
在制作场景恢复的时候可以选择调用函数来解决,下面的函数就是为此写的。因为之前用的场景恢复只报错了,看报告后大概了解了Object、Method、Arguments、retVal等参数的意义,于是写了这个方法,一方面可以截图,另一方面可以在报告中看到哪个对象出问题了。因为我经常是通过公司的自动化平台调用测试案例,一般晚上或凌晨执行,第二天看结果,看结果的时候一般直接从QC打开报告查看,这样方便自己定位问题。
这个方法的作用我简单描述一下:首先是指定一个目录,然后检查是否从QC调用的(因为有时候自己单机执行也用到这个),如果是就记录测试集的名称,如果不是就放到SingleTest目录,然后判断对应的目录是否存在,不存在就创建目录。之后是创建日期时间标签,然后把文件完整路径组合起来,并加上了案例名称,测试机器等等(因为有很多台机器,方便查看是否某台机器出问题了)。之后模拟2次回车按键是防止有异常对话框存在,然后把原来的对象语句自己还原回来,这样如果是某个对象执行什么操作的时候语句出错,就可以在报告里看到了。
当然并不是很完善,比如时间标签的分秒没有加0的判断,Arguments其实是个集合,只不过我只考虑了1个的情况,没考虑多个的情况。
需要用这个的朋友可以自己稍微维护改进一下。使用方法就是自己创建一个场景恢复,然后选择指定文件里的函数,下面的函数最好单独保存为一个文件,因为我之前把他和我的函数库放在一起,发现里面的初始化函数被执行了2次,可能和场景恢复有关,分开后就没问题了。
'用于恢复场景控制。
Function RecoveryFunctions(Object, Method, Arguments, retVal)
'有错误发生时,对Desktop进行截图并保存
' SaveTestError ""
Set objWS = CreateObject("WScript.Shell")
strDesktopFolder = "T:/TestData/测试组/测试截图/"
If QCUtil.IsConnected then
If TypeName(QCUtil.CurrentTestSet) <> "Nothing" Then
set CurrentTSTest = QCUtil.CurrentTestSet
strDesktopFolder = strDesktopFolder & CurrentTSTest.Name '如果从QC的测试集运行的,则保存到测试集名字的目录下
Else
strDesktopFolder = strDesktopFolder & "SingleTest" '如果不是从QC运行,保存到SingleTest目录下
End If
Else
strDesktopFolder = strDesktopFolder & "SingleTest"
End If
Set objFSO = CreateObject("Scripting.FileSystemObject")
If objFSO.FolderExists(strDesktopFolder) Then
Set objFolder = objFSO.GetFolder(strDesktopFolder)
Else
Set objFolder = objFSO.CreateFolder(strDesktopFolder)
End If
'确定保存文件的名称
tmpTime=Time()
t=Split(tmpTime,":")
If Len(t(0))<2 Then
t(0) = "0" & t(0)
End If
tmpTime=t(0) & t(1) & t(2)
tmpDate=CStr(Date())
tmpYear = CStr(Year(tmpDate))
tmpMonth = CStr(Month(tmpDate))
tmpDay = CStr(Day(tmpDate))
'如果月或日不足两位,前面补0
If Len(tmpMonth) < 2 Then
tmpMonth = "0" & tmpMonth
End If
If Len(tmpDay) < 2 Then
tmpDay = "0" & tmpDay
End If
tpmDate=tmpYear & tmpMonth & tmpDay
' strTimeStamp = CStr(Year(Now)) & CStr(Month(Now)) & CStr(Day(Now)) _
' & "_" & CStr(Hour(Now)) & CStr(Minute(Now)) & CStr(Second(Now))
strTimeStamp = tpmDate & "_" & tmpTime
strFile = strDesktopFolder & "/[测试案例]" & Environment("TestName") & "_[测试机器]" & Environment("LocalHostName") & "_[测试时间]" & strTimeStamp & "_Error.png" '组合出截图文件的名称
'对Desktop截图并保存
Desktop.CaptureBitmap strFile
reporter.Filter = 0
Reporter.ReportEvent micFail,"案例失败","本处提交失败报告是为了避免下面因为数据问题导致错误报告没有正常提交。"
reporter.Filter = 3
set WshShell = CreateObject("WScript.Shell")
WshShell.SendKeys "{ENTER}"
WshShell.SendKeys "{ENTER}"
strStepInfo = "Test(" & Environment("TestName") & ")-Action(" & Environment("ActionName") & ") 发生非预期错误,测试退出"
' strDetails = "错误编号:" & CStr(Err.Number) & ",错误描述:" & Err.Description
On Error Resume Next
oClass=Object.GetTOProperty("micclass")
oName=Object.GetTOProperty("name")
reporter.Filter = 0
Reporter.ReportEvent micFail, strStepInfo, oClass & "(" & Chr(34) & oName & Chr(34) & ")." & Method & " " & Arguments(0) & " 出现错误,错误编号:" & retVal
' Arguments应该是1个或多个参数,此处只考虑了1个的情况,以后需要维护。
reporter.Filter = 3
'清除Error并退出Test
If err.number<>0 Then
Err.Clear
End If
' Reporter.ReportEvent micFail, strStepInfo, Method & " " & Arguments(0) & " 出现错误,错误编号:" & retVal
On Error Goto 0
systemutil.CloseProcessByName("iexplore.exe")
ExitTest
End Function |
“我们决定下个月28号进行验收”,客户很轻松地在不经意之间和我说了这句让我朝思暮想的话,这句话使历时三个月的验收日期终于定下来了。回顾这三个月,我可是费了不少心力。日期虽然定了,但是和合同规定的日期足足晚了三个月。
我所负责的这个软件开发项目开始做得还算比较顺利,测试工作也早早已经完成。但客户迟迟不肯验收,原因是客户卡在一个小问题上,说此问题查清后再验收。这个小问题在大多数情况下是不会出现的,只有在特殊的操作下才会出现。由于一直无法找到重现此Bug的规律,故这个小问题一直没有很好的解决彻底,结果使到项目验收一次又一次被搁置。再这么拖下去,我真不知如何给公司交待了。
为什么客户迟迟不肯进行验收?
