测试用例分析与设计是整个测试生命周期中非常重要的一个活动,该测试活动的输出是后续测试执行的主要输入,其质量直接影响后续测试效率、有效性及测试质量。测试用例分析与设计的过程,采用的技术与方法,以及测试人员的测试经验与技能等,都会影响最终的测试用例质量。
图1是测试用例设计生命周期示意图。在该示意图中,包括了测试用例设计相关的主要测试活动,可能可以采用的技术与方法等。主要的测试活动包括:
1)确认测试用例设计的参考输入来源;
2)识别初始测试条件(测试点);
3)采用测试类型分析与功能交互分析细化测试条件;
4)采用测试用例设计技术与方法设计测试用例;
5)输出测试用例规格说明。
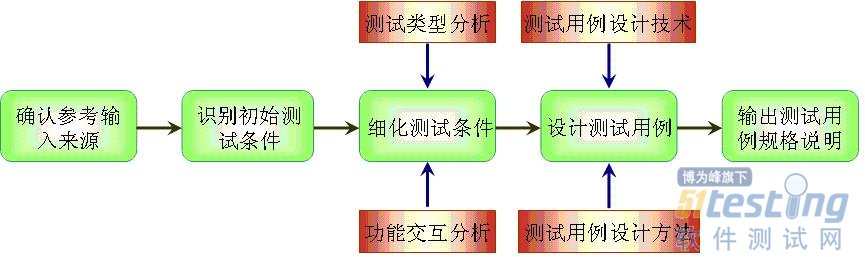
图1 测试用例设计生命周期
1)确认参考输入来源
测试用例设计不能仅仅依靠测试人员大脑中的一些经验和知识,良好的测试用例设计需要参考各种不同的参考输入文档。其中包括:
(1)开发文档,指的是软件开发过程中的各种软件工作产品,例如:系统需求规格说明、概要设计规格说明等;
(2)用户需求,测试的工作不仅是验证开发文档中定义的要求是否满足,同时也需要确认软件产品是否真正满足用户的需要。因此,测试人员了解用户需要是非常必要的。
(3)标准与规范,开发文档中有些内容之来来源于标准与规范,而没有在文档中详细描述其中的要求,因此它们也是测试人员进行测试设计的重要参考依据;
(4)类似产品需求,随着迭代-增量开发模型应用越来越广,测试人员经产面临的产品是基于已有系统之上,因此,以前产品的版本信息和质量信息对于当前的测试也很重要;
(5)测试经验知识库,可以来自测试执行的经验、测试过程中发现的缺陷分析和分类、用户反馈的缺陷的分析和分类等;
(6)其他隐现需求,例如:和开发人员面谈得到的信息、杂志和网络中的一些缺陷列表等。
2)识别初始测试条件
测试人员得到测试用例设计的主要参考来源之后,需要对这些文档内容进行仔细学习和研究,并从不同的参考输入来源中识别初始的测试条件(或者测试点)。测试条件颗粒度可以根据参考输入文档的内容来确定,例如:一条需求条目映射为一条初始测试条件,或者多条需求条目映射为一条初始测试条件。
3)细化测试条件
根据参考输入来源获得的初始测试条件,通常来说颗粒度是比较粗的,测试人员需要采用测试类型分析和功能交互分析等方法进行细化。例如:针对某条初始测试条件,测试人员可以考虑是否在每个不同的测试类型上面都需要考虑。详细的测试类型分析与功能交互分析,请参考后续的文章。
4)设计测试用例
得到细化的测试条件之后,测试人员需要采用不同的测试用例设计技术与方法,来设计具体的测试用例。在设计测试用例的过程中,测试人员可能发现测试条件需要更新,或者当前的测试条件并适合设计。因此3)细化测试条件与4)设计测试用例之间并不是单向的测试活动,它们之间有时候需要不断的相互迭代。
5)输出测试用例规格说明
最后,包含测试步骤和期望结果的测试用例,按照测试对象特性或者特性组合形成不同的测试用例规格说明。
近段时间,一部分工作在进行自动化测试开发,一部分工作在于资源整合,一部分工作在自动化测试推广,而感触最深的就是推广了,自动化测试难点一在于应用,难点二则在于应用推广,再好的技术底蕴,再好的形式,没有一个好的推广过程,则也是不行的,根据这段时间和过去的一些教训,在此总结一下,希望不对的大家能指出。
一、现象分析
做过自动化测试推广的人员应该都会遇到这么几个现象:刚开始推广自动化测试时,测试人员都很好奇,都会积极的参与配合,但是测试人员的热情在一段时间之后会被自动化测试人员的不断变动性所打败,所以,作为一个测试人员,你应该把测试人员的信任值和热情度牢牢把握。
1、自动化测试人员总是不断的更新框架,从而导致测试脚本不断变更,造成测试人员不断去定位测试脚本和维护测试脚本,造成测试人员对自动化测试信任度降低。
2、测试脚本在还未规模化应用的时候,则去强行的开发大型的测试平台,这样带来的问题就是后期的变动性造成了平台架构的变动,从而导致测试脚本和测试平台的兼容性差。
3、测试开发人员犯的一个很大的错误就是不断推出一系列不成熟的工具,即只想着去开发一个工具,而把测试人员还是当成了“测试人员”,而不是用户,从而造成了测试人员对测试工具的使用的畏惧性。
4、不够双赢;很多时候,测试人员做的工作往往被忽略,例如:测试开发人员开发的脚本数量是一个绩效,造成对开发出的脚本质量往往不负责任,但是测试人员对别人开发的脚本和环境的维护则没法进行量化统计,这样测试人员还不如手工测试来的绩效高,这样,则造成了测试人员对自动化测试的积极性不高。
二、对现象的思考和实践分析
1、脚本的稳定性应该是放在第一位的,不管刚开始的设计和想法多么宏大,你也必须克制自己,不管线性脚本,不管封装也好,从最基础开始,让测试人员首先感觉到脚本的运行顺畅性,而不是频繁的维护。这也是一个前期自动化测试的一个先锋部对,不求一下攻克,只求快速获得情报和前线支持,为后面的大军进发做准备。
2、决定开发了一个框架的话,那么就要先考虑到可拓展架构,或者快速做一个原型,采取功能迭代增加的方式,一定记住的时,能抽像到底层的一定要抽象,千万不要把特性的东西写死在底层,而是要分离。不然你会发现:前期写死一个变量,也许会让你在后期的某一个拓展中造成你的所有脚本瘫痪。
3、测试平台、持续集成平台之类的都是架子,个人觉得,要保证的是:测试平台和测试脚本是分开的,即测试脚本可以脱离平台单独执行,而不是脚本需要依赖于平台执行,因为有时候移植工作其实是一个很大的工作量,你不能保证你的平台永远没有变化,平台好变,大量的脚本不好变。
4、预期开发一堆的全面化的复杂的测试工具,还不如在一个点上把一个工具做精了,让测试人员真正觉得好用,那么你的自动化测试才能慢慢被他们接受,从而配合你的工作。其实这种策略很常见:很多平台化的公司做大前都是从一个点开始,把一个点做精了,这样就可以以此为入口,从而建立起一个产品体系。少做即是多做,这真是真理啊。
5、分享一个我推广自动化测试的例子:在部门内部,以一个自动化测试活动为一个项目,测试人员做为项目负责人,我则可以作为项目协助人参与。例如:一个关键字测试驱动用例项目,测试人员来设计测试驱动设计文档,包括划分的关键字点、环境、参数等。由另外的手工测试执行人员来测试执行过程中,组装关键字,最终形成测试脚本用例。关键字、文档以及脚本便作为整个项目的输出,以项目为活动颗粒的好处是职责容易细分,进度容易把握,并且最重要的是能够让测试人员主动性更强。所以,在推广过程中,要采用各种策略让测试人员的能力提升和职业发展相结合,让他们的成果突出,这样你给他负责,他才对你负责。
总结:其实推广过程中,最大的经验就是一定要站在不同的角度上思考问题;学会以辅助的角度去做人做事;学会珍惜别人的时间和劳动成果,学会将别人的成果最大化,学会双赢;有时候学会自己宁愿多做点,不要告诉比人;也许,这样,你得到的将是你意想不到的。
先决条件 要充分理解本文,必须具备Windows 环境下桌面应用程序的工作经验,我认为读者对如何使用 Linux 桌面有一个基本的了解。使用一个运行的 Linux 计算来机探讨本文的概念和示例是很有帮助的。
概述
有时候第一次在 Linux 上运行一个应用程序需要一点额外工作。有些应用程序,比如服务器服务,可能无法安装为服务,因此您需要从命令行启动这些应用程序。对于启动这些应用程序的用户帐户而言,需要在应用程序文件中设置执行许可标志 (x)。
运行用户空间应用程序
Linux 在内核空间或用户空间运行进程。用户空间 是操作系统的区域,应用程序通常在此运行。简单地说,每个用户帐户有其自己的用户空间,应用程序在这个领域内运行。
默认情况下,只有 root 用户有权访问内核空间。root 用户 是 Linux 中的超级用户,相当于 Windows 中的管理员帐户。在 root 用户帐户下运行应用程序可能会引起安全风险,是不可取的。
很多服务器服务需要 root 权限启动服务。然而,服务启动后,root 帐户通常会将其移至服务帐户。严格地说,Linux 中的服务帐户 才是标准的用户帐户。主要区别是服务帐户仅用于运行一个服务,而不是为任何实际登录的用户准备的。
设置权限
您可以使用 chmod 命令在一个文件中设置执行权限。在 Linux 中,umask 设置通常用来防止下载的文件被执行,也有充分的理由相信,因为它有助于维护 Linux 计算机的安全性。
大多数 Linux 发行版具有一个值为 022 的 umask 设置,这意味着,默认情况下一个新文件权限设置为 644。权限的数字表示形式采用读 (4)、写 (2)、执行 (1) 的格式。因此,默认权限为 644 的应用程序下载意味着文件所有者有读写权限,而组用户和其他用户只有读权限。
例如,为每个人赋予一个文件的执行权限,使用 chmod a+x 命令。a 表示所有人,加号 (+) 表示添加,而 x 表示执行。同样地,如果应用程序是一个服务器服务,您应该确保只有授权帐户才有权执行此服务。
如果一个应用程序能够在标准用户帐户权限下运行,但只有特定组中的用户才需要使用它,您可以将该组所有者权限设置为可执行,然后将这些用户添加到该组中。
更具体地说,您可以在一个可执行文件中设置访问控制列表 (ACL) 权限,赋予特定用户或组权限来运行该应用程序。使用 setfacl 实用工具设置 ACL 权限。
对于这些需要以 root 用户启动进程的应用程序,比如服务器服务,您有几个选择。总结了允许用户执行需要 root 权限的服务器服务的各种选项。
选项 | 描述 |
作为 root 用户 | 不推荐用于服务器服务。当用户已经知道 root 密码而且应用程序泄露不是首要关注问题时,可用于应用程序。 |
SetUID | 由于安全问题,不推荐使用。SetUID 允许标准用户以另一个用户方式,比如 root 用户,执行一个文件。 |
sudo | 很常用,并且被认为是一个很好的实践。sudo 授予一个用户或组成员权限以执行可能额外需要 root 权限的文件。该用户不需要知道 root 密码。 |
带有文件权限的标准用户帐户 | 在一个文件上为用户所有者、组所有者或其他人(所有人)设置执行权限。这是授予那些不需要 root 权限来执行应用程序的用户的常用方法。 |
带有 ACL 权限的标准用户帐户 | 使用较少,但是如果您不想授予一个用户 sudo 访问或者更改文件的权限,这也是一个可行的解决方案。在一个文件上使用 setfacl 命令,您可以授予一个特定用户或用户组执行该文件的权力。 |
从命令行运行
在管理 Linux 服务器时,从命令行运行应用程序是一项基本的任务。很多应用程序使用 shell 脚本(类似于 Windows 批处理文件 .bat)来启动应用程序并执行其他任务,比如设置变量以及为其他用户分配进程。例如,应用程序可能需要一个 Java? Virtual Machine (JVM) 来执行。那样的话,shell 脚本可以设置适当的环境变量,然后执行 Java 命令来运行 Java Archive (JAR) 或类文件。这同样适用于使用 Perl、Python、甚至 C# 的应用程序。(当然,C# 编译的应用程序可以在 Linux 上运行)
从命令行或者 shell 提示符执行应用程序的一个常用方法是使用 ./ 命令。如果您在 Linux 中使用句号 (.) 和正斜杠 (/),就意味着告诉环境您想要以可执行文件运行该文件。例如,运行一个名为 myapp 的可执行文件,您可以使用 ./myapp 命令。同样地,您可以在文件名之前加上语言环境,比如:
● sh
● php
