
灵活运用数据库主外键
在最近的工作中发现,公司现有表都是没有主外键关系的,也就是没有加数据库主外键约束,全部都是采用程序来控制数据的一致性。这点让我很是不解,从当初学习数据库,到参加工作使用数据库和设计数据库,一直都遵循数据库的三范式,表之间的关联采用数据库的主外键约束(请理解这是数据库的约束,而不是我们程序控制的约束)。于是查找了一些资料,现在的疑惑才慢慢解开。下面我将对数据库的作用,以及为什么出现应用程序,再到真正开发时如何设计数据库的一些理解和大家分享下,欢迎提出不同的见解。
数据库是什么
数据库,是计算机中运行的一个进程,它可以完成数据存储,查找,分析,数据挖掘等我们通常使用的功能(大家可以联想access数据库),只是其操作起来对人员的要求较高,必须要懂得sql语句的写法,深刻理解表之间的关系,当然也可以请专门的人员来帮忙将数据导出来,这样的工作实施起来麻烦还是比较大的。并不是每个人都懂sql语法,专门的人员(DBA)一般公司请不起,简单的操作人员,工作效率是个问题。数据库的功能是强大,但是面向的人群较为苛刻。所以在我的思维习惯中,数据库往往是一种后台的服务(不直接操作它,但是使用其提供的服务,sql语句就是它提供的接口),不过现在不能再这么认为了,我们可以仅仅利用数据库各种数据的操作,比如数据的录入,数据的分析等,但是这样的效率太低了,如果每天有上千条的数据(这里说少点)需要保持,那么单纯来使用数据库这将是一项浩大的工程,分析也一样,而且分析得出的数据用户不一定能看懂。于是有了我们的应用程序。
数据库之上的应用系统
如果单从数据库应用程序的角度来考虑,而不谈其它应用系统,其作用可以为我们提供一个透明的简单的数据录入,查询和分析。用户只需要点击某一个按钮就可以得到想要的结果。而且其面向的人群更大众化,正是有这样的特性,才使计算机真正的为更多人服务,用户完全可以认为不存在数据库,无论是网上购物,还是自己的数据备忘,抑或是分析最近关注信息的走势,都是一个按钮解决问题。再回到技术上,系统要想做到方便用户使用,到底应该怎么做?
需要知道的两个概念
OLAP和OLTP。一个是联机分析处理,一个是联机事务处理。联机分析强调的是数据查询和整合分析,数据修改较少,而联机事务则强调数据修改较多,对数据一致性要求较高。这就对应着两个系统,一个系统对查询的性能要求很高,方便数据的可移植,一个系统对数据完整性和一致性要求较高。因此我们在做系统设计时必须搞清楚系统的特性,如果是查询性能高而且数据结构的修改较多,数据移植频繁,那么在数据库的设计时就不能完全遵循三范式,因为这样数据库会有一定的自检策略而且比较豪性能,相反则更能很好的保证数据的正确性。
结论
知识还是要灵活运用的,范式在数据库中是真理,但是当和其它系统集成的时候就不一定完全合理,比如数据的冗余,如果经常做统计查询,那么将统计结果放到一张表中比关联几张表来查询快多了,而且用户看中的就是这个,其它让我们大胆相信自己的程序能够控制后,做好数据准确的把门将军。让数据库的最后一道关用在其它地方吧。
以下是引用片段: Error Code : 1418 This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable) (0 ms taken) 解决方法如下: 方法1. mysql> SET GLOBAL log_bin_trust_function_creators = 1; 方法2. 系统启动时 --log-bin-trust-function-creators=1 方法3. 在my.ini(linux下为my.conf)文件中 [mysqld] 标记后加一行内容为 log-bin-trust-function-creators=1
● 外键
○ 定义
○ 作用
○ 主表和从表
○ 建键原则
○ 事件触发限制
● 外键简单实例
● 触发器实现
○ 建表语句
○ 关系说明
○ 实现级联删除
● 更改设置实现
● 总结
文首
今天给考试系统添加学生信息失败,原因是student与classes表有级联关系,作为从表的student表不能随意添加,这些都学过却还没怎么用过,借这次机会学习一下。
外键
说到级联删除不得不先说一下外键,外键的定义:“如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键;换而言之,如果关系模式R中的某属性集不是R的主键,而是另一个关系R1的主键则该属性集是关系模式R的外键”。
建立外键的sql语句:
| foreign key(idB) references A(idA) |
从语法分析也可以看出:外键是一种表之间字段值的引用关系。
主表和从表
主表和从表:以另一个关系的外键作主关键字的表被称为从表,具有此外键的表被称为主表。说白了就是:主表是被引用的表,外表是引用其他表的表。
那么外键有什么作用?外键作用可以说是:保持数据一致性,完整性,关联性,主要目的是控制存储在外键表中的数据。就是当你对一个表的数据进行操作,和他有关联的一个或更多表的数据能够同时发生改变,避免无效或是无用的改变和孤立的数据。
建键原则:
1、外键字段为主键
2、所有的键都必须唯一
3、避免使用复合键
4、外键总是关联唯一的键字段
外键约束事件触发。既然有外键约束,当违反约束时会发生什么?我们把它的反应看作事件,一共有四种:
