
试用例设计是测试过程中非常重要的一个活动,不管是文档化的设计输出,还是只是存在于他们脑海中的测试思想,其质量都会直接影响测试执行的质量。
尽管每个测试人员都掌握了不少的测试用例设计技术与方法,例如:等价类划分、状态转换测试等,但是如何将它们应用到具体的测试对象测试中去,很多测试人员都会感觉有些力不从心,甚至有无从下手的感觉。
下面是针对某个功能模块的一个简单的需求描述:该基本功能是为了创建某个条目,它的基本需求如下:
假如dataBit0 = 0, 并且cBPDU或者pBPDU的值不为1,那么创建请求会被拒绝。假如dataBit0 = 0, 并且cBPDU = 1或者pBPDU = 1,在满足下面条件下可以创建成功: (1)其他的bit不能为1; (2)TD的取值必须是Guranteed; (3)VLANpop的取值必须是disabled; |
假如你得到这样的一个需求描述,你准备如何来设计该功能模块的测试用例?通常来说,测试人员拿到需求规格说明之后,会根据其中定义的需求条目设计测试用例,类似于如下过程。

图1 通常的测试用例设计
针对上面的需求描述,根据图1直接设计测试用例,会不会觉得有些迷茫呢?即使测试人员设计了多个测试用例,覆盖了每条测试需求,是不是也会觉得评估测试覆盖率比较困难?
实际上,需求规格说明通常是针对开发人员而写的,并不一定直接适合测试的要求。因此,假如测试人员希望能够更好的进行测试用例设计,需要将需求规格说明转化成为测试人员可以方便使用的语言很重要,即在需求规格说明和设计测试用例之间增加一个桥梁:模型。在建立模型的过程中,测试人员不仅需要学习需求规格说明,同时也需要了解各种测试设计技术与方法,并能将两者数量的结合起来。图2是增加了“模型”概念的测试用例设计过程。

图2 改进的测试用例设计
还是以上面的需求描述为例,我通过学习该需求之后,发现它可能可以与决策表技术结合起来。因此,我将上述需求翻译为适合决策表技术的各种条件与输出,并根据它们的不同组合得到不同的结果。图3是我针对上述需求描述,基于决策表技术得到的初始决策表,然后可以基于此进行决策表优化,直至得到概要和详细的测试用例列表。

图3 初始决策表
根据图2的过程得到的图3的结果,是否觉得整个测试设计过程更加清楚,而且更加容易进行测试覆盖率等方面的评估?注意:这里只是根据需求描述得到的一些测试用例,并没有考虑其他方面的测试用例,例如非功能测试用例等。
需求规格说明对测试人员很重要,测试设计技术与方法也很重要,但更重要的是测试人员如何能够将两者有效的结合起来,并在此基础之上建立适合测试设计和评估的“模型”。而这通常是测试用例设计的难点所在,同时也是体现测试人员技术含量的地方。下面是测试人员在建立模型过程中可以参考的一些方向:
1、基于黑盒测试技术,例如:决策表模型、状态转换模型、正交矩阵模型等;
2、基于测试类型,例如:质量特性模型、缺陷分类模型等;
3、基于全局因素的全局因素模型;
4、基于功能交互的功能交互模型;
测试设计过程中建立有效的“模型”,测试人员设计测试用例相对会比较容易,并且可以很好的提高测试覆盖率,从而帮助提升产品质量。另一方面,通过建立模型,也可以帮助测试人员有效的评审测试对象功能的描述,例如可以发现需求中定义不清楚、遗漏等方面的问题。
摘要: Action() { int rc; int db_connection; // 数据库连接 int query_result; // 查询结果集 MYSQL_RES char** result_row; // 查询的数据衕 &nbs...
阅读全文
摘要: 方法一:要想使用LoadRunner监测MySQL数据库的性能,LoadRunner没有提供直接监测 MySQL的功能,所以,我们需要借助sitescope监控,然后在LoadRunner显示sitescope监测结果,这样间接地监控MySQL性能。 相信大家对LoadRunner应该十分熟悉了,所以在这里,我大概介绍下sitescope的安装和使用。 s...
阅读全文
用例设计的着眼点
1、测试的依据是需求规格说明书,首先应根据需求规格说明书对软件进行需求分解,然后针对每个测试需求去编写相应的测试用例;
2、测试用例的编写时,应按照需求规格说明书的内容,设计合理的测试用例,同时更重要的是考虑不合理的输入情况;
3、除了设计各子测试需求的测试用例外,还应考虑业务流程测试用例,业务流程测试用例主要由各种以验证业务流程正确性为主的测试用例组成。
测试用例的必备要素
1、项目名称和模块名称
当前用例所属的项目及被测的功能模块。
2、测试用例编号:是由字符和数字组合成的字符串,用例编号应具有唯一性、易用性。作为测试用例的唯一标识,命名方式采用“测试类别简称-项目名称-模块名称-序号”。
举例:F-RSXT-ZJJL-001
F是功能测试用例的缩写(S-安全测试 P-性能测试)
RSXT是项目“人事系统”的简称
ZJJL是模块“增加简历”的简称
001是具体的用例编号
3、用例名称
测试用例的具体名称
4、预置条件
执行当前测试用例需要的前提条件,描述要执行该用例,被测目标须达到的状态,例如,用具备正确权限的人员登录系统。
5、编制者和编制日期
当前用例的编制人员以及编制用例的日期(格式为“年-月-日”)。
6、测试步骤:执行当前测试用例需要经过的操作步骤,需要明确的给出每一个步骤的描述,测试用例执行人员可以根据该操作步骤完成测试用例执行
7、预期结果:当前测试用例的预期输出结果,包括返回值的内容、界面的响应结果、输出结果的规则符合度等等。 在我们的测试培训中,有具体的功能测试实践课程,课程中会选择一个实际的项目,让学员亲身去体验整个测试的流程,包括测试计划
1、测试计划阶段:
理解测试需求,编写测试计划,并根据需求规格说明书,完成系统的需求分解;
2、测试设计阶段:
