
简介:
单元测试和性能测试在测试领域属于要求相对较高的测试活动,也是测试工程师成长、向上发展的反向。单元测试评测我们的代码实现功能的情况,性能测试则企图分析应用程序的性能表现和负载能力。那么“单元性能测试”能做什么?我们可以这样说,单元性能测试以单元测试的形式对代码进行性能测试。单元性能测试像单元测试一样,需要测试人员编写测试代码,但现在关注的不是代码的功能实现情况了,而是想得到被测试代码的性能数据,包括执行方法耗时、多线程并发是否线程安全、内存是否泄漏、是否存在短期循环对象等。单元性能测试相对于系统性能测试更容易定位问题,对关键的方法进行测试,可以降低系统性能风险,减少系统集成后系统性能测试的工作量。本篇文档演示如何使用JUnitPerf程序包对代码进行多线程并发测试。
待测代码DateUtil:
我们待测的程序代码为com.loggingselenium.DateUtil类。这个类中有一个私有静态成员timeFormator和一个静态方法compareDateTime(String dateTime1, String dateTime2)。
package com.loggingselenium;
import java.util.Date;
import java.text.SimpleDateFormat;
public class DateUtil {
private static SimpleDateFormat timeFormator =
new SimpleDateFormat("yyyyMMdd HH:mm:ss");
public synchronized static int compareDateTime(String dateTime1, String dateTime2) {
try {
Date date1 = timeFormator.parse(dateTime1);
Date date2 = timeFormator.parse(dateTime2);
if (date1.before(date2))
return -1;
if (date1.after(date2))
return 1;
else
return 0;
} catch (Exception e) {
throw new RuntimeException("解析日期时间格式出错,期望的字符串格式为[yyyyMMdd HH:mm:ss]");
}
}
} |
单元测试代码UnitTestDateUtil:
我们的测试代码com.loggingselenium.UnitTestDateUtil如下:
package com.loggingselenium;
import junit.framework.TestCase;
public class UnitTestDateUtil extends TestCase {
protected void setUp() throws Exception {
super.setUp();
}
protected void tearDown() throws Exception {
super.tearDown();
}
public void testCompareDateTime(){
String dateTime1="20120111 01:02:03";
String dateTime2="20130111 01:02:03";
String dateTime3="20130111 01:02:03";
assertEquals(-1, DateUtil.compareDateTime(dateTime1, dateTime2));
assertEquals(1, DateUtil.compareDateTime(dateTime2, dateTime1));
assertEquals(0, DateUtil.compareDateTime(dateTime2, dateTime3));
}
} |
经过运行单元测试代码,可以验证com.loggingselenium.DateUtil类的compareDateTime(String dateTime1, String dateTime2)的功能已经实现了,可以用来比较两个日期时间的大小了。
对方法进行多线程测试ThreadTestDateUtil
虽然通过了单元测试,这个方法的功能实现了,但在多线程并发调用该方法的时候会出现抛出异常。手写多线程并发测试代码,com.loggingselenium.ThreadTestDateUtil继承java.lang.Thread线程类,重新实现其run()方法,用于调用com.loggingselenium.DateUtil类的compareDateTime(String dateTime1, String dateTime2)。在main()方法中创建两个线程并启动线程执行调用日期时间比较的方法。
package com.loggingselenium;
public class ThreadTestDateUtil extends Thread {
public void run() {
int i1=DateUtil.compareDateTime("20130111 01:02:03","20130111 01:02:03");
int i2=DateUtil.compareDateTime("20120111 01:02:03","20130111 01:02:03");
System.out.println("i1="+i1);
System.out.println("i2="+i2);
}
public static void main(String a[]) {
Thread t = new ThreadTestDateUtil();
t.start();
Thread t2 = new ThreadTestDateUtil();
t2.start();
}
} |
编译、运行该方法,控制台报异常:
java.lang.RuntimeException: 解析日期时间格式出错,期望的字符串格式为[yyyyMMdd HH:mm:ss]
at DateUtil.compareDateTime(DateUtil.java:43)
at TestDateUtil2.run(TestDateUtil2.java:3)
使用JUnitPerf进行多线程测试JUnitPerfTestDateUtil
我们手写多线程并发测试代码的一个弊端是,如果我们需要测试100个线程,我们就需要创建100个线程实例Thread t,t1,t2,t3……并一一启动这些线程。JunitPerf包可以帮助我们更容易对代码进行多线程并发测试。
首先,访问http://www.clarkware.com/software/junitperf-1.9.1.zip下载我们需要的junitperf-1.9.1.jar,放到我们单元测试项目的构建路径。
在测试代码com.loggingselenium. UnitTestDateUtil的基础上进行修改,创建新测试类JUnitPerfTestDateUtil,以使用JunitPerf进行多线程并发测试。新测试类中compareDateTimeLoadTestMethod()实现以5个线程执行testCompareDateTime(),这个单元测试方法调用我们的日期时间比较方法。方法compareDateTimeLoadTestMethod()只会运行1次,会有5个线程运行方法testCompareDateTime(),等于有5个线程调用方法compareDateTime(String dateTime1, String dateTime2)。我们可以指定需要的线程数目,JunitPerf也提供了丰富的接口供我们选用。
package com.loggingselenium;
import com.clarkware.junitperf.LoadTest;
import com.clarkware.junitperf.TestMethodFactory;
import junit.framework.Test;
import junit.framework.TestCase;
import junit.framework.TestSuite;
public class JUnitPerfTestDateUtil extends TestCase {
public JUnitPerfTestDateUtil(String name) {
super(name);
}
protected void setUp() throws Exception {
super.setUp();
}
protected void tearDown() throws Exception {
super.tearDown();
}
public void CompareDateTime() {
String dateTime1 = "20120111 01:02:03";
String dateTime2 = "20130111 01:02:03";
String dateTime3 = "20130111 01:02:03";
assertEquals(-1, DateUtil.compareDateTime(dateTime1, dateTime2));
assertEquals(1, DateUtil.compareDateTime(dateTime2, dateTime1));
assertEquals(0, DateUtil.compareDateTime(dateTime2, dateTime3));
}
protected static Test compareDateTimeLoadTestMethod() {
int users = 5;
Test factory = new TestMethodFactory(JUnitPerfTestDateUtil.class,
"CompareDateTime");
Test loadTest = new LoadTest(factory, users);
return loadTest;
}
public static Test suite() {
TestSuite suite = new TestSuite();
suite.addTest(compareDateTimeLoadTestMethod());
return suite;
}
public static void main(String args[]) {
junit.textui.TestRunner.run(suite());
}
} |
编译、运行该测试方法,使用Run as Application,控制台可能输出如下结果,有2个Error:
…..EE
Time: 0.053
There were 2 errors:
1) CompareDateTime(com.loggingselenium.JUnitPerfTestDateUtil)java.lang.RuntimeException: 解析日期时间格式出错,期望的字符串格式为[yyyyMMdd HH:mm:ss]
at com.loggingselenium.DateUtil.compareDateTime(DateUtil.java:18)
at com.loggingselenium.JUnitPerfTestDateUtil.CompareDateTime(JUnitPerfTestDateUtil.java:22)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at com.clarkware.junitperf.TestFactory.run(TestFactory.java:83)
at com.clarkware.junitperf.ThreadedTest$TestRunner.run(ThreadedTest.java:75)
at java.lang.Thread.run(Unknown Source)
2) CompareDateTime(com.loggingselenium.JUnitPerfTestDateUtil)java.lang.RuntimeException: 解析日期时间格式出错,期望的字符串格式为[yyyyMMdd HH:mm:ss]
at com.loggingselenium.DateUtil.compareDateTime(DateUtil.java:18)
at com.loggingselenium.JUnitPerfTestDateUtil.CompareDateTime(JUnitPerfTestDateUtil.java:22)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at com.clarkware.junitperf.TestFactory.run(TestFactory.java:83)
at com.clarkware.junitperf.ThreadedTest$TestRunner.run(ThreadedTest.java:75)
at java.lang.Thread.run(Unknown Source)
FAILURES!!!