1、级联:当主表更改时,从表跟从更改。
2、不执行任何操作。
3、设置null。
4、设置默认值。
我的看法
这些听着挺玄,我说说自己的看法:主表、从表和外键的定义:我把我的笔记本借给你用,可以把“我”当作是主表、“笔记本”当作外键、“你”当作从表,就是说“你”在使用(引用)“我”的“笔记本”;外键的作用就是:现在你想把我的笔记本卖了扔了送人(增加更新删除等),得看看我允许不允许,我想搬家走人,你不把笔记本还给我,我不能搬;建键原则:借之前首先咱得说好了,我只有这么一台笔记本,你也最好是也只借了我这台笔记本,避免你也借了别人的笔记本,不知道哪个是我的了。事件触发:我说你赶紧把笔记本还给我,你可以选择还给我,可以选择不搭理我等。总而言之,由于这笔记本,“你”和“我”关联起来,这台笔记本怎么样,不能一个人说了算。
简单实例
说了这么多,咱先说个简单的实例:建立两个表t_main和t_branch,并设置外键。语句的意思是t_main中的id是t_branch 的外键。
create table t_main
(
id int primary key,
[content] varchar(100) not null
)
create table t_branch
(
mainId int Primary key ,
[content] varchar(100) not null,
foreign key(mainId) references t_main(id)
) |
执行语句,现在我想直接在t_branch中插入一条数据insert into t_branch values(3,'分支表'),提示如下:INSERT 语句与 FOREIGN KEY 约束"FK__t_branch__mainId__4F7CD00D"冲突。该冲突发生于数据库"beidaqingniao",表"dbo.t_main", column 'id'。
我想删除t_main语句drop table t_main,提示如下:无法删除对象 't_main',因为该对象正由一个 FOREIGN KEY 约束引用。
在这两个表中,该外键的作用是,t_main中没有的外键值t_branch不能插入,而t_branch 正在引用t_main所以也不能只先删除t_main,否则t_branch中的数据会被孤立。我觉得,外键对主表的作用更倾向于不能删除,而对从表的作用更倾向于不能随便添加。
级联删除
但是如果想级联删除怎么办?总结出三种办法。
sql语句修改设置:因为默认的外键触发是“不执行任何操作”,所以我们可以使用sql语句更改设置:
| FOREIGN KEY(id)REFERENCES tabley(id) on delete cascade on update cascade |
意思是从表会跟随主表的改变而改变。
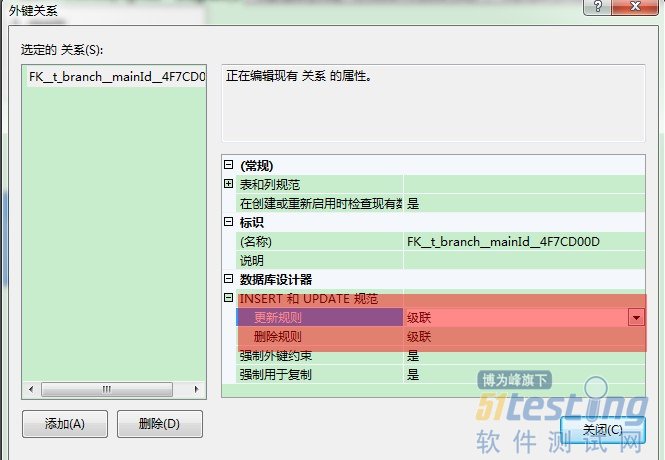
可视化修改:不想写代码,也可以可视化操作,新建数据库关系图,选择主表和从表添加,其关系也会自动添加。选择主表或从表---右键---关系---insert和update规范---级联。如图:
当然也可以使用触发器,触发器的基础知识,欢迎访问我的博客《详解sql中的触发器》
-- =============================================
-- Author: 李达
-- Create date: 2012年6月10日 18:11:46
-- Description: 简单的级联删除
-- =============================================
ALTER TRIGGER [dbo].[trigCascadeDelete] --触发器名
ON [dbo].[main] ---作用于哪张表
instead of delete ---什么动作触发
AS
BEGIN
declare @id int --声明@id变量
select @id=id from deleted --取出要删除的id
delete from branch where mainId =@id --先删除从表中的数据行
delete from main where id =@id ---再删除主表中的数据行
END |
总结
看过的知识不是你的,学过的知识不一定是你的,只有总结、运用后,才能更好的掌握知识,眼高手低的结果就是纸上谈兵。
面向对象的软件分析设计过程备忘
一、业务分析与需求收集
1、重点梳理主业务流程,逐步完善分支流程。整理和发现业务流程中的涉众以及他们的业务目标和系统目标,显式目标以及隐式目标;
2、整理涉众们在系统中所承担的角色以及各自的职责;
3、在流程的运转过程中,发现和查找业务实体、他们之间的关系以及关键实体的生命周期(由谁在什么场景下创建、中间状态的变化以致最后的消亡);
4、在流程的运转过程中,有哪些业务规则以及各种隐式的规则;
5、不断的提问和验证流程的正确性和完整性(即使是边界以外的流程也不要放过,最少要做到心中有数)。是否有遗漏的涉众?是否有遗漏的职责或者行为?是否有遗漏的实体?是否有遗漏或者未被发现的实体关系?实体的生命周期是否完整?收集的需求或者信息能否支撑整个流程的运转,需求与需求是否有相互矛盾之处?是否有履行同样职责的人或者物(需要合并或者抽象)?多退少补!
