
Java对多线程程序的锁定已经有良好的支持,通常使用synchronized修饰一个方法或者一段代码。但是有一个问题,多个线程同时调用同一个方法的时候,所有线程都被排队处理了。该被调用的方法越耗时,线程越多的时候,等待的线程等待的时间也就越长,甚至于几分钟或者几十分钟。对于Web等对反应时间要求很高的系统来说,这是不可以接受的。本文就介绍一种自己实现的锁定方法,可以在没有拿到锁之后马上返回,告诉客户稍候重试。
某一段程序同一时刻需要保证只能单线程调用,那么策略很简单,最先到的线程获取锁成功,在它释放之前其它线程都会获取失败。首先要构造一个全局的系统锁仓库,代码如下:
/*
* LockStore.java 2012-5-15
*/ import java.util.Date;
import java.util.HashMap;
import java.util.Map; /**
* 公用的内存锁仓库. 分为获取锁和释放锁两种操作。
*
* @version 1.0
*/
public final class LockStore {
// volatile保证所有线程看到的锁相同
private static volatile Map<String, Date> locks = new HashMap<String, Date>(); private LockStore() { } /**
* 根据锁名获取锁
*
* @param lockName
* 锁名
* @return 是否锁定成功
*/
public synchronized static Boolean getLock(String lockName) {
Boolean locked = false; if (StringUtils.isEmpty(lockName)) {
throw new RuntimeException("Lock name can't be empty");
} Date lockDate = locks.get(lockName);
if (lockDate == null) {
locks.put(lockName, new Date());
locked = true;
} return locked;
} /**
* 根据锁名释放锁
*
* @param lockName
* 锁名
*/
public synchronized static void releaseLock(String lockName) {
if (StringUtils.isEmpty(lockName)) {
throw new RuntimeException("Lock name can't be empty");
} Date lockDate = locks.get(lockName);
if (lockDate != null) {
locks.remove(lockName);
}
} /**
* 获取上次成功锁定的时间
*
* @param lockName
* 锁名
* @return 如果还没有锁定返回NULL
*/
public synchronized static Date getLockDate(String lockName) {
if (StringUtils.isEmpty(lockName)) {
throw new RuntimeException("Lock name can't be empty");
} Date lockDate = locks.get(lockName); return lockDate;
}
}
锁仓库提供了三个方法,都是静态的,可以在系统内任意地方调用。 这里要提的是锁名,是一个字符串,可以随意构造,通常是需要锁定的方法名+需要单线程处理的标识。比如部门ID。这样不同的部门有不同的锁,独立运行,同一个部门同一个锁,单线程处理。具体使用如下: /*
* LockTest.java 2012-6-19
*/ import java.text.SimpleDateFormat;
import java.util.Date; /**
* 锁仓库的使用
*
* @version 1.0
*/
public class LockTest {
public Boolean doSomething(String departmentId, StringBuffer message) {
// 同一个部门同时只能有一个处理, 不同部门可以并行处理
String lockName = "doSomething_" + departmentId;
Boolean result;
if (LockStore.getLock(lockName)) {
try {
// do things here
} finally {
LockStore.releaseLock(lockName);
result = true;
}
} else {
Date lastLockDate = LockStore.getLockDate(lockName);
String messageStr = "您所在的部门已经在处理中, 启动时间为:"
+ getDateDetailDesc(lastLockDate);
message.append(messageStr);
result = false;
} return result;
} /*
* 获取日期的具体时间描述
*/
private String getDateDetailDesc(Date date) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss");
return sdf.format(date);
}
} |
通过以上设计,系统内部任何耗时且需要保证单线程的地方都可以用该方法实现非阻塞式的访问,提高用户体验。甚至于有的调用本身就要求这样的设计,只需处理一次,比如做日终。锁名的自定义带来了锁粒度的灵活设定,可以在运行时根据参数实现任意级别的锁定。 |
一、定义