Tests run: 5, Failures: 0, Errors: 2
多线程并发测试失败,我们的比较日期时间大小的方法存在线程不安全的问题,我们需要在DateUtil中方法前加上线程同步关键字synchronized:
| public synchronized static int compareDateTime(String dateTime1, String dateTime2) {......} |
再次运行单元测试方法,可以发现多线程并发下存在的问题得到了解决。
版权声明:本文出自 lobster 的51Testing软件测试博客:http://www.51testing.com/?194329
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
您是否遇到测试Windows软件时,要安装部署新操作系统或一堆兼容性软件的情况?如果有,花费多长时间?20分钟、半个小时甚至更多?
可以在10分钟之内做到吗?
部署一个Windows测试环境之后,如何让其他人可以很轻松地复用呢?

问题的产生
1、客户端测试环境的概念
所谓客户端测试环境,是指部署在Windows操作系统下的应用软件测试环境,主要涉及操作系统和应用软件,测试环境应该能够满足被测客户端软件启动、运行、执行测试用例的基本操作,同时又能满足各种特殊测试用例的执行需求,如安全性测试用例、兼容性测试用例等。
操作系统包括Windows主流系统版本,如Windows XP、Windows Server 2003、Windows Vista、Windows 7、Windows Server 2008,版本包括中文和英文等。
应用软件按类别大概分为即时通信、输入法、浏览器、网络下载、视频播放、图片工具、安全防护、系统工具、办公学习、开发工具、股票网银、游戏休闲等。
当测试客户端软件时,需要根据软件产品设计、需求设计编写测试用例。在用例设计过程中,需要考虑用例的执行测试环境,比如用例A需要在Windows XP系统下执行,用例B需要在安装诺顿杀毒软件的环境下执行,用例C执行环境为Windows 7+XX网游+卡巴斯基等。
我们的测试用例执行环境越丰富、越接近大部分主流用户环境,才能够更大程度地保证客户端软件满足用户的正常使用。
2、客户端测试环境管理需求
客户端测试环境管理的最主要需求是提高测试效率,测试环境的高效管理对于提升工作效率至关重要。
当执行测试用例需要某个特殊的测试环境时,一般情况下简单测试环境手工部署平均时间在10分钟~30分钟,部分复杂环境部署约数小时,比如需要安装部署某个版本的操作系统或下载安装某个大型杀毒软件等。此时环境部署的时间往往超过测试用例执行的时间,最让我们头痛的不是测试本身,而是测试环境的搭建。
当执行完毕某个测试用例时,往往会因为执行其他用例的需要而改变已搭建好的测试环境,这样下次回归需要重新手工部署搭建,这些重复劳动极大降低了测试效率。如果能够自动保存我们辛苦部署的测试环境,下次可以直接复用就好了。
Windows系统下的应用软件数量和种类不胜枚举,初次搭建环境时手工下载安装这些应用软件也是极为耗时的一项工作,想一想我们需要到各大软件下载站,找到各个版本的应用软件,然后辛苦下载下来,再逐个安装。多么枯燥乏味的工作!如果能够将这部分工作全部自动化实现,会极大节省部署时间。
另外,在一个团队人员众多,而硬件测试机器资源有限的情况下,想想大家争抢测试机器的局面吧!我们迫切需要一个管理系统,来帮助大家协调测试机器的占用问题。比如先占用了环境的人,有权使用固定时间,这段时间别人不能强占;到期后别人可以抢占,大家有序竞争,至少不会发生环境使用的互踢现象。
综上,客户端测试环境的管理需求如下。
(1)能够对测试环境进行自动化快照备份管理,持续复用。
(2)能够自动化部署应用软件,降低初次部署时间成本。
(3)能够管理机器资源池,提高机器使用效率。
软件测试作为软件质量保证的重要手段已引起软件用户和开发人员越来越多的关注。然而在对测试认识逐渐深化的过程中,首先应该弄清几个问题。
非进行测试不可吗?
世界软件市场将有一个突飞猛进的发展,应用程序的类型越来越复杂,从传统客户/服务器应用,到基于浏览的Internet/Intranet应用,再到混合型应用等等。在这些大量的、日渐复杂的应用程序中,由于GUI的对象丰富,使得状态组合数量巨增;软、硬件来自不同厂商,程序运行环境复杂;版本不断升级以及同时使用某个厂家的不同版本,致使程序运行环境经常改变;并发用户的数量逐渐增多,对性能要求不断提高等等。可见,随着软件业的发展,测试成为必然。
据统计,在软件开发总成本中,用在测试上的开销要占30%到50%。如果把维护阶段考虑在内,讨论整个软件生存期时,测试的成本比例也许会有所降低,但实际上维护工作相当于二次开发,乃至多次开发,其中必定还包含有许多测试工作。因此,有人估计软件工作有50%的时间和50%以上的成本花在测试工作上。因此,测试是必需的,问题是我们应该思考“采用什么方法、如何安排测试?”
测试和调试可以相互替代吗?
为了判断应用系统是否合格,而用预先确定的一系列数据在系统中运行,并与预期的结果进行比较,这一过程称为测试。它是软件质量保证的重要手段。然而,有些人往往把测试和调试混为一谈,这是不正确的。
简单地说,测试是一种检验,经过测试人们会看到一些现象。这些现象也许是可疑的征兆,但往往不能直接从测试的结果中找到错误的根源。这就需要充分利用测试结果和测试提供的信息进行全面分析,以便找到错误的根源和出现错误的原因。紧接着便是纠正已发现的错误。测试以后进行的这些工作称为调试或排错。
我们不能把两者混为一谈。但它们毕竟有着密切的关系,常常是在测试以后紧接着要着手排错。实际上,这两种工作经常交叉进行,是不可相互替代的。
科学的测试应从何时开始?