一般来说,当软件开发项目到了具备验收的各项条件之后,开发团队就会着手准备验收阶段的工作。但如果这时发生客户不愿意验收的话,这是一个让开发团队很头痛和很普遍的问题。原因是多方面的,主要有如下几种情况:
(1)开发团队没有摆正心态:这只是小问题吗?
一个软件项目完成测试和修正后,但卡在一个小问题上客户不肯验收,这就是平时我们经常说的“小问题,大学问”。也许,许多开发人员不明白:不就是一个小小的问题吗?为什么要小题大作?实际上这样的想法是因为许多开发团队只会站在自我利益为第一位。因此,当出现有小问题时,认为多一事不如少一事,主要需求和功能能完成就行了。
因此,作为开发团队要摆正自己的位置和心态,不是说只要完成了合同中规定的内容,完成了合同书规定的工作,并且按合同测试了就可以验收了。表面上看是客户仅仅由于他们发现的一些小小的BUG,小题大作不肯验收。实际上,当客户不同意在此时验收时,他们的判断往往不是招标书、合同、技术协议、需求规格说明书等文档。而是开发团队不能给客户足够的信心,客户不满意开发团队对BUG的处理态度,客户认为这不是小问题,所以不肯验收。
(2)没有抓住领导意图,客户满意度不够
我们在软件开发验收过程中得到很多的经验教训,最常见的问题是在开发过程中没有抓住客户的关键负责人或重要领导的意图,没有了解客户看重的是什么。而等到开发团队提出要验收的时候,客户又总是觉得这也不满意那也不满意,总之是不愿意验收。主要原因是开发过程中与客户的关系没有提升,没有使客户真正的满意。例如,对客户反馈问题时服务不到位,当要求客户验收时才再发现问题仍未得到及时解决,就会让客户心存担忧,或让客户失去信任。
(3)开发流程不规范,验收标准没有达成一致
在项目开始的时候没有和客户在验收标准达成一致,导致客户总是拿项目的小问题说事。实际上,验收标准是很重要的,这需要与客户进行详细的沟通,明确验收前需要完成的工作。验收标准中不光要有需要完成的工作内容和任务,还需要有一个相对固定的工期,使双方都能朝着这个方向去努力,防止无限制的拖延。
(4)没有处理好问题跟踪记录
由于许多开发合同上规定的只是一个大概的框架,再加上在开发之前没有与用户进行比较具体的交流和讨论,没有清晰的了解清楚客户心目中的产品究竟是什么样子。结果是双方对需求都有不同的理解,例如某些需求并不是客户真正想要的,而很多潜在的需求在项目初期却没有提出来。再由于在开发过程中,没有写好备忘录和问题跟踪记录,时间一长,双方也就忘记了很多承诺和约定,到了验收的时候就可能重新翻出来。这种事情是最让开发团队头痛的,明明说可以先不做的内容最终验收的时候又成了必要条件。这样最后要验收时,大家就非常容易卡在一些理解差异的问题上了。
(5)客户因资金原因推迟验收
有时,客户迟迟不肯验收或故意推迟验收,有可能客户是以推迟验收而推迟结算和要支付的款项。对于有这种想法的客户是最让开发团队为难的了。动用法律吧,担心破坏了长久建立的关系;不动用法律吧,还真有这么不客气的客户。
什么是软件开发项目验收?
(1)什么是软件开发验收?
项目验收,也称范围核实或移交。它是核查项目计划规定范围内各项工作或活动是否已经全部完成,可交付成果是否令人满意,并将核查结果记录在验收文件中的一系列活动。软件开发项目验收是每个开发团队乃至每个开发人员都想要的结果,因为一旦验收通过就可以收验收结算款了,项目也可以告一段落。验收作为开发项目的最后一个环节,不但是对软件开发质量和软件的可交付性起到“一锤定音”的作用,而且它关系到开发团队能否收到结算款和实现利润的标志之一。
(2)项目验收的标准和要点
项目验收看似简单,但在操作上却是极其复杂和重要的工作,因为项目验收无固定统一的标准。一般来说,项目验收的标准包括:项目合同书、国际惯例、国际标准、行业标准、国家和企业的相关政策、法规。因此,开发团队对项目验收的标准情况了解越多,后期项目验收的难度和风险就越小。因此,细读项目验收的标准例如合同书是第一步,必须要先弄清楚这个是什么项目,项目合同中有那些客户关注的问题。这样才能在验收前,有针对性准备好项目验收工作。
在项目验收的时候,对于项目中可能存在的一些问题,不要让客户想等系统没有一点问题或保证以后没有问题的情况下才验收。如果客户这样想开发团队就麻烦了,微软那么牛,做的操作系统还天天打补丁。开发团队要让客户明白,所谓验收,就是依照合同需求和能够满足企业的需求,结果和预期结果一致就应该算通过了,而且还容许有一些小错误留在验收后改正。
一般来说,现场长时间验收检查不太可行。因此,在验收前准备阶段,项目负责人应主动、积极的与客户密切沟通,及时、准确地收集和理解验收条件。特别是客户对即将验收项目的真实、初步意见和评价,最好是在验收前就沟通好和形成书面正式的《项目评价报告》。如还留有一些可能影响或暂时不影响项目整体验收通过的细节、小问题、变更或异议、分歧等,应与客户协商解决处理好,做到事先沟通、达成共识。强调已经基本上完成项目内容,满足合同要求。
如何顺利地让客户进入验收状态?
