
首先这个ptotocol是指应用层的协议,是你的客户端使用什么协议访问你的服务器server。
在选择protocol遇到困难时,说明我们在学习LR的过程中,至少存在两个方面的问题:
1、对LR的工作原理认识不清。
LoadRunner属于应用在客户端的测试工具,在客户端模拟大量并发用户去访问服务器,从而达到给服务器施加压力的目的。所以说LoadRunner模拟的就是客户端,其脚本代表的是客户端用户所进行的业务操作,即只要脚本能表示用户的业务操作就可以。
2、网络通信的基础知识不牢。
不了解这个协议的选择原则,不了解被测试系统的总体架构。
说到通信协议我们来熟悉一下协议的分层,按照OSI的分层模型,分层结构如下:
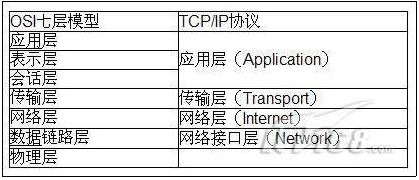
按照TCP/IP协议的分层,分层结构如下:
第一个分层是由OSI制定但不实用,后一个是目前广泛运用且被业界认做既定标准的协议分层,下文探讨的LoadRunner协议选择即按TCP/IP协议的分层模型讨论。
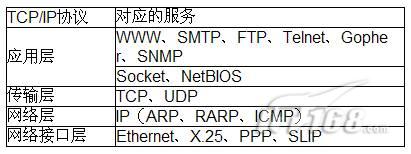
接着来说说LoadRunner-VuGen中的协议分类,VuGen(LR8.1)中的协议分类如下表所示:

那现在来说说如何解决问题,首先,你要通过一定的渠道来了解测试对象的应用层通信协议:
1、通过询问开发人员获知所运用的协议,通常这是最基本也是最直接的要领 ;因为没有人比开发人员更清楚他们所开发的运用 程序运用的什么通信协议了;
2、通过概要或细致设计手册获知所运用的协议,在没有开发人员支持的情况,通过概要设计或细致设计获知所运用的协议不失为第二简便要领 ;
3、通过协议分析工具捕包分析,然后确定被测对象所运用的协议。在运用协议分析工具分析协议流程当中一定要摒除底层协议,不要被底层协议所迷惑;
4、通过以往测试体会确定被测对象所运用的协议,当然通过这种要领确定的协议有一定的不准确性;
其实也可以尝试用多种协议来分别录制脚本,看哪些是成功的,哪些录制的脚本内容为空。录制成功的,也可以比较一下脚本的差别。
最后来说一说选择脚本的一些基本原则【转载】:
B/S结构,选择WEB(Http/Html)协议;
C/S结构,可以根据后端数据库的类型来选择,如SybaseCTLib协议用于测试后台的数据库为Sybase的运用 ;MSSQLServer协议用与测试后台数据库为SQL Server的运用 ;对于一些没有数据库的Windows运用 ,可选用Windows Sockets底层协议;运用了数据库但运用的是ODBC连接的数据则选择ODBC协议;
对于有些运用纯JAVA编写的C/S结构的东东,采用JAVA,而且不能录制只能手工编写代码(工作量和难度还是有的)。同样不能录制的还包括C、VB Script、VB、VBNet User协议。
对于Windows Sockets协议来说,最适合的那些基于Socket开发的运用 程序;但是由于网络通讯的底层都是基于Socket的,因此几乎所有的运用 程序都能够通过Socket来录制,哪可能有人会问,哪既然Socket都能录制下来,还要那么多协议做什么,价格还贼贵,其实最主要的原由就是Socket录制的代码可读性较差,如果Socket的脚本可读性较高的话,实话就没有其他协议出现的必要性了。
对于邮件来说,首先要看你收邮件的途径,如果你通过WEB页面收发邮件,毫无疑问,你选择协议时就须要选择HTTP协议,如果你通过邮件客户端,像OutLook、FoxMail之类的,则须要根据操作不同选择不同的协议了,例如发邮件你可能要选择SMTP、收邮件你可能须要选择POP3。
前言
无线产品线的很多模块基本上都属于前端类型,前端模块一般具有如下几个特征:接收处理用户请求,本身不维护数据,从后端模块获取数据,进行build页面后展示给用户。

从图示可以看到,针对前端测试,我们需要根据手机特性,针对用户和前端的输入输出进行针对性的测试。
问题及解决方法分析
目前wap前端测试采用的方法有如下几个:
对于build页面的系统逻辑部分的case,采用自动化方式进行测试
对于页面展示部分的case,使用能够支持wml和xhtml页面的pc浏览器(比如opera或者安装了wmlbrowser的firefox)进行测试
对于前端页面的重大调整,比如尝试使用新的页面元素,采用真机或手机模拟器的方式进行,但主要偏重于验证是否由于新元素的使用引入了兼容性问题
由于真机测试的效率得不到很好的保证,且手机浏览器比pc浏览器种类纷繁复杂(包括手机内置浏览器及第三方开发的浏览器),难以依靠几款手机或浏览器进行覆盖,因而在wap前端测试中采用真机进行的比较少。测试中比较多的采用pc浏览器进行模拟,而手机和pc浏览器之间又存在较多的差异性,给wap的前端测试带来了诸多bad case甚至bug。
从输入角度
由于手机提交请求的差异性,比如部分手机提交不符合http协议规范的header,给无线的前端测试带来了诸多的问题,典型示例如下:
发现由于某些手机提上来有key没value的header字段而使web server抛出异常而处理失败。
前端架构升级项目,web server上线过程中发现部分手机发送的get请求携带content-length=0,web server对于此类不符合http协议规范的请求直接抛弃而拒绝服务。
为了避免以后再出现类似问题,我们考虑的解决办法是:收集并分析用户请求的差异性,形成case库及参考文档,供以后测试参考。
从输出角度
目前wap页面包括wml和xhtml两个版本,由于手机浏览器的兼容性没有pc浏览器的兼容性好,经常可能会由于一些小的语法错误导致页面无法正常显示,典型示例如下:
页面中url参数的&符未转义
由于手误,在从xhtml版本修改为wml版本时带入了不支持的标签
这种问题往往用pc浏览器比如ff不容易发现,而依靠真机或者手机模拟器测试又不够高效。针对这一问题,我们的解决思路如下:首先保证我们的wap页面是符合规范的;在我们符合规范的情况下尽可能的收集bad case并予以规避。
改进实践
手机header数据仓库
整个数据仓库形成思路如下:
步骤1:首先不依赖于web server,编写socket server,通过日志得到请求
