
1、测试资源不足和保证软件质量的矛盾
没有可用的测试团队或测试人员,在很多小型开发团队和小公司都普遍存在测试资源不足的问题,甚至在某些大公司也可能出现。严格的成本控制,导致测试资源相对不够;失败的项目开发计划会导致压缩测试的时间来保证研发的时间;到了测试的时候,就肯定出现你们现在这样的情况。最后的结果呢,是所有人都得不了好:领导会因为客户的投诉而头疼甚至被老板骂;项目经理会对质量负主要责任,对整个项目负主要责任。如果有测试团队,测试会对质量控制负主要责任。没有,项目经理负主要责任。
应对办法有以下几个:让开发人员做测试;让有限的测试人员只测试主要核心功能点;项目经理死扛,自己亲力亲为;降低软件质量;让领导充分意识到这个矛盾的风险。
2、项目日程表异常紧急和按时上线的矛盾
这类项目最大的问题是时间成本。时间成本越紧,失败风险越大。要提高这种项目的成活几率,只有一个办法。砍范围。把所有可有可无的需求砍掉,放到下一期去实现。确保团队能够以合理的生产率产出成果。项目经理要做的最重要的就是,想尽一切办法,把优先级低的功能砍掉。集中资源保证高优先级需求的产出。要随时告诉明白客户,团队最大的产出是多少,团队正在做哪些功能。及时让客户进行确认和调整。让客户明白风险在哪里有多大。这是非常考验项目经理沟通、谈判、组织协调能力的。能把客户啃下来,保证团队正常工作,还有1、2分活的可能。不然,最后就当替罪羊吧。团队、老板、客户,都需要你承担责任。
3、团队的生产率严重低于估计和项目按时上线的矛盾
项目竞标的时候是公司专家组资深架构师按照已有生产率来进行项目估时和报价的,但项目开始以后出现资源不足问题,例如:原来C++团队的资深工程师走光了,只有两个新人可用。原先是按照资深C++开发工程师的生产率来估计的时间,现在给你这样的一个团队,生产率和资深C++开发工程师相差很多倍。项目日程表却异常紧急,这怎么办? 没办法。这种项目的失败风险是极高的。解决办法只有找外援或者项目经理死扛了,否则这类项目失败是必然的。团队人员突然离开是项目的一个极大的风险,特别是核心资深开发人员,公司往往处于成本原因不可能对每个人有一个备份的人员,所以核心资深开发人员突然离开往往使项目处于高危状态。
4、项目经理兼任Team Leader的矛盾
项目经理和Team leader这两个职位貌似是一样的,其实不一样。项目经理的职责包括:项目进度控制,成本控制,需求控制,风险管理,配置管理、任务分配以及与客户相关的沟通和交流等。而Team leader的主要职责包括技术方案确认,开发计划制定和跟踪,技术架构设计,重要技术问题攻关,核心代码编写和技术指导以及开发团队管理。对于小公司来说,为了节约成本很可能把两个角色让一个人来承担,这样的混合角色对个人能力要求非常高,需要两方面的专业知识,两方面都得一手把握,压力很大。现在很多大公司基本都将这两个角色分拆了,项目经理就是管进度,做协调,Team Leader就负责开发相关事宜,另外还有一个角色,叫Product Manager,这个角色主要是市场和开发之前做协调了。按照我的理解,项目经理需要对项目功能和需求(产品)有非常深入的了解,对软件开发过程相当有经验,同时具有很强的沟通能力,因为客户都是牛的一塌糊涂,你要引导客户的需求,那是沟通功夫了得。另外,项目经理是项目总负责人,对领导对跨项目和部门也需要及时的沟通协调以获得最佳的资源,以解决过程中的问题。而Team leader需要控制开发过程中的系统性风险,总体架构把我和关键核心部分开发。软件开发过程有很多的环节,任何一个环节出现大的差错都会导致焦头烂额并最终项目失败。但是在大多数公司,我们都不会称其为失败,一般会说:项目延期,好的延期半年,差的甚至有的延期1年!核心竞争力:开发管理+过硬的技术能力。
5、有限的资源和时间与按时上线的矛盾
项目管理的主要矛盾就是如何在有限的成本(资源)和时间内高质量的完成系统。根据毛*泽(东思想,革命为什么成功,要能分清各个阶段的革命主要矛盾,集中优势兵力来予以打击。在时间管理上就是轻重/缓急。轻重,即是否为核心需求;缓急,即优先级、顺序。 资源有限,那就把核心资源放在核心功能和最大风险的部件上。我记得自己工作那几年,从来不考虑这种问题,领导让做啥就做啥,被动式积极(有任务就全力以赴,没任务就自学、不闻不问),那时候我只是一位执行者。 其实,任何事情都可以分成两阶段:先分配,再执行(日常生活中,我们做任何事情都是先在脑子里分配好了)。而在公司,这两件事往往是分离的:领导做分配,下属做执行。
分配任务的核心原则,就是先分清轻重缓急,作为管理者,一定要将它养成习惯。
运用实证(实证依赖的是观察和经验,而不是理论和纯逻辑推理)方法进行调试可以充分利用软件的独特能力来告诉你软件运行的状态,而发挥这种能力的关键是找到能够重现问题的方法。
为什么重现问题如此重要?
不能重现问题,就几乎不可能取得进展,因为实证过程依赖于我们观察存在缺陷的软件执行的能力。
如何重现?
要做的第一件事很简单,就是按照缺陷报告描述(或提示)的步骤做,要做好问题重现就要抓好控制,而需要控制的因素如下:
1、软件本身:如果缺陷存在于最近修改的地方,那么你应该首先保证你调试运行的软件和缺陷被提交时使用的软件是同一个版本
2、软件的运行环境:如果要与外部系统进行交互,那么可能需要确保你使用的是相同的外部系统
3、你提供的输入:如果一段代码的运行情况受软件的配置影响很大,而缺陷又与这段代码有关,那么应该使用用户的配置来进行调试
控制软件本身:最好的办法就是创建一个自动化的构建过程
控制运行环境:要知道缺陷出现时软件所使用的环境,记住:软件环境包括了可能影响软件运行的所有因素。
控制输入:要找出输入数据以便准确重现问题。如果无法获得需要的所有信息,有两种选择:一是推测一下可能的输入是什么,二是把它们记录下来。
推测可能输入:出发点是假设问题确实存在,然后运用逆向工程的方法推测出能够导致问题的必要条件。
回溯:通常我们知道发生了什么事,但不清楚为什么会发生,此时可以使用回溯法,如果运气好,这个逻辑可以直接重现问题,即使不能完全重现,也可以提供有用的线索,再加上其他异常的现象,就可以排除某些可能性。
探测可能的输入值:黑盒技术中边界值分析可以在这里使用,因为输入值范围的边界是最有可能出现错误的地方,而相当于白盒测试中的边界值分析的分支覆盖,也可以在这里派上用场,可以尝试创建一些输入,使用这些输入可以覆盖同一代码块中的不同分支。
有效地识别能重现问题的输入顺序需要你转变思路——你不必证明系统工作正常,而要证明它不正常。
利用错误条件:当试图重现一个问题的时候,考虑一下是否有一些错误条件出现在运行的过程中,并去解释为什么问题会发生,然后,想想如何使错误条件表现出来或模拟出来,并且是否可以使你重现问题。
引入随机性:选取一系列不同输入值的一种方法就是引入一些随机输入值。
在推测重现问题时需要使用的数据过程中,记住:你需要验证与缺陷报告不符的结论。你找到了一种使软件出现缺陷的方法,并不意味着你找出了缺陷报告中的缺陷(尽管你已经清楚地发现了一个需要修正的缺陷)。
记录输入值:使用日志记录输入值。获取日志最简单的方法就是在整个代码中正确地放置了对System.out.printfln()或类似方法的调用,当然,也可以使用日志框架来完成更为复杂的功能(此处略去该方法)。
是否应该把日志留在代码中?
