了解软件或者服务版本:软件或服务版本可以通过“标志获取”或者应用程序的指纹来识别获得;
4)发现脆弱的软件版本:识别软件和服务的缺陷,从而有助于发起针对漏洞的攻击。
端口扫描主要有经典的扫描器(全连接)以及所谓的SYN(半连接)扫描器。此外还有间接扫描和秘密扫描等。TCP扫描方式是通过与被扫描主机建立标准的TCP连接,因此这种方式最准确,很少漏报、误报,但是容易被目标主机察觉、记录。SYN方式是通过与目标主机建立半打开连接,这样就不容易被目标主机记录,但是扫描结果会出现漏报,在网络状况不好的情况下这种漏报是严重的。
2、快速安装nmap进行企业端口扫描
nmap是一个网络探测和安全扫描程序,系统管理者和个人可以使用这个软件扫描大型的网络,获取那台主机正在运行以及提供什么服务等信息。nmap支持很多扫描技术,例如:UDP、TCP connect()、TCP SYN(半开扫描)、ftp代理(bounce攻击)、反向标志、ICMP、FIN、ACK扫描、圣诞树(Xmas Tree)、SYN扫描和null扫描。nmap还提供了一些高级的特征,例如:通过TCP/IP协议栈特征探测操作系统类型,秘密扫描,动态延时和重传计算,并行扫描,通过并行ping扫描探测关闭的主机,诱饵扫描,避开端口过滤检测,直接RPC扫描(无须端口影射),碎片扫描,以及灵活的目标和端口设定。
为了提高nmap在non-root状态下的性能,软件的设计者付出了很大的努力。很不幸,一些内核界面(例如raw socket)需要在root状态下使用。所以应该尽可能在root使用nmap。
nmap运行通常会得到被扫描主机端口的列表。nmap总会给出well known端口的服务名(如果可能)、端口号、状态和协议等信息。每个端口的状态有:open、filtered、unfiltered。
● open状态意味着目标主机能够在这个端口使用accept()系统调用接受连接;
● filtered状态表示防火墙、包过滤和其它的网络安全软件掩盖了这个端口,禁止 nmap探测其是否打开。
● unfiltered表示这个端口关闭,并且没有防火墙/包过滤软件来隔离nmap的探测企图。通常情况下,端口的状态基本都是unfiltered状态,只有在大多数被扫描的端口处于filtered状态下,才会显示处于unfiltered状态的端口。
根据使用的功能选项,nmap也可以报告远程主机的下列特征:使用的操作系统、TCP序列、运行绑定到每个端口上的应用程序的用户名、DNS名、主机地址是否是欺骗地址、以及其它一些东西。
在使用之前,我们需要下载该软件的源码包进行安装。下载完成后,以作者下载到的版本为例:nmap-5.00.tgz,用户执行如下安装命令即可:
(1)解压缩软件包
(2)切换到安装目录
(3)使用configure命令生成make文件
(4)编译源代码
(5)安装相关模块
3、四步骤使用nmap确定企业网络开放端口
(1)扫描实施第一步:发现活动主机
使用nmap扫描整个网络寻找目标,已确定目标机是否处于连通状态。通过使用“-sP”命令,进行ping扫描。缺省情况下,nmap给每个扫描到的主机发送一个ICMP echo和一个TCP ACK,主机对任何一种的响应都会被nmap得到,扫描速度非常快,在很短的时间内可以扫描一个很大的网络。该命令使用如下所示:
[root@localhost ~]# nmap -sP 10.1.4.0/24
Nmap finished: 256 IP addresses (125 hosts up) scanned in 7.852 seconds |
通过该扫描,可以发现该公司网络中有125台主机是活跃的,也就是说有机可趁,下一步就是要进行更详细的扫描,来扫描这些主机到底有些什么活动端口。
(2)扫描实施第二步:扫描端口扫描
通常情况下,当nmap的使用者确定了网络上运行的主机处于连通状态,下一步的工作就是进行端口扫描,端口扫描使用-sT参数。如下面结果如示:
[root@localhost ~]# nmap -v -sT 10.1.4.0/24
Host 10.1.4.11 appears to be up ... good.