级联删除是指删除包含主键值的行的操作,该值由其它表的现有行中的外键引用。在级联删除中,还删除其外键值引用删除的主键值的所有行。
级联更新是指更新主键值的操作,该值由其它表的现有行中的外键引用。在级联更新中,更新所有外键值与新的主键值相匹配。
三层架构是指一种架构思想。通常他将整个业务应用划分为:表现层(UI)、业务逻辑层(BLL)、数据访问层(DAL)。区分层次的目的是为了“高内聚、低耦合”的思想。
二、特点
大家都知道,级联删除与级联更新操作,都是指主表的信息删除或更新后,外键表中的相应信息随主表保持一致,也同样做出删除或更新操作,不然就会发生错误,保持数据的事务性。
而关于三层架构的分层问题,我们之前就讨论过。看似简单,但是越是往细处想,越是发现疑点重重,很多知识都掌握的似是而非。
之前,我们谈论过,我们的架构设计,一般DAL层是与表一一对应的。这是一种规则,可以使DAL层与BLL层之间的关系更加清晰、简洁。但是,我们知道,在实际应用中,真正实现一个逻辑对应一个表是比较困难的,我们的业务不可能彼此孤立,而只能相对孤立。
因此,我认为:我们在设计之初,大方向依然按照DAL与表一一对应的原则进行设计。这里有一点需要注意:所写的SQL语句,一定是要放在存储过程里面的,因为存储过程是预编译类型。业务修改时,我们只需要修改对应存储过程,实现对修改封闭的原则。
三、比较
通过上面的分析,我们可以得出:级联操作与三层机构设计思想是彼此矛盾的。前者只适用于多表间的操作关系,而后者的宏观路线是单对单。
然而,我认为,通过编写存储过程或者触发器来实现级联操作,这样可以使得三层架构的设计更加灵活多变、更加具有弹性。
我们来看机房收费系统中的一个功能:充值功能。我们在充值的时候,不仅要更新卡表内余额,同时也要增加充值记录。
我们之前的做法是,在DAL层对应卡表编写进行更新余额,在充值记录表中添加相应记录。然后在BLL层实现他们的协调工作。
这样做有一个很大的弊端,充值的过程是一个顺序过程,现更新,在添加记录。如果中途断电,那么数据就会不完整了。
看下面的例子,首先是数据库关系图
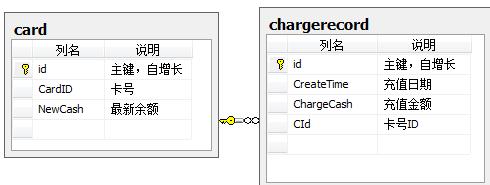
编写下面触发器,实现起来就非常方便了。
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: 刘正权
-- Create date: 2012年5月7日
-- Description: 充值时,更新最新的余额的同时,增加充值记录
-- =============================================
CREATE TRIGGER trigCharge
ON card
Update
AS
BEGIN
Update chargerecord set c.ChargeCash=i.ChargeCash
from chargerocord c,Deleted d, Inserted i
where c.CId=d.id
END
GO |
四、结论
我认为,级联操作与三层架构或者多层架构的思想是不矛盾的。想反,它使得分层更加灵活多变。
回归测试的策略及方法
业界的回归测试策略基本上有两种:
● 全部回归,也就是把之前的所有的测试用例,无论是手动的,还是自动的,全部跑一遍
● 部分回归,定性分析代码改动有哪些影响,代码改动的文件/模块和其他的文件/模块的依赖性,然后选择被影响到的文件/模块相应的测试用例来跑一遍
第一种的好处就是,通过大量的跑测试用例,可以尽量多的发现哪些功能是否有被影响到,缺点就是如果你的测试用例库很大,那这个是相当消耗时间和人力的;
第二种的好处就是,不需要消耗大量的时间和人力,缺点就是因为是定性分析,所以有可能漏掉一些没有被分析出的影响;
那么有没有其他第三种办法,用定量分析的方法来进行回归测试,答案是肯定的,可以依赖代码覆盖这个方式。
总的来说是这样的:
1、每次跑完一个测试用例就把对应的代码覆盖情况录入关系型数据库,这样数据库里面就有了测试用例和代码覆盖率的一一对应的表格。(代码覆盖率可以是文件级别或者是函数,类级别的)详情可以见下图:
2、对于修改的代码,分析是属于哪个函数,类或者是文件的,然后去数据库查找所对应的测试用例
3、这些对应的测试用例就是我们需要的,可能会因为代码改变而受到影响的测试用例。
测试用例 | 代码覆盖(文件级别) |
TC1 | File1, File2 |
TC2 | File1, File2,File3 |
TC3 | File3 |
......
| ...... |
TCn | File1, |
比如,数据库里面已经有上面这样一张表格,那么假如开发修改了文件File3里面的代码,根据上面的表格我们知道TC2,TC3是和File3有关联的测试用例,所以我们可以挑出TC2,TC3出来执行,这样就是通过定性的方法来执行回归测试。
当然你的代码覆盖也可以是函数级别的:
测试用例 | 代码覆盖(函数级别) |
TC1 | Func1,func2,func3 |
TC2 | Func1,func2 |
TC3 | Func1,func3 |
| ...... | ...... |
TCn | Func1 |
那么当func3函数有修改,我们就知道TC1,TC2,TC3都是相关的测试用例,就可以挑出TC1,TC2,TC3出来跑。(对于新增的函数,我们只能通过文件级别的代码覆盖表格来找,因为之前没有这个函数对应的测试用例,但是有这个函数所在的文件所对应的测试用例)。
此外,也可以通过数据挖掘,寻找出文件与文件直接,或者是控件(dll)与控件之间的依赖性,比如文件A引用了文件B的函数(可以通过“函数名”在代码库里面进行全文搜索,就知道那些函数被其他函数引用了),那么他们就有了依赖性(A对B有依赖,如果C对A有依赖,那么C对B也有了依赖,这里面设计到递归),控件1含有文件A,控件2含有文件B,那么控件1对2就有了依赖性;通过数据挖掘把依赖性寻找出来以后,如果文件B被修改,那么所有对它有依赖的文件/控件有可能受到影响,我们就可以把这些对应的测试用例找出来跑一遍;
