
性能测试用户模型(一):概述、术语定义、基础数据、压力度量
性能测试用户模型(二):用户模型图
基础数据分析
以下图表均取自互联网,本文是在“已经获取所需数据”的前提下,讲解性能测试的一些设计思路。至于如何才能取得这些数据,将在后续的文章中说明。
系统访问量分布
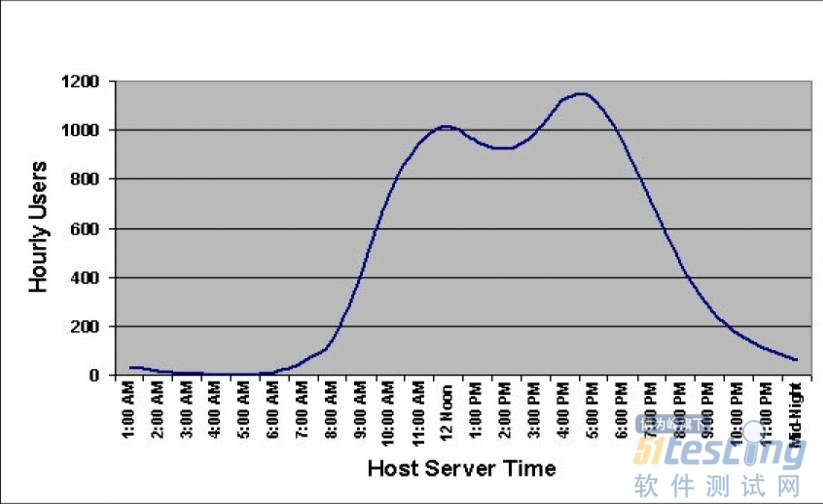
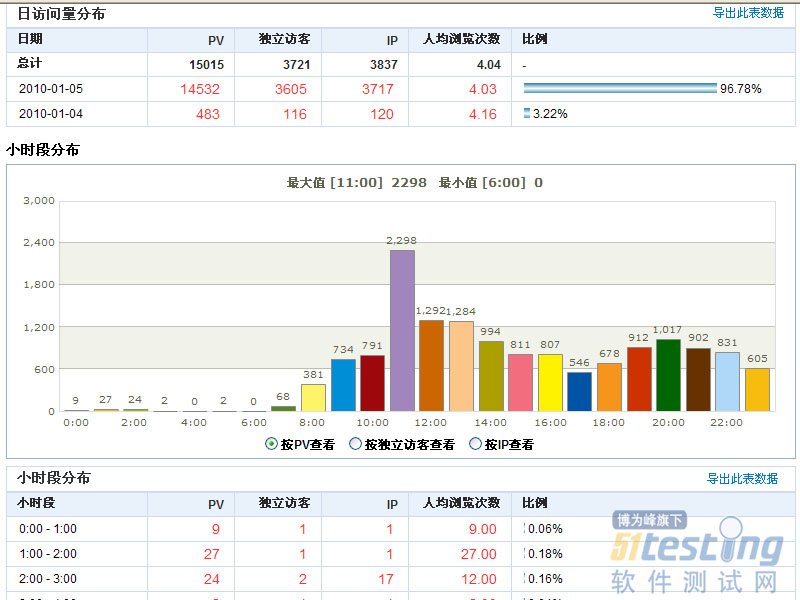
由系统的日访问量分布图,可知系统的访问压力集中在哪个时间段内。系统的压力是在一天中平均分布的,还是集中在某几个更小的时间段内。根据此信息,我们对测试场景的时间进行设计,如从分布图中明显看出每天的大部分访问量集中在9:00~11:00和14:00~16:00两个时段,那么就可以设计2小时内完成一半访问量的测试场景。
用户的平均活跃时间
用户活跃时间,是指用户一次使用系统的时长,可用来指导测试脚本的设计,即每个虚拟用户脚本应该在多长时间内执行完。
由系统访问量分布和用户活跃时间两个数据,可以对系统使用的并发度进行估算。比如已知系统在2个小时内有200访问量,且分布接近于平均,用户的平均活跃时间为30分钟,那么此时间段的并发度应为:200*30/120=50。这里并发度50传递的信息是,在一个用户活跃周期内,总共会有50个用户与服务端进行交互(即相对并发)。也就是说任意时间点,最大的绝对并发可能性是50,当然实际可能远低于此,可以根据业务特点再乘以相应比例进行估算。
在性能测试时,可以依据此数据设计系统高峰期压力的测试场景。比如我们已知,系统压力最大时,单位时间段内活跃用户有100人(并发度100),那么这种压力场景,就可以以用户平均活跃时间为测试时间段,启动100个虚拟用户并在该时间段内完成各自的工作量。
即请求之间的间隔(思考)时间,如在编辑页面上停留多久才会点提交按钮。如果无此数据,性能测试脚本只有运行时长是有数据(活跃时间)支撑的,脚本中的各请求之间的思考时间,只能通过常规判断和猜测,由性能测试人员自己掌控。收集到此数据后,性能测试脚本会更加符合真实用户的操作习惯,更加接近真实用户。
热点模块(页面)
分析系统各模块或页面的访问频率,可以用来检查性能测试是否设计了足够的覆盖、是否遗漏的用户频繁使用的功能,并据此对用户模型进行完善。
此外,此数据可用来分析各模块或功能所涉及到的工作量,如每天平均完成多少次提交操作、多少次统计操作。这对于确定系统的使用压力有很大的作用。
场景数据
最后,综合所有数据,为特定测试场景制订出成如下表格:
总体 |
| 场景名称 | 100用户负载场景 |
| 场景描述 | 模拟系统使用高峰期时,在2小时左右有100用户的访问 |
| 场景时长 | 2h |
| 场景加载策略 | 每4.5分钟加载5个虚拟用户。因为要在2小时内完成100用户的访问,而每个用户的运行时间在30分钟左右,那么在1小时30分钟时就最后一批用户就要开始访问系统,即90分钟内加载100个用户。 |
| 虚拟用户数 | 100 |
| 用户模型 | 见XX用户模型 |
| 虚拟用户运行时间 | 30min |
| 平均思考时间 | 30~60s |
| 场景并发度 | 25。 虚拟用户数*(虚拟用户运行时间/场景时长) |
操作说明 |
登录 | Think Time | 平均8s,最小5s,最大20s |
Pass/Fail 条件 | 如果失败,重试一次,依然失败就中止。 |
数据 | 每虚拟用户使用不同的账号 |
... | | |
可以说,用户模型表达的是,系统运行中的压力是如何分布的。
而场景数据表达的是,要给系统施加多大的压力。
只有结合用户模型和场景数据两部分,才能构造出一个确定的负载场景。
如果到这里都已经做好,并且经过了技术负责人和业务负责人的确认,那么接下来要做的就是按照设计来实现测试脚本了。
ava利用JDom来解析处理XML数据格式:
需要的包jdom-1.1.2.jar
1、将数据转换成XML格式的数据进行传递
Element rootList, firstList, secondItem, thirdItem;
//根元素标签名
rootList = new Element("root");
//根元素标签内的属性名与值
rootList.setAttribute("project", pname);
//生成Doc文档
Document Doc = new Document(rootList);
//获取文档中的根标签
rootList = Doc.getRootElement();
for (int i = 0; i < judges.size(); i++)
{
//生成新的元素
firstList = new Element("flayout");
firstList.setAttribute("percent", "percent");
//加入根级元素中
rootList.addContent(firstList);
}
XMLOutputter XMLOut = new XMLOutputter();
