上一章介绍了探索式测试的定义。在实际项目的测试执行过程中,读者是否曾遇到如下的几个现象:
测试人员按照一个测试用例来执行测试,得到的程序输出与预期输出不一致。
测试人员判断程序的行为并不是缺陷,但根据新的输出想到了新的测试思路。
测试人员根据新的测试思路采用不同的输入并检查程序输出。
测试人员再次根据新的测试结果选择新的输入,反复地探索下去,最终发现了一个程序缺陷。
测试人员发现该缺陷的测试思路或测试用例并没有出现在最初的测试设计或测试用例文档中。
相信有很多读者熟悉上述的情景,也许有些人认为这是测试设计的遗漏,但笔者要告诉读者的是,千万不要怀疑你的测试设计能力,因为这是非常正常的现象。由 于我们还没有真正深入地了解产品,不可能在测试设计的时候想到所有测试场景,且在需求分析阶段不可能评审到所有的隐含需求,所以最初的测试设计并不能捕获 程序的所有缺陷。为了发现尽可能多的缺陷,测试人员需要在测试过程中,根据测试反馈持续地优化测试模型、调整测试设计。这是一个研究、实践和探索的过程。 了解探索式测试的思维将有助于测试人员更有效地测试。
根据测试专家Erik Petersen对于探索式测试的理解,笔者抽象出探索式测试的思维模型 CPIE(Collation,Prioritization,Investigation,Experimentation),如图2.1所示。该测试 模型包含迭代的4个阶段:整理、排序、调查和实验。
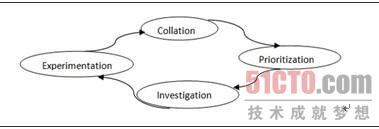
图2.1 探索式测试的思维模型
整理(Collation):尽最大可能收集关于被测产品的信息,去了解和理解它们。
排序(Prioritization):确定所有测试任务的优先级。
调查(Investigation):对即将执行的测试任务进行仔细的分析并确定测试输入和预期输出。
实验(Experimentation):实际地去测试,验证我们的预测是否正确,检查我们在整理阶段获取到的信息是否正确。根据实验结果,测试人员将收集更多的信息,并调整测试任务的优先级。
对于探索式测试的思维过程,测试专家 James Bach提出了如图2.2所示的思维模型。该模型包含一组启发式问题,以推动测试人员在知识(Knowledge)、分析(Analysis)、实验 (Experiment)和测试故事(Testing Story)上深入探究。
知识:掌握产品特性、开发技术、测试技术和领域规则等测试需要的知识。
分析:分析产品风险、测试覆盖、测试方法、测试先知 和产品缺陷等测试相关因素。
实验:配置、操作、观察和评估被测产品。
测试故事:用测试计划、测试报告和可工作的产品等组成测试报告,以准确地反映测试状态和产品质量。

图2.2 探索式测试的思维过程
从图2.1和图2.2可以看出James Bach和Erik Petersen的观点都强调通过实验(Experiment)来持续改进测试设计。他们认为瀑布式的测试设计和用例编写并不会产生优质的测试设计,测试 人员还需要在测试执行的时候持续扩展新的测试思路,完善测试设计。在探索式测试过程中,测试学习、测试设计、测试执行和测试评估是互相支持和驱动的活动。第4章将讲述几个案例来说明探索式测试这种迭代优化的测试风格。
摘要:Linux里有很丰富的各种命令,有些是很难用的。然而,学会了前面说的这8个命令,你已经能处理大量的log分析任务了,完全不需要用脚本语言写程序来处理它们。
每个程序员,在职业生涯的某个时刻,总会发现自己需要知道一些Linux方面的知识。我并不是说你应该成为一个Linux专家,我的意思是,当面对Linux命令行任务时,你应该能很熟练的完成。事实上,学会了下面8个命令,我基本上能完成任何需要完成的任务。
注意:下面的每个命令都有十分丰富的文档说明。这篇文章并不是来详尽的展示每个命令的各种功用的。我在这里要讲的是这几个最常用的命令的最常见用法。如果你对linux命令并不是很了解,你想找一些这方面的资料学习,那这篇文章将会给你一个基本的指导。
让我们从处理一些数据开始。假设我们有两个文件,分别记录的订单清单和订单处理结果。
- order.out.log
- 8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
- 8:23:45 112, 1, Joy of Clojure, Hardcover, 29.99
- 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99
- order.in.log
- 8:22:20 111, Order Complete
- 8:23:50 112, Order sent to fulfillment
- 8:24:20 113, Refund sent to processing
|
cat
cat – 连接文件,并输出结果
cat 命令非常的简单,你从下面的例子可以看到。
- jfields$ cat order.out.log
- 8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
- 8:23:45 112, 1, Joy of Clojure, Hardcover, 29.99
- 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition,
|
就像它的说明描述的,你可以用它来连接多个文件。
- jfields$ cat order.*
- 8:22:20 111, Order Complete
- 8:23:50 112, Order sent to fulfillment
- 8:24:20 113, Refund sent to processing
- 8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
- 8:23:45 112, 1, Joy of Clojure, Hardcover, 29.99
- 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition,
|
如果你想看这些log文件的内容,你可以把它们连接起来并输出到标准输出上,就是上面的例子展示的。这很有用,但输出的内容可以更有逻辑些。
sort
sort – 文件里的文字按行排序
此时sort命令显然是你最佳的选择。
- jfields$ cat order.* | sort
- 8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
- 8:22:20 111, Order Complete
- 8:23:45 112, 1, Joy of Clojure, Hardcover, 29.99
- 8:23:50 112, Order sent to fulfillment
- 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99
- 8:24:20 113, Refund sent to processing
|
就像上面例子显示的,文件里的数据已经经过排序。对于一些小文件,你可以读取整个文件来处理它们,然而,真正的log文件通常有大量的内容,你不能不考虑这个情况。此时你应该考虑过滤出某些内容,把cat、sort后的内容通过管道传递给过滤工具。
grep
grep, egrep, fgrep – 打印出匹配条件的文字行
假设我们只对Patterns of Enterprise Architecture这本书的订单感兴趣。使用grep,我们能限制只输出含有Patterns字符的订单。
- jfields$ cat order.* | sort | grep Patterns