另外一种数据挖掘的方法是,通过bug数据库来挖掘, 比如在执行TC1(目的是为了测试Component A)的时候发现的Bug,她的root cause是Compoent B,那么Component A和Compoent B就有了耦合关系,以此类推,就知道Compoent。
探索性测试是一个特殊的测试过程,它的测试活动和测试内容是动态变化的,更多的是通过测试执行的结果来指导后续的测试活动,花在文档上的时间很少,这也就意味着探索性测试的可管理性不强,对于每个测试人员执行的测试活动的进度和效果很难监控。为了更好地开展探索性测试,Jonathan Bach提出了一种“基于会话的测试管理(Session-basedtest management,缩写为SBTM)”方法,这种方法可以对探索性测试进行更好地管理,把探索性测试的优势更好地发挥出来。
基于会话的测试管理是一种用于管理探索性测试的方法。这里的会话(Session)是指测试工作的基本单位,在一个会话中测试工作是连续进行的,不会被打断。会话中的测试活动是为了实现某个具体的目标,同时测试活动的结果是可评审的。任何可能会被电话、会议、电子邮件或其他非测试活动打断的测试活动,都不适合成为一个会话。在一个会话中,测试人员应该专注于测试活动而不被打扰。在每个会话结束的时候,应创建描述已进行的测试活动的报告,该报告通常称为会话单(Session Sheet)。测试经理需要对该会话的报告或者会话单进行评审。一个会话可以持续90分钟,也可以是3个小时,对于会话的持续时间并没有严格的要求,通常情况下,每个测试人员一天完成的测试会话不要超过3个。
由于每个会话持续的时间比较短,所以对于每个会话进行报告的周期也相应比较短,但是内容也很简洁。Jonathan Bach将一个测试会话中的任务分成三类:
1、创建会话:建立测试环境和增进对产品的理解。
2、测试设计和执行:细查测试对象,寻找问题。
3、缺陷调查和报告:开始于测试人员发现某些疑似失效的问题。
上述的三个任务并不一定是顺序执行的,在实际的操作中经常都是重叠的。每个测试会话完成后,测试人员要填写会话单。基于会话的测试管理中的会话单主要包括:
1、会话章程(Session Chapter):主要描述会话的任务和可能采用的策略,会话的章程可能是测试人员自己选择的,也可能是测试经理分配的。
2、测试人员姓名。
3、起始的日期和时间。
4、任务分解(以会话的形式):通常分别描述测试设计和执行、缺陷调查和报告。
5、数据文件:描述测试会话中使用的数据文件。
6、测试备注:对于测试活动中的任何特别的说明都可以记录在这里。
7、问题:描述测试过程中碰到的问题,例如:由于测试环境不足,有些测试没有执行。
8、缺陷:描述测试过程中发现的缺陷。
测试经理根据测试人员提交的会话单,在测试团队内进行任务报告会议。在任务报告会议中,测试经理回顾测试活动、改善章程、从测试人员处取得反馈、估算和计划进一步的会话。任务报告的议程主要是简要地检验以下各项,并明确下一步的测试会话章程。
1、经过:在会话期间发生了什么?
2、结果:会话取得了什么成果?
3、展望:还有什么有待解决的问题?
4、障碍:要进行良好的测试有些什么障碍?
5、感受:测试人员对上述项的感觉?
在探索性测试中,测试的对象和内容比较发散,经常出现具体的测试活动和会话章程不一致的情况。那么在最后的会话单中要对会话章程进行修改,以保证提交的会话单如实地反映了实际的测试活动。如果需要的话,也可以新建一个新的会话来记录这次测试活动。虽然不建议会话的持续时间太长,但是在实际的测试过程中,仍然会出现一个会话占用测试人员一整天的情况,通常可能是因为会话环境的搭建或者缺陷的调查花费的时间比预期的要大。这种情况下也没有必要强行把会话拆成多个更小的会话,可以根据测试的需要保留这些持续时间较长的会话。一个测试会话最好是在没有被打断的情况下持续地进行,但有时候可能需要参加一个紧急的会议,或者开发人员修复紧急的缺陷而需要测试人员的帮助,这个时候测试会话不得不被打断。这种情况下,测试会话的中止和恢复是允许的。
设计测试用例是个很大的主题,而且其中所需要的方法也很多。我计划一点一点的总结并记录下来。我这次讨论的不是针对一个软件的测试用例设计,而是针对一个模块或多个模块用例的设计。
今天我要写的主要是我自己在工作中所用的一些方法,当然不是最好用的。但我一直在研究最高效,最实用的方法。
首先我们要了解一下为什么要设计测试用例以及它在软件测试中的地位。
影响软件测试的因素很多,软件本身的复杂程度,开发人员的素质(包括分析,设计,编程和测试),测试方法和技术的应用。那么如何保证测试质量的稳定呢?测试用例就可以把一些人为的因素减低,因为人员的流动不会造成测试用例的流动,而且我们可以在以后的测试中不断的维护和更新测试用例。所以说测试用例的设计和编制是软件测试活动中最重要的。它是测试工作的指导和软件测试必须遵守的准则。它更是软件测试质量稳定的根本保障。
当自己接受到一个设计测试用例的任务时,如何对一个庞大的模块进行设计测试用例呢?这时候测试用例的划分就显的尤为重要。
我总结的测试用例的划分有三种:
1)按照功能划分
2)按照路径(业务流程)划分
3)按照功能和路径(业务流程)划分
目前我用的方法是第三种。第一种按照功能划分,优点是最简捷,但其缺点是:对于复杂操作的程序模块,其各功能的实施是相互影响,紧密相关,环环相扣的。如果没有严密的逻辑分析,很容易产生遗漏。第二种纯粹按照路径划分也容易造成对功能点的遗漏。所以我基本都是大方向用功能块的划分来走,然后再结合上路径(业务流程)的划分方法。
例如下面的一个模块测试,我就先按照功能划分为几大块,然后针对每个功能块再按照路径(业务流程)来划分:

那么有人会问,当我拿到一个任务的时候,简单一点还好办,一旦复杂了就没有头绪,无处下手了。我告诉大家不会的。只要你按照我的这个流程来设计我认为是不会无处下手的的:
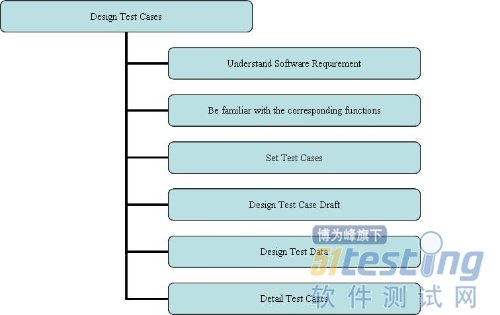
在这个流程当中,我要强调的重点是前两步:"Understand Software Requirement" and "Be familiar with the corresponding functions".