有一种传统的观念认为:“应用系统开发完毕,再对它进行测试。”用这种思想来指导测试工作是相当危险的。
对于软件质量的判断决不只限于程序本身,它和编码以前所完成的需求分析及软件设计工作密切相关。很显然,表现在程序中的错误,并不一定是编码所引起的,很可能是详细设计、概要设计阶段,甚至是需求分析阶段的问题引起的。错误在初期也许只是范围很小的隐藏问题,但由于各开发阶段的连续性,使其逐步扩展。如果早期开发中出现的错误不能及时发现和解决,将带到设计、编码、测试等各阶段,影响会逐步扩大。这就要付出不必要的人力、物力来修正错误。可见,解决问题、纠正错误应追溯到前期的工作,越早着手越好。科学的测试是贯穿整个产品生命周期中的测试。
考虑到以上这些情况,我们将测试分成如下阶段:模块测试、集成测试、确认测试和系统测试。对程序的最小单位——模块进行测试,是为了检验每个模块能否单独工作,从而发现模块的编码问题和算法问题;集成测试是将多个模块连接起来,以检验概要设计中对模块之间接口设计的问题;确认测试则应以需求规格说明书中的规定作为检验尺度,发现需求分析的问题;最后的系统测试是将开发的软件与硬件和其他相关因素(如人员的操作、数据的获取等)综合起来进行全面检验,这样的做法涉及到软件需求以及软件与系统中其他方面的关系。
我们应着眼于整个软件生存期,特别是着眼于编码以前各开发阶段的测试工作,以保证软件的质量,这就要突破原来对测试的理解。据有关机构研究表明:在开发周期中,每推后一步实施错误检查,成本就会增加10%。因此,查找、修改错误的最佳开始时间是在项目设计阶段,之后还要伴随着开发过程的每一个环节,保证测试与开发的同步进行。
对软件能够做到彻底测试吗?
既然测试的目的就是查找软件中的错误,那么为了得到高质量的软件,能不能借助测试工具将所有隐藏的错误全部找出来呢?
我们知道,只有对应用的每一个运行环境、语句、条件分支、路径等进行穷举测试,才能确保测试的彻底性。但往往这种做法工作量过大,所用时间过长,实际是不现实的,因而也就失去了实用价值。软件工程的总目标是充分利用有限的人力和物力资源,高效率、高质量地完成测试开发项目。在测试阶段既然穷举测试是不现实的,为了节省时间和资源,提高测试效率,就必须精心设计测试用例,这样采用这些测试数据能够取得最佳的测试效果。掌握测试量的度是至关重要的。一位有经验的软件开发管理人员在谈到软件测试时曾这样说过:“不充分的测试是愚蠢的,而过度的测试是一种罪孽。”测试不足意味着让用户承担隐藏错误带来的危险;过度测试则会浪费许多宝贵的资源。到测试后期,即使找到了错误,然而已经付出了过高的代价。总之,进行测试是为了使软件中蕴涵的缺陷低于某一特定阈值,使产出/投入比达到最大。
之前的文章中曾出现过“并发度”这个概念,这个词不知道是不是我原创,它意在表达“并发”的可能性,是压力的一种度量。一些同学可能还没有理解这个概念的意义,下面我们看看它是怎么来……
看过之前文章的同学应该知道,我将“并发”这个容易产生误解的词拆分成了“相对并发”和“绝对并发”。为什么这么做呢?那是因为“绝对并发”说的是同一时刻发生的事情,这通常是我们无法观测和衡量的。而“相对并发”说的是一个时间段内发生的事情,这是很容易观测到的。从某种程度上,也可以说“相对并发”是为了弥补我们无法有效评估“绝对并发”的压力而出现的。
但是有时候,性能测试工程师仍然需要回答“系统可以处理多少个并发请求”这类的问题,或者是需要测试一些绝对并发的极限场景。这类问题和测试场景是有意义的,但是在没有“绝对并发”相关数据的情况下,我们如何处理?显然胡乱拍板是不可以的,那么我们只有根据一些可观测的数据进行合理的推测和估算,“并发度”就是这样产生的。
假设我们已经分析得出,系统的使用压力集中在2个小时内,在这个时间段内共有100个用户访问(活跃用户),且压力是平均分布的(否则就可以说压力集中在更小的时间段内了),平均每个用户使用系统的时间是30分钟(活跃时间),那么我们可以画出下面一张图来表示服务端所承受的压力。
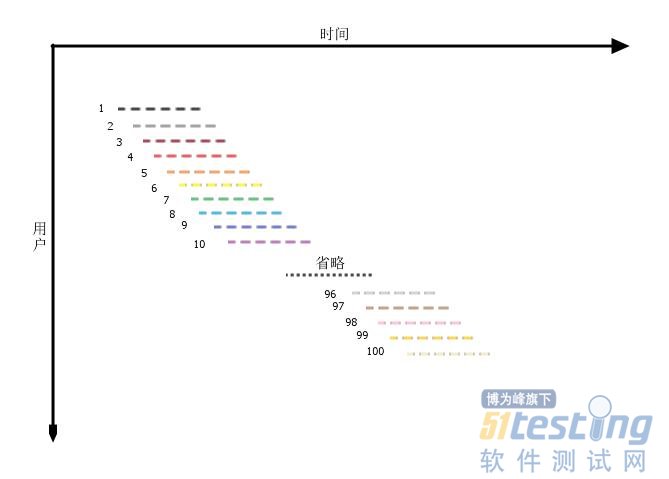
这是一张从服务端视角来看的交互图。横轴是时间,纵轴是访问用户,每一条横线表示一个用户与系统的交互过程,不同的用户用不同颜色做了标识。在这张图中,什么是并发度呢?我们选取时间轴上的一个点,延纵轴方向做一条平行线,这条线穿过的横线的数量,就是并发度。
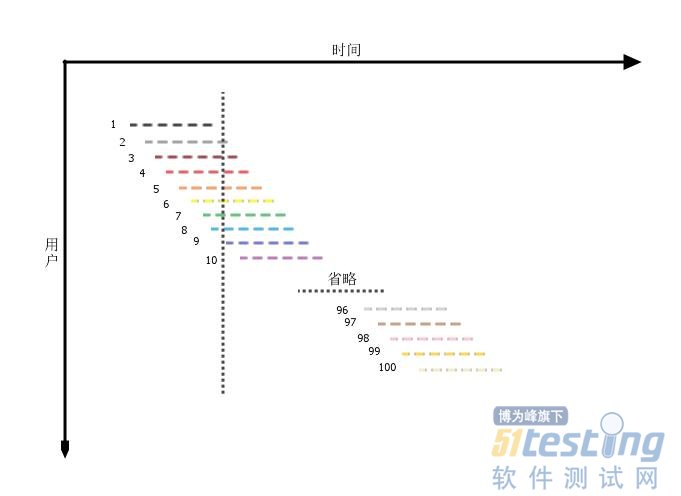
并发度表示,在一个时间点上,可能与服务端进行交互的用户的数量。为什么说是“可能”呢?因为图中的每一条横线代表的是用户与系统的交互过程,也可以说是用户的活跃区间,在这个区间段内,用户只是处于一种活跃状态,而并不是说一直保持着与服务端的交互,这也是图中的横线用的是虚线的原因。所以,并发度表达的,是系统在一定的访问分布下,可能承受的最大并发压力,它是一种可能性。
这样这个概念应该比较容易理解了,我们再来看看并发度的值是如何得出的。继续之前的分析结果“系统的使用压力集中在2个小时内,在这个时间段内共有100个用户访问,且压力是平均分布的,平均每个用户使用系统的时间是30分钟”,依然利用刚刚做的那条线,记对应的时间轴刻度为B,我们需要知道的是,有多少条代表交互过程的横线与之相交。
很明显,开始时间点在B之前,结束时间点在B之后的横线,它的起点必须落在从B向前一个用户活跃时长的区间内,即下图的AB区域内。
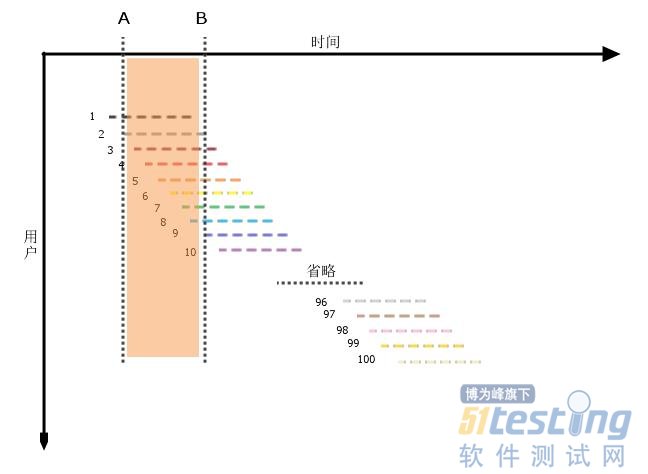
接下来只需简单的算术就可以了,100个用户访问平均分布在2小时内,AB时长为平均用户活跃时间,即30分钟,那么在AB区域内有100*30min/2h=25个用户访问。这25个用户在B时刻都可能会与系统发生交互,对系统照成压力,虽然只是一种理论上的可能性。
这就是并发度,理解它的意义了么?