● python
● perl
● java
但更多情况下,套装应用程序使用 shell 脚本,以 #! 符号设置环境变量提供该语言的运行时可执行路径,比如 #!/usr/bin/python。您也应该熟悉这种方法。
清单 1 使用 catalina.sh 默认脚本通过 ./ 方法启动 Apache Tomcat 应用程序服务器。然后,使用 sh 方法启动服务器。因为默认端口是 8080,标准用户不需要对其进行特别修改就可以启动该服务。
清单 1. 从命令行执行应用程序
| $ ./catalina.sh start
Using CATALINA_BASE: /opt/apache-tomcat-7.0.26
Using CATALINA_HOME: /opt/apache-tomcat-7.0.26
Using CATALINA_TMPDIR: /opt/apache-tomcat-7.0.26/temp
Using JRE_HOME: /usr
Using CLASSPATH: /opt/apache-tomcat-7.0.26/bin/bootstrap.jar:
/opt/apache-tomcat-7.0.26/bin/tomcat-juli.jar
$ ./catalina.sh stop .....................................................................
$ sh catalina.sh start Using CATALINA_BASE: /opt/apache-tomcat-7.0.26
Using CATALINA_HOME: /opt/apache-tomcat-7.0.26
Using CATALINA_TMPDIR: /opt/apache-tomcat-7.0.26/temp
Using JRE_HOME: /usr
Using CLASSPATH: /opt/apache-tomcat-7.0.26/bin/bootstrap.jar:
/opt/apache-tomcat-7.0.26/bin/tomcat-juli.jar |
考虑启动一个典型 Hypertext Transfer Protocol (HTTP) Web 服务器。在 Linux 中,任何低于 1024 的端口被认为是一个权限端口,只有 root 可以打开权限端口。因为,默认情况下,Web 服务器运行于端口 80,root 需要启动该进程。然而,如上所述,以 root 用户运行一个服务被认为是不安全的。正确的步骤是以 root 启动 该服务,然后将其转移到一个标准用户或者服务帐户。
幸运的是,许多服务器服务由脚本来执行这一操作。如果您从头开始构建 Apache Web 服务器,您将会发现它以 root 用户启动,然后将 httpd 线程转交给 apache 用户。
清单 2 启动一个默认的 Apache 2 Web 服务器编译。安装流程也做了一些事情,包括使 apachectl 命令可执行。因为该流程需要使用端口 80,使用 root 用户权限启动。然而,ps 命令显示 httpd 流程在 apache 用户帐户下运行。
清单 2. 启动 Apache Web 服务器
# cd /usr/local/apache2/bin
# apachectl start
#ps aux | grep httpd
apache 23094 0.0 0.3 11784 1912 ? S 10:41 0:00 /usr/sbin/httpd -k start
apache 23095 0.0 0.3 11784 1912 ? S 10:41 0:00 /usr/sbin/httpd -k start
apache 23096 0.0 0.3 11784 1912 ? S 10:41 0:00 /usr/sbin/httpd -k start
apache 23097 0.0 0.3 11784 1912 ? S 10:41 0:00 /usr/sbin/httpd -k start
apache 23098 0.0 0.3 11784 1912 ? S 10:41 0:00 /usr/sbin/httpd -k start |
在后台运行应用程序
一些安装的软件可能不像 Apache Web 服务器那样用户友好。您很可能需要在流程启动后以后台方式运行它,除非您正在进行故障排除,或者想要看看应用程序到底怎么了。如果您没有这么 做,shell 关闭后应用程序将终止。运行服务器服务时,可不希望每次关闭终端 shell 或者退出时服务都会停止!
如果在后台运行一个应用程序,即使关闭了 shell 窗口,应用程序也会继续运行。您可以通过在执行命令结尾附加一个 (&) 符号来启动应用程序。例如,您可以使用 vi 编辑器打开文件,然后使用 vi /etc/sysconfig/network & 命令在后台运行该文件,因为 & 可以打开 /etc/sysconfig/network 文件并将其保留在后台。即使在退出后,您也可以使用 nohup 实用工具支持进程继续运行。例如,nohup vi /etc/sysconfig/network &。
清单 3 在 Vim 编辑器中打开一个用来编辑的文件,然后将其放在后台。
清单 3. 在后台运行应用程序
| # vi /etc/sysconfig/network & [1] 24940 # jobs [1]+ Stopped vi /etc/sysconfig/network |
您可以输入 jobs 命令来查看您在后台上运行的所有应用程序。为在后台上运行的每个任务分配了一个序列号,从 1 开始。 清单 3 中的任务序列号是 1。24940 是进程 ID (PID)。您可以使用 fg 命令和特定的任务号将应用程序移到前台。在本例中,进程没有被用户所使用,因此显示为 Stopped。但是,命令 fg 1 打开终端并回到编辑文件的活动进程。
从桌面运行应用程序
在 Linux 中从桌面运行图形用户界面 (GUI) 应用程序与在 Windows 中没多大区别。通常,您需要了解特定的桌面环境下应用程序在菜单中是如何分组的。Linux 有足够的桌面应用程序,可用于各种任务。有一些应用程序是 Linux 本机固有的,还有另外一些应用程序可能是在一个常用运行时环境中使用 C# 开发的跨平台应用程序,比如,.NET Framework 应用程序。您会发现,使用一个 Wine 这样的虚拟环境,您甚至可以在 Linux 上运行您最喜爱的 Windows 应用程序。
Linux 本机应用程序 您很有可能会为您最喜爱的基于 Windows 的应用程序找到一个替代的 Linux 应用程序。在桌面上运行 Linux 本机应用程序比较直观。与 Windows 一样,您通常可以在菜单中找到这些已组织的应用程序,当您想要一个 Windows 应用程序时,只需单击并运行即可。
对于那些需要 root 权限的应用程序,将会提示您输入 root 密码,然后才开始运行。这在概念上类似于 Windows 中的 Run as Administrator 选项。否则,您运行的所有程序都会位于您所登录帐户的用户空间中。
在 Windows 中,您可以创建桌面快捷键。Linux 也有类似的快捷键 launcher,您可以将它放在面板或桌面上。单击 launcher 时,快捷键将执行程序。
图 1 显示 GNOME Desktop 上 Mozilla Firefox Web 浏览器的两个 launcher。一个 launcher 位于面板上,另一个位于桌面上。
图 1. 查看桌面或面板上的 launcher

Mono
许多 Windows 应用程序都是使用 .NET Framework 开发的。Mono 是 .NET 的一个开源实现,可在很多平台上运行(包括 linux)。事实上,Mono 网站称其为 C# 和 Common Language Runtime (CLR) 的一个实现,与 .Net 是二进制兼容的。此项目目前由 Xamarin 支持。
在 Linux 上,您可以执行使用 .NET framework(或 Mono)开发的应用程序,就像在 Windows 上一样。但是,记住 Linux umask 和默认文件权限。您仍然需要提供文件的执行权限,这样 Linux 才会允许执行可执行文件。
在 Mono(可以安装在您的 Linux GNOME 桌面上)上开发的一些跨平台应用程序,比如 F-Spot,同本机 GNOME 应用程序一同位于菜单中。F-Spot 是一个管理照片的开源应用程序。尽管它是 C# 应用程序,但是在 GNOME 桌面上表现为一个本机应用程序。为应用程序创建一个 launcher 后,就可以像在 Windows 中那样单击并运行。
图 2 演示了基于 Mono 的应用程序 F-Spot 的位置,以及为其创建桌面或面板 launcher 的方法。
图 2. 为 F-Spot 创建一个 launcher

Wine
Wine 使您可以在 Linux 和其他操作系统上运行 Windows 软件。有了 Wine,您就可以像在 Windows 中那样安装和运行应用程序。Wine 仍然在积极的发展中,而且并不是所有的 Windows 程序都可以使用 Wine。如果您的应用程序是为 Windows 操作系统编译的,您就会发现它可以使用 Wine 来充分运行,前题是它是一个桌面应用程序而不是一个服务器应用程序。一定要检查 Wine 文档关于在 Linux 上运行该应用程序的可行性,因为 Wine 并不完全支持所有的应用程序。
当您在 Linux 中使用 Wine 时,在您帐户主目录下有一个模拟 Windows 环境的隐藏文件夹,如 清单 4 所示。
清单 4. 模拟 Windows 环境的 Wine 的隐藏文件夹
$ cd /home/tbost/.wine/drive_c/windows
$ls
cf8e.tmp
command
explorer.exe
Fonts
help
hh.exe
inf
Installer
ls.txt
Microsoft.NET
notepad.exe
pwd.txt
regedit.exe
rundll.exe
system
system32
system.ini
temp
twain_32.dll
twain.dll
winhelp.exe
winhlp32.exe
win.ini
winsxs |
使用 Wine 安装一个应用程序之后,您通常可以在桌面菜单中找到它,然后以在 Windows 中同样的方式来运行。
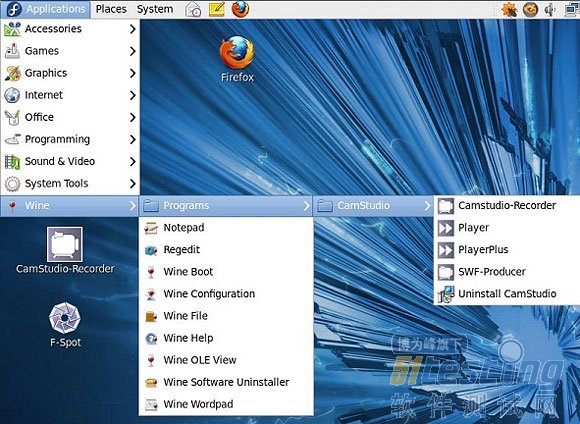
例如,Camstudio 是一个开源工具,用于记录和管理屏幕视频。目前还没有 Linux 操作系统的版本。但是,使用 Wine 就可以在 Linux 桌面安装 Windows 版本。与 Wine 相关的应用程序通常分组为 Applications > Wine > Programs,如 图 3 所示。
图 3. 使用 Wine 在 Linux 上运行一个 Windows 应用程序
结束语
在管理一个 Linux 服务器时,您肯定会遇到从桌面和命令行执行软件的问题。了解如何设置适当的权限和用户帐户后,您就可以安全地运行这些应用程序。使用长期运行的进程,比如 服务器服务,您可以从命令行执行,并在后台进行适当设置。如果您的应用程序适合于从桌面运行,也可以那样做,有时候甚至可以是 Windows 应用程序!
