
Interfaces 接口
在软件工程中,由一份“契约”规定来自不同的开发小组的软件之间如何相互作用是非常常见的。每个小组都可以在不知道别的组的代码的前提下独立开发自己的代码。Java中的interface就是这样的一份“契约”。
举个例子,假设在未来社会有一种智能汽车,它可以在自动运载旅客而不需要人工操作。汽车生产商开发了软件(当然是用Java)来控制这种汽车停止,发动,加速,左转等等。电子导航仪器生产商负责开发接受GPS位置数据和交通状况无线传输的电脑系统,并且应用这些信息来驾驶汽车。
汽车生产商必须公布工业标准interface,该interface需详细解释哪些methods可以用于控制汽车运动(该标准适用于任何汽车,任何生产商)。导航系统生产商就可以应用这个interface所介绍的各种methods来控制汽车。任何一个工业厂商都不需了解其他厂商是如何实现他们的软件的。事实上,只要大家都严格遵守所公布的interface,每个厂商对其自己的软件都有高度所有权,并且保有随时修改的权利。
在java中的interface
在java编程语言里,一个interface是引用类型(reference),它与class相似,因此只能包含常量(constants),方法签名(method signatures)和嵌套类型(nested types)。Interface不得含有方法的具体代码(method body)。 Interface 不可被实例化(instantiated),只能被其它class实现(implemented)或者被其它interface继承。
定义一个interface与创建一个新类类似:
- public interface OperateCar {
- // constant declarations, if any
- // method signatures
- // An enum with values RIGHT, LEFT
- int turn(Direction direction,
- double radius,
- double startSpeed,
- double endSpeed);
- int changeLanes(Direction direction,
- double startSpeed,
- double endSpeed);
- int signalTurn(Direction direction,
- boolean signalOn);
- int getRadarFront(double distanceToCar,
- double speedOfCar);
- int getRadarRear(double distanceToCar,
- double speedOfCar);
- ……
- // more method signatures
- }
|
如想使用上面这个interface,你需要写一个class来实现它。当一个可被实例化的class实现某个接口时,它需要提供所有该interface所声明的所有方法(methods)的具体代码。
在上面的自动化汽车的例子中,汽车生产商即是接口实现者。由雪佛兰公司的实现方法当然不同于本田公司的方法,但是它们都遵循同一个接口。 导航系统生产商是这个接口的使用者,他们的系统将根据汽车方位的GPS数据,数字化地图和交通情况来驾驶汽车。因此,这个导航系统将会涉及以下的方法(methods): 转弯,切道,刹车,加速等等。
API 接口
自动化汽车的例子展示了interface在工业标准应用程序接口(API, Application Programming Interface)中的应用. 在商业软件中,API也很常见。 通常来说,一个公司发售的软件包中会含有其他公司希望应用在自己的产品中的复杂方法(methods)。比如一个包含了数字图形处理方法的软件包就可以出售给开发终端客户图像软件的公司。购买后,该公司就可以应用interface所定义的方法。当图像处理公司向所有客户公开它的API的同时,这些API的实现方法是高度保密的。事实上,只要保留住原始的interface不被改变,这些API的实现方法很可能在将来被重写。
Interfaces 和多重继承
在java编程语言里,interface还有另外一个重要作用。 尽管Interface是与类一起使用的,但它并不是类的层次结构的一部分。java编程语言不支持多重继承,但是interface提供了替代方案。
在java中,一个类只能继承于单一的类,但是它可以实现多个接口。因此,对象可以有多重类型:属于它自身类的类型,和属于它所继承的所有接口的类型。这意味着,如果声明一个变量是某个接口类型,这个变量可以指代任何实现该接口的类的实例。这部分会在“使用接口类型”中详细讨论。
定义一个interface
一个接口的定义是由 修饰词(modifiers),关键词 interface, 接口名称,由逗号分隔开的父接口(parent interfaces),和接口实体(interface body)。
例子如下:
- public interface GroupedInterface extends Interface1, Interface2, Interface3 {
- // constant declarations
- // base of natural logarithms
- double E = 2.718282;
- // method signatures
- void doSomething (int i, double x);
- int doSomethingElse(String s);
- }
|
Public规定了这个接口可以被任何包中的任何类所使用。如果你声明这个接口是public的,它只能被同一个包里的类所使用。
一个接口可以继承其它接口,就像一个类能后继承其它类一样。但是类只能继承一个父类,而接口却可以继承任何数目的接口。
接口实体(interface body)
接口实体中含有它所包含的所有方法的声明。每个声明都以引号为结束,因为接口不用实现它所声明的方法。接口中所有的方法都默认是public的,因此修饰词public可以被省略。
接口还可以声明常量。同样的,常量的修饰词public, static和final可以被省略。
接口的实现
为了声明某个类实现了某个接口,你需要在类的声明中使用implements。你的类可以实现多个接口,所以implements关键词后面可以跟随多个由逗号分隔的接口名称。为了方便,implements关键词多跟在extends关键词的后面。
一个接口实例—Relatable
Relatable是一个用来比较两个对象大小的接口。
- public interface Relatable {
- // this (object calling isLargerThan)
- // and other must be instances of
- // the same class returns 1, 0, -1
- // if this is greater // than, equal
- // to, or less than other
- public int isLargerThan(Relatable other);
- }
|
如果你想比较两个相似的对象的大小,不管该对象属于什么类,这个类需要实现Relatable接口。
只要有办法可以比较对象的相对大小,任何类都可以实现Relatable接口。对字符串来说,可以比较字符数;对书来说,可以比较页数;对学生来说,可以比较体重。对平面几何对象来说,比较面积是很好的选择;对三维对象来说,就需要比较体积了。所有以上的类都能实现int isLargerThan()方法。
如果你知道某个类实现了Relatable接口,你可以比较从这个类实例化的对象了。
Relatable接口的实现
下面是一个三角形类,它实现了Relatable接口。
- public class RectanglePlus
- implements Relatable {
- public int width = 0;
- public int height = 0;
- public Point origin;
- // four constructors
- public RectanglePlus() {
- origin = new Point(0, 0);
- }
- public RectanglePlus(Point p) {
- origin = p;
- }