Interesting ports on 10.1.4.11:
Not shown: 1673 closed ports
PORT STATE SERVICE
80/tcp open http
MAC Address: 00:1E:65:F0:78:CA (Unknown) |
可以清楚地看到,端口扫描采用多种方式对网络中主机的TCP活动端口进行了全面的扫描,由于扫描的主机数太多(125台),上面仅仅给出了2台主机的TCP端口情况,也就是主机10.1.4.1和10.1.4.11,并且,主机10.1.4.1打开的端口非常多,网络服务也相对比较丰富,并且从IP地址的构成来看,该主机极有可能是网关(一般网关的IP地址设定为X.X.X.1),我们于是就锁定了这台主机进行后续的扫描。
数据库设计,一个软件项目成功的基石。很多从业人员都认为,数据库设计其实不那么重要。现实中的情景也相当雷同,开发人员的数量是数据库设计人员的数倍。多数人使用数据库中的一部分,所以也会把数据库设计想的如此简单。其实不然,数据库设计也是门学问。
从笔者的经历看来,笔者更赞成在项目早期由开发者进行数据库设计(后期调优需要DBA)。根据笔者的项目经验,一个精通OOP和ORM的开发者,设计的数据库往往更为合理,更能适应需求的变化,如果追其原因,笔者个人猜测是因为数据库的规范化,与OO的部分思想雷同(如内聚)。而DBA,设计的数据库的优势是能将DBMS的能力发挥到极致,能够使用SQL和DBMS实现很多程序实现的逻辑,与开发者相比,DBA优化过的数据库更为高效和稳定。如标题所示,本文旨在分享一名开发者的数据库设计经验,并不涉及复杂的SQL语句或 DBMS使用,因此也不会局限到某种DBMS产品上。真切地希望这篇文章对开发者能有所帮助,也希望读者能帮助笔者查漏补缺。
一、Codd的RDBMS12法则——RDBMS的起源
Edgar Frank Codd(埃德加·弗兰克·科德)被誉为“关系数据库之父”,并因为在数据库管理系统的理论和实践方面的杰出贡献于1981年获图灵奖。在1985 年,Codd 博士发布了12条规则,这些规则简明的定义出一个关系型数据库的理念,它们被作为所有关系数据库系统的设计指导性方针。
1、信息法则:关系数据库中的所有信息都用唯一的一种方式表示——表中的值。
2、保证访问法则:依靠表名、主键值和列名的组合,保证能访问每个数据项。
3、空值的系统化处理:支持空值(NULL),以系统化的方式处理空值,空值不依赖于数据类型。
4、基于关系模型的动态联机目录:数据库的描述应该是自描述的,在逻辑级别上和普通数据采用同样的表示方式,即数据库必须含有描述该数据库结构的系统表或者数据库描述信息应该包含在用户可以访问的表中。
5、统一的数据子语言法则:一个关系数据库系统可以支持几种语言和多种终端使用方式,但必须至少有一种语言,它的语句能够一某种定义良好的语法表示为字符串,并能全面地支持以下所有规则:数据定义、视图定义、数据操作、约束、授权以及事务。(这种语言就是SQL)
6、视图更新法则:所有理论上可以更新的视图也可以由系统更新。
7、高级的插入、更新和删除操作:把一个基础关系或派生关系作为单个操作对象处理的能力不仅适应于数据的检索,还适用于数据的插入、修改个删除,即在插入、修改和删除操作中数据行被视作集合。
8、数据的物理独立性:不管数据库的数据在存储表示或访问方式上怎么变化,应用程序和终端活动都保持着逻辑上的不变性。
9、数据的逻辑独立性:当对表做了理论上不会损害信息的改变时,应用程序和终端活动都会保持逻辑上的不变性。
10、数据完整性的独立性:专用于某个关系型数据库的完整性约束必须可以用关系数据库子语言定义,而且可以存储在数据目录中,而非程序中。
11、分布独立性:不管数据在物理是否分布式存储,或者任何时候改变分布策略,RDBMS的数据操纵子语言必须能使应用程序和终端活动保持逻辑上的不变性。
12、非破坏性法则:如果一个关系数据库系统支持某种低级(一次处理单个记录)语言,那么这个低级语言不能违反或绕过更高级语言(一次处理多个记录)规定的完整性法则或约束,即用户不能以任何方式违反数据库的约束。
二、关系型数据库设计阶段
(一)规划阶段
规划阶段的主要工作是对数据库的必要性和可行性进行分析。确定是否需要使用数据库,使用哪种类型的数据库,使用哪个数据库产品。
(二)概念阶段
概念阶段的主要工作是收集并分析需求。识别需求,主要是识别数据实体和业务规则。对于一个系统来说,数据库的主要包括业务数据和非业务数据,而业务数据的定义,则依赖于在此阶段对用户需求的分析。需要尽量识别业务实体和业务规则,对系统的整体有初步的认识,并理解数据的流动过程。理论上,该阶段将参考或产出多种文档,比如“用例图”,“数据流图”以及其他一些项目文档。如果能够在该阶段产出这些成果,无疑将会对后期进行莫大的帮助。当然,很多文档已超出数据库设计者的考虑范围。而且,如果你并不精通该领域以及用户的业务,那么请放弃自己独立完成用户需求分析的想法。用户并不是技术专家,而当你自身不能扮演“业务顾问”的角色时,请你选择与项目组的相关人员合作,或者将其视为风险呈报给PM。再次强调,大多数情况,用户只是行业从业者,而非职业技术人员,我们仅仅从用户那里收集需求,而非依赖于用户的知识。
记录用户需求时,可以使用一些技巧,当然这部分内容有些可能会超出数据库设计人员的职责:
● 努力维护一系列包含了系统设计和规格说明信息的文档,如会议记录、访谈记录、关键用户期望、功能规格、技术规格、测试规格等。
● 频繁与干系人沟通并收集反馈。
● 标记出你自己添加的,不属于客户要求的,未决内容。
● 与所有关键干系人尽快确认项目范围,并力求冻结需求。
此外,必须严谨处理业务规则,并详细记录。在之后的阶段,将会根据这些业务规则进行设计。
当该阶段结束时,你应该能够回答以下问题:
● 需要哪些数据?