很多核心Java面试题来源于多线程(Multi-Threading)和集合框架(Collections Framework),理解核心线程概念时,娴熟的实际经验是必需的。这篇
文章收集了 Java 线程方面一些典型的问题,这些问题经常被高级工程师所问到。
0、Java 中多线程同步是什么?
在多线程程序下,同步能控制对共享资源的访问。如果没有同步,当一个 Java 线程在修改一个共享变量时,另外一个线程正在使用或者更新同一个变量,这样容易导致程序出现错误的结果。
1、解释实现多线程的几种方法?
一 Java 线程可以实现 Runnable 接口或者继承 Thread 类来实现,当你打算多重继承时,优先选择实现 Runnable。
2、Thread.start ()与 Thread.run ()有什么区别?
Thread.start ()方法(native)启动线程,使之进入就绪状态,当 cpu 分配时间该线程时,由 JVM 调度执行 run ()方法。

3、为什么需要 run ()和 start ()方法,我们可以只用 run ()方法来完成任务吗?
我们需要 run ()&start ()这两个方法是因为 JVM 创建一个单独的线程不同于普通方法的调用,所以这项工作由线程的 start 方法来完成,start 由本地方法实现,需要显示地被调用,使用这俩个方法的另外一个好处是任何一个对象都可以作为线程运行,只要实现了 Runnable 接口,这就避免因继承了 Thread 类而造成的 Java 的多继承问题。
4、什么是 ThreadLocal 类,怎么使用它?
ThreadLocal 是一个线程级别的局部变量,并非“本地线程”。ThreadLocal 为每个使用该变量的线程提供了一个独立的变量副本,每个线程修改副本时不影响其它线程对象的副本(译者注)。
下面是线程局部变量(ThreadLocal variables)的关键点:
一个线程局部变量(ThreadLocal variables)为每个线程方便地提供了一个单独的变量。
ThreadLocal 实例通常作为静态的私有的(private static)字段出现在一个类中,这个类用来关联一个线程。
当多个线程访问 ThreadLocal 实例时,每个线程维护 ThreadLocal 提供的独立的变量副本。
常用的使用可在 DAO 模式中见到,当 DAO 类作为一个单例类时,数据库链接(connection)被每一个线程独立的维护,互不影响。(基于线程的单例)
ThreadLocal 难于理解,下面这些引用连接有助于你更好的理解它。
《Good article on ThreadLocal on IBM DeveloperWorks 》、《理解 ThreadLocal》、《Managing data : Good example》、《Refer Java API Docs》
5、什么时候抛出 InvalidMonitorStateException 异常,为什么?
调用 wait ()/notify ()/notifyAll ()中的任何一个方法时,如果当前线程没有获得该对象的锁,那么就会抛出 IllegalMonitorStateException 的异常(也就是说程序在没有执行对象的任何同步块或者同步方法时,仍然尝试调用 wait ()/notify ()/notifyAll ()时)。由于该异常是 RuntimeExcpetion 的子类,所以该异常不一定要捕获(尽管你可以捕获只要你愿意).作为 RuntimeException,此类异常不会在 wait (),notify (),notifyAll ()的方法签名提及。
6、Sleep ()、suspend ()和 wait ()之间有什么区别? Thread.sleep ()使当前线程在指定的时间处于“非运行”(Not Runnable)状态。线程一直持有对象的监视器。比如一个线程当前在一个同步块或同步方法中,其它线程不能进入该块或方法中。如果另一线程调用了 interrupt ()方法,它将唤醒那个“睡眠的”线程。
注意:sleep ()是一个静态方法。这意味着只对当前线程有效,一个常见的错误是调用t.sleep (),(这里的t是一个不同于当前线程的线程)。即便是执行t.sleep (),也是当前线程进入睡眠,而不是t线程。t.suspend ()是过时的方法,使用 suspend ()导致线程进入停滞状态,该线程会一直持有对象的监视器,suspend ()容易引起死锁问题。
object.wait ()使当前线程出于“不可运行”状态,和 sleep ()不同的是 wait 是 object 的方法而不是 thread。调用 object.wait ()时,线程先要获取这个对象的对象锁,当前线程必须在锁对象保持同步,把当前线程添加到等待队列中,随后另一线程可以同步同一个对象锁来调用 object.notify (),这样将唤醒原来等待中的线程,然后释放该锁。基本上 wait ()/notify ()与 sleep ()/interrupt ()类似,只是前者需要获取对象锁。
7、在静态方法上使用同步时会发生什么事?
同步静态方法时会获取该类的“Class”对象,所以当一个线程进入同步的静态方法中时,线程监视器获取类本身的对象锁,其它线程不能进入这个类的任何静态同步方法。它不像实例方法,因为多个线程可以同时访问不同实例同步实例方法。
8、当一个同步方法已经执行,线程能够调用对象上的非同步实例方法吗?
可以,一个非同步方法总是可以被调用而不会有任何问题。实际上,Java 没有为非同步方法做任何检查,锁对象仅仅在同步方法或者同步代码块中检查。如果一个方法没有声明为同步,即使你在使用共享数据 Java 照样会调用,而不会做检查是否安全,所以在这种情况下要特别小心。一个方法是否声明为同步取决于临界区访问(critial section access),如果方法不访问临界区(共享资源或者数据结构)就没必要声明为同步的。
下面有一个示例说明:Common 类有两个方法 synchronizedMethod1()和 method1(),MyThread 类在独立的线程中调用这两个方法。
- public class Common {
-
- public synchronized void synchronizedMethod1() {
- System.out.println ("synchronizedMethod1 called");
- try {
- Thread.sleep (1000);
- } catch (InterruptedException e) {
- e.printStackTrace ();
- }
- System.out.println ("synchronizedMethod1 done");
- }
- public void method1() {
- System.out.println ("Method 1 called");
- try {
- Thread.sleep (1000);
- } catch (InterruptedException e) {
- e.printStackTrace ();
- }
- System.out.println ("Method 1 done");
- }
- }
|
- public class MyThread extends Thread {
- private int id = 0;
- private Common common;
-
- public MyThread (String name, int no, Common object) {
- super(name);
- common = object;
- id = no;
- }
-
- public void run () {
- System.out.println ("Running Thread" + this.getName ());
- try {
- if (id == 0) {
- common.synchronizedMethod1();
- } else {
- common.method1();
- }
- } catch (Exception e) {
- e.printStackTrace ();
- }
- }
-
- public static void main (String[] args) {
- Common c = new Common ();
- MyThread t1 = new MyThread ("MyThread-1", 0, c);
- MyThread t2 = new MyThread ("MyThread-2", 1, c);
- t1.start ();
- t2.start ();
- }
- }
|
字体: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿
10、什么是死锁
死锁就是两个或两个以上的线程被无限的阻塞,线程之间相互等待所需资源。这种情况可能发生在当两个线程尝试获取其它资源的锁,而每个线程又陷入无限等待其它资源锁的释放,除非一个用户进程被终止。就 JavaAPI 而言,线程死锁可能发生在一下情况。
● 当两个线程相互调用 Thread.join()
● 当两个线程使用嵌套的同步块,一个线程占用了另外一个线程必需的锁,互相等待时被阻塞就有可能出现死锁。
11、什么是线程饿死,什么是活锁?