- public RectanglePlus(int w, int h) {
- origin = new Point(0, 0);
- width = w;
- height = h;
- }
- public RectanglePlus(Point p, int w, int h) {
- origin = p;
- width = w;
- height = h;
- }
- // a method for moving the rectangle
- public void move(int x, int y) {
- origin.x = x;
- origin.y = y;
- }
- // a method for computing
- // the area of the rectangle
- public int getArea() {
- return width * height;
- }
- // a method required to implement
- // the Relatable interface
- public int isLargerThan(Relatable other) {
- RectanglePlus otherRect
- = (RectanglePlus)other;
- if (this.getArea() < otherRect.getArea())
- return -1;
- else if (this.getArea() > otherRect.getArea())
- return 1;
- else
- return 0;
- }
- }
|
使用接口类型
在你定义一个新的接口时,你其实在定义一个新的引用类型。在你能使用数据类型名称的地方,都可以使用接口名称。如果你定义了一个类型为接口的引用变量,该变量能指向的对象所在的类必须实现了该接口。
下例是一个在一对对象中返回较大对象的方法:
- public Object findLargest(Object object1, Object object2) {
- Relatable obj1 = (Relatable)object1;
- Relatable obj2 = (Relatable)object2;
- if ((obj1).isLargerThan(obj2) > 0)
- return object1;
- else
- return object2;
- }
|
通过把数据类型object1转换成Relatable,对象obj1可以调用isLargerThan方法。
同理,只要是实现了Relatable的类,也可以使用下面的方法。
- public Object findSmallest(Object object1, Object object2) {
- Relatable obj1 = (Relatable)object1;
- Relatable obj2 = (Relatable)object2;
- if ((obj1).isLargerThan(obj2) < 0)
- return object1;
- else
- return object2;
- }
- public boolean isEqual(Object object1, Object object2) {
- Relatable obj1 = (Relatable)object1;
- Relatable obj2 = (Relatable)object2;
- if ( (obj1).isLargerThan(obj2) == 0)
- return true;
- else
- return false;
- }
|
这些方法适用于任何“Relatable”的类,而无关它们的继承关系。实现了Relatable的类,它们既属于自身(或者父类)的类型,也属于Relatable类型。这使得它们具有了多重继承的优点,因为它们可以同时具备父类和接口的行为。
重写接口
假设你开发了一个接口名为DoIt:
- public interface DoIt {
- void doSomething(int i, double x);
- int doSomethingElse(String s);
- }
|
然后,你想加入一个新的方法在这个接口里,因此代码变成:
- public interface DoIt {
- void doSomething(int i, double x);
- int doSomethingElse(String s);
- boolean didItWork(int i, double x, String s);
- }
|
如果你这么修改了,所有实现了旧的DoIt接口的类都会出错,因为它们不再正确的实现这个接口。所有使用这个接口的程序员会严重抗议你的修改。
你需要预估你的接口用户的需求,并从开始就完善的设计好这个接口。但是这常常是无法做到的。另一个解决方法就是再写一个接口。例如,你可以写一个DoItPlus的接口继承原有的接口。
- public interface DoItPlus extends DoIt {
- boolean didItWork(int i, double x, String s);
- }
|
现在你的用户可以选择继续使用旧接口DoIt,或是升级的新接口DoItPlus。
总结
接口就是两个对象间的沟通协议。
一个接口的声明包含一些方法的签名(signatures),但不需要实现它们;也可能含有一些常量。
实现某接口的类必须实现该接口所声明的所有的方法。
在任何使用类型名称的地方都可以使用接口的名字。
面向对象的类测试技术研究
摘要:类是面向对象软件的基本构成单元,类测试是面向对象软件测试的关键。从基于服务的、基于对象动态测试模型的、基于流图的以及基于规约的四个方面论述了类测试的思想和方法。
关键词:面向对象;软件测试;类测试
1、面向对象软件的类测试
面向对象软件从宏观上来看是各个类之间的相互作用。在面向对象系统中,系统的基本构造模块是封装了的数据和方法的类和对象,而不再是一个个能完成特定功能的功能模块。每个对象有自己的生存周期,有自己的状态。消息是对象之间相互请求或协作的途径,是外界使用对象方法及获取对象状态的唯一方式。对象的功能是在消息的触发下,由对象所属类中定义的方法与相关对象的合作共同完成,且在不同状态下对消息的响应可能完全不同。对象中的数据和方法是一个有机的整体,测试过程中不能仅仅检查输入数据产生的输出结果是否与预期的吻合,还要考虑对象的状态。模块测试的概念已不适用于对象的测试“类测试将是整个测试过程的一个重要步骤。
面向对象软件的类测试与传统软件的单元测试相对应,但类包含一组不同的操作,并且某特殊操作可能作为一组不同类的一部分存在。同时,一个对象有它自己的状态和依赖于状态的行为,对象操作既与对象的状态有关,但也可能改变对象的状态。因此,类测试时不能孤立地测试单个操作,要将操作作为类的一部分;同时要把对象与其状态结合起来,进行对象状态行为的测试“类的测试内容分为:(1)基于服务的测试(测试类中的每一个服务);(2)基于状态的测试(考察类的实例在其生命周期各个状态下的情况);(3)基于响应状态的测试(从类和对象的责任出发,以外界向对象发送特定的消息序列的方法来测试对象的各个响应状态)。
2、类测试技术
2.1 基于服务的类测试技术
基于服务的类测试主要考察封装在类中的一个方法对数据进行的操作,它可以采用传统的白盒测试方法。为克服软件测试的盲目性和局限性,保证测试的质量,提高软件的可靠性,下面我们介绍一种类的服务的测试模型及相应的测试策略。
BBD通常有两种获取途径。一是采用逆向工程的方法根据源程序画出流程图,然后构造出BBD。但这毕竟是在缺少软件开发前期的分析、设计文档或文档不齐全的情况下退而求其次的办法。当源程序不正确时构造出来的BBD就是错误的。另一种途径就是追根溯源,在软件的分析、设计阶段就根据测试的需要构造出相应的BBD。这样就能从根本上解决问题,正确地指导类的服务的测试。
2.2 基于层次增量的类测试
层次增量测试的基本思想是:首先分别测试父类的各个成员函数,再测试成员函数间的相互作用,把测试用例和执行信息保存在/测试历史中,在测试子类时,根据父类的测试历史修改部分的定义以及实现语言的继承映射来决定子类中的哪些特征应当重测试以及父类的哪些测试用例可以复用。
这种根据类间继承关系的层次特性对类进行增量测试的技术是由M.Harrold等人提出的,其特点是复用父类的测试信息来指导子类的测试。