● 数据该被怎样使用?
● 哪些规则控制着数据的使用?
● 谁会使用何种数据?
● 客户想在核心功能界面或者报表上看到哪些内容?
● 数据现在在哪里?
● 数据是否与其他系统有交互、集成或同步?
● 主题数据有哪些?
● 核心数据价值几何,对可靠性的要求程度?
并且得到如下信息:
● 实体和关系
● 属性和域
● 可以在数据库中强制执行的业务规则
● 需要使用数据库的业务过程
(三)逻辑阶段
逻辑阶段的主要工作是绘制E-R图,或者说是建模。建模工具很多,有不同的图形表示方法和软件。这些工具和软件的使用并非关键,笔者也不建议读者花大量时间在建模方法的选择上。对于大多数应用来说,E-R图足以描述实体间的关系。建模关键是思想而不是工具,软件只是起到辅助作用,识别实体关系才是本阶段的重点。
除了实体关系,我们还应该考虑属性的域(值类型、范围、约束)
(四)实现阶段
实现阶段主要针对选择的RDBMS定义E-R图对应的表,考虑属性类型和范围以及约束。
(五)物理阶段
物理阶段是一个验证并调优的阶段,是在实际物理设备上部署数据库,并进行测试和调优。
三、设计原则
(一)降低对数据库功能的依赖
功能应该由程序实现,而非DB实现。原因在于,如果功能由DB实现时,一旦更换的DBMS不如之前的系统强大,不能实现某些功能,这时我们将不得不去修改代码。所以,为了杜绝此类情况的发生,功能应该有程序实现,数据库仅仅负责数据的存储,以达到最低的耦合。
(二)定义实体关系的原则
当定义一个实体与其他实体之间的关系时,需要考量如下:
● 牵涉到的实体:识别出关系所涉及的所有实体。
● 所有权:考虑一个实体“拥有”另一个实体的情况。
● 基数:考量一个实体的实例和另一个实体实例关联的数量。
关系与表数量
● 描述1:1关系最少需要1张表。
● 描述1:n关系最少需要2张表。
● 描述n:n关系最少需要3张表。
(三)列意味着唯一的值
如果表示坐标(0,0),应该使用两列表示,而不是将“0,0”放在1个列中。
(四)列的顺序
列的顺序对于表来说无关紧要,但是从习惯上来说,采用“主键+外键+实体数据+非实体数据”这样的顺序对列进行排序显然能得到比较好的可读性。
(五)定义主键和外键
数据表必须定义主键和外键(如果有外键)。定义主键和外键不仅是RDBMS的要求,同时也是开发的要求。几乎所有的代码生成器都需要这些信息来生成常用方法的代码(包括SQL文和引用),所以,定义主键和外键在开发阶段是必须的。之所以说在开发阶段是必须的是因为,有不少团队出于性能考虑会在进行大量测试后,在保证参照完整性不会出现大的缺陷后,会删除掉DB的所有外键,以达到最优性能。笔者认为,在性能没有出现问题时应该保留外键,而即便性能真的出现问题,也应该对SQL文进行优化,而非放弃外键约束。
(六)选择键
1、人工键与自然键
人工健——实体的非自然属性,根据需要由人强加的,如GUID,其对实体毫无意义;自然健——实体的自然属性,如身份证编号。
人工键的好处:
● 键值永远不变
● 永远是单列存储
人工键的缺点:
● 因为人工键是没有实际意义的唯一值,所以不能通过人工键来避免重复行。
笔者建议全部使用人工键。原因如下:
● 在设计阶段我们无法预测到代码真正需要的值,所以干脆放弃猜测键,而使用人工键。
● 人工键复杂处理实体关系,而不负责任何属性描述,这样的设计使得实体关系与实体内容得到高度解耦,这样做的设计思路更加清晰。
笔者的另一个建议是——每张表都需要有一个对用户而言有意义的自然键,在特殊情况下也许找不到这样一个项,此时可以使用复合键。这个键我在程序中并不会使用其作为唯一标识,但是却可以在对数据库直接进行查询时使用。
使用人工键的另一根弊端,主要源自对查询性能的考量,因此选择人工键的形式(列的类型)很重要:
● 自增值类型 由于类型轻巧查询效率更好,但取值有限。
● GUID 查询效率不如值类型,但是取值无限,且对开发人员更加亲切。
2、智能健与非智能键
智能键——键值包含额外信息,其根据某种约定好的编码规范进行编码,从键值本身可以获取某些信息;非智能键,单纯的无意义键值,如自增的数字或GUID。
智能键是一把双刃剑,开发人员偏爱这种包含信息的键值,程序盼望着其中潜在的数据;数据库管理员或者设计者则讨厌这种智能键,原因也是很显然的,智能键对数据库是潜在的风险。前面提到,数据库设计的原则之一是不要把具有独立意义的值的组合实现到一个单一的列中,应该使用多个独立的列。数据库设计者,更希望开发人员通过拼接多个列来得到智能键,即以复合主键的形式给开发人员使用,而不是将一个列的值分解后使用。开发人员应该接受这种数据库设计,但是很多开发者却想不明白两者的优略。笔者认为,使用单一列实现智能键存在这样一个风险,就是我们可能在设计阶段无法预期到编码规则可能会在后期发生变化。比如,构成智能键的局部键的值用完而引起规则变化或者长度变化,这种编码规则的变化对于程序的有效性验证与智能键解析是破坏性的,这是系统运维人员最不希望看到的。所以笔者建议如果需要智能键,请在业务逻辑层封装(使用只读属性),不要再持久化层实现,以避免上述问题。