开发自测被多个团队实践,开发自测的效果也是不一而足的,具体怎么样的开发自测方式是更好的,每个人都有自己的观点和看法,这里说说自己对开发自测的方法的一些探讨。
一、传统研发流程的弊病
在讨论开发自测之前,我们先看看未进行开发自测的研发流程
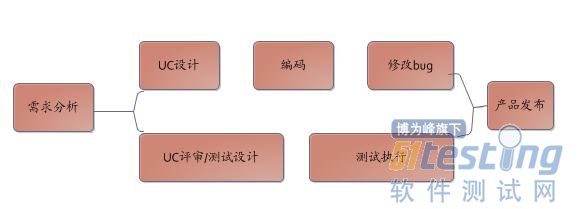
从这个流程可以看出:
1、开发和测试处于两条线,开发实现功能,测试确保开发实现功能是正常的。
2、对于项目质量的保证工作都在开发编码完成后进行,虽然有时候可能开发完成一部分编码后测试就可以进行测试了。
3、项目质量的保证完全由测试负责,开发只管实现功能
这个流程最容易出现的问题是:
1、测试介入时间较晚,bug修复成本大。
2、开发提测的版本不稳定,Bug多,因为开发不对质量负责,开发自认为实现了功能或者说修改了bug,至于实现或者修复bug是否有影响开发并不关心,导致一个功能或者bug反复修改,反复测试,沟通成本高,容易导致项目延期
3、如果开发延期提交测试,测试时间被压缩, 项目上线质量不高,事实上,在产品过程中这种情况经常出现。
4、测试和开发对立,开发认为测试做的都是低级工作却总是找自己麻烦,而测试觉得开会没有做好产品,代码质量低。
不论从测试效率还是项目质量来说,开发不参与测试对产品/项目来说是没有好处的,于是经历过这些痛苦之后,开始强调开发自测。
二、开发自测的不同需求
通常情况下,我们要求开发自测,开发会同意自测,他们的做法是在提交测试代码之前,本地的程序调通,主线流程可以走通,然后告诉测试说,已经做过测试了,没有任何的测试设计,没有任何的测试结果,这样的开发自测,虽然可以降低一部分显而易见的bug数量,但是对于产品的质量或者风险并没有降低多少。
理想中的开发自测,希望开发对于编写的每个方法都有测试方法,对于每个uc都有正常流程,异常流程的测试,希望开发可以像测试一样去思考,可以像测试一样的耐心细致,发散思维,有明确的测试过程和结果,并且能够对产品的质量负责。可是开发并不这么想,他们认为,系统设计,技术架构,追求高技术的代码才是他们的首要工作,他们实现了产品的需求,他们的工作算是完成了,他们会写点单元测试,或者他们想了解测试是怎么做的, 也会去做一些测试的工作,这些或许只是他们的业余工作或者爱好而已。当测试要求他们写单元测试,接口测试,写测试报告的时候,他们会表现的非常的反感,为了不扩大事态,测试只好对开发自测的结果不做评定,依然还按照既有的方式进行测试。
测试期望的开发自测和开发自认为的自测是完全不同的,也可以说,会有对立的一面,但是我们都知道bug越早发现,解决的成本越低,风险也越小。如果都在测试过程中测试,都有测试去测试,那么测试发现的bug要确认,提到缺陷管理库中,开发看到bug再模拟场景,查看代码,修复,然后再提交测试,验证,通过后再关闭bug,这个过程中的沟通,确认,还有打开一系列系统的时间是非常浪费的,而且开发也不希望自己在专心做事情的时候被打扰。
三、不同类型的开发自测探讨
了解了测试和开发对开发自测不同的需求后,对于测试,还需要了解测试的种类,通俗的来说,测试可以分为单元测试,接口测试,系统测试,单元测试主要是针对单个方法的测试,接口测试更多的是集成测试,而系统测试,则是站在用户使用场景,对整个系统进行测试,而无论是单元测试,接口测试,还是系统测试,都可以进行自动化测试。
针对不同的测试类型,开发自测的方法也是不同的,下面逐一探讨。
一般的研发流程是这样的:

1、需求分析
针对一个需求,开发考虑的是如何实现这个需求,或许这个需求可能不合理,但是,测试首先要考虑的是,这个需求是否符合用户的习惯,然后再考虑如何去测试这个需求,在需求评审阶段,针对某个需求,要进行充分的交流,确保开发和测试对需求的理解是一致的,并且这个需求是有必要实现的,重复的需求讨论对理解整个需求实现的目的,实现的方法都有重要的价值,这也算是一种开发自测。
2、分析设计
分析设计其实就是UC设计及技术方案设计,在这个阶段,测试完全可以参与UC设计,技术方案设计,了解开发的设计思路,根据UC及设计进行测试策略的设计,比如项目需要用到哪些测试类型,不同的测试类型具体怎么做,是否需要针对特定的测试类型进行测试框架的开发,有哪些测试场景,这些测试场景的测试是否需要特定的测试数据。当测试参与分析设计并且将针对这个需求的测试思路和开发进行沟通,那么开发不但对如何实现需求有了清晰的思路,对如何测试需求也有了清晰的思路,这样开发在实现需求的时候,就会考虑会有哪些业务场景,会有哪些异常情况,会有哪些测试点,谈不上是测试驱动开发,但是对于业务场景的全面性,对于程序代码的可测性都是非常好的帮助,而且对于后面具体测试类型的开发自测展开也是非常有好处的。
3、单元测试
技术方案确定后,开发完全进入了编码阶段,这个时候,开发最烦思路被打断,但是,我们通常都会要求开发写单元测试,理由是,首先,一个方法有测试代码证明这个方法是按照预期方式进行的,其次也需要确保这个方法被其他方法调用时能够正常调用,开发会认同单元测试由开发编写,也会对对一些的简单方法,写一个正常流程的测试方法,但是往往开发写了测试代码,准备了测试数据,只保证在测这个方法的时候,测试代码是可运行的,而一旦测试数据被改动了,或者程序有改动,测试方法便无法执行了,而对于那些需要依赖外部环境或者第三方接口的方法,开发几乎是不会去写测试代码的,这样,开发虽然写了单元测试代码,但是单元测试代码是不可用的,对开发来说是浪费时间,对测试来说,让开发做单元测试,结果却没有效果。
单元测试是最基本的,也是最容易执行的,更是成本最低的一种测试方法,让开发做好单元测试,可以说是有了开发自测。开发不讨厌写代码,而且还擅长写代码,但是开发厌恶搭建测试环境准备测试数据,而这恰恰是测试擅长的,那么,可以考虑针对单元测试可以为开发做些什么。就单元测试来说,除了xunit,Mock是最好的单元测试工具,让开发掌握了mock技术,然后让开发了解单元测试思路,开发会爱上单元测试的,开发也希望自己写的代码有测试代码保证。关于单元测试,衡量的最常用的标准就是持续集成和代码覆盖率,让开发写单元测试代码,还要让开发能够对单元测试有成就感,当开发的单元测试代码每天都被构建并且将测试结果发送给开发,当有代码变动引起了单元测试构建,构建结果发现了bug,开发会认识到单元测试的价值,会热衷于进行单元测试,如果开发写的代码覆盖率很高,对开发来说,也是一种成就感。
4、代码review
开发完成了单元测试,组织开发进行代码review也是非常有必要的,代码review不完全是为了找出代码中的错误,更重要的是可以让有经验的开发对代码的设计进行审查,降低代码的复杂度,耦合性,减少重复无用的代码,能够使得代码更好的和其他系统进集成,同时,测试参与代码review,可以对代码的可测性提出建议。
代码review看起来很美好,但是执行起来却绝非易事,因为开发实现了某个功能,review的时候却发现这种实现方式不是很美好,开发会觉得反正功能是可用的,等后面有时间再进行修改,这样的理由也无可厚非,但是,现在的修改可能只是一两个小时,后面的修改却是一两个日常,让开发或者开发TL意识到这种时间的差别,可能对代码review的接受程度会更高。
5、集成测试