答案仁者见仁智者见智,如果在代码中嵌入日志,无疑,当问题再次发生时可以快速寻找到它,但是,它却容易导致代码变得难以理解,同时,它将类似注释内容而停滞,一成不变。因此,最佳的选择是注重实效,一旦将它嵌入代码,确保你的日志随时更新,与代码保持一致,而非为了日志而做日志。
负载和压力:关于负载测试工具的问题,通常是找到一个办法让它们重现真实的负载,但创建大量简单的交互行为可能并不会产生足够的负载来重现需要调试的问题。解决方法之一是使用日志记录真实的负载量,然后使用负载测试工具去重现它。
压力测试工具也是类似的,只是它不直接产生负载。
问题重现曾经是一个重要的障碍,下面我们将聊聊如何改进问题重现。不管是什么样的重现问题的方法,只要有,就比没有强。但是如何让重现问题既可靠又方便呢?
最小化反馈周期:和软件开发的其他众多领域一样,问题重现也是要使反馈周期最小,所经过的周期越短,反馈就越及时,其相关性就越高。
因此,最先要关注的就是找出问题重现中哪些方面是不需要的,将它们剔除掉,称为将问题重现最小化。那么,哪些元素可以被剔除呢?往往这要靠直觉。你了解软件,并且知道哪些模块可能被一些特定输入所影响,如果直觉不对,那么一些非直接的方法可能会帮助到你。
改进问题重现不是一蹴而就的事,而是在整个诊断过程中要牢记在心的东西。
将不确定的缺陷变为确定的:要做到这一点,需要明白不确定性从何来?
1、开始于不可预知的初始状态
当你的软件从未经初始化的内存读取数据时,通常会出问题。如果你有理由相信,是这个原因导致了不确定性问题,那么你最好的选择可能是使用调试内存分配器,来强制内存被初始化为一个众所周知的值,或用内存完整性检验软件来检测是否引用了未初始化的内存。
2、与外部系统进行交互
由此引起的不确定性问题往往不是因为二者表现不一,而是因为时间上微妙的不同。解决的策略是能够精确控制从外部系统接收了什么,以及何时接收的。最好的选择可能不是试图直接控制外部系统,而是用你能控制的东西替换它,比如调试子系统或代替测试。
3、故意地使用随机性
由此导致的不确定性听起来还是很正常的,幸运的是,大部分所谓使用随机数的软件都是通过确定性算法产生的伪随机数,因此这个是完全可以预测的行为。
4、多线程
由此引起的不确定性最难处理。在多核系统盛行的今天,往往我们处理的并不是真正的并发。而在缺乏并发控制的结构化方法下,我们不得不依靠一些特殊的方法。因此,在处理方法中最有效的工具之一就是不起眼的sleep()方法,它允许你强制一个线程长时间等待而出现竞争状态。
例如,假设你正在工作的软件中多个乖哦工作线程并行处理工作项目,工作线程使用下面的java代码来获得工作项目:
if (item=workQueue.lockWorkItem())
{
item.process();
workQueue.writeResultAndUnlock(item);
} |
你试图跟踪一个间歇出现的缺陷,有时同一个工作项目会同时分配给两个工作线程。遗憾的事,这种情况极少出现,那么,你可以将代码更改为如下形式来增加重现该问题的几率:
if (item=workQueue.lockWorkItem())
{
Thread.sleep(1000);
item.process();
workQueue.writeResultAndUnlock(item);
} |
注意:尽管sleep()方法在重现问题和诊断阶段很有用,但在修复缺陷阶段它不是一个适合的方法。
自动化:一个自定义测试不仅能够方便的运行,而且当诊断结束开始修复的时候,对于即将编写完成的测试来说,它是一个很好的起点。如果确定缺陷重现需要通过日志,那么可以选择重放日志文件。
迭代:在诊断的过程中,你构建了足够多关于如何以及为何软件如此运行的信息,可以用此不断改进重现,如下图:
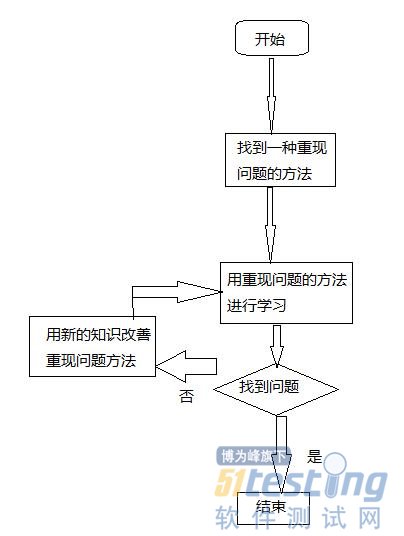
通过如下步骤反复改进:
1、你确定一个特定的模块已包含在内,其中有导致缺陷的元素,这样可以创建一个更小的文件。
2、进一步诊断,发现能通过用桩模块替代与第三方服务器交互的子系统,让问题每次都出现,桩模块可以很容易返回已经确定的响应。
3、最后,把跟踪范围缩小到一个特定函数,通过设置一组具体的参数调用该函数来创建单元测试,以便重现问题。
如果真的不能重现问题该怎么办?
首先,不要轻易给出“缺陷不存在”的结论,除非尽力获取了更多额外信息,用尽了所有可用的办法依然不能重现问题。其次,在相同区域解决不同的问题,尽管没有你目前跟踪的缺陷那么严重和紧急,也许它们蒙蔽了真正缺陷所在,也许会让你找到重现问题的关键因素,当然,也许没有任何帮助。第三,试着让其他人参与其中,这样可以获取其他人的不同角度看待问题,尤其是反馈错误的人。第四,充分利用用户群体,有些时候,缺陷出现在外部系统而非开发系统中,但这需要用户为你收集所需要的信息,从某种角度来说,并不理想。最后,可以使用推测法,你所需要做的是把自己融入到软件中,在想象中执行软件,执行每一步,考虑有哪些出现错误的可能性,尝试解释你跟踪的缺陷。
正常来说,我们有能力重现问题,而在下一章中,我们将会看到如何用重现来诊断问题。
作为一个新兴的职业,银行软件测试融合了银行业务和软件测试两个职业的知识体系,在国内银行业越来越受到更多的重视测试队伍也在不断地发展壮大。目前国内大型商业银行都有自己专职的测试队伍。
测试部门作为一个成本中心需要分享经营部门的利润。伴随着测试队伍的发展壮大,银行决策者需要认真思考业务发展需要和测试部门规模之间的配置问题。为此,需要科学地进行测试工作量分析和掌握评估方法。
根据IT业的人力资源配置模型测试人员和开发人员的配置比例为1/3一1/5。而根据我国银行业的实际配置情况测试人员的数量配备几乎无法满足这样的要求。
测试人员的工作t如何分析和评估才能确保测试人员数量配置是科学的。这是银行软件测试工作需要研究的问题。
一、银行测试工作的特点
与专业测试公司不同,银行软件测试由于受组织结构、人力资源管理模式、系统的复杂程度以及银行业务的特殊要求等因素的影响银行软件测试工作与专业测试公司的测试工作差别较大。
1、组织结构不同导致测试的责任不同
作为银行内部的职能部门,测试工作无疑是测试部门的核心职责。换句话说测试任务的承接与否是不具备可选择性的,不管版本的质量和测试条件如何,测试工作都要如期开展;
而专业的测试公司它会根据自身的人员结构和版本的复杂程度决定是否承接项目,所以银行测试部门与专业的测试公司的责任是不同的。
2、人力资源成本的核算方式不同