- 8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
- 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition,
|
假设退款订单113出了一些问题,你希望查看所有相关订单——你又需要使用grep了。
- jfields$ cat order.* | sort | grep ":\d\d 113, "
- 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99
- 8:24:20 113, Refund sent to processing
|
你会发现在grep上的匹配模式除了“113”外还有一些其它的东西。这是因为113还可以匹配上书目或价格,加上额外的字符后,我们可以精确的搜索到我们想要的东西。
现在我们已经知道了退货的详细信息,我们还想知道日销售和退款总额。但我们只关心《Patterns of Enterprise Architecture》这本书的信息,而且只关心数量和价格。我现在要做到是切除我们不关心的任何信息。
cut
cut – 删除文件中字符行上的某些区域
又要使用grep,我们用grep过滤出我们想要的行。有了我们想要的行信息,我们就可以把它们切成小段,删除不需要的部分数据。
- jfields$ cat order.* | sort | grep Patterns
- 8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
- 8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99
-
- jfields$ cat order.* | sort | grep Patterns | cut -d"," -f2,5
- 1, 39.99
- -1, 39.99
|
现在,我们把数据缩减为我们计算想要的形式,把这些数据粘贴到Excel里立刻就能得到结果了。
cut是用来消减信息、简化任务的,但对于输出内容,我们通常会有更复杂的形式。假设我们还需要知道订单的ID,这样可以用来关联相关的其他信息。我们用cut可以获得ID信息,但我们希望把ID放到行的最后,用单引号包上。
sed
sed – 一个流编辑器。它是用来在输入流上执行基本的文本变换。
下面的例子展示了如何用sed命令变换我们的文件行,之后我们在再用cut移除无用的信息。
- jfields$ cat order.* | sort | grep Patterns \
- >| sed s/"[0-9\:]* \([0-9]*\)\, \(.*\)"/"\2, '\1'"/
- 1, Patterns of Enterprise Architecture, Kindle edition, 39.99, '111'
- -1, Patterns of Enterprise Architecture, Kindle edition, 39.99, '113'
-
- lmp-jfields01:~ jfields$ cat order.* | sort | grep Patterns \
- >| sed s/"[0-9\:]* \([0-9]*\)\, \(.*\)"/"\2, '\1'"/ | cut -d"," -f1,4,5
- 1, 39.99, '111'
- -1, 39.99, '113'
|
我们对例子中使用的正则表达式多说几句,不过也没有什么复杂的。正则表达式做了下面几种事情
● 删除时间戳
● 捕捉订单号
● 删除订单号后的逗号和空格
● 捕捉余下的行信息
里面的引号和反斜杠有点乱,但使用命令行时必须要用到这些。
一旦捕捉到了我们想要的数据,我们可以使用 \1 & \2 来存储它们,并把它们输出成我们想要的格式。我们还在其中加入了要求的单引号,为了保持格式统一,我们还加入了逗号。最后,用cut命令把不必要的数据删除。
现在我们有麻烦了。我们上面已经演示了如何把log文件消减成更简洁的订单形式,但我们的财务部门需要知道订单里一共有哪些书。
uniq
uniq – 删除重复的行
下面的例子展示了如何过滤出跟书相关的交易,删除不需要的信息,获得一个不重复的信息。
- jfields$ cat order.out.log | grep "\(Kindle\|Hardcover\)" | cut -d"," -f3 | sort | uniq -c
- 1 Joy of Clojure
- 2 Patterns of Enterprise Architecture
|
看起来这是一个很简单的任务。
这都是很好用的命令,但前提是你要能找到你想要的文件。有时候你会发现一些文件藏在很深的文件夹里,你根本不知道它们在哪。但如果你是知道你要寻找的文件的名字的话,这对你就不是个问题了。
find
find – 在文件目录中搜索文件
在上面的例子中我们处理了order.in.log和order.out.log这两个文件。这两个文件放在我的home目录里的。下面了例子将向大家展示如何在一个很深的目录结构里找到这样的文件。
- jfields$ find /Users -name "order*"
- Users/jfields/order.in.log
- Users/jfields/order.out.log
|
find命令有很多其它的参数,但99%的时间里我只需要这一个就够了。
简单的一行,你就能找到你想要的文件,然后你可以用cat查看它,用cut修剪它。但文件很小时,你用管道把它们输出到屏幕上是可以的,但当文件大到超出屏幕时,你也许应该用管道把它们输出给less命令。
less
less – 在文件里向前或向后移动
让我们再回到简单的 cat | sort 例子中来,下面的命令就是将经过合并、排序后的内容输出到less命令里。在 less 命令,使用“/”来执行向前搜索,使用“?”命令执行向后搜索。搜索条件是一个正则表达式。
| jfields$ cat order* | sort | less |
如果你在 less 命令里使用 /113.*,所有113订单的信息都会高亮。你也可以试试?.*112,所有跟订单112相关的时间戳都会高亮。最后你可以用 ‘q’ 来退出less命令。
Linux里有很丰富的各种命令,有些是很难用的。然而,学会了前面说的这8个命令,你已经能处理大量的log分析任务了,完全不需要用脚本语言写程序来处理它们。
取这个名字时,曾想过 产品经理决定产品质量,战略决定质量等等,最后还是选择更加直接的一把手的态度决定产品质量。
无论任何产品,能决定产品质量,甚至产品本身的,只有一个人。
我们知道很多耳熟能详的故事:
乔布斯做手机的时候,强硬的下了死命令:不管你们怎么搞,我的手机只允许有一个物理按键。无数的开发人员崩溃,说不可能。乔布斯依然坚持,说我们就是要重新塑造手机这个行业,用梦想激情来指引大家。
三星在笔记本行业奋勇拼杀的时候。总裁感受到苹果的压力,决议做超薄笔记本,杀出血路。当年就扔了几个硬币给研发部门,说把笔记本做成这几个硬币落在一起的厚度内。无数的硬件工程师崩溃,说不可能。提高奖励,再提高奖励,然后,东西就出来了。
腾讯在推出邮箱时,这个产品是马化腾亲自抓的。α版本刚出来,马化腾命令全公司必须用自己的邮箱,进行内测和用户体验测试。无数的腾讯人面对一个简陋的邮箱抓狂。马化腾冲在第一线,作为用户进行体验,自己提交了数百个bug和使用建议、改进方案。
喏,这就是优秀的产品,所必须具备的核心条件:对产品完美的高要求及亲力亲为。
在我们身边见到过无数的质量不靠谱的产品,甚至我们自己也在做质量不靠谱的产品。难道没有一个人对这些东西产生质疑,对产品质量试图改进什么吗?