类中的特征被分为6种类型:新特征:子类中新定义的特征;递归特征:在父类中定义、未被子类重定义的继承特征;重定义特征:在父类中定义、又在子类中重定义的特征,重定义特征在子类中屏蔽了同名(同参数表)的父类特征;虚新特征虚特征是指其实现尚不完整、留待子类重定义的特征,虚新特征是指子类中新定义的虚特征;虚递归特征:在父类中定义的虚特征,被子类继承后未重定义的特征;虚重定义特征:在父类中定义的虚特征,在子类中被重定义的特征,重定义特征在子类中屏蔽了同名(同参数表)的父类特征。
父类中各个成员函数的测试采用传统的单元测试技术,可以把传统的基于规约和基于程序的测试技术相结合选择测试集。类中每一个成员函数的测试历史是一个三元组{mi(TSi,test),(TPi,test)},其中mi为成员函数;TSi为基于规约的测试集;TPi为基于程序的测试集;test标识该测试集是否要(重)运行。
同一类中成员函数的相互作用的测试实际上是一种集成测试,如何进行这一测试是根据类图来确定的。在类图中,节点表示类中的一个成员函数或数据成员,有向边表示发送消息。测试数据集的选择也可应用基于规约和基于程序的测试方法。测试历史的形式也是一个三元组{mi(TISi,test),TIPitest},其中mi是类图中某一子图的根节点;TISi是基于规约的集成测试集;TIPi是基于程序的集成测试集;取表示该测试集要全部(重)运行,取表示部分(重)运行,取表示无需(重)运行。一个类的测试历史是各成员函数测试历史的集合和集成测试历史集合的并集。
2.3 基于流图的类测试技术
把传统的基于流图的测试技术应用于类测试提出了一种构造类流图的框架。在类流图中,节点表示操作,操作A和操作B之间的有向边表示允许某引用类(client)在调用操作A之后调用操作B,确定节点间是否可以联边的依据是该类的规约。
传统程序流图的测试充分性准则可以在类流图中找到对应,如类流图的节点覆盖要求测试时的操作序列应使每个操作至少执行一次,分支覆盖要求测试时的操作序列应覆盖类流图中的每条边至少一次。还可以在类流图上给出类似于数据流的定义性出现!引用性出现、定义-引用对等概念。在类流图中,所有对象的定义性出现和引用性出现根据操作(节点)中是否定义或引用该对象来确定,然后在谓词性引用和控制操作。计算性引用和非控制操作之间建立对应关系,从而可以类似地给出数据流准则中的定义覆盖准则、引用覆盖准则和定义-引用路径覆盖准则等。图4给出堆栈类(类名为Stack,T为栈元类型)的类流图,表1给出每个操作的定义性和引用性使用情况。
基于流图的类测试技术把传统的基于规约的测试应用于类测试,完全依赖于类的实现,系统地而不是随机地产生测试用例,且可全部自动化。
许多考虑采用敏捷的组织没有把团队迁移到开放式环境就尝试创建项目团队。敏捷价值和原则中,当团队成员可以随时接触到所有其他团队成员、易于获得所有的项目进度图表、在鼓励交流的环境中时,团队可以更好地工作。敏捷测试专家Lisa和Janet分享了敏捷测试团队的人力资源经验。
测试人员和客户与程序员坐在一起可以促进必要的交流。如果实际情况不允许重新迁移位置,那么团队可以创造性地解决这问题。
Janet分享了自己的故事:
我曾经在这样一个团队工作,空间问题使得所有团队成员不能坐在一起。程序员有一个可以使他们方便结对编程的区域,但是测试人员和客户坐在其他的区域。首先,是测试人员走到程序员坐的用户故事白板区域去参加每日站立会议,当他们有需要问程序员的问题时,也是这样。基本没有程序员走到测试人员的区域(大约50英尺的距离)。我开始准备一些招待他们的糖果,并鼓励开发人员在需要的时候拿一些。但是有一条规矩——如果他们来拿糖果,他们必须问其中一个测试人员一个问题。随着时间的过去,所有的团队成员都会相互走到另一个区域了。不是一边总走向另一边,交流也更频繁了。
团队规模给组织带来了不同类型的挑战。小团队意味着小的区域,所以通常更容易将成员的位置换到一起。大的团队可能分布在全球,这时需要虚拟交流工具。调动大团队的座位通常意味着整修目前的空间,很多组织不愿意这么做。明白你的限制,努力找到团队遇到的问题的解决方法,而不是仅仅接受现实并“保持现状”。Janet举了一个例子:
我工作过的一个团队一开始在楼层的一角,但是通过三年的扩张,逐渐的占据了楼层的75%。墙被拆掉了,去掉了办公室,创建了大的开放区域。团队在这种开放区域工作地很出色,但是所有的开放空间意味着墙没有了。窗子变成用户故事板和白板,白板按顺序卷起以便团队需要时使用。
坐在一起的团队并不总是存在于完美世界中,分布式团队有另外的一些挑战。分布式团队需要帮助团队交流和合作的技术。电话会议、视频会议、网络摄像机和即时消息是一些可以促进在不同位置的团队实时协作的工具。不管团队是在一个位置的还是分布式的,通常存在的一个同样的问题是,敏捷团队需要什么资源,如何获取它们。
新的敏捷团队成员和他们的经理对于团队的组成有很多疑问。可以使用在传统项目中同样的测试人员吗,或者是否需要聘用那个不同类型的测试人员?需要多少测试人员?是否需要具有其他专业技能的人?
关于测试人员和开发人员的“正确”比例的问题已经有很多讨论。组织使用这个比例来确定项目需要的测试人员的数量,可以根据这个数量来聘用测试人员。在传统项目中,没有“正确的”比例,每个项目需要自己估计。需要的测试人员的数量是不同的,依赖于应用的复杂性、测试人员的技能和使用的工具。
Lisa和Janet曾经工作在不同的测试人员——开发人员比例的团队,从1:20到1:1都有。以Janet来说:
我曾从事一个开发消息处理系统的项目,他们的比例是1:10。GUI很少,我手动测试应用的这一部分,查看可用性和是否符合客户的期望。程序员做所有的自动化回归测试,我同他们一起验证编写的测试用例的有效性。我把测试的用户故事,包括某些用户故事的负载测试,分配到开发人员。
我从来没觉得没有足够的时间做需要的测试,因为开发人员相信质量是整个团队的责任。
Lisa则分享了自己的故事:
我曾经是一个有20名程序员的团队的唯一一名专业测试人员,该团队开发在线商店网站的内容管理系统。当程序员负责手动测试和测试自动化时,团队才真正有工作效率。一个或两个程序员在每个迭代的中扮演测试人员,在编码前编写面向客户的测试并执行手动测试。其他的程序员在迭代中承担起测试自动化的任务。
相反的,我现在的团队每三或五个程序员有两个测试人员。我们生产的基于web的财务应用有非常复杂的业务逻辑,有很高的风险,而且密集测试。测试任务通常与编码任务的时间一样多。即使是测试人员——开发人员高比例,程序员也会做一些功能测试自动化并部分承担手动测试任务。专门的测试任务,例如编写高层次的测试用例和详细描述面向客户的测试通常由测试人员完成。
与其关注比例,团队更应该估计他们需要的测试技能并找到合适的资源。负责测试的团队可以持续地估计是否有需要的技能和数量。使用回顾总结来确定是否需要聘用更多的测试人员是一个解决方法。
测试人员适合敏捷团队的工作需要一定的条件。我们不会过多讨论聘用什么类型的测试人员的细节,因为每个团队的需求是不同的。但是,我们相信态度是一个重要的因素。下面是Lisa的团队如何聘用一个新的敏捷测试人员的故事:
我们招募另一名测试人员的第一次尝试并不是很成功。第一个工作招聘公告吸引了很多人,我们面试了三名应征者,但是没有找到合适的人选。程序员希望找到“技术人员”,但是我们也需要有同业务人员合作和帮助他们描述实例和需求的技能的人。为了吸引有正确的态度和思想的应聘者,我们努力明确工作招聘公告的内容。
在听取Janet和敏捷测试社区的其他同事的想法和建议以后,Lisa改变了工作招聘公告,包含如下的条款:
● 熟悉黑盒和GUI测试用例,设计测试减轻风险,帮助业务专家定义需求。
● 熟练编写简单的SQL查询和插入/更新语句,掌握Oracle或其他关系型数据库的基础知识。
● 至少使用某种脚本语言或编程语言和/或开源测试工具超过一年。
● 使用基本Unix命令的能力。
● 擅长与程序员和业务专家协作。
● 最好有基于上下文环境的测试、探索性测试或场景测试的经验。
● 融入自组织团队的能力,即与同事协调确定每天的任务,而不是等待分配的工作。
Lisa表示:这些需求带来了更适合敏捷测试工作的应聘者。我通过小心的筛选,排除了有“质量警察”思想的人。追求职业发展和对敏捷开发显示出兴趣的测试人员更倾向于有正确的思想。团队需要对测试工具和自动化领域有较强能力的人,所以学习的热情是极为重要的。这种新颖的招募测试人员的方式是值得的。当时,找到好的“敏捷测试”候选者是不容易的,但是接下来进行得更顺利。我们发现把测试职位公告放到不那么明显的位置,例如Ruby的邮件列表或者本地敏捷用户组,可以帮助延伸到更广阔范围的合适的候选者。招聘敏捷测试人员教授了我许多关于敏捷测试思想。有良好技能的测试人员对于任何传统测试团队都是有价值的,但是因为他们对测试的态度,可能不适于敏捷团队。
