
敏捷团队的管理其实的确面临着很多的挑战。蔡老师分别从敏捷管理的挑战、接受敏捷、敏捷下面的组织结构、敏捷架构下的沟通、敏捷下的KPI考核、以及机会和发展几个方面进行深入的讨论。
其实我觉得各个公司施行敏捷的时候都会遇见这次讲师所分享的一些问题,基本上都是有共同点的。比如第一点,每个Scrum Team都会有自己的一个基调。每个测试你所跟随的人不同,跟随的team也不同,然后所接触的项目也不同,碰见的问题也不同,甚至作息时间也会有所不同。这样的情况下,管理其实是最最麻烦的。我自己之前也一直烦恼一个问题就是,在这样的情况下,我应该如何进行test team这样一个团队的横向分享,比如好的case,好的bug,又或者要push某个process的时候怎么办。我表示真的很烦恼,如有人有好的解法,还希望在我blog下面留言。
第二个问题点,如何在做好管理的同时,又避免Scrum Master和Test Leader同时给测试发号施令。这个问题其实也很常见。Master和Leader横向交流不同,每个人安排任务的切入点也不同,就往往会导致测试们很辛苦。一会儿要处理这个,一会儿要处理那个。最终会导致加班,情绪也不稳定。
第三个问题点,一旦敏捷了,就会造成很多的“不规范”,那么在这种情况下面应该怎么进行KPI的考评呢?
第四个问题点,当你的团队每个成员都被分派到了各个Scrum Team之后,如何保持test team一个高涨的氛围,如何去维持一个很好的气氛,是否能够一直保证大家一条心呢?
第五个问题点,Scrum Master和Test Leader如何体现自己的KPI。一旦敏捷了之后,作为一个leader的话,我相信很多人会觉得这个职位越来越虚,好像自己离团队成员以及项目越来越远,那么怎么样才能够体现自己的KPI呢,我相信也是很多人困扰的原因所在。
第六个问题点,测试管理者的出路在哪里,或者说规划,或者方向在什么地方?
如何去接受敏捷,这点我相信很多人也能够体会。如果你作为一个测试经理,那么推广敏捷我相信是非常值得期待的一件事情。但是敏捷并非那么容易被团队成员以及高层领导所接受,或者说那么快的接受。就测试成员来讲,首先他会多了一个“婆婆”,Scrum Master。至少从心理上来讲,会有一些抵触的心理。其次 ,每个测试人员被安排到独立的Scrum Team中,那么相比以前的团队合作可能会多出很多的工作量不说,可能相对dev和pm来讲更加的弱势。从企业高层来讲,我个人觉得一般会碰见这样几个问题。一种就是觉得现在的模式很好啊,为何要去改变呢?一种就是可能看到敏捷之后,觉得测试team更加偷懒了,没有doc的输出,没有一个团队的合作。所以综上所述,接受敏捷需要时间,需要引导。
敏捷模式下面的团队架构,蔡老师给出了四种架构,我自己其实比较偏向于测试人员上面一定要是测试leader,测试leader上面可以是别的一个职位。为什么呢?一方面来讲,测试leader和测试人员最为熟悉也是最贴近的一个角色,无论是工作安排还是沟通都比较好。另外,就如我上一篇写的文章中提到的,我还是认为能够理解测试的只有测试,所以无论安排和沟通测试leader能够更加从测试的角度出发进行思考,这样对于测试人员的发展会非常有利。
这种敏捷的架构中必须尽量要保证产品,项目,测试,开发等几个角色互相促进,互相帮助去推动产品,不要有什么勾心斗角。否则结果可能就和敏捷的初衷背道而驰。
敏捷模式下的沟通,这里其实就是两点,敏捷模式下测试经理和Scrum Master的沟通以及和组员的沟通。和Scrum Master的沟通主要是为了让Scrum Master分配的任务更加符合项目情况,符合测试人员 的水平。和组员的沟通主要是引导大家去接受敏捷,并且不停地指出错误纠正,帮助大家和Scrum Master更好的沟通,以免测试人员感觉自己被卖掉了。
测试管理者在该模式下还有一个很重要的沟通对象,就是自己的上级。其实这这点并不难,我更觉得在各个企业哪怕不敏捷也需要做到这样几点。定期的说明自己的想法和建议,包括怎么落实怎么执行。花时间好好总结自己团队完成任务的情况,业绩,让上级一目了然。最后就是引导上级去接受敏捷。
敏捷下面的KPI考核。这点其实哪怕不敏捷很多公司也很迷茫。敏捷之后,需要进行全方位的考核。1.测试人员所负责模块的质量。2.case和bug的质量 3.工作的态度和方法 4.Scrum Mater的反馈。主要要注意的就是作为测试管理者,要对于Scrum Master给出的feedback有所过滤,每个Master都会有自己的性格特征。作为管理者当考核的时候听取Master的意见的时候需要根据其不同的性格进行有针对性的过滤,以达到最好最公正的评价效果。 5.对于团队的服务 6.组内其他成员的反馈
在考核的过程中,测试管理者要像以前一样的了解自己的组员,而不是放到每个team之后就不理不问。我觉得甚至要比以前更加的了解。同时,考核也是one one的一个过程,在期间需要更多的引导测试人员主动去展现自己的业绩,主动去研究新的技术,主动帮助团队的成员,提升自己的主观能动性。这样敏捷才会越来越好,越来越有效。
敏捷模式下蔡老师还提到了一个补位的概念,顾名思义,就是要了解每个team项目,人员的特征。在一些特殊的,突发的情况下,测试人员可以进行灵活的补位调整,这样就不会对于项目、产品造成很大的影响。
敏捷带来的机会其实很多,就如我自己在创业团队中的初期一直是敏捷的一种模式,对于测试人员自身的要求会相应的提高,同时测试人员学到的东西也会更多。测试人员会相比以前的团队中认识更多的同事,会提升自己的人际交往能力。作为管理者,敏捷也在考验你的管理能力。就关于敏捷的好处来讲,我总结就是作为测试人员,你了解的流程更多了,你了解的产品项目信息更多了,你接触的技术面更广了。但有一点,需要大家谨记,就是要不停地和同行沟通,要不停地进行学习。
敏捷是把双刃剑,要看用的好不好。就如刚在微博上面发的一样,大家根据实际情况进行选择运用,否则很容易导致测试在企业中的流程也好,文档也好,技术也好没有沉淀和积累。合理运用传统流程和敏捷才是王道。
本文转载于51testing 如有版权问题 请找他们 本人只是学习备份而已!
前段时间有新的产品需要招人,安排和参加了好几次面试,下面就谈谈具体的面试问题,在面试他人的同时也面试自己。
面试问题是参与面试同事各自设计的,我也不清楚其他同事的题目,就谈谈自己设计的其中2道题。
过去面试总是会有如何测试Google首页,测试杯子,测试电话之类的,有偷懒的嫌疑,这次来个具体的,第一个题目如何测试下面这个表:
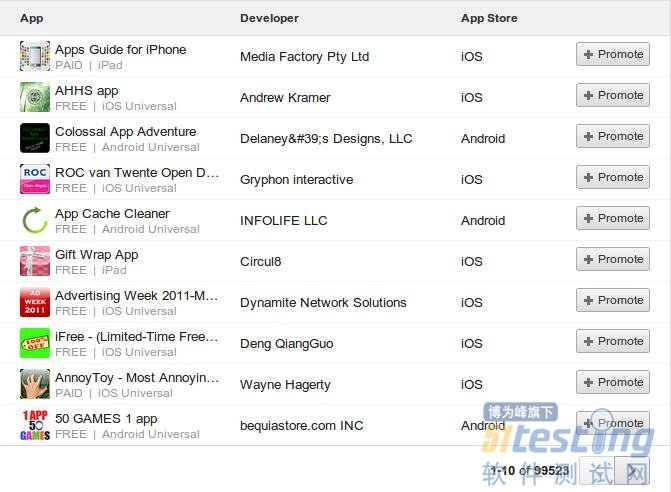
一、第一个问题设计测试用例
面试里得到的很多回答就是一条条罗列,例如:
1、界面显示是否正常,各种浏览器、分辨率,文字是否显示正常
2、这个数据是否和数据库一致
3、promote按钮是否正常使用
4、上一页下一页按钮是否正常
5、列表标题是否支持排序,排序功能是否正常(很奇怪,这个提到的人不多,类似的下拉列表的Autocomplete也很少人提到)
6、......