6、划分业务边界与系统边界,哪些是需要由系统来完成的职责,哪些是由别的系统或者人工完成的职责。
7、可借助UML的组件图或者时序图、活动图、状态图来完成High Level层面的流程整理和业务建模。
二、概要设计(用例驱动功能需求,认真对待非功能性需求)
1、整理系统用例以及他们的参与者与系统边界。系统用例与服务最为密切,通常会演变为最后的服务接口。可借助UML用例图来完成用例建模。
用例的特征:
用例具有相对独立性;用例的执行结果对于参与者来说是可观测的和有意义的;用例必须由一个参与者发起的;用例必然是以动宾短语的形式出现的;用例是一个需求单元、分析单元、设计单元、开发单元、测试单元甚至是一个部署单元。
用例的粒度:
在概念建模阶段:粒度以能描述一个完整的事件流为宜;
在系统建模阶段:粒度以能描述操作者与计算机的一次完整交互为宜;
用例不是功能,用例是参与者对系统的期望以及目标,功能则是达成这个目标的步骤而已。
2、用活动图或者时序图描绘重点用例及其场景。
设计目标:为了完成该用例,需要由哪些角色介入协作完成,他们各自的职责是什么?只关注做什么,当前阶段不需要关注怎么做(不同阶段不同视图所关注的问题是不一样的。不分阶段不分视图的天马行空式的混沌思维,不是科学的分析方法,只会把问题复杂化)。
3、完成当前用例有哪些规则,以及需要建立哪些实体,之后需要明确实体与实体之间的关系(关联?聚合?一对一?一对多?)。
4、只需要针对核心和关键的用例建模,循环迭代。
5、划分高层职责、确立彼此之间的交互方式及其主要交互数据。
三、详细设计(在概要设计的基础上演进与精化,只需要针对核心和关键的用例建模)
1、根据之前的用例设计,定义服务接口并确定接口参数与返回值。
2、根据概要设计过程中的活动图和时序图,将完成相应职责的角色或者对象设计为相应职责的类或者接口,并将关键步骤定义为该类或接口的方法,并确定方法参数与返回值,可借助UML类图来完成接口、类的建模。
3、分析模型的变化点,对于清晰明确的变化点,建立抽象模型以适应变化并设计已知实现。对于相对模糊不清的变化点,建立抽象模型,隔离变化,将问题集中到一个局部的点,可在之后变化点明朗化之后重构(只影响某个局部的点)。概要设计阶段我们思考“做什么?”,当前阶段我们需要思考“怎么做?”,或者是技术选型,或者是架构模式,需要做出决策。
4、认真思考类或者接口中的每一个属性、方法以及方法参数。精炼、精炼、再精炼!
取一个好名字;
方法的设计应当具备原子性与职责单一性,方法参数列表也应当尽量精炼,越是简单的方法越容易被组合与重用。
只暴露需要暴露的服务与接口方法,不多暴露一个不需要暴露的服务与接口方法。没暴露的方法可以随意重构与扩展,方法一旦暴露出去,就需要一直维护并保持其兼容性。
5、不要考虑实体的储存形式,我们需要思考的是设计一个类,该类当中应该有哪些属性与方法,以及每个属性的适用场景与业务含义。
任何形式的数据都应该能转换为OO设计中的类对象。可存储可配置的场景也应该可以通过API来实现,JAVA是程序语言,任何形式的数据表现形式,最后还是通过相应的类及其方法调用来完成相应的职责。
6、只需要针对核心和关键的用例建模,循环迭代。
7、划分高层职责、确立彼此之间的交互方式,建立高层接口以及通讯方式,确定通讯协议以及报文格式。
注意:
A、实体建模时,需要认真思考实体的每一个属性,明确其使用场景与业务含义。同一个人在不同的场景下可能扮演不同的角色,角色的不同决定了其属性也不同。Jack在家是父亲的角色,他同时也是一个教师,因此“课程”是教师的属性而不是父亲的属性,即使他们都属于Jack这个维度。请参考DCI的设计理论。
B、实体建模时,即使需求方没有提出有关需求,但仍需要维护某些关系。实体与实体关系是在某个业务场景下客观存在的,如果因为需求方暂时没有提出相关需求,而放弃或者丢失客观存在的实体关系,一旦今后提出相关需求,可能会带来相当大的重构代价。
编写背景:
最近亲自在跟两个重要项目,感受很多,明天准备写其中一个项目的项目测试总结在组内分享,有一个还在背后默默关注。
在深圳工作1年了,每当组内的测试人员出现一些很常识的问题和面试过的测试人员回答的一些问题;非常明显的感觉到南北测试人员工作水平和对测试工作理解的差异,在深圳想找到有共鸣的人好难啊。
今天写这个文章,只是把工作中的一些片段和场景与大家分享,希望测试新人在做测试工作中多一些执着、多一些思考和多问为什么?