因近期想搞个知识库,所以选择solr,现在最新的solr是4.0,所以用solr4.0。
服务器:tomcat6
JDK :1.6
SOLR :4.0
中文分词器 :ik-analyzer,mmseg4j
安装:目前mmseg4j的版本是mmseg4j-1.9.0.v20120712-SNAPSHOT,经过测试,发现这个版本有bug:
java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.l ucene.analysis.Tokenizer.reset(Ljava/io/Reader;)V
由于solr4.0对其中的有些类与方法做了调整,所以还是等待mmseg4j新版本修复吧。果断使用了ik-analyzer。
一、将apache-solr-4.0.0\example\webapps\solr.war放在tomcat的webapps下启动服务器解压该war包,另外还需要增加几个jar包:
apache-solr-dataimporthandler-4.0.0.jar
apache-solr-dataimporthandler-extras-4.0.0.jar
这两个jar包可以在solr的dist中可以找到
另外还需要相应数据库的驱动包,比如
mysql-connector-java-5.1.13-bin.jar
二、将apache-solr-4.0.0\example下的solr拷贝至apache-tomcat-6.0.29-solr\bin下
三、在apache-tomcat-6.0.29-solr\bin\solr\collection1\conf下的solrconfig.xml增加以下数据库配置
- <requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
- <lst name="defaults">
- <str name="config">data-config.xml</str>
- </lst>
- </requestHandler>
四、将apache-tomcat-6.0.29-solr\bin\solr\collection1\conf下增加data-config.xml文件,内容如下:
- <dataConfig>
- <dataSource type="JdbcDataSource"
- driver="com.mysql.jdbc.Driver"
- url="jdbc:mysql://localhost:3306/solrdb"
- user="root"
- password="888888"/>
- <document name="content">
- <entity name="node" query="select id,author,title,content from solrdb">
- <field column="id" name="id" />
- <field column="author" name="author" />
- <field column="title" name="title" />
- <field column="content" name="content" />
- </entity>
- </document>
- </dataConfig>
五、增加中文分词器,ik-analyzer的配置如下:
它的安装部署十分简单,将IKAnalyzer2012.jar部署亍项目的lib目录中;IKAnalyzer.cfg.xml不stopword.dic文件放置在class根目录(对于web项目,通常是WEB-I NF/classes目彔,同hibernate、log4j等配置文件相同)下即可
solr4.0中schema.xml配置解析器:
- <schema name="example" version="1.1">
- ……
- <fieldType name="text" class="solr.TextField">
- <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
- </fieldType>
- ……
- </schema>
- <?xml version="1.0" encoding="UTF-8" ?>
- <schema name="example" version="1.5">
- <types>
-
- <fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
-
-
- <fieldType name="string" class="solr.StrField" sortMissingLast="true" />
- <!-- IKAnalyzer 配置 -->
- <fieldType name="text" class="solr.TextField">
- <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
- </fieldType>
-
- </types>
-
-
- <fields>
- <field name="id" type="string" indexed="true" stored="true" required="true" />
- <field name="author" type="text" indexed="true" stored="true" multiValued="false"/>
- <field name="title" type="text" indexed="true" stored="true" multiValued="false"/>
- <field name="content" type="text" indexed="true" stored="true" multiValued="false" />
- <field name="_version_" type="long" indexed="true" stored="true"/>
- </fields>
-
- <uniqueKey>id</uniqueKey>
- <defaultSearchField>content</defaultSearchField>
- <solrQueryParser defaultOperator="OR"/>
- <copyField source="title" dest="content"/>
- <copyField source="author" dest="content"/>
-
-
- </schema>
解析:multiValued的个人理解是配置true则返回单条数据,false则可以返回多条,以后深入理解了再详解。defaultSearchField配置默认搜索索引,copyField可以讲 title、author字段添加至content默认搜索中
七、登录管理页面:
中文分词器分词的示例:

query示例:

作为软件测试人员(SQA/SQC),做的最频繁并且最主要的活动之一就是编写测试用例了。首先,请记住以下所有的讨论都是关于编写测试用例,而不是设计/定义/确认测试用例(TC)。
这项主要活动有几个重要的关键因素,让我们先来大概了解一下吧。
A、测试用例要易于定期修改和更新
我们生活在 一个不断变化的世界,软件也不能免于变化。需求也是如此,这就直接的影响到了测试用例。不论什么时候,一旦需求发生变化,测试用例就需要更新。然而,并不 是只有需求的变化才会引起测试用例的版本变化和更新。在测试用例执行过程中,脑海中会涌现出许多的想法,单个测试用例的许多子条件会引起更新甚至测试用例 的补充。除此而外,在回归测试中一些补丁和/或波纹都会需要修订或是新的测试用例。
B、测试用例要易于分配于执行用例的测试人员
当然了,让单独一个测试员执行完所有的测试用例是几乎不太可能的。正常情况下,一个单独的应用程序会有几个测试员分别负责测试不同的模块,因此,根据他 们自己在应用程序中测试的部分测试用例也会相应的分配开。一些和应用程序集成相关的测试用例有可能会由多人执行而有的则只是由单独的个人执行。
C、测试用例要易于集群和批处理
属于一个测试场景的测试用例通常都会要求以一些特定序列或小组格式来执行,这很正常,也是很常见的。可能会有一些测试用例是其他测试用例的先决条件,同 样的,根据AUT的业务逻辑,一个单独的测试用例会在几个测试条件中存在,而一个单独的测试条件也可能会由多个测试用例组成。
