最近看了不少有关
探索性测试的讨论和观点,老实说越看越糊涂。所以忍不住吐槽一下,在这里和大家讨论一下探索性测试。希望对于想
学习和尝试探索性测试的朋友有所帮助澄清,或者是更加糊涂,^_^。
探索性测试有很多很多的定义:
百度百科的定义:“同时设计测试和执行测试”。 嗯。。什么意思?
Cem 老人家的正式定义:“a style of software testing that emphasizes the personal freedom and responsibility of the individual tester to continually optimize the quality of his/her work by treating test-related learning, test design, test execution, and test result interpretation as mutually supportive activities that run in parallel throughout the project”。啊。。 糊涂了。。。
有人说:“手工测试就是探索性测试”。 更糊涂了。。。
又有人说:“探索性测试就是一边探索一边测试”。 彻底糊涂了。。。。
。。。。。
那么探索性测试到底是啥玩意啊?
我们先来看一个例子吧。很多人都玩过猜数字的游戏吧。我心里想一个数字,你来猜。你可以问任何问题,我回答“是”还是“不是”。然后你通过不断问问题和 我的回答来最终猜到我心想的数字。在猜对的情况下问的问题越少得分越高。比如,我心里想了一个数字。你可以问“大于零?”,我说“是”。你现在知道是正数 了,你然后问“小于100?”,我说“是”。你现在知道是小于100的正数,你然后问“小于50?”,我说“不是”。你现在知道是介于50和100间的 数。你继续再问几次后因该就能猜对了。
在这个简单的游戏中有两个策略至关重要:
1、你要根据前面问题的答案来分析和设计下一个问题。第一个问题可能不着边,但是第二个问题会让你跟接近你想要的答案。第三个会更加靠近,以此类推。
2、仅仅根据前面问题的答案来设计下一个问题可以最终帮你猜对数字,但是要想用最少的问题来猜对数字不仅要根据前面问题的答案,而且需要对问题本身其它 知识加以综合运用使用其它策略和技术。比如在知道是小于100的正数后,你可以使用binary search,最多猜6次就可以猜对;如果你不知道binary search,你可以猜是否小??90?小于80?小于70?… 猜上十几次也可以猜对;或者猜是否小于99?小于98?小于97?… 猜上几十次也可以猜对。所以采用不同策略直接决定你猜对的速度。
所以两个关键因素:前面问题的答案+有效的策略。
探索性测试和猜数字游戏完全一样。在这里要猜的数字就是你要找的bug。你问的问题就是你做的测试,每个问题的答案就是你测试过程中产品的输出。第一轮 你只有一个非常模糊的范围比如测试某个模块的某个功能。在你测试的时候通过观察产品的反应和输出来判断分析下一步做什么会发现bug。当然实际测试中不会 像猜数字那样直接和简单。
下面我们来看一下一个真实的测试例子。有一次我在测试一个用户界面的录入页面。用户可以输入比如姓名,年龄,等等很多信息,最后系统根据输入的内容处理保存到数据库中。 当然我对每一个输入框都会尝试不同的数据比如空值,很长的字符串,空格等等,系统都没有问题。但是我注意到每次保存的时候系统都会生成一个本地文件,该文 件的名字是其中一个输入框的我的输入。该输入框的唯一限制就是不可以为空不可以超过255个字符。我想到文件名字中不可以有斜杠“\”,于是我就在该输入 框中如入“ab\cd”,它通过了输入校验,但是保存的时候系统就崩溃了。这就是探索性测试一个非常典型的例子,通过观察分析上一次测试的产品反应和输出 来判断系统会有问题的地方,然后设计调整步骤和测试数据反复尝试直到完全验证模块没有问题或找到bug.
探索性测试和手工测试的区别: 手工测试通常是指完全按照预先设计好的步骤一步一步人工测试直到验证了所要验证的功能。如果结果和预期结果一致,则验证通过;如果不一致,则是bug.可 以看出手工测试过程单调没有思考没有变通。在上面的猜数字的游戏中你明明已经知道是正数,你还在按照游戏开始前设计的步骤问大于-100? 大于-90?。。。。当然现实生活中 没有这样的傻子,在你“手工”测试的时候你或多或少已经使用“探索性”了,只不过你没有意识到罢了。所以很多人误认为探索性测试是个时髦新测试技术,研究 了半天又不知道到底新在那里和自己一致做的有什么不同。或者恍然大悟原来自己已经探索了很多年了。但是探索性测试有效率高和效率低之分,所以有人干脆就把 效率高ET的才叫ET, 效率低的ET叫手工测试。这也是让人糊涂的原因之一吧。
测试自动化就是把手工测试的每个步骤有测试自动化工具来完成。好处是不用人做了,缺点是测试过程中仍然没有思考没有变通。
Ad-hoc测试(随机测试):没有预先设计好的步骤,也没有明确目标,也没有策略。在上面猜数字的游戏中你明明知道是正数,你还在东一榔头,西一棒槌的乱猜等于100?等于-100?等于0?。。。当然也有可能被你一不小心蒙对了。
探索性测试和测试自动化各有各的优缺点。至于什么时候开始测试自动化,什么时候开始ET,先测试自动化后ET,还是先ET后测试自动化需要看项目产品具体情况了。没有绝对对错,以尽早发现bug,发现更多的的bug为宗旨。另外既然ET和测试自动化的各自优缺点,微软有 些组最近两年在尝试“探索性测试自动化”的方式来把探索性测试和测试自动化相结合,充分发挥各自的优点。看到这里你可能要恨我了,我刚学会测试自动化,你 又提倡ET了;我刚搞清楚ET,你又开始提倡探索性测试自动化了。。。 呵呵,人类发展过程就是通过社会分工,扬长避短。专注于做自己擅长的事情,把自己不擅长做的事情交给擅长的人去做。社会发展是如此,云计算是 如此,测试也是如此。有人说过:“The computer is incredibly fast, accurate, and stupid (test automation). Man is unbelievably slow, inaccurate, and brilliant (exploratory test). The marriage of the two is a force beyond calculation。”
其实我们可以看到探索性测试入门容易或者你已经在做了多年了,难得是有效地探索性测试,或者做效率高的 ET(否则被别人不屑为手工测试了J)。那么如何根据前面的测试结果来分析和思考,如何才能敏锐地嗅觉到通向bug的种种线索?当然有多种方式来训练自己 这方面的能力。还有如何衡量考核ET的效率,投入和产出比率?欲知详情,请听下回分解。。。。
所谓伟大的测试团队是什么意思? “拥有明星队员的团队是好团队,但没有一个明星队员的团队是一个伟大的团队”——无名氏。
上述的引言使我们进入了伟大团队及其特性的讨论之中。这篇文章源于作者在不同团队中的工作经历,对团队成员在时间非常紧迫和项目非常复杂的情况下的表现的观察。本文适合于那些想寻求合适成员以求在项目中有出色表现的软件测试团队。
为什么软件测试团队有的成功而有的失败?