为第一步中分解得出的具体的测试需求,设计相应的测试用例;
3、测试执行阶段:
按照自己设计的测试用例,执行测试,并记录用例执行结果,提交测试过程中发现的缺陷;
4、测试总结阶段:
对测试过程中发现的缺陷进行整理分析,完成测试报告。
在这个过程中,每个环节工作产品的评审是由老师和学员共同完成的,其中问题最多的环节就是测试设计阶段,部分学员在上课时都会跟我说,“老师,设计测试用例好烦,为什么要设计测试用例,真正做测试项目时也要向这样设计测试用例吗?”我总是笑笑,很肯定的对他们说:“要的”。
软件测试也是一个工程,也需要按照工程的角度去认识它,即在具体的测试实施之前,需要我们需要明白我们测什么,怎么测试等等,也就是说通过制定测试用例指导测试的实施。
其实设计测试用例并不是想象中的那么复杂,只要条理清晰,有耐心,并掌握基本的功能测试用例设计方法,设计出好的测试用例并不是件复杂的事情。
培训中,我也发现其实有两类学员,一类是总抱怨要设计的用例太多,什么时候才能设计完成,就一直停留在阅读需求说明书的阶段,而不愿意动手去做;而另一类呢,则是不管结果怎样,我先开始着手做起来。很显然,后一种是收益较多的一类,因为只有自己去动手做了,才会发现事情的难易程度到底怎样,才会了解事情的本质,以及自己在哪方面有所欠缺,而且,也只有当你有了中间结果时,老师才会去帮你检查,指导你测试用例设计时存在的一些不足或欠考虑的地方。
什么事情不要只是去想,想着它有多么的困难和复杂,一切事情都有解决的办法,不管事情有多复杂,它也是一点一点完成的,夸张点说,我们应本着愚公移山的精神,等到过程中,说不定也就会有神仙来帮忙呢。
下面简单介绍下设计测试用例时的几个注意点:
测试用例基本准则
1、测试用例应具有代表性:能够代表并覆盖各种合理的和不合理的、合法的和非法的、边界的和越界的以及极限的输入数据、操作、环境设置等;
2、测试结果应具有可判定性:即测试执行结果的正确性是可以判定的,每一个测试用例都应有相应得期望结果;
3、测试结果应是可再现的:即对同样的测试用例,系统的执行结果应当是相同的。
2)可靠性测试。根据软件需求和设计提出的要求,对软件容错性、易恢复性、错误处理能力进行测试。
3)易用性测试。根据软件设计中提出的要求,对软件的易理解性、易学性和易操作性进行检查和测试。
4)性能测试。根据软件需求和设计中提出的要求,进行软件的时间特性、资源特性测试。
5)维护性测试。根据软件需求和设计中提出的要求,对软件的易修改性进行测试。
6)可移植性测试。根据软件需求和设计中提出的要求,对软件在不同操作系统环境下被使用的正确性进行测试。
11、软件测试分为哪几个阶段?每个阶段都是干什么的?
测试阶段 | 主要依据 | 测试人员及方式 | 测试内容 |
单元测试 | 系统设计文档 | 开发人员。白盒测试 | 又叫模块测试。 主要测试软件模块的源代码,接口、路径 |
集成测试 | 概要设计、需求文档 | 开发人员。白盒测试 | 又叫组装测试、联合测试、灰盒测试。 将一些“构件”集成一起时,测试它们能否正常运行,接口、路径、功能、性能 |
系统测试 | 需求说明书 | 一般由独立的测试人员执行。黑盒测试 | 测试软件系统是否符合所有需求,包括功能性需求和非功能性需求,功能、健壮性、性能、用户界面。 |
确认测试 | 规格说明书 | 第三方。黑盒测试 | 又叫有效性测试。 验证软件的功能和性能及其他特性是否与用户的要求一致。 |
验收测试 (UAT) | 需求文档 | 由客户或最终用户执行。黑盒测试 | 确定产品是否能够满足合同或用户所规定需求的测试。 |
12、测试中的木桶原理是什么?在软件产品生产方面就是全面质量管理(TQM)的概念。产品质量的关键因素是分析、设计和实现,测试应该是融于其中的补充检查手段,其他管理、支持、甚至文化因素也会影响最终产品的质量。应该说,测试是提高产品质量的必要条件,也是提高产品质量最直接、最快捷的手段,但决不是一种根本手段。反过来说,如果将提高产品质量的砝码全部押在测试上,那将是一个恐怖而漫长的灾难。
13、软件测试策略和方法有哪些?静态测试方法:人工测试方法(代码会审,代码走查,桌面检查等);动态测试方法:白盒测试方法、黑盒测试方法、穷举测试方法。
静态测试:基本特征是对软件进行分析,检查和测试是不实际运行被测试的软件。
动态测试:通过运行软来检验软件的动态举行为和运行结果的正确性,其两个基本要素是被测试程序、测试数据。
14、测试何时结束?当功能性测试用例通过率达到100%,非功能性测试用例通过率达到90%时,允许正常结束测试。
15、测试用例需要有些什么?测试环境、测试数据、测试步骤、预期结果。
16、用例设计原则是什么?覆盖软件需求规格说明书所有的测试点;指出实际输出值和预期结果;考虑各种输入输出条件和边界值;设计应考虑其可执行性。
17、当在HTML中写JavaScript脚本的时候可能会造成页面性能慢或是有错误,这个怎么解决呢?
通常,JavaScript脚本写在HTML页面中body部分的前面,这可能要在网页上设置一些可运行脚本之类的配置,或尽可能避免。
18、在测试工作中,你是怎么和开发人员沟通呢?怎么能达到一致目的呢?
当发现问题的时候,描述到bug管理器bug free、Test Track Pro等上面,并提供一些截图上载作为证据,或当面和开发人员沟通,尽量把问题描述清楚,这些都不存在问题,但关键就是有很多开发人员并不承认这是他程序的错误或认为not a bug,不予修改,当遇到这种情况我会尽可能跟他沟通,尽可能去重现问题,根据需求讲道理,此时根据需求是很重要的,当我们实在沟通不下去的时候,在这种不明确bug性质情况下会发邮件让项目经理大家一起评审,是他的问题就改,not a bug就打回。
19、假如项目已完成差不多,但客户的需求不明确,在我们内部也没有定义,这种情况怎么办呢?