如何才能顺利地让客户进行验收是一直困挠开发团队的一个难题,为了避免项目验收遥遥无期的局面,建议加强以下几方面工作。
(1)及时解决问题,端正处理BUG的态度
既然发现软件存在问题,就应该尽力去解决,这是开发团队的责任。客户不肯验收,主要是害怕承担责任,毕竟还有问题没有解决嘛。如果换做我,我也不会给你验收的。因此,要想让客户方验收,首先要做好合同的明确规定和服务承诺。并以此为依据,让客户放心,让客户方验收。在开发过程中给客户感觉是不是用心的做事是很重要的,否则的话后期验收就会有点困难了。
在项目过程中,需要注意平时承诺的积累,比如要做到讲诚信、讲原则。主要是三条:做不到的事情千万别随意承诺、承诺的事情一定要努力做到、每次做到的事情都要进步一点点。按这三条做事,即使在与与客户沟通中有这样或那样的不愉快和矛盾,客户也会慢慢接受,也会用更多积极性眼光看存在的BUG问题。当然,项目中如果有关键瑕疵,也是客户忌讳的,开发团队一定要理解这些瑕疵并解决好。
(2)平衡和识别项目干系人需求
在项目验收阶段前,要尽量识别和关注所有项目干系人的需求和态度,并时刻给客户灌输只要完成那几项工作就代表项目可以验收了。当客户不肯验收时,要与客户展开深入的交流,明确客户为什么不愿意验收。有时客户的问题只是借口,所以要根据客户的表现判断出这个背后的问题所在。当找到问题后,协调相关的资源来解决。有时和客户直接把问题摊开沟通,或许是比较好的解决方法。
总之,开发团队应要对项目利害关系者进行关注,和关注他们关注的内容,或者他们担忧的内容。作为开发团队要做到尽量做好所能控制的事情,另外一些很难由开发团队控制的事情则需要借用一些其它的力量去完成。比如关注项目利害关系者的一些秘密需求是否得到了满足,或请高层领导运用一些商业手段来促成项目的验收等。
(3)重视阶段性成果验收,提高客户感知度
其实,软件开发项目验收远非是仅仅对系统的测试和检验这样简单,它是开发团队和客户在开发过程中双方合作博弈的结果。因此,在项目开发过程之中,与客户的沟通和绩效汇报是非常重要的。客户之所以迟迟不验收项目,简单的说是因为客户对开发团队做的项目不满意。
一般来说,满意=感知-期望。因此,客户不满意是因为客户的感知度非常低,而期望很高。换句话说,是由于开发团队对项目需求没有定义好,或者没有分析好,或在定义需求的时候没有考虑到客户的感知和期望,导致现在的项目验收困难。所以,一方面量化和降低客户的期望值,另一方面尽量提高客户的感知度是非常重要的。方法可以是对于每一个阶段性的成果,尽量让客户可以参与并且验收,目的是为了尽可能来提高客户的感知度。
(4)清晰处理好客户反馈问题的跟踪状态
在一个项目开发周期中,每次客户的反馈问题都需要认真做好跟踪记录。下次工作要根据前次备忘录的双方约定或客户的反馈问题继续进行,保障项目在双沟通的基础上不断前进,并用备忘录约束双方的行为。
建议在收集项目出现的各种问题时,采用问题跟踪记录表的形式,这样可以一目了然地显示出曾经收集到的各种问题、目前的解决情况、以及还有什么问题没有解决,或准备什么时候解决。这样客户和开发团队就都会对目前的情况非常了解,通过不断地解决出现的问题,来收敛可能出现的问题。当存在的问题越来越少时,也就表示项目开发已经在接近验收的标准了,也可使客户在需要验收的时候不能再找各种各样的借口来拖延验收。
渗透性测试是信息安全人员模拟黑客攻击,用来发现信息安全防御体系中漏洞的一种常用方法。但它不同于真正的黑客攻击。首先,黑客入侵大多是悄无声息的,像间谍一样秘密进行,而渗透性测试事先要与用户签订好协议;其次,渗透测试是为了发现、验证安全漏洞的影响而进行的,注重入侵者可能的通道,并非关注用户的敏感信息内容。所以,渗透性测试时一种安全服务,简称渗透服务。
国内渗透服务开展不好的原因:
1、技术性要求很高。渗透与实际的入侵是同样的思路,需要渗透者有很强的逆向思维,有一定漏洞挖掘的能力,仅仅使用常规的入侵手段,面对安全意识较强的用户,渗透效果会很不理想;用最新的“0Day”资源去做渗透,成本又过高,同时,这种方法会给用户带来心理上的恐慌。要得到用户的认可需要掌握好这个“度”,当然没有深厚的技术功底,就只能被挡在服务大门的外边了;
2、用户的纠结。作为企业信息安全的管理人员,当然不希望自己辛苦建立的安全防御体系被说成千疮百孔;花钱请人来做渗透,无疑是自己要“上京赶考”,很煎熬啊;若渗透没有成果,又无法向领导解释这样的服务的必要性,无法验证自己安全工作的成绩,不暴露问题的严重性,安全保障工作也难以得到领导的重视。所以,心情是复杂的;如何衡量渗透服务的效果是面临的首要问题;
3、用户领导的顾虑。用渗透的方式检验目前的安全防御体系是否坚固,好比是“实战演习”,显然是有必要的。但是渗透毕竟是从自己不知道的地方进入到自己网络的内部,对于渗透者的工作的可控性是有难度的,渗透者除了给自己最后汇报的,是否还知道了其他的什么?孰轻孰重,领导肯定是有顾虑的;
4、渗透者的纠结。渗透是为了验证用户防御体系的缺陷,每次渗透服务后,把发现的漏洞通告给用户,当然希望用户堵上它,可是下一次来渗透的时候,又需要再发现新的漏洞,否则就无法渗透成功,而发现有价值的漏洞不是一件容易的事情,即使你技术再好,也有很多偶然的成分;因此渗透者很纠结,知道了的全说出来,以后工作会越来越挑战极限,毕竟这是商业;知道的不全说,对用户似乎很不公平,也违背了信息安全人员的职业道德。另外,验证的毕竟部分漏洞,未验证的漏洞也不少,也许是时间上的不充裕,也可能是自己还没有找到适合的方法,但这不等于别人就做不到,搞技术的人,心情上很复杂。
正确定位渗透服务的目标:
这项工作的好处是共知的,“养兵千日,用在一时。”保持安全机制的有效性,唯一的办法就是经常性的“实弹演习”,渗透服务就是一种“实弹演习”。
面对各方面人员复杂的心情,关键是正确定位渗透性测试服务的具体目标,定位大家的角色。目标清晰了,责任清楚了,大家的顾虑就可以打消了。
渗透性测试是一种安全服务,不是黑客入侵的情景再现。
渗透服务的目标应该是部分验证安全漏洞可以被利用的程度,利用这些漏洞能给用户造成什么样的损害。简单地说,渗透服务是确认漏洞能给用户带来的损失有多大,从而可以评估修复这些漏洞的代价是否值得。
通过渗透服务,用户的收益是多方面的:
1、对信息安全系统整体进行了一次“实战演练”,在实战中锻炼安全维护团队应变的能力;
2、系统评估了业务系统,在技术与运维方面的实际水平,管理者清楚了目前的防御体系可以抵御什么级别的入侵攻击;
3、发现安全管理与系统防护中的漏洞,可以有针对性地进行加固与整改;
4、若定期地进行渗透服务,不仅可以逐步提高系统安全的防御能力,而且可以保持管理人员的警觉性,增强防范意识;
如何确定渗透服务的考核目标:
很多渗透测试服务(目前与安全评估服务一起提供的有很多)给用户的报告就是一大堆的漏洞列表,告诉你要打补丁,买设备,以及一些很虚的安全管理建议。用户往往对这些漏洞的威胁不了解,面对如此多数量的、稀奇古怪的漏洞根本不知所措。第一,因为怕影响业务运行,不能全部打上补丁,哪些必须打,哪些可以不打,总是一本糊涂账;第二,即使打上补丁,心里也不踏实,漏斗就少了吗?下次检查又是同样多的漏洞,好想补丁永远也补不完。
其实发现漏洞只是服务的第一步,验证哪些漏洞是可以被利用的,可以被利用到什么程度,才是渗透服务真正应该回答的,比如能获取系统管理员权限,能篡改系统数据,能植入木马等等,这样用户对漏洞的威胁就有切身的体会了。
渗透服务是模拟黑客入侵,但不是真正的入侵,作为商业服务,用户如何确定渗透服务的考核目标呢?我们先来分析一下黑客攻击的方式。

开发环境要不要和测试环境隔离?要就是说,是不是要各用一套数据库等基础设施?
