
按照软件缺陷的产生原因,可以将其划分为不同的缺陷类别:
1、功能不正常
简单地说就是所应提供的功能,在使用上并不符合产品设计规格说明书中规定的要求,或是根本无法使用。这个错误常常会发生在测试过程的初期和中期,有许多在设计规格说明书中规定的功能无法运行,或是运行结果达不到预期设计。最明显的例子就是在用户接口上所提供的选项及动作,使用者操作后毫无反应。
2、软件在使用上感觉不方便
只要是不知如何使用或难以使用的软件,在产品设计上一定是出了问题。所谓好用的软件,就是使用上尽量方便,使用户易于操作。如微软推出的软件,在用户接口及使用操作上确实是下了一番功夫。有许多软件公司推出的软件产品,在彼此的接口上完全不同,这样其实只会增加使用者的学习难度,另一方面也凸显了这些软件公司的集成能力不足。
3、软件的结构未做良好规划
这里主要指软件是以自顶向下方式开发,还是以自底向上方式开发。如果是以自顶向下的结构或方法开发的软件,在功能的规划及组织上比较完整,相反以自底向上的组合式方法开发处的软件则功能较为分散,容易出现缺陷。
4、提供的功能不充分
这个问题与功能不正常不同,这里指的是软件提供的功能在运作上正常,但对于使用者而言却不完整。即使软件的功能运作结果符合设计规格的要求,系统测试人员在测试结果的判断上,也必须从使用者的角度进行思考,这就是所谓的“从用户体验出发”。
5、与软件操作者的互动不良
一个好的软件必须与操作者之间可以实现正常互动。在操作者使用软件的过程中,软件必须很好地响应。例如在浏览网页时,如果操作者在某一网页填写信息,但是输入的信息不足或有误。当点击“确定”按钮后,网页此时提示操作者输入信息有误,却并未指出错误的哪里,操作者只好回到上一页重新填写,或直接放弃离开。这个问题就是典型的在软件对操作互动方面未做完整的设计。
6、使用性能不佳
被测软件功能正常,但使用性能不佳,这也是一个问题。此类缺陷通常是由于开发人员采用了错误的解决方案,或使用了不恰当的算法导致的,在实际测试中有很多缺陷都是因为采用了错误的解决方法,需要加以注意!
7、为做好错误处理
软件除了避免出错之外,还要做好错误处理,许多软件之所以会产生错误,就是因为程序本身对于错误和异常处理的缺失。例如被测软件读取外部的信息文件并已做了一些分类整理,但刚好所读取的外部信息文件内容已被损毁。当程序读取这个损毁的信息文件时,程序发现问题,此时操作系统不知该如何处理这个情况,为保护系统自身只好中断程序。由此可见设立错误和异常处理机制的重要性!
8、边界错误
缓冲区溢出问题在这几年已成为网络攻击的常用方式,而这个缺陷就属于边界错误的一种。简单来说,程序本身无法处理超越边界所导致的错误。而这个问题,除了编程语言所提供的函数有问题之外,很多情况下是由于开发人员在声明变量或使用边界范围时不小心引起的。
下面是一个典型的缓冲区溢出的边界错误:
Void func (void)
{
int I;
char buffer[256]; //Buffer定位为256
for (I=0;I<512;I++) //越界
buffer[I]=’t’;
….} |
9、计算错误
只要是计算机程序,就必定包括数学计算。软件之所以会出现计算错误,大部分出错的原因是由于采用了错误的数学运算工时或未将累加器初始化为0.
10、使用一段时间所产生的错误
这类问题是程序开始运行正常,但运行一段时间后却出现了故障。最典型的例子就是数据库的查找功能。某些软件在刚开始使用时,所提供的信息查找功能运作良好,但在使用一段时间后发现,进行信息查找所需的时间越来越长。经分析查明,程序采用的信息查找方式是顺序查找,随着数据库信息的增加,查找时间自然会变长。这就需要改变解决方案了!
11、控制流程的错误
控制流程的好坏,在于开发人员对软件开发的态度及程序设计是否严谨。软件在状态间的转变是否合理,要依据业务流程进行控制。例如,用软件安装程序解释这类问题最方便直观。用户在进行软件安装时,输入用户名和一些信息后,软件就直接进行了安装,未提示用户变更安装路径、目的地等。这就是软件控制流程不完整导致的错误问题。
12、在大数据量压力下所产生的错误
程序在处于大数据量状态下运行出现问题,就属于这类软件错误。大数据量压力测试对于Server级的软件是必须进行的一项测试,因为服务器级的软件对稳定性的要求远比其它软件要高。通常连续的大数据量压力测试是必须实施的,如让程序处理超过10万笔数据信息,再来观察程序运行的结果。
13、在不同硬件环境下产生的错误
这类问题的产生与硬件环境的不同相关。如果软件与硬件设备有直接关系,这样的问题就是数量相当多。例如有些软件在特殊品牌的服务器上运行就会出错,这是由于不同的Server内部硬件了不同的处理机制。
14、版本控制不良导致的错误
出现这样的问题属于项目管理的疏忽,当然测试人员未能尽忠职守也是原因之一。例如一个软件被反映有安全上的漏洞,后来软件公司也很快将修复版本提供给用户。但在一年后他们推出新版本时,却忘记将这个已解决的bug-fix加入到新版本中。所以对用户来说,原本的问题已经解决了,但想不到新版本升级之后,问题又出现了。这就是由于版本控制问题,导致不同基线的merge出现误差,使得产品质量也出现了偏差。
15、软件文档的错误
最后这类缺陷是软件文档错误。这里所提及的错误,除了软件所附带的使用手册、说明文档及其它相关的软件文档内容错误之外,还包括软件使用接口上的错误文字和错误用语、产品需求设计PD、UI Spec等的错误。错误的软件文档内容除了降低产品质量外,最主要的问题是会误导用户!
版权声明:本文出自 cmriqa 的51Testing软件测试博客:http://www.51testing.com/?489136
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
摘要:黑盒测试着眼于外部结构,不考虑内部结构,只依据程序的需求规格说明书,检查程序的功能是否符合它的功能说明;而
白盒测试着眼于内部结构,对软件的过程性细节做细致的检查。
关键词:黑盒测试;白盒测试;测试用例
一、引言
随着软件市场的成熟,人们对软件作用的期望值也越来越高,我国的软件企业已越来越意识到软件测试的重要性,逐渐加大软件测试在整个软件开发的系统工程中的比重。
软件测试并非传统意义上产品交付前单一的“找错”过程,而是贯穿于软件过程的始终,是一个科学的质量控制过程。而对于任何工程产品都可以使用以下两种方法之一进行测试,即黑盒测试与白盒测试。
二、黑盒测试在软件测试中的作用
黑盒测试也称为功能测试、行为测试或数据驱动测试,在测试时,把程序看作一个不能打开的黑盒,测试人员完全不考虑程序内部的逻辑结构和内部特性,只依据程序的需求规格说明书,检查程序的功能是否符合它的功能说明,因此黑盒测试是基本测试。例如:我们用C#编写“计算器”应用程序,我们如果输入7并按sqrt键,就会得到结果2.645751311。使用黑盒子测试方式,不管“求平方根”要经历多少复杂运算,只关心他的运行结果。
黑盒测试方法主要有等价类划分、边值分析、因――果图、错误推测等,主要用于软件确认测试。“黑盒”法着眼于程序外部结构、不考虑内部逻辑结构、针对软件界面和软件功能进行测试。“黑盒”法是穷举输入测试,只有把所有可能的输入都作为测试情况使用,才能以这种方法查出程序中所有的错误。实际上测试情况有无穷多个,人们不仅要测试所有合法的输入,而且还要对那些不合法但是可能的输入进行测试。黑盒测试的主要缺陷是难于衡量系统的完整性,而白盒测试正好可以弥补这个缺陷。
“黑盒”表示看不见盒子里头的东西,意味着黑盒测试不关心软件内部设计和程序实现,只关心外部表现,即通过观察输入与输出即可知道测试的结论。任何人都可以依据软件需求来执行黑盒测试。黑盒测试注重于测试软件的功能性需求,着眼于程序外部结构,不考虑内部逻辑结构,主要针对软件界面和软件功能进行测试,多应用于测试过程的后期。它是一种根据软件需求,设计文档,模拟客户场景随系统进行的实际测试.这种测试技术涵盖了测试的方方面面,它主要是为发现以下几类错误:是否出现功能错误或遗漏;在接口上能否进行正确的输入与输出;是否存在数据结构错误或外部数据库访问错误;性能上是否能够满足要求;是否有初始化或终止性错误。