比较少的听到按照测试类型来设计的,例如界面测试用例、功能测试用例、大数据测试用例等等,
也没有听到按照正常用例和异常用例来罗列。
二、如果你来设计这个表,还会做哪些完善
1、可能有些人注意到,这个结果总共有99523个,提供的翻页只有前进后退,是否加个go to page的功能
2、貌似我们以前见过列表翻页还有提供第一页和最后一页,那是否也加上
3、结果很多,是不是加个搜索(其实这个数据是搜索得到的)
4、这个列表一页只显示10个结果,是否可以多显示些,是否加个每页显示数目
...
问到第二个问题,有些面试人员就迷惑了,经常听到的是“我们都是根据需求测试的”,那我问,你们对用户体验关注么,
得到很多回答是“设计好的,我们只是测试下”,被动式的测试居多。
三、如果你来实现这个表会怎么做
1、最简单的,拉个控件,之后连接到数据库,搞个dataset/datatable数据绑定读取数据显示
2、直接连接到数据库如果数据量大时,前台等待过久怎么办,哦,有AJAX,异步获取数据
3、还有没有更好的,预加载,生成10页的结果放在服务端,这个技术在网购网站首页的促销商品大量使用
这是一个优化的问题,可惜很多测试对于开发的设计实现没有任何的兴趣或是根本不去了解。
了解了下,有很多公司是不能看代码的,能看代码的也没有编辑的权限,把测试定位成开发的服务,但并没有充分利用测试可以帮助开发定位错误,
让开发更快的修复缺陷,更多的是选择让测试熟悉业务。
四、某位测试工程师自己写了个自动化脚本进行翻页,可是翻页到1万多结果的时候,浏览器崩溃了,你来研究下是什么原因
这个问题很多人思索后放弃了,那么我提示说崩溃的时候,浏览器占用了2G的内存,极少有人提到查看日志。
1、使用自动化的时候,是否可以再写个脚本监控浏览器操作的资源使用情况
2、内部测试系统是否可以打开debug模式用来记录日志
3、是否可以查看开发代码,看看开发实现翻页部分的代码
4、和开发沟通,一起来排查错误
...
很失望,到这个问题很少得到满意的答复,测试的同学们在广度上有所突破外是否也注重下深度,我自己也逐渐意识到这些问题,刚好作为面试题目。
相似的问题,如何测试下拉列表,有兴趣的同学可以练练手。
另一题目是关于文件读写
有一个文件,存放着地理信息,类似下面,想从里面取出IP地址用在其他地方,即如何从一个文件中取出IP地址存入另一个文件。
1.0.0.0|apnic debogon project|null|7|0r||12|0|22581|4|0||
1.0.1.0|chinanet fujian province network|null|591|41||43|0|35075|4|0||
1.0.2.0|chinanet fujian province network|null|591|41||43|0|35075|4|0||
1.0.3.0|chinanet fujian province network|null|591|41||43|0|35075|4|0||
1.0.4.0|level collins street|null|7|0r||12|0|3719|4|0||
1.0.5.0|level collins street|null|7|0r||12|0|3719|4|0||
1.0.6.0|level collins street|null|7|0r||12|0|3719|4|0||
1.0.7.0|level collins street|null|7|0r||12|0|3719|4|0||
1.0.8.0|chinanet guangdong province network|null|20|47||43|0|7392|4|0||
1.0.9.0|chinanet guangdong province network|null|20|47||43|0|7392|4|0||
...
这个第一步就很多人放弃了,理由基本上是“以前学校学过某某语言,后面工作就没写过代码”, 稍微好点的呢,“可以说下思路么”,也行,那说下思路吧。
少数人会想到使用awk命令直接在teminal运行,也有想到写个小脚本来读取写入。
应该说不管开发测试,很多都是计算机相关专业毕业的,我想在现行教育体制下,大学里至少都学过C语言吧,可是有些测试人选择测试职业后,
直接把Coding的技能抛弃了,注意,是自己抛弃了,虽然在公司工作上不用编码,但是工作后呢,有没有自己写些东西。
好了,假设写了个小脚本,例如理想情况下第一竖线前都是IP地址,写个python脚本如下:
#!/usr/bin/python2.4
#
import re
geofile=open('geo.csv','r')
lines=geofile.readlines()
for line in lines:
a=line.split('|')
ipfile=open('ip.txt','a')
print >> ipfile,a[0]
geofile.close()
ipfile.close() |
接下来请对写的这个命令也好,脚本也好测试。
1、正常用例
2、异常用例
这个问题可以从2种角度入手,一种直接把它当作黑盒来测试,不知道里面的实现,提供不同的输入文件查看输出结果;另一种可以采用单元测试。
可惜很多面试人纠结在文件的第一列是不是IP地址,需要判断。
脚本写好了,也测试了,如果这个地理信息文件很大呢,具体点,这个是全球地理信息文件,超过2G,你写的这个脚本执行要很久哦。
这又是个优化问题,整个面试只有一位同学说可以采用分割文件的做法,先分割再合并,他也是提到使用awk命令的同学。
可惜没有听到使用多线程多进程的方式。
这次面试感慨颇多,面试的对象基本是工作2、3年的测试工程师,但对测试的认识普遍还是几年前的样子,面试要求也是一再降低,统计下来,9个候选人能选中一个。
虽然外面宣传的测试职业前途非常光明,不过在实际工作中,中小型企业测试人的地位普遍低于开发,除了几个大公司。
测试如果想要提高自己的地位,首先要提高自己的技能,不仅仅是在测试技术上,开发技术和对开发设计的理解也是需要提高的,这样才能获得和开发同等的交谈资格。
许多Windows系统管理员,还兼职着微软SQL Server数据库管理员(DBA)的身份。另一方面,企业将许多机密的信息存储到了SQL Server数据库中。作为一名DBA新手,则需要了解SQL Server的安全模式和如何配置其安全设置,以保证“合法”用户的访问并阻止“非法”访问。而在SQL Server中登陆、用户、角色、权限提供了对数据库访问的权限,接下来在数据库安全性上着重分析它们的关系。
● 安全层次和验证模式
一、安全层次
SQL Server支持三级安全层次。在我们登陆到SQL Server时,其实我们是经过了三步的验证。
第一层次是用户提供正确的账号和密码登录到SQL Server,或者已经成功登陆了一个可以映射到SQL Server的windows账号。但是在SQL Server登陆并不意味着能够访问数据库,而是要经过第二层次的验证。
第二层次的权限允许用户与一个或多个数据库相连,这一层次的实现要在数据库对象的用户中绑定登陆账户。
第三个层次的安全权限允许用户拥有对指定数据库中的对象的访问权限,例如:可以指定用户有权使用哪些表和视图、运行哪些存储过程。在第一层次中的windows账号,其实是在我们装机时给windows指定的自己登陆到windows系统的账号,而作为windows系统管理员的我们其实也兼职了SQL Server的管理权,那我们如何设置才能保证只有我们指定的用户才能访问SQL数据库呢?就是我们下面要说的验证模式。
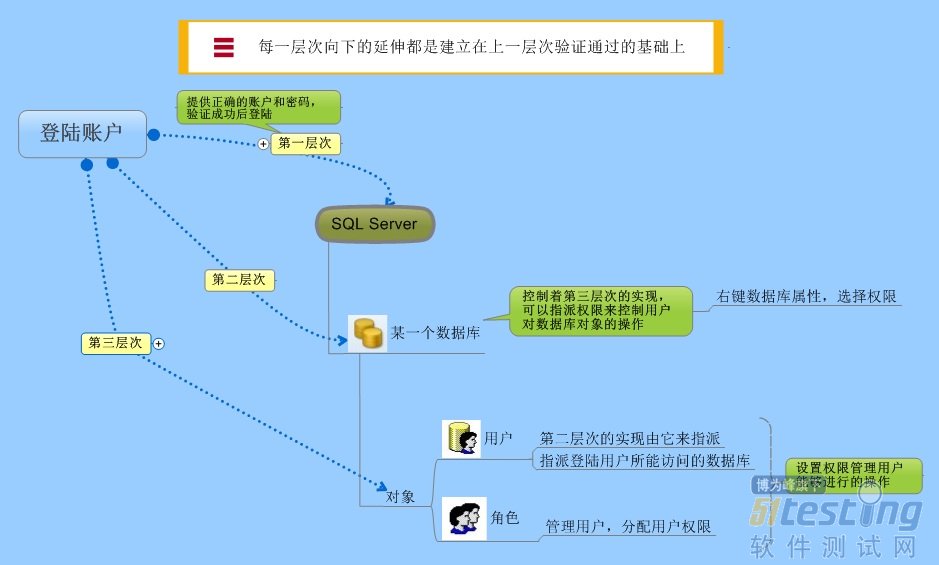
二、SQL登陆验证模式

SQL的登陆验证模式有两种,一种是Windows的验证模式,另一种是Windows和SQL Server混合验证模式。如果我们选择windows模式登陆并把windows账号映射到SQL Server的登陆上,那么合法的windows用户也就连接到了SQL Server中。