我会把自己当客户,设身处地的为客户提出问题或建议,比如最常见的是易用性操作,软件规范等。
20、你是怎么理解测试的?测试的目的是发现程序中有错,是为了证明程序有错,而不是证明程序无错,尽可能发现并改正被测试软件中的错误,提高软件的可靠性。测试能发现错误的测试是成功的测试,否则是失败的测试。
21、你对自己做测试是怎么个想法?我想一直做下去会有收获的吧,会去不断完善自己的技能,把自己没学会的技能都去学习下,会不断完善自己。 1、软件的生命周期是什么?指从软件产生到报废整个周期包括:可行性分析、项目计划、需求分析、概设、详设、编码、调试、维护。
2、软件开发模型有哪些?瀑布模型、渐增模型、演化模型、迭代模型、原型模型、螺旋模型、喷泉模型、智能模型、混合模型。
3、一套完整的测试包括哪些?测试计划、测试设计、测试开发、测试执行、测试评估。
4、软件测试生命周期是什么?从测试项目计划建立到bug提交的整个测试过程,包括:软件项目测试计划、测试需求分析、测试用例设计、测试用例执行、bug提交五个阶段。
5、一个典型B/S架构由哪三个组件构成?数据访问层、业务逻辑层、实体层。
6、OSI网络七层协议及每一层的功能是什么?OSI网络七层协议从下向上的顺序为:物理层、数据链路层、网络层、传输层、会话层、表示层、和应用层。
物理层:本层规范了各网络媒体的定义、网络的连接方式等内容。
数据链路层:本层定义了帧(frame)的格式及通过网络的方式。帧中有MAC地址(网卡的号),帧要传送的来源与目的地是依据MAC进行传送的。该层有个重要的ARP(Address Resolution Protocol)协议,用它来对应MAC和IP地址。
网络层:IP 是网络层的重要内容。本层的功能是让数据包(Packet)可以在不同的网络间进行传递;这层包括IP协议、ICMP协议、ARP协议、RARP协议。
传输层:将计算机数据打包为数据包(packet),然后提供给网络层进行包头的建立;这层包括TCP协议、UDP协议。
会话层:本层中定义的两个地址间的信道的连接与挂断,即计算机与计算机之间的沟通方式。两个计算机在通信前先要进行会话,确认是否可以进行传输。如三次握手协议。
表示层:将用户本地的数据格式转换为网络的标准格式,然后交给传输层的协议处理。同时把远程的数据转换成本地应用程序的格式,然后将给应用程序处理。即本层定义了数据的语法及格式,当数据不符合要求时进行格式的转换。
应用层:本层完全与应用程序有关。这层包括FTP、Telnet、SMTP、HTTP、RIP、NFS、DNS。
7、什么是网络协议?它的三要素是什么?常见的网络协议有哪些?
网络协议是网络上所有设备(网络服务器、计算机及交换机、路由器、防火墙等)之间通信规则的集合,它规定了通信时信息必须采用的格式和这些格式的意义。
网络协议的三要素是:语法(用来规定信息格式);语义(用来说明通信双方应当怎么做);时序(详细说明事件的先后顺序)。
当今局域网中最常见的三个协议是:Microsoft的NetBeui、Novell的IPX/SPX、交叉平台的TCP/IP协议。NetBeui即NetBios Enhanced User Interface,是为IBM开发的非路由协议,用于携带Netbios通信.。IPX是Novell用于Netware客户端/服务器的协议群组,避免了NetBeui的弱点,它具有完全的路由能力,可用于大型企业网。TCP/IP即Transmission Control Protocol/Internet Protocol,中文译名为传输控制协议/互联网络协议协议,TCP/IP(传输控制协议/网间协议)是一种网络通信协议,它规范了网络上的所有通信设备,尤其是一个主机与另一个主机之间的数据往来格式以及传送方式。具有可扩展性和可靠性需求。
8、关系数据库的三个基本要素是什么?相关数据、一定组织方式、共享。
9、目前linux操作系统提供一个常用文本编辑器是什么?有几种模式?vi编辑器。有(文本输入)(命令)两种模式。
10、测试计划的目的是什么?测试计划工作的内容都包括什么?其中哪些是最重要的?
测试的目的是发现程序中有错,是为了证明程序有错,而不是证明程序无错,尽可能发现并改正被测试软件中的错误,提高软件的可靠性。测试能发现错误的测试是成功的测试,否则是失败的测试。
软件集成测试具体内容包括:
1)功能性测试
(1)程序的功能测试。检查各个子功能组合起来能否满足设计所要求的功能。
(2)一个程序单元或模块的功能是否会对另一个程序单元或模块的功能产生不利影响。
(3)根据计算精度的要求,单个程序模块的误差积累起来,是否仍能够达到要求的技术指标。
(4)程序单元或模块之间的接口测试。把各个程序单元或模块连接起来时,数据在通过其接口时是否会出现不一致情况,是否会出现数据丢失。
(5)全局数据结构的测试。检查各个程序单元或模块所用到的全局变量是否一致、合理。
(6)对程序中可能有的特殊安全性要求进行测试。
浅谈软件的质量意识
“质量问题是关键,但是现在又有多少企业是重视质量的,反倒是年年都生产出一大堆的垃圾。一个企业质量意识形态是由上而下的,领导注重质量才能把质量提上去,单单是靠下层员工有质量意识而领导要求的却是数量,要求的是短期效益,这样的质量是根本提升不了,中国建筑寿命缩短到30到40年就是一个事例”
那我想说的是:这样的环境,我们无法改变。但是我们可以选择,如果你愿意暂时牺牲一些所谓的管理职务,进入真正的重视质量的企业。你就可以在正确的路上走完人生未来的职场之路。但世上无完美的事,即使一个重视质量的企业,在内部也会有部分中基层人员局部的不够重视质量,只要数量和进度。大多数情况下公司高层(最高的那几个)是重视质量的,因为他们更在乎长期利益,更在乎卖出去的产品或服务的品质代表他在客户面前的面子和人品。所以,如果高层不是投机取巧型,上市捞一把就跑的投机分子,足可以在环境中坚持。这个坚持不是1-2个月会改变的,有可能会是1-2年才会改变的,毕竟产品的bug很可能要在放量上市时,才会大量暴露,这时公司的高层中层都不得不开始重