所以黑盒测试实际上是检查以下几点是否满足要求:
1、c正确性 (Correctness):计算结果,命名等方面。
2、d可用性 (Usability):是否可以满足软件的需求说明。
3、e边界条件 (Boundary Condition):输入部分的边界值,就是使用等价类划分,试试最大最小和非法数据等等。
4、f性能 (Performance):程序的性能取决于两个因素:运行速度的快慢和需要消耗的系统资源。如果在测试过程中发现性能问题,修复起来是非常艰难的,因为这常常意味着程序的算法不好,结构不好,或者设计有问题。因此在产品开发的开始阶段,就要考虑到软件的性能问题。
5、g压力测试 (Stress): 多用户情况可以考虑使用压力测试工具,建议将压力和性能测试结合起来进行。如果有负载平衡的话还要在服务器端打开监测工具 , 查看服务器 CPU 使用率,内存占用情况,如果有必要可以模拟大量数据输入,对硬盘的影响等等信息。
6、h错误恢复 (Error Recovery):错误处理,页面数据验证,包括突然间断电,输入错误数据等。
7、i安全性测试 (Security):特别是一些商务网站,或者跟钱有关,或者和公司秘密有关的 web 更是需要这方面的测试。
8、j 兼容性 (Compatibility):不同浏览器,不同应用程序版本在实现功能时的表现。
应用黑盒测试技术,能够设计出满足下述标准的测试用例集:
(1)所设计出的测试用例能够减少为达到合理测试所需要设计的测试用例总数;
(2)所设计出的测试用例能够告诉我们,是否存在某些类型的错误,而不仅仅指出与特定测试相关的错误是否存在。
三、白盒测试在软件测试中的作用
白盒测试也称结构测试或逻辑驱动测试,是一种以理解软件内部结构和程序运行方式为基础的软件测试技术,通常需要跟踪一个输入经过了哪些处理,这些处理方式是否正确。这种方法是把测试对象看作一个打开的盒子,它允许测试人员利用程序内部的逻辑结构及有关信息,设计或选择测试用例,对程序所有逻辑路径进行测试。
白盒测试关注的是被测对象的内部状况,需要跟踪源代码的运行。通过检查软件内部的逻辑结构,对软件中的逻辑路径进行覆盖测试;在程序不同地方设立检查点,检查程序的状态,以确定实际运行状态与预期状态是否一致。白盒测试者必须理解软件内部设计与程序实现,并且能够编写测试驱动程序,一般由开发人员兼任测试人员的角色。在很多测试人员,尤其是初级测试人员认为,白盒测试是只有非常了解程序代码的高级测试人员才能做的测试。熟悉代码结构和功能实现的过程当然对测试有很大的帮助,但有些白盒测试是不需要测试人员懂得每一行程序代码的。假如我们有如下程序:
voidDoWhite_Box(int a,int b,int c)
{
inti=0,j=0;
if((a>4)&&(c<20))
{
i=a*b-1;
j=sqrt(i);
}
if((a= =5)||(b>15))
{
j=a*b+10;
}
j=j%3;
} |
对于上面的程序,设计两个测试用例则可以满足条件覆盖的要求。
测试用例的输入为:
{ a=5、b=15、c=15}
{ a=2、b=15、c=15}
上面的两个测试用例虽然能够满足条件覆盖的要求,但是也不能对判断条件进行检查,例如把第二个条件b>15错误的写成b<15,、上面的测试用例同样满足了分支覆盖。
软件的白盒测试是对软件的过程性细节做细致的检查。通过在不同点检查程序状态,确定实际状态是否与预期的状态一致。白盒测试主要是想对程序模块进行如下检查:
1、对程序模块的所有独立的执行路径至少测试一遍。
2、对所有的逻辑判定,取“真”与取“假”的两种情况都能至少测一遍。
3、在循环的边界和运行的界限内执行循环体。
4、测试内部数据结构的有效性,等等。
白盒测试的主要方法有语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、条件组合覆盖、路径覆盖等,它是深入到代码一级的测试,使用这种技术发现问题最早,而且效果也是最好的。该技术主要的特征是测试对象进入了代码内部,根据开发人员对代码和程序的熟悉程度,对有需要的部分进行软件编码,开发人员根据自己对代码的理解和接触来进行软件测试。
四、白盒测试与黑盒测试的关系
白盒测试和黑盒测试都是非常重要的环节,不存在技术含量谁高谁低的问题,只是两者的偏重不同,使用的技术也不同。黑盒测试人员偏重于业务方面,而白盒测试人员侧重于实现方式;黑盒测试注重整体,而白盒测试则更注重局部。白盒测试是对过程的测试,黑盒测试是对结果的测试。
五、测试用例
实际上测试情况有很多个,不仅要测试所有有限的输入,而且还要对那些不合法但可能的输入进行测试。这样看来,完全测试是不可能的,所以我们要进行有针对性的测试,通过制定测试案例指导测试的实施,保证软件测试有组织、按步骤,以及有计划地进行。测试行为必须能够加以量化,才能真正保证软件质量,而测试用例就是将测试行为具体量化的方法之一。其中逻辑覆盖技术是白盒测试的典型技术,而等价划分、边界分析、因果图等技术则是黑盒测试的较典型的技术。
六、结束语
黑盒测试和白盒测试是两种不同的测试方法。在整个的测试过程中两种方法都会用到,但以经验来看,在一个项目中测试工程师还是以黑盒测试为主,白盒测试为辅。因为你首先要用黑盒测试来验证结果是否正确,或者说目标是否正确,如果结果正确,然后再用白盒测试来验证,这个正确的结果是不是由于正确的过程产生的。如果结果不正确,那么用白盒测试来找到过程中错误的地方。只有先做好黑盒测试,然后用白盒测试验证,这个测试才能说做的完整了。
我们在测试项目管理中,初期预研阶段,就要通过仔细分析和研究,确定以后工作中所要采用的测试类型。不同的测试项目,所选取的测试类型也必定不同。具体选用哪些,需视项目实际情况而定!
简单来说,这些不同的测试类型,是按照不同的测试对象和测试范围划分的。
我们以手机终端软件的测试项目为例,具体分类及包含关系如下图示:
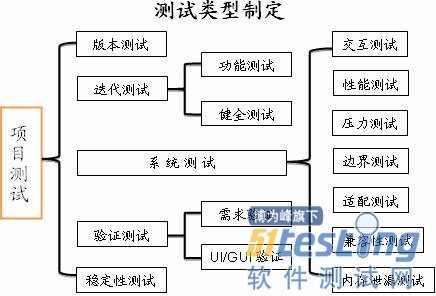
版本测试(Build Check/ Release Test)是开发完成代码设计和Code review、集成并发布后,测试人员拿到该测试版本,首先要做的一类测试。
它的测试范围极窄,大概包括20~30条用例,都是最基本的功能用例,需保证1人在半小时内测完。
对软件项目来说,根据子模块的大小、需求粒度等,每个子模块只选取3-5条基本用例。
Build Check的目的是为了第一时间验证版本的正确性/稳定性,保证之后的测试中,各子模块不会出现严重的、阻塞基本功能的Block Issues。
如果在版本测试中发现阻塞正常测试的严重问题,需第一时间提交给开发解决。测试工作暂时Block,转而关注问题的分析、解决与跟进。
如版本测试顺利通过,才能开展后续的所有测试,所以它是测试工作的一个前提条件。
目前很多持续集成工具如Hudson等均可加入实现了自动化测试执行的版本测试套件,当自动生成Daily Build后,马上开始后续的Unit Test、Coverage Test、Lint Test、Build Check等。
在项目开始的需求开发阶段,敏捷开发模式下,我们执行的是迭代测试,包括功能测试和健全测试。
因在开发阶段,PD/UI都不够稳定,开发也在频繁进行代码修订,这个时期不适合采用大规模的产品测试。
而迭代测试是适合于敏捷开发模式下的一类测试,它可以紧跟开发/需求/UI的变更步伐,做一些小规模、针对性的测试工作。
其中,功能测试(Function Test)是测的最基本功能点和需求,也就是UI上的功能模块设计、业务流程设计、需求点设计实现等。它模拟是正常用户的正常行为,一般均为单任务,不牵扯交互、压力、异常操作等。而健全测试(Sanity Test)是系统测试的一个子集,它包含的是系统测试用例中的基本部分,相当于在系统测试之前所做的一次预测试。
健全测试达到标准,表示已达系统测试开始的准入条件之一,决定是否可进行全面的系统测试!