这问题有解决方案吗?答案究竟是“是”还是“否”,取决于成员如何向团队的共同目标看齐,不应是抑制个人兴趣,而是对问题有一致认识而共事。
团队的成功也依靠带头人的领导特质——“船长”
本文目标是帮助软件测试工程师或是相信团队合作的人理解优秀团队的特质,并在自己团队中培养这些特质。
从长远的角度看考虑,成功的团队依靠的不是被认为是“明星”的个人,而是组成这个星群的全体,这样才能创造出伟大的团队。
伟大软件测试团队的特质初始阶段——问自己下列问题:你们团队的新成员知道自己入选团队的原因吗?
团队新成员常常会为自己在团队中存在的价值而感到困惑。虽然你可能会说他/她不需要知道目标,只要根据任务安排进行工作就可以了,这是很多高管的想法。 但是清晰明确地定义角色和职责可以帮助个人在更大的背景下理解这个项目。它包括工作相关内容、个人技能以及早期定义的团队共同目标。这些将会对工作会有巨 大的作用(帮助),因此也会改善其质量。
领导权:随着任务和团队规模的增加,项目的复杂性也随之增加,这时让一个领导者跟踪每个人的任 务情况是不太可能的。因此,一个解决办法就是下放权力给个人。然而,如果没有经过深思熟虑,这种虚拟的权利经常表现为一种阻碍而非解决方案。仅仅委派给个 人作为负责人,而没有认真考虑过他/她是否能胜任不会带来预期的效果。
想表现的像一个负责人,他应该具有和领导者接近的思维方式和行使 自己未来领导者职责的自豪感。这些人会在促进团队团结一致的过程中发挥重要作用,而那些对团队漠不关心的人则会毁了团队。负责人的职责不仅是给团队成员分 配任务,而要以更开阔的视角认清手上的任务及形势,给团队成员带来共识。当成员处理任务遇到困难时予以支持、鼓励,以同伴而不是领导的身份纠正成员们的错 误,提出建议,在适当时机采纳老员工的意见,这些都有利于共同目标的实现。合作以及团队中牢固的相互依存感可以消除彼此间的相互指责,增加学习与进步的机会。
团队中专职成员的知识
专职成员是指那些在相同项目或类似工作中投入大量时间的人。他们掌握大量关于项目的知识,是团队的资源。通过合适的方法激励出他们的专业知识,从而使整个团队都会从中受益。这些人应该在其他工作上表现勤奋而非自大。常言说:“往昔成会滋生自满”。他们是重要的成员,少了他们可能会影响到整个团队,但这不是唯一的准则。因为这也给了其他有相同能力的人在这个位子上表现的机会。
激励——关键因素激励不总是把大家聚集起来发表演说,而是抓住每一次机会将这些话单独说给每个成员。每个成员都有独特的个性和工作方式。对Test Leader来说,这个工作要比“说”来的复杂,因为它要求领导者不仅从分配任务的角度而且从整个项目的角度,去体会每个成员的想法。积极正向的领导态度将会给团队注入强大的活力-- 这一点来源于在伟大测试团队中的工作经验。如果领导者抱怨工作时间过长或坚持要求团队成员按无法实现的计划行事,你的态度也会反映在你们的团队中。真正的 领导者应该是这样的,尽管计划不合理,还是要给团队成员注入信心,让他们相信自己的能力。同时,在背后为团队为这个计划所做的努力做出解释和辩护,而不是 推迟计划使得成员工作变得简单。
认可
每个人都希望自己的工作得到认可。当一个人 因为工作受到奖励,领导者就有责任告诉其他人获奖原因。在这个问题上,领导者的决定必须是公正的。它会使受到奖励的人得到团队成员的尊重。团队成员们也会 照这个样子去努力,最终团队也会从中获益。在一个虚职领导的团队中,成员们的工作经常会因为领导者看不见而得不到肯定。这时虚职领导就应该明确团队成员们 工作中的成就和贡献。关心成员的工作,团队成员欢迎,团队成员愿意将来也和他共事,这样的虚职领导将来就会成为真正的领导。
一对一面谈
经常可见在项目收尾时进行成员角色职责定义,并对成员进行评定。这是一个正常的流程。但非正式的一对一面谈也会对这个流程起到促进作用。这些非正式面谈 的话题应该是团队成员不愿在小组会议上谈的,诸如成员未来的发展机会、对今后领导者或者负责人的确定,以及在得到成员反馈以后,针对当下问题进行平等的沟 通和交流。适时恰当地公布反馈结果能够区分出这是把问题隐瞒的团队还是把问题看成一种机会的团队。团队表现不佳的责任通常在于团队结构不佳而不是个人能力 不够,当然还是要把个人送去培训来解决一些问题的。如果团队成员感到他们为了得到奖励和认可而要相互斗争,他们就会保留一些可能对团队有帮助的信息。当团 队有了问题,高效的团队领导者首先把关注点集中在团队结构,而非个人身上。
“不要告诉人们怎么做事,而是要告诉他们做什么,然后让他们的成就给你惊喜。”——乔治·巴顿
结论
创建一个成功的团队要考虑相当多的事情。关键词——团结一致、信任、尊重他人的意见、主张以及无畏的行动,这些是伟大团队的要素,一般说来,这些对任何 成功的团队都是必需的。读完本文以后,看一下你的团队,问你自己:“你工作在一个伟大的测试团队中吗?”或者“你愿意尽一切努力来构造一个伟大的测试团队 吗?”不要等了,下一秒就可以开始构造“伟大的测试团队”了。