能隔离当然最好,开发人员和测试人员不会互相干扰。但隔离是有代价的,它意味着你要多引一个数据库,如果你的系统是分布式的,你还要多维护一套MQ、RPC中间件等。
依我看,需不需要隔离要看系统是否满足下面的三个条件:
1、两个环境的系统总是要接触到同一份数据
2、数据被一个系统接触后,业务状态会改变;导致这份数据对另一个系统不再可用
3、很难禁止两个系统在同一时刻接触到同一份数据
解释:
条件1.如果两个环境共享数据库,但开发环境只处理北方数据,测试环境只处理南方的,那不用隔离
条件2.即使两个环境都会处理北方数据,但如果这种处理是只读的,也就是开发环境用了,测试环境可以再用,那也无所谓
条件3.即使数据被一个环境处理后,另一个不能用;但如果对数据的接触是人为触发的,也就是说开发环境被人触发数据改动时,不会干扰测试环境的测试,那也无所谓。
具体的场景:
1、纯读的网站不必隔离,它不满足条件2
2、有写、但所有操作都由用户触发的网站也不必隔离,因为它不满足条件3
3、以全局数据为目标的自启应用需要隔离,比如Quartz,Cron,MQ消费者等,因为它们不满足条件1。以MQ应用为例,如果外部发来的某个数据被测试环境消费过了,开发环境就无法再消费了,这时你应该为开发和测试环境各配一个MQ
4、对自启应用,如果实在不想隔离,就要在代码里做一些env-specific的东西,使得不同环境不会访问到相同的数据,比如开发环境只能访问数据库里flag=Dev的记录。不过,这种作法对程序和数据的侵入都很大,不值得提倡。但这种做法可以应用到其他环境的隔离上,比如预发环境和正式环境,它们必须使用相同的数据库。
用途:在s中找出以ct中的字符为分隔的字符串,即是源串中除去了含有分隔串中的所有字符后余下的一段段的字符串,每调用一次找到一串,找不到则返回空串。第一次调用必须传给它有效的字符串,第二次传NULL就可以了,每次调用返回找到的子串的时候都会把源串中该子串的尾部字符(原来是搜索串中的某一字符)修改成'/0'字符返回值为每次调用得到的字串。
下面看一下它的使用
char sbody[]= "Presetptz/r/nPreset1=hello/r/nPreset2=ttttt/r/nend/r/n";
///char *pbody= "Presetptz/r/nPreset1=hello/r/nPreset2=ttttt/r/nend/r/n";//errror
char except[] = "12/r/n";
char *ptoken = NULL;
ptoken = strtok(sbody,except);
while(NULL!=ptoken)
{
printf("%s/n",ptoken);
ptoken = strtok(NULL,except);
}
输出为:
Presetptz
Preset
=hello
Preset
=ttttt
end
下面我们看一下它的源码:
char *___strtok;//关键这个全局指针变量
char * strtok(char * s,const char * ct)
{
char *sbegin, *send;
sbegin = s ? s : ___strtok;//不等于NULL用原始字符串,否则用___strtok
if (!sbegin) {
return NULL;//结尾
}
sbegin += strspn(sbegin,ct);//
if (*sbegin == '/0') {
___strtok = NULL;
return( NULL );
}
send = strpbrk( sbegin, ct);
if (send && *send != '/0')
*send++ = '/0';
___strtok = send;
return (sbegin);
}
其中: ssize_t strspn(const char* s,char*accept)// 返回accept中任一字符在s中第一次出现的位置
char * strpbrk(const char * cs,const char * ct)//返回指向ct中任一字符在cs中第一次出现的位置
这个函数不难分析,___strtok指针指向除去第一个有效字串后面的位置,到这里我们应该清楚为什么第二次调用时只要传NULL就可以了,当然这里也暴露了它的缺点,就是说不能有两个线程同时使用strtok否则就会出现错误。还有就是我在使用这个函数时碰到的问题,如上面的代码如果我把sbody换成 pbody,则编译没有问题,运行时就会出错,为什么?还是自己的基本功不扎实,pbody在是个静态字符串,说白了,它是在编译时就已经赋值而且相当于是一个const常量,不能被修改,而strtok是需要修改字符串的,所以产生问题不足为奇。