故事1:搜索列表页的一个神奇bug
问题现象:一个已经测试通过并上线的商品搜索列表页,页面功能很简单、有搜索的筛选项、商品展示、商品翻页功能。通常大家在测试翻页功能时,基本测试点都是测试上一页、下一页、具体页数、页数输入框(正常、异常);有意思的是这个搜索列表结果有500多个商品1百页,我就一直点击下一页、一页一页的浏览商品,当浏览到第24页时,发现浏览器访问报错提示连接不上;访问其它网站或该网站的其它功能就正常。
问题分析:此处的点击下一页的翻页程序代码,每翻一页,URL请求就会多加一串字符
“swIFRPIDUwMH0gcHJpY2VfQ05ZOjUwMDxKaW1pPnByaWNlX0NOWTp7MCBUTyA1MDB9IHByaWNlX0NOWTo1MDA8SmltaT5wcmljZV9DTlk6ez
AgVE8gNTAwfSBwcmljZV9DTlk6NTAwPEppbWk+cHJpY2VfQ05ZOn”;
这串字符出现6次以上后,url访问长度超过2k浏览器请求就会参数丢失,导致页面访问报错
5个思考点:
思考1:为什么测试的时候没有发现呢?其中一个测试人员说,这个场景很少有人想到。
思考2:测试人员如何能测试出这种问题呢?我在想,聪明的办法那就是对设计实现熟悉了解,了解开发是如何实现的,应该可以想出来这个地方会有问题。另一个办法就是增加这样的测试点,用自动化测试脚本来测试这种大数据量的功能极限测试。
思考3:对比其它网站,为什么别的网站没有这种问题呢?开发在设计上没有考虑这种情况?
思考4:为什么开发没有自测发现这个问题?我在想,开发没有考虑到URL会有问题
思考5:我们如何改进和提高呢?我在想,测试除了要补充测试用例;开发要整理出搜索结果列表页的一些设计规范,同时要参考和同行对比;开发要对系统的实现逻辑加强极限测试。
最后我想,还好这个场景不常见,影响范围没有很大的杀伤力。
故事2:两个bug还是1个bug
现象:一个问题是:商品买满打XX折,从购物车进入到订单提交页中,商品总结算金额显示不正确;另一个问题是:商品买满减XX元,从购物车进入到订单提交页中,商品总结算金额显示不正确。开发认为这是1个bug,因为都是商品总结算金额显示不正确;我认为是2个bug,因为是两个不同的测试用例场景得出的问题,不能因为现象一样就认为是一个bug,同时怀疑代码里面的处理逻辑是不一样的。
分析:为什么这种问题在我过去工作8年的公司和开发团队,没有开发管理人员认为这类bug是1个,而认为是2个;而这位开发管理人员认为是1个;我在想:原因是这位开发管理人员很害怕bug?还是这位开发管理人员很不喜欢看到很多的bug,因为今天我们测试两个页面,4小时报了35个bug让人心情很不爽?答案不知道,只要解决就好。
5个思考点?
思考1:站在用户角度,如果是用户发现的,我们告诉用户是1个问题?用户能明白吗?
思考2:站在开发设计角度,需要知道那个地方的实现逻辑都是一个类或方法吗?即使是一个类或方法,当参数不一样时内部处理逻辑一样吗?找个时间问具体写代码的开发人员问问就知道了?
思考3:下次碰到此类开发管理人员该如何相处?我在想:只要改了就行,不能和这类人去纠结1个还是2个,因为道不同不能理解;但是测试工作总结时要算成2个。
思考4:为什么不能报成1个bug,因为当把多个bug放到1个bug里报时,如何有效跟踪?(比如:开发修改转测后,测试验证有一部分没有修改好,这个bug会来回修复、打开);如何有效做bug分析?(测试任务结束后,如何分类分析bug的错误类型及开发工作改进建议数据分析)。
思考5:为什么这么明显的bug开发没有自测出来?开发做自测了吗?这样的开发管理人员管理的开发团队,转测出现这样低级的bug,消耗了多少不必要的测试成本(测试环境部署+bug报告跟踪和验证时间)和开发修复版本成本?降低了多少工作效率?这类bug有多少?
最后我想:我要通过什么方法来改变?
生活还在继续、工作也在继续,世界之大、无奇不有,每天都有不同的见闻和收获,活着真好!