//将doc文档转换为字符串型的XML格式
String xmlinfo = XMLOut.outputString(Doc);
//将开头的去掉
xmlinfo = xmlinfo.replace("<?xml version=\"1.0\" encoding=\"UTF-8\"?>",
"");
//返回已经封装好的XML数据
return xmlinfo; |
2、将字符串中的XML解析出进行处理
//创建一个新的字符串
StringReader read = new StringReader(stadXML);
// 创建新的输入源SAX 解析器将使用 InputSource 对象来确定如何读取 XML 输入
InputSource source = new InputSource(read);
// 创建一个新的SAXBuilder
SAXBuilder sb = new SAXBuilder();
String projectName;
List<Judgestandard> standIndex = new ArrayList<Judgestandard>();
try {
// 通过输入源构造一个Document
Document doc = sb.build(source);
// 取的根元素
Element root = doc.getRootElement();
projectName = root.getAttributeValue("project");
// 得到根元素所有子元素的集合
Element et = null;
List nodes = root.getChildren();
// 第一级指标
for (int i = 0; i < nodes.size(); i++) {
et = (Element) nodes.get(i);// 循环依次得到子元素
Judgestandard judge = new Judgestandard();
//获取该元素中属性的值
String fid = et.getAttributeValue("mainid");
//获取元素的孩子数目
List fsize = et.getChildren();
// 第二级指标
for (int j = 0; j < fsize.size(); j++)
{
et = (Element) fsize.get(j);// 循环依次得到子元素
et.getAttributeValue("stdid")
} |
Java处理XML文档
不需要包
待处理的XML文档:
<?xml version="1.0" encoding="ISO-8859-1"?>
<root>
<ip>localhost</ip>
<port>8080</port>
</root>
static DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
static DocumentBuilder builder = null;
builder = factory .newDocumentBuilder();
//获取服务器根目录地址
Document document = builder.parse(new File("src/ip.xml"));
Element rootElement = document.getDocumentElement();
NodeList list1 = rootElement.getElementsByTagName("ip");
NodeList list2 = rootElement.getElementsByTagName("port");
Element ip = (Element) list1.item(0);
Element port = (Element) list2.item(0);
String s =ip.getFirstChild().getNodeValue().toString()+":"+port.getFirstChild().getNodeValue().toString();
System.out.println(s); |
许多年前农村土地承包责任制的出现,使之大农民的角色发生了根本性的改变,从而迎来了粮食产量和农民很生活的巨大改善。同时在Code Rivew 这一个群体活动中,让其有效运行起来一个最有效的方法就是分角色同时对某一角色赋予一定的责任。下面就对在我们团体中分角色的Code Review及其流程进行一个简单的讲解,同时也想和广大软件同仁们一起交流一下关于CodeReview的一些观点和看法。因为是本公司的方法所以也会有不足之处,欢迎讨论。
一、Code Review 角色分类
1、Author:被Review对象的作者。
2、moderator:一般由团队中开发经验丰富的人担任。
3、Recorder:主要用于记录在整个代码Review中情况。