一般健全测试用例数量占系统测试数的1/3左右,包括了所有K(Key)、M(Mandatory)型的测试用例,不包含O(Optional)型。
系统测试是在产品测试阶段进行,它的覆盖范围极广,是对于软件产品的最重要测试内容之一。
当前期敏捷开发阶段的需求测试(REQ Test)和基本功能测试、健全测试执行通过后,可认为产品质量已基本稳定,将前期测试结果作为准入条件,就可以开展后续的全面系统测试了。
应注意的是:系统测试(System Test)是针对整个产品、整个软件系统所做的全面测试,而不是只针对单个功能、REQ或单一业务流程。
它一般是在通过了Alpha release,迭代测试结束后,已经确保80%的功能集成且均REQ被分别测试,此时再开展系统测试,才有作用和意义。
我们在系统测试中,定义了如上图示所列的各种测试类型。
当然在不同的项目中,有时还需要定义一些Special Test Category如安全性测试、完整性测试、一致性测试、集成测试等。
举例如手机上的客户端项目中,比较特殊的用例类型就是三层结构测试,因客户端设计原因,它是处于底层数据连接和上层App应用之间的夹层。
所以可以设计基于“数据连接——客户端——上层应用”的三层结构测试,考核数据连接/设置/数据传输、上层App的启动、退出和异常场景等使用情况对于客户端的影响。
交互测试(Interaction Test)是指的在同一测试机型上,被测模块(如手机客户端)与本机其它模块之间的交互测试,
尤其是涉及接口调用和功能交叉的一些模块,类似客户端代码中调用的其它模块、客户端状态与数据连接设置的交叉、客户端计时与本地计时的功能交叉等。
互操作测试(Inter-Operability Test)是指的被测产品与其它机型之间的交互,主要涉及信息、协议、信号解析的匹配与兼容性问题。
例如不同机型对于短信的解析方式不同,可能导致互发后字符显示乱码,所以测信息时必须考虑互操作测试。
但这主要针对不同解析方式和协议兼容性的,如果客户端有统一定义的业务/测试协议规范,不涉及这个问题,系统测试中就可以不考虑这个类型!
性能测试(Performance Test)是针对产品/软件性能所做的度量测试,同时包括软件产品与竞品的性能对比测试。
首先要在各种业务规范、测试规范、SW设计文档、需求规格文档等各规范文档及UI/PD设计中,采集了所有的性能指标。
然后可使用本机自带工具、自己开发测试工具、自动化测试脚本、网上搜寻的工具等,对这些性能指标进行精准度量,得到性能指标的测试结果。
压力测试(Stress Test)是指在各种压力情况和异常场景下,产品/软件功能使用的测试工作。
如客户端的连续登录、下线100次,连续查询100次,各种异常下线,多用户同时登录,网络信号变弱等,尤其应关注各种异常场景下的功能使用状况。
这部分测试,如果能用自动化测试工具完成的,可测试100次。
一些涉及网络覆盖、信息接收、验证码输入等无法通过自动工具完成的,可手动执行20次。
边界测试(Boundary Test)是指各种功能使用在极限情况下的测试,不仅是界面上的边界,也包括功能中的极大/极小边界、极多/极少值等。
例如客户端的安装包,所能正常安装的最长路径长度(chars),最深存储文件夹层数(层),登陆用户名的最小字符数(个)等,都应当作为测试点。
如果边界测试的用例数较少,可以直接并入系统测试用例中,不必单独列为一类,以免增加统计难度。
兼容性测试(Compatibility test)是指产品或软件对于各种环境、设备、网络、解析规范等的适配能力测试。
比如普通的软件产品,要测试基于各种OS(例Windows XP/ Win 2000/ Linux/ Mac OS/ Ubantu)、不同支持软件(例Outlook2003/ Outlook2007)的兼容能力。
而手机客户端,主要通过四类测试来考核其兼容适配能力:终端适配测试、SIM卡兼容性测试、设备兼容性测试、网络兼容性测试。
终端适配测试就是上图中所说的适配测试,因手机客户端是一个嵌入式系统,软硬件不可分割,故并入兼容性测试中。
它测试的是不同分辨率、不同OS平台、不同硬件配置的机型对于客户端的适配兼容能力,我们在测试过程中,主要基于以下考虑:
市场主流机型Top 20,主流分辨率,市场占据较多的OS前三位及其版本、主流设计商的芯片、对大字体设置的支持能力等等。
SIM卡兼容性测试,是针对不同运营商、不同业务类型的SIM卡所做的兼容能力测试。
如客户端是基于移动SIM卡开发的业务功能,则其中的短线接收,必须用移动卡才能正常接收,而在项目初期研发阶段,可能开发未考虑处理SIM卡兼容问题,就会导致使用联通/电信SIM卡会死在短线发送界面。此类测试解决的就是这些漏洞和问题!
设备兼容性测试,这类测试需要借助一些专业的模拟网络环境和实验室,它可以模拟不同厂商的设备,保证客户端产品在所需的各种设备下都可以正常工作!
网络兼容性测试,对于客户端来说,主要就是外场测试,包括企业内部外场区域和外部区域、移动区域等。
它的测试目的是为了验证客户端在各种网络环境下的功能适配能力,执行的是全部功能+系统测试用例,在发现问题后还应做针对性测试。
系统测试中,还包括内存泄漏测试(Memory-Leak Test)、数据库测试(Database Test)。
内存测试主要针对应用软件的内存管理和释放机制,测试当大数据量传输、数据阻塞、频繁操作等异常情况下,内存使用和释放的正常性。
一般使用自动化工具来进行此类测试,少量的内存测试用例可并入性能测试用例中。
数据库测试是一类重要测试类型,主要测客户端与后台Server之间的数据传输、并发、准确同步等。
一般手机客户端和后台的各类服务器等都有数据交互,应当针对这些Server进行专门的服务器测试,其中数据库测试和文件系统测试自然是重要组成部分!
项目开发前期,即自Kick off至Alpha release阶段,跟随软件的快速变化,我们所做的是迭代测试(REQ Test/ Function Test/ Sanity Test)。此间每天采用CIS自动生成的Daily build,在更新版本上进行迭代式测试。在Scrum Team内随时与开发、产品进行沟通,快速反应解决问题。
项目中期,自Alpha release ~ Beta release阶段,功能模块已基本集成,需要开始执行大规模的系统测试,并穿插周期性的功能测试。测试频度和范围视项目的测试周期、人力而定,但一般开始要先执行一轮全面系统测试(Full ST),以正确、完整地评估软件产品质量。
之后再根据各模块成熟度和缺陷状况,决定如何对FT和ST进行针对性裁剪,选择新增模块、薄弱模块和重点模块的关键项用例来对软件产品做局部测试。
此期间延长软件版本的迭代周期,每周更换2~3个测试版本,而不是每天更新版本。但需随时监察Release note和与开发及时沟通,知道有较大的功能性改动或重要的bug-fix时,就及时更换新版本进行测试!
最后一个阶段——项目后期,也就是Beta release ~ Final/Product release之间的阶段,是产品发布测试期。此时已进入产品稳定和待发布期,在此期间,就不能像以前一样频繁更换测试版本了。一般产品质量较好时,我们采用每周更换一次新版本的更新频度。
在这个阶段内,需要做的就是针对发布版本(Release candidate)的产品级测试,包括所有系统测试类型、验收测试、缺陷跟进及处理等。
在产品发布之前1~2周,一定要最后做一次全面覆盖测试(Full Test),包含功能测试、系统测试的全部用例执行,以在最大程度上保证发布产品的总体质量!
如上所述,当功能测试、系统测试、缺陷数量等均已达QA所订的质量目标后,在正式发布之前,当PD/UI已完全确定、稳定时,我们要做一轮验证测试。
验证测试(Verification Test)是针对PD/UI/GUI的核查和验证,主要包括需求测试和UI验证。
需求测试是核查所有需求点,看其所标示的功能是否已在软件发布版本上正确、完整实现。
UI/GUI验证是核查软件产品的功能,是否与UI上标示的业务流程、界面显示完全一致,GUI中的每个Text/Graphic/Icon大小、颜色、色阶色深是否与定义一致。
最后一类测试,就是稳定性测试,主测两个指标——MTBF和MTTF,均使用自动化测试工具实现。
MTBF也就是平均无故障运行时间,应使用自动化Tool,在4台测试机上进行连续的、模拟用户行为的功能测试,取其均值作为考核指标。
另外MTTF测试是在Android系统下直接运行adb命令,模拟在测试机上乱点乱划的行为,考察无故障运行时间。这是另一类稳定性测试!
注意:为通过Alpha/Beta/Final release,我们有时会在里程碑截止日期(Milestone Deadline)到达之前,针对未达质量目标的功能测试/系统测试,再做一轮回归测试,以验证通过Release standard。
而各阶段测试期间,我们也会针对局部的重点问题、严重缺陷和关键功能,做一些针对性测试,如焦点测试、集中测试、探索测试、自由测试等。其实从真正意义上来说,这些已经不属于测试类型的范畴,而是一些不同的测试方法!