同样,我们肯定见过无数次尝试并失败的场面,甚至可以很容易的就模拟出种种场景:
一个第三方的人对某产品提出改进建议,这个人可能是测试、QA、销售、售前。然后产品的亲爹亲妈们顿时就会产生感情伤害,产生一种自己的孩子只能自己说丑,外人不能说不行的护犊子状态:
“谁会像你们测试人员这么变态,正常的人不会这么用这产品!”
“到底是你了解客户的心理,还是我了解客户的心理?”
“兄弟,你这个客户肯定是看科幻电影看多了,这种功能在目前的技术条件下是无法实现的,你还是多去公关给客户洗脑吧!”
“售前的兄弟别添乱了,这么多客户需求都在排队,先满足客户的功能,打入市场,在慢慢优化客户的体验,我们是在和时间和对手赛跑”。
自己的boss提出产品改进建议,几番讨论后变成资源索取的场面:“老总,你看目前我们团队有XX人,有XX个产品在并行开发,上次高层会议刚刚排过优先级,先做XX,再做XX。我们的工作计划已经排到明年了。您的建议非常好,但是我们没有资源,您看看是不是在给点资源?”
如果是外面的人在提需求,比如是最终客户、业内同行、或者跨界热心人士,那么,就会出现罗永浩这句经典的对答:在充分了解某产品之前,不停地给产品挑 刺,这也不对,那也不行。可实际上呢,挑刺是最容易最廉价的事,任何设计都有缺点,发现这些并不困难。但你通常不会想到的是,设计是各种因素权衡妥协的结 果,某处的一个小缺陷可能是为了防止更大缺陷所做的牺牲。
恩,这是一句直指本心的吐槽,足可以代表了无数产品的制造者的心声,在一个个“多快好省”的要求下,生产出存在大大小小问题的产品,并美其名曰,挑刺容易,做产品难。但是,你们真的没看懂,这是一句反讽吗?
试图把一个产品做到极致,往往会遇到各方面的阻力。这个时候,有一个人,他本身对产品的态度和偏执度,才能决定这款产品,到底是一个什么品质的东西。没 有任何一款产品能同时满足多快好省,当你在各个标准之间做选择的时候,有且只有,唯一的人,才能做这个决定,并且对这个产品负责。
所以,跳过各种伟大的企业文化,产品质量标准,这个企业的灵魂,他的产品意识和对产品质量战略性考虑的结论,才是决定最终产品的质量的核心因素。
1)探索性测试与脚本化测试的主要区别:1)探索性测试将更多更高的认知水平的工作放在测试执行,而脚本化测试则更关注测试设计;2)前者更强调测试活动的并行和相互反馈(学习、设计、执行与结果分析等),而后者的测试活动是相对串行的。
2)脚本化测试的主要优点是:1)尽早发现缺陷;2)不同利益相关者参与评审;3)可重用性;4)测试覆盖率评估。
3)脚本化测试强调测试的尽早介入,如尽早设计测试用例。但是测试人员越早设计测试用例,对测试对象的了解越少,对风险的了解也越少。测试人员对测试对象的了解是一个逐步的过程,脚本化测试需要更多的工作量以应对这个过程(需求的细化和变更等)。
4)提供测试对象的质量信息是测试的一个主要目的。但是不同的人对质量的理解是不一样的,脚本化测试能预先定义所有利益相关者的质量要求吗?脚本化测试能预先定义不同缺陷的来源吗?回答是不能。而这正是探索性测试引入的一个初衷。
5)测试对象的需求是不断变更的、不同开发人员会犯不同的错误、测试环境与组合也是不断变化的,通过脚本化测试很难及时跟踪这些问题,即使能也需要考虑时间与成本。探索性测试的及时反馈与不断修正是一个解决之道。
6)“复现缺陷,并确定复现的具体步骤”、“下棋”、“刑侦现场”、“拼图游戏”等,其中的思维应该是探索性,还是脚本化?哪个效率更高?
7)组织内引入探索性测试,需要测试人员掌握各种技术与方法、知识、技能与实践,并以此为支撑,不是每天喊着这个概念就可以成功实施的。这个理念也同样适用于敏捷开发与测试。车是好车,但是我们的路修好了吗?
8)不管是文档化还是存在于测试人员的头脑中,好的测试设计是什么?好的测试设计应该是随着测试环境不断变化的(例如测试组合、测试环境),以不断扩大测试覆盖率,并将关注点放在高风险的区域。
9)不同的测试对象和测试目标,需要不同的测试策略和测试技术,而这将得到不同的测试用例、不同的测试文档与不同的测试结果。
10)探索性测试没有脚本化特点,并代表它是不做准备的,它也不是随机的,而是提供更多的选择。探索性测试同样需要设计各种支撑性的内容:测试数据、失效模式、模型等。没有测试计划文档,也不代表探索性测试是没有计划的。
11)探索性测试如下象棋,其规则很简单。但是我们在欣赏象棋比赛的时候,不会说:“啊,下象棋的规则真精彩!”相反,我们关注的是隐含在这些规则下选手选择下一步如何走的技巧与技能,它的技术含量也不在其规则,而在选手的技巧与技能。规则简单,技巧复杂。
12)探索性测试的学习、设计、执行与结果分析等测试活动是相对并行并且是相互支撑的,了解这个并不代表测试人员掌握了探索性测试。正如婴儿学会了爬,并不代表就懂得了走、跑与跳等运动技能。
13)探索性测试过程中的一个重要挑战是如何设计测试用例(尽管不一定是脚本化的,也可能是在测试执行的时候进行测试设计),例如:从测试技术到测试用例、从失效模式到测试用例、从风险列表到测试用例、从测试思想到测试用例。
14)从用户现场反馈了一个问题:他们在配置某个功能的时候,界面上打印了一些奇怪的信息,然后系统就重启了。此时测试人员更倾向于采用探索性测试,而面临的首要挑战就是“如何从失效模式设计测试用例”,以复现该问题。
15)探索性测试本身不是一种技术,而是一种测试方式或者思维。那么,脚本化测试应该是什么呢?是技术?不是方式或者思维?