我们做的接口测试,无论是service的接口测试还是web层的接口测试其实就是集成测试,因为都需要依赖一定的外部环境,比如数据库,比如其他系统提供的接口,接口测试一般是在开发编码完成以后进行,要进行开发自测,接口测试可以提前进行,在开发进行设计的时候,产品/项目需要几个接口,这些接口需要哪些参数,实现什么功能其实已经是确定好了的,那么根据接口的定义,测试可以提前进行接口测试的准备,比如接口测试用例的设计,测试环境搭建,测试数据准备,根据这些内容看是否需要为产品,项目的接口测试开发新的接口测试的框架,这些都可以在开发进行编码的时候完成。
开发编码完成后,或者开发一两个接口提测后,测试可以先行进行接口测试,理顺测试环境,等开发编码都完成后,集中开发/测试的力量,一鼓作气将接口测试完成,编码对开发来说不是什么难事,如果开发准备好了测试环境,有测试用例,有测试框架,开发完成接口测试的速度还是相当快的。
这里需要说明的是,开发可能会觉得单元测试做了,怎么还要做接口测试,单元测试和接口测试关注的重点不一样,所以并没有重复之说,而且,单元测试和接口测试是最底层,成本最低,且最容易自动化的测试手段,而且也是以开发最擅长的编码方式进行。
开发写接口测试,并不是说接口测试的工作也完全由开发来做,接口测试应该是开发和测试共同配合来完成,分别发挥各自的优势又能分别学习各自的优势。通过接口测试,开发可以学习测试思维,测试技巧,而开发也可以从开发那边学习到开发技巧,更重要的是,做好了接口测试,在后续系统测试阶段,就算是发现了bug,修改了代码,通过跑单元测试和接口测试代码,完全可以第一时间回归到改动是否影响了其他代码,而不用非要等功能测试的时候才能验证。
6、页面自动化
进入系统测试阶段,开发的主要工作变成了修改bug,工作变得相对轻松了,而传统意义上的测试工作真正开始了,测试的工作开始繁重,如果前期的单元测试,接口测试做的出色的话,这个阶段发现的bug可能更多的集中于前端bug或者就是需求变更,前端bug的预防减少,涉及到前端测试的内容,暂时不进行讨论,真正功能性的bug是相对较少的,这个时候开发可以做什么,可以做页面自动化的脚本编写。编码是开发擅长的,只要开发掌握了自动化测试框架,知道哪些用例需要写自动化脚本,开发写自动化脚本是非常快速的。至于开发自动化框架的培训可以在项目需求阶段进行,自动化测试用例的抽取可以在测试设计阶段完成。
这样,在项目测试阶段,单元测试,接口测试在持续的进行,可以快速发现,定位代码变化引起的问题,降低沟通成本,增加开发空余时间用来写自动化脚本,等项目测试完成后,页面自动化脚本又可以基本完成,立体的一套自动化测试体系初步构建完成,在这个过程中,开发和测试密切配合降低了无谓的沟通成本,提高了产出效率,增强了项目的质量。
7、项目维护
产品发布了,并不意味着产品的结束,各种新的需求都会以日常的形式来进行,日常有大有小,而针对日常的测试也应该视日常大小而进行,一些小的,简单的日常完全可以由开发自己开发并测试完成,通过前面在项目中的自测过程,开发对测试流程非常的属性了,小日常完全可以应付,并且当开发认为没有测试去测试的时候,自测会更加认证,而对于一些大日常的测试,则可以参考前面整个的流程进行开发自测的展开。其实,在项目维护阶段,针对不同的子应用或者模块,可以形成模块开发负责制,每个模块,应用都有一个开发进行负责,负责人对自己负责模块的需求,开发,质量保证都需要了解,这样可以增加开发的质量意识,降低变化引起的风险。
开发自测看起来很美好,但是实施起来却存在,首先,开发会排斥进行测试,其次,开发做测试会比较随意喜欢一次性的测试,第三,开发会认为自己的测试不专业,还需要测试进行测试浪费资源。因为这些原因,开发自测不是一蹴而就的,需要不断的推进,为开发自测提供基础支持,让开发养成自测的习惯,并且意识到自测对于保证项目质量,提高效率的重要性,只有开发从心底愿意进行自测,开发测试才算是真正运行有效的。
开发自测的目的并不是增加开发的工作量,降低测试的工作量,而是要弱化开发/测试的角色,降低开发/测试的对立,通过开发和测试的共同努力,扬长避短,形成一套立体的质量保证体系。
今天发现Mysql的主从数据库没有同步
先上Master库:
mysql>show processlist; 查看下进程是否Sleep太多。发现很正常。
show master status; 也正常。
mysql> show master status;
+-------------------+----------+--------------+-------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+-------------------------------+
| mysqld-bin.000001 | 3260 | | mysql,test,information_schema |
+-------------------+----------+--------------+-------------------------------+
1 row in set (0.00 sec)
再到Slave上查看
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: No
可见是Slave不同步
下面介绍两种解决方法:
方法一:忽略错误后,继续同步
该方法适用于主从库数据相差不大,或者要求数据可以不完全统一的情况,数据要求不严格的情况
解决:
stop slave;
#表示跳过一步错误,后面的数字可变
set global sql_slave_skip_counter =1;
start slave;
之后再用mysql> show slave status\G 查看:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
ok,现在主从同步状态正常了。。。
方式二:重新做主从,完全同步
该方法适用于主从库数据相差较大,或者要求数据完全统一的情况
解决步骤如下:
1、先进入主库,进行锁表,防止数据写入
使用命令:
mysql> flush tables with read lock;
注意:该处是锁定为只读状态,语句不区分大小写
2、进行数据备份
#把数据备份到mysql.bak.sql文件
[root@server01 mysql]#mysqldump -uroot -p -hlocalhost > mysql.bak.sql
这里注意一点:数据库备份一定要定期进行,可以用shell脚本或者python脚本,都比较方便,确保数据万无一失
3、查看master 状态
mysql> show master status;
+-------------------+----------+--------------+-------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+-------------------------------+
| mysqld-bin.000001 | 3260 | | mysql,test,information_schema |
+-------------------+----------+--------------+-------------------------------+