相逢是开始,相聚是过程,相持是成功。——亨利·福特
最近通过各种渠道发现大家对一些
测试工具的基本情况不太清楚,经常会问类似于watir与watir webdriver的区别,我有1个项目,是用watir还是用
selenium webdriver呢,之类的问题,在这里笔者不才略微总结一下,希望能给大家一个较为清晰的认识。
Waitr与Watir-WebDriver有什么区别?
Watir是非常优秀的一款自动化测试工具。其使用ruby作为脚本语言进行开发,能够在ie上实现元素定位、操作等自动化任务;
Watir WebDriver是Selenium WebDriver的一个封装。简单来说如果selenium webdriver是手机上 的安卓系统,那么watir webdriver就是MIUI。watir webdirver就是将selenium webdriver包装了一下,使得selenium webdriver的api更加的友好。当然watir webdriver也不是毫无根据的对selenium webdriver进行封装,watir webdriver使用了watir的api组织形式对selenium webdriver进行封装,这样watir的代码跟watir webdriver的代码看上去就很”相似”了。这也是大家无法分辨watir与watir webdriver区别的原因。
另外watir webdriver相比较watir有如下的一些优点:
watir webdriver支持多浏览器, 而watir只支持ie
watir webdriver支持html5, 而在这方面watir不太明确
watir webdriver对弹出框(js alert confirm)的处理更加友好
watir webdriver支持移动设备,如iPhone和androrid
QTP和watir的区别是什么?
首先最明显的区别是:QTP是商业工具,其不是免费的;而watir是开源的测试工具,使用免费。
QTP支持脚本的录制,而watir不可以;
QTP的脚本语言是vbscript,而watir使用ruby进行脚本的开发;
QTP上手很容易,一般测试人员哪怕不会脚本语言都可以通过QPT录制回放脚本来进行用例的开发;相对来说,watir则需要一定的代码基础;
QTP对IE和Firefox都有支持,但是watir只支持IE(尽管firewaitr支持firefox,但是工具目前更新速度不快,可以忽略);
QTP是有软件界面的,而watir只是一个代码库;
那么我应该选择QTP还是watir?
如果预算允许且自动化测试对浏览器的兼容性要求不高的话是可以选择QTP的;
如果预算有限,但是项目只要求支持IE的话建议选择watir,学好watir测试人员日后的发展有一定的好处;
如果预算有限,项目又要求支持多浏览器,那么推荐使用watir webdriver;
我应该选择watir webdriver还是selenium webdriver? 从本质上说selenium webdriver 和 watir webdriver是没有任何区别的,就跟中国男足输1个和输10个是没有任何分别一样。
从笔者的经验上来说,watir webdriver的api更加的丰富和友好,如果你可以使用ruby作为开发语言的话,强烈推荐watir webdriver。
如果你的项目要求你使用java javascript之类的语言,那么你只能选择selenium webdriver了。
我是新手,这么多测试工具我该选择哪一个作为入门的学习工具呢?
如果你有决心有时间的话,那么推荐watir作为web测试的入门工具,原因是你可以通过watir学习到ruby,js,html,dom等 一系列的知识;然后再转watir webdriver 甚至是selenium webdriver,学习曲线是相对平滑的;
如果你有决心但没时间却又急于求职的话,那么用熟QTP也是一个捷径。
selenium和webdriver的关系是什么?
webdriver是selenium2的一部分;
webdriver提供了多浏览器间统一的api,并将会持续更新,而selenium1将不再维护;
selenium2等于webdriver加selenium1
webdriver比selenium强在哪儿?
wd的api比se更加的面向对象,更加友好;
wd解决了se的软肋同源问题;
wd多浏览器间的行为更加一致;
wd支持iphone和安卓;
se1不再更新,而webdriver社区非常活跃。
作为新人,我想学习脚本语言,我该从哪一门开始呢?