16)什么使得测试活动具有探索性测试特点呢?答案在于测试人员的认知投入:测试人员如何应对持续变化的情况。
17)探索性测试不一定会有测试用例文档的输出,这并不代表它没有测试设计。探索性测试的设计不是为了控制,而是为了指导你的测试。
18)探索性测试更强调个人和交互,而不是过程和工具;更强调应对变化而不是遵循计划;更强调可工作的软件而不是可理解的文档;更强调相互合作而不是合同谈判;从这个层面而言,探索性测试是敏捷的。
这个问题是回应我上一篇博文的。因为我正在雇用一个
测试员,我觉得应该给他点刺激。以下是
软件测试这个职位一般应该具备的品质。
一个好的软件测试员应该…
● 经常思考,什么是我现在能执行的最好的测试。
● 提交的bug含义明确,有清晰的复现步骤,能用简洁的语言把问题描述清楚。
● 不会因为开发人员的做法受影响。测试员不应该仅仅是因为他们能够理解那些决定开发人员做法的技术难点,就去全力维护自动化。应该做的是交流在当前有意义的领域,自动化是怎么工作的。
● 有能力理解利益相关者的业务。
● 足够专业,能认识到一个系统的某个部分对整个系统的影响;
● 有很强的解决问题的技巧。他们能够控制很多变数,并最终找到引发问题的那一个。他们能恰到好处的坚持。他们知道何时应该停止这个问题转向下一个。
● 能够熟练的沟通和倾听,务必做到完全彻底的理解。
● 非常谦逊的去问所有的问题(甚至是愚蠢的问题),同时又有足够的怀疑精神,能从众多资源中找到答案(保持信任但仍需验证)。
● 服从组织安排,坚持完成任务,同时留意未来的新任务。
● 有能力从海量的相互关联中隔离观察到的软件行为,并与整个团队交流这些软件行为。他们能够看着一个不完整的系统的部件,通过想象整个系统来推断该系统实际的优缺点。
● 是开发人员和业务分析人员的受尊敬的伙伴。他们越能理解测试人员的工作有多么努力,就越能表现的更友好。
● 自己发现了产品初期的bug就很兴奋,用户发现了产品后期的bug就很沮丧。
● 有能力处理让人紧张的截止日期,快速做出决定,并且为了利益相关者的终极最佳利益而放弃一些喜欢的流程。
● 是软件测试社区的积极的参与者,阅读测试书籍和测试博客,并参加本地的测试团体。
● 有良好的职业道德;能按时完成任务,完不成时进行良好的沟通,必要的时候一周工作40个小时以上,专业的,能服从组织安排, 关注整个团队的成功,诚实的,遵守规定的工作流程,遵守SOX法案,等等。
我还漏掉了什么吗?以下是有价值的评论回复:
另一个没有提到的品质是,测试人员应该有能力阅读和理解代码。举例说,如果测试人员看过单元测试的代码了,他就能用不同的方式实现自动化。如果单元测试做了完备的边界检查,然后测试人员就可以更专注于业务逻辑验证了。
1、最好能具备良好的代码能力
2、快速学习能力
3、这还有一些(至少在我们这里)
① 一个好的测试员知道目前自动化测试的实现程度,在需要的时候能够做一些更新;
② 一个好的测试员能够在执行测试用例期间对用例进行维护(如果跳过了任何一个用例,给出解释);
③ 一个好的测试员知道什么时候违背一条测试用例是正确的,什么时候是不正确的;
④ 一个好的测试员尊重开发人员和其他的测试员的时间。
4、①一个好的测试员知道什么时候应该测试盒子外面;
②一个特别好的测试员永远不会停止问问题;
③知道验证和确认之间的区别;
别以为我会支持你说的这条,“测试员工作越努力,开发人员和业务分析人员越友好”。这会导致人们问一些愚蠢的问题,比如说这个,“测试员是否应该为有缺陷的软件负责”。
原文出处:http://www.testthisblog.com/2010/04/who-is-good-tester.html
在实际的j2ee项目中,系统内部难免会出现一些异常,如果把异常放任不管直接打印到浏览器可能会让用户感觉莫名其妙,也有可能让某些用户找到破解系统的方法。
出来工作一年时间了,我也大概对异常处理有了一些了解,在这呢小弟简单介绍下个人对异常处理的见解,抛砖引玉,希望各位大神提出宝贵的意见和建议。
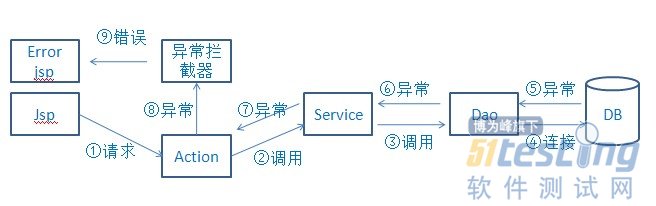
就拿spring+struts2+hibernate项目说明:通常一个页面请求到后台以后,首先是到action(也就是所谓mvc的 controller),在action层会调用业务逻辑service,servce层会调用持久层dao获取数据。最后执行结果会汇总到 action,然后通过action控制转发到指定页面,执行流程如下图所示:

而这三层其实都有可能发生异常,比如dao层可能会有SQLException,service可能会有 NullPointException,action可能会有IOException,一但发生异常并且程序员未做处理,那么该层不会再往下执行,而是向 调用自己的方法抛出异常,如果dao、service、action层都未处理异常的话,异常信息会抛到服务器,然后服务器会把异常直接打印到页面,结果 就会如下图所示:
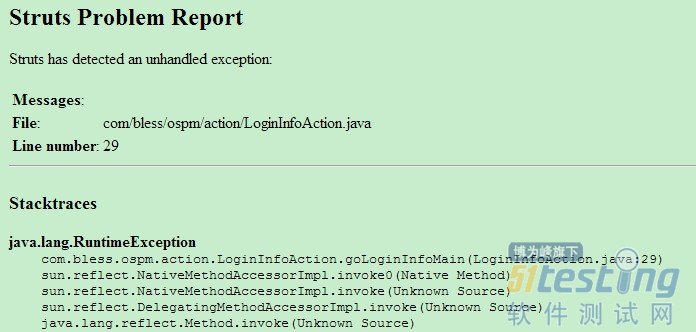
其实这种错误对于客户来说毫无意义,因为他们通常是看不懂这是什么意思的。
刚学java的 时候,我们处理异常通常两种方法:①直接throws,放任不管;②写try...catch,在catch块中不作任何操作,或者仅仅 printStackTrace()把异常打印到控制台。第一种方法最后就造就了上图的结果;而第二种方法更杯具:页面不报错,但是也不执行用户的请求, 简单的说,其实这就是bug(委婉点:通常是这样)!