视质量,来亡羊补牢,否则所有先前的投资就有可能付之东流。在此我分享2个我几年前的经历吧。
N年前我参与一个项目时,在看了该项目的需求,了解了项目成员和项目技术积累现状后,看到项目的计划时间表时,我心里就敢肯定决不可能按时交付项目的。当然,我内心也希望能发生奇迹该项目能幸运的按时交付。在后续的产品设计阶段,我看到了产品架构文档和部分设计文档后发现架构师设计时思考的过于简单,很多场景未考虑,或考虑时选取的算法过于简单,当时就给架构师提出了几十个可能的设计问题,在架构师确认了二十多个后,邮件正式发给了PM。可惜,PM和架构师都没有采取行动去改进(因为项目的基本功能实现的时间和人力太紧张了),我心里只能是暗暗的祝福他们好运,但这时我可以肯定这个项目不可能按时完成了。 结果在1年后,碰到该产品的测试人员,他告诉我那个项目几乎延期了60%的工期,而且产品测试时发现了大量设计的问题,为了修改和验证这些设计问题,开发和测试都加了很多班阿。此时,我既喜既忧。喜的是我的判断,我的质量预言兑现了。忧的是这个项目的所有参与人,公司都付出了太多的代价了,如果当初架构师和PM能把我发现的设计缺陷及早修正,或许也能减少后期所付出的代价。
M年前,我到一个新公司后发现很多测试人员和测试经理为了与开发人员有一个良好的人际关系,对bug要求不严。甚至有的组出现不做压力测试的情况,理由是压力测试出来的bug开发改不了,测了也没有意义。同时项目中PM和开发经理权力过大,只要进度,进度和质量冲突时,一定是牺牲质量,测试经理早已习惯,也不坚持质量了。整个氛围普遍是等出了问题后再亡羊补牢,提前做的预防性工作都不受支持,认为是浪费。 很多开发领导认为,只要我有测试部这个组织,找来了几十个测试人员,我的质量就OK了,可是在一个测试人员都对开发人员过于偏软的氛围中,测试人员在很多关口也随大流了。虽然我当时很看不惯,但无奈我个人的力量是有限的,我只有尽可能地在我的领域做好工作。并
在心中期盼我的预测不要兑现。可是M+1年后公司很多产品在市场上忽然出现了很多问题,PM日子过得难受,开发和测试经理日子过的也难受。我的预言又一次兑现了。从此以后这个公司的开发人员和PM们痛定思痛,终于把质量放在了第一位,进度可以延迟但质量不会让步了。同时测试人员也被要求必须严格地做黑脸。M+2年后,该公司的产品因为价格便宜质量又高,销量猛涨了几倍。
我想我的答案已在分享的2个案例中了。真的是应了《无间道》中的那句话“出来混迟早要还的!” 我现在往往只需要几天时间就能提前预判该项目最后的进度和质量结局,虽然我心里依然希望该项目能走大运,能创造奇迹,希望我的预言是错误的。
基于以上面临的问题,一种“开后门”的方法引起了我们的注意,“后门”是指RD在程序中专门为了某些目的开设的访问通道,通过这些隐秘不为人知的数据访问通道,可以实现特殊的产品功能。对于自动化来说,我们可以通过这种方式将程序的一些界面信息暴露,当然也不局限于UI的信息,我们也可以将任意测试程序需要的信息通过后门的方式暴露给我们自己的测试程序即可以实现自动化相关的需求。
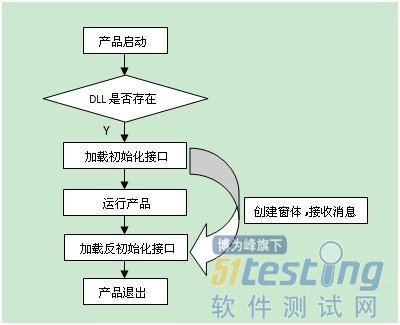
这个想法在后期的实践中逐步优化,最终形成了一套基于Proxy架构的自动化解决方案。当被测程序启动时,加载Proxy,并将皮肤引擎的指针(全局变量)传入Proxy中,自动化脚本通过与Proxy通信,实时获取UI的各种信息该框架包含两大部分:
1、一部分是以Pywinauto(Pywinauto是一些用于自动化测试Windows标准图形界面的模块的集合。它可以允许你很容易的发送鼠标、键盘动作给Windows的对话框和控件)为操作基础,pyunittest为case组织框架的python脚本部分,这部分包含了关键字的封装,case的实现。
2、另一部分是植入到被测程序内部的Proxy,当被测程序启动时,加载Proxy,并将皮肤引擎的指针(单例)传入Proxy中,自动化脚本通过与Proxy通信,实时获取UI的各种信息,从而达到自动化的操作以及验证的目的。
整个自动化框架图如下:
执行
稳定性测试不同于功能测试的自动化,它属于一种概率性的测试,需要长期运行过后才能得出最后的测试结论,即使稳定性测试通过,也不能保证系统实际运行的时候不出问题。所以要尽可能的提高测试的可靠性,我们可以通过多次测试,延长测试时间,增大测试压力来提高测试的可靠性。
当稳定性场景存在多组时,为了保证运行的及时性与可靠性,同时也为了满足测试环境的丰富性,稳定性测试的执行需要多台机器才行。如果条件允许,可以使用不同环境及配置的物理机进行测试,也可以使用虚拟机,构建丰富的环境中心来满足稳定性测试的需求。
当存在多个运行环境和多组case时,为了保证测试场景组合的多样性,各组case要阶段性的循环在每个运行环境中执行,因此需要一个清晰明确的执行计划和记录:
 客户端稳定性测试
客户端稳定性测试
稳定性测试是在保证功能完整正确的前提下,必不可少的一项测试内容,通过对软件稳定性的测试可以观察在一个运行周期内、一定的压力条件下,软件的出错机率、性能劣化趋势等。进而大大减少软件上线后的崩溃卡死等现象,为软件的逐步优化提供方向及验证。
无论是服务器端还是客户端,对稳定性的测试无非是就是测试系统的长期稳定运行能力。在系统运行过程中,对系统施压,观察系统的各种性能指标,以及服务器的指标。不同于服务器端的稳定性测试的是,客户端软件是运行在单机环境下,所以不存在并发用户数的概念,取而代之的是一些多进程长时间的操作,以及各种复杂的并发场景的组合。一款客户端软件,它的稳定性测试需求基本包括:
1、长时间运行及各种操作下,软件的稳定性以及各种性能指标的劣化趋势。
2、多进程或多线程运行时的稳定性。
3、不同操作系统,在不同宿主软件下运行的稳定性。
稳定性测试实施
整个稳定性测试的包括三大部分:
1、场景的设计及实现
2、稳定性测试的执行
3、最后结果的校验
场景设计