探索性测试是指依据包含测试目标的测试章程同时进行测试设计、测试执行、测试记录和学习,并且是在规定时间内进行的测试。在测试对象规格说明较少或不完备,且时间压力大的情况下,使用探索性测试可以起到较好的效果。探索性测试可以作为对其他更为正式和系统化测试的补充,例如:基于需求规格说明的测试。同时,探索性测试可以用于测试过程的检查,以确保能发现最严重的缺陷。
探索性测试是一个不断交互的过程,根据当前测试执行的结果,调整后续的测试设计和测试执行活动。在探索性测试的开始,并没有像传统的测试方法那样对所有的测试活动和测试任务进行计划和设计,而是根据测试活动的不断开展,动态调整后面的测试活动和测试任务,测试设计和测试执行是同时进行的。测试设计和测试执行同时进行并不意味着这两个活动在实际的测试过程中在时间上完全重叠,而是与传统的顺序的测试活动方式相比较而言,这里的测试设计和测试执行并没有严格的顺序关系,各个活动之间互相影响,动态调整。
探索性测试并不是孤立的测试方法,它可以和其他各种测试方法同时进行。虽然这种方法和传统的测试技术不同,但是在实际的测试过程中,测试人员却是经常不自觉地使用这种测试方法。
☆示例:探索性测试
① 当测试人员发现了一个缺陷后,通常会对发现的缺陷进行一系列的调查,以确定重现这个缺陷的前提条件。同时,适当地对这些前提条件进行改变,来检查在发现该缺陷的区域附近是否存在其他的缺陷。这是一种典型的探索性测试,测试人员根据已经了解的知识来判断下一步的测试内容。
② 当某个缺陷被开发人员修复后,测试人员要进行相应的确认测试。但是有经验的测试人员除了进行确认测试以外,还会执行一些额外的测试来检查该缺陷的修复是否对程序的其他地方造成了影响。
这两个例子都是测试人员在测试过程中对探索性测试的应用。例子中的场景比较简单,涉及的测试管理工作很少,更多的是依赖于测试人员的个人技能。那么还有哪些情况适用于探索性测试的方法?下面列出了一些常见的场景,在这些场景中可以考虑采用探索性测试的方法:
1、对新产品和功能需要在短时间内提供反馈信息。
2、快速了解产品的质量。
3、已经采用了传统的测试方法,开始寻求测试的多样性。
4、在最短时间内发现最重要的缺陷。
5、对测试人员的工作进行检查。
6、调查并定义一个具体的缺陷。
7、调查一个具体的风险状态,来决定传统测试方法的测试深度和范围。
● 原因
● 触发器
○ 简介
○ 分类
○ INSERTED和DELETED
○ 优缺点
● 语法
○ 建立触发器
○ 删除触发器
○ 修改触发器
○ 开启和禁用
○ 提醒和保护
● 示例
原因
今天看教程再次提及触发器,以前看数据库视频、牛腩视频、天轰穿都讲到过触发器,而只知道触发器的几个简单应用,感觉学的甚差,所以借此机会仔细学学触发器。
触发器
触发器简介:
触发器(trigger)是个特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发,当对一个表进行操作( insert,delete, update)时就会激活它执行,触发器经常用于加强数据的完整性约束和业务规则等。在我看来触发器实际上就是一个事件,就像C#中,点击一个按钮会触发相应的操作。
触发器的分类:
(1)DML( 数据操纵语言 Data Manipulation Language)触发器:是指触发器在数据库中发生DML事件时将启用。DML事件即指在表或视图中修改数据的insert、update、delete语句。
(2)DDL(数据定义语言 Data Definition Language)触发器:是指当服务器或数据库中发生(DDL事件时将启用。DDL事件即指在表或索引中的create、alter、drop语句也。
(3)登陆触发器:是指当用户登录SQL SERVER实例建立会话时触发。
其中DML触发器最为常用,根据DML触发器触发的方式不同又分为以下两种情况:
(1)AFTER触发器:它是在执行INSERT、UPDATE、DELETE语句操作之后执行触发器操作。它主要是用于记录变更后的处理或检查,一旦发生错误,可以用Rollback Transaction语句来回滚本次扣件,不过不能对视图定义AFTER触发器。
(2)INSTEAD OF触发器:它在执行INSERT、UPDATE、DELETE语句操作之前执行触发器本身所定义的操作。而INSTEAD OF触发器是可以定义在视图上的。
INSERTED和DELETED
在SQL SERVER 2008中,DML触发器的实现使用两个逻辑表DELETED和INSERTED。这两个表是建立在数据库服务器的内存中,我们只有只读的权限。DELETED和INSERED表的结构和触发器所在的数据表的结构是一样的。当触发器执行完成后,它们也就会被自动删除:INSERED表用于存放你在操件insert、update、delete语句后,更新的记录。比如你插入一条数据,那么就会把这条记录插入到INSERTED表:DELETED表用于存放你在操作 insert、update、delete语句前,你创建触发器表中数据库。比如你原来的表中有三条数据,那么他也有三条数据。也就是说,我们可以使用这两个临时的驻留内存的表,测试某些数据修改的效果及设置触发器操作的条件。
触发器的优缺点:
触发器可通过数据库中的相关表实现级联更改,可以强制比用CHECK约束定义的约束更为复杂的约束。与 CHECK 约束不同,触发器可以引用其它表中的列,例如触发器可以使用另一个表中的 SELECT 比较插入或更新的数据,以及执行其它操作。触发器也可以根据数据修改前后的表状态,再行采取对策。一个表中的多个同类触发器(INSERT、UPDATE 或 DELETE)允许采取多个不同的对策以响应同一个修改语句。