那么发生异常到底应该怎么办呢?我想在大家对java异常有一定了解以后,会知道:异常应该在action控制转发之前尽量处理,同时记录log日志,然后在页面以友好的错误提示告诉用户出错了。大家看下面的代码:
//创建日志对象
Log log = LogFactory.getLog(this.getClass());
//action层执行数据添加操作
public String save(){
try{
//调用service的save方法
service.save(obj);
}catch(Exception e){
log.error(...); //记录log日志
return "error"; 到指定error页面
}
return "success";
} |
如果按照上面的方式处理异常以后,我们用户最后看到的页面可能就会是下面这种形式(我想这种错误提示应该稍微友好点了吧):

然后我们回到刚才处理异常的地方,如果大家积累了一些项目经验以后会发现使用上面那种处理异常的方式可能还不够灵活:
①因为spring把大多数非运行时异常都转换成运行时异常(RuntimeException)最后导致程序员根本不知道什么地方应该进行try...catch操作
②每个方法都重复写try...catch,而且catch块内的代码都很相似,这明显做了很多重复工作而且还很容易出错,同时也加大了单元测试的用例数(项目经理通常喜欢根据代码行来估算UT case)
③发生异常有很多种情况:可能有数据库增删改查错误,可能是文件读写错误,等等。用户觉得每次发生异常都是“访问过程中产生错误,请重试”的提示完全不能说明错误情况,他们希望让异常信息更详尽些,比如:在执行数据删除时发生错误,这样他们可以更准确地给维护人员提供bug信息。
如何解决上面的问题呢?我是这样做的:JDK异常或自定义异常+异常拦截器
struts2拦截器的作用在网上有很多资料,在此不再赘述,我的异常拦截器原理如下图所示:
首先我的action类、service类和dao类如果有必要捕获异常,我都会try...catch,catch块内不记录log,通常是抛出一个新异常,并且注明错误信息:
//action层执行数据添加操作
public String save(){
try{
//调用service的save方法
service.save(obj);
}catch(Exception e){
//你问我为什么抛出Runtime异常?因为我懒得在方法后写throws xx
throw new RuntimeException("添加数据时发生错误!",e);
}
return "success";
} |
然后在异常拦截器对异常进行处理,看下面的代码:
public String intercept(ActionInvocation actioninvocation) {
String result = null; // Action的返回值
try {
// 运行被拦截的Action,期间如果发生异常会被catch住
result = actioninvocation.invoke();
return result;
} catch (Exception e) {
/**
* 处理异常
*/
String errorMsg = "未知错误!";
//通过instanceof判断到底是什么异常类型
if (e instanceof BaseException) {
BaseException be = (BaseException) e;
be.printStackTrace(); //开发时打印异常信息,方便调试
if(be.getMessage()!=null||Constants.BLANK.equals(be.getMessage().trim())){
//获得错误信息
errorMsg = be.getMessage().trim();
}
} else if(e instanceof RuntimeException){
//未知的运行时异常
RuntimeException re = (RuntimeException)e;
re.printStackTrace();
} else{
//未知的严重异常
e.printStackTrace();
}
//把自定义错误信息
HttpServletRequest request = (HttpServletRequest) actioninvocation
.getInvocationContext().get(StrutsStatics.HTTP_REQUEST);
/**
* 发送错误消息到页面
*/
request.setAttribute("errorMsg", errorMsg);
/**
* log4j记录日志
*/
Log log = LogFactory
.getLog(actioninvocation.getAction().getClass());
if (e.getCause() != null){
log.error(errorMsg, e);
}else{
log.error(errorMsg, e);
}
return "error";
}// ...end of catch
}
需要注意的是:在使用instanceof判断异常类型的时候一定要从子到父依次找,比如BaseException继承与RuntimeException,则必须首先判断是否是BaseException再判断是否是RuntimeException。
最后在error JSP页面显示具体的错误消息即可:
<body>
<s:if test="%{#request.errorMsg==null}">
<p>对不起,系统发生了未知的错误</p>
</s:if>
<s:else>
<p>${requestScope.errorMsg}</p>
</s:else>
</body> |
以上方式可以拦截后台代码所有的异常,但如果出现数据库连接异常时不能被捕获的,大家可以使用struts2的全局异常处理机制来处理:
<global-results>
<result name="error" >/Web/common/page/error.jsp</result>
</global-results>
<global-exception-mappings>
<exception-mapping result="error" exception="java.lang.Exception"></exception-mapping>
</global-exception-mappings> |
上面这是一个很简单的异常拦截器,大家可以使用自定义异常,那样会更灵活一些。
以上异常拦截器可以使用其它很多技术替换:比如spring aop,servlet filter等,根据项目实际情况处理。
【补充】ajax也可以进行拦截,但是因为ajax属于异步操作,action通过response形式直接把数据返回给ajax回调函数,如果发生异常,ajax是不会执行页面跳转的,所以必须把错误信息返回给回调函数,我针对json数据的ajax是这样做的:
/**
* 读取文件,获取对应错误消息
*/
HttpServletResponse response = (HttpServletResponse)actioninvocation.getInvocationContext().get(StrutsStatics.HTTP_RESPONSE);
response.setCharacterEncoding(Constants.ENCODING_UTF8);
/**
* 发送错误消息到页面
*/
PrintWriter out;
try {
out = response.getWriter();
Message msg = new Message(errorMsg);
//把异常信息转换成json格式返回给前台
out.print(JSONObject.fromObject(msg).toString());
} catch (IOException e1) {
throw e;
} |
以上是个人拙见,勿拍砖,谢谢。
性能测试新手误区(一):找不到测试点,不知为何而测 性能测试新手误区(二):为什么我模拟的百万测试数据是无效的?