1 row in set (0.00 sec)
4、把mysql备份文件传到从库机器,进行数据恢复
#使用scp命令
[root@server01 mysql]# scp mysql.bak.sql root@192.168.128.101:/tmp/
5、停止从库的状态
mysql> stop slave;
6、然后到从库执行mysql命令,导入数据备份
mysql> source /tmp/mysql.bak.sql
7、设置从库同步,注意该处的同步点,就是主库show master status信息里的| File| Position两项
change master to master_host = '192.168.128.100', master_user = 'rsync', master_port=3306, master_password='', master_log_file = 'mysqld-bin.000001', master_log_pos=3260;
8、重新开启从同步
mysql> start slave;
9、查看同步状态
mysql> show slave status\G 查看:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
好了,同步完成啦。
在昨天接近凌晨的时候,看到一条围脖是阐述了一个现象。现在移动互联网很多团队中会出现项目分类很多,项目发布周期短,测试和开发人员少这样屡见不鲜的情况。时间一长,身在这样团队的员工真的有苦说不出,因为他们整天很忙碌,却断断续续,最终发布的产品还极其不稳定。相信昨天我看到这条围脖的作者也是这样的感受。
这里我简单介绍以下在这样特定的迭代周期中的测试能够采取的几种解决方案。
1、测试用例分类和优先级
一般情况,公司会要求写很多的测试用例。当然这些用例的数量肯定是远远超越在段时间内测试人员能够执行完的。(这里也就不去提这些测试用例是不是一直维护,以及更新的问题了,大家懂得)那么此时按照一般的情况,我们将测试用例分成“基本功能”,“定制功能”,“场景测试”,“回归测试”这样几类,当然根据每个公司的产品业务不同可以再进行分类。优先级的话一般分成P1,P2,P3三类。曾经其实尝试过按照标准的4类划分,后来发现其实P4的用例真的用到的概率非常小,所以去除了。
那么在快速迭代中,我们先要清楚要发布的产品的核心功能,业务是什么。比如你发布一个pptv的电视盒子,那么毫无疑问,核心价值就是看视频。发布一个输入法,核心价值就是输入。这些核心价值绝对是在基本功能中,并且是P1的。作为测试人员你需要定制一套规则。因为在多少时间内能够执行完多少用例你应该是最清楚的,而在有限时间内我们需要去执行的就是那些最最有效,对于降低产品风险最高的用例。你分别在一天,半天,5小时,1小时这些时间内去执行哪些用例组合。打比方说,你有2个小时进行一个产品的发布,那么此时你一定是这样一个策略:“基本功能”(核心功能)P1+回归测试(核心功能)P1+“定制功能”(核心功能)P1+其他。而这些不是靠拍脑袋,也不是靠每个人的定义,而是需要有一个文档进行归类,约束,引导的。比如2年前我写的一分用例概括表。
每个功能点的用例都有号码分类,可以看到都有两个白色没有写的区域,第一个是这个功能用例的数量,第二个就是是否实现自动化。这个表也起到了能够让leader或者团队的成员一目了然的作用。

2、逻辑分层测试
这里的逻辑分层可能需要对测试人员的要求相对会高点。需要进行分析,从而减去不必要的工作量。举两个例子。曾经测试过一个机顶盒升级的功能,这里我们分析一下。测试目标两个1.系统目录中的文件是否被更新 2.版本号是否更新。 用户升级有几种方法

那么是不是我们测试这个功能就必须将这些点进行排列组合呢?答案是大部分测试人员不会这样做,但是他们并不知道该怎么做。但是我们进行逻辑上的分析发现最关键的一个功能点——升级这个功能的逻辑,我们其实只需要写个很简单的工具查看这个功能是不是正确,验证之后,无论升级文件的来源,至少升级这个功能是正常的。接下来U盘和网络的升级其实都是将升级文件先放在本地的一个储存器中,读取之后升级。那么我们的测试点就变成了系统是否可以正常读取各种渠道的文件了。我们知道,android或linux这样一个升级的工作必然夹杂着网络的切换,开机,关机等等测试人员看着很头疼的事项。那么我们分析拆分之后也就变的没有那么繁琐了。
发现很多测试人员知道各种写用例的方法,但是却没有就自己测试产品功能的分析能力。这样其实最后发现测试用例的数量很臃肿,质量也不尽人意。其实主要问题就是出在这里。
另外还有探索性测试的方法,这里就不详细说了,需要用到探索性测试方式中,旅游法,通宵法等进行产品功能的分析,总结,然后实践。同样也是能够起到很好的效果。
这里也顺带说下开发面临这种情况下,就算不搭建CI,也需要通过ant+xml配置的方法进行快速自动的编译版本,否则真的是哑巴吃黄连。另外平时勤快的使用find bugs,lint,MAT等工具进行代码的检查,ios的话同样多使用一些自带的分析工具和instruments里面的工具。相信会好很多。
今天之所以谈到单元测试,是因为在进行系统测试时,在即将结束的时候却发现了很多严重的问题,经过我自己的分析认为是开发人员在进行单元测试时,逻辑的覆盖面不全。
在网上可以搜索到很多关于单元测试的资料,但是在这里我还是想在唠叨两句,说说单元测试的思路,其实这是我在学校时老师讲解的,但是到了工作中,有了更深刻的体会,那么接下来直接步入正题吧!
1、首先分析实时单元测试的必要性,并且对测试人员进行单元测试的培训
针对这一点有人会说,单元测试既然是开发人员来做的,为什么还要给测试人员培训呢,我个人认为在进行单元测试时,开发与测试人员配合协作,有利于测试的进行,测试人员可以尽可能多提供的测试场景,在并且此时测试人员可以根据单元测试的情况,在后续测试中能够更准确的把握测试的重点。
2、确定单元测试的范围
看到第二点也许也有人会体会出疑问吧,已经进行单元测试了,怎么还有确定范围呢,换个角度想,如果这个项目比较紧张,但是又必须进行单元测试,那么此时只要保证主要逻辑结构争取就可以了,再者,如果你新添加的功能只影响到部分逻辑,那么就完全没有必要进行全部逻辑的覆盖。
3、做完以上两点准备工作,接下来就开始进行单元测试
a)静态检查、代码交叉走读
b)通过单元测试用例进行单元测试
其实针对a就需要开发人员养成良好的编码习惯了,因为在代码交叉走读这部分,是需要别人阅读自己的代码的,如果某个人的代码写的很不规范,那么别人阅读起来也很耽误时间。
而b部分,我们需要先搭建单元测试的环境、编写单元测试用例、执行、根据事先制定好的的单元测试出口准测,进行单元测试报告的撰写。
单元测试的简易思想图:

单元测试说起来相对容易,但是执行起来却真的很不容易,一是因为工作量大,二是没有意识到单元测试的价值。
其实在研发或者开发一个项目时,在最初始时应该将整个软件的流程图架构起来,这样在后续迭代增加新功能时,可以通过流程图准确的发现对整个软件的影响程度,但是前提条件要保证流程图设计的正确性。
个人认为单元测试是一个不断积累的过程,所有规则的前期执行都是举步维艰的,但是当真正的执行起来后,会发现通过单元测试得到的收益也是最大的。
以上仅是个人意见,如有错误请大家及时指出!