测试场景一般是指模拟平常的压力,以及模拟实际中用户的日常操作,如果包含数据库,那么数据库要存有一定的数据。一般来说客户端产品的稳定性测试包括:
自动化脚本
自动化测试是稳定性测试的基础,对于使用标准控件的客户端软件来说,可以使用市面上较为通用的自动化及性能测试软件QTP或LoadRunner,这些软件对标准控件支持较好,可以很方便快速的搭建起自动化测试的框架,为稳定性测试提供基础。
但由于目前客户端软件的界面开发为了更加快速,同时融入业界前沿的皮肤技术,为用户创建更加高效,专业的界面,大多数都采用了DirectUI的技术,这种方式是直接在父窗口上绘图。即子窗口不以窗口句柄的形式创建,只是逻辑上的窗口,绘制在父窗口之上。对于这种非标准控件如果使用QTP等自动化测试工具就会显得力不从心了。
结果
从稳定性的测试目的中可以得出在对稳定性结果的判断需要从以下几个方面进行:
1、判断是否崩溃
a)对于能够被崩溃上报进程捕获的的崩溃比较好办,可以通过判断是否有崩溃上报进程来进行判断。
b)在测试机上安装任意的debugger工具(例如windbg)就可以检测各种类型的崩溃情况(只要有崩溃就会触发debugger的调用,检测是否出现debugger进程就ok)
c)对于那种运行在宿主程序中的插件,单独插件的崩溃有时不会导致宿主程序的整个崩溃,所以对插件崩溃的检测需要记录运行正常时的pid或tid,发现其消失就判断为崩溃,因为插件运行在宿主程序中不是一个进程就是一个线程。
2、判断是否假死
a)对于单进程程序,只要主窗口发消息即可,找对主窗口是关键,通过枚举某个进程的全部窗口句柄,找parent为null,visible 为true,不是托盘程序的那个窗口句柄。
b)强制主窗口重绘(这个重绘方式各产品可能不一样,有的发消息就可以,有的需要移动位置),然后截图,白色的就是假死(判断白色的已有现成的代码)
3、判断是否存在性能劣化的趋势
a)这点也属于性能测试中资源占用情况的测试,可以再稳定性测试的同时使用性能检测工具进行检测。
待改进点
1、自动化判断,定位异常信息。目前一些偶现的卡死和崩溃无法捕获到堆栈信息,对定位意义的不大,需要在崩溃或卡死时保留住现场,不能连续的执行后续的case。
2、操作步骤及数据选取的随机性。可以考虑引入Fuzzy以及解析用户日志的方式增加操作步骤及测试数据选取的随机性。
3、测试case在各个执行环境中循环切换的自动化。目前这种循环还是靠手工保证,后续可以考虑从在每台测试机器上动态调用测试脚本,代替手工的切换及运行。
4、测试脚本的稳定性:稳定性的测试不仅是对被测程序稳定性的验证,同时也考验我们自动化测试脚本运行的是否稳定,而且在长时间的运行过程中可能会出现各种阻碍脚本运行的但却是正常的情况,所以需要增加各种判断和轮询的机制,另外为了保证场景的多样性都需要我们的脚本更加通用和周密,一不小心,被测程序还没挂呢,我们自己先停了……对于脚本的稳定性一直在测试的过程中不断完善,积累经验。
性能测试的主要手段是通过产生模拟真实业务的压力对被测系统进行加压,研究被测系统在不同压力情况下的表现,找出其潜在的瓶颈。
目前,典型的企业IT系统的架构为:系统是由客户端,网络,防火墙,负载均衡器,Web服务器,应用服务器(中间件),数据服务器等等环节组成。根据木桶原理,即木桶所能装的水取决于最短的那块木板,整个系统的性能要得到提高,每个环节的性能都需要优化。因此,我们需要找到最短的那块木板(系统瓶颈)来,先对其进行优化。
一个良好的性能测试工具必需能做到以下几点:
1、提供产生压力的手段;
2、能够对后台系统进行监控;
3、对压力数据能够进行分析,快速的找出被测系统的瓶颈。
产生压力的手段,主要是通过编写压力脚本,这些脚本以多个进程或线程的形式在客户端进行运行,来模拟多用户对被测系统的并发访问,以此来达到产生压力的目的。压力脚本执行的功能和被测系统客户端软件执行的功能应该一样,从而产生真正的业务压力。编写压力脚本的工作实际上就是重新编写客户端软件。最有效的方式是通过性能测试工具录制客户端软件和服务器之间的通讯包,自动产生脚本,然后在自动生成的脚本的基础上进行少量修改,如:关联动态内容,指定批量测试数据等,通常,压力脚本的准备往往占据整个性能测试项目的50%的时间和工作量。
对后台数据的监控。监控应该不在被测系统上安装任何软件,即达到“无代理”监控。原因有两个:假若安装了“代理”软件,它会对被测系统的分析结果产生影响,造成测试结果的不准确性。二,还会对用户系统的稳定性造成潜在的影响,引起客户的反感。“无代理”方式,即不在被测系统上安装任何软件,仅仅通过改变被测系统的配置,就可以对被测系统进行监控。
压力测试完毕后,我们会得到详尽的性能数据,包括最终用户的响应时间,后台系统各个部件的运行数据。由于数据非常庞大,数据分析工具是必要的。它帮助性能测试人员去阅读,解读好分析数据,辅助测试人员定位系统的瓶颈。
性能测试工具的组成部分有4个:虚拟用户脚本产生器Vugen(Virtual User Generator),压力调度和监控系统Conductor,压力产生器Player,压力结果分析工具Analysis。
进行性能测试项目的一般步骤:
1、用户确定需要录制的交易,通过用户操作和Vugen的录制,记录并生成自动化脚本。
2、修改脚本,确保脚本可以回放成功。
3、Conductor是一个集中控制平台,它和压力产生器player互连,制定脚本在player上分配,并控制player向被测系统的加压方式和行为。
4、Conductor同时负责搜集被测系统的各个环节的性能数据。各个player会记录最终用户响应时间和脚本执行的日记。
5、压力执行结束后,player将数据传送到Conductor中,Conductor负责数据的汇总。
6、数据分析工具Analysis读取压力测试数据,进行分析工作,确定瓶颈和调优秀方法。
7、针对性地进行系统调优,重复压力测试数据,进行分析工作,确定性能是否得到提高。
好了,这就是今天的收获了~~~
那么原型有什么用呢?