作为自负盈亏的测试企业,专业的测试公司的成本核算会根据测试软件的评估质量、确保产品质量的目标和工期等因素核算人力资源成本;而银行测试人员的成本核算与项目没有直接的对应关系银行测试人员的人力投入在特定的时期内是相对固定的。
成本观念的不同决定不同版本、不同项目测试的深入程度是不同的。
3、银行工作性质和系统的藕合
度决定测试的难度较高、风险较大银行经营货币这种特殊商品,决定了测试工作不仅要实现产品功能完善性的目标而且还要证明系统的可用性、安全性。因此。测试涉及内容多、范围广;
银行计算机系统结构复杂多应用之间祸合度高、关联性强。决定了测试的过程异常复杂。相对于测试公司来说,对测试人员的专业水平要求更高,即银行测试人员是熟悉银行业务和测试技术的复合型人才。
4、银行的持续经营决定测试工
作的长期性和连续性随着银行的持续经营和业务不断扩展,业务部门的需求也是不断变化的。新需求产生新功能,进而产生新的测试要求,但测试的对象是在主体功能不变的情况下,部分或个别业务功能的优化和完善。
为此。要求测试人员对银行业务比较精通且测试人员需要相对固定,如从事个金专业测试的人员在短期内是难以胜任会计专业的测试工作,在银行所属业务体系架构不发生变化的情况下测试工作要按专业进行长期分工并持续开展。
5、测试的目标和标准不同
银行测试部门要完成的测试目标,不仅要验证功能的完善性,而且还要进行适应性测试。即功能测试之外还要满足性能、容量要求即开展全面性测试。目标是软件产品符合业务部门生产上的需要。不得产生安全生产责任事件。
鉴于银行软件测试部门的特点银行软件测试的工作量评估与专业软件测试公司的评估方法是不同的。
二、常用的软件测试工作量评估方法
测试工作量受测试的内容、测试的方法、质量要求、测试阶段多少等诸多因素的影响。测试工作量的差异是非常大的。本文主要阐述测试工作量评估方法常用的有以下几种。
1、DelPhi法
elPhi法是专家基于对特定工作的经验对工作量的估算而得出的定性评估方法,具体评估流程如下:
(1)工作量评估小组负责人向各位专家提供项目规格和估计表格:
(2)组织各位专家详细讨论与规模相关的因素:
(3)专家们匿名填写估算表格;
(4)汇总专家的意见,并将结论返回专家:
(5)专家讨论较大的估计差异;
(6)专家们重新评估直至差异逐渐缩小,最终达成一致意见。
oelPhi法是在没有历史数据情况下采取的针对性评估方法,操作简单方便,这是新测试项目的工作量评估采用的方法,可用于测试工作量的预算,并以此来编制测试的规划和指引。
elPhi法的缺点是精确度不高。专家组成员的工作经验和风格以及专家不同的个性将导致评估结果的差距会比较大。
2、比例评估法
根据开发承担的任务量,按比例评估测试的工作量。业界开发与测试的经验工作量分配为开发占总工作量的80%一65%测试占总工作量的20%一35%。比例评估法是基于软件全生命周期模型进行的工作量分配这是大量历史数据总结分析出来的量化结果。
根据开发的工作量估算出测试的工作量相对来说比较精确,这种方法适合于在软件开发公司承接软件开发项目时综合计算软件全生命周期的长度。
缺点表现在这种方法适用的前提是开发队伍与测试队伍的成熟度基本匹配。一旦出现成熟度差异,工作最评估的结果的差距较大。
3、WBS评估法
WBS(WorkBreakdownStrueture,工作分解结构)即将项目分解成可文付成果或划分成更小的、便于管理的正常的组成部分,直到工作和可文付成果被定义到工作包的层次。具体步骤如下:
(1)将测试项目进行逐层分解:
(2)最终分解为不可再分的行动;
(3)对各项行动所需的时间进行估计:
(4)逐级向上汇总工作量:
(5)核算出最终的测试工作量。WBs评估法是比较精确的工作量评估方法,可用于测试工作量的结算活动,W日S是项目管理活动的重要一个环节。WBS评估法是当前测试工作量评估所有方法中最精确的方法。它不仅完成了工作量评估工作。同时还完成了测试工作计划的编制,应用这种方法评估工作量能达到一举两得的效果。
但这种方法有其明显的缺点:一是编制W日S费时费力,投入的工作量巨大:二是若WBS编制不合理时评估的误差会非常大;三是在缺乏工作量定额数据的时候由于单位行动没有对应的劳动量数据,只能估算单位行动对应的工作量。工作量估算值稍有偏差,最终汇总结果就会差异较大。
关于测试工作量评估的方法还有很多。如根据以往测试经验或历史数据进行评估的项目经验比较评估法等,鉴于每种工作量评估方法都有其自身的优缺点在此不一一列举。在综合比较各种测试工作量评估方法的基础上结合银行测试的工作特点,本文设计了全新的测试工作量评估方法—测试工作定额评估法。
三、测试工作定额评估法
测试工作定额评估法就是将测试任务分解为不可拆分的活动。通过工作日写实或模拟操作换算出每项活动的定额工时,编制工时定额表。将活动与工时定额建立对应关系最终汇总计算出测试工作量的一种工作量评估方法。
1、将测试任务分解为具体活动根据项目管理的WBS方法将测试项目分解为各项测试行动再将测试行动细分成不可划分的活动。银行的适应性测试项目大致分解为以下几项行动。
1)测试前移行动。了解项目的设计、研发、编码以及单元、集成和系统测试的情况详细研究业务需求和软件需求根据应用改造、接口改造情况,编写测试案例。这几项行动可以分解为以下几项活动:一是项目开发情况调研:二是需求分析和评价:三是案例设计和编写,案例编写可以根据具体交易编写单个案例等。
2)测试计划行动。对项目进行详细的规划,编写测试计划,对方案进行讨论、评审并发布实施。可分解的活动有:一是各套环境的统筹规划;二是各套环境的计划编制:三是计划的讨论和修订:四是计划的推进和实施等。
3)测试准备行动。测试文档的编写和评审,测试环境准备和配置,参数安装和数据移行。可分解的活动有:一是测试案例的编写:二是测试案例的评审和培训:三是测试环境的配置和调试:四是参数文本的编制、检查和安装:五是移行文本的编制、移行和移行结果的检查等。
4)测试实施行动。这是测试过程中用时最多、也是最核心的行动维护测试环境,包含功能测试、非功能测试、回归测试、例行化测试、补丁测试等。测试实施可以分解的活动按测试案例或交易分解为单个的活动。
5)项目投产行动。项目投产行动是测试项目的收尾阶段是测试项目的最关键的行动可分解的活动有:一是投产方案的编制:二是投产文档的编写:三是投产验证方案及实施验证: 四是投产支持等。
2、核算测试活动的工时定额