在这此对新版本jmeter的学习+温习的过程,发现了一些以前不知道的功能,所以,整理出来与大分享。本文内容如下。
1、如何使用英文界面的jmeter
2、如何使用镜像服务器
3、Jmeter分布式测试
4、启动Debug 日志记录
5、搜索功能
6、线程之间传递变量
如何使用英文界面的JMeter
Jmeter启动时会自动判断操作系统的locale 并选择合适的语言启动,所以,我们启动jmeter后,其会出现一个倍感亲切的中文界面。但由于jmeter本身的汉化工作做得不好,你会看到有未被汉化的选项及元件的参数。而且部分翻译并不准确,因此对于英文比较好的牛人来说更喜欢纯正的英文界面。
强制以英文方式启动jmeter的方法如下:
在windows环境下,打开jmeter解压目录,bin目录下的jmeter.bat文件,也就是jmeter程序的启动文件,选择记事本方式打开。做以下修改:
.................
set HEAP=-Xms512m -Xmx512m
set NEW=-XX:NewSize=128m -XX:MaxNewSize=128m
set SURVIVOR=-XX:SurvivorRatio=8 -XX:TargetSurvivorRatio=50%
set TENURING=-XX:MaxTenuringThreshold=2
set RMIGC=-Dsun.rmi.dgc.client.gcInterval=600000 -Dsun.rmi.dgc.server.gcInterval=600000
set PERM=-XX:PermSize=64m -XX:MaxPermSize=64m
set LOCALE=-Duser.language=en -Duser.region=rem
set DEBUG=-verbose:gc -XX:+PrintTenuringDistribution .........
rem Server mode
rem Collect the settings defined above
set ARGS=%DUMP% %HEAP% %NEW% %SURVIVOR% %TENURING% %RMIGC% %PERM% %DDRAW% %LOCALE%
............. |
晕死,当我上面介绍了那么多后,在最新的2.8版本,我无意中发现了这个功能。

如何使用镜像服务器
在调试和修改测试计划的过程中,通常会为采样器增加一些额外的设置,例何设置额外的HTTP头、cookie管理器或认证管理器等,但当设置了这些内容后,sampler发出的请求是否就与预期的完全一支呢?
当然用户可以通过添加监听器来看查采样器发出的HTTP请求,但如果调试过程中并不想真正地把请求发送给被测应用,如何解决这个问题呢?
Jmeter 提供了一个名叫HTTP Mirror Server的组件,HTTP Mirror Server可以启动一个镜像的服务器,该服务器把所有接收到的请求原封不动地返回,这样就可以看到发出请求的具体内容了。
添加HTTP Mirror Server的方式:
右键点击“工作台”--->非测试元件--->HTTP Mirror Server

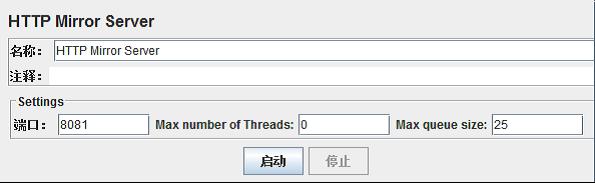
如果有必要的话需要修改端口号,点击“启动”按钮来启动Server。
采用JMeter 远程模式并不会比独立运行相同数目的非GUI 测试更耗费资源。但是,如果使用大量的JMeter 远程服务器,可能会导致客户端过载,或者网络连接发生拥塞。
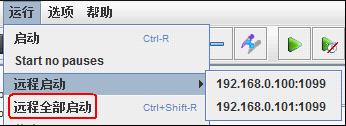
使用多台机器产生负载的操作步骤如下:
(1)在所有期望运行jmeter作为 负载生成器的机器上安装jmeter, 并确定其中一台机器作为 controller ,其他的的机器作为agent 。然后运行所有 agent 机器上的jmeter-server 文件(假定使用两台机器192.168.0.100 和192.168.0.101 作为agent)
(2)在controller机器的jmeter的bin目录下,找到jmeter.properties 文件,编辑该文件:
查找:
remote_hosts=127.0.0.1
修改为:
remote_hosts=192.168.0.100:1099,192.168.0.101:1099 |
这里要特别注意端口后,有些资料说明端口1644为jmeter的controller 和agent 之间进行通信的默认RMI端口号,但是在测试时发现,设置为1644运行不成功,改成1099后运行通过。另外还要留意agent的机子是否开启了防火墙等。
(3)启动controller 机子上的jmeter应用,选择菜单“运行”--->“远程启动”,来分别启动agent ,也可以直接选择“远程全部启动”来将所有的agent启动。
启动Debug 日志记录
大多数测试元件都支持Debug 日志记录。如果通过 GUI 运行测试计划,那么在选中测试元件后,可以通过“帮助”菜单enable debug或者disable debug。在“帮助”菜单 中有一个选项“What’s this node? ”,
通过它可以查看GUI 和测试元件的类名,如图 11 -7 所示。通过它们,测试人员可以决定修改哪一项JMeter 属性,以便修改日志级别。
例如:我们可以点击一个HTTP请求,选择菜单栏“帮助”--->what's this node ?