D、测试用例有相互依赖的趋势
测试用例中一个有趣并且重要的行为就是他们彼此之间是相互依赖的。在具有复杂业务逻辑的中型到大型应用程序中,这种趋势则更为明显。任何应用程序中能明 确的观察到这个行为的最清晰的地方就是,相同甚至不同应用的不同模块之间的互操作性。简单的说就是,不管相异模块或应用程序是在哪里相互依赖的,相同的行 为都体现在了测试用例中。
E、测试用例要易于在开发者间分配(尤其是在测试用例驱动开发环境中)
关于测试用例,重要的一点就是,它并不是只被测试人员使用的。在正常情况下,当开发人员修改bug的时候,他们间接的使用了测试用例来修改问题。同样 的,如果遵守的是测试用例驱动开发,那么开发员则直接使用了测试用例来构建他们代码的逻辑并覆盖测试用例中处理到的所有的场景。
所以,将以上的5点记住,这里给出一些编写测试用例的建议:
要简洁但是不能太简单;要复杂但是又不能太复杂。
这句话似乎是自相矛盾的,但是我发誓并不是如此。走完测试用例的每一步,正确序列和预期结果的正确映射都得要精确,这就是我所说的让测试用例保持简单。
而,使其复杂一点实际上指的是测试用例得和测试计划以及其他测试用例相融合。当需要的时候,参照其他的测试用例,相关工件,GUI等。但是做此事的时候 得均衡一下,不能让测试人员为完成单个测试场景就来回的搬运大堆的文件。另一方面,不要让测试人员希望你会压缩这些测试用例文件。在编写测试用例的时候, 请时刻记住你或者别人不得不修改并且更新这些测试用例。
测试用例编制完成之后,以一个测试人员的角度再审视一遍:
永远不要以为你写完测试场景的最后一个测试用例后就算完事了。回过头去从开始将所有的测试用例再看一遍,但是不要当自己是个测试用例的编写者或 测试策划者,以测试人员的角度审视所有的测试用例。理性的思考并且干运行你的测试用例,评估一下你所提到的每一步都是清晰易懂的,并且预期的结果和这些步 骤也是相协调的。
测试用例中规定的测试数据不仅要对实际的测试人员是可行的,而且也得是依据真实的实时环境的。要确保测试用例中没有依赖冲突,而且也要确认对于其他测试用例/工件/GUI的所有参考都是精确的,否则测试人员会陷入大麻烦中。
约束测试人员,但同时也让他们感到容易。
不要把测试数据都留给测试人员,给他们一个输入的范围,特别是当执行运算的时候或者是应用程序的行为是取决于输入的时候。也许你会把测试项目的 值分给他们,但是永远不要让他们自己来选择测试数据项目,因为,有意无意的,他们会使用相同的测试数据因而在执行测试用例的时候一些重要的测试数据会被忽 略掉。
根据测试类别和应用程序的相关领域对测试用例进行组织,这能让测试人员感到容易一些。清晰的指出哪些测试用例是相互依赖的/或是可批处理的。同样的,明确的指示出哪些测试用例是独立的,孤立的,因此,测试人员就可以按照自己的意愿管理他/她的全部测试活动。
成为一个贡献者
从不接受FS或设计文档原来的样子,你的工作不仅仅是将FS浏览一遍然后明确测试场景。作为一个和质量相关的资源,你要毫不犹豫的去贡献。要给 开发人员提建议,特别是在测试用例驱动开发环境中。建议一些下拉列表,日历控件,选择列表,单选按钮,更有意义的信息,警告,提示,可用性的改进等等。
不要忘记最终的用户
最重要的利益相关者就是将会实际使用AUT的最终的用户,所以,在编写测试用例的任何阶段都不要忘记他。事实上,在SDLC的任何阶段也都不能 忽视最终的用户,但是目前我只强调和我讨论的话题相关的。所以在识别测试场景的时候,不要忽视这些大多情况下被用户使用的用例,或者是那些甚至不太使用的 业务关键用例。把你自己想象成最终的用户,把所有的测试用例浏览一遍,判断一下你文档中测试用例执行的实际价值。
总结:
测试用例的编写是一项会对整个测试阶段产生重要影响的活动。这个事实使得测试用例文件编制这个任务变得非常的关键并且微妙。所以,编写测试用例 得先适当的计划一下,还得非常的具有条理性。编制测试用例文件的人必须记住,这项活动不是为他/她自己而做的,而是为了整个团队,这个团队包括了其他测试 人员和开发者,还有那些会被这项工作直接或间接影响到的客户。
所以,在这项活动进行的过程中必须给予适当的关注。对所有的使用者来说,测试用例文档必须是很好理解的,方式明确,维护简单。除此而外,测试用 例文档必须介绍所有重要的特征,必须覆盖AUT所有重要的逻辑流,伴随着实时和实际可接受的输入。你编写测试用例的战略是什么?和我们的读者分享你的建议 吧~也可把你的问题写在下面的评论中。
中午在单位食堂吃饭排了个长队,等了好半天。然后就想这不就是在跑性能吗??
如果把食堂看作一个在线系统,员工吃饭看作是一次业务处理。回过头来看系统性能测试分析中需要关注的点,其实颇有意思
首先最直观的性能表现就是打饭窗口的长队,可以说这是系统性能处理能力最直观的表现了。指标对应ResponseTime
队伍前进的快慢,对应每秒处理事务数TPS
同时进餐人数,对应并发请求数
我们再看看影响性能指标的相关因素
1)打饭窗口数--对应业务处理进程数,有时某个窗口存在多个打饭师傅,这时可以看作是多线程。处理进程(线程)的多少,是决定业务处理性能的最主要因素。
2)师傅的业务熟练程度--处理器的性能,计算能力
3)所点餐品多少和分布情况--对应数据的处理能力。所点餐品离窗口近,分布集中,自然处理起来快些,好比数据存储在内存库,不进行跨表、跨库的关联处理之类,性能自然较好。
4)刷卡付账环节--一般组合的餐品价格师傅都能快速算出来,但是比较多的菜品,计算起来要多花点时间。好比对于一些常见的请求,从缓存里读取自然会快些。
异常情况1:卡内金额不够、点菜结束又再点了一份。对应到这些异常处理或是重试会也影响处理性能。
异常情况2:看菜单上有的菜,点菜时却发现没有,需要重新确认。这个相当于业务请求先查询出携带的参数,响应却判参数不存在了。数据实时关联没做好,属于系统Bug(此Bug还存在啊)
5)选择的餐品类型---打饭的队伍比等面条、馄饨的队伍处理起来一般相对快些。不同业务,处理的方式不同,性能表现也不同。
另外,餐厅的面积是有限的,窗口数也是有限的,打饭师傅的数量也是有限的。所以系统处理能力或曰系统容量是有限的。貌似目前食堂还没达到处理极限(虽然用户满意度不高),暂时还不用扩容,呵呵
其实我们注意到,针对处理能力的问题,有两个现象:
1)二楼食堂人满为患,一楼食堂比较宽松。这个给我们的启示就是,在系统还具备处理能力的前提下,性能并不是影响用户选择的最主要参考(关键需求即业务本身的吸引力更重要)。但系统超过处理能力或者系统异常,无法提供服务后果还是很严重的。饿肚子咋干活。。
2)业务上存在分时处理,所有的业务请求被强制分时间段访问。这个是根据业务特点决定的,业务具有明显的峰谷特点,在系统容量无法处理大量并发时,对请求通过业务逻辑实现错峰分流,是解决性能问题一种常规手段。
上文也提到,餐品窗口有不同类型,面条、盖浇饭等。这个其实是根据业务特点实现的定向分流,提高资源处理效率。如果都混在一起,性能应该不好。
再一个,我们打饭其实包含了多个操作步骤:排队、取餐具、点餐、盛饭盛汤、落座、进食、返还餐具。对应到性能测试分析,可以借鉴的就是,业务处理要进行 细分,系统重点处理关键节点,业务请求本身能完成的事务由客户端完成,在请求时携带结果参数(餐具)。业务处理完成后,要及时完成垃圾回收释放资源。
另外一个比较重要的地方就是应急处理,系统发生异常时要能保证提供最基本的服务。饭点时员工吃不上饭应该是这个系统不能接受的问题。其实可以考虑开个零售点备些面包、方便面啥的,这样至少停电、停气时还能满足最基本的充饥需求。
基本就这么多,其实还有很多后台的工作我们看不到,其实应该对性能影响也是很大的,比如食材的准备、烹饪过程、配套设施的保障等,这边就不发散了。
总结一下,从食堂系统来看,我们做性能分析其实大致要关注以下几点:
1)业务请求的数量、并发请求数
2)业务处理效率
3)系统资源情况,处理能力
4)业务处理的关键节点
5)分流策略
6)异常处理和应急机制
版权声明:本文出自 danmy 的51Testing软件测试博客:http://www.51testing.com/?81672
用过好多自动化测试工具,对于一颗拥有程序员心的测试工程师来说,选择webdriver绝对能满足你的要求。使用Webdriver不要求你把一门语言研究的多精通,你只要知道语法,和常用的包,常用的类,常用的方法就足够。
说明一下,我使用的的是java。所以,在开始前,你的电脑上正确安装了jdk,然后有个使用习惯的开发工具,如eclipse。最好再装个maven,我的项目都是maven工程。下面我们开始:
到selenium的官方网站上下载几个包。一个是selenium-server-standalone.jar;还有一个是selenium- java.jar。如果你选择使用firefox(你就使用firefox吧,你会慢慢发现它的好处。)再下载个selenium-firefox- driver.jar
把它引用到你创建的maven工程中:下面是我pom.xml部分内容。
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>2.26.0</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-server-standalone</artifactId>
<version>2.26.0</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-firefox-driver</artifactId>
<version>2.25.0</version>
</dependency> |
如果在 maven dependencies中存在你引的包,并且没有奇奇怪怪的符号,那么,您就可以开始第一个webdriver自动化程序了。
我们就当你已经成功创建了需要的project并且默认你有一些selenium的相关知识。我们就用webdriver干些事吧,哈哈。
创建一个Login类。把下面代码拷到文件中,然后运行一下。就能看到打开www.lovo.cn,跳转到登陆页面,然后登陆成功。
package com.test.login;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
|
public class Login {
private WebDriver webDriver;
private String baseUrl;
private Logger logger = LoggerFactory.getLogger(this.getClass());
private WebElement element;
public void openBrowser() throws Exception{
webDriver = new FirefoxDriver();
webDriver.get(baseUrl);
}
public void clickLoginLink(){
try {
baseUrl = "http://www.lovo.cn/";
this.openBrowser();
element = webDriver.findElement(By.linkText("登录"));
if(element != null){
element.click();
if(webDriver.findElement(By.id("logusername")) != null){
logger.info("正常跳转到登陆页");
}else{
logger.error("打开登陆页面失败");
}
}else{
logger.error("没有找到登陆链接!!!");
}
} catch (Exception e) {
e.printStackTrace();
logger.error("发生未知错误!");
}
}
public void login(){
this.webDriver.findElement(By.id("logusername")).clear();
this.webDriver.findElement(By.id("logusername")).sendKeys("138****035");
this.webDriver.findElement(By.id("logpassword")).clear();
this.webDriver.findElement(By.id("logpassword")).sendKeys("123456");
this.webDriver.findElement(By.id("logimageCheck")).clear();
this.webDriver.findElement(By.id("logimageCheck")).sendKeys("5rkz");
this.webDriver.findElement(By.cssSelector("span.btntext")).click();
this.webDriver.findElement(By.cssSelector("div.text")).click();
if(this.webDriver.findElement(By.cssSelector("BODY")).getText().matches("^[\\s\\S]* 刘建东[\\s\\S]*$")){
this.logger.info("登陆成功!");
}else{
this.logger.error("登陆失败!");
}
}
public static void main(String[] args){
Login login = new Login();
login.clickLoginLink();
login.login();
}
} |
有时候打开firefox的时候会报错,说没有安装firefox之类的错误,这是因为你改变了firefox的默认安装路径。这种情况下,你可以根据FirefoxBinary类实现。
方法如下:
public WebDriver openFirefox() throws Exception{
File file = new File("你的firefox的安装路径+firefox.exe"); //这里注意对\进行转义
FirefoxBinary firefoxBin = new FirefoxBinary(file);
WebDriver webDriver = new FirefoxDriver(firefoxBin,null);
return webDriver;
} |
或者使用setCapabilit来设置
方法如下:
public WebDriver openFirefox() throws Exception{
DesiredCapabilities des = DesiredCapabilities.firefox();
des.setCapability("firefox_binary", "你的firefox的安装路径+firefox.exe");
WebDirver webDriver = new FirefoxDriver(des);
return webDriver;
} |
总结;
FirefoxDriver类有7个构造方法,意味着可以用7中方法打开firefox浏览器(其实比7种多),
FirefoxDriver()
FirefoxDriver(Capabilities desiredCapabilities)
FirefoxDriver(Capabilities desiredCapabilities, Capabilities requiredCapabilities)
FirefoxDriver(FirefoxBinary binary, FirefoxProfile profile)
FirefoxDriver(FirefoxBinary binary, FirefoxProfile profile, Capabilities capabilities)
FirefoxDriver(FirefoxBinary binary, FirefoxProfile profile, Capabilities desiredCapabilities, Capabilities requiredCapabilities)
FirefoxDriver(FirefoxProfile profile) |
最近因为开发一个项目的关系在研究《Head First设计模式》,想从中找到一些灵感,虽然之前也看过,但是每次
学习,都会有新的理解和感悟,非常感谢作者提供了这样一本让我受益匪浅的书!
面向对象程序设计(注意这里是面向对象,而不是基于对象)的一个很重要的设计原则就是:针对接口编程,而不是针对实现编程!可就是这样一句句很浅显的话,确包含了很多面向对象的知识在里面!
“什么是针对接口编程呢?”,“针对接口编程的真正意思是”针对超类型编程“。所以这里的”接口“就不再仅仅指的是java中的interface,还包括了抽象类,”超类型“在这里就是指”interface“和”abstract“类,当然不包括普通用于继承的类,因为普通的类虽然可以继承但是无法实现”多态“。而”多态“,正是”针对接口编程“的关键之所在!