(七)是否允许NULL
关于NULL我们需要了解它的几个特性:
● 任何值和NULL拼接后都为NULL。
● 所有与NULL进行的数学操作都返回NULL。
● 引入NULL后,逻辑不易处理。
那么我们是否应该允许列为空呢?笔者认为这个问题的答案受到我们的开发语言的影响。以C#为例,因为引入了可空类型来处理数据库值类型为NULL的情形,所以是否允许为空对开发者来说意义并不大。但有一点必须注意,就是验证非空必须要在程序集进行处理,而不该依赖于DBMS的非空约束,必须确保完整数据(所有必须的属性均被赋值)到达DB(所谓的“安全区”,我们必须定义在多层系统中那些区域得到的数据是安全而纯净的)。
(八)属性切割
一种错误想法是,属性与列是1:1的关系。对于开发者,我们公开属性而非字段。举个例子来说,对于实体“员工”有“名字”这一属性,“名字”可以再被分解为“姓”和“名”,对于开发人员来说,显然第二种数据结构更受青睐(“姓” 和“名”作为两个字段)。所以,在设计时我们也应该根据需要考虑是否切割属性。
(九)规范化——范式
当笔者还在大学时,范式是学习关系型数据库时最头疼的问题。我想也许会有读者仍然不理解范式的价值,简单来说——范式将帮助我们来保证数据的有效性和完整性。规范化的目的如下:
● 消灭重复数据。
● 避免编写不必要的,用来使重复数据同步的代码。
● 保持表的瘦身,以及减从一张表中读取数据时需要进行的读操作数量。
● 最大化聚集索引的使用,从而可以进行更优化的数据访问和联结。
● 减少每张表使用的索引数量,因为维护索引的成本很高。
规范化旨在——挑出复杂的实体,从中抽取出简单的实体。这个过程一直持续下去,直到数据库中每个表都只代表一件事物,并且表中每个描述的都是这件事物为止。
1、规范化实体和属性(去除冗余)
1NF:每个属性都只应表示一个单一的值,而非多个值。
需要考虑几点:
● 属性是原子性的 需要考虑熟悉是否分解的足够彻底,使得每个属性都表示一个单一的值。(和“(三)列意味着唯一的值”描述的原则相同。)分解原则为——当你需要分开处理每个部分时才分解值,并且分解到足够用就行。(即使当前不需要彻底分解属性,也应该考虑未来可能的需求变更。)
● 属性的所有实例必须包含相同数量的值 实体有固定数量的属性(表有固定数量的列)。设计实体时,要让每个属性只有固定数量的值与其相关联。
● 实体中出现的所有实体类型都必须不同
当前设计不符合1NF的“臭味”:
● 包含分隔符类字符的字符串数据。
● 名字尾端有数字的属性。
● 没有定义键或键定义不好的表。
2、属性间的关系(去除冗余)
2NF-实体必须符合1NF,每个属性描述的东西都必须针对整个键(可以理解为oop中类型属性的内聚性)。
当前设计不符合2NF的“臭味”:
● 重复的键属性名字前缀(设计之外的数据冗余) 表明这些值可能描述了某些额外的实体。
● 有重复的数据组(设计之外的数据冗余) 这标志着属性间有函数依赖型。
● 没有外键的复合主键 这标志着键中的键值可能标识了多种事物,而不是一种事物。
3NF-实体必须符合2NF,非键属性不能描述其他非键属性。(与2NF不同,3NF处理的是非键属性和非键属性之间的关系,而不是和键属性之间的关系。
当前设计不符合3NF的“臭味”:
● 多个属性有同样的前缀。
● 重复的数据组。
● 汇总的数据,所引用的数据在一个完全不同的实体中。(有些人倾向于使用视图,我更倾向于使用对象集合,即由程序来完成。)
BCNF-实体满足第一范式,所有属性完全依赖于某个键,如果所有的判定都是一个键,则实体满足BCNF。(BCNF简单地扩展了以前的范式,它说的是:一个实体可能有若干个键,所有属性都必须依赖于这些键中的一个,也可以理解为“每个键必须唯一标识实体,每个非键熟悉必须描述实体。”
3、去除实体组合键中的冗余
4NF-实体必须满足BCNF,在一个属性与实体的键之间,多值依赖(一条记录在整个表的唯一性由多个值组合起来决定的)不能超过一个。
当前设计不符合4NF的“臭味”:
● 三元关系(实体:实体:实体)。
● 潜伏的多值属性。(如多个手机号。)
● 临时数据或历史值。(需要将历史数据的主体提出,否则将存在大量冗余。)
4、尽量将所有关系分解为二元关系
5NF-实体必须满足4NF,当分解的信息无损的时候,确保所有关系都被分解为二元关系。
5NF保证在第四范式中存在的任何可以分解为实体的三元关系都被分解。有的三元关系可以在不丢失信息的前提下被分解为二元关系,当分解为两个二元关系的过程要丢失信息时,关系被宣称为处于第四范式中。所以,第五范式建议是,最好把现有的三元关系都分解为3个二元关系。