4、Reader (may be the same person as Author or leader)
5、Other reviewers:团队中的其它成员,但是一般不要人太多,因为对于一个讨论会议一来说一般要将参加会议的人控制在7人以内为最佳,这样这个会议才是可控的。
以上这些角色的职能会在Code Review中的不阶段而发生变化。
二、Code Review的流程及其角色在不同阶段的任务
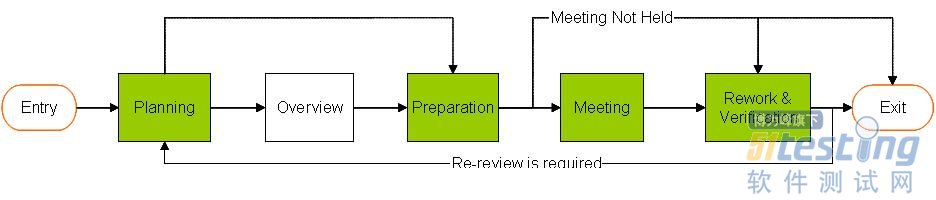
上图显示了整个Code Review活动流程情况,一般在一个Code Review活动会中Planning,Preparation,Meeting,Rework&Verfication是必须的,而Overview阶段会随着Review对象的不同而不同,对于一些Review工作大量的活动这个阶段是必须的,下面将详细描述每个阶段的任务,以及各个角色在相对应阶段的责任。
1、Planning:

这个阶段主要是对各个角色人员的确定以及确定所Review的对象是否已经达到能够被Review的阶段,这样以防止代码在仍有很大 问题的情况下进行Review而导致Review的整体效率太低。还有对整个Review过程所以经历的时间段有一个大体的划分。在这一阶段首先由Author确定谁来当本次Review的moderator(一般moderator只能从团队中有限的几个人内挑选,并不是每个人都可以充当这个角色的。)然后再邀请别人充当本次Review的Recoder,Other reviewers;
这个阶段各个角色的主要任务是:
Author:对整个Review过程制定计划,确定参加这次Rewview人员,为这些成员分发要Review的材料。
moderator:对整个要Review的对象进行分析查看是否达到能够开始Code Review的要求。
2、Overview:
对于大量的东西要Review的项目,或者大部分参与Review的人对要Review的东西都不是很熟悉的情况下。由Author开招开一个简短的站会整体解决一下所要Review的东西。
3、Preparation:
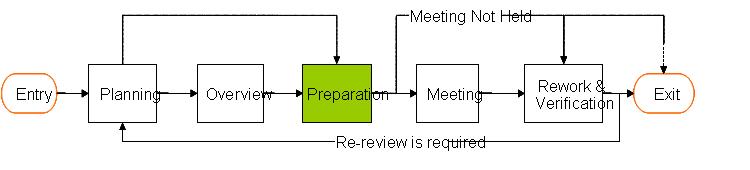
在这个阶段,所有参与的reviewers对所以review的东西各自进行走读,然后记录并提交发现的问题,然后由Author和moderator共同对reviewers所发现的问题进行汇总,分类,甄别。之后根据汇总上来的问题来进一步判断是否适合招开Review会议。如果汇总上来的问题比较多,比较严重则说明所要Reivew的文件尚未真正达到要求,则取消本次活动。由Author重新开发。如果发现的问题不是很多,则按时招开Review Meeting.
这个阶段各个角色的主要任务是:
reviewers:对所要Review的对象各自先进行走读,然后提交各自发现的问题。
moderator和Author:对reviewers提交上来的问题进行汇总总结查看是否符合Review的条件。
4、meeting:
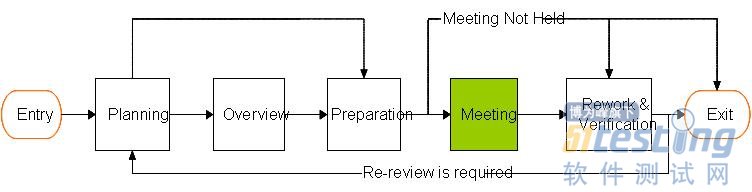
meeting做为整个review的核心和关键环节其主要任务是首先由Author主持对汇总上来的问题,逐个的分析然后给出自己的判断,是接受reviewers还是不接受reviewers提出的问题。对于有分歧的问题进行讨论,如果还有分歧则由moderator决定这个问题是否要改怎么改。在将所有汇总上来的问题分析完后,再由Author带着所有reviewers对代码进行走读。然后进一步分析和讨论代码中的问题。
这个阶段各个角色的主要任务是:
Author:逐个分析汇总上来的问题,并给出自己的分析。带领所有reviewers对代码进行走读;
moderator:分析判断Author对问题的分析判断是否合理,在关键时刻给出分歧问题的处理意见;
reviewers:讨论分析之前提出的问题,对代码进行集体的重新走读,以发现更多的问题;
Recorder:对整个Code Review进行记录,包括发现的问题以及问题的整改意见。
5、Rework&Verification:
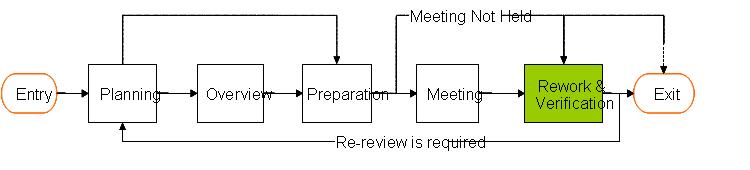
这个阶段主要是Author对整个Review过程提出的问题进行整改,然后提交由moderator对整个整改的情况进行评估。
总结:
通过对Code Review中的成员进行角色分工,从而赋予他们一定的职责,这样就能很好的提高他们的责任感从而大大提高代码走查的效率。
最近一直在想需求变更控制的事,资料也查了不少,可是查来查去,内容都差不多,无非是需求变更是一定要控制的,并且要经过申请、审批、执行、确认等流程,几乎所有的资料给出的都是这样的内容,更多的,除了后面的流程之外,甚至连为什么要做控制都没说明。下面说说我的理解。因为所管理的项目几乎都是以合同为基础的外部客户项目,所以讨论内容仅限于此类项目中,由客户提出的需求变更的管理。
为什么要做需求变更的管理?