Windows模式的登陆需要在SQL Server中设置。方法:
打开SQL Server企业管理器,找到安全性文件夹,打开后再登陆中新建一个windows身份验证模式的账户。需要注意的是在新建账户时,账户的名称一定要填我们windows账户的名字,如:我的计算机在用户中名称为张信秀,则在填名称时一定要填张信秀。

SQL Server的验证模式相对windows的登陆模式在设置上没有特别的要求,只需填上我们的密码即可。
接下来进入我们的重点——角色、权限,首先我们在图上来区分。
● 登陆、权限、角色
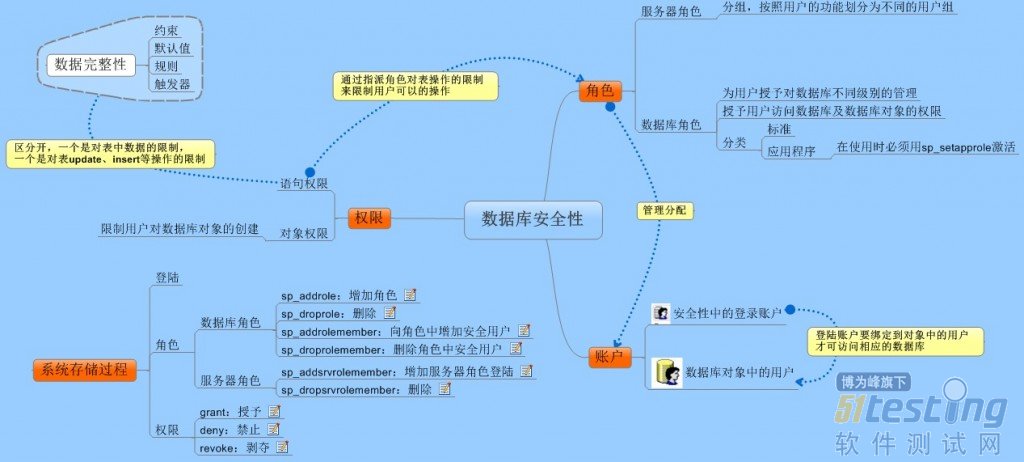
在往下说之前我们先介绍下安全账户。返回到安全层次上来说,账户在登录到SQL Server后,如果想获得访问某个数据库的权限,是必须要在SQL中获得安全账户的,确保登陆的账号是安全的,就好比是我们出国的护照签证一样,想要去哪个国家必须获得该国家的签证和出入境章,这个安全账户就是在数据库对象的用户中绑定一个登陆账号,证明这个登陆账号是安全的。
账户、角色、权限他们三者是没有严格的关系的,如果有的话就是角色给账户分配职能,而权限却又限制着角色和账户对数据库的操作。它们三者就好像是公司里的员工、职权、规章,公司按照职能非配不同的员工,但是每个员工却又受到公司规章的限制。
一、数据库角色
数据库角色控制着数据库的安全性。当最终用户成功地连接到分析服务器之后,会在那个服务器上的数据库角色中查找最终用户的用户名,来确定用户对数据库的可能操作。
数据库角色在创建时有两种:
1、标准角色:不允许嵌套,在使用时只需在安全账户中添加,通过分配权限确保了用户能够进行的操作;
2、应用程序角色:为了让标准角色嵌套,来控制角色所能进行的操作,创建后SQL Server把它当做账户看待(因为它是应用程序级别的),它的作用是为权限提供相应的加密,用存储过程sp_setapprole激活才可进行授予权限的操作。
二、权限
权限有三种类型,
1、语句权限:限制对表update、insert等的操作,在创建角色时或添加安全用户后设置;
2、对象权限:限制用户对数据库对象的创建,在数据库属性内设置;
3、暗示性权限:SQL Server数据库自带的那些角色或用户,如:服务器角色、数据库所有者(dbo)等拥有的权限,不需要了解他,因为它是系统自己设置的用户不能够设置。
最后我们在代码中应用下三者:
/*示例说明:在数据库company中创建一个拥有表product的所有权限、拥有表employees的SELECT权限的角色rtest随后创建了一个登录ltest,然后在数据库company中为登录ltest创建了用户账户utest同时将用户账户utest添加到角色rtest中,使其通过权限继承获取了与角色rtest一样的权限最后使用DENY语句拒绝了用户账户utest对表titles的SELECT权限。经过这样的处理,使用ltest登录SQL Server实例后,它只具有表product的所有权限。
*/ USE company --创建角色 rtest
EXEC sp_addrole 'rtest' --授予 rtest 对product 表的所有权限
GRANT ALL ON product TO rtest
--授予角色 rtest 对 employees 表的 SELECT 权限
GRANT SELECT ON titles TO rtest --添加登录 ltest,设置密码为pwd,默认数据库为pubs
EXEC sp_addlogin 'ltest','pwd','company' --为登录 ltest 在数据库 pubs 中添加安全账户 utest
EXEC sp_grantdbaccess 'ltest','utest' --添加 utest 为角色 rtest 的成员
EXEC sp_addrolemember 'rtest','utest' --拒绝安全账户 utest 对 employees 表的 SELECT 权限
DENY SELECT ON employees TO utest /*--完成上述步骤后,用 ltest 登录,可以对company表进行所有操作,但无法对employees表查询,虽然角色 rtest 有employees表的select权限,但已经在安全账户中明确拒绝了对employees的select权限,所以ltest无employees表的select权限--*/ --从数据库 company 中删除安全账户
EXEC sp_revokedbaccess 'utest' --删除登录 ltest
EXEC sp_droplogin 'ltest' --删除角色 rtest
EXEC sp_droprole 'rtest' |
● 总结:
在新建登陆时,利用服务器角色分配账户的功能,利用数据库角色管理用户对数据库进行的操作。在新建角色时为角色分配权限,来限制用户的操作。
懂得SQL Server安全性的机制后,我们就可以开发自己的数据库安全策略了。你下一步所需要的可能就是产生一个SQL Server脚本了。在SQL Server企业管理器中,右击一个数据库,选择“所有任务”,选择“生成SQL脚本”,这个选项能够产生一个脚本,对包括安全策略在内的数据库进行更新。一个脚本文件可以代替通过鼠标在SQL Server事件管理器中进行点击和选择的操作,大大减少DBA的工作量。
我们目前快不起来,不在于我们是否采取敏捷方式,而是我们基础太薄弱
1、开发人员不理解现有业务
2、开发人员不理解现有代码
3、开发人员不理解现有数据表关系、关键字段变化、VIEW、SP、报表
4、开发人员不理解MAP在典型场景中的实际应用,不了解MAP到底有多少函数可以帮助开发
5、开发人员大多是新人,对开发过程规范不了解。我们目前采取CMMI开发过程规范,光主节点就有78个。开发部门的老人也大部分只是只开发过一个子系统,对其他子系统的业务、代码、数据库也不了解。只是MAP和开发过程规范比武汉开发新人熟悉一些。
6、我们的设计人员也大多是新人,不了解现有业务和系统功能
7、我们的自测没有方法,多了工序,耗了人工和时间,但效果并不明显。
8、我们的代码审查没有方法,多了工序,耗了人工和时间,但效果并不明显。
9、我们的大数据量测试、多场景并发测试、集成跨子系统影响测试、安装部署测试、环境兼容性测试、权限点测试、帮助文件测试也是没有优化,消耗大量时间。
只有先把这些基础补起来,我们的开发效率、开发质量就会比我们现在好很多。所以我们今年大力启动多项针对性的关键行动计划来提升各个方面。但这些做到后我们也并不能做到3个月快速发版。
当然,我们还可以继续优化:
1、需求规划不能滞后,这是常见挤压下游设计、开发、测试时间的原因。需求分为功能增强和BUG修补。对于BUG,ERP3.0会提供BUG自动发回功能,让需求收集需求规划阶段能够优化缩短。
2、开发Leader在功能设计中期就进入,理解业务,设计数据库,设计功能代码实现和代码修改方案、设计接口、识别公共代码。
3、平台提供大量稳定性功能、代码审查工具、性能优化数据库设计指引,平台还提供日志、异常、输入规则校验底层框架,把这些都从业务代码中抽取出去,简化代码开发。平台应用架构组也梳理子系统代码分层解耦、JS代码缩减,力求业务子系统开发少写代码,只写业务代码。
4、设计部门进行设计模板化,平台应用架构组也提供代码模板,开发也尽量模板化COPY修改。简化开发,提高效率和质量。
但要想更快起来,我们必须引入敏捷项目管理、敏捷设计、敏捷开发、敏捷测试。
敏捷测试的核心是要和开发一起并行,把BUG消灭在开发的每天中,而不是在后期集中测试集中爆发。这要求咱们并行写测试用例、并行做自动化测试、并行持续每日自动构建自动脚本测试。咱们目前设计方法和测试方法不一致所以无法并行测试用例,这今年会解决;咱们代码各异没有模板,所以自动化测试跑不起来;我们功能自动化测试经验也尚浅需要加强;