回归测试(Regression Test),是针对之前的一轮测试进行的再次测试验证,以达到QA定义的质量指标。FT/ST等都可以做回归,但以ST Regression较为重要。
回归测试的范围主要包括以下三部分:上轮测试中的Fail case,需重新验证看是否已Pass;目前遗留的所有缺陷,进行修复验证;针对缺陷集中的薄弱模块、重点模块,进行引申测试。
焦点测试(Focus Test)也就是专题测试。当测试过程中发现严重且普遍、涉及模块较多、影响较大的缺陷或问题时,应马上安排人手进行专门性测试。Test Leader围绕此问题设计专题测试用例,测试人员在执行过程中,也要自己进行思维发散和延伸,多做一些周边的操作测试,以在最大程度上发现可能的隐藏缺陷!
集中测试(Test Workshop),亦称圆桌测试,也是在产品测试过程中经常采用的一种测试方式。顾名思义,它就是把一群用户级测试人员集中起来,在一个封闭会议室中,大家围着圆桌共同进行产品使用和测试。这些人可以是真正不了解产品的最终用户(End User),也可以是相互交换测试模块后的专职测试人员。测试的目的就是为了集中发现问题,尤其是那些因测试习惯性思维和行为盲区导致的潜在缺陷和风险点。
探索测试(Exploratory Test),简称ET,其实是一种有导向、有目的的自由测试方法。它采用了一些科学统计和分析方法,针对性地对一些重要、关键测试点和模块、范围进行测试。主要由一名ET Leader做主导,负责定义Test point、安排测试内容/人力/时间、一对一开会讨论、总结编写ET Report等。
自由测试(Free Test)就很简单了,大家都知道,就不多做赘述了。FreeTest可以随便找人来使用软件产品,寻找潜在的风险和隐藏的问题。也可以设定特定的目标用户群,从其中各抽出一部分人来集中进行自由测试。这样对样本点采集的全面性和可靠性更有意义,有时我们也会这样做!
总之,测试类型千变万化,但万变不离其宗。我们在真正的测试项目管理中,一定要认真考虑、分析清楚当前处于哪个阶段、面临哪些重要问题、针对这些情况应采取何种测试类型来应对。
天底下所有的技术、知识都是死的,运用存乎一心,只有它们变成了你身体的一部分,真正能够掌握、运用和创新改进的时候,你才能说“我真的会了!”
版权声明:本文出自 cmriqa 的51Testing软件测试博客:http://www.51testing.com/?489136
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
在进行性能则试前,需要完成性能测试的搭建工作,一般包括硬件环境、软件环境及网络环境,可以要求配置和开发工程师协助完成,但是作为一个优秀性能测试工程师,这也是你的必备技能之一。
性能测试环境与功能测试环境的区别
那么性能测试环境与功能测试环境有什么不同呢?性能测试对测试环境的干净、独立性要求更高,更为严格。对于一个相对较规范的公司,都会建立其独立的研发环境、测试环境、线网环境(最终运行软件的环境)。
这里多扯一点,系统可以分为C/S架构的系统与B/S架构的系统,C/S架构的系统又可以分为两种,第一种是基本不用与服务器连接的,比如我们用到的java虚拟机JVM,photo shop平面处理软件,我们可以开启软件更新功能,这时软件向服务器发请求,查当前版本是否是服务器端发布的最新版本,然后,提示用例是否需要更新或下载最新版本的软件。当然,我们也可以关闭更新功能或不检测更新。那么这个软件一样可以在电脑上运行。对于这类软件,我的主要测试环境就是用户的电脑。不同硬件配置、不同操作系统下对软件一系列,从安装使用到卸载。除了验证软件与硬件和系统的兼容性能,还需要验证与其它软件是否兼容。
第二种类型的C/S软件要时刻与服务器与连接,比如我的在线网游,QQ聊天工具等。从软件的启动就需要与服务器进行连接,对于此类软件,我们测试环境的重点依然是用户电脑,但服务器端必须也有一个相对应的测试环境支撑。
对于B/S的系统,我们测试环境的重点就要由用户电脑转为服务器端了,因为系统的所有功能都是由服务器端传递给用户的,所以需要验证服务器传递来的功能是否可用,以及功能的容错能力等。
再回到测试环境的问题上,对于一些企业为了节约资源,进行功能测试的测试环境,一台服务器可以运行多个系统,通过技术手段可以使系统之间是不会相互影响的(以前公司就是一台服务器上跑多个tomcat)。因为功能测试的重点大于系统对客户端发来的请求是否可以进行正确的处理。
那么性能测试为什么对系统的环境要求干净、独立呢?性能测试是要对整个系统运行的软件硬件环境进行测试的,如果某环境下运行多个系统,就很难判断其中的某个环境对资源的占用情况。
性能测试环境包含内容
一般web应用系统分为3层架构(在系统架构一章中有介绍)
* 表现层(web服务器)
* 业务逻辑层(应用服务器)
* 数据层(数据库服务器)
性能测试环境包含内容:
硬件:服务器、客户端、交换机等。
软件:数据库、中间件、被测系统、操作系统等。
网络:有线/无线/宽带、网络协议等。
如何保证测试环境与真实生产的一致性
保证性能测试与真实生产环境的一致性,具体从以下三个方面来看:
1、硬件环境,包括服务器环境、与网络环境
如服务器的型号以及是否和其它应用程序共享此服务器,是否在集群环境下,是否通过BIGIP进行负载均衡,客户使用的硬件配置情况,使用的交换机型号,网络传输速率。
2、软件环境
版本一致性
包括包括操作系统、数据库、中间件的版本,被测系统的版本。
配置一致性
系统(操作系统/数据库/中间件/被测试系统)参数的配置一致,这些系统参数的配置有可能对系统造成巨大的影响。所以,除了保证测试环境与真实环境所使用的软件版本一致,也要关注其参数的配置是否一致。
3、使用场景的一致性
● 基础数据的一致性
包括预测的业务数据量,以及数据类型的分配。很简单的一个列子,一个系统的数据库只有10条数据和一条数据库里几千万条数据,我们在对其进行性能测试时,得到的性能指标可能会有非常大的差别。
为了保证每次测试环境的更加一致性,磁盘的使用情况以及磁盘的碎片情况也会或多或少的影响的性能。
● 使用模式的一致性
尽量模拟真实场景下用户的使用情况,其实,我们在做性能测试前期的需求分析,其主要目的也就是为了更真实的模拟用户的使用情况。
性能测试环境的实施策略
上面讲测试环境与生产环境保持一致所需要注意的内容。其实在实际的测试中,我们很难搭建出与生产环境完全一致的一个测试环境,除非我们暂停生产环境用户于进行性能测试,这往往是不可能。一方面某些生产环境是不允许被暂停的,另一方面也为生产环境的安全性考虑。
性能测试环境并不像功能测试环境,为了节省资源可以一台服务器上运行多个系统。由于性能测试的特殊性,整个测试环境需要在严格的独立监控下管理,在很多情况下,我们很难申请到足够的且一致的资源(说白了就是老板是否愿意出钱给你买服务器搭建系统)。对于一个并未上线的项目,其生产环境的配置也属于暂定状态,性能测试的目的就是为了确定具体生产环境的硬件配置。这个时候更不可能用过高的配置来搭建性能环境(除非现成的环境放着不用)。
我们一般通过两种策略来搭建性能测试环境(预估方式均有误差)
1、通过建模的方式实现低端硬件对高端硬件的模拟
通过配置测试来计算不同配置下的硬件性能和系统处理能力的关系,从而推导出满足系统性能的真实配置情况,这种模拟需要精确的建模,模型的采样点越多,那么得到的结果越精确,从而将在低端配置下的性能指标通过该模型转化为高端配置下的最终预计性能指标。
例如:搭建一个低端环境,首先需要对这个环境的CPU和内存进行单独的性能基准测试,同过在不同的配置的性能测试,得到一个基准信息列表,当然,在进行这个性能测试的过程中,我们要确定硬件是系统的瓶颈。如果只用一个CUP,在性能测试过程中,其使用率很低,但得到的性能数据都非常底,这起码说明CUP不是系统的平静,这种情况下就无法得到想要的基准值。
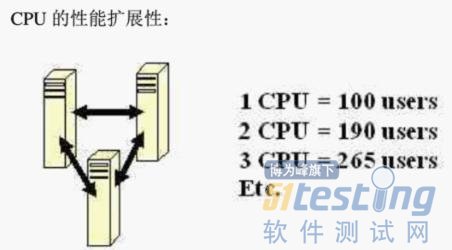
如上图,在一颗CPU情况下,运行100个用户且CUP使用率接近饱和(100%)。在增加至两颗CUP的情况下,可以运行190个用户且UPU使用率接近饱和(100%),以此做记录,那么我们就可以推算出运行800个用户需要多少颗CUP。
如果你在实际应用中使用的CUP型号及其频率并非完全一样,这个时候可以使用EVEREST工具计算每种CUP的得分,对其性能进行评估。
内存也可以使用此方法进行测试推导,这里需要我们多进行试验,对硬件的性能以及对整个项目的结构都要做深入的了解,以便尽量减少误差。
2、通过集群的方式计算
对于较大的系统来说,单台服务器的处理能力是有限的,通常都会采用集群的方式来进行负载均衡,完成对海量请求的处理。虽然无法获得整体集群的测试环境,但是可以对集群上的一个节点进行性能测试,得出该节点的处理能力,再计算每增加一个节点的性能损失,同样也可以能过建模的方式得到大型负载均衡情况下的预计性能指标。
例如:首先在单台服务器上获得具体的性能指标,每台服务器能够承受500用户并发,平均TPS为60,响应时间为2秒,接着,添加负载均衡策略,再次测试负载策略下的数据损耗。得出数据后添加1台负载均衡服务器,测试在两台服务器下每台服务器的性能指标,以此类推,可以得到下表:

随着负载均衡服务器的添加,平均每台服务器的处理能力会逐渐稳定,从而了解在什么情况下需要多少台负载均衡服务器。
对于测试环境的搭建,建议生成专门的文档进行管理,并进行配置管理,确保对测试环境做到基线控制。
------------------------------------------
这个性能测试系列以理论与性能测试的整体讲解为主,市面上的大部分书籍借着性能测试的表皮在讲性能测试工具loadrunner,那我何不找份loadrunner使用手册来看更好。
相关链接:
性能测试知多少----性能测试分类之我见
性能测试知多少---并发用户
性能测试知多少---吞吐量
性能测试知多少---响应时间
性能测试知多少---了解前端性能
性能测试知多少---性能测试工具原理与架构
性能测试知多少---性能测试流程
性能测试知多少---性能需求分析
性能测试知多少---性能测试计划
性能测试知多少---系统架构分析
性能测试知多少---测试工具介绍
QTP作为测试自动化的主流,已经很长时间了:以前的主流测试是window GUI应用,和普通WEB应用;没有那些复杂的其他环境,如flex silverlight wpf 手机等。
以前良好协作的自动化用例管理平台,是TD(qc),能够实现用例与自动化关联。
以至于:QC/QTP甚至成了自动化测试招聘的标准……现在呢?