先了解下new运算符,如下:
var a1 = new A;
var a2 = new A; |
这是通过构造函数来创建对象的方式,那么创建对象为什么要这样创建而不是直接var a1 = {};呢?这就涉及new的具体步骤了,这里的new操作可以分成三步(以a1的创建为例):
1、新建一个对象并赋值给变量a1:var a1 = {};
2、把这个对象的[[Prototype]]属性指向函数A的原型对象:a1.[[Prototype]] = A.prototype
3、调用函数A,同时把this指向1中创建的对象a1,对对象进行初始化:A.apply(a1,arguments)
其结构图示如下:
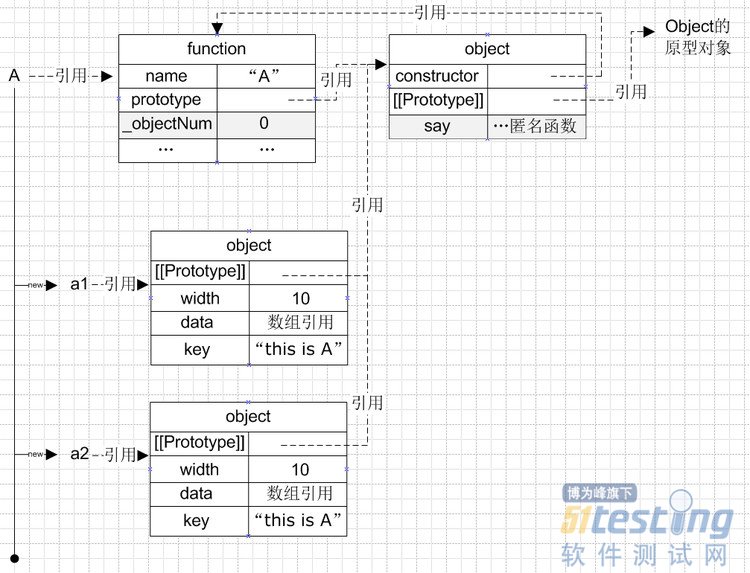
从图中看到,无论是对象a1还是a2,都有一个属性保存了对函数A的原型对象的引用,对于这些对象来说,一些公用的方法可以在函数的原型中找到,节省了内存空间。
四、原型链
了解了new运算符以及原型的作用之后,一起来看看什么是[[Prototype]]?以及对象如何沿着这个引用来进行属性的查找?
在js的世界里,每个对象默认都有一个[[Prototype]]属性,其保存着的地址就构成了对象的原型链,它是由js编译器在对象 被创建 的时候自动添加的,其取值由new运算符的右侧参数决定:当我们var object1 = {};的时候,object1的[[Prototype]]就指向Object构造函数的原型对象,因为var object1 = {};实质上等于var object = new Object();(原因可参照上述对new A的分析过程)。
对象在查找某个属性的时候,会首先遍历自身的属性,如果没有则会继续查找[[Prototype]]引用的对象,如果再没有则继续查找[[Prototype]].[[Prototype]]引用的对象,依次类推,直到[[Prototype]].….[[Prototype]]为undefined(Object的[[Prototype]]就是undefined)
如上图所示:
| //我们想要获取a1.fGetName alert(a1.fGetName);//输出undefined
//1、遍历a1对象本身
//结果a1对象本身没有fGetName属性
//2、找到a1的[[Prototype]],也就是其对应的对象A.prototype,同时进行遍历
//结果A.prototype也没有这个属性
//3、找到A.prototype对象的[[Prototype]],指向其对应的对象Object.prototype
//结果Object.prototype也没有fGetNam
|
简单说就是通过对象的[[Prototype]]保存对另一个对象的引用,通过这个引用往上进行属性的查找,这就是原型链。前几天看了《再谈js面向对象编程》,当时就请教哈大神,发现文章有的地方可能会造成误导(或者说和ECMA有出入),后来自己翻一翻ECMA,总算找到“标准”的理解……
本文适合初学者,特别是对构造函数、原型和原型链概念比较模糊的,大牛请路过,好了,让我们一步步来看看 js 的原型(链)到底有多神秘……
一、函数创建过程
在了解原型链之前我们先来看看一个函数在创建过程中做了哪些事情,举一个空函数的例子:
当我们在代码里面声明这么一个空函数,js解析的本质是(肤浅理解有待深入):
1、创建一个对象(有constructor属性及[[Prototype]]属性),根据ECMA,其中[[Prototype]]属性不可见、不可枚举
2、创建一个函数(有name、prototype属性),再通过prototype属性 引用 刚才创建的对象
3、创建变量A,同时把函数的 引用 赋值给变量A
如下图所示:
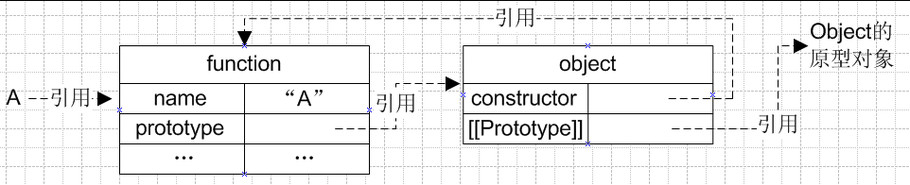
(注意图中都是“ 引用 ”类型)
每个函数的创建都经历上述过程。
二、构造函数
那么什么是构造函数呢?
按照ECMA的定义
Constructor is a function that creates and initializes the newly created object.
构造函数是用来新建同时初始化一个新对象的函数。
什么样的函数可以用来创建同时初始化新对象呢?答案是:任何一个函数,包括空函数。
所以,结论是:任何一个函数都可以是构造函数。
三、原型
根据前面空函数的创建图示,我们知道每个函数在创建的时候都自动添加了prototype属性,这就是函数的原型,从图中可知其实质就是对一个对象的引用(这个对象暂且取名原型对象)。
我们可以对函数的原型对象进行操作,和普通的对象无异!一起来证实一下。
围绕刚才创建的空函数,这次给空函数增加一些代码:
functionA() {
this.width = 10;
this.data = [1,2,3];
this.key ="this is A";
}
A._objectNum = 0;//定义A的属性
A.prototype.say =function(){//给A的原型对象添加属性
alert("hello world")
}
|
第7~9行代码就是给函数的原型对象增加一个say属性并引用一个匿名函数,根据“函数创建”过程,图解如下:

(灰色背景就是在空函数基础上增加的属性)
简单说原型就是函数的一个属性,在函数的创建过程中由js编译器自动添加。
五、继承
有了原型链的概念,就可以进行继承。
这个时候产生了B的原型B.prototype
原型本身就是一个Object对象,我们可以看看里面放着哪些数据
B.prototype 实际上就是 {constructor : B , [[Prototype]] : Object.prototype}
因为prototype本身是一个Object对象的实例,所以其原型链指向的是Object的原型
B.prototype = A.prototype;//相当于把B的prototype指向了A的prototype;这样只是继承了A的prototype方法,A中的自定义方法则不继承
B.prototype.thisisb = "this is constructor B";//这样也会改变a的prototype |
但是我们只想把B的原型链指向A,如何实现?