步骤2:其次分析header的key类型,给出key集合,并对出现概率较高的header查阅资料给出解释,形成参考文档
步骤3:再次针对每种key,工具生成value取值集合,并结合含义给出等价类划分,从而形成case库
针对步骤2,收集用户header,脚本分析得到不同的header集合。对于数量过万的header集合,即在用户请求中出现的比例大于1/1000的header,整理并形成参考文档。
针对步骤3,对于步骤2整理出来的100中key,分析线上引流数据生成其value取值,去重后得到的value全集,见附录。对于其中重要的key,划分其等价类集合。
wap页面规范性校验库
如何保证wap页面是符合规范的,就需要按照标准wml和xhtml的规范进行页面检查。wap页面规范性校验库包括如下两个步骤:
步骤1:总结目前使用的页面标准规范,形成参考文档
步骤2:封装开源xml校验库,集成到自动化框架中
针对步骤1,目前wap页面包括wml和xhtml版本,wml基本上都是”wml_1.1.xml”,xhtml基本上都是”xhtml-mobile10.zip”,整理其相应的规范内容见下表。
针对步骤2,调研目前开源的xml语法校验工具,比如http://validator.w3.org/,将开源的校验库封装成工具,且集成到自动化框架中,方便的进行调用,提高测试效率和覆盖率。目前实现为基于java语言,采用dom4j开发了wml&xhtml语法校验库,根据页面申明的dtd进行检查。之所以采用dom4j主要因为其是非常优秀的Java XML API。
另外由于wise页面采用的dtd规范基本一致,例如wml基本上都是”wml_1.1.xml”,xhtml基本上都是”xhtml-mobile10.zip”,因而采用dtd本地保存的方法,加快执行速度。封装到wise-test后,使用非常简单,case中只需调用check_validation(url),即可实现对指定url的语法检查。在升级项目中,对该工具进行了实践检验,基本上每个页面的自动化case都进行了语法检查,发现了在两个wml页面引入xhtml标签导致的页面解析失败问题。
(全文完)
1、概述
监控,在检查系统问题或优化系统性能工作上是一个不可缺少的部分。通过操作系统监控工具监视操作系统资源的使用情况,间接地反映了各服务器程序的运行情况。根据运行结果分析可以帮助我们快速定位系统问题范围或者性能瓶颈点。
nmon是一种在AIX与各种Linux操作系统上广泛使用的监控与分析工具,相对于其它一些系统资源监控工具来说,nmon所记录的信息是比较全面的,它能在系统运行过程中实时地捕捉系统资源的使用情况,并且能输出结果到文件中,然后通过nmon_analyzer工具产生数据文件与图形化结果。
nmon所记录的数据包含以下一些方面(也是我们在寻找问题过程中所关注的资源点):
● cpu占用率
● 内存使用情况
● 磁盘I/O速度、传输和读写比率
● 文件系统的使用率
● 网络I/O速度、传输和读写比率、错误统计率与传输包的大小
● 消耗资源最多的进程
● 计算机详细信息和资源
● 页面空间和页面I/O速度
● 用户自定义的磁盘组
● 网络文件系统
另外在AIX操作系统上,nmon还能监控到其他的一些信息,如异步I/O等。
2、下载安装nmon
如何获取nmon呢?我们可以在IBM的官方网站上免费下载获取,下载网址为:http://www.ibm.com/developerworks/wikis/display/WikiPtype/nmon。
nmon的安装步骤如下:
1)用root用户登录到系统中;
2)建目录:#mkdir /test;
3)把nmon用ftp上传到/test,或者通过其他介质拷贝到/test目录中;
4)执行授权命令:#chmod +x nmon。
3、nmon数据采集
3.1 数据采集
为了实时监控系统在一段时间内的使用情况并将结果记录下来,我们可以通过运行以下命令实现:
#./ nmon -f -t -s 30 -c 180
n -f:按标准格式输出文件:<hostname>_YYYYMMDD_HHMM.nmon;
n -t:输出中包括占用率较高的进程;
n -s 30:每30秒进行一次数据采集
n -c 180:一共采集180次
输入命令回车后,将自动在当前目录生成一个hostname_timeSeries.nmon的文件,如果hosname为test1,生产的文件为:test1_090308_1313.nmon。
通过sort命令可以将nmon结果文件转换为csv文件:
# sort -A test1_090308_1313.nmon > test1_090308_1313.csv
执行完sort命令后即可在当前目录生产test1_090308_1313.csv文件。
3.2 生成图形化结果
为了分析nmon监控获得的结果,IBM还提供了相应的图形化分析工具nmon_analyser,通过nmon analyser.xls工具可以把监控的结果文件转换成excel文件,方便分析系统的各项资源占用情况。
nmon analyser.xls工具的使用方法如下:
(1)打开nmon analyser.xls工具;
(2)调整excel宏安全性:工具-宏-安全性
(修改安全级别与可靠发行商)
(选择)安全级别:低
(勾上)信任所有安装的加载项和模板
(勾上)信任对于“Visual Baisc项目”的访问
(3)修改完后,确定-关闭nmon analyser.xls,重新打开;
(4)点击Analyse nmon data按钮,加载之前下载的test1_090308_1313.csv文件。
以下是分析结果的截图:

以上就是nmon的简单描述与使用介绍,大家可以根据自己所采集到的结果分析系统的情况。
在软件项目的开发过程中,需求管理贯穿了软件项目的整个生命周期,在软件项目管理中需求工程是软件开发的第一步,是关键的一步,也是最难把握的一步。需求管理做得好坏直接影响到软件的质量,甚至软件项目的成败。从软件的项目立项、研发、维护,用户的经验在增加,对使用软件的感受有变化,以及整个行业的新动态,都为软件带来不断完善功能、优化性能、提高用户友好性的要求。