光靠敏捷测试是不够的,保证代码稳定还得主要靠开发人员。所以敏捷开发需要开展单元测试靠开发人员主力保证代码稳定,在单个开发人员编码能力不强的状况下可以采用开发leader编写代码骨架普通开发人员填肉的配合结对编程,而且还得实时进行重构防止代码逐步腐烂导致开发进度开发质量连年下降。这两项也是咱们的空白。
单元测试,最大的误区是很多人以为是先完代码,然后写测试代码来测试已写的函数。其实不然,而是先按照业务场景先写测试函数,这样便于程序员通过输入输出、函数的定义、函数的串联来达到深刻理解业务需求。所以说,单元测试,其核心是测试驱动。
敏捷测试,想做到测试同步,就必须开发人员和测试人员都按照同样的业务场景去分析思考,测试根据场景分析得到测试用例,开发根据场景分析得到单元测试代码。这是同宗同源的。只有这样工作,才能真正保证测试用例编写和开发人员编写代码是同步的。
敏捷测试和敏捷开发的本质是让代码质量持续保持稳定,以便于可以随时发布。
敏捷设计的核心是用户故事(咱们叫用户流程场景,在UML中变形为用例图),这是敏捷测试、敏捷开发共同的源头,这样测试才好验证代码是否符合场景。可以采取咱们前段时间做的组织结构-岗位职责-一级流程-二级流程-功能点+UI草稿,这样来把用户流程场景和功能点映射在一起,并且容易做项目计划估算。用户故事有优先级,咱们也有。用户故事要求独立,咱们也是把一般和特殊分离,力求每个功能点归类成Grid/Form/Report。用户故事有一点比咱们做的先进,就是每个故事都必须具备验收条件,咱们以后也需要这么做。
敏捷项目管理的核心是20个工作日迭代一次。每个迭代周期包括详细设计、开发、测试、演示冲刺四个部分。分到每个环节也就是5天,所以必须持续稳定、同步测试。为了保证20个工作日迭代一次,就不能在这个迭代小周期内中途变更需求、变更设计。这些变更必须在下一个迭代周期去解决。通过有限的工作日来限定有限的需求,有限的人力。也就使需求稳定、人员稳定,这是开发效率开发过程不出异常的两个基础保证。
敏捷项目管理的任务是按小时来计算的。我们现在做不到按小时就是因为我们想在软件设计初期就深刻理解每个功能,但其实不可能做到。而敏捷可以,是敏捷不需要在初期深刻理解每个功能,而只需要把范围缩小到本迭代周期内要实现的功能聚焦思考即可。持续滚动迭代,会逐步思考精确。而且按小时算有个好处,每个迭代周期有多少小时是一定的(20天x8小时x人数),你放进本迭代周期的任务超出时间了,那就当然无法执行了,这也保证了迭代时间估算的准确性。
在这些支撑下,燃尽图只是一个类似丰田可视化看板而已。很多人误认为燃尽图是敏捷SCRUM的核心,其实不然,燃尽图只是表象,支撑它的东西才是核心。不过燃尽图中的正在排队的任务,正在开发的任务,已经开发完成的任务,需要返工修复的任务,还没有计划的任务,这些分类的任务在燃尽图中倒是一清二楚,令团队的每个人都很快明白进展和问题,并且认识信息一致。
至于:规划会、变更会、立会、周会、冲刺演示会,所有这些会议,全体团队成员(产品经理、PM、设计、开发leader、开发、测试、QA)都要一起参加;平时工作,项目团队都要坐在一起。这些方法都是为了让信息快速共享同步。这些敏捷项目管理方法大家平时已经在用了。
20天出一个小迭代版本,60天出一个大迭代版本,这是我们一切思考敏捷创新敏捷尝试敏捷的源泉。大家以此为根,把不以此为目的的旁枝措施都砍掉。否则极有可能走向照猫画虎邯郸学步,成了片面追求敏捷模式了。
以上上述所有能力和基础要想摸索通、准备好这些基础和人员能力模型提升、和咱们现状结合有效、并且产生规模效应,没有2-3年的努力是无法做到的,尤其在我们连年大量新人加入的情况下。所以新人培养模式如何快速培养新人是关键的前提,新人提升不快,咱们这些所有的高级职责和工作要求就无法执行。
在建立各领域的任职资格体系时,此为较早的一篇想法,一是和大家分享,二是给有志于从事管理的测试人员展示一下,除了技术之外,还应该关注那些方面。
一、考核维度
拟晋升为测试主管的测试工程师,需从三个方向进行综合考核评判:能力、业绩、态度,三者缺一不可。
其中:
能力细化为管理能力(项目管理、人员管理、技术管理)和素质能力(技术能力、沟通能力、表达能力);
业绩细化为绩效和各种工作交付件的数量、质量:案例、培训、经验分享、出差、评审;
态度细化为主动性、务实性和责任心;
360°考核细化为:上级、同事、下级、内部客户、外部客户。
二、要求标准
2.1 能力
2.1.1 项目管理
1、有实际负责过项目的经历,对本领域项目模型和运作模式较为理解并较为清晰的描述。熟悉本领域项目的优缺点,并有针对性的给出相关的测试建议和意见。
2、测试项目的交付成果可靠,测试遗漏率较低:通过访谈、封闭版本修改流确认。
3、明晰周例会的目的和作用,能召开合格的周例会。
4、明确工作分解分配的方法,能根据SMART原则,制定周计划。周计划的主动偏差率受控。
5、对所负责的项目进度、风险、缺陷、瓶颈点掌握全面,对项目保持动态评估。
6、对发布项目的技术支持和补丁版本发布,有较好的节奏,做好维护、备份、问题追溯、文档更新工作。
2.1.2 人员管理
1、了解自己属下的性格和技能情况,能指出每个下属的性格特点、技能优缺点,并且给于自己的使用建议和使用方法。
2、关心人员的成长和工作状态,在周例会中或其他正式场合沟通。
3、为下属量身制定提升计划,并取得实际的成果。
4、对不同性格的人、对新老员工有一定的区分对待的管理方法。
5、绩效面谈言之有物,对属下有指导和提升作用。
2.1.3 技术管理
1、熟悉公司研发的主流程,熟悉测试领域的交付件;熟悉测试流程,明确产品测试的各交付件和检查点。
2、对本领域的内部调试命令做到汇总,和定期更新,组织团队成员进行学习和考核。
3、对本领域的测试方法和测试用例,做周期性刷新计划,保持测试基础工作的建设和推进。
4、对本领域的测试工具进行摸索和运用,提高团队的自动化测试水平,提高团队工作效率。
2.1.4 技术能力
1、能执行本领域核心功能的测试设计工作,能对本领域的产品实现提出意见和建议,对业务实现逻辑较为清晰,可做到新人培训和测试指导。
2、掌握基础的QTP、loadrunner的使用方法,能完成部分功能自动化设计和执行工作,可做到新人培训和测试指导。
3、根据行业特点,对行业的特殊测试技术有所掌握,并能进行应用推广。
2.1.5 沟通能力
1、对别人的描述,能够总结出完整的思路,并提炼出重点。能够清晰的表达自己的意思和意图。
2、对外的技术支持沟通顺畅。
3、对领导的工作汇报清晰、准确。
2.1.6 表达能力
1、编写的各种交付件清晰准确:测试用例、测试报告、案例、总结等。
2、能制作较好的ppt,完成培训、汇报工作。
3、能准确的、正向的传达上级领导的指示。
2.2 业绩
2.2.1 绩效考核
个人绩效考评:年度为A,或四个季度含两个A,不得出现C,如果有C,需要额外进行说明。
2.2.2 案例编写
1、保持季度1篇的原创技术文档编写,评审结果要求两星以上(0-3分),有一定的深度和学习推广价值。
2、技术文档编写较多,在经验分享方便有较强主动性,作为业绩纳入考核。
2.2.3 培训反馈
1、年度完成对测试部门的培训课程1门,对产线相关领域的培训课程1门;
2、培训反馈结果在良好及其以上。
2.2.4 经验分享
1、建立组内的经验分享方式,组织团队成员在业务、行业、测试方面的知识分享方法和氛围。
2、自己主动分享的知识点数量和分享落地成果。
2.2.5 出差反馈
1、在各类售前、售中、售后性质的出差过程中,其他领域同事(售前、销售、办事处、客户等)的反馈和评价意见。
2、出差后的个人总结文档质量:软件测试建议、客户关心的业务功能、完善测试场景构建、经验技巧分享等。
2.2.6 业务评审
1、在产品立项过程中,各项评审活动提出的意见和建议数目、质量。
2、在各类同行评审、技术评审过程中,提出的意见和建议数目、质量。
3、在组内用例、文档、案例评审中,提出的意见和建议数目、质量。