如果你想做web方面的自动化而又想选择一门脚本语言开始的话,笔者推荐javascript。因为js配合html能做出多种效果,能够给让新人很快的获得成就感。另外前端人员目前相对紧缺,学好js无疑能够让你的身价有一定的增加。
如果你只是想学一门脚本语言,那么建议学习python,python的理念是做1件事件从来只有一种方法,尽管没有选择,但是至少也不会混乱和迷惑。另外python社区非常活跃,氛围很好。
如果你想学习watir和waitr webdriver,那么就从ruby开始。ruby入门容易精通难,而且经济价值没有py和js那么立竿见影。
总是脚本语言殊途同归,修行还是要看个人。
概述
在敏捷测试中UI的自动化测试(一般我们也称这层测试为功能测试或验收测试,本文单指Web UI的自动化测试)虽然没有单元测试那么广为提及,但因为其与最终用户最近,所以基于用户场景的UI自动化测试还是有其重要的意义的。使用UI自动化测试对产品的关键功能路径进行验证及回归,比起传统的QA手工执行Test case可以更快地得到反馈,也让发布变得更有信心。
理想状况下,我们应该将所有可以固化下来的Test case都自动化起来,而让我们的测试人员进行更有挑战性的探索性测试活动。让机器做已知领域的事儿,让人对未知领域进行探索。不过理想归理想,现实是残 酷的。虽然UI层的测试距离交付最近,但是成本也最高。编写和维护UI自动化测试需要付出比其他自动化测试更高昂的成本,这也是大多数团队放弃UI自动化 测试的主要原因。相比较系统的其他部分,UI是一个多变的层,如果UI自动化测试没有构建好,即使界面的一个微小改动,整个测试集可能就天崩地裂。这也就 是为什么我经常对team里其他人说:对于UI自动化测试,可维护性必须牢记心头。每当你写下一行测试代码时,你就必须记住你又给公司添加了一笔成本,而 且这个成本是持续增长的,如果review code的时候发现哪条测试代码维护性不好我会毫不犹豫的删掉。
或许有人觉得这有点小题大作,不就UI测试么,有什么难的。定位元素,然后拿到页面元素的值与期望进行比较不就可以了。难就难在定位元素上。一般我们会使用Selenium WebDriver, Watir, Sahi等工具驱动浏览器,进行元素定位(关于这些工具的详细使用可以参见官方文档,后文主要以Selenium WebDriver为示例)。这些工具在定位元素上基本上是大同小异:通过id, name, css, tagName, xpath等方式定位。这些定位方式,从前到后,一个比一个不靠谱。比如这个xpath,好不容易写出个xpath定位,然后突然有一天前端觉得某个地方 不美观,插入一个小东西,马上测试废掉。看着这种没有改变功能也把功能测试搞垮掉的现象是不是欲哭无泪。我有时天真的在想如果页面上每一个元素都有唯一的 id该多好啊。即使没有唯一的id,有name我也可以接受。不过这一切在遇到ExtJS之后都变了。
遭遇ExtJS
ExtJS是一个非常霸道的前端框架。使用ExtJS后,页面上几乎所有的一切都被ExtJS接管。尽管互联网提 供给用户的系统鲜有使用ExtJS,但是对于后台系统使用ExtJS确实带来了一些便利。使用ExtJS的基本组件就能组装出一个看起来还不错,功能强大 的应用。但是ExtJS非常霸道,被他接管后页面的生成基本上就是个黑盒子,而为了在各个浏览器的兼容它在各浏览器上生成的html还不一样。更可恨的是 默认情况下它给元素提供的id都是动态生成的。
在刚选择这个ExtJS的系统作为我们自动化测试的第一个试点时,我还有点暗暗高兴。比 起那些提供给普通用户使用的丰富多彩的前端来说,这些后台系统大多中规中矩,使用ExtJS后更是层次分明。而且后台系统UI的变动也不会太过于频繁,我 想或许这个系统很容易测试吧。
后来我看到同事代码里出现:
| webDriver.findElement(By.id("ext-gen-1306")) |
我还在想,我们的前端同学真有“创意”,还用这么随机的名字啊。后来厄运来了,我check out代码在我这里死活通过不了。Selenium报告找不到指定元素。不是吧,我可是使用id进行定位的啊。通过翻阅ExtJS的文档发现,原来类似 ext-gen-xxx这类id都是ExtJS动态生成的。好吧,我使用name进行定位吧,后来发现很多元素居然没有name属性。再来看看ExtJS 生成的html,基本上把通过xpath进行定位的路给堵死了。要了解ExtJS生成的html,可以去ExtJS官方查看一些Demo。
曙光
阅读ExtJS文档我们发现,ExtJS极其强调它的组件模型。而用ExtJS写的前端代码也呈现出很好的结构。因为之前曾从事过ASP.NET的开 发,我想是不是可以使用ASP.NET类似的方式先编写一些小控件类,这些类对ExtJS的基本组件进行包装。然后利用这些小控件类组装出一个个页面。这 样不仅能把单个元素的定位分散到单个控件类里,而且可以做到极大程度的复用。在传统的UI自动化测试中我们使用Page Object模式来封装一个个页面,但是对于ExtJS来讲页面的粒度还显得过大。如是模仿ASP.NET的控件模型,我创建了Control, Button, TextBox等一系列基本的控件类。而原来Page Object中的Page不再使用WebDriver直接定位元素了,我们通过这些基本控件组装页面。
实现
在这里我用一个简单的用户登录作为例子:
Control是我们的基本类型,所有的控件包括页面都从这个类派生。
Control只提供了很少几个方法:
public abstract class Control {
protected WebDriver webDriver;
protected Control parent;
public Control(WebDriver webDriver) {
this.webDriver = webDriver;
}
public String getQuery() {