需要注意的是,规范化的结果可能是更多的表,更复杂的查询。因此,处理到何种程度,取决于性能和数据架构的多方考量。建议规范化到第四范式,原因是5NF的判断太过隐晦。例如:表X(老师,学生,课程)是一个三元关系,可以分解为表A(老师,学生),表B(学生,课程),表C(老师,课程)。表X表示某个老师是上某个学生的某个课程的老师;表A表示老师教学生;表B表示学生上课;表C表示老师教课。单独看是无法发现问题的,但是从数据出发,"表X=表A+表B+表C"并不一定成立,即不能通过连接构建分解前的数据。因为可能有多种组合,丧失了表X反馈出的业务规则。这种现象,容易在设计阶段被忽略,但好在在开放阶段会被显现,而且并不经常发生。
推荐做法:
● 尽可能地遵守上述规范化原则。
● 所有属性描述的都应该是体现被建模实体的本质的内容。
● 至少必须有一个键,它唯一地标识和描述了所建实体的本质。
● 主键要谨慎选择。
● 在逻辑阶段能做多少规范化就做多少(性能不是逻辑阶段考虑的范畴)。
(十)选择数据类型(MS SQL 2008)
MS SQL的常用类型:
精确数字 | 不会发生精度损失 | bit tinyint smallint int bigint decimal |
近似数字 | 对于极值可能发生精度损失 | float(N) real |
日期和时间 | | date time smalldatetime datetime datetime2 datetimeoffset |
二进制数据 | | bingary(N) varbinary(N) varbinary(max) |
字符(串)数据 | | char(N) varchar(N) varchar(max) nchar(N) nvarchar(N) nvarchar(max) |
存储任意数据 | | sql_variant |
时间戳 | | timestamp |
GUID | | uniqueidentifier |
XML | 不要试图使用该类型规避1NF | xml |
空间数据 | | geometry geography |
层次数据 | | heirarchyid |
MS SQL中不在支持的或糟糕的类型选择
● image:被varbinary(max)取代。
● text和ntext:被varchar(max)和nvarchar(max)取代。
● money和smallmoney:开发过程中不好用,建议使用decimal。
常用类型选择:
类型选择的最基本规则是选择满足需要的最轻的类型,因为这样查询更快。
bool | 建议使用bit而非char(1),因为开发语言对其支持觉好,可以直接映射为bool或bool?。 |
大值数据 | 使用所有备选类型中最小的那种,类型越大,查询越慢,当字节大于8000时,应使用max。 |
主键 | 自增主键根据预期范围选择int或bigint,GUID使用uniqueidentifier而非varchar(N)。 |
(十一)优化并行
设计DB时就应该考虑到对并行进行优化,比如,MS SQL中的timestamp类型就是极好的选择。
四、命名规则
表——“模块名_表名”。表名最好不要用复数,原因是在使用ORM框架开发时,代码生成器根据DB生成类定义,表生成了某个实例的类型定义,而不是实例集合。表名不要太长。
● 原因之一,某些软件对表名最大长度有限制;原因之二,使用代码生成器往往会根据表名生产类型名称,之后懒人会直接使用这一名称,如果将太长的名称跨网络边界显然不是明智之举。
● 字段——bool类型用“Is”、“Can”、“Has”等表示;日期类型命名必须包含“Date”;时间类型必须包含“Time”。
● 存储过程——使用“proc_”前缀。
● 视图——使用“view_”前缀。
● 触发器——使用“trig_”前缀。
最近好忙好忙,整理下心情给大家分享下自己在工作中遇到的一点小技巧,希望给遇到同样麻烦的同学一点帮助。
我们知道Java项目打war包可以在Eclipse和MyEclipse工具中自动打包,就是右键,然后导出war包就可以了,可是我发现我的一个项目打war包的过程中遇到点小麻烦,导出的war包打开之后,里面少了很多东西,明显有问题。那怎么办呢,网上搜了许多偏方都没效果,请教同事,大家也没遇到过这种状况。
除了这种方法,我们可以运用DOS命令来手工打war包:
首先,打开DOS命令行,敲入“jar”,我们发现它提示不是内部或外部的命令这样的错误,这时八成是你的JAVA环境没有配置好,我们可以用JAVA_HOME方式或者直接在Path路径里配置,等配置好,(注意你的JDK版本,里面有jar.exe和javac.exe的版本适合)我们再敲入"jar",会出现如下效果,说明配置成功。
下面我们用DOS命令进入到你的项目中

好,现在我们来运行命令手工打包

回车键入,等待它自动执行完:
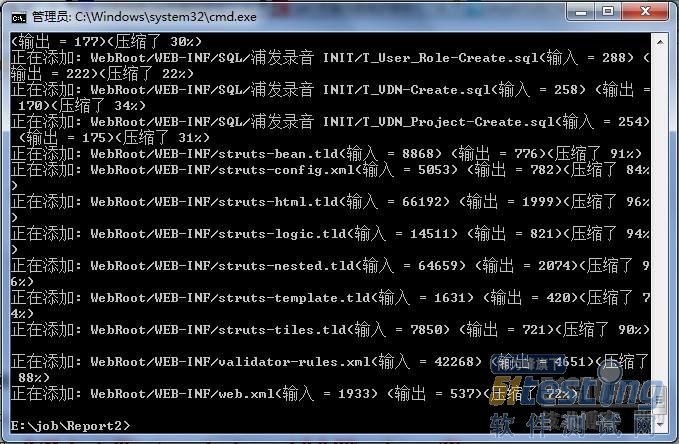
OK,打包完成,现在我们来看下目录下的war包
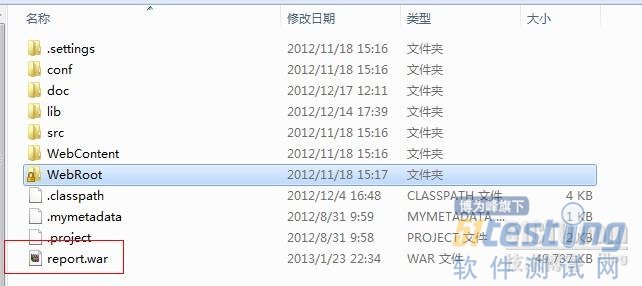
已经打好了,我们放到Tomcat的Webapps下,启动tomcat,自动解压完成。OK,大功告成。
对于自动化测试框架,其实并没有多数人想象中的那么高深玄乎,框架的概念只是一系列的被事先定义好的标准和规范。在自动化测试中我们经常提到的对测试需求的解析、脚本设计、测试执行、测试报告、维护管理等等,通过框架将它们串联并封装起来,从而使框架的终端用户能够更方便地使用。然而,一个好的自动化测试框架,不仅仅要能让用户方便使用,还需要考虑很多其他因素,下面就来分享一下一些个人的经验。
● 选择一种类型的框架
目前比较常见的自动化测试框架主要有3种:数据驱动框架、关键字驱动框架和混合型框架。
1、数据驱动框架(Data Driven Framework)
数据驱动最适合测试的业务逻辑固定不变的应用程序,只有测试数据会变化。通常测试数据会被配置在外部文件或数据库中。
2、关键字驱动框架(Keyword Driven Framework)
关键字驱动顾名思义,它提供了一系列通用的关键字,用户通过调用这些关键字并输入一些参数可以实现单个操作,比如,打开浏览器、打开某个网页、点击某个链接等等,然后通过组织这些关键字形成一个完整的测试流程。
3、混合型框架(Hybrid Framework)
混合型框架就是把数据驱动和关键字驱动整合起来,同时具备了两者的优点。与关键字框架不同的是,这种框架通常会提供一些针对于特定应用程序的关键字,比如登录、登出等。然后在完整测试流程的基础上,再应用一层数据驱动,这样就能使测试逻辑和测试数据更加灵活和可配置。
● 不必重新造轮
在设计框架的时候应该尽可能的沿用自动化测试工具已提供的功能。比如,一个基于selenium的框架,selenium本身就已经提供了打开浏览器和网页,点击按钮等功能,就不必花时间再去开发这样一些关键字,以减少开发成本。
● 可重用性
一个好的框架必须具有高度的可重用性。我们可以把一些单独的操作组合成一些最常用的测试流程,比如,把“输入用户名”、“输入密码”、“点击登录”三个操作组合成一个关键字“登录”。
● 配置管理
如同开发团队一样,自动化脚本也需要有配置管理,这样才能更有效地对脚本的提交、修改、版本控制、基线化等操作进行管理,所以在设计框架的时候需要考虑结合配置管理工具,如CVS、VSS、SVN等。
● 可配置性
1、外部可配置性
脚本的配置项应该放在外部文件中,像URL,路径,版本信息等,从而能使脚本在不同的环境下运行。另外配置文件的路径也不能写死,应采用相对路径,以保证框架能在不同的机器上顺利运行。
2、内部可配置性
当框架部署到不同的机器上时,会有不同的环境,要有能够自动根据不同的系统环境完成必要配置的能力。举个例子,比如一个selenium框架被部署到装有不同浏览器的机器上,框架应当能根据当前系统上装了哪些浏览器而分别运行它们。
● 对象库维护
在自动化测试中遇到的大多数问题基本上都是由于对象的属性变化导致的脚本失败,所以,对象库的维护能力对于一个框架来说十分重要。我们可以把对象库作为一个共享资源,由专人进行维护。对象库可以是一个外部的XML、Excel、数据库等。
● 执行模式
需要考虑到以下几种用例执行需求:
1、执行一个单独的用例
2、执行一个测试用例集
3、重新执行失败的用例
4、根据其他的用例或用例集的运行结果执行相应的用例或用例集
除了这些以外可能还有其他的方法,主要是根据项目的需求来的,所以只需要满足特定的项目测试需求就可以了,不必全部都实现。
● 状态监控
在脚本执行的时候,框架应当能够实时监控脚本的运行情况,如果碰到运行故障的时候应当能进行基本的容错恢复处理,这样的话不至于使脚本处在一个被block的状态,从而浪费大量时间。
● 测试报告
不同的应用程序往往会有不同的测试报告的要求,有时需要把许多用例集的运行结果结合起来(总的运行报告)看,多少个成功,多少个失败,通过率多少;有时又要看单独一个用例的执行情况,哪一步失败,失败原因是什么。
另一方面,多样化的测试报告表现形式也是需要考虑的。Excel、word、web、pdf、...等形式可以根据实际项目需要来选择,但不论做成何种形式都至少要保证测试报告的易读、易访问。
● 易调试性
一般情况下,调试(debugging)在开发测试脚本的过程中会占据大量时间,所以是否易于调试也是一个很重要的因素,直接影响到开发和维护框架的成本,不容忽视。
● 测试日志
一个好的框架应当能在测试执行过程中生产足够详细的日志信息(文字、截图等),这对于调试的帮助很大,同时也能我们快速定位到问题所在,节省时间。
● 易用性