原型声明:extern char *strcpy(char *dest,const char *src);
头文件:string.h 功能:把从src地址开始且含有NULL结束符的字符串赋值到以dest开始的地址空间 说明:src和dest所指内存区域不可以重叠且dest必须有足够的空间来容纳src的字符串。 返回指向dest的指针
(一)strcmp函数
strcmp函数是比较两个字符串的大小,返回比较的结果。一般形式是:
i=strcmp(字符串,字符串);
其中,字符串1、字符串2均可为字符串常量或变量;i 是用于存放比较结果的整型变量。比较结果是这样规定的:
①字符串1小于字符串2,strcmp函数返回一个负值;
②字符串1等于字符串2,strcmp函数返回零;
③字符串1大于字符串2,strcmp函数返回一个正值;那么,字符中的大小是如何比较的呢?来看一个例子。
实际上,字符串的比较是比较字符串中各对字符的ASCII码。首先比较两个串的第一个字符,若不相等,则停止比较并得出大于或小于的结果;如果相等就接着 比较第二个字符然后第三个字符等等。如果两上字符串前面的字符一直相等,像"disk"和"disks" 那样, 前四个字符都一样, 然后比较第 五个字符, 前一个字符串"disk"只剩下结束符'/0',后一个字符串"disks"剩下's','/0'的ASCII码小于's'的ASCII 码,所以得出了结果。因此无论两个字符串是什么样,strcmp函数最多比较到其中一个字符串遇到结束符'/0'为止,就能得出结果。
注意:字符串是数组类型而非简单类型,不能用关系运算进行大小比较。
if("ABC">"DEF") /*错误的字符串比较*/
if(strcmp("ABC","DEF") /*正确的字符串比较*/
(二)strcpy函数
strcpy函数用于实现两个字符串的拷贝。一般形式是:
strcpy(字符中1,字符串2)
其中,字符串1必须是字符串变量,而不能是字符串常量。strcpy函数把字符串2的内容完全复制到字符串1中,而不管字符串1中原先存放的是什么。复制后,字符串2保持不变。
例:
注意,由于字符串是数组类型,所以两个字符串复制不通过赋值运算进行。
t=s; /*错误的字符串复制*/
strcpy(t,s); /*正确的字符串复制*/
摘要: 排序算法很多地方都会用到,近期又重新看了一遍算法,并自己简单地实现了一遍,特此记录下来,为以后复习留点材料。 废话不多说,下面逐一看看经典的排序算法: 1、选择排序 选择排序的基本思想是遍历数组的过程中,以 i 代表当前需要排序的序号,则需要在剩余的 [i…n-1] 中找出其中的最小值,然后将找到的最小值与 i 指向的值进行交换。因为每一趟确定元素的过程中都会有一个选择最大值的子...
阅读全文
简介
数据库快照,正如其名称所示那样,是数据库在某一时间点的视图。是SQL Server在2005之后的版本引入的特性。快照的应用场景比较多,但快照设计最开始的目的是为了报表服务。比如我需要出2011的资产负债表,这需要数据保持在2011年12月31日零点时的状态,则利用快照可以实现这一点。快照还可以和镜像结合来达到读写分离的目的。下面我们来看什么是快照。
什么是快照
数据库快照是 SQL Server 数据库(源数据库)的只读静态视图。换句话说,快照可以理解为一个只读的数据库。利用快照,可以提供如下好处:
● 提供了一个静态的视图来为报表提供服务
● 可以利用数据库快照来恢复数据库,相比备份恢复来说,这个速度会大大提高(在下面我会解释为什么)
● 和数据库镜像结合使用,提供读写分离
● 作为测试环境或数据变更前的备份,比如我要大批导入或删除数据前,或是将数据提供给测试人员进行测试前,做一个快照,如果出现问题,则可以利用快照恢复到快照建立时的状态
快照的原理
与备份数据库复制整个数据库不同,快照并不复制整个数据库的页,而是仅仅复制在快照建立时间点之后改变的页。因此,当利用快照进行数据库恢复时,也仅仅将那些做出改变的页恢复到源数据库,这个速度无疑会大大高于备份和恢复方式。这个原理如图1所示(图摘自SQL Server 2008揭秘)。
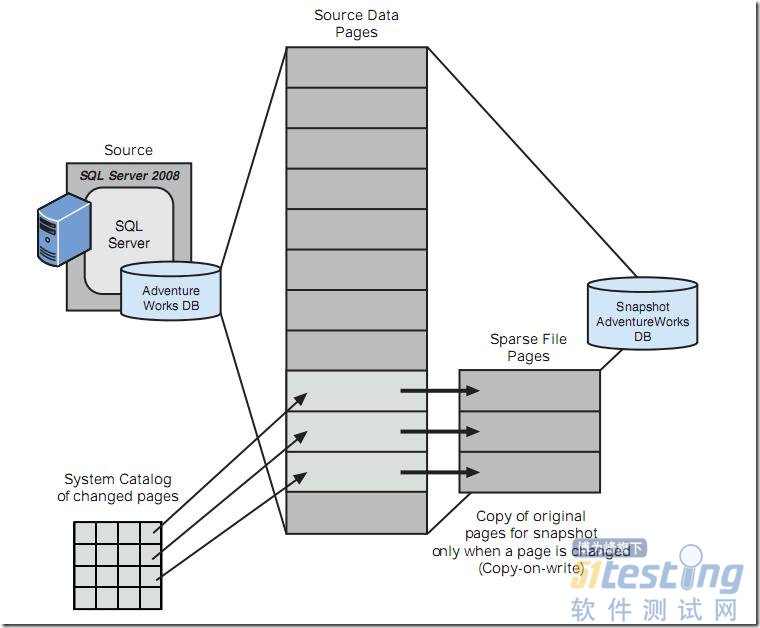
图1.镜像的原理
由图1可以看出,快照并不是复制整个整个数据库,而是当源数据库更改时,源数据库会将更改之前的数据存入快照数据库之后,再对源数据库进行更改。因此可以看出,源数据库上建立快照会给IO增加额外负担.当对快照数据库进行查询时,快照时间点之后更改的数据会查询快照数据库文件,而快照时间点之后未更改的数据,将会查询源数据库文件。这个概念如图2所示(图摘自SQL Server 2008揭秘)。