return StringUtils.EMPTY;
}
public String getId() {
JavascriptExecutor executor = (JavascriptExecutor) webDriver;
return (String) executor.executeScript("return " + this.getQuery() + ".id");
}
} |
在这里getQuery是一个非常重要的方法,这在后面会介绍。
public abstract class CompositeControl extends Control {
protected List <Control> children;
public CompositeControl(WebDriver webDriver) {
super(webDriver);
children = new ArrayList<Control> ();
}
public void addChild(Control control) {
this.children.add(control);
control.parent = this;
}
} |
所有的可以包含其他控件的类型都从CompositeControl派生,包括Page。比如下面的Window就是这类元素:
public class Window extends CompositeControl {
private String title;
public Window(String title,WebDriver webDriver) {
super(webDriver);
this.title = title;
}
@Override
public String getQuery(){
return String.format("Ext.ComponentQuery.query(\"window[title='%s']\")[0]",title);
}
} |
下面是一个基本控件Button的封装:
public class Button extends Control {
private String text;
public Button(String text, WebDriver webDriver) {
super(webDriver);
this.text = text;
}
@Override
public String getQuery() {
return this.parent.getQuery() + String.format(".query(\"button[text='%s']\")[0]", text);
}
public void click() {
webDriver.findElement(By.id(getId())).click();
}
} |
ExtJS提供了一个query接口,我们可以利用这个接口传入一些查询表达式查询到页面上的Ext控件,而这里的getQuery就是每个控件的查询表达式吧。因为页面上的ExtJS控件是层次的,所以我们可以利用这种嵌套关系进行精确的定位。
好了,来看看我们的登陆页面如何封装吧:
public class LoginPage extends ExtJSPage{
public LoginPage(WebDriver webDriver){
super(webDriver);
}
private TextBox txtUserName;
private TextBox txtPassword;
private Button btnLogin;
@Override
protected void init(){
txtUserName = new TextBox("userName", webDriver);
txtPassword = new TextBox("password", webDriver);
btnLogin = new Button("登录", webDriver);
Window win = new Window("登陆", webDriver);
win.addChild(txtUserName);
win.addChild(txtPassword);
win.addChild(btnLogin);
this.addChild(win);
}
public void login(String userName, String password){
txtUserName.setValue(userName);
txtPassword.setValue(password);
btnLogin.click();
}
} |
上面的TextBox和ExtJSPage没有提供代码,都很简单可以自行进行封装一下(熟悉ASP.NET的同学可能对这里代码有点眼熟)。
按照这种思路,只要我们封装好所有的基本ExtJS控件,对于所有的页面我们剩下的工作就是组装的工作了。在完成这些之后,我甚至发现使用 ExtJS的应用比那些没有使用ExtJS的应用更容易进行测试。在这里我们只需要完善我们的基本控件封装就可以让我们的测试更佳稳固,而对于编写测试的 人来说只需要集中精力关注Test case。
不知道得罪了哪路神仙,收到nagios报警,发现有个网站有CC攻击。看样子,量还不小,把服务器的负载都弄到40+了,虽然网站还能打开,但打开也是非常的缓慢。如果不是配置高点,估计服务器早就挂掉了。看来又是不一个不眠之夜了。
迅速查看一下nginx的访问日志:
#tail -f access.log

貌似全是像这样的状态。
我先紧急手动封了几个访问量比较大的Ip。
- #iptables -A INPUT -s 83.187.133.58 -j DROP
- #iptables -A INPUT -s 80.171.24.172 -j DROP
- ......