线程饿死和活锁虽然不想是死锁一样的常见问题,但是对于并发编程的设计者来说就像一次邂逅一样。
当所有线程阻塞,或者由于需要的资源无效而不能处理,不存在非阻塞线程使资源可用。JavaAPI 中线程活锁可能发生在以下情形:
● 当所有线程在程序中执行 Object.wait(0),参数为 0 的 wait 方法。程序将发生活锁直到在相应的对象上有线程调用 Object.notify()或者 Object.notifyAll()。
● 当所有线程卡在无限循环中。
这里的问题并不详尽,我相信还有很多重要的问题并未提及,您认为还有哪些问题应该包括在上面呢?欢迎在评论中分享任何形式的问题与建议。
相关链接:
Java程序员集合框架面试题
四、需求分析→数据库设计
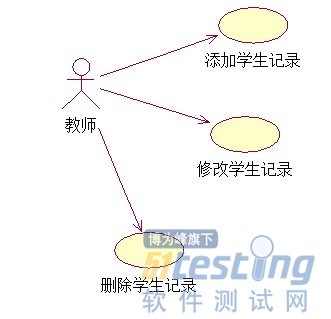
从这开始,就真正进入项目实战啦。先说点体会,我刚开始接触编程的时候,都是编写一些小东西,往往都是半天或者一天什么的就编完了,那时候根本没想过做程序之前还要有需求分析。经过快两年的学习, 接触的都是比较大的系统,才明白没有需求分析的程序都太业余了,没有任何技术含量。对于一个系统来说,如果需求分析不到位,那么将有灾难性的后果,从这节 的小标题就能看出,需求是数据库设计的基石,需求定了,数据库基本上就定了,数据库定了,程序的基本功能也就定了。我们以一个简单的学生管理系统为例子, 来分析一下需求。分析需求地球人一般都是用UML图,啥是UML图呢,就是一种把程序用图形表示的标准,它可以表示需求、程序流程、程序模块、程序功能等 等,可以说,UML图画完了,程序基本上就出来了,目前比较好的画UML的工具是Rational rose,不多说啦,剩下的就交给google了。本系统的需求非常简单,就是老师可以添加、删除、修改学生记录,学生的记录包括:学号、年级、班级、姓名、性别、年龄、备注(这些就是字段)。根据这些叙述,我们可以画出UML用例图(用例图就是用来分析需求的):
根据需求分析我们就可以设计数据库了,非常“简单”嘛,需要一个表就行了,把它命名为student表,里边添加刚刚提的那些字段就可以了。注意,数据 库中的一切,包括:数据库名、表名、字段名、存储过程等等,都要用英文,不可以出现中文,因为咱是专业菜鸟,不走业余路。接着往下看,教你如何创建数据 库。
作为专业教程,俺不会教你用鼠标建立数据库,咱们要用T-SQL语句建立数据库,也就是写数据库脚本。这样建立数据库,相当于留了个备份,无论到哪,只要有SQL环境,直接执行一下脚本数据就建好了,非常方便快捷,就算是第一次写脚本,也比用鼠标建立数据库快。在大型系统开发时,脚本还可以作为数据库维护的依据,非常有用。那么怎样写呢,打开SQL server 2005 Management Studio,输入帐号密码登录平台,然后点一下左上角的"新建查询"就可以打开查询分析器了,我们可以在这输入任何SQL语句。
第一步先创建数据库,我先把创建数据库的标准格式给大家:
create database studentManager
On primary
(
name=student_data,
filename='E:\SQL Server2008 SQLFULL_CHS\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\student_data.mdf',
size=3,
maxsize=unlimited,
filegrowth=1
)
Log on
(name=student_log,
filename='E:\SQL Server2008 SQLFULL_CHS\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\student_log.ldf',
size=1,
maxsize=20, |
相信看着这个很多人都蒙了,简单说一下,其实这么多代码,也就第一句最重要,意思是创建一个名字叫studentManager的数据库。On primary下边的是对数据库的一些初始设置,比如:路径、初始大小、增量等等。Log on下边的是对数据库日志的 设置,也是那么几项。很明确的告诉大家,除非是特殊需求,否则我们没必要管那么多,默认的就够咱们用了,创建数据库就一句话:create database studentManager,输入完后点一下工具栏上的“执行”,就搞定啦。数据库建完了,就该在数据库里建表了,还是先给出代码:
--指定数据库
use t_studentManager;
--创建t_student表
create table t_student
(
number varchar(20) PRIMARY KEY, --PRIMARY KEY 是主键约束
grade varchar(10) NOT NULL, --NOT NULL是非空约束
class varchar(10) NOT NULL,
[name] varchar(20) NOT NULL, --name属于sql保留字,所以用方括号括起来
sex varchar(1) NOT NULL CHECK(sex in ('男','女')), --CHECK约束,意思是性别字段只能是男或女。
age int NOT NULL,
remark varchar(100),
addTime datetime DEFAULT(getdate())--默认值约束,getdate()获取服务器时间
);
给大家解释一下,刚刚我们创建完数据库,在这要引用一下,也就是use,这样才可以在指定数据库中建表。
create table当然就是建表的意思了,在表名前最好加一个“t_”,表示是表(table),这样容易区分,而且专业。括号里的就是这个表中的字段,格式是: 字段名类型 约束,注意每个字段写完后边都要加逗号(最后一个就不用加啦),表示分隔。举这个例子,约束用的还是比较全的,重点说说约束。约束可是数据库中相当重要的 东西,它保证了数据库的安全和稳定,同时也保证了数据完整性。约束主要有6种,分别是:NOT NULL约束(非空约束)、PRIMARY KEY约束(主键约束)、FOREIGN KEY约束(外键约束)、UNIQUE约束(唯一约束)、CHECK约束(检查约束)、DEFAULT约束(默认值约束)。这些约束可以用在任何字段的后 边,一个字段也可以有多个约束,用空格分隔即可,比如上边的sex字段,就同时使用了非空约束和检查约束。当然,有些约束只能用一次,比如主键约束。我只 是提了一下这些常用约束,大家了解我的目的就达到了,以后具体用到,再去google,就怕你不知道有这些约束。在查询分析器中执行这段代码,表就建立好 了,提示一下:SQL查询分析器可以选中执行,也就是你选中那些代码就执行那些代码,建表的时候注意不要再次执行建数据库的语句哦。
五、优化数据库。
数据库设计是程序的根基,也是一门艺术。上一节我们设计的数据库,太随意了,什么都没有考虑,作为专业菜鸟,这样是不行的。
优化数据库,先要了解数据库设计三范式,简单说下:
1、第一范式:是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。
2、第二范式:第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
3、第三范式:第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
这三个范式大致的意思就是:数据库中表的职责要单一,依赖关系明确,尽量减少数据库数据冗余。从网上查,可以查到很多个人理解,我在这也不理解 了,核心思想就是我刚刚说的。我首先声明,三范式只是一个整体的指导思想,并不可能完全遵从,有时候数据冗余未必是坏事,要考虑实际情况。
很明显,刚刚我们设计的数据库不符合三范式的要求。在此表中学生应该依赖的是学号,而我们冒昧的把班级、年级也放在了这里,学生当然也应该依赖 于班级、年级。这样一来,表就乱了,造成的直接后果就是数据不完整,比如我们由于失误,插入了一个年级是100的学生,而根本就没有100这个班级。这样 还有个比较大的问题就是数据冗余,因为我们每插入一个学生,不得不记录一次班级、年级,造成大量无用数据。所以我们要改,要把一个表拆成三个,分别是:年 级表、班级表、学生表。这样一来,数据库就显得漂亮多了。刚刚是一个表,我们还应付得过来,现在三个表,记不住了怎么办?别急,刚刚提到了UML图,它可 以用来设计数据库。在程序设计过程中,数据库中的每一个表,都会在程序中映射成一个类,而表中的每一个字段,都是类中的一个属性,它们的类型是一致的,我 们管他叫做实体类(可以提前google一下三层架构哦),这时我们可以借助于UML中的类图画出数据库的结构。如下图:
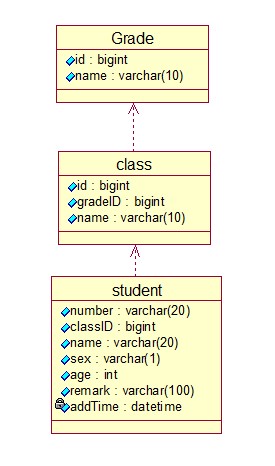
通过UML类图,清晰的描述了表之间的关系。所以,在大型项目开发中,必须借助工具设计数据库,展示数据库的结构和关系,这样我们才能优化、改进 数据库,数据库不是一下就能设计成功的,往往要根据需求的理解而发生变动。很多童鞋可能会问为什么用实体类,我只说一句话:用实体类便于在程序中对数据库 进行操作,实体类是对数据的打包,便于数据传递。剩下的就要去google啦~不多说。这下我们的数据库设计算是完工了,删掉原来的数据库,对照这UML 实体类图写优化后的数据库脚本,代码如下:
| --创建数据库
create database studentManager; --指定数据库
use t_studentManager; --创建年级表
create table t_grade
(
id bigint IDENTITY(1,1) PRIMARY KEY,
[name] varchar(10) NOT NULL
); --创建班级表
create table t_class
(
id bigint IDENTITY(1,1) PRIMARY KEY,
gradeID bigint NOT NULL,
[name] varchar(10) NOT NULL,
CONSTRAINT FK_class_gradeID FOREIGN KEY(gradeID) REFERENCES t_grade(id) --外键约束
); --创建t_student表