1、Understand Software Requirement: 当接到一个任务的时候,我们首先接触到的是需求说明书,那就要了解需求说明,或者应该说掌握其需求说明。其中的任何一个细节都不能忽略,都要把它搞得很清楚。不仅要搞清楚每个功能块所实现的功能,更要从业务的角度理解其功能块之间的关系。因为任何的软件测试都不能脱离实际的业务逻辑,否则测试是没有意义的。
2、Be familiar with the corresponding functions.如果这个模块已经实现,那就更好办了。可以结合需求说明直接操作该软件,以便提高对该软件功能的理解。
我们接到测试用例设计的任务,不要急着下手,首先按照我上面所说的两步来完成。等把这些前提工作完成了,现在基本就对要设计的软件了解差不多70%了。
当我们完成前两步以后,开始对测试用例进行划分,就可以采用我上面推荐的功能加上路径(业务流程)的划分方法。当我们罗列出很多测试用例以后,那我们是否要对所有的测试用例进行详细的设计呢?这个就不一定了,因为往往时间或者资源的关系我们无法覆盖到所有的测试用例。那我们这里就需要采取优先级的顺序来进行选取了。
我们为每个测试用例设置优先级需要采取两个原则:
1、将使用频率比较高的设置为高优先级的。
2、根据测试用例失败后对系统的影响大小还设置其优先级。
这样将两者相加就得到了每个测试用例的优先级了。根据优先级的排序就可以更有针对性的进行测试用例的详细设计了。这是我们先不急着设计测试用例,我们还要为每个测试用例设计相关的测试数据。
我们对测试数据的设置有两个要求:
1、正常数据
2、非法数据
我们要优先考虑正常数据,而且正常数据的设计必须是有实际意义的。然后再考虑设计非法数据。这两种数据中都应该包含边界数据,因为边界数据往往是容易出错的地方。
当我们设计完测试数据后,就可以开始对测试用例进行详细设计了。具体测试用例的模板可以根据自己公司的要求来定义。我这里给出测试用例模板的一些要包括的要素:
1、Objective
2、Testing Configuration
3、Test Steps & Results
另外在具体的测试步骤中,我们需要包含的主要内容是:操作步骤,测试数据以及期望结果。
当我们完成了这些工作,一个完整的测试用例就写完了。
摘要: /* * LoadRunner Java script. (Build: 15) * Script Description: * * 作者:谷博涛&...
阅读全文
前几天和群里的一个朋友聊天,他提到了自己的一个问题,为什么感觉自动化测试推广很难,当时和他简单的讨论了一下,也有一些很有亮点的东西。
现在各个公司都在做自动化测试,但是在实施自动化测试的过程中碰到了很多问题,推广难是其中最普遍的问题之一。很多公司在初期的自动化测试做的不错,但是想推广的时候却发现效果不尽人意,和预期所想象的差太远。为什么?原因当然有很多,我主要想聊其中的两个原因,一个是自动化测试的易用性,另一个是自动化测试的用例设计问题。
自动化测试的易用性是什么?简单的说,就是自动化测试人员开发的脚本,易于使用、易于维护、易于排查问题。首先说易于使用,笔者所在公司使用RFT做自动化测试,采用了IBM的三层结构的设计,还引用了很多第三方JAR包来扩展自动化测试的功能,组内一直用的很好。后来有功能测试人员把这套脚本拿过去,却反馈说不好用,过去一看,原来是没把JAR包加到构建路径里,然后过去解决问题:加JAR包、设置工程依赖、设置编译目录、设置脚本执行参数,一会儿搞定,由此想到,这其实就反映的是自动化测试的易用性问题。如果我们开发的脚本不能被功能测试人员广泛的使用起来,那么自动化测试的推广自然无从用起。笔者现在也正在这方面努力改善。争取做到能让功能测试人员一键执行自动化测试:自动部署新程序、自动下载自动化测试脚本、自动编译自动化测试执行包、自动执行测试、第二天来看结果,而且自动化测试的内容简单明了,一目了然。如果能做到这种程度,大家都喜欢用自动化测试、都乐于用自动化测试,推广工作自然水到渠成。易于维护和易于排查就不细说了,因为做自动化测试的人都懂得要让自己的脚本有一定的扩展能力和可维护性。
第二点要说的是自动化测试的用例设计,其实这是一个老生常谈的问题,就不再这里细说了,只是强调几点大家容易忽视的:决定自动化测试效果的不是测试脚本如何编写,而是你的用例如何设计;一份糟糕的测试用例只会让自动化测试做无用功,自然没人爱用;如果我们的自动化测试用例,覆盖了软件大部分的核心功能和业务场景,那么自然会变的重要。
在群里的那位朋友,把自动化测试推广难的原因归结于测试环境混乱和开发过程,我觉的这是影响推广效果的两个因素,但是不是主要原因。自动化测试推广难在于没人爱用;没人爱用的原因是因为测试人员觉得自动化测试不能提高他们的工作效率和工作质量。
那么自动化测试如何提高测试人员的效率和质量?