随着WEB2.0+,移动互联网的兴起,QTP/QC还能胜任吗?
数年之前,EJB也是标准,但是EJB造成了一些招致IT人员反感的问题:开发调试维护困难,方案太重与应用服务器紧密绑定(昂贵)性能低下……
我们回过头来看看,QTP/QC也不是与这个很类似吗?
QTP成也对象仓库败也对象仓库,录制的东西不比手写,手写的是自己的孩子自己认识,可维护性强;
QTP如果你不与QC关联,很难关联用例与需求QTP实际运行性能低下,特别是插件(先不考虑插件的价格)QTP做测试,必须有框架……这里不想讨论LR。
如果我们不用QTP/QC,开源世界里能否有东西胜任呢?
答案是肯定的。回头看看EJB:Hibernate取代了EntityBeanSpring成了粘合剂这二者联手将java世界的标准,送进了博物馆。
那么QTP/QC中,开源世界的对位应该是哪些呢?
我认为:QTP的取代者,会是webdriver,webdriver就像hibernate的地位;当然,你也可以不用webdriver,就你可以不用hibernate而用myBatis/dbutil等取代一样,你也可以用watir/htmlunit/seleniumRC/webaii/white/sikuli/bromine等任何来代替webdriver的地位;就跟你想在写原生sql一样,你也可以写(win32ole)win32api, linux xdotool来完成自动化。
Hibernate这头熊是如何被唤醒的?我们来回忆一下,当时hibernate的问题是sessionfactory获取datasource,依赖jndi查找,而Spring用了依赖注入解决了这个问题;Sring成了真正意义上的企业级粘合剂,更关键的是spring所带来的一种务实的思想。
那谁来把QTP从QC上解耦,并能提供良好的用例组织和管理呢?
答案就是BDD目前的事实标准:Cucumber!!
引用维基百科:行为驱动开发(缩写BDD)是一种敏捷软件开发的技术,它鼓励软件项目中的开发者、QA和非技术人员或商业参与者之间的协作。BDD最初是由Dan North在2003年命名[1],它包括验收测试和客户测试驱动等的极限编程的实践,作为对测试驱动开发的回应。在过去数年里,它得到了很大的发展[2]。
2009年,在伦敦发表的“敏捷规格,BDD和极限测试交流”[3]中,Dan North对BDD给出了如下定义:BDD是第二代的、由外及内的、基于拉(pull)的、多方利益相关者的(stakeholder)、多种可扩展的、高自动化的敏捷方法。它描述了一个交互循环,可以具有带有良好定义的输出(即工作中交付的结果):已测试过的软件。
BDD的重点是通过与利益相关者的讨论取得对预期的软件行为的清醒认识。它通过用自然语言书写非程序员可读的测试用例扩展了测试驱动开发方法。行为驱动开发人员使用混合了领域中统一的语言的母语语言来描述他们的代码的目的。这让开发着得以把精力集中在代码应该怎么写,而不是技术细节上,而且也最大程度的减少了将代码编写者的技术语言与商业客户、用户、利益相关者、项目管理者等的领域语言之间来回翻译的代价。
Dan North创造了首个BDD框架:JBehave[1];之后是Ruby语言的基于故事的RBehave[4],后来被纳入了RSpec项目[5]。他还与大卫赫利姆斯基、Aslak Helles?y及其他人开发了RSpec,并一起编写了《The RSpec Book: Behaviour Driven Development with RSpec, Cucumber, and Friends》。RSpec中第一个基于故事的框架,后来被主要由Aslak Helles?y开发的Cucumber取代。
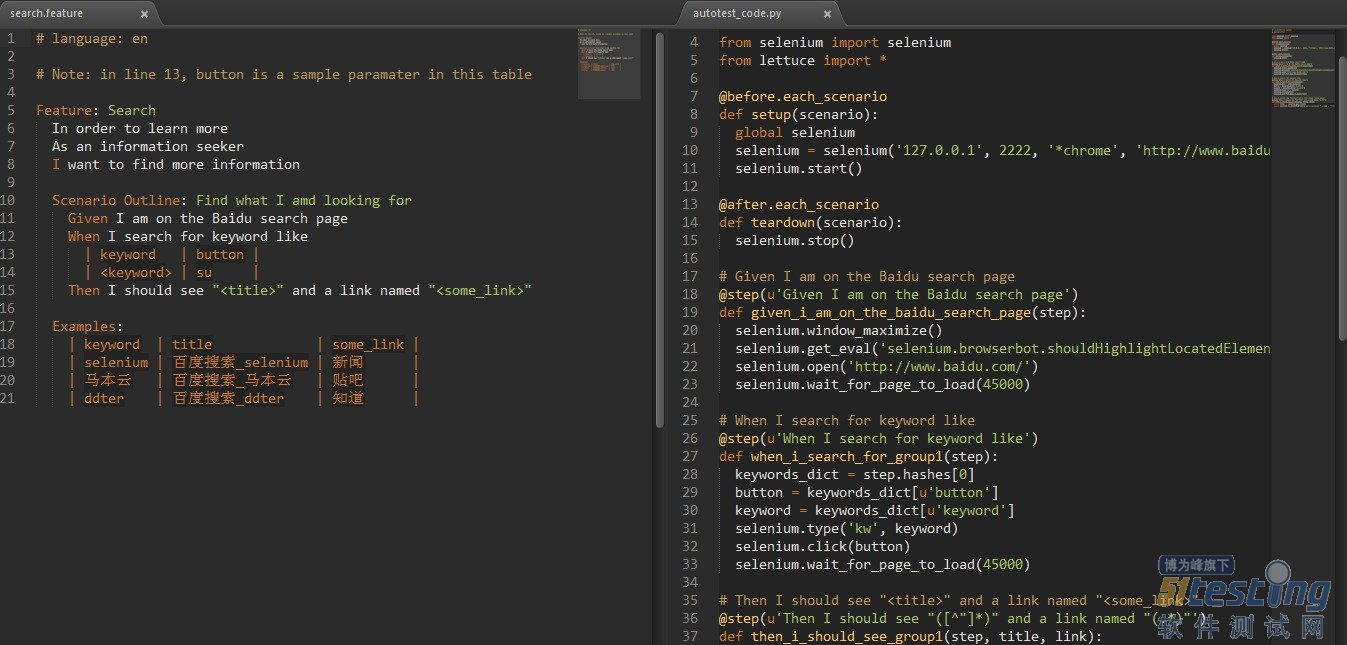
这一大段话,头都要晕掉了吧。OK,我们来看一个典型的BDD用例(用户故事):
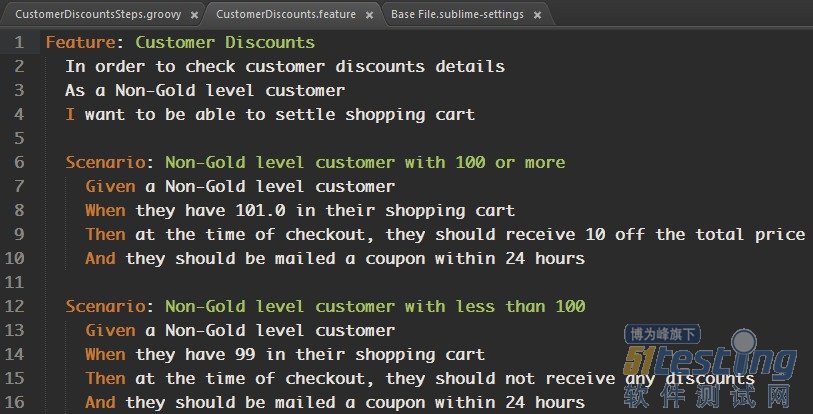
你可以认为,这就是两个测试用例!那他与普通的测试用例有什么不同呢?