进行需求变更管理的主要原因有两个,一个是防止范围蔓延引起的进度、成本、质量上,甚至严重时导致项目全面失败的问题;另一个是为以后留下筹码,以后要求追加费用也好,或者让客户看到我们送给他们的人情也好,总之是为了使以后与客户相关的工作更顺畅。除了这两个原因之外,当然还有一些不是特别重要的原因,比如使需求、设计、开发、测试之间对变更的理解一直等等。
需求变更管理的流程
需求变更管理的流程,在绝大多数的资料中,第一步都是提出变更申请。事实上,在此之前,还有至少一件事要做,就是与客户一起,约定变更管理的流程,最好在合同中约定,至少也要在启动会上约定。而变更申请的提出,也应该按照约定的流程来,不是由客户的任何一个角色直接提给项目组中的任何角色,而是客户处提出的所有需求变更,都归总到客户处的需求变更负责人处,由负责人判断哪些需要作为需求变更提出,哪些不需要提出,需要提出的需求变更,由负责人提交给项目经理。
项目经理收到需求变更申请之后,要做的第一件事,不是审批,而是详细了解需求变更提出的前因后果和客户想通过需求变更解决什么问题,了解清楚这些之后,首先尽可能寻找系统外解决问题的办法,若实在找不到,或者系统外解决办法可行性太低时,再进行变更工作量的评估和影响的分析,分析完之后,才能进行变更的审批。在所有的审批人中,销售人员起到很重要的作用,因为销售要给出变更所需费用的来源,并要给出承诺,否则变更没办法继续。其他审批人则根据自己的角色和职责进行审批即可。
审批完成之后,是执行环节。对绝大多数的变更,都可以不用马上执行变更动作,可以几个变更作为一批一起执行,一方面可以降低频繁变更对项目工作的影响,另一方面对一些客户一时兴起变过来过不久又变回去的变更可以起到拦截作用。
再之后是确认,需求变更之后的原型,需要在修改完之后就确认,而最终变更结果,则在系统验收时,统一确认。
摘要:软件测试的类型通常分为白盒测试和黑盒测试,其中基于等价类的划分法与基于判定表的测试法都是较为典型和实用的黑盒测试技术方法。在实际工作中,为了使测试用例的覆盖更加全面,测试目的更加明确,通常不仅仅局限于某一种测试手段。针对等价类和判定表这两种方法各自的特点,可以将两者有机结合,通过对输入条件进行等价类划分,对输出行为进行判定表列举,用综合的手段进行软件测试工作,从而达到使测试用例的设计覆盖全面、条理清晰的目的。
关键词:等价类;判定表;软件测试
1、概述
软件测试的类型一般来说,可以划分为白盒测试类型和黑盒测试类型。黑盒测试针对的主要是软件功能的正确性和完整性。黑盒测试的理念,是将程序内部的逻辑结构看成一个黑盒子,单纯依据给定的软件需求规格说明中约定的功能要求,设计测试输入数据,观察测试输出结果,通过结果的正确性来验证软件的正确性。黑盒测试的方法比较多,其中较为典型的是等价类划分法和判定表驱动法,实际工作中可以将两种方法有机结合进行软件测试。
2、等价类划分法
等价类划分法的一般定义,是依据程序的实际情况,把测试输入划分成具有代表性的几种分类,类与类之间彼此不相交;然后从每个分类中选取部分数据作为测试用例的输入。这其中选取的输入数据在测试中的作用等价于该类中的其他数据,因此对每一个特定的类来说,不需要将该类中所有的输入都作为测试输入,仅选取本类中具有代表性的输入即可覆盖某一方面的验证,大大减少了测试用例的数量,提高了测试效率。
进行等价类划分时须将对应输入分为有效等价类和无效等价类。有效等价类是指符合程序需求规格说明描述,合理可行且有意义的输入数据所构成的集合。通过有效等价类的输入,可以测试程序是否实现了需求规格说明中所要求实现的功能项。无效等价类是有效等价类的补集,与有效等价类正好相反,通过无效等价类的输入,可以测试程序的功能实现是否会出现意外情况。两种等价类必须同时被考虑,以确保软件的可靠性。
根据通用的定义,可以根据以下原则进行等价类划分:
1)如果输入条件规定了输入值的强制集合,则可确定一个有效等价类和一个无效等价类;
2)如果输入条件规定了取值范围,或者规定了所取值的个数,则可确定一个有效等价类和两个无效等价类;
3)如果规定了一组输入数据的数量为n,且程序需对每个输入值分别处理,则可确定n个有效等价类和一个无效等价类;
4)如果输入条件为布尔值,则可确定一个有效等价类和一个无效等价类。
5)如果输入数据有必须遵守的规则,则可确定一个遵守规则的有效等价类和若干个从不同角度违反规则无效等价类;
6)已知的大等价类可以根据实际情况进一步划分为更小的等价类。
等价类一经确定,可以构造等价类划分表。然后为每一个等价类规定一个唯一的编号,并设计测试用例来 覆盖所有的等价类。用例设计原则为:1个用例应覆盖尽可能多的有效等价类,直到所有有效等价类都被覆盖为止;1个用例仅覆盖一个尚未被覆盖的等价类,直到所有无效等价类都被覆盖为止。
3、判定表驱动法