1、要让测试人员易于使用自动化测试;
2、永远永远的把用例设计摆在自动化测试工作的首位!
相关链接:
自动化软件测试推广经验分析总结
版权声明:本文出自 dreamever 的51Testing软件测试博客:http://www.51testing.com/?31621
原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。
编写背景:
工作所在的部门启用了新的绩效考核制度,也开始了我参与对测试人员的工作进行绩效考核这一管理活动,第一次的考核结果让我有很多的感想,因此今天把它记录下来,也许突然有一天回头看这一感想,又会是另外一份心情。
思考:给测试人员进行绩效考核的目的是什么?
经过思考,我总结的答案是:
1、为了了解工作情况,如:工作进度、工作状态。
2、对每个人的工作进行评比,夸奖好的,批评差的。这个看起来有点像在学校上学时候的考试。
思考:有了这样的绩效考核目的,要用什么样的方式、方法去实现呢?
怎么样的绩效考核方式是最有效的呢?
对于现在的我,在现在这个小公司要想做好这个绩效考核,真是要好好思考。
1、不同的工种,不能用同一种考核方式。如:测试人员的考核方式就不能和开发人员的考核方式相同。
2、不同工种的考核结果是没有可比性的。如:测试人员的考核结果和开发人员的考核结果进行对比是没有意义的。
以上这两点不知道我的领导是否认同,还需要等到下一次考核的时候和他沟通沟通。
这是工作以来,第一次站在一个管理角色去思考、去做绩效考核这个工作。这第一次的考核工作让我不知道用什么语言来描述我的感受。
考核的结果是:测试组整体的分数都比开发的低,从排名和等级划分上可以说是包尾了。从分数上看,我的第一感觉是:难受。第二感觉是:生气。在和领导进行一系列沟通后,在回家的路上一直在思考、分析着这个结果,问题出在那里呢?问题出在那里呢?????冷静的思考后,自己安慰自己,原因应该是这些吧:
1、这次开发人员和测试人员使用的工作考核方式是同一种考核方式。
2、这次把开发人员的考核分数拿来和测试人员的进行排名对比。
很显然,一直这样下去,测试人员的工作即使在怎么努力、分数超过开发人员的机率会很低很低,这样的对比规则,对测试人员来说,很不公平。这样的对比规则,很没有意义。更让我郁闷的是,面对这样的现象,我想不到很好的解决方法,目前只能鼓励测试人员加强自己的综合能力,自己给自己争气,对我来说,在测试人员的管理工作上,无形中出现了一个困难,只能是乐观面对了。
唉,工作种类不一样,放在一起作对比,永远说不清。
测试人员的工作,开发能作么?开发人员能写好测试需求、测试计划、测试用例、测试分析报告文档么,先不说写好,先说会写么?开发人员知道怎么样去执行测试么?知道发现 bug 应该怎么有效正确的去描述么?怎么快速有效的发现程序的问题么?能把握好整个软件测试的质量和进度么?测试,说的简单,真正做好没有这么简单。就拿黑盒测试举例,测试项有:业务流程测试、功能测试、安全性测试、性能测试、数据测试、用户友好性测试、配测试、兼容性测试。这些测试项所使用的测试方法、测试点,都能想全了、想到重点了么,想到了还只是第一步,真正要去执行测试的时候,测试环境的搭建、测试用例的编写与执行、 bug 的描述以及错误等级的正确划分、 bug 的回归、用测试工具进行测试,对测试工具正确有效使用的把握,这些对开发人员来说,会做么,能做好么?测试工作也有很大的工作压力,面对一个不熟悉的软件,面对一个什么说明文档都没有的大软件,要在最短的时间内,最有效的完成测试,要保证产品在发布后,不出现严重的问题,想尽一切办法的发现严重问题。这种对软件质量上的责任压力是很重的,还有其它我就不举例了。
开发人员的工作,测试能作么?测试能看懂开发人员的代码么?测试能写代码测试开发人员的程序么?测试能明白理解开发人员是怎么开发的么?测试能明白开发人员所说的工作术语么?测试能看明白开发人员的开发成果么?开发人员的工作也有很大的压力,要在最短的时间内编写出质量高的代码,实现功能,还要进行一遍又一遍的调试,需求一变,又要修改代码,自测时,发现问题,要进行调试找原因和解决方法,容易么?不容易。测试人员发现的问题,还要去找原因要想最好的解决方法。容易么?不容易。
我很同情那些把测试和开发放在一起作对比行为的人,因为他们对这两个工作中的其中之一理解有所欠缺从而导致这样的结果。说了那么多,好像扯远了。
最后,我得出这么个结论:这样的绩效考核方式,对测试人员来说,起不到激励作用。如果碰到不能正确心态去理解的测试人员,反而会起反作用,很打击工作积极性。因此领导在问我意见的时候,在不适合的说话时间、说话场合我只能说“无所谓”,心不甘情不愿的无所谓!!!!!!!!!!!!!!