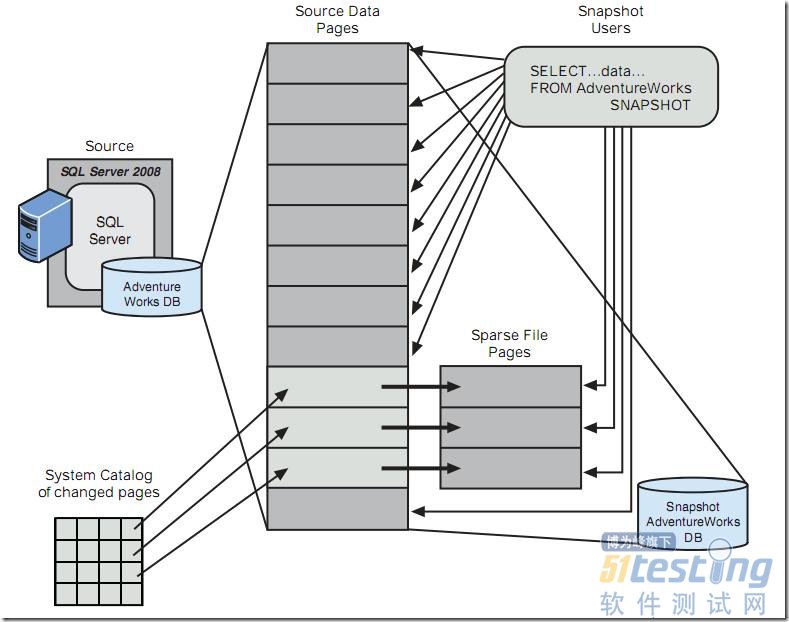
图2.查询快照数据库时查询的分布
写入时复制(Copy On Writing)和稀疏文件(Sparse Flie)
由上图中可以看出,快照数据库的文件是基于稀疏文件(Sparse File),稀疏文件是NTFS文件系统的一项特性。所谓的稀疏文件,是指文件中出现大量0的数据,这些数据对我们用处并不大,却一样占用着磁盘空间。因此NTFS对此进行了优化,利用算法将这个文件进行压缩。因此当稀疏文件被创建时,稀疏文件刚开始大小会很小(甚至是空文件),比如图3所示的文件就是一个稀疏文件。虽然逻辑上占了21M,但文件实际上占了128KB磁盘空间。
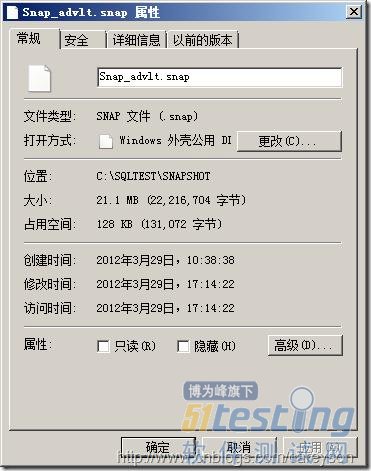
图3.一个稀疏文件
对于快照来说,除了通过快照数据库文件的属性来看快照的大小之外,也可以通过DMV来查看,如图4所示。
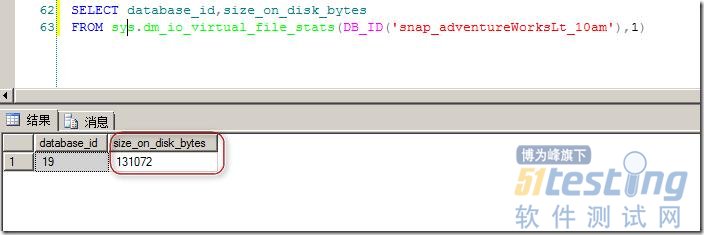
图4.通过DMV查看快照数据库大小
而当快照创建后,随着对源数据库的改变逐渐增多,稀疏文件也会慢慢增长,概念如图4所示。
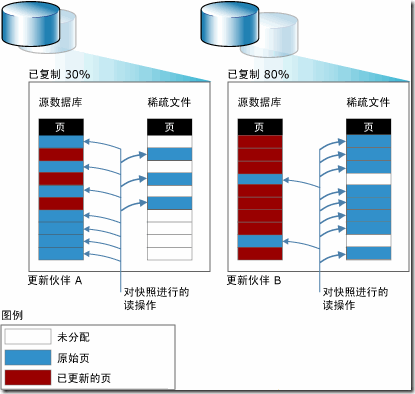
图5.随着源数据库的更改越来越多,稀疏文件不断增长
所以,通常来说,当稀疏文件增长到源数据库文件大小的30%时,就应该考虑重建快照了。
而稀疏文件的写入是利用了微软的写入时复制技术(Copy-On-Writing),意思是在复制一个对象时并不是真正把对象复制到另一个位置,而是在新的对象中映射一个指针,指向原对象的位置。这样当对新对象执行读操作时,直接指向原对象。而在对新的对象执行写操作时,将改变部分对象的指针指向到新的地址中。并修改映射表到新的位置中。
使用快照的限制
使用快照存在诸多限制,由于列表太长,我只概括的说一下主要限制。
● 当使用快照恢复数据库时,首先要删除其他快照
● 快照在创建时的时间点上没有commit的数据不会被记入快照
● 快照是快照整个数据库,而不是数据库的某一部分
● 快照是只读的,意思是不能在快照上加任何更改,即使是你想加一个让报表跑得更快的索引
● 在利用快照恢复数据库时,快照和源数据库都不可用
● 快照和源数据必须在同一个实例上
● 快照数据库的文件必须在NTFS格式的盘上
● 当磁盘不能满足快照的增长时,快照数据库会被置为suspect状态
● 快照上不能存在全文索引
其实,虽然限制看上去很多,但只要明白快照的原理,自然能推测出快照应该有的限制。
快照的创建和使用
无论是使用SSMS或是命令行,快照只能通过T-SQL语句创建。在创建数据库之前,首先要知道数据库分布在几个文件上,因为快照需要对每一个文件进行copy-on-writing。如图6所示。
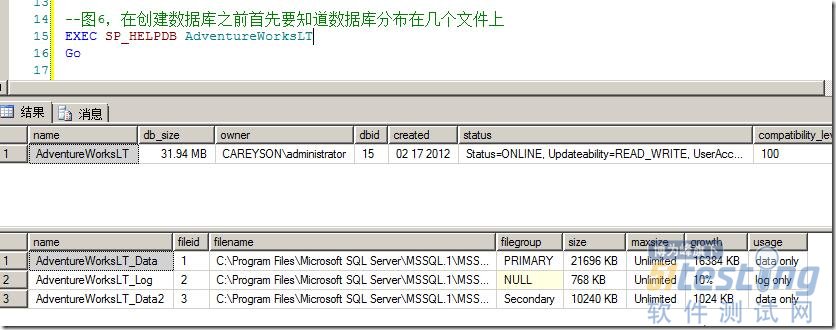
图6.首先查出数据库的文件分布
根据图6的数据库分布,我们通过T-SQL创建快照,如图7所示。
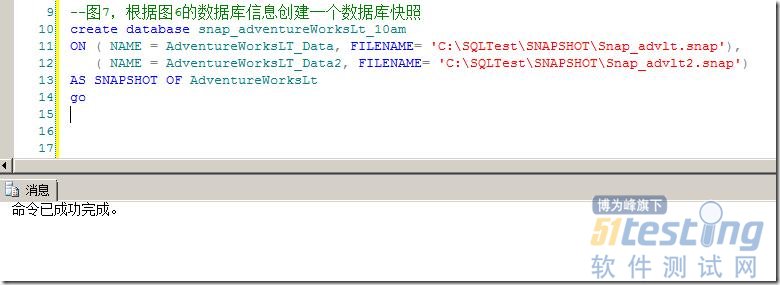
图7,根据图6的数据库信息创建一个数据库快照
当快照数据库创建成功后,就可以像使用普通数据库一样使用快照数据库了,如图8所示。

图8.快照数据库和普通数据库一样使用
通过如下语句可以看到,快照数据库文件和源数据库的文件貌似并无区别,仅仅是快照数据库文件是稀疏文件,如图9所示。
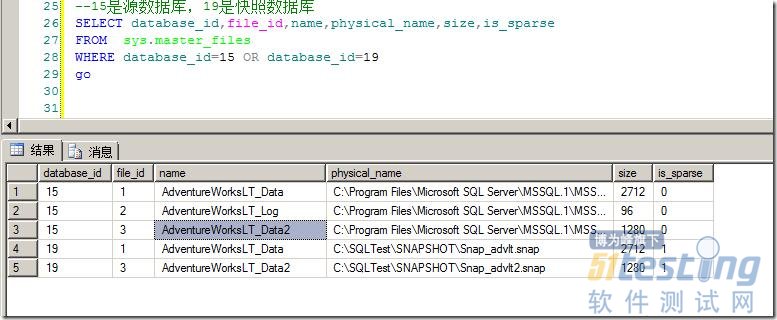
图9.源数据库和快照数据库
而删除快照数据库和删除普通数据库并无二至,也仅仅是使用DROP语句,如图10所示。
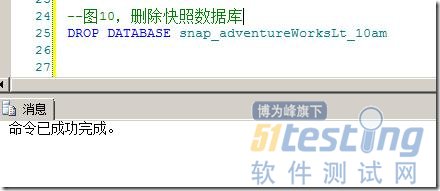
图10.删除快照数据库
我们也可以利用快照恢复数据库,这个恢复速度要比普通的备份-恢复来的快得多,这也可以将数据库呈现给测试人员,当测试结束后,恢复数据库到测试之前的状态。如图11所示。
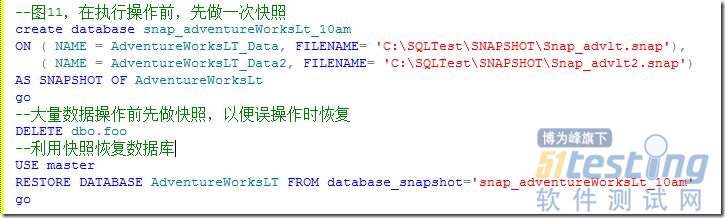
图11.利用快照恢复数据库
使用快照其他一些需要考虑的因素
1、快照数据库的安全设置继承源数据库的安全设置。也就是说能访问源数据库的用户或角色也能访问快照数据库,当然,因为快照数据库是只读的,所以无论任何角色或人都无法修改快照数据库。
2、我们由文章前面图5看出,随着快照存在的时间越来越长,快照会不断增长。所以推荐在快照达到源数据库大小30%之前,重新创建快照。
3、由于快照会拖累数据库性能,所以数据库不宜存在过多快照。
总结