在项目管理过程中,项目经理经常面对用户的需求变更,如果不能有效处理这些需求变更,项目计划会一再调整,软件交付日期一再拖延,项目研发人员的士气将越来越低落,将直接导致项目成本增加、质量下降及项目交付日期推后。这就决定了项目组必须拥有需求管理策略和有效的落地。
让我们一起来回顾一下实际研发过程中,通常会面临到的需求管理挑战:
1、缺乏需求的集中管理
按照需求工程的说法,在进入开发环节之前,开发团队和客户之间需要形成一份完整的需求规格说明书,详细地说明目标软件的各种需求,这其中包括功能性需求、非功能性需求和其他各种约束。在典型的瀑布模型中,需求规格说明书是在需求分析阶段完成的。然而,由于软件外部环境的变化,很少有哪个项目在需求分析阶段就能将所有可能的需求准确无误地包含进来,并且在开发阶段不需要修改,一句话,需求的变更是不可避免的。需求的变更也需要及时地反应到需求管理中。
除此之外,在实际的敏捷软件开发中,对开发而言,需求的来源不一定像瀑布模型那样完善的需求规格说明书,而通常有以下几种:
1)客户初始的业务需求:很多客户可能只会告诉我们,它想做一个系统或者工具平台,大致是什么样子,应该具备哪些功能,但这种需求往往比较抽象,缺乏细致的分析。这种需求可能源自于一次交谈,或者一封Email,形式上并不正式。
2)客户对项目快速原型的反馈意见:对于需求,在实际项目开发中,客户关注的业务功能,项目经理关注的是抽象设计,而开发人员关注的却是具体实现。在项目初期,客户往往也不是很清楚他们要什么,或者理想中的产品到底最后会是什么样的,界面布局,操作流程等等。这一点,在新产品的开发中尤为明显。
这时候,就需要开发团队能够按照现有的理解快速地开发一个原型,作为开发团队和客户讨论和分析需求的共同基础,原型能够帮助用户更好地发掘和定义需求。客户对于原型的论证作为反馈意见也可以使开发团队更加直观和感性地认识客户的需求。
3)客户对每个迭代周期发布的版本的修改建议
如果该企业采用的是敏捷开发,每个迭代周期都要发布一个可用的版本给客户,该版本尽可能多地实现了当前迭代周期内的需求以及之前迭代周期内遗留下来的需求。客户要验证需求的实现是否符合他们的要求,并提出修改意见和建议。
4)客户在研发周期中的需求变更
需求来源的特殊性决定了软件开发过程中需求管理的特殊性,尤其是对于一个同时承担数个小项目的开发团队而言,不同的项目需求是由不同的开发人员或QA分别进行管理和跟踪的,缺乏集中的管理,对于需求的跟踪也比较原始。往往是手工整理需求邮件和需求列表,然后形成简单的需求文档,在需求查询和状态维护方面存在明显不足。
2、需求变更频繁
软件开发的显著特点之一就是灵活性、机动性、对变化的快速响应能力。尤其是敏捷开发过程,需求变更更为频繁。敏捷开发的口号是拥抱需求变化,也就是说,开发团队对于客户提出的需求变更通常是抱以欢迎的态度,尽管这些变更可能会给项目计划和项目进度带来麻烦,但这种观念上的转变更能体现开发团队和客户之间合作的诚意。
客户在迭代周期中的变更大致可以分为五种类型:添加新需求、删除本次迭代周期内的需求、删除之前迭代周期内的需求、更改本次迭代周期内的需求、更改之前迭代周期内的需求。这就是说,开发团队需要实时高效地管理这些变更,并且将需求变更涉及到的迭代周期内项目计划和人员安排变更的影响最小化。
3、缺乏有针对性的需求管理流程
传统的需求管理过程,尤其是其中的变更控制过程是针对那些组织机构清晰,只能定义明确的传统软件项目,其流程相对比较严谨和死板。同时,为了弥补需求变更对项目进程带来的影响,开发人员常常需要快速的进行功能修改和增加,而没有遵循统一的流程控制,从而常常使得软件开发的有序性被破坏,人为地增加了工作量。这就需要有更为高效和精简的需求管理过程以及相应的工具支持。
4、需求、测试用例、Bug管理脱节
软件开发中,需求和测试用例是紧密联系的,通常来说,一条需求只有通过了所有针对该需求的测试之后才能说这条需求的实现真正实现了。而测试的结果是产生Bug报告,如果针对某条需求的一个测试用例没有通过测试,换句话说,也就是产生了一个Bug,这就说明该需求根本没有完成。同时,需求的变更直接影响到与该需求相关的测试用例的更新,继而影响到现有Bug的状态的更新。然而现实情况却是,大多数敏捷开发团队都没有实现需求、测试用例和Bug的一体化管理。
我们希望在需求、测试用例和Bug之间建立一种动态的联系,能够实时地更新三者的状态,并且实现三者之间状态的动态联动,从而减少开发团队在管理和维护需求、测试用例和Bug时的工作量。
5、缺乏量化的项目管理反馈
企业在项目管理中,需求的频繁变更对项目管理者评估需求、制定迭代周期内的项目计划都是个巨大的挑战。管理者在需求评估经验和能力上的不足,以及管理者对团队成员开发能力认识不足容易造成需求评估出现大的误差,虽然这种误差是不可避免的、但是我们希望可以通过历史评估数据的反馈来帮助项目管理者积累经验,逐步修正和调整自己的判断和评价体系,从而尽可能减小由于评估误差引起的项目风险。而没有工具的支持,历史的准确数据则很难获取。
总结以上问题,显而易见,需求管理是软件项目中一项十分重要的工作,据调查显示在众多失败的软件项目中,由于需求原因导致的约占到45%,因此有效的需求管理是企业软件开发项目顺利达成目标的重要支撑条件。如何理解项目开发的目的和用途,梳理用户需求,监控需求变化,进行需求确认,对需求风险进行防范,并利用工具进行有效的实施需求管理工具,方能推进软件项目良性发展,达到用户与软件开发企业的双赢。
有效的需求管理方法与工具
方法一:量化需求管理
如前所述,企业研发项目通常规模巨大,涉及部门众多,需求功能描述文件中包含众多内容,若仅仅只用整篇的文档来指导开发和测试工作,很容易引起任务分配的混乱;当发生需求变更时,也很难追溯历史版本。
TechExcel公司推出的DevSuite产品研发管理软件,从实践中提炼出一个行之有效的解决方法——用规范点(Specification,以下简称Spec)量化需求,正规表达每一个功能单元。只需打开《需求功能描述书》的WORD文档,就可以利用插件,将其中的功能单元逐条地复制出来,在需求管理系统 DevSpec中直接生成Spec。相对于需求,Spec是更面向技术人员的语言。
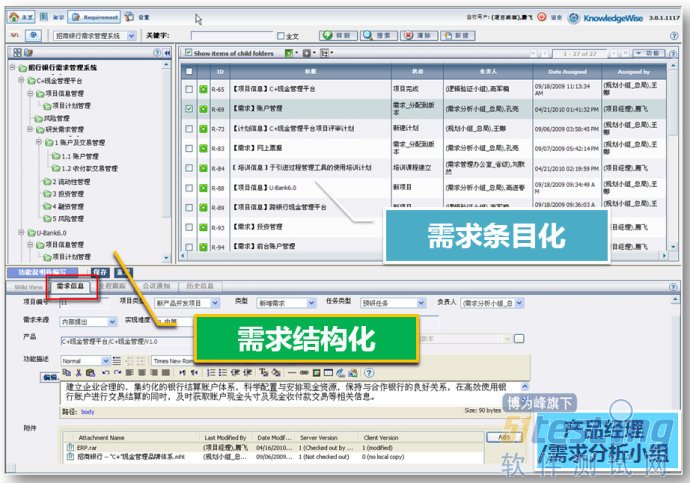