用户故事关联了需求,是包含了需求的用例故事贯穿整个软件生命周期,直到验收故事是软件的商业价值,是最“有效文档”OK了!那如何把故事跟自动化关联起来呢?BDD框架提供了最简单最直接的方式:正则关联。

BDD就是如此神奇!他提供了最简单的方式,就向胶水融合一样可以把任意代码与用户故事关联起来且不限于:单元测试,集成测试,UI自动化,接口验证,安全等。
BDD框架,普遍自带数据驱动,关键字驱动,参数化。
一个典型的ui automation例子(点击图片查看大图):
运行结果:
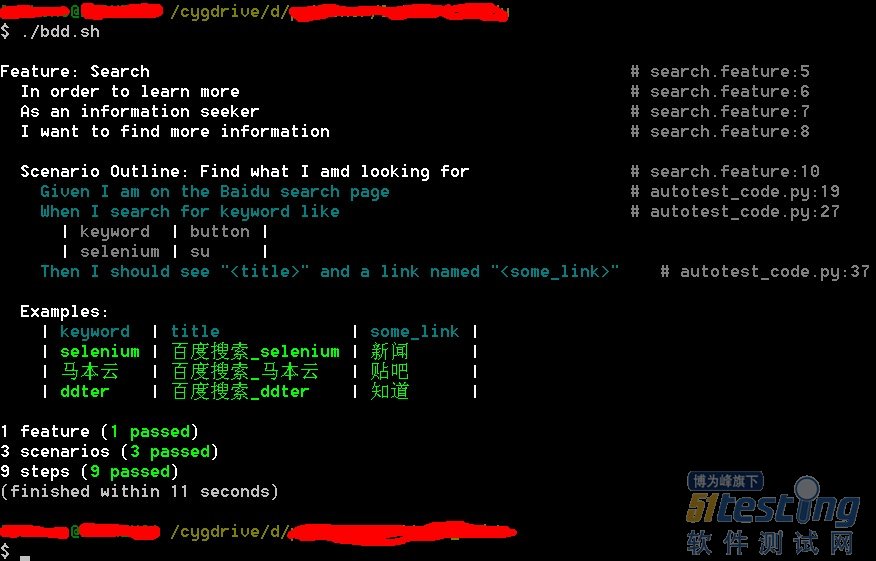
说几点:
● BDD,只是一种思想,一种轻量级测试实践;BDD注重有效文档,注重用户故事的拆分细化 。
● story可以使得黑盒与自动化人员分离;只要story控制的好,可以招廉价开发来实现自动化
● 就跟你可以用google guice, picocontainer替换spring一样,BDD框架可以自由选择,因为都是提供相同风格的功能
● 比如py里可以用lettuce,.net上有cuke4nuke,groovy有easyb, spock,sikuli也支持BDD等
● VBS受限于语言表达力,就别想BDD了。
● 如果你的企业愿意花几十万(不是为了只卖最贵),还不如只花几万来投在人力建设上,通过开源测试来提升团队, 企业里没有什么比人才更可贵的了。
● BDD对粘合自动化或者框架的唯一要求,支持代码编写并启动,比如selenium watir等,而依赖特定GUI的不见得适合。
● 你不见得需要想开发QTP框架样重复造轮子,合理的使用开源社区现有轮子即可。
● BDD可以与bromine/robotium一起,测试iphone/android。
● BDD工具完全可以与CI整合,方式多种多样。
目前情况下,BDD缺少一个GUI界面的故事管理工具,你可以自己开发一个,或者买商业的,不过更多的人选择把story帖在墙上。
随着cucumber-jvm的火热,到了该是BDD成为测试主流的时候了,毕竟BDD只是一种思想,一种表现形式,不是一种具体的思路,也不强制你购买某个厂商的工具(当然thoughtworks也有BDD工具twist);现在企业都讲究整合,作为广大发展中测试人员,特别是在成长中公司的测试人员,拿起你的斧头,把该砍的都砍掉,做轻量级测试吧!你会找到自己的乐趣的。
常用BDD框架:JBehave rspec cucumber cuke4nuke spock等等常见支持与BDD粘合的工具:watir selenium celerity white UIA3.0 robotium bromine(iphone) webaii soapui(core)等
常见与BDD一起使用的编程语言:ruby python groovy node.js java c# erlang lua,就是没有VBSwebdriver,自动化(特指测试自动化)领域的hibernate;cucumber,自动化领域的spring。当冬眠的熊遇上春天……
让广大自动化人员在开源世界中热起来吧!
软件测试人员的职责是根据一定的方法和逻辑,寻找或发现软件中的缺陷,并通过这一过程来证明软件的质量是优秀还是低劣。所以,怎样发现缺陷,成为大部分测试人员关注的焦点。在软件测试过程中,软件测试人员一般需确保测试过程中发现的软件缺陷得以关闭。但在实际测试工作中,软件测试人员需要从综合的角度来考虑软件质量,对找出的缺陷保持一种平常心。这就需要明确以下几个原则:
1、并不是测试人员发现的每个缺陷都是必须修复的。
测试是为了发现程序错误,而不能保证程序没有错误。不管测试计划和执行多么努力,也不是所有缺陷发现了就能修复。有些软件缺陷可能会完全被忽略,还有一些可能推迟到后续版本中修复。
一般不修复软件缺陷原因如下:
没有足够的时间。在任何一个项目中,通常是软件功能较多,而程序设计人员和测试人员较少,并且可能在项目进度中没有为开发和测试留出足够的时间。在实际开发过程中,经常出现客户对软件的完成提出一个最后期限,在此时间点之前,必须按时完成软件。这就导致了时间的有限性和任务紧迫性,在此压力下就有可能忽略一些缺陷。
不算真正的缺陷。在某些特殊场合,错误理解、测试错误或设计说明书变更,会使测试人员把一些软件缺陷不作为缺陷来处理。
修复的风险太大。这种情况比较常见,软件本身是脆弱而复杂的,修复一个缺陷,常常可能导致其它更严重问题的出现。在紧迫的产品发布进度压力下,修改软件缺陷必须评估其影响程度和风险,以决定是否可修改。
2、发现缺陷的数量说明不了软件的质量
软件中不可能没有缺陷,发现很多的缺陷对于测试工作来说,是很正常的事。缺陷的数量大,只能说明测试的方法很好,思路很全面,测试工作卓有成效。但以此来否认软件的质量,还是不具客观性的。
如果测试中发现的缺陷,大部分都是提示性错误、文字错误等,或错误的等级很低,而且这些缺陷的修复几乎不会影响到执行指令的部分。但对于软件的基本功能和性能,发现的缺陷很少,通常这样的测试证明了“软件的质量是稳定的”,因而属于良好软件的范畴。这样的软件只要处理好发现的缺陷,基本就可以发行使用了。而进行完整的回归和大规模测试,就是增加软件开发的成本,浪费商机和时间。
发过来,如果在测试过程中发现的缺陷较少,但这些缺陷都集中的功能没有实现、性能未达标、经常引起死机或系统崩溃等现象,而且出现几率大,多数用户使用过程中都会发现这样的问题。那这样的软件就不能随便就发布,因为发布风险太大了!