在jmeter的bin\目录下,找到jmeter.properties 文件,关于日志级别的属性如下:
#Logging levels for the logging categories in JMeter. Correct values are FATAL_ERROR, ERROR, WARN, INFO, and DEBUG
# To set the log level for a package or individual class, use:
# log_level.[package_name].[classname]=[PRIORITY_LEVEL]
# But omit "org.apache" from the package name. The classname is optional. Further examples below. log_level.jmeter=INFO
log_level.jmeter.junit=DEBUG
#log_level.jmeter.control=DEBUG
#log_level.jmeter.testbeans=DEBUG
#log_level.jmeter.engine=DEBUG
#log_level.jmeter.threads=DEBUG
#log_level.jmeter.gui=WARN
#log_level.jmeter.testelement=DEBUG
#log_level.jmeter.util=WARN
#log_level.jmeter.util.classfinder=WARN
#log_level.jmeter.test=DEBUG
#log_level.jmeter.protocol.http=DEBUG
# For CookieManager, AuthManager etc:
#log_level.jmeter.protocol.http.control=DEBUG
#log_level.jmeter.protocol.ftp=WARN
#log_level.jmeter.protocol.jdbc=DEBUG
#log_level.jmeter.protocol.java=WARN
#log_level.jmeter.testelements.property=DEBUG
log_level.jorphan=INFO |
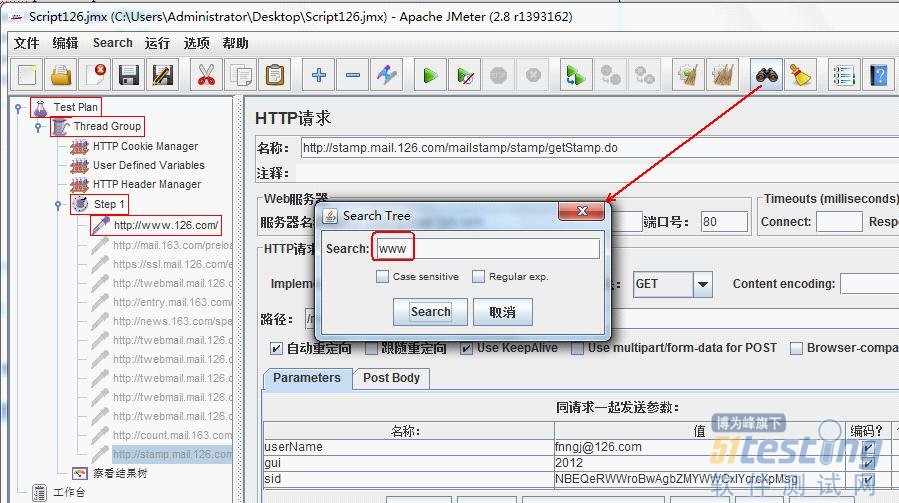
搜索功能
这是在使用一个变量或含有一定的URL或参数测试计划树和元素有时很难找到。现在一个新的特点是从2.6开始,你可以访问它的菜单搜索。它提供了搜索与下列选项:
* 使搜索区分大小写区分大小写:
* 正则表达式是一个正则表达式搜索文本,如果有的话将被搜索的正则表达式树的组件,例如“\ BTEST \ b”将匹配任何组件,包含测试组件的搜索元素
线程之间传递变量
JMeter 变量作用域局限于所属线程。这样设计是经过深思熟虑的,目的是让测试线程能够独立运转。有时候用户可能需要在不同线程间(可能属于同一个线程组,也可能不属于同一个线程组)传递变量。
其中一种方法就是使用属性。属性为所有 JMeter 线程所共享,因此当某个线程设置一个属性后,其他线程就可以读取更新后的值。
如果存在大量数据需要在线程间传递,那么可以考虑使用文件。例如,测试人员可以在一个线程中使用监听器,保存响应到文件(Save Responses to a file)或者 BeanShell PostProcessor 。而在另外一个线程中使用HTTP 采样器的“file: ”协议来读取文件,接着使用一个后置处理器或者BeanShell 测试元件提取信息。
如果在测试启动前测试人员就能获得测试数据,那么最好将数据保存到文件中,使用CSV Dataset读取。
这最后一个技巧,操作较为麻烦,暂时不给详细的例子。算是提供个思路吧!知道有这当子事儿就行了。日后有机会再实践^_^
一个测试管理者在考虑提升组织的测试能力、进行一系列测试改进时,除了考虑测试技术本身的因素外,还有一项不能忽略,那就是测试的组织结构。
《TPI Next》里面划分测试关键域时,专门单独划分了一个“test organization”的key area,并且定义“A test organization meets the needs of projects for test resources, test products and test services.”,认为测试组织就是关于“the right people expertise and experience at the right place.”的事情。 本文探讨的测试的组织结构只是“test organization”的一部分,重点探讨测试的组织结构如何与开发的组织结构相对应的问题,基本上对应TPI里的controlled level,即“A test organization enables uniformity in test approach, test products and procedures, agreements and clear test results.”
为什么 谈测试管理时,要谈测试的组织结构?其实,组织结构在有关测试管理的探讨中有着不可忽视的作用,它体现着管理思想,也反过来对测试管理有辅助的作用,这就 像经济基础决定上层建筑一样,测试管理理念达到了什么层次,就会制定相应的测试组织结构,以更好的落实这个理念。实践证明,很多测试过程中出现的问题最后 都与组织结构有关系。
而谈到测试的组织结构时,势必要先参考开发的组织结构。对于传统的瀑布开发模式而言,一个系统有可能会划分为几个模块来实现,开发的组织结构基本上是和模块一一对应的,我们就拿这种典型的情况讨论一下相应的测试组织结构应该如何划分。
一个产品的开发可以分解为多个模块来实现,这个产品的某个功能或特性经常需要多个模块配合实现。假如每个模块对应一个开发项目组,测试项目组的划分经常会有两种选择,一是也按照模块划分,二是按照特性划分,一个特性可以跨多个模块。那么二者各有什么优缺点呢?
按照模块划分的测试项目组,由于和开发项目组存在一一对应的关系,二者关系更为紧密,开发人员和测试人员的交流也更为顺畅,会经常一起探讨模块级的细节 和实现,有利于在产品开发阶段(发布给测试前)测试人员的前期介入,这种前期介入包含很多方面,例如测试人员对设计文档的评审检视、测试分析与设计的分工 合作、测试人员参与的前期代码走读、集成测试等等,更多地测试前期介入的内容可参考这篇blog。 因此,按照模块划分的测试组织对模块会进行比较充分的测试,但这种模式也存在一些弊端,比如对于涉及到多个模块的特性,测试人员在测试分析设计和评审检视 中往往考虑欠佳,测试人员对整个系统层面的把握不是很到位,同时测试人员和开发人员的过于“亲密”也造成测试无法扮好“黑脸”的角色。
按照特性划分的测试项目组,对上述弊端可以做到较好的规避。但这个时候常常是测试为了避免受开发思路的太多影响,独立彰显测试的价值,从测试设计到测试执 行都会另起一套,更多的从测试的角度、从客户的角度考虑问题,更多的站在特性一级、系统一级考虑问题,测试在把系统当作一个黑盒进行系统测试方 面越来越擅长,此时的测试管理者如果不注意把握一个“度”的话,就会出现“测试后移”的现象,测试人员把眼光聚焦在后端,致力于问题发现,渐渐的,代码走 读、集成测试等前端测试的活动测试做的偏少了,甚至都移交给了开发人员。可是开发人员“天生”的对问题不敏感,其质量难以保证,很多开发人员认为开发人员 所做的测试“测不彻底”是很正常的事,反正后面有测试人员做后盾。那么时间长了,这种模式的弊端也会逐渐暴露:纯黑盒的系统测试周期拉得很长,因为缺陷迟 迟不能收敛,开发在版本转测试后也疲于奔命修改问题单使得人力迟迟无法释放;如果产品的需求控制不好的话,新需求的不断合入会加剧问题的恶化,新需求将无 法得到有效跟踪、设计和验证;很多本应该在UT、IT发现的问题都遗留到了系统测试阶段,测试部为了保证产品的质量,花费大部分时间验证这些前期遗漏的问 题,而没有精力站在客户角度、从组网场景、应用场景开展对需求的系统级验证,导致问题在网上频频爆发;而如果测试人员稳定度不高时,测试人员的不断更新, 会导致了解系统内部实现的测试人员越来越少,随着产品的快速更新演进(对比较复杂的产品而言),测试人员在系统架构层面的讨论上显得力不从心,等等。
那么究竟应该选择什么样的组织结构才会最大化测试效率呢?答案是没有定论。这要结合开发的组织结构、开发模式、测试人员构成、产品复杂度、需求稳定度、组织的测试经验积累、当前产品的软肋是模块还是系统等因素综合考虑。
但是至少有两点是可以确定的:
1)上述两类典型的测试组织结构无论选取哪一种,都与测试组织的成熟度没有必然的关系;
2)无论选取上述的哪一种,甚或是第三种、第四种,组织结构都不是一成不变的。实际上,有的组织会经常在这两种组织结构形式之间来回变换,以适应不同的历史形势。