客户业务需求可以在平台中进行集中管理,并以需求结构化和条目化的形式管理需求,为需求的评估、追踪与变更管理提供了基础。同时,通过系统强大的页面自定义能力,我们可以管理需求的来源、难度、实现时间、实现成本等,这些信息为需求优先级的评估,提供了量化的指标,帮助项目经理准确的排布需求优先级,让团队优先实现最重要、最紧急、客户价值最高的需求。
此外,需求说明书、分析设计文档、评审记录等,均可以以附件形式保存,且能对文档的版本进行有效的管理。
方法二:有序管理需求变更
在实际项目中,实现需求变更的成本随着开发进度呈指数级增长。需求变更的流程化管理能保障正常的开发进度,将变更及时反应到开发和测试等部门。
以下描述的是一个典型过程(如图1)。一项变更请求在需求管理系统中被提交后,与之关联的各个部门,如市场、项目管理、产品研发、QA、测试等,都会有相关人员接到系统通知而介入。他们将组成评估团队,根据实施难度、周期、费用、对其他机制的影响等指标,对该变更进行全面考察和评估。
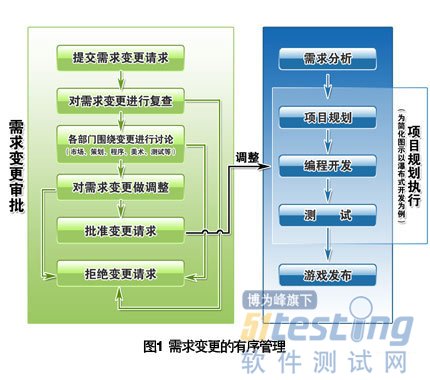
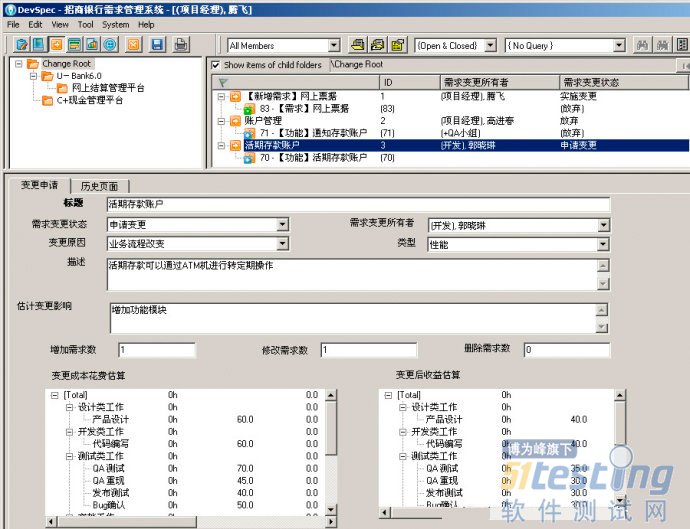
DevSpec提供了专门的变更管理视图,在这里,我们可以管理各个项目中的需求变更任务,不论是需求增加、减少或是改变,我们都会为之建立一条变更记录,在这条变更记录中,记录了变更的来源、原因、具体描述和变更成本、收益估算,这些信息可以成为变更评估的标准与依据。
每个变更任务均可以和在变更中受影响的需求相关联,包括增加的、减少的和变更的需求。通过需求变更列表,我们可以清晰的看到项目中当前有多少变更任务,影响了哪些需求,也能够察看到整个项目周期中总计发生了多少变更,总计影响了多少需求条目。
方法三:标准的需求管理流程
需求管理的整个过程都可以用标准、有效的工作流控制起来,如需求变更流程的设定,通常包括请求、复查、讨论、调整、批准和拒绝等状态,只有具备权限的项目成员才能改变状态。按照预设的流程,各方审批全部通过后,该变更才能被接受。
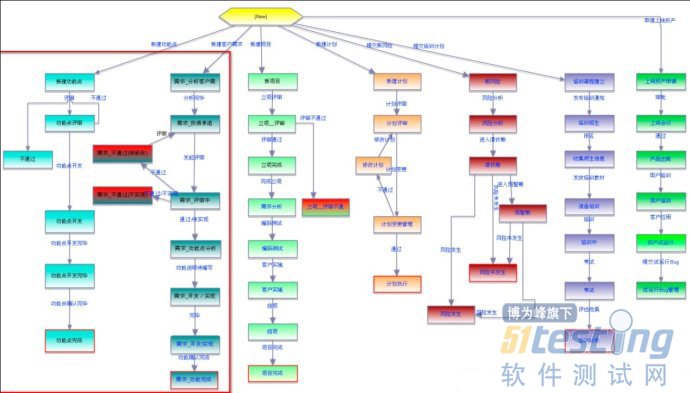
DevSuite提供了灵活的工作流程定制和管理能力,图形化工作流引擎将工作流图形转变为工作流脚本,因此项目管理员可以在图形化界面中,轻松快速的定制项目组项目管理流程。
如上图中红色框内为需求的工作流程,用户可以根据公司的实际业务流程,定制符合需要的需求流程图,系统可以同时定义多条项目工作流程,以适应不同规模、不同类型的项目。
方法四:需求有效驱动开发与测试
在理想的研发管理平台中,需求管理与所有规划、开发、测试管理过程相集成。因此,需求的正规表达Spec,以及围绕Spec正在或将要进行的开发任务和测试任务,都能被纳入综合考虑的范畴,便于评估团队估算该变更造成的“牵一发而动全身”的潜在影响。有时,还要结合商业需求进行考量,为了赶上产品的最佳发布时机,有些变更将被拒绝。
变更请求被批准后,与之相关联的开发、测试任务都会在系统中被一一标记出来,以提醒程序和测试部门的相关负责人,引发这些任务的需求已经变更,请他们做出相应的调整处理。在系统中跟踪这些任务的进展,可以实时掌握该变更的落实情况。变更完成后,也可以核算它对开发周期和费用的实际影响,与评估时的预测相对比,找出差异的原因,为将来更准确地评估提供参考。
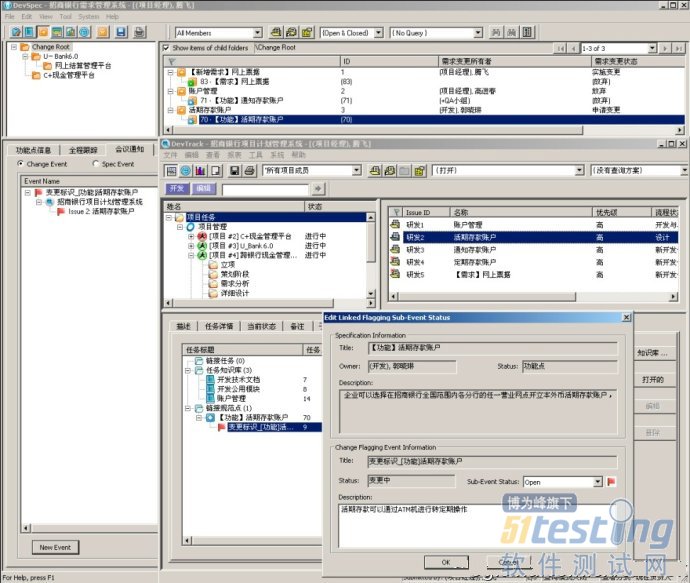
DevSuite提供了变更标识功能,通过变更标识子任务,我们可以选择受影响的开发、测试任务,建立变更标识子任务,该子任务将以旗帜形式反映到开发、测试任务中。变更标识子任务不但能够标识变更,还能够帮助团队进行变更反馈,通过文字记录和状态改变,任务负责人员可以将需求变更对于任务的影响及时回馈给需求管理人员。另外,对于需求实际改变的内容,需求负责人员可以创建变更推送子任务,通过邮件系统,可以将变更信息发送给该需求的干系人。
方法五:需求指导项目规划与执行
纵使项目最初都有比较全面的计划,延期仍然会时常发生,即便是在管理机制比较成熟的大型研发企业中,跳票也不可避免。通常情况下,导致跳票主要有以下几点原因:功能设计规划过多,很多又无法删除,如不增加开发时间,产品几乎不能完成;缺乏有经验的管理或开发人员,不能准确估计工作量;任务执行缺乏规范,开发人员随意更改功能设计,影响整体进度;过高的人员流动率,导致知识的流失,任务不能及时跟进。
针对以上问题,只要从量化需求入手, 有序管理需求变更,用正规表达、可量化的Spec来指导项目规划、编程和测试,就能把风险降到最低。
基于结构化的Spec集合,可以将项目分解为多个子项目,将Spec直接分配到各自对应的子项目中,以此来规划和估算子项目的工作量。项目管理人员为每个子项目分配资源,安排优先顺序,确定项目里程碑。
在项目执行时,可以为每一个Spec产生出一系列开发任务。自定义的工作流机制确保每一个任务从提交到最终解决的生命周期都严格符合业务流程,保证任何时刻都有唯一的负责人、状态和截止日期。这样,不仅能规范产品研发过程,还能降低人员流动带来的风险。任务的流转及相关知识文档,如源代码、设计资源等,都得到系统完整的记录,还能与任务关联,便于追溯。一旦有人离开项目,接替的人员能够查看任务和文档信息,迅速弥补人员空缺。
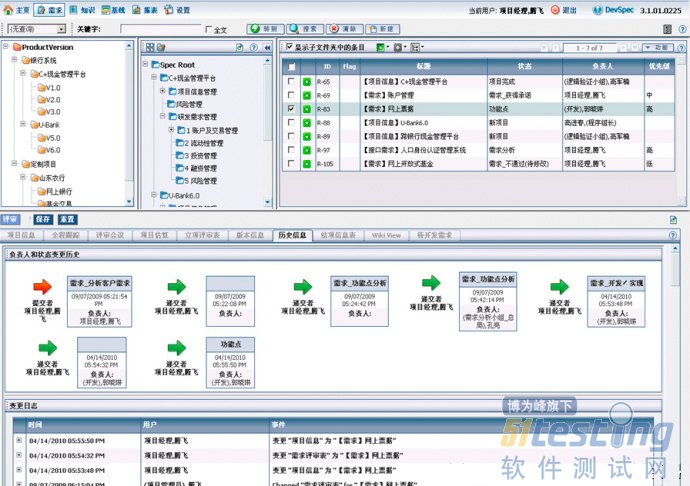
DevSuite需求管理视图提供产品版本树管理,产品经理可以创建新产品和版本,每个需求和功能点可以在多个产品和版本实现。通常一个产品的各个功能可能会分布在不同的项目中实现,项目经理如何在产品发布的时候知道每次发布实现了那些功能,各个功能点的负责人是谁,通过DevSpec视图提供的产品版本树功能,项目经理可以轻松的过滤出每个发布版本实现了那些客户需求。
支持产品的版本规划,当收集到的需求经过评审等规定流程决策后,将需求与规划好的产品版本关联起来,通过产品版本视图可以直接追踪到需求与产品版本的关系,未决定开发的需求可以不设定版本,等决定后再关联相应产品版本。
以上所述的需求管理经验和系统工具的支持,希望与大家共同分享与探讨,探索出一条以有效的需求管理推动项目执行、产品研发整个生命周期的最佳途径!