判定表也叫决策表,在所有的功能性测试方法中,基于判定表的测试方法是最严格的,因为判定表具有逻辑严格性。从20世纪60年代初开始,判定表就一直被用来表示和分析复杂的逻辑关系,作为编写程序的辅助工具。判定表很适合描述不同条件集合下采取行动的若干组合情况。
判定表由4个部分组成,分别为条件桩、动作桩、条件项和动作项。其中条件桩列出了各种可能的单个条件,动作桩列出了可能采取的单个操作,条件项列出了所给条件的多组取值组合,动作项列出了在给定条件项的各种取值情况下对应采取的动作。
判定表的规则是任何一个条件组合的特定取值及其相应要执行的操作。在判定表中贯穿条件项和动作项的一列就是一条规则。判定表中列出多少组条件取值,也就有多少条规则,条件项和动作项就有多少列。
应该依据软件需求规格说明来建立判定表,首先确定规则的个数,然后列出所有的条件桩和动作桩,填入动作项形成初始判定表,再通过合并相似规则或相同动作来简化,形成最终判定表。
4、等价类结合判定表测试
在实际测试工作中,我们倾向于不仅仅只使用一种测试方法,而是恰当的将多种测试方法有机结合,达到最优的测试效果。这里以实例说明如何将等价类划分与判定表驱动有机结合起来进行软件测试。
某模块具有数据接收和处理功能,其中接收的数据格式包含了方式字、数据域和校验和3个部分。该模块将接收到的数据进行CRC校验,根据接收的数据进行处理:若接收的数据正确,则将对应缓冲区地址内容设置为接收的数据域内容,且置相应的遥测字;若接收的数据错误,则对应缓冲区地址内容不作设置,且置相应的遥测字。
这个实例里,我们可以先对输入条件进行等价类划分,然后通过建立判定表,确立规则,从而得出最终的测试用例。这里的输入条件就是需要接收的数据。根据相应的通信协议,数据格式中的方式字可分为AAh、BBh、CCh、DDh共4种,数据域根据其长度可分为16字节、32字节、128字节3种,校验和可分为正确和错误两种。我们通过通信协议的规定,可以划分出输入数据等价类,对每种输入条件的等价类都进行相应的编号。
根据等价类划分,继续采用判定表驱动法形成测试用例。将已按等价类划分好的输入作为条件桩,产生判定表。
根据该表,根据规则最终产生了7个测试用例,覆盖了所有输入的有效等价类和无效等价类。下面进行两点说明:
1)根据测试方法的一般选择原则,若输入条件之间存在组合关系时,一般选用因果图法结合判定表驱动法进行测试用例的设计。本例中的各个输入之间存在简单的组合关系,但由于各输入均为1组数据,且存在有效和无效的情况,而非独立的状态,或独立的输入条件,采用因果图法易造成图的关系复杂,不利于分析;采用等价类划分法则利于信息的归类与分析,再结合判定表驱动法来理清各等价类的组合关系,使用例设计清晰,并可判断是否覆盖所有的等价类,是否存在可合并的冗余用例。
2)为了简化实例便于说明,本例没有考虑输入边界的取值,实际工作中还可加入对输入条件的边界取值考量,产生更多有效和无效的边界等价类,再加以组合进行测试。
5、总结
测试用例的设计方法种类很多,在实际测试中,应当不局限于单个测试手段。依据每个具体的软件的具体特点,制定具有针对性的测试策略,综合使用各种方法,使其有机结合,从各个角度充分测试,从而更加有效的提高测试效率和测试覆盖度。
如何进行测试管理?想必每位测试管理者都有这个疑惑,我也不例外。
经过了2个公司的测试管理经历,其实总的来说不外乎测试计划、测试用例、测试执行、测试跟踪和测试总结。
今天说一下测试计划。
测试计划,首先顾名思义,应该是为测试的所有工作进行全局的计划安排,测试计划中包括了所有的测试工作,比如说测试背景、测试目的、测试范围、测试策略、测试方法、测试阶段、测试完成标准、测试工作量、测试资源、测试环境、测试进度等等。测试进度是上至管理者、下至项目经理都会关心的一件事情,并且是仅此一件事情,由此可见测试之外的人员的肤浅,当然,不能称之为肤浅,因为你得理解,他们也只能关心到这一层面了。
有几个方面稍作记录,供大家参考。
1、测试工作量的估算
测试工作如同项目工作一样,都需要进行估算,且不说成本的估算,那是第三方测试关心的事情,一般公司内都是作集成测试和系统测试,而任何人都知道测试不是无休止的。所以我们需要对测试进度进行估算,但是首先我们需要估算测试的工作量。通常来说,测试人员在项目开始便介入项目,开展相应的测试工作,而并不是到了项目测试阶段才参与项目。
测试的工作量是根据测试范围和测试阶段、测试方式来确定的,主要因素是测试范围,所以我们需要确定测试范围。测试范围又是通过项目需求或者产品需求规格说明而来,因此这就是我们提取测试范围和测试需求的一个好方式。
通常来说,建议对测试工作进行细化,对每项工作都进行工作分解,分解的粒度可以自己定义,以可以把分解后的工作量准确的估算出为准。WBS之后,那么可以粗略的将所有工作的工作量求和,得出最终的测试工作量,当然,一般来说回归测试的遍数可以认为是3次,那么最后制定出调整因子,可以选择20%用以浮动的工作量。