易学易用对于自动化测试框架来说也很重要,因为毕竟是要面向最终用户的,如果框架很难上手,会失去用户群体,那框架也就没有存在的意义了。所以在保证易用性的基础上,最好有一个详细的框架说明文档,对于新手来说帮助会比较大。
● 灵活性
灵活性是指框架应当能保证在目前的基础上做二次开发的能力,这个其实跟软件开发的标准是一样的,预留足够的可扩展性以便未来的版本升级。
● 性能
框架设计不宜过于复杂,太复杂的框架会增加脚本的加载、运行时间,从而导致运行脚本的效率低下。所以在设计框架的时候,也要考虑到性能这一因素。
● 引用外部工具
有一些外部工具本身就提供了自动化接口的,我们不妨可以把它融入到框架中,可以省去不少工作量。比如,经典的QTP+QC框架。
● 编码规范
好的编码规范能使脚本易读、易维护、易管理。下面列出了一些点:
1、变量、常量、函数、文件、脚本的命名规范
2、函数、函数库的注释规范
3、对象命名规范
最后需要说一句,自动化测试框架永远没有最好的,只有最适合的!
Session介绍
Cookie是Web产品测试过程中不可缺少的一部分,我们需要通过Cookie信息辨别用户,得到属于自己的结果数据,例如DWR接口测试过程中,需要在请求头信息中传入测试用户的cookie信息,才可以得到该用户学习的课程,发表的博客,或者关注的用户等。Cookie信息通过模拟登陆操作就可以获得。但是,你有没有注意到你获得的Cookie是由什么组成的?是否包含NTES_SESS信息,是否包含SessionID信息?
NTES_SESS是URS返回的Cookie信息,NTESSTUDYSI是云课堂返回的Session信息,NTESSTUDYSI存储SessionID信息,不同的产品会配置不同的变量名。这个信息对于接口测试来说并不是必须的,但是却会在性能测试过程中起到很关键的作用。Cookie和Session有什么区别,为什么性能测试过程中必须需要Session信息?下面,我们一一阐述:
Cookie是什么:
cookie是小甜饼、小型文本文件,因为HTTP协议是无状态的,浏览器无法区分这次请求来自于哪个浏览器,因此产生了随着HTTP请求一起被传递给服务器的Cookie信息。Cookie是保存在客户端的,存在内存中的cookie,浏览器关闭后就消失了,存在时间是短暂的;存在硬盘中的Cookie,但存储时间长度超过过期时间或者用户手动清除时,cookie信息会消失。
Session是什么:
Session是会话,当用户第一次对网站服务器发生请求时,服务器会创建Session信息,生成SessionID用来唯一标识用户,并会把该SessionID返回给客户端浏览器(只存在内存,并不存在硬盘中),在会话结束之前的每次请求,浏览器会自动将该SessionID附加在请求头信息中,服务端接受请求时,检测是否存在SessionID(不存在或者Session过期都会重新生成Session),并通过该SessionID以键值对的方式查询用户信息。服务端的Session使用类似散列表的结构存储用户信息。
Session的常见实现形式是会话Cookie(Session Cookie),即未设置过期时间的Cookie,这个Cookie的默认生命周期为浏览器会话期间,只要关闭浏览器窗口,Cookie就消失了,这种形式的Session是和Cookie绑定在一起的。而平常所说的Cookie主要指的是另一类Cookie——持久Cookie(Persistent Cookies)。持久Cookie是指存放于客户端硬盘中的Cookie信息(设置了一定的有效期限)。持久Cookie一般会保存用户的用户ID,该信息在用户注册或第一次登录的时候由服务器生成包含域名及相关信息的Cookie发送并存放到客户端的硬盘文件上,并设置Cookie的过期时间,以便于实现用户的自动登录和网站内容自定义。
我们在执行接口测试之前,首先会通过URS得到用户Cookie信息,这份Cookie信息中至少会得到NTES_SESS字段对应的Values值,如果在获取Cookie时,我们同时跳转到产品页面,向该产品服务器发送请求(例如云课堂),那么在我们得到的Cookie信息中同样存在NTESSTUDYSI字段,该字段就是该产品的Tomcat服务器产生的32位的SessionID +jvmRoute设置的后缀名。在做接口测试时,如果请求头中没有传入SessionID信息,那么每次执行时,Tomcat都会重新生成一份Session;即便你传入该SessionID信息,如果SessionID过了超时时间设置,Tomcat还是会重新生成一份,Tomcat默认的Session过期时间为30Min。
性能影响
虽然只是一个小小的SessionID,却会对性能测试的产生很大的影响:
1、Session缺失:
在做Lofter产品的性能测试时,测试getHomePage接口,发现响应时间比较慢,JVM内存在测试过程中一直增长,Young GC收集不过来,Old区内存不断增长,最终会导致频繁Full GC,使用Jmap定位到堆内存中java.util.concurrent.ConcurrentHashMap$Segment对象不断增加,但是并不知道这个对象时谁在什么时候产生的。我们Dump出来此时的堆内存,使用MAT (Memory Analyzer Tool)工具进一步分析,到底是什么操作产生了大量的ConcurrentHashMap$Segment。
由上图可以看到这个对象是由org.apache.catalina.session.StandardManager产生的,session.StandardManager就是存储Session的容器。
通过了解Session的原理得知,我们在测试过程中,只是传入了Cookie信息,在Cookie中没有包含SessionID信息,所以每次请求时,Tomcat都会检查是否存在该标识信息,如果没有则会创建。如果我们测试过程中有几十万次请求,那么Tomcat会创建几十万个Session信息,假设一条Session需要2K的数据,那几十万的Session可能会使得Session容器占用上百兆的空间。同时需要注意,因为我们每个请求都会创建Session,这个Session是创建了以后不会被使用的(下次请求中依然没有携带SessionID),即垃圾Session,但是垃圾Session在过期之前是会一直存在内存中的,默认的Session保存时间是30Min,这样的垃圾Session会在内存中保存至少30Min,如果在这30Min中内我们不停的发送请求,Session容器占用的内容空间会 不断扩大,最终会影响我们的测试结果。
2、Session过期
即便我们在请求中加入了SessionID,但是还可能会产生不停的创建Session问题,这是为什么?因为Session是存在过期时间的,默认的Tomcat中web.xml中设置的session过期时间为30Min,如果我们得到的SessionID在30Min后使用,依据Tomcat的Session机制,首先会检查是否存在SessionID,如果有的话,检测是否过期,如果传入的SessionID已经过期,Tomcat还是会每次都自动生成Session信息。
Mark,Session的过期时间有三种设置方式:一种是Tomcat的配置文件web.xml中设置,一种是webroot项目代码中的配置文件web.xml中设置,一种是代码中设置session.setMaxInactiveInterval(15*60),所以我们在测试中要记得检测和确认这三个地方。
3、SessionID后缀不匹配
在测试云课堂项目中,我明明已经修改了每个地方的Session过期时间,请求中传入了没有过期的SessionID,可是为什么还是会不停的创建Session?
一般我们的产品架构是Nginx+Tomcat方式,静态请求走Nginx,动态请求通过Nginx访问到Tomcat。Nginx处理Session采用了session sticky方案,需用到第三方模块jvm_route,需要在Nginx的配置文件中upstream.conf中设置:
upstream study {
server 10.120.36.68:8010 srun_id=qa18-8010;
server 10.120.36.97:8010 srun_id=qa19-8010;
jvm_route $cookie_NTESSTUDYSI reverse;
keepalive 100;
} |
该配置文件中配置了一个Nginx连接两个Tomcat,当请求过来时,会依据SessionID中的后缀来查找请求发送到哪个Tomcat,例如NTESSTUDYSI=1816E5ECBC052F6ABA420FEE7B06DA86.qa18-8010;就会把带这个SessionID的请求发送到 10.120.36.68(qa18)这台机器上去。
在qa18这台机器的Tomcat配置文件server.xml中,会设置jvmRoute="qa18-8010",这样保证生成的SessionID的后缀是qa18-8010,如果这个两个后缀不一致的话,同样会出现问题。
例如如果Nginx配置文件中upstream.conf中设置的srun_id=qa18-8010,而tomcat配置文件中设置的jvmRoute="qatest18-8010",那么获取Cookie得到的SessionID后缀则为qatest18-8010,当发送请求到Nginx时,检测到SessionID的后缀和设置的server服务器无法匹配,则会丢失session,使得发送到Tomcat的动态请求依旧是没有Session信息的请求,造成session丢失,测试过程中还会有session不断的创建。