第一部分:重构
第二部分:设计原则与代码所有权
第三部分:进化型设计
第四部分:灵活性与复杂性
第五部分:测试驱动开发
第六部分:性能与过程调优
可维护性与效率
比尔:我在丹佛机场的红地毯俱乐部(Red Carpet Club)[1]中常常碰到名人。今年夏天我碰到了 Calista Flockhart (卡莉斯塔·弗洛克哈特)[2], 而去年我碰到了你。我是个追星族,但是由于害怕哈里森·福特,没敢跟 Calista 搭讪。不过,你和我倒是坐下来喝了杯啤酒。记得当时你曾对我说过,应该以程序员能读懂的字符格式来序列化对象,而不是以二进制代码格式。当我提到字符格式 要比二进制码格式慢时,你说,从效率的角度来看,二进制代码格式使得软件更加难以维护。那么,能否请你谈谈关于序列化方式的具体案例?一般地说,你如何在 可维护性与效率之间寻找平衡点?
马丁:效率永远是第一位的,前提是你能正确理解它。很多时候问题在于,人们以为做某些事情是为了效率着想,但他们却从不使用性能分析器(profiler)。如果你出于效率的考虑而做某件事,但却不使用性能分析器,那么你所宣称的根本就不着调。
序列化所牵扯的问题要多一些。使用二进制代码做序列化的问题之一就是你无法去查看结果。当你需要存储序列化的对象时,这个问题就更加突 出。Java 的一个典型问题就是如果你改变了一个类,那么就无法读取以前所序列化的对象。类似的,如果一个客户端和一台服务器正通过序列化的对象进行通讯,假如一端的 数据结构进行了更新而另一端没有,那么整个通讯就彻底失效了。
有一个小窍门可以让你绕开这个问题。不要序列化对象本身,而是把数据从对象中提取出来,放到一个字典里,然后再序列化那个字典。这么做会使你能够应对一些变化。
比尔:但是,字典是“不明确的”。我们之前刚刚说起过这点。
马丁:的确,字典不是“明确的”。不过,如果你往类里添加一个字段,并把这个多出来的值放到字典里 的话,不会有什么问题。因此,这是一个比较强壮的机制。XML 一般也比较强壮,因为你可以对你所不了解的数据视而不见。二进制序列化的主要问题就是它的脆弱性。在我的书《企业应用架构模式》中,更多地提到了序列化的 方式。例如,在数据库中传输和存储数据时,就需要考虑介于字符和二进制之间的序列化格式。
编写可性能调优的软件
比尔:你在《重构》一书中写道:“编写能快速运行的软件的秘诀就在于先编写可性能调优的软件,然后对执行速度进行调优。” 我该怎样编写可性能调优的软件呢?
马丁:只要做到软件结构合理就可以。
比尔:怎么讲?
马丁:因为结构合理的软件可以更容易地进行改动。
比尔:也就是说,这时候软件要更容易地进行改动,不是为了添加新功能,而是为了提升已有功能的性能。
马丁:结构合理的软件能够更容易地进行调优。你应该首先专心于让软件结构合理、设计清晰,然后,在性能调优器的引导下,完成性能优化过程。
优化
马丁:还有一件事需要牢记:性能优化与版本和具体的实现是密切相关的。当你拿到 Java 的一个新版本时,一定要把以前所做的优化都撤消,然后重走一遍优化过程,以确保那些优化手段仍然奏效。通常你会发现,你为上一个版本的虚拟机 (virtual machine)或优化型编译器(optimizing compiler)所做的性能优化往往使当前的版本变慢,也即,之前的优化手段如今往往起到适得其反的作用。
比尔:要记住以前为了提升性能都做了哪些改动可不是件容易的事情。
马丁:你必须这么做——先撤销,再重新应用。我知道这不容易。这就要求你对优化过程中所做的每个改动都要有详细的记录。要知道,旧的优化所造成的一些微不足道的性能损失,在新的版本下有时候可能会变得非常显著。
Craig Larman (拉曼 C [3]) 曾经讲过一个故事,我到现在都还很喜欢这个故事。Craig 有一次在 JavaOne 的大会上做性能优化的讲座。他提到了两个广为人知的技术:对象池(object pooling)和线程池(thread pooling)。对象池就是重用已有的对象,而不是每次都创建新的对象。线程池的原理基本类似。讲座结束后,有两个人来到 Craig 跟前。这两个人都是设计高性能虚拟机的。其中一个虚拟机是 Hotspot,另一个好像是 JRocket。一个人告诉 Craig,线程池的效果不错,但对象池则使得虚拟机的运行变慢;而另一个人告诉 Craig 的恰恰相反。
所以,你有可能在一种虚拟机上优化了性能,但拿到另一种虚拟机上,却减慢了其运行速度。对此,你要特别小心。对象池就是一个很好的例子。 很多人热衷于对象池,但起码有一半的情况下,人们并不去测量对象池的效果到底是好是坏。在 Java 的早期日子里,对象池非常重要,因为垃圾回收(garbage collection)功能还不是很完善。但在垃圾回收技术更新换代之后,对象池的效果就大大降低了,因为那些生存周期很短的对象可以被低成本地回收。只 有那些生存周期很长的对象,才适合使用对象池技术,因为对它们进行垃圾回收的成本很高。
从这里可以看出,规则也是在不断变化的。这就是为什么要对性能调优很仔细的原因所在。不要妄想根据源代码就能预测机器会做什么。当你与虚拟机或优化型编译器打交道时,性能调优是唯一的手段,因为编译器和虚拟机所做的事情,远远超出你的想象。记住,不要预测,要实测。
模式的意义
比尔:你在《设计是否已死》这篇文章中表示:“对我来说,模式仍然是至关重要的,”尤其是考虑到极限编程的话。那么今天,模式处于一个什么样的地位呢?