性能测试新手误区(三):用户数与压力
经常会有性能测试新手问这样的问题:
C/S的系统如何录制,应该选择什么协议呢?
待测系统A的一个功能,是由B系统调用的,也需要搭建B系统的测试环境并对其录制么?
我的回答是,先弄清楚你想测的是什么?对它而言,压力又是什么?
新手总是想着如何录制客户端的操作,如何模拟客户端的点击。这种想法应该是受到了主流测试工具影响,性能测试的入门基本都是从工具开始,比如使用最广的 LR,其最方便好用的功能应该就是录制了。但是需要清楚的是,录制只是为性能测试提供便利的一个功能(可以傻瓜式的产生向服务器施加压力的脚本),录制本 身并不是性能测试的根本或者所必需,能够产生压力的那些脚本或是程序才是关键所在。
第一个问题,比如一个即时通讯类的软件如何测试?
首先要明确你想测的是客户端还是服务端,如果是服务端,那么服务端承受的压力是什么呢?
是每一条消息都要经过服务器么?
服务器是要将消息进行存储,还是仅仅转发?
不同的功能,如普通会话和多人会话,从服务端来看的区别是什么?
客户端是如何同服务端通信的,是采用了一些标准的开源协议(如XMPP),还是经过了自己的重新扩展?
……
为了回答那两个看似很简单的问题(想测什么?压力是什么?),其实你需要了解整个系统的运行方式。这些信息完全可以从一些设计文档或者开发人员的口中获取到,并不需要你能读懂源码。
如果我知道了这个软件使用了XMPP协议,一条普通的会话是客户端向服务器发送了这样一条信息:
而多人会话是客户端发送了这样的信息:
消息类型:多人
接收人:A, B, C
消息内容:XXX |
那么应该会知道,表面上这些不同的功能,其实只是客户端发送信息中个别字段的区别而已。那么我就可以想办法直接向服务器发送这些信息,让服务器根据接收 信息的内容去完成相应的功能。也许根本没有必要去想如何录制客户端发起一个会话并发送消息这个动作,或者发送文件、群消息等等其他操作。
至于如何实现,如果你有编码能力,可以将开源代码引入到自己的测试代码中(需是标准协议),否者可能需要让程序的开发人员实现一个测试程序。不 要不敢开口,开发人员协助进行性能测试是很正常的,而且这种工作量不会很大,只是把程序中的一些代码封装成一个可配置可方便调用的执行文件。
让开发人员来实现测试工具不丢脸,怕的是你自己不知道测试工具应该实现成什么样。(当然,如果自己可以看源码来实现工具那就更好了)
第二个问题,同样的,所谓的B系统调用A系统这个动作,是如何实现的?
会不会只是一个简单的HTTP请求?
或者是调用A系统的一个webservice接口?
你要测的是A的这个功能么?
如果是,那我们为什么一定要通过B系统来录制这A的这个功能呢?完全可以直接向A发送请求或者是调用接口(如LR中的webservice协议)。
至于具体如何做,可能有很多现成的接口测试工具,也可能仍然需要开发人员的协助。比如B与A之间传递的数据是经过加密的,那对(黑盒)测试来说就会非常困难,这种情况下,确实有可能通过B来录制会更简单。
在51Testing上看到的一个问题,问如何测试一个统计报表的另存为(excel)功能。
点这个按钮后,服务器会生成一张报表,然后弹出浏览器的另存为对话框,保存为本地文件。提问题的这个人遇到的困难是,LR中好像没法录制“另存为”这个动作。
之所以会有这样的问题,根本原因还是没有理解系统的运行原理,没有区分哪是服务器、哪是客户端。
一般来说,这个过程是这样的:
1、点另存为按钮时,向服务器发送了一个计算报表的请求,这个请求中会包含一些参数,如报表类型、统计时间等等。
2、服务器计算完成后,将结果数据返回给客户端(浏览器)。
3、浏览器本身的功能,将数据保存为一个本地文件。
(这里假设了计算过程是另存为按钮触发的,如果是打开页面时就计算完,那点按钮时甚至有可能根本没与服务器进行交互)
如果明白了这个过程,那么就不会纠结于录制“另存为”这种事情了,你要做的只是向服务器发送一个请求,然后接收响应数据。
那么就不需要生成本地文件了么?当然不是,否则怎么验证返回的数据没有问题呢。只不过这个文件的操作需要自己来实现了,创建文件、写入数据、关闭文件。
最后再总结一下要点:
● 理解系统的运行原理
● 区分服务端和客户端
● 弄清楚你要测的是什么,哪些东西其实是可有可无的
● 要模拟的是服务器的压力,而不是客户端的操作
● 录制只是一种手段,很多情况下并不是最佳选择
● 开发人员的协助是应当的,但前提是你要明确的知道应该如何测试
相关链接:
性能测试新手误区(一):找不到测试点,不知为何而测
性能测试新手误区(二):为什么我模拟的百万测试数据是无效的?