开发过程的质量决定了软件的质量,软件测试过程的质量同样决定了软件测试的质量和有效性。软件测试在软件质量的保证环节起着至关重要的作用,在文献中定义了软件评价过程模型,这是国际上共同遵守的软件评测过程标准。但是在软件测试过程中,测试用例的设计、测试执行过程中的人员都对测试结果有很大的影响。如何约束这些可变因素,量化测试过程的有效性,辅助改善测试过程、使测试过程变得更为有效,是目前软件测试过程中有待解决的问题。针对上述问题,本文提出了一种基于缺陷驱动的测试过程有效性的评价方法,该方法通过统计系统上线后一定周期内(建议统计时间高于3个月,小于12个月)客户反馈的系统缺陷数结合测试过程中发现的缺陷数进行测试执行过程和测试用例设计过程的评价,从而达到对测试过程有效性评 价的目的。
1、 软件测试过程及相关评价方法
1.1 软件测试过程
软件测试是一个为了找出错误而执行程序/系统的过程。它强调软件测试是一个找错的过程,而不仅仅证明系统是可以运行的过程。软件测试过程包括了计划、执行、检查、改进,其主要具备了可重复性、可再现性、公正性和客观性等特性。
1.2 缺陷探测率
缺陷探测率(Defect Detetion Percentage,缩写 DDP),是衡量测试工作效率的软件成本的重要指标之一。计算方法如下:

其中,Bugstester是软件测试过程中发现的错误数,Bugscutomer是客户方发现并反馈给技术支持人员并进行修复的错误数。DDP越高,说明测试过程中发现的问题数量越多,发布后客户发现的问题越少,这样就降低了外部故障不一致的成本,测试过程有效性高。
1.3 六西格玛质量评价方法
σ(西格玛)是希腊文的字母,在统计学中称为标准差,用来表示数据的分散程度。六西格玛是由GE从一种全面质量管理方法演变成为一个高度有效的企业流程设计、改善和优化的技术,并提供了一系列同等地适用于设计、生产和服务的新产品开发工具。在软件质量评价方面,六西格玛方法也得到了广泛的应用。六西格玛改进的标准流程(DMAIC)分为定义、测量、分析、改进和控制五个阶段。其中西格玛水平与软件质量评价如下表:
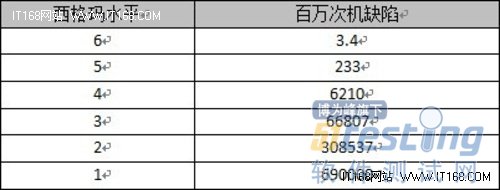
▲表1 西格玛水平业绩
由于任何检验、验证手段都不可能发现并排除所有缺陷,因此测试过程的有效性达应用六西格玛的99.997%,那么测试过程就是可信的、有效的。
2、基于缺陷驱动的软件测试过程有效性效性评价方法
2.1 测试执行过程缺陷遗漏率
测试执行过程的好坏主要有测试计划、测试执行过程和测试记录等阶段决定。在测试执行过程中,完全的测试是不可能的,测试需要终止。因此在测试过程中,能够发现全部的缺陷是不可能的,必然会有一部分遗漏。从而将一些问题暴露给用户,从而影响用户的满意度、易用性。但是在测试过程中评价一个测试过程的有效性是很困难的,但是通过一段时间的系统上线应用,统计用户反馈缺陷数目,进而比较容易评价测试过程的有效性,就如同2.2节中缺陷探测率的方法。但是缺陷探测率的评价方法仅仅只是通过缺陷数目来决定测试过程的好与坏,这仅仅停留在测试结果的评价阶段,却没有覆盖的整个测试过程。因此在缺陷探测率的基础之上,本文提出一个测试执行过程缺陷遗漏率(Test-Process Lose Defect Percentage,缩写PLDP)的概念。同时在这之上加入了缺陷严重程度的约束条件。其中缺陷严重程度大体分为如下:
严重程度1(致命的):软件产品在正常运行环境下无法继续为用户提供服务,并无其他工作方式满足同样功能,或者软件产品失效后造成人身伤害或者危机人身安全。
严重程度2(严重的):极大的影响软件产品提供给用户的服务,或者严重影响系统要求或基本功能的使用。
严重程度3(一般的):软件产品功能需要增强或者存在缺陷,但是存在对应的补救方法解决。
严重程度4(轻微的):细小的问题,不需要补救方法或者功能增强,或者操作不方便,容易导致用户误操作。
不用缺陷严重程度,将其定义为不同的权重值分别为w1=5代表严重程度1、w2=3代表严重程度2、w3=2代表严重程度3和w4=1代表严重程度4。按照缺陷严重程度计算出带有缺陷严重程度权重的缺陷基数(Defect Base Numbers,缩写DBN),定义如下:
其中wi为上述的各个严重程度的权重, 代表对应缺陷严重程度的缺陷数。
因此可以定义PLDP如下:

其中,DBNInTCcostomer是客户方发现并反馈给技术支持人员的错误并且该已被设计的测试用例覆盖的错误数计算出来的缺陷基数。DBNInTCcostomer是软件测试过程中发现的缺陷数计算出来的缺陷基数。测试执行过程缺陷遗漏率是用来软件测试过程中测试执行及其之后阶段的评价方法,测试用例覆盖到的缺陷,在测试执行过程中并未发现,是测试工程师执行测试用例时出现的问题。PLDP越小,测试过程中的测试执行过程有效性越高。
2.2 测试用例丢失率
测试用例的设计处于测试过程中的上游阶段,是测试执行的基础。测试用例的设计过程覆盖了测试计划、测试规格说明书等测试过程阶段。但是如何评价测试用例设计的优劣目前还无很好的办法。因此针对上述问题,本文提出测试用例丢失率(Test-Case LosePercentage,缩写TCLP)来评价测试用例的优劣程度。定义如下:

其中,TestCasedesign是有客户方发现并反馈给技术支持人员的错误并且被测试用例覆盖的测试用例数。是软件测试过程中设计的测试用例数。测试用例丢失率是用来评价测试过程中,测试用例设计及其之前阶段的评价方法。客户发现的问题测试用例并未覆盖到,是测试计划、测试规格说明书和测试用例设计阶段问题。TCLP越小,测试过程中的测试用例设计及其之前的阶段的有效性越高。
2.3 测试过程有效性评价方法
测试过程失效率是由测试执行过程缺陷遗漏率和测试用例丢失率二者进行综合考量的。测试过程失效率(Ineffectivityof Testing Process Percentage,缩写ITPP)定义如下:
ITPP =(PLDP+TCLP)/2
测试过程有效性(Effective of Testing Process,缩写ETP)评价方法是通过测试过程失效率进行评价,测试过程失效率越小,测试过程的有效性越高。
ETP = 1-ITPP
对于一个测试项目的测试过程中,测试过程的有效性主要是通过系统上线运行后一定周期内客户发现缺陷数量为统计基础的。由于测试过程也是受各种因素影响,测试有效性达到100%是一个理想值,显示测试过程无法满足。因此本文引入六四格玛理论,当测试有效性达到99.997%时,就认定为测试过程是一个高质量的检测、检验过程;达到四西格玛93%以上99.997%以下,说明测试过程有待改进,但整体测试过程能够基本保证被测软件质量;达到二西格玛68%以上93%以下,说明测试过程不可信,测试结果无参考价值,测试过程必须改进。具体评价结果如下表所示:
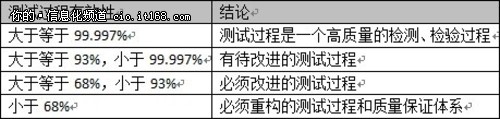
▲表2 测试过程有效性评价结论对比表
3、结论
软件测试过程的有效性决定了测试结果的可信度,保证了软件产品的质量。本文通过分析软件测试过程,将其分成测试用例及其前期阶段和测试执行及其后期阶段,以被测产品上线运行一定时间内客户发现的缺陷和测试过程中发现缺陷为基本出发点,应用测试执行过程缺陷遗漏率和测试用例丢失率对软件过程有效性进行了评价,通过通过引入六西格玛质量评价方法对软件测试过程有效性进行了初步的划分。但是目前该方法仅仅只在部分软件系统中进行了初步的时间,例如对系统上线运行多长时间统计缺陷数等关键参数还需进一步分析研究。
db2look导出ddl 详细用法(转)
DB2的db2look命令诠释如下:
db2look 版本 8.2
db2look:生成 DDL 以便重新创建在数据库中定义的对象
语法: db2look -d DBname [-e] [-u Creator] [-z Schema] [-t Tname1 Tname2...TnameN] [-tw Tname] [-h] [-o Fname] [-a]
[-m] [-c] [-r] [-l] [-x] [-xd] [-f] [-fd] [-td x] [-noview] [-i userID] [-w password]
[-v Vname1 Vname2 ... VnameN]