如果项目能力成熟度比较高,需求文档写得比较完整和详细,那么也可以采取另外一种方法,就是根据需求文档进行推导测试工作量,这个方法是从网上找来的,在实际中试用过2次,呵呵,试用结果证明,某些参数需要根据以往的经验值调整。
以系统测试为例:
(1)由需求文档的页数计算出系统测试用例的页数(推荐比例为1.5)
(2)由系统测试用例页数计算编写系统测试用例时间(推荐比例为1)
(3)由系统用例计算执行系统测试时间(推荐比例为2)
(4)用执行系统测试计算回归测试时间(推荐比例为0.5)
2、测试进度的制定
测试工作量制定出之后,根据测试的资源对测试进度进行估计,当然,估计的最终结果要跟项目的测试进度相对比,我本人认为可以参考COCOMO方法,进行测试工期的估算,当然,也可以根据每个公司的以往经验值进行类推估算。
3、测试进度的更新
一般情况下,测试计划不会被严格的执行,通常伴随着都是项目的延期、测试阶段的压缩,如此一来,测试进度的更新是经常发生的事情。所以需要注意的一点是,测试进度估算完毕后,排定时最好不要以具体的时间点到时间点的方式,而是采用工作量和工期天数来表示,这样在开发阶段影响了测试计划后,不需要频繁的调整。
另外,在测试时间被压缩后,如果测试计划制定的详细,包括了各项测试需求和他们的优先级,那么此时可以利用测试需求的优先级,跟项目经理协商,调整测试范围和测试需求,在短的时间内优先测试重要的功能点,而一些不常用的和级别低的测试需求可以转移到用户现场或者后期进行。
对于项目中计划的更改或者需求、设计的更改,项目组一定要注意及时通知测试人员,其实就是项目的干系人,所有的干系人都需要及时通知到,这也是项目中配置管理的重要职责。需求或设计发生变动时,测试人员需要及时调整测试计划和测试用例,其中尤属测试用例的调整工作量较大,这种情况的频繁发生要求我们制定测试用例时,需要保证测试用例的条理性和通用性,避免具体数据的及早设入。
另外,关于测试的更新管理应在测试计划中规定好,明确更新周期和暂停测试的原则。例如,小版本的产品更新不能大于每天三次,一个相对大的版本不能每周大于1次,规定紧急发布产品仅限于何种类型的修改或变更,由谁负责统一维护和同步更新测试环境。测试暂停可以表现在产品错误发布或者服务器数据更新等情况,是比较有必要的一个方面,有利于测试管理者有效安排测试资源的合理运用。
Java集合类中,某个线程在 Collection 上进行迭代时,通常不允许另一个线性修改该 Collection。通常在这些情况下,迭代的结果是不确定的。如果检测到这种行为,一些迭代器实现(包括 JRE 提供的所有通用 collection 实现)可能选择抛出此异常。执行该操作的迭代器称为快速失败 迭代器,因为迭代器很快就完全失败,而不会冒着在将来某个时间任意发生不确定行为的风险。
因此,当一个线程试图ArrayList的数据的时候,另一个线程对ArrayList在进行迭代的,会出错,抛出ConcurrentModificationException。
比如下面的代码:
- final List<String> tickets = new ArrayList<String>();
- for (int i = 0; i < 100000; i++) {
- tickets.add("ticket NO," + i);
- }
- System.out.println("start1...");
- for (int i = 0; i < 10; i++) {
- Thread salethread = new Thread() {
- public void run() {
- while (tickets.size() > 0) {
- tickets.remove(0);
- System.out.println(Thread.currentThread().getId()+"Remove 0");
- }
- }
- };
- salethread.start();
- }
- System.out.println("start2...");
- new Thread() {
- public void run() {
- for (String s : tickets) {
- System.out.println(s);
- }
- }
- }.start();
|
上述程序运行后,会在某处抛出异常:
java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(Unknown Source)
at java.util.ArrayList$Itr.next(Unknown Source)
at mytest.mytestpkg.Tj$2.run(Tj.java:138)
Vector是线程同步的,那么把ArrayList改成Vector是不是就对了呢?