|
紧急封了几个ip后,负载降了一些了,网站访问速度有所提升了,但是不一会,又来了一批新的Ip, 受不了了,看来要出绝招了。写了shell脚本,让他逮着了,就封。发现他攻击的状态都相同,每一个攻击ip后面都有 HTTP/1.1" 499 0 "-" "Opera/9.02 (Windows NT 5.1; U; ru) 的字段,那我们就来搜这个字段。
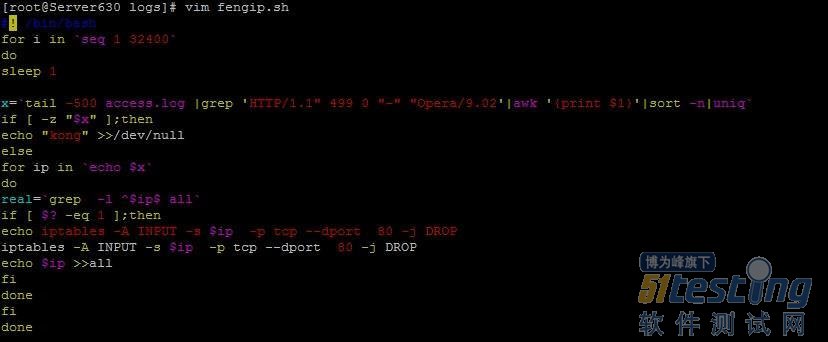
- #vim fengip.sh
- #! /bin/bash
- for i in `seq 1 32400`
- do
- sleep 1
- x=`tail -500 access.log |grep 'HTTP/1.1" 499 0 "-" "Opera/9.02'|awk '{print $1}'|sort -n|uniq`
- if [ -z "$x" ];then
- echo "kong" >>/dev/null
- else
- for ip in `echo $x`
- do
- real=`grep -l ^$ip$ all`
- if [ $? -eq 1 ];then
- echo iptables -A INPUT -s $ip -p tcp --dport 80 -j DROP
- iptables -A INPUT -s $ip -p tcp --dport 80 -j DROP
- echo $ip >>all
- fi
- done
- fi
- done
|
脚本写好了。如图
我们来运行一下,运行几分钟后,如下图所示
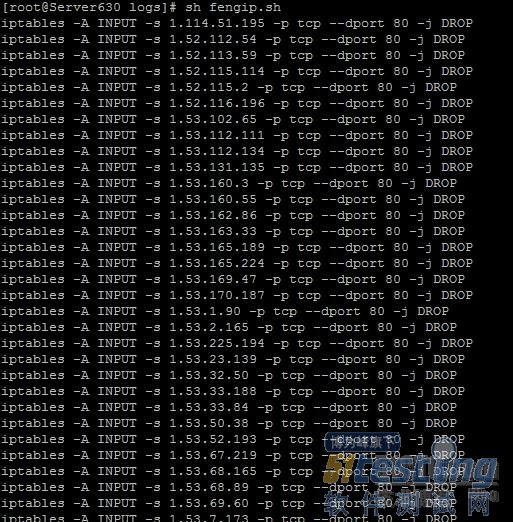
经过半个小时的观察,服务器负载也降到0.几了,脚本也不断在封一些CC攻击的ip。
一直让他运行着,晚上应该能睡个好觉了。
下来我们来对脚本进行解释一下。
- #vim fengip.sh
-
- #! /bin/bash
- Touch all #建立all文件,后面有用到
- for i in `seq 1 32400` #循环32400次,预计到早上9点的时间
- do
- sleep 1
-
- x=`tail -500 access.log |grep 'HTTP/1.1" 499 0 "-" "Opera /9.02'|awk '{print $1}'|sort -n|uniq` #查看最后500行的访问日志,取出包含 'HTTP /1.1" 499 0 "-" "Opera/9.02' 的行的ip并排序,去重复
- if [ -z "$x" ];then
- echo "kong" >>/dev/null #如果$x是空值的话,就不执行操作,说明500行内,没有带 'HTTP/1.1" 499 0 "-" "Opera/9.02' 的行
- else
- for ip in `echo $x` #如果有的话,我们就遍历这些ip
- do
- real=`grep -l ^$ip$ all` #查看all文件里有没有这个ip,因为每封一次,后面都会把这个ip写入all文件,如果all文件里面有这个ip的话,说明防火墙已经封过了。
- if [ $? -eq 1 ];then #如果上面执行不成功的话,也就是在all文件里没找到,就用下面的防火墙语句把ip封掉,并把ip写入all文件
- echo iptables -A INPUT -s $ip -p tcp --dport 80 -j DROP
- iptables -A INPUT -s $ip -p tcp --dport 80 -j DROP
- echo $ip >>all
- fi
- done
- fi
- done
|
脚本很简单,大牛略过啊。。。
有什么不明白话,欢迎一起探讨学习。
Sql Server系 统内存管理在没有配置内存最大值,很多时候我们会发现运行Sql Server的系统内存往往居高不下。这是由于他对于内存使用的策略是有多少闲置的内存就占用多少,直到内存使用虑达到系统峰值时(预留内存根据系统默认 预留使用为准,至少4M),才会清除一些缓存释放少量的内存为新的缓存腾出空间。
这些内存一般都是Sql Server运行时候用作缓存的,例如你运行一个select语句, 执行个存储过程,调用函数;
1、数据缓存:执行个查询语句,Sql Server会将相关的数据页(Sql Server操作的数据都是以页为单位的)加载到内存中来, 下一次如果再次请求此页的数据的时候,就无需读取磁盘了,大大提高了速度。
2、执行命令缓存:在执行存储过程,自定函数时,Sql Server需要先二进制编译再运行,编译后的结果也会缓存起来, 再次调用时就无需再次编译。
在我们执行完相应的查询语句,或存储过程,如果我们不在需要这些缓存,我可以将它清除,DBCC管理命令缓存清除如下:
--清除存储过程缓存 DBCC FREEPROCCACHE --注:方便记住关键字 FREEPROCCACHE 可以拆解成 FREE(割舍,清除) PROC(存储过程关键字简写),CACHE(缓存) |
--清除会话缓存 DBCC FREESESSIONCACHE --注: FREE(割舍,清除) SESSION(会话) CACHE(缓存) |
--清除系统缓存 DBCC FREESYSTEMCACHE('All') --注:FREE SYSTE MCACHE |
--清除所有缓存 DBCC DROPCLEANBUFFERS --注: DROP CLEAN BUFFERS |
虽然我们已经清除了缓存,但是sql并未释放相应占用的内存。 它只是腾出新的空间为之后所执行脚本所用。Sql Server 并没有提供任何命令允许我们释放不用到的内存。因此我们只能通过动态调整 Sql Server可用的物理内存设置来强迫它释放内存。
操作原理是调整内存配置大小。手动操作方法:
1、打开Sql Server Management(企业管理器);
2、打开Sql Server实例的属性面板;
3、找到内存设置,改变其中的最大服务器内存使用即可 。
使用脚本操作:
--强制释放内存
CREATE procedure [dbo].ClearMemory
as
begin
--清除所有缓存
DBCC DROPCLEANBUFFERS