与此同时,虽然触发器功能强大,轻松可靠地实现许多复杂的功能,为什么又要慎用?过多触发器会造成数据库及应用程序的维护困难,同时对触发器过分的依赖,势必影响数据库的结构,同时增加了维护的复杂程序。
语法
建立触发器
CREATE TRIGGER 触发器名称
ON 表名
{ FOR | AFTER | INSTEAD OF }
{ [ INSERT ] [ , ] [ DELETE ] [ , ]
[UPDATE ] }
AS
SQL 语句 [ ... n ] |
删除触发器:
| DROP TRIGGER 触发器名 [ , ... n ] |
修改触发器:
ALTER TRIGGER 触发器名称
ON 表名
{ FOR | AFTER | INSTEAD OF }
{ [ INSERT ] [ , ] [ DELETE ] [ , ]
[UPDATE ] }
AS
SQL 语句 [ ... n ] |
开启和禁用:
disable trigger trigDB on database --禁用触发器
enable trigger trigDB on database --开启触发器 |
提醒和保护:
print '删除了触发器***'
raiserror('数据一致性验证',16,1)
rollback transaction |
示例
在S表创建UPDATE触发器:
Create trigger tri_Updates
on s
for update
as
print 'the table s was updated' |
禁止删除SC表中成绩不及格学生的记录:
CREATE TRIGGER tri_del_grade
ON SC FOR DELETE
AS
IF EXISTS(SELECT * FROM DELETED
WHERE Grade < 60)
ROLLBACK |
禁止将SC表中不及格学生的成绩改为及格:
create trigger tri_update_grade
on sc for update
as
if update(grade)
if exists(select * from inserted,deleted
where inserted.sno=deleted.sno and inserted.grade>=60 and deleted.grade<60)
begin
print '不能将不及格的成绩改为及格'
rollback
end |
最近一周基本上都是加班到深夜,原因是最近有两个产品的发布,不凑巧的是这两个产品的开发是还在试用期的新人,更不凑巧的这两个产品是原来的产品经理遗留下来的需求。需求本身也存在些许需求描述不清晰的地方。所以加班看来就是在所难免的通往不确定未来的必经之路。
加班是苦逼和悲催的,但是莫名其妙的加班尤其是加班后的奇妙莫名就就是不可原谅的,作为没有理想破灭的PM,我就像那个专治各种牛皮癣的老中医一样,在各种不服和纠结后尝试再一次去寻求解决问题的方法。也许我不能看到曙光,但我一定不能允许自己在黑夜中沉睡。因为我TMD就不相信这个世界上有专治老中医的牛皮癣。
互联网企业和传统软件企业在流程上最大的不同估计就是互联网为了适应用户需求而必须做出快速反应。所以互联网企业的研发流程多是敏捷的。敏捷就目的是适应变更,敏捷的表象是快速发布,但是从来不会有Boss告诉我,敏捷就意味着损失质量。
项目管理的三要素是:时间、范围、成本,从来就没有把质量放在三要素中,如果有人告诉你项目的三要素包括质量,那就让他去查查PMbok吧。
因为对于项目来说,质量是前提,是很难妥协和变通的。但是显然、质量即使不和时间成线性上的反比,但肯定是反向相关的。一个女人12个月生出来的孩子不一定会更好,但是5个月就把孩子生出来,大概是好不到哪里去了。
然后,无论是PM或者Dev抑或是Qa对线上故障都战战兢兢、如履薄冰。原因在于老板只看结果,不看过程。出来问题,老板的板子迟早是会打下来的,谁的屁股都不是金刚不坏屁股。
快速发布,如何保证质量?
在我看来如下三个关键点上的质量保证尤为重要1:PRD的Review; 2:代码的Review; 3:Testcas的Review。当然这里的Review是指保证质量的方法和手段,而不是大家走马观花的看看。并且我也从来不认为其他环节尤其是过程的执行力就不重要,就如同一个男人,如果3分钟都坚持不了,那还谈何技巧呢?
在这里,我们先假定质量是指狭义上的软件质量。
1、PRD的质量。所有软件开发模式都认可这样两个原则,a:质量是规划出来的,而不是测试出来;b:越在项目早期进行质量保证活动,效果会越好,并且成本也会越低。基于这两个原则,我们就更加可以相信,PRD文档的重要性。PRD文档作为产品的Mother和DNA在一开始就决定了产品未来的摸样,并且PRD是指导开发进行设计开发以及测试人员进行测试设计的关键性文档甚至是唯一文档。因为PRD文档在整个产品开发生命周期中的作用牵一发而动全身。PRD文档的质量依赖于用户、需求调研的广度和深度以及需求分析的经验和技能这无容置疑。但我们在此显然并不是为了告诉大家如何做好需求分析。我们只从Review的角度来看看如何在最后环节来保证PRD的不出错,没错Review不能保证我们的产品是一款优秀的产品,但是能够保证这款产品是一个不容易出错的产品。PRD的Review需要关键人物的参与、尤其是当PRD涉及到多个产品项目或者多个模块时,因为只有关键人物才有对系统整体的把控能力,能够帮助产品人员预防各种潜在和难以发现的陷阱。这些关键人员一般包括:业务的代表、开发的代表、测试的代表、运营的代表,这里的代表不是随便找个人就代表的,应该是这些team的leader.