所谓工时定额就是指单项活动需要消耗的工时标准工时定额是通过对历史数据的归纳、分析,最终计算出来的单位活动的时间消耗量,因为是历史数据的收集定额的产生办法有很多种本文提出了两种工时定额计算方法。
1)工作写实定额法通过现场记录测试人员的行动及行动对应的时间汇总写实对象所有行动的全部时间消耗合并相同活动的时间消耗。挑选出有效时间和无效时间,对比分析行动分析结果。最终换算出单位活动的工时定额。
题组成员记录写实数据相对规范、真实和准确,但耗时费力:员工自行填写的写实资料在规范性、信息的真实性方面相对较差但可以在信息收集汇总以后通过比较法、筛选法、判断法等方法对数据进行修正也能达到预期的效果。工作写实定额法的具体实施步骤如下。
① 编制写实工作表。工作表应包含的内容有活动名称、活动类别、工时区间、活动关联对象等。
② 写实。通过现场描述测试人员的活动,记录单项活动所投入的时间。
③ 汇总统计。将所有写实资料进行汇总,得出每项活动的消耗时间。增补工作表中没有编制的活动项目,完善写实表。
④ 数据分析。这是写实活动中最复杂的一项工作,需要分析三个要素:
一是数据的真实性由员工自行填写的写实资料,会存在个别信息不真实的情况,如夸大工时耗费。这可以通过比较同一项活动的平均时间耗费的离散程度进行判断;
二是数据的复杂度分析。如单个交易的测试时间。由于交易分为联机交易和批量交易其工时耗费的差距是非常大的。批量交易的测试有的一个批量就能完成有的需要几个批量才能完成测试工作,相同活动的复杂度是差距非常大的;
三是分析业务之间的关联性和逻辑关系通过逻辑关系分析工作量的正常范围。
⑤ 测算工时定额。根据写实工时量。分析剔除无效工时后得出单项活动的工时定额。
⑥ 完善工时定额。根据测试队伍的成熟度和生产力的发展情况定期修订工时定额。
(2)模拟操作定额法对各项测试活动抽取样本操作员,对各项测试活动进行模拟操作测试记录各项测试活动的操作时间最终汇总算出各项活动的标准时间。实施模拟操作应该注意的事项:
一是样本的选取范围,由于测试队伍是由各层级的人员组成的,因此样本点要覆盖各层次的人员;
二是样本的操作技能,由于需要计算的是定额水平,因此样本的操作技能应在测试队伍的平均偏上的水平,不能过高或过低,否则都会影响定额的标准;
三是测试的时间选择,由于工时定额受环境的制约。为此模拟操作的时间应选择在测试的过程中。这样能真实再现环境对定额的影响。
模拟操作法的具体实施步骤如下。
① 编制模拟活动表,详细列举测试的各项活动。
② 选取操作样本在测试队伍的各层级挑选适量样本,需要说明的是不同的测试活动可以由不同的样本操作员完成。
③ 模拟测试对各项测试活动现场进行时间测试。取各层级样本该项活动的平均时间,计算出该层级人员的工时定额;取全部样本该项活动的平均时间计算出该项活动的工时定额。
④ 数据修正,由于模拟操作过程中的细微差异对定额的水平都会产生较大的影响为此必须结合模拟操作的具体情况,对测试数据进行必要的修正。
近年来,随着社会对信息化依赖程度的不断加深,对于软件质量更是提出了安全、可靠、稳定、易用、效率等全方位的要求。因此保证和加强软件质量成为制约社会信息化高速发展的重要因素。
软件测试是控制软件质量的重要手段,目前我国还没有适应国情的、系列化协调配套的、工程化的信息系统生产过程管理、质量评测、控制技术的规范和法律规程指导,因此以第三方测试工程为基础,对信息系统的建设进行质量保证是非常必要的。
第三方测试可以避免开发方内部测试由于思维定势而造成问题的漏测和误判,尤其体现在涉及业务流程、安全可靠性、易用性和可扩充性等方面;同时也可以避免用户自测的盲目性和非专业性。
第三方测试的目的是尽可能多地发现系统目前存在以及潜在的问题,借助长期积累下来的丰富的行业测试经验,更客观地从用户角度和专业角度出发,投入足够的人力、物力,运用专业的测试工具更好地进行测试以保证软件质量。
现在以某一集团公司的企业应用为例介绍第三方测试的实施案例。
该企业应用是该集团业务规范化运营和一体化管理的信息支撑系统,建设目的在于整合新、旧业务系统,实现历史数据和实时数据的集中存储和统一管理,同时通过整合后的统一管理平台来提高公司管理水平,为领导决策的正确性提供可靠的理论依据。
业务系统基于目前较为主流的J2EE三层架构,采用B/S运行模式,应用服务器使用Weblogic并且采用集群策略,数据库服务器使用Oracle并且采用集群策略,具体网络拓扑图如图1所示。
本次测试根据相关国家标准和企业标准,针对企业应用的业务需求,对其在功能度、性能、安全可靠性、易用性、资源占用率、兼容性、可扩充性和用户文档八个方面进行了测试。
功能度方面主要采用黑盒测试方法,包括因果图分析、等价类划分、边界值分析等,根据用户需求说明书和用户操作手册,分别对系统的全部功能点和主要业务流程进行测试。由于该系统多个模块涉及到工作流,公文和业务单据的流转是测试的重点,尤其是验证特殊流程分支中单据的走向和状态以及异常处理是否会导致单据的丢失等等。
安全可靠性方面,结合功能考察软件的用户权限限制、用户和密码封闭性、留痕功能、屏蔽用户错误操作、错误提示的准确性、数据备份恢复手段等方面。
易用性方面,考察软件的用户界面友好性、易学习性和易操作性等等。
兼容性方面,考虑软件、硬件和数据的兼容性。
可扩充性方面,考虑软件结构的功能可扩展性和异种数据库的结构等等。
用户文档方面,考虑文档的完整性、一致性、易理解程度和操作实例等等。
下面重点介绍一下性能测试的关注点。
在性能测试方面,针对该企业关注的用户登录、单据查询、批量转账等关键业务点进行负载压力测试,同时监控应用服务器和数据库服务器的资源使用情况,包括CPU占用率、硬盘使用状况以及事务处理平均响应时间等相关参数,考察系统在各种情况下的性能表现。
测试前期需求分析中确定该操作的最大并发用户数为50人,采用逐步加压的方式对系统进行压力测试,分析在不同负载情况下系统的承受能力。
关注点1:
交易吞吐量和交易响应时间是评估系统性能的重要概念。
吞吐量:系统服务器每秒能够处理通过的交易数。
交易响应时间:是系统完成事务执行准备后所采集的时间戳和系统完成待执行事务后所采集的时间戳之间的时间间隔,是衡量特定类型应用事务性能的重要指标,标志了用户执行一项操作大致需要多长时间。
关注点2:
随着负载增加,当吞吐量不再递增时,交易平均响应时间是否会递增。
随着负载增加,当吞吐量不再递增时,交易平均响应时间一般会递增。
当系统达到吞吐量极限时,客户端交易会在请求队列中排队等待,等待的时间会记录在响应时间中。
关注点3:
根据上述测试结果,服务器资源使用情况是否合理?