create table t_student
(
number varchar(20) PRIMARY KEY, --PRIMARY KEY 是主键约束
classID bigint NOT NULL,
[name] varchar(20) NOT NULL, --name属于sql保留字,所以用方括号括起来
sex varchar(1) NOT NULL CHECK(sex in ('男','女')), --CHECK约束,意思是性别字段只能是男或女。
age int NOT NULL,
remark varchar(100),
addTime datetime DEFAULT(getdate()),--默认值约束,getdate()获取服务器时间
CONSTRAINT FK_student_classID FOREIGN KEY(classID) REFERENCES t_class(id) --外键约束
); |
在讲代码之前,必须先说什么是外键约束,外键约束就是:A表的某个字段用到了B表的主键字段,那么A表中的这个字段就叫外键,A、B两个表间的 约束关系就叫外键约束。A表的外键字段必须依赖于B表的主键字段,如果向A表外键字段中添加一个B表主键字段中不存在的数据,那么将失败。外键约束保证了 数据的完整性和合理性。
这段代码,我还是要重点说说约束,与上一次创建表不同的是,不仅仅是表多了,而且最后多了外键约束,CONSTRAINT是创建一个约束,后边 接约束名;FOREIGN KEY代表该约束是外键约束,括号里写字段名,代表这个字段是外键;REFERENCES是参考的意思,也就是参考哪个表里的哪个字段,也就是主键在哪, 后边接"表名(字段名)"。其实我是故意把它写在最后的边的,外键约束也是约束,完全可以放在字段定义的最后边,也就是NOT NULL那个位置上,我这样写是想告诉大家还有另一种写法,所有的约束都可以类似这样写,就是换个位置,我现在提出来避免大家以后见到发蒙。需要注意的 是,创建表的括号里,无论是写约束还是写字段,都要用逗号分隔,千万别忘了。
最近读了Steve Souders的High Performance
Web Sites: Essential Knowledge for Frontend Engineers(O’Reilly, 2007),这本书的副标题是 “14 Steps to Faster-Loading Web Sites”。在你发现此书面向对象为开发人员,从而停止阅读之前,考虑以下几点:
● 作者的研究表明,网页响应时间约80%-90%是由前端设计决定的。而我的经验中,这个数字更应该是50%-80%,但我的经验多来自于那些被重新设计为WEB架构的多用户应用,或者是那些有着严重后端性能问题的应用(请我来定位问题)。
● 和性能测试人员有关的几乎所有的工具、培训、文章和会议,都集中在系统的后端。以至于大部分人认为,系统的前端性能无需担心,因为我们无法控制客户端的系统。
● 根据我的经验,网站的前端设计和开发,几乎不会考虑到性能问题,除了尽量减小图片的大小。我也从未让团队做过客户端页面的HTML代码审查,从未在这些代码上做过单元测试,也从未见过测试人员有意的对HTML进行一些性能测试。
结合上面几点,你将得知,没有人关注页面上的可能存在的性能优化,而这种优化很可能是最容易实现,效果却又最明显的。读了这本书我发现,我经常对大多数 的前端性能问题进行测试,但自己却没有意识到。作者提到的一些内容,我可能永远也不会想到去测试,不对这些内容进行更主动的测试是个错误,这些测试的成本 是非常低的,无论是在时间上,还是在所需的工具和资源上。实际上,在测试网站的时候,我经常拿出整个性能测试的前15分钟来完成大部分的前端测试,虽然我 承认,15分钟只够测试几个页面。
通过这篇文章,我讲解了如何通过手工、负载生成工具、网络协议分析工具、助手网站以及浏览器插件,来进行测试。我已经通过以下免费工具(不是免费试用版,是无任何限制的免费版)完成了这些工作。 如果你的公司不允许使用免费软件,我相信只要简单的搜索一下,就可以找到一堆可以替代的工具,这些工具将花费你公司足够多的钱,从而让他们重视。(如果你 认为这只是个笑话,很可惜它不是。在咨询过我的团队和接受我培训的个人中,有超过50%的人说过不允许在公司的机器和网络上使用免费、开源、共享、甚至是 有时间限制的免费试用版软件。)
● 免费或者开源的负载生成工具
○ JMeter (http://jakarta.apache.org/jmeter/)
○ WebLoad (http://www.webload.org/)
○ OpenSTA (http://www.opensta.org/)
● 免费或者开源的网络协议分析工具
○ Ethereal (http://www.ethereal.com/)
○ Fiddler (http://www.fiddlertool.com/)
● 免费的浏览器插件
○ Firebug (http://www.getfirebug.com/) with YSlow (http://developer.yahoo.com/yslow/) for Firefox
○ HttpWatch (http://www.httpwatch.com) for IE
● 免费的助手网站
○ Web Page Analyzer - from Website Optimization: Free Website Performance Tool and Web Page Speed Analysis (http://www.websiteoptimization.com/services/analyze/)
○ Gomez Instant Site Test (http://www.gomez.com/info_center/instant_test.php)
有了这些,让我们来看一些你只需看完本文能做的测试,这些测试只需在web层面上即可进行,却可能会显著的改善终端用户的响应时间。
HTTP请求数
页面的获取不是在一个事务中完成的。通常HTML文件需要一个请求,样式表需要一个或多个请求,外部脚本需要一个或多个请求,图片、多媒体内容、以及第 三方那个内容如广告等需要多个请求。即使很多对象已经存在于浏览器缓存中了,还是需要频繁的向服务器发送请求,以确认缓存中的对象是否“fresh”。这 意味着页面上的每一个对象都十分可能会增加负担,进而在用户视角上降低了了性能,即使客户端的浏览器已经缓存了所需的对象。如下几种途径,可以确定页面发 送了多少个请求,以及请求的内容。
无论你用哪种方法,你将首先清除掉浏览器的缓存,或者访问页面两次(一次通过ctrl + F5来强制刷新缓存)以确保能够看到所有的请求。因为这些方法只能收集到真实的请求,如果不清除或刷新缓存可能会导致一些遗漏,让你以为没有去请求一些样 式表、脚本、图片和多媒体内容,很多配置或条件会对此产生影响,而你可能不知道要去设置这些。
1、如果你使用了负载生成工具或者网络协 议分析工具,你可以直接开始录制了,然后浏览感兴趣的页面。在你录制的内容中寻找“GET”语句,看一下请求了什么。记住,有些工具,录制下来的脚本默认 只显示基础的HTML请求,不包括子请求(对样式表、图片、脚本等的请求),如果要看到所有的请求需要进一步的设置。
2、如果你的测试环境允许装浏览器插件,那么有好几种方法可以使这个工作变得简单。根据你所用的浏览器,或者希望测的浏览器,我推荐:
a)FireFox:FireBug+YSlow
b)IE: HttpWatch
3、如果你无法使用任何工具,你仍将有几种选择:
a)访问上面列出的一个助手网站,输入你想测试的页面的URL,点提交。
b)FireFox中,右击页面,选Page Info,导航至Media Tab。注意,这个方法不会显示脚本和样式表,但会显示出请求的图片和其他多媒体内容。
c)IE中,右击页面然后选择View Source。这里,你需要搜寻“link”和“img”字段。如果你找到了样式表的连接(到.css文件的连接),你还需要手动的下载每个样式表,然后 在其中搜索“url”字样,因为这些可能会用来请求脚本、图片和多媒体内容。(这是目前为止最笨的方法,但仍能为你提供信息)
有了你的请求列表以后,第一件事要做的就是看看数量——过多的请求会让页面变慢。有如下几个指标来判断是否是过多的请求。
1、外部样式表请求多于一个。确实有一些时候是应该将页面样式拆分成几个样式表,但这情况并不常见,而且对性能显然没有好处。一般来说,只有当有一个主样式表应用到很多页面,第二个大的样式表只应用到几个页面时,保留多于一个样式表才是个好方法。
2、同一域中脚本的请求多于一个。虽然连接多个外部脚本比连接多个样式表有更好的理由,多个外部脚本连接比 一个连接性能更好,仍然是不常见的。如果你测试的页面是一个复杂的数据输入表单,那么将表单的验证脚本同其他页面的通用脚本分离可能会有些意义。这样做会 减少其他页面(除了表单)的大小,从而改善那些页面的性能,但多出的请求还是会轻微的降低表单页面的性能。不管如何,多于一个外部脚本,至少是值得注意一 下的。
3、大量的图片。我没法说“大量的”是多少,但我可以告诉你,IE7和FireFox 2.x默认每主机名可以有2个并行下载(HTTP/1.1,大部分新网站都是)。这意味着,不管你的图片大小是多少,浏览器一次只能下载两个,只有当之前 的两个都处理完,才会开始接下来的两个。在HTTP/1.0中是不同的,FireFox默认每主机名可以有8并行下载,IE各版本不同,但肯定不会低于 2。这种变化产生的效果就是,使用类似大小但是数量最少的图片易于产生最佳的性能。这和小图片总是好的那种观点是相反的。将几个小图片合成一个或两个大些 的图片,通常会改善性能。当然,这就又会出现一个临界点。图片大小和图片的数量是值得前端工程师仔细研究的,测试多种选择以达到最佳性能。有一个广受好评 的“rull-of-thumb”(提供类似问题的指导),奉劝当一个页面超过12个请求时,一定要谨慎。Souders的这本书和Andrew B. King的in Speed Up Your Site: Web Site Optimization(New Riders, 2003)中都采用了这个数字,而Aaron Hopkins在网站上发表的文章“Optimizing Page Load Time”让这个数字更有说服力。