2、代码的Review。结对编程和测试驱动是敏捷流程在开发阶段保证代码质量的关键方法,然后大部分公司的资源都很难允许这样做。在所有老板的概念中如果公司不出现争抢资源以及资源不够的现象,那个就是应该裁员的时候了。然后开发团队总会有些新人的进入或者对新的项目不熟悉的团队成员。在这种情况下,让经验丰富的工程师去Review新手代码或者做交叉代码Review是一种成本较低但性价比还不错的选择。
3、Testcase的Review。Testcase最应该被保证的是所有用户操作而导致程序运行的轨迹和分支需要覆盖,功能测试是无法覆盖到代码分支的,这是因为功能测试和单元测试的测试对方不同,但是功能测试已经要覆盖到用户的所有操作,正常或者异常,以及这种操作下程序可能的处理结果,从而确认结果是符合预期的。在这里有两种选择,PM写Testcase还是专业的测试工程师,在我的职业生涯中,这两种情况都有发生,但我个人更倾向于由专业的测试工程师来写Testcase。的确,PM一定是所有人里面对需求最清楚的人,但PM的思维模式是用户正向参与产品,也就是说绝大部分的用户是基于满足自己需求的方式来使用产品的,PM首先要思考的是如何让用户的核心需求最容易和方便的得到满足或者实现。但软件的问题中80%的问题却恰恰发生在犄角旮旯的程序毛刺中,而如何从鸡蛋里面挑骨头却是测试工程师的思维模式。所以说,PM很难写出来高质量的Testcase。但是,Testcase Review的关键人物一定是PM和Dev。没有谁比他们更加清楚自己设计和实现的产品了。
对于互联网产品来说,重量级的质量保证流程显然无法适应快捷的发布需求,所以对软件中关键阶段的产出进行质量保证是解决问题的最有效方法。但是我并不敢肯定这种方法的普遍适用性,所以你自己看着办吧!
1、了解产品的商业目标:
每次接到的新项目,它都是针对一个新的业务领域,我们接触过产品管理,产品代购,物流管理等等软件。每个产品针对的业务领域不同,该产品的商业目标也是不同的。我们作为测试和开发人员首先要抓住该项目的商业目标,这样才能知道产品的重点在哪里,也就知道产品的主要风险在哪里,该如何针对其商业目标开发我们的测试用例。比如我接触过的Route Version项目,它是关于交通工具管理系统,收集所有交通工具每天的数据,在这个项目当中报表是最多的,也是该项目最主要的功能,那我们就需要在项目一开始把报表系统最为一个风险考虑进来,包括其采用的开发技术,以及如何测试还有很多的测试数据,都是需要提前考虑清楚的,而且既然是报表系统,那么它就会和很多其他模块有着许多的联系,这样集成测试就显得特别重要了。我们还开发的另外一个项目GTO,它是一个代购网站,将卖家和买家都召集到这个网站上进行交易,其中一个最重要的业务是招标系统,招标系统是个很专业的业务领域,如果提前没有把它的流程搞得很清楚,就会对后面的开发造成不小的影响。
2、测试驱动设计:
测试人员可以发挥过去在其他项目中积累的对客户需求的理解,以一个代表“用户”的角色与老板,与开发负责人一起商讨产品应该具备哪些功能,如何设计才能满足用户的需求。对于能力很强,经验丰富的测试人员还可以参与产品的架构评审,设计方案质量的把关。确保产品的设计满足最初的需求规划,产品的设计缺陷不会留给用户。我们把这个阶段的测试活动都定义为“测试驱动设计”。在我接触的项目当中,我参与了很多项目的设计阶段,发现很多产品设计不合理的地方,也就是易用性比较差,但平常总结的比较少,在这方面对专业软件关注的也比较少,所以自己也不能提出更多有建设性的意见,希望以后我能将所有工作中碰到的这些问题总结出来,不断提升自己在产品设计阶段的能力。
3、测试覆盖率的问题:
有效的测试覆盖率是最重要的测试工作目标,需要说明的是测试覆盖率不等于代码覆盖率。通过单元测试可以达到代码覆盖率100%,但是单元测试只能保障消除产品编码的问题,针对产品设计的问题则很难发现。发现产品设计问题的最主要方法还得需要基于黑盒的测试分析和设计。
如何做好测试分析和测试设计,需要从以下几个方面来大致达到一个比较高的有效测试覆盖率:
1、将软件所有的功能按照用户实际场景划分,开发测试用例;
优点:可以覆盖到主要的基本场景;
缺点:从事场景分析的人无法做到了解用户所有的场景,这样就会有场景遗漏;
2、通过软件内部实现流程的路径及依赖关系分析入手,开发测试用例;
优点:可填补前面没有覆盖到的一些场景,特别是异常处理和分支交互处理的场景;
缺点:仍然会遗漏真实环境中的一些偶然小概率事件;
3、依赖基于经验的测试分析和设计,例如:错误猜测法或探索性测试法;
优点:对测试设计再次作出补充;
缺点:测试用例的完整度取决于组织内部经验的积累量及测试人员思维的发散能力和创造性;
使用以上三个方面的测试分析和设计,基本上能覆盖到被测对象的绝大部分应用场景,充分保障产品质量,减少问题遗漏。
因此:测试的核心技术是测试分析和测试设计的能力,它决定了后续所有测试活动的质量及效果。同时,要做好一个测试任务,掌握广泛的测试类型也是必要的核心技术。
4、测试结束的时间:验证系统已100%满足项目需求规格,就可以作为测试结束的标准;大厦在满足的基础上如果还有时间和资源,就可以开展探索性测试,继续以挖掘bug为动机进行测试,探索性测试覆盖的内容可以是测试用例之外的场景,考虑一下还有哪些场景没有测试到。在测试计划时间结束前,都可以一直把探索性测试做下去,以发现bug为准,结束标准只有一个:测试时间结束了。
本文是《LoadRunner没有告诉你的》系列的第六篇,我将继续保持“无废话”的原则,用尽可能简洁、明确的语句来表述我对性能测试的看法和经验。在这篇文章中,我们要讨论的是如何获取“有效的”性能需求。
一个实际的例子
为了便于大家的理解,我们先来看一个性能需求的例子,让大家有一个感性的认识,本文后面的讨论也会再次提到这个例子。
这是一个证券行业系统中某个业务的“实际需求”——实际上是我根据通过网络搜集到的数据杜撰出来的,不过看起来像是真实的 ^_^
系统总容量达到日委托6000万笔,成交9000万笔
系统处理速度每秒7300笔,峰值处理能力达到每秒10000笔
实际股东帐号数3000万
这个例子中已经包括几个明确的需求:
最佳并发用户数需求:每秒7300笔
最大并发用户数需求:峰值处理能力达到每秒10000笔
基础数据容量:实际股东帐号数3000万
业务数据容量:日委托6000万笔,成交9000万笔——可以根据这个推算出每周、每月、每年系统容量的增长模型
什么是“有效的”性能需求?