答案是否定的,事实上,无论是ArrayList还是Vector,只要是实现Collection接口的,都要遵循fail-fast的检测机制,即在迭代是时候,不能修改集合的元素。一旦发现违法这个规定就会抛出异常。
--------------------------------------------------------------------------------
事实上,Vector相对于ArrayList的线程同步,体现在对集合元素是否脏读上。即ArrayList允许脏读,而Vector特殊的机制,不会出现脏读,但是效率会很差。
举个例子,一个集合,有10个线程从该集合中删除元素,那么每个元素只可能由一个线程删除掉,不可能会出现一个元素被多个线程删除的情况。
比如下面的代码:
- final List<String> tickets = new ArrayList<String>();
- for (int i = 0; i < 100000; i++) {
- tickets.add("ticket NO," + i);
- }
- System.out.println("start1...");
- for (int i = 0; i < 10; i++) {
- Thread salethread = new Thread() {
- public void run() {
- while (true) {
- if(tickets.size()>0)
- System.out.println(Thread.currentThread().getId()+ tickets.remove(0));
- else
- break;
- }
- }
- };
- salethread.start();
- }
|
for循环构造10个线程删除同一个集合中的数据,理论上只能删除100000次。但是运行完发现,输出的删除次数108494次,其中很多数据都是被多个线程删除,比如下面的输出片段:
17ticket NO,35721
14ticket NO,35699
11ticket NO,35721
18ticket NO,35721
17ticket NO,35729
11ticket NO,35729
14ticket NO,35729
17ticket NO,35729
14ticket NO,35734
17ticket NO,35734
13ticket NO,35721
可以看到35721,35729都被多个线程删除。这事实上就是出现了脏读。解决的办法就是加锁,使得同一时刻只有1个线程对ArrayList做操作。
修改代码,synchronized关键字,让得到锁对象的线程才能运行,这样确保同一时刻只有一个线程操作集合。
- final List<String> tickets = new ArrayList<String>();
- for (int i = 0; i < 100000; i++) {
- tickets.add("ticket NO," + i);
- }
- System.out.println("start1...");
- final Object lock=new Object();
- for (int i = 0; i < 10; i++) {
- Thread salethread = new Thread() {
- public void run() {
- while (true) {
- synchronized(lock)
- {
- if(tickets.size()>0)
- System.out.println(Thread.currentThread().getId()+ tickets.remove(0));
- else
- break;
- }
- }
- }
- };
- salethread.start();
- }
|
这样得到的结果就是准确的了。
当然,不使用synchronized关键字,而直接使用vector或者Collections.synchronizedList 也是同样效果:
- final List<String> tickets =java.util.Collections.synchronizedList(new ArrayList<String>());
- final List<String> tickets =new Vector<String>();
|
vector和Collections.synchronizedList 都是线程同步的,避免的脏读的出现。
每个项目测试计划都会不一样,但是一般情况下,每个公司都会有相应的模板,尤其是项目很频繁的公司,相对应的模板应该就更全面,并且更容易修改,更能适应新项目。
并且,经常接触测试计划的人可能会察觉到,实际上很多测试的计划都大同小意,里面有很多相似的模块,像是说明,缺陷管理,项目通过标准,暂停标准,恢复标准,风险管理,等等,都是可以直接套用的,并且这其中有过多的官方的术语,就是一种套话,客套话,很多文字是为了使文章更好去读,读起来更舒服,充当的是绿叶的角色。
但是基本上说包含核心的内容都是根据不同的项目量身定做的,比如具体要测试特性,测试的milestone,schedule等等,这些是测试人员的测试的依据,时间安排的标准,是绝对马虎不得的,这也是测试计划的精髓所在。
所以总的来说测试计划可以宏观的认为包含两个部分,一个是具体项目的测试安排,日程安排,人员分工,任务分工,里程碑的成果物等等,另一个是,适用于很多项目的一些约定俗成的标准,管理的方案,风险、缺陷的管理等等,这些不必随着项目的变化而更改,只要有一份模板,针对不同的项目进行简单的更改就可以了。
其实这种写测试计划的方法也可以减少你的时间,更高效更有速度的阅读测试计划,因为当你拿到手中的是20几页的测试计划时,如果你选择从头一点一点的看,那真的很佩服你,如果是你的母语还好,文档若是一种外语,对自己来说很闹心,对公司来说也很浪费成本呀。一旦你清楚了测试计划中的窍门,你完全可一跳过那些标准,直接找到最核心的安排,分工,这样可以为您省去很多时间,也可以为公司创造更大的价值。
如果您不是第一次接触测试计划,想必对这些会有一些感觉,对于读测试计划而言,知道这些是不够的,而需要的是去剖析一篇测试计划,一旦将其中的各个模块都弄懂了,在以后的阅读中就会是飞速了,不管阅读那个公司的,因为他们的本质是一样的,就有点像只要你掌握了一门编程语言,在去学其他的语言,也就是几个小时的事了。
所以,理论讲到这里开篇也开到这里,接下来,我们就以随便的一篇文档进行剖析,最后可能会给各位一些网上普遍的测试模板,可以作为练习,自己阅读一下,是否可以快速阅读。
我的这篇文档并非母语,所以各位要有准备,我们先从目录入手,简单预览一下:
Test plan
1,introduction
2,test items
3,features to be tested
4,feature not to be tested
5,approach
6,item pass/fail criteria
7,suspension criteria and resumption requirement
8,test deliverables
9,testing task and schedule
10,environmental needs
11,staffing
12risks management
13,approvals
看起来有点多,不过仔细分析一下,里面需要写项只有1,3,4,8,9,10,11这几项,并且每一项需要写的东西都不多,其他的模块基本上都是绿叶啦!
在这些需要写的模块中,有些还只是更改部分就行了,并且,在有些项目中,其中的有些东西都可以省略,但是要看具体公司的规定,有些公司测试计划是越多越好呀,显得严谨周密,结果让写的人闹心,看得人也不舒心呀!