HTTP请求的顺序
很多类似的方法都可以用来确定页面上请求的顺序(前面提到的助手网站和FireFox的“Page Info”除外,为了突出数量和大小等问题,将请求按类型或者大小进行了分组和排序)。我们所关注的顺序是:
1、首先请求样式表。在样式表下载完之前,页面是不会显示的。或者是下载完样式表要重新刷新页面。基于这一点,让样式表在HTML页面之后第一批请求是非常重要的。
2、最后请求脚本(至少是要靠后)。当开始请求一个脚本的时候,在脚本完全下载完之前不会再发出对其他对象 的请求。此外,脚本下载过程中,浏览器将暂停显示页面内容。这意味着在脚本下载过程中完成的任何对象的下载,都不会被显示出来,从而给人感觉页面的展现停 止了。所以一定要把脚本的请求放到用户最感兴趣的对象之后。记住,大多数用户眼中的响应速度是由他们感兴趣的内容决定的,而不是整个页面的载入时间。
不管你是看HTML源文件还是录制请求,你需要关注的就是样式表最先被请求,脚本在最后或者至少是非常靠后时请求。有一个常见的争论,说负责与 用户交互的脚本(如图像映射、对象反转)应该早些被请求,这样用户会有更好的体验,即便整个页面还正在下载过程中。但我的经验里,由于下载而产生的页面停 止比无法获得图像映射、对象反转功能更容易使用户变得焦躁甚至是离开页面。
重定向和隐藏错误
你仍然可以使用相同的方法来检查重定向问题(3xx状态码),客户错误(4xx),和服务器错误(5xx)。这里,你关注的信息是:
1、过多的3xx。3xx状态表示,请求被处理了,但是浏览器需要到另一个地址去获取所需对象,这就产生了 附加的请求和响应。虽然有很多的原因可以使用重定向,检查一下是否有意使用和存在好理由还是值得做的。比如,将一个删除掉的页面重定向到新地址,或者将明 显拼错的页面重定向到正确的地址,这就是个好的使用理由。图片的父级目录被移动了,没有人去维护更新链接,这就不是一个需要使用重定向、从而接受一些性能 下降的好理由。
2、任何4xx。用户的请求有问题时就会返回4xx状态码。最常见的是404,表示服务器上找不到被请求的对象。一般说来,如果页面的显示和功能都正常,但请求却返回了4xx,那就说明页面请求了不需要的对象,也耗费了多余的时间。
3、任何5xx。5xx表示处理请求时,服务器上发生了错误。任何5xx的状态都需要开发团队注意。
我将这些都称作隐藏错误,是因为当它们发生在非主HTML上时,用户通常是察觉不到的。有时,这些状态码预示着有更深层的错误,但是无论如何,它们都导致了与页面内容无关的请求,这些请求通常也都是完全没有必要的。
HTTP响应头 要检查HTTP响应头,需要使用负载生成工具、网络分析工具或者是浏览器插件。如果你没有这些工具,一个助手网站可以帮到你。我推荐Peter Forret的网站“View and analyze HTTP headers” (http://web.forret.com/tools/analyze.aspx),你只需输入页面的URL,网站就会获取到web服务器返回的一 系列HTTP头,这样就可以检查页面过期和缓存等配置了。至于具体哪些是合适的、哪些是不不要的性能损失,这是和很多内容息息相关的,如网页和对象变化的 频率、用户访问网站的频率、还有用户看到过时内容的相对风险。但是不管怎样,下面的这些是永远值得检查的:
1、过期时间是否恰当。如果一个对象的HTTP响应中没有过期时间这行,每次用户请求包含这个对象的页面 时,都会向服务器发送一个请求,来判断缓存的这个版本是否“新鲜”。如果你有一些不易过期的对象(如公司的Logo),你可以通过设置一个未来很远的日期 来避免这种有效性检查。过期时间最多应用在图片上,但在脚本、样式表、AJAX和FLASH等内容上也经常是适用的。检查一下没有过期时间的对象吧,看看 是不是有不合适的。
2、ETags是否恰当。ETags是一种web服务器和浏览器使用的认证手段,用来判断客户机器上缓存的 对象是否和服务器上的匹配。使用ETags的问题在于,它们对于一个特定的服务器通常是唯一的,这意味着如果网站有多个web服务器,ETags是会出现 问题的。如果你确定只有一个web服务器,那么使用ETags是个不错的主意。如果是多个服务器,你就必须查明是否考虑到了这点,或者干脆建议不使用 ETags。
3、其他缓存控制。你可能会看到类似的内容,Cache-Control、Last-Modified、Pragma、Set-Cookie、Age。如果你看到了,那么确保这些配置是有意义的。如果没有找到,而你又觉得应该有这些东西,那么找人看一下吧。
说到底,其实本质内容就是你要检查HTTP响应头,来判断网站是否已被合理配置来利用浏览器的缓存。通常,判断这些配置是否恰当的唯一方法,是同管理员和架构师探讨网站是如何使用的、以及是如何设计的,尤其是和浏览器缓存有关的地方。
源文件和其他对象
最后,如果你没以前没做过这些,你需要手工检查HTML源文件、css、脚本、图片以及其他对象。到现在,我还没发现任何一款能够节省我们的时 间、对各种情况做出充分检查、并对前端性能提出建议的工具,虽然一些网站使用的HTML、脚本、图片的编辑器还是有一些帮助的。最后,关于前端性能测试, 我的建议是:
1、确保脚本和CSS没有写在HTML源文件中。将脚本和CSS直接写在HTML中来提高性能,几乎是不可 能的。原因很简单:网页的主HTML是更新最为频繁的部分之一,因此从缓存中受益最少。既然HTML很可能每次都要下载,只有尽量减小大小才是上策。将脚 本和CSS与HTML分离,以便利用缓存,是肯定会提高性能的。
2、确保样式和脚本不重复。样式和脚本包含重复内容是非常恶心的。有时,不同的文件中有重复内容,有时在同一个文件中就会重复。你可能不想花费时间去做一个全面检查,那么只需快速的扫描一遍源文件,经常就能发现是否存在明显的重复。
3、检查代码最小化。最小化,指压缩和优化代码,让相关功能使用最少的代码行数。当检查HTML源文件、外部脚本和样式表时,需要注意过多的注释、空格、换行、变量名长度、以及其他能够增加文件大小的内容。
4、检查图片的大小和压缩。虽然大家都明白,仍然还有很多网页设计者使用这样一些图片格式,要么有不必要的 文件大小、要么是同显示尺寸不同的尺寸、要么就是超过了所需要的品质。通常,GIF格式的图片是被压缩成64位甚至更少颜色的,它们完全满足大部分的图片 和缩略图;JPG格式的图片被压缩成256位或者更少,对于照片来说也完全够用;通过HTML的height/width属性来缩放图片,不如创建再一个 新的大小的图片。
这些内容,靠常识判断即可。例如,一些网站将所有的文件、目录以及变量的名字减少到两个甚至更少的字符,将这作为一种减小文件大小的策略。从纯 粹的性能角度来看,这是好的;但是,对大多数网站来说,维持这些东西所产生的工作量完全抹杀了它的价值。你需要同团队一起,在去重、最小化、压缩和实用性 之间找到一个平衡点。
总结
本文介绍了几种测试,可以用来判断网站是否可能会出现前端性能问题。检查这些可能的性能优化,可能会让用户感受到的响应时间提升50%甚至更 多。我确信,一旦你有了自己的工具箱、插件和助手网站,并且实际的练过几次之后,你只需花费比读这篇文章更少的时间,就能检查一个网站是否有这些问题了。 有了这么大性能优化的可能性,又在时间和工具上投入这么少,我实在是找不到任何不进行这些测似的理由。
大自然素以平衡为美,稳定,可持续是很多事物的一个稳态。
捕鱼,讲究猎杀不绝,生生不息。
做公司思考着如何构建自运营的公司,做团队思考着如何构建可持续发展的团队。而做我们测试,思考如何构建稳定,可持续发展的测试体系,如果,我想,可以称之为完美测试体系。
顺应自然的运行法则,我自底向上进行一个分析和思考,看看我梦想中的完美测试体系。
阶段一,运转起来。
要有这样一群人,他们能够分析需求,制定测试计划与策略,完成用例编写和执行工作,其中,有一定经验的测试项目经理。
他们能够,有效按照用户需求,进行黑盒用例设计,对被测系统进行功能测试,边界测试,一定容错和异常测试,加一些场景测试和必要有效的性能测试。
好了,流程制定起,运转起来,这个阶段完美吗?也挺好的,稳定,有效,并且,可以比较OK的完成老板给定的任务。然而,许多团队易出现一种现象,进入该 稳定的状态后,由于项目紧,大家工作忙无有效能力提高,一个项目接一个,忙,无改进,忙,死循环。 人走人来,可谓稳定而不完美。
阶段二,打破平衡,改进效益。
要有自动化,打破忙的重复的劳动,也许一开始并不顺利,毕竟新生事物刚开始成长都是艰难的,相信自己,做下去。
要有业务专家,深度挖掘测试需求,改进一开始很可能并不合理的测试点,精简无用冗长的测试用例,方便手工测试,方便自动化。
要有性能专家,不断改进性能测试需求。
如何打破?有潜力的,主动性好的人,不要给予100%项目时间,50%-70%够了,指派更有前瞻性的工作,例如,新的测试技术产出,自动化实践,即将 进行的下版本测试分析预研性工作。记住,管理人员敢于失败敢于承担。培养起骨干人员,不断有所产出。形成一个小的可持续改进循环。静等有能力的人出现。
阶段三,旋转,完美起来。
有了骨干人员的成长,相信,一定有能力完成:
1、自动化可以在项目初期提交自动化需求,融合自动化在测试流程中,在适当的时候使用自动化测试,也许,当前自动化已经复用完成了许多功能模块的覆盖。这是自动化专家可以完成的工作。
2、业务精通的测试分析专家,能够有效制定精细的测试策略,包括版本模块的测试重点,使用哪些技术测试,制定有效的分层测试战略。分层测试在这里可以大 规模节省成本,例如,使用自动化完成关键部分的接口级测试,而不是做难于大规模产出效益的UI级自动化。使用UI自动化测试最有必要,易于改动引发问题的 部分。分层测试可以有效节省测试用例设计和可测性的工作量。通过模块分离,可以有效分离BUG产生原因,便于开发修改和回归。
3、性能测试专家,与测试策略同时制定,分析系统可能存在的性能问题,完成高效的性能测试需求,如,利用什么样的工具或改进现有工具,高效完成哪些性能指标测试。
4、高效执行团队,固定的不易于改变的,通过一次手工执行和方便的自动化框架构建下次可快速回归的执行过程。有效的BUG review,和有针对性的发散性和探索性测试,构建场景测试的团队。如有需求,构建安全测试团队。
我们来看看,现在一次完美的测试过程:
项目立项,由用户和BOSS立项,研发和测试跟进,各技术专家评审需求,除提供有效的场景供用户和开发确定外,测试分析专家(架构师)给予可测 试性需求,包括不限于,用户级需求的可测试性分析;白盒测试的约束和接口,如库的导出标准;与开发的架构师一起确定整体设计方案是否合理有效,并指导或确 定可测试性设计要求。
项目设计,开发在处理用户需求的同时,跟进前期测试,完成自动化测试需求,测试专家的可测试性需求跟踪和测试策略的制定。
项目编写集成,项目的自动化工程师和执行人员介入,按照项目流程和策略进行集成测试,并同时产出相关自动化用例,完成制定的测试分析专家的分层测试策略与其他测试策略。
项目系统测试,根据策略,至少2轮以上,快速回归自动化,集成发散性测试和探索性测试,充分发挥大家的思考发散能力,将上一阶段的问题发现并提交,并回溯起来,不断改进前期过程。
项目稳定性和场景测试,由相关人员进行场景测试,保证到最终用户的可靠的使用。
是否完美呢?它有高效的运作方式,有经验丰富和技术牛人指导前期,有完整高效的分层策略和自动化保证快速开发,有稳定性与用户场景保证最终的可 靠性发布。如果说不完美,有一点,还缺少那么一点点预见性,那么,培养具有市场前瞻性的技术专家吧,例如,提前半年分析超大流量的测试技术,提前研究移动 终端的快速测试技术。
自底向上,意味着,很多东西我们管理需要培养起有能力的人员由他们自然推动,而不是靠从上向下的强推自动化,强推所谓的敏捷流程。
至于流程,在完美测试体系中,它应该融入到我们的研发和测试平台中。自然随性,不知不觉跟进了流程。这是流程的最高境界。
在测试界中,易于出现无成就感的问题,在这里,没有任何问题,每个人有向上发展的动力,有其不同的价值体现。最终的大牛进入研发过程改进中。
所谓大局观,是一种思路,在管理过程中,抓住前瞻性的重要不紧急工作,把它做好。那么,自然,稳定的,可持续的完美测试体系,在未来,可成矣。
“饮鸩止渴”, 万万不可。
loadrunner连接数据库sqlserver2008(2005) 1、下载JDBC驱动(sqljdbc4.jar)
2、在run_time setting下的classpath把这驱动引入。
3、编写及哦啊本
/*
* LoadRunner Java script. (Build: _build_number_)
*
* Script Description:
*
*/
import lrapi.lr;
import java.io.*;
import java.sql.*;
import lrapi.web;
public class Actions
{
int sum=0;
int ColumnCount=0;
//String dbserverip = lr.eval_string("<dbserver>");
//定义数据库连接串
String conURL="jdbc:sqlserver://xx.xx.x.xx\\sql1;DatabaseName=NewDB";
//连接数据库用户名
String user="prj_tmp_rw";
//数据库口令
String password="xxxxx";
Statement stat;
ResultSet Result1;
Connection conn;
public int init() throws Throwable {
//加载JDBC驱动
lr.think_time(5);
Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");
System.out.println("驱动加载完成");
//连接数据库
lr.think_time(5);
conn = DriverManager.getConnection(conURL,user,password);
lr.think_time(5);
stat=conn.createStatement();
return 0;
}//end of init
public int action() throws Throwable {
lr.think_time(5);
lr.start_transaction("lr_Query_data_trans");
Result1=stat.executeQuery("<QueryParm>");
ResultSetMetaData rsmd = Result1.getMetaData();
ColumnCount = rsmd.getColumnCount();
System.out.println("结果集的列数:" + ColumnCount);
if(ColumnCount==0)
{
lr.end_transaction("lr_Query_data_trans",lr.FAIL);
}
else
{
lr.end_transaction("lr_Query_data_trans",lr.PASS);
}
return 0;
}//end of action
public int end() throws Throwable {
Result1.close();
stat.close();
conn.close();
return 0;
}//end of end
}
针对两方面的计划风险,需要作出以下改进措施,并坚决执行:
1、资源共享。组织培训,尽快使原有两个组中的核心业务知识共享,同时,每个成员还会负责原有的日常测试工作,在开发部门的开发模式不调整的情况下,继续以项目为单位,进行测试。同时,在培训和自学中,尽快掌握其他业务,同时,达到可以对其他业务的手工操作熟练掌握,最终可以实现招标,采购测试人员的交叉。
2、技术共享。测试工作中的技术应用,通过会议,培训,工作安排,达到两组完全融合,技术平衡,测试管理平衡,测试规范,文档平衡统一,测试技术技能应该平衡。
3、对人员的工作分配和使用,除了按现有的方式暂时分配工作,增加一项考核内容,就是管理部门分配的其他项目的业务水平和测试认知的考核,通过考核,使测试人员尽早的进入这种“多进程”的工作方式,最终的考核结果,会和测试人员的职级产生影响,最终的原则应该仍是在优胜劣汰的原则.
3.3.2 计划外风险
1、开发模式的改变。重组的技术开发部门是否仍是以项目为单位,进行产品开发,功能整改工作,还是会有新的开发模型?这将直接影响到测试管理部门的职责行使、工作安排。
2、公司整改战略思想的政策支持度。四个部门同时整改,造成原有的工作模式和工作方式,在各部门都产生重要影响力,势必会在行使之初,有些资源利用,调配,以及资源的掌握上,有一个适应的过程,这不只是测试部门。如果在短期内,四个整改部门出现不兼容的情况,公司的整理处理方针是什么?
针对计划外的风险,没想过具体方式方法,只能暂时这样制订:
1、如果开发模式改变,只能灵活的制订相应的测试策略,调整原来的测试方式,集中讨论,形成对应的处理机制。
2、如果出现不利于公司前进的因素出现,测试部门整改的一个中间部门,和前一级,下一级部门尽早协调,争取早日更好的接轨,倘若行不通,以公司指令和调配为准。
四、测试管理部发展规划
4.1 部门建设
部门整合后,会对测试建设提出两个目标,以此为目标,打造体系完善的测试管理部。
4.1.1 短期目标:
实现两个测试组的融合:资源融合,技术融合,业务融合,工作融合,计划用3-5个月实现。
具体规划:
1、工作考核
2、部门绩效考核
3、近期工作安排
4、培训安排
5、业务测试交互
6、人员定岗,定职
4.1.2 长期目标:
把测试管理部发展为综合业务水平高,测试技能突出,测试影响力大,测试经验丰富的团队。
具体规划:
1、部门测试影响力
2、测试技术掌握
3、职级确定
4、部门协作
5、人才培养和留任
6、人才引入
一、现任岗位工作
1.1 工作内容
1、负责招标测试组的测试管理工作,测试组成员的测试工作进行安排,测试工作方式,测试技能,进行分析和掌握,并针对不同的测试人员的工作和技术特点,采取不同的方式进行管理和指导,提供建设性的意见和建议,并带领组员共同学习和创新,用于项目的测试具体工作中,提高测试水平;
2、指导测试人员,并和项目其他部门沟通,以提前测试执行时间为目的,对项目的需求完善,进行答疑;对项目开发进度和缺陷修改,进行督促,从而使测试在良性状态下顺利进行,同时对整个项目进度和质量起到重要作用;
3、熟悉招标的各项业务,在业务熟悉的基础上,转化为测试需求,并结合现有的测试组工作状态进行分析,制订相关的规范和流程,并在提高测试技术水平和测试方法上,开展一系列的尝试工作,并做出相关的文档,以及对相关的技术难点攻关;
4、对测试的需求,计划,用例和缺陷进行评审,提出指导意见和改进方法,完善原有的项目测试工作,尤其是对测试需求和缺陷提交的规范进行细致的引导;
1.2 工作业绩
1、基本熟悉招标网平台中的各种类型招标的基本流程,并对流程中的业务进行理解,转化为测试思想,指导测试工作的执行;
2、对“竞争性谈判”项目的测试管理进行规范,以公司原有的相关规格说明书为指导,和测试人员讨论后,结合项目实际情况和以往工作经验,制订相应的QC中的管理流程,脚本编辑更易理解和易使用的信息,方便,有效的用于测试需求和缺陷的编写;
3、参与其他项目例会,掌握测试人员跟进项目组的实际测试工作,作指导性的意见,并协调其他部门,更好的为测试开展提供方便;
4、针对一些项目中的成形的业务和功能操作,手工测试执行繁琐。提出自动化测试框架的搭建需求,因为招标测试组以往的自动化测试进展水平较低,从头开始构建自动化测试框架思想,并编写完成框架思想和一部分针对具体项目的概要设计工作。
5、通过了解业务功能,以及整体产品运行的硬件平台和产品整体结构框架,开始引入性能测试分析的内容,并对tomcat实行监控,数据库进行性能分析,并对具体项目,编制性能测试方案和部分测试用例,并完成了原型脚本的编写,使之可以更好的在场景中运行。
二、竞聘匹配度分析
2.1 工作经历分析
1、从2002从事软件测试行业至今,经历了这个行业的发展过程,同时,积累了丰富的工作经验,并且转化为管理和技能,可能更好的用于公司的测试工作中,做出贡献;
2、在原来公司,有过三年互联网测试经验,并且针对网站和平台的每次改版,都充分发挥了测试负责人和测试实施者应有的作用,保证每个产品都能顺利上线;
3、在测试这个行业中,有过5年既是测试工作师又兼测试组长的双重经历,从而更了解测试人员的工作和想法,同时,更方便上下兼容,并且可以更好的和兄弟部门沟通交流;