性能测试新手误区(三):用户数与压力
RCA背景、概念、开展目的 IOWA 州立大学
质量管理学 院认为:很多公司在设备发生故障后,都能够很快修复,但往往很难发现哪些是引起这些故障的根本原因,这样会导致故障会再次发生。这里所说的根本原因,是指 导致设备失效的基本原因,如果该原因得到纠正,将会避免该事故重发。根本原因分析技术是一个发现和消除根本原因的过程,能够有效防止这些问题的发生,只有 当这个根本原因被发现和消除后,这个问题才能够被彻底解决。
而美国能源部1992年发布的《根本原因分析指南》(DOE-NE- STD-1004-92)中,把根本原因定义为:指一种原因,当这种原因被纠正以后,将会防止此类事故或者类似事故的再次发生。根本原因并不是一种仅仅导 致这次事故发生的原因,在更大的范围内,极有可能对发生的其他事故还存在着影响。根本原因最基本的特征应该是:从逻辑上能够被识别并能够被纠正。可能会有 一系列的原因都能够被识别,从一个导致另一个,但是这一系列的原因应该能够被追溯到最基本的,并且能够被识别和纠正的原因。
在我国大亚 湾核电站的建设和运行过程中,由美国PII(performance improved international)公司提供了RCA方法,该公司把RCA定义为:通过一整套系统化、逻辑化客观化和规范化的分析方法,找出设备故障的故障机理 和根本原因,并通过制定合理的纠正行动彻底消除这些根本原因,从而恢复设备功能,防止同样或者类似故障重复发生的一种解决设备故障问题的分析技术。
同样,RCA分析也早已在航空航天、医疗领域、应急处理等行业中广泛使用。

根本原因分析(Root Cause Analysis 后简称RCA),本原因分析(RCA)是一项结构化的问题处理法,用以逐步找出问题的根本原因并加以解决,而不是仅仅关注问题的表象。根本原因分析是一个 系统化的问题处理过程,包括确定和分析问题原因,找出问题解决办法,并制定问题预防措施。在组织管理领域内,根本原因分析能够帮助相关者发现组织问题的症 结,并找出根本性的解决方案。
笔者建议在软件测试相对成熟或流程清晰的质量团队或公司,可以有意识的开展RCA工作项RCA方法在软件产品质量管理中应用的目的在于:
a、从缺陷与问题中进行学习;
b、系统化的确定需要改进的区域或过程;
c、防止重复犯错
拒绝空谈,为了让好的方法,更加具有执行力。笔者将阅读了国内、台湾、医疗行业的相关资料,整理如下,其中罗列准入与验收标准,方便大家可量化的执行。
RCA验收目标
1、RCA活动是有计划的,控制分析成本;
2、RCA应包含缺陷分类分析与过程管理问题整理;
3、RCA应包含对缺陷与问题的根本问题的分析与推理,结合不同角色收集得出;
4、RCA的结果是一个或多个纠正操作建议(在开发过程中进行一些更改与优化,以消除产生错误的原因)
5、应保持RCA结果的准确记录与跟踪;
RCA进出标准与有效输入/出
进入标准(缺陷分类分析与过程管理问题整理)
1、缺陷分类分析进入;
a、单次测试的缺陷计数,如 缺陷数≥X个需进行RCA分析;
b、遗留缺陷计数;如 遗留缺陷数≥X个需进行RCA分析;
c、按缺陷分类(缺陷严重等级、缺陷类型、) ;如 遗留性能缺陷数、遗留界面缺陷等需进行RCA分析;
2、或事件触发;
a、违背当前周期的质量目标的;
b、重要“事件”或哨兵“事件”(如现场反馈严重缺陷、重复出现的缺陷等,又称单一缺陷或整整一类缺陷);
c、过程管理发现问题(如提交质量低、迭代次数超计划、需求理解不一致、需求确认问题多)
有效输入
1、事件报告
2、事件相关数据
3、测量结论(以往RCA分析所确定的措施的实施情况);
有效输出
根本原因分析(Root Cause Analysis)应用XXX事件分析报告
退出标准
完成RCA应用XXX事件分析报告并经QA Manager确认;
导致类似事件的同类原因未再次产生;
笔者结合自身实践,整理出,可执行的RCA分析流程。简言之,算是个“最佳实践”分享给大家。
RCA活动实施流程
RCA活动角色划分(示例)

本文出自:http://kan.weibo.com/con/3487898360697968
摘要:运用系统工程方法,结合银行业务软件的特点,为银行业务软件的测试建立指标体系,用层次分析法确定各指标的权重,并用可能-满意度法计算各指标的满意度,最后通过计算综合满意度对测试作出评价。
关键词:银行业务软件 软件测试评价
而众多的软件系统中,银行业务软件以其高复杂性、高安全性、高准确性、高效率性给软件测试带来了一系列难度,尤其是在测试评价方面,仍然停留在比较初级 的阶段,常见的方法有缺陷走势图、缺陷严重程度分布图等等。这些方法可以很清楚看出软件缺陷的走向和分布情况,对于测试评价有一定帮助。但是这些方法存在 指标量化不够,评价指标过于单一的缺点,重复操作性低,在实际使用中对进行测试结果评价的人员要求很高等问题,从而影响评价的效果。
本文运用系统工程方法为银行业务软件的测试建立指标体系,用层次分析法确定各指标的权重,并用可能-满意度法计算各指标的满意度,最后通过计算综合满意度对测试作出评价。
一、评价指标体系建立
要对软件测试结果进行评价,软件的行为特性,如可靠性、正确性、健壮性、可扩展性和性能等,是最基本的指标。但由于银行业务软件的行为特性比较抽象,难以量化,不能直接作为评价指标,必须对之建立量化的子指标。在实际测试中最容易量化的就是测试用例数、程序代码行数、问题修改时间、程序响应时间和测试问题数以及数据量、交易量。