2.3 态度
2.3.1 主动性
1、针对目前团队存在的问题和薄弱环节,能否从内部主动性的角度出发,改善或解决问题。
2、周期性总结团队建设和规划方便的计划,制定组内学习计划,组内总结例会。
2.3.2 务实性
1、针对项目、团队建设提出的方案务实可行。
2.3.3 责任心
1、遇到问题,合理判别,不任意推诿责任,也不盲目承担责任,做好份内的工作。
2、明确知晓自己的岗位职责,外部冲击较大时,明确区分哪些是不可抗力,哪些是借口理由,率领团队努力应对。
2.4 360°考核
2.4.1 上级
2.4.2 同事
2.4.3 下级
2.4.4 内部客户
2.4.5 外部客户
由产品线和部门领导、人力资源共同出面,约请各角色,对此人在能力、态度、业绩方面做综合考评。
前几天听英语用到虚拟光驱装resseta stone,没想到各种不顺,把我的本本给整瘫痪了。后来重整旗鼓,装了云端,总算是把它搞定了,由于瘫痪来的很突然,所以我的一些数据不小心丢了一些。我新建的数据库日志文件就悲催的丢啦。其实新建一个数据库完全可以,只是觉得现在碰到了,而且也不是没有时间,可以查找一下解决方案,以备以后自己和他人遇到一些类似的情况不必再犯难。
下面来说一下恢复方法:
如果你的数据还在数据库服务器中,请执行以下三步
1、停止数据库服务。
2、将需要恢复的数据库文件复制到另外的位置,然后在SQL Server Management Studio中删除要恢复的数据库。
3、启动数据库服务。
接下来
1、新建同名的数据库(数据库文件名也要相同)。
2、停止数据库服务。
3、用备份的.mdf文件覆盖新数据库的同名文件。
4、启动数据库服务。
5、在查询分析器中:运行如下代码将数据库设置为紧急状态
| alter database dbname set emergency |
例如恢复的数据库名为:MRcharge,图如下
6、然后再查询中输入如下语句就可以恢复数据库了:
use master declare @databasename varchar(255) set @databasename='MRcharge' exec sp_dboption @databasename, N'single', N'true' --将恢复数据库置为单用户状态 dbcc checkdb('MRcharge',REPAIR_ALLOW_DATA_LOSS) dbcc checkdb('MRcharge',REPAIR_REBUILD) exec sp_dboption 'MRcharge', N'single', N'false' --最后再将恢复数据库置为多用户状态 |
注意:这种方法恢复必须保证你建立数据库和恢复数据库用的是统一版本,即:都是sql server 2000,或者 2005,或者2008。
我曾想用sql server 2008恢复2005的数据库,结果提示版本过低,无法打开,需要升级,于是我在建数据库的时候特意把兼容级别改成2005的,结果还是一样。
跨版本恢复待求解,请指点。
1、什么是进程(Process)和线程(Thread)?有何区别?
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。一个线程可以创建和撤销另一个线程,同一个进程中的多个线程之间可以并发执行。
进程与应用程序的区别在于应用程序作为一个静态文件存储在计算机系统的硬盘等存储空间中,而进程则是处于动态条件下由操作系统维护的系统资源管理实体。
2、Windows下的内存是如何管理的?
Windows提供了3种方法来进行内存管理:虚拟内存,最适合用来管理大型对象或者结构数组;内存映射文件,最适合用来管理大型数据流(通常来自文件)以及在单个计算机上运行多个进程之间共享数据;内存堆栈,最适合用来管理大量的小对象。
Windows操纵内存可以分两个层面:物理内存和虚拟内存。
其中物理内存由系统管理,不允许应用程序直接访问,应用程序可见的只有一个2G地址空间,而内存分配是通过堆进行的。对于每个进程都有自己的默认堆,当一个堆创建后,就通过虚拟内存操作保留了相应大小的地址块(不占有实际的内存,系统消耗很小)。当在堆上分配一块内存时,系统在堆的地址表里找到一个空闲块(如果找不到,且堆创建属性是可扩充的,则扩充堆大小),为这个空闲块所包含的所有内存页提交物理对象(在物理内存上或硬盘的交换文件上),这时就可以访问这部分地址。提交时,系统将对所有进程的内存统一调配,如果物理内存不够,系统试图把一部分进程暂时不访问的页放入交换文件,以腾出部分物理内存。释放内存时,只在堆中将所在的页解除提交(相应的物理对象被解除),继续保留地址空间。
如果要知道某个地址是否被占用/可不可以访问,只要查询此地址的虚拟内存状态即可。如果是提交,则可以访问。如果仅仅保留,或没保留,则产生一个软件异常。此外,有些内存页可以设置各种属性。如果是只读,向内存写也会产生软件异常。
3、Windows消息调度机制是?
A)指令队列;B)指令堆栈;C)消息队列;D)消息堆栈
答案:C
处理消息队列的顺序。首先Windows绝对不是按队列先进先出的次序来处理的,而是有一定优先级的。优先级通过消息队列的状态标志来实现的。首先,最高优先级的是别的线程发过来的消息(通过sendmessage);其次,处理登记消息队列消息;再次处理QS_QUIT标志,处理虚拟输入队列,处理wm_paint;最后是wm_timer。
4、描述实时系统的基本特性
在特定时间内完成特定的任务,实时性与可靠性。
所谓“实时操作系统”,实际上是指操作系统工作时,其各种资源可以根据需要随时进行动态分配。由于各种资源可以进行动态分配,因此,其处理事务的能力较强、速度较快。
5、中断和轮询的特点
对I/O设备的程序轮询的方式,是早期的计算机系统对I/O设备的一种管理方式。它定时对各种设备轮流询问一遍有无处理要求。轮流询问之后,有要求的,则加以处理。在处理I/O设备的要求之后,处理机返回继续工作。尽管轮询需要时间,但轮询要比I/O设备的速度要快得多,所以一般不会发生不能及时处理的问题。当然,再快的处理机,能处理的输入输出设备的数量也是有一定限度的。而且,程序轮询毕竟占据了CPU相当一部分处理时间,因此,程序轮询是一种效率较低的方式,在现代计算机系统中已很少应用。
程序中断通常简称中断,是指CPU在正常运行程序的过程中,由于预先安排或发生了各种随机的内部或外部事件,使CPU中断正在运行的程序,而转到为响应的服务程序去处理。
轮询——效率低,等待时间很长,CPU利用率不高。
中断——容易遗漏一些问题,CPU利用率高。
6、什么是临界区?如何解决冲突?
每个进程中访问临界资源的那段程序称为临界区,每次只准许一个进程进入临界区,进入后不允许其他进程进入。
(1)如果有若干进程要求进入空闲的临界区,一次仅允许一个进程进入;
(2)任何时候,处于临界区内的进程不可多于一个。如已有进程进入自己的临界区,则其它所有试图进入临界区的进程必须等待;
(3)进入临界区的进程要在有限时间内退出,以便其它进程能及时进入自己的临界区;
(4)如果进程不能进入自己的临界区,则应让出CPU,避免进程出现“忙等”现象。
7、说说分段和分页
页是信息的物理单位,分页是为实现离散分配方式,以消减内存的外零头,提高内存的利用率;或者说,分页仅仅是由于系统管理的需要,而不是用户的需要。
段是信息的逻辑单位,它含有一组其意义相对完整的信息。分段的目的是为了能更好的满足用户的需要。
页的大小固定且由系统确定,把逻辑地址划分为页号和页内地址两部分,是由机器硬件实现的,因而一个系统只能有一种大小的页面。段的长度却不固定,决定于用户所编写的程序,通常由编辑程序在对源程序进行编辑时,根据信息的性质来划分。
分页的作业地址空间是一维的,即单一的线性空间,程序员只须利用一个记忆符,即可表示一地址。分段的作业地址空间是二维的,程序员在标识一个地址时,既需给出段名,又需给出段内地址。
8、说出你所知道的保持进程同步的方法?