第1项中,有三项需要更改:
product summary(产品目录),主要就是列出一些项目的功能特性,包含哪些模块,哪些软件,对与比较大的系统列出来,更有利于后面的分析,但是小的系统就没什么必要了。references(参考文献),这个就比较随意了,一般都会列出不同参与者的一些资料
product milestore candidates(里程碑),这个是比较重要的,但是在后期也会出现,这里就是一个概览,一般都用表格的方式。
第3项,是核心的东西,一般的就用这项来代替需求分析了,可能额外没有具体的需求分析文档,所以阅读时这是最重要的,和需求是统一等级的,所以在编写的时候也不仅仅测试经理自己写,可能更多的回去参考开发的需求,或者开发文档中的一些特性项目,这个应该不需要原创太多,主要是需求分析人员已经做好的东西搬过来了。
第4项相对前面,就会好理解很多,主要由于一些硬性条件没法满足,无法进行测试的东西做一些说明。
第8项,可以和里程碑相对应起来,但是又没有里程碑那么重要,就是在测试过程的小阶段说产生的成果物提前进行的一个预计,主要就是为了把一个很大的目标(一个一年或半年的项目顺利完成),拆分成一个月的成果检验(里程碑),然后再拆分两周的小任务,可以指导你短期的工作,但是,这个也会根据时间做适当的相应的调整的。
第9项,这里主要的就是将里程碑进行完善和优化,要能够具体看了就知道怎么实施的文档。还有就是日程的安排,要对时间把握,另外有写时候会额外加一个文档schedule,专门就是做时间方面的计划的。
第10项是,环境要求,这个就比较容易了,有什么写什么。
第11项也是比较重要核心的东西,但是,有写的很详细,有些写的很宽松;对于大的项目,这个就会写的很简略,因为周期半年的项目没办法一下子把人员的任务都安排好呀,只能标记上需要哪些团队,都负责什么样的任务。具体的在根据具体的情况进行人员的分配。但是有些时候,对于项目比较小,可能就几周,人员也不多的时候,就需要将具体的分工分配下去,我当时分工分的很细,所以当时这个花费我很多时间去写,对后期的影响也很大,正因为这个任务分配的仔细,后期人执行起来有计可循,按照规定,每个人完成任务也都很有成就感。
其余的就是额外的,基本也是不用动的,这其中包含了一个大块,里面有些很多文档的内容很丰富占了整个测试计划的很大的篇幅。
第2项,列出了使用的测试的步骤,基本每个项目都可以按照这么去测试,里面包括冒泡,功能性能之类的,还会对具体的做一些特定的说明,尤其是公司会使用特定的工具。
第5项这是篇幅最大的一个,里面冉冉就是一个测试方案的缩写版本,所以,这部分完全可以取代测试方案了,里面包括了测试用例的设计规则,使用的测试的方法(冒烟,交互性,系统,性能等等),缺陷管理的方法,缺陷曲线,会议评审的方式,测量和度量,这些都包括目标和范围,所以里面分析的很细,想必很多公司在弄这个的时候都是集结了很多经验的。
第12项,风险管理,就是根据公司制定的了。
综上所述,对这一个测试计划做了简单 的分析,相信可以类比到很多的测试计划。
最后,再小小的总结一下,测试计划,其实是很简单的文档,写起来简单,读起来也简单,因为他有太多的相似和雷同,手中只要有一个模板,就有参考,再根据实际情况做一些小的调整。要弄清楚的是测试计划中核心部分和绿叶部分。
在项目开发中,代码质量是非常重要的一环。高质量的代码对项目完成质量、能否按时完工有重大影响。而一个团队中开发成员的配置往往是金字塔形的。基于开发成本考虑,项目主管或小组长一般由经验丰富的资深高级程序员担任,开发成员则由普通程序员、新员工、实习生组成。各个开发成员水平参差不齐,以及该行业内开发人员的高流动性。这样的条件和环境必然带来代码质量问题。项目主管难于把握项目进度,很容易造成项目延期,即使加班不少。
既然问题存在了,就必须解决它。解决的思路就是代码审查。
代码审查的前提:
1、统一项目组内部代码审查必要性思想,消除猜忌,建立融洽的团队合作气氛。代码审查不是挑刺。不建议使用审查中问题的发现率作为绩效考评标准。
2、确立合乎自己项目组要求的代码规范文档;
3、确立代码审查者:项目组成员少于3个,组长是审阅者。多了则要适当按模块分小组,每组不多余3人,每小组选经验丰富的程序员做为代码审阅者。要求代码审阅者与被审阅人最好为同一模块开发者。小组长的工作安排时就应考虑其代码审查职能,并相应减少其代码工作量。
4、确立审查标准、部署审查代码工具。普通程序员代码提交之前由代码审阅者实施审查。审阅代码者多于2人同时又有代码提交时,审阅代码者互审。
代码审查内容:
1、代码风格。通过代码复查,一方面督促开发人员按照规范编写代码,另一方面也使开发人员自身形成良好的编程习惯。代码风格的审查,由于内容比较单一,我们常常可以通过一些代码复查的工具来自动完成,提高复查的效率。
2、重大缺陷。预先整理编写代码审查的重大缺陷列表,并根据实践经验不断更新、补充、积累审查项目,并在每次审查中逐一检查。这些审查项目根据经验划分等级、优先级。
3、设计逻辑与思路的审查。这部分的审查是代码复查中最核心、最有价值的部分。代码风格与重大缺陷的审查,虽然重要但简单而机械,可以通过软件自动检查;而设计逻辑与思路的审查,却是复杂而有深度的审查,需要有一定理论深度和编码经验的人才能完成,而且对新手尤其重要。在新手完成编码以后,让老手去进行代码复查,指出新手的问题,指导新手设计。这样的过程最初可能需要重构,甚至重新编码。新手的进步、成长速度是加快的。老手通过对新手的指导,整理和升华自己的设计思路与理论,同时也是对自己另一方面的锻炼与提高。最终整个团队都得到了提高。
但代码审查无疑也带来了很高的代价。时间、人力与代码质量,其本身就是鱼和熊掌不可兼得。因此不同公司、同公司不同发展时期就会采取不同的代码复查策略。审时度略,实事求是,每个项目组都应该提出适合自己的代码审查方法。