--打开高级配置
exec sp_configure 'show advanced options', 1
--设置最大内存值,清除现有缓存空间
exec sp_configure 'max server memory', 256
EXEC ('RECONFIGURE')
--设置等待时间
WAITFOR DELAY '00:00:01'
--重新设置最大内存值
EXEC sp_configure 'max server memory', 4096
EXEC ('RECONFIGURE')
--关闭高级配置
exec sp_configure 'show advanced options',0
GO |
下面提供内存查看功能的一些脚本语句:
--内存使用情况 SELECT * FROM sys.dm_os_performance_counters
WHERE counter_name IN ('Target Server Memory (KB)','Total Server Memory (KB)') |
--查看最小最大内存
SELECT configuration_id as id,name as 名称,minimum as 配置最小值, maximum as 最大值,
is_dynamic as 是否动态值, is_advanced as 是否优先, value_in_use AS 运行值,
description as 描述 FROM sys.configurations
最近在做应用的性能优化,在review代码的过程中积累了一些规则和经验。做到这些规则的目的很简单,就是写出“优美”的代码来。
1、注释尽可能全面
对于方法的注释应该包含详细的入参和结果说明,有异常抛出的情况也要详细叙述;类的注释应该包含类的功能说明、作者和修改者。
2、多次使用的相同变量最好归纳成常量
多处使用的相同值的变量应该尽量归纳为一个常量,方便日后的维护。
3、尽量少的在循环中执行方法调用
尽量在循环中少做一些可避免的方法调用,这样可以节省方法栈的创建。例如:
- for(int i=0;i<list.size();i++){
- System.out.println(i);
- }
|
可以修改为:
- for(int i=0,size=list.size();i<size;i++){
- System.out.println(i);
- }
|
4、常量的定义可以放到接口中
在Java中,接口里只允许存在常量,因此把常量放到接口中声明就可以省去public static final这几个关键词。
5、ArrayList和LinkedList的选择
这个问题比较常见。通常程序员最好能够对list的使用场景做出评估,然后根据特性作出选择。ArrayList底层是使用数组实现的,因此随 机读取数据会比LinkedList快很多,而LinkedList是使用链表实现的,新增和删除数据的速度比ArrayList快不少。
6、String,StringBuffer和StringBuilder
这个问题也比较常见。在进行字符串拼接处理的时候,String通常会产生多个对象,而且将多个值缓存到常量池中。例如:
- String a="a";
- String b="b";
- a=a+b;
|
这种情况下jvm会产生"a","b","ab"三个对象。而且字符串拼接的性能也很低。因此通常需要做字符串处理的时候尽量采用StringBuffer和StringBuilder来。
7、包装类和基本类型的选择
在代码中,如果可以使用基本数据类型来做局部变量类型的话尽量使用基本数据类型,因为基本类型的变量是存放在栈中的,包装类的变量是在堆中,栈的操作速度比堆快很多。
8、尽早的将不再使用的变量引用赋给null
这样做可以帮助jvm更快的进行内存回收。当然很多人其实对这种做法并不感冒。
9、在finally块中对资源进行释放
典型的场景是使用io流的时候,不论是否出现异常最后都应该在finally中对流进行关闭。
10、在HashMap中使用一个Object作为key时要注意如何区分Object是否相同
在jdk的HashMap实现中,判断两个Object类型的key是否相同的标准是hashcode是否相同和equals方法的返回值。如 果业务上需要对两个数据相同的内存对象当作不同的key存储到hashmap中就要对hashcode和equals方法进行覆盖。
nmon_analyser统计分析工具可以很好的分析 指定时间段的系统性能。
nmon工具分为2部分:AIX性能监控和数据采集的工具和对nmon采集数据进行分析工具。
AIX性能监控和数据采集的工具:
newer_nmon4aix12e.tar.gz适用操作系统为:
aix51
aix522
aix527
aix530
aix534
aix535
aix536
aix537
aix61
nmon12f_aix612.gz 适用操作系统为:
aix6.1.2
nmon采集数据进行分析工具:
nmon_analyser.zip
把信息收集工具ftp到aix操作系统,并解压
gunzip newer_nmon4aix12e.tar.gz
tar -xvf newer_nmon4aix12e.tar
运行AIX性能监控和数据采集的工具:
通过信息收集工具在Aix平台的运行,收集指定一段时间的系统信息,生成hostname_yymmdd_hhmi.nmon文件:
例:
./nmon12e_aix537 -fAW -m /nmon/log -s 60 -c 2400
在/nmon/log 目录下生成格式为hostname_yymmdd_hhmi.nmon的文件,命令间隔为60秒钟,重复运行1440次(即1天)。
把该文件下载到本地,解压nmon_analyser.zip 文件,
打开nmon analyser v33e3.xls
点击按钮Analyse nmon data
选择hostname_yymmdd_hhmi.nmon文件进行分析就能得到所要的数据。
nmon分析工具下载:
http://wenku.baidu.com/view/aa1f3312cc7931b765ce156c.htm
http://hi.baidu.com/jiaju111/blog/item/ea2b2464f73213f8f6365428.htmll