应用服务器资源合理。由测试结果来看,不同负载下的两台应用服务器CPU占用情况相当,并且都低于70%。
数据库服务器资源占用不合理。从测试结果可以明显看出,不同负载下的两台数据库服务器CPU占用情况始终差距较大,其中一台负载较大,而另一台比较空闲,由此可知,数据库集群策略并未生效,需要调整集群策略。
传统的软件测试流程:一般是在软件开发过程中进行少量的单元测试。然后在整个软件开发结束阶段,集中进行大量的测试,包括功能和性能的集成测试和系统测试。随着软件开发的越来越复杂,传统的软件测试流程不可避免的给我们带来以下问题:
问题一:项目进度难以控制,项目管理难度加大。
大量的软件错误往往只有到了项目后期系统测试阶段才被发现,解决问题花费的时间很难预料, 经常导致项目进度无法控制,同时在整个软件开发过程中,项目管理人员缺乏对项目质量的了解和控制,加大了项目管理难度。
问题二:对项目风险的控制能力较弱项目风险在项目开发较晚的时候才能够真正降低。往往是经过系统测试之后,才真正确定该设计是否能真正满足系统功能、性能和可靠性方面的需求。
问题三:软件项目开发费用超过预算。在整个软件开发周期中,错误发现的越晚,单位错误修复成本越高,错误的延迟解决必然导致整个项目成本的急剧增加。
IBM Rational 软件自动化测试最佳成功经验解决传统测试问题。
核心的三个最佳成功经验是:尽早测试、连续测试,自动化测试,并在此基础上提供了完整的软件测试流程和一整套的软件自动化工具,使我们最终能够做到:一个测试团队,基于一套完整的软件测试流程,使用一套完整的自动化软件测试工具,完成全方位的软件质量验证。
成功经验一:尽早测试
所谓尽早测试是指在整个软件开发周期中通过各种软件工程技术尽量早的完成各种软件测试任务的一种思想。IBM Rational 主要在以下三个方面为我们提供的尽早测试的软件工程技术:
首先,软件的整个测试生命周期是与软件的开发生命周期基本平齐的过程。即当需求分析基本明确后我们就应该基于需求分析的结果和整个项目计划来进行软件的测试计划;伴随着分析设计过程同时应该完成测试用例的设计;当软件的第一个发布出来后,测试人员要马上基于它进行测试脚本的实现,并基于测试计划中的测试目的执行测试用例,对测试结果进行评估报告。这样,我们可以通过各项测试指标实时监控项目质量状况,提高整个项目的控制和管理。
项目计划、需求管理―――测试计划
测试计划、分析设计―――测试设计
测试设计―――测试实现
测试实现―――测试结果评估
其次,通过迭代是软件开发把原来的整个软件开发生命周期分成多个迭代周期,在每个迭代周期都进行测试,这样在很大程度上提前了系统测试发生的时间,这在很大程度上降低了项目风险和项目开发成本。
最后,IBM Rational的尽早测试成功经验还体现在它扩展了传统测试阶段从单元测试,集成测试到系统测试、验收测试的划分,将整个软件的测试按阶段划分成开发员测试和系统测试两个阶段。它把软件的测试责无旁贷的扩展到了整个开发开发人员的工作过程。通过提前测试发生的时间来尽早的提高软件测试的质量、降低软件测试成本。
成功经验二:连续测试
测试成功经验连续测试是从迭代式软件开发模式得来的。在迭代化的方法中,我们将整个软件的开发目标划分为一系列更易于实现和达到的小目标,这些小目标都有定义明确的阶段性评估标准。迭代就是为了完成一定的阶段性目标而从事的一系列开发活动,在每个迭代开始前都要根据项目当前的状态和所要达到的阶段性目标制定迭代计划,而且每个迭代过程中都包括需求,设计,编码,集成,测试等一系列的开发活动,都会增量式集成一些新的系统功能。通过每次迭代都产生一个可运行的系统。通过对这个可运行系统的测试来评估该次迭代有没有达到预定的迭代目标,并以此为依据来制定下一次迭代目标。由此可见,在迭代式软件开发的每个迭代周期,我们都会进行软件测试活动,整个软件测试的完成是通过每个迭代周期不断增量测试和回归测试实现的。
成功经验三:自动化测试
在整个软件测试的过程中都要尽早测试,连续测试,可以说完善的测试流程是前提,自动化测试工具是保证。IBM Rational的自动化测试成功经验主要是指利用软件测试工具提供完整的软件测试流程的支持和各种测试的自动化实现。
为了使软件测试团队更好的进行测试,IBM Rational在提供了测试成功经验之外,还为我们提供了一整套的软件测试流程和自动化测试工具,使软件测试团队可以从容不迫地完成测试任务。
0、引言
随着软件行业的发展。软件产品已经影响到我们社会的诸多领域,人们对软件作用的期望值也越来越高,对软件质量重要性的认识也逐渐增强。
然而,软件缺陷(bug)是伴随软件产品开发过程而产生的敷衍品,采用新的技术和方法,也不能完全消灭软件缺陷。因此,在软件开发过程中尽早地引入软件测试技术来保证软件质量,降低软件缺陷率,已经得到软件业的认可。软件开发过程中的每—个阶段都会有相应的文档和产品产生,对这些文档和产品进行严格评审和测试,可以尽早发现问题。及时找出与需求分析和项目计划中的不符合项。对软件的缺陷的早发现,早处理,能够大大减少传统软件测试在软件产品成型后发现问题、修改问题所带来的人力物力的浪费。
1、软件缺陷管理
软件缺陷管理就是对软件开发过程中所发现的软件缺陷进行跟踪管理。并记录软件缺陷的状态信息,保证每个被发现的软件缺陷都能关闭。软件缺陷管理是软件开发过程中项目管理流程中重要的组成部分。软件测试流程管理其在本质上就是软件缺陷管理的文档化、规范化流程。
1.1 软件缺陷报告
软件缺陷报告(bug报告)是测试过程中提交的最重要的文档。它的重要性丝毫不亚于测试计划。并且比其他的在测试过程中产出的文档对产品的质量的影响更大。它记录了软件bug发生时的环境、步骤及相关结果,以保证修复错误的开发人员可以重复报告的bug,从而有利于分析bug产生的原因,定位bug。因此有效的缺陷报告能够:
(1)减少开发部门的二次缺陷率。
(2)提高开发修改缺陷的速度。
(3)提高测试部门的信用度。
(4)增强测试和开发部门的协作。
要想写好—个好的缺陷报告应遵循以下的条款:
(1)精简:缺陷报告要清晰而简短。用最直接、简练的语言来描述最有用、最重要的信息。
(2)准确:确保上报的每一个bug都是有效的、可验证的,而不是因为自己理解、安装、错误操作等其他因素而产生的bug。
(3)中性:用客观的语言来描述bug.在描述中不添加任何个人性格语言色彩。
(4)精确:清晰地描述bug产生的步骤,保证语言的干净,有条理。
(5)定位:根据公司或行业的相关标准对发现的bug进行准确定位,并尝试用最简短的步骤来重现这个bug。
(6)归纳:尝试对发现的问题进行归纳。
(7)重现:检查上报的bug是否可以重现。如果不是可重现的,应说明问题的偶然性。
(8)隔离:上报一个bug进行相应的bug隔离,写清发生此bug时的环境信息。
(9)检查:同行评审是发现问题的最有效的手段之一。
1.2 传统的软件测试流程
当—个软件项目要进行相应的测试时,一般都要经过制定测试计划,测试环境及用例设计,实施测试,单元测试,集成测试,系统测试,评估测试,最后给出相应的测试报告这几个流程。
传统的测试流程虽然和软件工程中的V型开发模型有一定的对应关系,但是测试流程和开发流程还是两个独立的流程,在软件测试流程的前期,只是单独地做计划,没有对软件的开发流程编码前的所有操作进行相应的审核和评审。真正开始测试也是等到软件产品成型后。才运行测试用例。在软件开发周期中,缺陷发现的越迟。其修复的代价也就越高。因此,要想提高软件的开发效率,就必须将软件的测试贯穿到软件的整个开发流程中。
2、基于开发过程的测试流程
根据软件开发流程的特点,软件的开发流程可分为:产品立项、需求调研、概要设计、详细设计、编码&单元测试、集成测试、系统测试、验收测试几个阶段。那么与之对应的测试的各个阶段。
测试流程在项目立项时就与之同步启动,并且覆盖软件开发的整个流程。这就要求在进行软件测试过程中要考虑审核和评审软件开发过程中各个阶段的文档和产品。在测试流程的各个阶段需要评审的文档和产品。
在软件测试流程中加入考虑对软件开发流程各个阶段文档集产品的评审。那么就要对相应的评审或测试结果进行文档化,形成新的软件缺陷报告或记录。项目组长或高层人员通过对这些文档的阅读,可以清楚地知道软件在开发的各个阶段存在的问题,能将因前期设计问题出现的软件缺陷问题消除在萌芽状态,保证软件开发效率和软件质量。测试流程中各个阶段产生的记录文档。
基于开发流程的软件测试流程具有以下的优点:
(1)在软件开发的各个阶段都加入软件评审和图3加入文档和产品评审的测试流程测试工作,保证了软件开发整个过程的开发效率和软件质量。
(2)摆脱了传统测试流程和开发流程相互独立,软件测试只针对成型软件产品负责的状况。
(3)针对软件开发流程中的各个阶段的评审和测试结果进行详细的文档化。有利于项目组长或高层进行质量把关。
(4)通过对软件开发过程的全程评审或测试,可以大大减少测试人员和开发人员的后期工作量,有利于对软件进行优化和升级。
3、结束语
任何软件开发组织想完全消灭软件缺陷都是不现实的,也是不可能实现的。要想开发出高质量的软件产品,除了要有严格的开发流程和开发标准外。在软件的开发过程中全程引入软件质量保障也是一种行之有效的手段。通过对软件开发流程各个阶段的文档和产品的评审和测试,形成详细的文档化结果,是保障软件产品质量和减少后期工作量的有效管理方案。随着软件规模的不断扩大,软件缺陷数量的不断增加,这个管理方案的优势就会更为显著。
三层架构之解耦和单元测试
依赖注入DI很大程度的帮助测试单元化。这对层与层之间的依赖关系,几乎是真理。
如对数据读写的依赖关系,用IRepository替换之后,所有用到IRepository的类,如Serivce这一层的ExamService,在测试时,只需要传入一个Mock的IRepository类,就不需要使用真实的数据库对它测试了.