[-wrapper WrapperName] [-server ServerName] [-nofed]
db2look -d DBname [-u Creator] [-s] [-g] [-a] [-t Tname1 Tname2...TnameN]
[-p] [-o Fname] [-i userID] [-w password]
db2look [-h]
-d: 数据库名称:这必须指定
-e: 抽取复制数据库所需要的 DDL 文件
此选项将生成包含 DDL 语句的脚本
可以对另一个数据库运行此脚本以便重新创建数据库对象
此选项可以和 -m 选项一起使用
-u: 创建程序标识:若 -u 和 -a 都未指定,则将使用 $USER
如果指定了 -a 选项,则将忽略 -u 选项
-z: 模式名:如果同时指定了 -z 和 -a,则将忽略 -z
联合部分的模式名被忽略
-t: 生成指定表的统计信息
可以指定的表的数目最多为 30
-tw: 为名称与表名的模式条件(通配符)相匹配的表生成 DDL
当指定了 -tw 选项时,-t 选项会被忽略
-v: 只为视图生成 DDL,当指定了 -t 时将忽略此选项
-h: 更详细的帮助消息
-o: 将输出重定向到给定的文件名
如果未指定 -o 选项,则输出将转到 stdout
-a: 为所有创建程序生成统计信息
如果指定了此选项,则将忽略 -u 选项
-m: 在模拟方式下运行 db2look 实用程序
此选项将生成包含 SQL UPDATE 语句的脚本
这些 SQL UPDATE 语句捕获所有统计信息
可以对另一个数据库运行此脚本以便复制初始的那一个
当指定了 -m 选项时,将忽略 -p、-g 和 -s 选项
-c: 不要生成模拟的 COMMIT 语句
除非指定了 -m 或 -e,否则将忽略此选项
将不生成 CONNECT 和 CONNECT RESET 语句
省略了 COMMIT。在执行脚本之后,需要显式地进行落实。
-r: 不要生成模拟的 RUNSTATS 语句
缺省值为 RUNSTATS。仅当指定了 -m 时,此选项才有效
-l: 生成数据库布局:数据库分区组、缓冲池和表空间。
-x: 如果指定了此选项,则 db2look 实用程序将生成授权 DDL
对于现有已授权特权,不包括对象的原始定义器
-xd: 如果指定了此选项,则 db2look 实用程序将生成授权 DDL
对于现有已授权特权,包括对象的原始定义器
-f: 抽取配置参数和环境变量
如果指定此选项,将忽略 -wrapper 和 -server 选项
-fd: 为 opt_buffpage 和 opt_sortheap 以及其它配置和环境参数生成 db2fopt 语句。
-td: 将 x 指定为语句定界符(缺省定界符为分号(;))
应该与 -e 选项一起使用(如果触发器或者 SQL 例程存在的话)
-p: 使用明文格式
-s: 生成 postscript 文件
此选项将为您生成 postscript 文件
当设置了此选项时,将除去所有 latex 和 tmp ps 文件
所需的(非 IBM)软件:LaTeX 和 dvips
注意:文件 psfig.tex 必须在 LaTeX 输入路径中
-g: 使用图形来显示索引的页访存对
必须安装 Gnuplot,并且 <psfig.tex> 必须在您的 LaTeX 输入路径中
还将随 LaTeX 文件一起生成 <filename.ps> 文件
-i: 登录到数据库驻留的服务器时所使用的用户标识
-w: 登录到数据库驻留的服务器时所使用的密码
-noview: 不要生成 CREATE VIEW ddl 语句
-wrapper: 为适用于此包装器的联合对象生成 DDL
生成的对象可能包含下列各项:
包装器、服务器、用户映射、昵称、类型映射、
函数模板、函数映射和索引规范
-server: 为适用于此服务器的联合对象生成 DDL
生成的对象可能包含下列各项:
包装器、服务器、用户映射、昵称、类型映射、
函数模板、函数映射和索引规范
-nofed: 不要生成 Federated DDL
如果指定此选项,将忽略 -wrapper 和 -server 选项
LaTeX 排版:latex filename.tex 以获得 filename.dvi
示例: db2look -d DEPARTMENT -u walid -e -o db2look.sql
-- 这将生成由用户 WALID 创建的所有表和联合对象的 DDL 语句
-- db2look 输出被发送到名为 db2look.sql 的文件中
示例: db2look -d DEPARTMENT -z myscm1 -e -o db2look.sql
-- 这将为模式名为 MYSCM1 的所有表生成 DDL 语句
-- 还将生成 $USER 创建的所有联合对象的 DDL。
-- db2look 输出被发送到名为 db2look.sql 的文件中
示例: db2look -d DEPARTMENT -u walid -m -o db2look.sql
-- 这将生成 UPDATE 语句以捕获关于用户 WALID 创建的表/昵称的统计信息
-- db2look 输出被发送到名为 db2look.sql 的文件中
示例: db2look -d DEPARTMENT -u walid -e -wrapper W1 -o db2look.sql
-- 这将生成由用户 WALID 创建的所有表的 DDL 语句
-- 还将生成适用于包装器 W1 的用户 WALID 所创建所有联合对象的 DDL
-- db2look 输出被发送到名为 db2look.sql 的文件中
示例: db2look -d DEPARTMENT -u walid -e -server S1 -o db2look.sql
-- 这将生成由用户 WALID 创建的所有表的 DDL 语句
-- 还将生成适用于服务器 S1 的用户 WALID 所创建所有联合对象的 DDL
-- db2look 输出被发送到名为 db2look.sql 的文件中
方法一
在控制中心的对象视图窗口中,选择所要导出表结构的数据表,按住Ctrl或Shift可多选,单击鼠标右键,选择->生成DDL即可。
方法二
◆第一步:打开DB2的命令行工具,在DB2安装目录的BIN文件夹下新建一个文件夹data,并且进入该目录。
创建该目录: mkdir data
进入该目录: cd data
◆第二步:导出表结构,命令行如下:
db2look -d dbname -e -a -x -i username -w password -o ddlfile.sql
执行成功之后,你会在刚才新建的文件夹下找到该sql文件。
◆第三步:导出数据,命令行如下:
db2move databasename export -u username -p password
至此,导出数据结束。
2导出表中数据
export to [path(例:D:"TABLE1.ixf)] of ixf select [字段(例: * or col1,col2,col3)] from TABLE1;
export to [path(例:D:"TABLE1.del)] of del select [字段(例: * or col1,col2,col3)] from TABLE1;
导入表的数据
import from [path(例:D:"TABLE1.ixf)] of ixf insert into TABLE1;
load from [path(例:D:"TABLE1.ixf)] of ixf insert into TABLE1;
load from [path(例:D:"TABLE1.ixf)] of ixf replace into TABLE1; // 装入数据前,先删除已存在记录
load from [path(例:D:"TABLE1.ixf)] of ixf restart into TABLE1; // 当装入失败时,重新执行,并记录导出结果和错误信息
import from [path(例:D:"TABLE1.ixf)] of ixf savecount 1000 messages [path(例:D:"msg.txt)] insert into TABLE1;// 其中,savecount表示完成每1000条操作,记录一次.