要想获得有效的性能需求,就要先了解什么样的需求是“有效的”。有效的性能需求应该符合以下三个条件。
1. 明确的数字,而不是模糊的语句。
结合上面的例子来看,相信这个应该不难理解。但是有的时候有了数字未必就不模糊。例如常见的一种需求是“系统需要支持5000用户”,或者“最大在线用户数为8000”。这些有数字的需求仍然不够明确,因为还需要考虑区分系统中不同业务模块的负载,以及区分在线用户和并发用户的区别。关于这方面的内容,在下面两篇文章中的留言内容中有精彩的讨论:
2. 有凭有据,合理,有实际意义。
通常来说,性能需求要么由客户提出,要么由开发方提出。对于第一种情况,要保证需求是合理的,有现实意义的,不能由着客户使劲往高处说,要让客户明白性能是有成本的。对于第二种情况,性能需求不能简单的来源于项目组成员、PM或者测试工程师的估计或者猜测,要保证性能需求的提出是有根据的,所使用的数据和计算公式是有出处的——本文后面的部分会介绍获得可用的数据和计算公式的方法。
3. 相关人员达成一致。
这一点非常关键。如果相关人不能对性能需求达成一致,可能测了也白测——特别是在客户没有提出明确的性能需求而由开发方提出时。这里要注意“相关人员”的识别,通常项目型的项目的需要与客户方的项目经理或负责人进行确认,产品型的项目需要与直属领导或者市场部进行确认。如果实在不知道该找谁确认,那就把这个责任交给你的直属领导;如果你就是领导了,那这领导也白当了 ^_^
如何获得有效的性能需求
上面提到了“有效的”性能需求的一个例子和三个条件,下面来我们将看到有哪些途径可以帮助我们获得相关的数据——这些方法我在实际的工作中都用过,并且已经被证实是可行的。这几种方法由易到难排列如下:
1. 客户方提出
这是最理想的一种方式,通常电信、金融、保险、证券以及一些其他运营商级系统的客户——特别是国外的客户都会提出比较明确的性能需求。
2. 根据历史数据来分析
根据客户以往的业务情况来分析客户的业务量以及每年、每月、每周、每天的峰值业务量。如果客户有旧的系统,可以根据已有系统的访问日志,数据库记录,业务报表来分析。要特别注意的是,不同行业、不同应用、不同的业务是有各自的特点的。例如,购物网站在平时的负载主要集中在晚上,但是节假日时访问量和交易量会是平时的数倍;而地铁的售票系统面临的高峰除了周末,还有周一到周五的一早一晚上下班时间。
3. 参考历史项目的数据
如果该产品已有其他客户使用,并且规模类似的,可以参考其他客户的需求。例如在线购物网站,或者超市管理系统,各行业的进销存系统。
4. 参考其他同行类似项目的数据
如果本企业没有做过类似的项目,那么可以参考其他同行企业的公布出来的数据——通常在企业公布的新闻或者成功解决方案中会提到,包括系统容量,系统所能承受的负载以及系统响应能力等。
5. 参考其他类似行业应用的数据
如果无法找打其他同行的数据,也可以参考类似的应用的需求。例如做IPTV或者DVB计费系统的测试,可以参考电信计费系统的需求——虽然不能完全照搬数据,但是可以通过其他行业成熟的需求来了解需要测试的项目有哪些,应该考虑到的情况有哪些种。
6. 参考新闻或其他资料中的数据
最后的一招,特别是对于一些当前比较引人关注的行业,涉及到所谓的“政绩”的行业,通常可以通过各种新闻媒体找到一些可供参考的数据,但是需要耐心的寻找。例如我们在IPTV和DVB系统的测试中,可以根据新闻中公布的各省、各市,以及国外各大运营商的用户发展情况和用户使用习惯来估算系统容量和系统各个模块的并发量。