马丁:模式给了我们瞄准的目标。我还会做一些预先设计。模式就是用来干这个的。模式还给了我们以重 构的目标。我们得以知道我们改进的方向。了解模式还有助于我们找到设计美感,因为模式至少都是一些好的设计。你可以从它们身上学到很多。因此,我仍然认为 模式起着重要的作用。其实,很多积极推动极限编程运动的人,本身就活跃在模式社区里。这两个社区在很大程度上是重叠的。
敏捷宣言
比尔:最后一个问题,敏捷宣言到底是怎么一回事?
马丁:哦,那是一群投入到敏捷软件方法领域的人,聚在一起,彼此印证心得。这个领域包括极限编 程,scrum,crystal,修错驱动开发(fix-driven development),和动态系统开发方法(DSDM)。我们意识到我们之间有很多共同之处,因此决定把我们所认同的写下来。我们把这份宣言看作是一 种象征——在这面大旗下汇聚了支持此类方法的人们。在那次聚会中,我们决定使用“敏捷方法”这个词。这份宣言可以作为敏捷软件开发的一个定义。借助这份宣 言,我们共同呼吁,软件业的主流应该朝着这个方向前进。
比尔:让我们来看看四条原则中的一条:“个人与交互重于过程和工具”。这是什么意思?
马丁:这条原则大意是说,与其借重过程和工具来加强对软件开发的管理,不如更多地关注于团队及其成员,关注于每个个体以及他们之间在个人层面上的交互。
比尔:你是说提升他们的技能么?
马丁:要远比这个丰富得多。它包括了提升技能;它还包括要竭尽全力使程序员们身心愉悦,从而得以留 住人才;它还意味着更认真地对待个性冲突,注重人与人的相处,而不是试图找出某个完美的软件开发过程,然后要求大家都来遵守这个过程。我对这条原则的理解 是,应该是团队选择适合其的软件开发过程,而不是让团队来适应指定的开发过程。
尽管在那次聚会上,我们中的许多人都津津乐道于自己所采用的开发过程,并且我们当中的几个人还是软件工具销售商,但我们一致同意,对于一个项目的成功来说,软件开发过程和工具只是次要的因素,最主要的因素还是团队,是团队中的成员,是他们人性化的合作与努力。
除了常规的计算匹配文件数量外,这个程序打印出执行过程中池中的最大线程数量。但从ExecutorService接口不能得到这个信息。因此,我们必须将pool对象转型成一个ThreadPoolExecutor类对象。
import java.io.*;
import java.util.*;
import java.util.concurrent.*; public class ThreadPoolTest
{
public static void main(String[] args) throws Exception
{
Scanner in = new Scanner(System.in);
System.out.print("Enter base directory (e.g. /usr/local/jdk5.0/src): ");
String directory = in.nextLine();
System.out.print("Enter keyword (e.g. volatile): ");
String keyword = in.nextLine(); ExecutorService pool = Executors.newCachedThreadPool(); MatchCounter counter = new MatchCounter(new File(directory), keyword, pool);
Future<Integer> result = pool.submit(counter); try
{
System.out.println(result.get() + " matching files.");
}
catch (ExecutionException e)
{
e.printStackTrace();
}
catch (InterruptedException e)
{
}
pool.shutdown(); int largestPoolSize = ((ThreadPoolExecutor) pool).getLargestPoolSize();
System.out.println("largest pool size=" + largestPoolSize);
}
} /**
* This task counts the files in a directory and its subdirectories that contain a given keyword.
*/
class MatchCounter implements Callable<Integer>
{
/**
* Constructs a MatchCounter.
* @param directory the directory in which to start the search
* @param keyword the keyword to look for
* @param pool the thread pool for submitting subtasks
*/
public MatchCounter(File directory, String keyword, ExecutorService pool)
{
this.directory = directory;
this.keyword = keyword;
this.pool = pool;
} public Integer call()
{
count = 0;
try
{
File[] files = directory.listFiles();
ArrayList<Future<Integer>> results = new ArrayList<Future<Integer>>(); for (File file : files)
if (file.isDirectory())
{
MatchCounter counter = new MatchCounter(file, keyword, pool);
Future<Integer> result = pool.submit(counter);
results.add(result);
}
else
{
if (search(file)) count++;
} for (Future<Integer> result : results)
try
{
count += result.get();
}
catch (ExecutionException e)
{
e.printStackTrace();
}
}
catch (InterruptedException e)
{
}
return count;
} /**
* Searches a file for a given keyword.