本文简单讲述了数据库快照的概念,原理以及使用。数据库快照可以在很多场景下使用,无论是用于报表,还是和镜像配合提供负载,以及利用快照恢复数据库,使用得当的话,快照将会是一把利器。
序言:产品、市场与测试,大家看到这个题目,不知道是否会有些疑惑,他们之间的关系会是什么,在做自动化测试已经有这么一段时间了,在这段时间中,我深深体会到,不管自动化测试,还是类似的测试技术,如果真要能够快速占领公司的测试市场,技术底蕴是一个方面,产品和市场策略也很重要,这几个月,空闲的时间,都会在看产品管理以及数据分析的知识,然后基于两者去看待测试,似乎也颇有一些风趣。
前一段时间,我曾负责做过两个产品:一个是自动化测试平台、一个是自动化测试执行端。在做完前者后,我被调出负责部门自动化需求挖掘、推广和应用。也很好的有机会去使用之前的测试平台,在对其推广和应用过程,才逐渐发现平台的应用效果很差,最后测试人员在使用一段时间后,逐渐放弃,原因如下:
1、产品原因:平台功能强大,包括:执行界面、任务管理分配、拓扑管理、脚本管理、执行端管理,但是却显得非常复杂且没有重点,对于测试人员反而加重了熟悉和使用负担。并且测试平台需要
2、市场原因:没有对测试部门的整体现状好好分析,就急于开发平台,当时测试部门的情况是测试框架还不统一,测试脚本执行状况不是很良好并且测试覆盖率不足。可以理解为市场需求还未发展到那一步,这也许跟很多“创新型”公司正因为太过于创新,超脱于市场需求太大而死掉的原因类似吧。
3、当然,还有一些其他的原因,包括技术原因、人员原因,但是这些都是次要的,就不详说了。
因此,后来我在部门放弃了测试平台的使用,采用产品管理的手段重新做了一款自动化测试执行端,至今看来,效果还是不错的,至少测试人员都对它有所依赖了。
1、“市场状况分析”:首先将所有技术组的自动化测试状况收集分析,发现现在他们的测试脚本都存在各种问题,每个技术组都有一个单独的测试框架,因此,我先引入软件配置管理(svn),将测试框架和测试脚本进行统一,如果移植工作量太大,则继续按前方式进行,但是先花力气将测试脚本稳定,尽量让脚本可以单独运行无误起来。
心得:一个产品的崛起,需要的是市场某个阶段的稳定。基础不牢,一味的追求吹嘘上层应用,那么泡沫就这样产生了。
2、“市场需求调研”:对几个小组的自动化测试接口人进行调研,发现他们以前用平台的时候,觉得最方便的还是在于执行部份,所以依托了于这样的需求,我好好写了一份自动化测试执行端的需求分析报告,包括:需求点、功能点以及使用分析(解决的问题)。然后,在设计上,采用了可拓展似的tab,可以不断添加新的功能集合。
心得:一个好的产品就是踏踏实实的为需求服务的,并且是可拓展的,这个可拓展的原则就是基于一个思想即可。这个自动化测试执行端的理念就是:让自动化测试执行一条线(从导入—配置管理—执行—结果都能在界面上查看)
3、市场应用和反馈:之后,快速完成编码,这个过程就忽略吧,高科技营销魔法之父,摩尔有一本书叫:《公司进化论:伟大的企业如何持续创新》,其能告诉你:产品与对应的市场、用户都是有自己的生命轨迹的。一个产品生命周期里有五种用户群:创新者—早期追随者—早期主流用户—晚期主流用户—落伍者。而在每个测试技术小组,自动化测试接口人都是很好的早期追随者,他们因为强制性的要求参与自动化测试,所以他们的需求目的性强,需要迅速能够解决问题的测试产品,但是这里有一个问题在于他们有时候虽然对产品某个地方不满意,但也会将就着用,而不会反馈,所以就需要你的积极沟通了,只有这样,你才能将早期的追随者的价值发挥到最大,从而能够让你的产品继续推广。
心得:一定要区分用户群,发挥每个用户群的最大价值,要做一款细致的产品,那么一定不要用无所谓的心态,而是要把每一个点都做好。现在的产品层出不穷,特别是互联网产品,也许你因为某一秒的延时就错失了很多用户,从而让你的产品的用户群无法从早期追随者跨越到早期的主流用户。。
总结:也许很多测试人员总觉得上面两个产品与自动化测试的从业人员或者测试开发人员相关,与做手工测试的没有什么关系,但我个人觉得不然,如果我们在测试这条路上走行进的时候,就像做产品和市场一样,能够更多的想想我的测试需求目的是什么,我的核心测试策略在哪?我的测试能够带来多大的价值?也许会更有收获呢,共勉之。
之后,我想总结一下:数据、分析和测试,看看数据能给测试带来什么?
版权声明:本文出自 散步的SUN 的51Testing软件测试博客:http://www.51testing.com/?382641
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
相关链接:
测试,人人都是产品经理之测试产品的选择和创造
/*
目的:使用for循环添加多条有规律的数据,比如说:a1、a2、a3......a1000