很多时候我们需要利用参数在存储过程中重新组织SQL语句,在存储过程中拼接的SQL语句只是一个字符串,不会被直接执行,所以加一个execute执行它就可以了。具体看如下演示代码:
代码:
set ANSI_NULLS ON
set QUOTED_IDENTIFIER ON
go
-- =============================================
-- Author: yy
-- Create date: 2012-1-17
-- Description: 存储过程SQL字符串拼接示例
-- =============================================
CREATE PROCEDURE [dbo].[Test]
@FileName varchar(10), --字段名
@Operator varchar(1), --操作符
@FileValue varchar(10) --字段值
AS
DECLARE @TempSql varchar(100) --临时存放sql语句
BEGIN
set @TempSql= 'select * from Comment where ' + @FileName + @Operator + char(39) + @FileValue + char(39) --拼接sql字符串,char(39)为单引号
execute(@TempSql) --执行sql字符串
END |
测试:
| execute Test 'newsid','>',4 |
在这解释一下“ALTERPROCEDURE [dbo].[Test]”至“AS”之间的代码和“AS”至“BEGIN”之间的代码有什么区别,像我这种SQL新手应该会有疑问:为什么@TempSql要定义在“AS”至“BEGIN”之间?因为,“AS”至“BEGIN”之间定义的为临时变量,前边必须加DECLARE,和其他语言中普通变量的使用方法相同;而“ALTER PROCEDURE [dbo].[Test]”至“AS”之间定义的是存储过程被调用时传入的必要参数,必须在调用的时候就赋值,不可以加DECLARE,可以理解为字符常量,一旦调用时被赋值,就再无法改变,就上边例子来说,类似@FileName=’xxx’的写法是错误的。因为@TempSql只是用来接受SQL语句的临时变量,没有初值,但必须接受值,所以要定义在“AS”至“BEGIN”之间。
“通过一次真正彻底地代码审查(code reviews),仔细阅读你的代码,找出问题,这是我知道的最好的方式去检测早期的bug,但是他们很少去这样干过。某种意义上是因为他们花了大量的时间去写好代码,但是我认为主要是因为绝大部分程序员害怕其他人审查自己的代码。作为专业的程序员我们要克服阻力,如果你不愿意别人阅读你的代码,然后只是按照自己的意愿写,如果其他人没法读懂它,又怎能让别人使用呢?”Jim Waldo – 《Java语言精粹》的作者
我强烈赞同code review 是软件生命周期管理中重要的一部分,因为它能帮助我们交付高质量代码、合格作品。
传统上code review仅是一个形式,通常在代码提交之前由团队负责人或高级程序员负责。在敏捷开发环境中,通过团队合作code review 更系统化,代码的目标和期望应该能用编码指南清晰的定义出来,code review的目标是协同合作,而不是查错。总之code review对整个团队尤其每个程序员都有好处,所以每个人都应该参与进来。

code review的好处:
俗话说三个臭皮匠赛过诸葛亮,code review 更易于发现代码bug等问题
3、保证代码质量以及提高代码可读性
2、团队之间建立信任
1、指导初级程序员
编码标准是独立于语言的,对于Java 程序员来说,我想从以下几个范围来做code review
Java code review的标准:
合适的变量声明;如:实例变量还是静态变量、常量等
9、性能问题;如:当没有线程安全问题时使用ArrayList,HashMap替代Vector,Hashtable
8、内存问题;如:本应使用对象重用或者对象池时却被不恰当的初始化,没有在finally块中关闭昂贵的资源。
7、数据访问问题:从数据库一次获取数据太多,请求太多的数据库调用。
6、线程安全问题;如:Java API类像SimpleDateFormat,Calendar,DecimalFormat等不是线程完全的,在JSP中声明变量也不是安全的,存储状态信息在Struts action类中或者多线程servlet也不是线程安全的。
5、对错误的处理:异常抛出而没有保持原始模型(希望Java7修复它),没有记录到日志系统中
4、System.out常被log4j替换
3、设计问题:没有重用代码,没有清晰的责任分离。如:业务逻辑嵌套在servlet中,而没有使用业务逻辑层,可视化元素(如HTML,CSS)嵌入在后台。
2、代码文档:没有注释,没有头文件等
1、从给定的框架中遵循最佳实践:如Spring3中注解替代xml文件对于IOC, 对于每一个简单的部署使用外部属性替代硬编码值等
你应该为团队做个code review的文档和模板,随着项目的开始同步更新,学习更多你项目中选择的软件。
工欲善其事必先利其器
code review 工具:
3、Crucible 是 Atlassian公司的工具用来不间断处理的审查工作,Crucible能做代码审查而且高度集成在JIRA和FishEye中,支持Subversion、Git等其他类型的VCS。一个通用的例子就是Crucible提供一个转换凭证的工作流,从打开》审查》解决,另一种情景是在代码改变后check- in了之后自动审查。
2、Gerrit ,Gerrit一个基于web的code review系统。通过Git版本控制系统能方便在线做code reviews。
1、Checkstyle: 并不只是一个code review 工具,更是一个开发工具确保开发者的代码遵循标准,在每一次code review中节省时间。
最重要的是,使用Checkstyle能使代码检查成为一个相对简单的任务,你可以把code review 作为日常活动中的一部分而不需要在项目结束的时候才开始,因为那时候项目的交付期限让你的生活一团糟了。