我们的另外一层Controller也用到Service这一层,同样我为Service这一层的实现也提出一个接口IExamService,在Controller的构造器中传入IExamService的Mock类。因此,很容易的让测试关注于Controller本身的行为和功能。甚至可以在ExamService类实现之前,我们就可以测试和实现Controller类。这是依赖注入的优势。
这一整套分层,解耦和测试我们已经实现了,并形成一个规范的过程和成形的框架。现在已经简单到按部就班,就能轻松完成,甚至后期都可以考虑自动生成这部分代码。但这部分现在不是本文的重点。
业务域的简单案例---构造器赋值
当我们的注意力转移到业务域时,情景有了悄悄的改变。业务域中,类与类之间有更多更复杂的依赖关系。相比之下,三层之间反而简单。
这里,把我正在做的考试(Exam)类做一个简单的背景介绍。考试,对于身经百战的我们应该不陌生了,让我们好好分析,看看熟悉身影的陌生之面。另外,我这里考试更多是拿社会化考试作分析目标。
一个考试有三个很重要的要素:考试代码(考试定义);考区(北京考区,湖南考区);考试日期。这三个要素,唯一标识一个考试,也就是说,同一个考区,同一个考试定义在同日期,我就认为是同一个考试。很简单的逻辑,为了体现这个逻辑,我把这三个要素,放在考试类的构造器中。为什么?任何一个要素的缺失,考试对象的存在都没有任何含义,所以一开始构造的时候,就要传入。从另一个角度,考区+考试定义+日期是考试的业务ID,是唯一标识,必须贯穿于业务对象的始终。
看代码:
public class Exam
{
public Exam(District district, ExamDef exam_def, Date date)
{
District = district;
ExamDef = exam_def;
Date = date;
}
} |
通过构造器,从外部传入三个对象后,把它们赋给考试的三不属性,而这三个属性是只读,Private是为了给nHibernate和构造器使用的。为什么?如前所说他们是业务动,在创建之后,再修改没有任何含义。
看代码:
public class Exam
{
public Exam(District district, ExamDef exam_def, Date date)
{
District = district;
ExamDef = exam_def;
Date = date;
}
public virtual ExamDef ExamDef { get; private set; }
public virtual District District { get; private set; }
public virtual Date Date { get;private set; }
} |
传统nUnit测试示例
好了,背景已经足够了。让我们来针对这部分功能进行测试。喂,等等,我们……现在有功能吗?有!我测试的描述就是,
当从构造器链构造考试类时,三个属性应该要赋相应的值。
是的,足够简单使我们一目了然,也足够复杂,我们需要用测试来保障它的功能。1、保证它被运行---覆盖测试;2、保证它是按我的设计进行的---行为测试。
看代码:
[TestFixture]
public class when_create_an_exam
{
[Test]
public void it_should_assign_parameters_to_properties()
{
//Arrange
var stub_exam_def = new ExamDef("98");
var stub_district = new District("01");
var stub_date = new Date(2011, 1, 1);
//Action
var subject = new Exam(stub_district, stub_exam_def, stub_date);
//Assert
Assert.AreEqual(stub_district,subject.District);
Assert.AreEqual(stub_exam_def,subject.ExamDef);
Assert.AreEqual(stub_date,subject.Date);
}
} |
引入三个中间变量和另外三个类的定义我就不在这罗嗦了。我的命名方式也曾为人病诟,也不在这辩解。只看实质内容:分别创建三个类的实例,用于测试,至于这三个类的具体内容,我其实并不关心。所以用个词Stub来表示我的不关心。DDD的核心理念之一:名符其实。最后,我的断言只判断属性的值是否与构造器传入值相符。OK,完成!
坏味道?---重构的提出
过一段时,间。我们再回头看看这段测试,会有些小小的不舒服。特别,我们还有更多的类有类似的构造器赋值功能,还有更多更复杂的功能等着我们去测试,我们在做商业软件,不是吗?随着类似的测试更得越多。这些小小的不舒服会越积越大。
这面的测试有什么问题?
1、测试有三部分:建立测试环境;调用被测功能,(测试的本体);断言。上面的代码,我甚至都已经刻意用注释分离出了这么三块,但仍不是语法级别的分离。
2、对第三方的类依赖较为严重,这是本文的重点---单元测试单元化。对Exam类来说ExamDef, District都是插足的第三者。
3、测试代码太多,被测的实际上只有三行,虽然这不是原则性的问题,但是本着更好,更快,更强的精神,这个问题也是值得解决的。
好了,你提出的问题已经太多了,我没办法一下子解决。3个还多?是的,我们的口号是“只要一个好”。
MSpec的引入--- AAA语法
言归正传,让我们本着选代和重构的原则来把这些问题一个一个解决。是的,测试也需要重构,测试代码还有bug呢?一点不奇怪。你没碰到过?噢,因为你根本不写测试代码。
关于测试的三段式,我曾经看过有人确实在nUnit的框架下一步一步重构,形成良好了测试框架。这里我就不这么麻烦了,直接上工具MSpec!测试的三段式,有个说法,叫AAA语法,分别是Arrange,Action,Assert。3A级语法,多酷!
而MSpec用了自己的名词,分别是Establish, Because, It。看看下面改造之后的测试代码就清楚什么意思了。
看代码:
public class When_create_an_exam_by
{
private Establish context =
() =>
{
stub_exam_def = new ExamDef("98");
stub_district = new District("01");
stub_date = new Date(2011, 1, 1);
};
private Because of =
() => subject = new Exam(stub_district, stub_exam_def, stub_date);
private It should_assign_to_properties =
() =>
{
subject.District.ShouldEqual(stub_district);
subject.ExamDef.ShouldEqual(stub_exam_def);
subject.Date.ShouldEqual(stub_date);
};
private static ExamDef stub_exam_def;
private static District stub_district;
private static Date stub_date;
private static Exam subject;
} |
再看一看测试运行的结果,就明了代码即文档的含义了。
看截图:
从nUnit升级到MSpec,给人一种耳目一新的感觉。开始也许会有些不习惯。但是,一旦习惯之后再也不想回头了。
Rhino Mock --- 我演我
好了,看看第二个问题。一开始,我们依乎不觉得这是个大问题,不就是直接创建一个依赖美吗,创建就完了呗,一行代码而已。仍然,需要提醒注意,我们是在做商业软件。一旦展开了,一个类不可能只是一、两个类,特别是间接关联的,会更多,拔出萝卜带出泥。就拿这个考试类来说,在我们的实际项目中,它还有考试科目列表属性,还通过报考类与考生有间接联系。而报考类又与订单类,事务类有交互有关系。考虑所有这些级联关系,难道我为了测试这个构造赋值功能把所有的类全部创建出来?