方法:从上面看1-1000是一个有序序列,并且前面的a都是固定的,所以只需要用for循环将1-1000循环出来就可以了。
但是loadrunner使用的是C语言的语法,所以不能向在java中一样,将两个变量直接相加(+)(+:连字符)
所以这个时候就需要将首先将int变量转换成string,然后再用lr_save_string()函数将该变量用loadrunner可以识别的参数化方式保存起来,再应用到录制的脚本中就可以了
函数简介:
| int itoa ( int value, char *str, int radix ); |
函数目的:将int类型转换成string
参数介绍:value: 要转换的int型的值
str: 目标字符串,即将转换成的string值保存到str中
radix:转换数字时所用的基数 10:十进制;2:二进制……
| int lr_save_string (const char *param_value, const char *param_name); |
函数目的:将param_value值保存到param_name变量中
参数介绍:param_value:要保存的值
param_name: 变量名称
问题:为什么要用itoa()和lr_save_string()两个函数相结合使用呢?
因为lr_save_string()中的两个参数都是char类型的指针,int类型的值必须经过转换才能在lr_save_string()函数中使用,所以此处就要将itoa()和lr_save_string()两个函数相结合使用。
*/
Action() { int i; char str[100]; //定义一个数组用来保存int类型转换后的值 for(i=0;i<=9;i++){ itoa(i,str,10); lr_save_string(str,"ID"); lr_output_message("==str:=%s==ID:=%s====",str,lr_eval_string("{ID}")); } |
/*
用lr_save_string()将数组保存到变量中以后就可以应用到Loadrunner录制的脚本中了
{ID}:是loardrunner识别参数的方式
web_url("login", "URL=http://server0.im.sonoro.cn:18001/login?username=a{ID}&password=test&autoLogin=false&1211433835878&1211433835878", "TargetFrame=", "Resource=0", "RecContentType=text/html", "Referer=http://server0.im.sonoro.cn:18001/proxy.html?1211433821547", "Snapshot=t6.inf", "Mode=HTML", LAST); */ return 0; } |
版权声明:51Testing 软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像。 51testing软件测试网欢迎与业内同行进行有益的合作和交流,如果有任何有关内容方面的合作事宜,请联系我们。
lr_eval_string()函数的主要是返回脚本中的一个参数当前的值,返回值类型为char型.一般多用在调试脚本时输出参数的值.具体用法如下:
lr_output_message("The parameter1's value is %s",lr_eval_string("{parameter1}")),其中参数parameter1在之前已经定义了.你的代码中将int型数据拷 贝到char型数组里是不行的,参考一下2#楼的代码.
1 lr_eval_string(), eval应该是evaluate的缩写。
功能 如果只有一个参数,则返回当前参数的值。它的参数必须是{newParam} 的形式,也就是被大括号包起来
应用:对每个迭代过程中需要需要使用参数化的内容的时候。lr_output_message("value : %s", lr_eval_string("The row count is: {row_cnt}"));
例如:有一个int的参数化值{paraInt},如果直接把它作为一个int是错的。必须atoi(lr_eval_string({ParaInt}))
所以不能直接把一个int变量作为参数。
2.如何实现“我想把iTemp转换成字符串存到变量chArr里”
int iTemp=3;
char chArr[1024] = {0};
// if not unicode
itoa( itemp, charr, 10 );
应该可以