存在自增长字段的数据导入:
load from [path(例:D:"TABLE1.ixf)] of ixf modified by identityignore insert into TABLE1;// 加入modified by identityignore.
解除装入数据时,发生的检查挂起:
SET INTEGRITY FOR TABLE1 CHECK IMMEDIATE UNCHECKED;
命令只对数据通过约束检查的表有效,如果执行还不能解除,有必要检查数据的完整性,是否不符合约束条件,并试图重新整理数据,再执行装入操作.
另外,对load和import,字面上的区别是:装入和导入,但仍未理解两者之间的区别.
只是性能上load显然优于import.(load 需要更多的权限)
今天跟上海几个公司的测试负责人一起聊起了这个话题。
任何一个事物都是在不断发展、变化的;QA也不例外。QA作为一个行业来说正在发生着变化;QA从业人员的career、skillsets也会有相应的影响和演变。
为什么变,怎么变,什么会变,什么会不变,QA这个行业会怎么样,QA人员的career会怎么样,这写都是大问题;这里讲讲楼主的一些浅见吧:
要讲这写问题,首先看看目前传统的,或者流行的,qa是做什么工作的。
1、做测试和测试管理;功能测试主要,性能测试部分;执行一般来说是手工和自动化结合;
2、组织内的流程管理、驱动流程变革;
3、各个质量环节的metrics制定、验收标准指定、验收等;
4、质量活动相关的工具选型、开发,提供服务,维护;
5、others 。。。
Q:为什么变?
随着项目管理、软件行业的发展,越来越多的聚合在发生。
一个场景:
快速迭代、敏捷开发、极限编程、结对编程等越来越普及,需要测试人员有competitive的能力来一起推动项目前进。这种情况下,测试人员需要detailed来了解design,做code review,。。。,可以看到测试人员做了跟dev人员越来越一致的工作,除了dev人员implement feature 而测试人员design & implement testing;competitive的能力使得这个测试人员在某些情况下可以比较简单的来implement feature,vice versa;
另外一个场景:
项目需要快速上线,开发人员花了半天时间实现了功能,测试人员花2小时做了E-E验证。。。
以上是目前非常typical的两个场景。
场景一,对测试人员的skillset的要求基本跟研发一致,除了要focus一些case design;
场景二,测试人员做的是更加类似于验收测试的工作;更象PM做的
所以会变;
Q:怎么变
个人认为,任何工种都是应该朝着极致的方向发展。QA也不例外;
但是QA怎么变,还是要来看QA做了哪些事情;
一个原则:不管QA怎么变,Dev怎么变,质量相关的事情总归是需要来做的;可能是做的方式上,执行人上,做得时间上,会变化而已
Q:QA会变怎样?
1、QA的测试工作会变
在质量工程的各个环节中,QA不大会再大包大揽,从底层测试到E2E都全部cover;可能性比较大的,测试工作中,相对比较底层的接口功能、性能测试等,会由dev人员来解决;而跨domain的integration testing,还是由QA来实现比较好;而验收测试等,PM会参与更多,QA会做的更少;
2、QA对组织的质量总体贡献
a)质量整体控制。对各个质量活动的监控--怎么做,做到什么程度,metrics是怎么样的,指定流程和执行监控;
b)提供测试框架选型、确定、推广和维护;比如web自动化测试框架,facebook的php自动化测试框架二次开发、维护等;
c)和SCM、Ops合作,release quality、production quality的策略制定和实施;
d)质量相关工具开发、二次开发、维护等;比如测试管理工具,缺陷管理工具;etc.
Q:行业、个人会怎么变?
1、更加专业化;专业壁垒加深;
2、测试架构师
3、测试开发、开发测试
但是不管怎么变,个人认为,质量相关的工作只会越来越重要,投入需要越来越大;因为质量越来越重要。
引言
有次需要测试 50 台左右的设备,每个都要连上电脑并搭好测试环境。这种事当然用服务器下发配置最方便,但条件不允许哦,只得手工一台台设。
写了个批处理配置脚本,放到 U 盘上,最好再配上 autorun.inf,嘿嘿~
备忘脚本
GOTO COMMENT
我是配置网络测试环境脚本
呵呵~
:COMMENT @echo off
title -- 关闭防火墙,设置ip,安装Endpoint --
MODE con: COLS=80 lines=30
color 0A
cls net stop sharedaccess set /p lst_ip=输入 IP 的最后一个字段:
set IP=192.168.0.%lst_ip: =%
echo 设置 ip 为 %IP%
cmd /c netsh interface ip set address name="本地连接" source=static mask=255.255.255.0 addr=%IP%
If Exist "IxEndpoint\setup.exe" (
echo 开始安装 IxEndpoint...
IxEndpoint\setup.exe -s
) Else (
echo 安装文件不存在!
GOTO EXIT ) echo.
echo 设置并安装完毕! :EXIT
pause
exit |
总结
1、set /p var=提示语,手动输入变量值;%lst_ip: =% 为字符串替换,将空格替换为空
if 命令格式: IF [NOT] ERRORLEVEL number command
IF [NOT] "string1"=="string2" command
IF [NOT] EXIST file command
2、setup.exe -s 涉及程序的静默安装,而静默选项则取决于程序的制作格式
用InstallShield技术打包的程序,需要把 setup.iss 文件(安装问答文件)和将要静默安装的程序 setup.exe 保存在同一个目录中,然后 setup.exe -s。
那么,如何判断程序的制作格式? 一般,安装文件的右键属性对话框中应该有“InstallShield (R) Setup Launcher”或者其他类似的字样,说明是InstallShield打包。
有时程序又被压缩了一层,需要解压后才见得到 setup.exe;iss 文件可以去软件的安装目录里找找,一般都有,请认准此后缀。
当在软件领域考虑风险时,作为山东省软件评测中心的技术人员,我想大家应该要关注以下问题:什么样的风险会导致软件项目的彻底失败?软件质量要达到什么程度才是“足够的”?