再进一步思考,我们会给出一个自然的解决方案,把考区类,考试定义类抽象出两个接口来,构造器传入接口定义,而不是类本身。这其实是对层与层之间依赖注入的一个模仿。但是,相信我,这个方向是另一个梦魇的入口。业务域和多层之间完全是不同的环境。不想太深入讨论,可能独立一篇文章都打不住。
幸好,我们有另一个工具Rhino Mock,能帮助我们解决类的模拟的问题。改造之后的测试代码如下。唯一的影响是,你需要为被模拟的类,加入一个至少是protected的无参数构造器。这其实不是个大问题,如果你同时在项目中使用nHibernate的话,也会有类似的要求。
看代码:
public class When_create_an_exam
{
private Establish context =
() =>
{
stub_exam_def = MockRepository.GenerateMock<ExamDef>();
stub_district = MockRepository.GenerateMock<District>();
stub_date = MockRepository.GenerateMock<Date>();
};
//...此处省略的没有修改的代码
} |
可以看到,这一次的重构,把考试代码、考区代码等,其实你根本不关心的信息已经省略掉了。
AutoMocking --- 懒的最高境界
到这还不够,最后一个问题是填饱我们肚子的最有一块烧饼。
隆重介绍AutoMocking,自动模拟。当你的测试类从AutoMock的Specification类继承时,它会自动为你创建一个被测试对象subject,并且根据被测试对象构建器的参数定义,全自动的创建模拟对象。而引用这些模拟对象的方式,
很简单Dependency<ExamDef>,就是依赖注入的依赖这个词。已经不需要太多的解释---名如其实。
再看代码:
public class When_create_an_exam:Specification<Exam>
{
private It should_assign_to_properties =
() =>
{
subject.District.ShouldEqual(DependencyOf<District>());
subject.ExamDef.ShouldEqual(DependencyOf<ExamDef>());
subject.Date.ShouldEqual(DependencyOf<Date>());
};
} |
三行实现代码,对应三行测试代码。简洁的不能再简洁了。
前言:
事务是OLTP系统中的主要部分。它管理数据一致性和数据并发问题,当多个资源同时被读取或者修改相同数据时,SQLServer会通过锁定机制来确保数据库中的数据总是处于一个有效状态。在SQLServer中,锁管理器是负责实现这些锁机制。SQLServer对于不同的资源类型提供不同的锁类型,如数据库、文件、对象、表、区、页和键。
当你使用事务时,依然会遇到由事务引起的问题,这些通常是由于锁、阻塞和死锁引起的。
本系列将讲解这三部分的概念。
确定长时间运行的事务:
长时间运行的事务会阻塞其他事务,并且引发新一轮的长时间运行事务!这将严重影响数据库服务器的性能。
作为DBA,你需要经常监控服务器的事务,当你发现有长运行的事务时,需要使用必须的步骤纠正。本文将讲解通过事务的持续时间去监控这些事务,如果经常找到一些事务持续时间很长,你可能需要查找是否被其他事务阻塞了,或者深入研究事务的语句是否有问题。
准备工作:
本文使用SQLServer2012的示例数据库AdventureWorks2012数据库。
步骤:
1、打开SQLServer,连接到AdventureWorks2012数据库。
2、输入以下脚本,使其开启一个简单的事务:
USE AdventureWorks2012
GO
BEGIN TRANSACTION
SELECT *
FROM Sales.SalesOrderHeader |
3、不关闭窗口,在新窗口中输入以下代码,监控当前正在运行的事务:
SELECT ST.transaction_id AS TransactionID ,
DB_NAME(DT.database_id) AS DatabaseName ,
AT.transaction_begin_time AS TransactionStartTime ,
DATEDIFF(SECOND, AT.transaction_begin_time, GETDATE()) AS TransactionDuration ,
CASE AT.transaction_type
WHEN 1 THEN 'Read/Write Transaction'
WHEN 2 THEN 'Read-Only Transaction'
WHEN 3 THEN 'System Transaction'
WHEN 4 THEN 'Distributed Transaction'
END AS TransactionType ,
CASE AT.transaction_state
WHEN 0 THEN 'Transaction Not Initialized'
WHEN 1 THEN 'Transaction Initialized & Not Started'
WHEN 2 THEN 'Active Transaction'
WHEN 3 THEN 'Transaction Ended'
WHEN 4 THEN 'Distributed Transaction Initiated Commit Process'
WHEN 5 THEN 'Transaction in Prepared State & Waiting Resolution'
WHEN 6 THEN 'Transaction Committed'
WHEN 7 THEN 'Transaction Rolling Back'
WHEN 8 THEN 'Transaction Rolled Back'
END AS TransactionState
FROM sys.dm_tran_session_transactions AS ST
INNER JOIN sys.dm_tran_active_transactions AS AT ON ST.transaction_id = AT.transaction_id
INNER JOIN sys.dm_tran_database_transactions AS DT ON ST.transaction_id = DT.transaction_id
ORDER BY TransactionStartTime
GO |
4、下面是结果的截图:

5、现在来关闭事务,在第一个窗口中输入:
分析:
上面例子中先打开一个窗口,然后建立一个新查询。在另外一个窗口中,查询了当前正在运行的事务。
本例中使用了下面3个DMV:
1、sys.dm_tran_session_transactions:提供视图相关的信息,并包含了特定会话的信息。
2、sys.dm_tran_active_transactions:返回实例级别上,所以正在活动的事务信息。
3、sys.dm_tran_database_transactions:返回数据库级别上的事务信息。
例子中使用了DB_NAME()来返回当前数据库,作为筛选特定数据库上的事务信息。
测试执行与跟踪阶段的管理重点是保证测试按照计划的顺利和有效实施。通过规范测试流程,加强测试的有效性的检查,及时报告测试进度,促进测试团队的交流,成为决定这一阶段工作成败的关键。
1、确保测试数据信息流通畅
管理国际化测试流程应该保证测试数据内容的有效传递,例如被测试软件的Build如何在编译工程师和测试团队之间及时传递,发现问题如何反馈,谁负责解答。
如果设计需求发生了改变,测试用例需要相应的更新。在测试过程中发现的测试用例无法执行的问题,需要通过有效的渠道,将这些信息及时地传送给合适的人员。
当测试的范围或测试时间发生改变时,测试管理人员应该及时将这些信息进行处理,调整测试人员的数量和工作内容,并且通知测试团队成员。
为了保证测试过程的数据信息有效传递,在项目的准备阶段需要确定传递的数据的类型(Build,文档,进度报告等),数据传递的方式(电子邮件,FTP等),数据传递的频率(每天或每周),数据的发送方的负责人和联系方式,数据接收方的负责人和联系方式。
2、Build验证测试与常规测试无缝集成
由于国际化测试和本地化测试同时测试数十种测试平台和语言,因此,按照先执行Build接受测试(或者成为Build验证测试),通过后再按照测试用例执行常规测试,可以快速确认当前版本是否存在重大的不适和大规模常规测试的缺陷。