* @param file the file to search
* @return true if the keyword is contained in the file
*/
public boolean search(File file)
{
try
{
Scanner in = new Scanner(new FileInputStream(file));
boolean found = false;
while (!found && in.hasNextLine())
{
String line = in.nextLine();
if (line.contains(keyword)) found = true;
}
in.close();
return found;
}
catch (IOException e)
{
return false;
}
} private File directory;
private String keyword;
private ExecutorService pool;
private int count;
} |
构建一个新的线程的代价还是有些高的,因为它涉及与
操作系统的交互。如果你的程序创建了大量生存期很短的线程,那就应该使用线程池。一个线程池包含大量准备运行的空闲线程。你将一个Runnable对象给线程池,线程池中的一个线程就会调用run方法。当run方法退出时,线程不会死亡,而是继续在池中准备为下一个请求提供服务。
执行器(Executor)类有大量用来构建线程池的静态工厂方法,下表给出了一个总结。
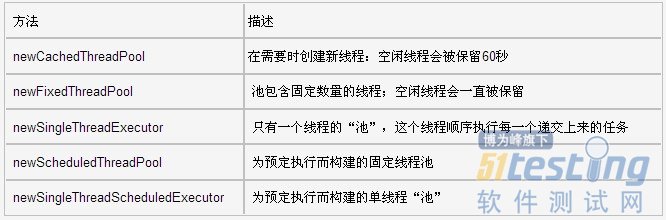
newCachedThreadPool、newFixedThreadPool和newSingleThreadExecutor这三个方法返回ThreadPoolExecutor类(这个类实现了ExecutorService接口)对象。
向线程池提交任务的方法为:将一个实现Runnable或Callable接口的对象提交给ExecutorService:
Future<?> submit(Runable task)
Future<T> submit(Runable task, T result)
Future<t> submit(Callable<T> task)
线程池会在适当的时候尽早执行提交的任务,调用submit时会返回一个Future对象,用以查询该任务的状态,或者取消该任务。
第一个submit方法提交一个Runable对象返回一个Future<?>,可使用该对象调用isDone、cancel、或者isCancelled来查询任务状态。但是此Future对象的get方法在任务完成的时候知识简单的返回null
第二个版本的submit方法同样提交一个Runable对象,并且返回Future的get方法在任务完成的时候返回传入的result对象
第三个submit方法提交一个Callable对象,并且返回的Future对象将在计算结构、准备好的时候得到它。
当想要注销一个线程池,可调用shutdown方法,该方法启动该线程池的关闭序列。此时线程池并不是马上就壮烈牺牲了线程也没了,而是等待所以任务都完成以后,线程池中的线程才会死亡,被关闭的执行器不再接受新任务。也可以调用shutdownNow,此时线程池会取消正在排队等待处理的任务并且试图中断正在执行的线程。
下面总结了在使用连接池时应该做的事:
1、调用Executor类中静态的newCachedThreadPool或newFixedThreadPool方法。
2、调用submit来提交一个Runnable或Callable对象。
3、如果希望能够取消任务或如果提交了一个Callable对象,那就保存好返回的Future对象。
4、当不想再提交任何任务时调用shutdown。
除了常规的计算匹配文件数量外,这个程序打印出执行过程中池中的最大线程数量。但从ExecutorService接口不能得到这个信息。因此,我们必须将pool对象转型成一个ThreadPoolExecutor类对象。
import java.io.*;
import java.util.*;
import java.util.concurrent.*; public class ThreadPoolTest
{
public static void main(String[] args) throws Exception
{
Scanner in = new Scanner(System.in);
System.out.print("Enter base directory (e.g. /usr/local/jdk5.0/src): ");
String directory = in.nextLine();
System.out.print("Enter keyword (e.g. volatile): ");
String keyword = in.nextLine(); ExecutorService pool = Executors.newCachedThreadPool(); MatchCounter counter = new MatchCounter(new File(directory), keyword, pool);
Future<Integer> result = pool.submit(counter); try
{
System.out.println(result.get() + " matching files.");
}
catch (ExecutionException e)
{
e.printStackTrace();
}
catch (InterruptedException e)
{
}
pool.shutdown(); int largestPoolSize = ((ThreadPoolExecutor) pool).getLargestPoolSize();
System.out.println("largest pool size=" + largestPoolSize);
}
} /**
* This task counts the files in a directory and its subdirectories that contain a given keyword.
*/
class MatchCounter implements Callable<Integer>
{
/**
* Constructs a MatchCounter.
* @param directory the directory in which to start the search
* @param keyword the keyword to look for
* @param pool the thread pool for submitting subtasks
*/
public MatchCounter(File directory, String keyword, ExecutorService pool)
{
this.directory = directory;
this.keyword = keyword;
this.pool = pool;
} public Integer call()
{
count = 0;
try
{
File[] files = directory.listFiles();
ArrayList<Future<Integer>> results = new ArrayList<Future<Integer>>(); for (File file : files)
if (file.isDirectory())
{
MatchCounter counter = new MatchCounter(file, keyword, pool);
Future<Integer> result = pool.submit(counter);
results.add(result);
}
else
{
if (search(file)) count++;
} for (Future<Integer> result : results)
try
{
count += result.get();
}
catch (ExecutionException e)
{
e.printStackTrace();
}
}
catch (InterruptedException e)
{
}
return count;
} /**
* Searches a file for a given keyword.
* @param file the file to search
* @return true if the keyword is contained in the file
*/
public boolean search(File file)
{
try
{
Scanner in = new Scanner(new FileInputStream(file));
boolean found = false;
while (!found && in.hasNextLine())
{
String line = in.nextLine();
if (line.contains(keyword)) found = true;
}
in.close();
return found;
}
catch (IOException e)
{
return false;
}
} private File directory;
private String keyword;
private ExecutorService pool;
private int count;
} |