进程间同步的主要方法有原子操作、信号量机制、自旋锁、管程、会合、分布式系统等。
9、Linux中常用到的命令
显示文件目录命令ls 如ls
改变当前目录命令cd 如cd /home
建立子目录mkdir 如mkdir xiong
删除子目录命令rmdir 如rmdir /mnt/cdrom
删除文件命令rm 如rm /ucdos.bat
文件复制命令cp 如cp /ucdos /fox
获取帮助信息命令man 如man ls
显示文件的内容less 如less mwm.lx
重定向与管道type 如type readme>>direct,将文件readme的内容追加到文direct中
10、Linux文件属性有哪些?(共十位)
-rw-r--r--那个是权限符号,总共是- --- --- ---这几个位。
第一个短横处是文件类型识别符:-表示普通文件;c表示字符设备(character);b表示块设备(block);d表示目录(directory);l表示链接文件(link);后面第一个三个连续的短横是用户权限位(User),第二个三个连续短横是组权限位(Group),第三个三个连续短横是其他权限位(Other)。每个权限位有三个权限,r(读权限),w(写权限),x(执行权限)。如果每个权限位都有权限存在,那么满权限的情况就是:-rwxrwxrwx;权限为空的情况就是- --- --- ---。
权限的设定可以用chmod命令,其格式位:chmod ugoa+/-/=rwx filename/directory。例如:
一个文件aaa具有完全空的权限- --- --- ---。
chmod u+rw aaa(给用户权限位设置读写权限,其权限表示为:- rw- --- ---)
chmod g+r aaa(给组设置权限为可读,其权限表示为:- --- r-- ---)
chmod ugo+rw aaa(给用户,组,其它用户或组设置权限为读写,权限表示为:- rw- rw- rw-)
如果aaa具有满权限- rwx rwx rwx。
chmod u-x aaa(去掉用户可执行权限,权限表示为:- rw- rwx rwx)
如果要给aaa赋予制定权限- rwx r-x r-x,命令为:
chmod u=rwx,go=rx aaa
11、makefile文件的作用是什么?
一个工程中的源文件不计其数,其按类型、功能、模块分别放在若干个目录中。makefile定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。因为makefile就像一个Shell脚本一样,其中也可以执行操作系统的命令。makefile带来的好处就是——“自动化编译”。一旦写好,只需要一个make命令,整个工程完全自动编译,极大地提高了软件开发的效率。make是一个命令工具,是一个解释makefile中指令的命令工具。一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
12、简术OSI的物理层Layer1,链路层Layer2,网络层Layer3的任务。
网络层:通过路由选择算法,为报文或分组通过通信子网选择最适当的路径。
链路层:通过各种控制协议,将有差错的物理信道变为无差错的、能可靠传输数据帧的数据链路。
物理层:利用传输介质为数据链路层提供物理连接,实现比特流的透明传输。
13、什么是中断?中断时CPU做什么工作?
中断是指在计算机执行期间,系统内发生任何非寻常的或非预期的急需处理事件,使得CPU暂时中断当前正在执行的程序而转去执行相应的事件处理程序。待处理完毕后又返回原来被中断处继续执行或调度新的进程执行的过程。
14、你知道操作系统的内容分为几块吗?什么叫做虚拟内存?他和主存的关系如何?内存管理属于操作系统的内容吗?
操作系统的主要组成部分:进程和线程的管理,存储管理,设备管理,文件管理。虚拟内存是一些系统页文件,存放在磁盘上,每个系统页文件大小为4K,物理内存也被分页,每个页大小也为4K,这样虚拟页文件和物理内存页就可以对应,实际上虚拟内存就是用于物理内存的临时存放的磁盘空间。页文件就是内存页,物理内存中每页叫物理页,磁盘上的页文件叫虚拟页,物理页+虚拟页就是系统所有使用的页文件的总和。
15、线程是否具有相同的堆栈?dll是否有独立的堆栈?
每个线程有自己的堆栈。
dll是否有独立的堆栈?这个问题不好回答,或者说这个问题本身是否有问题。因为dll中的代码是被某些线程所执行,只有线程拥有堆栈。如果dll中的代码是exe中的线程所调用,那么这个时候是不是说这个dll没有独立的堆栈?如果dll中的代码是由dll自己创建的线程所执行,那么是不是说dll有独立的堆栈?
以上讲的是堆栈,如果对于堆来说,每个dll有自己的堆,所以如果是从dll中动态分配的内存,最好是从dll中删除;如果你从dll中分配内存,然后在exe中,或者另外一个dll中删除,很有可能导致程序崩溃。
16、什么是缓冲区溢出?有什么危害?其原因是什么?
缓冲区溢出是指当计算机向缓冲区内填充数据时超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。
危害:在当前网络与分布式系统安全中,被广泛利用的50%以上都是缓冲区溢出,其中最著名的例子是1988年利用fingerd漏洞的蠕虫。而缓冲区溢出中,最为危险的是堆栈溢出,因为入侵者可以利用堆栈溢出,在函数返回时改变返回程序的地址,让其跳转到任意地址,带来的危害一种是程序崩溃导致拒绝服务,另外一种就是跳转并且执行一段恶意代码,比如得到shell,然后为所欲为。通过往程序的缓冲区写超出其长度的内容,造成缓冲区的溢出,从而破坏程序的堆栈,使程序转而执行其它指令,以达到攻击的目的。
造成缓冲区溢出的主原因是程序中没有仔细检查用户输入的参数。
17、什么是死锁?其条件是什么?怎样避免死锁?
死锁的概念:在两个或多个并发进程中,如果每个进程持有某种资源而又都等待别的进程释放它或它们现在保持着的资源,在未改变这种状态之前都不能向前推进,称这一组进程产生了死锁。通俗地讲,就是两个或多个进程被无限期地阻塞、相互等待的一种状态。
死锁产生的原因主要是:? 系统资源不足;? 进程推进顺序非法。
产生死锁的必要条件:
(1)互斥(mutualexclusion),一个资源每次只能被一个进程使用;
(2)不可抢占(nopreemption),进程已获得的资源,在未使用完之前,不能强行剥夺;
(3)占有并等待(hold andwait),一个进程因请求资源而阻塞时,对已获得的资源保持不放;
(4)环形等待(circularwait),若干进程之间形成一种首尾相接的循环等待资源关系。
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
死锁的解除与预防:理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和解除死锁。所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态的情况下占用资源。因此,对资源的分配要给予合理的规划。
死锁的处理策略:鸵鸟策略、预防策略、避免策略、检测与恢复策略。
阅读提示:本文作者从项目管理的角度来讨论对变化需求管理的策略。首先是讨论在构建前需求的质量,然后说明了如何在构建过程中对需求进行跟踪,最后讲述了当真正发生需求变更的时候,我们应该如何去面对。
需求总是在变化,客户总会有新的想法,项目好像没有终结,我们软件开发人员应对软件需求变化时,为了拥有更多的准备,应该做些什么呢?