”什么是多态呢?“,多态(Polymorphism)按字面的意思就是“多种状态”,指同一个实体同时具有多种形式。在面向对象语言中,接口的多种不同的实现方式即为多态。引用Charlie Calverts对多态的描述——多态性是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。如果一个语言只支持类而不支持多态,只能说明它是基于对象的,而不是面向对象的。利用多态,程序可以针对”超类型“编程,执行时会根据实际状况执行到真正的行为,不会被绑死在超类型的行为上。
以下是非多态和多态的对比:
例子:假设有一个类Animal,有两个子类(Dog与Cat)继承Animal:
针对实现编程是这样做的:
class Animal {
String name;
String sex;
public void Display()
{
System.out.println("name =" + name + "sex =" + sex);
}
public void Sound()
{
System.out.println("make sound!");
}
} class Dog extends Animal{
public void Sound()
{
System.out.println("wang...wang...wang...");
}
} class Cat extends Animal{
public void Sound()
{
System.out.println("miao...miao...miao...");
}
} public class AnimalTest {
public static void main(String[] args)
{
Dog dog = new Dog();
dog.Sound();
Cat cat = new Cat();
cat.Sound();
}
}
在上面这种针对实现的做法中,dog的行为来自Animal超类的具体实现,或是重载后的Sound方法,这种依赖于”实现“的做法会被”实现“绑得死死的,没办法更改dog行为,除非在Dog中写更多的代码! 而”针对接口/超类型编程"做法如下: class Animal {
String name;
String sex;
public void Display()
{
System.out.println("name =" + name + "sex =" + sex);
}
public void Sound()
{
System.out.println("make sound!");
}
} class Dog extends Animal{
public void Sound()
{
System.out.println("wang...wang...wang...");
}
} class Cat extends Animal{
public void Sound()
{
System.out.println("miao...miao...miao...");
}
} public class AnimalTest {
public static void main(String[] args)
{
Animal animal = new Dog();
animal.Sound();
animal = new Cat();
animal.Sound();
}
} |
在这个例子中,Animal animal = new Dog();表示我定义了一个Animal类型的引用,指向新建的Dog类型的对象。由于Dog是继承自它的父类Animal,所以Animal类型的引用是可以指向Dog类型的对象的。 在这种方式中,程序在执行时会根据animal的实际状况(对应哪个子类的赋值)执行到真正的行为(哪个子类的方法),不会被绑死在超类型的行为上,这也就是“在运行时指定具体实现的对象”,这也是多态的宗旨!当然“多态”的真正含义并不仅仅限于此,而“针对接口编程”正是利用了面向对象的这种“多态”特征来达到其“接口和具体实现分离“这一目的的! 多态总结: (1)多态是通过: 1、接口 和 实现接口并覆盖接口中同一方法的几不同的类体现的 2、父类 和 继承父类并覆盖父类中同一方法的几个不同子类实现的. (2)通过将子类对象引用赋值给超类对象引用变量来实现动态方法调用。 (3)java 的这种机制遵循一个原则:当超类对象引用变量引用子类对象时,被引用对象的类型而不是引用变量的类型决定了调用谁的成员方法,但是这个被调用的方法必须是在超类中定义过的,也就是说被子类覆盖的方法。 1、如果a是类A的一个引用,那么,a可以指向类A的一个实例,或者说指向类A的一个子类。 2、如果a是接口A的一个引用,那么,a必须指向实现了接口A的一个类的实例。 |
如果说测试计划提出了“做什么”,则测试设计则是明确了“怎么做”。即测试方案需要在测试计划指导下进行,方案是对计划的进一步细化和明确。
测试方案的核心内容是:测试策略选取、测试子项细分。测试策略就是如何用最少的资源满足测试质量的要求,既高效、低成本、较高质量的完成测试。测试子项细分就是对已经在计划中明确的测试范围、测试项的粒度控制,既然要做细分,就应该有优先级、侧重点的考虑。
文档是要服务于测试活动本身的。规范、标准是一方面,另一方面只要能够做好测试,文档也可以写的略些。以下大段内容来自于GBT 9386-2008-《计算机软件测试文档编制规范》,是我国的国家标准。我们的测试方案是可以依据此及公司具体情况来做裁剪的。
1、目的:
通过测试设计及其相关测试来详细地规定测试方法和标识要测试的特征。
2、提纲:
a)测试设计说明标识符;
b)要测试的特征;
c)方法细化;
d)测试用例标识;
e)特征通过准则。
3、详细说明:
3.1 测试设计说明标识符
为该测试设计说明规定唯一的标识符。若在相关的测试计划中有规定,则应引用。
3.2 要测试的特征
标识测试项,并描述做为该设计说明对象的特征和特征组合。尽管可能还有某些其他特征,但不必标识他们。
3.3 方法细化
将测试计划中描述的方法进行细化,包括要采用的具体测试技术。应标识分析测试结果的方法(例如,比较程序或可视化审查)。
指明为选择测试用例提供合理依据的任何分析结果。例如,可以规定允许限定容错的条件(例如,区别有效输入与无效输入的那些条件)。
归纳任何测试用例的共同属性,可以包括各种输入约束(如,针对一组相关测试用例的所有输入必须是真)、任何共享环境的要求、
任何共享特殊规程的需求、以及任何共享测试用例之间的依赖关系。
3.4 测试用例标识
列出与该设计有关的每一测试用例的标识并简要描述。某个特定的测试用例可能在两个以上的测试设计说明中出现。
列出与该测试设计说明有关的每个规程的标识及简要描述。
3.5 特征通过准则
给出用于判断特征或特征组合是否通过或失败的准则。
一个测试方案的例子:
XX项目测试方案
1、引言
项目的背景和简要介绍
2、环境搭建策略
2.1 配置环境搭建
(1)资源要求
客户端包括:
软件:
硬件:
服务器端包括:
软件:
硬件:
(2)搭建策略
描述环境搭建的步骤;
2.2 测试管理工具环境搭建
(1)资源要求;
(2)搭建策略;
2.3 测试项目环境搭建
(1)资源要求;
(2)搭建策略;
3、测试数据准备
测试数据准备、风险;
4、测试规程设计
若在计划中明确,则此处可略;
5、批准
批准人:
批准时间:
摘要:软件测试是软件质量保证的一个重要组成部分,除了要具备一定的客观条件外,还受到许多主观因素特别是测试人员、组织和管理等方面的影响.在对这些主观因素以及软件测试软环境的构成与优化作了一些研究和探讨后,提出了一些可行性建议。
关键词:软件测试;单元测试;测试文档;
一、引言
软件测试作为软件开发的一个重要阶段,除了必须具备被测软件、测试工具、测试技术等一些必备的客观条件外,还受到测试人员、组织管理、测试策略等相关主观性较强的因素的影响。这些因素的综合作用——本文称之为软件的“测试软环境”,决定了软件测试的成败。
二、软件测试软环境的构成要素
1、测试人员
测试人员是软件测试的执行者,他们的素质将直接影响到软件测试的成败。软件测试是一项严谨的工作,一名优秀的软件测试工程师应具备以下的素质:
(1)沟通能力。测试者必须能够与测试涉及的所有人员(包括技术人员和非技术人员)进行沟通。由于人本身具有排他性,因此,当你试图从别人的程序中寻找 错误或缺陷时,往往会遭到反对或对抗。测试者应尽量避免冲突和发生矛盾,要对每个人具有足够的理解和同情,具备了这种能力可以将测试人员与相关人员之间的 冲突和对抗降低到最低程度。