常规测试即根据测试计划的要求,运行测试用例测试,在项目的缺陷管理库中报告和修正缺陷。为了保证每一个缺陷都是有效的缺陷,测试团队中需要安排对软件熟悉的高级测试工程师首先验证缺陷,关闭那些由于测试人员错误操作或者理解错误而报告的缺陷。
另外,在多个测试组同时测试时,可能会重复报告缺陷,也需要专人负责关闭缺陷。这样做可以有效节省开发人员修正缺陷的时间。
在进行多语言本地化测试过程中,某些缺陷是属于过重本地化版本共同存在的缺陷,因此,可以参考其他语言报告的缺陷,避免漏报。
为了尽早修正缺陷,测试人员应该每天跟踪缺陷的修正情况,并且对缺陷修正人员的任何反馈及时答复。例如,如果因为缺少了关键步骤,缺陷修正人员无法复现缺陷,则他们会在缺陷报告中要求测试人员补充所需要的详细内容,并且把缺陷的状态修改成“Need More Info”状态。测试人员尽量及时补充遗漏的缺陷信息。
测试任务紧张,测试时间不足,赶不上测试的进度要求,是测试人员经常遇到的问题。需要根据具体的情况正确处理,例如,如果在计划内,编译人员没有成功地编译出被测试的Build,而测试的时间不能落后于计划时,可以与测试管理人员讨论是否可以先选择在典型平台测试,优先执行高优先级的测试案例。
3、收集项目测试数据,跟踪和控制测试进度
由于国际化测试团队可能分布于不同的国家和地区,分别执行不同本地化版本或不同的测试类型的测试,因此,对于这些团队的进度和质量跟踪更有挑战性。
毫无疑问电子邮件是最常用的交流方式,除此之外,即时通信工具(例如,MSN)和电话也经常采用。为了便于跟踪,最好在使用及时通信工具和打完电话后,将交谈内容以电子邮件的形式发送给对方和相关人员。
对于外包测试而言,项目进展的信息交流显得尤为重要。最常用的是定期(例如,每周一次)进行项目电话会议,实现拟定会议主题,软件开发公司的测试项目管理人员和来自外包测试服务公司的测试管理人员,就测试的进度和问题进行系统交流。
对于被测试项目而言,典型的测试管理应该包括一个全球项目经理(GPM)和多个本地项目经理(LPM)。GPM负责整个项目全部的测试管理,通过收集LPM的测试项目信息,集中向产品经理报告。
项目测试进度报告是对项目进度跟踪的主要文档。对于比较严格的测试项目,LPM需要每天向GPM报告测试的进展,包括当天运行的测试用例,报告的缺陷,需要解决的测试问题等。
通常,可以每周一次或每两周一次由各个参与测试的团队向GPM报告测试的进展情况。GPM汇总测试信息,作为下次项目电话会议的讨论内容。对于需要软件开发人员和文档创作人员回复的问题,GPM及时与他们联系,将他们的反馈及时告知各个测试团队的测试经理。
除了测试进度外,测试质量的有效性和测试耗费的时间也是需要跟踪和控制的内容。测试的有效性可以由专门的质量保证人员负责,测试花费的时间与人力资源影响着测试的项目预算和成本。如果由于测试需求的变更,引起测试工作量和测试内容的增加,应该要求软件开发公司的项目负责人增加测试预算。
4、测试过程的风险管理
处理项目测试风险是测试执行阶段无法回避的问题,虽然在测试计划中已经分析了可能的项目风险,但是,“计划没有变化快”。实际测试项目过程中,总会出现这样或那样的事先没有料到的意外情况。这时候的处理原则是在不影响测试进的和质量的情况下,如何优化现有资源,保证测试的覆盖率。
由于测试人员的变动引起的资源紧张,可能是测试过程中遇到的较大问题,尤其是那些与语言相关的测试问题,如果没有备用的测试人员,则将影响测试的进度。因此,关键岗位的测试人员应该有备用替补人员。
对于测试数据丢失,例如网络病毒引发的网络瘫痪,关键测试文件无法得到引起的问题,属于不可抗拒的客观因素。因此,需要加强数据的安全备份。
对于那些可能会引起测试进度滞后,或测试质量降低的风险,测试方首先要积极寻求内部解决,例如,增加测试人员,通过加班赶上进度。另外,要及时将这方面的信息告知GPM,以便及时调整整个项目的测试进度和内容。
从接触软件测试工作开始,相信所有人都希望减少软件测试后漏测的问题(tester希望,开发经理希望,老板希望),但事实是一直以来都没有很好的真正解决产品漏测的问题以及如何减少功能组合爆炸的问题。过去几年因为工作任务的缘故,我在历经几年自动化测试、系统测试和缺陷预防工作后,又回到测试的本源开始思考功能缺陷的测试应该如何做好?从2011年版本到2012年版本直到2013年终于优化完善出了自己的功能测试方法体系,没想到居然在软件测试行业从业近10年时才搞明白了10年前就开始的问题。过去的5年通过实践补充了自己在缺陷预防领域的技能和认知、可测试性设计领域的技能和认知、产品可靠性测试(稳定性测试)领域的技能和认知,直到2年前才开始真正介入功能测试方法改进。最后才意识到原来我们不少漏测的问题,不是性能测试可以发现的,也不是稳定性测试可以发现的,更不是自动化测试能发现的,现有的功能测试用例及方法也发现不了--多功能组合下和不同用户操作序列下才发生的bug。怎么办?以及如何解决组合爆炸的问题--我们一直都在回避。如何让我们投入测试时间最多的功能测试用例该多的地方多,该少的地方少?搞了半天,原来测试领域最基本的工作都没做好,然后就开始疯狂追踪上层建筑,或是简单实行拿来主义拿来一些工具或方法,虽然所拿来的这些工具或方法对局部的确是有优化作用,但你知道自己的全局全貌在哪里吗?知道全部漏测的测试根因在哪里吗(而不是产品技术根因), 如果不知道则容易陷入盲目乐观与更加保守的状态。听说有个工具或方法能发现很多bug--于是开始盲目乐观引入,希望能从此解决完所有测试漏测的问题,结果确实能发现一部分问题但是还是有不少漏测,结果--开始更加保守,对新工具和新方法不再相信和信任,从此对漏测问题放在一边交给其他人去关心。那我就是那位被迫要去关心和解决漏测问题的非主流测试工程师,幸运的是经过过去几年的思考与学习,如今随着个人稳定性测试模型和功能测试模型方法体系的完善,终于让我有信心有知识去应对任何软件的漏测问题, 可以阶段性的结束对漏测问题领域的专注思考,投入更多精力于其他测试技术和方法体系了, 故写此文阶段性纪念下。下面分享一部分如何减少功能缺陷漏测的干货吧,与各位共勉:
功能缺陷的测试方法流程
第一步:功能测试分析 —功能测试阶段
目的:提取功能测试对象
准备功能测试数据
减少因为功能测试对象遗漏的漏测
第二步:功能验证—功能测试阶段
目的:检查功能是否已基本正确实现
测试方法:
● 基于生命期:对象创建 -使用- 销毁 的验证
● 数据测试方法:静态数据测试方法和动态数据测试方法 (边界值和数据等价类、7因子数据类型)
减少功能的基本逻辑错误漏测和数据处理错误的漏测
第三步:单功能内测试 —功能测试阶段
目的:发现功能是否存在分支情况、异常情况处理不足的缺陷
测试方法:
● 功能内子功能的场景插入法
● 重复法设计
● 反叛法设计
● 取消法设计
● 测一送一法设计
● 场景删除法设计
减少功能内代码的漏测
第四步:多功能间组合测试 —系统测试阶段的用户场景测试
目的:发现功能间配合工作时存在的缺陷
测试方法
● 基于用户场景的测试 (Scenario Test)
减少多功能间组合错误的漏测
为什么需要用户场景的测试模型?
补充多个功能组合的测试用例解决传统正交组合测试后3个及以上功能组合缺陷的漏测
通过常见用户操作序列的场景设计解决数学式穷尽组合爆炸的问题减少组合测试时间和成本,获得最佳投入产出比的组合测试
用户场景测试的测试步骤是不同角色用户最常用的基本操作序列
用户场景的探索测试是不同角色用户非常用的操作序列
用户场景的探索测试
在用户场景测试用例执行结束后 , 再用专项时间进行多功能组合的探索测试,补充用户场景测试用例之外的用户操作序列,提高用户操作序列的覆盖面。因为用户最常用的操作序列已在用户场景测试用例中覆盖,但又不能对非常规的操作序列不进行测试, 因此将非常规的操作序列的测试与测试成本进行一个平衡,通过专项的探索测试时间来补充这部分的测试。
在补充用户操作序列的探索测试中可用的探索测试方法有:
收藏家法
同时开启多个功能,同时工作。
技术根因
同时多个功能交互容易出现资源竞争处理的错误。
地标法
改变一系列规定顺序操作的先后顺序。
技术根因
在实际场景中用户因为对操作不熟悉难免会操作的步骤不是标准的步骤顺序,而程序实现时对于这些改变了操作顺序的操作步骤缺乏容错处理则会出现程序错误。
混票法
把最不常用的功能与常用功能进行组合
技术根因
在功能测试阶段由于时间及优先级限制,测试人员习惯把常用功能进行组合测试,时间一久就容易忘掉不常用功能与常用功能的组合,而用户的使用习惯中也一定会出现不常用功能与常用功能一起组合的场景