这个世界唯一不变的就是变化了。月有阴晴圆缺,潮涨潮落,千年前的沧海是现在的良田,这是自然界的变化;人有悲欢离合,生老病死,这是人情世故。变化是并不一定总是给我们带来惊喜,更多的是带来意外,使得我们被迫去作一些改变来适应这种变化。
所以,变化也是我们人类得以从简单生物进化到今天的推动力。
回到我们软件需求这个论题上来,无疑,变化是需求的一个基本特性。
没有一成不变的需求,无论我们在正式构建之前对需求进行了多么深入的开发,和客户进行了多少回合的反复验证,而最终却不得不接受这样的现实:系统正式上线之后,在客户提交的试运行报告中,客户的需求发生了变化,或者客户又提出了新的需求等等。
我们的软件开发人员陷入了这样的一个困境:需求总是在变化,客户总会有新的想法,项目好像没有终结,即使验收通过,那也是草草完事,而不是想象中的那么完美。
这是一个残酷的现实。之所以Fred Brooks敢在1987的《没有银弹》这篇论文中强调即使不存在银弹,也能使得软件工程的生产力在十年之内提高十倍,这也是基于软件需求自身复杂性的原因。
在本文中,笔者从项目管理的角度来讨论对变化需求管理的策略。首先是讨论在构建前需求的质量,然后说明了如何在构建过程中对需求进行跟踪,最后讲述了当真正发生需求变更的时候,我们应该如何去面对。
我们先来看软件需求的生命周期,正如软件项目具有一般的过程,软件需求也有着一个普遍的生命周期,如图1所示:
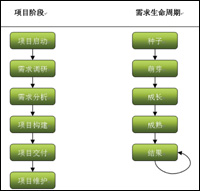
图1:软件普遍的生命周期
图1中的项目阶段反映的是一般的项目过程,不管采用瀑布模型还是迭代开发或者是其他的软件开发生命周期模型,这样的一个基本过程都是需要遵循的。而需求的生命周期和项目的阶段也是一一对应的。
在项目的启动阶段,我们需要对项目进行可行性分析,完成立项报告,在这个阶段,也就种下了需求的“种子”,这个“种子”也决定了下面所有阶段的努力是否有成果,如果项目根本就是不可行的,那么就别提最后的“结果”了,“种子”是否能“萌芽”也都是个未知之数。
如果通过了可行性分析,完成了项目的启动过程。接下来我们就要把需求这颗“种子”种下去,通过需求调研和需求分析阶段的努力,需求的“种子”开始“萌芽”,并且一直“成长”,直到“成熟”,需求“成熟”之后,我们就可以构建需求基线,进入项目构建阶段。
如果对还没有“成熟”的需求就开始构建,那么后果就是在构建阶段需求的反复变化,开发人员疲于奔命。
对“成熟”的需求进行构建,我们所交付的才是优质的“果实”,当然,项目后期也不可避免有需求变更,这时,只要我们按照规定的流程进行需求变更,将变更控制在一个可以接受的范围,这是不会影响到我们最终的交付的“果实”。
做好需求变更的管理,最终的目的是为了有优质的交付品。从上面的图中,我们可以得知,首先必须要有良好的“种子”和健康的“果树”,最后才有可能结出优质的“果实”。所以,做好需求开发是有效需求变更管理的基础。
重视需求开发
需求开发是在问题及其最终解决方案之间架设桥梁的第一步,是软件需求过程的主体。一个项目的目的就是致力于开发正确的系统,要做到这一点就要足够详细地描述需求,也就是系统必须达到的条件或能力,使用户和开发人员在系统应该做什么,不应该做什么方面达成共识。
我们都知道开发软件系统最为困难的部分就是准确说明开发什么,最为困难的概念性工作便是编写出详细技术需求,这包括所有面向用户、面向机器和其它软件系统的接口。
需求开发就是为了解决这些问题,它必不可少的成果就是对项目中描述的用户需求的普遍理解,一旦理解了需求,分析者、开发者和用户就能探索出描述这些需求的多种解决方案。
这一阶段的工作一旦做错,将最终会给系统带来极大损害的部分,由于需求获取事物造成的对需求定义的任何改动,都将导致设计、实现和测试上的大量返工,而这时花费的资源和时间将大大超过仔细精确获取需求的时间和资源。
首先,软件需求不能如实反映用户的真正需要。比较常见的一种误解是需求的简单和复杂程度决定了用户是否能够真正理解相应的内容:误认为客户只能看懂简单的需求,但是对开发没有直接帮助;只有复杂的需求才有用,但是大多用户又不可能看得懂。事实上,造成这类问题的主要原因是捕获的需求不能反映用户的视角,因而,用户站在自己的立场上很难判断需求是否完备和正确,特别是在开发活动的早期。
其次,软件需求不能被开发团队的不同工种直接共用。理论上,开发团队所有成员的工作内容都受软件需求制约;现实中,如果不采用理想的需求捕获方式,只有分析人员的工作看起来和软件需求的内容直接关联,其它人的工作内容和软件需求的关联并不直观,形式上的差异或转述往往不易察觉地造成了诸多歧义、冗余或者缺失。
本文并不会就此开始探讨需求开发的问题,只是强调需求开发过程的重要,以及需求开发过程对需求变更的影响。就拿笔者亲身参与的一个项目来说:我们遵循一般的软件开发过程,通过前期一段时间的调研,做需求分析,客户基本确认之后,开发人员就投入到紧张的开发工作中,由于项目时间要求紧迫,在经过测试人员的简单确认之后,进入到试运行阶段。
结果是,在客户的试运行报告中,提出了很多问题,其中就有一条,关于一个数据查询条件的设置,客户要求的是模糊匹配查询,而实现的却是精确匹配查询。在相关的需求文档中,却找不到任何相关的需求说明。
需求开发完成之后,进入系统构建阶段,下面我们来谈构建过程中如何做好需求跟踪,以便于后期需求变更的管理。
构建过程中的需求跟踪
跟踪需求是高质量软件开发过程中必需的一个特性。用以保证开发过程中每一个步骤的正确性,以及该步骤与上一步的一致性。经验表明,在需求规格、架构、设计、开发和测试阶段,对需求的跟踪能力是确保实现高质量软件的重要因素,同时也为需求变更管理提供有力的支持。
跟踪这些需求在每个阶段的变化,并且分析变更带来的影响,是现代软件过程的一个主线,尤其是在一些事关重大的软件工程项目中,需求跟踪的影响更加突出。
历史数据表明,如果需求没有被完整的跟踪,那么总会有遗失的需求或者是没有解决的需求,或者是需求的变更没有彻底进行,导致部分影响被忽略了,而往往是这样的失误导致很严重的安全问题和可靠性问题,给客户带来不可估量的损失。
这样的教训往往是非常惨痛而且印象深刻,笔者至今尤对这样的一次“事故”记忆犹新。那是参加的一个预算项目,在我们开发即将结束的时候,客户由于业务情况发生变化,提出了一条业务数据修改规则的变更。
对于这个这个业务数据的写规则,虽然我们在需求文档中有记录,但是没有将其与设计、开发构件一一对应,建立它们之间的关联,导致在处理这条变更的时候,开发人员遗漏了一种情况的处理。
而这样的问题直到在客户的应用系统运行半年之后才由客户发现,虽然事情最后通过升级软件、人工加工数据处理了这次意外,但是,事故给企业带来的不仅是金钱上的损失,也给企业的声誉带来非常不利的影响。
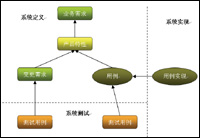
图2:需求跟踪模型
在图2跟踪模型中,箭头代表的是跟踪的方向,模型表明,不仅在需求定义的领域跟踪需求,而且我们也在实现领域和测试领域跟踪需求。
在系统定义领域,包括有三个方向的跟踪:从业务需求到产品特性的跟踪;从用例到产品特性的跟踪;从变更的需求到产品新特性的跟踪。对于每一种跟踪,我们都可以使用类似于如下的一个表格来管理。在实际项目中,要做好需求的跟踪管理并非易事,也许我们可以使用电子表格,办公软件来协助处理,确实,它们对于项目的管理非常有用。
但是,表格的问题在于难于维护,特别是当项目较大,存在复杂的关联关系的情况,改变一个链接可能涉及到很多相关的链接,在这种情况下,维护就成了一场噩梦。
在这种情况下,我们要么简化需求跟踪处理,对大的模块进行跟踪;要么使用专门的需求管理工具。如果是大型项目,最好使用工具来进行管理。这样,在我们面临需求变更的时候,才能有备无患。
因时而变,做好需求变更控制
就如前文所述,变化总是避免不了的。变更天生就是软件过程的一部分。在这种情况下,我们需要建立一个管理变更的过程,使得变更的工作得到控制,并能高效的发现变更,进行影响分析,将变更有效的集成到现有系统中。
产生需求变更的因素包括内部因素和外部因素,不管需求变更来自哪里,都需要遵循一个既定的流程来提出变更请求。
这样的渠道根据实际的企业情况有各自的方案。一般说来,如果是来自客户的变更,都需要遵照一个固定流程,通过一种正式的方式提交。即使客户口头的提出,那么也需要通过会议记录、文件交由客户签字确认后才正式进入变更流程。
否则,如果在没有正式依据下就进行需求变更,这样的项目将进入无休止的修改和维护状态。
对于提出的变更请求,首先可以通过项目小组指派专人负责进行分析,包括该变更的可行性分析,对其他需求的影响分析,对项目进度的影响分析等。在这个过程中,就需要利用前文中所述的各种需求跟踪表格。
通过需求跟踪表格,列举出该变更所涉及需要修改的其他需求,影响的其他用例、测试用例、用例实现等。然后才可以对工作量进行估算,评估该变更的可行性以及对项目进度影响等。
变更开发结束之后,也需要组织相关人员对变更进行评审,这样的评审往往能发现不少潜在的问题,比如有遗漏的需求没有修改等。只有评审通过后,才能进入下一阶段,对变更相关的文档、产品进行维护,使得需求文档、设计文档、产品保持一致性。至此,整个需求变更过程结束。
需求变更管理是需求管理中的一个重要部分,只有有效的需求变更管理提才能高产品的可能性,并使最终产品更接近于解决需求,提高了用户对产品的满意度,从而使产品成为真正优质合格的产品。从这层意义上说,需求变更管理是产品质量的基础。
笔者通过对需求开发、需求跟踪和需求变更过程三个方面对需求的变更管理进行讨论。一方面希望能引起业界对需求管理的关注,另外也希望能借此抛砖引玉,引发各位方家对需求管理方面的讨论。
管理变更步骤:
● 提出变更请求
● 变更分析
● 变更评审
● 制定变更计划
● 变更需求的开发
● 变更结果评审
● 维护变更
跟踪需求变更的问题:
● 谁提出变更;
● 什么时候提出变更;
● 变更的内容是什么;
● 为什么变更;
● 变更处理意见;
● 变更执行结果。
1、基于风险的测试可以解决测试过程中的3大问题:
(1)穷尽测试不可能,如何选择测试重点?