第一种是通过改变原型链引用地址
| B.prototype.__proto__ = A.prototype; |
ECMA中并没有__proto__这个方法,这个是ff、chrome等js解释器添加的,等同于EMCA的[[Prototype]],这不是标准方法,那么如何运用标准方法呢?
我们知道new操作的时候,实际上只是把实例对象的原型链指向了构造函数的prototype地址块,那么我们可以这样操作
这样产生的结果是:
产生一个A的实例,同时赋值给B的原型,也即B.prototype 相当于对象 {width :10 , data : [1,2,3] , key : "this is A" , [[Prototype]] : A.prototype}
这样就把A的原型通过B.prototype.[[Prototype]]这个对象属性保存起来,构成了原型的链接
但是注意,这样B产生的对象的构造函数发生了改变,因为在B中没有constructor属性,只能从原型链找到A.prototype,读出constructor:A
var b = new B;
console.log(b.constructor);//output A |
所以我们还要人为设回B本身
B.prototype.constructor = B;
//现在B的原型就变成了{width :10 , data : [1,2,3] , key : "this is A" , [[Prototype]] : A.prototype , constructor : B}
console.log(b.constructor);//output B
//同时B直接通过原型继承了A的自定义属性width和name
console.log(b.data);//output [1,2,3]
//这样的坏处就是
b.data.push(4);//直接改变了prototype的data数组(引用)
var c = new B;
alert(c.data);//output [1,2,3,4]
//其实我们想要的只是原型链,A的自定义属性我们想在B中进行定义(而不是在prototype)
//该如何进行继承?
//既然我们不想要A中自定义的属性,那么可以想办法把其过滤掉
//可以新建一个空函数
function F(){}
//把空函数的原型指向构造函数A的原型
F.prototype = A.prototype;
//这个时候再通过new操作把B.prototype的原型链指向F的原型
B.prototype = new F;
//这个时候B的原型变成了{[[Prototype]] : F.prototype}
//这里F.prototype其实只是一个地址的引用
//但是由B创建的实例其constructor指向了A,所以这里要显示设置一下B.prototype的constructor属性
B.prototype.constructor = B;
//这个时候B的原型变成了{constructor : B , [[Prototype]] : F.prototype}
|
图示如下,其中红色部分代表原型链:
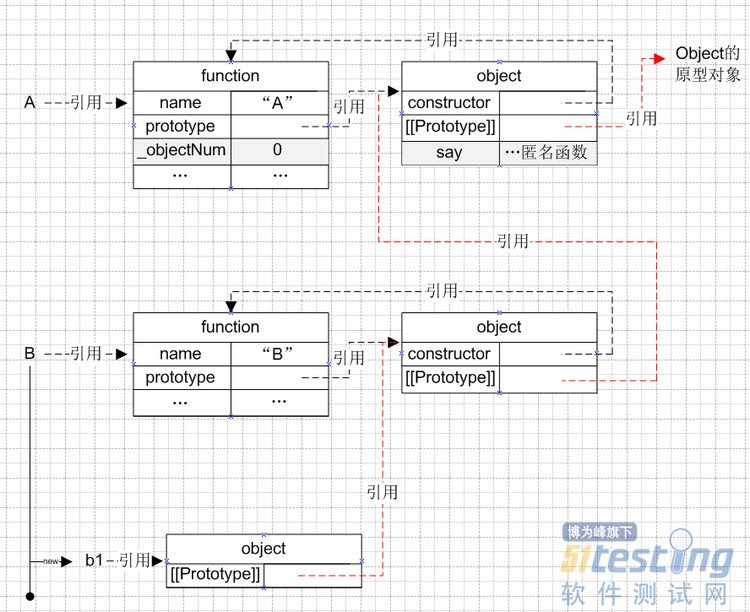
作为初学者浅陋的理解,本文目的在于更具象地去理解js的面向对象,疏漏之处请指正。
前段时间考试系统要新添加一个功能,要把学生表的信息批量导入,也就是需要从excel中导入到数据库表,小女子不才,找了好长时间才解决。
一、如果表是没有建立的,我们需要在数据库表中重新建立一个表盛放excel数据的时候:
在sql server中的导入语句:
SELECT * intocity2 FROM OpenDataSource( 'Micros 前段时间考试系统要新添加一个功能,要把学生表的信息批量导入,也就是需要从excel中导入到数据库表,小女子不才,找了好长时间才解决。
一、如果表是没有建立的,我们需要在数据库表中重新建立一个表盛放excel数据的时候:
在sql server中的导入语句:
SELECT * intocity2 FROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0', 'DataSource="f:\test.xls";User ID=Admin;Password=;Extendedproperties=Excel 5.0')...[Sheet1$]
这里需要注意的是,如果直接写这个语句,会出现这样的错误:
SQL Server 阻止了对组件'Ad HocDistributed Queries' 的STATEMENT'OpenRowset/OpenDatasource' 的访问,因为此组件已作为此服务器安全配置的一部分而被关闭。系统管理员可以通过使用sp_configure 启用'Ad Hoc Distributed Queries'。有关启用'Ad HocDistributed Queries' 的详细信息,请参阅SQL Server 联机丛书中的"外围应用配置器"。
所以,我们这里需要启动服务:
启动语句为:
execsp_configure 'show advanced options',1
reconfigure
execsp_configure 'Ad Hoc Distributed Queries',1
reconfigure |
当然,用完之后要记得关闭:
关闭语句为:
execsp_configure 'Ad Hoc Distributed Queries',0
reconfigure
execsp_configure 'show advanced options',0
reconfigure |
因为考试系统是基于asp.net实现的,所以,一下是asp.net的实现代码,需要注意的是,因为语句中存在”,\等特殊符号,所以,我们需要使用转义字符来使这些特殊符号成为字符串类型,这里是一些常用的转义字符符号:http://baike.baidu.com/view/73.htm
protectedvoid btntoLaad_Click(object sender, EventArgs e)
{
SqlConnectionmycon = new SqlConnection("server=.;database=qingniao;uid=sa;pwd=123");
string sqlstr = "SELECT * into cityFROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0', 'Data Source=\"f:\\test.xls\";User ID=Admin;Password=;Extended properties=Excel5.0')...[Sheet1$]";
SqlCommand cmd = new SqlCommand(sqlstr, mycon);
mycon.Open();
cmd.ExecuteNonQuery();
mycon.Close();
} |
这样,数据库中会建立一个city表,来存储excel中的数据。
二、将excel表导入到已经存在的数据库表
这里需要注意的是,excel表中的数据必须要和数据库表中的数据一致
比如,如果数据库表的字段为
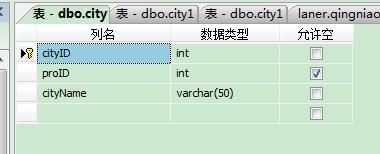
则相应的excel的表字段为:

oft.Jet.OLEDB.4.0', 'DataSource="f:\test.xls";User ID=Admin;Password=;Extendedproperties=Excel 5.0')...[Sheet1$]
这里需要注意的是,如果直接写这个语句,会出现这样的错误:
SQL Server 阻止了对组件'Ad HocDistributed Queries' 的STATEMENT'OpenRowset/OpenDatasource' 的访问,因为此组件已作为此服务器安全配置的一部分而被关闭。系统管理员可以通过使用sp_configure 启用'Ad Hoc Distributed Queries'。有关启用'Ad HocDistributed Queries' 的详细信息,请参阅SQL Server 联机丛书中的"外围应用配置器"。
所以,我们这里需要启动服务:
启动语句为:
execsp_configure 'show advanced options',1
reconfigure
execsp_configure 'Ad Hoc Distributed Queries',1
reconfigure |
当然,用完之后要记得关闭:
关闭语句为:
execsp_configure 'Ad Hoc Distributed Queries',0
reconfigure
execsp_configure 'show advanced options',0
reconfigure |
因为考试系统是基于asp.net实现的,所以,一下是asp.net的实现代码,需要注意的是,因为语句中存在”,\等特殊符号,所以,我们需要使用转义字符来使这些特殊符号成为字符串类型,这里是一些常用的转义字符符号:http://baike.baidu.com/view/73.htm
protectedvoid btntoLaad_Click(object sender, EventArgs e)
{
SqlConnectionmycon = new SqlConnection("server=.;database=qingniao;uid=sa;pwd=123");
string sqlstr = "SELECT * into cityFROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0', 'Data Source=\"f:\\test.xls\";User ID=Admin;Password=;Extended properties=Excel5.0')...[Sheet1$]";
SqlCommand cmd = new SqlCommand(sqlstr, mycon);
mycon.Open();
cmd.ExecuteNonQuery();
mycon.Close();
} |
这样,数据库中会建立一个city表,来存储excel中的数据。
二、将excel表导入到已经存在的数据库表
这里需要注意的是,excel表中的数据必须要和数据库表中的数据一致
比如,如果数据库表的字段为
则相应的excel的表字段为:
protectedvoid btnExist_Click(object sender, EventArgs e)
{
SqlConnection mycon = new SqlConnection("server=.;database=qingniao;uid=sa;pwd=123");
string sqlstr = " insert intocity1 SELECT * FROM OpenDataSource( 'Microsoft.Jet.OLEDB.4.0', 'DataSource=\"f:\\test.xls\";User ID=Admin;Password=;Extendedproperties=Excel 5.0')...[Sheet1$]";
SqlCommand cmd = new SqlCommand(sqlstr,mycon);
mycon.Open();
cmd.ExecuteNonQuery();
mycon.Close();
} |
这里同样需要开启服务,和第一种的方式一样。
三、既然已经存在的表,一般都会存在一些设置,比如说主键、外键或者是其他,如果主键或者外键冲突,就会出现导入失败的问题。所以,我们需要对excel表中的数据进行判断。
则先需要把数据导入到datatable中
protected void btnLeadingIn_Click(objectsender, EventArgs e)
{
DataTable dt=new DataTable();
dt = CreateExcelDataSource("F:\\abc.xls");
SqlConnection sqlCon = con();
sqlCon.Open();
GridView1.DataSource = dt;
GridView1.DataBind();
for (int i = 0; i < dt.Rows.Count;i++)
{
//导入数据库,把数据写入数据库应该就是非常简单了,这里就不多写了
}
}
public static DataTableCreateExcelDataSource(string url)
{
DataTable dt = null;
// string connetionStr ="Provider=Microsoft.Ace.OleDb.12.0;" + "Data Source=" + url+ ";" + "Extended Properties='Excel 8.0;HDR=Yes;IMEX=1';";
string connetionStr = "Provider=Microsoft.Jet.OleDb.4.0;"+ "data source=" + url + ";Extended Properties='Excel 8.0;HDR=YES; IMEX=1'";
string strSql = "select * from[Sheet1$]";
OleDbConnection oleConn = new OleDbConnection(connetionStr);
OleDbDataAdapter oleAdapter = new OleDbDataAdapter(strSql,connetionStr);
try
{
dt = new DataTable();
oleAdapter.Fill(dt);
return dt;
}
catch (Exception ex)
{
throw ex;
}
finally
{
oleAdapter.Dispose();
oleConn.Close();
oleConn.Dispose();
}
}
|
当然,我感觉我这里把datatable中的数据一条一条的取出来判断至少是非常耗时间耗内存的,而且这里最好加上回滚事物,因为在我们导入过程中会经常出现这样活那样的问题,采用事物,可以在出错的时候把数据回滚到没有导入之前的状态,防止意外事件发生,这里我就不往上加了。
以上是三种是我们实现了的excel导入,当然,我想方法还不止这些,当然,除了导入,还有的就是从数据库表导出到excel表中,因为我做的那部分系统没有涉及到,所以这里就不再提了。
下面说一下我在解决的过程中绕的弯路:
一、我没有把导入数据库的种种做法弄清楚,比如是直接创建表呢还是在已经存在的表中导入,所以以至于刚开始总是找不到合适的方法。
二、在后来的查找过程中,我发现我有一个很大的毛病,就是我的关键字是在“asp.net中、、、、、”,其实,既然是往数据库中导入,asp.net只是一个执行一下,所以,因为有了关键字的约束,查出来的资料少不说,而且还形成了一种思维定式,除了asp.net之外的其他都一概不看。
三、对查不来的信息不能加以理解,只是能用就用,不能用就换,也就是我因为转义字符串那一块弄了很长时间的原因,因为当我们在sql执行查询语句没有错误的时候,需要把它放在asp.net中执行,因为这些语句需要string字符串来显示,而这个执行语句中有包含引号,所以需要转义字符,在解决引号的问题之后,我发现还是不正确,一直折腾了好久才发现是路径F:\test.xls中“\t“是table的转义字符,所以这里需要两个\来转义\,这就是应该写成这样“F:\\test.xls”,而当我写成这样的时候,我才想起来,其实最开始查询的时候所有的代码都是这样的,只是那些我没用上,当时也没多想,以为路径就应该是这样的,最终导致还继续在这个上面栽跟头。