程序响应时间和数据量、交易量可以对程序性能作出评价,而问题数量及问题的修改时间则可以对程序的可靠性、健壮性、可扩展性、正确性进行很好的评价。不 同严重程度的问题对测试结果的影响是不一样的,比如一般问题可能对程序正确性影响不大,而紧急问题却可能导致程序无法运行从而对程序正确性造成严重影响。 所以对于程序正确性的评价必须区分一般问题、重要问题和紧急问题。
除了问题的严重程度外,一定测试阶段内程序错误问题的新增数量、关闭数量和总数都是很好的评价指标。总数决定了问题发现是否充分;关闭数量反映了问题修改的速度;新增数量则很容易反映出问题修改的质量。
每一种数量还要区分绝对数量和相对数量。这是因为在一个100行的程序和一个10000行的程序之间直接比较问题个数是没有意义的。相对数量是指某类问 题数占问题总数的百分比。还有估计相对数量是指某类问题数占估计问题总数的百分比。至于使用绝对数量还是使用相对数量作为评价指标,可视具体情况而定,或 者综合考虑两方面指标。
除了定出指标外,还需要为这些指标定义满意度范围,从而定义满意度函数。这可以通过历史数据统计和有经验的专家估计来确定。
根据上述分析结果,结合银行业务软件的特点,将银行业务软件满意度确定为评价的总体目标(O),将其可靠性、健壮性、可扩展性、正确性和性能定为一级指标(即准则层A),然后再进行分解细化,构造出一个评价指标目标树。
1、正确性
程序的正确性可以用程序错误问题的数量及问题的处理时间来评价。
程序错误数量主要考虑测试期内新增数量、关闭数量和总数量。
问题处理时间是指程序错误类的问题从产生到关闭所花费的人力。由于问题的处理必须考虑到修改对象的复杂度,所以还需要评价平均修改时间,也就是处理时间/修改对象的复杂度(本文中采用代码行数)。问题处理时间可以直接标准化后使用,也可以为其定义满意范围。
2、健壮性
健壮性是指在异常情况下,软件能够正常运行的能力。这一能力的评价在实际中难以量化,但可以通过对异常情况下,软件不能正常运行的情况进行评价。所以对 于健壮性可以采用输入错误、操作错误和环境错误的数量来衡量。由于银行业务软件对输入数据的检查在用户需求中有明确的要求,所以输入错误的情况统一归入程 度错误而作为正确性的评价指标。那么评价程序健壮性的就剩下操作错误数量和环境错误数量两个主要的指标。
3、可扩展性
程序的可扩展性主要体现在需求变更的处理上。需求变更包括对已有需求的改变和新需求。需求变更的影响范围和需求变更的修改时间可以对程序的可扩展性进行 很好的评量。实际上需求变更的影响范围也可以通过修改时间来衡量。那么对程序可扩展性进行评价的主要就是需求变更的平均修改时间。
4、可靠性
凡是测试出现问题(需求变更除外)都认为对程序的可靠性有影响,所以可靠性的评价指标主要就是除了需求变更外的所有问题的数量及问题的平均修改时间。
5、性能
对于性能的评价最主要的指标就是程序响应时间。程序响应时间的评价也必须区分绝对时间和相对时间。绝对时间就是指不考虑环境因素影响,而只考虑 程序本身执行的响应时间,比如对于联机测试,程序响应时间控制在5秒以内。相对时间是指考虑环境因素影响,如本底数据量、并发交易量等,对程序响应时间做 相应的平均处理,比如单位本底数据量程序响应时间、单位并发交易量程序响应时间。
二、指标权重确定
本文采用层次分析法来确定各指标的权重。
1、判断矩阵建立
组建专家团对目标树同层次各项指标,按其在上一层指标中的重要性,进行两两间重要程度比较建立判断矩阵:
2、相对重要程度的计算
由于测试评价不需要十分精确的权重计算,所以本文直接采取简单易理解的求和法来计算各指标的相对重要程度。当然也可以直接借助现有的计算软件来进行精确的计算。
首先将判断矩阵按列归一化:
然后按行求和:
最后再进行归一化:
3、一致性检验
由于判断矩阵的产生带有很大主观性,往往出现判断的不一致。所以必须对判断矩阵的一致性进行检验。
首先求取最大特征根:
计算一致性指标:和一致性比值:
如果 ,则该判断矩阵的一致性是可以接受的。
三、满意度计算
首先根据已经收集的测试数据对最底层指标计算满意度。例如,针对联机测试,评价性能的子指标响应时间的满意范围为[3,30]且满意度递减,那么这个指标的满意度表示如下式:
经测试联机交易的平均响应时间为5秒,用上式计算可得响应时间的满意度为:
将同一层的各评价指标的满意度计算加权和,得到上一层评价指标的满意度数值。如果一个评价指标有子层评价指标,那么它的满意度可以直接使用子层 评价指标的加权满意度和,也可以对加权满意度和再按此指标的满意度表达式计算满意度。例如对于指标联机交易性能,其子层评价指标的加权满意度和为0.9, 这个满意度值可以直接反映到更上一层指标的满意度中;如果为它定义满意范围为[0.5,1.0]且满意度递增,那么经计算后可得联机交易性能的满意度为 0.8。
满意度的计算一直往上直到最终的目标层。
四、评价分析
经过满意度计算后,评价指标树中各层评价指标都会有其满意度值。可以直接通过判断目标层的满意度,来判断对本次测试的结果是否满意。如果总体不满意,则可以从上至下逐层检查是哪些指标导致总体满意度偏低。
五、总结
本文结合银行业务软件的特点,为银行业务软件测试评价建立评价指标体系,使用层次分析法计算各指标的权重,并用可能-满意度法对测试结果进行评价。
本文所论述的测试只限于测试阶段,其实按照W模型的思想,测试是贯穿整个软件工程流程的,比如在需求分析阶段就必须为系统测试作准备,在概要设 计阶段就必须为集成测试作准备。而且测试不只是针对软件进行,还包括每一阶段的工作成果,如需求规格、设计规格等等。但由于对这些工作成果测试研究还不够 成熟,在实际运用中可操作性不强。这方面理论和技术的发展将会使银行业务软件的测试更加完善和高效。