当没有办法消除风险,甚至连试图降低该风险也存在疑问时,这些风险就是真正的风险了。在我们能够标识出软件项目中的真正风险之前,通过测试识别出对管理者和开发者而言均为明显的风险是很重要的。风险预防便成了全程软件质量保证的重点之一。
在前面的几篇文章中我们也阐述了风险管理的重要性,怎样才能做好风险管理以及预防哪?以下是我们评测中心在测试方面总结的部分经验,希望能给大家带来帮助。
1、测试的尽早介入
测试应该在软件开发生命周期的早期介入,从而保证测试团队更早的完成测试件的准备。这样就可以保证测试对象交付之后,测试团队可以马上开始正式测试。另外,测试团队在软件开发生命周期的早期介入,可以将测试活动,例如:测试分析、测试设计和测试实现等作为静态测试的一种手段,从而可以在早期达到发现缺陷和预防缺陷的目的,避免某些缺陷在高级别的动态测试中才被发现。
2、测试环境的检查
测试团队在测试执行正式开始之前,应该检查测试环境,并保证测试环境可用。在测试环境检查过程中,可以实施另一项风险缓解活动:在正式的测试执行开始前测试早期版本。例如:测试团队在测试正式开始之前验证测试件和测试环境的有效性、测试对象的安装过程,以及其他可能的测试执行过程。假如在测试执行正式开始之后,才发现测试件的质量低下、测试环境无法达到测试执行的要求,将会导致测试执行的延期,从而导致项目的延期。
3、测试入口准则的定义
测试团队面临的一个重要挑战是开发团队经常延期交付测试的软件版本,从而导致测试团队测试执行的延期,或者测试团队在无法更改测试完成日期的情况下,处于过高的时间压力之下。测试团队定义更严格的入口准则,是避免由于测试团队的原因而导致项目延期的有效方法。当然制订严格的入口准则的目的不仅仅是为了保证测试团队的利益,通过这种方式也可以让开发团队认识到交付高质量软件的重要性,从而促进开发团队提交高质量的软件。
4、可测试性的要求
测试团队应该对规格说明中的可测试性问题进行仔细评审,并且提出更加方便测试人员开展测试的需求和要求。例如:在可能的情况下,可以要求开发团队将测试对象的某些输入框,修改为不可修改的下拉菜单(例如:输入框输入的是日期格式)。经过这样的修改之后,在保证软件功能的前提下,测试人员不需要对各种输入格式进行测试,从而可以大量的减少测试团队的测试工作量,并且可以更好的实现测试的自动化。
5、不断进行项目进度和质量监控
测试团队,至少测试经理应该积极参与整个项目的进度以及测试对象质量的监控。测试团队可以更早的参与软件工作产品的评审,例如:需求规格说明。根据在早期评审中发现的缺陷分布和缺陷类型,测试团队可以采取合适的措施和手段,对测试对象中的不同部分进行优先级的划分。另外,测试团队应该积极参与整个项目的缺陷和变更管理。
版权声明:本文出自山东省软件评测中心 张凯丽,51Testing软件测试网原创出品,未经明确的书面许可,任何人或单位不得对本文进行复制、转载或镜像,否则将追究法律责任。
http://www.51testing.com
这两周产品线加速bug收敛速度以来,开发和测试人员陆续的反馈了一些问题,大部分都属沟通类或者细节类。对几种典型问题,测试人员也经过了组内讨论,希望能在细节方面,大家都能注意互相提醒一下,提高产品线的运作效率。
一、resolve的bug,验证不通过,然后把bug进行reject操作----------这个处理过程,会出现一些疑义。
目前测试组进行约定,测试人员验证resolve的bug,未通过验证后,首先要做的是和开发人员进行沟通,而不是直接把bug进行reject操作。(让开发人员给出原因 这样不是更好吗)
bug验证不通过,可能存在很多方面的问题:
1.1 版本编译问题(版本控制)
1.2 多封闭版本提交错误问题
1.3 模块编译和整体编译时间不一致问题
1.4 测试人员版本未更新(指定专人更新测试服务器 或者持续化集成)
1.5 测试人员验证条件不满足,实际bug未得到有效验证。
1.6 开发人员resolve为模块提交时间,和实际版本可获取时间有提前性。
很多时候,bug验证未通过,不是开发人员或者测试人员的问题,流转环节的问题,需要大家一起沟通讨论,才能定位,从而提高团队的运作效率。
同时,针对resolve的bug,特别是很难复现的bug,也希望开发人员能够说明解决的问题点,给出建议的测试方法。
针对必现或者很容易复现的bug,测试人员知道验证方法,按照原来的操作步骤进行多次验证,如果未出现问题,那么就认为解决。
针对很难复现的问题,如果没有开发人员的指导,测试人员去验证此类的问题,只能依靠拷机,大规模的覆盖测试,一段时间后没有出现此bug,再进行关闭。实际上,这种验证方式,效率很低,而且不一定真正的验证到了问题点。
所以这是一个双向沟通的过程:开发人员主动的说明问题原因、解决方案和相关测试建议;测试人员主动去询问问题原因、解决方案和相关测试建议。
二、一个较难复现的问题出现,bug打出去,开发人员要求复现,到底要不要做?(先分严重性,然后按步骤复现)
针对这个问题,开发人员和测试人员每天都要纠结好一阵。从产品线现状而言, 也不可能做到一刀切,按照严格的要求去必须复现或者必须不去复现。
无论是开发人员或者测试人员,大家都有自己的任务指标。很多时候,就需要动态的把握具体的工作。
是否要复现某问题,给测试人员提出几个判断的标准:
1、开发人员是否没有相关测试设备、测试环境,必须要使用测试环境来复现。
高清项目以来,很多设备单价都很高,产品线的设备不多,或者新产品的demo板卡不多,针对这种情况,测试肯定是需要协调资源,提供给开发人员自行复现,或者帮忙复现问题的。还有,比如大容量的测试,长考,mcu的三级级联适配逻辑等,都可以根据实际的bug情况,很直观的判断是否需要在测试环境进行复现。
2、如果要复现问题,开发人员是否提供捕获信息的要求,提供新版本进行复现?
一个bug出现,大家在测试环境查了半天没有定位,然后重启,回头给测试人员说,再复现一下。--------这种表现,是效率很低的体现。
如果一定要复现问题,希望能大致判断几个问题点,然后和测试人员沟通下,需要如何捕获信息,捕获那类信息?是不是提供debug版本进行复现,或者根据预判的点增加打印信息版本进行复现?
一个很浅显的认识: 一个bug,如果出现问题后,根据结果状态无法定位,那么再复现出现问题,我们认为依然无法定位。那么我们就尝试捕获问题出现前,问题发生过程中的一些状态、逻辑。那么肯定就涉及到对一些信息进行捕获,对一些过程态进行打点、跟踪和反馈。
这也是希望开发人员能积极和测试人员沟通的点。
如果一定要复现问题,那么,让我们大家的工作更有价值,有效率。
3、问题或者项目优先级。