(2)如何在有限的测试时间内完成测试;
(3)如何合理利用测试资源完成测试。通过采用基于风险的测试,平衡测试时间、成本、范围与质量。
2、基于风险的测试,其测试策略可以归纳为:在达到可接受的风险程度前提下,寻求更小的测试工作量。当然,问题是如何去实施这个测试策略?
3、基于风险的测试,可以将风险分成两类:技术风险与管理风险。技术风险指的是影响产品质量的潜在问题,也称之为质量风险/产品风险;而管理风险指的是影响产品及时发布的潜在问题,也称之为项目风险。
4、基于风险的测试需要考虑3个方面的因素:测试对象存在的失效模式、风险的可能性与风险的严重程度。其中失效模式有助于设计测试用例以发现其中的缺陷;而可能性与严重程度得到的风险级别,有助于测试管理。
5、基于风险的测试可以分为2个方向:基于风险的测试设计和基于风险的测试管理。测试设计主要参考测试对象的失效模式,以此设计测试用例发现可能的缺陷;而测试管理主要考虑风险级别,并根据风险级别采取应对措施。
6、基于风险的测试,根据风险分析过程中得到的风险级别确定测试优先级,实施测试优先级的策略有2种:基于广度优先或者基于深度优先。
7、基于风险的测试设计,其关键在于识别测试对象中存在的与质量相关的风险,或者说测试对象可能存在问题的地方/失效模式,并分析以何种方式可以触发该失效。
8、基于风险的测试管理,根据风险级别确定测试重点与优先级、制定测试计划与资源分配、评估测试进度与覆盖率、基于剩余风险分析什么时候结束测试。
经过了近2年的努力,多数研发团队都用上了技术质量部自主研发的Bug管理工具Kelude_Issues,告别了商业工具和其他的开源工具。这个过程中Bug跟踪流程也发生了比较多的变化,下图是现在Kelude_Issues的Bug跟踪流程图:
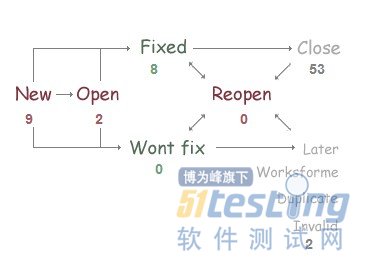
这个流程还是有着比较多的“淘宝特色”,我想可能很多用惯了其他Bug管理产品的同仁,看着这个图会感觉不太习惯,觉得状态比较多,箭头也多,有点绕。
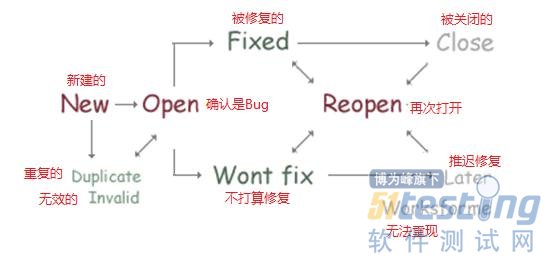
在经典的Bug跟踪流程里面,对于“状态”概念的定义,是比较清楚的,一般来说这些状态会比较常见,当然由于工具的不同,所用的英文单词也会有些差别,这个不用纠结,领会精神。
New:新创建的Bug
Open:经过了PM的确认,确实是个Bug
Assigned:已经分配给开发工程师进行解决
Resolved:开发工程师解决了,等待测试工程师验证(注意是解决,不是fix)
Closed:通过了验证,关闭
这里最容易引起混淆的概念,就是“Resolved”——被解决过了。最常见的解决方式,就是Fixed,被修复了;有时因为一些原因,暂时无法修复,只能Later,其实Later也是一种解决方式,常见的解决方式有以下几个:
Fixed:被修复了
Later:暂时不修复,后面的版本再修复
Wont Fix:不修复了,其实是一种Later的特例,无限期Later
Invalid:根本不是Bug,往往由于对需求的误解
Duplicate:重复的,相同的Bug已经被提交过一次了
Not Reproducible:无法重现,在淘宝叫做Works for Me
严格来说,这一组“解决方式”,是属于同一层面的,它们都需要由测试或者PM来验证,如果验证不通过,那就回到Open状态,验证通过就Close。而在淘宝Bug流程中,这些“解决方式”都被设置成了“状态”,其实也挺好,更加直观。但是这里有一个很要命的问题,就是那个“wont fix”状态被刻意放大了,跳了出来成为了一个抽象的概念,这让很多开发工程师非常困惑,到底wont fix代表什么意思?
由于wont fix被错误的使用,引起了比较多的争议,记得当初优昙狠狠的挑战了一把,争论了很久,现在想来还是有道理的。也有很多开发表示,为什么我要Invalid,还要经过wont fix呢,多不方便,于是我们做了调整,变成了下面这个样子:
这样虽然解决了上面开发提出问题,但是这个流程依然有点不伦不类的,所以我们咬咬牙,继续改,彻底的改,成了这样的流程:
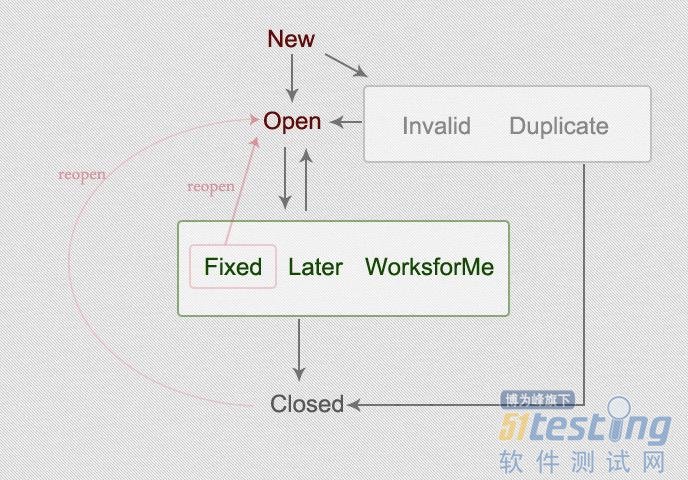
这个流程和经典的流程相比,还是有一些区别,我们依然选择把一些常用的“解决方式”,直接定义为“状态”,这样大家就不用理解那个抽象的“Resolved”了。当然,我们有一点跟经典Bug流程吻合,就是最后Bug都要回归Closed状态,之前大家都习惯了“只有Fixed才能Close”,这个习惯需要重新适应一下。
这里有人会问,最后都是Closed,怎么区分Later呢,我需要把Later的全翻出来,怎么找?这个问题还是比较好解决的,只要在Close Bug的时候,把当前的状态也记录下来就可以了,这样大家就能看到类似于Closed(Fixed)、Closed(Later),这样就比较好区分了。
还有一个概念我们也比较常用,就是Reopen,目前Open和Reopen是两个独立的状态,但是它们的含义却是很接近的。由于我们把Reopen视为修复失败,是一种过错的表现,以后我们只要关注Fixed到Open和Closed到Open的记录即可,不用为了“度量”,单独定一个状态出来。