(2)技术能力。由于开发人员对不懂技术的通常持一种不屑或轻视的态度,因此,一旦测试小组的某个成员作出 了一个错误的判断,将直接导致他甚至整个测试小组的可信度降低,相反,则会大大增强测试人员的信心和测试工作的说服力。一个优秀的测试人员必须既明白被测 软件系统的概念,又要熟悉并会使用相关的工具,而要做到这一点需要有几年的编程经验,只有通过这样的经验积累才会对软件的开发有更加深刻的了解。
(3)耐心。软件测试是一项非常烦琐的工作,很容易使人变得懒散,甚至烦躁不安。作为一个测试人员,你必须要有足够的耐心和自律能力,有时你需要花费惊人的时间去识别、排除一个故障,有些看似毫无成就的工作,往往就在你的苦思冥想后豁然开朗。
(4)兴趣和自信心。测试者应对自己所从事的工作具有浓厚的兴趣,对自己的观点有足够的自信,如果具备了这两点,那么在开发过程中,不管遇到什么样的困难,都能克服。
(5)怀疑与探索精神。一个软件从开发到投入使用通常要经历许多的循环往复,难免出现这样或那样的错误和缺陷,测试人员应具有叛逆心理,敢于怀疑,勇于探索,在可能的条件下,充分发挥自己的潜能,创造性地开展工作,力求寻找出软件中存在的故障。
(6)其它方面的素质。具有良好的判断能力,有一定的幽默感,逻辑思维敏捷等等。
2、组织与管理
(1)测试小组
由于软件故障的产生主要来源于软件需求分析、设计和编码阶段,因此,需求分析、软件设计和程序编码等各个阶段所得到的文档资料,包括需求规格说明书、设 计规格说明书以及源程序都是软件测试的对象,而由此产生的测试组织与管理也是分阶段的,测试小组的人员组成方式也是不一样的。
需求分析阶段。这一阶段的测试人员应包括:用户、项目经理、系统分析员、软件设计、开发以及测试人员。他们需要进行多次讨论和协商来确定软件的功能,以此作为评价需求规格说明书的依据。
软件设计阶段。人员组成应包括:系统分析员、软件设计人员、测试负责人以及用户。这一阶段的主要工作是按照需求分析规格说明书的要求对系统结构的合理性以及过程处理的正确性进行审查,用户的作用在这一阶段不是非常突出。
软件测试阶段。软件测试作为保障软件质量的一个重要的手段,通常包含以下一些测试:单元测试、集成测试、确认测试、系统测试和验证测试。其中,单元测试由编程小组内部的编程人员交叉进行,其它测试工作则要由测试组来完成,此时,测试组成员的组成应包括:测试经理、测试技术人员、软件开发人员、相关技术支持人员以及用户。需要注意的是,在单元测试阶段,要严格杜绝编程人员测试自己编写的程序。
(2)测试管理
测试工作的管理,尤其是对于包含多个子系统的大型软件系统,其测试工作涉及大量的人力和物力,有效的测试管理是保证有效测试工作的必要前提。
首先,软件测试的有效实施需要测试组织与开发组织充分配合。虽然测试活动看似是对开发人员劳动成果的不断“挑剔”,但测试工作的出发点是:确保 开发人员的劳动成果成为可被接收的、更高品质的软件产品。测试经理应在组织协调各组织工作方面发挥作用,并和他们一起工作,甚至对公司以外的个人和组织都 是如此。测试经理在工作中所要处理的人员关系可用图1表示。此外,测试经理所处的职位要求他能提交日常主要工作的有关信息,如状态报告、测试计划、评估报 告等,同时,还要根据当前的状态做出一些重大决策,这些决策可能会对整个测试过程产生一定的影响。
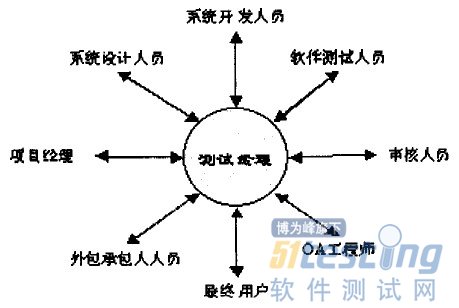
图1 测试经理的人际关系角色
其次,为确保软件测试在软件质量保证中发挥应有的作用,建立和完善软件测试管理体系是十分必要的。从软件工程的角度出发,软件测试管理所涉及的管理对象包含以下几个方面:
● 测试资源。包括对人员分配、工作环境、相关设施等的管理。
● 测试计划。根据资源配备情况,制定总体测试计划,确定各个阶段的测试目标和策略。
● 分析与设计。测试分析与设计就是确定测试目标并且如何以一种高效执行的方式组织测试的过程。这个过程需要根据测试计划选择合适的测试方案,设计出好的测试用例。
● 测试实施。测试实施是指测试人员根据测试计划,利用测试资源来运行测试用例以获得测试数据、开发测试规程的过程。这个过程涉及到测试环境的设置、测试数据的收集以及测试验证等具体的工作。
● 测试管理。测试管理作用于测试的各个阶段,其管理的对象包括测试组织的建立、测试过程的控制、测试计划和测试规程的制订与管理等等。
三、测试软环境的构建
1、测试人员
在一个测试小组中,并不是所有的测试人员都需要具有同样的技能,由于分工不同,他们所起的作用也不同。一般情况下,测试小组中测试人员的构成一般包括:
开发人员。最好的情况是:让开发人员去做单元测试,如果需要的话还可以让他们做集成测试。
用户。通常在测试阶段会给测试提供很好的帮助。
技术支持人员。熟悉软件产品的流程,与用户有更多的沟通,往往更能理解用户的想法。
QA人员。他们了解产品质量的重要性,对测试小组的工作是一个很好的补充。
技术文员。这是测试工作中必不可少的一个角色。由于工作的需要,他们关注测试过程中的很多细节问题,并按照要求完成相关的技术文档的编制,使得整个测试工作都有据可查。
2、测试组织
由于软件的规模大小不一,软件测试的方法也比较多,因此,测试组织的构成形式也多种多样。表l列出了各种测试组织的一些优缺点。测试组织如何进行内部构造和设置职位,这在很大程度上取决于政策、企业文化、质量标准、成员的技术和知识水平,以及产品的风险。

表1 各种测试组织的优点和缺点
3、工作环境
对许多测试人员和管理人员来说,工作环境似乎不是最重要的问题,而且长期以来也没有得到重视,但测试人员所处的工作环境对他们的生产力和工作效果所起的作用是非常重要的。
测试人员为了完成他们的工作,需要有特定的基本需求,他们需要有一个自己的办公空间,能够方便地与小组中的其他人员进行交流而不互相干扰,在资源配置许可的情况下可以自由使用各项设施,所有这些条件的满足都会对整个小组的工作效率产生很大的影响。
四、测试软环境的优化
从测试软环境的构成来看,由于测试人员的主观性较强,测试管理和测试策略的灵活性较大,因此这几个方面都可以作为软环境优化的出发点,以提高软件测试的效率。
1、测试小组的优化
挑选合适的人员来从事适当的工作,这是每一个管理者都必须面临的挑战。事实上,由于很少有大学会设立软件测试方面的 课程,因此,要在很短的时间里寻找到合适的软件测试员是非常困难的。通常情况下,优秀的软件测试人员都是经过长期的经验积累后由开发人员转变而来。另外, 确定测试小组的其他人员也是要考虑的一个重要方面。
技能培训作为测试人员提高自身素质的重要手段,对整个测试工作的实施能够起到事半功倍的作用。在确定了测试小组的组 成人员后,管理者有责任、有必要对他们进行相关的技能培训。这种培训包括:专业技能、业务知识、交流能力等。培训的方式可以采用指导、内部培训、由相关培 训机构实地培训等多种形式。
2、测试管理的优化
前面已经提到,对测试过程的有效控制是测试工作顺利进行的基础,而对测试工作的有效管理则是提高测试效率的有力保障。
(1)测试规范化
软件测试是一项相当烦琐的工作,必须加以规范,避免随意性。测试文档的编写就是测试工作规范化的一个重要组成部分。软件测试文档通常分为两类, 测试计划和测试分析报告。测试计划用来指导一个测试过程,包括测试的目的、内容、策略、进度等,而测试报告则对测试的结果进行分析说明,指出软件所具有的 功能以及存在的缺陷。通常情况下,软件测试文档规定了进行软件测试所必须具备的条件,这些条件作为测试资源必须在测试进行之前落实。
(2)管理制度化
测试管理是整个软件产品质量保证的一个重要组成部分,管理的制度化是保证有效测试工作的必要前提。由于测试工作长期以来没有受到足够的重视,几 乎没有可供参考的、已实现的、完整的测试管理方面的资料。通常情况下,可以将管理工程的一些基本原理用于测试工作中,根据测试过程的进展情况,吸收其他组 织或行业的先进经验,对整个测试工作进行计划和管理,使得一些行之有效的方法和机制逐渐制度化,进一步规范整个测试过程。
五、小结
长期以来,由于软件测试在软件开发中没有得到足够的重视,使得可遵循的测试规范尤其是测试管理方面的知识及相关资料非常缺乏,本文所提到的测试 软环境及其构成要素在很多软件开发方面的书籍中有所提及,而在一些专门讲述软件测试的书中往往更多地注重讲解各种测试策略和测试方法。而忽略了组织与管 理,随着人们对软件开发过程的认识逐渐加深,软件测试也越来越得到了应有的重视。