版权声明:本文出自 cmriqa 的51Testing软件测试博客:http://www.51testing.com/?489136
最近两个项目中游荡,首次接触facebook游戏的测试,感触还是很多的。与之前的web2.0的互联网应用相比,webgame的测试更多样,也更加的复杂。留下点Memory,对Webgame进行自动化测试是挑战新的开始。 根据游戏整体架构的不同,在协议测试方面还是可以有很大的发展余地的。比较流行的facebook游戏进行自动化测试的还是比较多的,不过由于游戏UI方面的修改比较的多,所以在一开始选取好的测试方法是很重要的。
在游戏测试中用的比较多的是类似于按键精灵的这样的方式hook,利用windows api进行屏幕点的操作,以下是比较简单的实现,是通过autoit3对游戏FARMVILLE进行的操作,点击这里下载。
自动化的实现主要是将FARM中的田地size化,通过在1280x800的屏幕中,进行模拟对屏幕点的操作。实际效果还是很棒的,测试时遇到修改的情况的话可以通过修改excel中FARM的田地参数进行修改。可以使用更多的API进行定时,定点的收割。
以上提到的是使用windows api半hook的方式进行的自动化测试。
我们还可以通过真实的tcp,http或者https的协议来进行相关的自动化测试。
主要看在facebook中的游戏整体架构,使用flash前台通过json或者amf协议进行协议发送的话可以利用python的pyamf或者 perl的amf3解析包解析后进行协议层的自动化测试,这样可以减轻前段UI测试的压力,一般游戏的UI测试用例非常的多,很多涉及购买等操作的可以利 用协议自动化测试进行。
flash的自动化测试可以分为UI层面的测试及协议层面的测试。
flash的UI层面的测试:
UI层面的测试建议在基本UI及核心玩法已经确定的情况下运用,这样比较有实效性,返工率比较低。
主要实现的手法之前的Jason已经介绍过了,windows hook技术及Browsers本身的特性。
关于Browers本身的特性,这里需要提下iMacros这个在FF中的插件,iMacros插件版不支持flash的自动化,pro版可以通过代码实现很多的逻辑性操作。
Pro版实现flash自动化的效果也可分为屏幕定位及元素定位的方法,在整体实现上还是很有效果的。
flash的协议层面测试:
协议层面的测试做自动化测试的效果比较好,使用性比较高。主要的做法为,通过各种编程手段及辅助工具(http watch或者charles)来共同实现。
简单介绍下python下的framework:
首先需要python的pyamf包,可以通过这里来安装。
之后我们需要Mechanize包,这是发送http及https包比较easy的类。
通过已有的python test framework框架将测试用例变量化,最后输出报告格式化,这样整体的测试框架就出来了。
做协议测试的另一个方面是验证UI无法放松的边界值对后台逻辑的影响,很多游戏的失败就是因为这个原因。
python的 Pyamf 解析包是对amf协议的解析利器,可以使你轻松的实现类似于对html-text的操作,我们也可以利用Mechanize来进行相应的协议自动化测试。
Pyamf在协议测试中我们主要需要用到的类有三类:
1、amf3协议包体类:
envelope = pyamf.remoting.Envelope(amfVersion=3)
产生的envelope对象就是之后对你需要传递数据的封装对象。
2、pyamf amf3协议的转换类:
message = pyamf.remoting.encode(envelope)
产生的message 就可以利用urllib2.Request进行传递了。
3、pyamf amf3协议的解码类:
res = urllib2.urlopen(req);
content = res.read();
content = pyamf.remoting.decode(content)
这里最后产生的content就是返回amf3整体解析好的数据,可以根据需要将返回值进行解析,返回值可能是list{list{……},”jason”=jason},可以根据需要最后做相应的assert。更多pyamf类相关信息,查询这里。
之前介绍了如何进行webgame自动化测试的 思路及针对flash进行的自动化测试的框架。在对游戏进行自动化测试的时候,总是会思考大部分的致命BUG都来源于随机的操作,那么我们如何进行这些方 面的自动化测试呢。这时FUZZ模糊的思想又体现到我们的面前,我们可以将需要生成的测试用例交给COMPUTER来自动生成,并且自动执行得到相应的报 告,整体FUZZ模糊测试的概念就比较清晰了。
我们主要使用的是模糊测试中的自动协议生成测试并与协议测试相结合进行自动化测试。
利用pairwise的思想进行模糊测试。
我们需要考虑的模糊因素有以下几点。
1、各种类型的对象的模糊参数设计,模糊参数默认值。
2、组合参数对象的顺序模糊。
3、非正常类型的参数模糊,针对XSS。
利用设计的用例组合进行穷举算法生成相应的用例。
以下以最简单的用例做个实例:假设需要参数:”id=12&Goodid=12300&name=jason”。
针对ID的设计可以为{-65536,-1,0,12,65536},针对Goodid的设计可以为 {-65536,-1,0,12300,65536},针对name的设计可以为{jason,null,None,”",…………},针对参数顺序 {(id,goodid,name),(id,name,goodid)……}
根据上面的测试用例集合自动产生相应的测试用例,然后进行相应的协议自动化测试。当然这里设计的用例不完善仅供参考思路。
模糊测试的使用可以借助很多已有的测试用例类,类似之前Jason介绍的sulley一样,它的用例库比较的全,这样测试覆盖率会比较高。
Linux提供了多种方式让用户进行远程管理,如Telnet,它的基本应用就是提供远程管理,共享远程系统中的资源。Telnet使用户坐在自己的电脑前通过网络进入另一台电脑,并把用户输入的每个字符传递给主机。再将主机输出的每个信息回显在屏幕上,这样的连接可以发生在同一个房间,也可以发生在地球的两端。但Telnet服务在本质上是不安全的,原因在于在Telnet整个通信过程中采用明文传送数据,在当今的网络环境下这样的操作如果发现在Internet上无异于自杀。
SSH(Secure Shell)则不同,它是以远程联机服务方式操作服务器时的较为安全的解决方案,最初由芬兰一家公司开发完成,但由于版权等相关问题,目前大多使用OpenSSH来代替。它可以将所有传输的数据进行加密,这样“中间人”功能方法就不太可能成功。而且SSH在传输数据的过程中会对数据进行压缩,这样也可以加快数据的传输速度。总之SSH的功能很好、很强大,正在逐渐取代Telnet,成为远程登录主要选择。
SSH同Telnet相同采用客户机/服务器的工作方式。目前主要有二个互不兼容的版本,分别是1.x及2.x。而OpenSSH 2.x同时支持1.x及2.x。
下面将以RHEL 5为例讲述SSH服务在远程登录中的应用:
在RHEL 5中默认情况下已经安装并已开启SSH,但在使用前最好还是检查进程及端口是否工作正常。

在实验过程中,将用户将在football.example.zqin上通过SSH远程登录到golf.example.zqin上。在讲述配置过程前先介绍几个在SSH中常用的命令:
ssh [user@]hostname [command]
远程连接到指定服务器
◆ [user@]:远程计算机的用户名,如不输入表示使用root进行连接
◆ [command]:连接成功后直接执行的命令
scp [user@]host:/path [-rpC]
文件在ssh客户端与服务器端之间复制
◆-r:递归
◆ -p:保留原文件权限
◆ -C:传输中压缩数据
rsync srcfile host:/path
在客户端与服务器间同步文件,这个命令是一次性的,如果需要定时执行,要使用crontab。在同步是只从srcfile到host:/path。

一、通过SSH远程登录

1:通过ssh命令连接远程计算机,未输入用户名则默认使用root。
2:如果是第一次连接到远程计算机,由于OpenSSH不知道该计算机所以出现警告提示此处输入yes,OpenSSH会将这台计算机识别标记加入~/.ssh/know_hosts文件中,第二次连接时就不会出现警告。
3:输入远程计算机root用户口令。