4、加入必联至今,一直引导招标测试组的测试管理工作,并对组里人员进行测试理论指导和技术指导,同时,让组成员的工作状态都饱满起来;
5、对测试和管理的工作有很强的兴趣和信心。
2.2 技术分析
1、熟悉Linux,Windows系统,并且熟悉web技术开发的框架和体系结构,可以熟练的配置相应的测试环境,同时对测试版本进行控制;
2、熟悉软件工程,项目管理的理论和方法,对各种开发和测试模型有很好的认识和理解,并可以灵活用于项目中;
3、软件测试整体过程中,测试需求、测试计划用例,测试执行,以及对缺陷的分析和定位,有敏锐的想法和解决方案;
4、对软件测试主流的辅助工具,如:TD,QC,JIRA,QTP,LR,可以很好的使用,并用于实际的测试过程中;
5、熟悉ORACLE数据库的操作和使用;
6、对开源的部分测试工具,有一定的理解和使用能力,如:ruby,selenium等;
7、从事多年的测试工作,具有良好的语言表达能力和文字,文档编写处理能力,同时,英语四级水平使得看一些英文文档,稍借助翻译软件,即可形成中文的专业文章,可学习和共享给其他组员;
2.3 管理分析
1、可以根据资源配置,可以形成以垂直管理为主导,多结构化的管理方式,既体现首席管理者的指导管理和协调管理职能,又会根据具体情况,分层次和组合的进行测试工作的开展;
2、可以对项目的测试时间,质量和成本的控制能力较强,在测试开始之际,就会建立一个测试预警方案;
3、以往的工作中,会主动管理和工作,主动向上传递,提交测试信息;主动向下关注,指导测试工作的良性进行,使每个人都有工作可做;对自身而言,除此之外,会对部门的建设和技术,学习,培训等方面,开展实际的工作;
4、可以充分利用测试资源,特别是人的应用,同时,对测试部门成员有完整,全面的认识和理解,支持;
5、通过原有的工作经验,结合现有测试部门的管理工作,仍然会实行优胜劣汰的方式,可以犯错,但是不能无所作为。
6、在管理沟通方面,在工作周报和月报中,建立相应的板块,除了工作总结,应该会有学习总结,问题总结,个人建议意见填写,这些内容和考核绩效结合;在例会,面对面交流过程中,讨论是关键字;
7、可以和兄弟部门,从属部门,其他职能部门有良好的沟通。主要是充分利用公司各种资源,如:员工之间的私交,工作上的上下级关系,项目整体关系,公司OA等,形成良好的沟通氛围,完成自己想要达到的目的。
三、测试管理部组织规划
3.1 组织目标
首先我们需要明白测试管理部的目标是什么?就我个人理解,主要是三个方面:
1、测试管理部统一后,可以更方便的调用两个部门的测试人员,进行业务互换测试,同时,可以在业务熟悉之后,产生新的测试要点,拓宽测试人员的业务知识和测试水平;
2、技术共享。原来两个测试组,采购和招标因为所谓业务不同,造成的技术不平衡情况有望在统一后的测试管理部打破,同属测试部成员,根据项目要求以及业务掌握情况,会在统一安排下,互相扶助,从而达到技术和业务双赢
3、增强测试持续发展,降低测试预期分险。两个组的资源分散,主要是人力,每个人再分散到一个项目中,造成业务,技术孤立,使某项目或产品的可持续测试不能进行,同时,提高测试水平,提高项目质量受到很大限制,测试管理部的可以更优分配资源,两个项目可以由至少两人同时参与,共同协作,达到1+1优于2的要求。
3.2 岗位规划
设想根据不同的业务,不同的项目开发,划分两个级别的测试工作人员,记为高级测试工程师,测试工程师。
因为公司原有的制度中对测试技能职级未做细分,所以在测试管理部组建之后,会暂时按原有的方式职级进行工作安排,通过工作和技术在实际的应用中发挥的作用,测试管理部会提交各人的工作总结,学习总结,技能实际掌握情况,形成部门绩效考核,再由整个技术部门和相关的人力等职能部门,对测试人员职级进行调整。
在未做调整之前,测试管理部经理会尽快了解测试部内的人员技能水平和业务水平,进行工作安排,在工作中进行考核,同时,为了项目测试顺利执行,对业务能力熟悉的人员,安排相应的测试前期的准备工作,同时,会有一个辅助人员会加入,作为辅助测试人员,主要为了熟悉业务和测试过程,也为了增强该项目的可持续测试。
根据项目大小,细分模块,尽量安排至少两人以上参与测试工作,从测试需求,用例设计,测试执行,分工协作,但是每个人的在项目中的测试工作,是独立的完成,最后,进行测试整合,形成测试相关文档,完成测试整体工作。
3.3 风险分析
3.3.1 计划风险
1、测试资源风险:部门组建之初,会出现暂时的资源迭代的情况,主要是人力资源,需要每个人在主负责相关的测试项目的工作外,需要对其他项目进行测试跟踪和学习,测试人员是否可以跟进部门安排的工作,尽快完成从单业务测试向多业务的了解和掌握,从而可以开展测试工作,需要时间来证明。同样,测试管理部对部门整体的测试环境的掌握,测试经理对部门的实际了解和最终流畅运作,需要一定的时间来组织和构建。
2、人员风险:新的整体部门的组建,虽然会维持一些原有的流程和作业规范,但根据实际情情,势必会进行调整,原有人员是否可以适应新的工作方式,在原有的成型的工作习惯基础上,是否可以学习,加强业务知识,专业技能,是否能顺利的完成任务,需要保守估计。
针对两方面的计划风险,需要作出以下改进措施,并坚决执行:
1、资源共享。组织培训,尽快使原有两个组中的核心业务知识共享,同时,每个成员还会负责原有的日常测试工作,在开发部门的开发模式不调整的情况下,继续以项目为单位,进行测试。同时,在培训和自学中,尽快掌握其他业务,同时,达到可以对其他业务的手工操作熟练掌握,最终可以实现招标,采购测试人员的交叉。
2、技术共享。测试工作中的技术应用,通过会议,培训,工作安排,达到两组完全融合,技术平衡,测试管理平衡,测试规范,文档平衡统一,测试技术技能应该平衡。
3、对人员的工作分配和使用,除了按现有的方式暂时分配工作,增加一项考核内容,就是管理部门分配的其他项目的业务水平和测试认知的考核,通过考核,使测试人员尽早的进入这种“多进程”的工作方式,最终的考核结果,会和测试人员的职级产生影响,最终的原则应该仍是在优胜劣汰的原则.
3.3.2 计划外风险
1、开发模式的改变。重组的技术开发部门是否仍是以项目为单位,进行产品开发,功能整改工作,还是会有新的开发模型?这将直接影响到测试管理部门的职责行使、工作安排。
2、公司整改战略思想的政策支持度。四个部门同时整改,造成原有的工作模式和工作方式,在各部门都产生重要影响力,势必会在行使之初,有些资源利用,调配,以及资源的掌握上,有一个适应的过程,这不只是测试部门。如果在短期内,四个整改部门出现不兼容的情况,公司的整理处理方针是什么?
针对计划外的风险,没想过具体方式方法,只能暂时这样制订:
1、如果开发模式改变,只能灵活的制订相应的测试策略,调整原来的测试方式,集中讨论,形成对应的处理机制。
2、如果出现不利于公司前进的因素出现,测试部门整改的一个中间部门,和前一级,下一级部门尽早协调,争取早日更好的接轨,倘若行不通,以公司指令和调配为准。
四、测试管理部发展规划
4.1 部门建设
部门整合后,会对测试建设提出两个目标,以此为目标,打造体系完善的测试管理部。
4.1.1 短期目标:
实现两个测试组的融合:资源融合,技术融合,业务融合,工作融合,计划用3-5个月实现。
具体规划:
1、工作考核
2、部门绩效考核
3、近期工作安排
4、培训安排
5、业务测试交互
6、人员定岗,定职
4.1.2 长期目标:
把测试管理部发展为综合业务水平高,测试技能突出,测试影响力大,测试经验丰富的团队。
具体规划:
1、部门测试影响力
2、测试技术掌握
3、职级确定
4、部门协作
5、人才培养和留任
6、人才引入
4.2 人员激励
测试管理部的测试人员的激励,主要从以下方面进行阐述:
1、从工作安排上来说,主要是要让每个人都清楚自己的工作任务,明确知道自己在做什么,从而使每个人都是在工作,对于主动工作的人员,在部门的绩效考核和公司的考核中,要有一定的体现;
2、职级进行分类后,根据员工的工作情况,可以和其他职能部门协商,升,降职级以此对工作作肯定和否定,这种方式慎用,主要是部门内部的工作和部门建设出现问题,原因分析确实因为个人所致的。
3、配合公司的薪水,奖金,福利制度,对人员的工作进行奖,罚。
4、对每个人兴趣的,和测试相关的培训,学习给予支持和鼓励,并可以在项目进度允许情况下,可安排员工重点去攻关,学习,培训,从而得到学习总结和成果,共享于测试部门,提高所有人相关知识。
5、测试人的自我激励:主要是对这个职业的热爱,态度的积极性,对待工作主动思考,同时会影响到其他人。
五、测试管理部业务规划
5.1 招标网业务规划
1、现有项目的日常测试工作稳定运行。对业务比较复杂的项目,加入新的测试人员,参与学习和辅助测试工作;
2、进一步提取原来两个组中的精华和集合点,形成共同的基于公司业务和项目开发的完整的测试工作流程;
3、基于招标平台的状态机设置以及业务流,结合自动化测试框架的思想,把原有的成形的功能模块和节点集成到自动化测试框架中;
4、开展基于测试工作环境下的性能测试和性能分析
5、在开发机构完善,测试相对独立后,考虑搭建一个真正意义上的测试环境,从提取代码,编译,部署到版本测试控制,测试执行,测试分析,测试结果生成,在测试管理部的测试服务器上完成;
6、加强部门可持续发展建设。以学习、工作效率还有积极主动性作为衡量工作的比重较高的标准。
5.2 采购网业务规划
工作方式同招标业务。
六、测试管理部职能行使
6.1 测试职能
1、行使参与项目预审,参与项目评审工作;
2、行使测试组建,测试准备,测试执行,测试分析,测试报告生成的工作;
3、按项目进度,行使对需求的完善,开发过程中的失误,错误进行验证,控制项目进度,控制时间成本,控制质量的工作;
4、加强部门建设过程中的学习和培训,以及参与其他部门的技术,业务交流的工作;
5、用户验收测试完成后,用户培训手册,用户操作说明的编制工作。
6.2 部门沟通
1、利用公司的现有资源,如mail,RTX,OA等,保持现有的交流风格和方式;
2、贯彻测试理论到整个项目过程中,整个部门以重视产品质量为前提的工作状态下进行相关工作。
3、积极和其它相关部门互换意见,寻求共赢点。
4、测试产生的数据,即时通过测试管理QC或其他相关手段,反馈给相关部门,同时,其他部门产生的数据,流经测试时,测试管理部积极处理,如果出现停顿,测试部相关人员主动查找停顿原因;
5、测试人员通过工作的主动性,从测试和质量控制环节上,带动其他部门的主动性,并且通过工作上的主动开展,形成部门沟通的良性循环。