4:已成功连接到远程计算机,此时输入的所有命令将在远程计算机中执行,可通过exit命令退出。
不知道是OpenSSH有Bug还是其它原因,有时一切配置正常但总无法连接到远程计算机,此时可将客户端~/.ssh里面内容删除后再试。
二、通过密钥方式远程登录
在使用ssh连接到远程计算机时每次需要输入远程计算机的密码,如企业中有多台服务器需要通过ssh进行管理时这样可能比较麻烦。可以通过使用密钥文件的方式,先在本机生成一对密钥文件,再将公钥文件复制到远程计算机,只要私钥文件在本机那样连接远程计算机时不需要输入密码。
当然为了安全,可以在生成密钥对时对私钥文件设置密码,这样连接到远程计算机时输入的密码就是私钥文件的密码,而不是远程计算机的用户密码。为了方便可以将私钥文件的密码保存在当前计算机,这样连接到远程计算机时什么密码都不需要输入,但私钥文件如果复制到其它计算机时还是需要输入私钥文件的密码。具体配置步骤如下:
◆ 生成密钥对文件
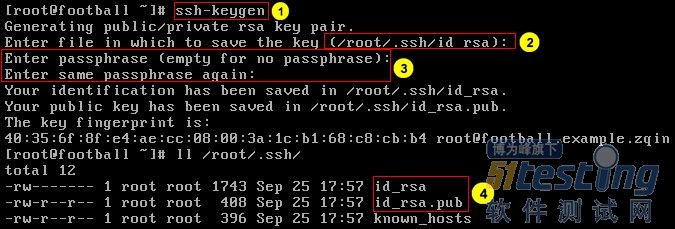
1:生成密钥对。
2:输入私钥文件的名称,直接回车使用默认名称。
3:输入私钥文件密码。
4:完成后在用户家目录.ssh中会自动生成密钥对文件,id_rsa为私钥文件,id_rsa.pub为公钥文件。
◆ 将公钥复制到远程计算机
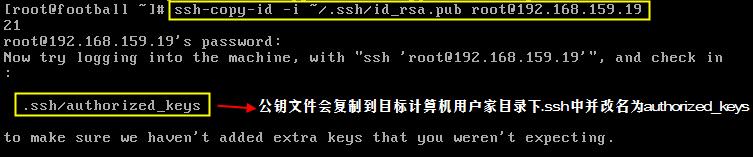

1:ssh-cop-id命令会将指定的公钥文件复制到远程计算机。
2:输入远程计算机root用户密码。
3:公钥文件被复制到远程计算机后,会自动更名为authorized_keys。
◆ 再次连接到服务器


此处输入的是私钥文件密码,而不是远程计算机root用户的密码。
◆ 将私钥文件密码保存到本机

1:启用代理功能。
2:保存私钥口令。
3:输入私钥口令。
当完成上述步骤后,再次连接到远程计算机时无需输入任何密码。
前言
软件测试的价值与成功更多的源于经验和管理,能不能把一个测试项目计划、组织的井井有条和快速高效,把一个庞大的任务科学的细分并在合适的点上进行监督,用丰富的经验预判并规避可能的风险,这才是决定一个测试项目是否成功的关键。相对开发而言,测试对于实施者个人的技术水平和工具应用上的要求相对弱一点。
孤独九剑+足够的实战经验=测试高手
第一式:庐山面目——什么是测试及其核心价值所在
第二式:蓬门始开——测试的从业人员应该具备的素质
第三式:仙源何处——教你了解主要的测试门类和方法
第四式:矫如龙翔——如何开发测试用例
第五式:浮云遮日——如何定义测试流程
第六式:伯仲伊吕——如何制定测试计划
第七式:语报平安——如何书写测试报告
第八式:春寒锦袍——如何管理团队以及激励团队
第九式:江上鼓鼙——产品上市之后测试的角色定义
第一式:庐山面目
所谓软件测试,就是出于正常合理的目的[r1] ,在特定的时间环境[r2] ,用事先制定的标准[r3] 衡量一种软件产品或特性是否符合预期。
[r1]软件测试是为了软件质量足够可靠。凡是都有度,不是为了软件没有BUG,质量完美。
[r2]每一个开发的项目都是有周期的(版本周期);测试要在一定的环境中进行(case预置条件)。
[r3]可以让测试人员在测试的时候有章可循,也可以避免开发人员受到过多无中生有的骚扰。事先制定的标准可以帮助测试人员获得更大的发言权。
测试本身并不是在创造什么东西,而是由确认、验证、保证、评估、审核、报告等动作组成的统一体。
测试有两个主要的作用:第一是确认我们在做一个正确的东西(以软件的特性说明书为标准);第二是确保开发活动的方向是正确的[r4] 。
[r4]在设计阶段参与,预测项目行进的方向,预测项目的风险并及时排除;在项目执行过程中,注意监督每一步都是按照事先确定的方向和时间在走,如果偏离或延迟能及时发现并纠正,项目就会始终健康的进行下去了。
软件工程V模型图(必须会画)。
软件测试是为了软件质量足够可靠。
看一个BUG值不值得修改,不仅要考虑到它可能给公司带来的直接损失,还要考虑到品牌和信誉受到伤害而带来的间接损失。
专业的测试必须要由无利害关系、独立的人或团队来进行。原因如下:
第一:开发人员编写的程序,就好比父母对待自己子女一样,凝聚了心血的成果,所以审视的目光通常不会客观;
第二:有的时候设计和开发人员本身的理解可能有误,陷在错误的圈子里不能自拔,这是必须由他山之石来引入全新的思维才可能跳出这个圈子;
第三:对开发人员来讲,发现了BUG是一种痛苦,因为这意味着自己要投入更多的时间,加班甚至牺牲周末,而且领导不会领这种情,谁让你编的代码有问题呢?
不想当元帅的士兵不是好士兵(野心)。
BUG是否需要修改:在各执一词,公说公有理婆说婆有理,谁也说服不了对方的时候,这个时候就需要项目的高层来做出判断和决定。
除非到了不得已的时候,否则还是应该尽量依靠软件特性说明书[r5] 来做测试的准则,这对各方来说都是容易把握而且风险小的选择。
[r5]基线需求+局方需求+差异化需求(case)
开发项目中究竟会遇到哪些阻碍,事先我们无法一一看清楚,这是就需要项目管理者的经验和洞察力。测试在这个时候能起的作用就是提供数据和事实来帮助项目管理者作出正确的决定。
软件测试报告的主要内容:
第一:软件成熟度的定量评估
第二:测试用例通过率和不通过率
第三:软件成熟度的变化趋势
第四:今后可能的问题和成熟度走向(开发进行中,添加一些新的不稳定模块)
第五:严重问题的列表
第六:一些关键问题的风险评估
在接下来的文章中,我将从6个方面讲一讲如何进行性能测试,以下观点是我们根据多年经验的总结,如有问题,欢迎拍砖。
一、性能测试提前准备关注点
1、性能测试的环境配置需要能够尽可能的模拟版本的现场使用,包括外网的设备,软件网元,各种硬件平台,操作系统,软件平台;
2、性能测试需要准备合适的模拟脚本来尽可能全真的模拟客户可能的操作,比如同时并行网页操作,同时进行socket连接等。而且要超出客户的真实可能情况。
二、性能测试需要出两类数据
1、基准测试对比数据:比较本版本和前一版本的性能指标的情况。用以发现本版本的功能合入是否影响了基准的性能。基准测试的情况下,本版本的新增功能和特性默认都是不打开的,保持和前一版本一致。
2、单个功能的性能对比数据:验证本版本中,新增的功能和特性打开的时候,此功能对于版本的性能的影响。
三、性能测试过程关注点
1、资源的占用情况:查看资源的使用情况。资源包括CPU,内存,硬盘等。
2、资源的释放情况:查询系统在业务处理停止后是否可以正常的释放资源,以供后续业务使用。按道理业务停止,资源应该及时释放。常见问题,内存泄露,资源吊死,导致系统不能正常释放资源,严重情况导致宕机。可以用很多工具来检测资源情况。
3、异常测试:性能测试的情况在一定的话务(一般是模拟现场的用户)的情况下,进行硬件倒换,双机倒换,业务切换等。包括破坏性的输入接入来验证系统在高负荷情况下的容错性。
4、查询告警等信息:一般系统都会在出问题的时候,进行通知和告警,这些信息是暴露问题的最好手段,性能测试需要及时查看。
5、长时间运行:性能测试是模拟设备长时间的运行,这个是很好的检查版本在外场测试的手段。可以检查出很多跟时间,定时器等相关的积累效应的故障。
6、日志检查:性能测试需要经常的分析系统的日志,包括操作系统,数据库,软件版本等日志。
7、查看业务响应时间:长时间的测试后,查看业务响应的时候是否在客户可以接受的范围。比如网页的响应时间,终端登录时长等。
四、性能测试的人员要求
1、性能测试的人员必须是骨干,不能使用新人进行性能测试。
2、性能测试的人员必须对全系统非常熟悉,对于问题定位手段使用熟练。能够牵头带领开发人员进行性能相关的问题排查。
五、性能测试报告
1、性能测试报告要体现基准性能数据,单个功能的性能数据。用于评估版本是否可以在原有的硬件环境下保持同样的处理能力。
2、性能测试报告需要满足各个测试利益相关者的要求。所以性能测试进行前需要获得测试利益相关者的要求,做成明细表,然后再开始性能测试。
六、性能测试的工具要求
1、性能测试必须有一定的工具准备,包括LR等 。很多产品的性能测试需要自研性能测试工具,工具的最高境界是可以全真的模拟客户的操作。 特别说明,LR仅仅是一种工具,而性能测试是一套理论和方法。
2、性能测试工具使用过程中,需要搀和手工操作。比如模拟客户购物的网购动作。工具和手工需要有效结合。用以弥补工具的某些不可预知的不足。
版权声明:本文出自山东省软件评测中心 张凯丽,51Testing软件测试网原创出品,未经明确的书面许可,任何人或单位不得对本文进行复制、转载或镜像,否则将追究法律责任。